Downloaded 672 times










![Canonical Word Count from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount.run()](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-14-2048.jpg)
![Canonical Word Count from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount.run() The quick brown fox jumps over the lazy dog the, 1 quick, 1 brown, 1 fox, 1 jumps, 1 over, 1 the, 1 lazy, 1 dog, 1](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-15-2048.jpg)
![Canonical Word Count from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount.run() I like this Hadoop thing i, 1 like, 1 this, 1 hadoop, 1 thing, 1](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-16-2048.jpg)
![Canonical Word Count from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount.run() dog, [1, 1, 1, 1, 1, 1] dog, 6](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-17-2048.jpg)
![Canonical Word Count from mrjob.job import MRJob import re WORD_RE = re.compile(r"[w']+") class MRWordFreqCount(MRJob): def mapper(self, _, line): for word in WORD_RE.findall(line): yield (word.lower(), 1) def reducer(self, word, counts): yield (word, sum(counts)) if __name__ == '__main__': MRWordFreqCount.run() cat, [1, 1, 1, 1, 1, 1, 1, 1] cat, 8](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-18-2048.jpg)



![Pig UDFs Users can write user-defined functions to extend the functionality of Pig Can use jython (faster) or cpython (access to more libs) b = FOREACH a GENERATE revster(phonenum); ... m = GROUP j BY username; n = FOREACH m GENERATE group, sortedconcat(j.tags); @outputSchema(“tags:chararray") def sortedconcat(bag): out = set() for tag in bag: out.add(tag) return ‘-’.join(sorted(out)) @outputSchema(“rev:chararray") def revstr(instr): return instr[::-1]](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-24-2048.jpg)

![- Library from snakebite.client import Client client = Client(”1.2.3.4", 54310, use_trash=False) for x in client.ls(['/data']): print x print ‘’.join(client.cat(‘/data/ref/refdata*.csv’)) Useful for doing HDFS file manipulation in data flows or job setups Can be used to read reference data from MapReduce jobs](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-26-2048.jpg)





![PySpark Word Count Example import sys from operator import add from pyspark import SparkContext if __name__ == "__main__": if len(sys.argv) != 2: print >> sys.stderr, "Usage: wordcount <file>" exit(-1) sc = SparkContext(appName="PythonWordCount") lines = sc.textFile(sys.argv[1], 1) counts = lines.flatMap(lambda x: x.split(' ')) .map(lambda x: (x, 1)) .reduceByKey(add) output = counts.collect() for (word, count) in output: print "%s: %i" % (word, count) sc.stop()](https://image.slidesharecdn.com/hadoopwithpython-150311143445-conversion-gate01/75/Hadoop-with-Python-32-2048.jpg)


The document discusses using Python with Hadoop frameworks. It introduces Hadoop Distributed File System (HDFS) and MapReduce, and how to use the mrjob library to write MapReduce jobs in Python. It also covers using Python with higher-level Hadoop frameworks like Pig, accessing HDFS with snakebite, and using Python clients for HBase and the PySpark API for the Spark framework. Key advantages discussed are Python's rich ecosystem and ability to access Hadoop frameworks.
