Downloaded 33 times


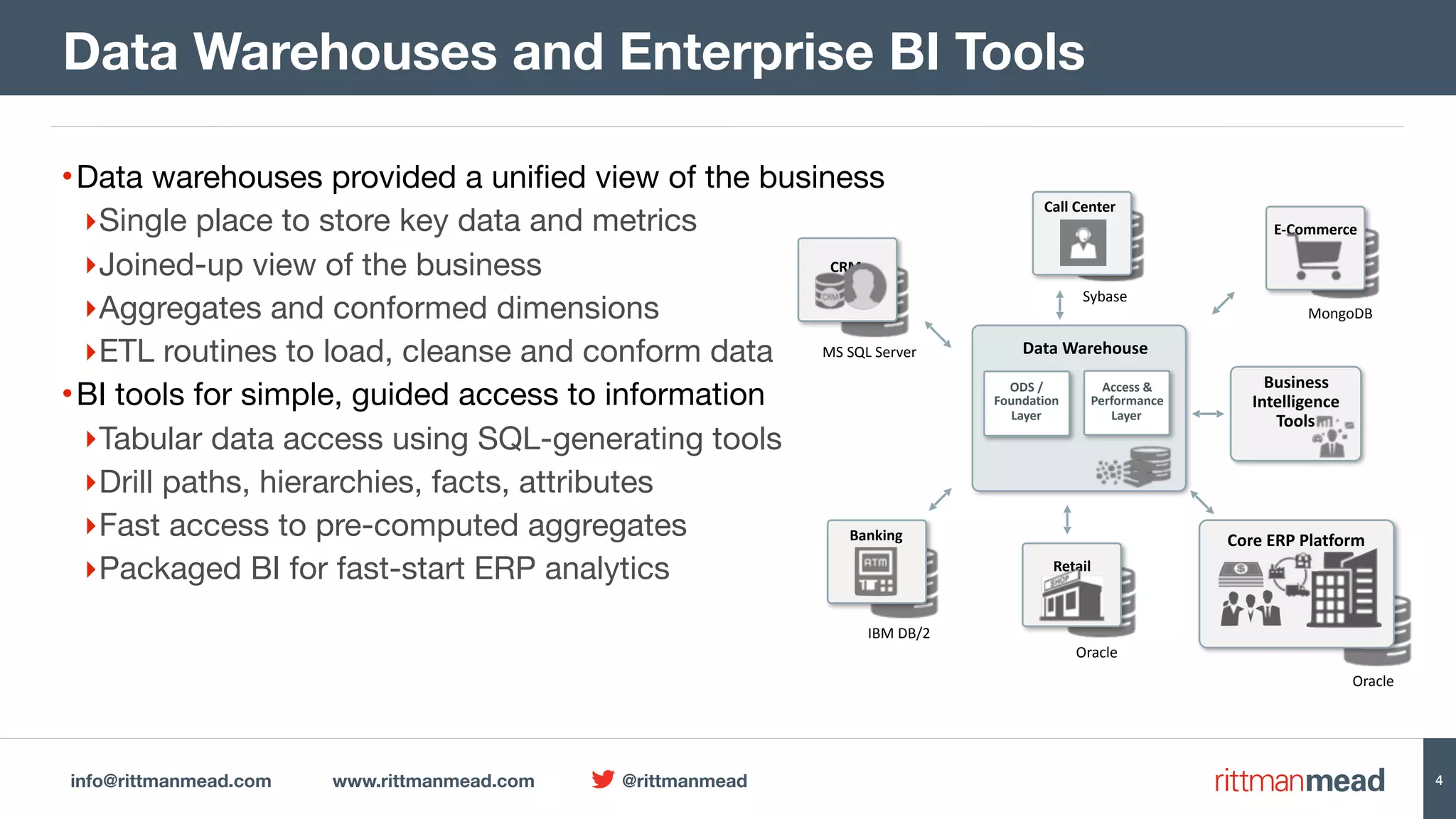


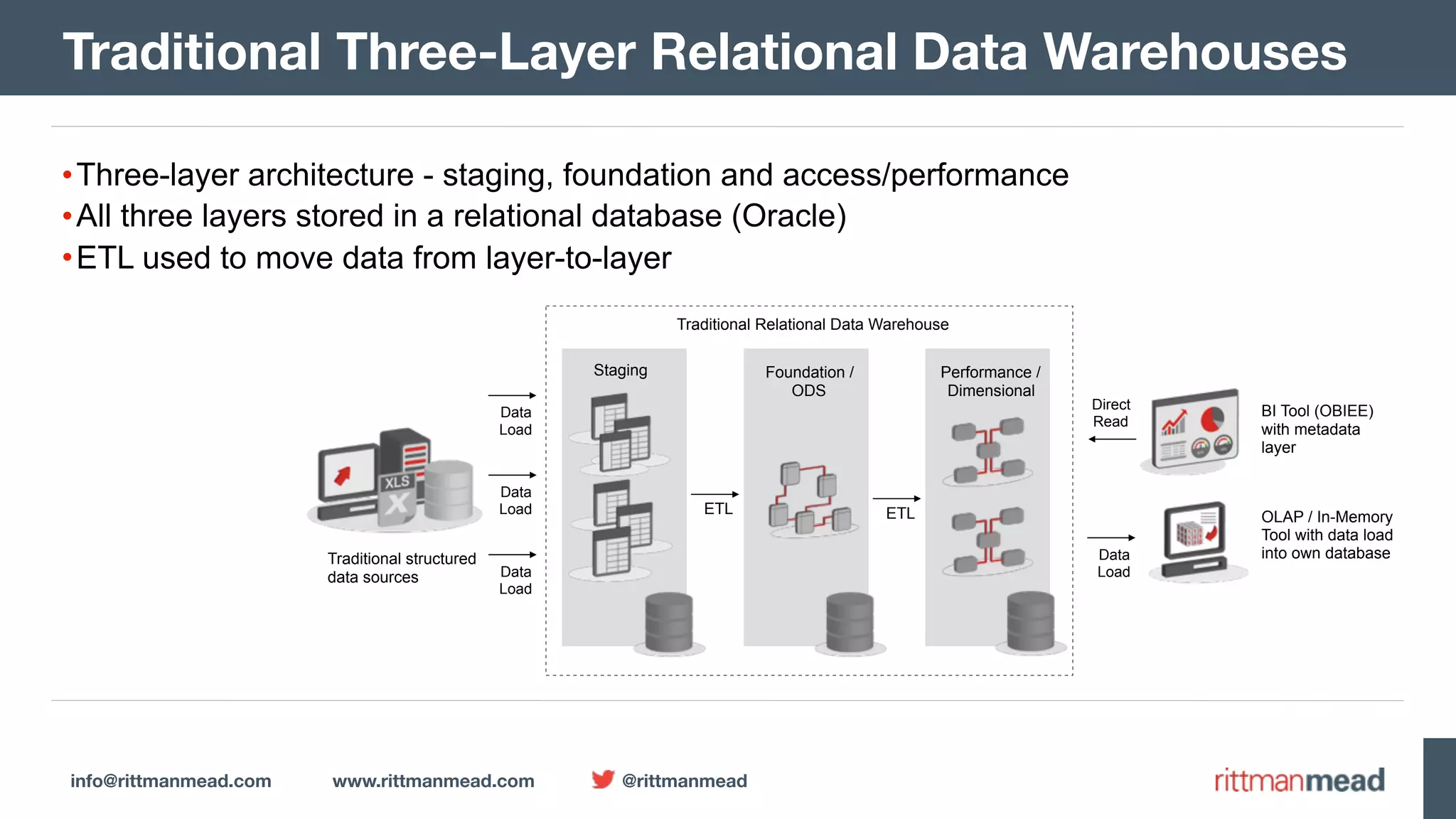


