The document discusses handling unknown words in named entity recognition using transliteration. It proposes an approach where named entities in training data are transliterated into other languages and stored in transliteration files. During testing, if an unknown entity is encountered, it is checked against the transliteration files and assigned the corresponding tag if found. The approach is shown to achieve 95.8% recall, 96.3% precision and 96.04% F-measure on a multilingual named entity recognition task handling words from English, Hindi, Marathi, Punjabi and Urdu. Performance metrics for named entity recognition systems such as precision, recall and F-measure are also discussed.

![International Journal on Natural Language Computing (IJNLC) Vol. 2, No.4, August 2013 88 In one of the approaches, unknown word can be allotted a specific tag e.g. unk tag in order to handle unknown words in NER [1][2]. Capitalization information cannot be used to identify the POS tag, since Capitalization can exists in unknown words also. Also, Capitalization information is only restricted to identify Named Entities in English [3][4]. 3. OUR APPROACH In our approach, we have considered ‘OTHER’ tag to be ‘Not a Named Entity’ tag. Figure 1 depicts our approach during training in NER. We process each token of training data and check its tag. If the token is not tagged with ‘OTHER’ tag, then we transliterate the token into different languages and save these transliterated Named Entities along with their tags in a file. If the token is attached with ‘OTHER’ tag, then we simply process the next token in a sentence and continue this procedure until all the training sentences are not processed. NO YES NO YES Figure 1 Steps taken while performing training in Named Entity Recognition If we have the sound mapping of one language into any other language, then we can easily perform the transliteration task. e. g. If ‘Ram/PER plays/OTHER cricket/OTHER’ is a training sentence, then the transliteration task will transliterate Ram into other languages, since Ram is a Named Entity that is attached to ‘PER’ tag and not ‘OTHER’ tag. ‘plays’ and ‘cricket’ are not the Named Entities, since these are tagged by ‘OTHER’ tag, so transliteration is not performed on it. So, our approach is a language independent based approach, that is capable of recognizing Named Entities from a text written in any of the Natural languages, provided that it has been trained on a TRAINING DATA (PROCESS EACH TOKEN) IF NOT OTHER TAG? TRANSLITERATE TOKEN AND ATTACH ITS TAG IF END OF SENTENCE REACHED? EXIT PROCESS NEXT TOKEN START](https://image.slidesharecdn.com/handlingunknownwordsinnamedentity-130912045433-phpapp01/75/HANDLING-UNKNOWN-WORDS-IN-NAMED-ENTITY-RECOGNITION-USING-TRANSLITERATION-2-2048.jpg)


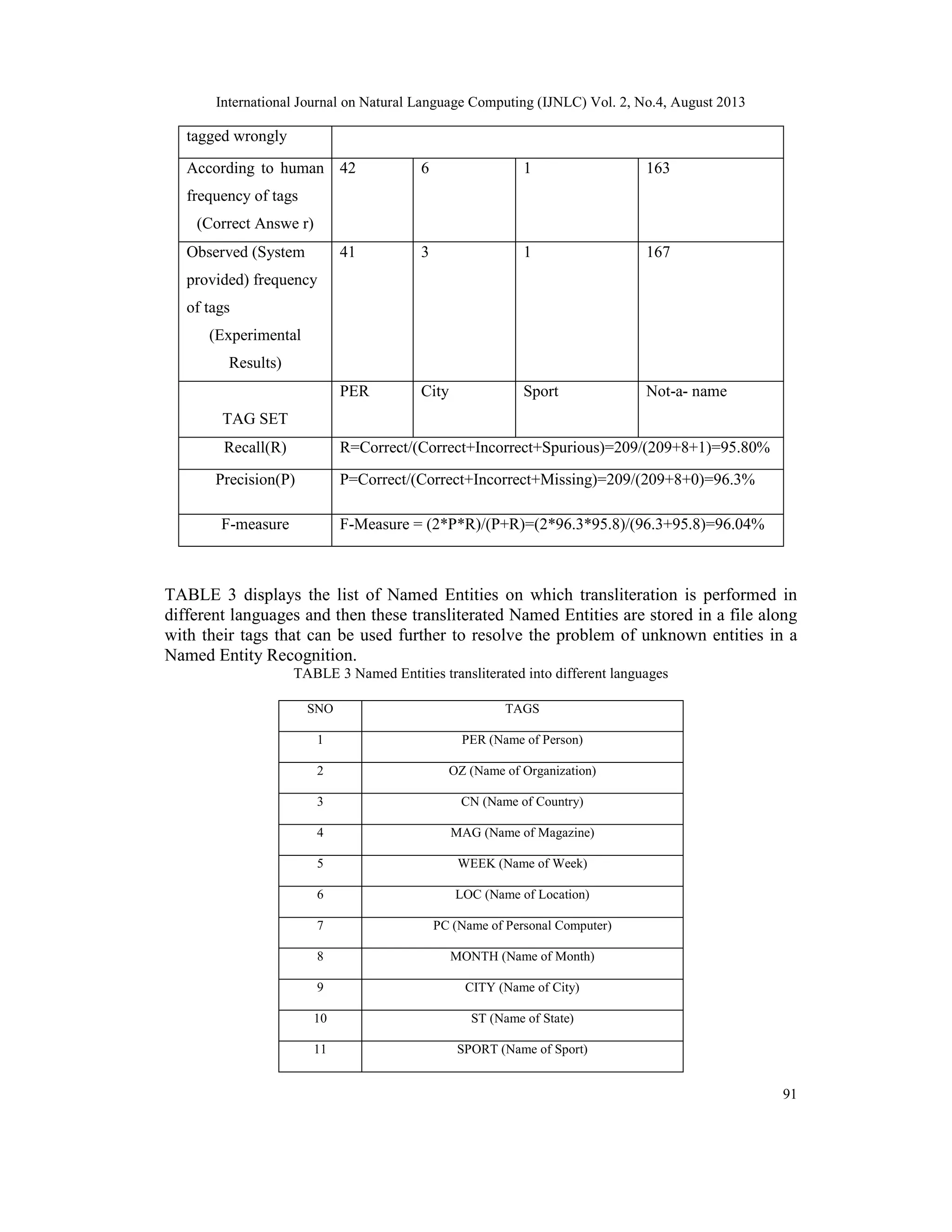
