Download to read offline







![Step 2: Build Huffman Tree & Assign Codes • It is a binary tree in which each character is a leaf node – Initially each node is a separate root • At each step – Select two roots with smallest frequency and connect them to a new parent (Break ties arbitrary) [The greedy choice] – The parent will get the sum of frequencies of the two child nodes • Repeat until you have one root Slide 11](https://image.slidesharecdn.com/greedyalgorithmshuffmancoding-220914090203-5408368e/75/Greedy-Algorithms-Huffman-Coding-ppt-11-2048.jpg)







Huffman coding is an efficient lossless data compression technique that reduces file sizes by encoding characters based on their frequency of occurrence, achieving between 20%-90% compression. It involves creating a binary tree where more common characters receive shorter codes and less common characters receive longer codes, ensuring unique decoding. The process includes scanning for character frequencies, building a Huffman tree, encoding the original file using the tree, and decoding it back to its original form.
Overview of greedy algorithms, specifically Huffman coding.
A lossless data compression technique with 20%-90% compression, ensuring no information loss.
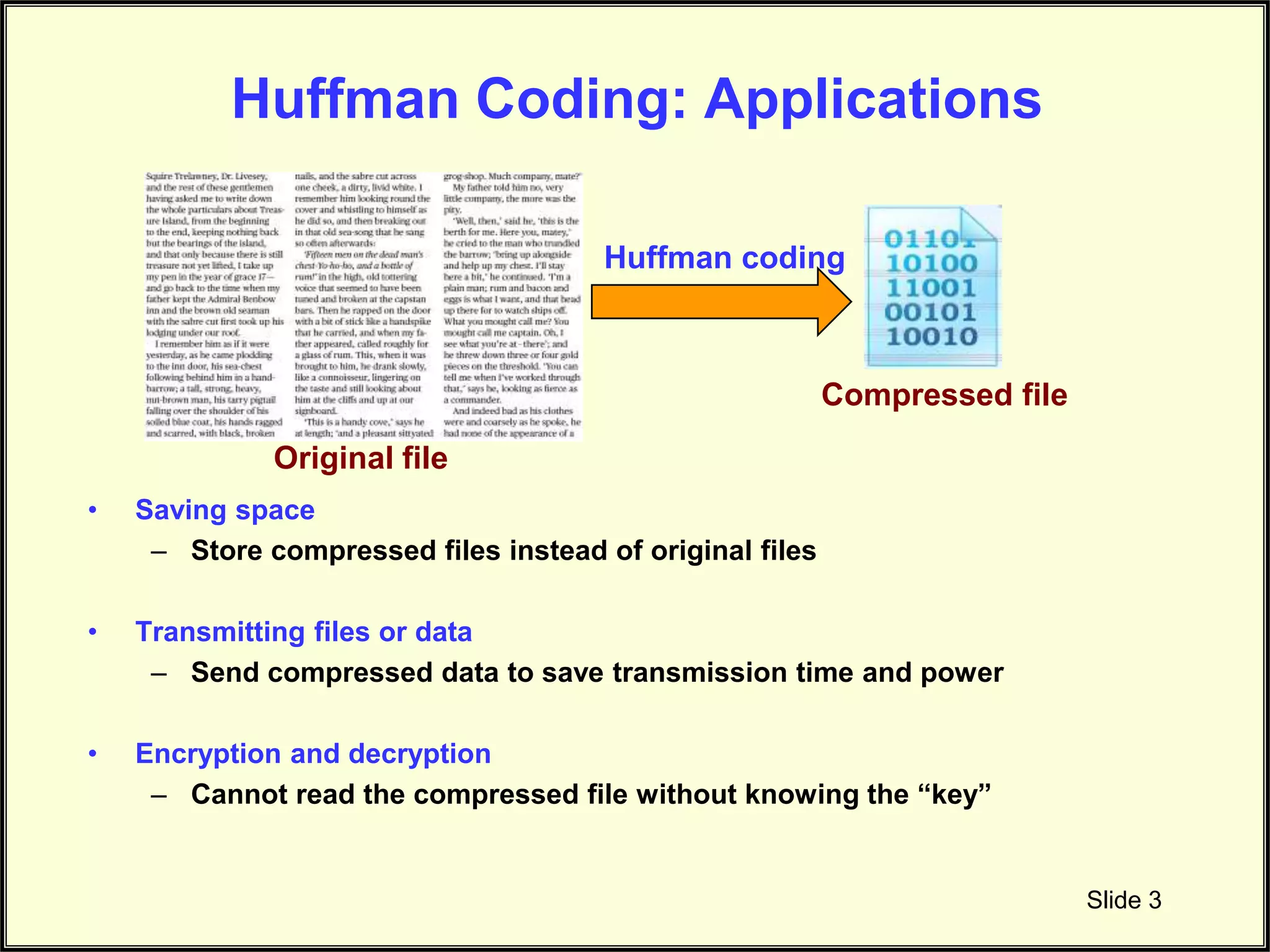
Huffman coding helps in space-saving, faster data transmission, and encryption, aiding data security.
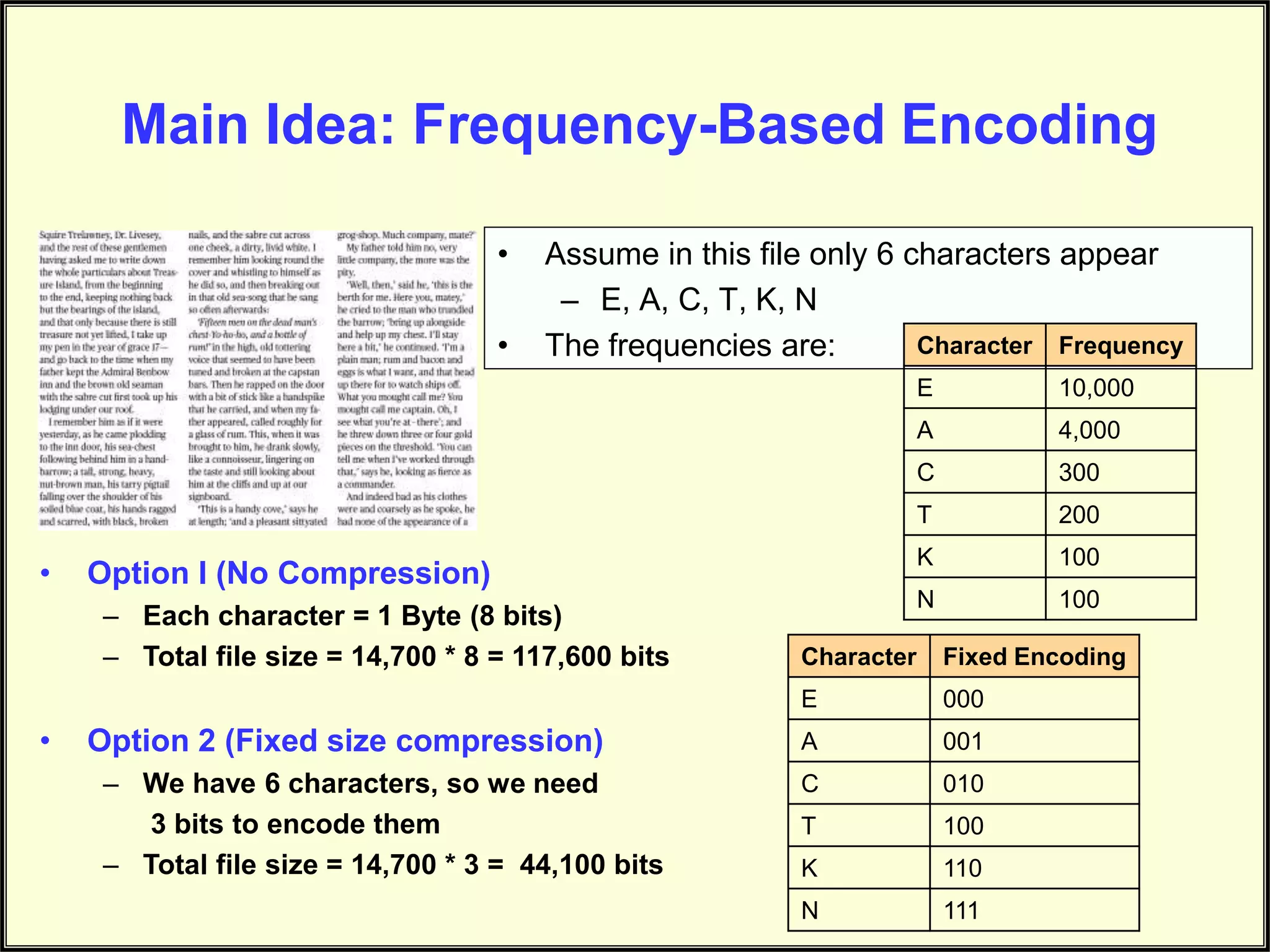
Explains character frequencies in a sample file, showcasing different encoding options and their bit size.
Describes Huffman compression utilizing variable-length codes for efficient data representation.