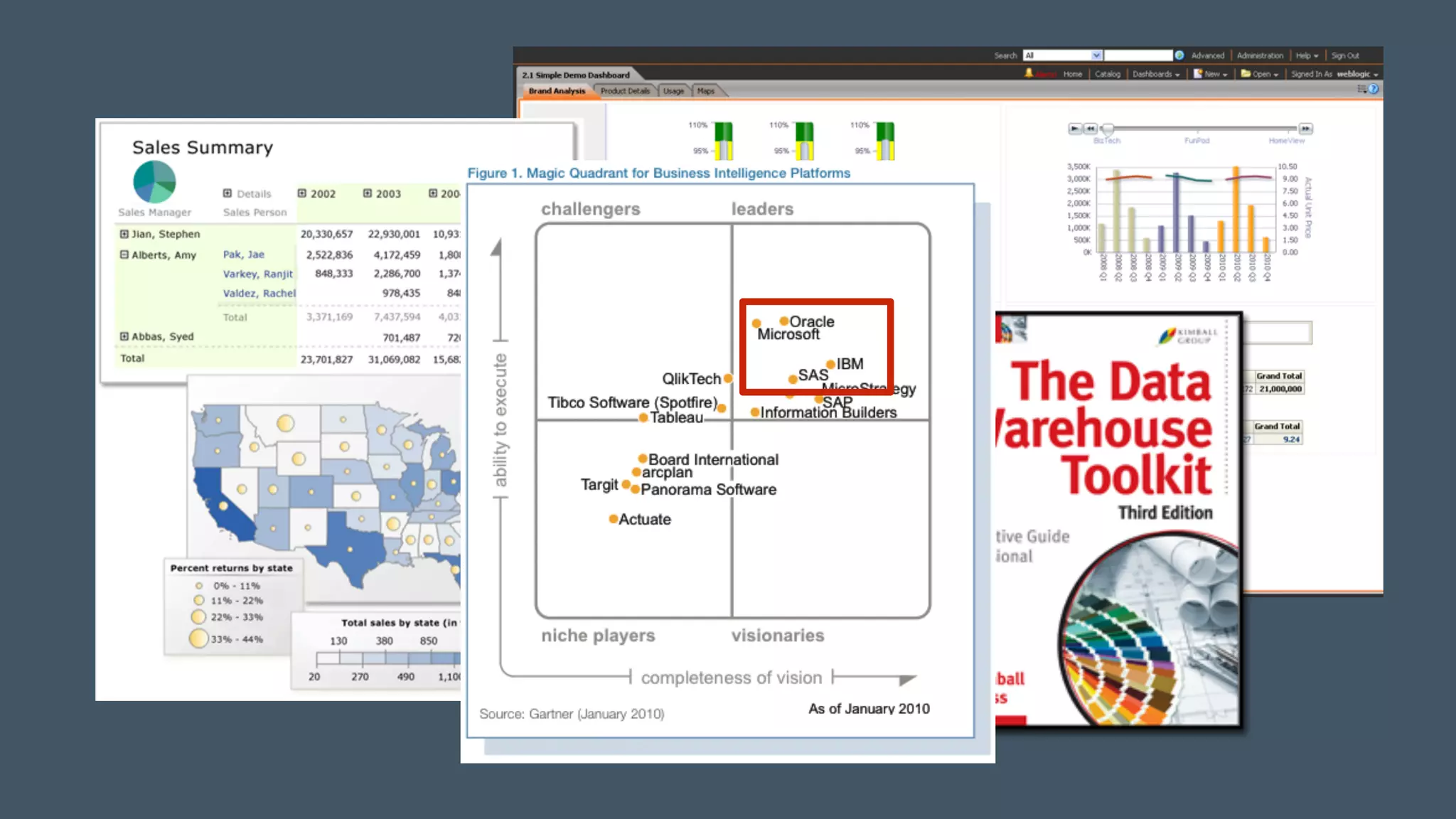











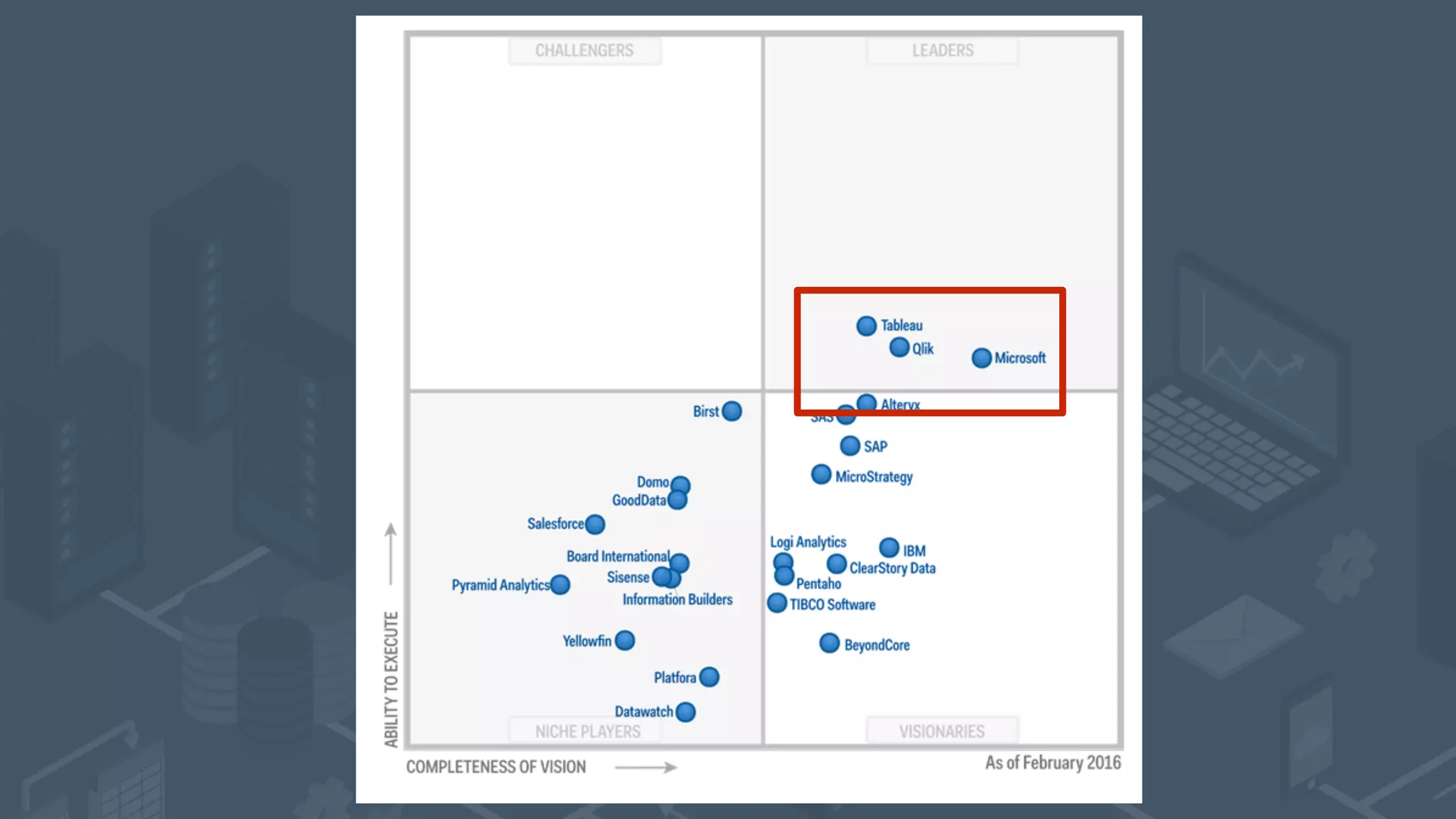

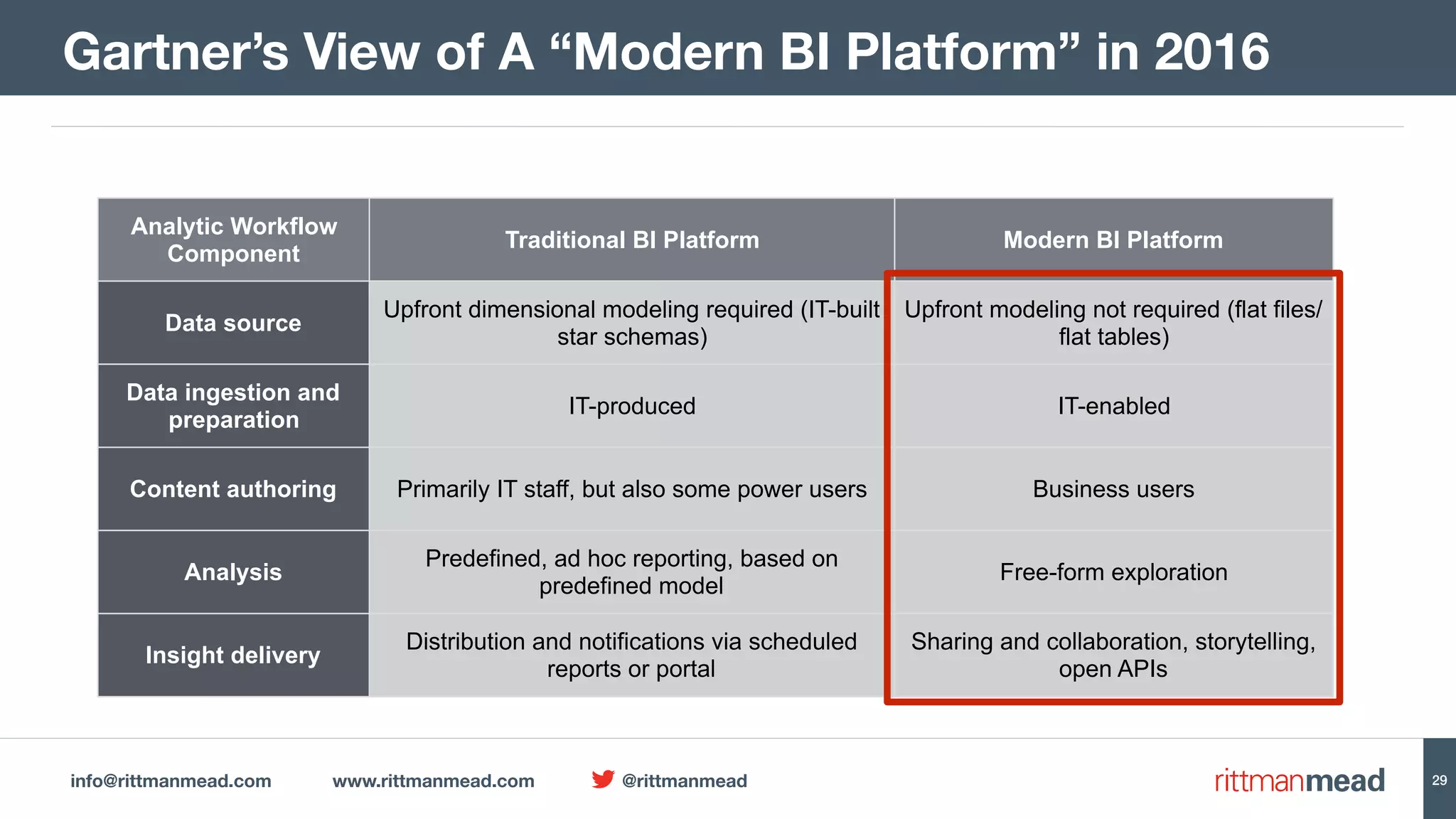


