Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PDF, PPTX
710 views
[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation
2022/01/21 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Download
Download as PDF, PPTX
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PPTX
【DL輪読会】Trajectory Prediction with Latent Belief Energy-Based Model
by
Deep Learning JP
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
PDF
Mean Teacher
by
harmonylab
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PPTX
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
【DL輪読会】Trajectory Prediction with Latent Belief Energy-Based Model
by
Deep Learning JP
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
Mean Teacher
by
harmonylab
Bayesian Neural Networks : Survey
by
tmtm otm
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
近年のHierarchical Vision Transformer
by
Yusuke Uchida
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
What's hot
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
semantic segmentation サーベイ
by
yohei okawa
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PDF
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
PPTX
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
PDF
MIRU2016 チュートリアル
by
Shunsuke Ono
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
semantic segmentation サーベイ
by
yohei okawa
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
MIRU2016 チュートリアル
by
Shunsuke Ono
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Similar to [DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation
PDF
[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...
by
Deep Learning JP
PPTX
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PDF
BA-Net: Dense Bundle Adjustment Network (3D勉強会@関東)
by
Mai Nishimura
PDF
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PPTX
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
PPTX
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
PDF
[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α
by
Deep Learning JP
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
PDF
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
PDF
[DL輪読会]Unsupervised Learning of 3D Structure from Images
by
Deep Learning JP
PPTX
20190831 3 d_inaba_final
by
DaikiInaba
PDF
論文紹介:DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Networ...
by
matsunoh
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PPTX
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
PPTX
CVPR2018 参加報告(速報版)2日目
by
Atsushi Hashimoto
PPTX
Cvpr2018 参加報告(速報版)3日目
by
Atsushi Hashimoto
PDF
【2015.08】(4/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
【2015.08】(1/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...
by
Deep Learning JP
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
BA-Net: Dense Bundle Adjustment Network (3D勉強会@関東)
by
Mai Nishimura
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unk...
by
Kazuyuki Miyazawa
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α
by
Deep Learning JP
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
【DL輪読会】Learning Instance-Specific Adaptation for Cross-Domain Segmentation (E...
by
Deep Learning JP
[DL輪読会]Unsupervised Learning of 3D Structure from Images
by
Deep Learning JP
20190831 3 d_inaba_final
by
DaikiInaba
論文紹介:DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Networ...
by
matsunoh
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
CVPR2018 参加報告(速報版)2日目
by
Atsushi Hashimoto
Cvpr2018 参加報告(速報版)3日目
by
Atsushi Hashimoto
【2015.08】(4/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
【2015.08】(1/5)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
More from Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
Recently uploaded
PDF
論文紹介:"Reflexion: language agents with verbal reinforcement learning", "MA-LMM...
by
Toru Tamaki
PDF
論文紹介:"MM-Tracker: Motion Mamba for UAV-platform Multiple Object Tracking", "M...
by
Toru Tamaki
PDF
論文紹介:Simultaneous Detection and Interaction Reasoning for Object-Centric Acti...
by
Toru Tamaki
PDF
論文紹介: "Locality-Aware Zero-Shot Human-Object Interaction Detection" "Disentan...
by
Toru Tamaki
PDF
ReflecTrace: Hover Interface using Corneal Reflection Images Captured by Smar...
by
sugiuralab
PDF
AIアクセラレーターが切り拓く未来: 技術革新の加速とそれがもたらす社会的・経済的影響
by
Data Source
PDF
AIアクセラレーターの力で加速する次世代AI技術: 革新が変革するテクノロジーの未来
by
Data Source
PDF
AIアクセラレータの力で加速する人工知能の未来: 技術革新と産業革命を促進する力
by
Data Source
PDF
AIプロセッサの未来: 革新技術が切り開く次世代コンピュータ革命とその無限の可能性
by
Data Source
PDF
ADAS自動運転の未来: 次世代の技術革新が切り開く新しいモビリティ社会とその可能性
by
Data Source
PDF
ADAS自動車の未来: 次世代運転支援技術が実現する新たな運転体験とその進化の可能性
by
Data Source
PDF
手軽に広範囲でプライバシーを守りながら人数カウントできる ~ LoRaWAN AI人流カウンター PF52 日本語カタログ
by
CRI Japan, Inc.
