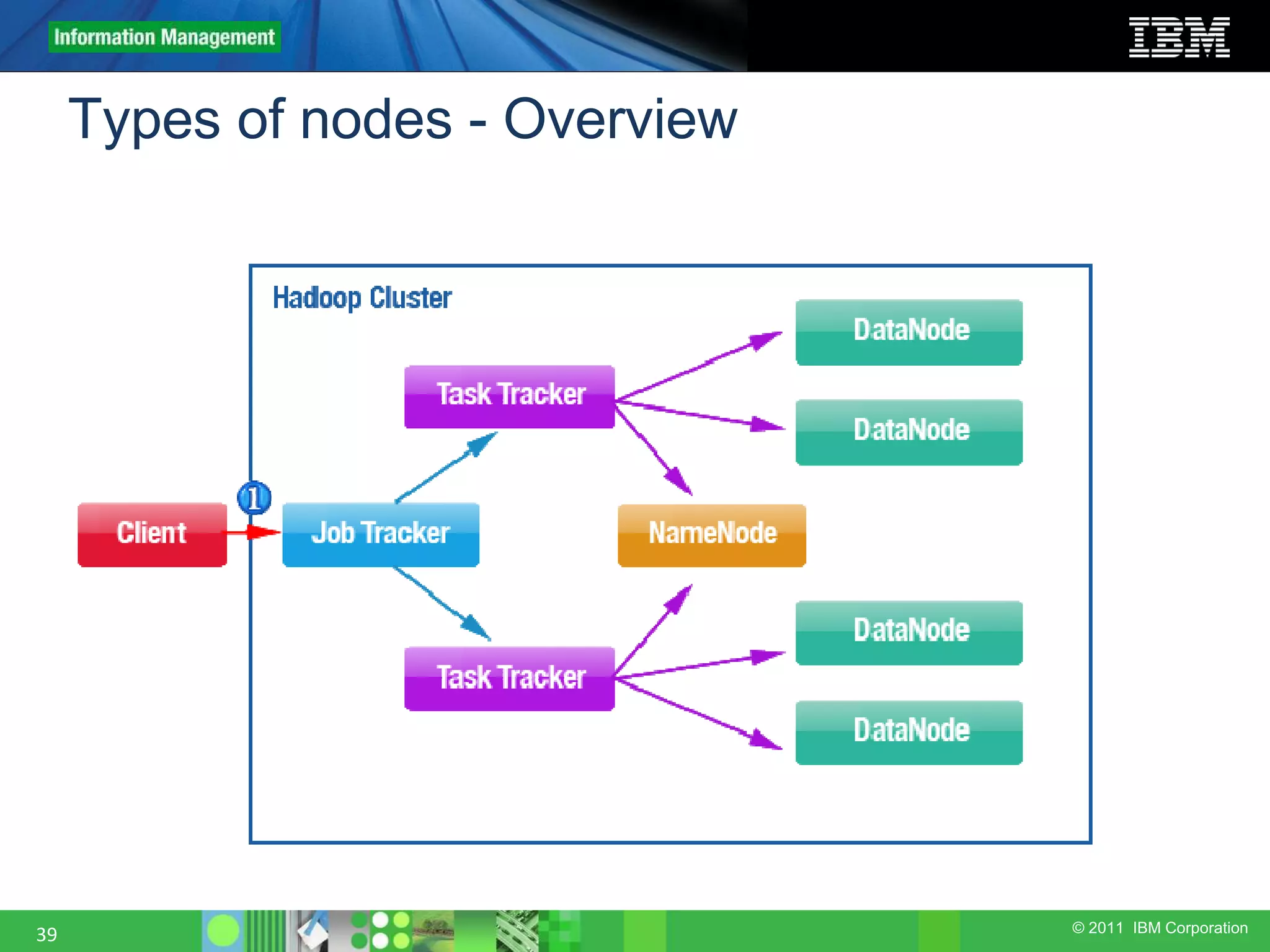
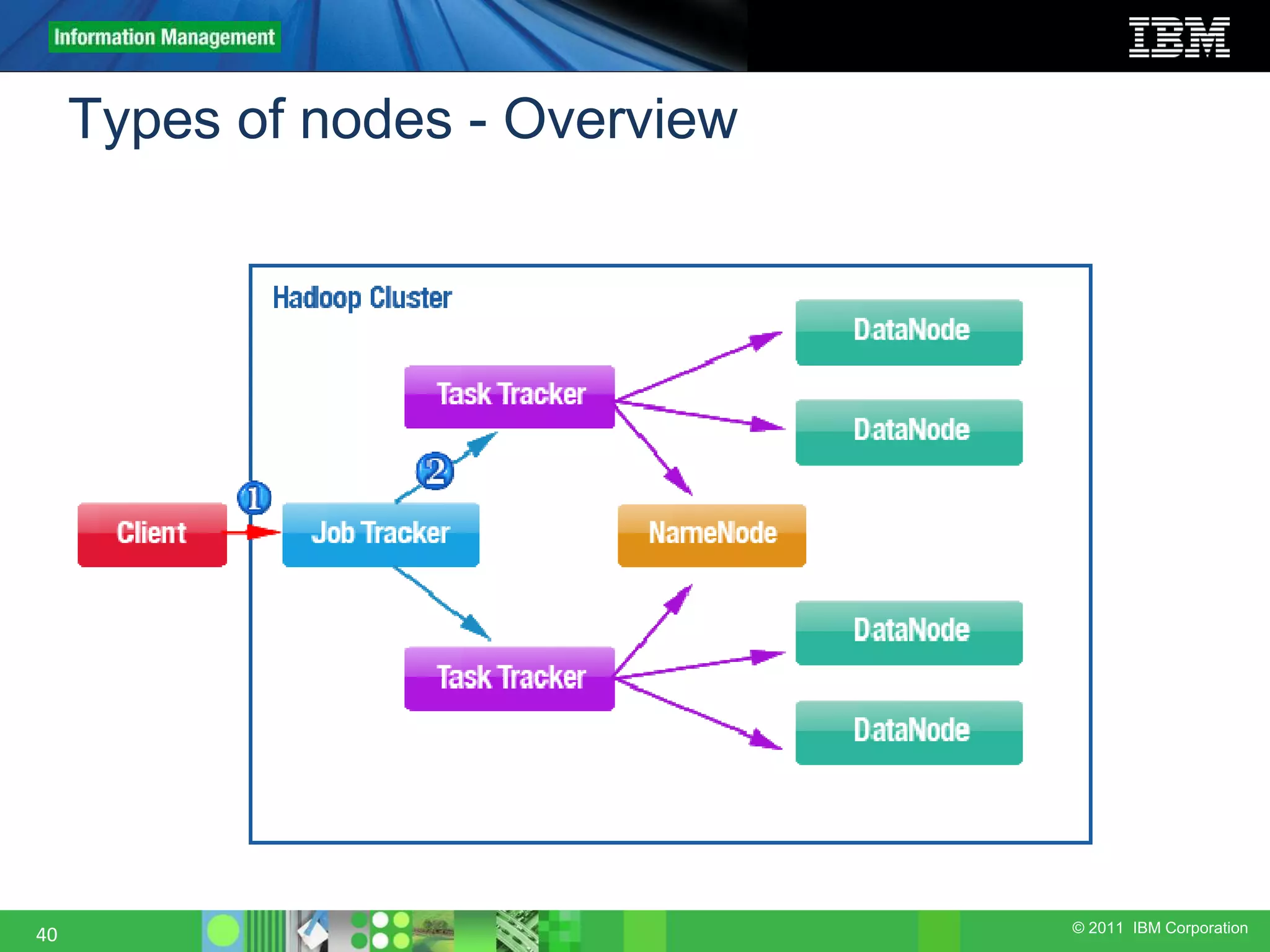
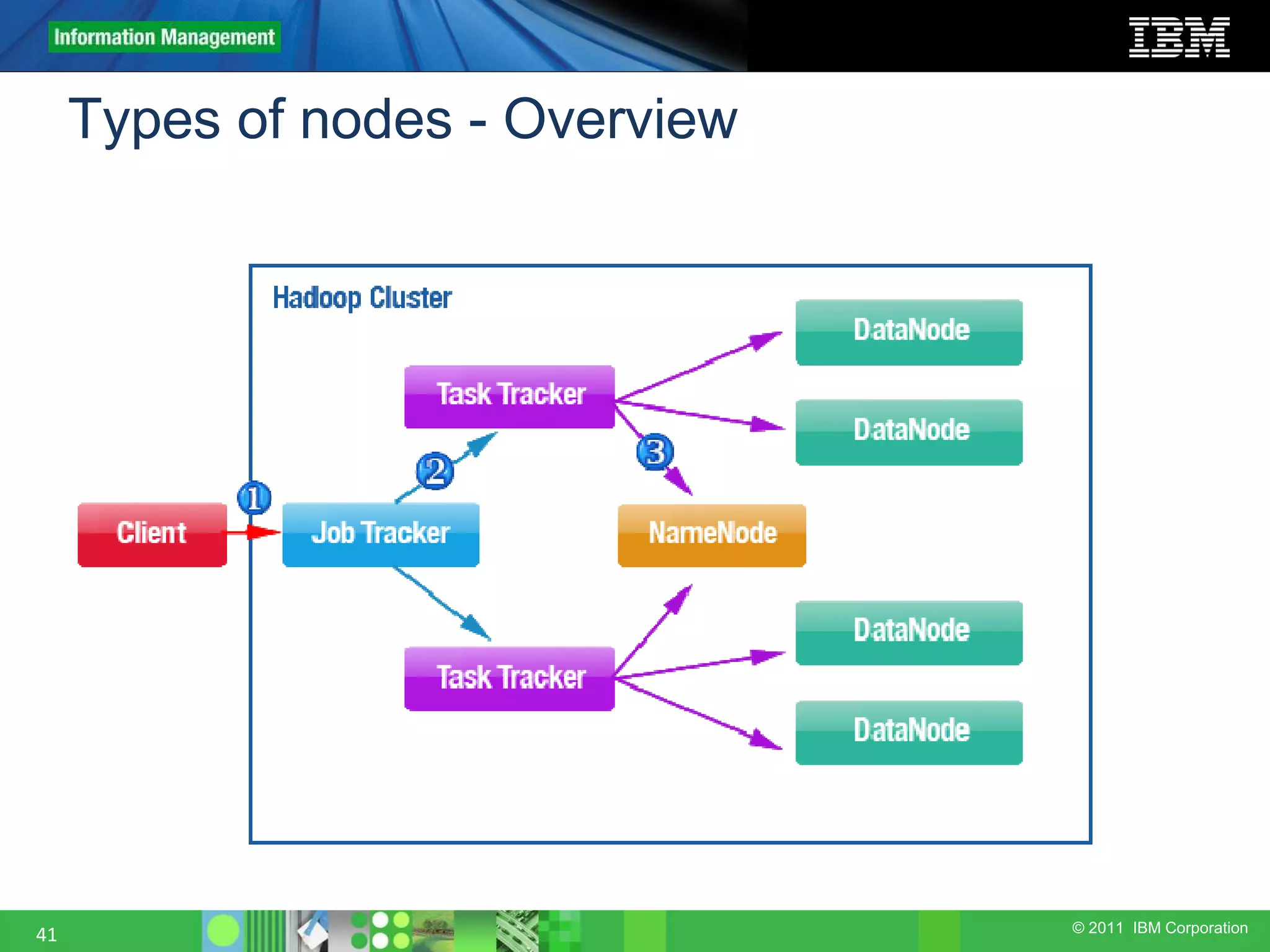
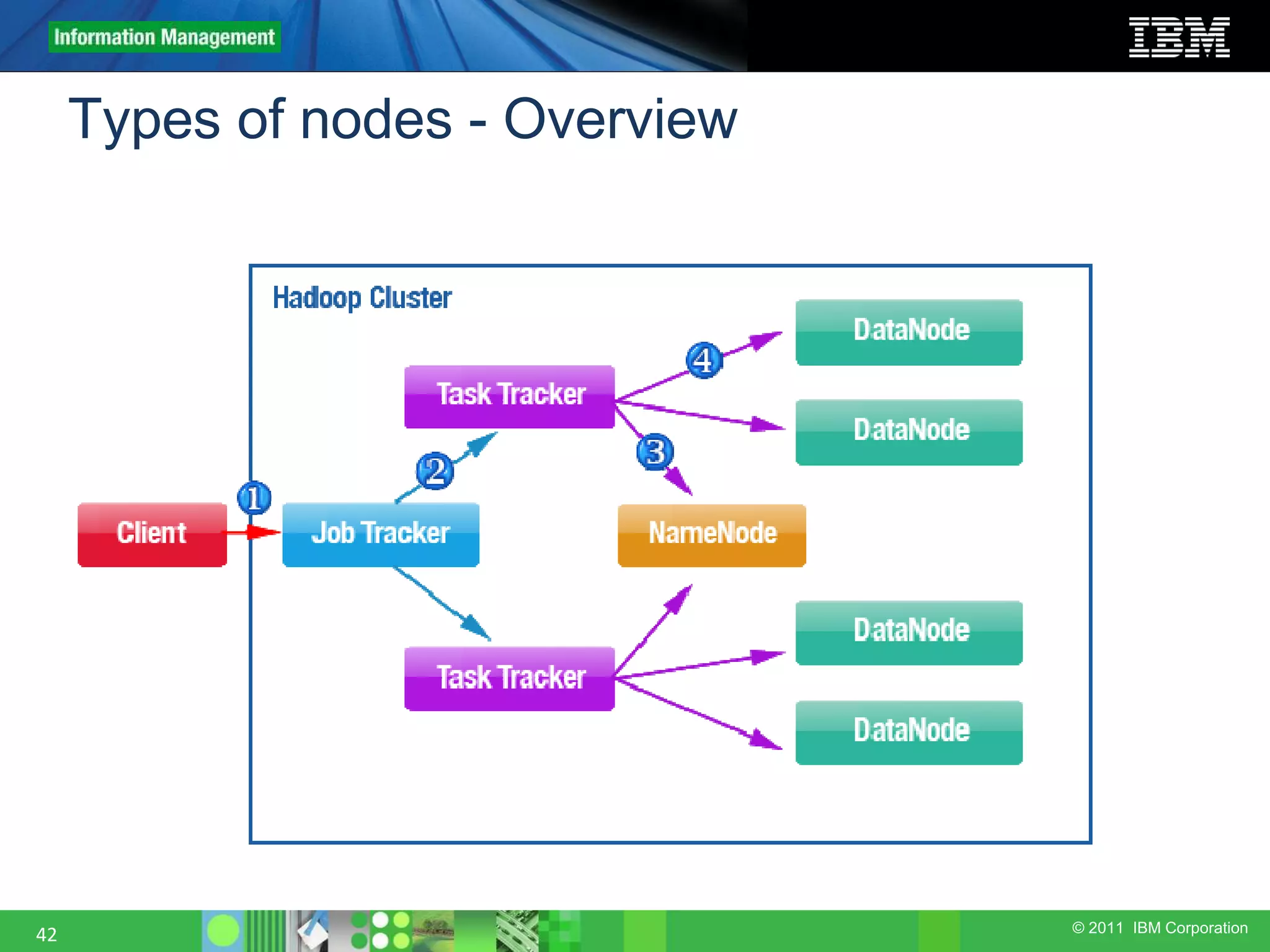
