This document provides an overview of several deep generative models including autoencoders (AE), variational autoencoders (VAE), generative adversarial networks (GAN), adversarial autoencoders (AAE), VAE/GAN hybrid models, and adversarial domain adaptation (ADA). It describes the key objectives and training procedures of each model, such as minimizing reconstruction loss in AEs, matching the encoded latent distribution to a prior in VAEs, and making generated samples indistinguishable from real data for the discriminator in GANs. Graphical representations are also shown to illustrate how these models relate latent and observed variables.
Overview of deep generative models and their relevance in music and audio generation.
Discussion about MuseGAN, a model for composing pop songs using GANs, with references to the authors and publication.
Outline of the presentation covering various deep generative models such as AE, VAE, GAN, AAE, VAE/GAN, and ADA.
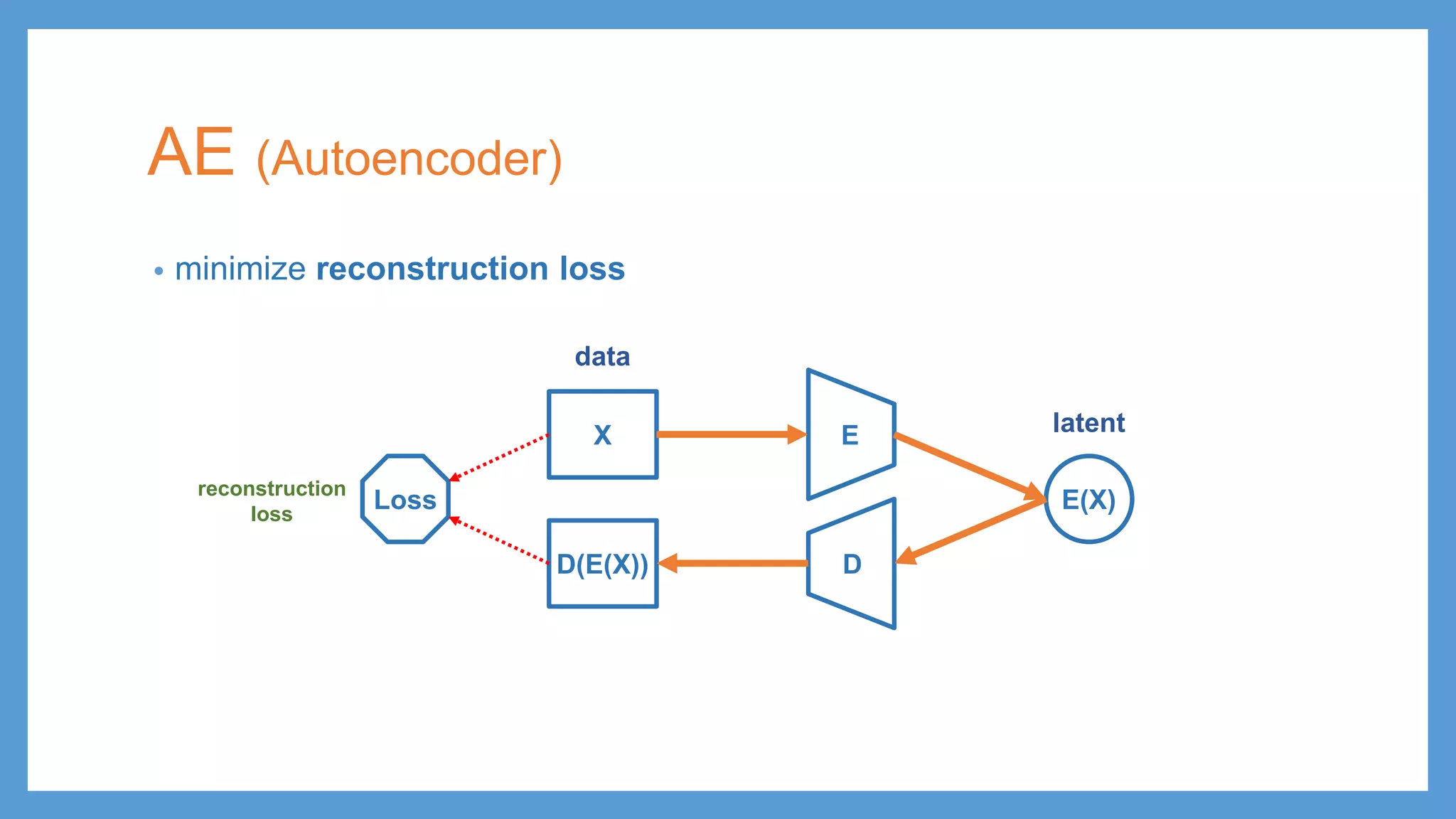
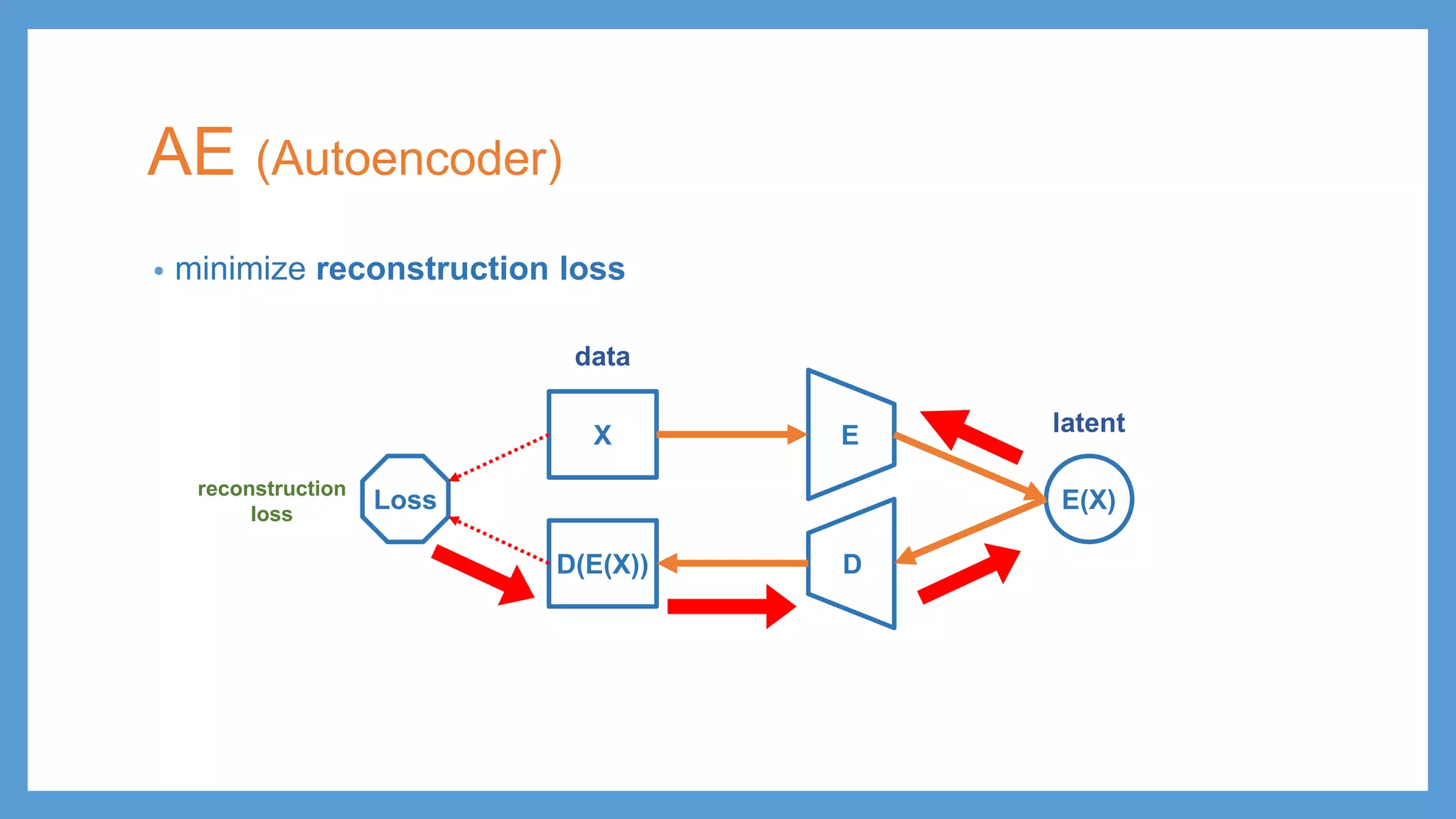
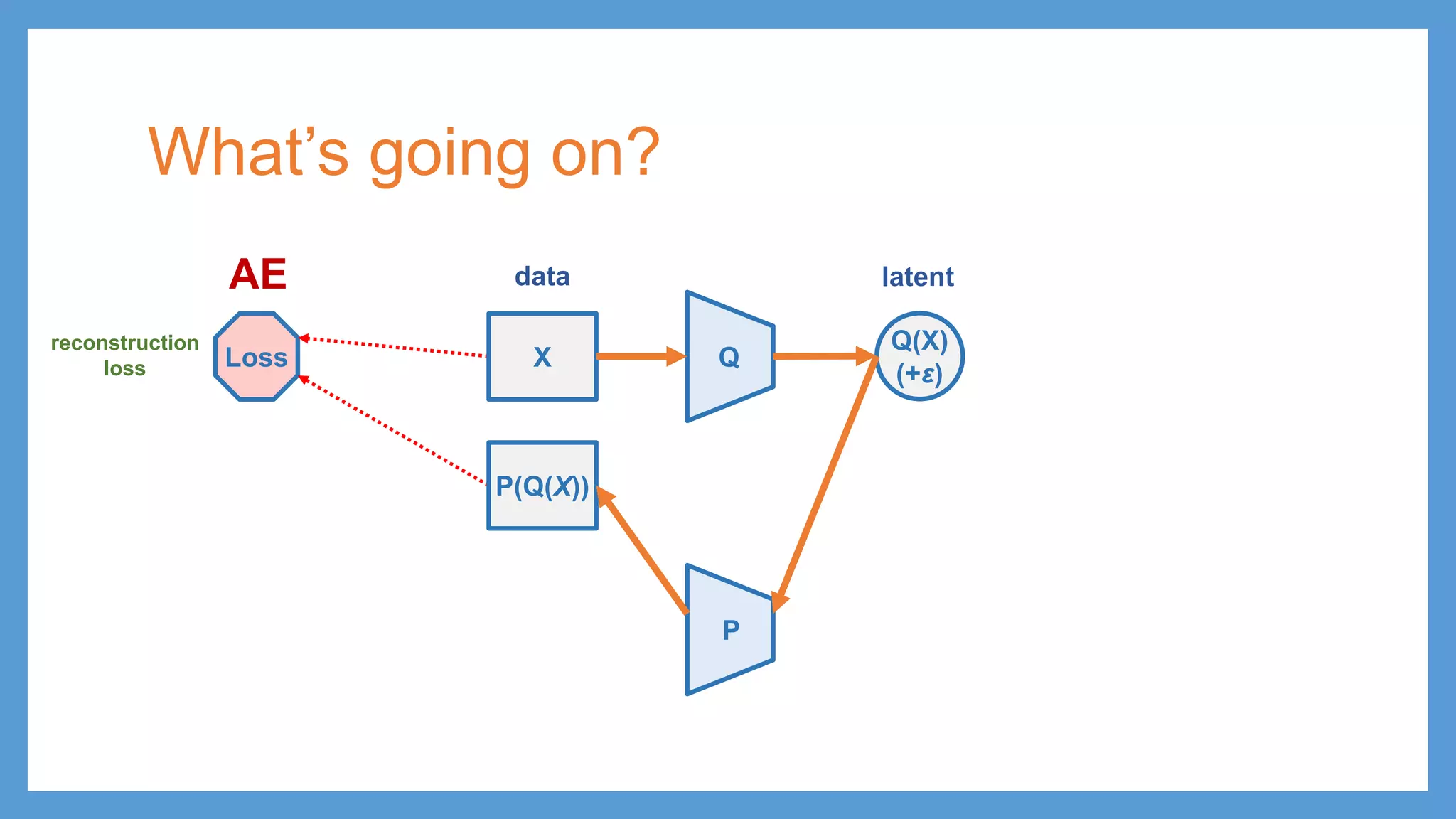
Introduction to Autoencoders (AE), emphasizing minimizing reconstruction loss and its components.
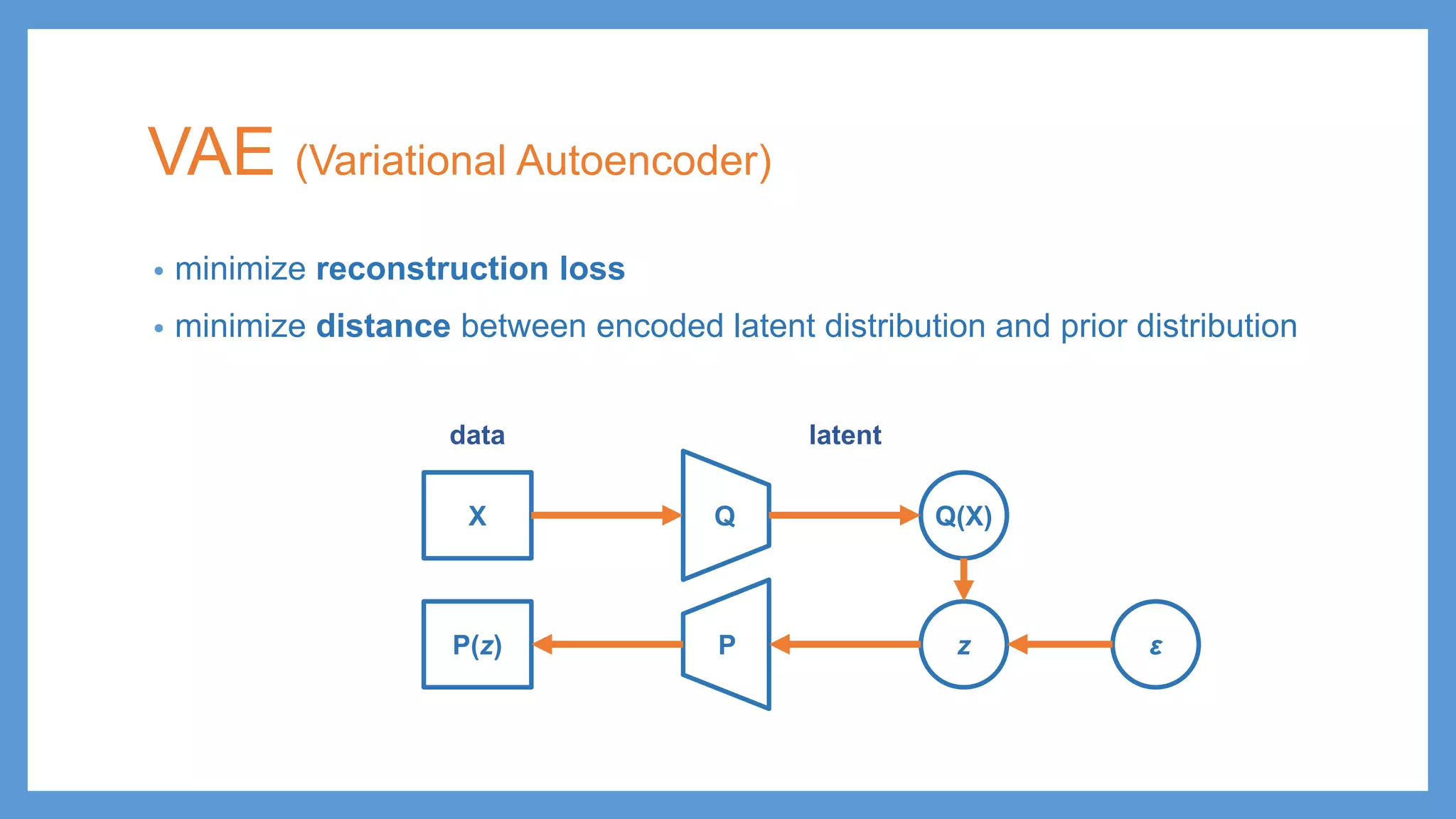
Description of VAE including minimizing reconstruction loss and distance between distributions, with details on KL divergence.
Exploration of GANs focused on the training process and the roles of generator and discriminator in minimizing distribution distance.
Comparative analysis of GAN and VAE highlighting their generation qualities, stability, and output characteristics.
Description of AAE architecture focusing on reconstruction loss and adversarial training to distinguish between distributions.
Overview of integrating VAE and GAN concepts, building on representation and training processes.
Clarifications on elements involved in models like VAE and GAN, focusing on latent variables and representation quality.Explanation of ADA's goal to classify unlabeled data in target domains using labeled data from source domains.
Discussion on unifying principles across various generative models and parameters involved in the generative and inference processes.