PDF
歴史好きのスクラム話 JBUG名古屋#5 AI時代のデータドリブンなプロジェクト管理
by
Tatsuya Naiki
論文紹介:"Reflexion: language agents with verbal reinforcement learning", "MA-LMM...
by
Toru Tamaki
論文紹介:"MM-Tracker: Motion Mamba for UAV-platform Multiple Object Tracking", "M...
by
Toru Tamaki
論文紹介:Simultaneous Detection and Interaction Reasoning for Object-Centric Acti...
by
Toru Tamaki
論文紹介: "Locality-Aware Zero-Shot Human-Object Interaction Detection" "Disentan...
by
Toru Tamaki
ReflecTrace: Hover Interface using Corneal Reflection Images Captured by Smar...
by
sugiuralab
AIアクセラレーターが切り拓く未来: 技術革新の加速とそれがもたらす社会的・経済的影響
by
Data Source
AIアクセラレーターの力で加速する次世代AI技術: 革新が変革するテクノロジーの未来
by
Data Source
AIアクセラレータの力で加速する人工知能の未来: 技術革新と産業革命を促進する力
by
Data Source
AIプロセッサの未来: 革新技術が切り開く次世代コンピュータ革命とその無限の可能性
by
Data Source
ADAS自動運転の未来: 次世代の技術革新が切り開く新しいモビリティ社会とその可能性
by
Data Source
ADAS自動車の未来: 次世代運転支援技術が実現する新たな運転体験とその進化の可能性
by
Data Source
手軽に広範囲でプライバシーを守りながら人数カウントできる ~ LoRaWAN AI人流カウンター PF52 日本語カタログ
by
CRI Japan, Inc.
歴史好きのスクラム話 JBUG名古屋#5 AI時代のデータドリブンなプロジェクト管理
by
Tatsuya Naiki
[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation
1.
DEEP LEARNING JP [DL
Papers] Geometric Unsupervised Domain Adaptation for Semantic Segmentation Yuting Lin, Kokusai Kogyo Co., Ltd.(国際航業) http://deeplearning.jp/ 1
2.
書誌情報 • タイトル – Geometric
Unsupervised Domain Adaptation for Semantic Segmentation • 著者 – Vitor Guizilini, Jie Li Rares, Ambrus, Adrien Gaidon (TRI) • ICCV2021(poster)に採択 • Paper – https://openaccess.thecvf.com/content/ICCV2021/papers/Guizilini_Geometric_Uns upervised_Domain_Adaptation_for_Semantic_Segmentation_ICCV_2021_paper.pdf • Code – https://github.com/tri-ml/packnet-sfm(別のプロジェクト?) 2
3.
概要 • Unsupervised Domain
Adaptation (UDA)の課題 • 多くの手法は、敵対的な学習を採用 • 識別器の学習が難しい • domainのsemanticに関するギャップを接近させにくい – proxy/pretext taskで性能を向上 • segmentation以外のタスクも同時に学習(回転角度を予測) • Global表現より、画素レベルの表現の学習が必要 • 本論文は、画素レベルの表現学習を実現するproxy taskを利用したUDA手 法を提案 3
4.
既往研究 - UDA •
基本は、self supervised learning (a.k.a pseudo label)で行う – pixel/feature/outputレベルで、sourceとtargetをalignment – 直接domainの分布に対した方法の効果は限定的 • proxy taskの活用 – source domainの他のmodalityを利用し、学習をガイド – SPIGANは疑似的depth情報を追加の正則項で学習 – GIO-Adaはdepthとnormal情報で、targetへのstyle transferを学習 – DADAはdepthとsegmentationをshared encoderで推定 – 提案手法は、target domain(video)においても、depthを同時に推定することで (geometricな情報を利用)、性能を向上 4
5.
既往研究 - Self-supervised
learning (SSL) • 主な流派 – pre-training + fine-tuning – multi-task learning: rotation, patch jigsaw puzzlesなど • domain-invariant & fine-grained特徴を学習できる • 汎化性能が高い – GUDAは後者を採用 5
6.
