Download as PDF, PPTX


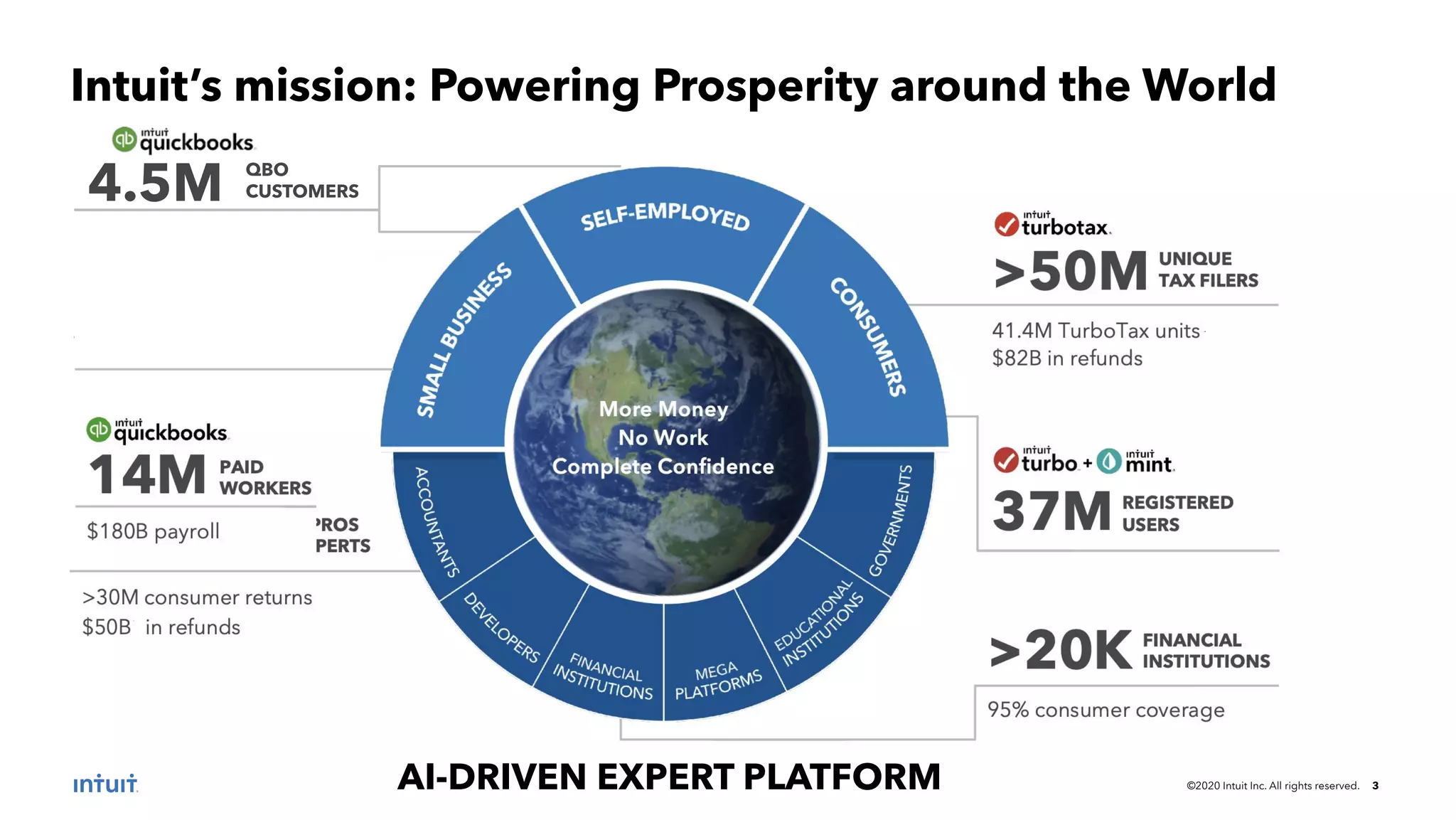

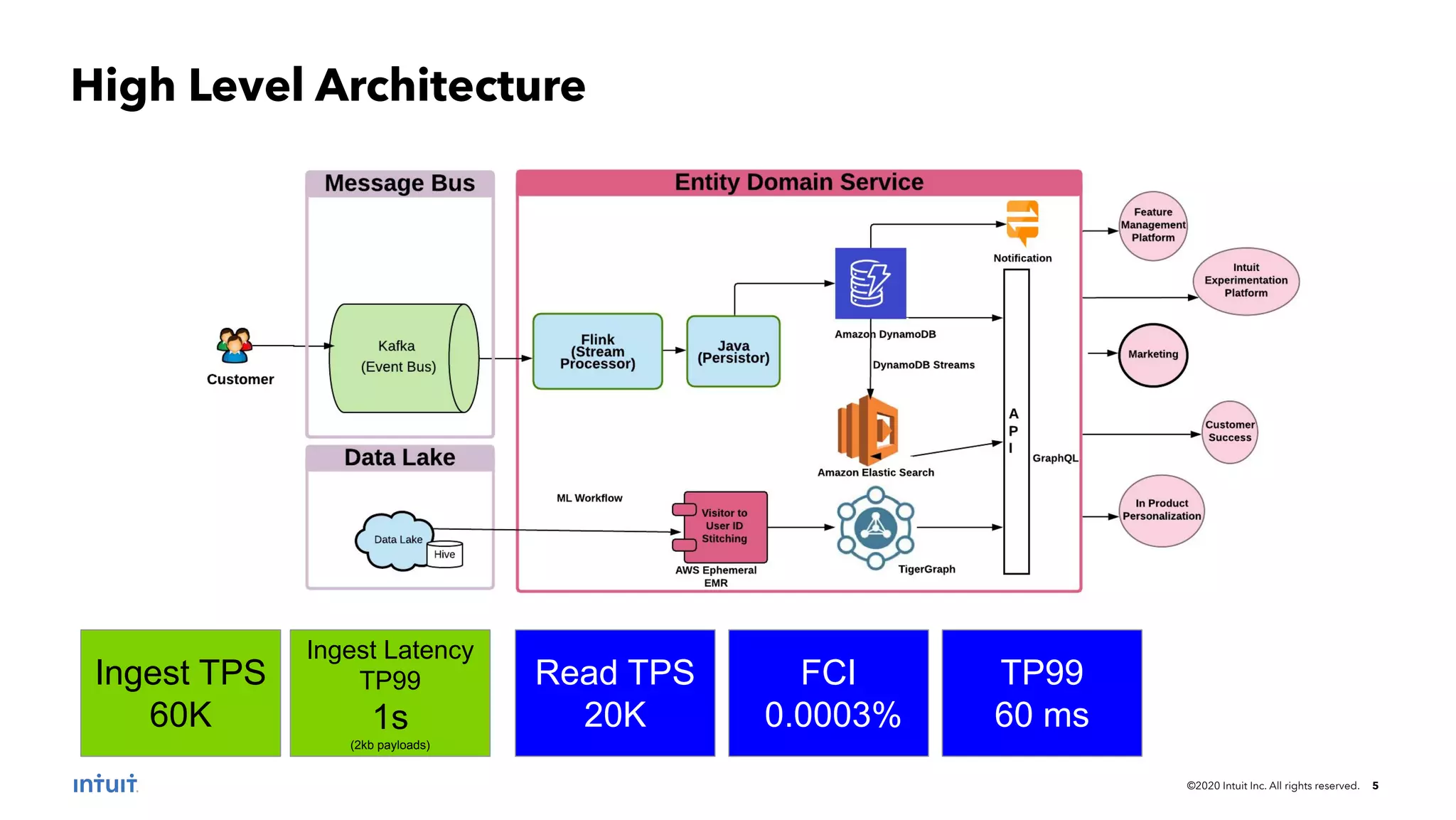