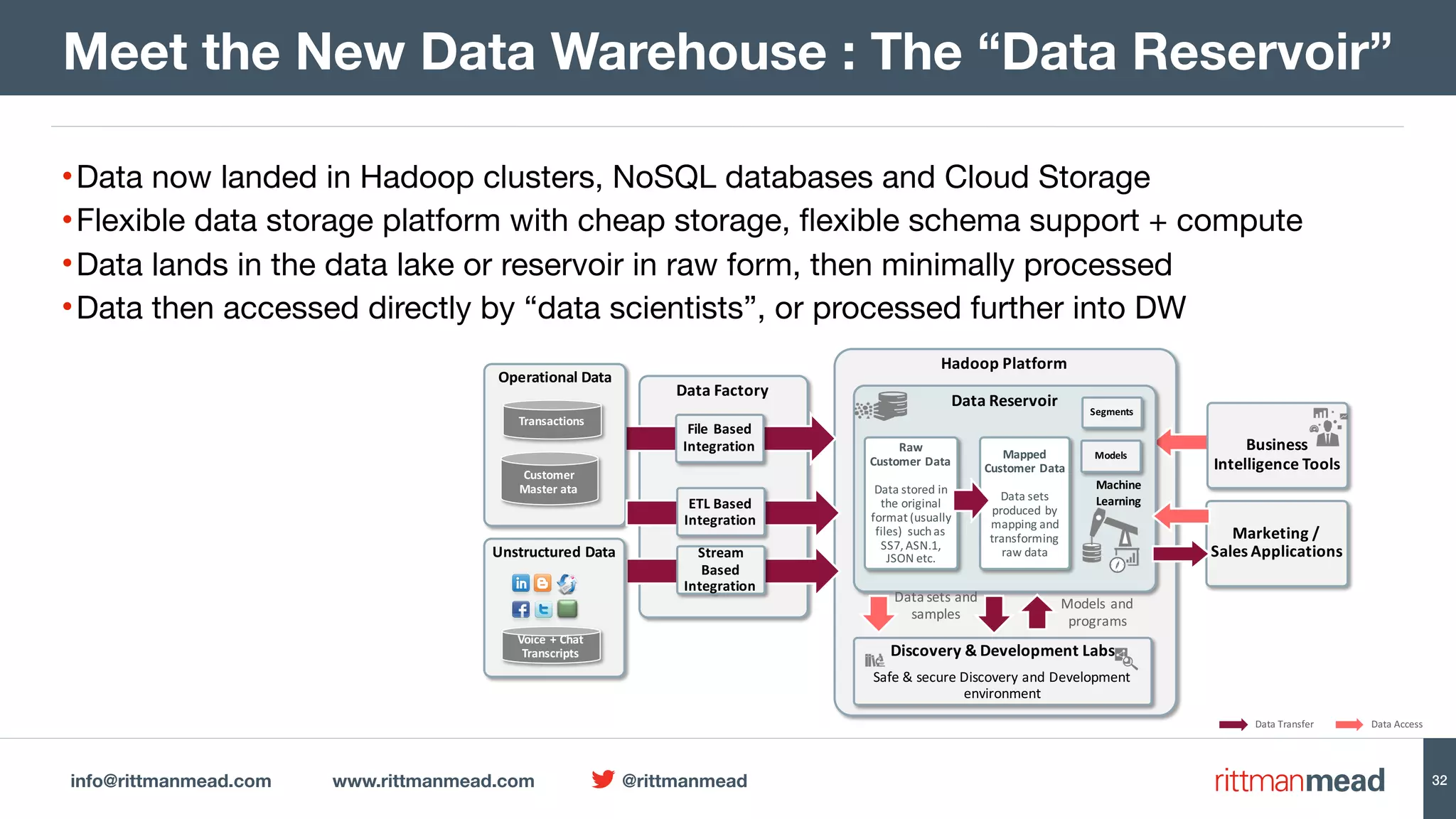

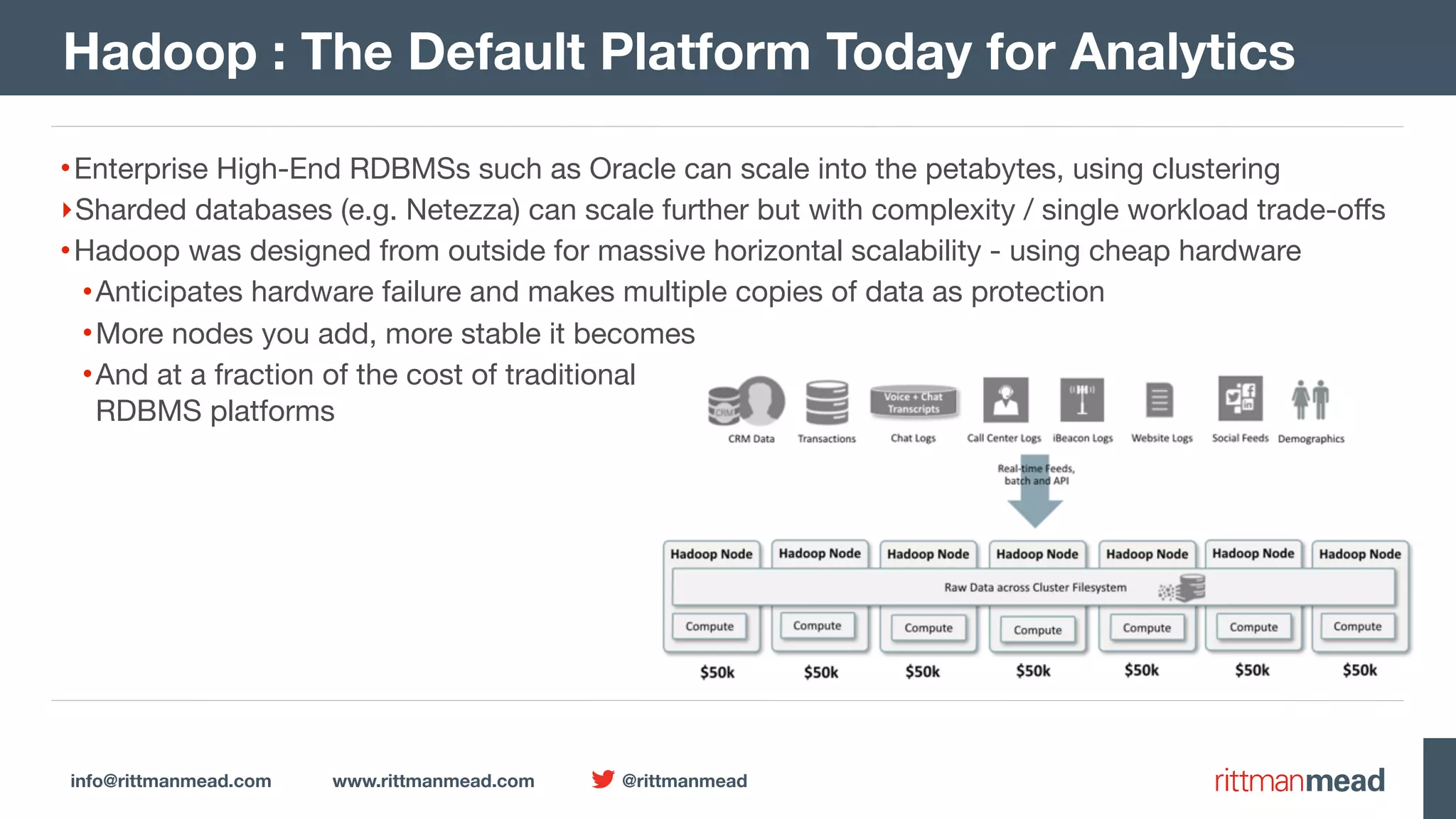
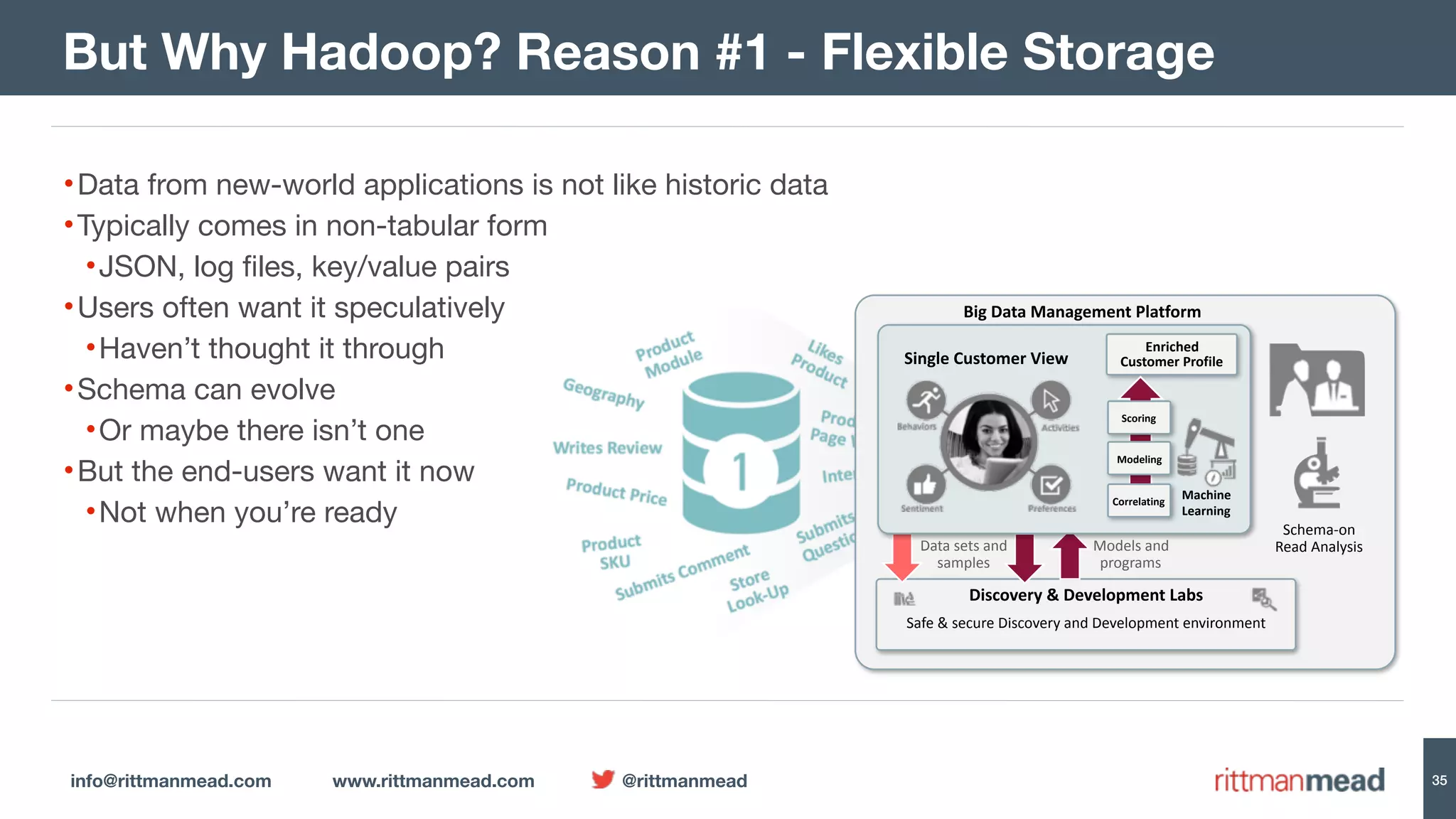