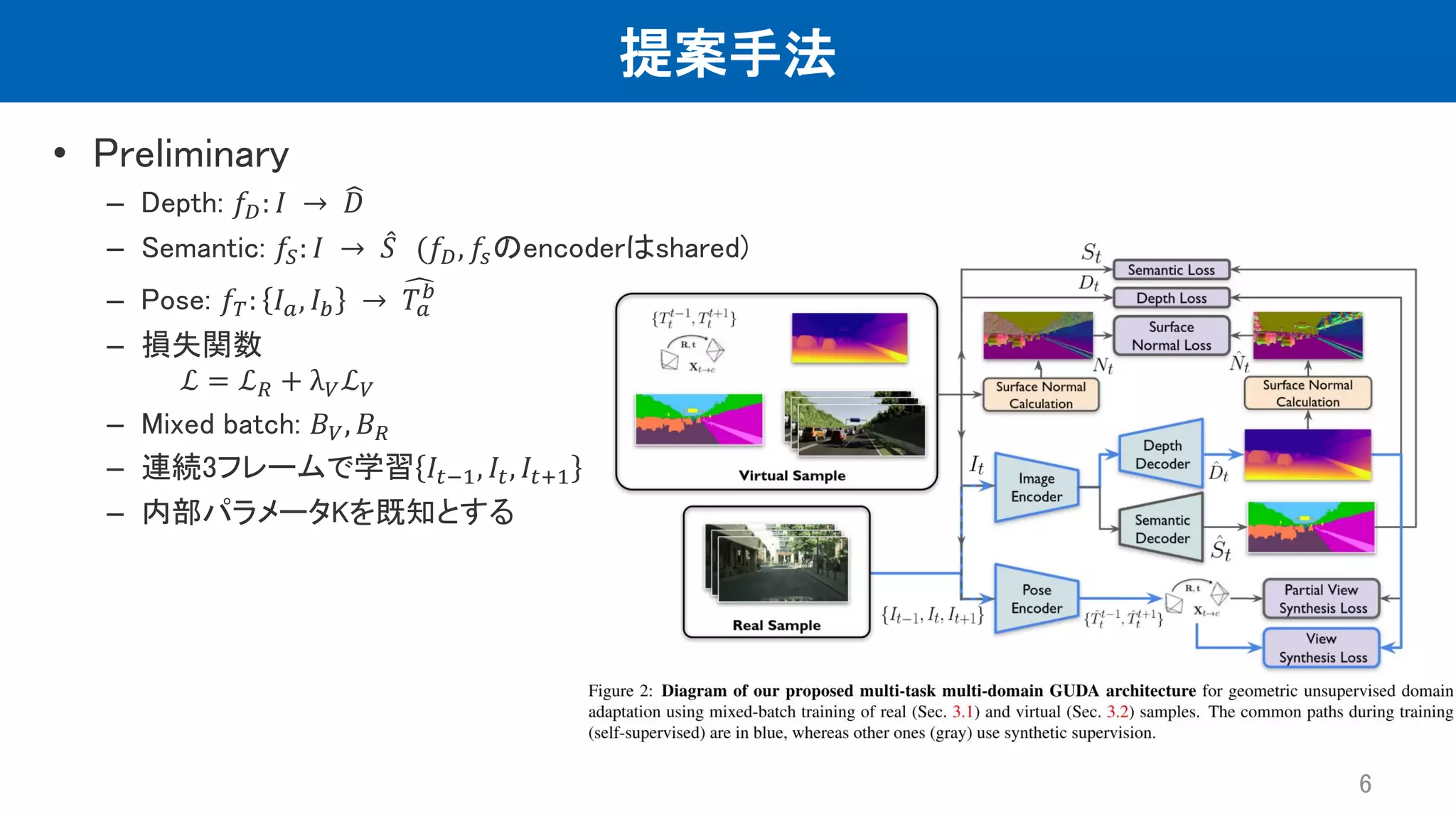
提案手法 • Preliminary – Depth:
𝑓𝐷: 𝐼 → 𝐷 – Semantic: 𝑓𝑆: 𝐼 → መ 𝑆 (𝑓𝐷, 𝑓𝑠のencoderはshared) – Pose: 𝑓𝑇: 𝐼𝑎, 𝐼𝑏 → 𝑇𝑎 𝑏 – 損失関数 ℒ = ℒ𝑅 + λ𝑉ℒ𝑉 – Mixed batch: 𝐵𝑉, 𝐵𝑅 – 連続3フレームで学習 𝐼𝑡−1, 𝐼𝑡, 𝐼𝑡+1 – 内部パラメータKを既知とする 6
7.
提案手法 • Real sample処理 –
Loss関数 ℒ𝑅 = ℒ𝑃 + λ𝑃𝐿ℒ𝑃𝐿 where ℒ𝑃: self-supervised photometric loss ℒ𝑃𝐿: optional pseudo-label loss 7
8.
