How well wedid it? by Federico Lochbaum IWST 2025 Passed! 5 / 33
6.
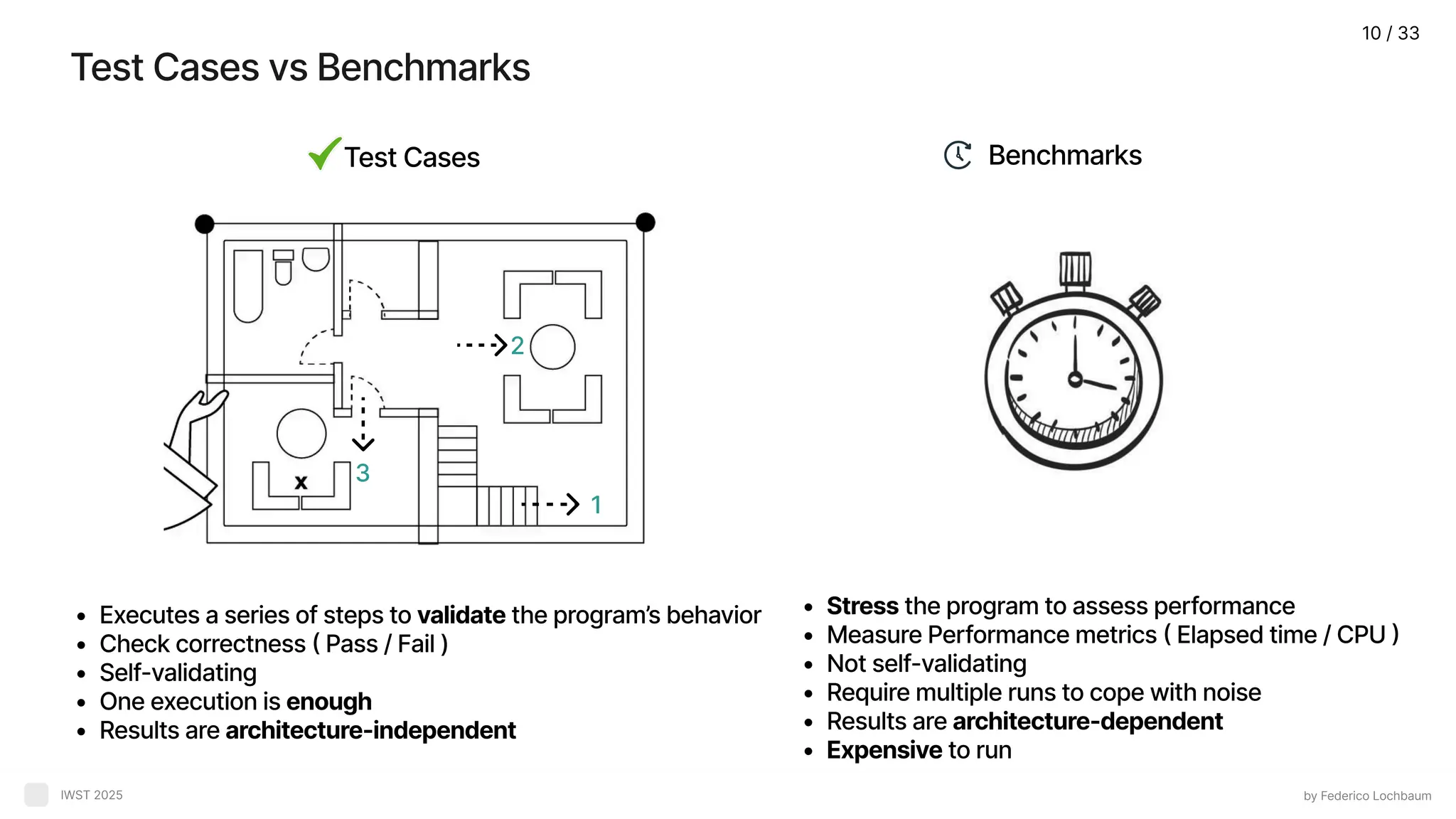
Benchmarks by Federico Lochbaum IWST2025 Measure execution time ( wall-clock time Often made by averaging benchmarking results, looking to reduce contextual varianc Some work proposes using other kinds of metrics, like energy consumption or memory usage 6 / 33
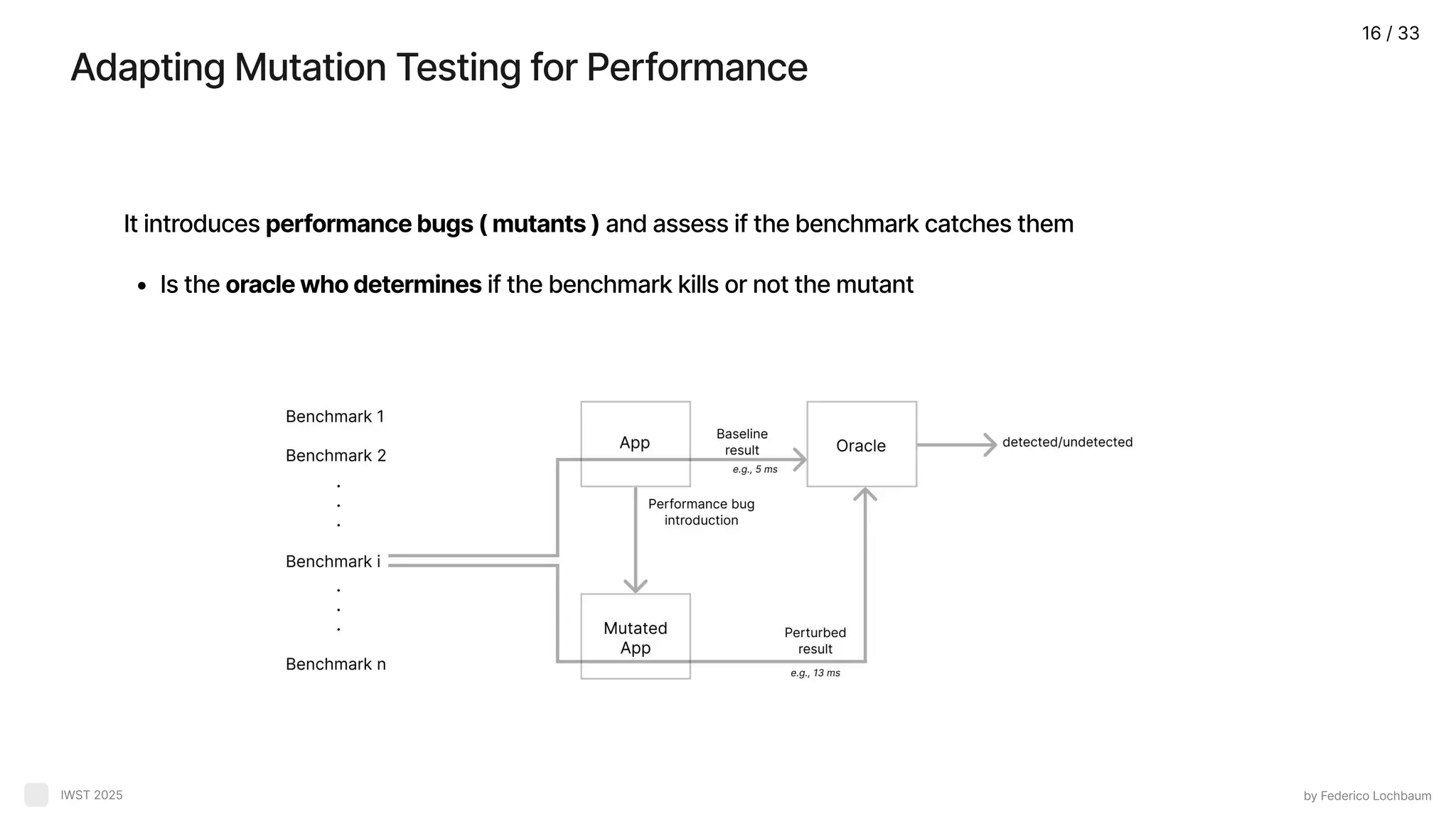
Problem: Assessing BenchmarkQuality by Federico Lochbaum IWST 2025 A lack of systematic methodologies to assess benchmark effectiveness What does it mean benchmark quality How to measure benchmark effectiveness detecting performance bugs How are introduced performance issues in a target program to detect them ? 13 / 33
14.
