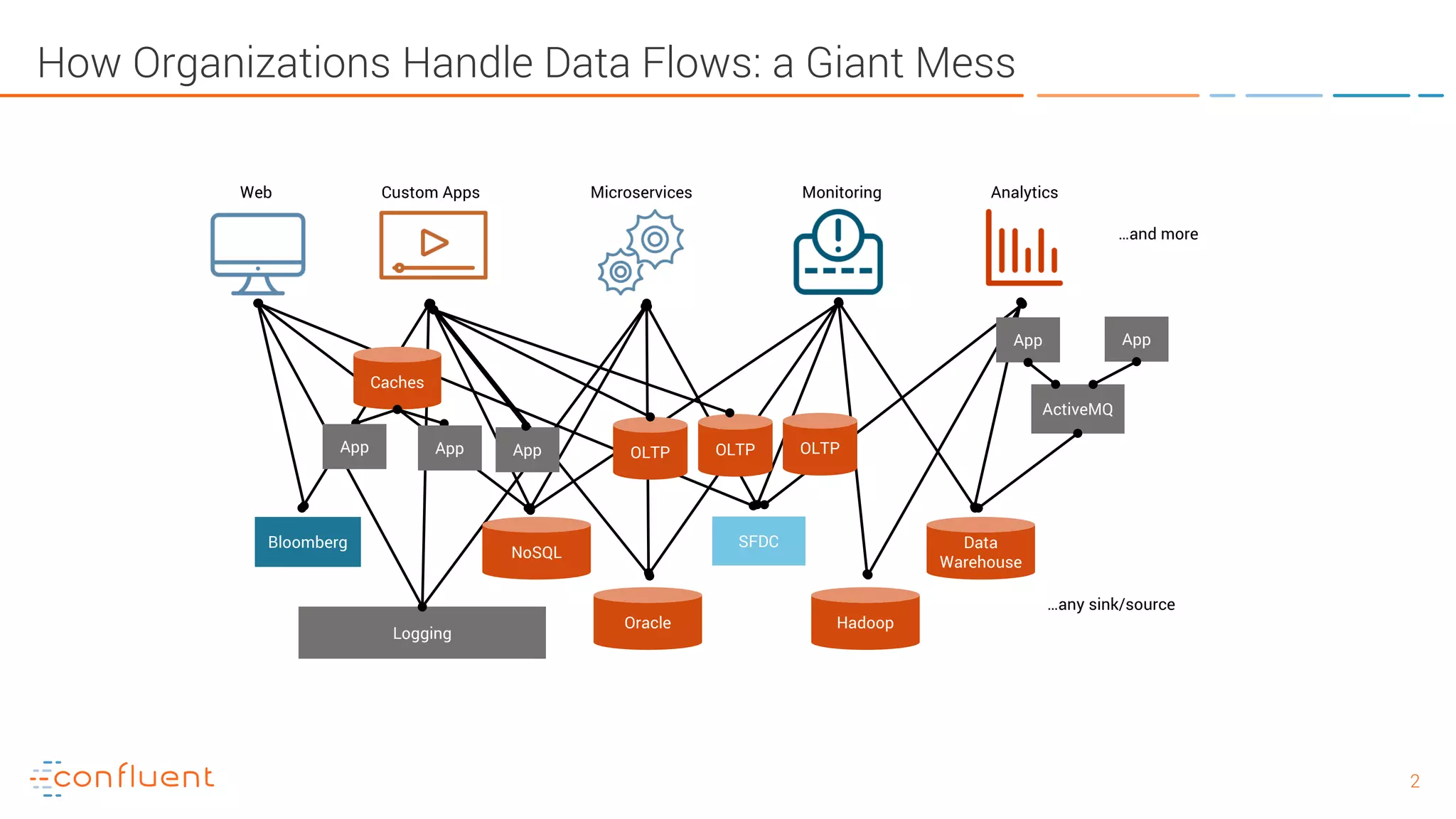
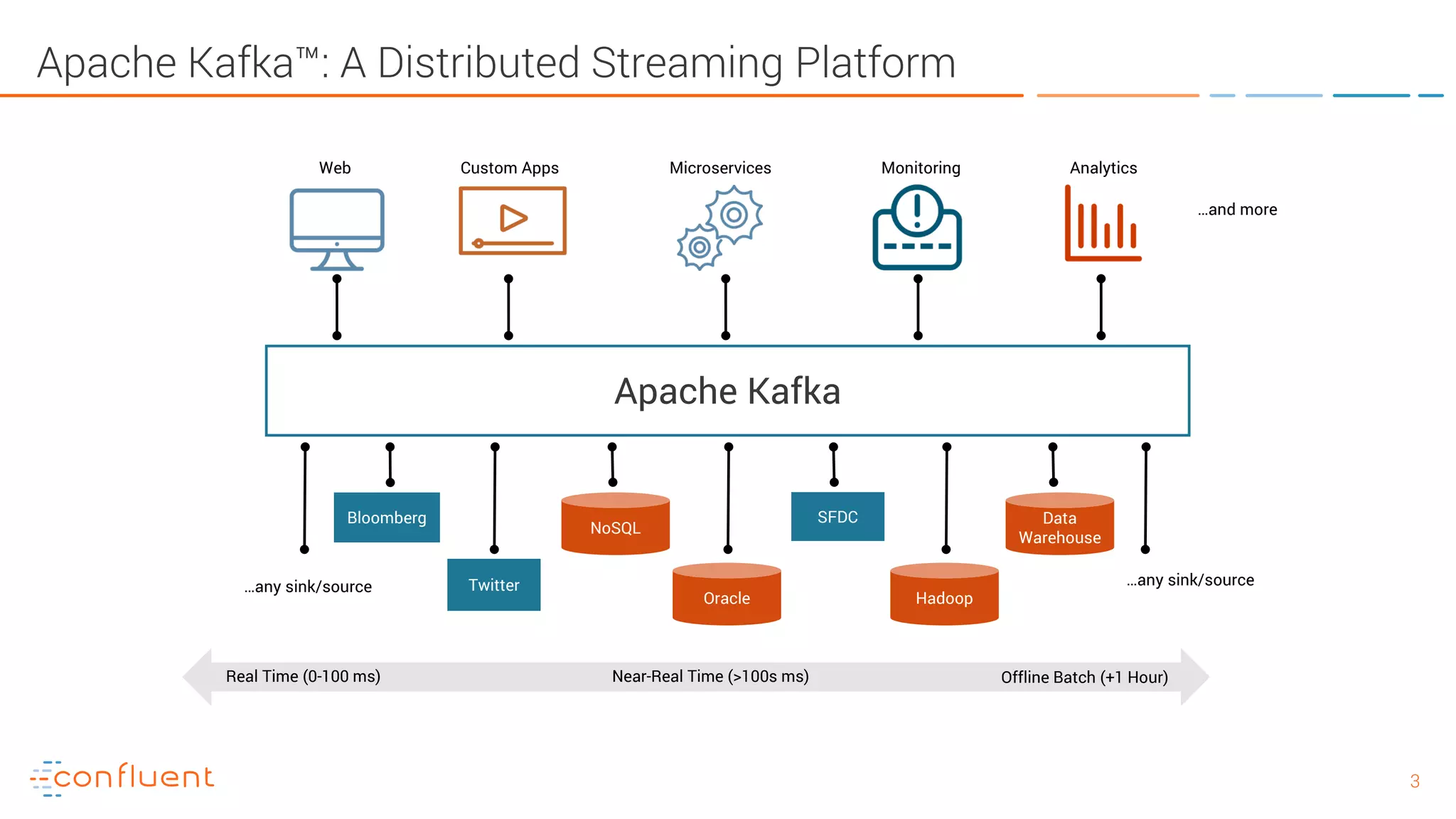
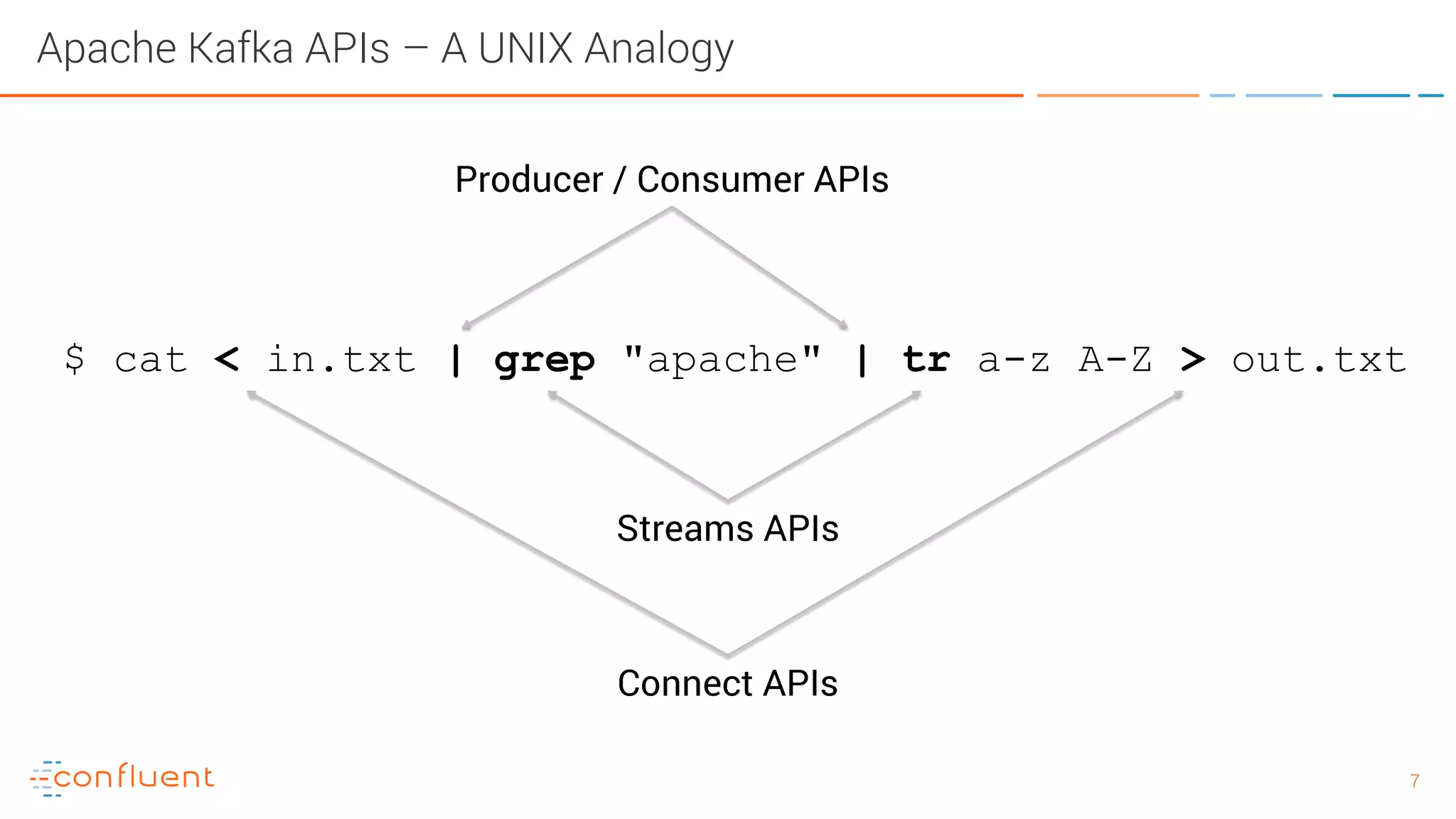
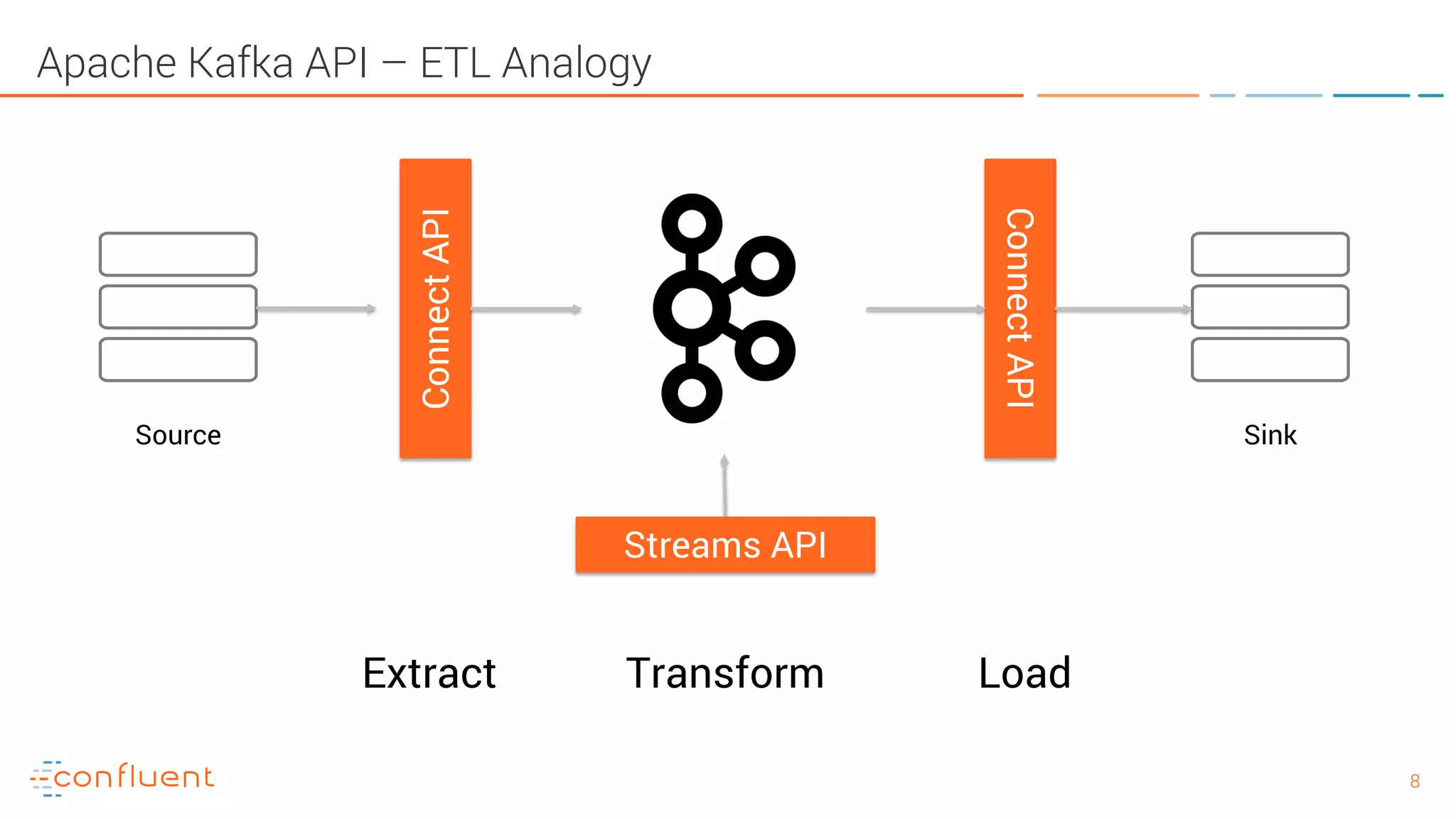
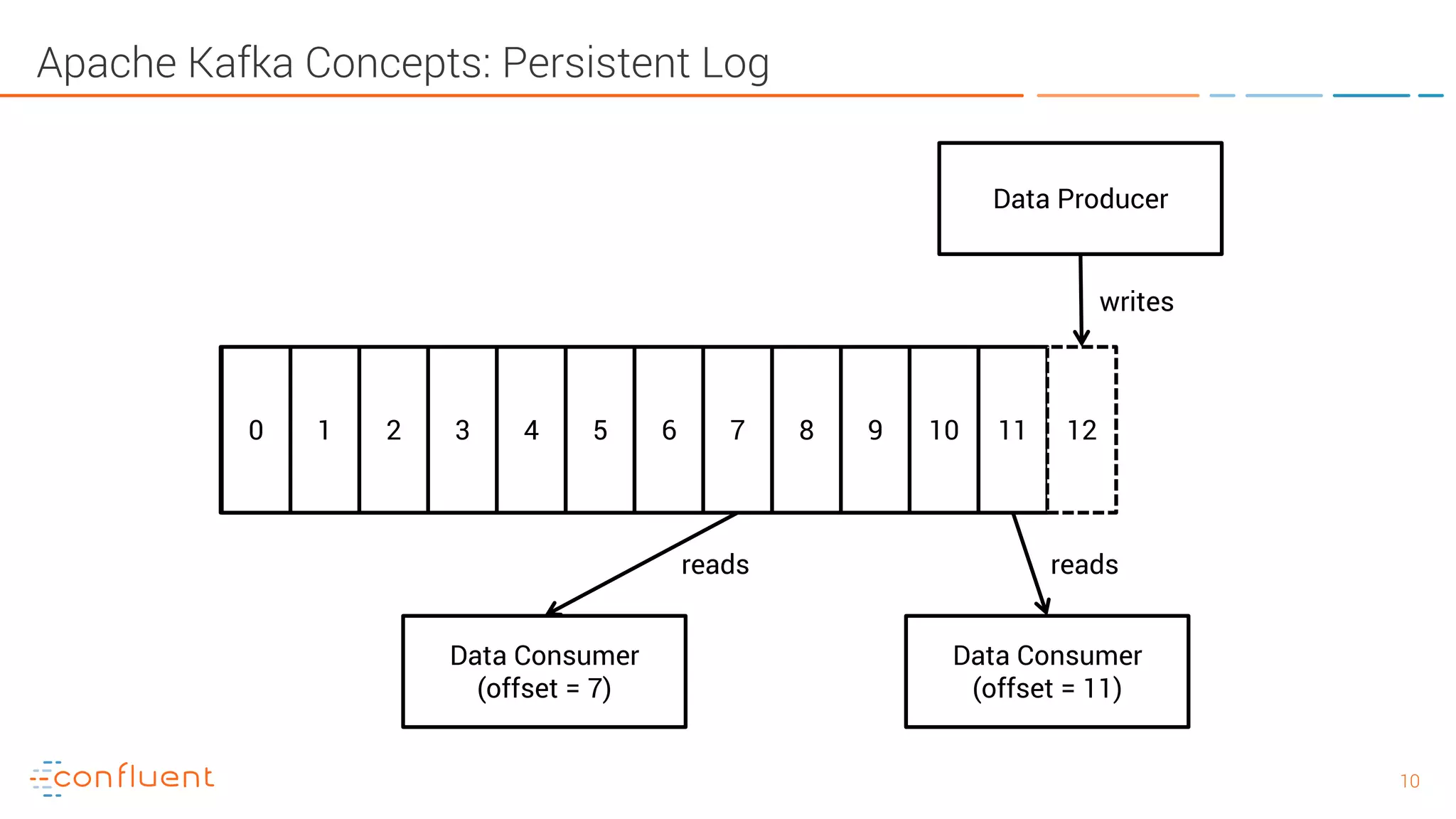
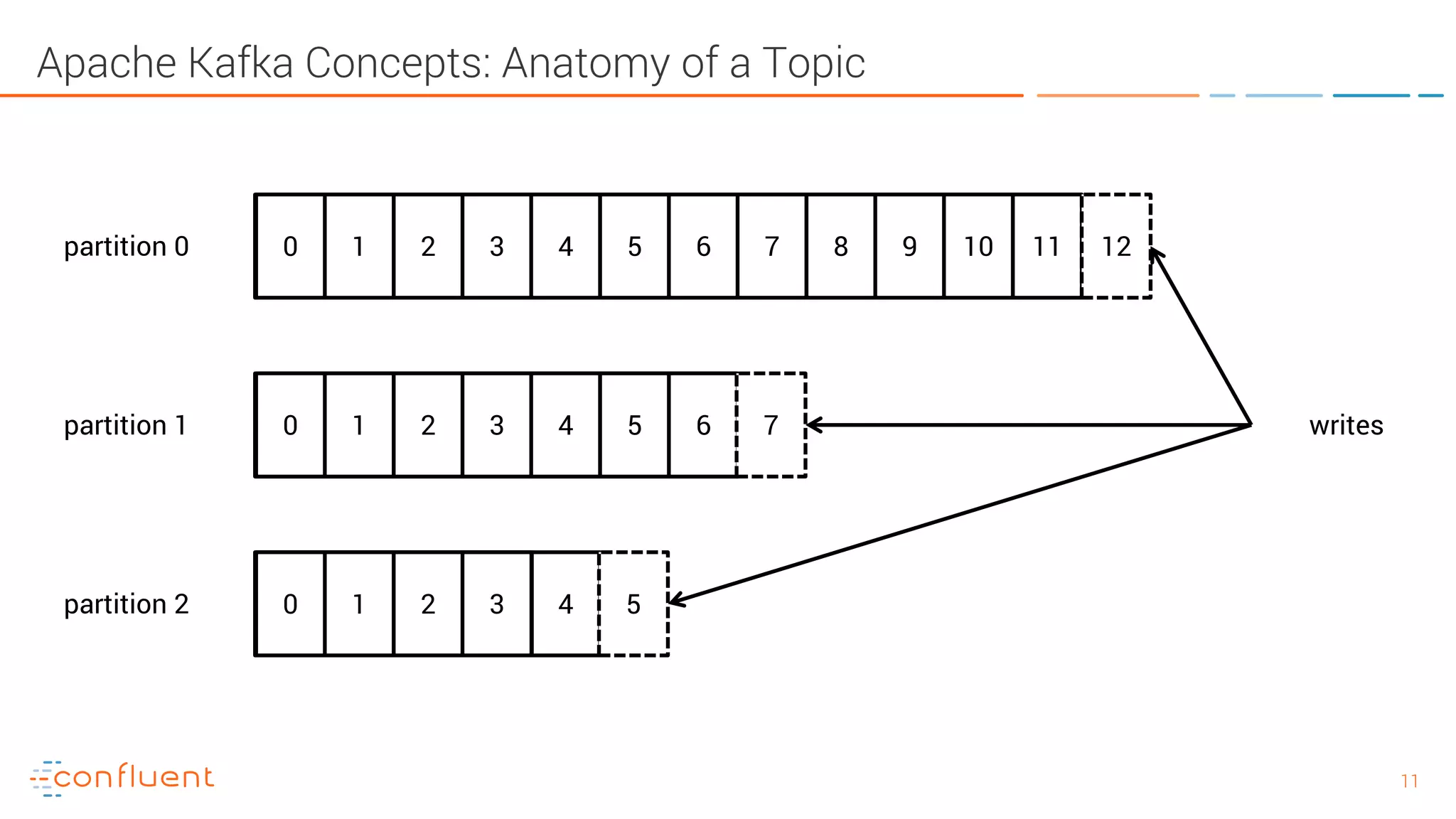