In-depth comparison of different models including VAE, GAN, InfoGAN, and AAE with regards to approach and performance.
List of references cited throughout the presentation regarding deep generative models and related research.
Introduction to Deep GenerativeModels Herman Dong Music and Audio Computing Lab (MACLab), Research Center for Information Technology Innovation, Academia Sinica
2.
MuseGAN Learn about ourrecent work on using GAN to compose pop song at https://salu133445.github.io/musegan/ Hao-Wen Dong, Wen-Yi Hsiao, Li-Chia Yang and Yi-Hsuan Yang. 2017. MuseGAN: Symbolic-domain Music Generation and Accompaniment with Multi-track Sequential Generative Adversarial Networks. arXiv preprint arXiv:1709.06298.
3.
Outline • Brief introductionto deep generative models • AE (Autoencoder) • VAE (Variational Autoencoder) • GAN (Generative Adversarial Networks) • AAE (Adversarial Autoencoder) • VAE/GAN • ADA (Adversarial Domain Adaption) • Reformulation • Graphical model representation • Connection to Wake-sleep Algorithm
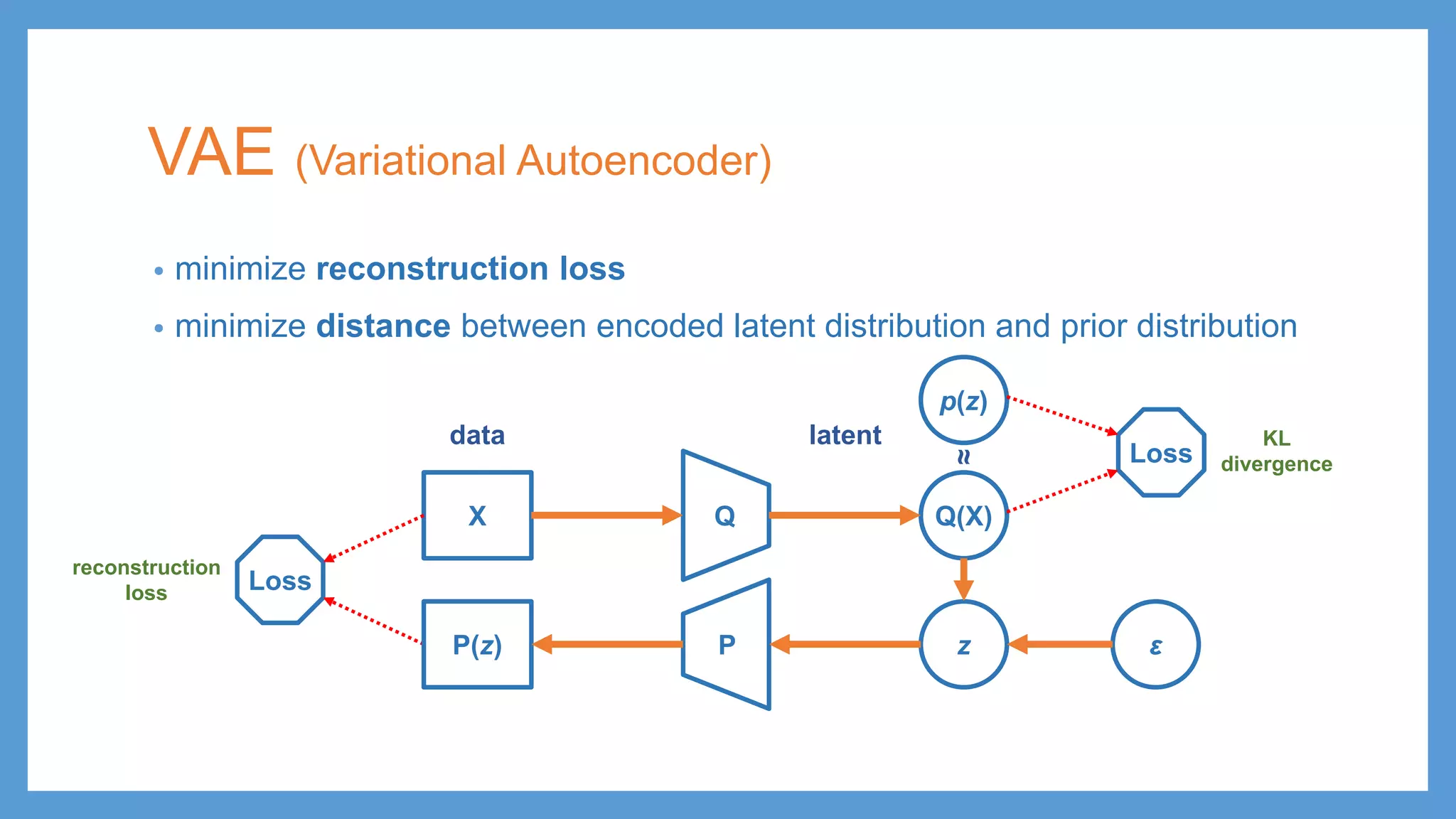
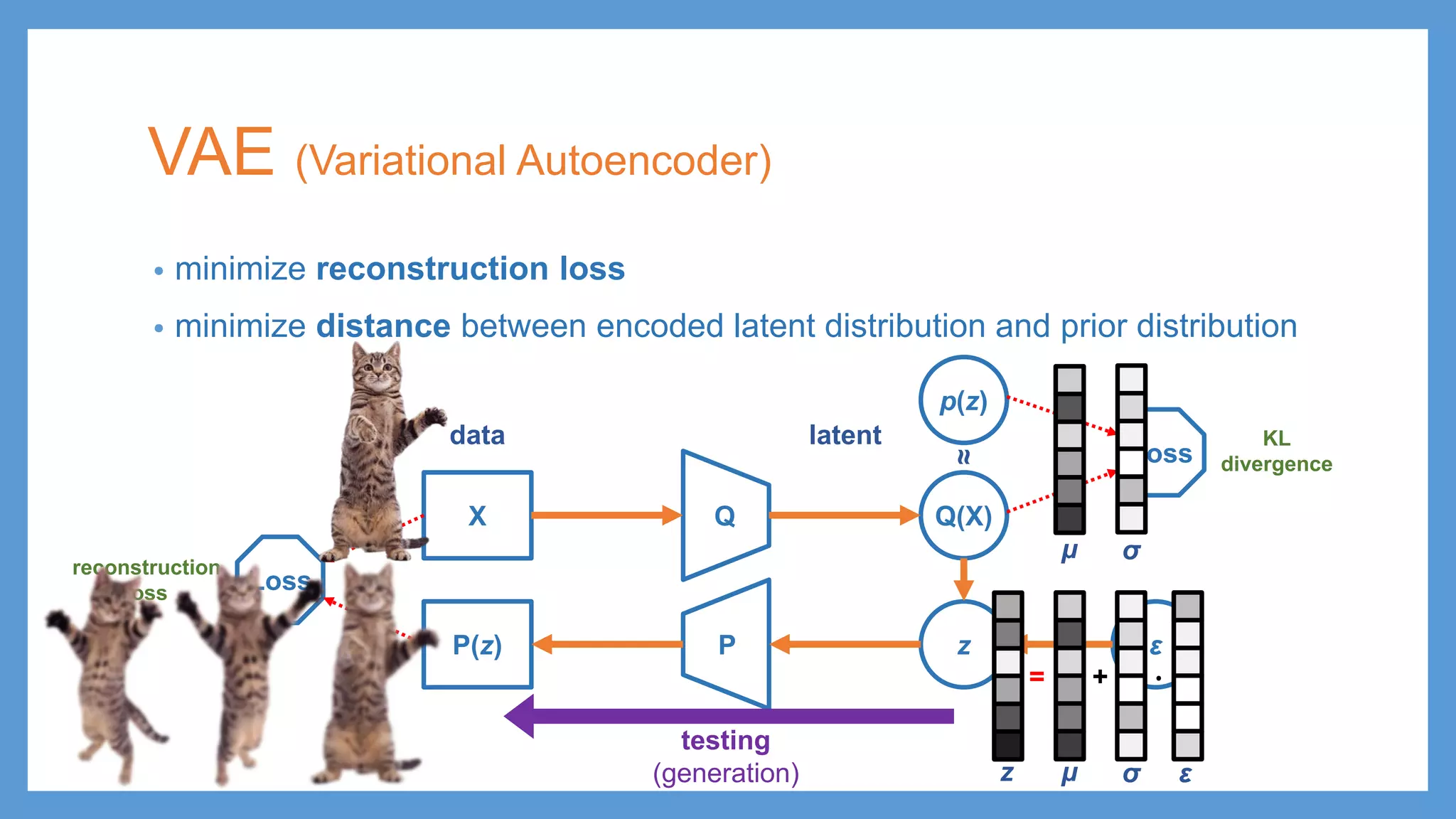
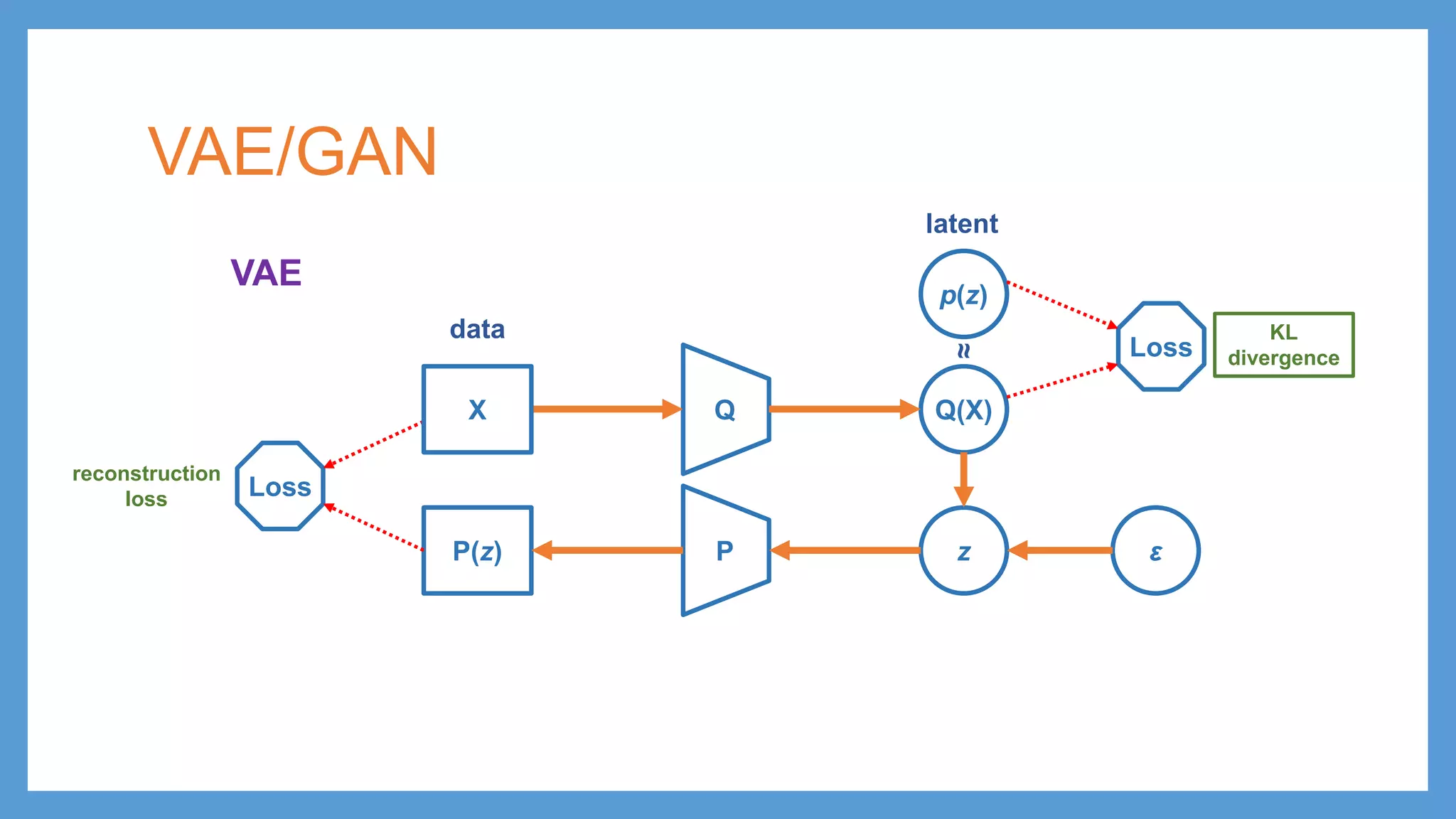
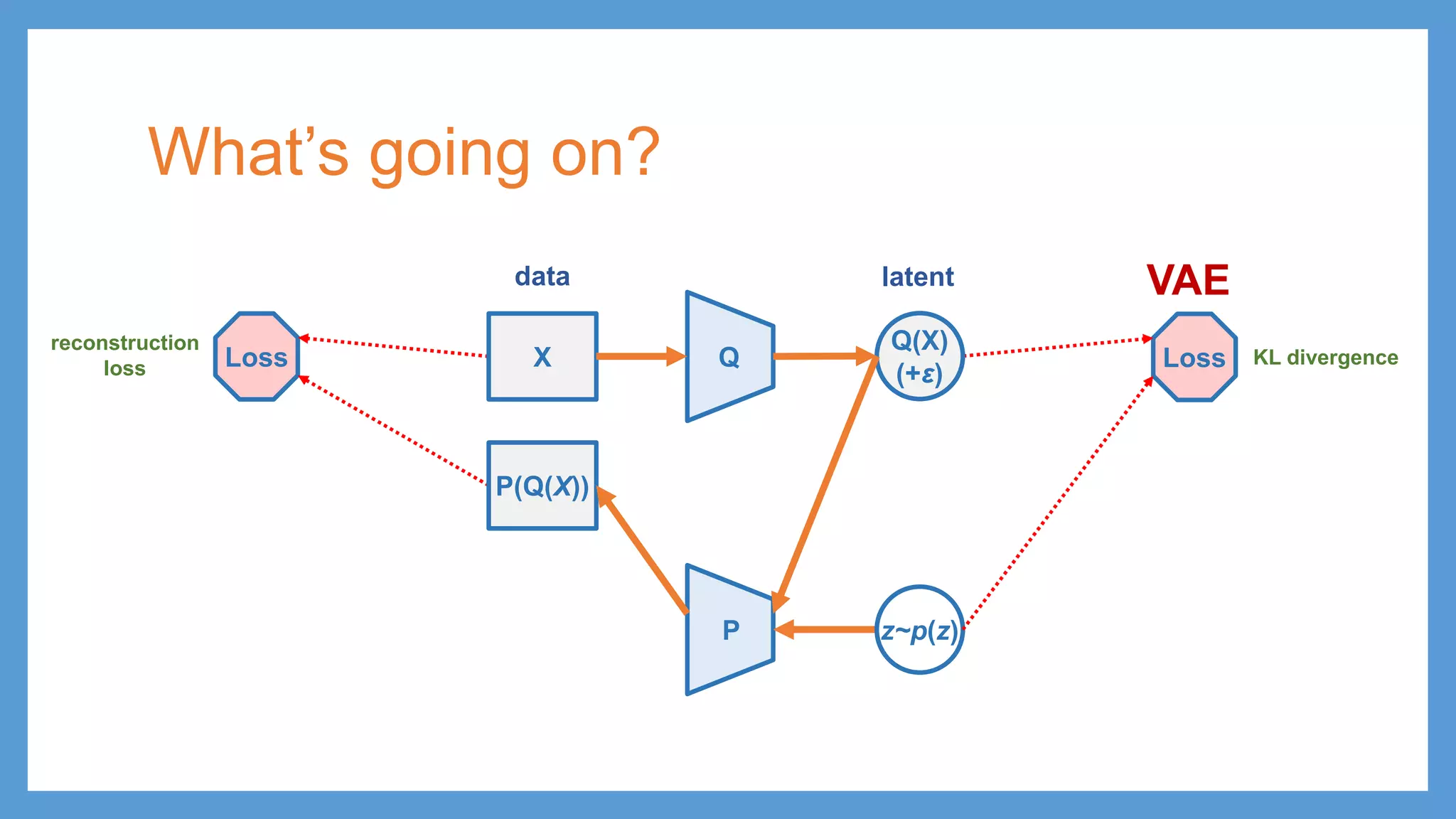
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) PP(z) z ε latentdata
8.
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss Loss PP(z) z ε reconstruction loss KL divergence latentdata ≈
9.
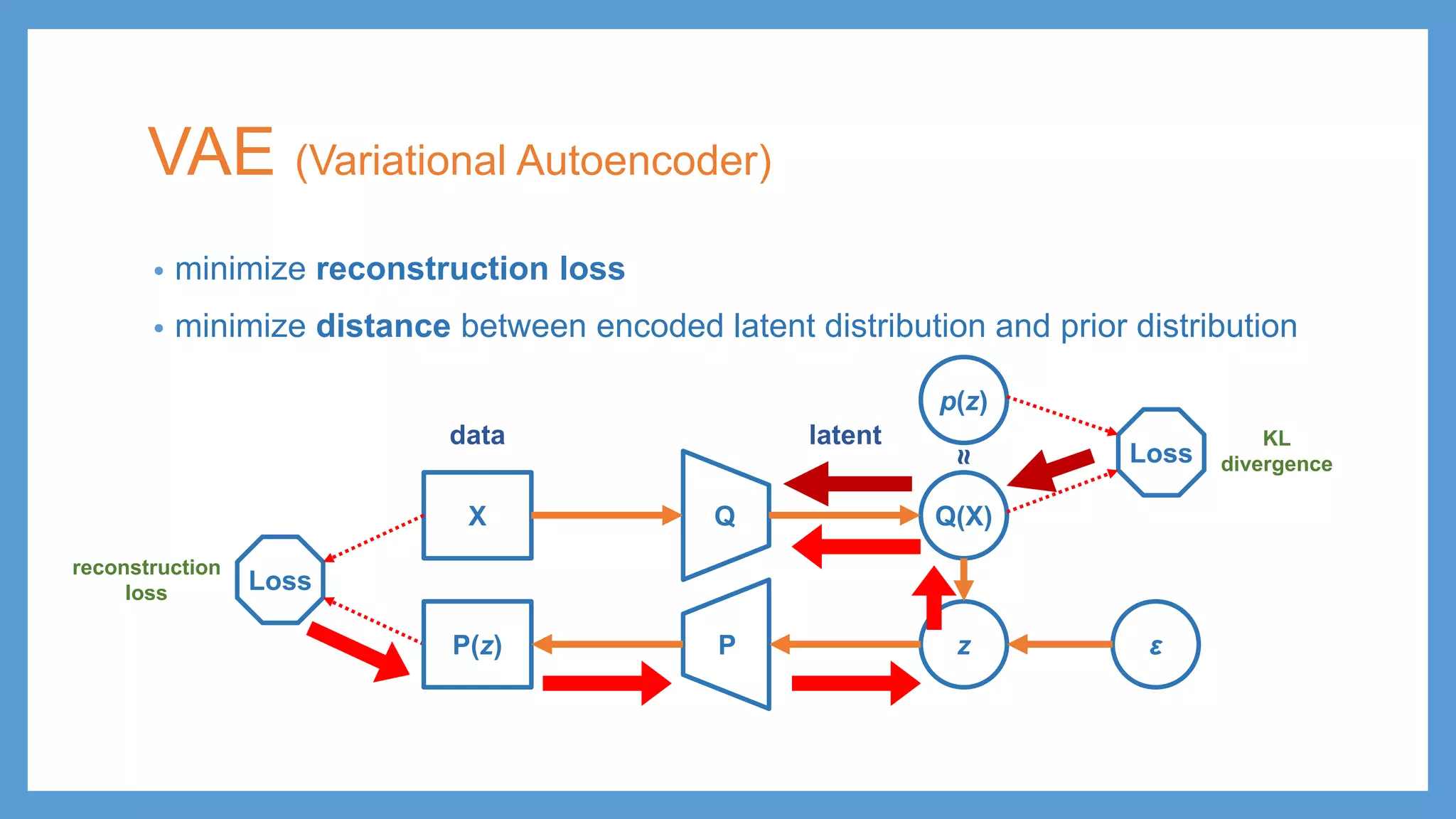
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss Loss PP(z) z ε reconstruction loss KL divergence latentdata ≈
10.
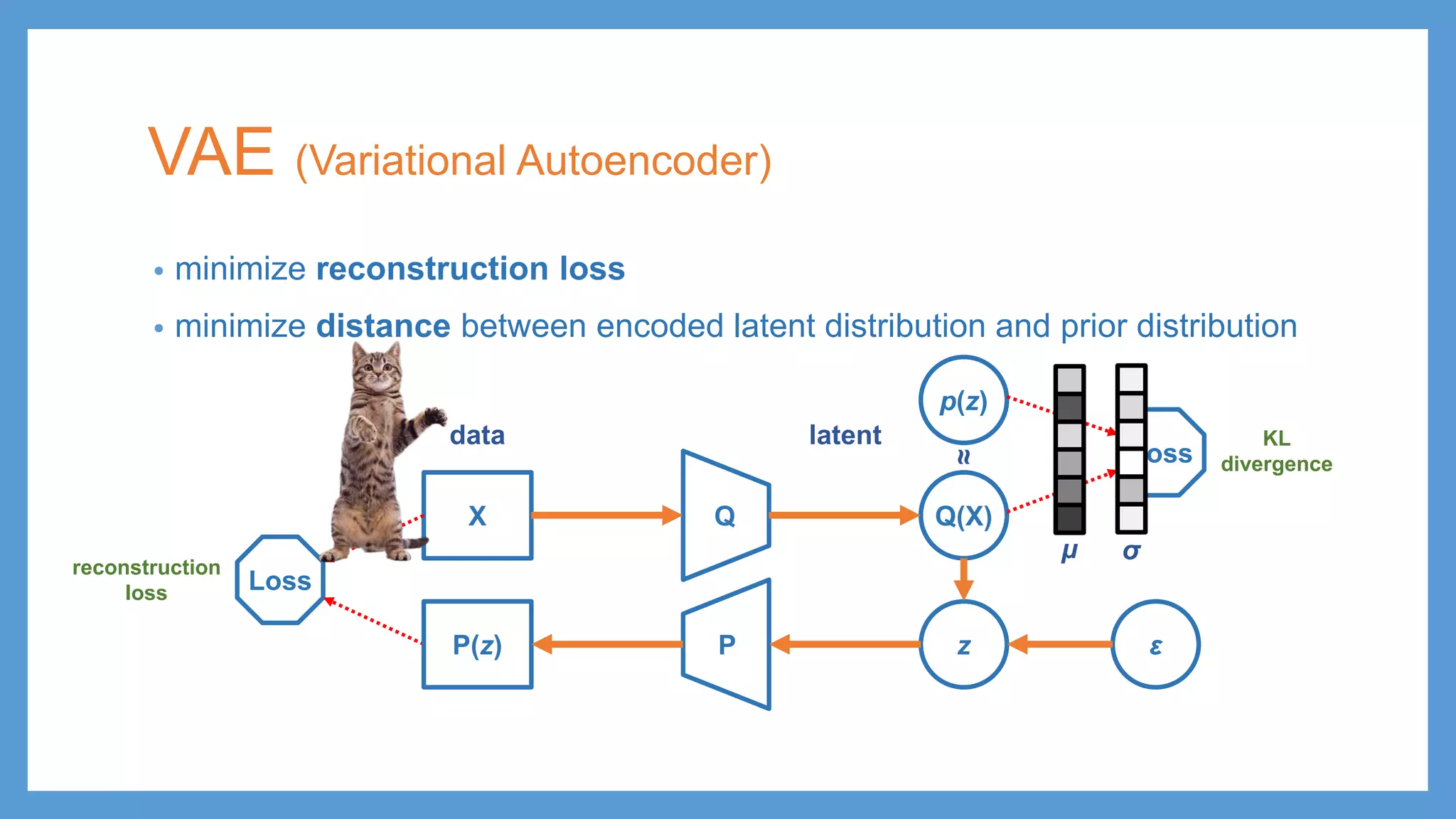
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss Loss PP(z) z ε reconstruction loss KL divergence latentdata μ σ ≈
11.
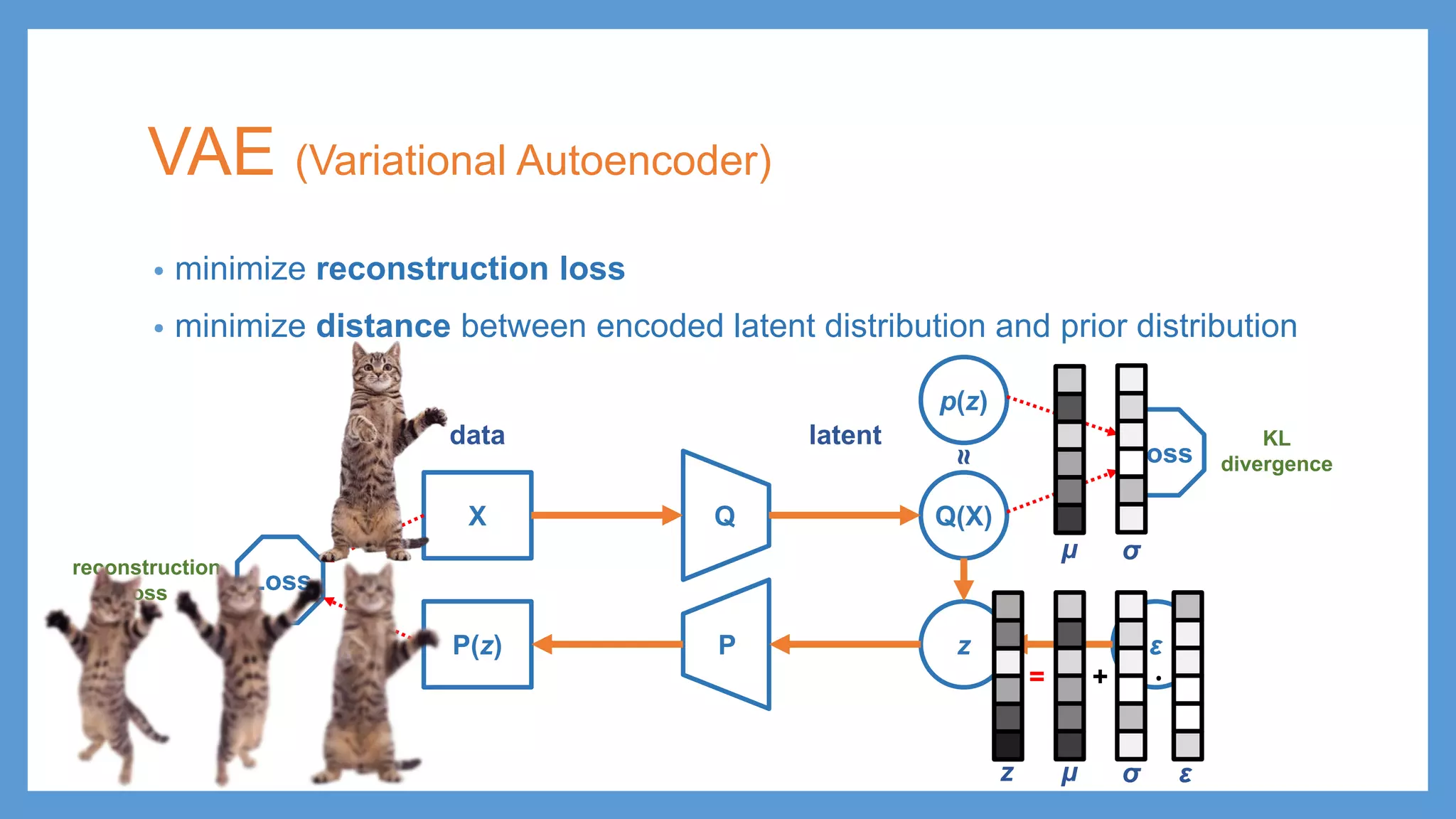
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss Loss PP(z) z ε reconstruction loss KL divergence latentdata μ σ μ = z σ + ∙ ε ≈
12.
VAE (Variational Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss Loss PP(z) z ε testing (generation) reconstruction loss KL divergence latentdata μ σ μ = z σ + ∙ ε ≈
13.