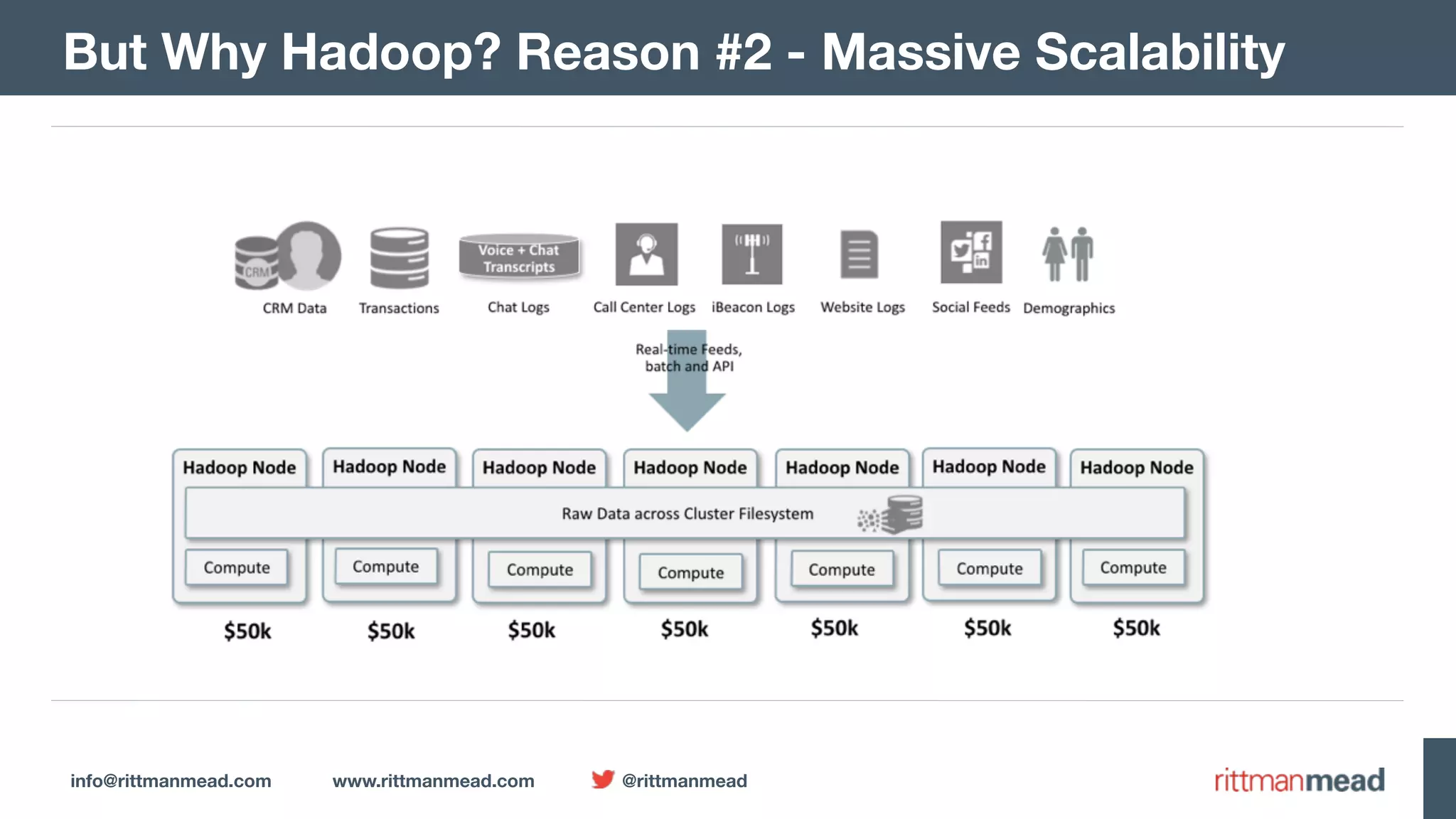


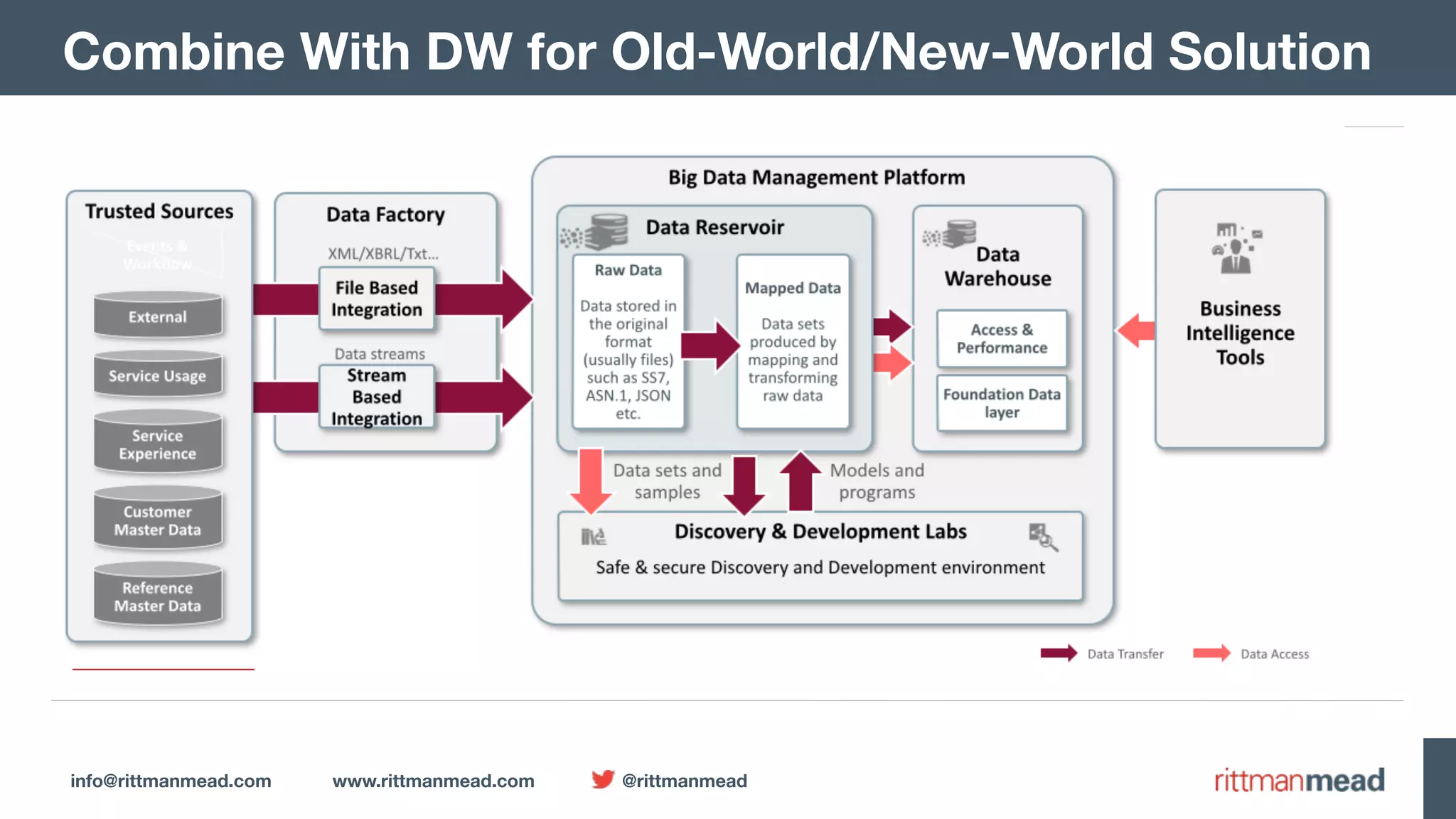
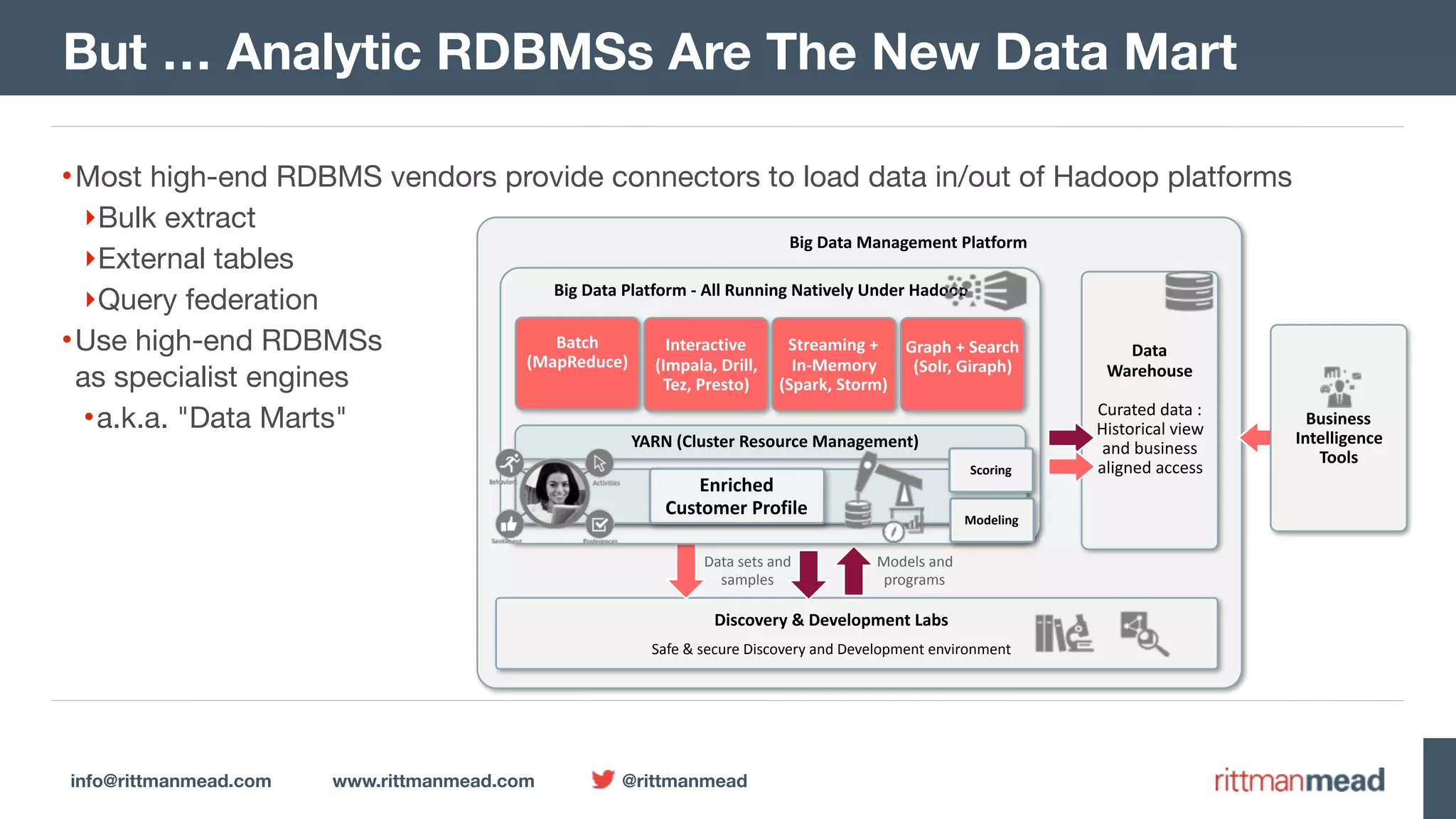