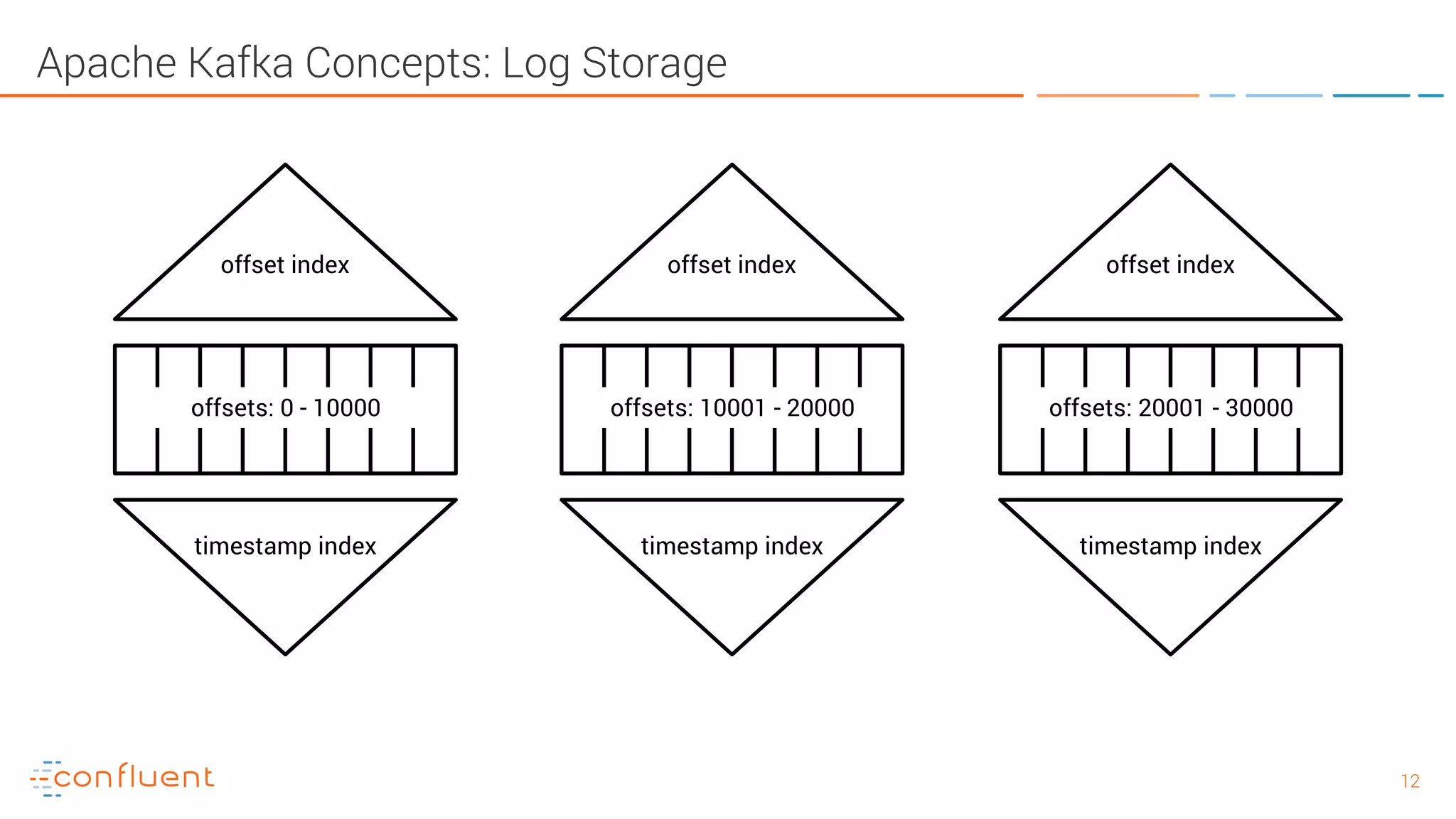
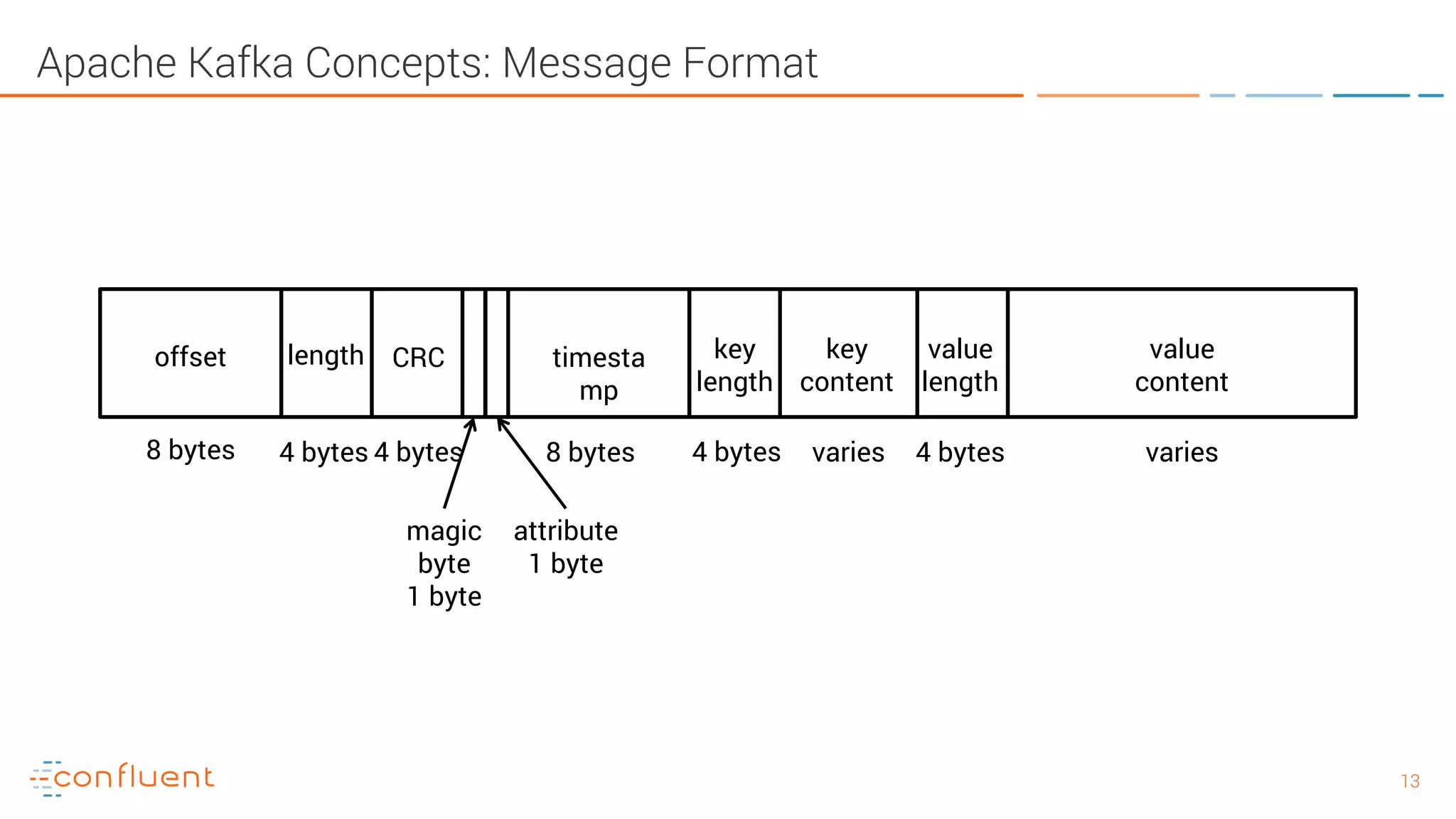
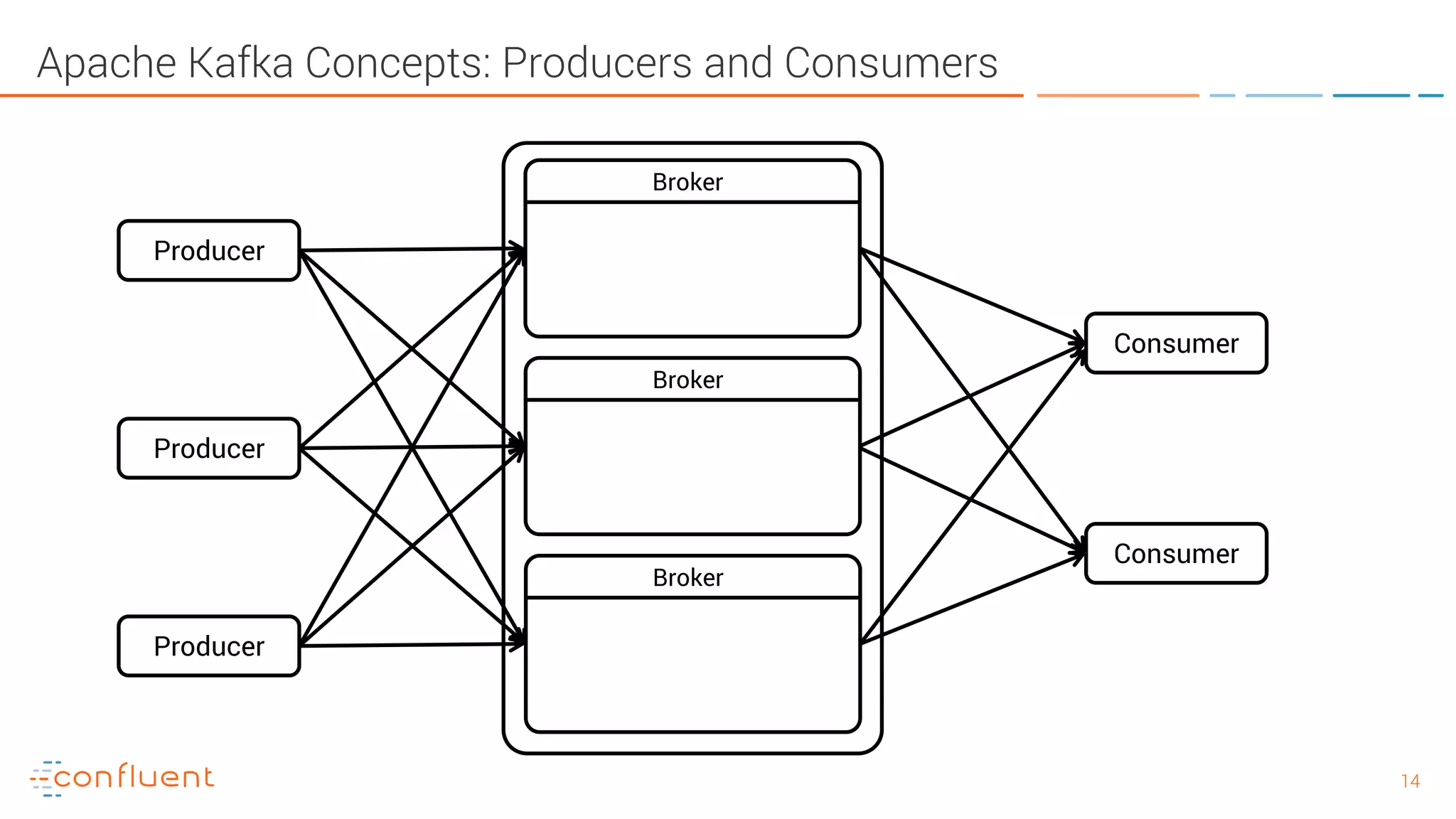
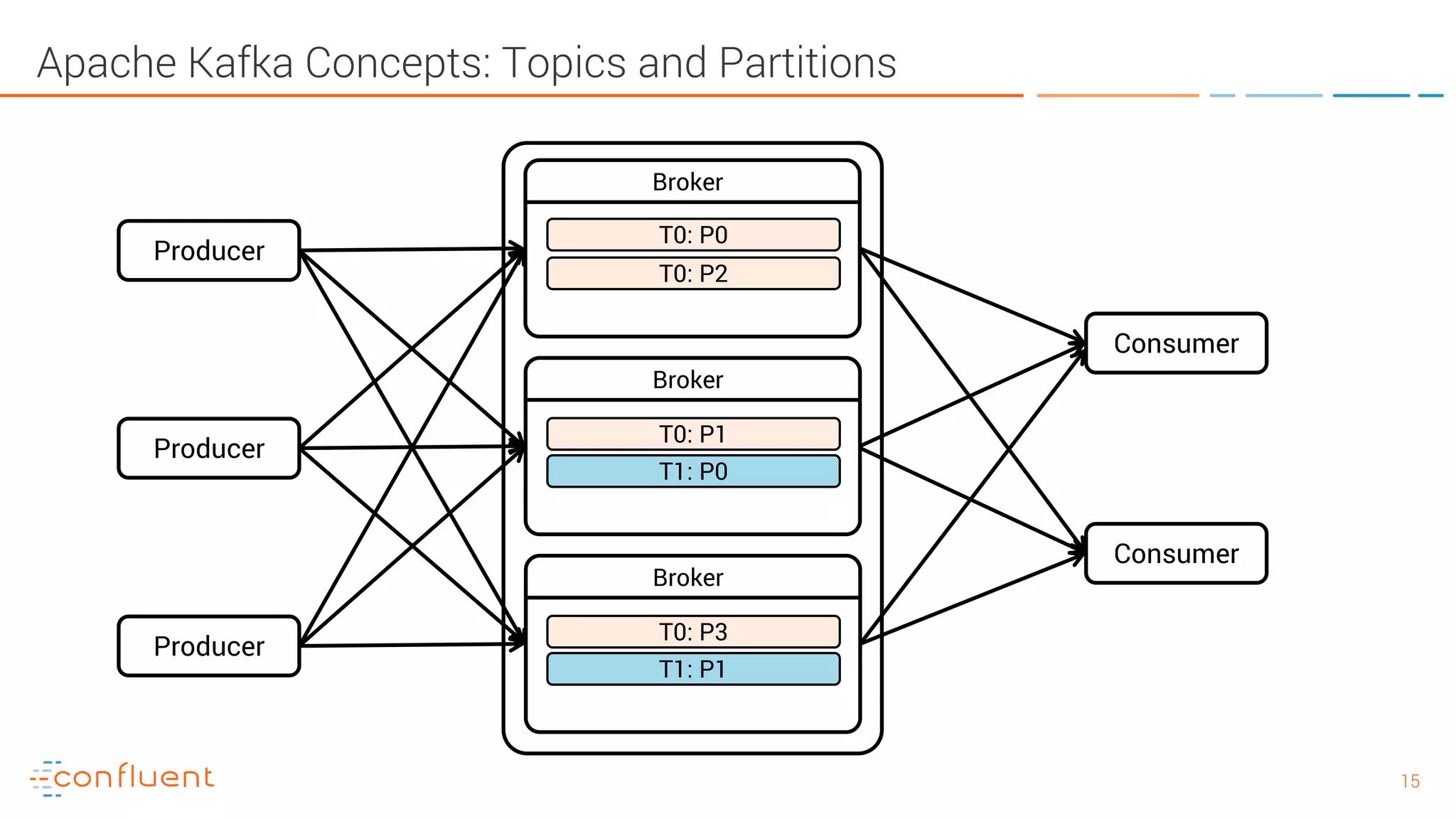
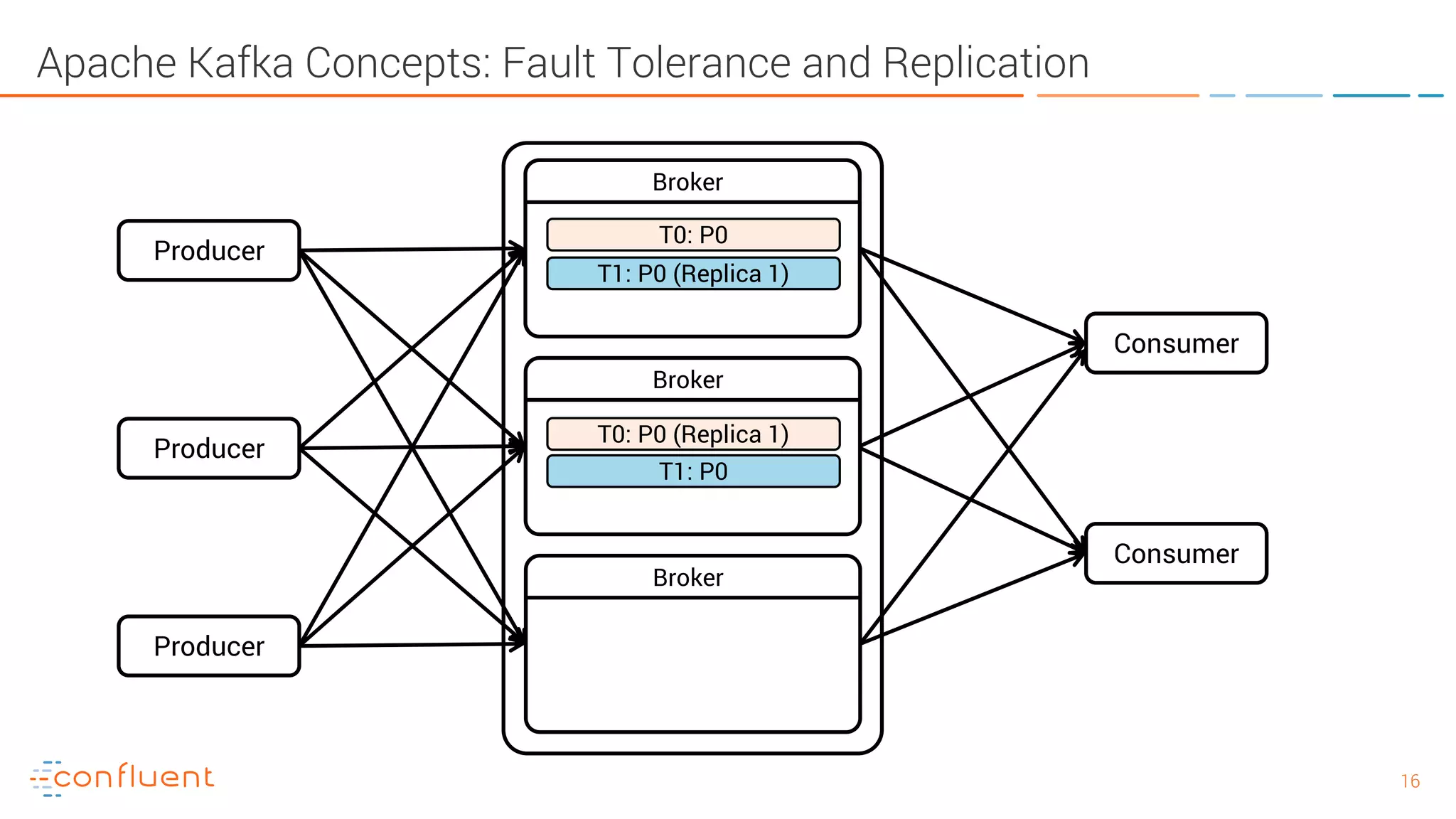
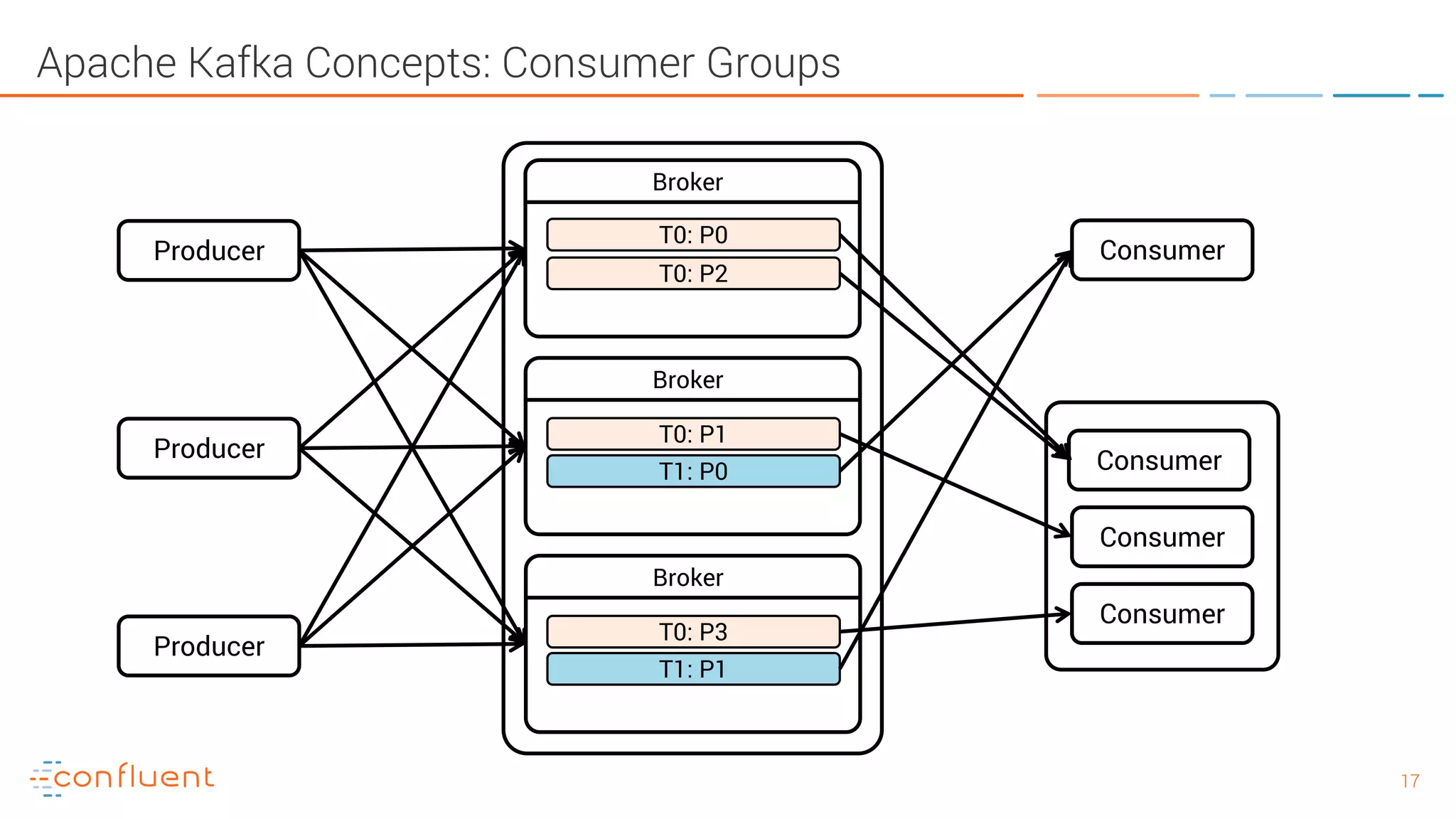