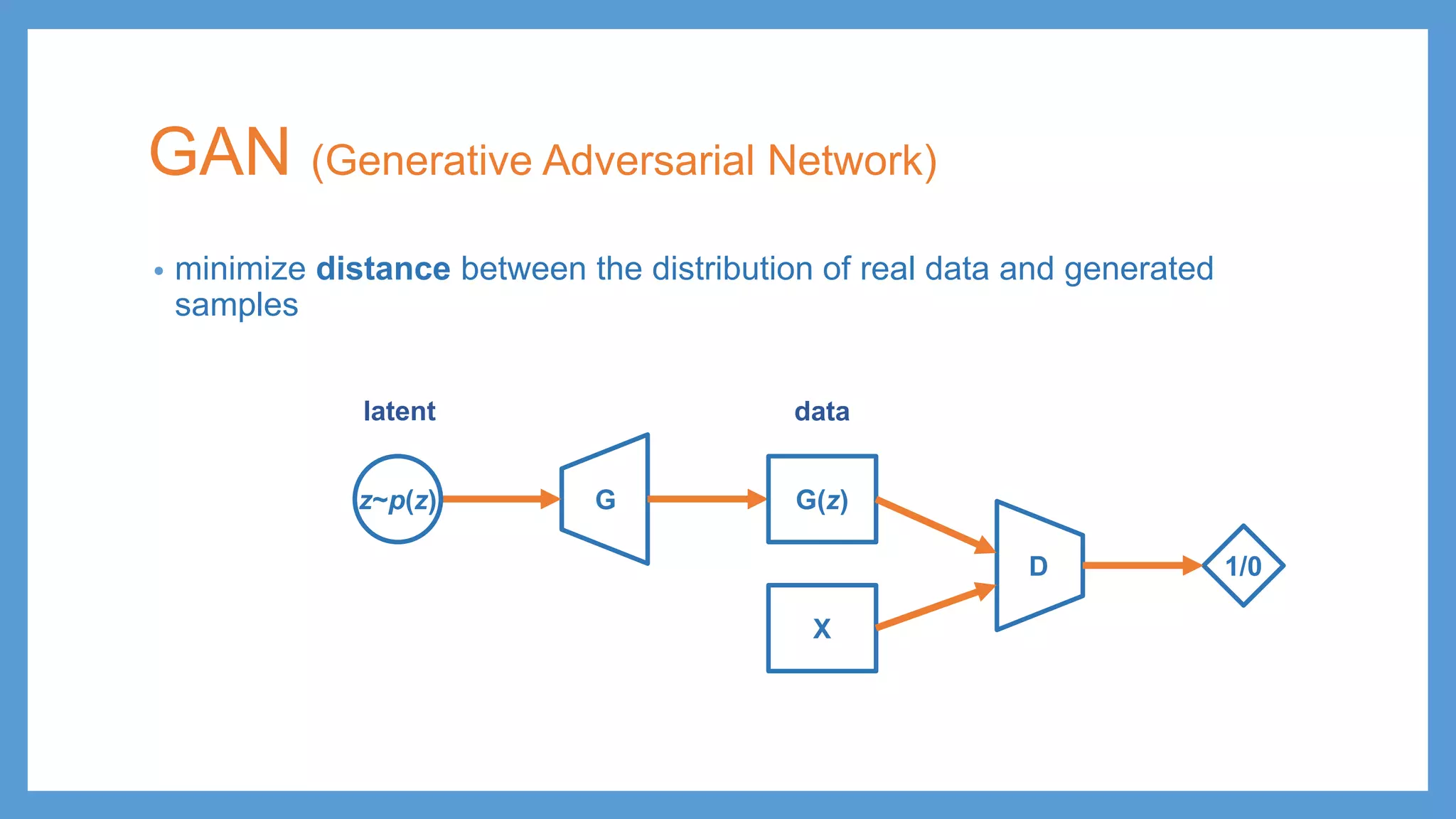
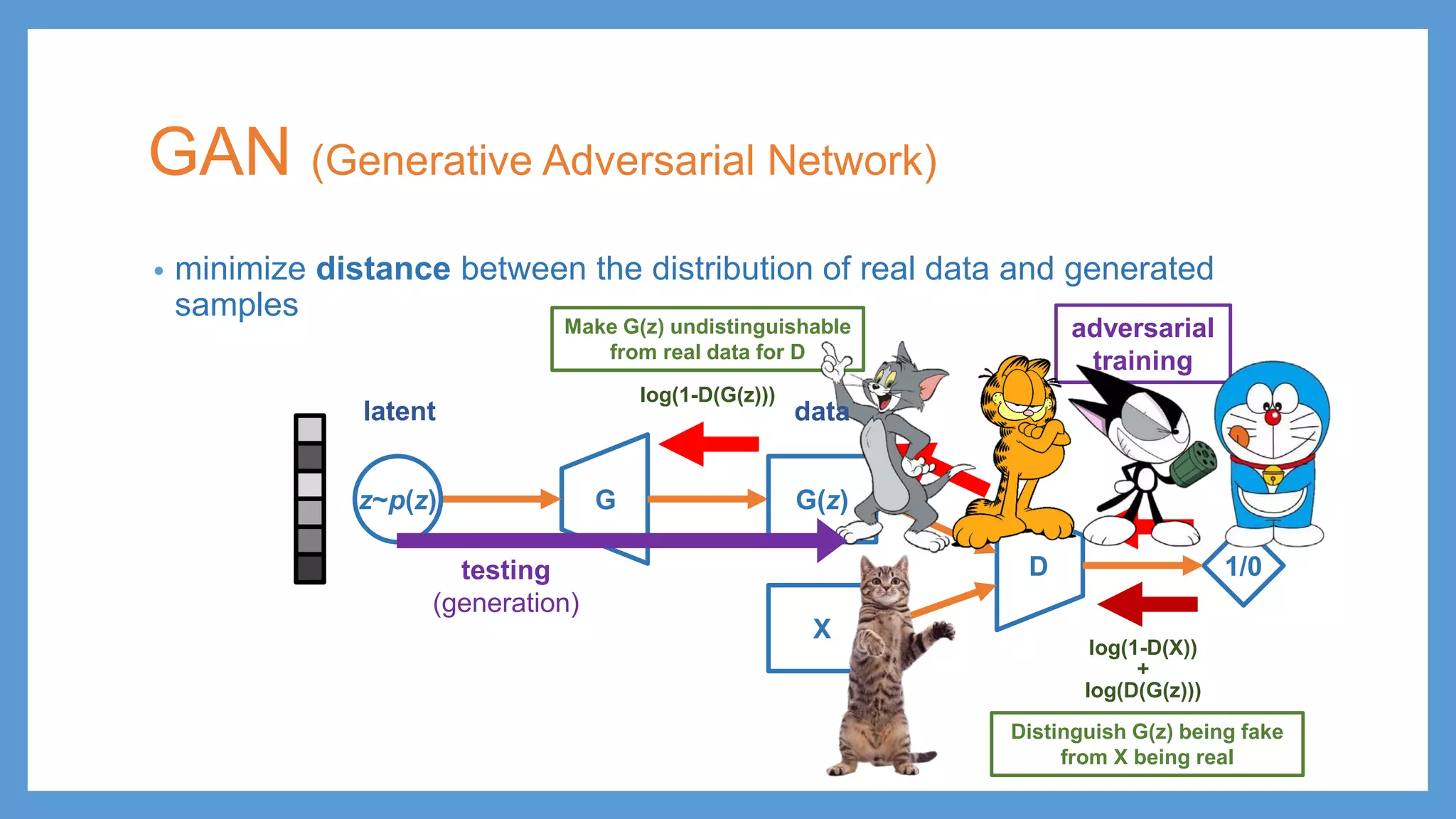
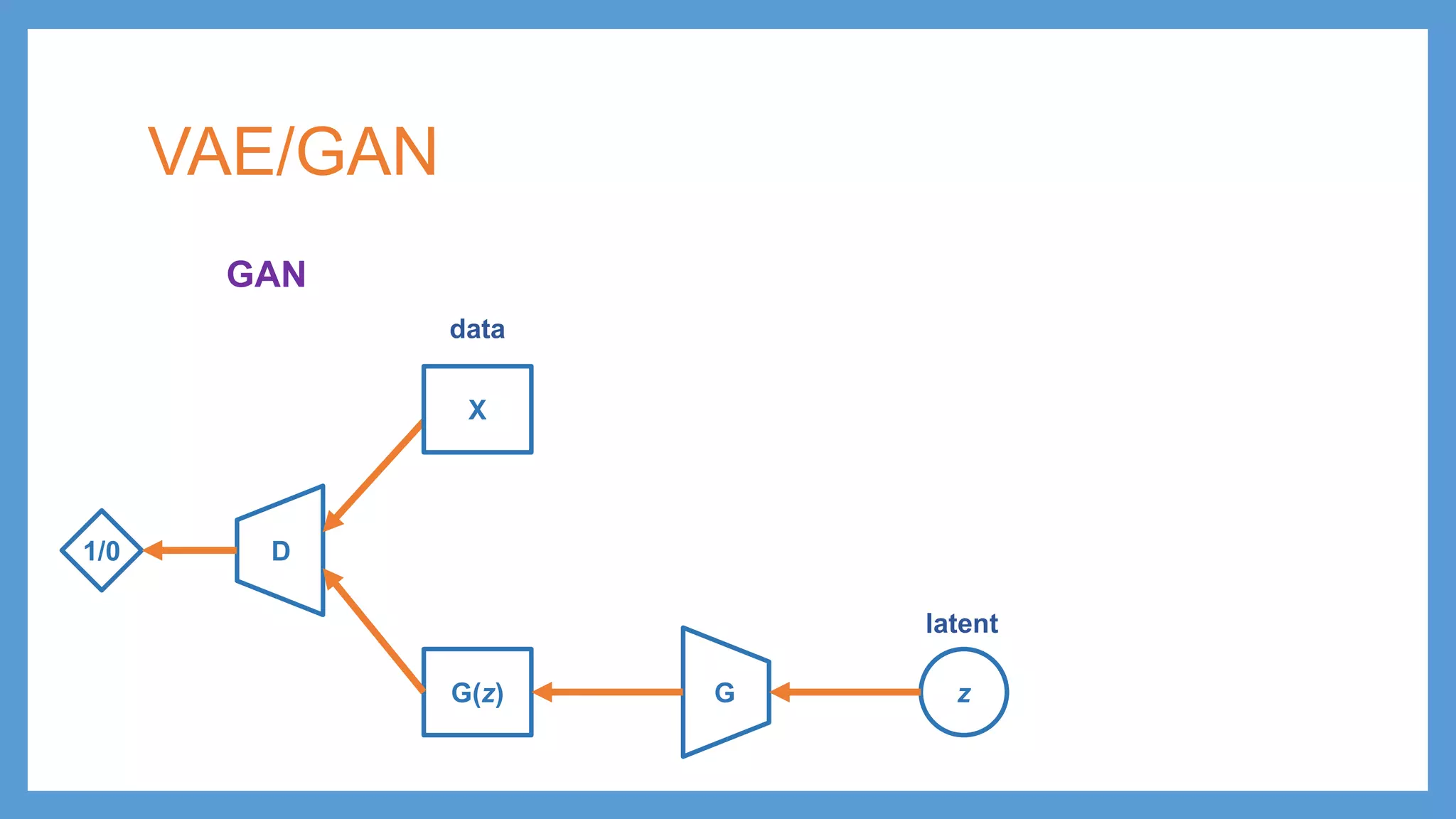
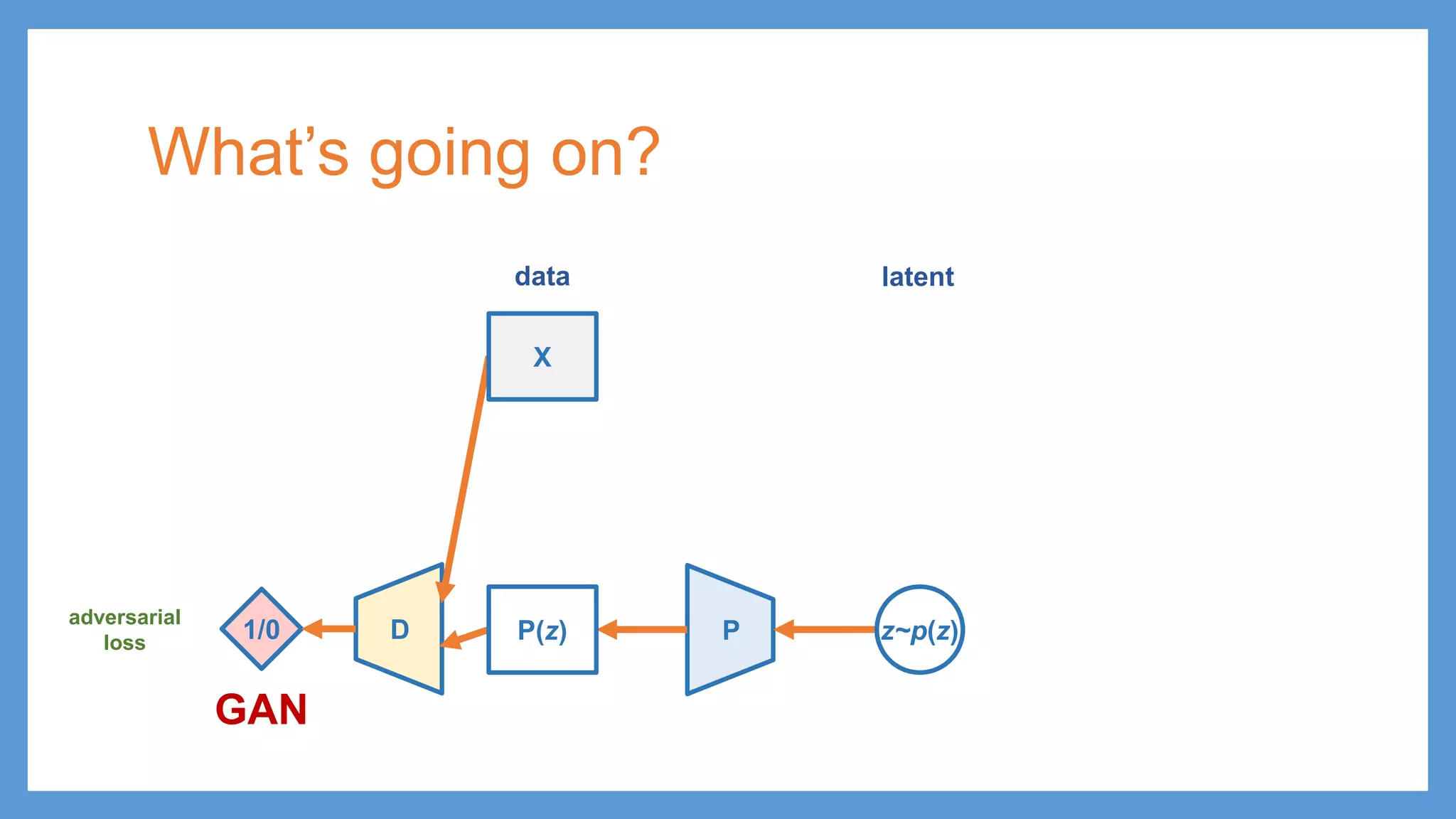
GAN (Generative AdversarialNetwork) • minimize distance between the distribution of real data and generated samples Gz~p(z) G(z) D X 1/0 latent data
14.
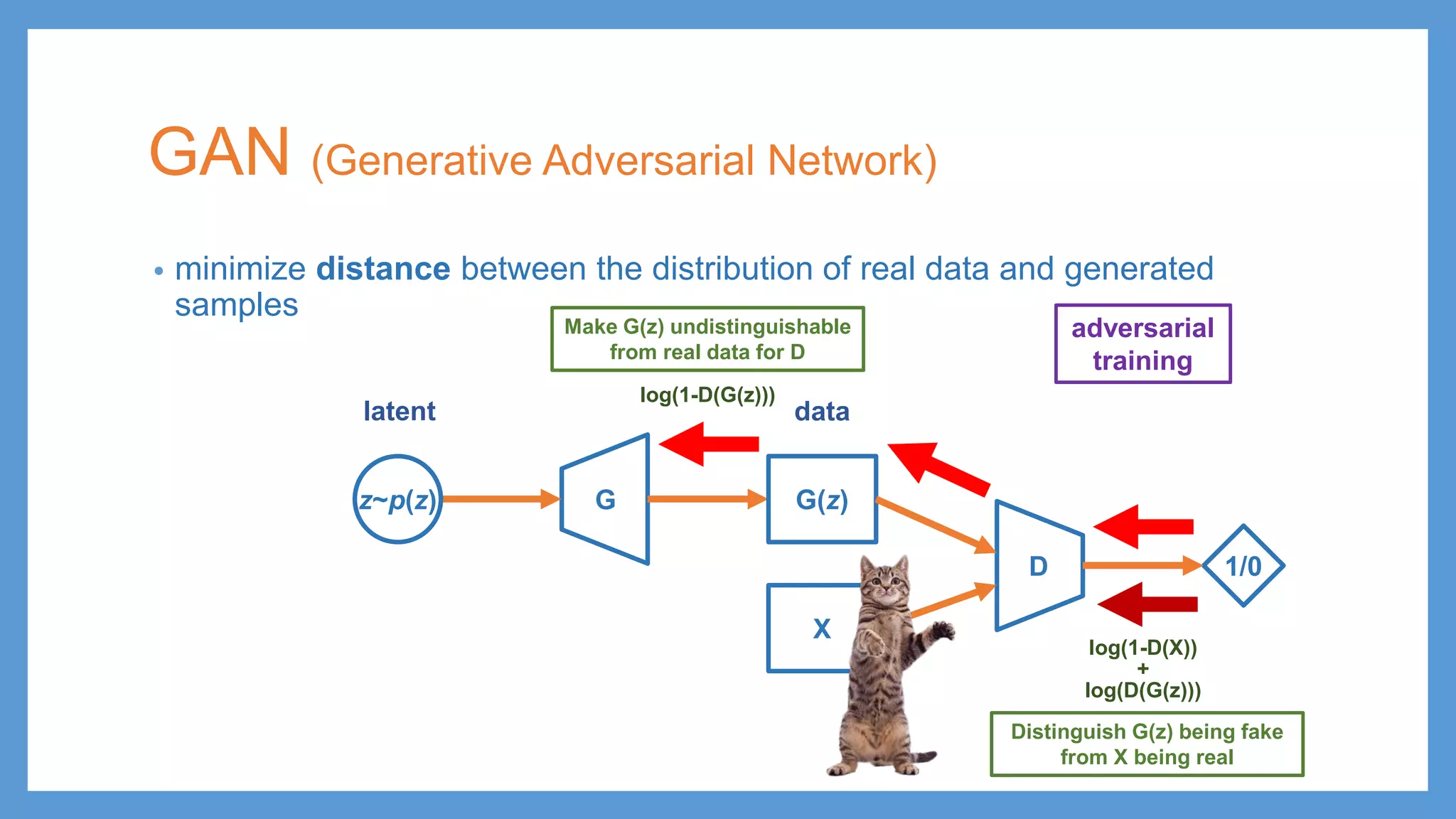
GAN (Generative AdversarialNetwork) • minimize distance between the distribution of real data and generated samples Gz~p(z) G(z) D X 1/0 adversarial training log(1-D(X)) + log(D(G(z))) log(1-D(G(z))) Make G(z) undistinguishable from real data for D Distinguish G(z) being fake from X being real latent data
15.
GAN (Generative AdversarialNetwork) • minimize distance between the distribution of real data and generated samples Gz~p(z) G(z) D X 1/0 adversarial training log(1-D(X)) + log(D(G(z))) log(1-D(G(z))) Make G(z) undistinguishable from real data for D Distinguish G(z) being fake from X being real latent data
16.
GAN (Generative AdversarialNetwork) • minimize distance between the distribution of real data and generated samples Gz~p(z) G(z) D X 1/0 adversarial training log(1-D(X)) + log(D(G(z))) log(1-D(G(z))) Make G(z) undistinguishable from real data for D Distinguish G(z) being fake from X being real latent data
17.
GAN (Generative AdversarialNetwork) • minimize distance between the distribution of real data and generated samples Gz~p(z) G(z) D X 1/0 adversarial training log(1-D(X)) + log(D(G(z))) log(1-D(G(z))) Make G(z) undistinguishable from real data for D Distinguish G(z) being fake from X being real testing (generation) latent data
18.
GAN vs VAE •GAN • Generator aim to fool the discriminator • Discriminator aim to distinguish generated data from real data • output images are sharper • higher diversity, lower stability • VAE • Objective: reconstruct real data • using pixel-to-pixel loss • output images are more blurred • lower diversity, higher stability GAN VAE A. B. L. Larsen, S. K. Sønderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
19.
GAN vs VAE •GAN • Generator aim to fool the discriminator • Discriminator aim to distinguish generated data from real data • output images are sharper • higher diversity, lower stability • VAE • Objective: reconstruct real data • using pixel-to-pixel loss • output images are more blurred • lower diversity, higher stability GAN VAE A. B. L. Larsen, S. K. Sønderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
20.
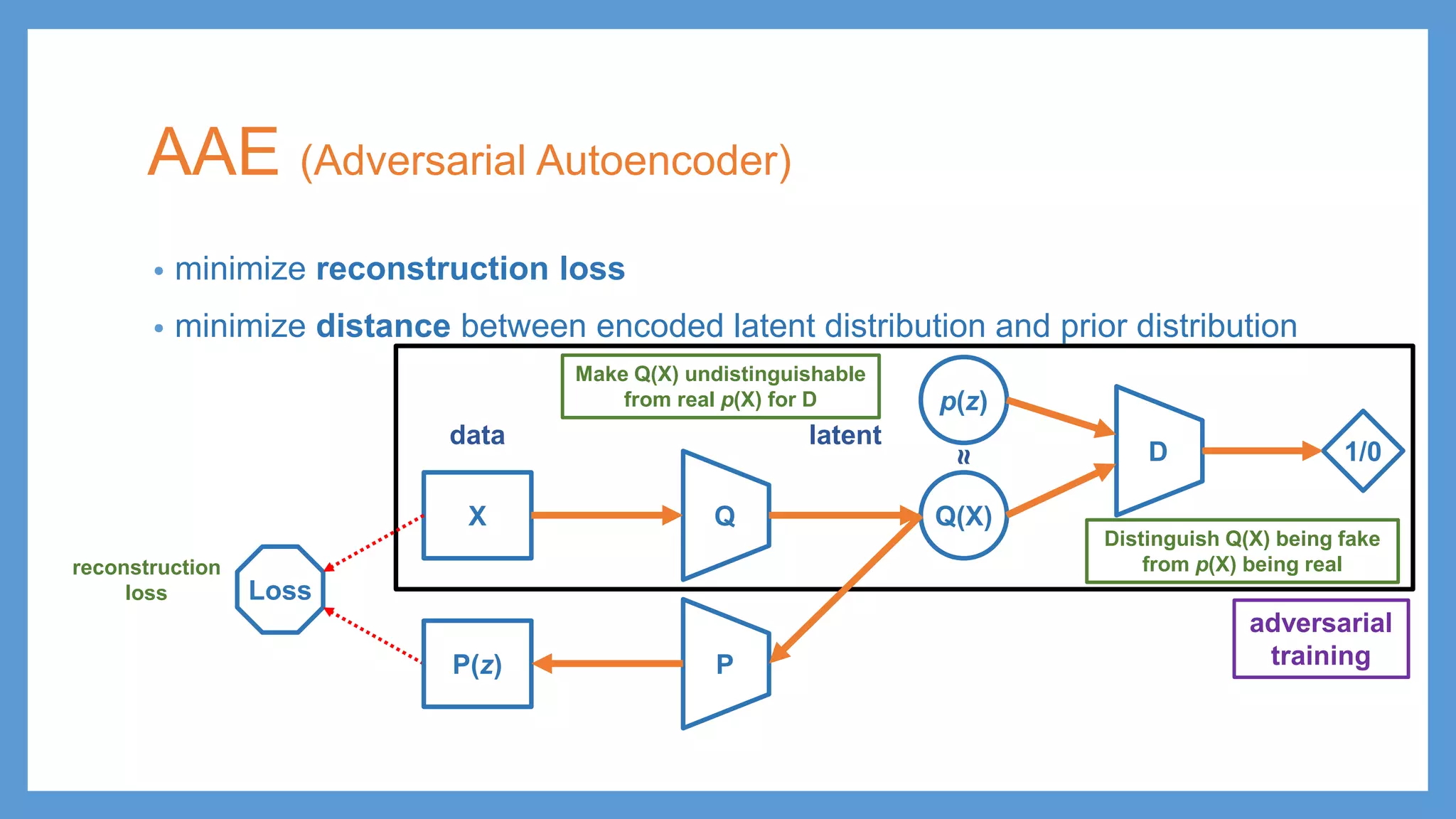
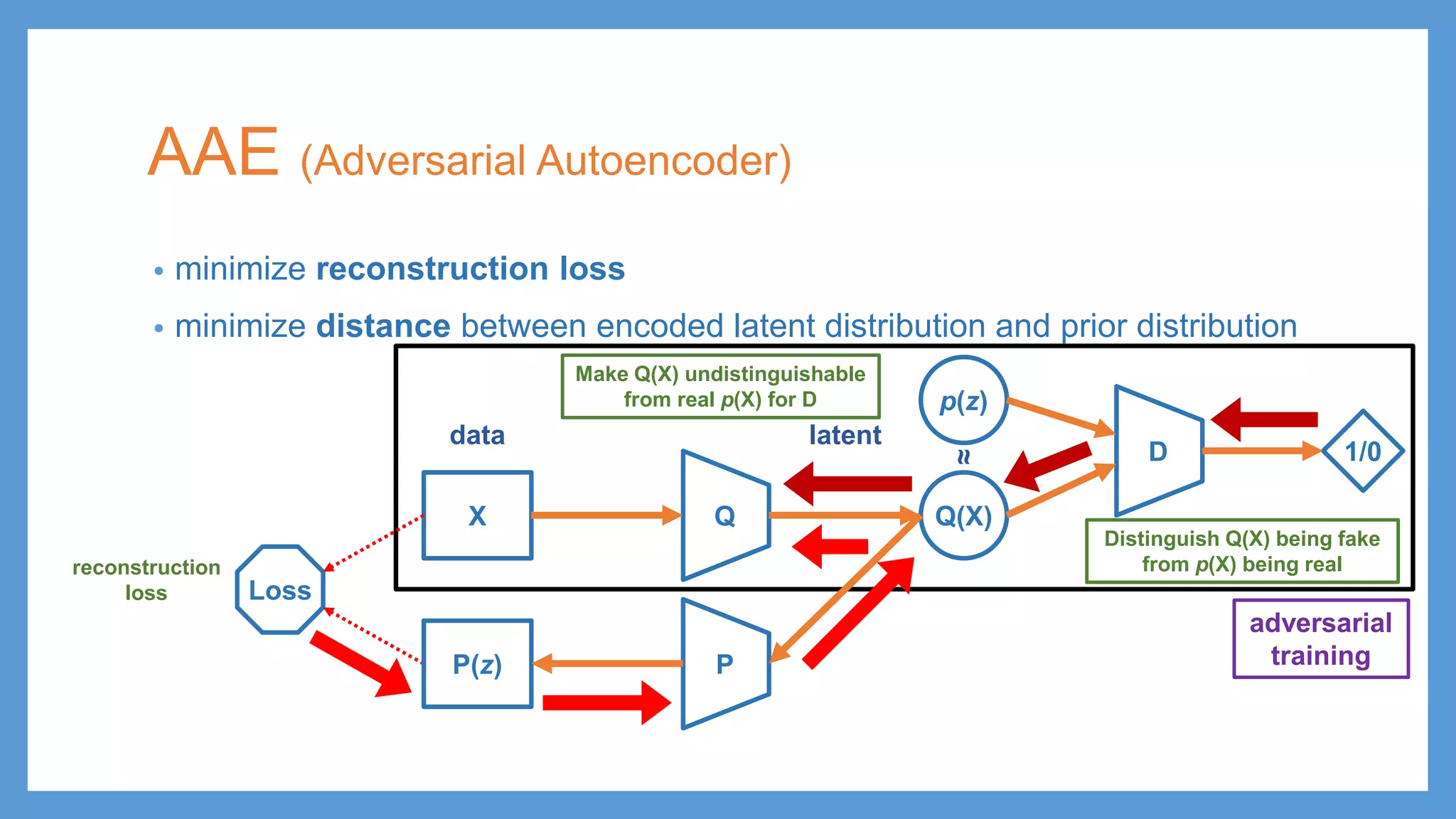
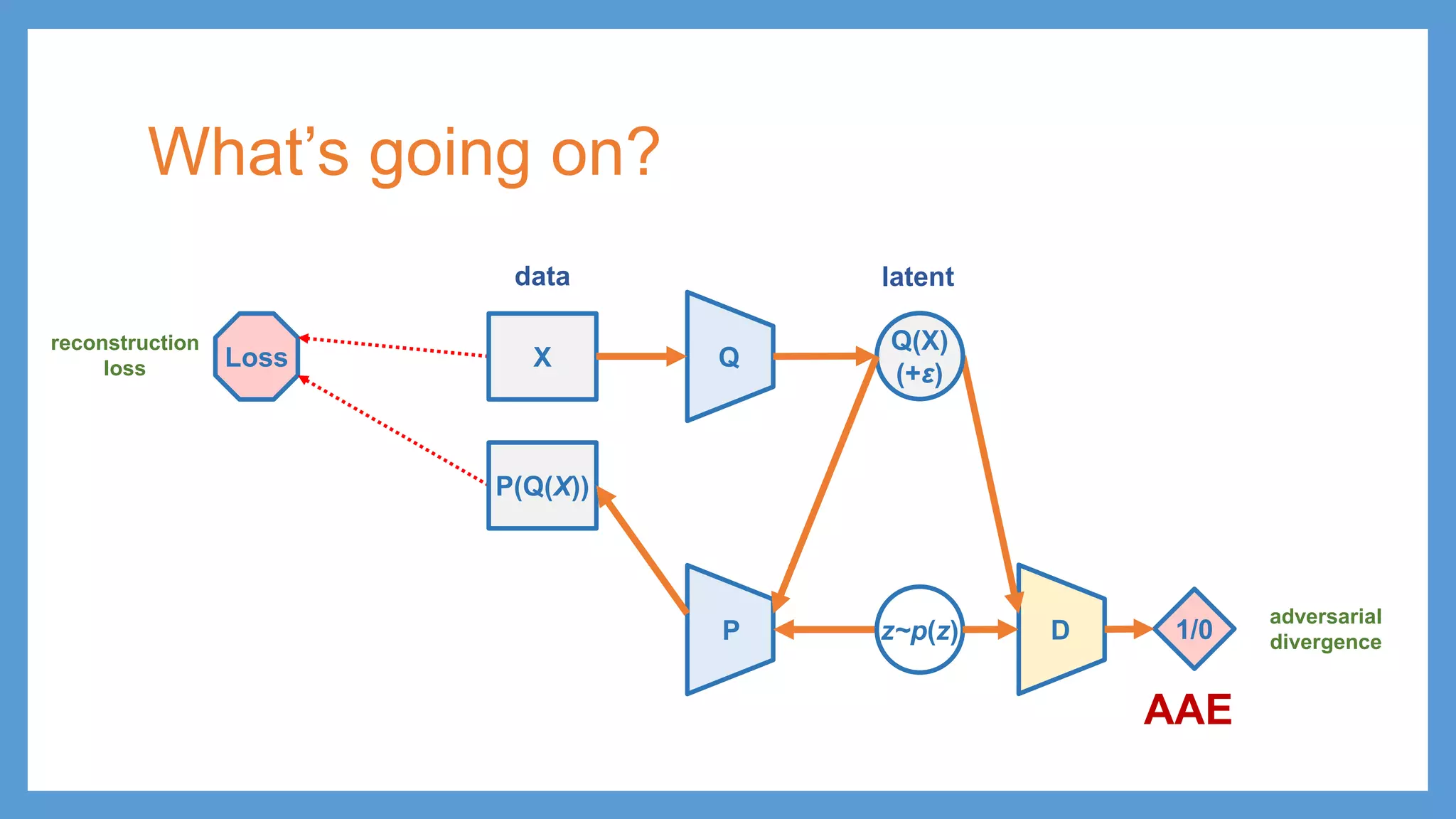
AAE (Adversarial Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss PP(z) z ε reconstruction loss latentdata ≈ Loss KL divergence
21.
