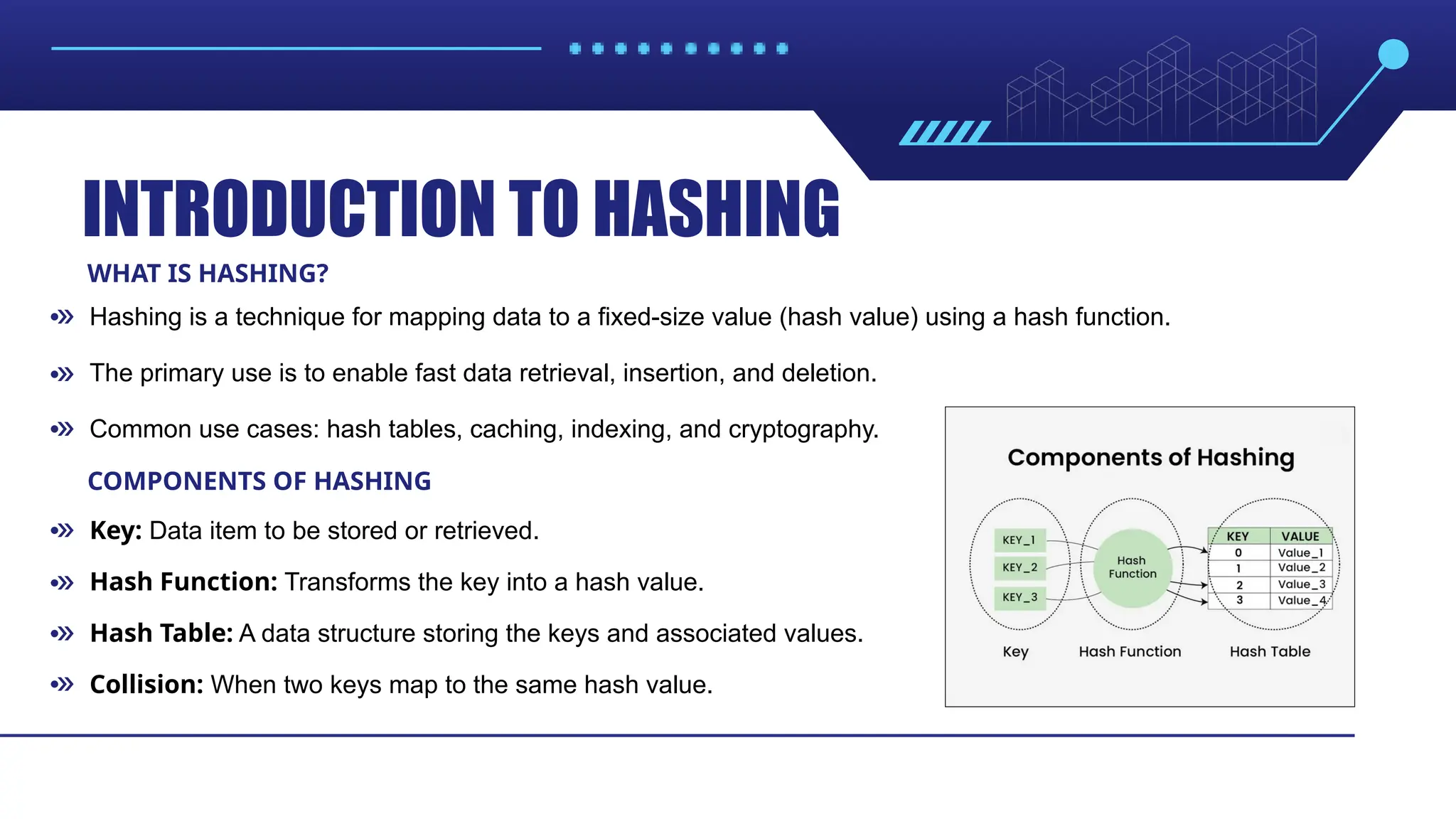
INTRODUCTION TO HASHING WHATIS HASHING? COMPONENTS OF HASHING Hashing is a technique for mapping data to a fixed-size value (hash value) using a hash function. Key: Data item to be stored or retrieved. The primary use is to enable fast data retrieval, insertion, and deletion. Hash Function: Transforms the key into a hash value. Common use cases: hash tables, caching, indexing, and cryptography. Hash Table: A data structure storing the keys and associated values. Collision: When two keys map to the same hash value.
3.