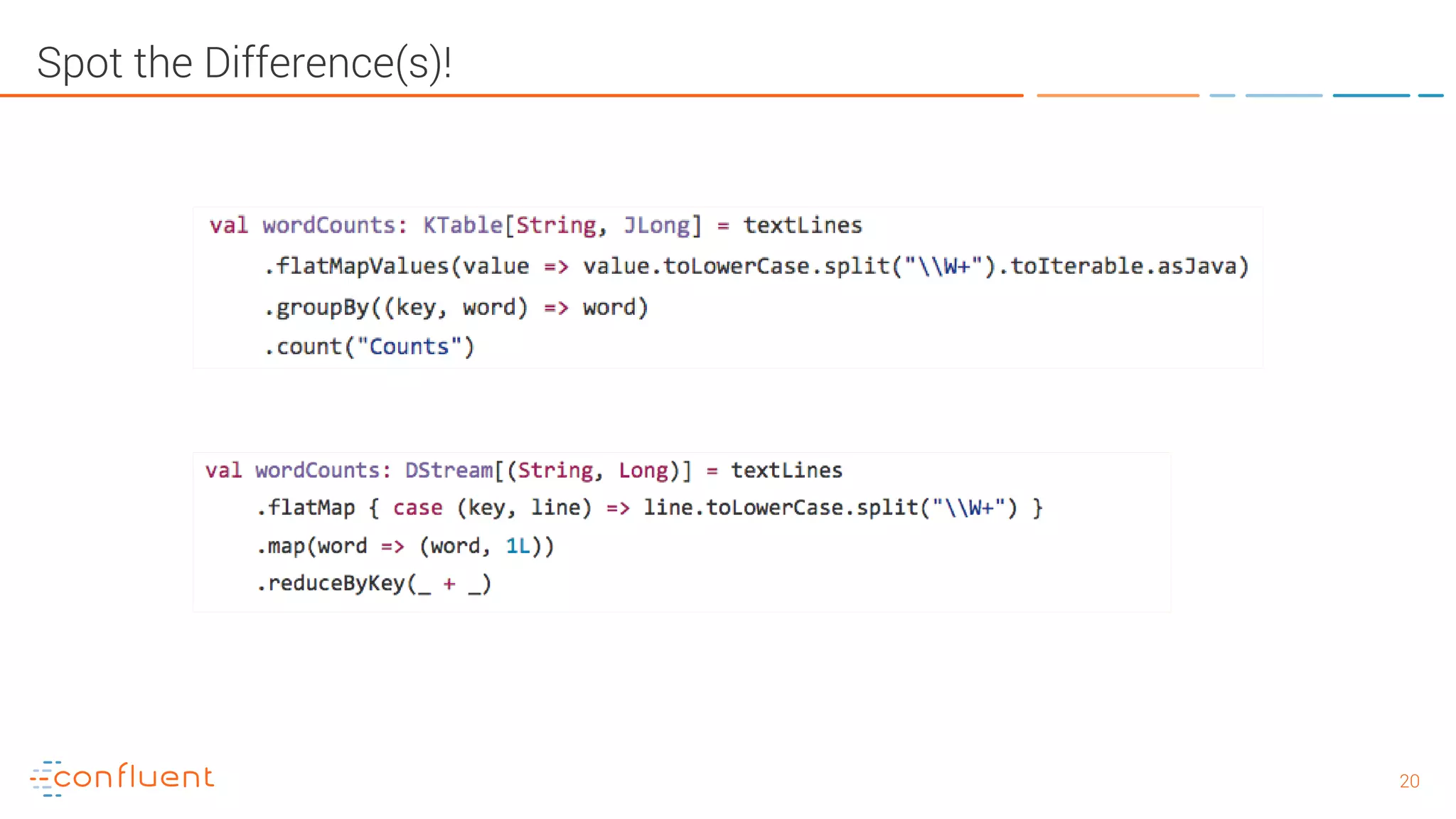
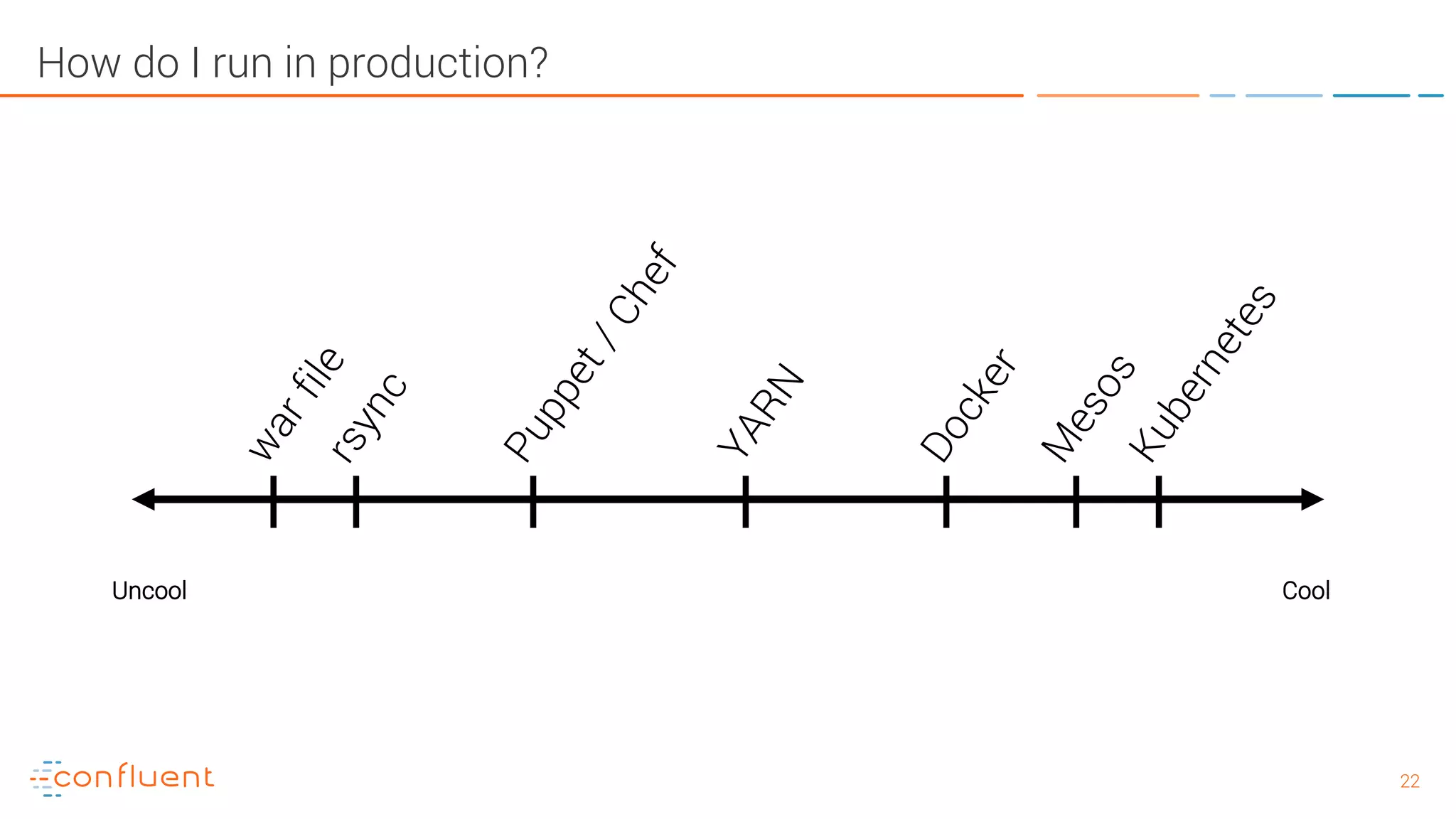
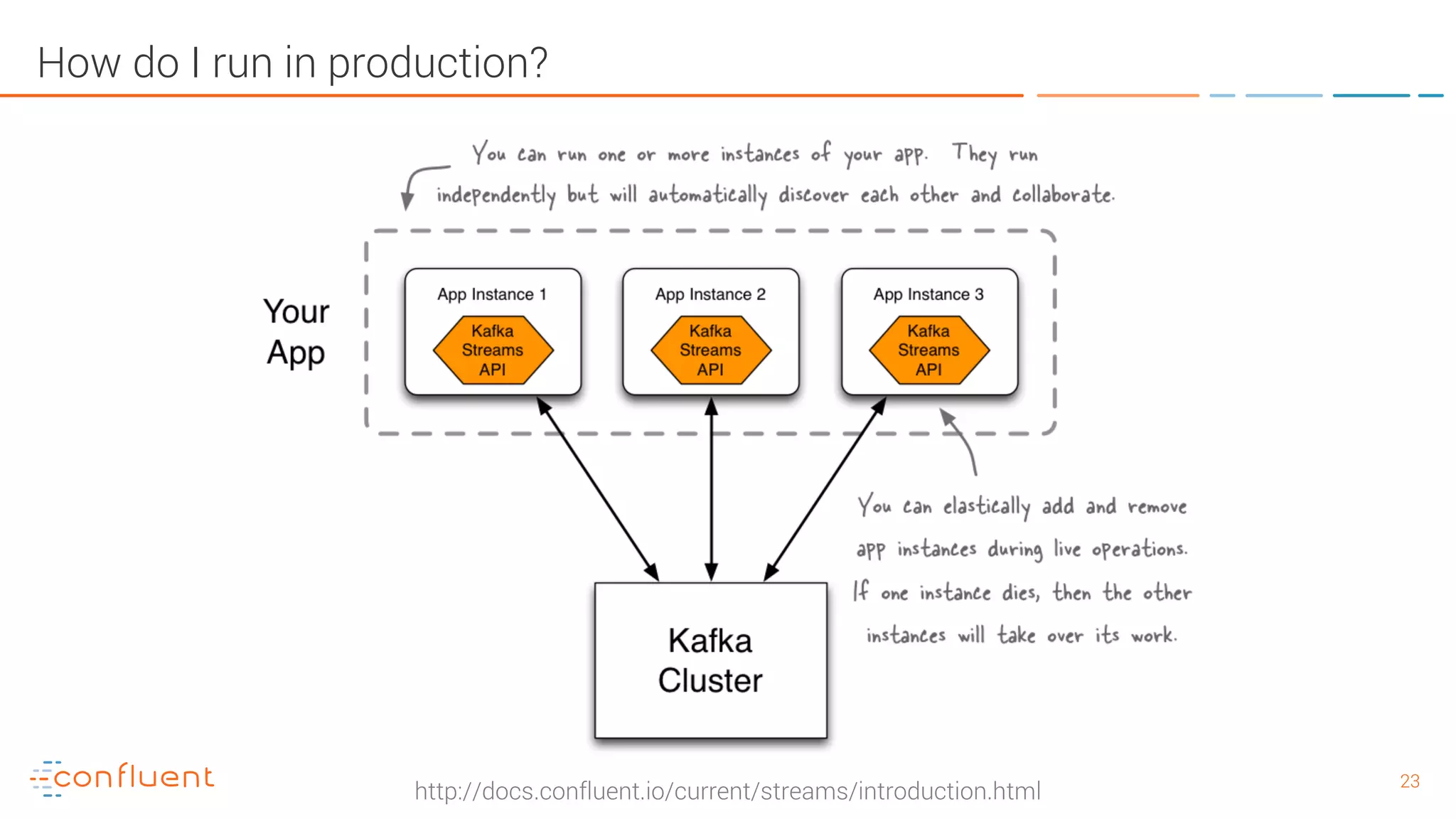
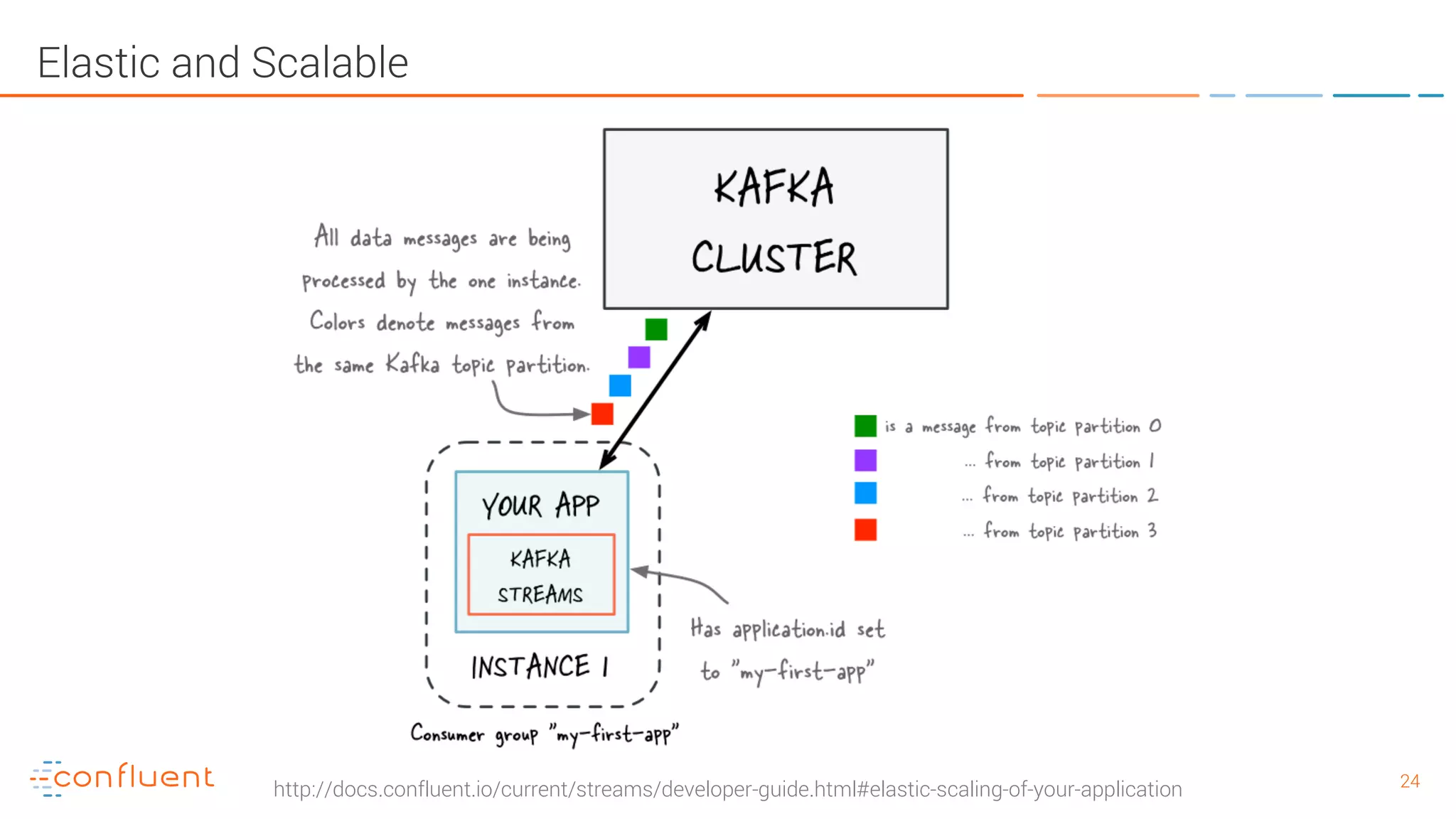
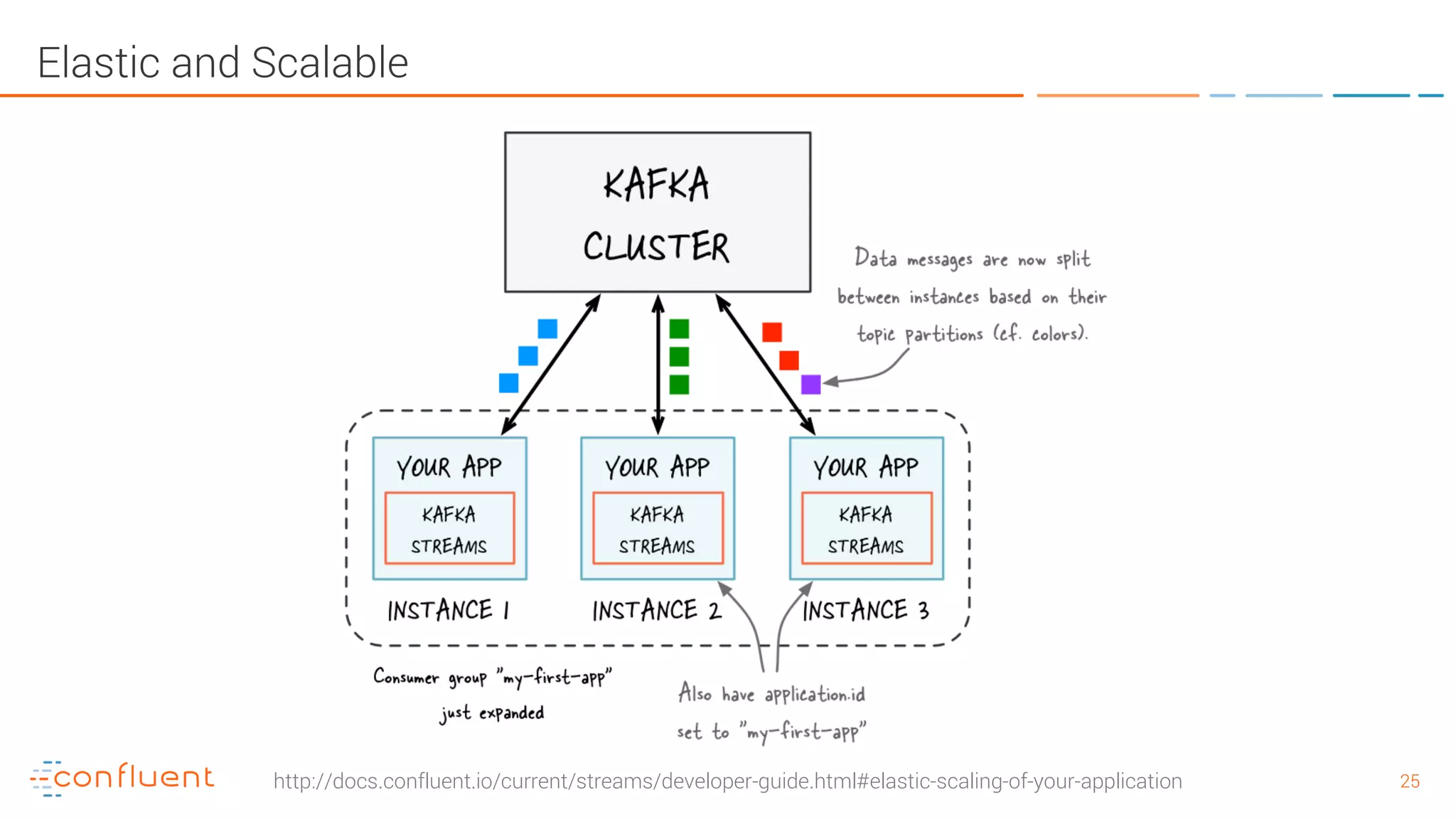
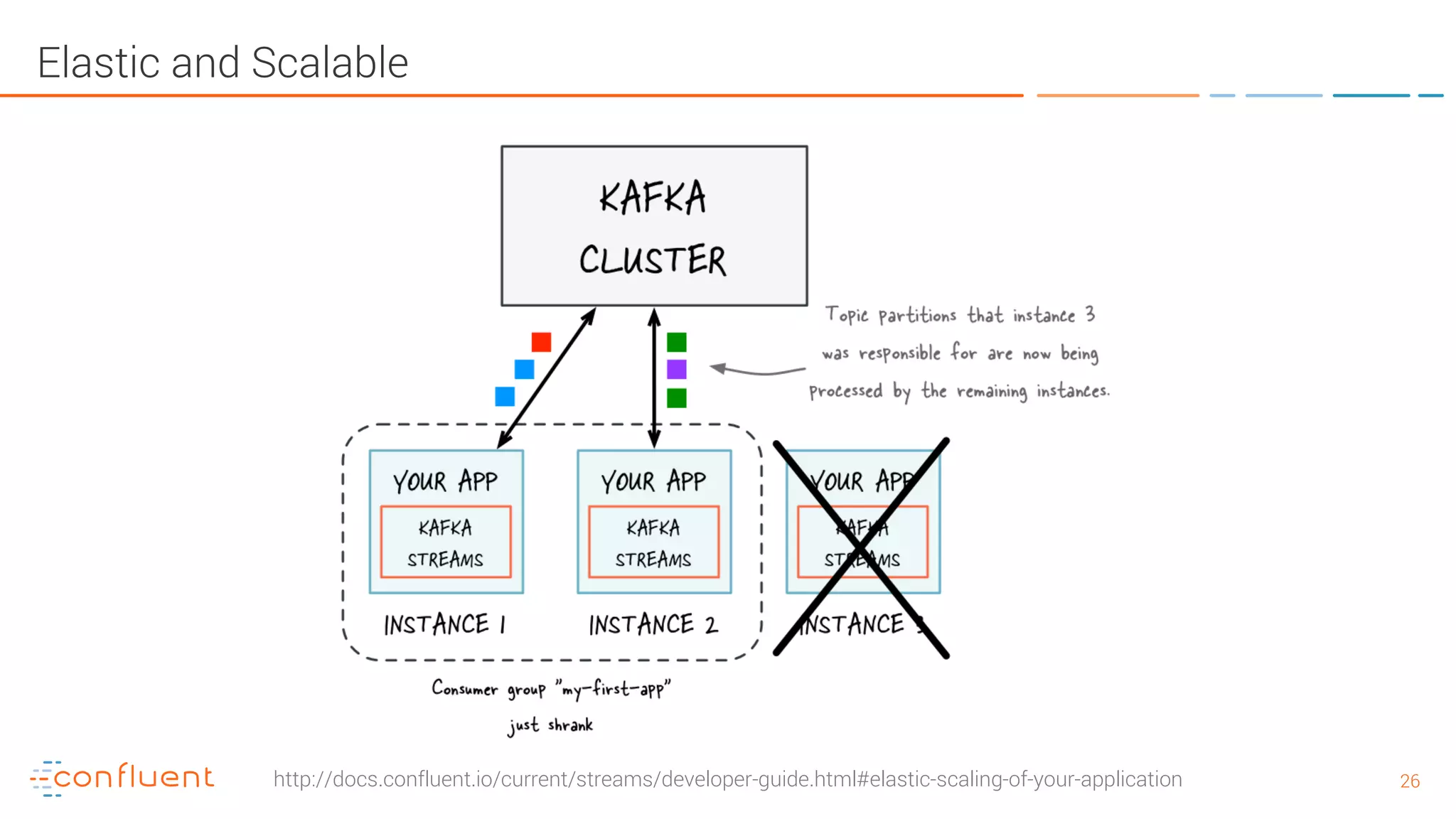