Describes variable-length coding and addresses encoding and decoding processes in Huffman coding.
Simplifies the decoding of fixed-length codes using a straightforward method for character extraction.
Highlights complexities in variable-length decoding but reassures guaranteed unique decoding with Huffman.
Outlines main steps: getting frequencies, building a tree, encoding, and decoding.
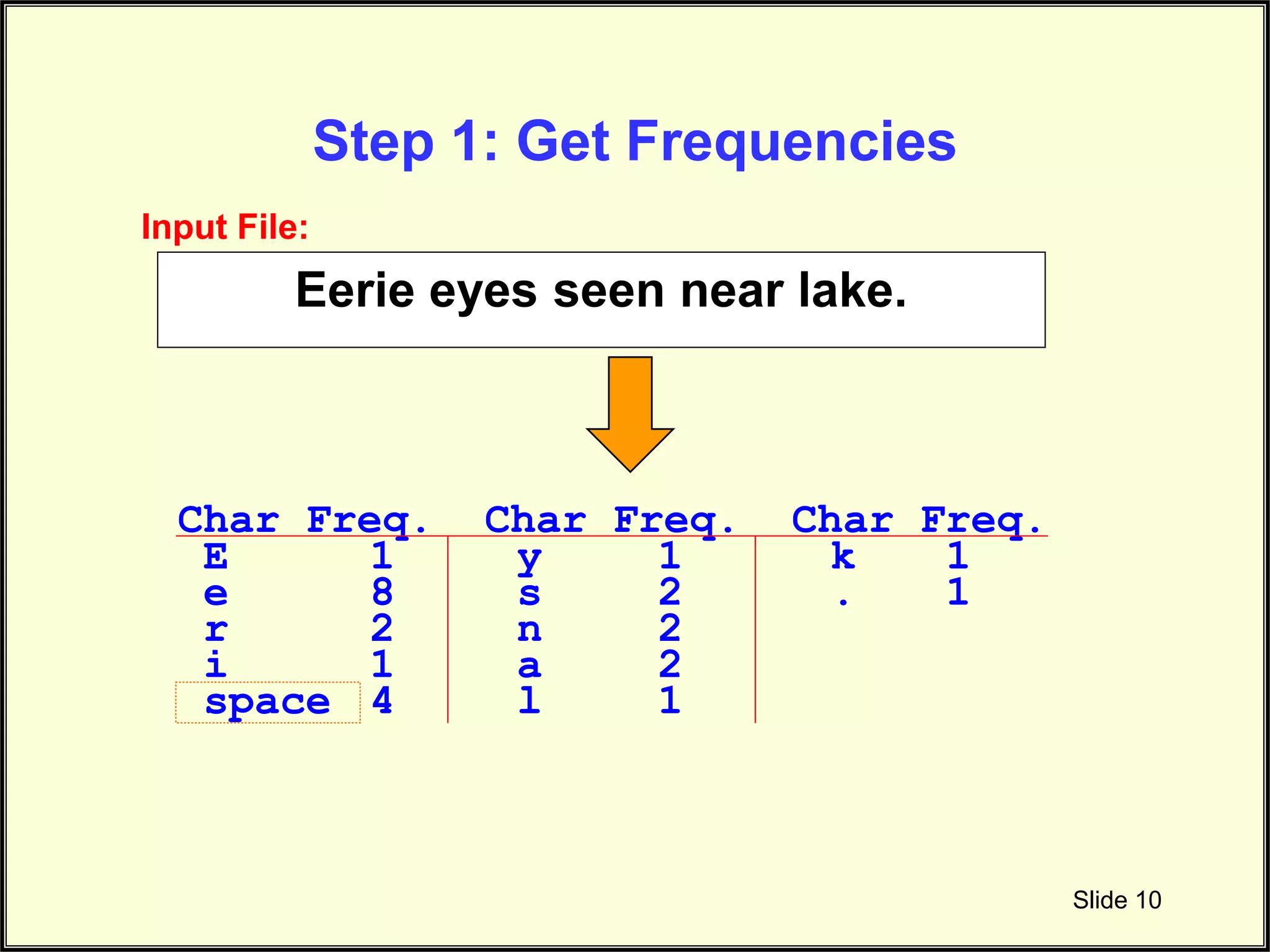
Demonstrates counting character frequencies in a given input file utilizing sample data.
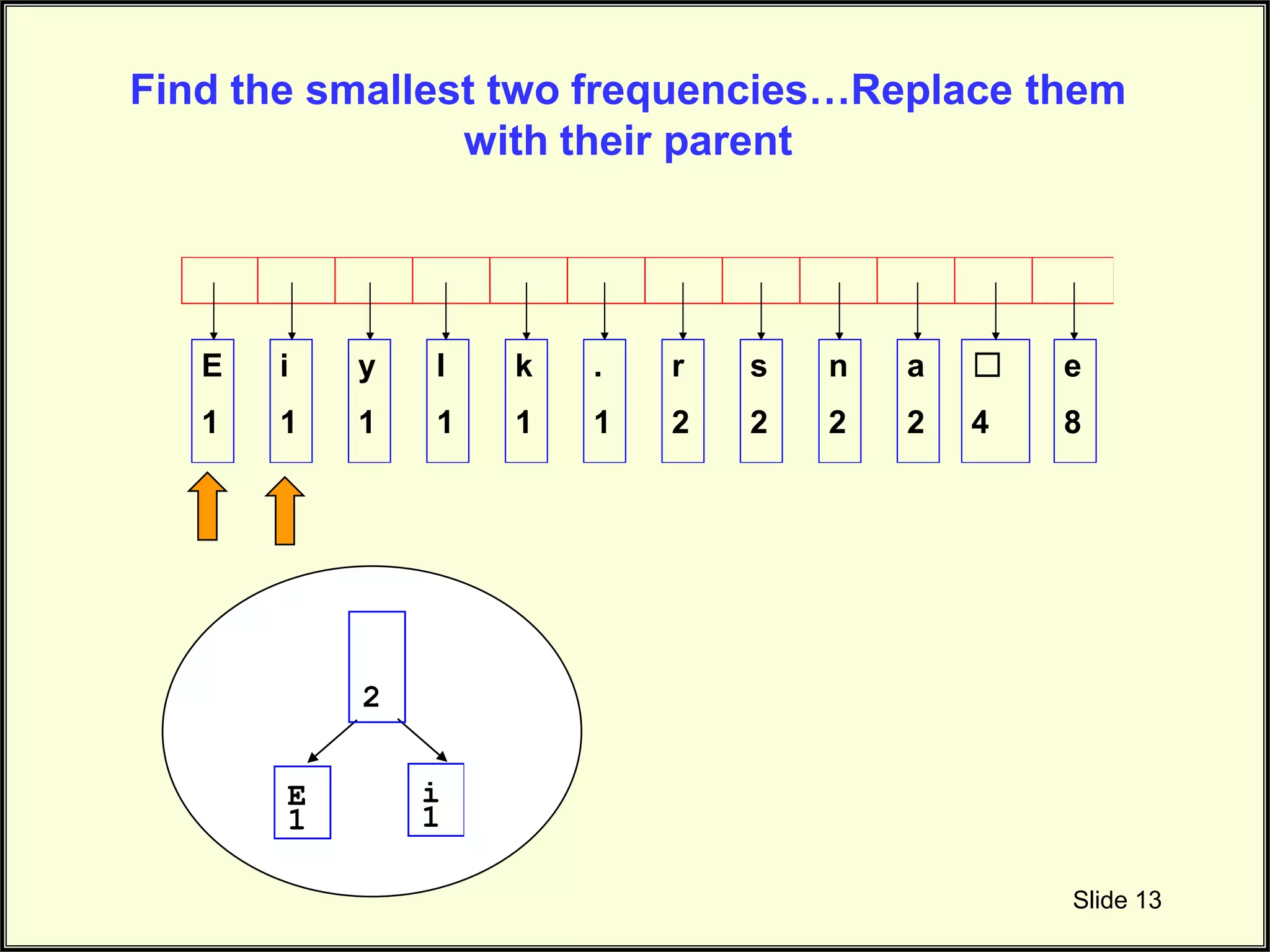
Details the construction of the Huffman tree using frequency-based selections for node connection.
