Download as PDF, PPTX






![9© Cloudera, Inc. All rights reserved. ● DStream ○ Consumer poll for group coordination & discovery ○ Identify new partitions, from offsets ○ Pause consumer ○ seekToEnd to get untilOffsets ● KafkaRDD ○ Fixed [enable.auto.commit = false, auto.offset.reset = none, spark-executor-${group.id}] ○ Attempts to assign offset range consistently for optimal consumer caching ● KafkaRDDPartition iterator ○ Initialize/lookup CachedKafkaConsumer with executor group ■ consumer assigned per single topic, partition with internal buffer ■ on cache miss, seek and poll Spark Streaming Kafka Consumer # 2](https://image.slidesharecdn.com/stratasj-kafkasparkstreaminghambletonmedasani-180316020605/75/How-to-build-leakproof-stream-processing-pipelines-with-Apache-Kafka-and-Apache-Spark-9-2048.jpg)


![14© Cloudera, Inc. All rights reserved. ● ZooKeeper ○ znode - /consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset) ○ Only retains latest committed offsets ○ Can easily be managed by external tools ○ Leverage existing monitoring for Lag, no historical insight Offset Management in ZooKeeper](https://image.slidesharecdn.com/stratasj-kafkasparkstreaminghambletonmedasani-180316020605/75/How-to-build-leakproof-stream-processing-pipelines-with-Apache-Kafka-and-Apache-Spark-14-2048.jpg)





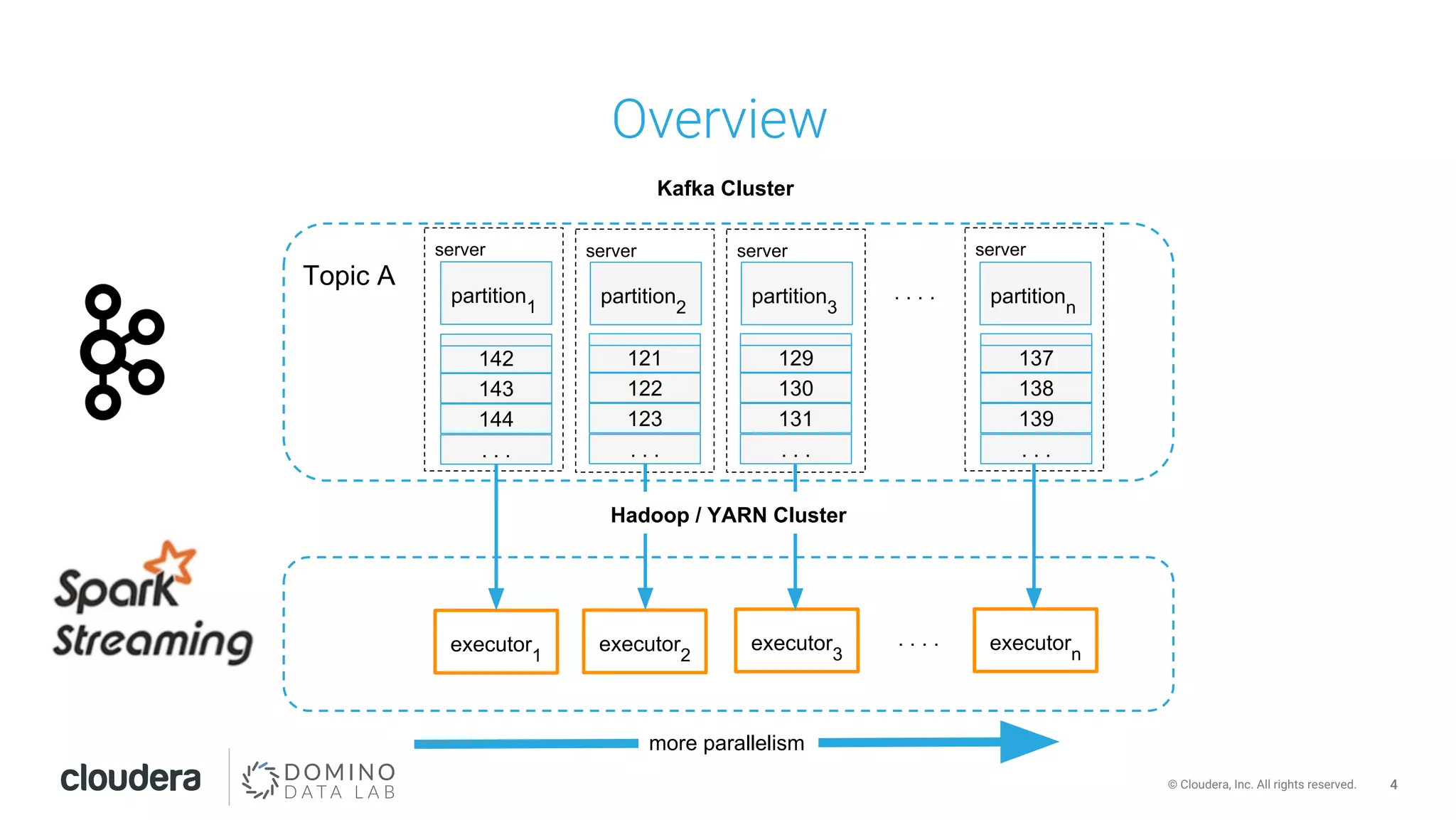
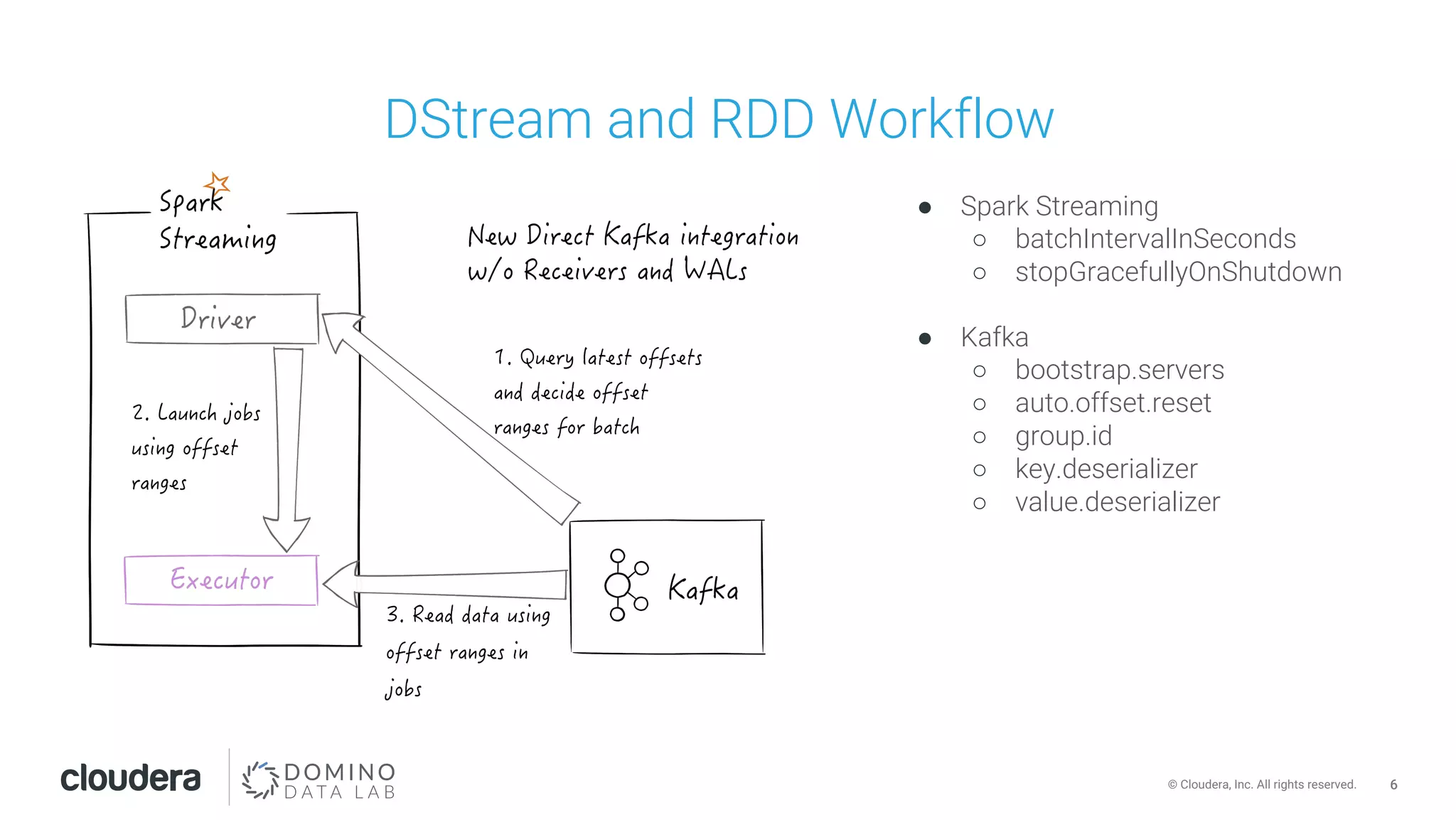
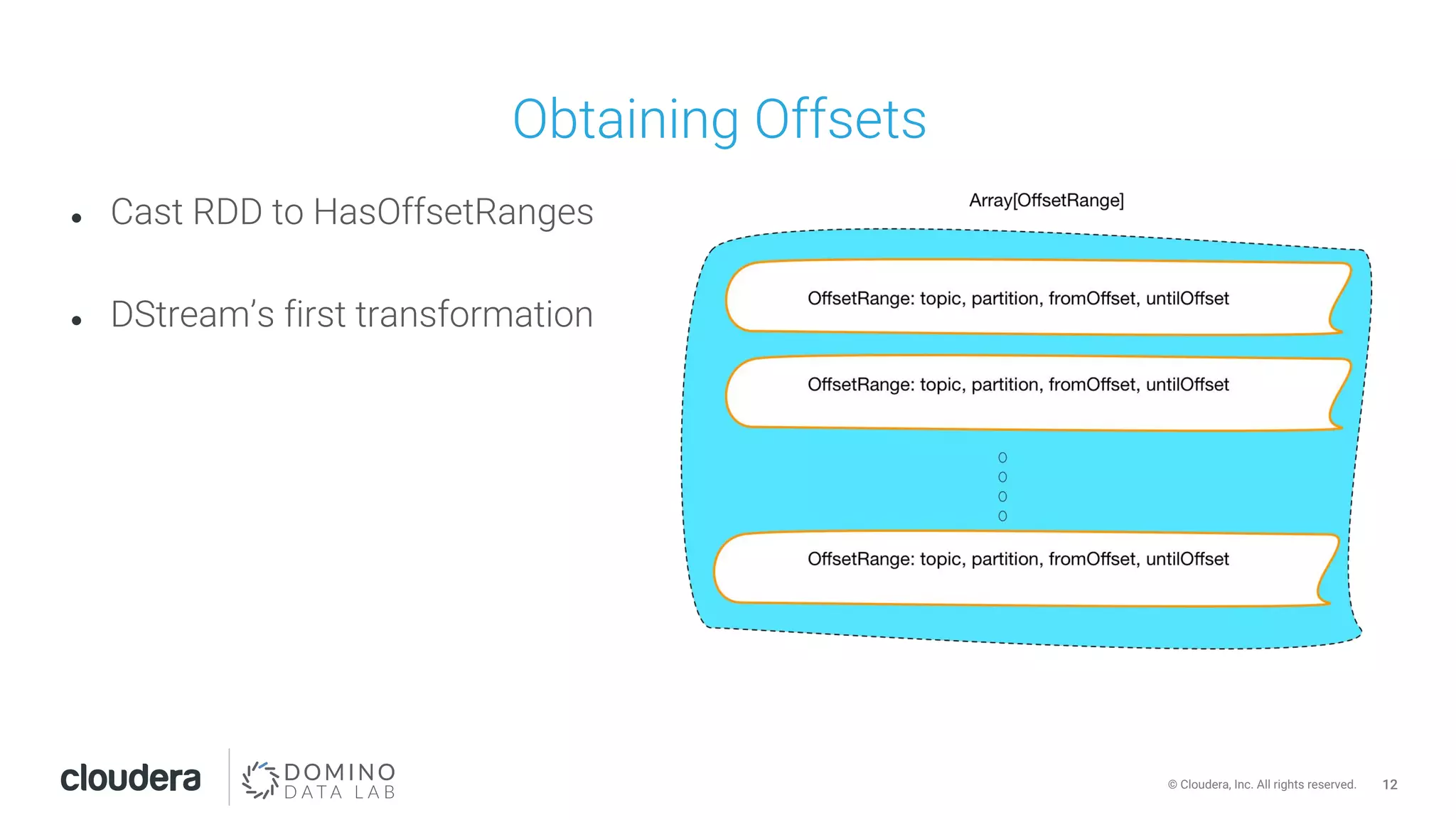