AAE (Adversarial Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss PP(z) reconstruction loss latentdata ≈ D 1/0 adversarial training Make Q(X) undistinguishable from real p(X) for D Distinguish Q(X) being fake from p(X) being real
22.
AAE (Adversarial Autoencoder) •minimize reconstruction loss • minimize distance between encoded latent distribution and prior distribution QX Q(X) p(z) Loss PP(z) reconstruction loss latentdata ≈ D 1/0 adversarial training Make Q(X) undistinguishable from real p(X) for D Distinguish Q(X) being fake from p(X) being real
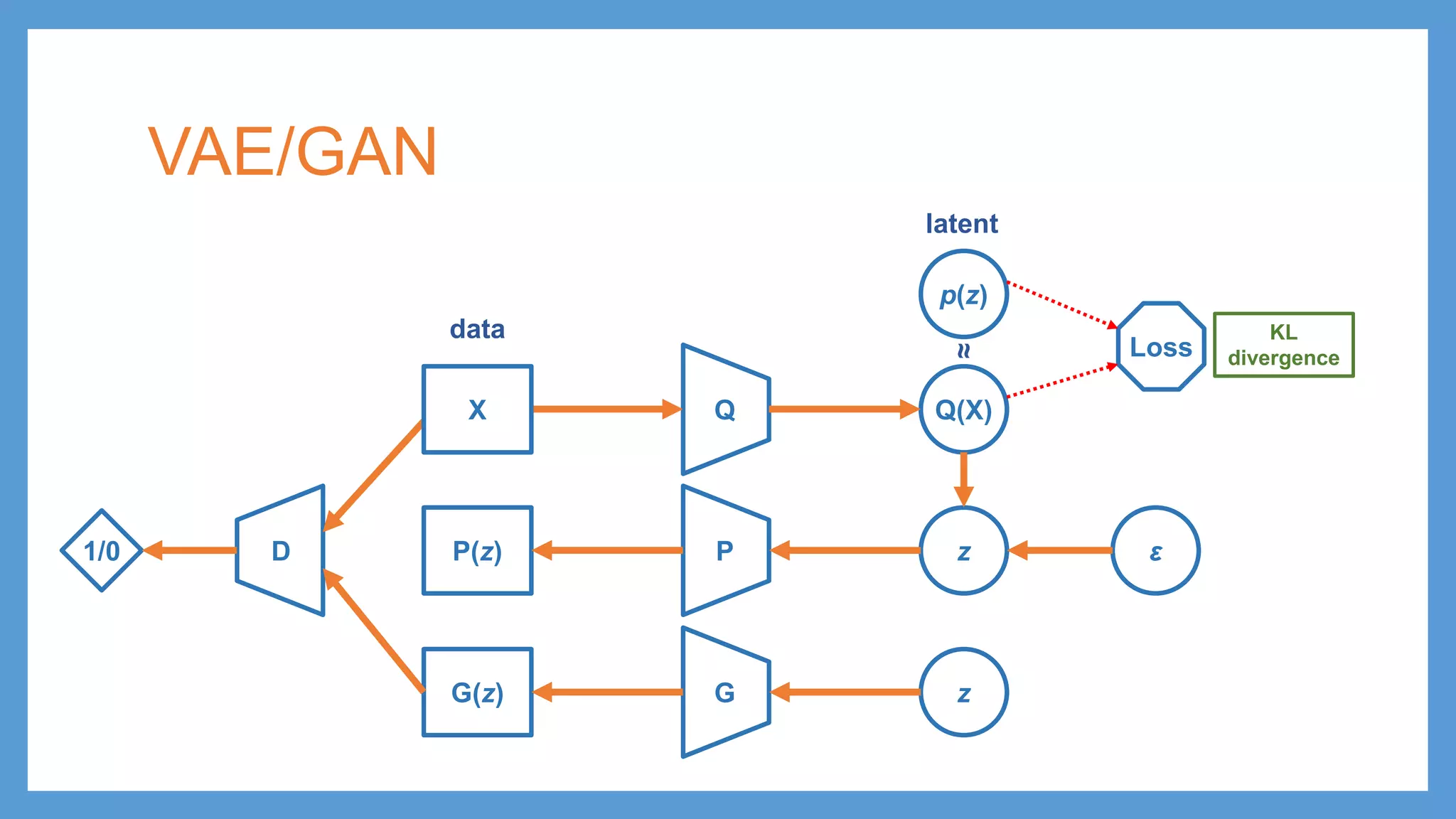
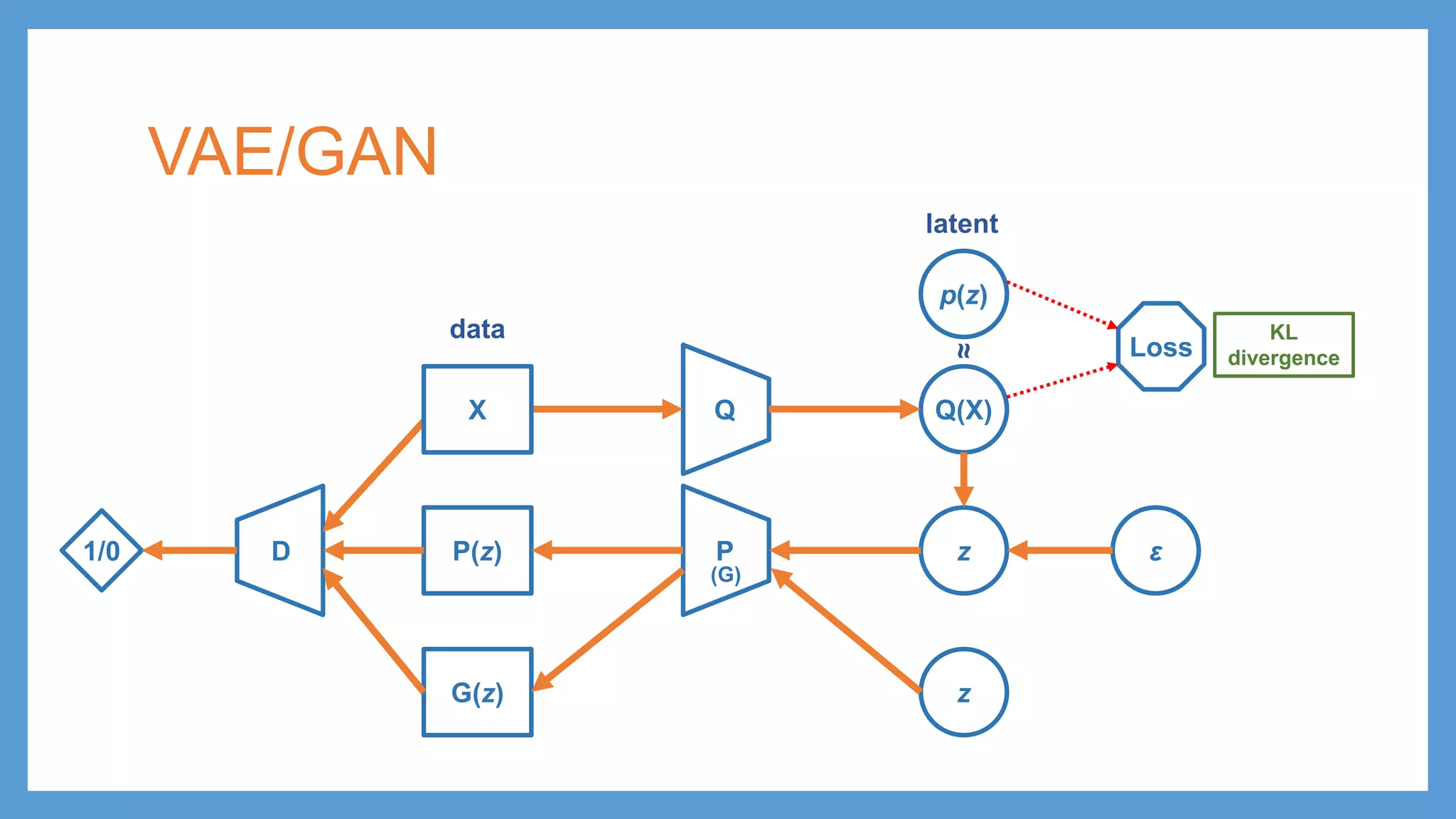
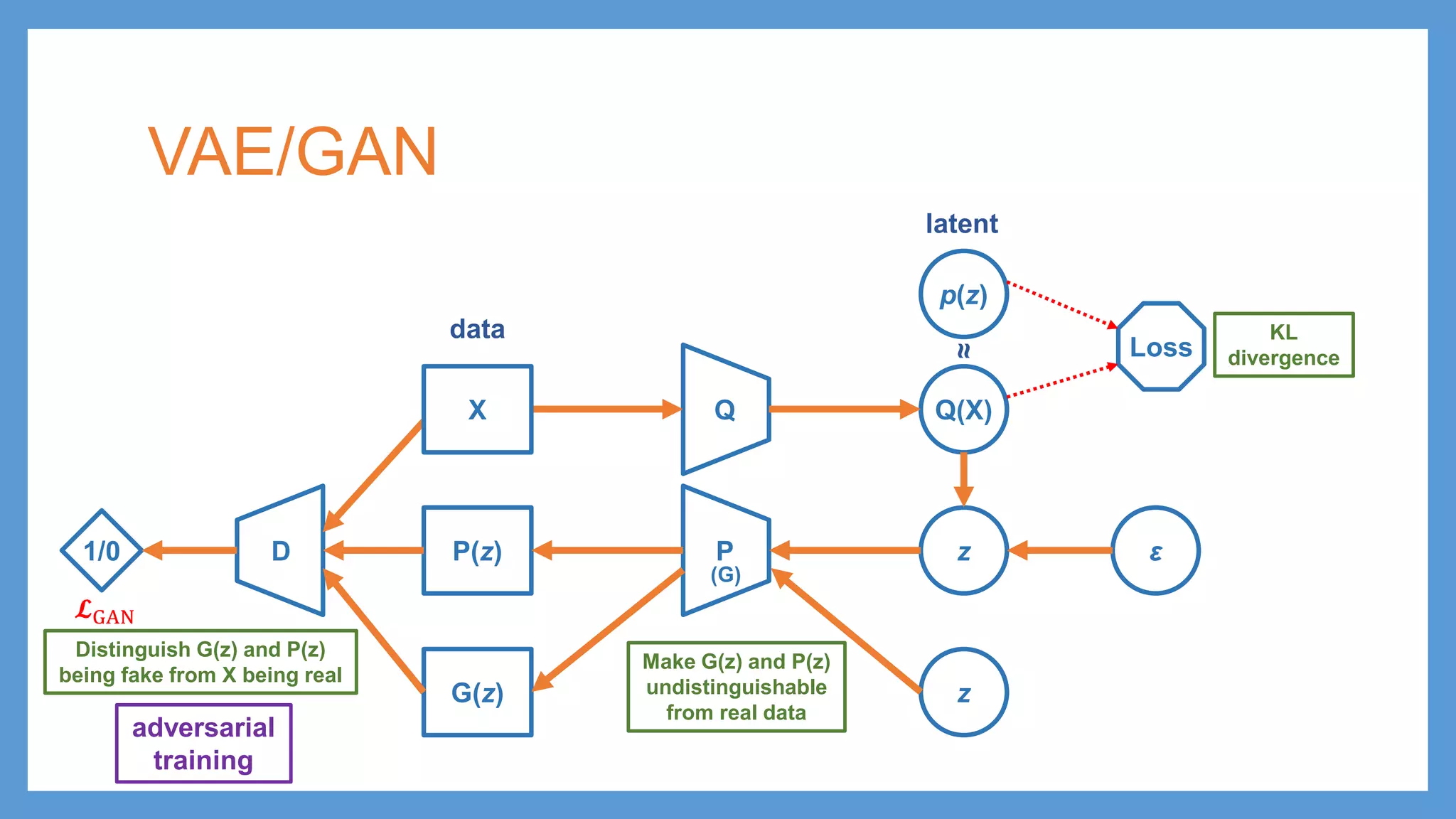
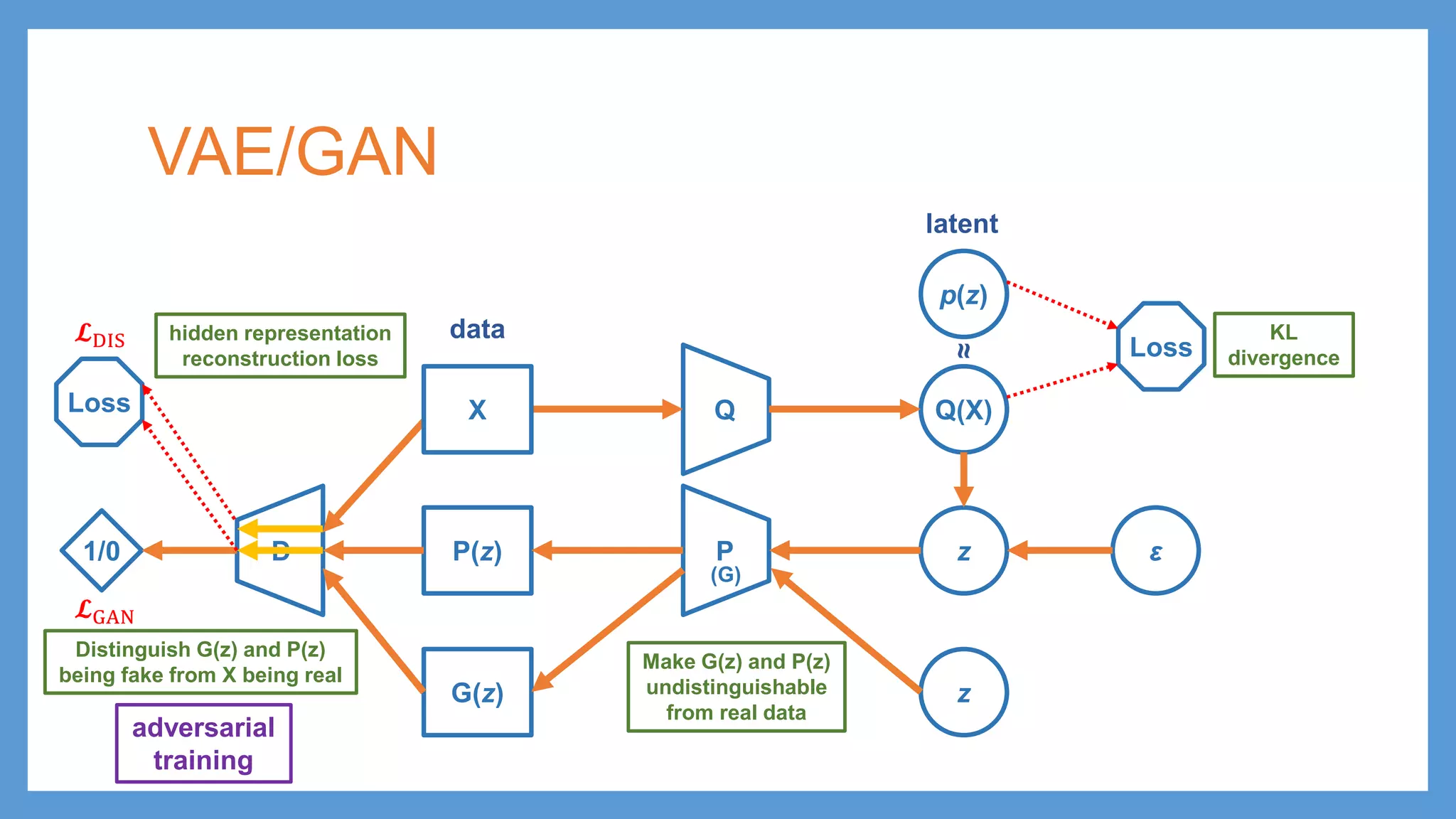
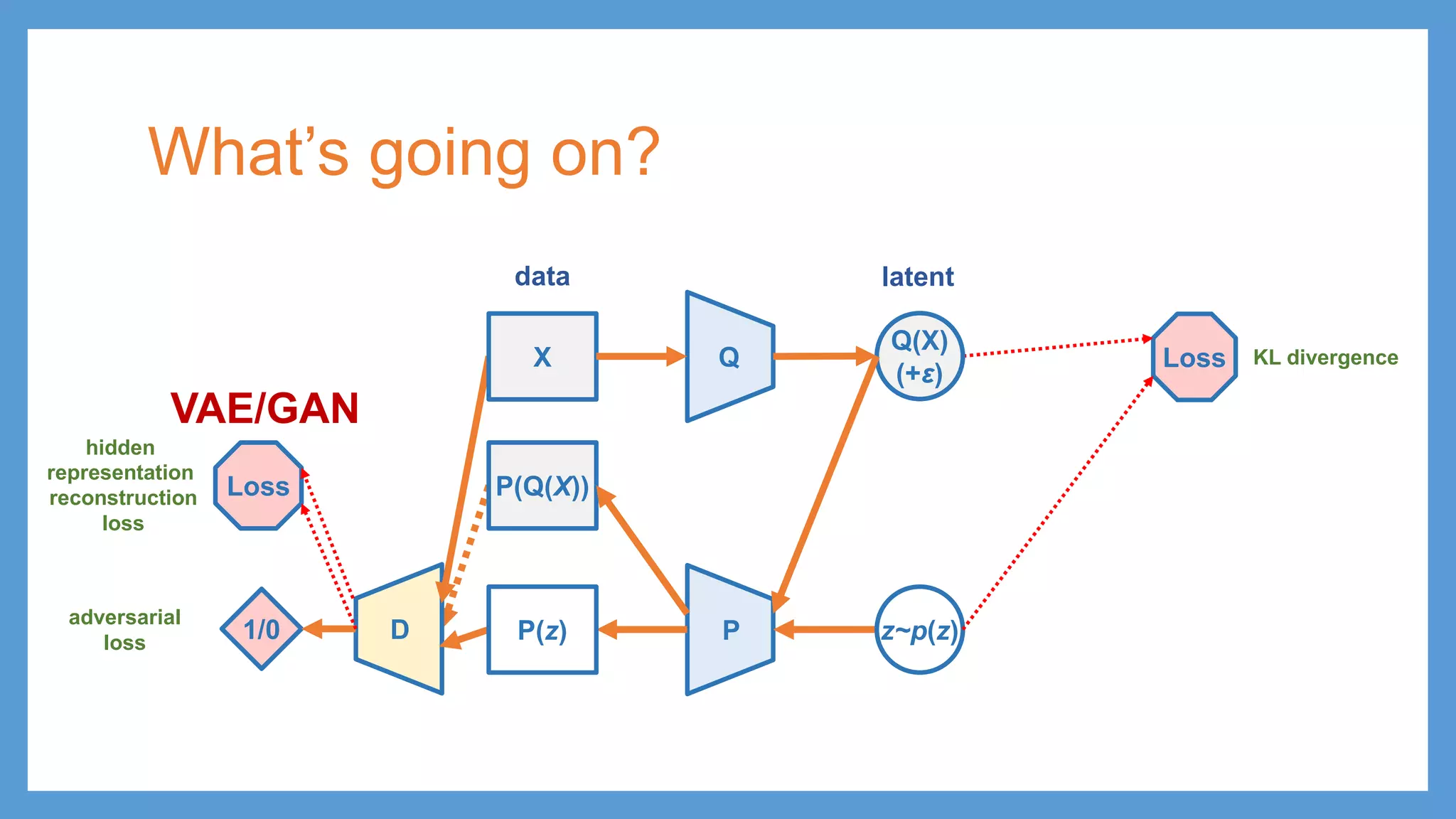
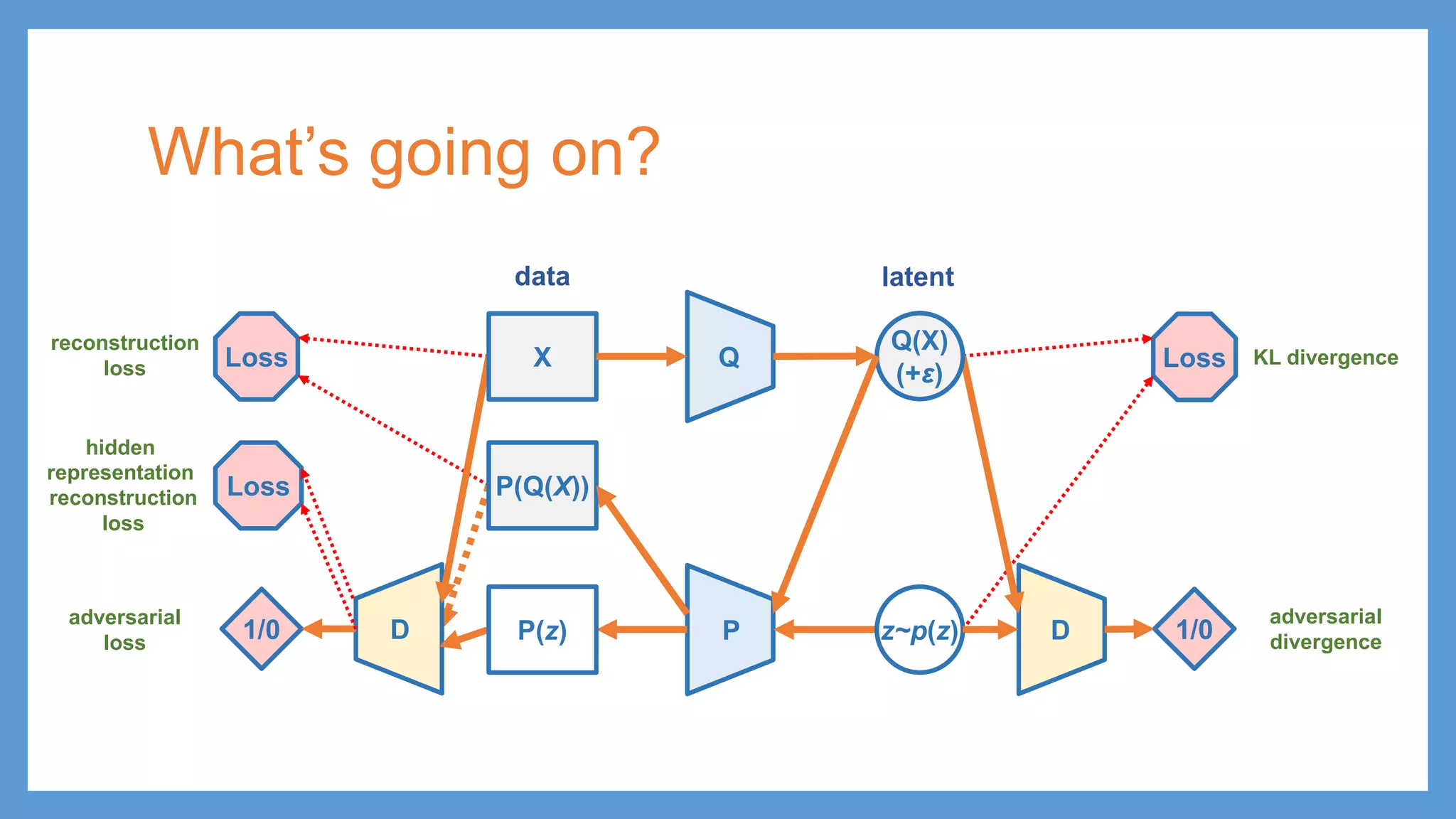
VAE/GAN Q Q(X) p(z) Loss PP(z) zε KL divergence latent data ≈ G(z) z D1/0 adversarial training Distinguish G(z) and P(z) being fake from X being real 𝓛𝓛GAN (G) X Make G(z) and P(z) undistinguishable from real data
28.