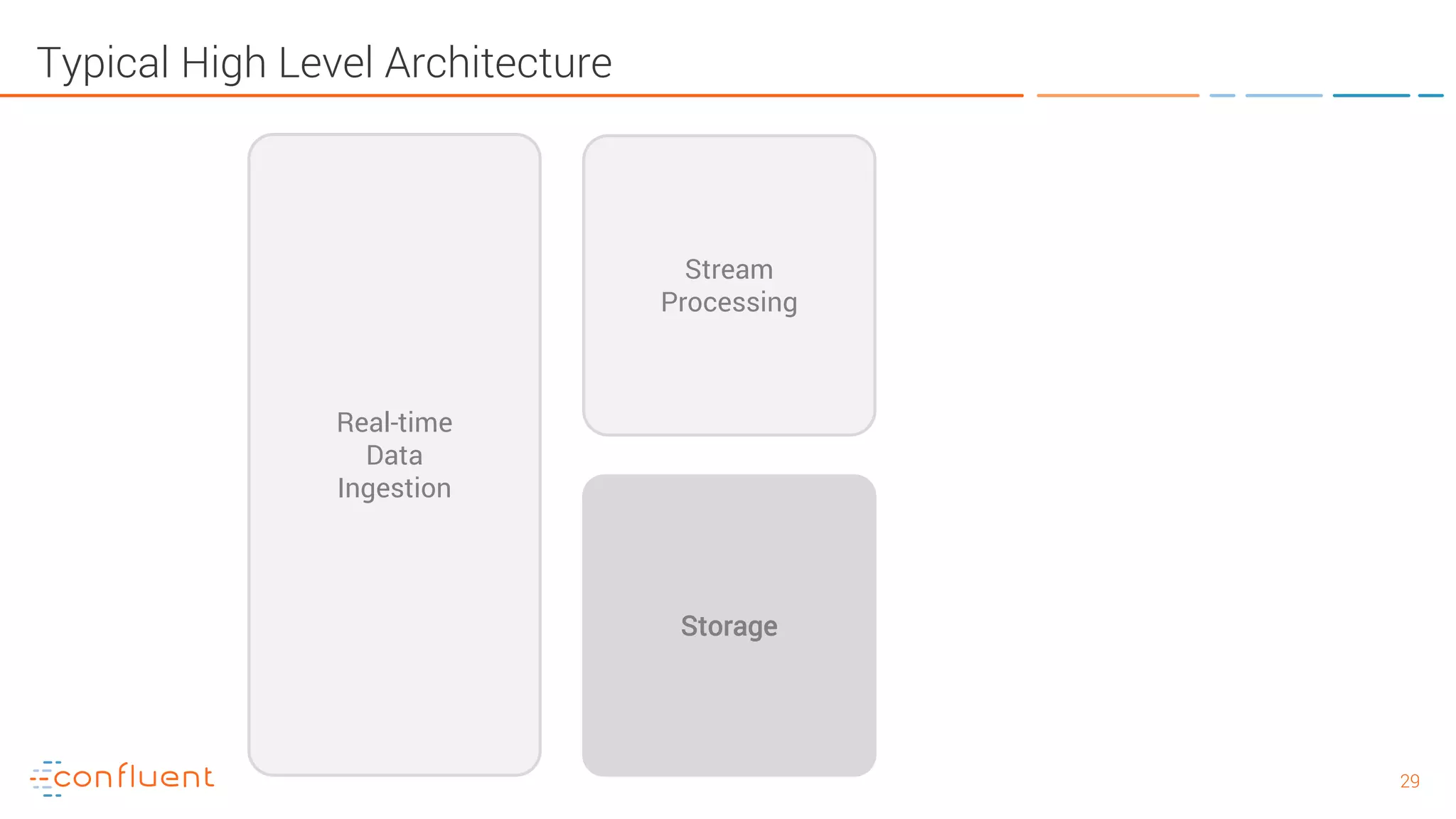
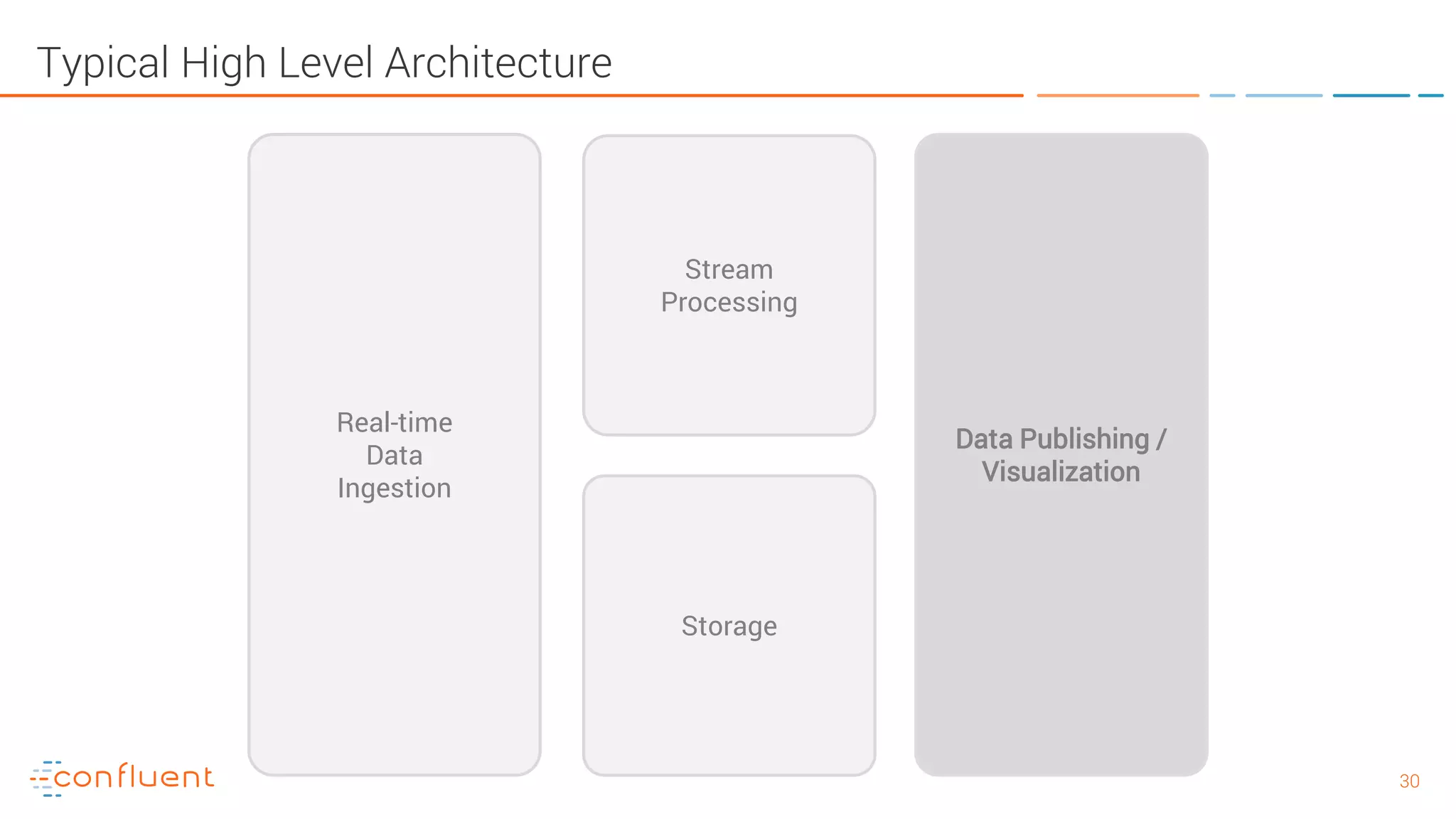
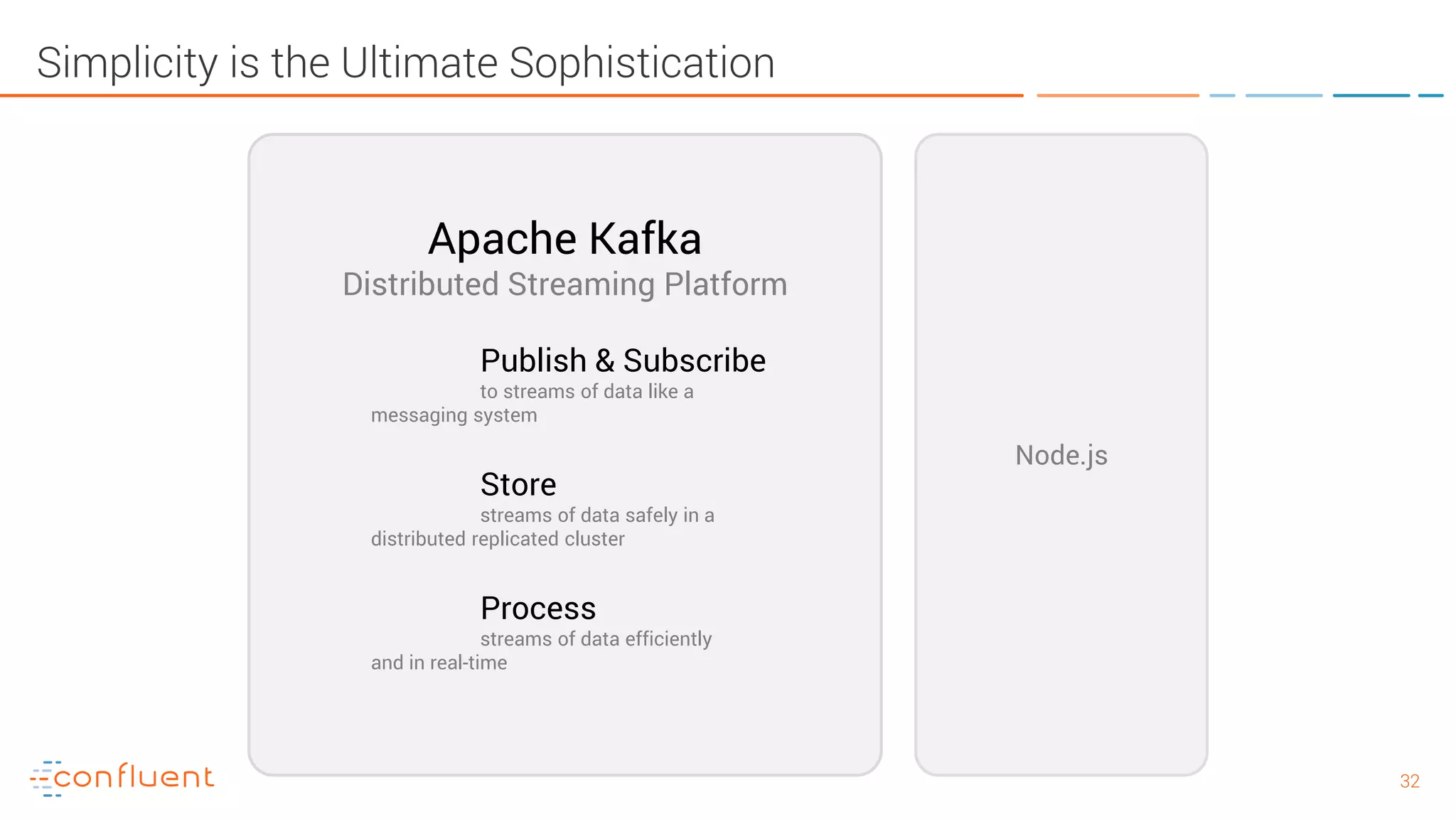
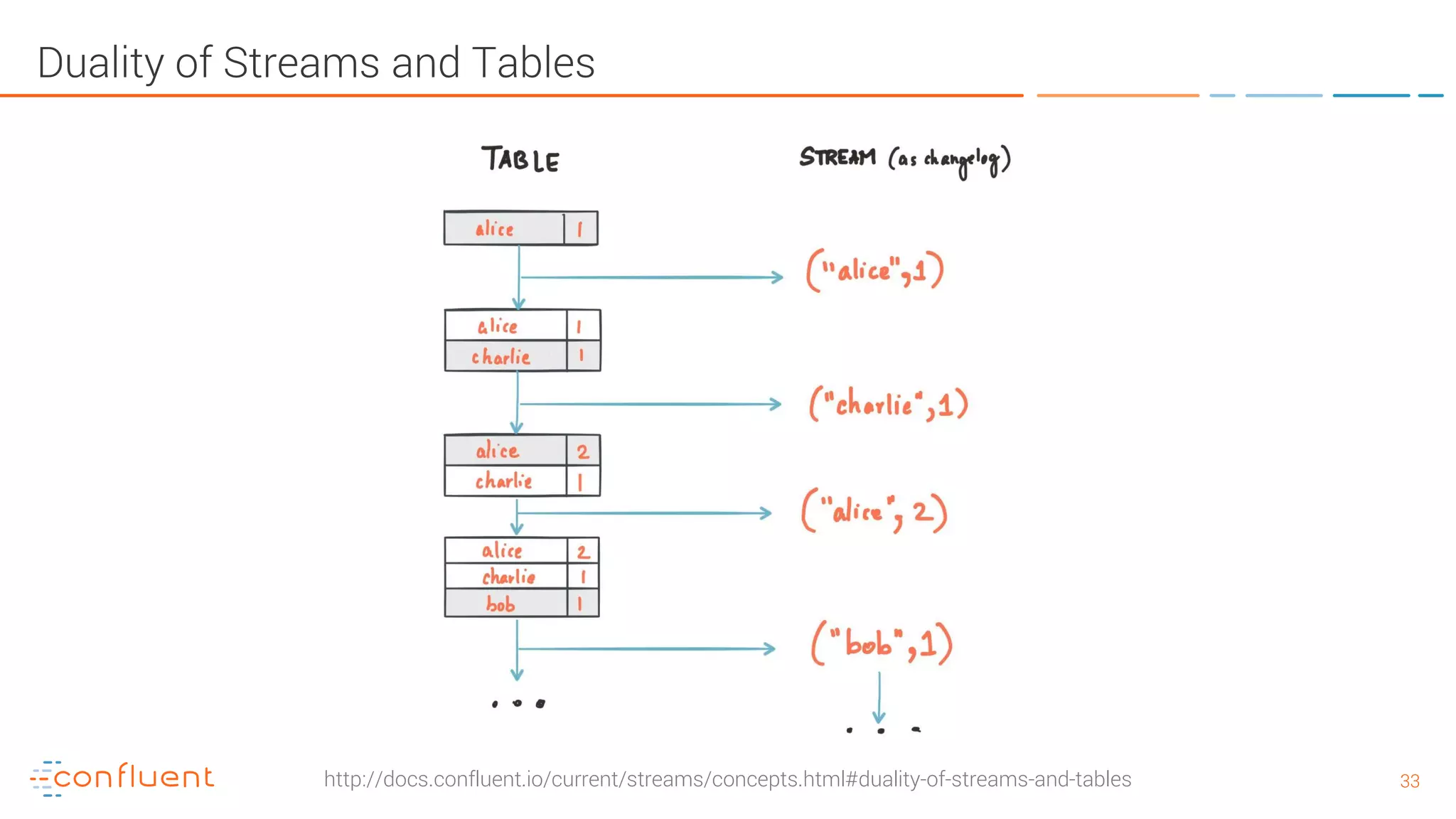
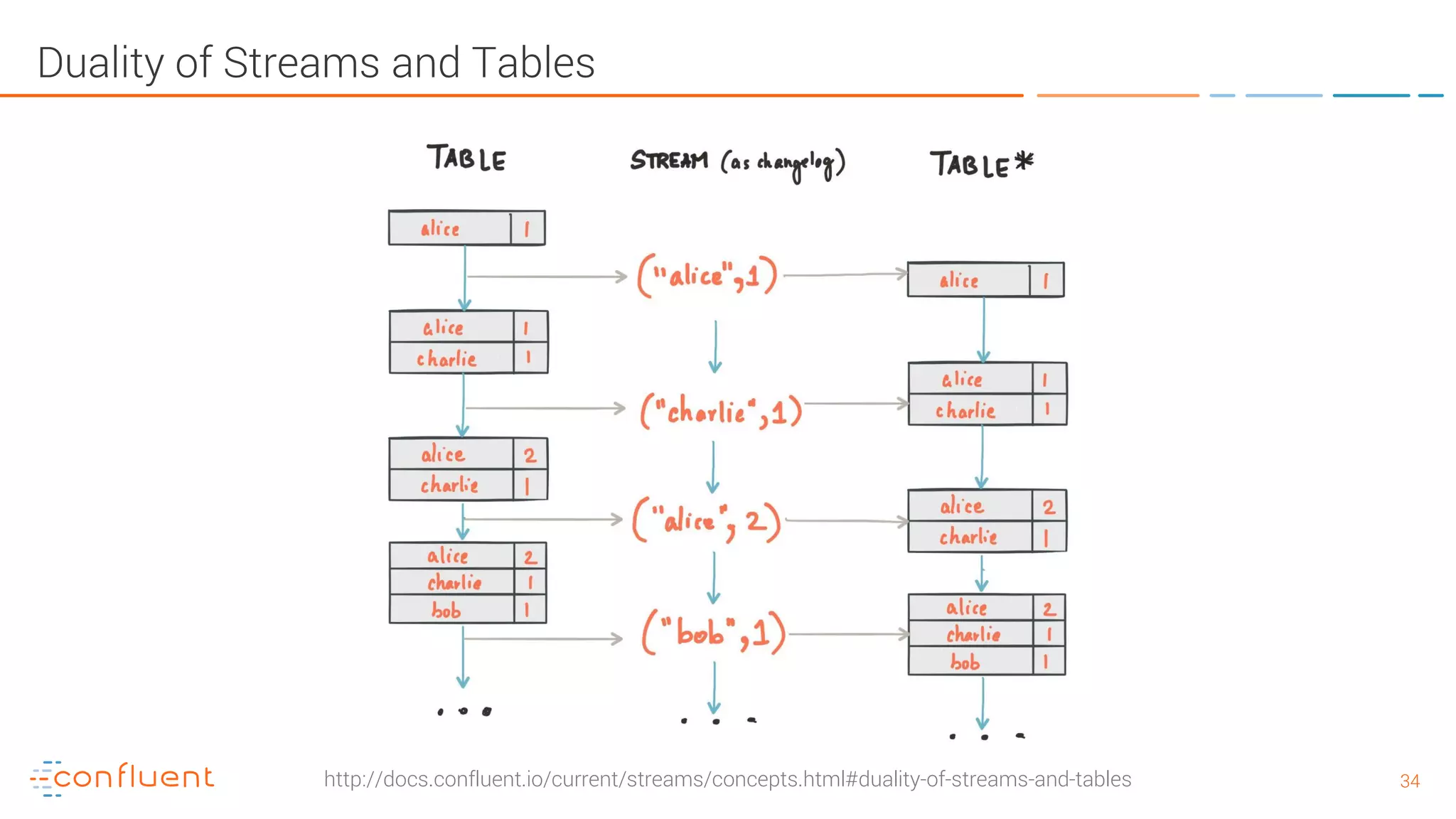