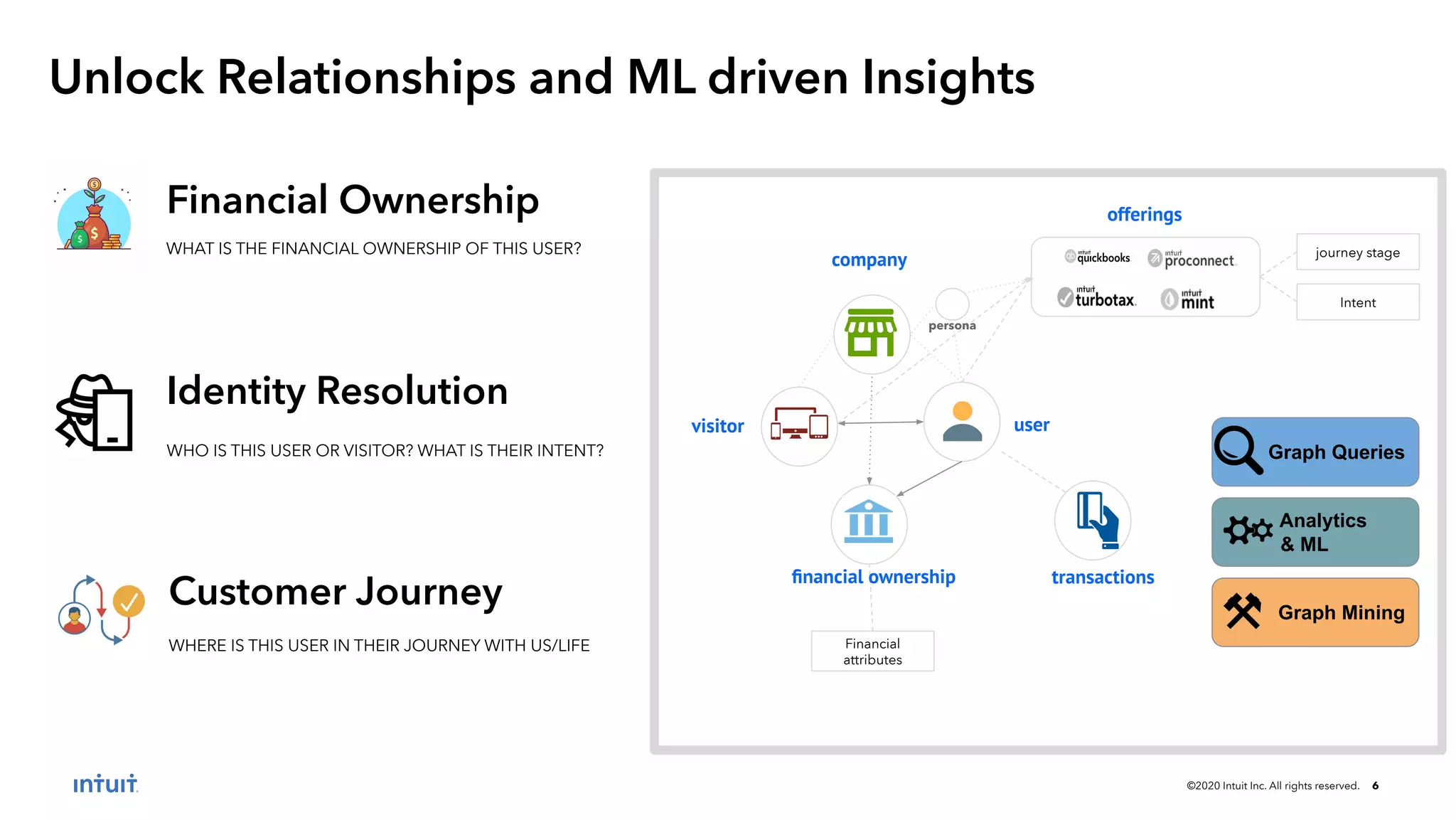
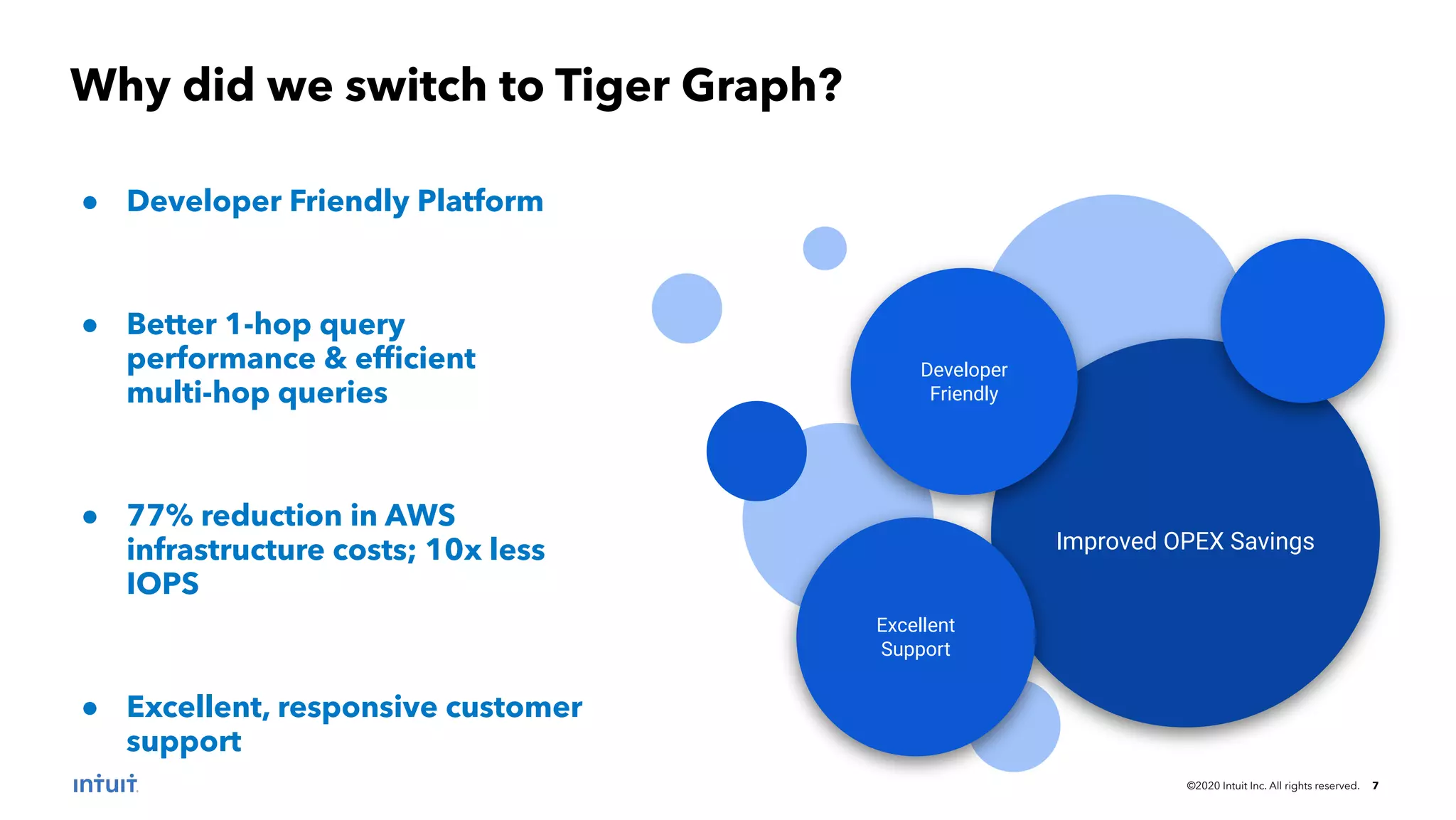
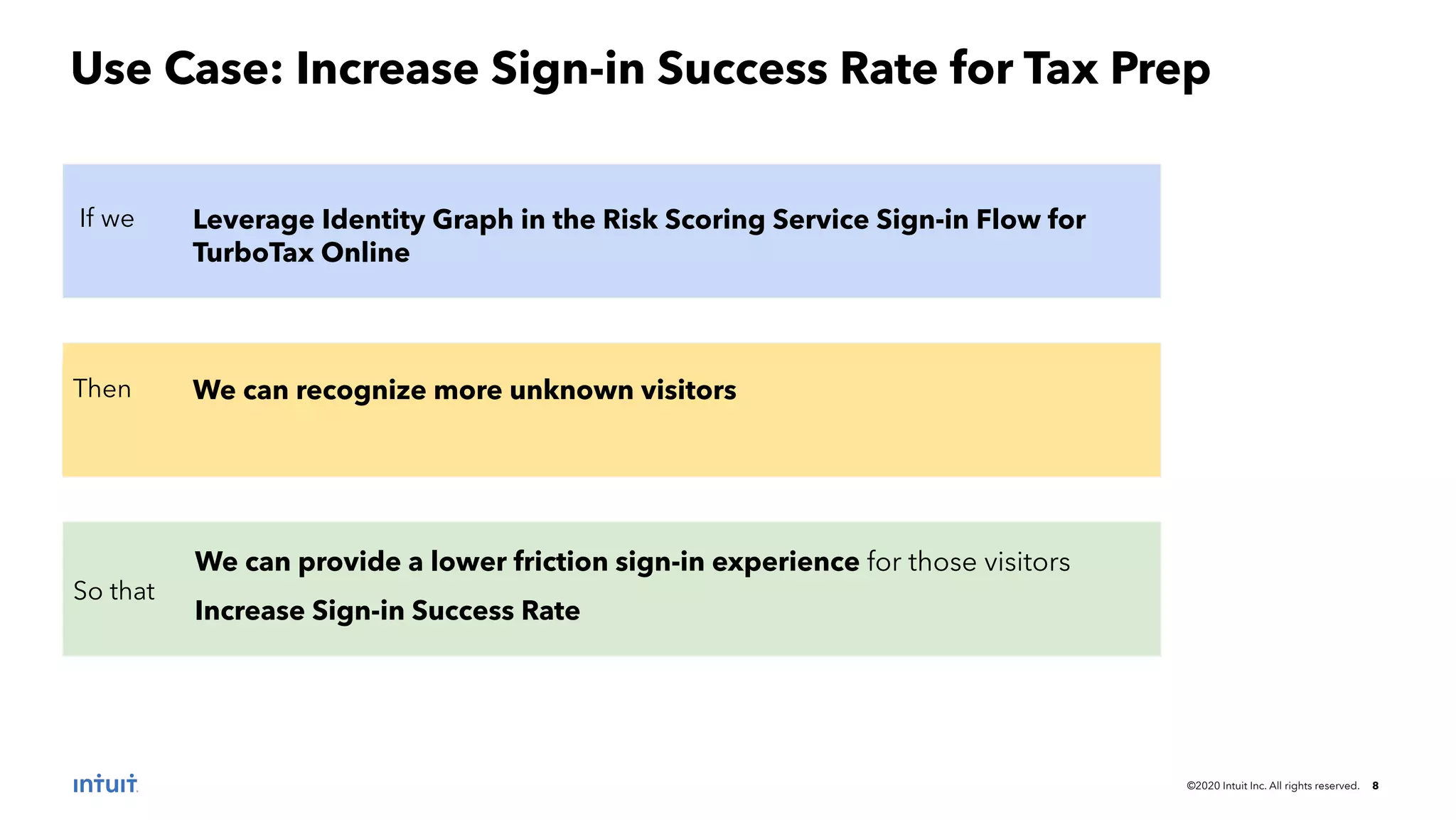