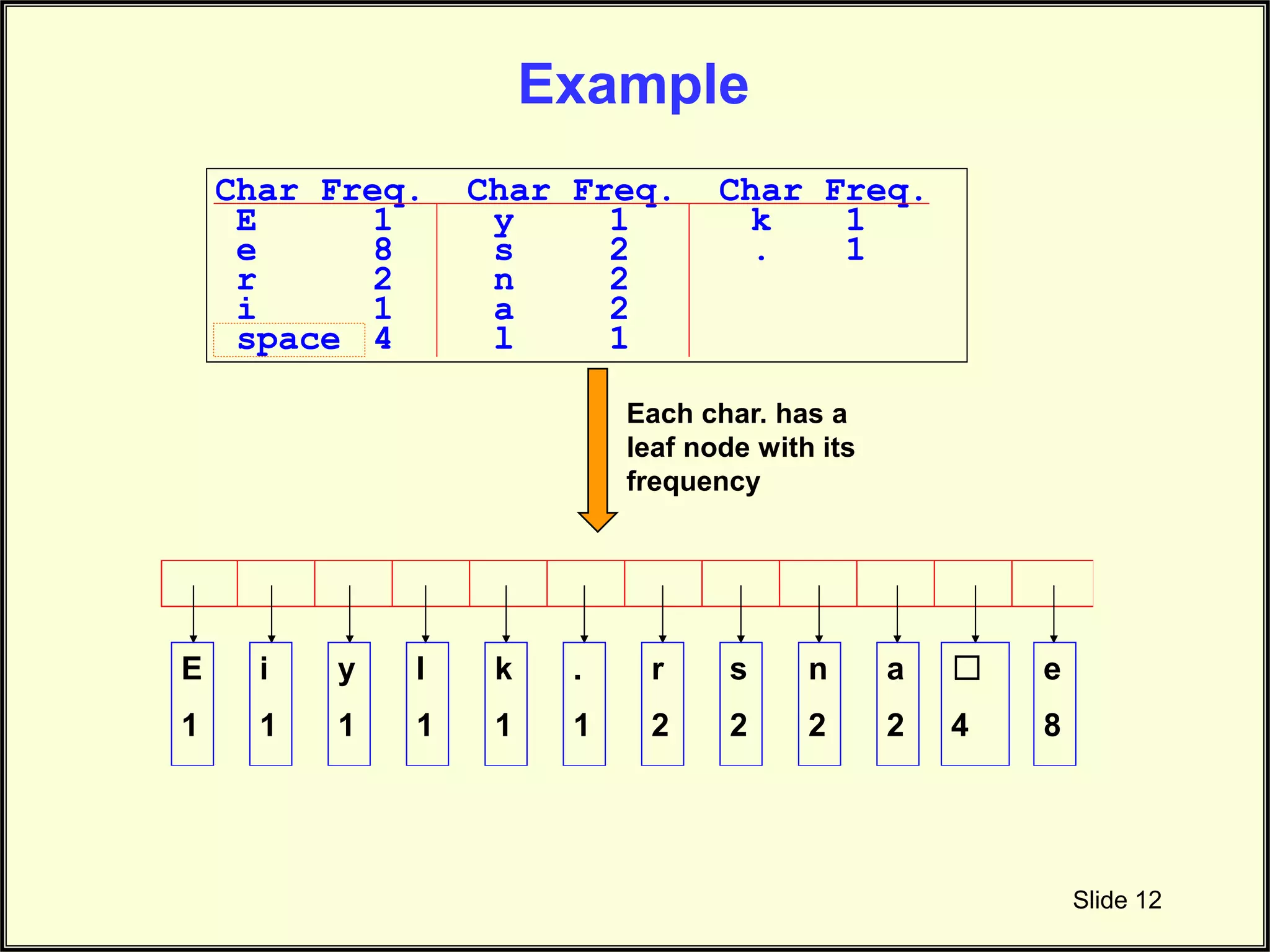
Illustrates the initial setup of node frequencies as leaf nodes within the Huffman tree.
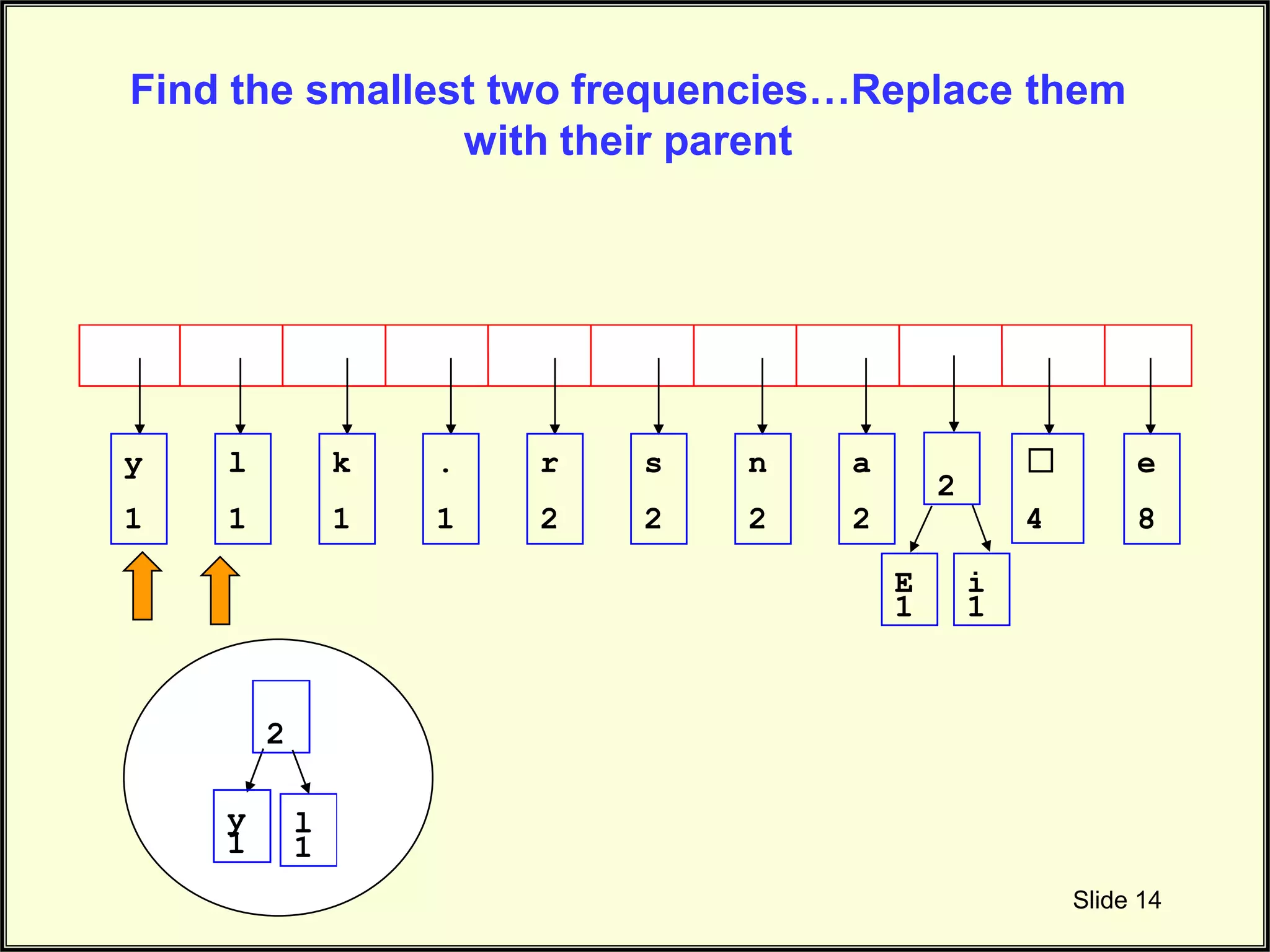
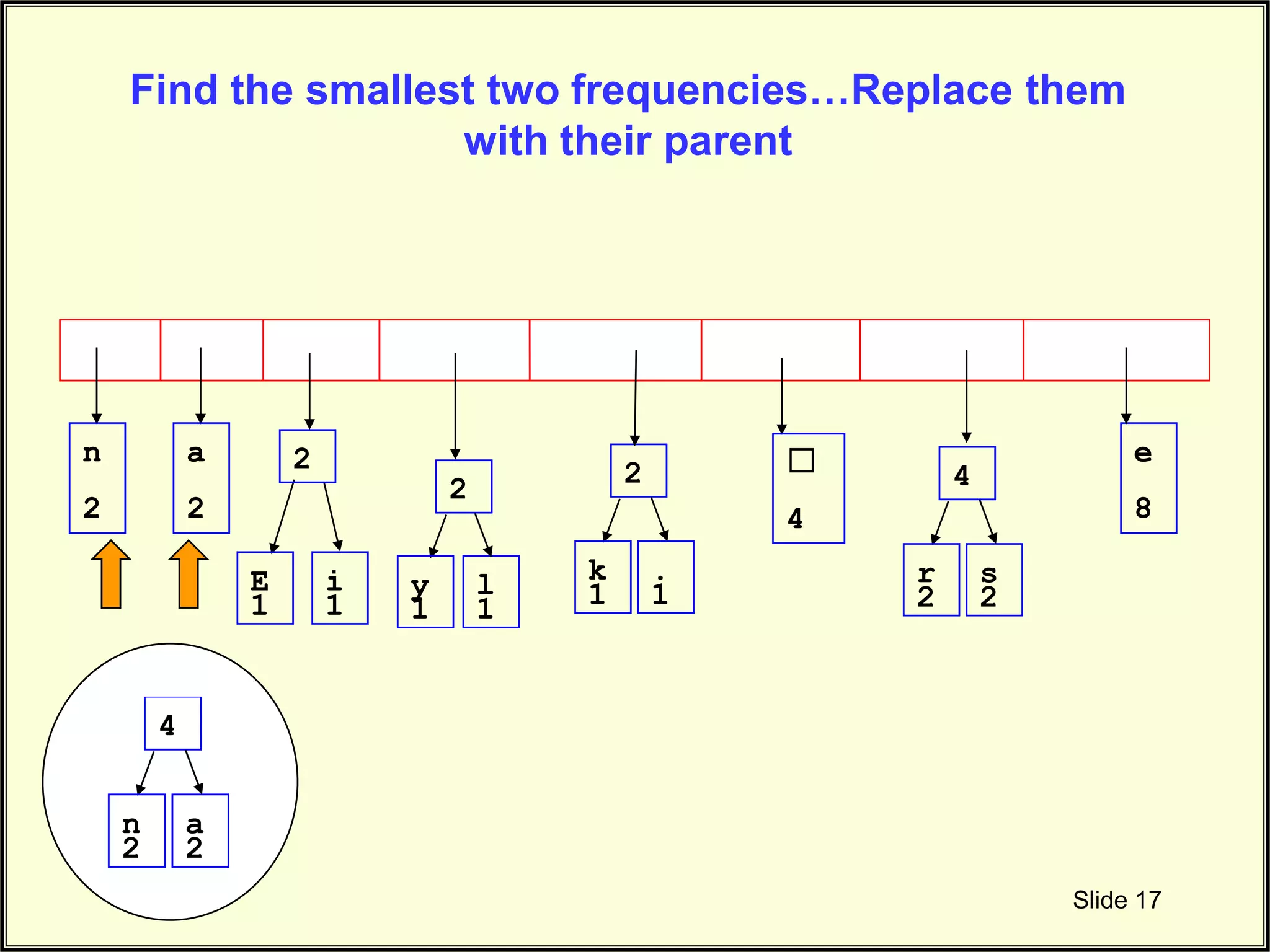
Describes merging the two smallest nodes to form parent nodes during the tree-building process.