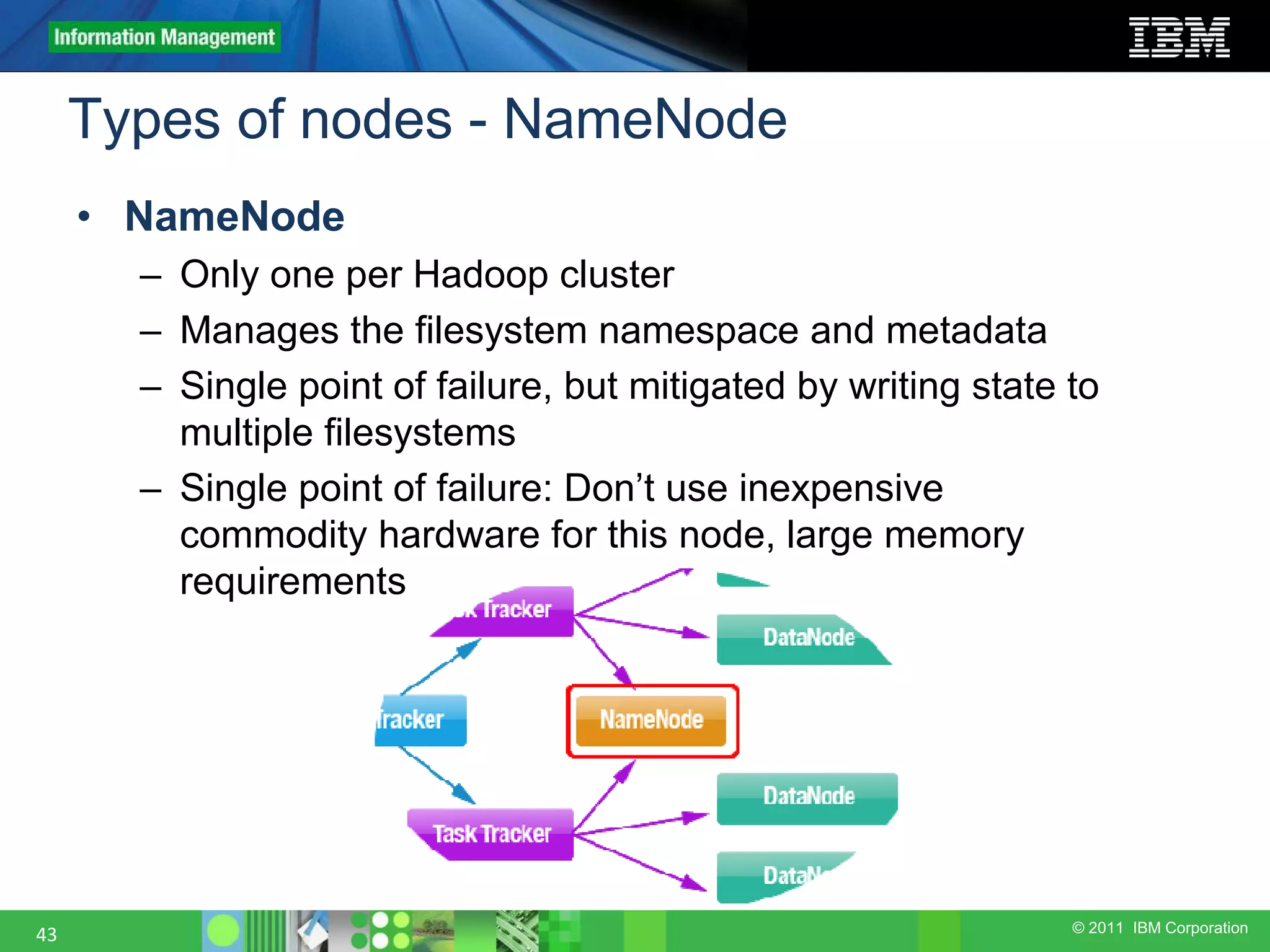
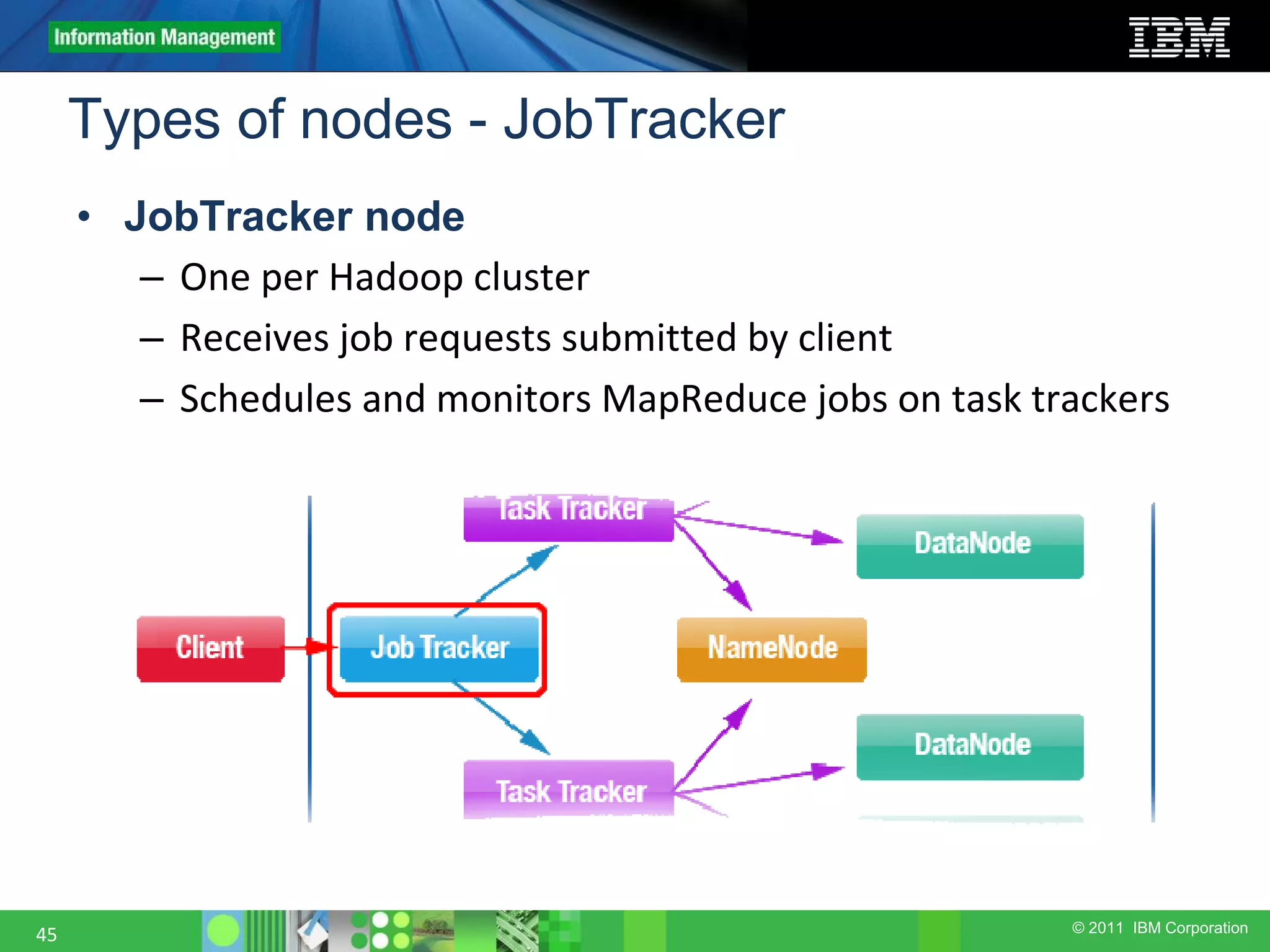
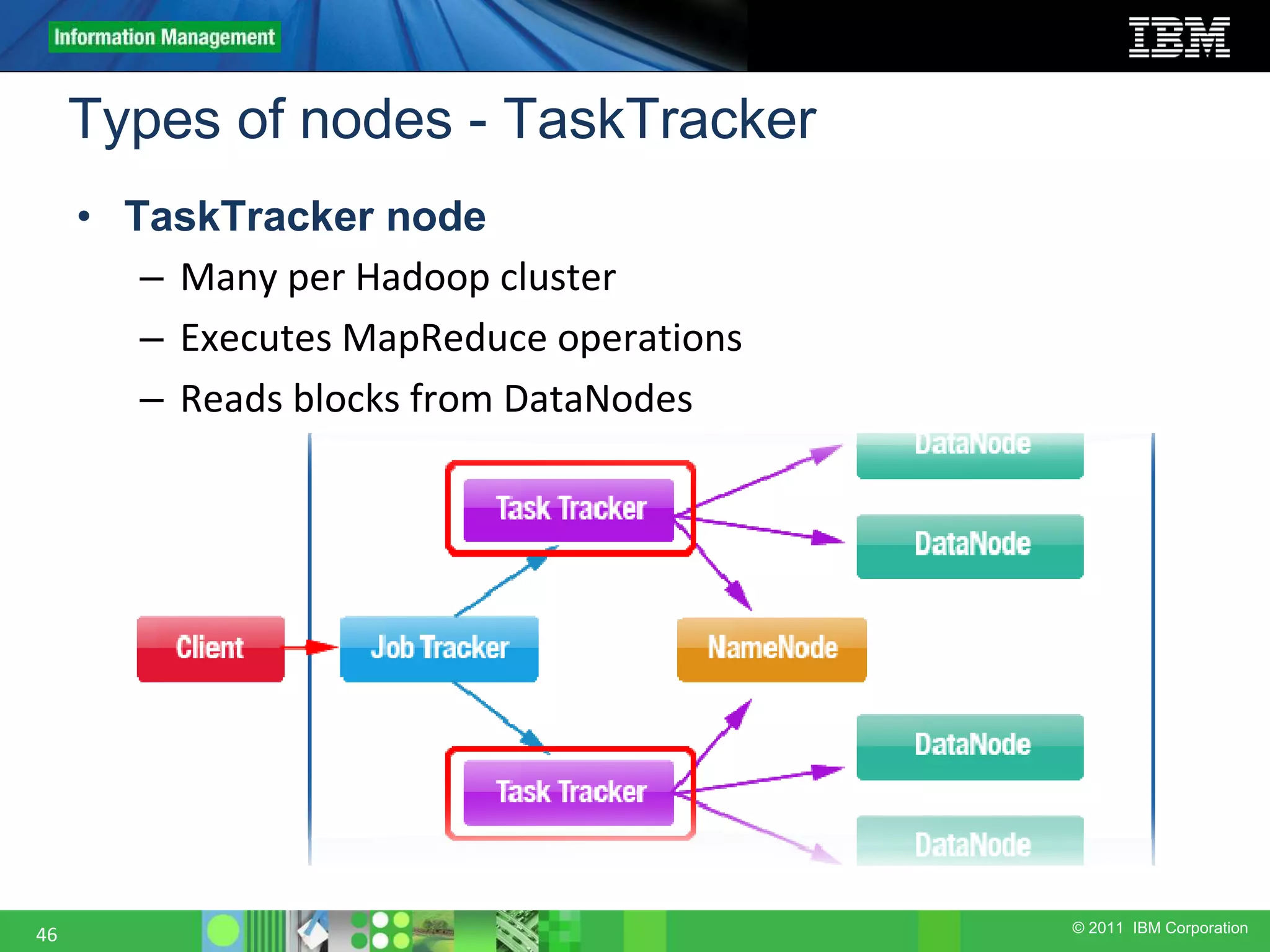
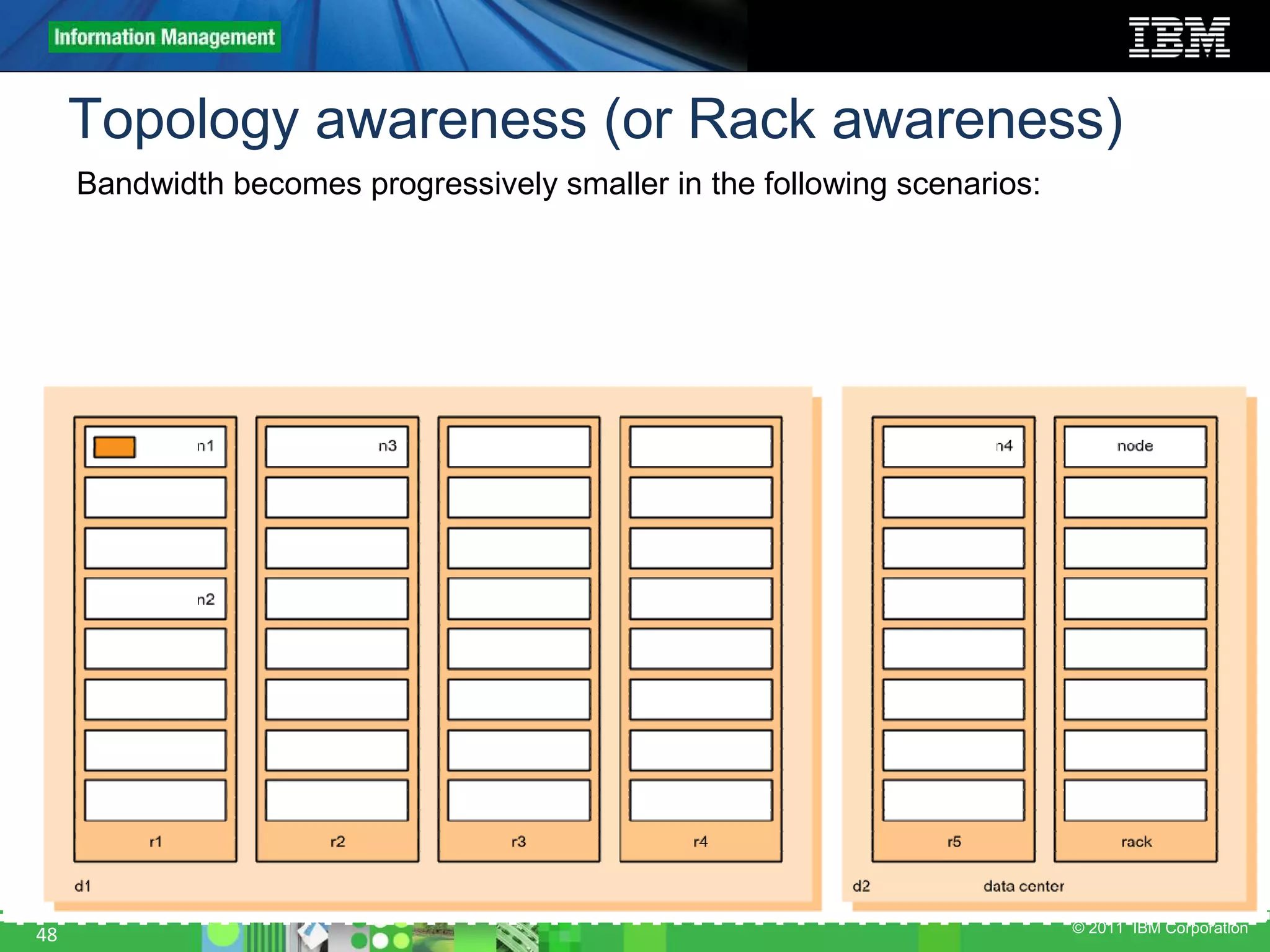
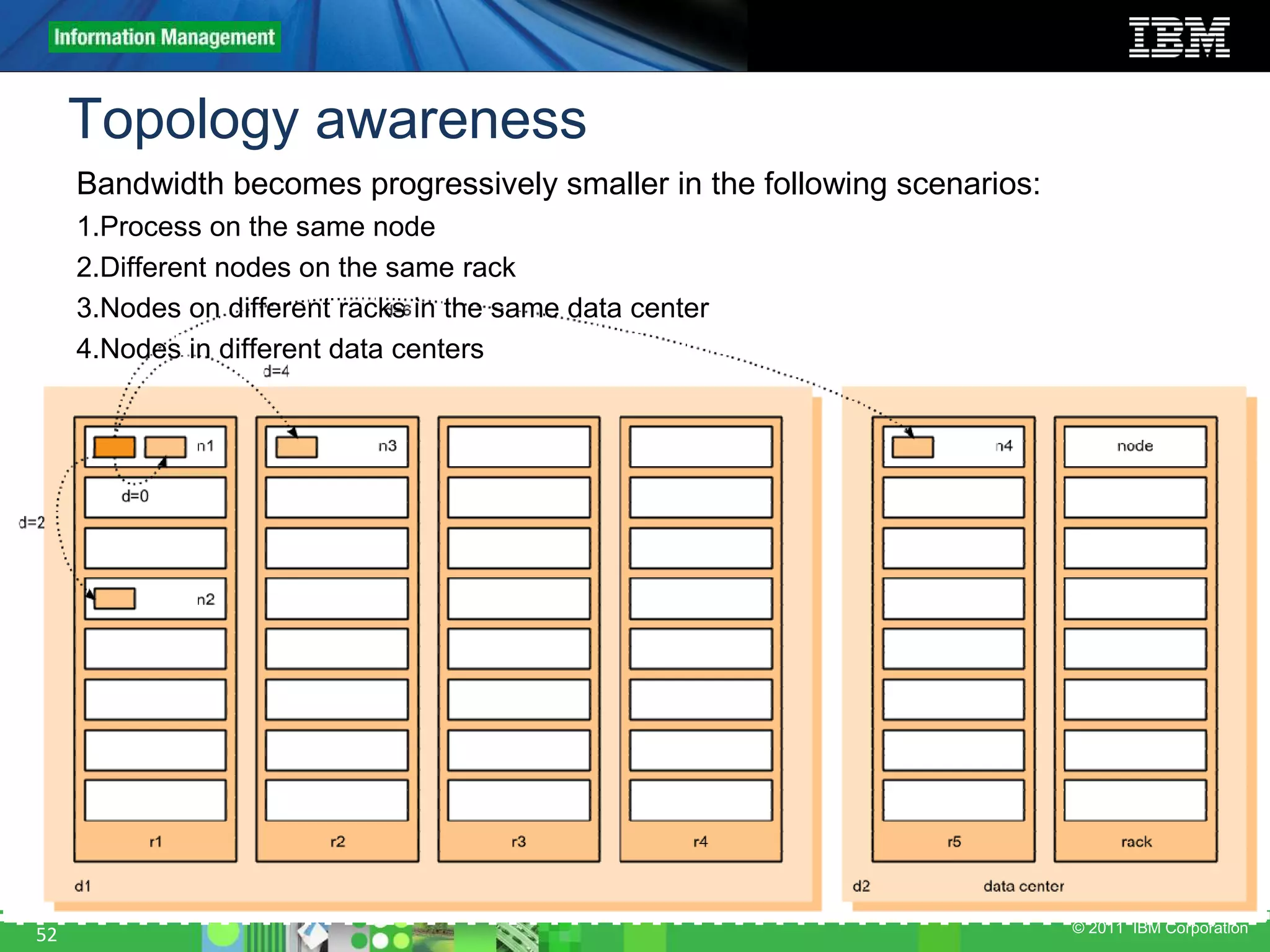