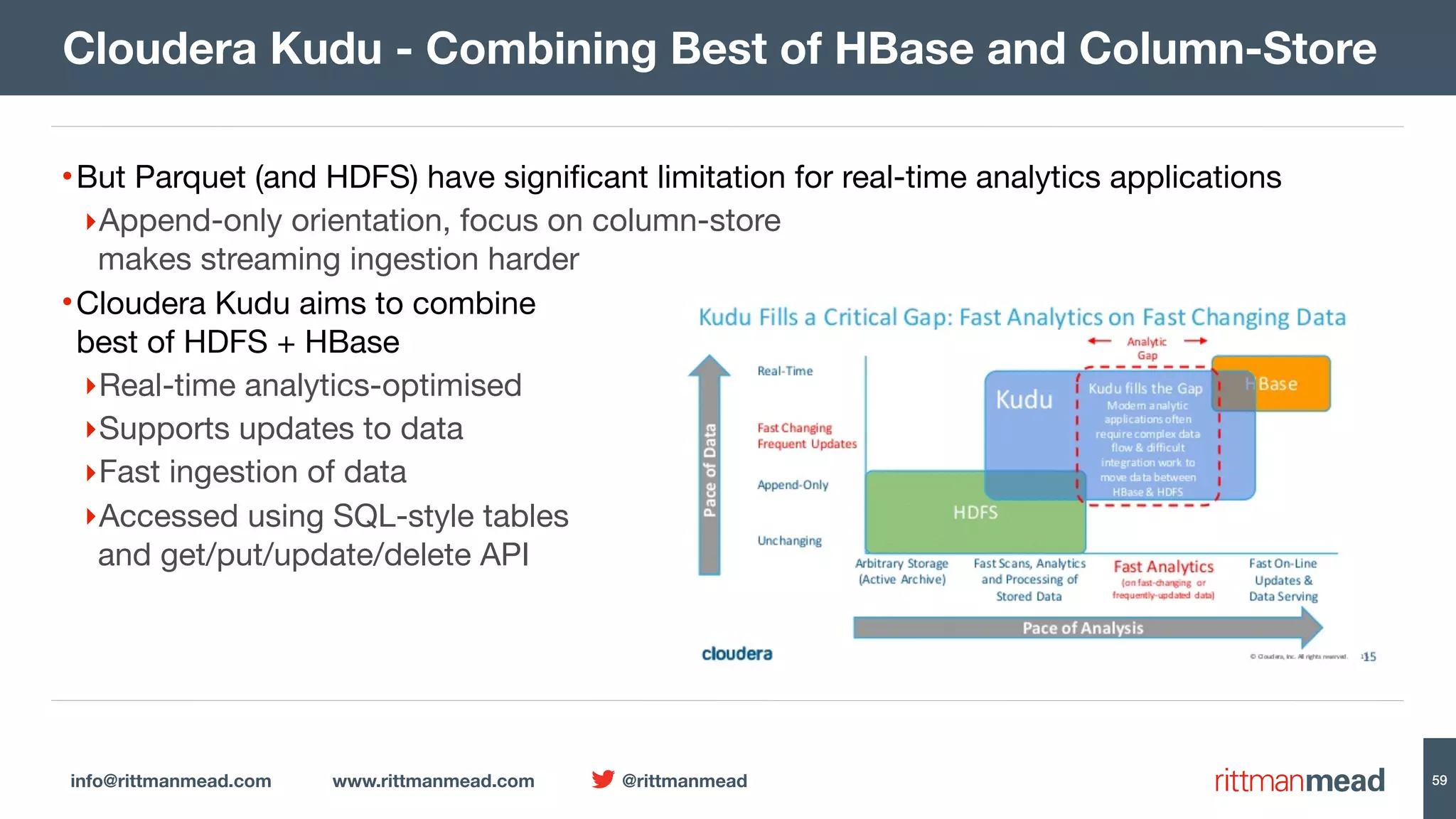





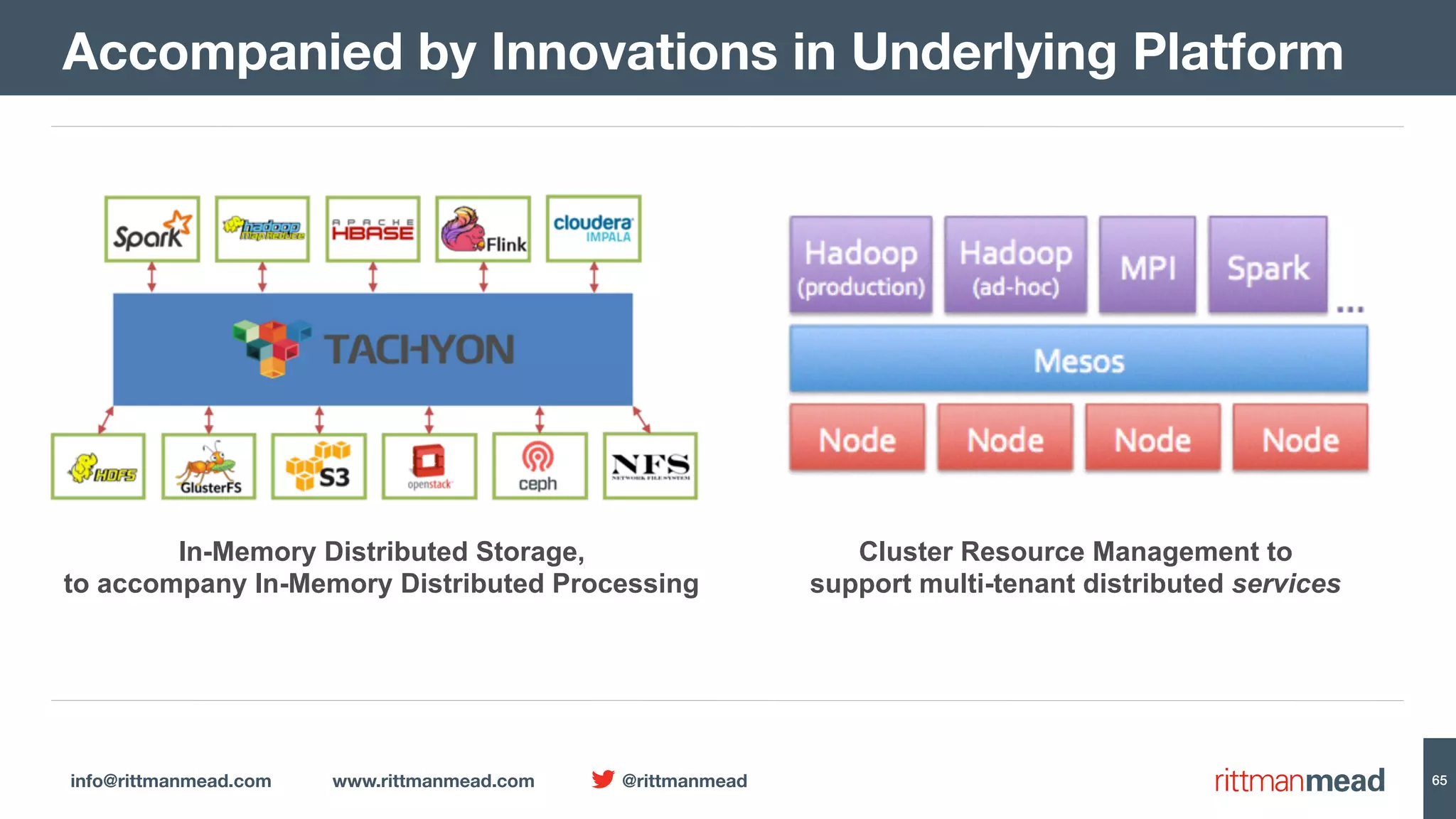