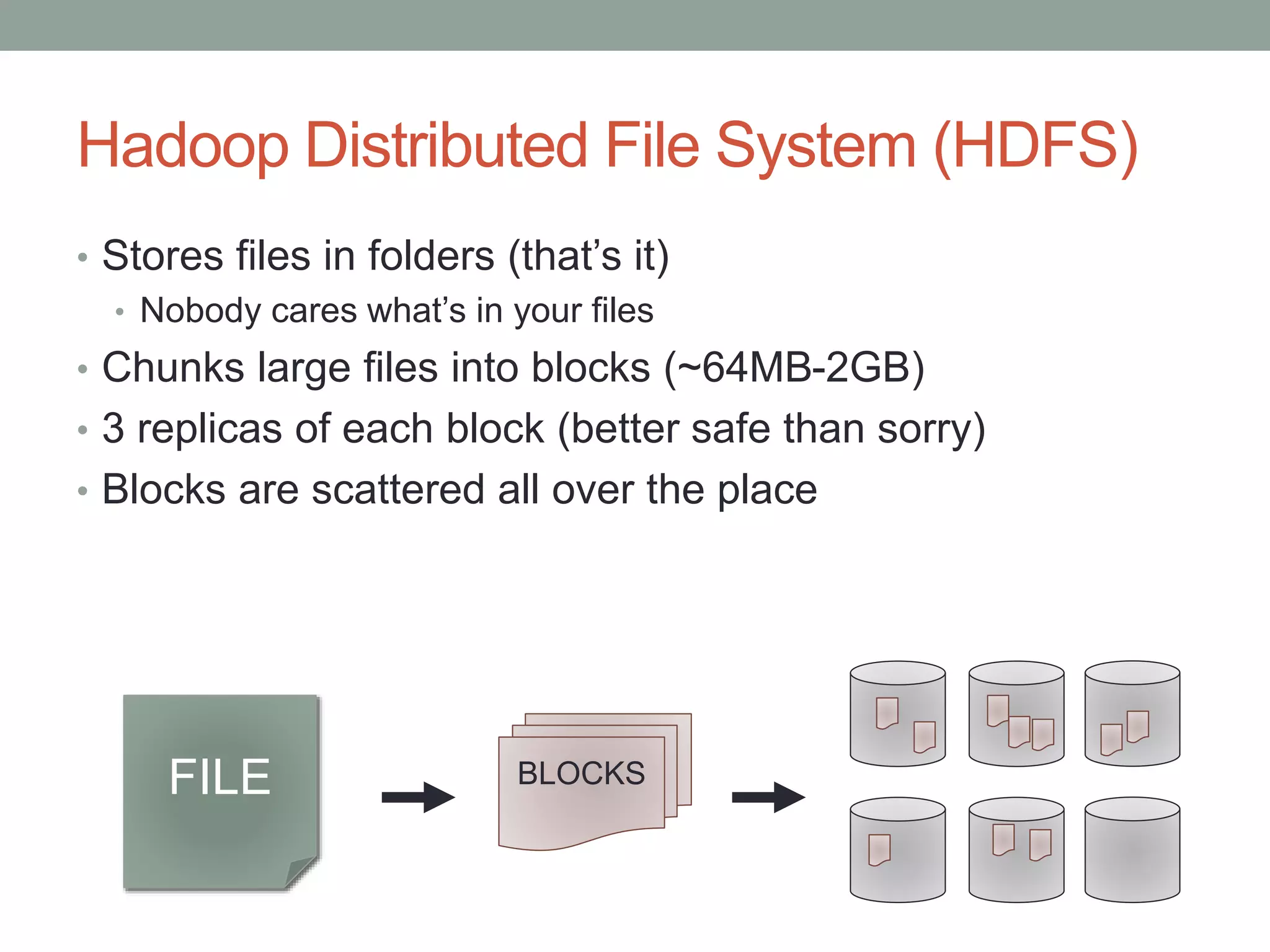
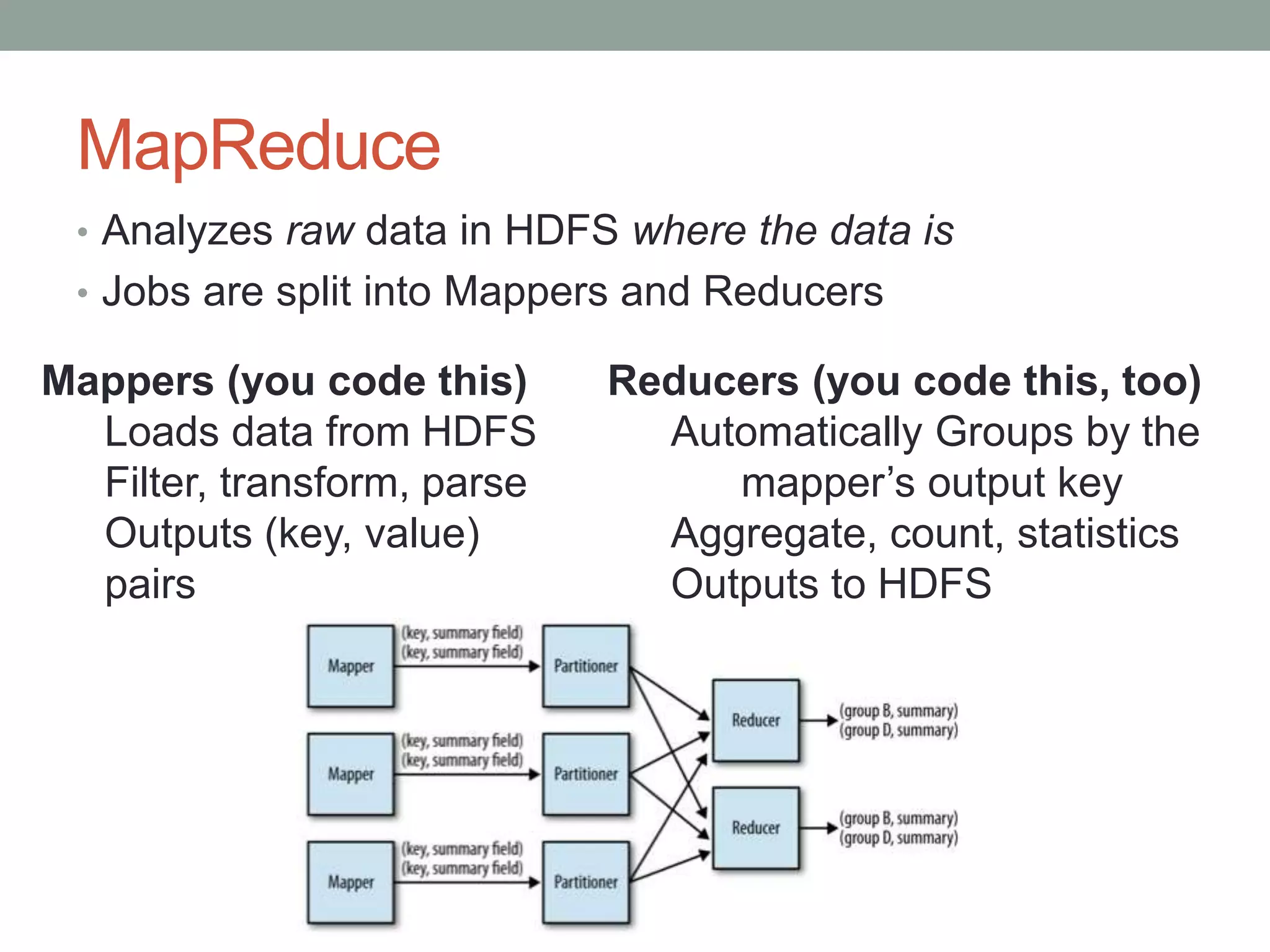
Introduction to Hadoop, covering the Hadoop Distributed File System (HDFS), MapReduce framework, and the Hadoop ecosystem including Pig, Hive, and others.