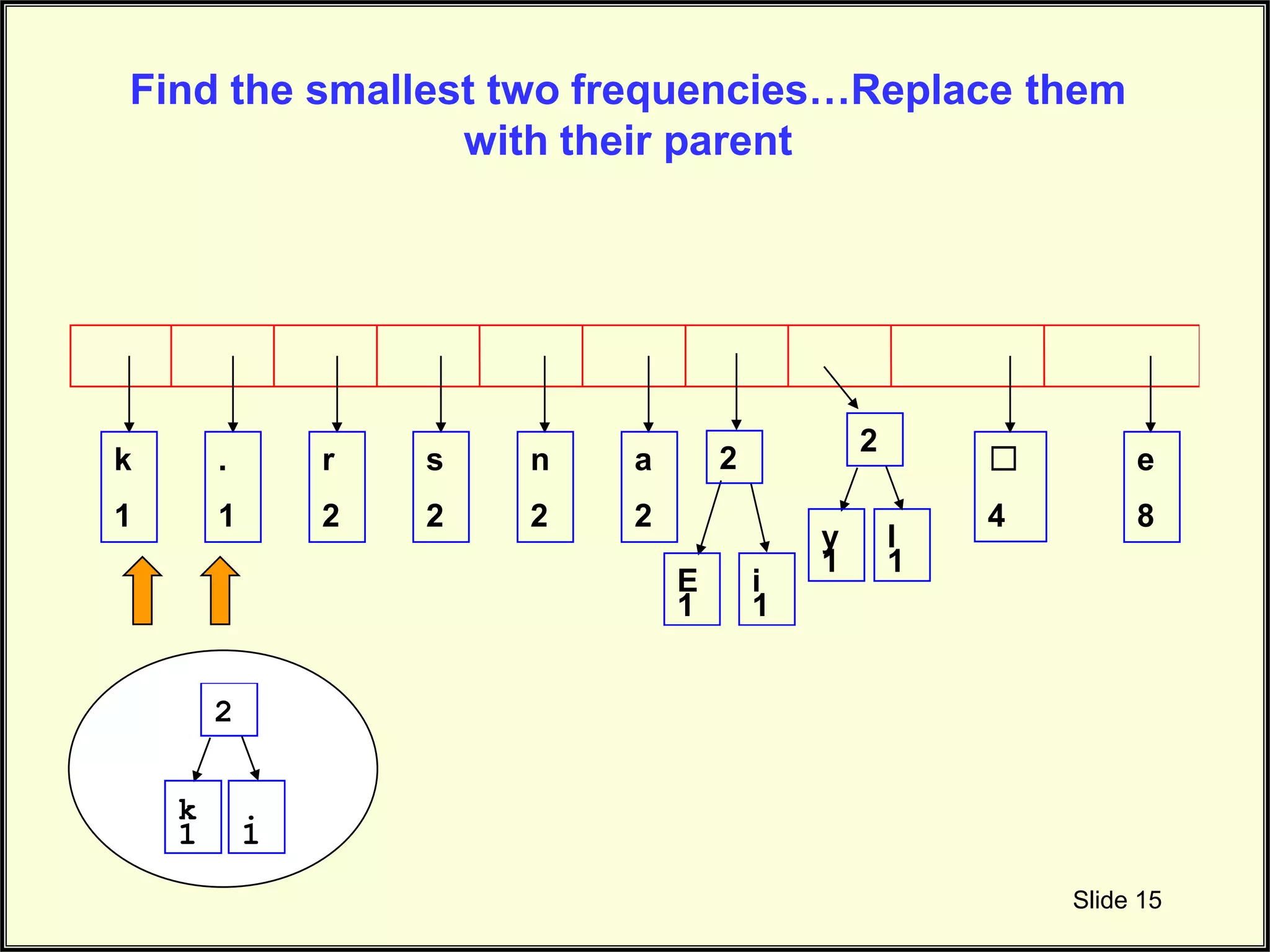
Continues the explanation on constructing the Huffman tree by merging nodes based on frequency.
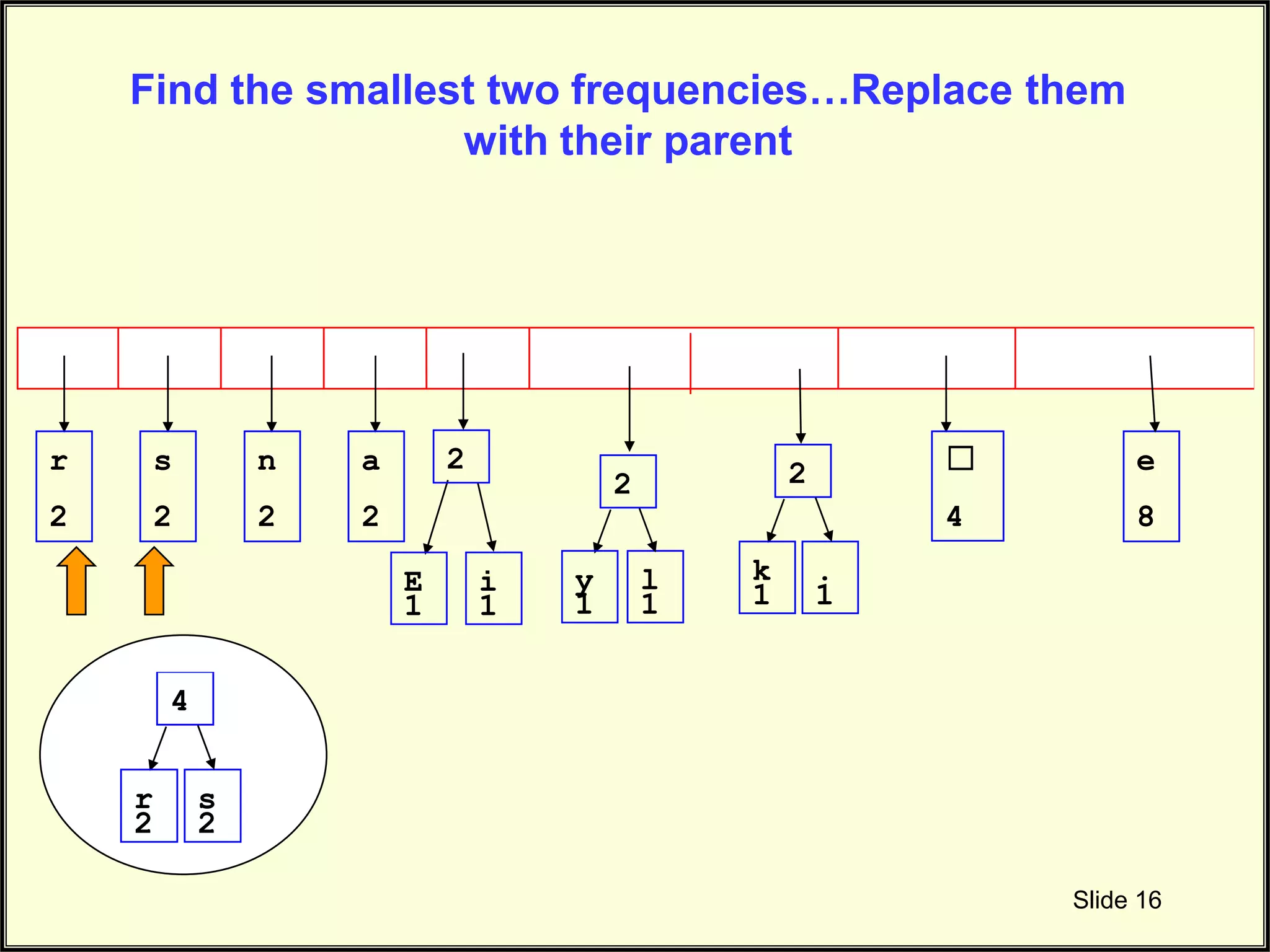
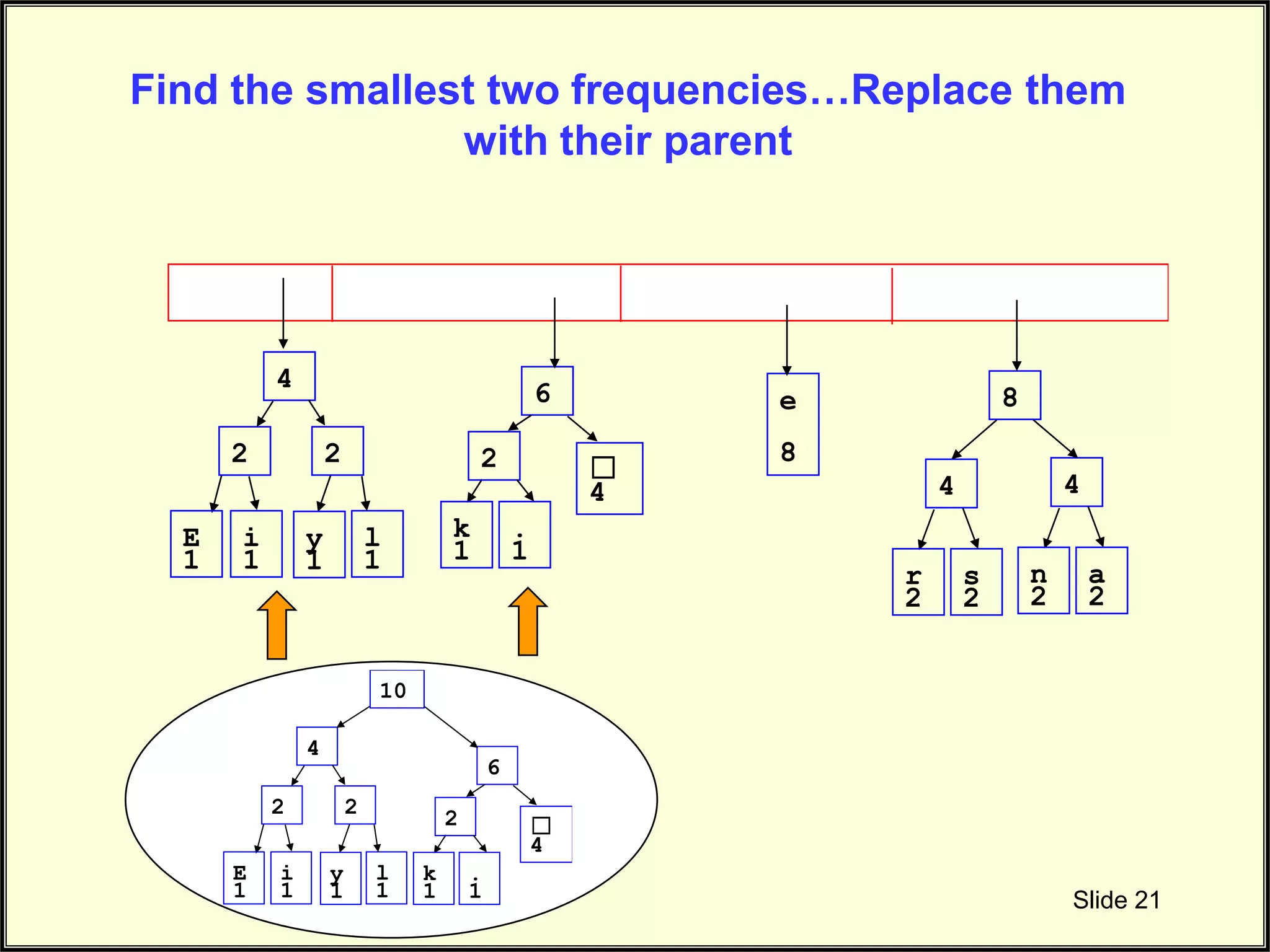
Continues to illustrate the connecting of nodes