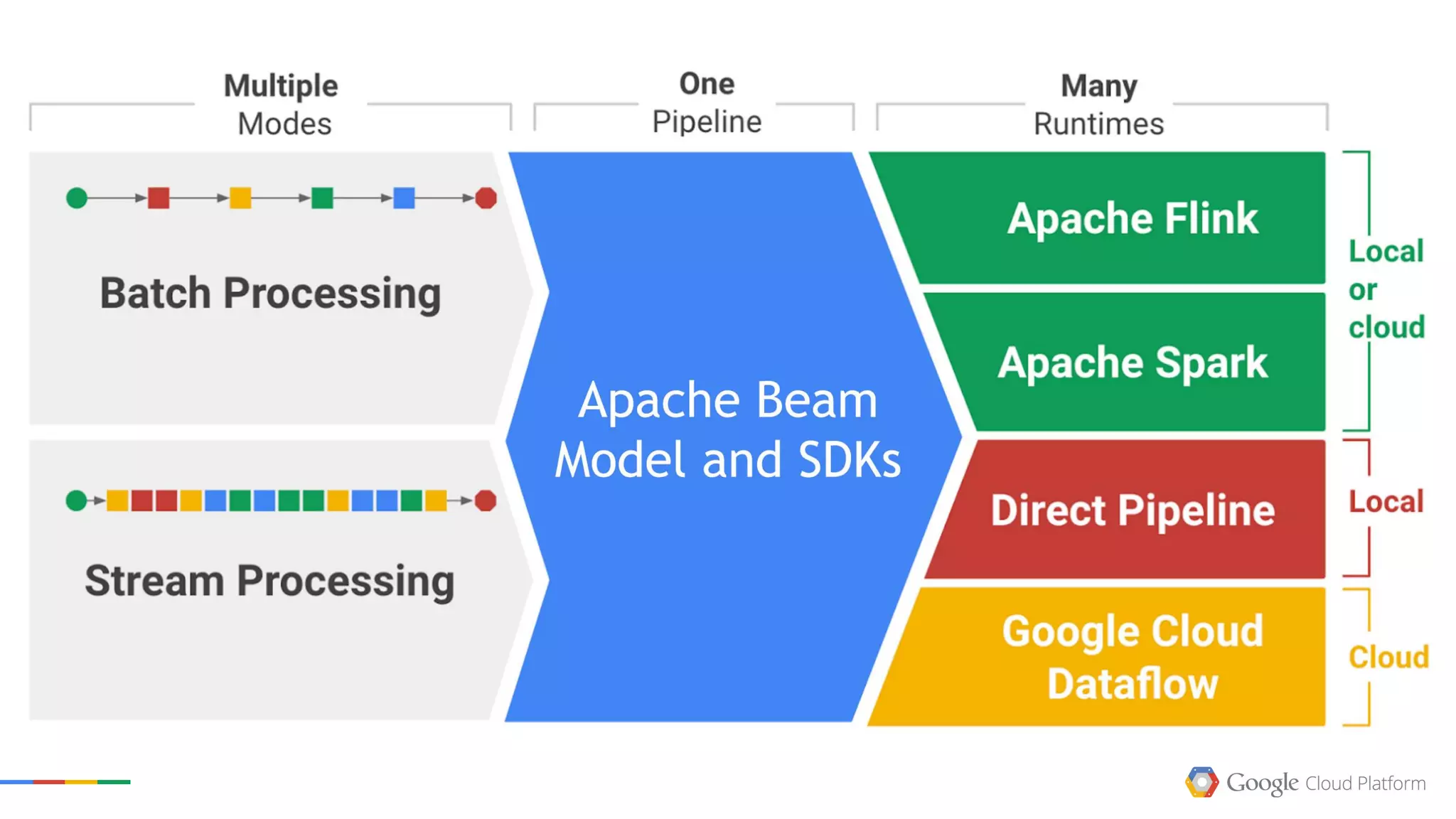

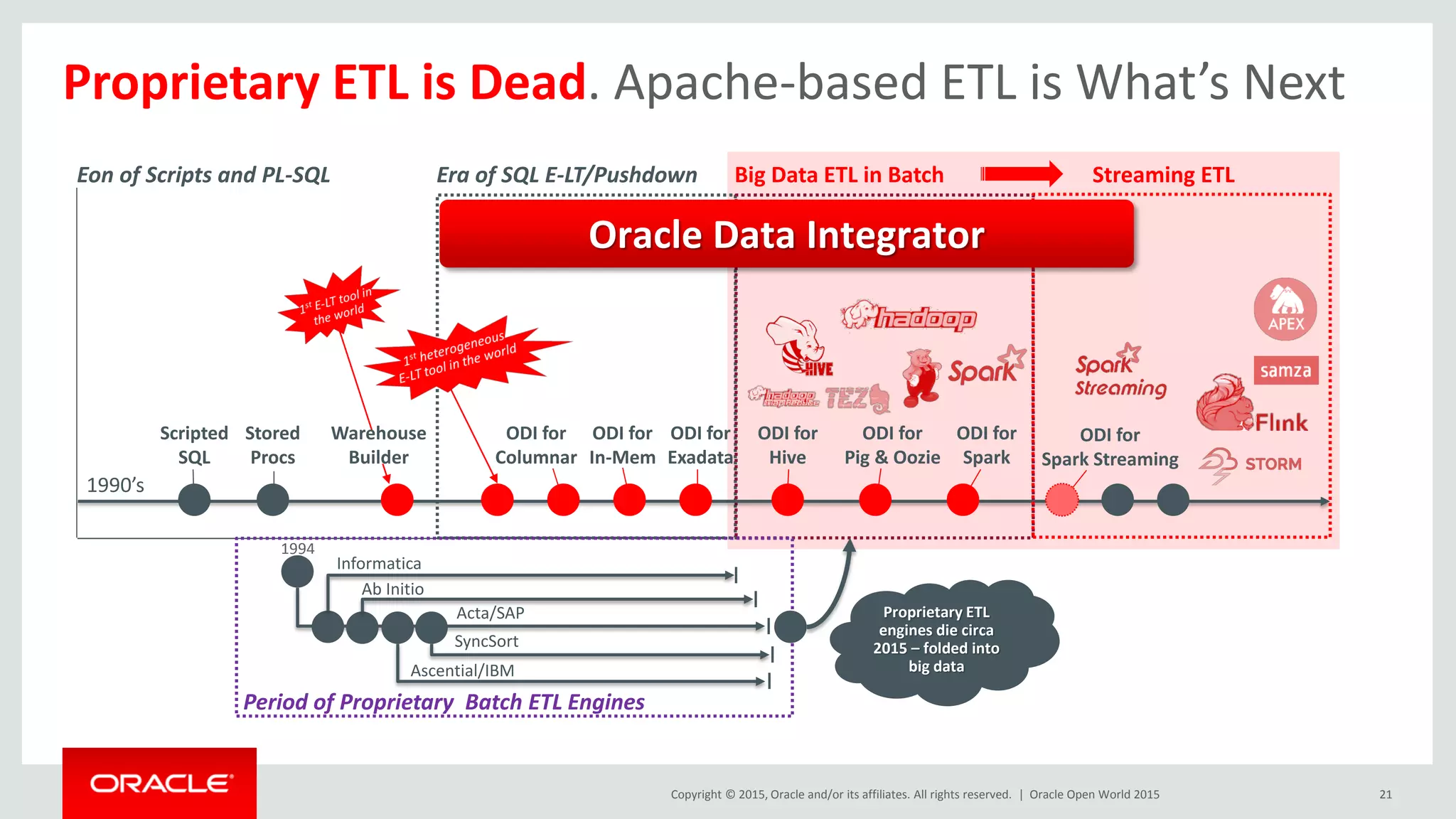