提案手法 • Real sample処理:Self-Supervised
Photometric Loss – Self-Supervised depthとpose推定は、view synthesis問題 𝐼𝑡 = 𝐼𝑡′ 𝜋 𝐷𝑡, 𝑇𝑡 𝑡′ , 𝐾 where 𝐼𝑡=predicted target image, 𝐼𝑡′=reference image, 𝐷𝑡=predicted depth map, 𝑇𝑡 𝑡′ =relative transformation, 𝜋=projection operation – 再構築誤差は、structural similarity (SSIM) とL1 distance in pixel spaceで構成され るstandard photometric lossで求める ℒ𝑃 𝐼𝑡, 𝐼𝑡 = 𝛼 1 − 𝑆𝑆𝐼𝑀 𝐼𝑡, 𝐼𝑡 2 + 1 − 𝛼 𝐼𝑡 − 𝐼𝑡 1 • SSIMは解像度が異なるoutputの平均を取る • auto-maskingと最小再投影誤差で、動物体とオクルージョンによる影響を抑える 8
9.
提案手法 • Real sample処理:
Pseudo-Label Distillation – Pseudo-Labelを教師とし、Cross Entropy Lossでrealデータのセグメンテーションを学 習 ℒ𝑃𝐿 = ℒ𝑆 መ 𝑆, 𝑆𝑃𝐿 where መ 𝑆=predicted semantic map, 𝑆𝑃𝐿 =Pseudo Label of same sample 9
10.
提案手法 • Virtual sample処理 –
Loss関数 ℒ𝑉 = ℒ𝐷 + λ𝑆ℒ𝑆 + λ𝑁ℒ𝑁 + λ𝑃𝑃ℒ𝑃𝑃 where ℒ𝐷: supervised depth loss ℒ𝑆: supervised semantic loss ℒ𝑁: surface normal regularization term ℒ𝑃𝑃: optional partially-supervised photometric loss 10
11.
提案手法 • Virtual sample処理:
Supervised Semantic Loss – bootstrapped cross-entropy loss: scoreが低いK(0.3×H×W)の推定結果のみ逆伝 播に ℒ𝑆 = − 1 𝐾 𝑢=1 𝐻 𝑣=1 𝑊 𝑐=1 𝐶 𝕝 𝑐=𝑦𝑢,𝑣,𝑝𝑢,𝑣 𝑐 <𝑡 log 𝑝𝑢,𝑣 𝑐 where t=run-time threshold 11
12.
提案手法 • Virtual sample処理:
Supervised Depth Loss – Scale-Invariant Logarithmic loss (SILog) ℒ𝑆 = 1 𝑃 𝑑∈𝐷 ∆𝑑2 − 𝜆 𝑃2 𝑑∈𝐷 ∆𝑑 2 where ∆𝑑 = log 𝑑 − log መ 𝑑 P: depthがvalidの画素数 12
13.
提案手法 • Virtual sample処理:
Surface Normal Regularization – Depth推定は画素ごとに行うため、smoothingをかけた方が性能が良い – Depthから計算したNormalをsmoothing 𝒏 = 𝑷𝑢+1,𝑣 − 𝑷𝑢,𝑣 × 𝑷𝑢,𝑣+1 − 𝑷𝑢,𝑣 where 𝑷 = ∅ 𝒑, 𝑑, 𝐾 画像上の点pを3Dに投影した点P – Cosine類似度でnormal正則化を行う ℒ𝑁 = 1 2𝑃 𝒑∈𝐷 1 − ෝ 𝒏 ∙ 𝒏 ෝ 𝒏 𝒏 – Geometricな情報を学習できるようになった • 境界の鮮明化 • 遠い物体の精度向上 13
14.
提案手法 • Virtual sample処理:
Partially-Supervised Photometric Loss – Virtualデータも連続画像の場合、Self-Supervised Photometric Lossも適用できる – depth/poseごとの教師があるため、depth/poseにdecouple – Original: 𝐼𝑡 = 𝐼𝑡′ 𝜋 𝐷𝑡, 𝑇𝑡 𝑡′ , 𝐾 – Depth: 𝐼𝑡 𝐷 = 𝐼𝑡′ 𝜋 𝐷𝑡, 𝑇𝑡 𝑡′ , 𝐾 – Pose: 𝐼𝑡 𝑇 = 𝐼𝑡′ 𝜋 𝐷𝑡, 𝑇𝑡 𝑡′ , 𝐾 ℒ𝑃𝑃 = 1 3 ℒ𝑃 𝐼𝑡, 𝐼𝑡 + ℒ𝑃 𝐼𝑡, 𝐼𝑡 𝐷 + ℒ𝑃 𝐼𝑡, 𝐼𝑡 𝑇 14
15.