in Huffman tree during frequency combination.
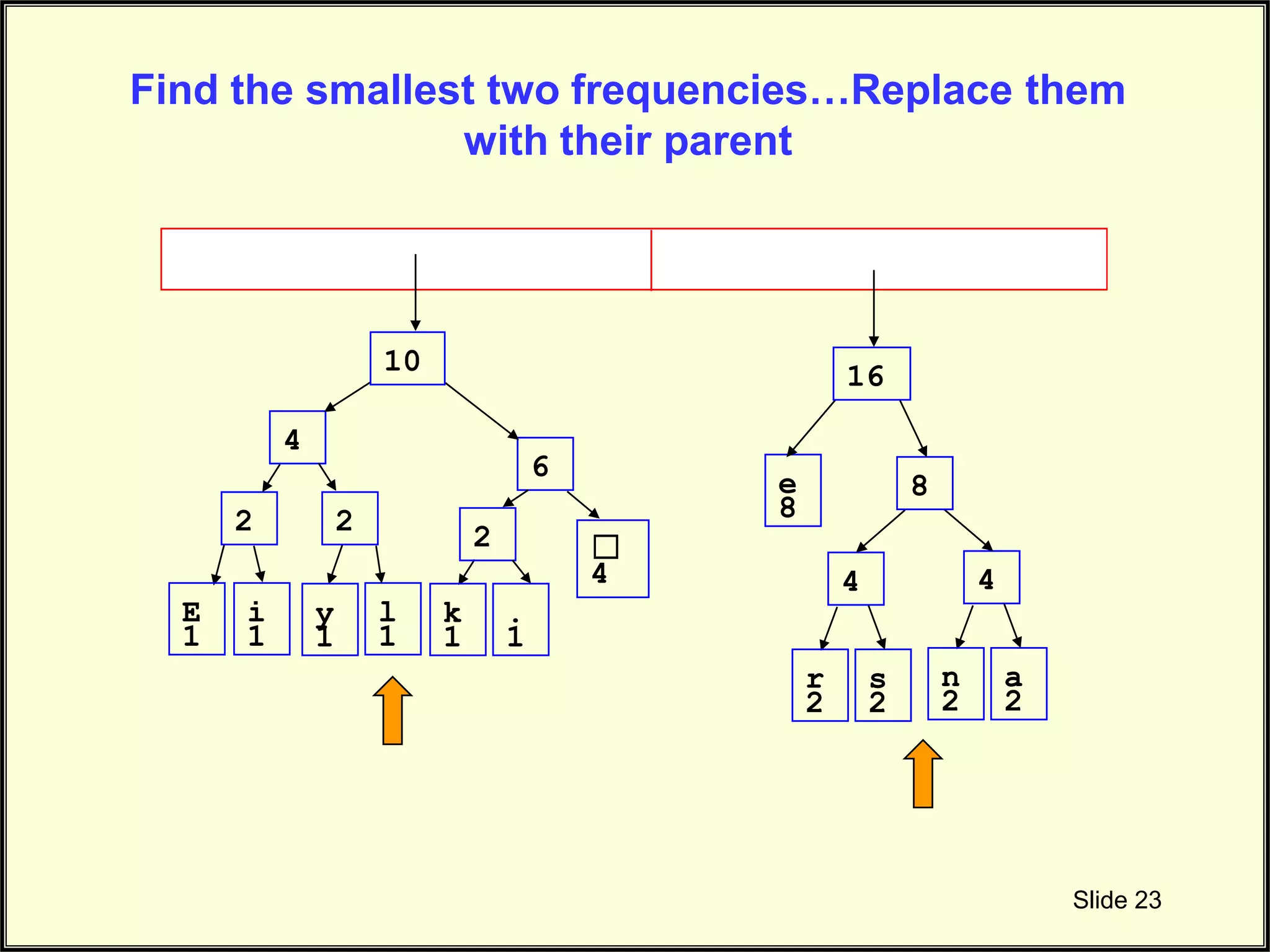
Final steps in connecting nodes based on frequency to complete the Huffman tree structure.
Final adjustments to the Huffman tree, showcasing the integration of all character nodes.