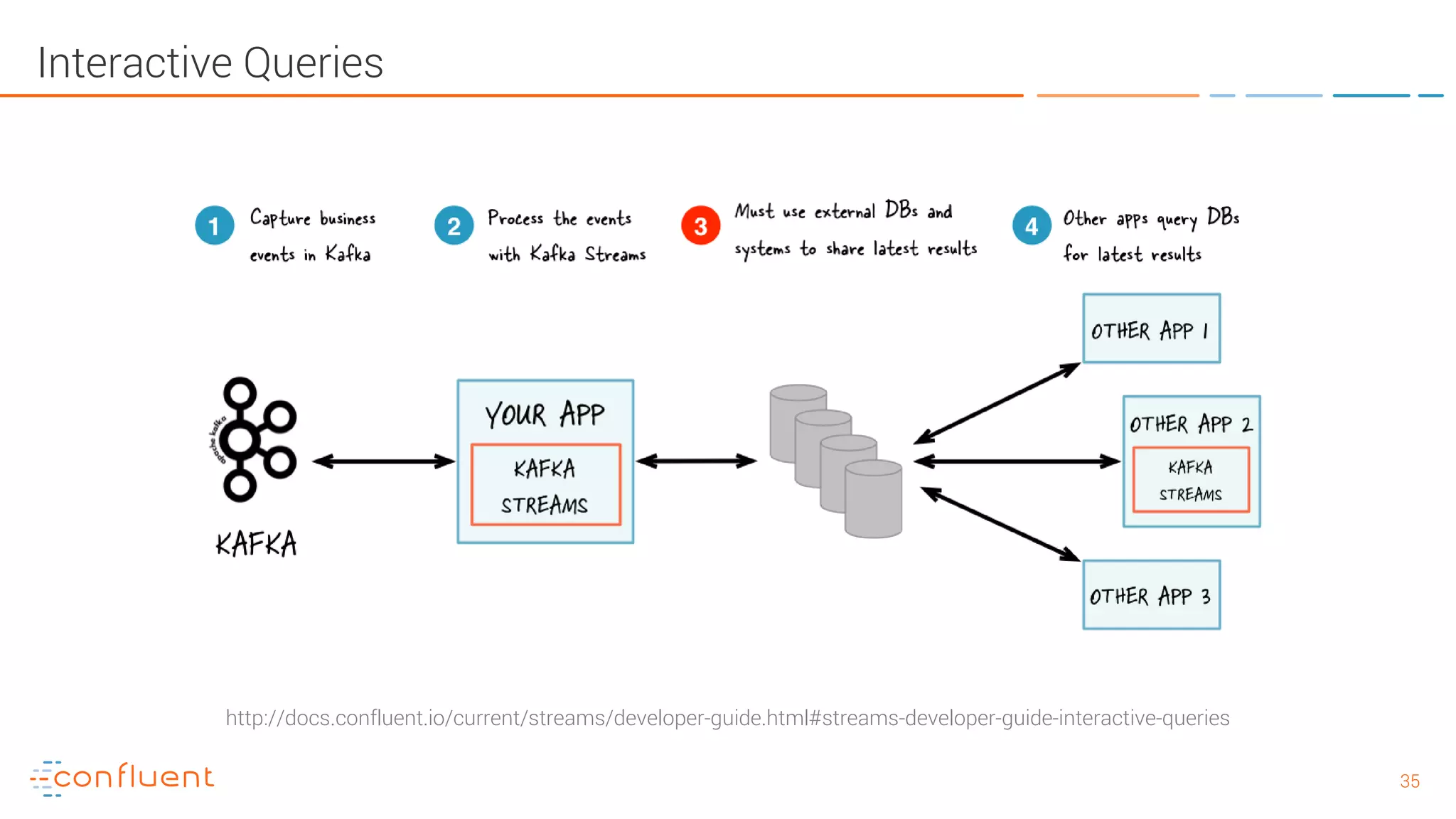
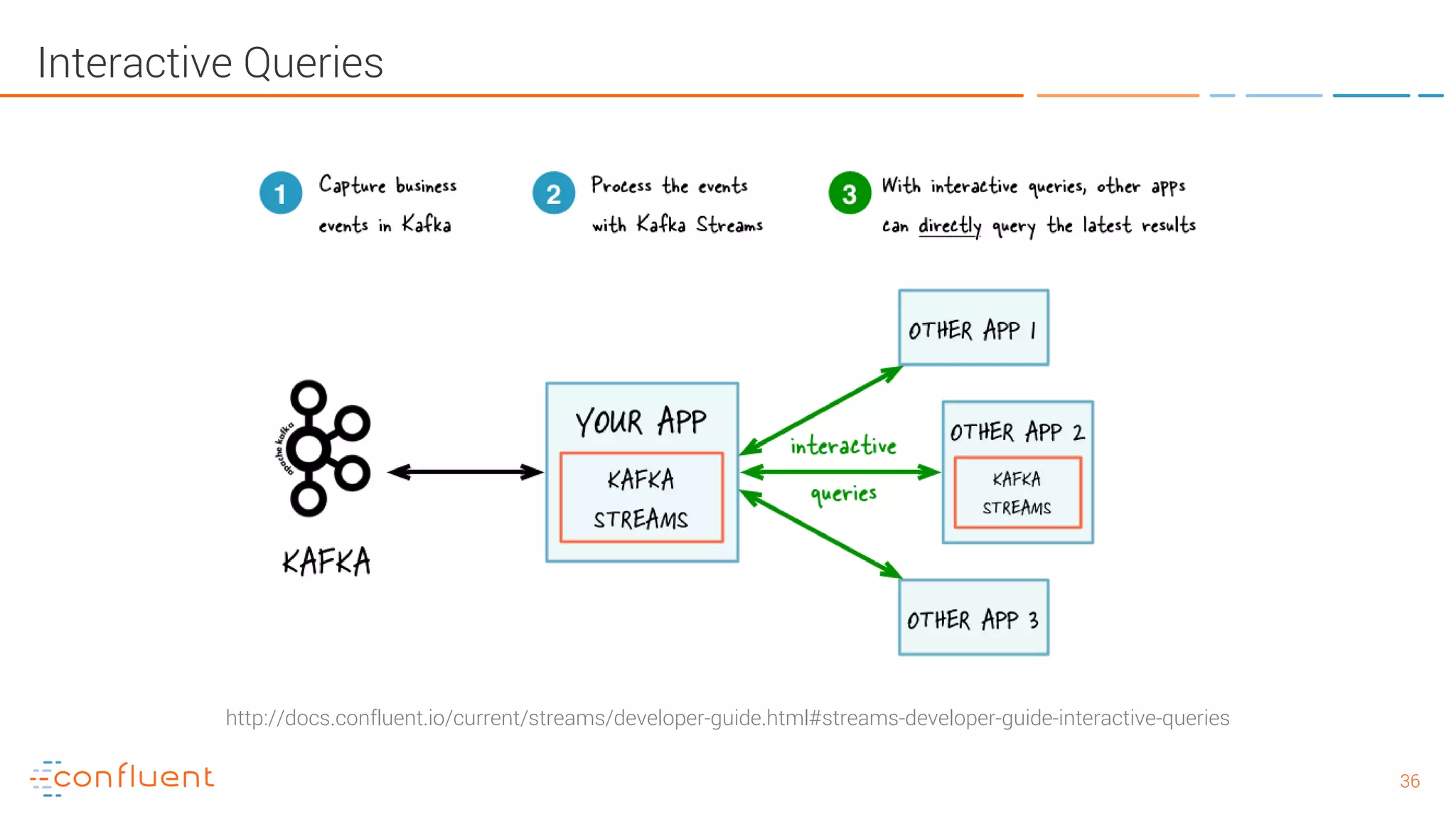
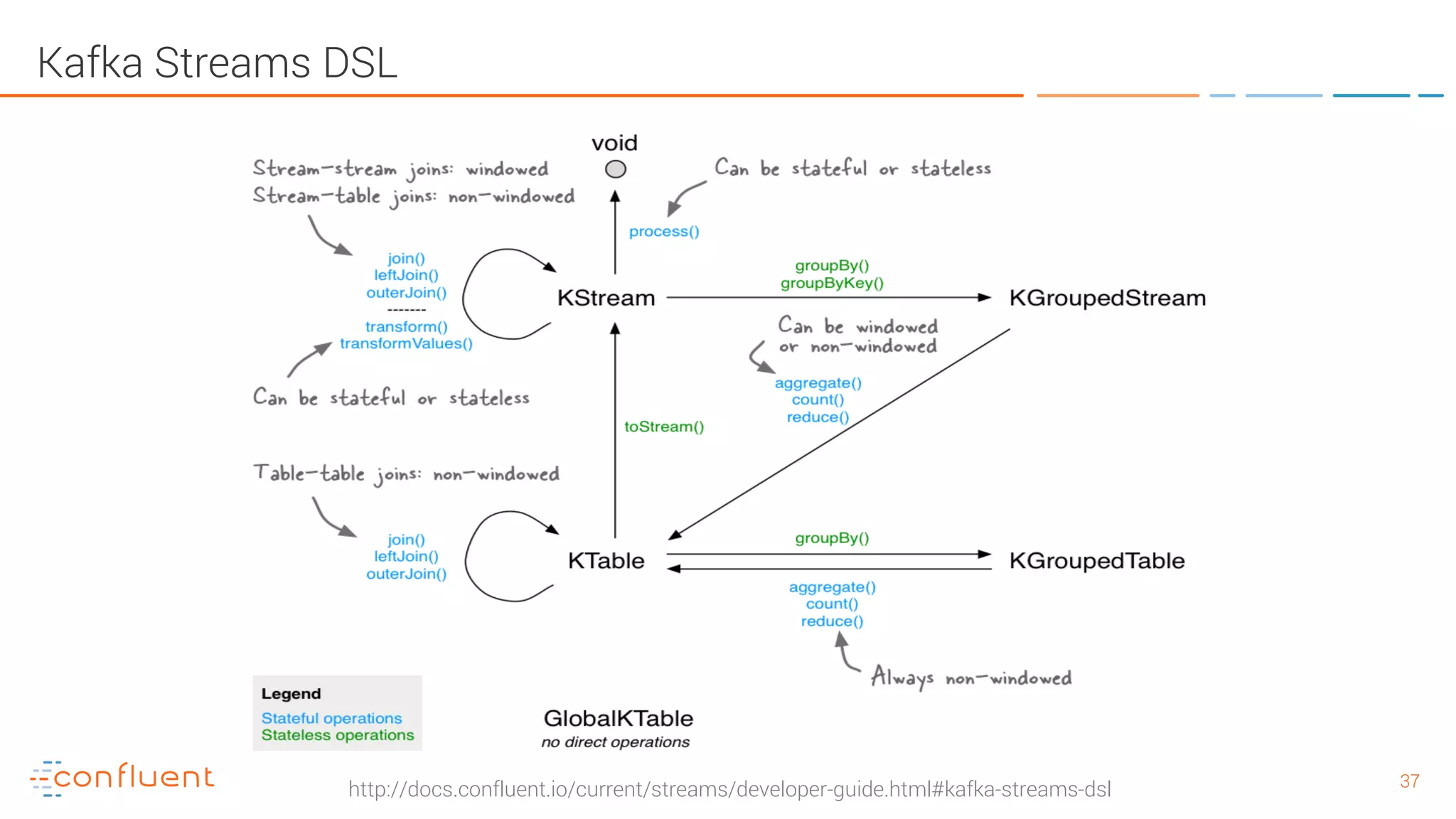
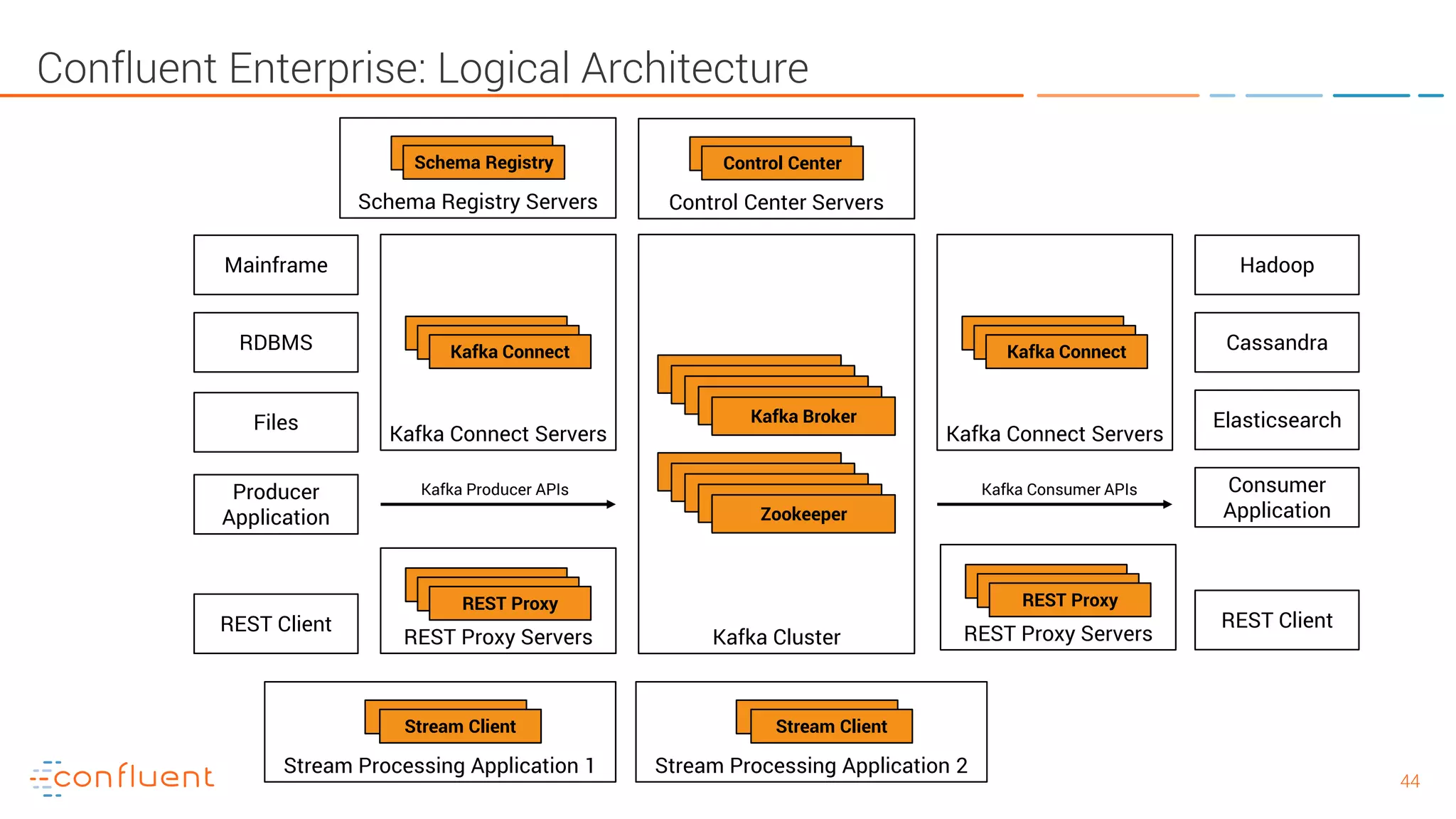
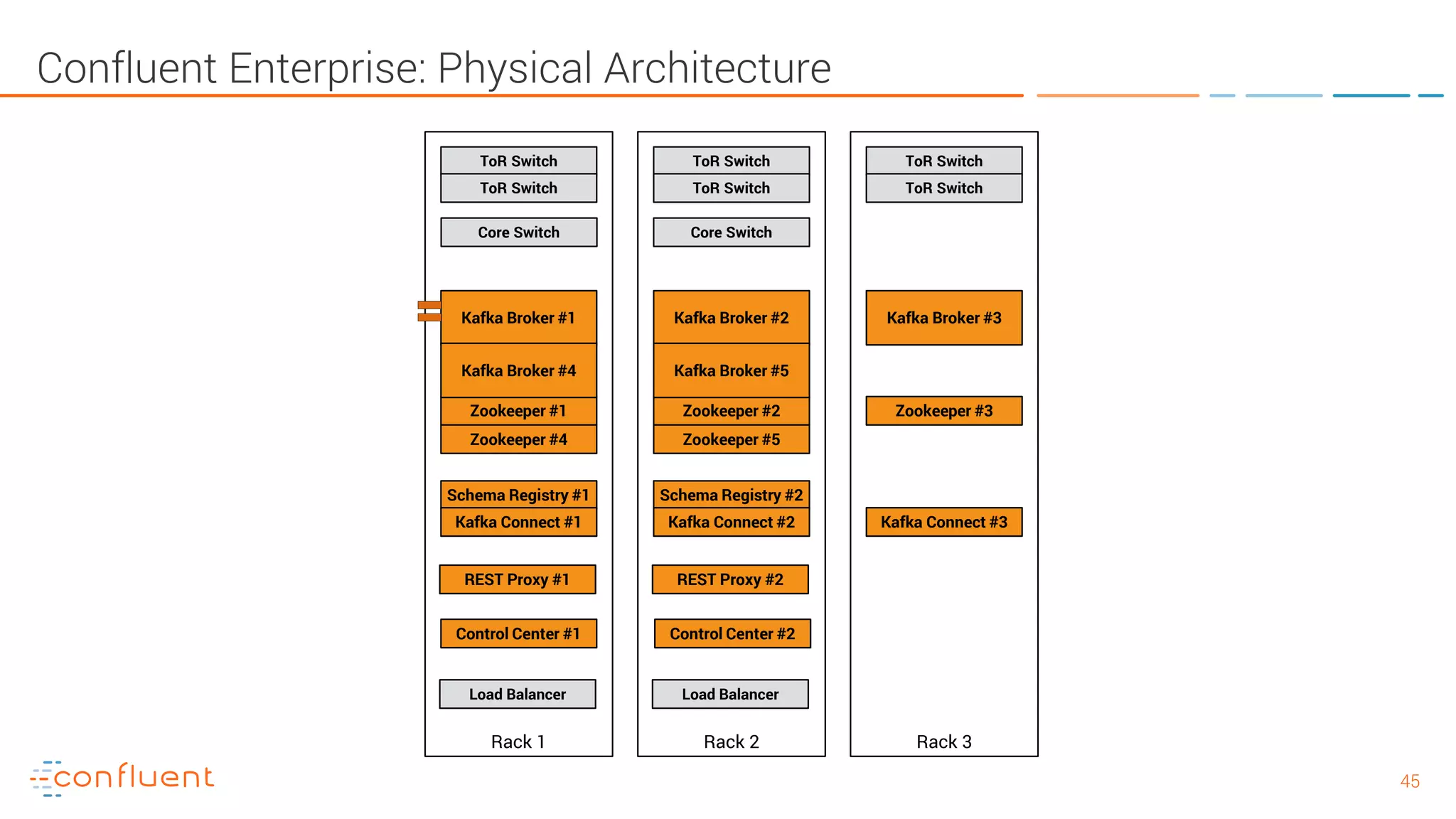
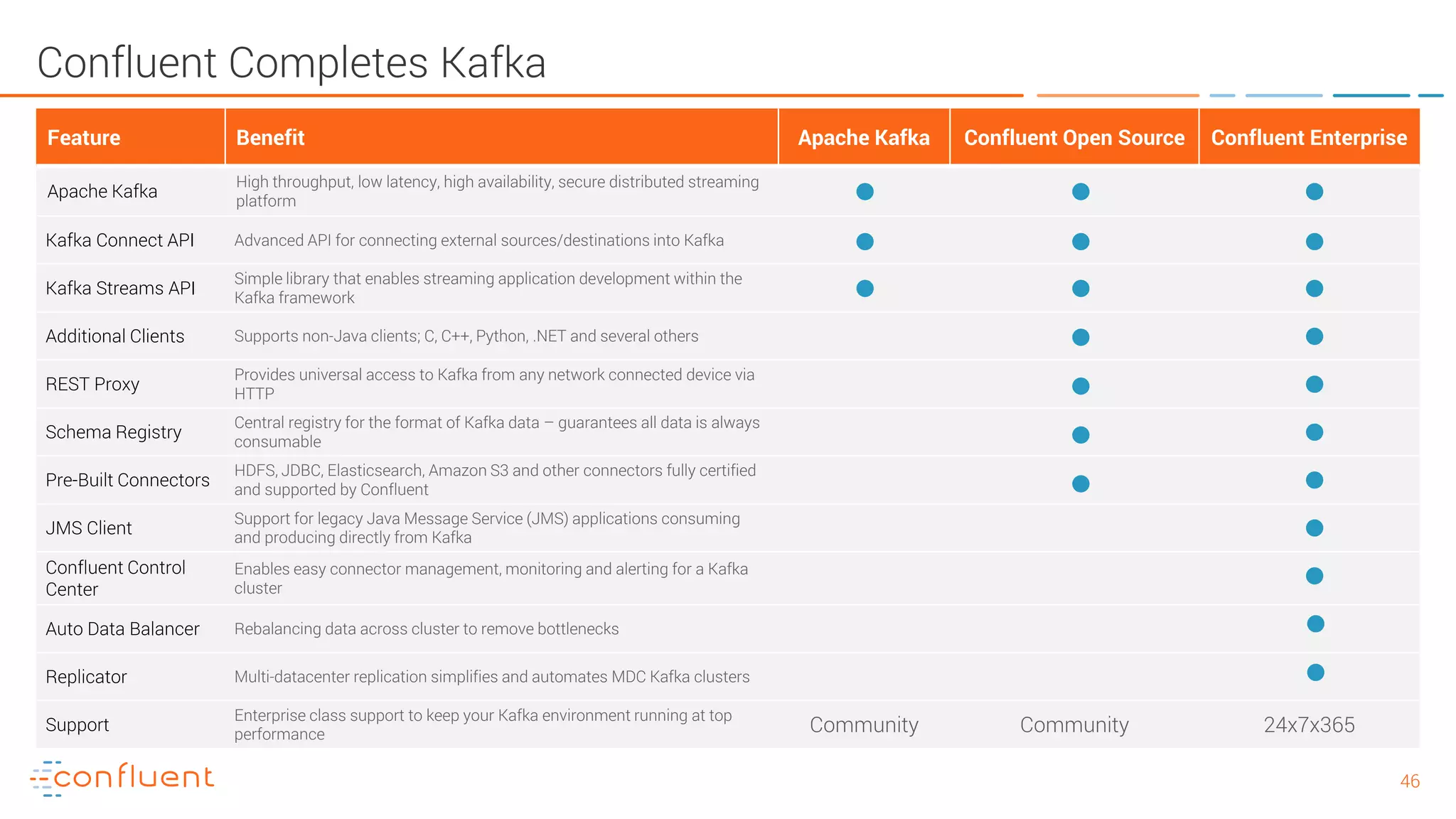
