The course program document outlines the schedule for a one-day tutorial on comparison of optimization methods. The schedule includes sessions on discrete models in computer vision, message passing algorithms, quadratic pseudo-boolean optimization, transformation and move-making methods, and recent advances such as dual decomposition and higher-order models. All materials from the tutorial will be made available online after the conference at the listed URL.


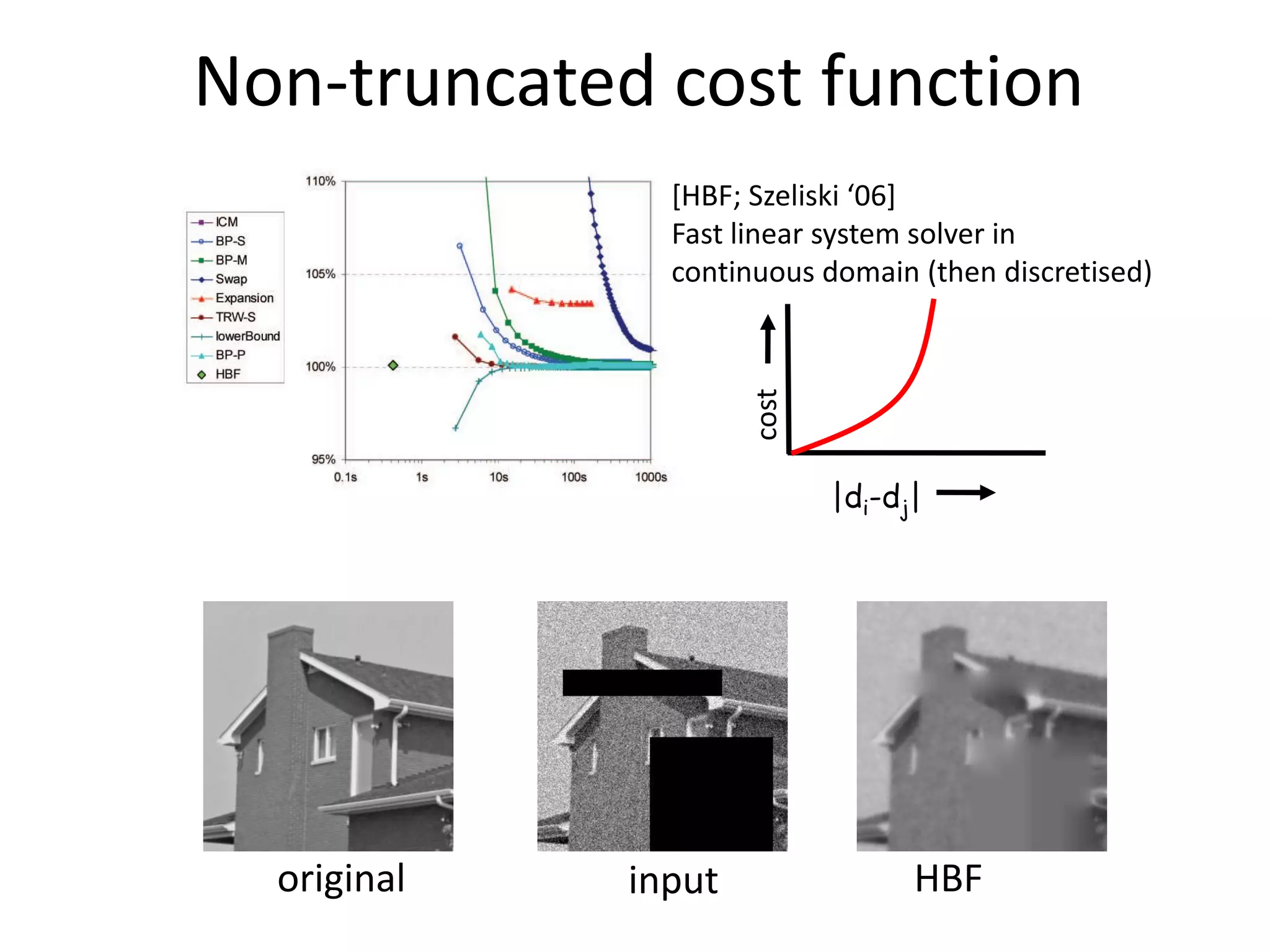
![Why is good optimization important? Input: Image sequence [Data courtesy from Oliver Woodford] Output: New view Problem: Minimize a binary 4-connected pair-wise MRF (choose a colour-mode at each pixel) [Fitzgibbon et al. ‘03+](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-3-2048.jpg)



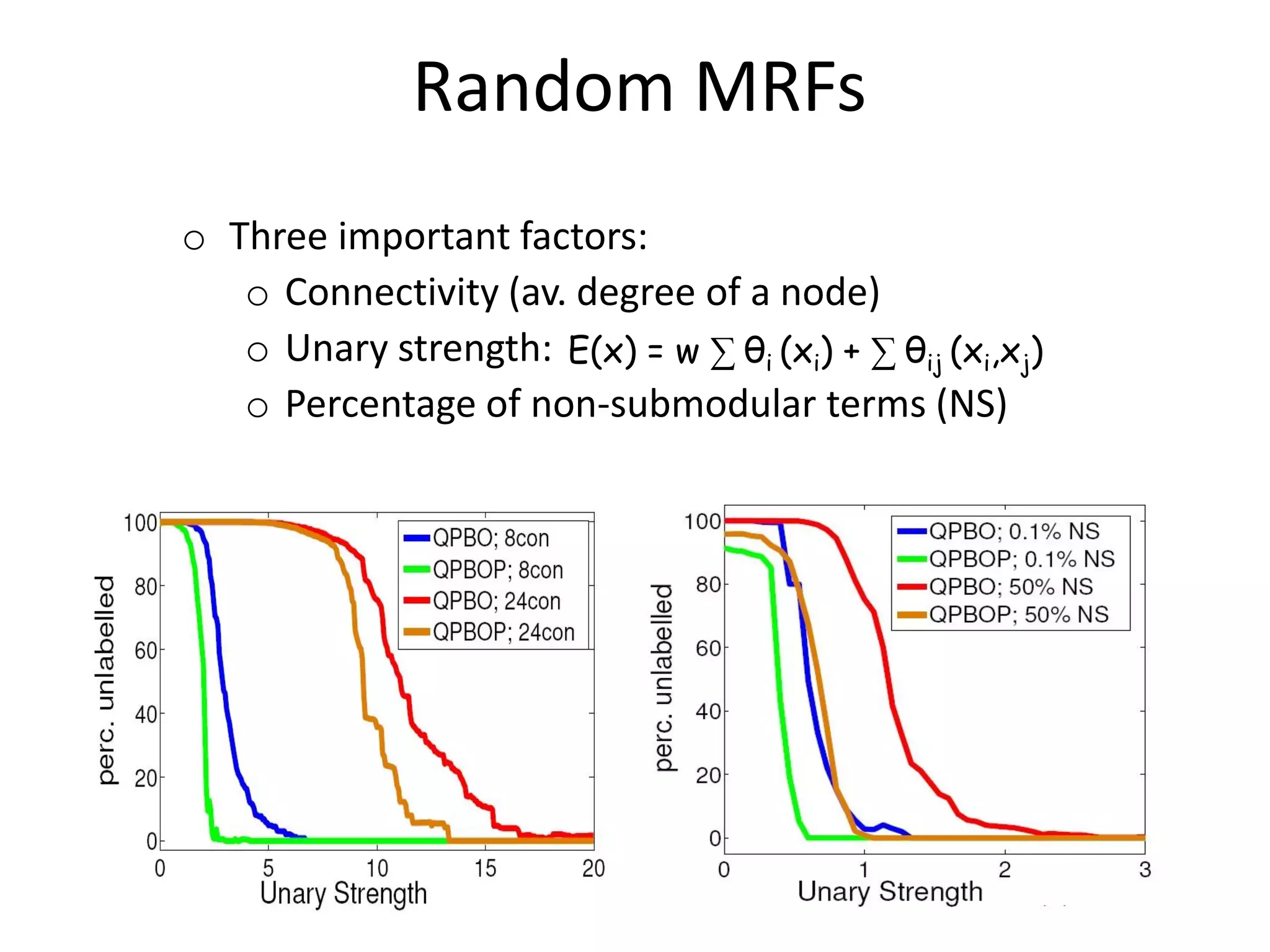