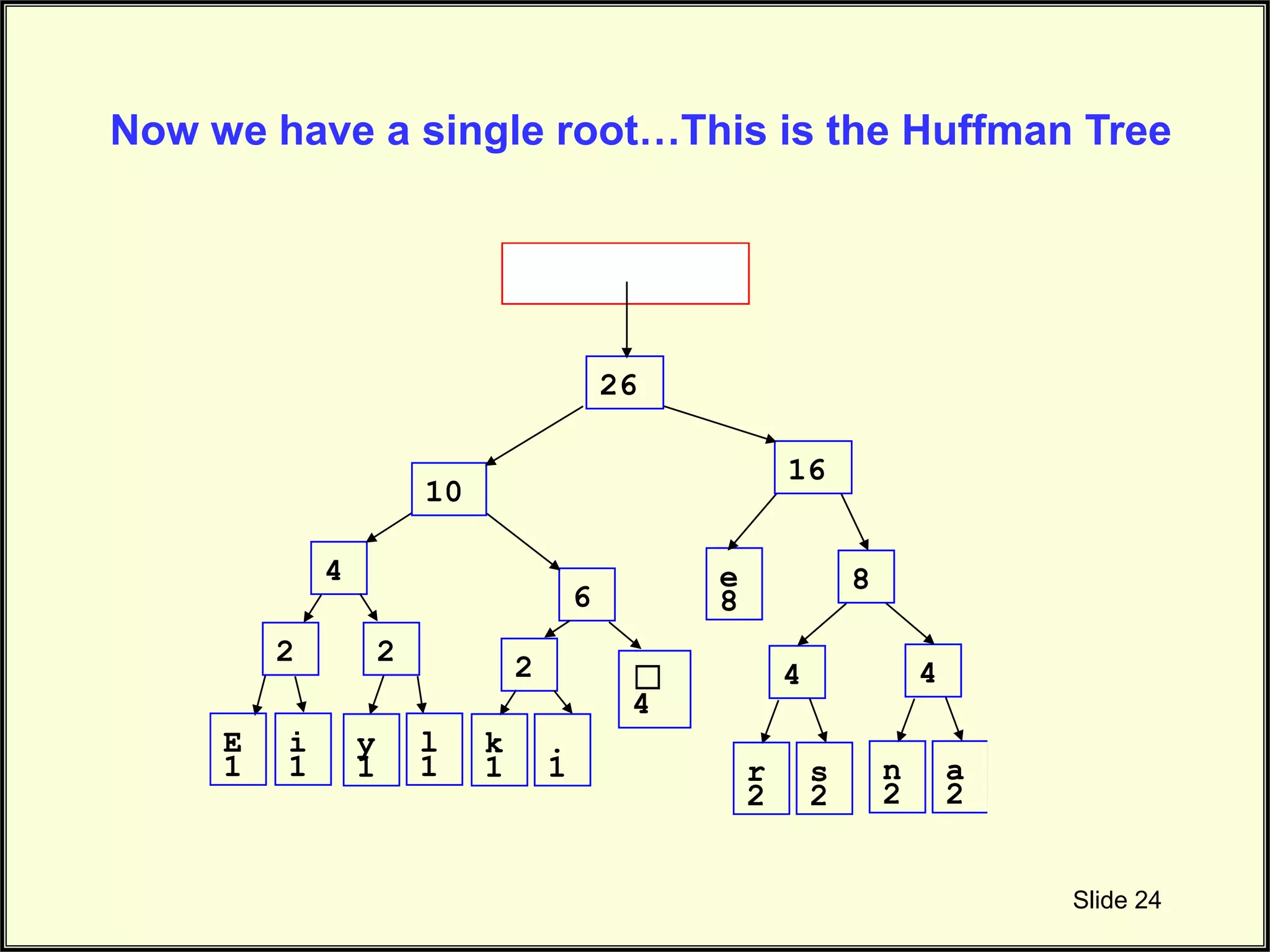
Completes the Huffman tree construction by integrating all character nodes with respective frequencies.
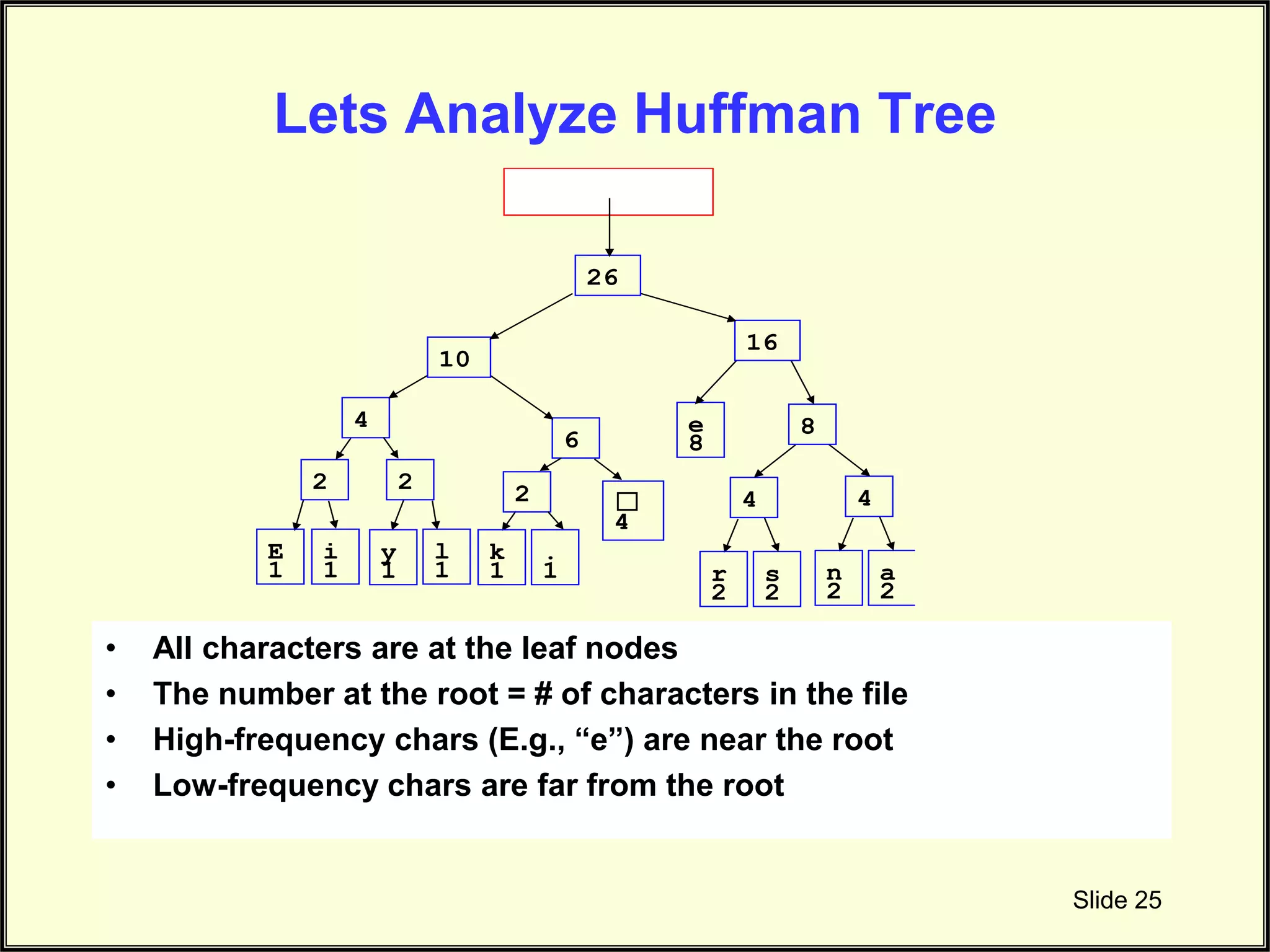
Summarizes the completed Huffman tree structure and its organization based on character frequency.
Discusses how the root reflects total character count and position of high/low frequency characters.