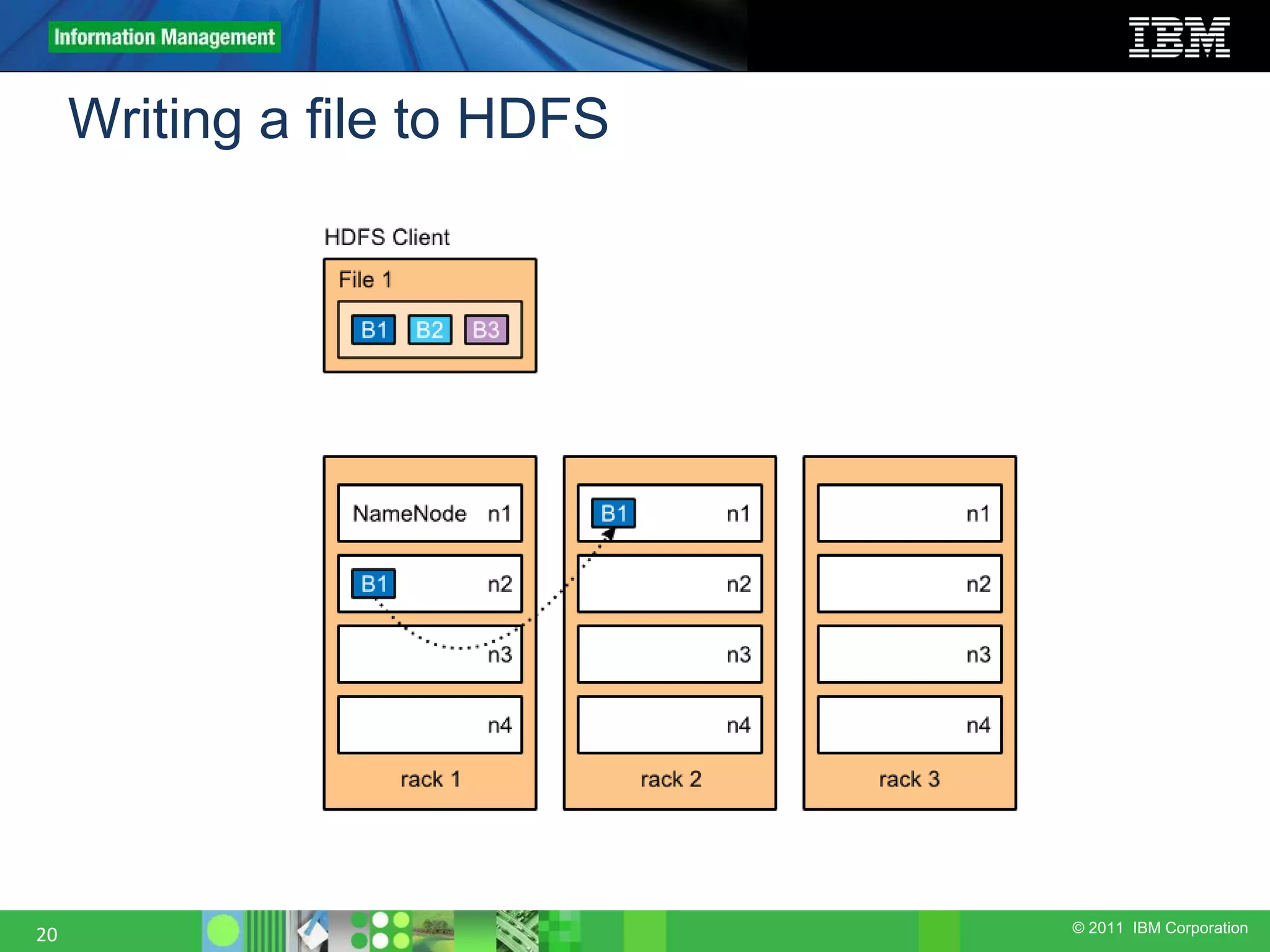
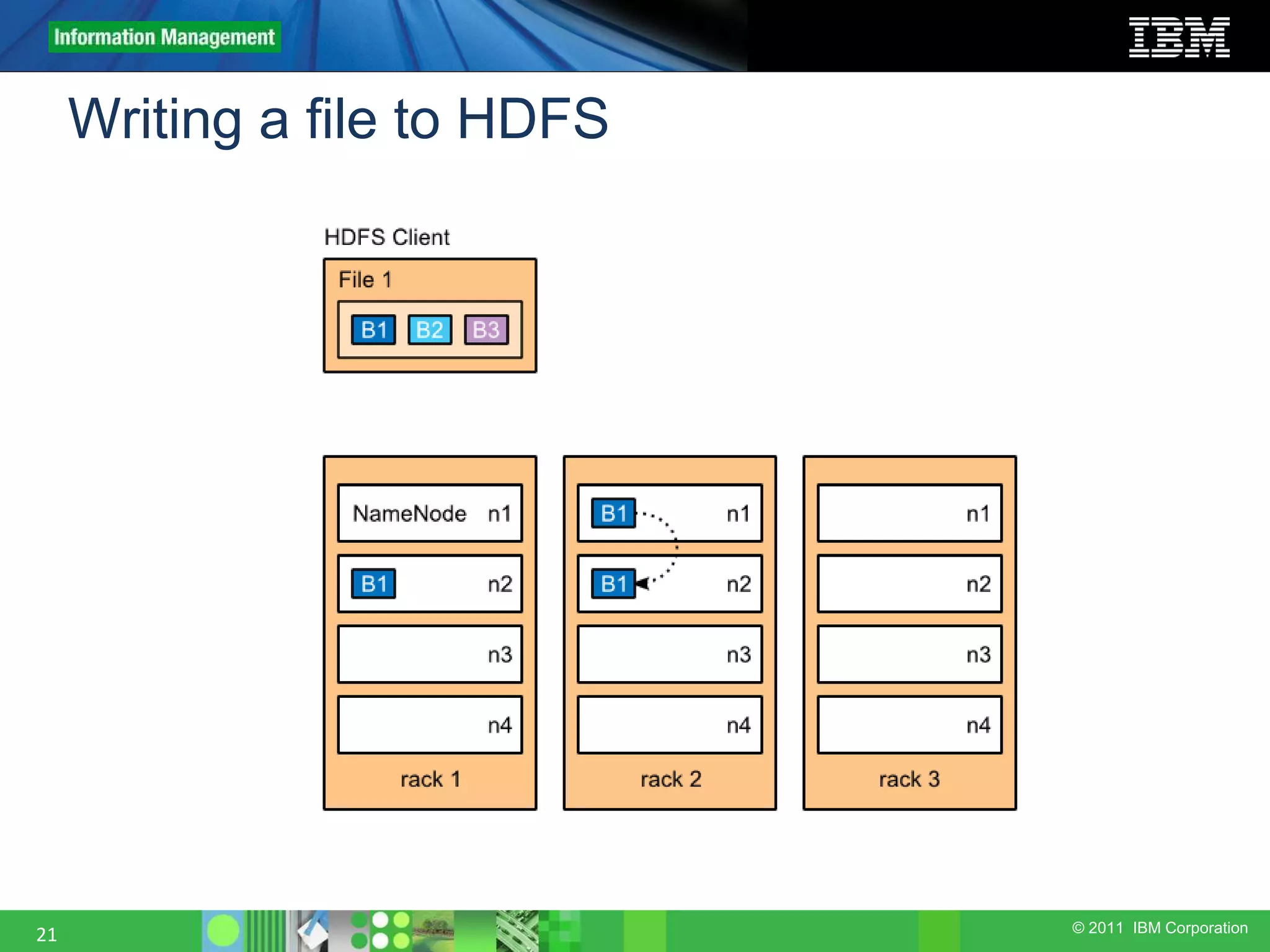
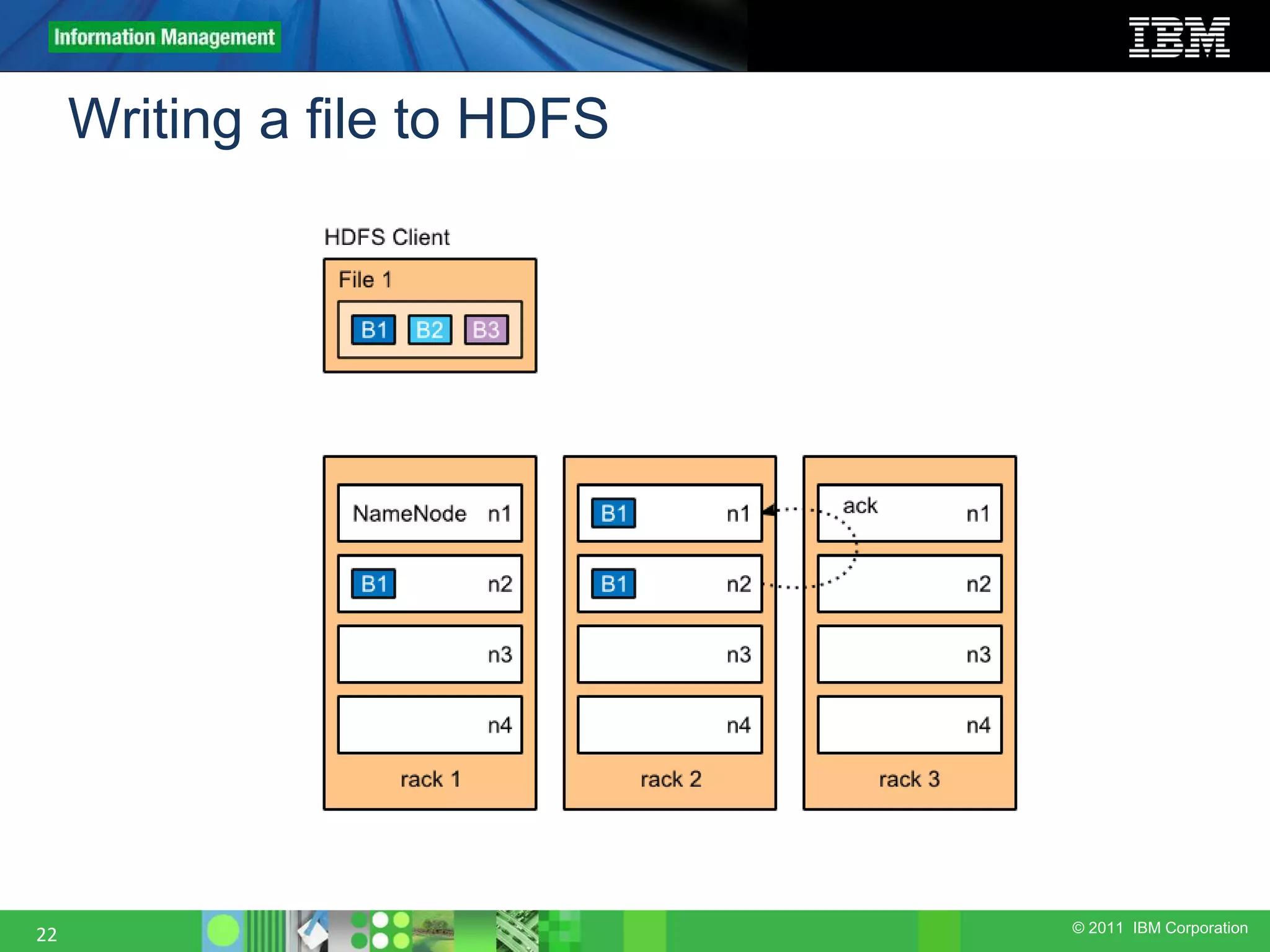
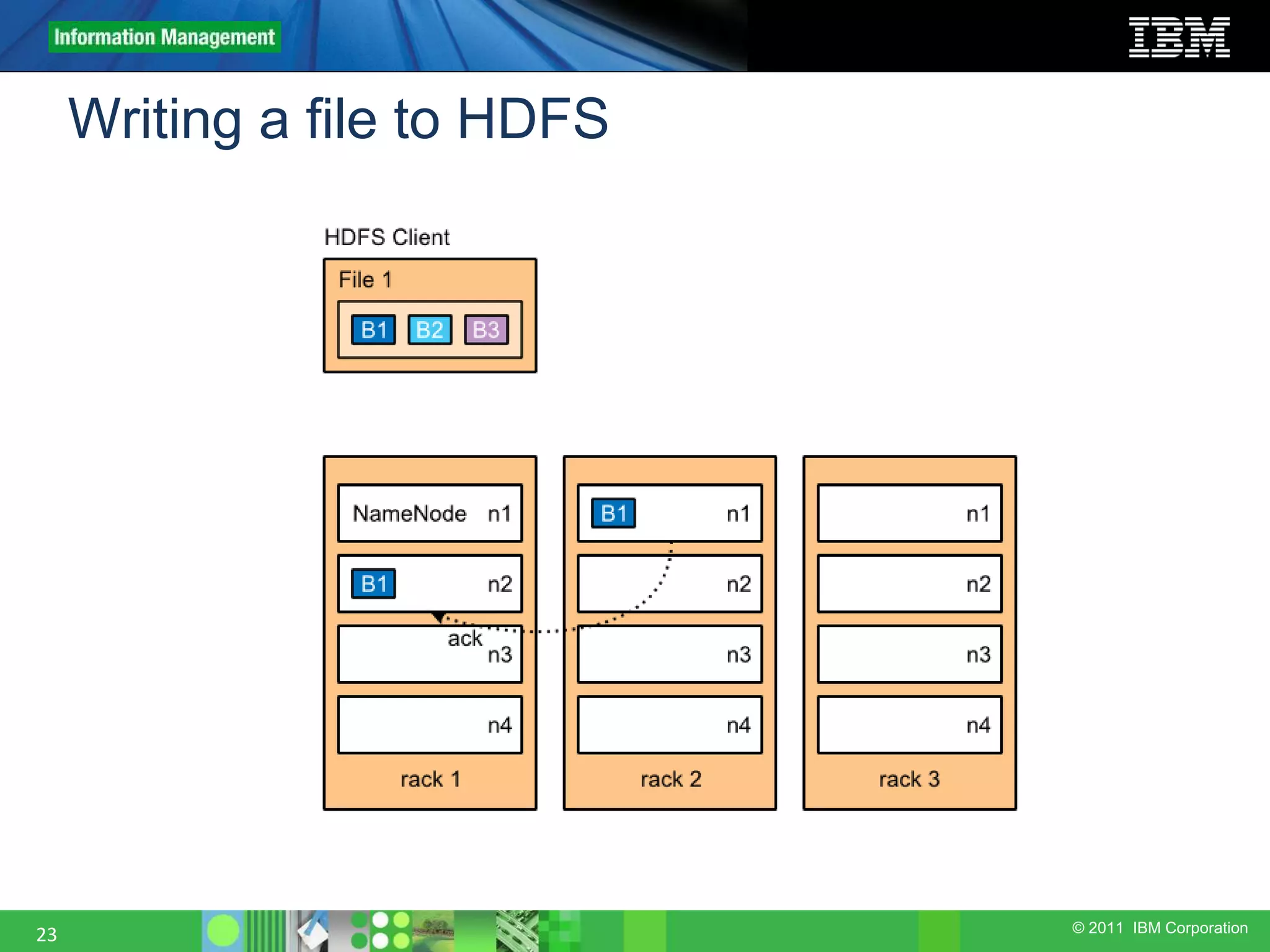