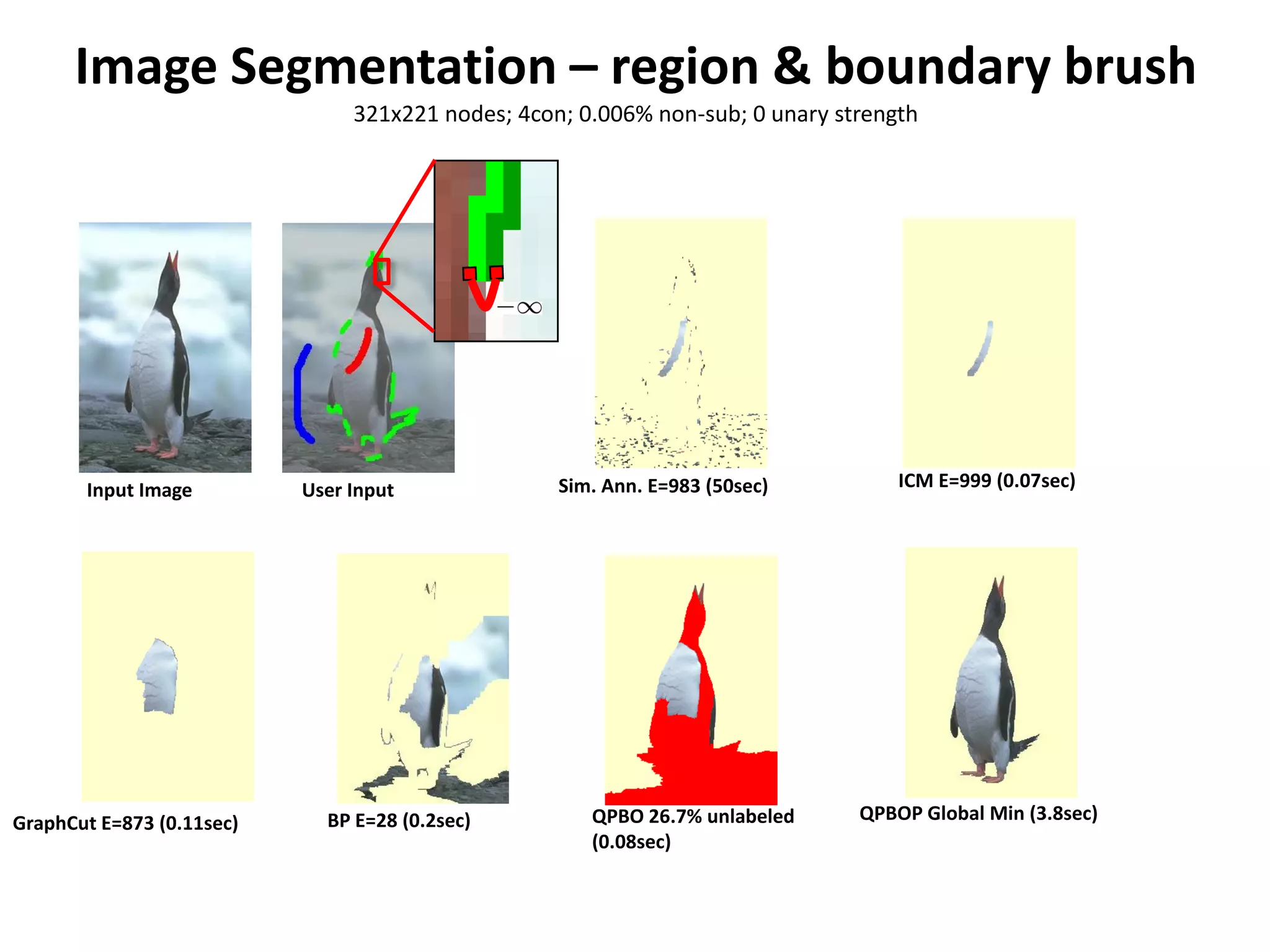
![Diagram Recognition [Szummer et al ‘04] 71 nodes; 4.8 con.; 28% non-sub; 0.5 unary strength • 2700 test cases: QPBO solved nearly all (QPBOP solves all) Ground truth QPBOP (0sec) - Global Min. Sim. Ann. E=0 (0.28sec) QPBO: 56.3% unlabeled (0 sec) BP E=25 (0 sec) GrapCut E= 119 (0 sec) ICM E=999 (0 sec)](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-9-2048.jpg)












![Add global constraints to LP Basic idea: T ∑ Xi ≥ 1 i Є T References: [K. Kolev et al. ECCV’ 08] silhouette constraint [Nowizin et al. CVPR ‘09+ connectivity prior [Lempitsky et al ICCV ‘09+ bounding box prior (see talk on Thursday) See talk on Thursday: [Lempitsky et al ICCV ‘09+ bounding box prior](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-27-2048.jpg)