VAE/GAN Q Q(X) p(z) Loss PP(z) zε KL divergence latent data ≈ G(z) z D1/0 adversarial training Distinguish G(z) and P(z) being fake from X being real 𝓛𝓛GAN Loss 𝓛𝓛DIS hidden representation reconstruction loss (G) X Make G(z) and P(z) undistinguishable from real data
29.
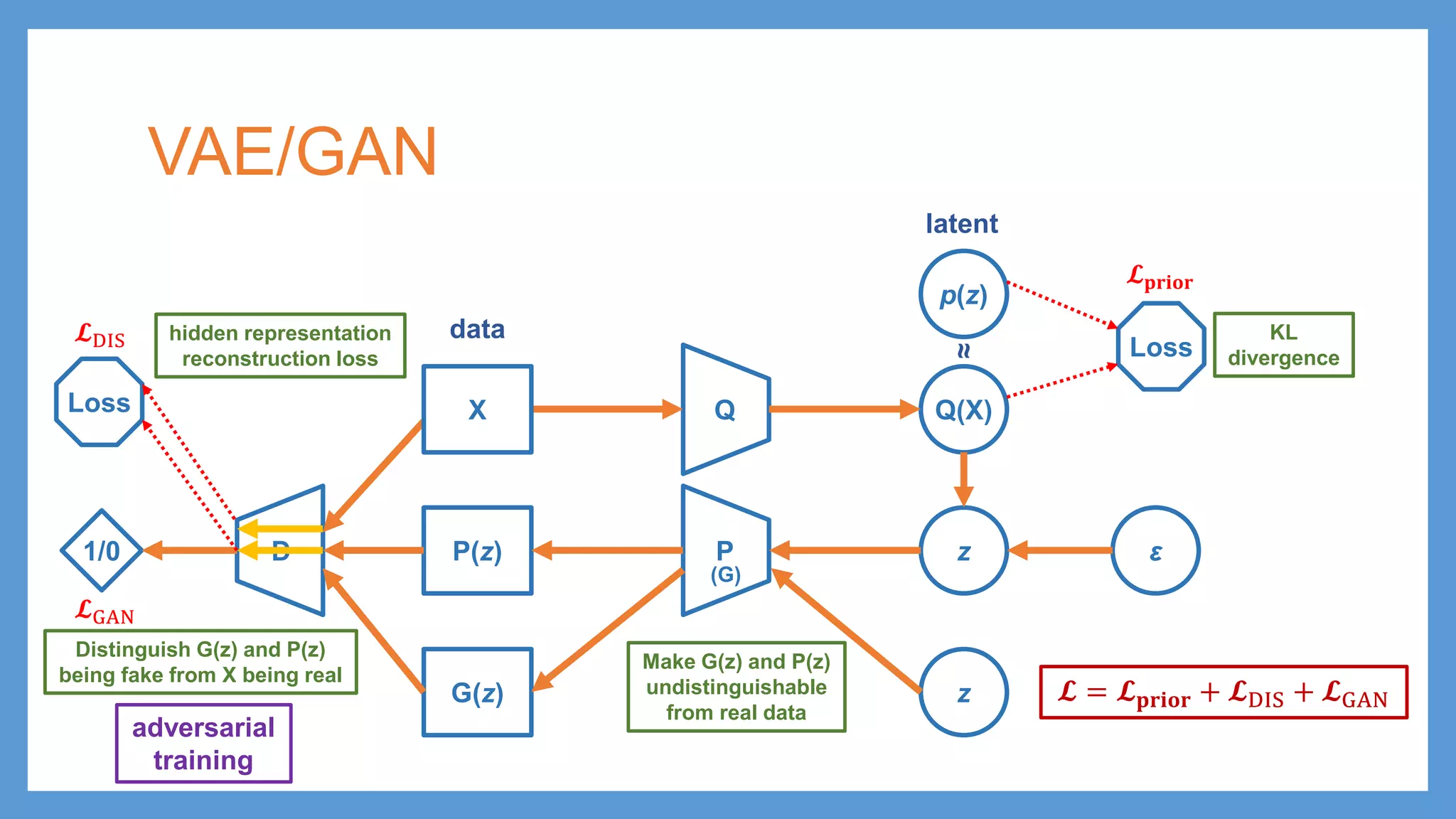
VAE/GAN Q Q(X) p(z) Loss PP(z) zε KL divergence latent data ≈ G(z) z D1/0 adversarial training Distinguish G(z) and P(z) being fake from X being real 𝓛𝓛GAN Loss 𝓛𝓛DIS hidden representation reconstruction loss 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 (G) X Make G(z) and P(z) undistinguishable from real data 𝓛𝓛 = 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 + 𝓛𝓛DIS + 𝓛𝓛GAN
30.
VAE/GAN Q Q(X) p(z) Loss PP(z) zε KL divergence latent data ≈ G(z) z D1/0 adversarial training Distinguish G(z) and P(z) being fake from X being real 𝓛𝓛GAN Loss 𝓛𝓛DIS hidden representation reconstruction loss 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 (G) 𝓛𝓛 = 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 + 𝓛𝓛DIS + 𝓛𝓛GAN X Make G(z) and P(z) undistinguishable from real data
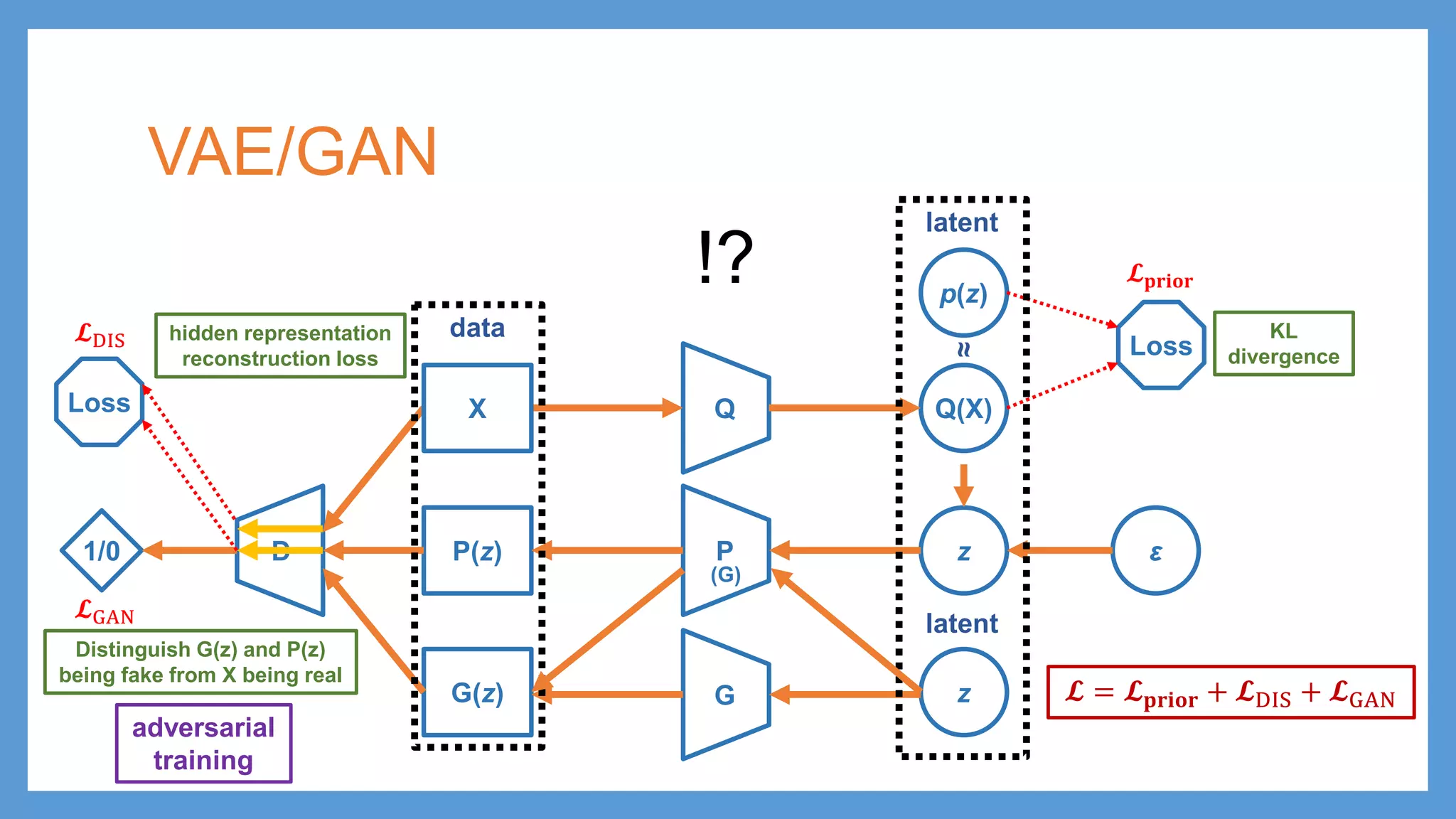
VAE/GAN Q Q(X) p(z) Loss PP(z) zε KL divergence latent data ≈ G(z) zG latent D1/0 adversarial training Distinguish G(z) and P(z) being fake from X being real 𝓛𝓛GAN Loss 𝓛𝓛DIS hidden representation reconstruction loss 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 (G) 𝓛𝓛 = 𝓛𝓛𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩𝐩 + 𝓛𝓛DIS + 𝓛𝓛GAN !? X
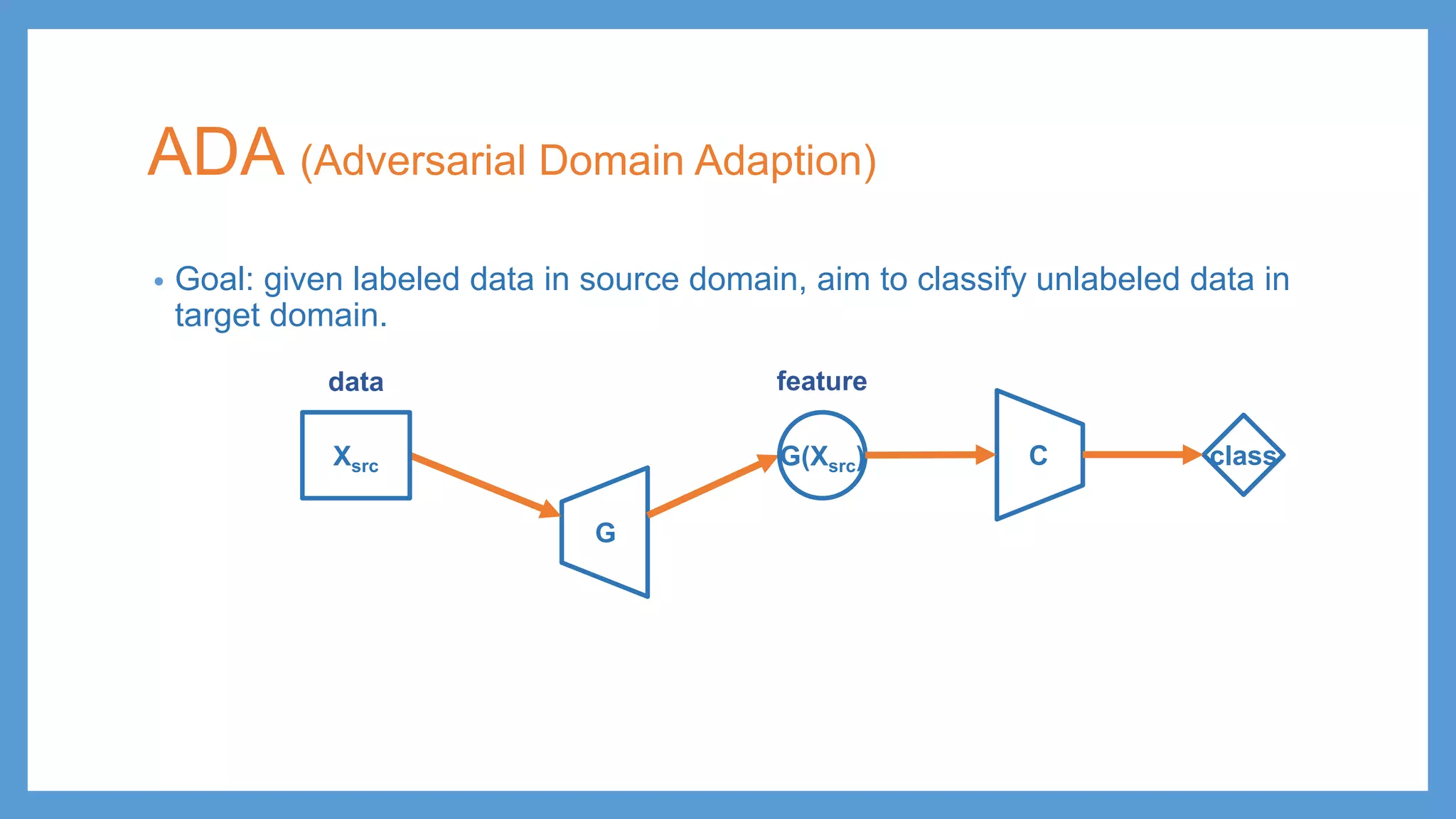
ADA (Adversarial DomainAdaption) • Goal: given labeled data in source domain, aim to classify unlabeled data in target domain. G G(Xsrc) data feature Xsrc C class
40.
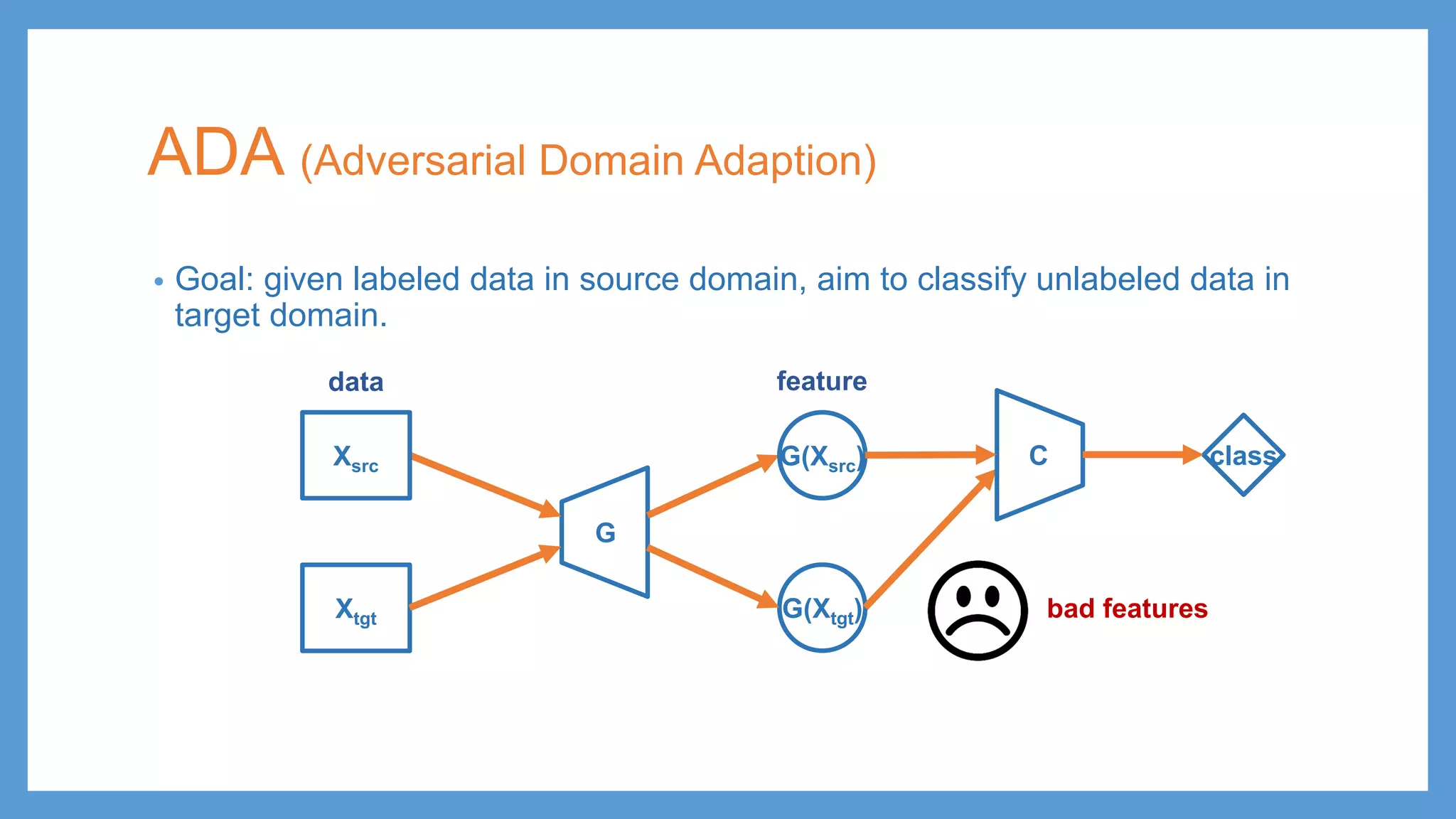
ADA (Adversarial DomainAdaption) • Goal: given labeled data in source domain, aim to classify unlabeled data in target domain. G G(Xsrc) Xtgt data feature Xsrc G(Xtgt) C class bad features
41.
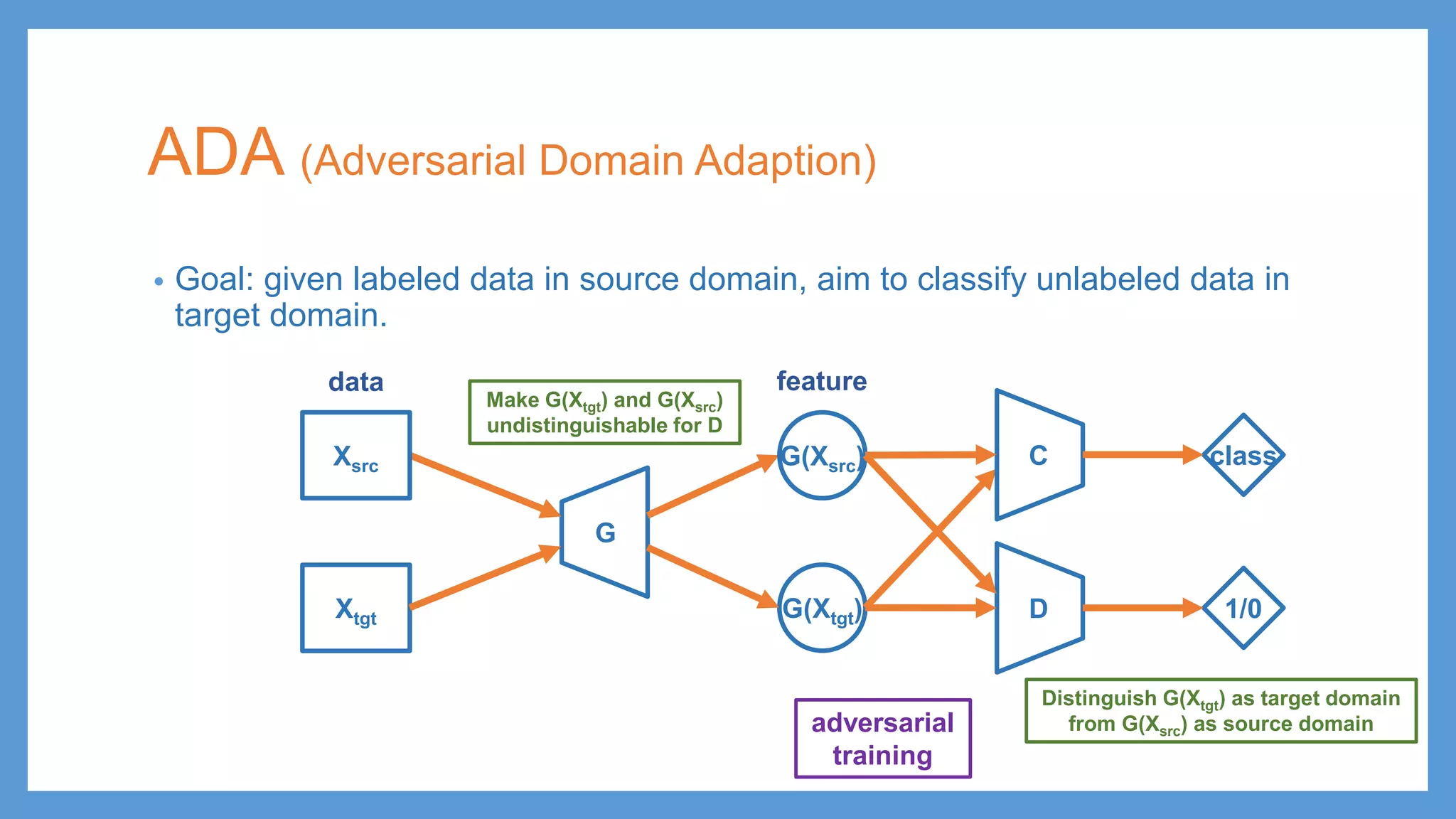
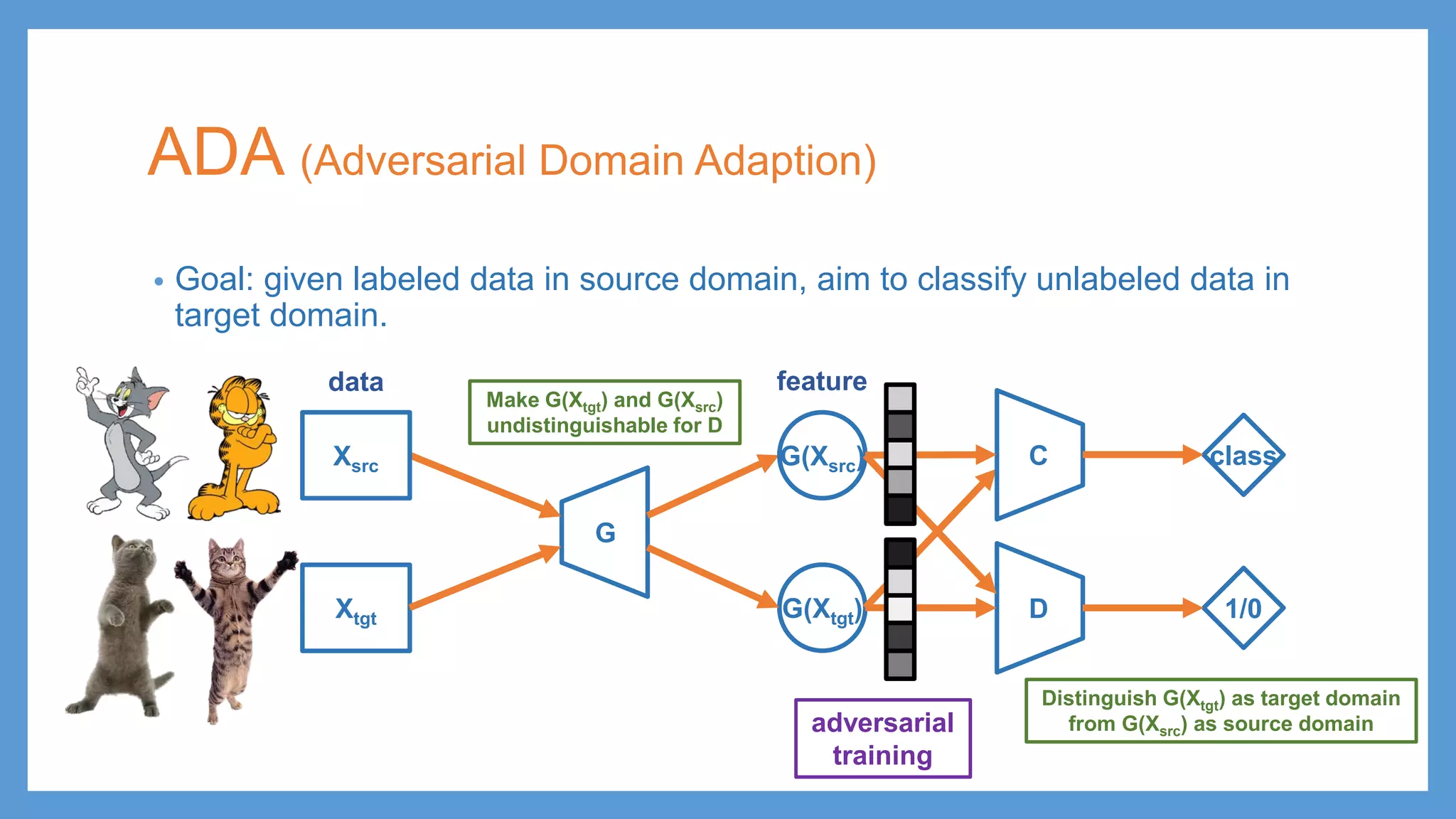
ADA (Adversarial DomainAdaption) • Goal: given labeled data in source domain, aim to classify unlabeled data in target domain. G G(Xsrc) Xtgt adversarial training Make G(Xtgt) and G(Xsrc) undistinguishable for D Distinguish G(Xtgt) as target domain from G(Xsrc) as source domain data feature Xsrc G(Xtgt) D 1/0 C class
42.