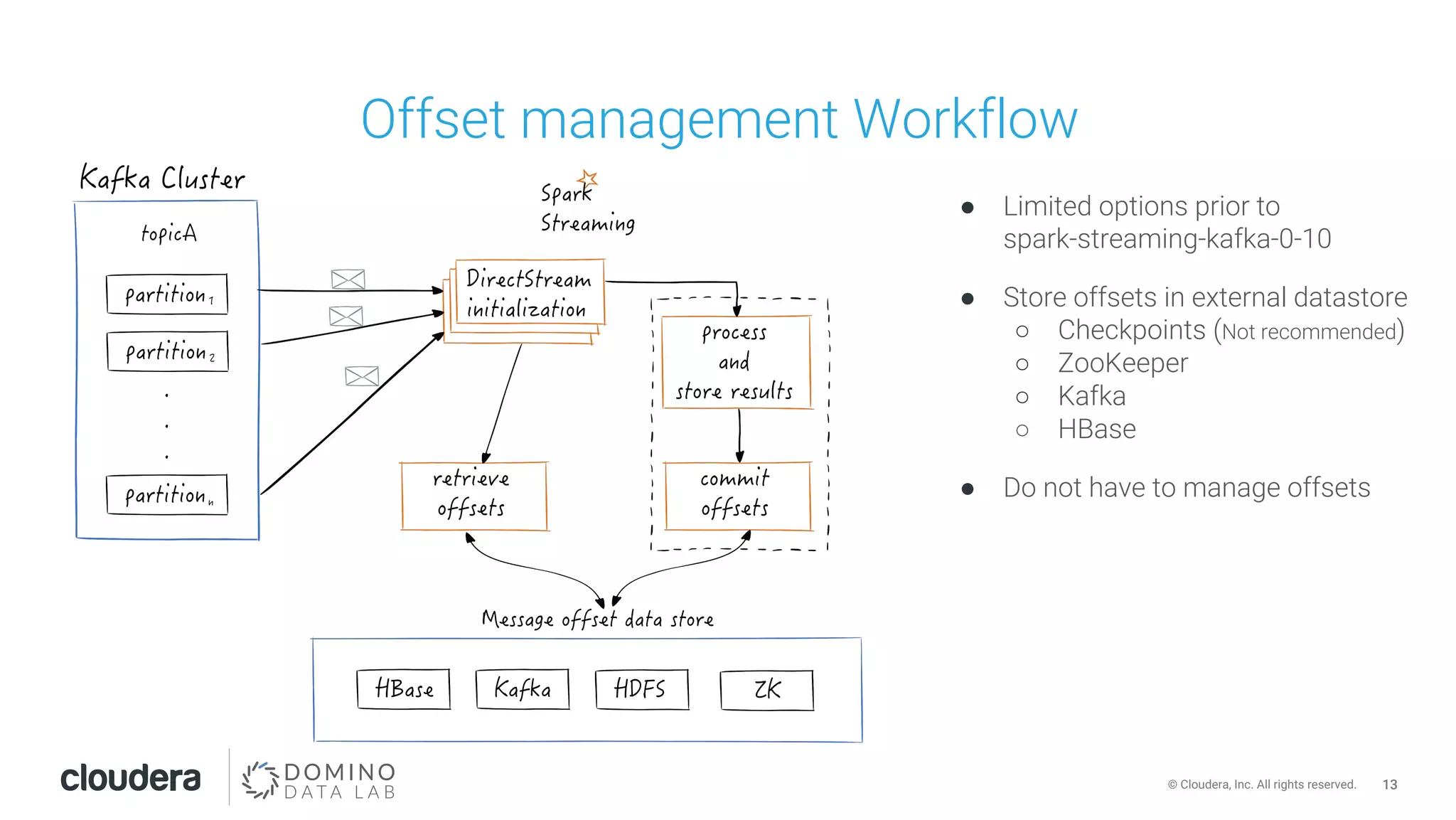
This document discusses building leakproof stream processing pipelines with Apache Kafka and Apache Spark. It provides an overview of offset management in Spark Streaming from Kafka, including storing offsets in external data stores like ZooKeeper, Kafka, and HBase. The document also covers Spark Streaming Kafka consumer types and workflows, and addressing issues like maintaining offsets during planned and unplanned maintenance or application errors.