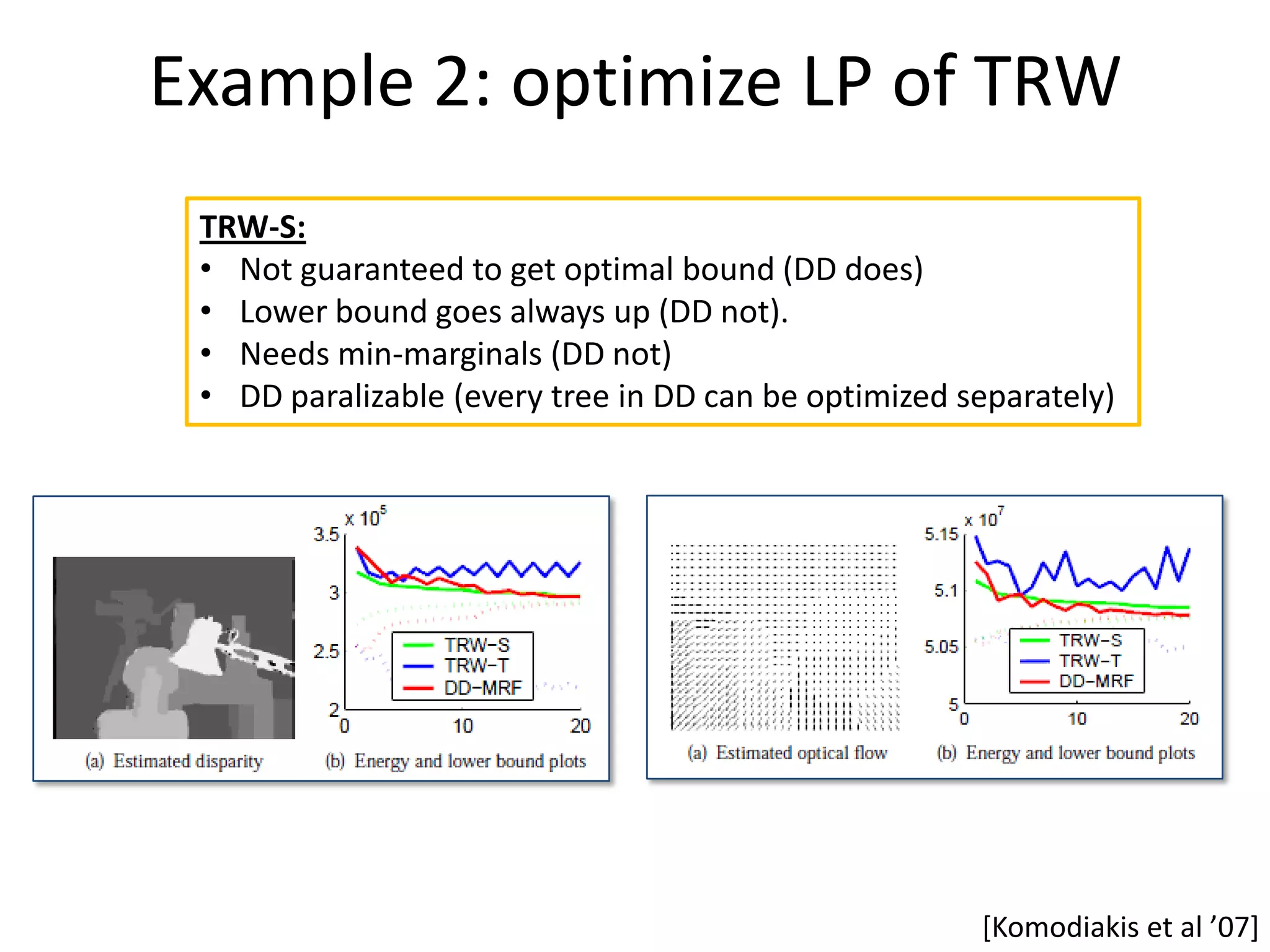
![Dual Decomposition • Well known in optimization community [Bertsekas ’95, ‘99+ • Other names: “Master-Slave” [Komodiakis et al. ‘07, ’09+ • Examples of Dual-Decomposition approaches: – Solve LP of TRW [Komodiakis et al. ICCV ‘07+ – Image segmentation with connectivity prior [Vicente et al CVPR ‘08+ – Feature Matching [Toressani et al ECCV ‘08+ – Optimizing Higher-Order Clique MRFs [Komodiakis et al CVPR ‘09+ – Marginal Probability Field *Woodford et al ICCV ‘09+ – Jointly optimizing appearance and Segmentation [Vicente et al ICCV 09]](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-28-2048.jpg)
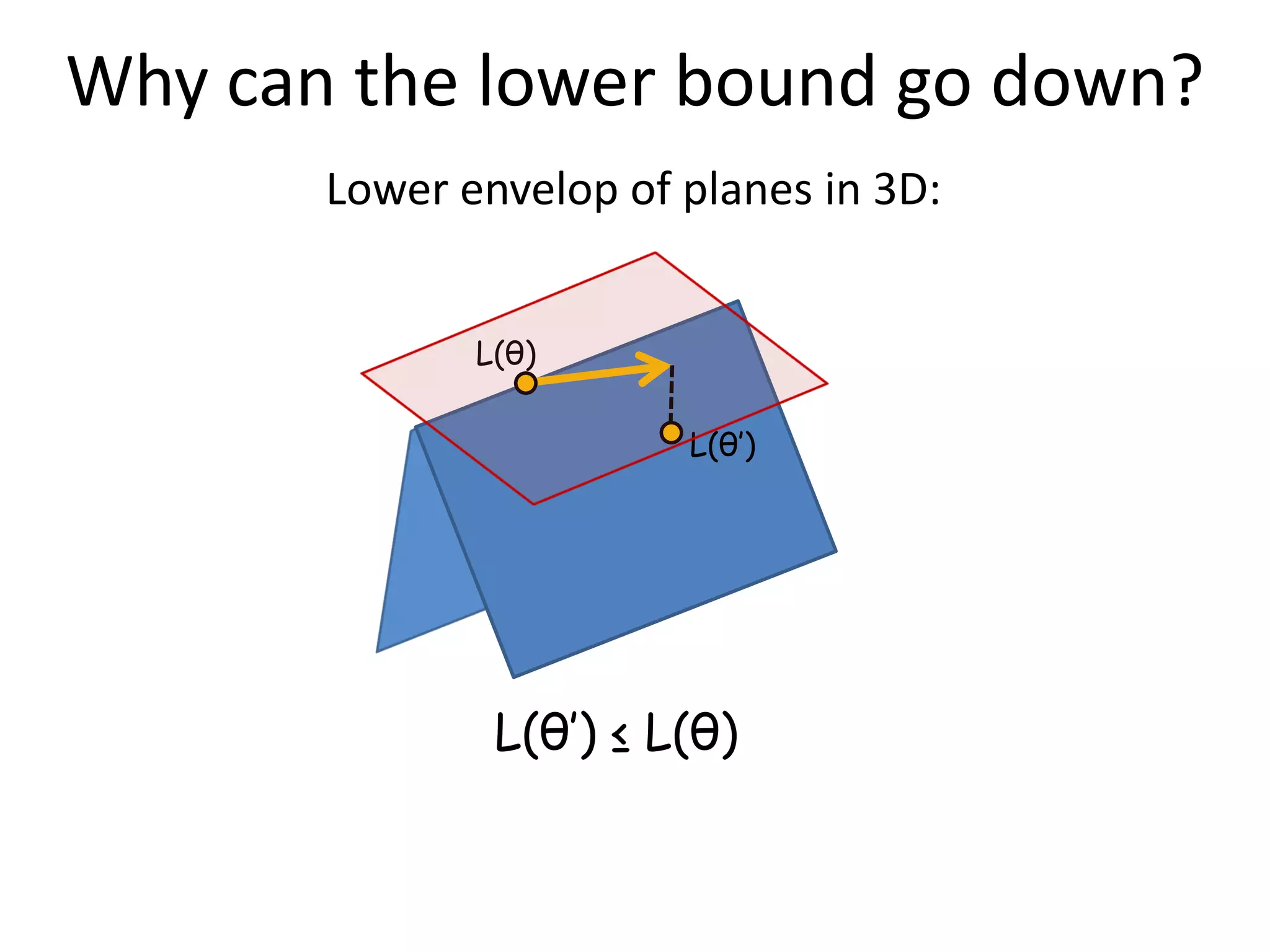
![Dual Decomposition Hard to optimize Possible to optimize Possible to optimize min E(x) = min [ E1(x) + θTx + E2(x) – θTx ] x x ≥ min [E1(x1) + θTx1] + min [E2(x2) - θTx2] = L(θ) x1 x2 “Lower bound” • θ is called the dual vector (same size as x) • Goal: max L(θ) ≤ min E(x) θ x • Properties: • L(θ) is concave (optimal bound can be found) • If x1=x2 then problem solved (not guaranteed)](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-29-2048.jpg)
![Why is the lower bound a concave function? L(θ) = min [E1(x1) + θTx1] + min [E2(x2) - θTx2] L(θ) : Rn -> R x1 x2 L1(θ) L2(θ) θTx’1 L1(θ) θTx’’1 θTx’’’1 θ L(θ) concave since a sum of concave functions](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-30-2048.jpg)

![How to maximize the lower bound? If L(θ) were to be differentiable use gradient ascent L(θ) not diff. so subgradient approach [Shor ‘85+ L(θ) = min [E1(x1) + θTx1] + min [E2(x2) - θTx2] L(θ) : Rn -> R x1 x2 L1(θ) L2(θ) θTx’1 L1(θ) θTx’’1 Subgradient g θTx’’’1 Θ’ Θ’’ Θ Θ’’ = Θ’ + λ g = Θ’ + λ x’1 Θ’’ = Θ’ + λ (x1-x2)](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-32-2048.jpg)
![Dual Decomposition L(θ) = min [E1(x1) + θTx1] + min [E2(x2) - θTx2] x1 x2 Subgradient Optimization: “Master” Θ = Θ + λ(x*-x2) 1 * x1* x2 * Θ Θ subgradient Subproblem 1 Subproblem 2 x* = min [E1(x1) + θTx1] 1 x2 = min [E2(x2) + θTx2] * “Slaves” x1 x2 • Guaranteed to converge to optimal bound L(θ) • Choose step-width λ correctly ([Bertsekas ’95]) • Pick solution x as the best of x1 or x2 • E and L can in- and decrease during optimization • Each step: θ gets close to optimal θ* Example optimization](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-33-2048.jpg)