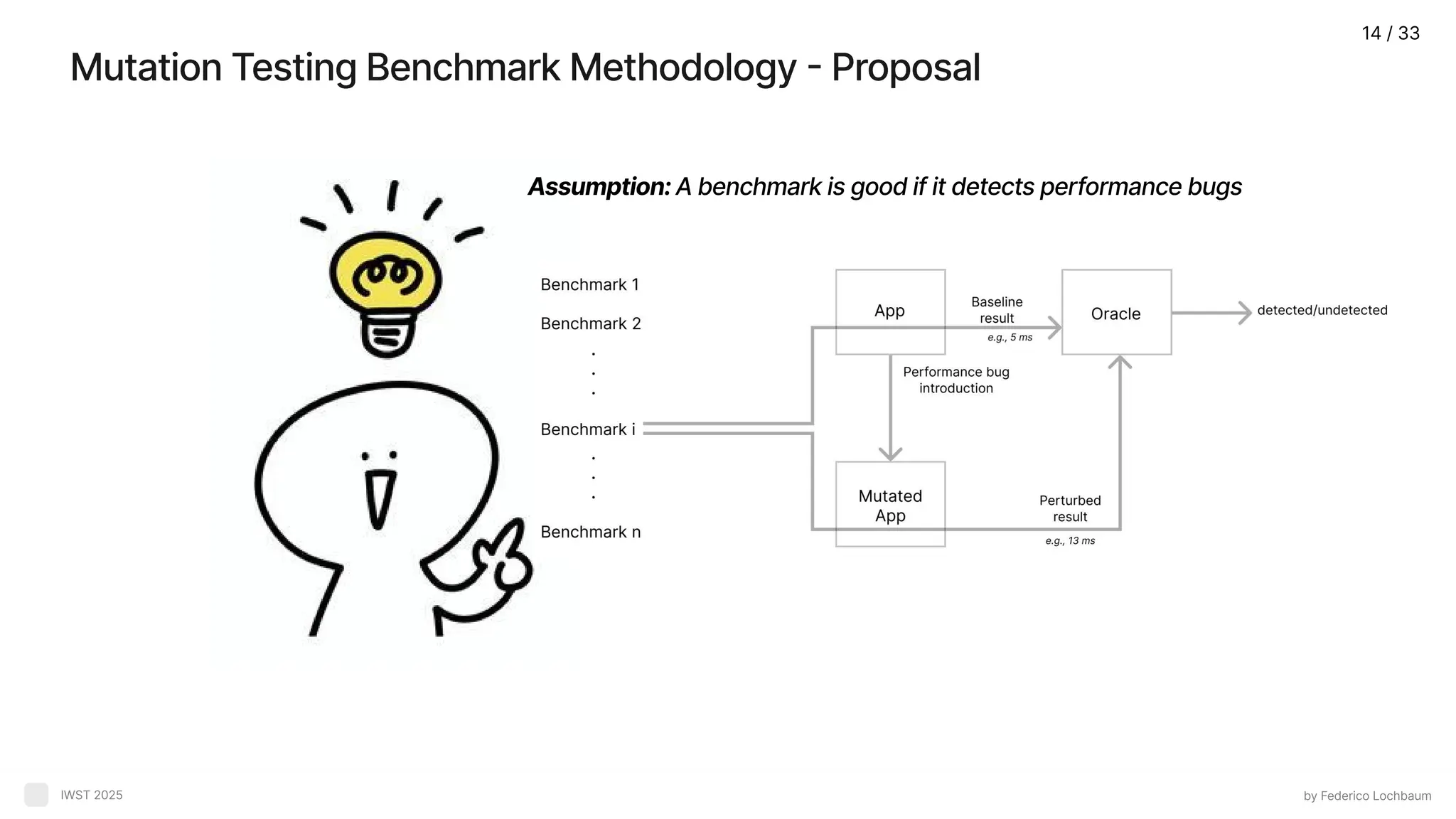
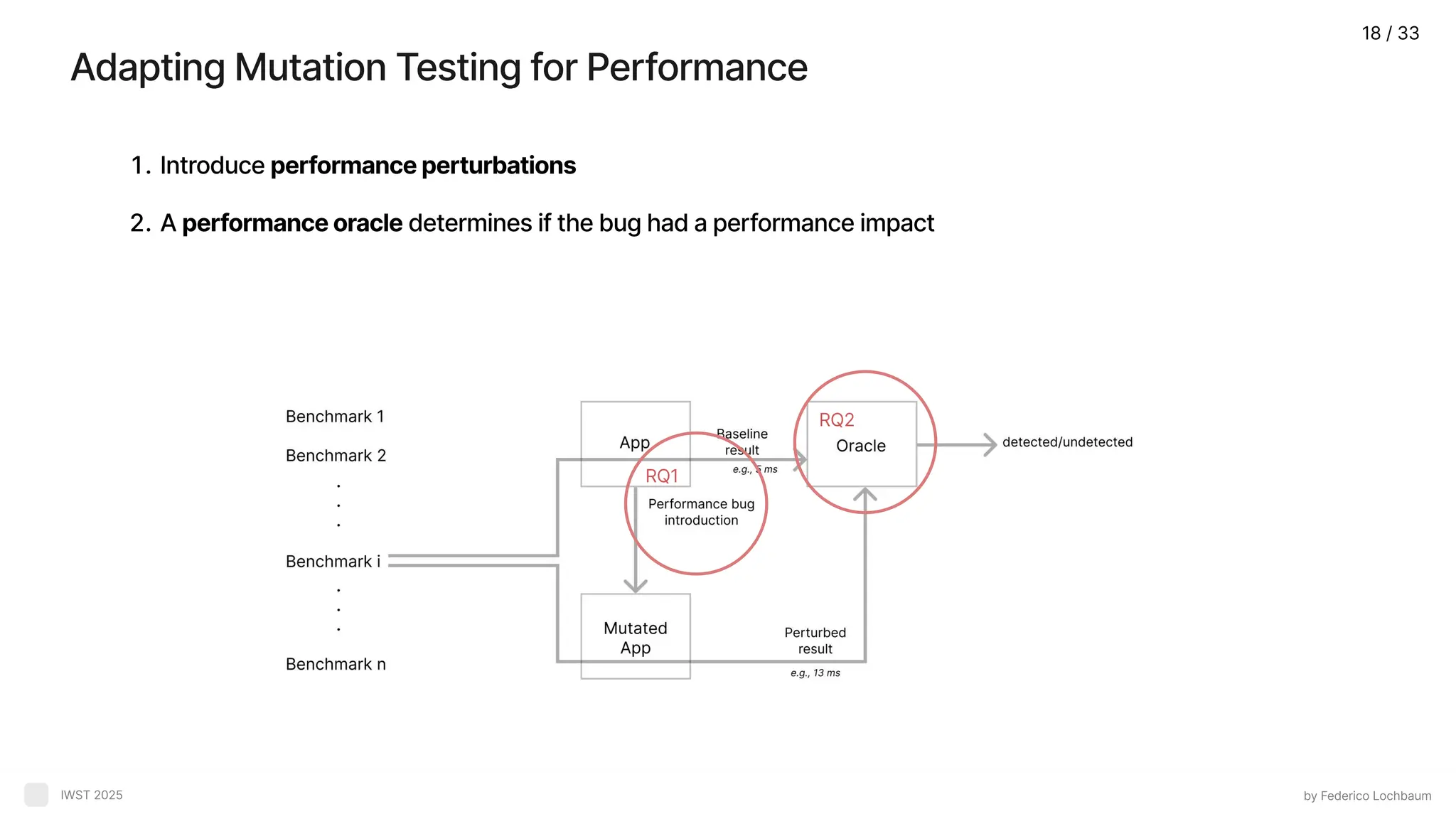
Mutation Testing BenchmarkMethodology - Proposal by Federico Lochbaum IWST 2025 Assumption:A benchmark is good if it detects performance bugs 14 / 33
15.