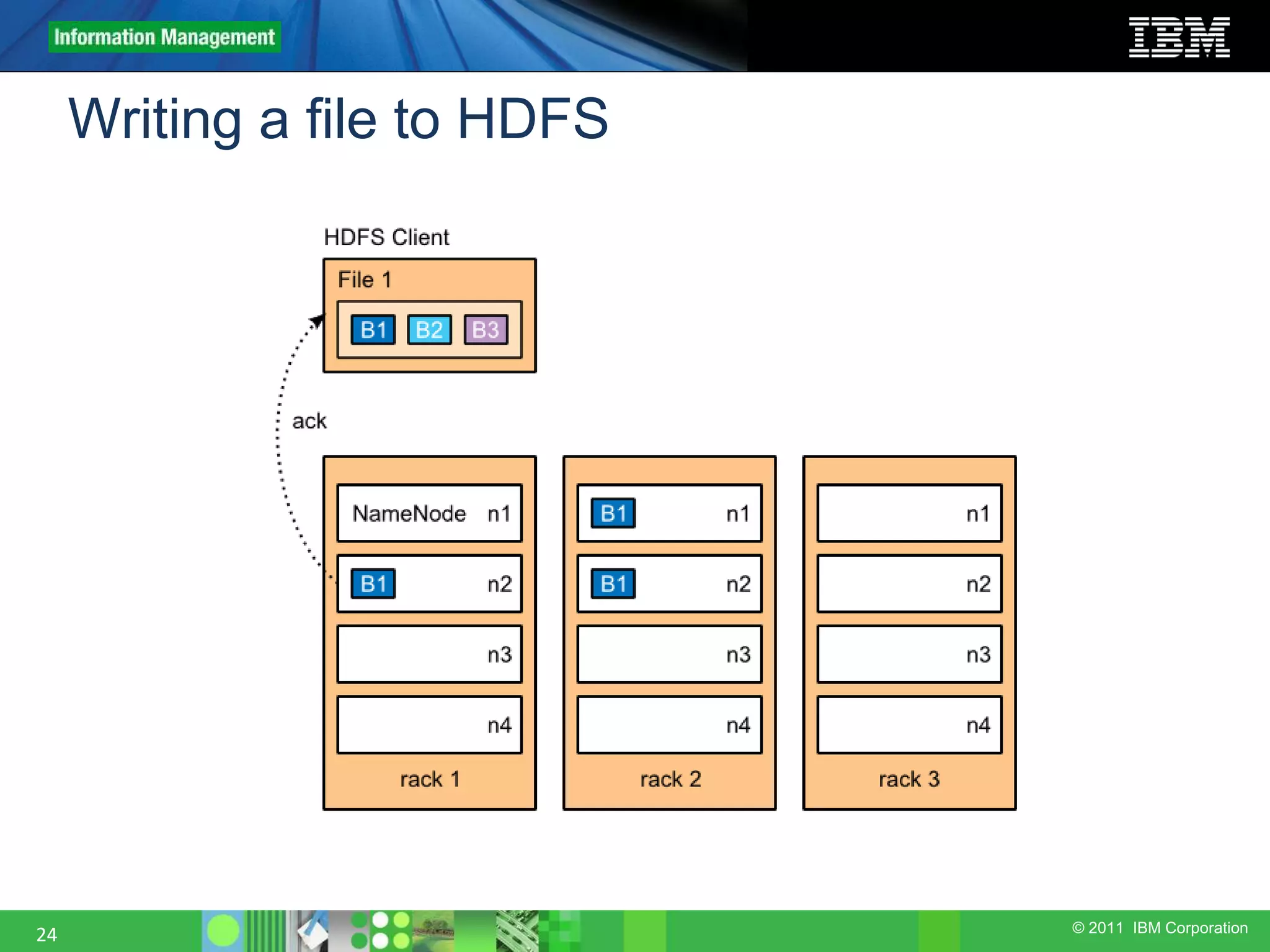
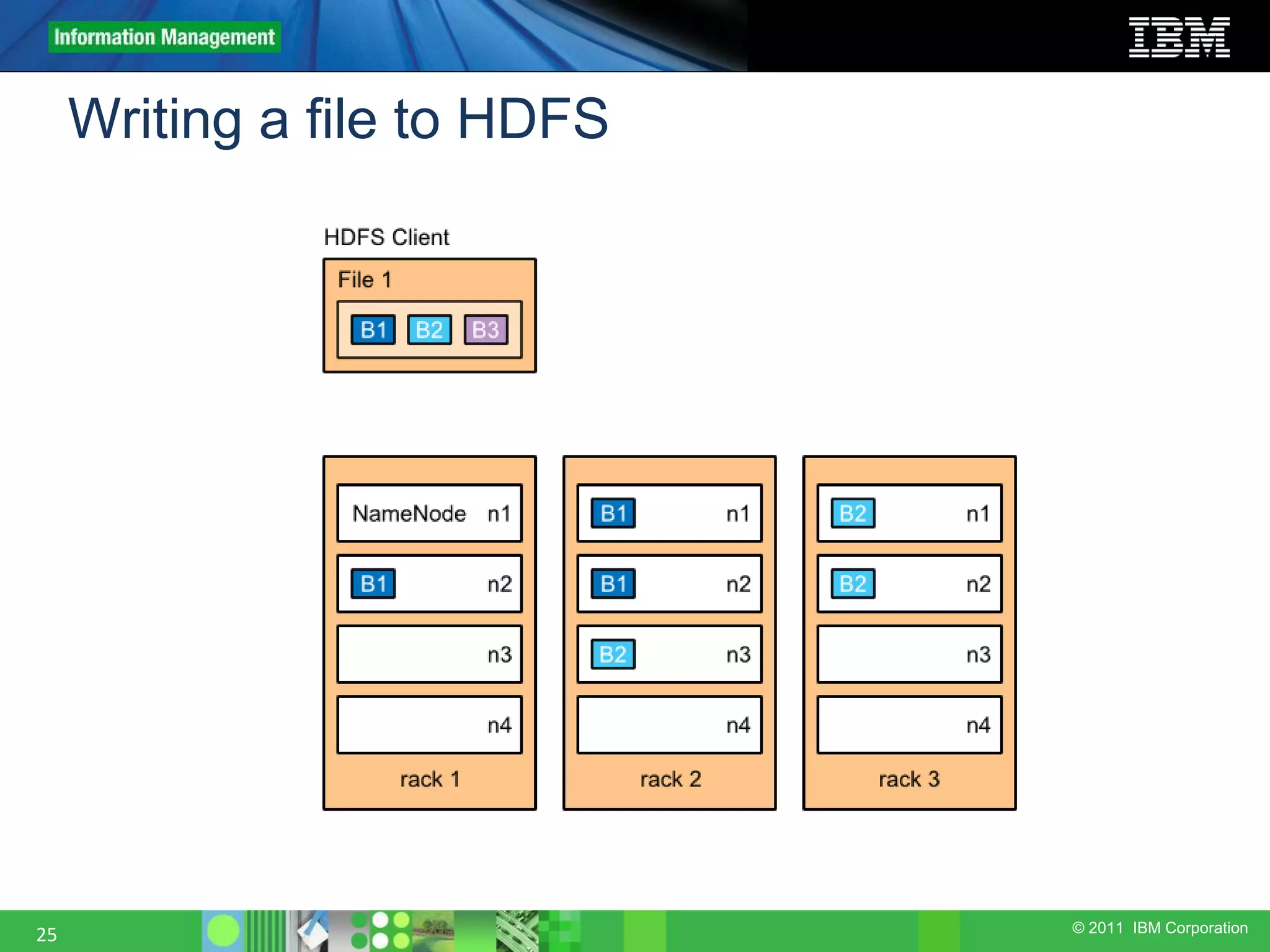
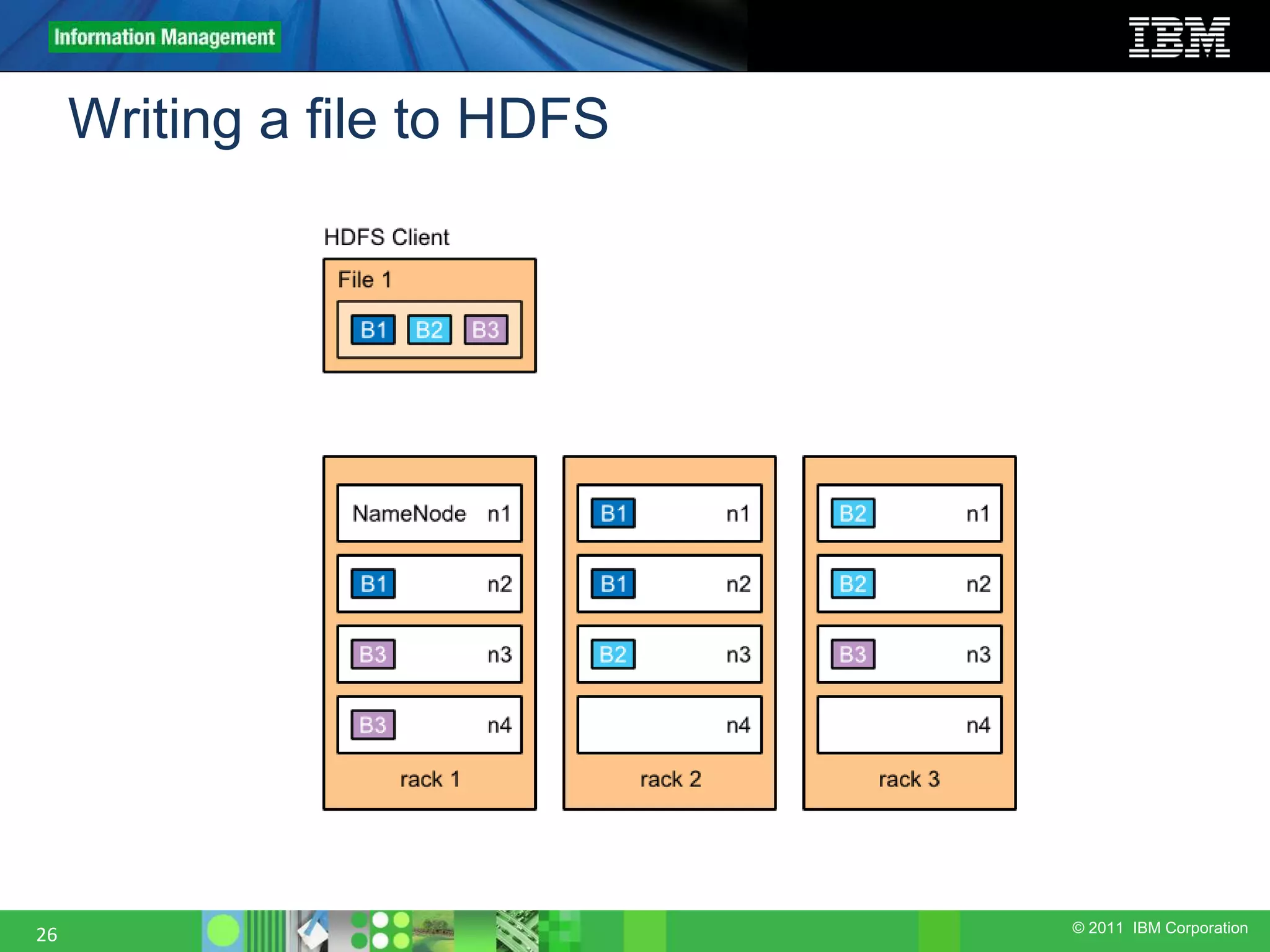
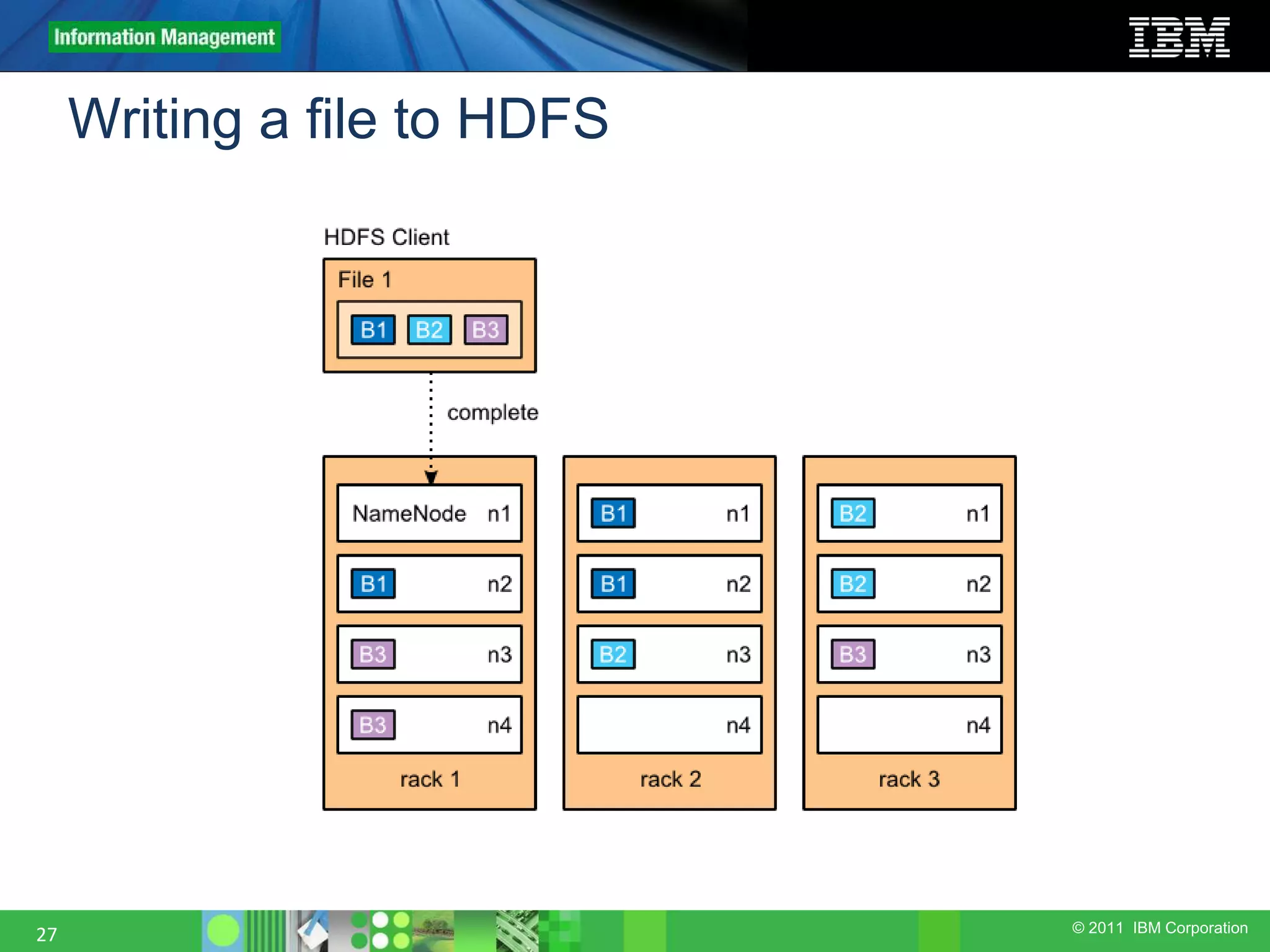
This document provides an overview of the Hadoop architecture, including its two main components: the Hadoop Distributed File System (HDFS) and the MapReduce engine. It describes HDFS' use of blocks and replication for reliability. It explains how files are written to HDFS and accessed via command line tools. It also outlines the different node types in Hadoop including the NameNode, DataNode, JobTracker and TaskTracker. Finally, it discusses topology awareness and how bandwidth decreases between processes on different nodes, racks and data centers.