![Analyse the model push x1p towards 0 1 push x2p towards 1 0 L(θ) = min [E1(x1) + θTx1] + min [E2(x2) - θTx2] Update step: Θ’’ = Θ’ + λ (x*-x*) 1 2 Look at pixel p: Case1: x* = x2p 1p * then Θ’’ = Θ’ Case2: x* = 1 x2p = 0 1p * then Θ’’ = Θ’+ λ Case3: x* = 0 x* = 1 1p 2p then Θ’’ = Θ’- λ](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-35-2048.jpg)

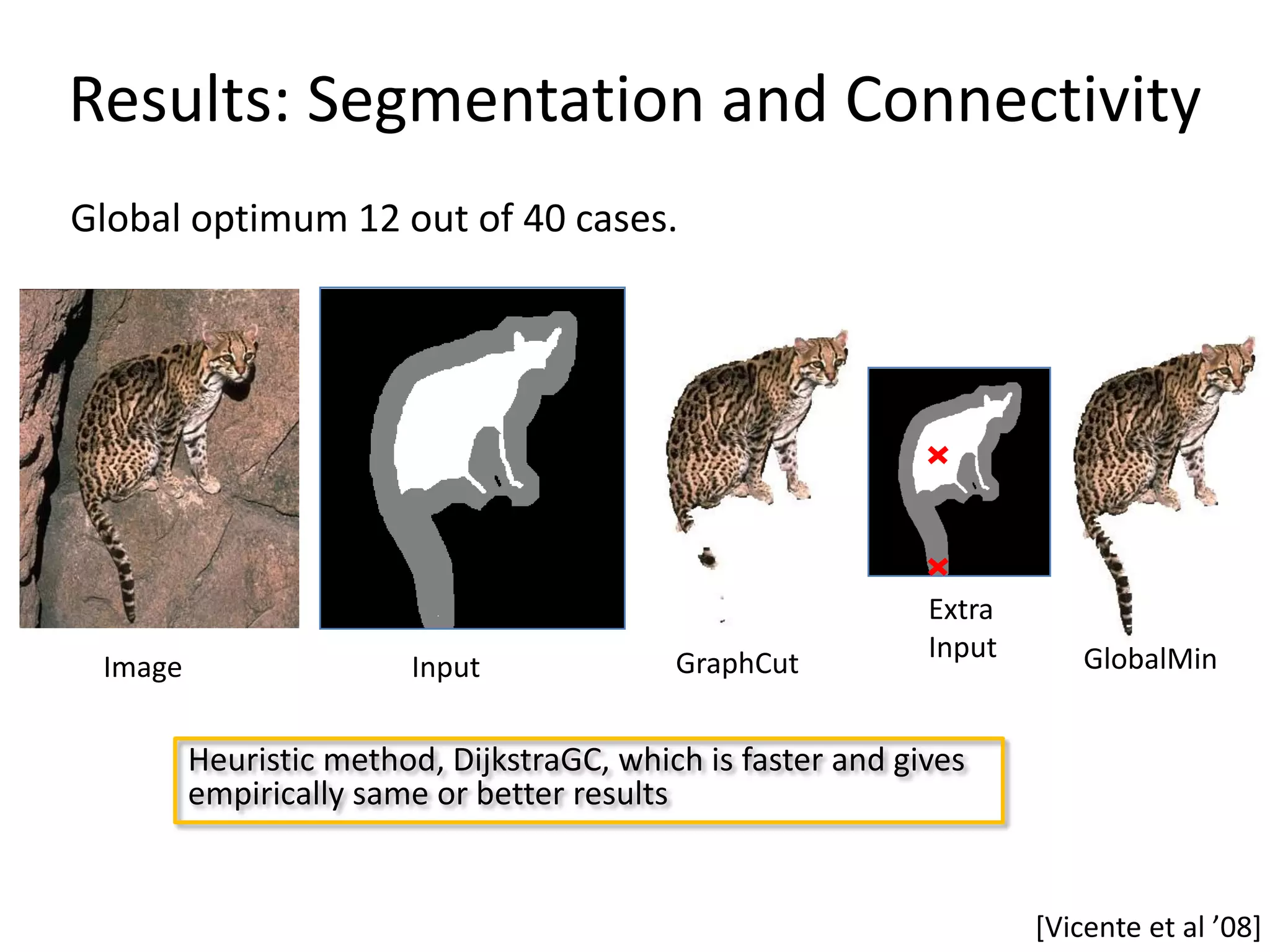
![Example 1: Segmentation and Connectivity E1(x) E(x) = ∑ θi (xi) + ∑ θij (xi,xj) + h(x) h(x)= { ∞ if x not 4-connected 0 otherwise Derive Lower bound: min E(x) = min [ E1(x) + θTx + h(x) – θTx ] x x ≥ min [E1(x1) + θTx1] + min [h(x2) + θTx2] = L(θ) x1 x2 Subproblem 1: Subproblem 2: Unary terms + Unary terms + pairwise terms Connectivity constraint Global minimum: Global minimum: GraphCut Dijkstra But: Lower bound was for no example tight.](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-37-2048.jpg)