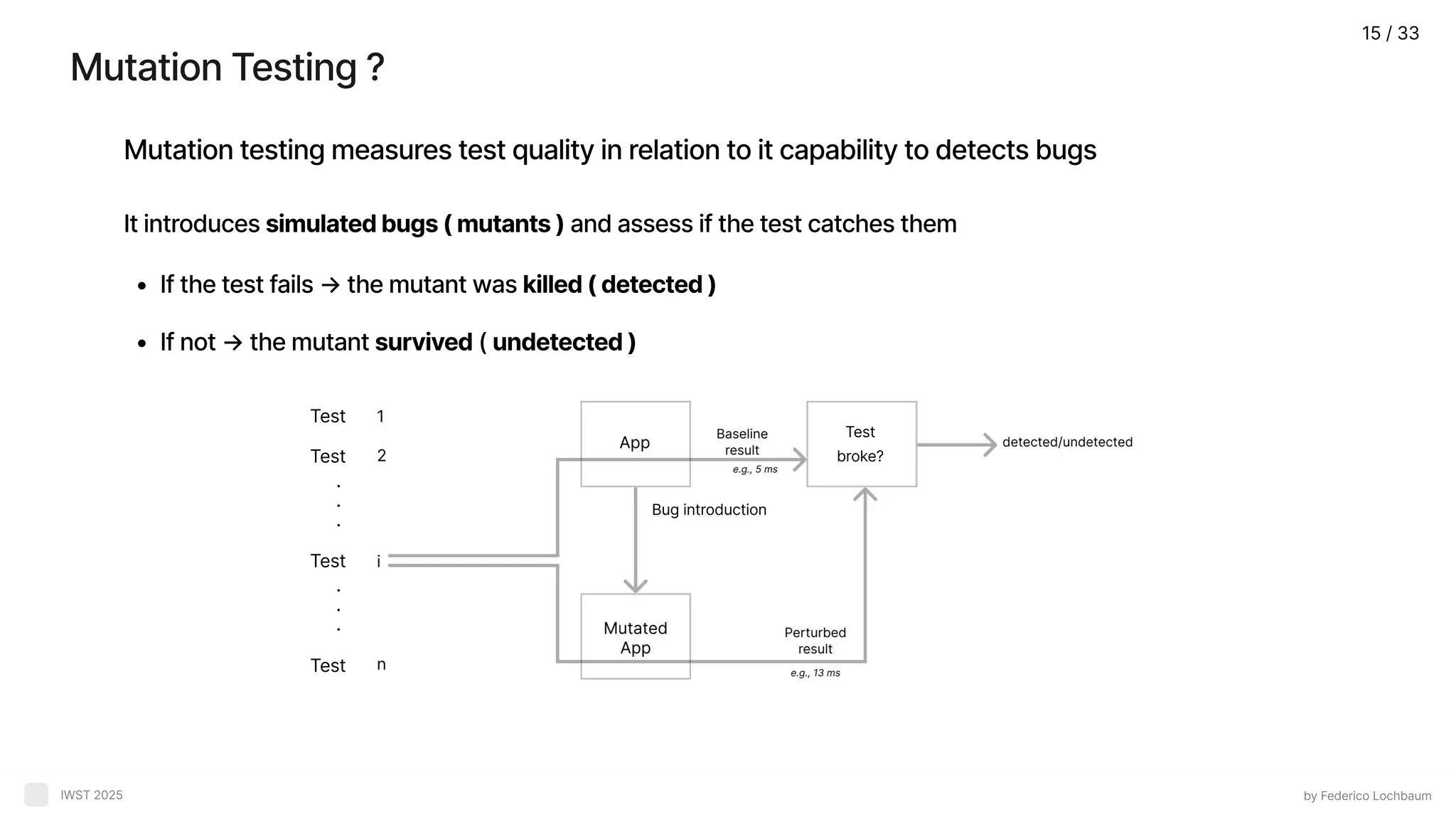
Mutation Testing ? byFederico Lochbaum IWST 2025 Mutation testing measures test quality in relation to it capability to detects bugs It introduces simulatedbugs(mutants) and assess if the test catches the If the test fails → the mutant was killed(detected If not → the mutant survived ( undetected) Test Test Test Bug introduction Test broke? Test 15 / 33
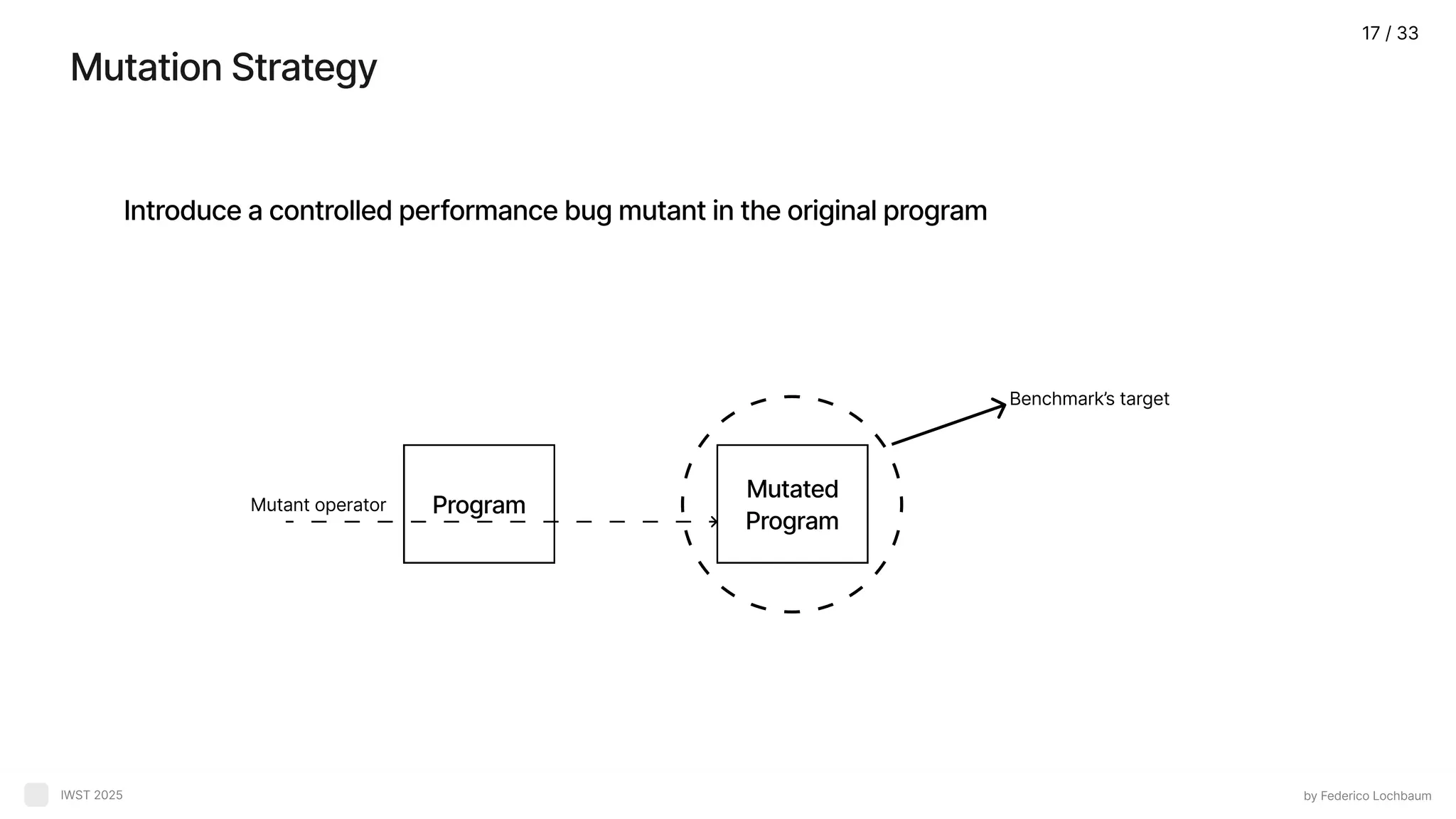
Mutation Strategy by FedericoLochbaum IWST 2025 Introduce a controlled performance bug mutant in the original program Program Mutated Program Mutant operator Benchmark’s target 17 / 33
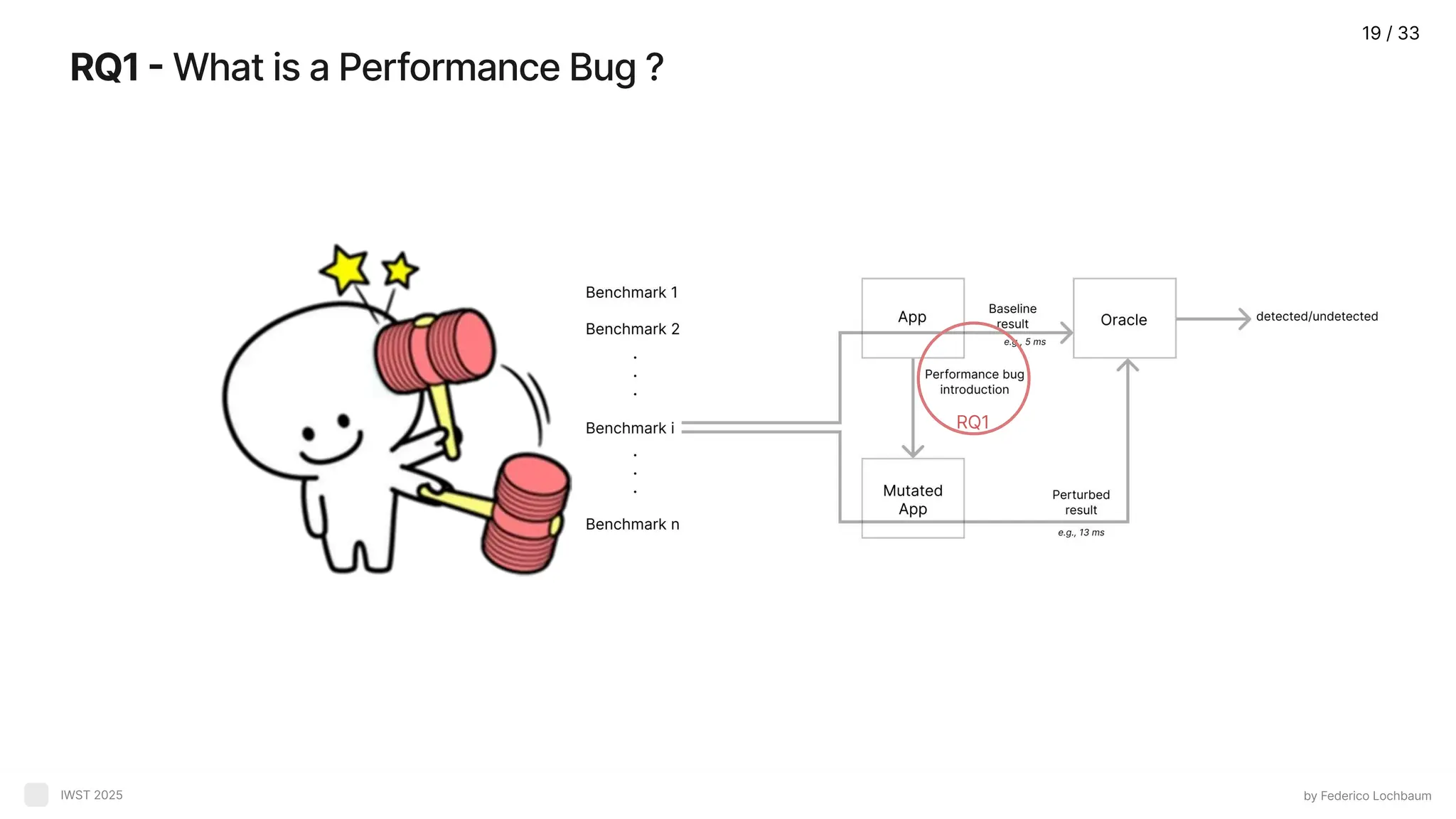
RQ1 - Whatis a Performance Bug ? by Federico Lochbaum IWST 2025 RQ1 19 / 33
20.