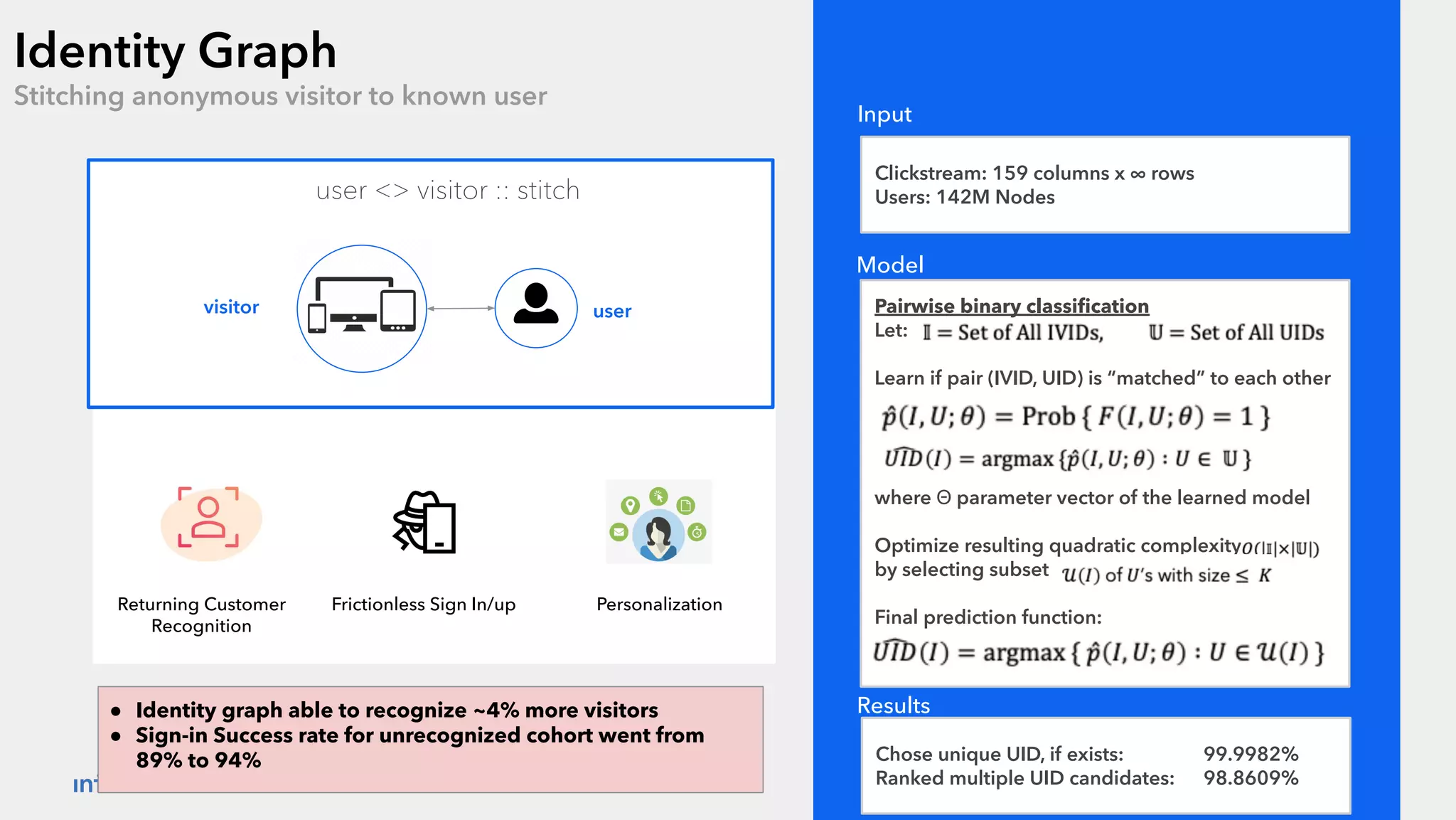


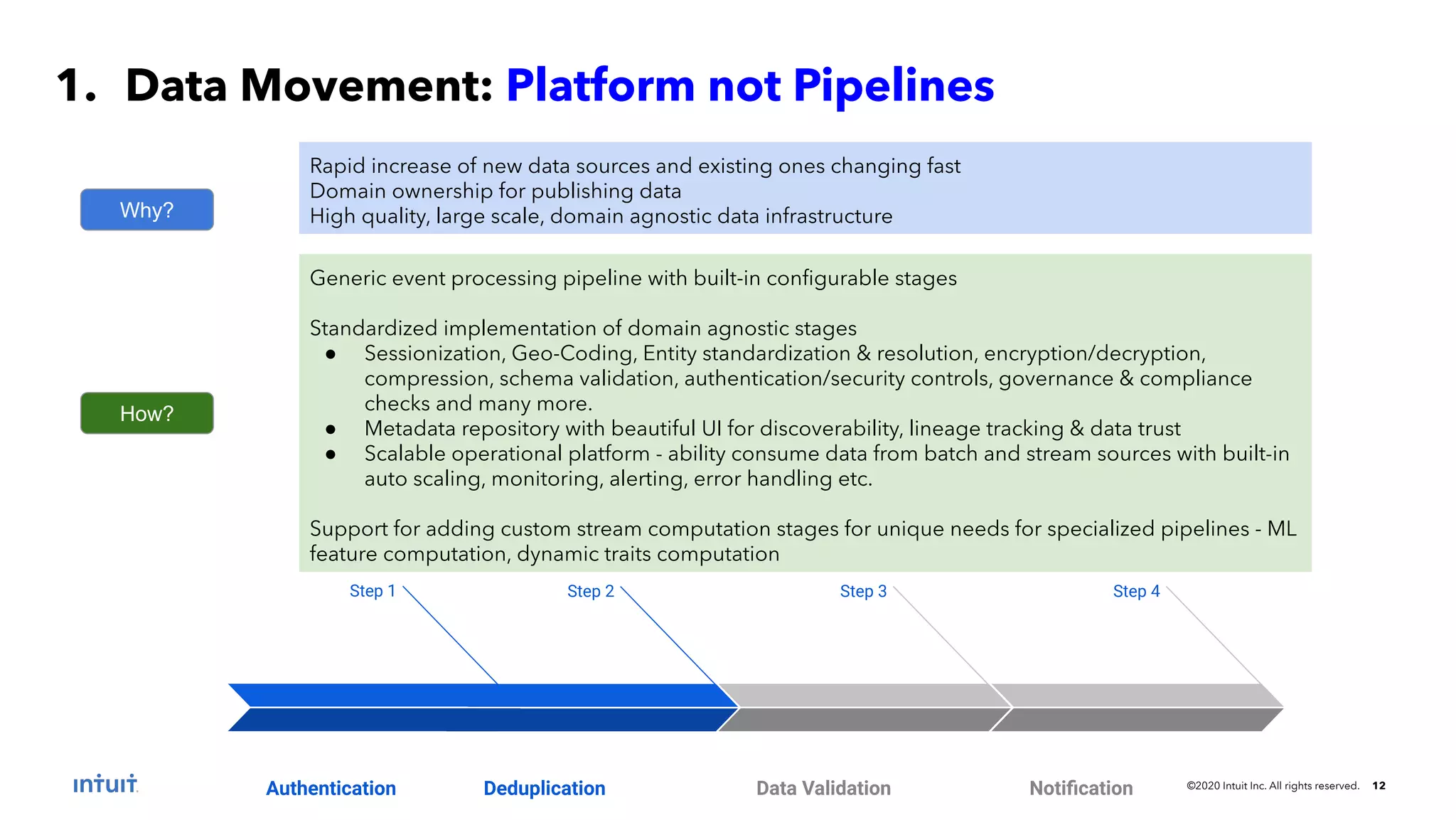






The document outlines the design patterns for building an AI-based customer data platform at Intuit, emphasizing the need for real-time data processing and identity resolution. It details architecture considerations, such as data movement, storage, and access, while highlighting the transition to Tiger Graph for improved performance and cost-efficiency. Key use cases, specifically enhancing user sign-in experiences through identity graphs, demonstrate the practical applications of these patterns.