INTRODUCTION TO HASHING HASHFUNCTION: HASH FUNCTIONS: CODE EXAMPLE: CALL THIS FUNCTION AS: 42%10 = 2 OUTPUT: 2 1. MODULO OPERATION: INDEX=KEY%TABLE SIZE 2. MULTIPLICATIVE HASHING: INDEX= (KEY×AMOD1)×TABLE SIZE , ⌊ ⌋ WHERE A IS A CONSTANT. 3. STRING HASHING: A function that converts input (keys) into a fixed-size integer (hash). Converts strings into unique hash codes using ASCII values or polynomial rolling. int hashFunction(int key, int tableSize) { return key % tableSize; // Simple Modulo Division } int result hashFunction(42, 10); Example: h(k) = k % N (modulus operation for a hash table size N).
4.
COLLISION: HASH TABLES AND COLLISIONHANDLING A data structure that stores key-value pairs, indexed by the hash of the key. Occurs when two different keys produce the same hash value. Store multiple keys of the same hash values in the same index using a linked list. This code does not generate direct output to the console or a file. Instead, it modifies the state of the table array, inserting nodes into the appropriate chains. COLLISION HANDLING METHODS 1. CHAINING (SEPARATE CHAINING) HASH TABLE: CODE EXAMPLE (CHAINING): OUTPUT BEHAVIOUR: struct Node { int key; Node* next; }; void insert(Node* table[], int key, int tableSize) { int index = key % tableSize; Node* newNode = new Node{key, table[index]}; table[index] = newNode; }
5.
TYPES: HASH TABLES AND COLLISIONHANDLING Linear Probing: Increment index sequentially to find an empty slot. Quadratic probing: Increment index quadratically. Double Hashing: Two hash functions to determine the next slot. Formula: Index=(Key+C1 i+C2 i2)%Table Size ⋅ ⋅ Formula: Index=(Hash1+Probe Hash2)%Table Size ⋅ • All keys are stored directly in the hash table by probing for the next available slot. The output of this code will be the index of the first empty slot for a given key, determined using linear probing. 2. OPEN ADDRESSING CODE EXAMPLE (LINEAR PROBING): OUTPUT BEHAVIOUR: int linearProbe(int table[], int tableSize, int key) { int index = key % tableSize; while (table[index] != -1) { // -1 indicates an empty slot index = (index + 1) % tableSize; } return index; }
6.
HASHING FOR STRINGS CODEEXAMPLE: #include <iostream> using namespace std; int stringHash(string s, int prime, int tableSize) { int hash = 0; int p = 1; for (char c : s) { hash = (hash + (c - 'a' + 1) * p) % tableSize; p = (p * prime) % tableSize; } return hash; } int main() { string s = "abc"; int prime = 31; int tableSize = 10; cout << "Hash value: " << stringHash(s, prime, tableSize) << endl; return 0; OUTPUT: For the string “abc”, the output will be: Hash value: 6
7.
HASHING WITH ARRAYS •Suitable for simple implementations. Using Arrays for Hash Tables: Assume we insert the following keys: 15, 25, 35, 45, 55. After inserting the keys, the hash table will look like this: Example of storing integers using modulo hash function: CODE EXAMPLE: const int TABLE_SIZE = 10; int hashTable[TABLE_SIZE] = {-1}; // Initialize with -1 for empty slots void insert(int key) { int index = key % TABLE_SIZE; while (hashTable[index] != -1) { index = (index + 1) % TABLE_SIZE; // Linear probing } hashTable[index] = key; } Index 0: -1 Index 1: -1 Index 2: -1 Index 3: -1 Index 4: -1 Index 5: 15 Index 6: 25 Index 7: 35 Index 8: 45 Index 9: 55
8.
HASHING WITH LINKED LIST •Handles collisions more effectively. Using Linked Lists for Chaining: Assume we insert the following keys: 15, 25, 35, 45, 55. After inserting the keys, the hash table will look like this: CODE EXAMPLE: const int TABLE_SIZE = 10; struct Node { int key; Node* next; }; Node* hashTable[TABLE_SIZE] = {nullptr}; void insert(int key) { int index = key % TABLE_SIZE; Node* newNode = new Node{key, hashTable[index]}; hashTable[index] = newNode; } Index 0: Empty Index 1: Empty Index 2: Empty Index 3: Empty Index 4: Empty Index 5: 55 -> 45 -> 35 -> 25 -> 15 Index 6: Empty Index 7: Empty Index 8: Empty Index 9: Empty
9.