RQ1- Performance Bug byFederico Lochbaum IWST 2025 Perturbation on program execution ( E.g.Latency, Locality issues Excessive consumption of time or space by design ( E.g.Long iterations, Bad implementation decisions Nooptimal data structure used for a problem ( E.g. Use an array instead of a dictionary to index a dataset ) 20 / 33
21.
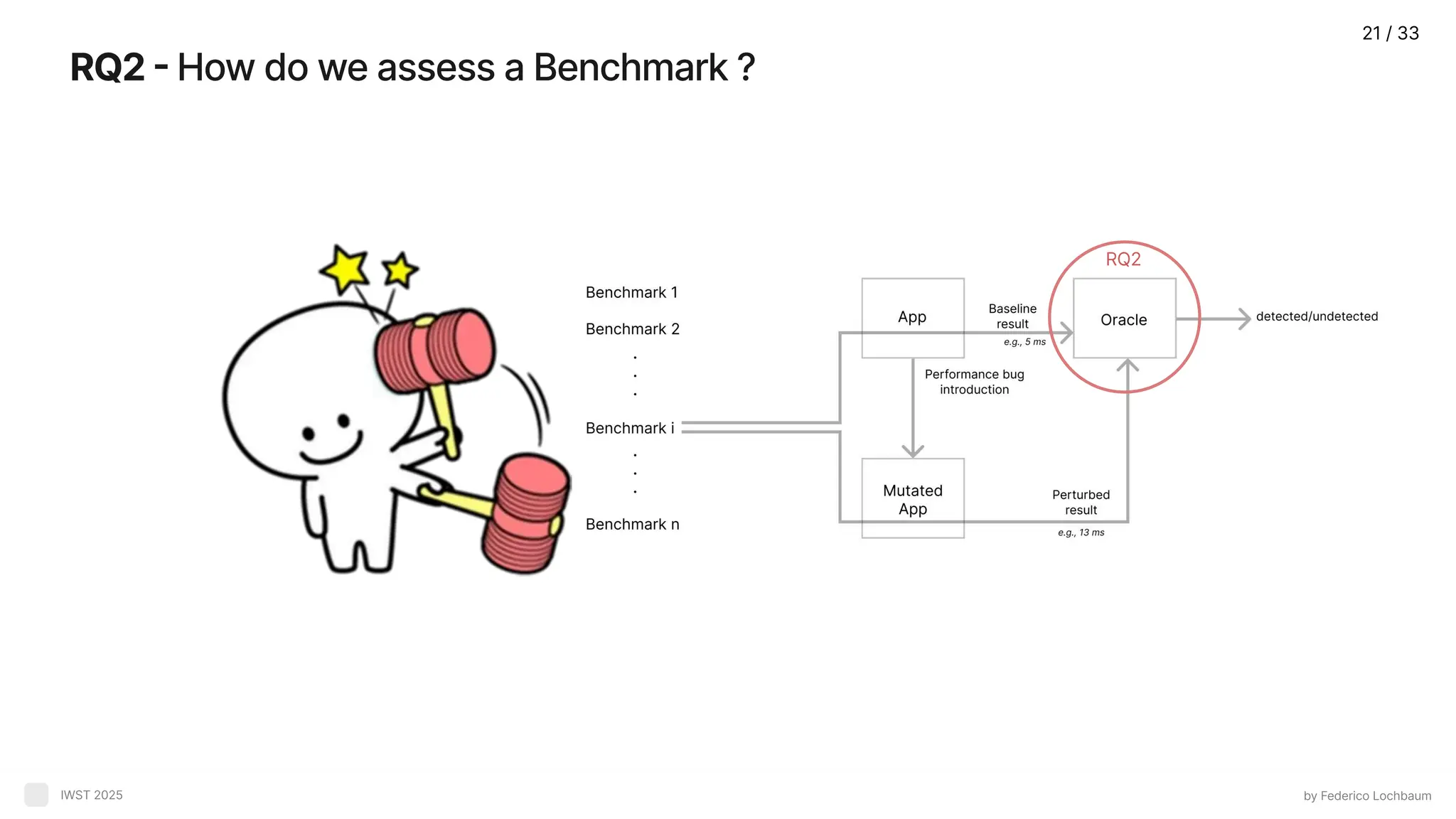
RQ2 - Howdo we assess a Benchmark ? by Federico Lochbaum IWST 2025 RQ2 21 / 33
22.