実験の設定 • ネットワーク – Shared
backbone: ResNet101 w/ ImageNet pre-trained – Depth/semantic decoder: [1] – Pose encoder: ResNet18 w/ ImageNet pre-trained – Pose decoder: conv layers数個 • Datasets – Real datasets: Cityscapes, KITTI, DDAD – Virtual datasets: SYNTHIA, VKITTI2, Parallel Domain, GTA5 15 [1] Digging Into Self-Supervised Monocular Depth Estimation. https://arxiv.org/pdf/1806.01260.pdf
16.
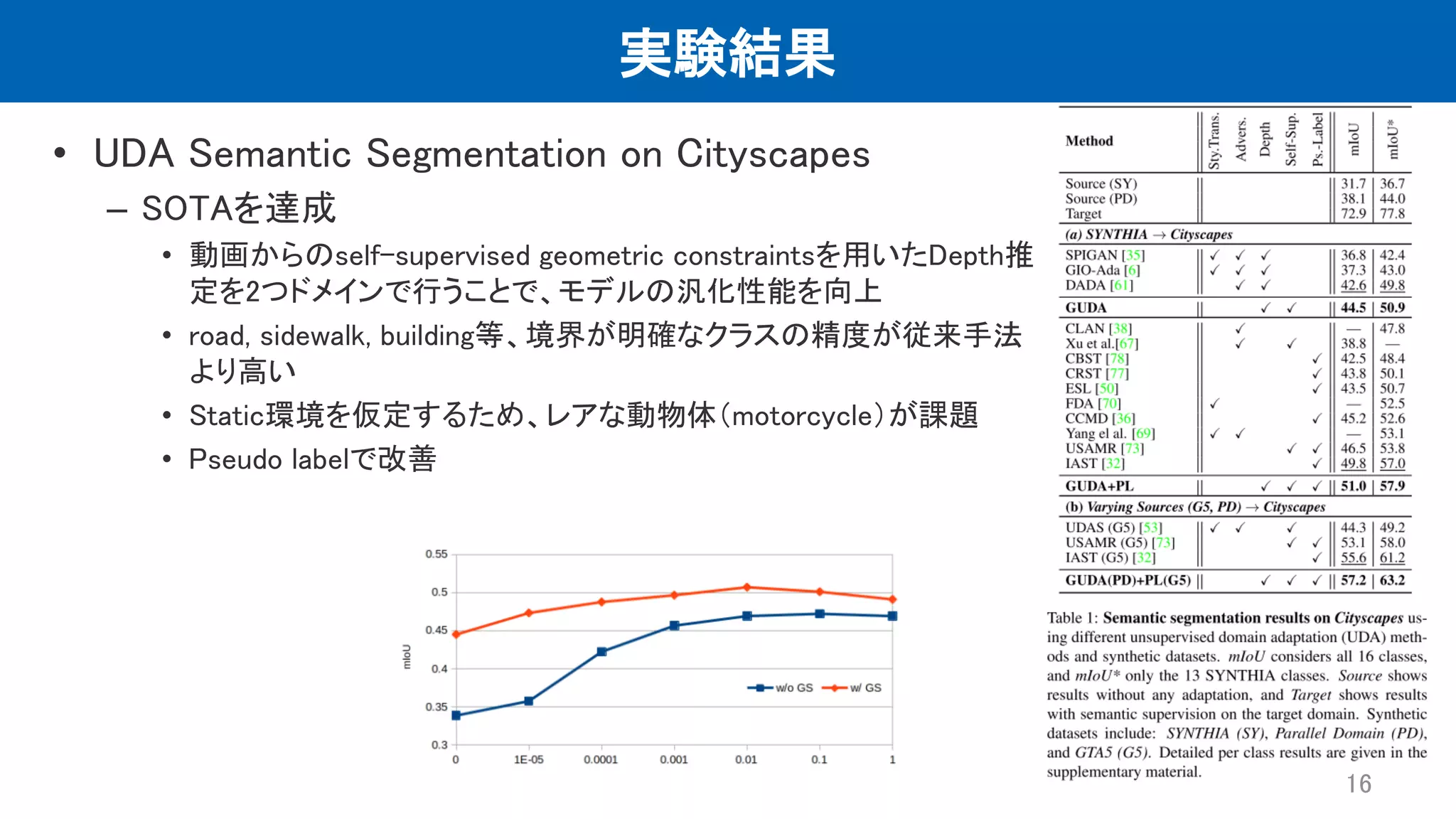
実験結果 • UDA Semantic
Segmentation on Cityscapes – SOTAを達成 • 動画からのself-supervised geometric constraintsを用いたDepth推 定を2つドメインで行うことで、モデルの汎化性能を向上 • road, sidewalk, building等、境界が明確なクラスの精度が従来手法 より高い • Static環境を仮定するため、レアな動物体(motorcycle)が課題 • Pseudo labelで改善 16
17.