![International Journal on Natural Language Computing (IJNLC) Vol. 2, No.4, August 2013 92 4. PERFORMANCE METRICS Performance Metrics is measure to estimate the performance of a NER based system. Performance Metrics can be calculated in terms of 3 parameters: Precision, Accuracy and F- Measure. The output of a NER based system is termed as “response” and the interpretation of human as the “answer key” [5]. Consider the following terms: 1. Correct-If the response is same as the answer key. 2. Incorrect-If the response is not same as the answer key. 3. Missing-If answer key is found to be tagged but response is not tagged. 4. Spurious-If response is found to be tagged but answer key is not tagged. [6] Hence, we define Precision, Recall and F-Measure as follows: [7][8][9] Precision (P): Correct / (Correct + Incorrect + Missing) Recall (R): Correct / (Correct + Incorrect + Spurious) F-Measure: (2 * P * R) / (P + R) 5. CONCLUSION In this paper, we have discussed about Transliteration. We have given our results obtained while performing Named Entity Recognition on multilingual corpus and handling unknown words using transliteration approach. We have also discussed about Performance Metrics which is a very important measure to judge the performance of a Named Entity Recognition based system. ACKNOWLEDGEMENT I would like to thank all those who helped me in accomplishing this task. REFERENCES [1] http://www.cse.iitb.ac.in/~cs626-460-2012/seminar_ppts/ner.pdf [2] http://staff.um.edu.mt/cabe2/publications/nfHmms.pdf [3] http://acl.ldc.upenn.edu/acl2002/MAIN/pdfs/Main036.pdf [4] http://www.sigkdd.org/explorations/issues/7-1-2005-06/4-Fu.pdf [5] Shilpi Srivastava, Mukund Sanglikar & D.C Kothari. ”Named Entity Recognition System for Hindi Language: A Hybrid Approach” International Journal of Computational Linguistics (IJCL), Volume (2) : Issue (1) : 2011.Available at http://cscjournals.org/csc/manuscript/Journals/IJCL/volume2/Issue1/IJCL-19.pdf [6] B. Sasidhar, P. M. Yohan, Dr. A. Vinaya Babu3, Dr. A. Govardhan,.“A Survey on Named Entity Recognition in Indian Languages with particular reference to Telugu” IJCSI International Journal of Computer Science Issues, Vol. 8, Issue 2, March 2011. [7] Asif Ekbal, Rejwanul Haque, Amitava Das, Venkateswarlu Poka and Sivaji Bandyopadhyay “Language Independent Named Entity Recognition in Indian Languages” .In Proceedings of the IJCNLP-08 Workshop on NER for South and South East Asian Languages, pages 33–40,Hyderabad, India, January 2008.Available at: http://www.mt-archive.info/IJCNLP-2008-Ekbal.pdf [8] Darvinder kaur, Vishal Gupta. “A survey of Named Entity Recognition in English and other Indian Languages” .IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 6, November 2010. [9] G.V.S.RAJU, B.SRINIVASU, Dr.S.VISWANADHA RAJU, 4K.S.M.V.KUMAR “Named Entity Recognition for Telugu Using Maximum Entropy Model”](https://image.slidesharecdn.com/handlingunknownwordsinnamedentity-130912045433-phpapp01/75/HANDLING-UNKNOWN-WORDS-IN-NAMED-ENTITY-RECOGNITION-USING-TRANSLITERATION-6-2048.jpg)