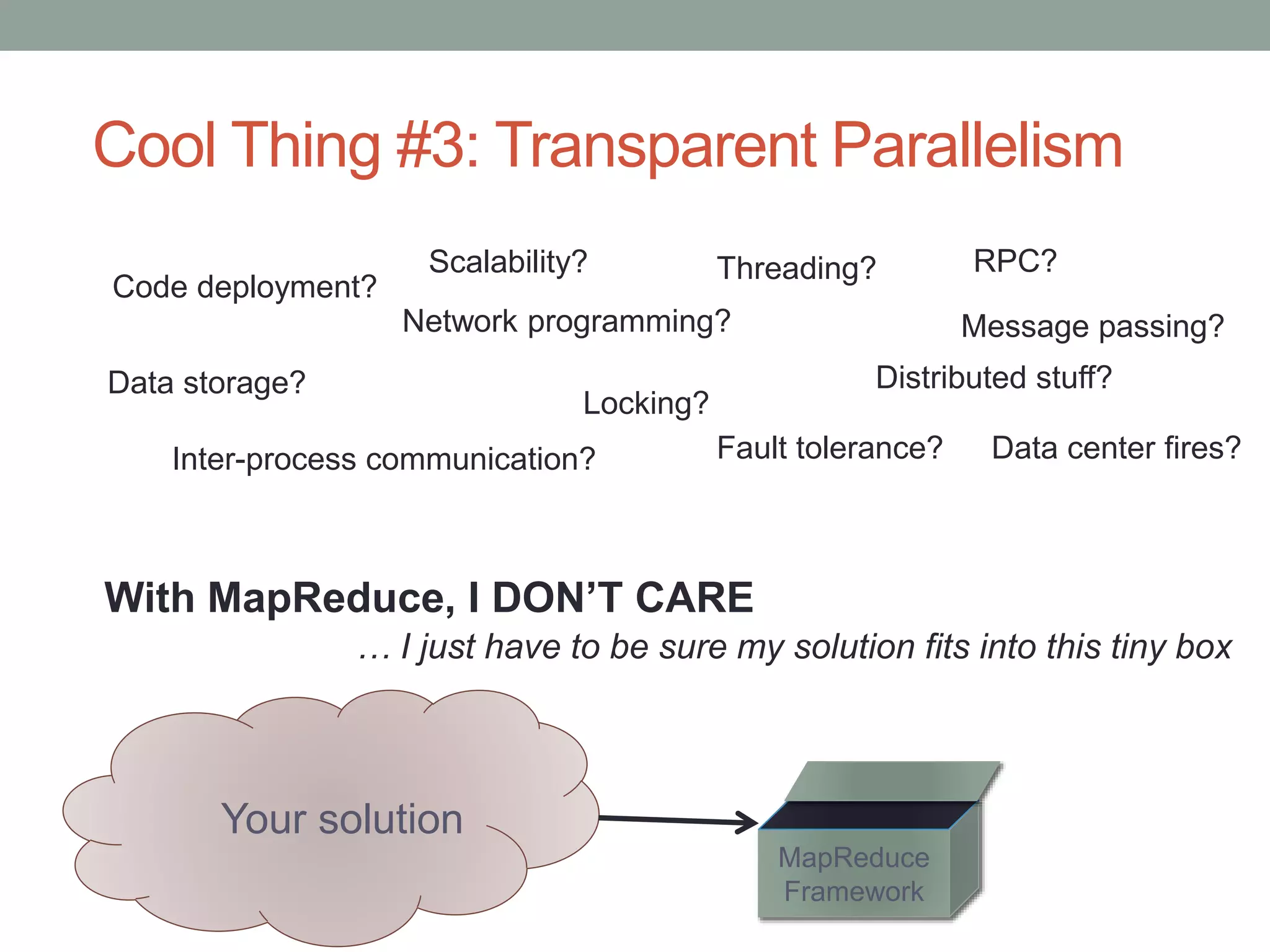
Discusses key features of Hadoop such as linear scalability, schema on read, transparent parallelism, and handling unstructured data.
Explains advantages and disadvantages of using Python for Hadoop, including performance issues and community support.
Introduction to mrjob for writing MapReduce jobs in Python, including a canonical word count example.
Continues with various implementations of word count using mrjob with sample outputs for different strings.
An overview of MRJOB with an emphasis on alternatives like Hadoop Streaming and Pydoop for Python integration.