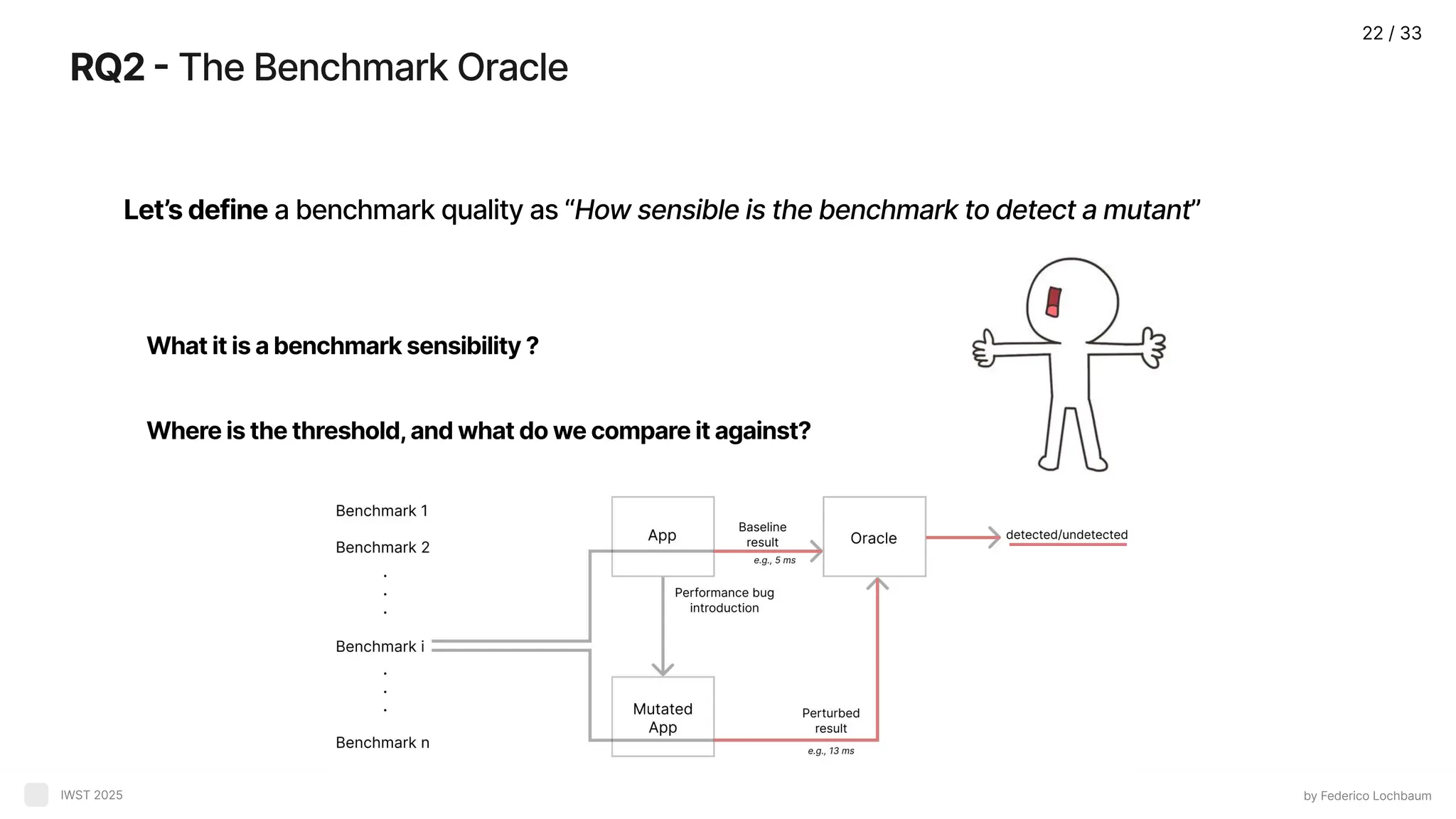
RQ2 - TheBenchmark Oracle by Federico Lochbaum IWST 2025 Let’s define a benchmark quality as “How sensible is the benchmark to detect a mutant” What it is a benchmark sensibility ? Where is the threshold, and what do we compare it against? 22 / 33
23.
Experimental Mutants: Sleepstatements byFederico Lochbaum IWST 2025 Why? - Represents latenc How? - Three mutantoperators, 10, 100, 500 millisecond Where? - At the beginning of every statement block 23 / 33
24.
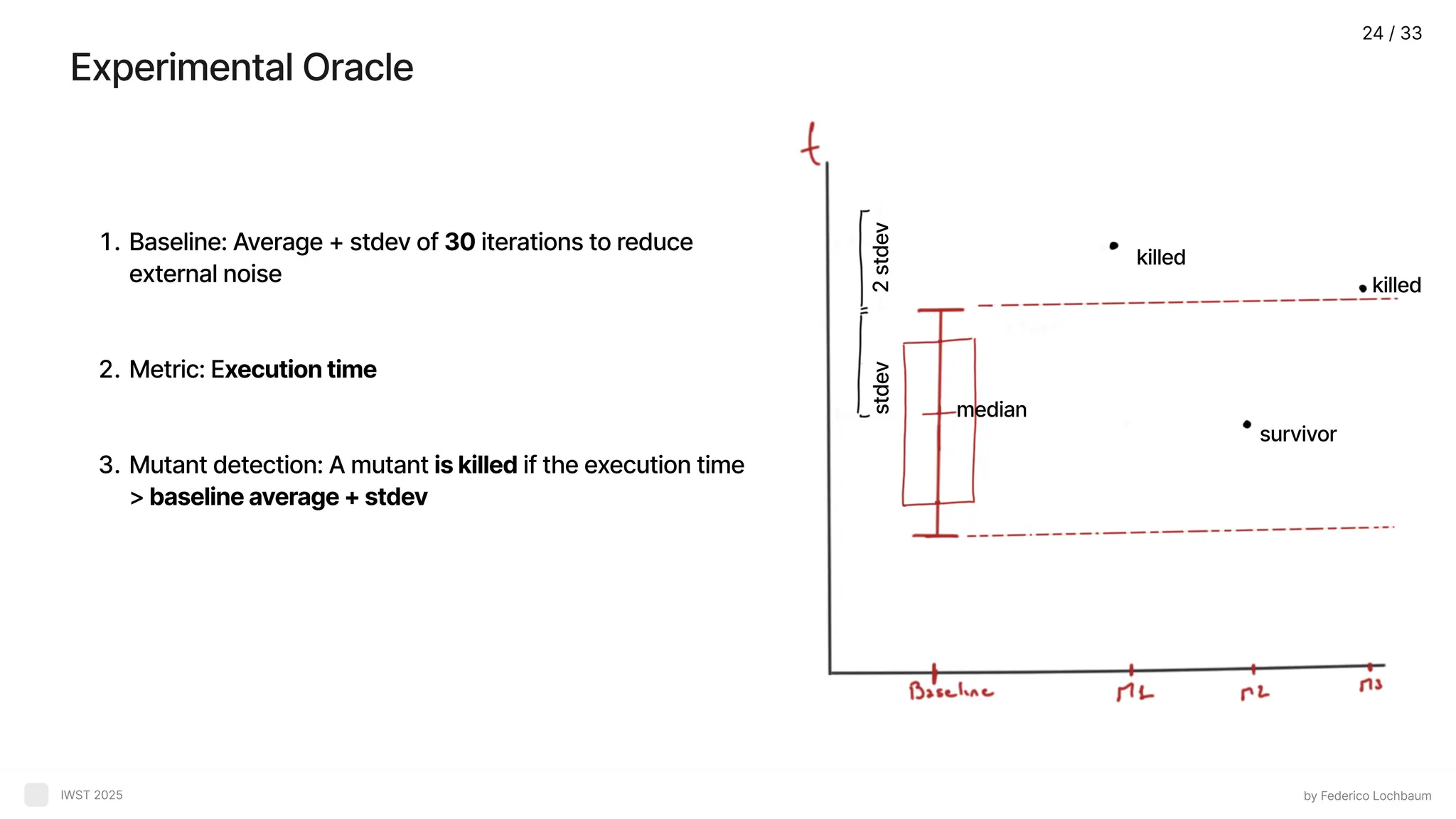
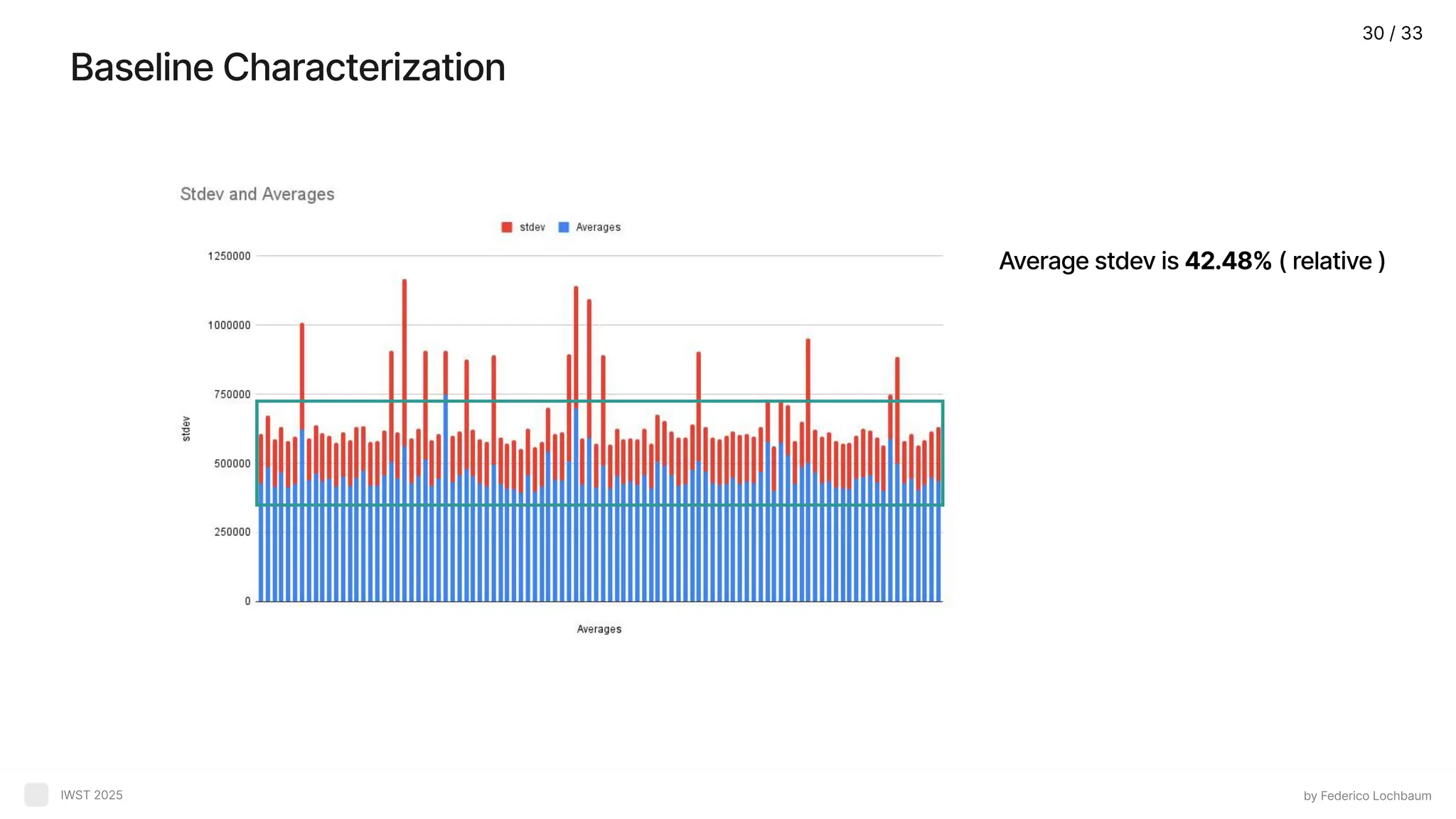
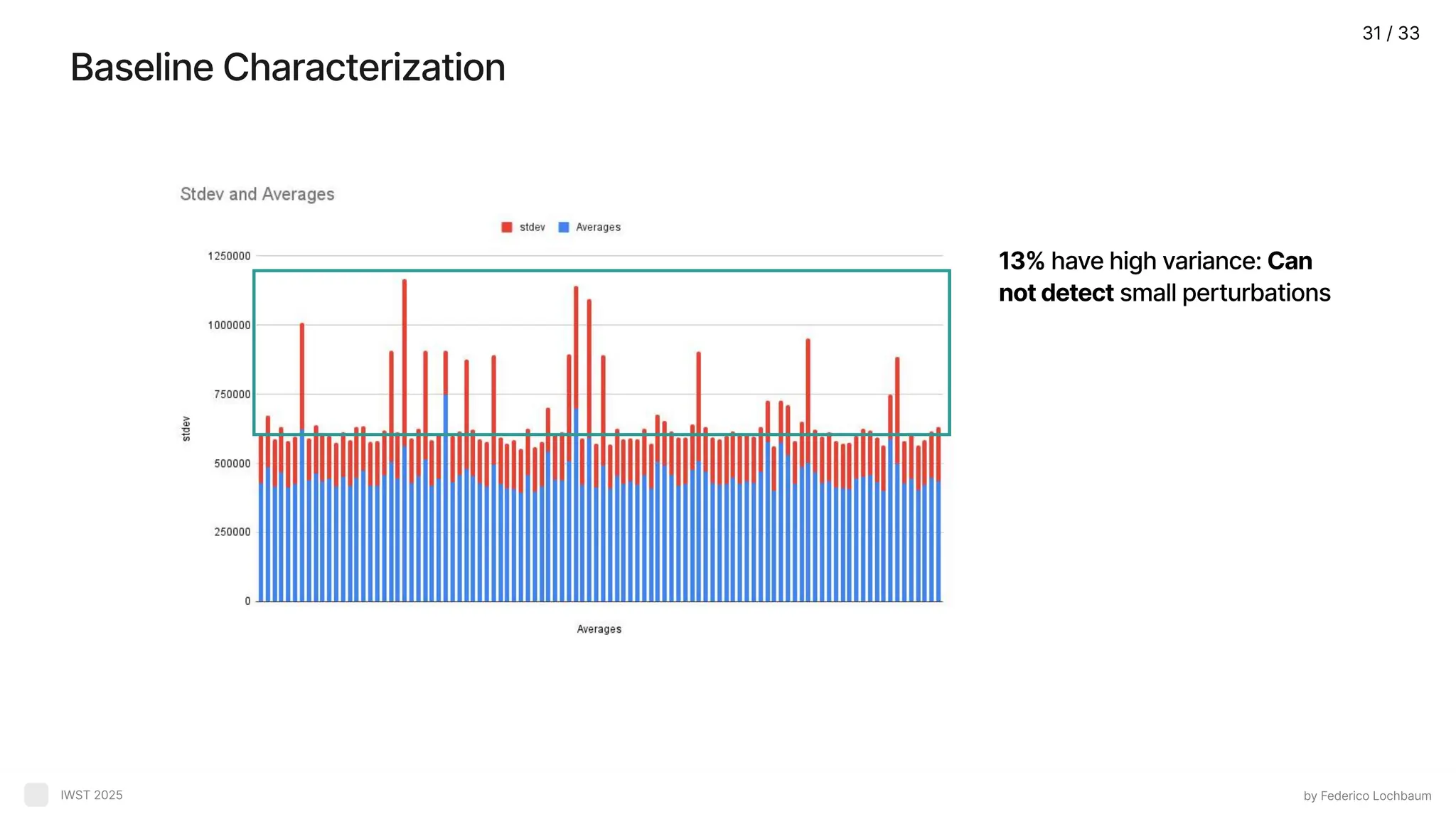
Experimental Oracle by FedericoLochbaum IWST 2025 Baseline: Average + stdev of 30 iterations to reduce external nois Metric: Execution tim Mutant detection: A mutant is killed if the execution time > baseline average + stdev median stdev 2 stdev killed killed survivor 24 / 33
25.
CaseStudy: Regular Expressionsin Pharo by Federico Lochbaum IWST 2025 WhyRegexes? → They are well know 100 Regexes are generated via grammar-basedfuzzing( MCTS We benchmark the regex matches:method with the generated regexe ‘b+a(b)*c+(b+c*b|b?(b+b)c?(b)*ab+a?aa)?a*’ matches: ‘bac’ ‘(bb(((b)b+)))+b+|b+’ matches: ‘bbbbb’ We assessthequalityofbenchmarks to find performance bugs on matches: method 25 / 33
26.
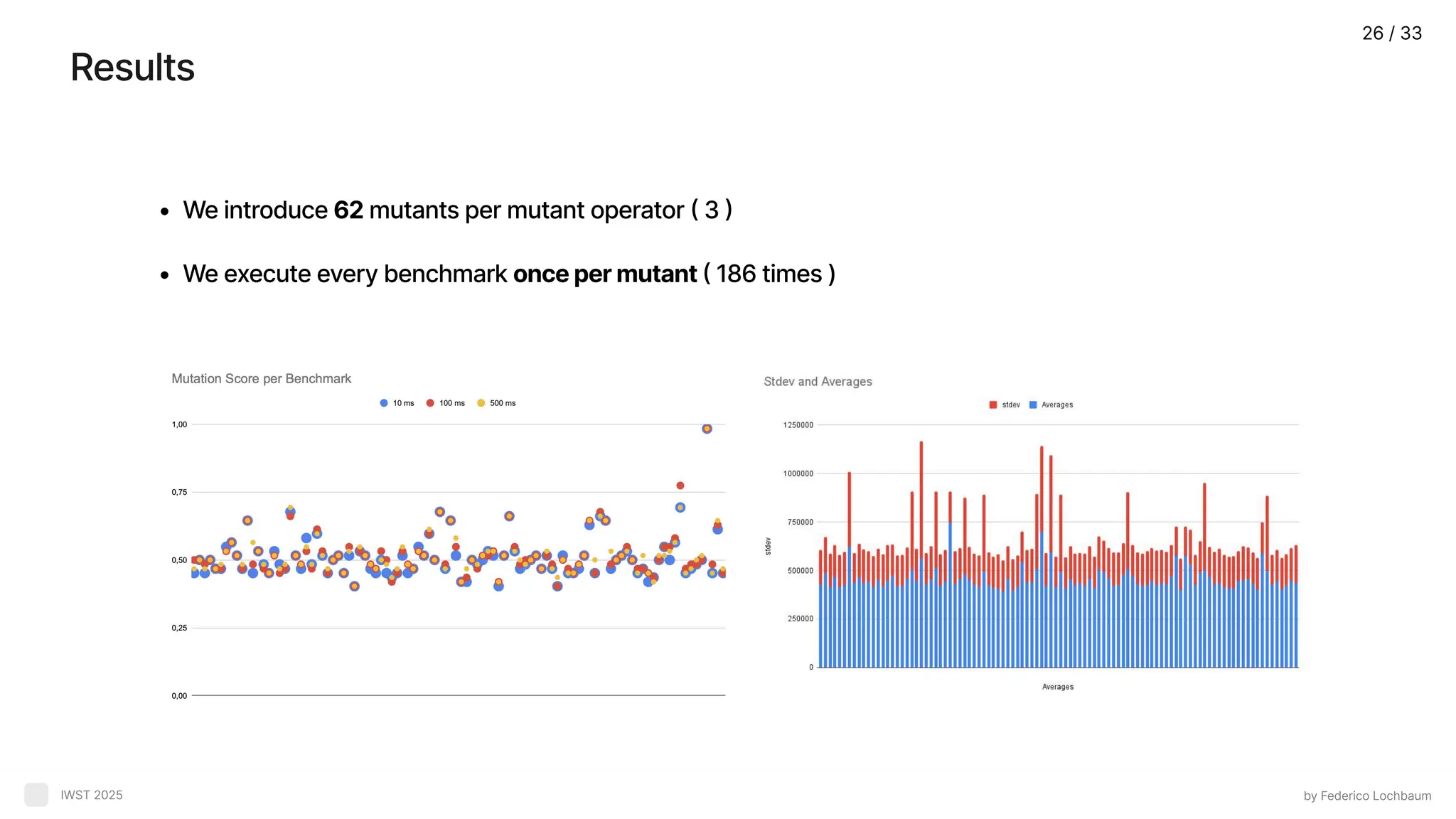
Results by Federico Lochbaum IWST2025 We introduce 62 mutants per mutant operator ( 3 We execute every benchmark once per mutant ( 186 times ) 26 / 33
27.