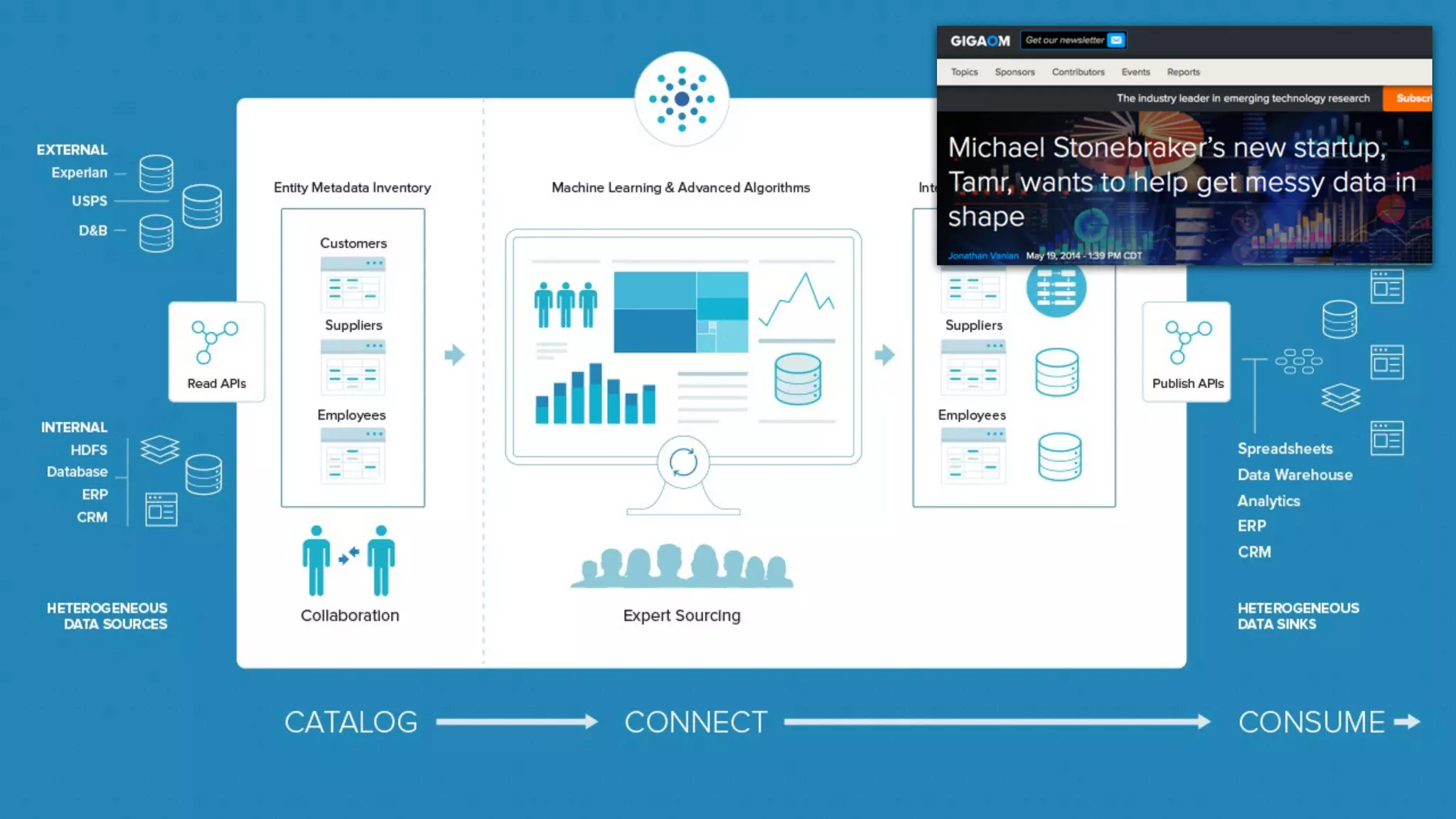
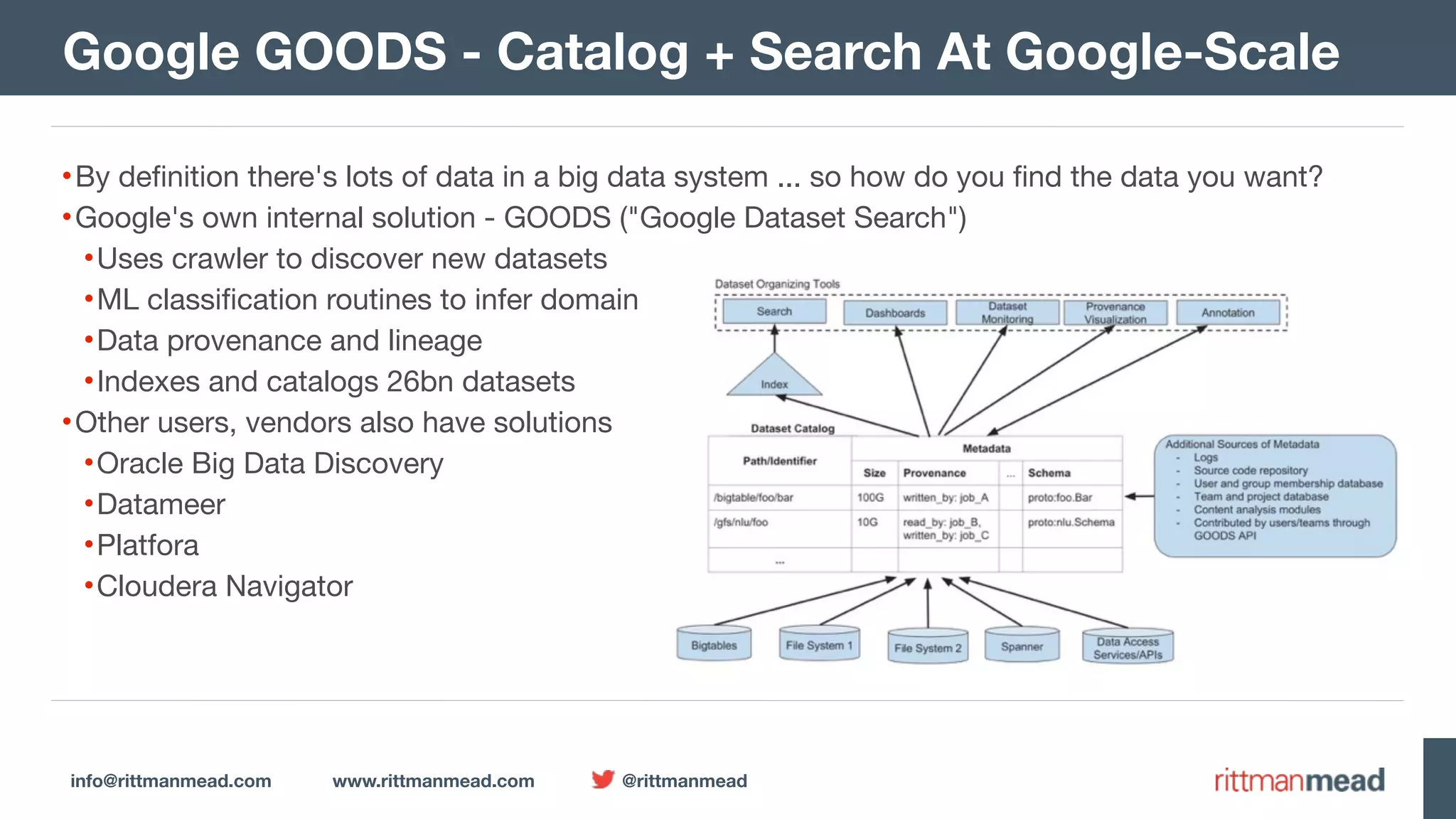