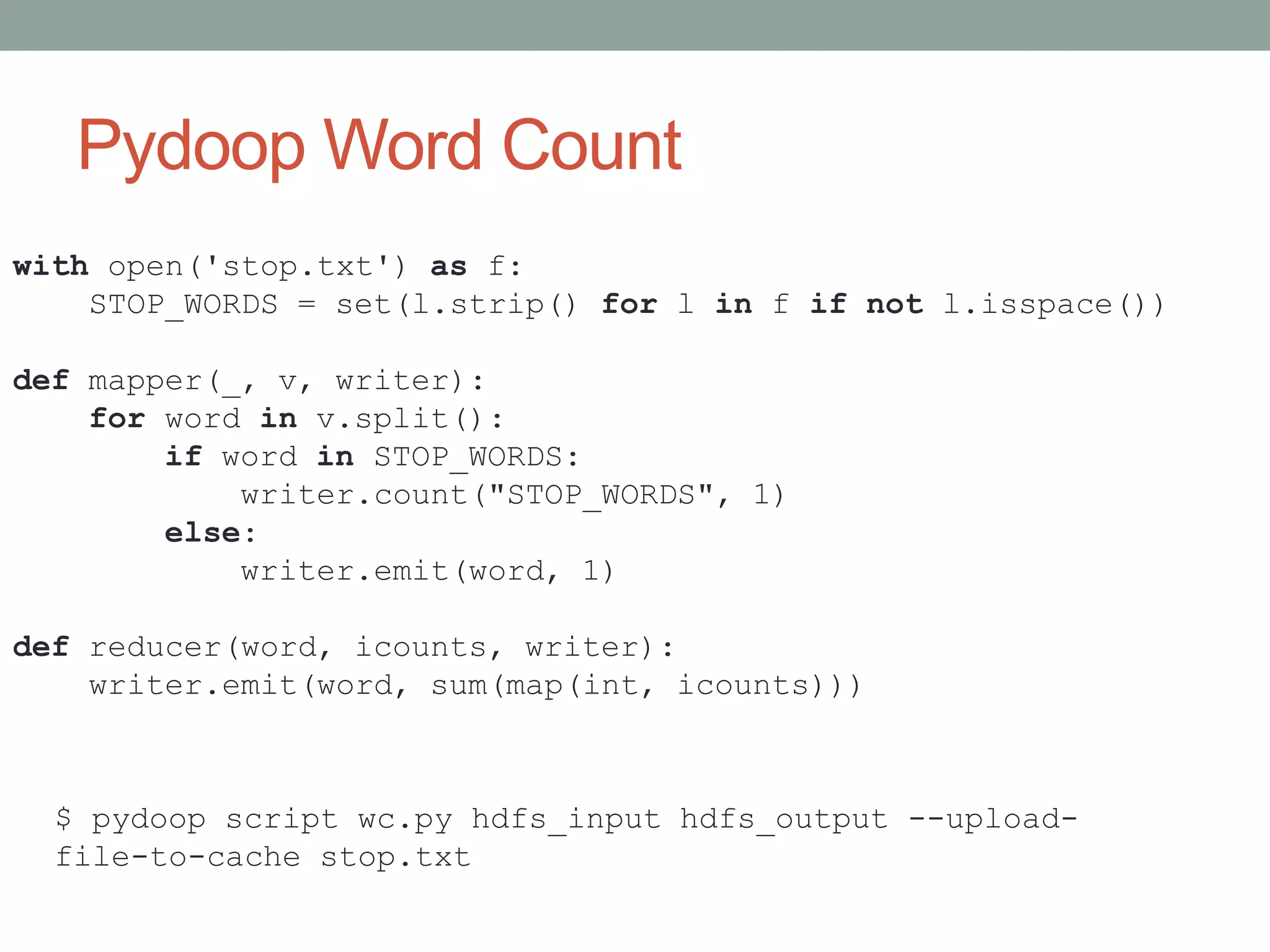
Describes Pydoop for writing MapReduce jobs in Python, focusing on performance and usage with sample code.
Introduction to Pig for data analysis in Hadoop with examples of Pig Latin syntax and user-defined functions.
Overview of Snakebite, a pure Python client for HDFS, explaining library usage and CLI commands.
Introduces Apache HBase, a NoSQL database on Hadoop, its use cases, and Python client options.
Overview of Apache Spark as a cluster computing system, including its capabilities and use of PySpark.
Provides a sample PySpark code for a word count application demonstrating its syntax and operations.
Wraps up the presentation, reiterating the main focus on Hadoop with Python.