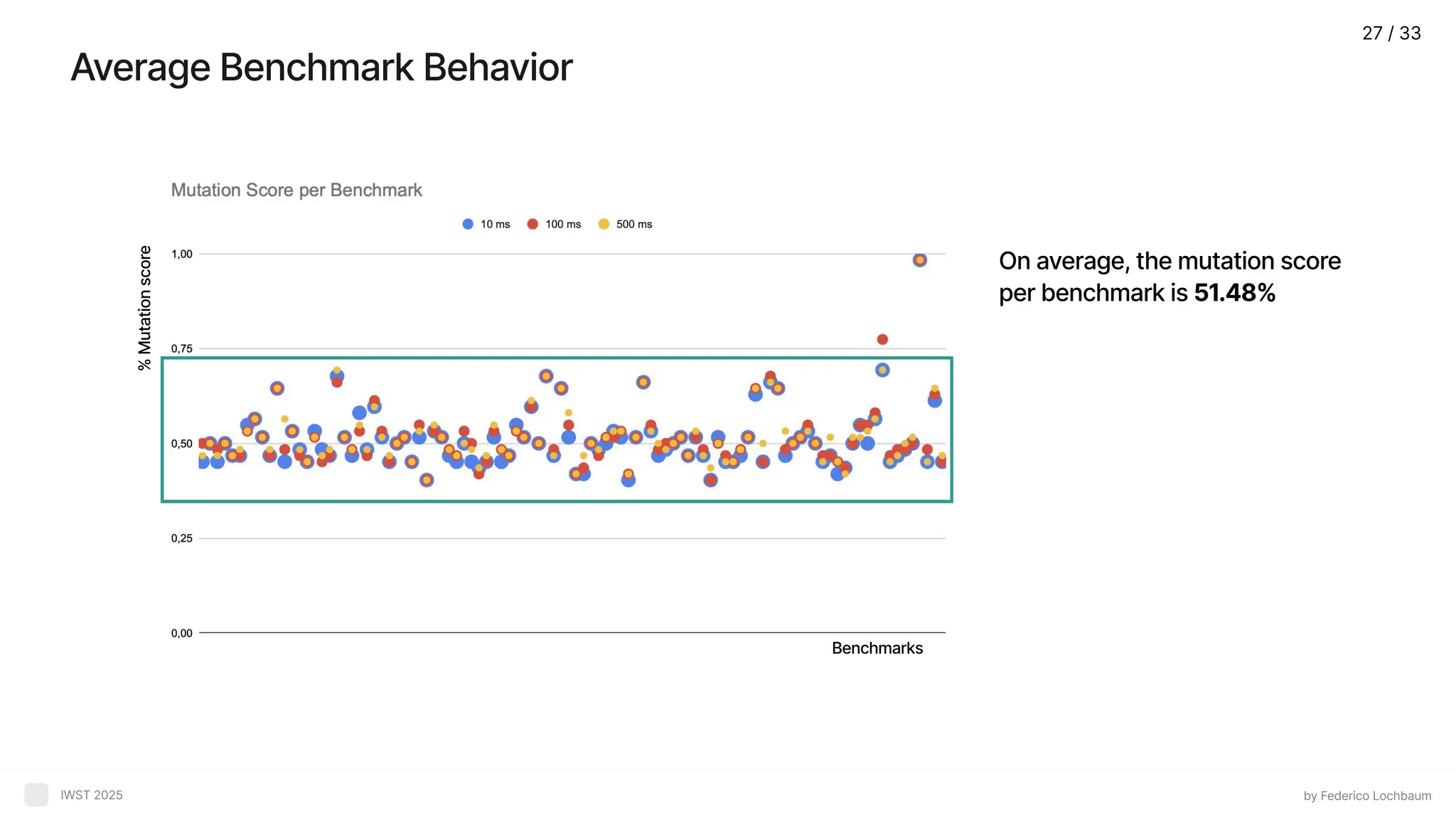
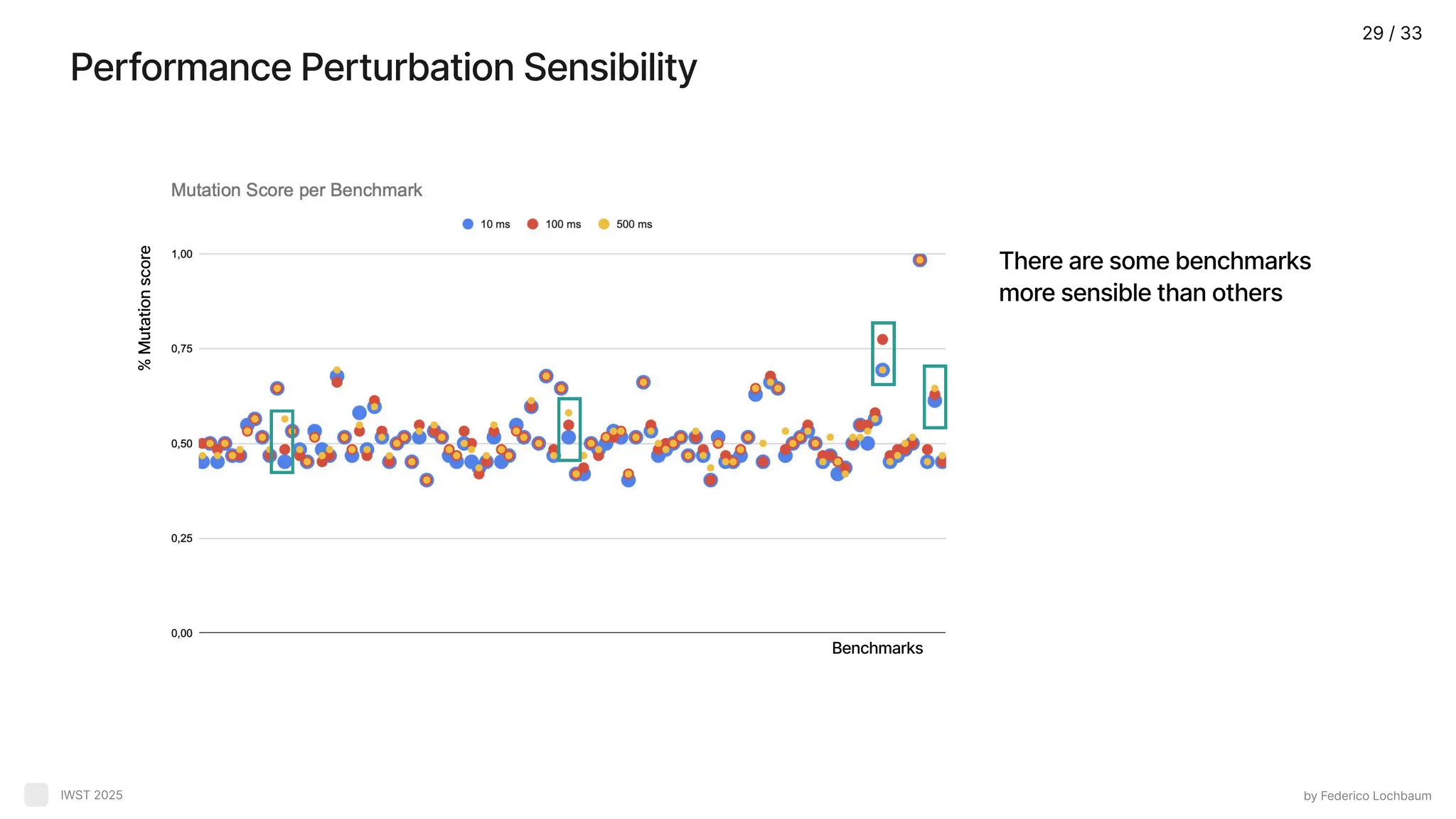
Average Benchmark Behavior byFederico Lochbaum IWST 2025 On average, the mutation score per benchmark is 51.48% % Mutation score Benchmarks 27 / 33
28.