CONCLUSION: HASHING INC++ Hashing is a technique to map data to a fixed-size value using a hash function, allowing for efficient data retrieval, insertion, and deletion. Hashing plays a crucial role in optimizing data access and storage in many computer science applications. A good hash function is key to minimizing collisions and improving performance. Understanding different collision resolution techniques (e.g., chaining, open addressing) is vital for effective use of hashing in real-world problems. Fast data lookup by mapping keys to values Efficient implementation of sets, maps, and dictionaries Ensures data integrity using hash functions like MD5 and SHA. Used in digital signatures and password hashing. Stores frequently accessed data for faster retrieval. A hash table stores keys and values, with the hash function determining the index in the table. Collisions occur when two keys map to the same index. This can be resolved using methods like chaining (linked lists) and open addressing (e.g., linear probing). RECAP OF KEY CONCEPTS: APPLICATIONS OF HASHING: FINAL THOUGHTS: DATABASE INDEXING HASH TABLES DATA INTEGRITY CRYPTOGRAPHY CACHING


![COLLISION: HASH TABLES AND COLLISION HANDLING A data structure that stores key-value pairs, indexed by the hash of the key. Occurs when two different keys produce the same hash value. Store multiple keys of the same hash values in the same index using a linked list. This code does not generate direct output to the console or a file. Instead, it modifies the state of the table array, inserting nodes into the appropriate chains. COLLISION HANDLING METHODS 1. CHAINING (SEPARATE CHAINING) HASH TABLE: CODE EXAMPLE (CHAINING): OUTPUT BEHAVIOUR: struct Node { int key; Node* next; }; void insert(Node* table[], int key, int tableSize) { int index = key % tableSize; Node* newNode = new Node{key, table[index]}; table[index] = newNode; }](https://image.slidesharecdn.com/dsapresentation-250406191457-4cdc2a80/75/DSA-Presentation-of-Data-Structures-and-Algorithms-pptx-4-2048.jpg)
![TYPES: HASH TABLES AND COLLISION HANDLING Linear Probing: Increment index sequentially to find an empty slot. Quadratic probing: Increment index quadratically. Double Hashing: Two hash functions to determine the next slot. Formula: Index=(Key+C1 i+C2 i2)%Table Size ⋅ ⋅ Formula: Index=(Hash1+Probe Hash2)%Table Size ⋅ • All keys are stored directly in the hash table by probing for the next available slot. The output of this code will be the index of the first empty slot for a given key, determined using linear probing. 2. OPEN ADDRESSING CODE EXAMPLE (LINEAR PROBING): OUTPUT BEHAVIOUR: int linearProbe(int table[], int tableSize, int key) { int index = key % tableSize; while (table[index] != -1) { // -1 indicates an empty slot index = (index + 1) % tableSize; } return index; }](https://image.slidesharecdn.com/dsapresentation-250406191457-4cdc2a80/75/DSA-Presentation-of-Data-Structures-and-Algorithms-pptx-5-2048.jpg)

![HASHING WITH ARRAYS • Suitable for simple implementations. Using Arrays for Hash Tables: Assume we insert the following keys: 15, 25, 35, 45, 55. After inserting the keys, the hash table will look like this: Example of storing integers using modulo hash function: CODE EXAMPLE: const int TABLE_SIZE = 10; int hashTable[TABLE_SIZE] = {-1}; // Initialize with -1 for empty slots void insert(int key) { int index = key % TABLE_SIZE; while (hashTable[index] != -1) { index = (index + 1) % TABLE_SIZE; // Linear probing } hashTable[index] = key; } Index 0: -1 Index 1: -1 Index 2: -1 Index 3: -1 Index 4: -1 Index 5: 15 Index 6: 25 Index 7: 35 Index 8: 45 Index 9: 55](https://image.slidesharecdn.com/dsapresentation-250406191457-4cdc2a80/75/DSA-Presentation-of-Data-Structures-and-Algorithms-pptx-7-2048.jpg)
![HASHING WITH LINKED LIST • Handles collisions more effectively. Using Linked Lists for Chaining: Assume we insert the following keys: 15, 25, 35, 45, 55. After inserting the keys, the hash table will look like this: CODE EXAMPLE: const int TABLE_SIZE = 10; struct Node { int key; Node* next; }; Node* hashTable[TABLE_SIZE] = {nullptr}; void insert(int key) { int index = key % TABLE_SIZE; Node* newNode = new Node{key, hashTable[index]}; hashTable[index] = newNode; } Index 0: Empty Index 1: Empty Index 2: Empty Index 3: Empty Index 4: Empty Index 5: 55 -> 45 -> 35 -> 25 -> 15 Index 6: Empty Index 7: Empty Index 8: Empty Index 9: Empty](https://image.slidesharecdn.com/dsapresentation-250406191457-4cdc2a80/75/DSA-Presentation-of-Data-Structures-and-Algorithms-pptx-8-2048.jpg)