![Example 1: Segmentation and Connectivity E1(x) E(x) = ∑ θi (xi) + ∑ θij (xi,xj) + h(x) h(x)= { ∞ if x not 4-connected 0 otherwise Derive Lower bound: x’ indicator vector of all pairwise terms min E(x) = min [ E1(x) + θTx + θ’Tx’ + h(x) – θTx + h(x) - θ’Tx’] x,x’ x,x’ ≥ min [E1(x1) + θTx1 + θ’Tx’1] + min [h(x2) + θTx2] + x1,x’1 x2 min [h(x3) + θ’Tx’3] =L(θ) x3,x’3 Subproblem 1: Subproblem 2: Subproblem 3: Unary terms + Unary terms + Pairwise terms + pairwise terms Connectivity constraint Connectivity constraint Global minimum: Global minimum: Lower Bound: Based on GraphCut Dijkstra minimal paths on a dual graph](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-38-2048.jpg)
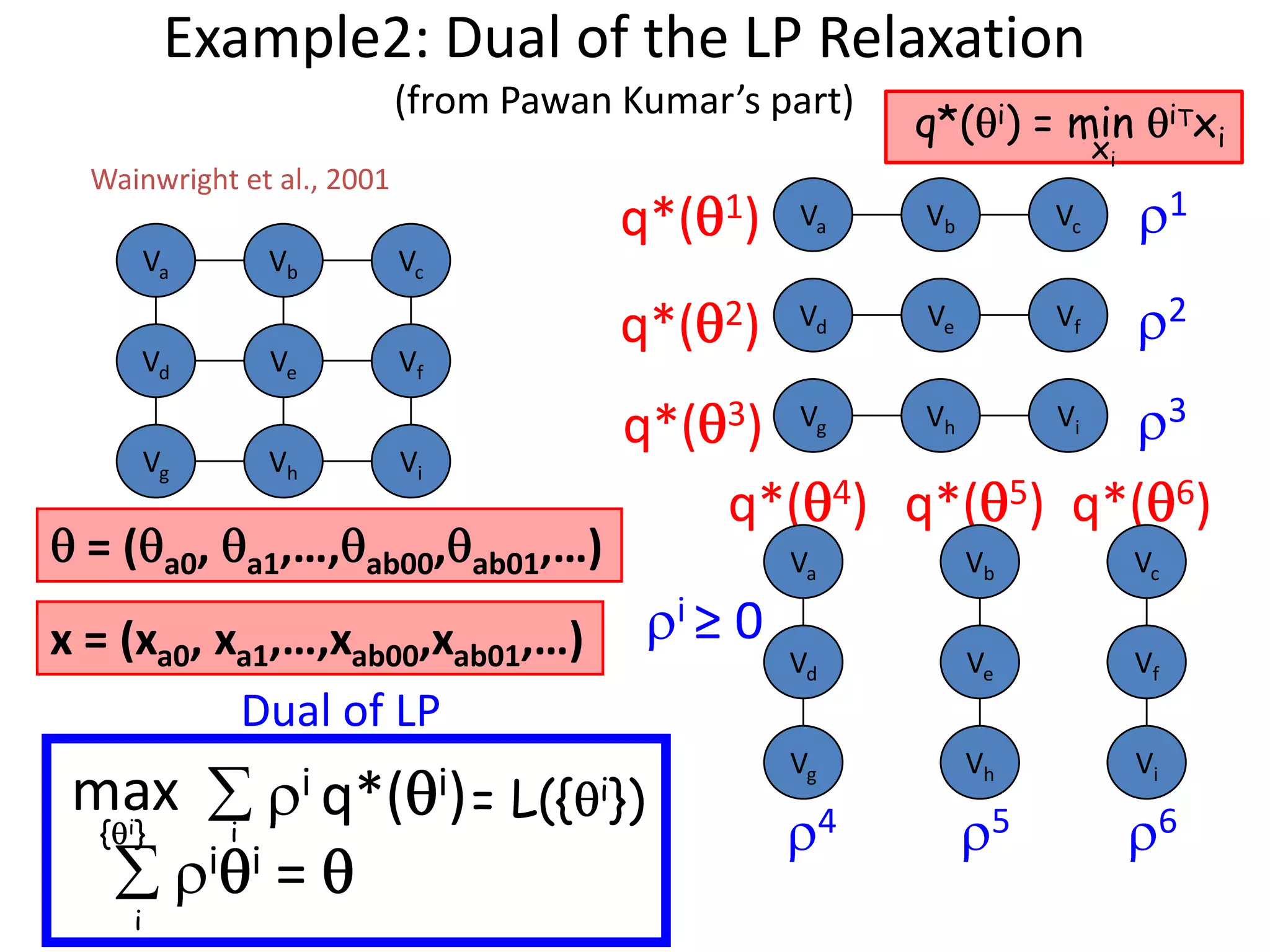