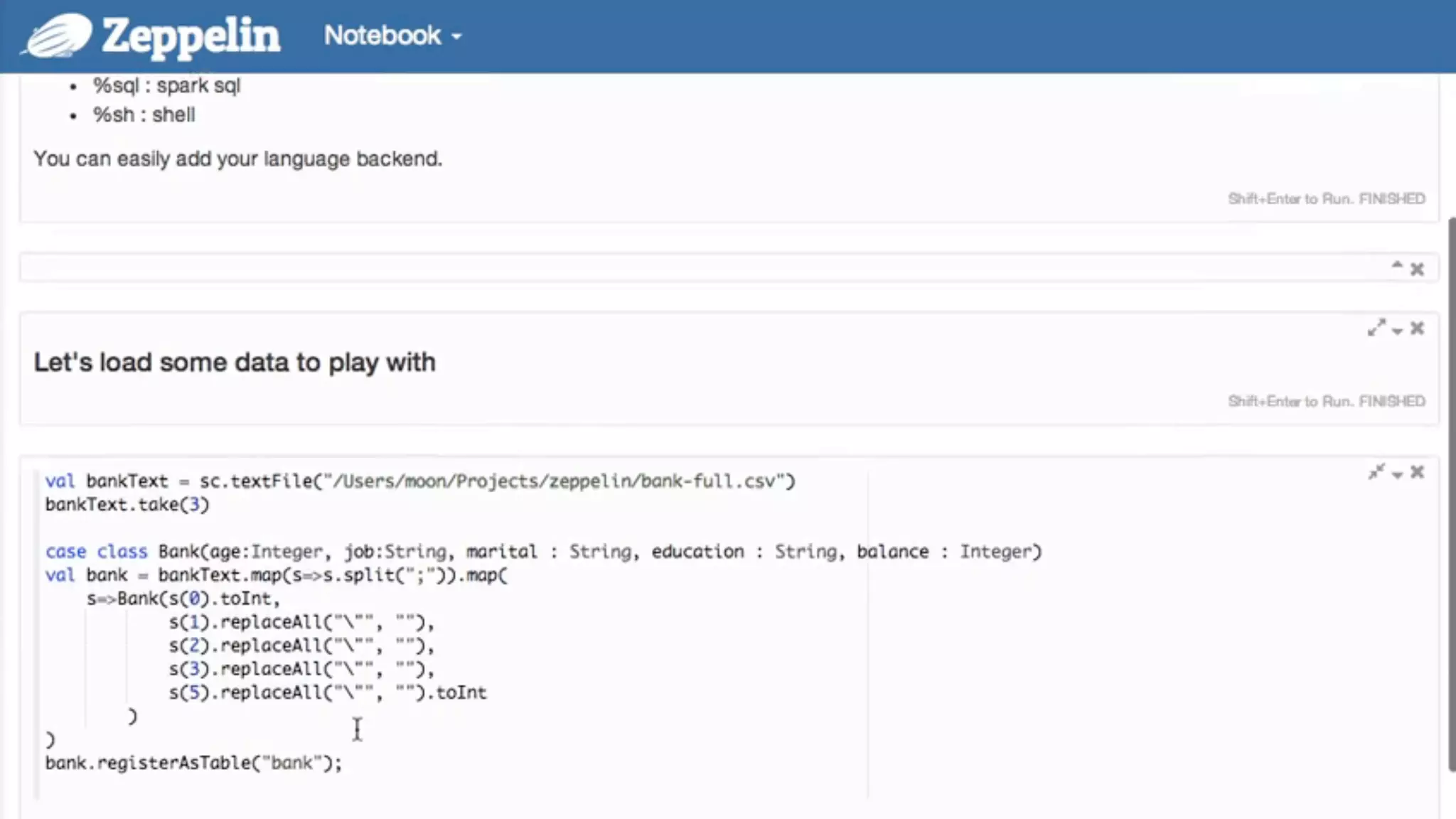


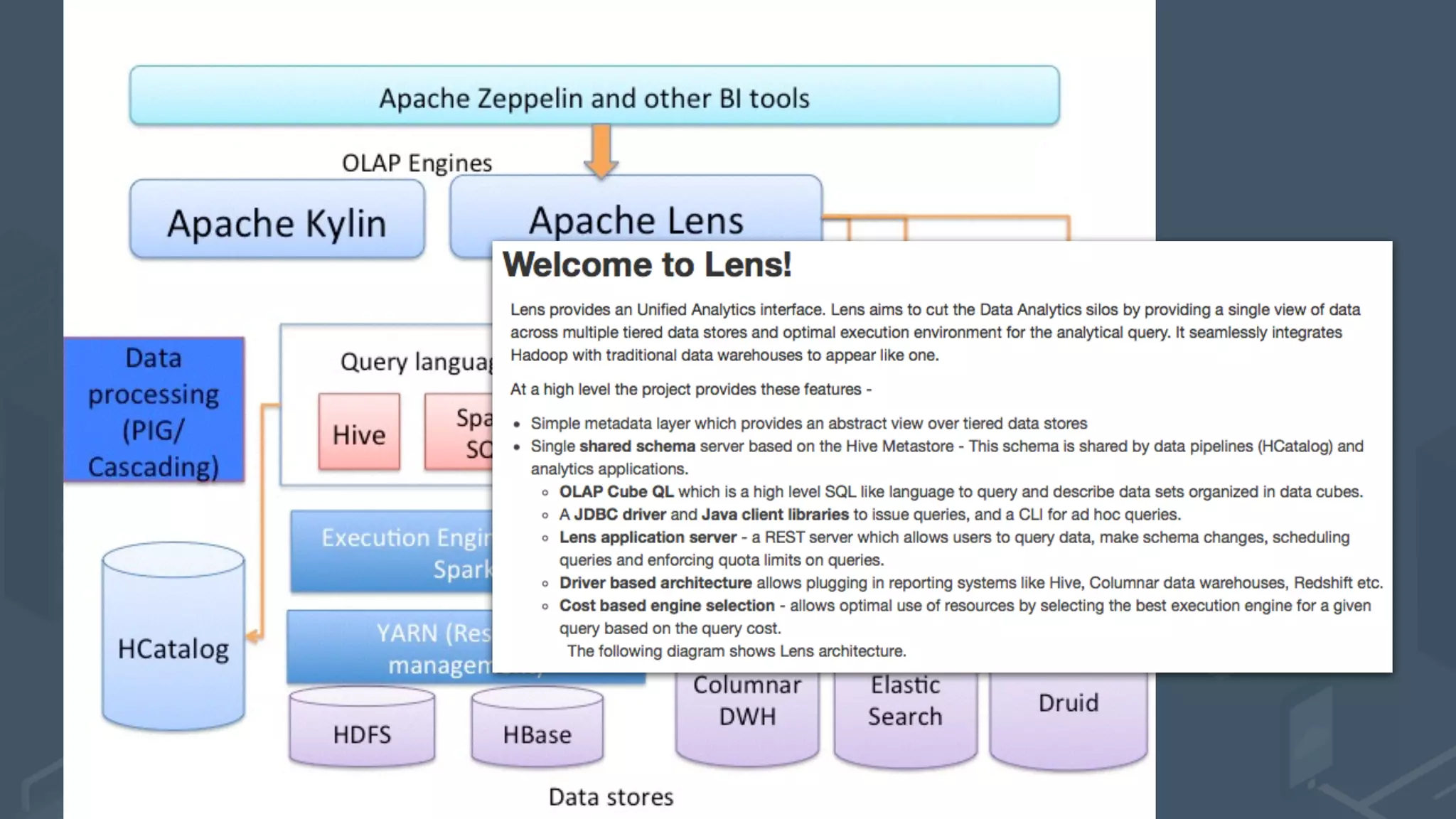
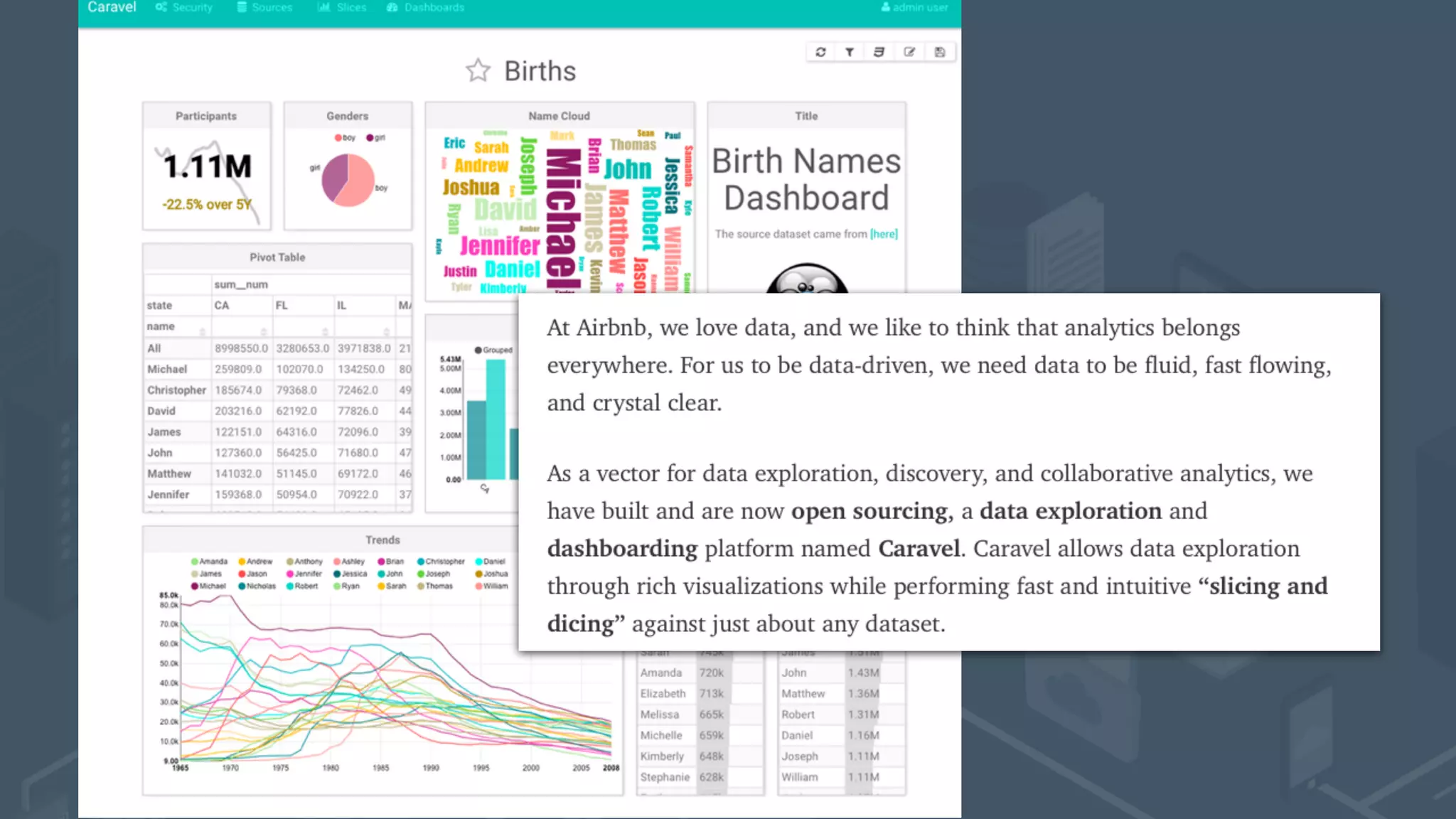






The document presents a talk by Mark Rittman, an expert in Oracle business intelligence and data warehousing, discussing the evolution of BI tools from traditional reporting to modern self-service analytics powered by Hadoop. It outlines the significant changes in BI architecture, including the transition to cloud and NoSQL databases, while emphasizing the importance of flexible and scalable data processing frameworks. Rittman also highlights the emergence of new analytics platforms that integrate advanced techniques like machine learning and real-time data access.