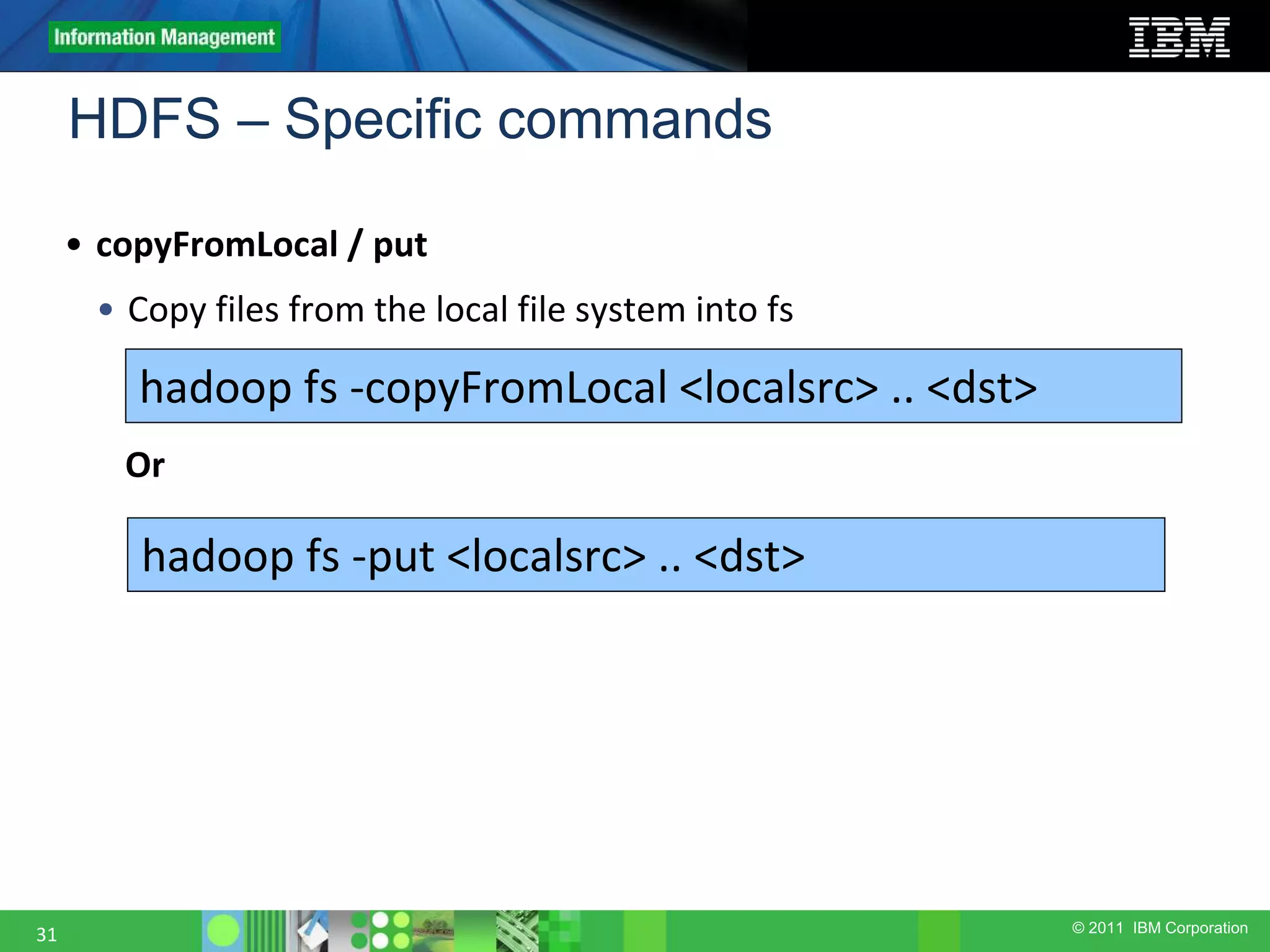
![© 2011 IBM Corporation HDFS – Specific commands 32 • copyToLocal / get • Copy files from fs into the local file system hadoop fs -copyToLocal [-ignorecrc] [-crc] <src> <localdst> hadoop fs -get [-ignorecrc] [-crc] <src> <localdst> Or](https://image.slidesharecdn.com/1-180914061126/75/hadoop-architecture-Big-data-hadoop-32-2048.jpg)
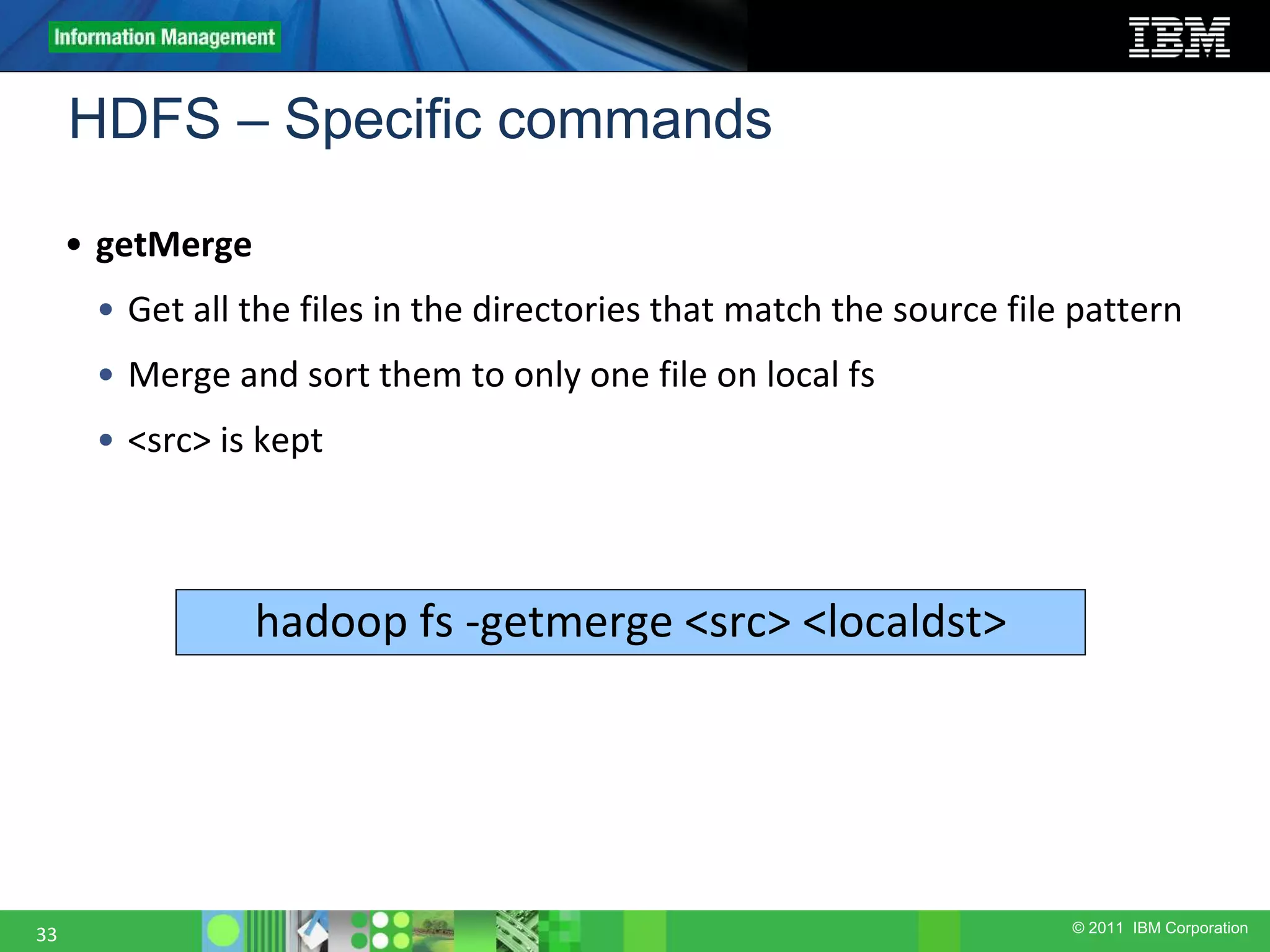
![© 2011 IBM Corporation HDFS – Specific commands 34 • setRep • Set the replication level of a file. • The -R flag requests a recursive change of replication level for an entire tree. • If -w is specified, waits until new replication level is achieved. hadoop fs -setrep [-R] [-w] <rep> <path/file>](https://image.slidesharecdn.com/1-180914061126/75/hadoop-architecture-Big-data-hadoop-34-2048.jpg)