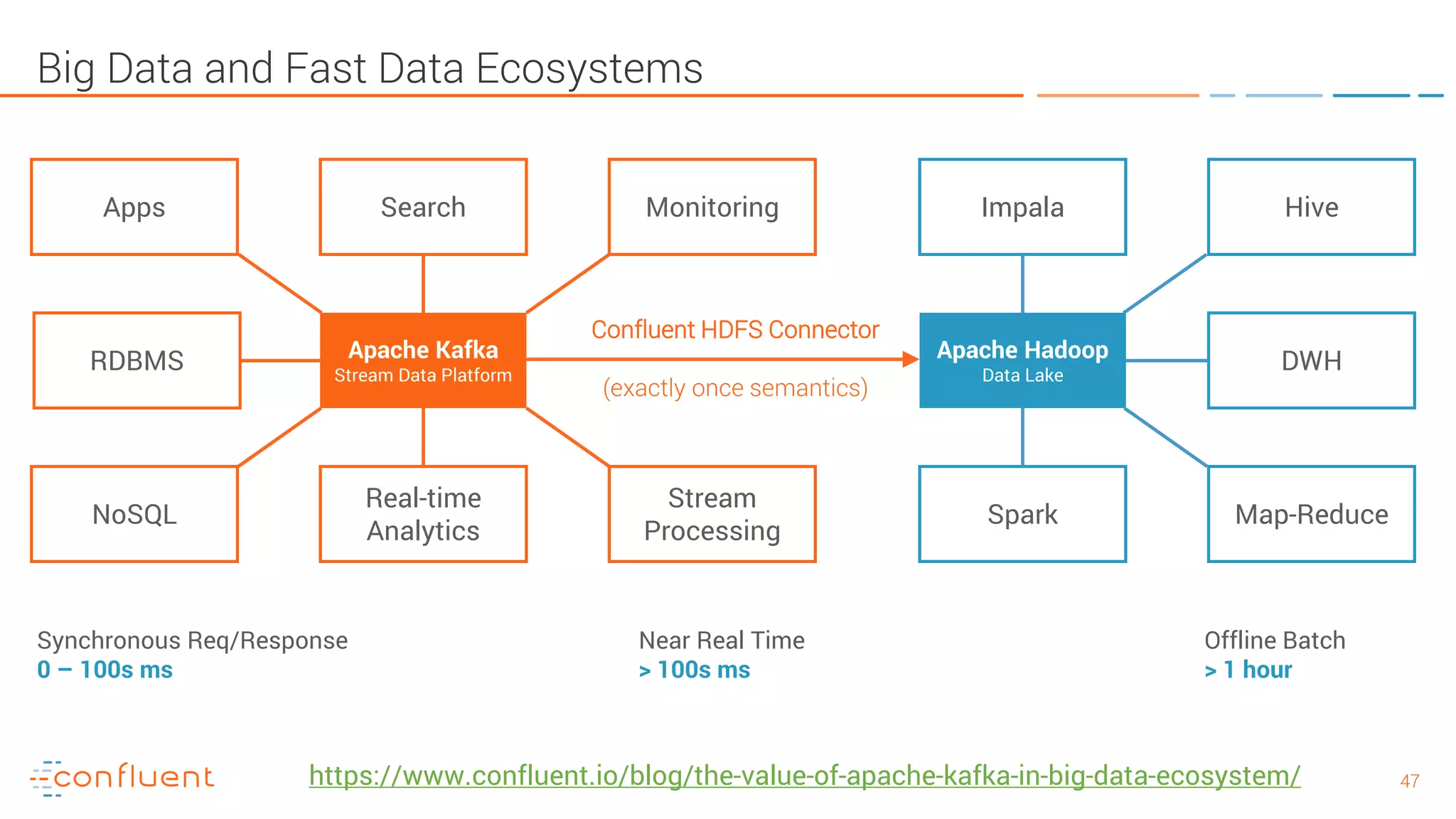
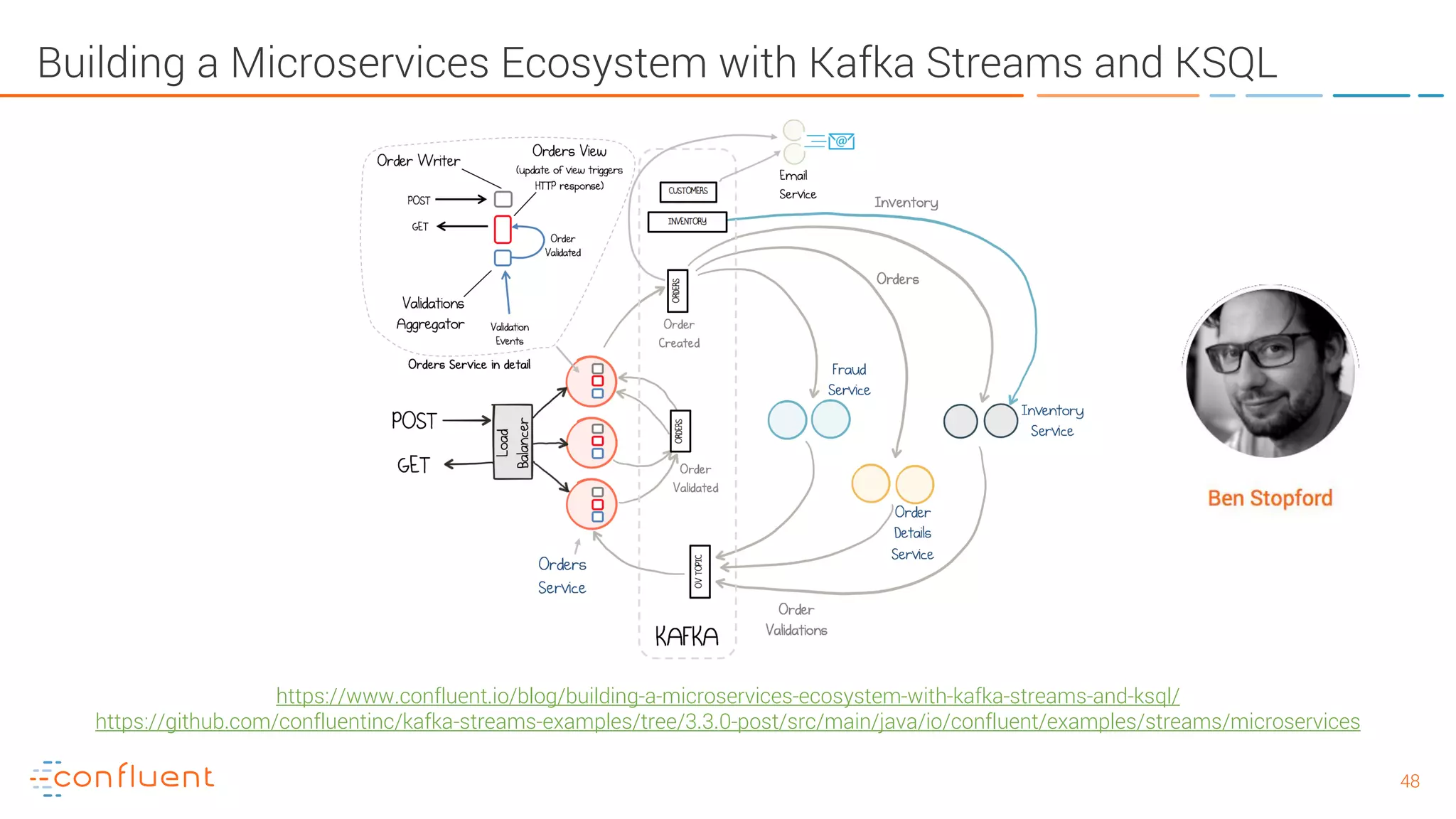
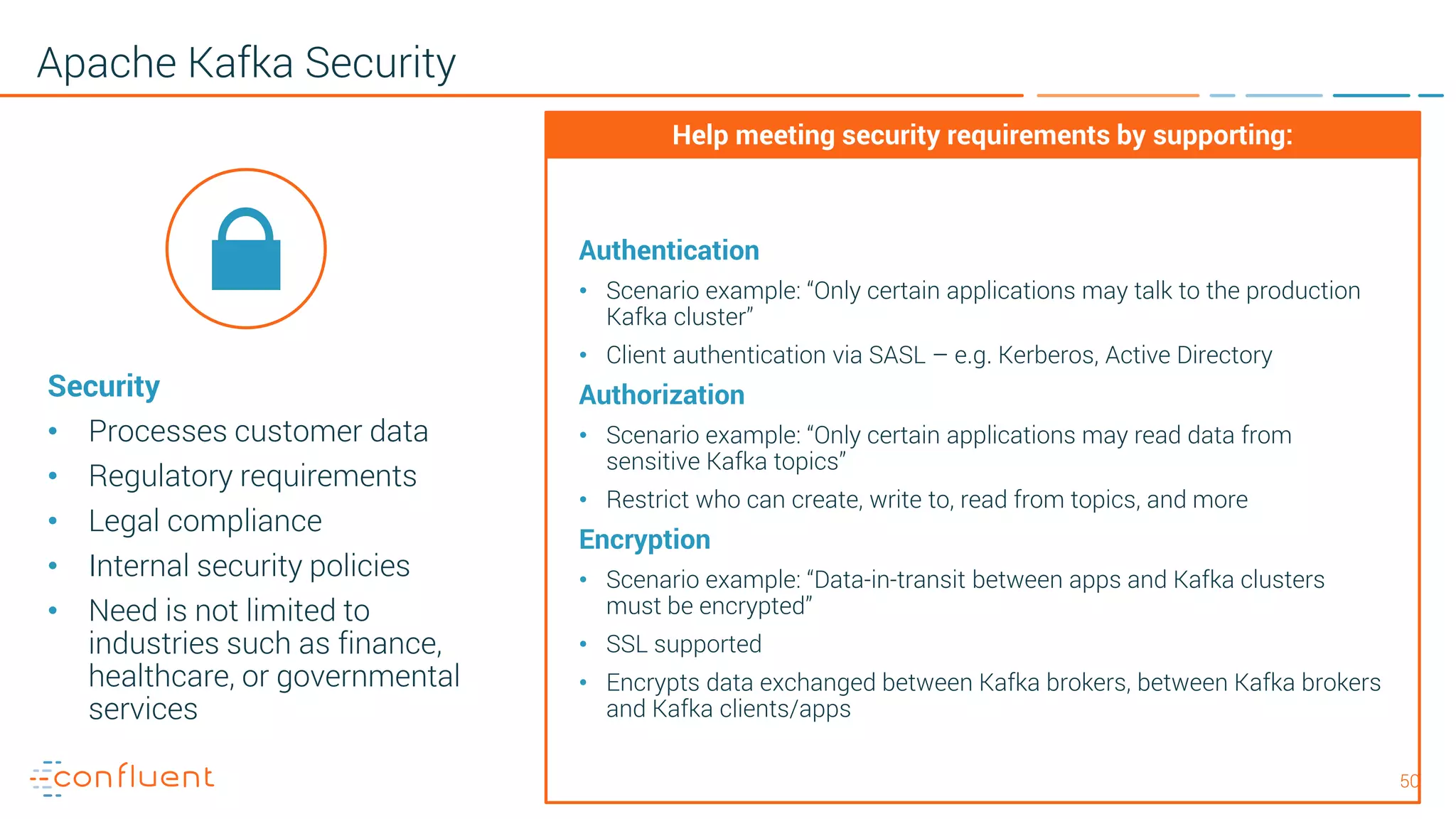
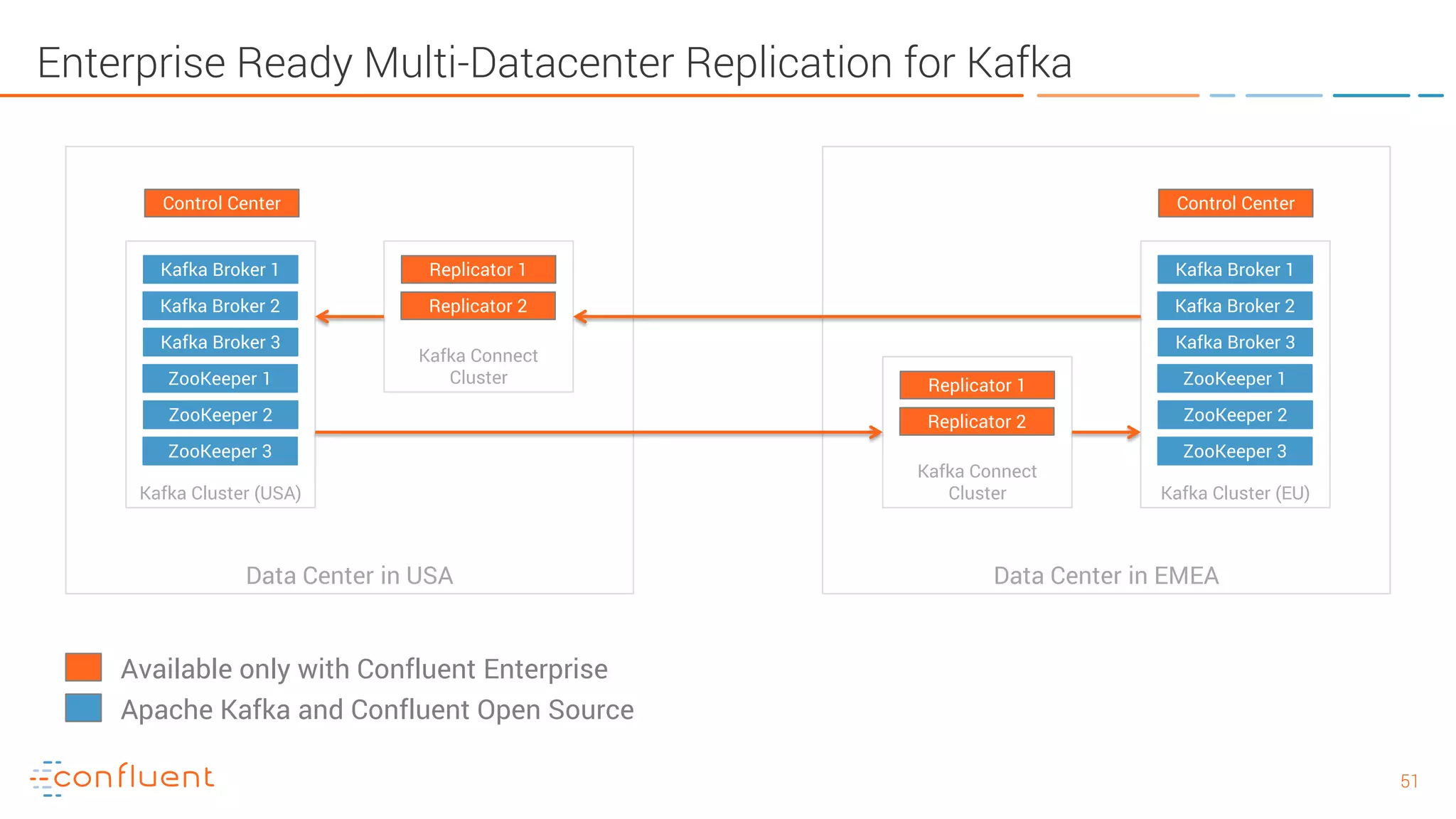
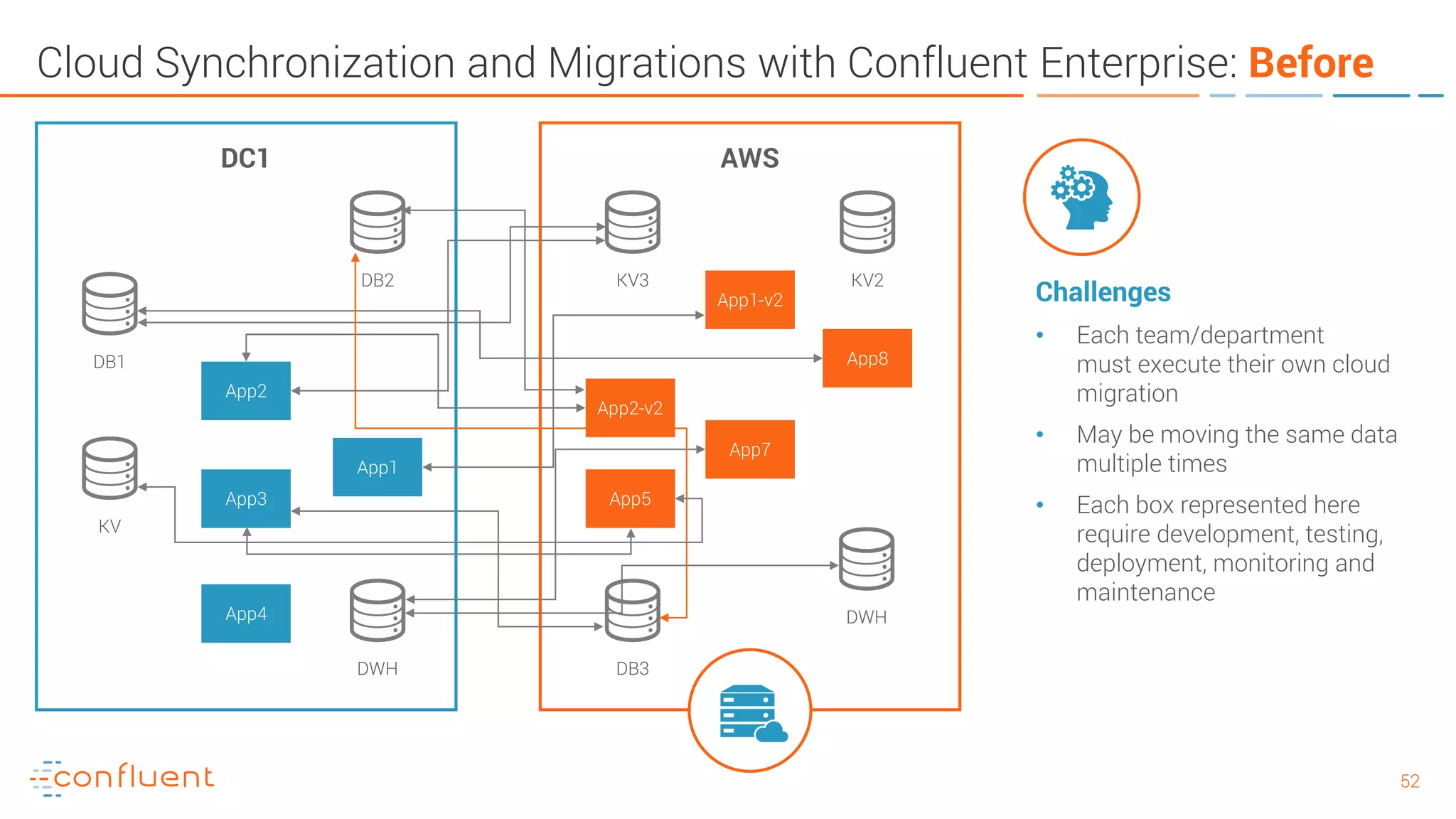
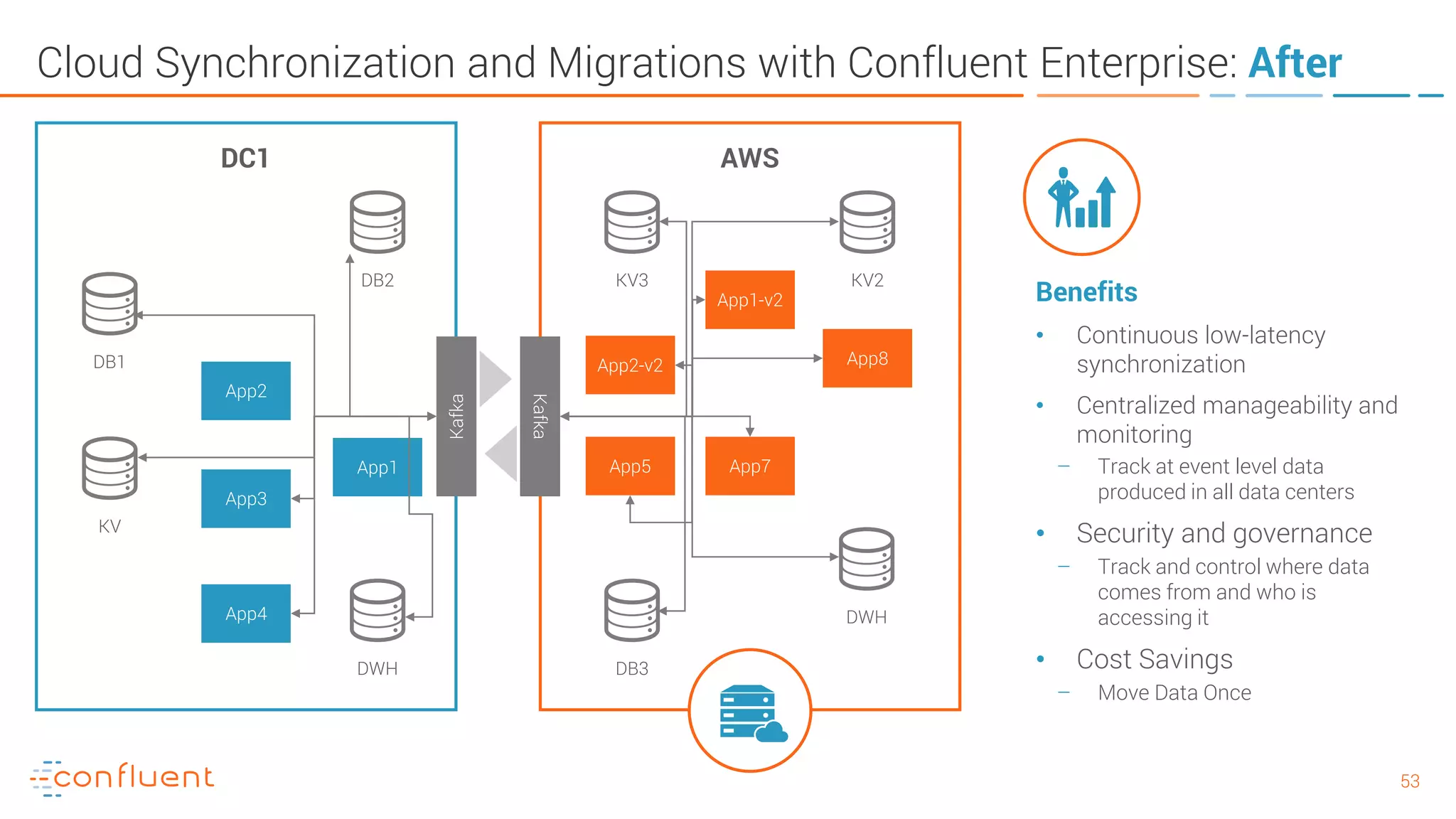
The document provides an introduction to Apache Kafka and its integration with Confluent, highlighting its capabilities as a distributed streaming platform for data handling. It discusses various applications of Kafka in industries, the shift from batch to stream processing, and includes overviews of Kafka's architecture, APIs, and security features. Notably, it emphasizes the practicality of building real-time applications and offers resources for further learning and implementation.