ADA (Adversarial DomainAdaption) • Goal: given labeled data in source domain, aim to classify unlabeled data in target domain. G G(Xsrc) Xtgt adversarial training Make G(Xtgt) and G(Xsrc) undistinguishable for D Distinguish G(Xtgt) as target domain from G(Xsrc) as source domain data feature Xsrc G(Xtgt) D 1/0 C class
43.
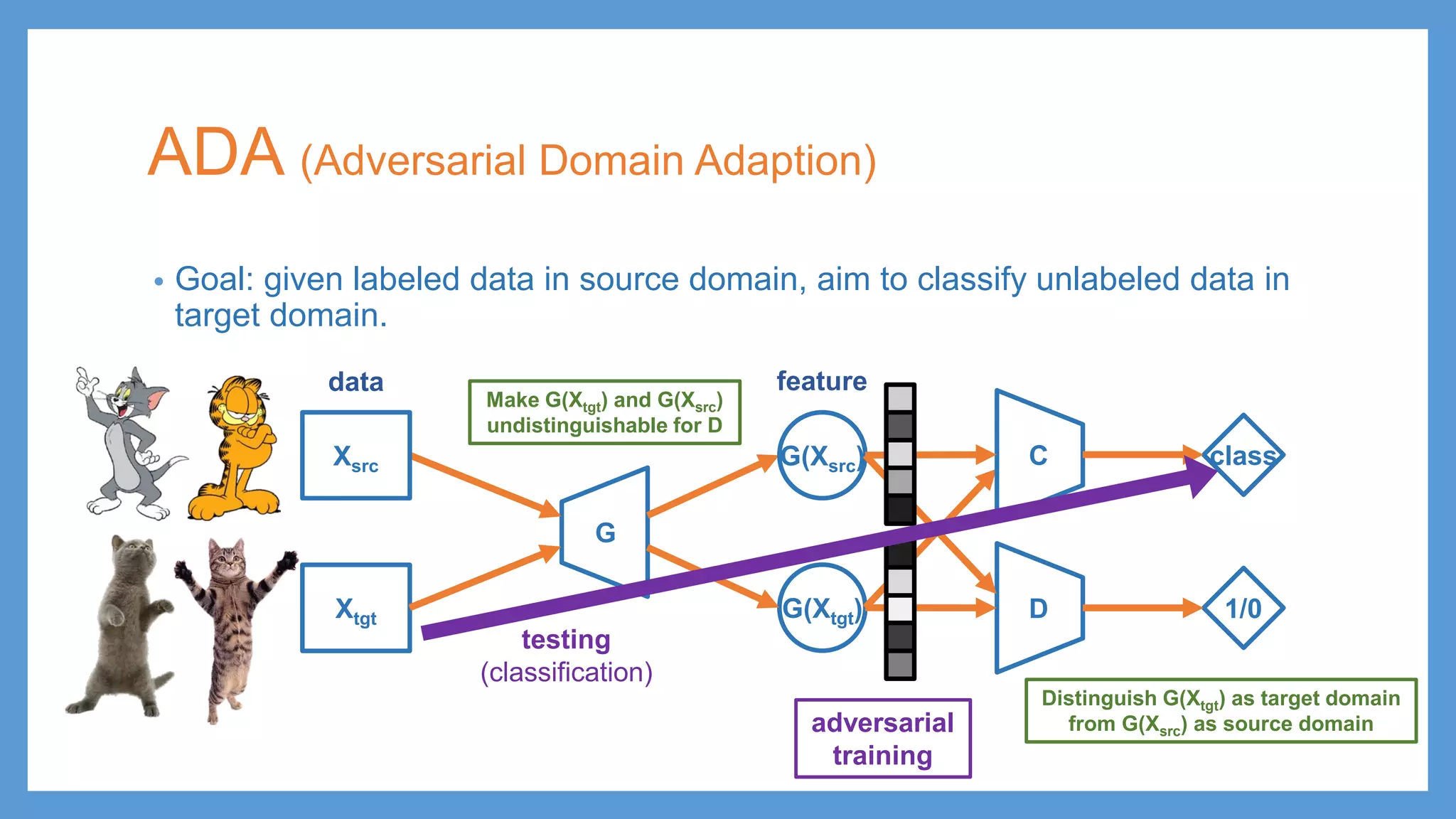
ADA (Adversarial DomainAdaption) • Goal: given labeled data in source domain, aim to classify unlabeled data in target domain. G G(Xsrc) Xtgt adversarial training Make G(Xtgt) and G(Xsrc) undistinguishable for D Distinguish G(Xtgt) as target domain from G(Xsrc) as source domain data feature Xsrc G(Xtgt) D 1/0 C class testing (classification)
44.
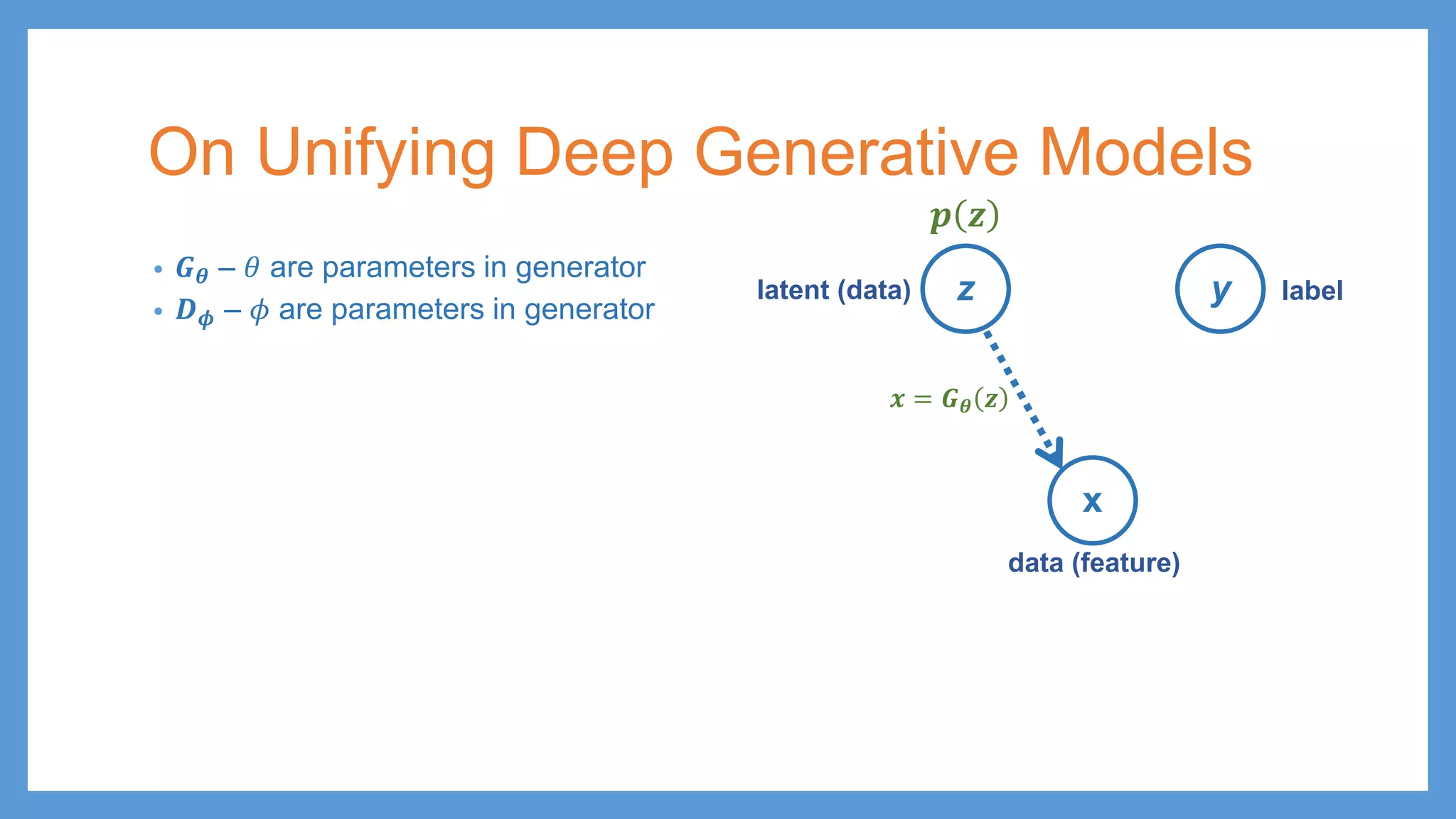
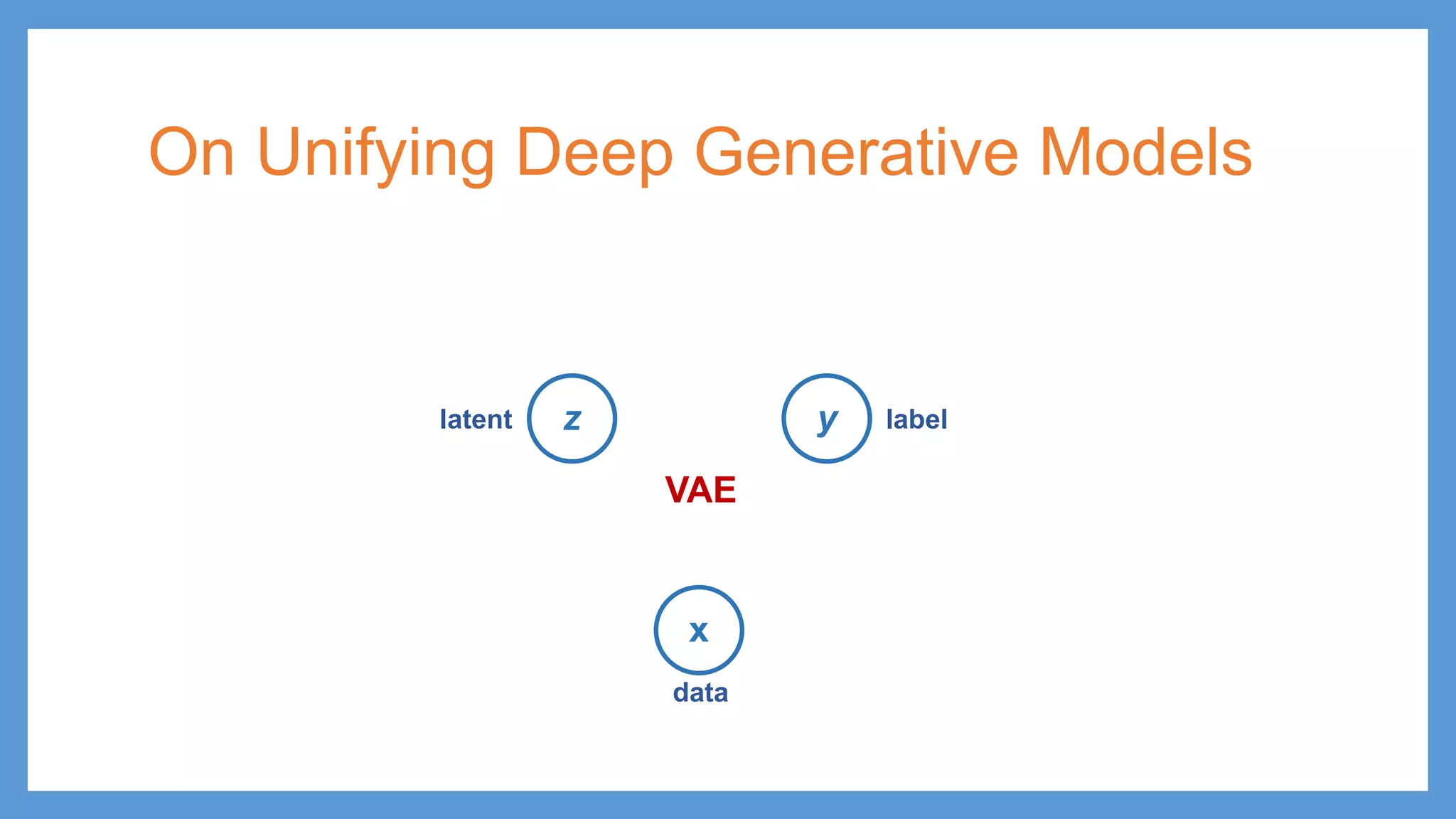
On Unifying DeepGenerative Models z y x latent (data) data (feature) label
45.
On Unifying DeepGenerative Models z y x latent (data) data (feature) label 𝒑𝒑 𝒛𝒛
46.
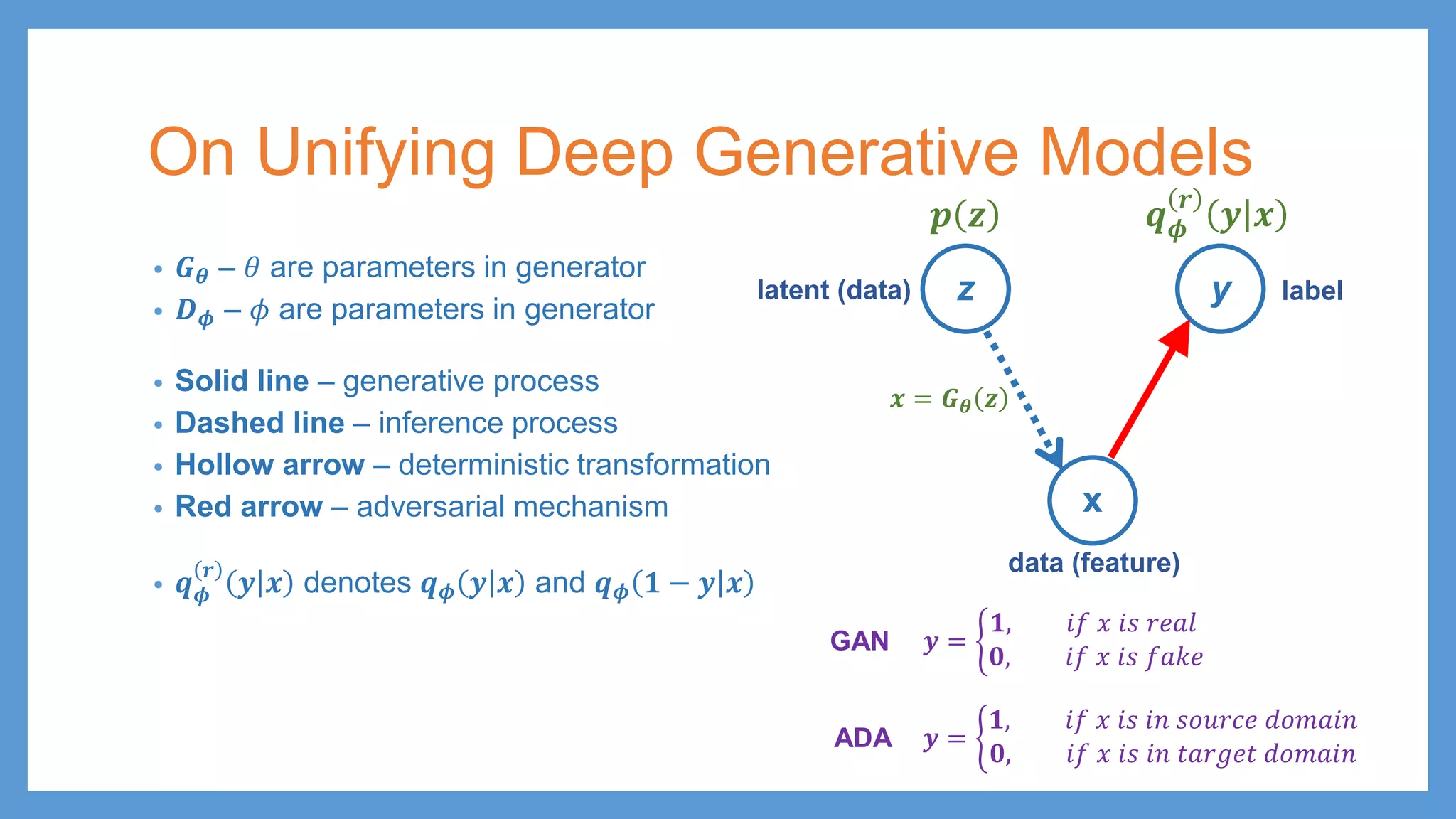
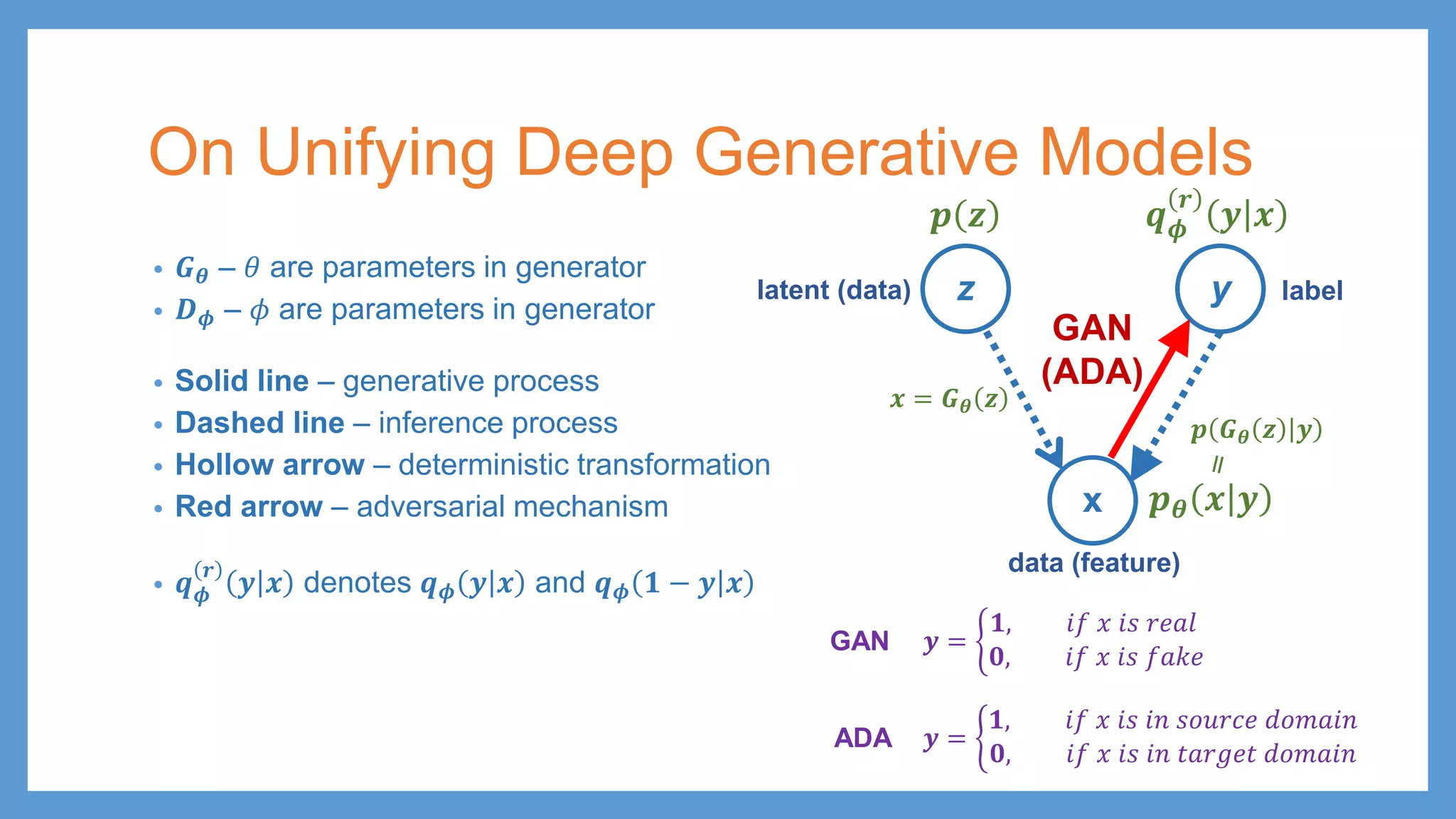
On Unifying DeepGenerative Models • 𝑮𝑮𝜽𝜽 – 𝜃𝜃 are parameters in generator • 𝑫𝑫𝝓𝝓 – 𝜙𝜙 are parameters in generator z y x latent (data) data (feature) label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛
47.
On Unifying DeepGenerative Models • 𝑮𝑮𝜽𝜽 – 𝜃𝜃 are parameters in generator • 𝑫𝑫𝝓𝝓 – 𝜙𝜙 are parameters in generator • Solid line – generative process • Dashed line – inference process • Hollow arrow – deterministic transformation • Red arrow – adversarial mechanism • 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 denotes 𝒒𝒒𝝓𝝓 𝒚𝒚 𝒙𝒙 and 𝒒𝒒𝝓𝝓 𝟏𝟏 − 𝒚𝒚 𝒙𝒙 z y x 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent (data) data (feature) label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 = � 𝟏𝟏, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑖𝑖𝑖𝑖 𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠 𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑 𝟎𝟎, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑖𝑖𝑖𝑖 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑 ADA 𝒚𝒚 = � 𝟏𝟏, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟 𝟎𝟎, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑓𝑓𝑓𝑓𝑓𝑓𝑓𝑓 GAN
48.