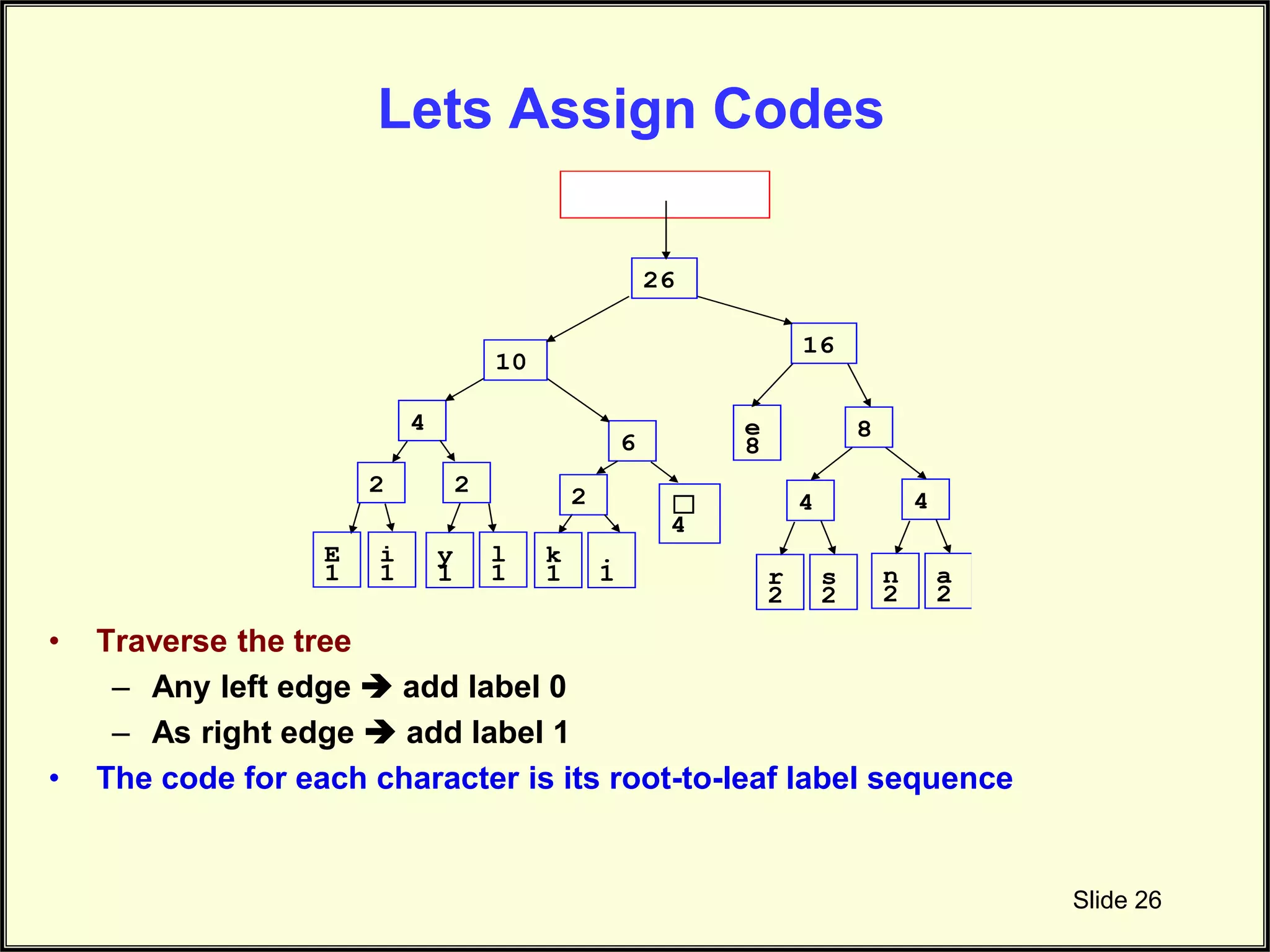
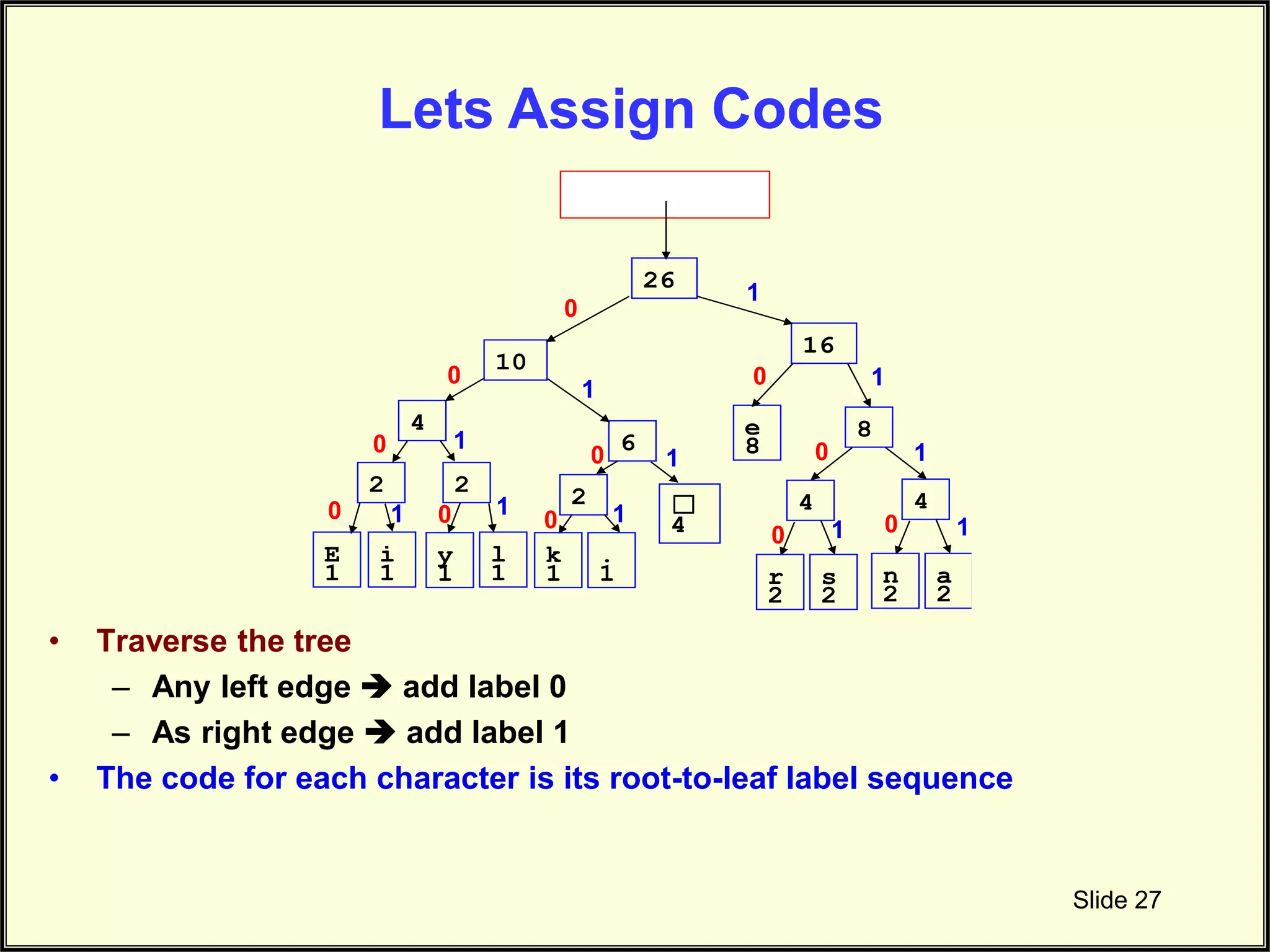
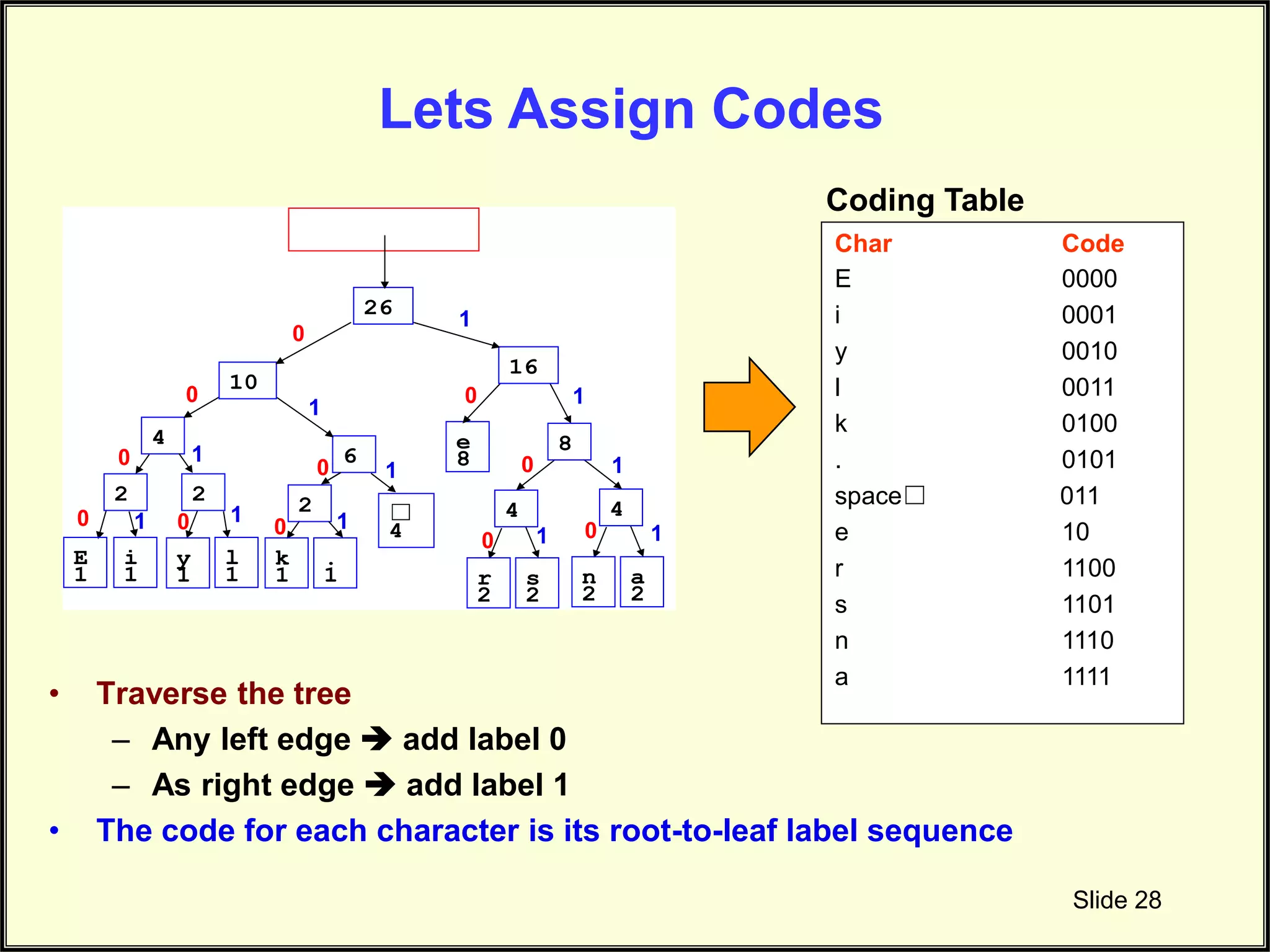
Illustrates how to assign codes for characters using traversal from the Huffman tree.