![Example2: Dual of the LP Relaxation “Original “i different “Lower bound” problem” trees” min Tx = min iTx x ∑ ≥ ∑ min x iTx i = L({ i}) x i i i q*( i) Subject to i = i Use subgradient … why? θTx’1 q*( i) concave wrt i ; q*( i) = min iTx i θTx’’1 xi θTx’’’1 Projected subgradient method: θ Θi = [Θi + λx *] i Ω Ω= {Θi| ∑ Θi = Θ } i Guaranteed to get the optimal lower bound !](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-41-2048.jpg)





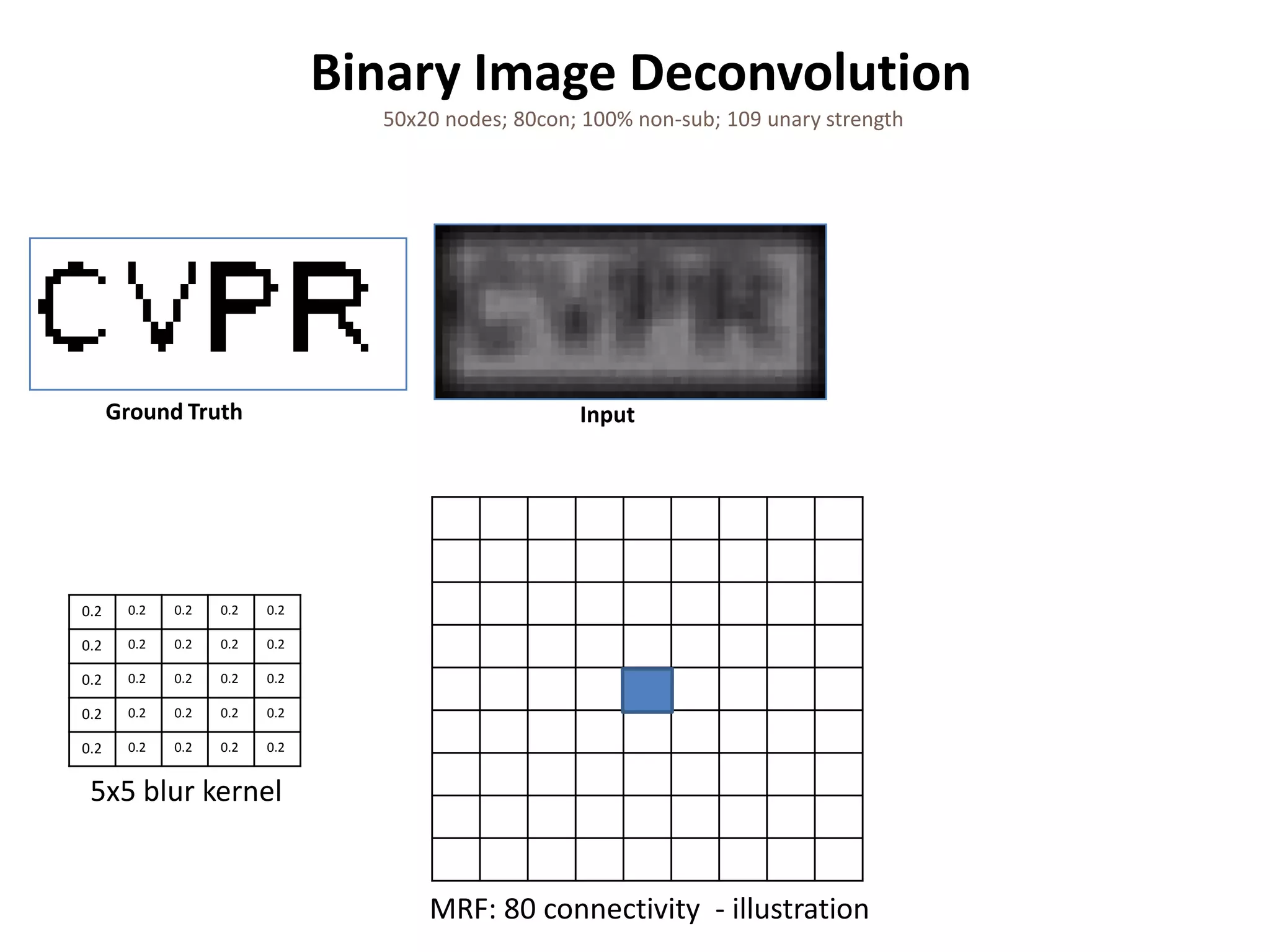
![New-View Synthesis [Fitzgibbon et al ‘03] 385x385 nodes; 8con; 8% non-sub; 0.1 unary strength Ground Truth Graph Cut E=2 (0.3sec) Sim. Ann. E=980 (50sec) ICM E=999 (0.2sec) (visually similar) QPBO 3.9% unlabelled QPBOP - Global Min. (1.4sec), BP E=18 (0.6sec) (black) (0.7sec) P+BP+I, BP+I](https://image.slidesharecdn.com/iccv09part5rothercomparisondualdecomposition-110515234250-phpapp02/75/ICCV2009-MAP-Inference-in-Discrete-Models-Part-5-52-2048.jpg)