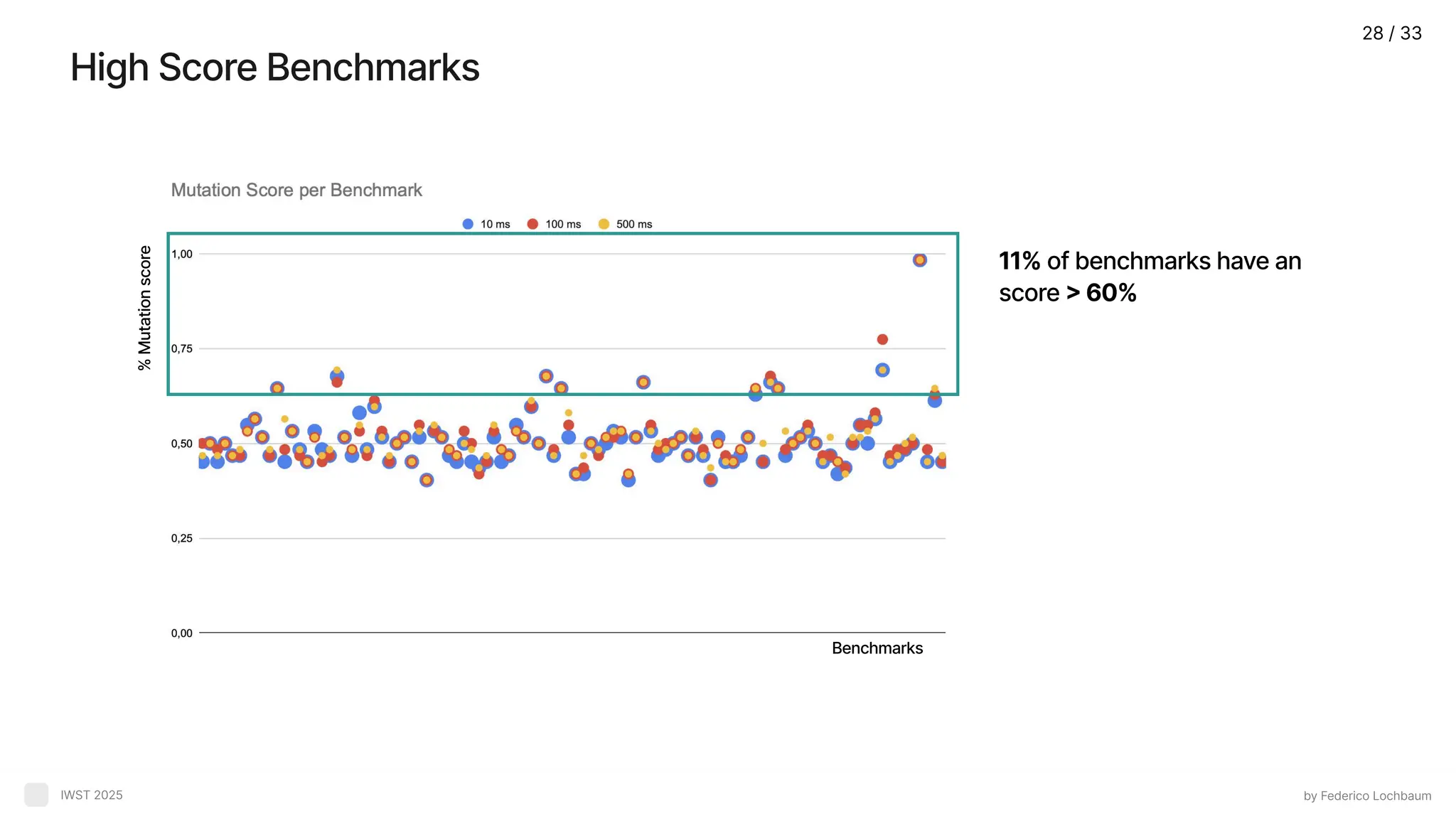
High Score Benchmarks byFederico Lochbaum IWST 2025 11% of benchmarks have an score > 60% Benchmarks % Mutation score 28 / 33
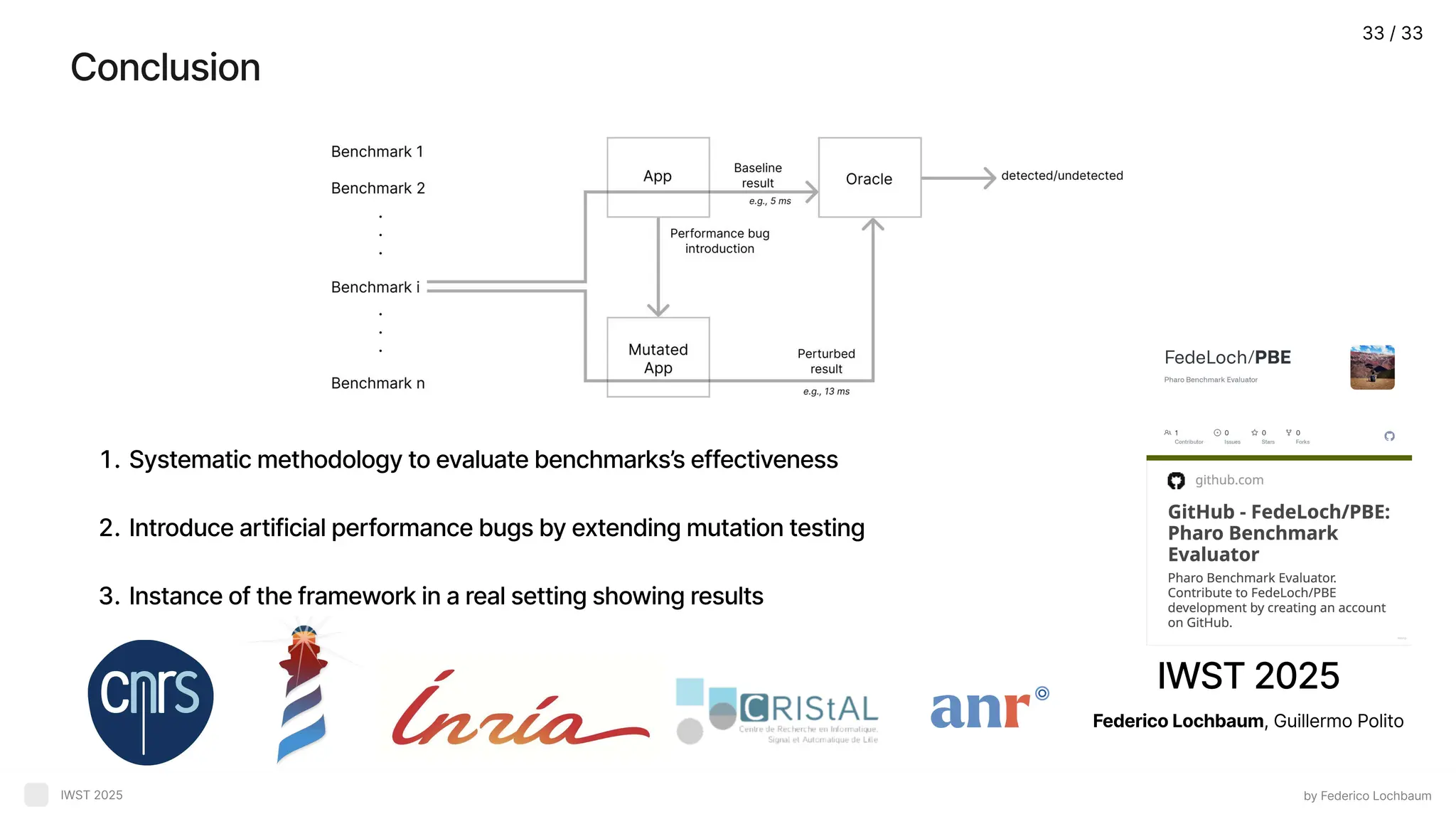
IWST 2025 Federico Lochbaum,Guillermo Polito Conclusion by Federico Lochbaum IWST 2025 Systematic methodology to evaluate benchmarks’s effectiveness Introduce artificial performance bugs by extending mutation testing Instance of the framework in a real setting showing results 33 / 33