Explains the traversal method used for labeling characters with respective compressed codes.
Showcases the generated codes for characters derived from the Huffman tree.
Provides a summary of the steps of applying the Huffman algorithm for data compression.
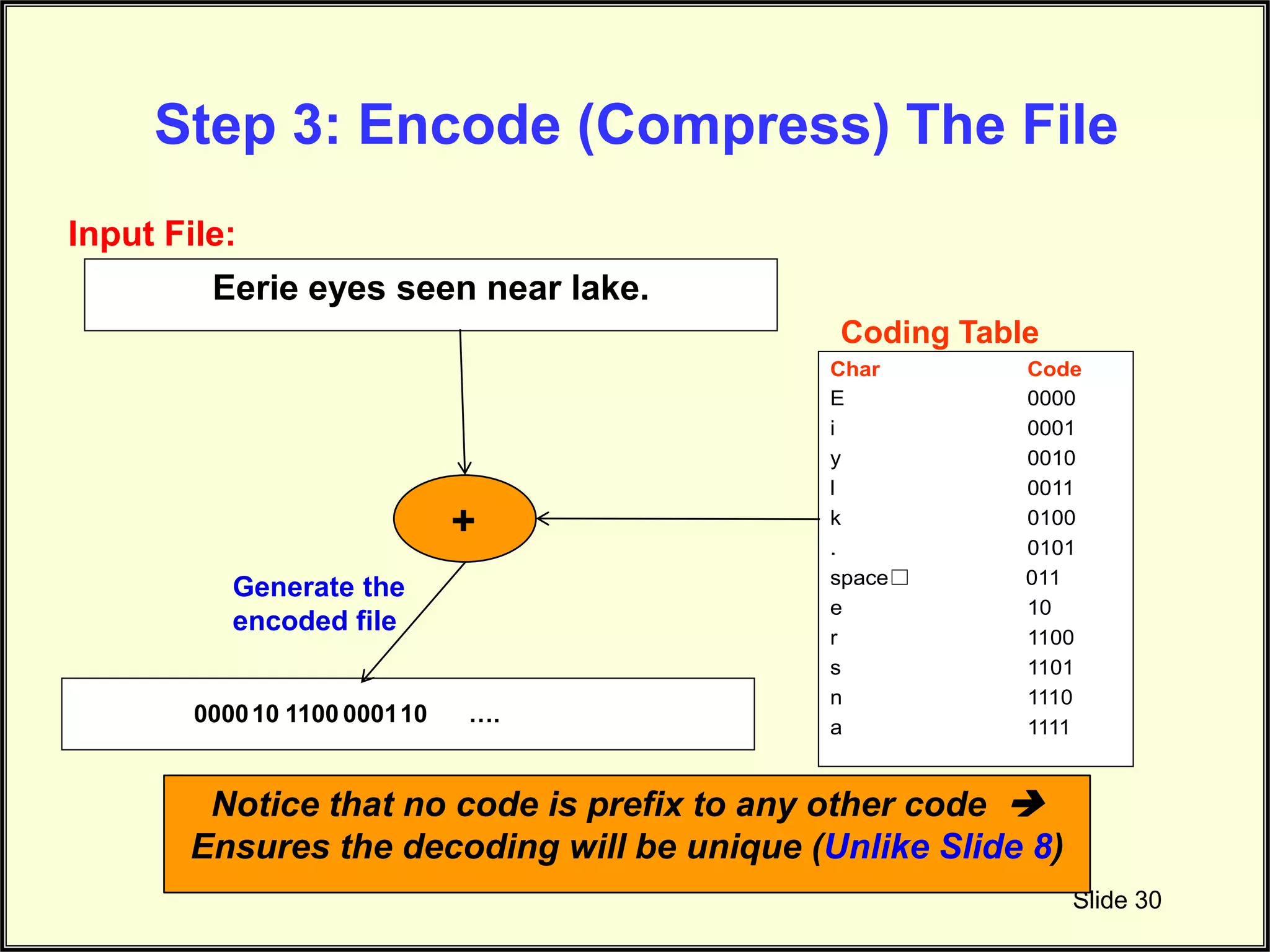
Illustrates how to generate an encoded file through the Huffman coding process.
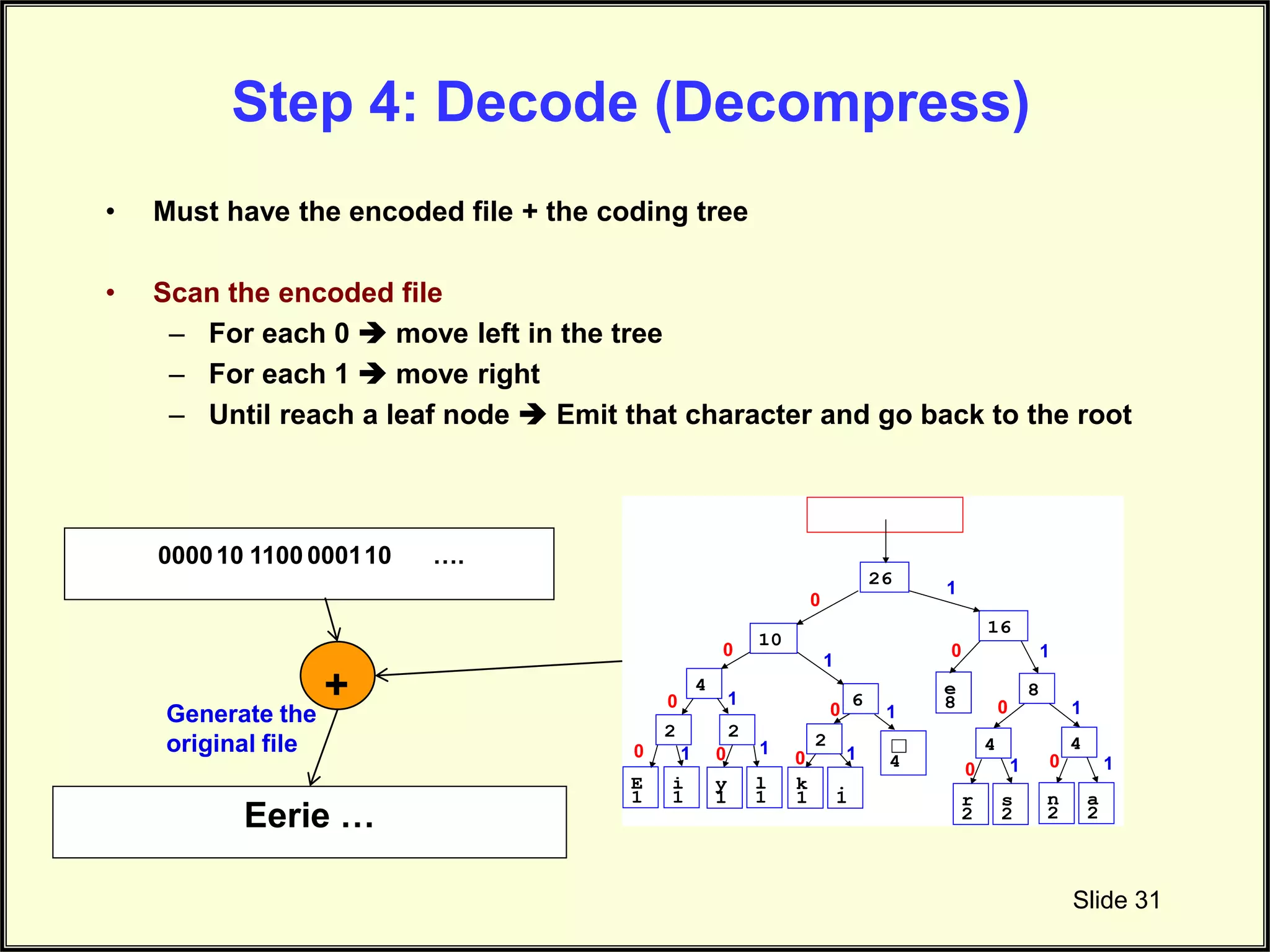
Details steps needed to decode the encoded file back to its original form.
Recaps Huffman algorithm steps: frequency analysis, tree building, encoding, and decoding.