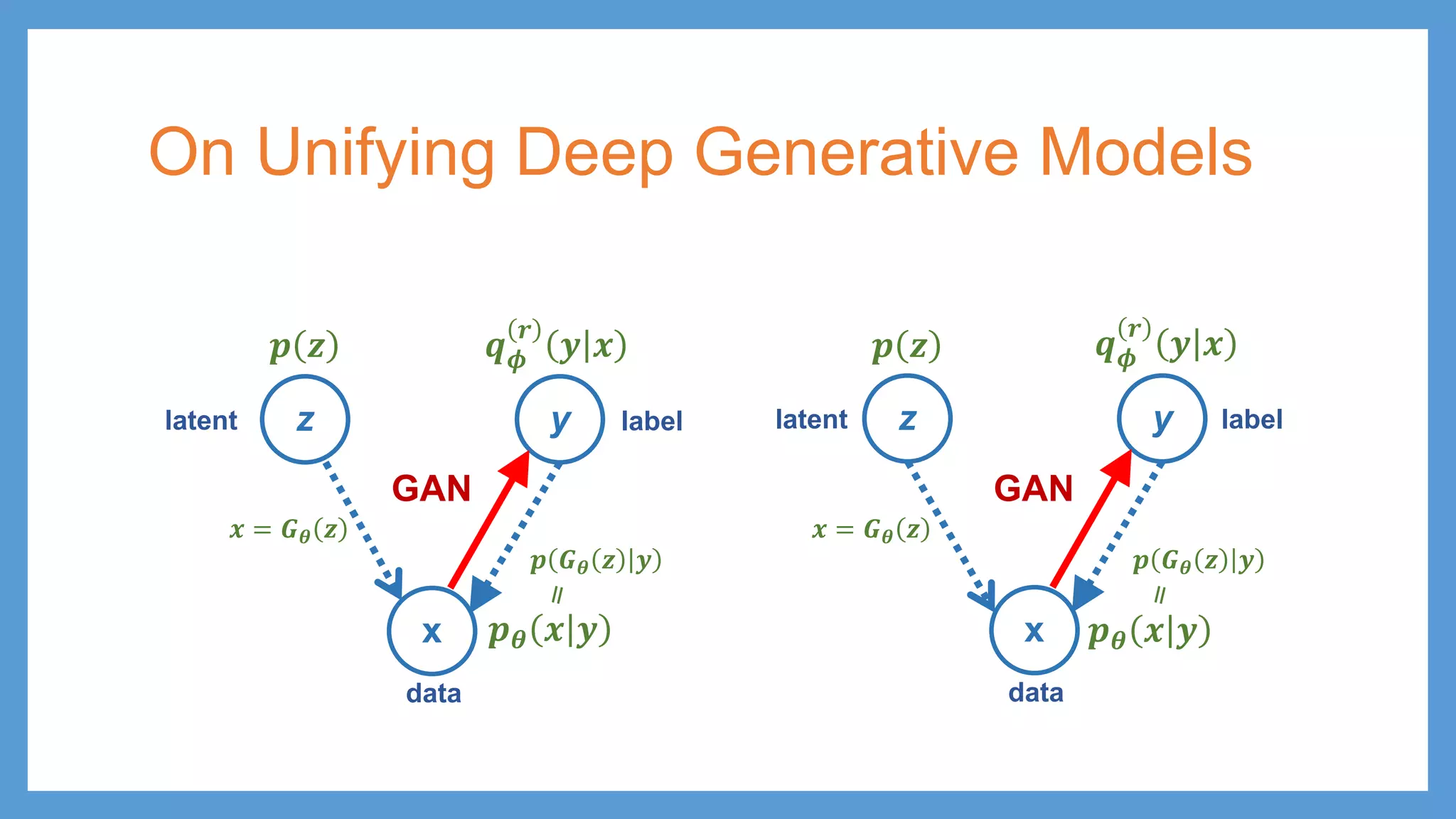
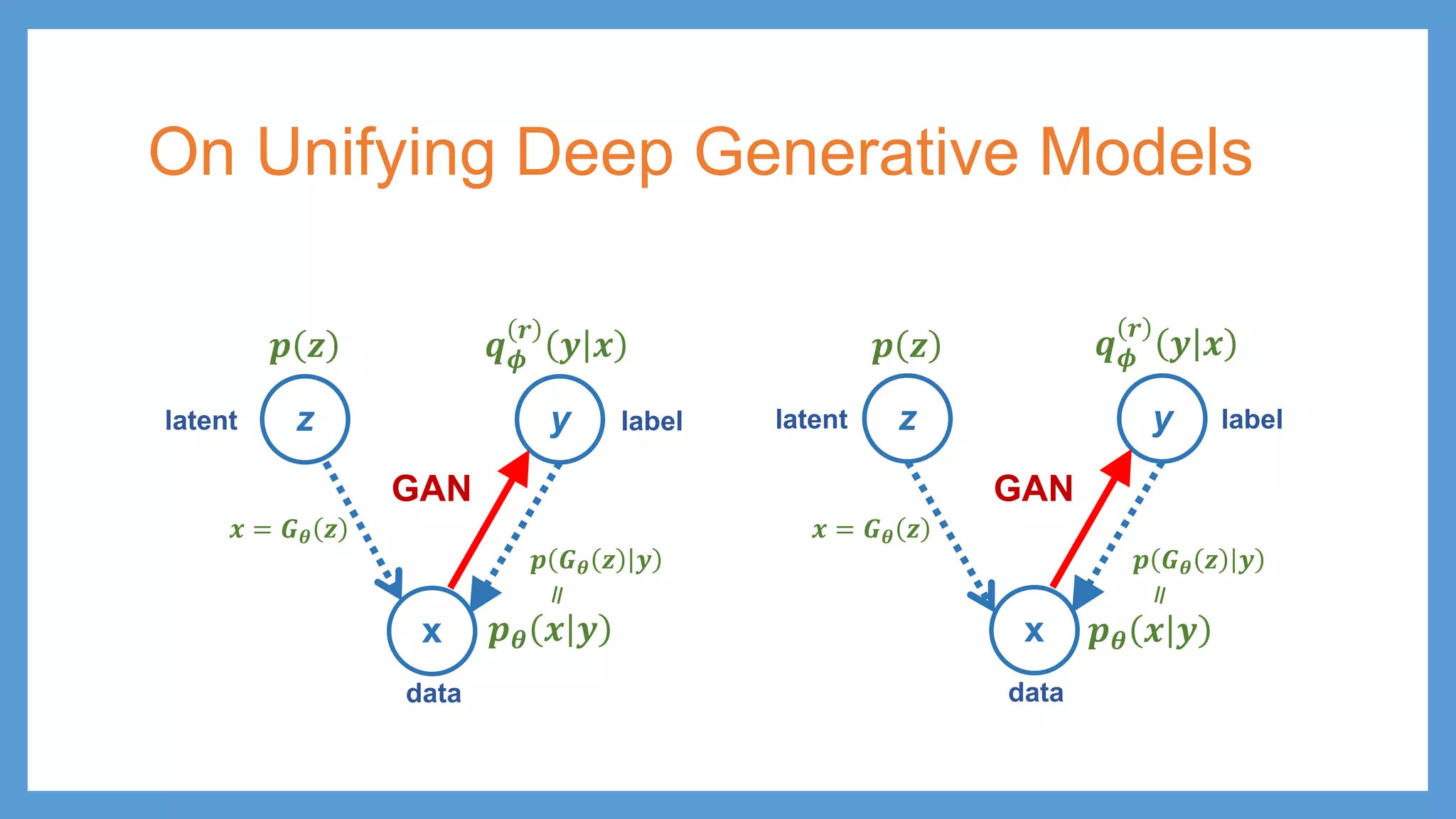
On Unifying DeepGenerative Models • 𝑮𝑮𝜽𝜽 – 𝜃𝜃 are parameters in generator • 𝑫𝑫𝝓𝝓 – 𝜙𝜙 are parameters in generator • Solid line – generative process • Dashed line – inference process • Hollow arrow – deterministic transformation • Red arrow – adversarial mechanism • 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 denotes 𝒒𝒒𝝓𝝓 𝒚𝒚 𝒙𝒙 and 𝒒𝒒𝝓𝝓 𝟏𝟏 − 𝒚𝒚 𝒙𝒙 z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒚𝒚 = � 𝟏𝟏, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟 𝟎𝟎, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑓𝑓𝑓𝑓𝑓𝑓𝑓𝑓 GAN 𝒚𝒚 = � 𝟏𝟏, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑖𝑖𝑖𝑖 𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠 𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑 𝟎𝟎, 𝑖𝑖𝑖𝑖 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑖𝑖𝑖𝑖 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑 ADA latent (data) data (feature) label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN (ADA)
On Unifying DeepGenerative Models z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data labelz y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN 𝒑𝒑 𝒛𝒛 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN
56.
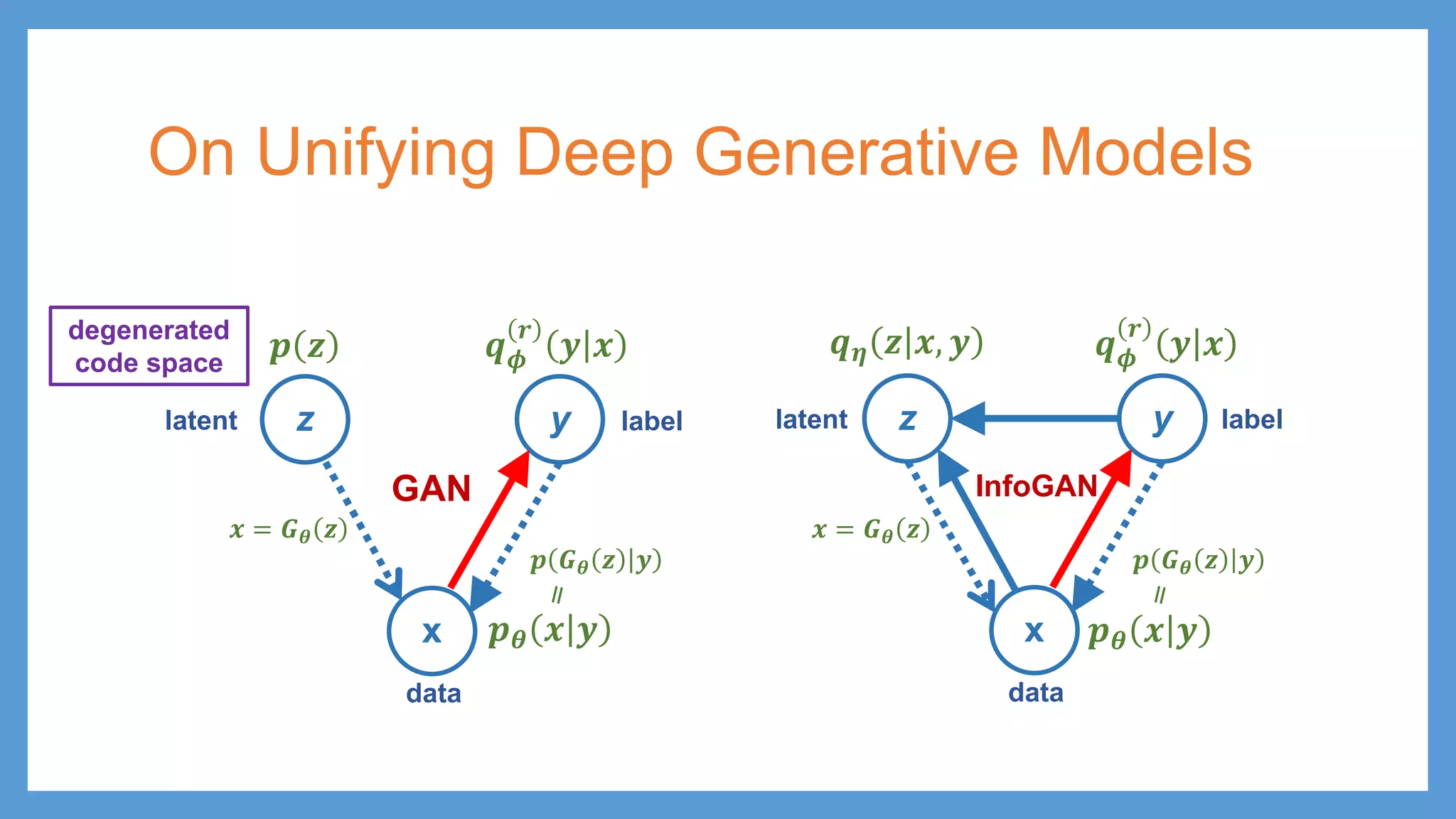
On Unifying DeepGenerative Models z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data label 𝒒𝒒𝜼𝜼 𝒛𝒛 𝒙𝒙, 𝒚𝒚 InfoGAN z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN degenerated code space 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚
57.
On Unifying DeepGenerative Models z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data labelz y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN 𝒑𝒑 𝒛𝒛 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN
58.
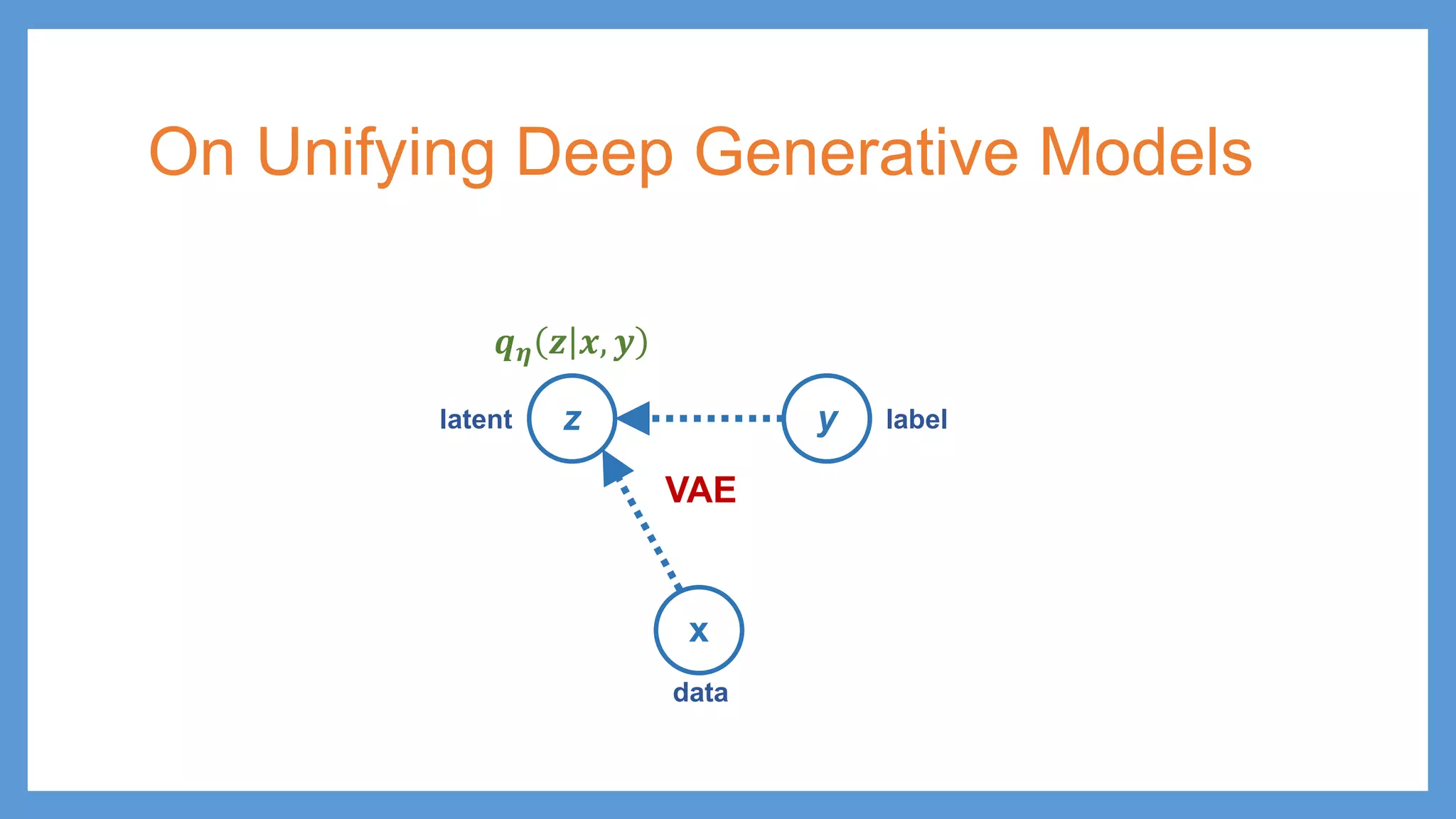
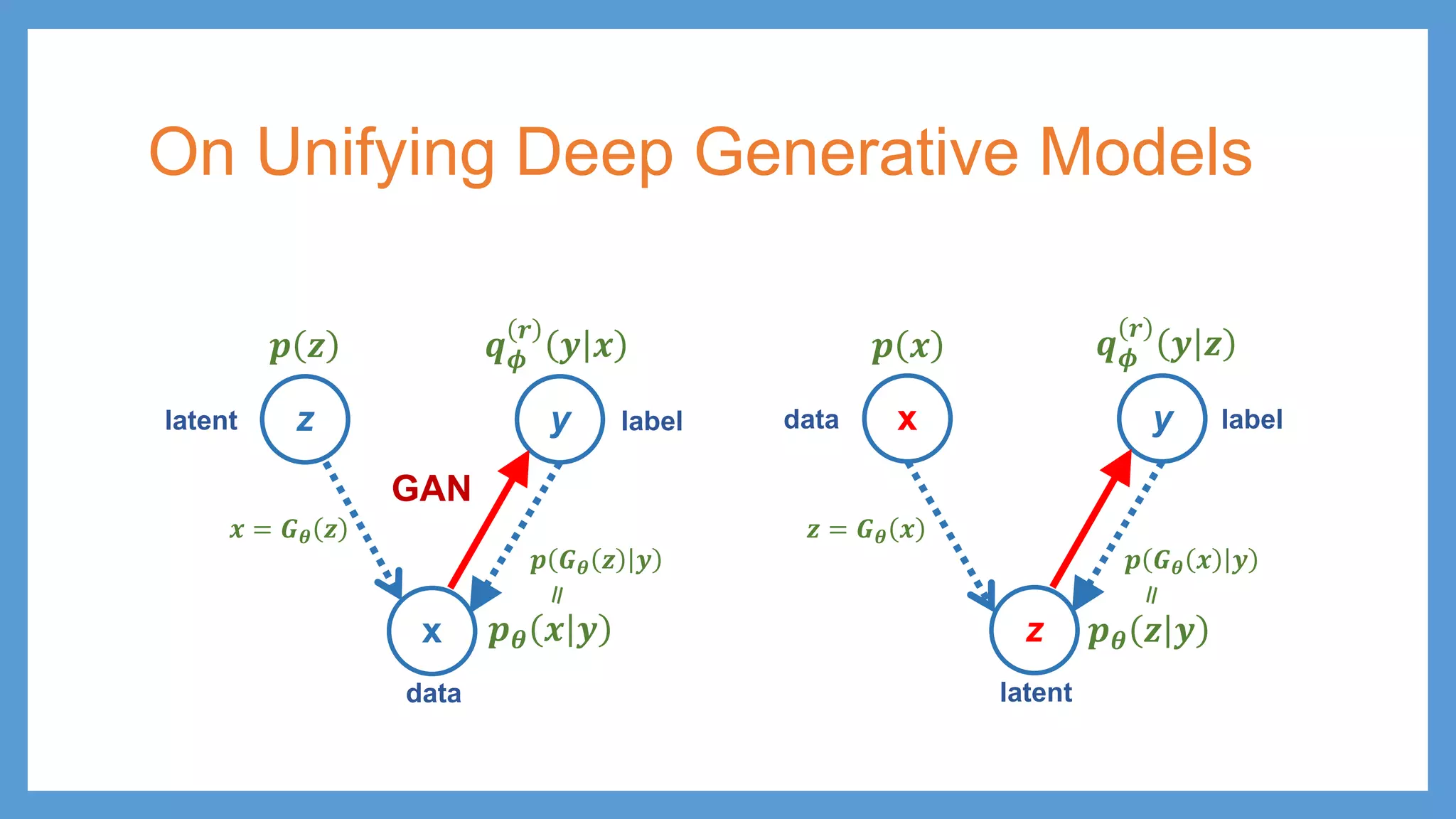
On Unifying DeepGenerative Models x y z 𝒑𝒑𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒛𝒛 data latent labelz y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN 𝒑𝒑 𝒙𝒙 𝒛𝒛 = 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒚𝒚
59.
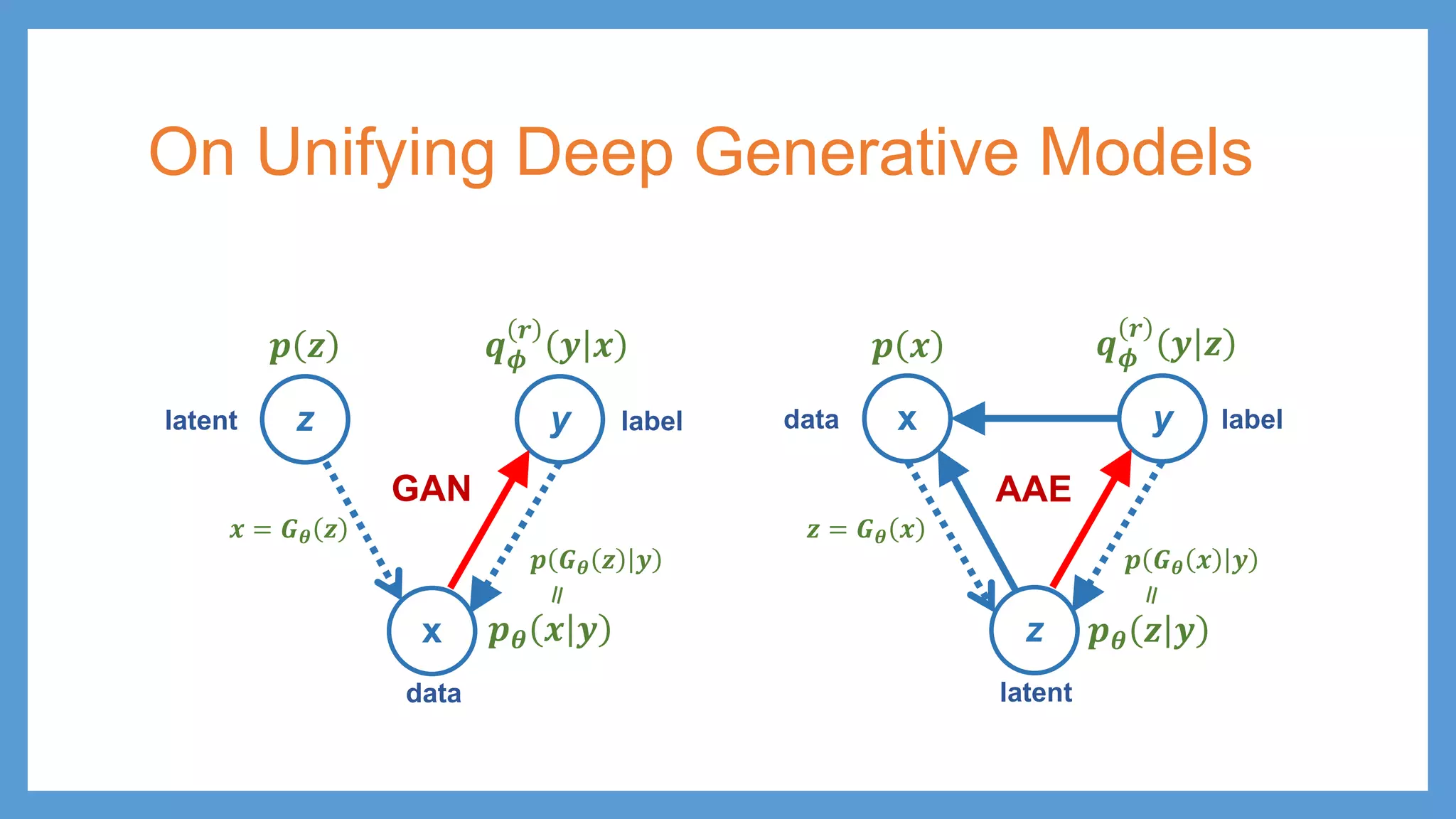
On Unifying DeepGenerative Models x y z 𝒑𝒑𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒛𝒛 data latent label AAE z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN 𝒑𝒑 𝒙𝒙 𝒛𝒛 = 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒚𝒚
60.
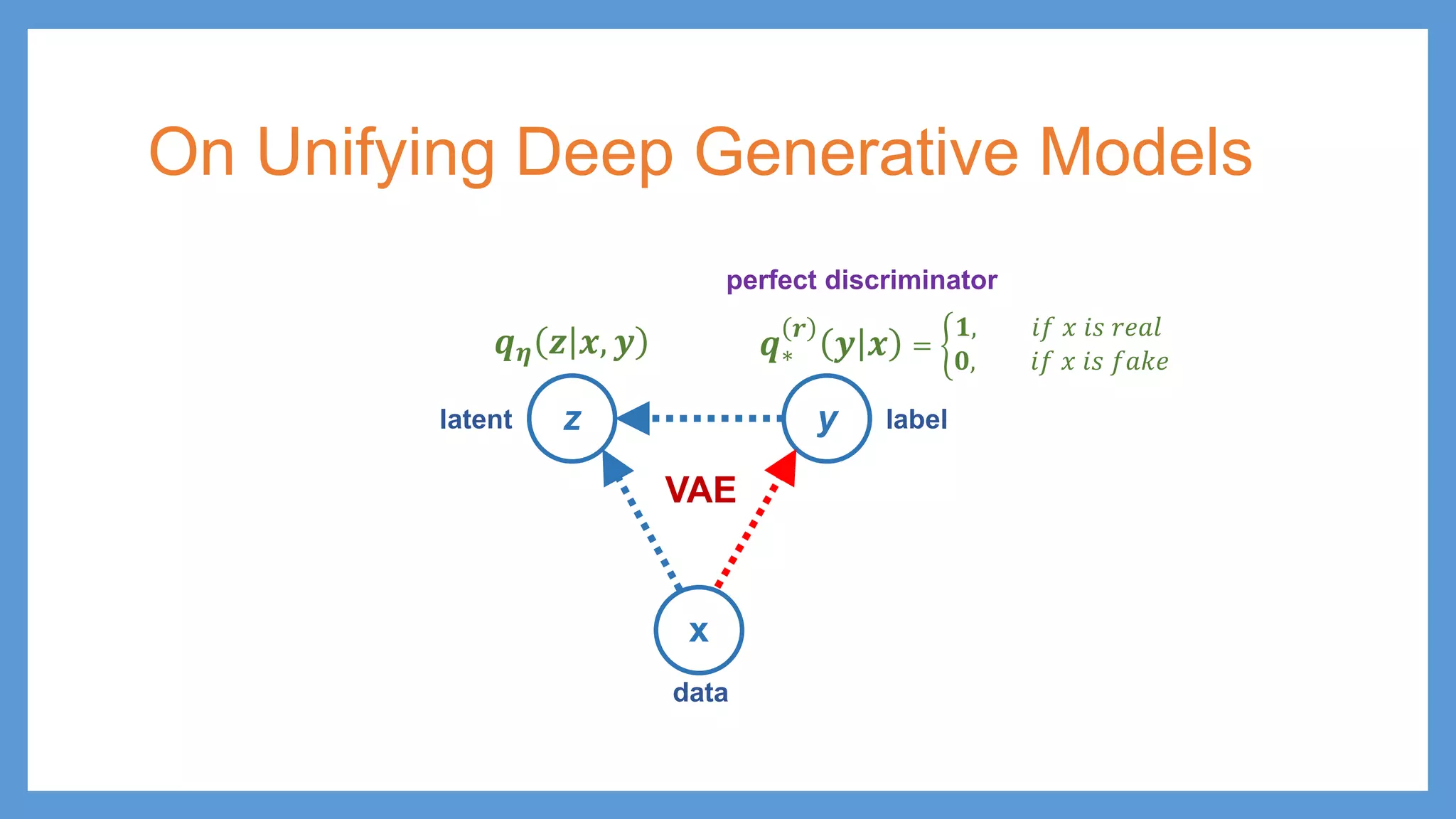
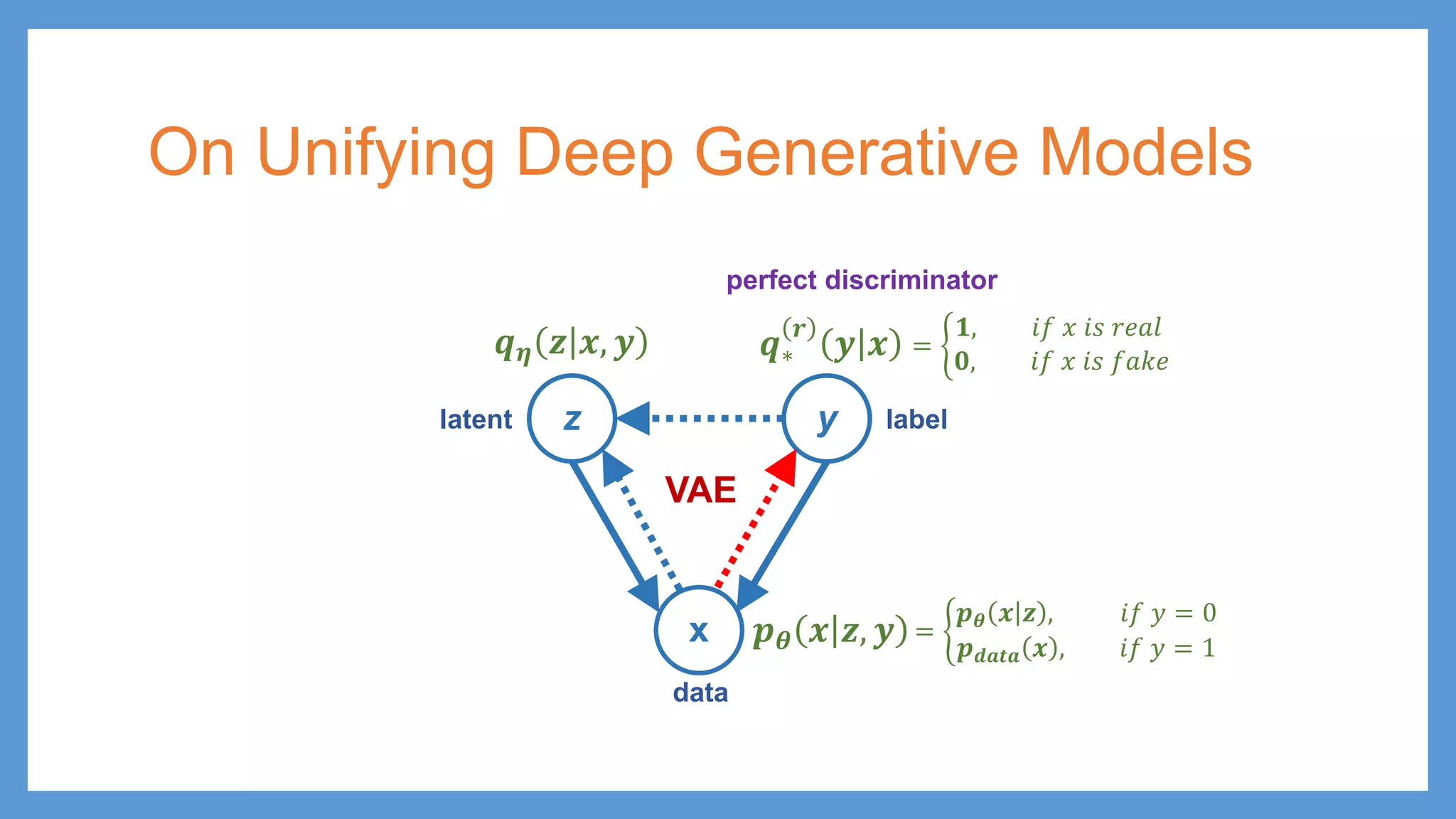
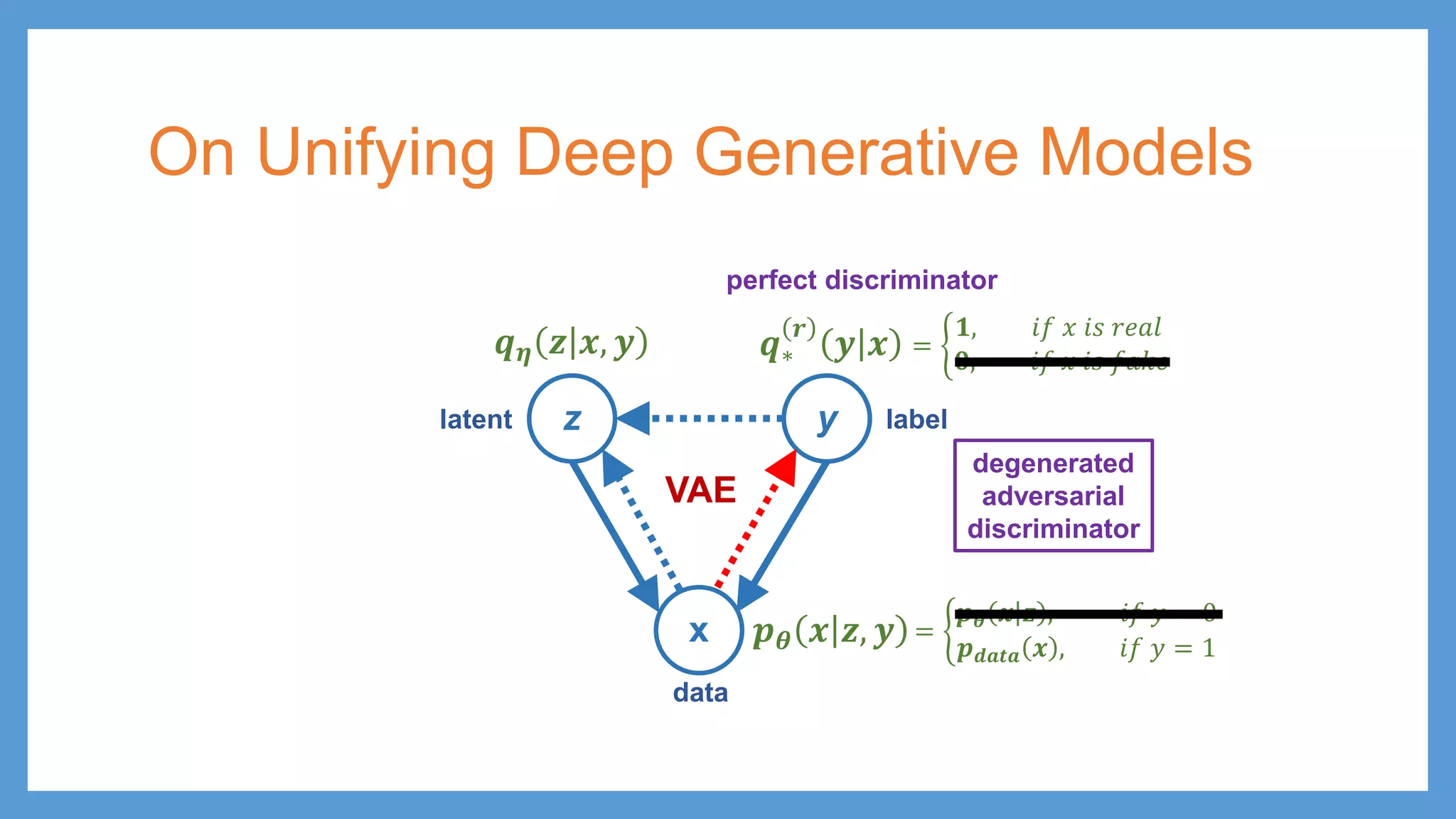
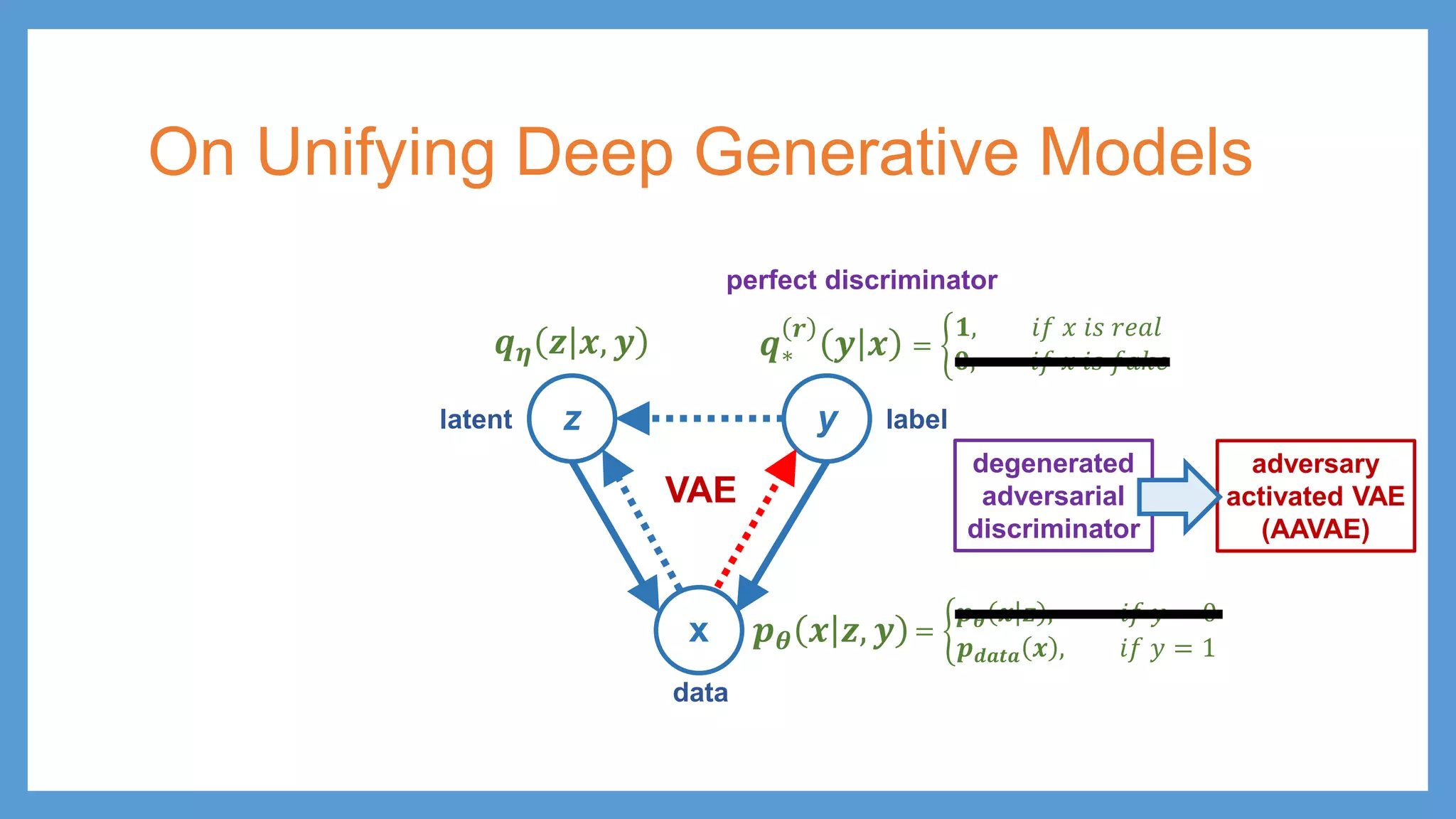
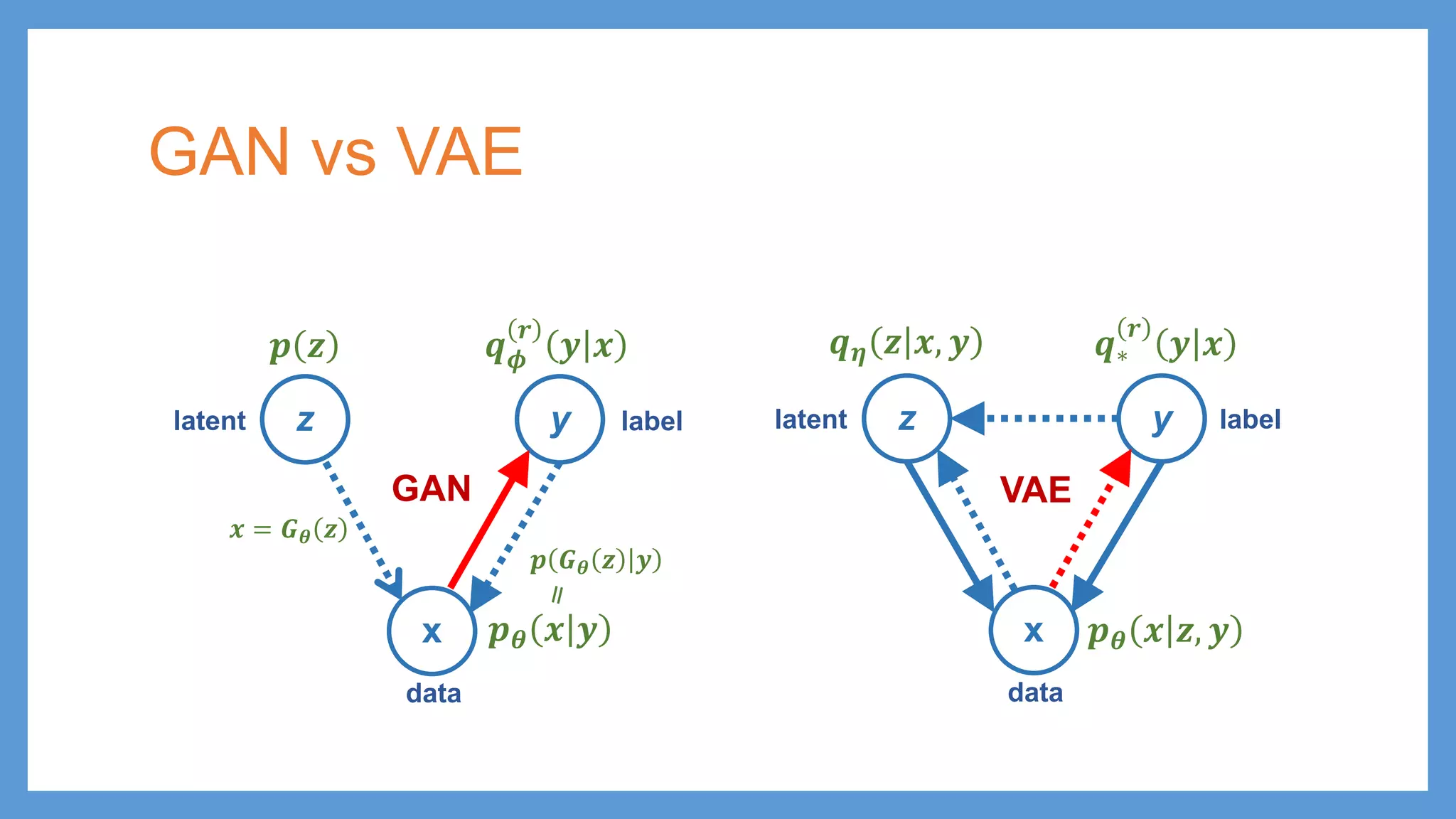
GAN vs VAE zy x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 latent data label 𝒑𝒑 𝒛𝒛 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛 GAN z y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒛𝒛, 𝒚𝒚 𝒒𝒒∗ 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data 𝒒𝒒𝜼𝜼 𝒛𝒛 𝒙𝒙, 𝒚𝒚 VAE label
61.
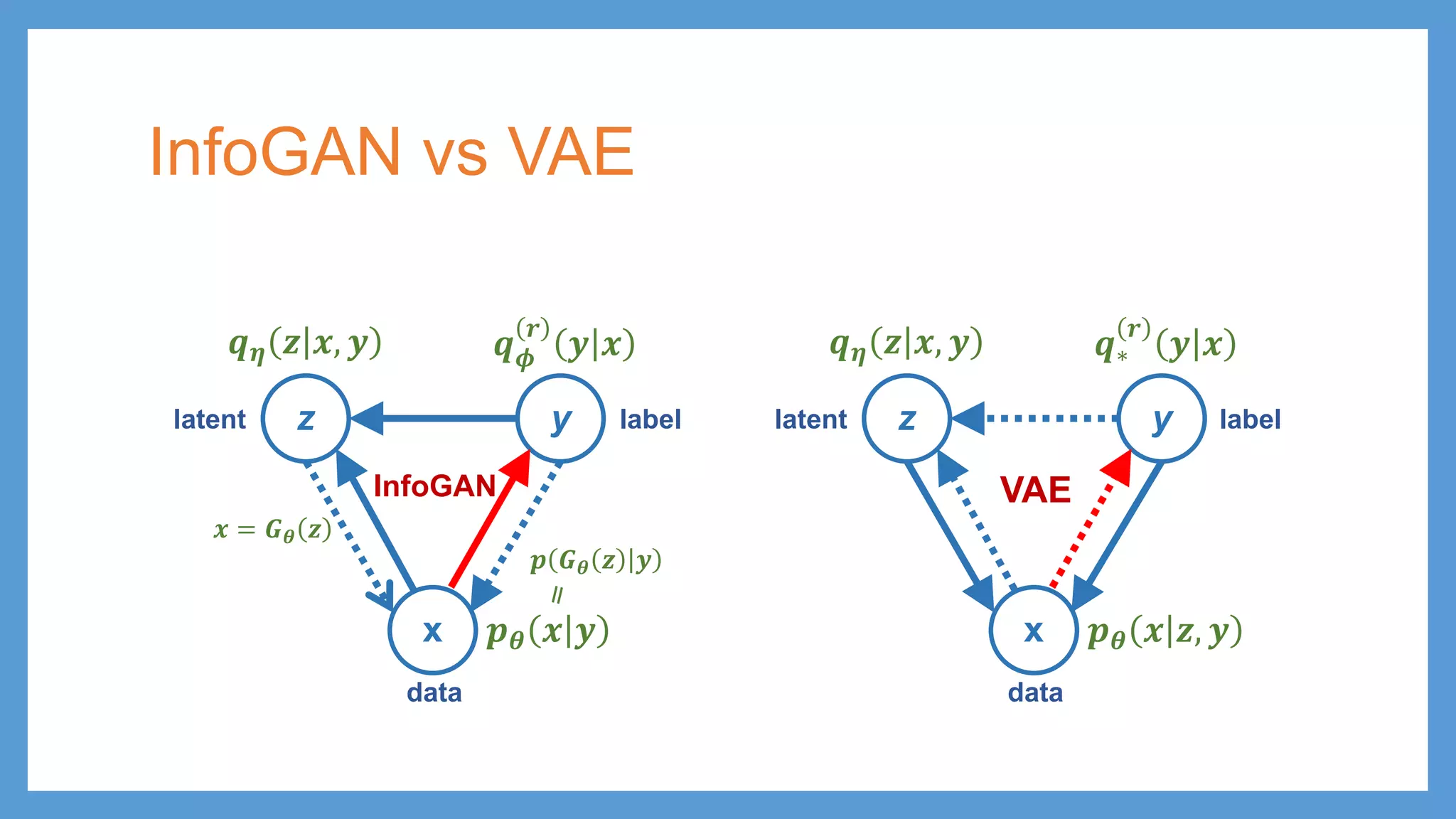
InfoGAN vs VAE zy x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒛𝒛, 𝒚𝒚 𝒒𝒒∗ 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data 𝒒𝒒𝜼𝜼 𝒛𝒛 𝒙𝒙, 𝒚𝒚 VAE labelz y x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data label 𝒒𝒒𝜼𝜼 𝒛𝒛 𝒙𝒙, 𝒚𝒚 InfoGAN 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛
62.
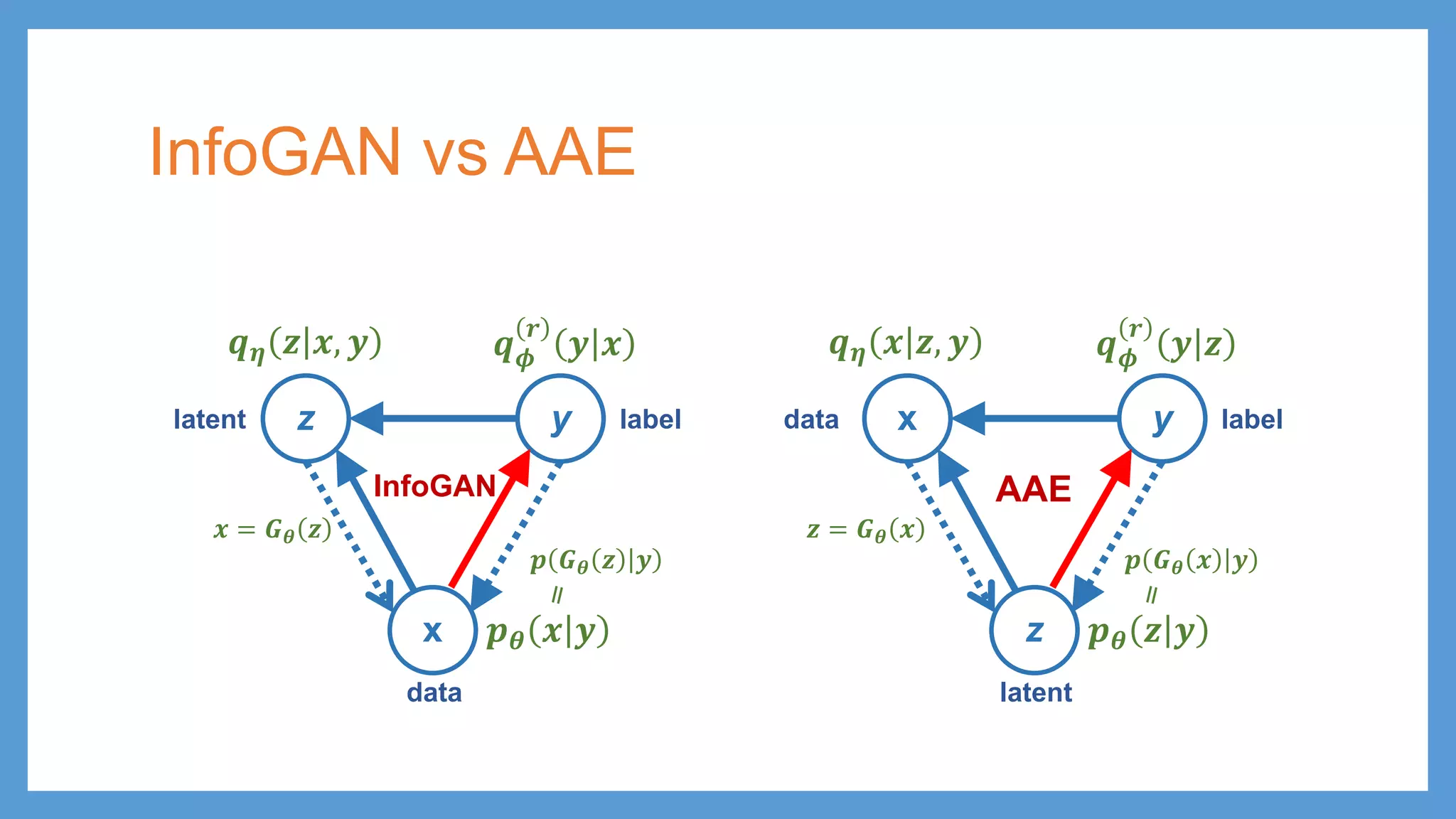
InfoGAN vs AAE zy x 𝒑𝒑𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒙𝒙 latent data label 𝒒𝒒𝜼𝜼 𝒛𝒛 𝒙𝒙, 𝒚𝒚 InfoGAN x y z 𝒑𝒑𝜽𝜽 𝒛𝒛 𝒚𝒚 𝒒𝒒𝝓𝝓 𝒓𝒓 𝒚𝒚 𝒛𝒛 latent label 𝒛𝒛 = 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒙𝒙 𝒚𝒚 𝒒𝒒𝜼𝜼 𝒙𝒙 𝒛𝒛, 𝒚𝒚 data 𝒑𝒑 𝑮𝑮𝜽𝜽 𝒛𝒛 𝒚𝒚 AAE 𝒙𝒙 = 𝑮𝑮𝜽𝜽 𝒛𝒛
63.
Wake-sleep Algorithm • 𝒉𝒉- general latent variables • 𝝀𝝀 - general parameters • 𝜽𝜽 - generator parameters • In wake phase, update 𝜽𝜽 by fitting 𝒑𝒑𝜽𝜽 𝒙𝒙|𝒉𝒉 to 𝒙𝒙 and 𝒉𝒉 inferred by 𝒒𝒒𝝀𝝀 𝒉𝒉|𝒙𝒙 . • In sleep phase, update 𝝀𝝀 based on generated samples. • VAE: 𝒉𝒉 → 𝒛𝒛, 𝝀𝝀 → 𝜼𝜼 • GAN: 𝒉𝒉 → 𝒚𝒚, 𝝀𝝀 → 𝝓𝝓 Wake: max 𝜽𝜽 𝔼𝔼𝒒𝒒𝝀𝝀 𝒉𝒉|𝒙𝒙 𝒑𝒑𝒅𝒅𝒅𝒅𝒅𝒅𝒅𝒅 𝒙𝒙 log 𝑝𝑝𝜃𝜃 𝑥𝑥 ℎ Sleep: max 𝜆𝜆 𝔼𝔼𝒑𝒑𝜽𝜽 𝒙𝒙|𝒉𝒉 𝒑𝒑 𝒉𝒉 log 𝑞𝑞𝜆𝜆 ℎ 𝑥𝑥
64.
References • D. P.Kingma, M. Welling. Auto-Encoding Variational Bayes. arXiv preprint arXiv:1312.6114, 2014 • I. J. GoodFellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio. Genrative Adversrial Nets. arXiv:preprint arXiv:1406.2661, 2014 • A. B. L. Larsen, S. K. Sønderby and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015 • A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow and B. Frey. Adversarial Autoencoders. arXiv preprint arXiv:1511.05644, 2016 • Z. Hu, Z. Yang, R. Salakhutdinov and E. P. Xing. On unifying deep generative models. arXiv preprint arXiv:1706.00550, 2017