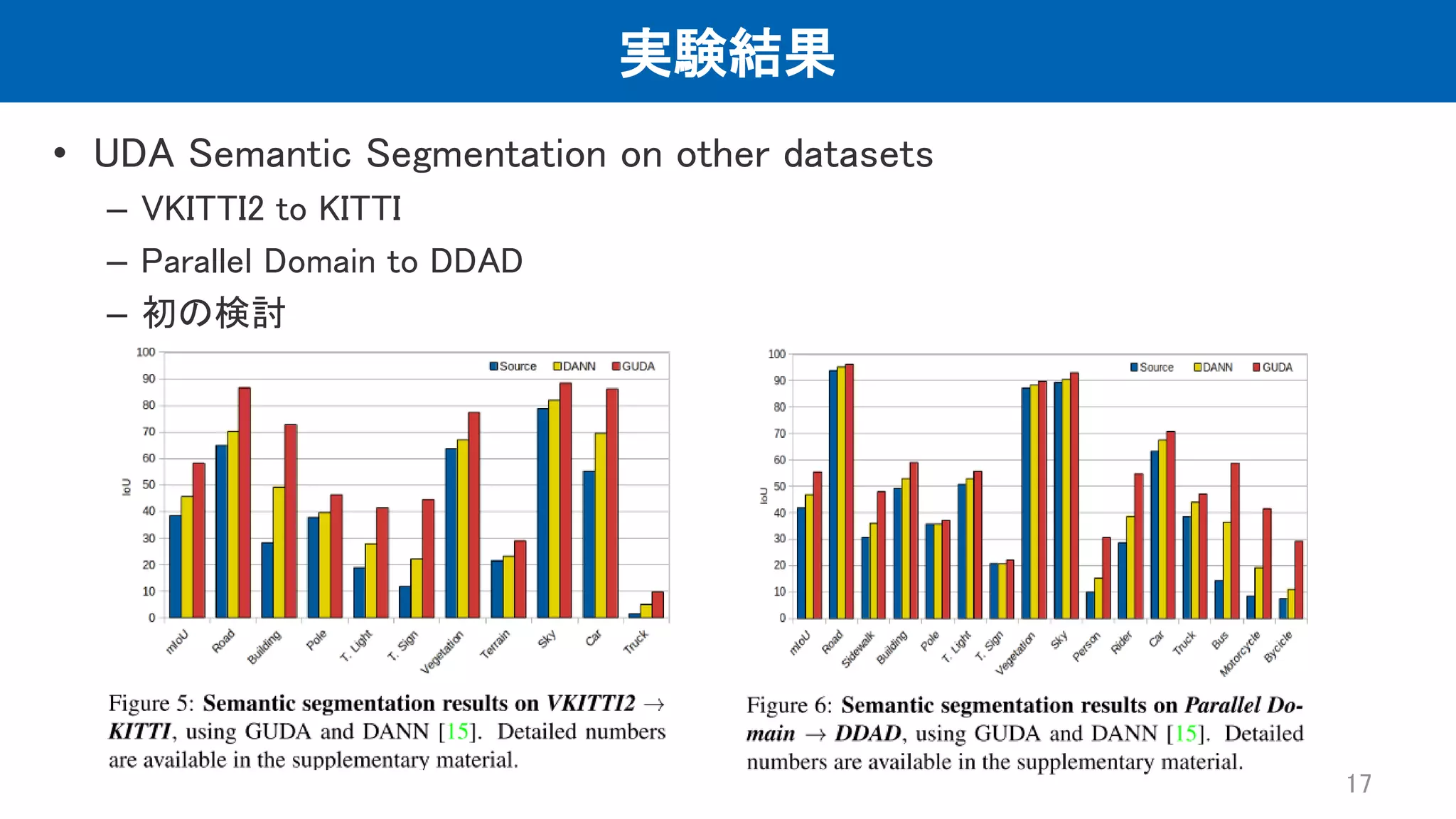
実験結果 • UDA Semantic
Segmentation on other datasets – VKITTI2 to KITTI – Parallel Domain to DDAD – 初の検討 17
18.
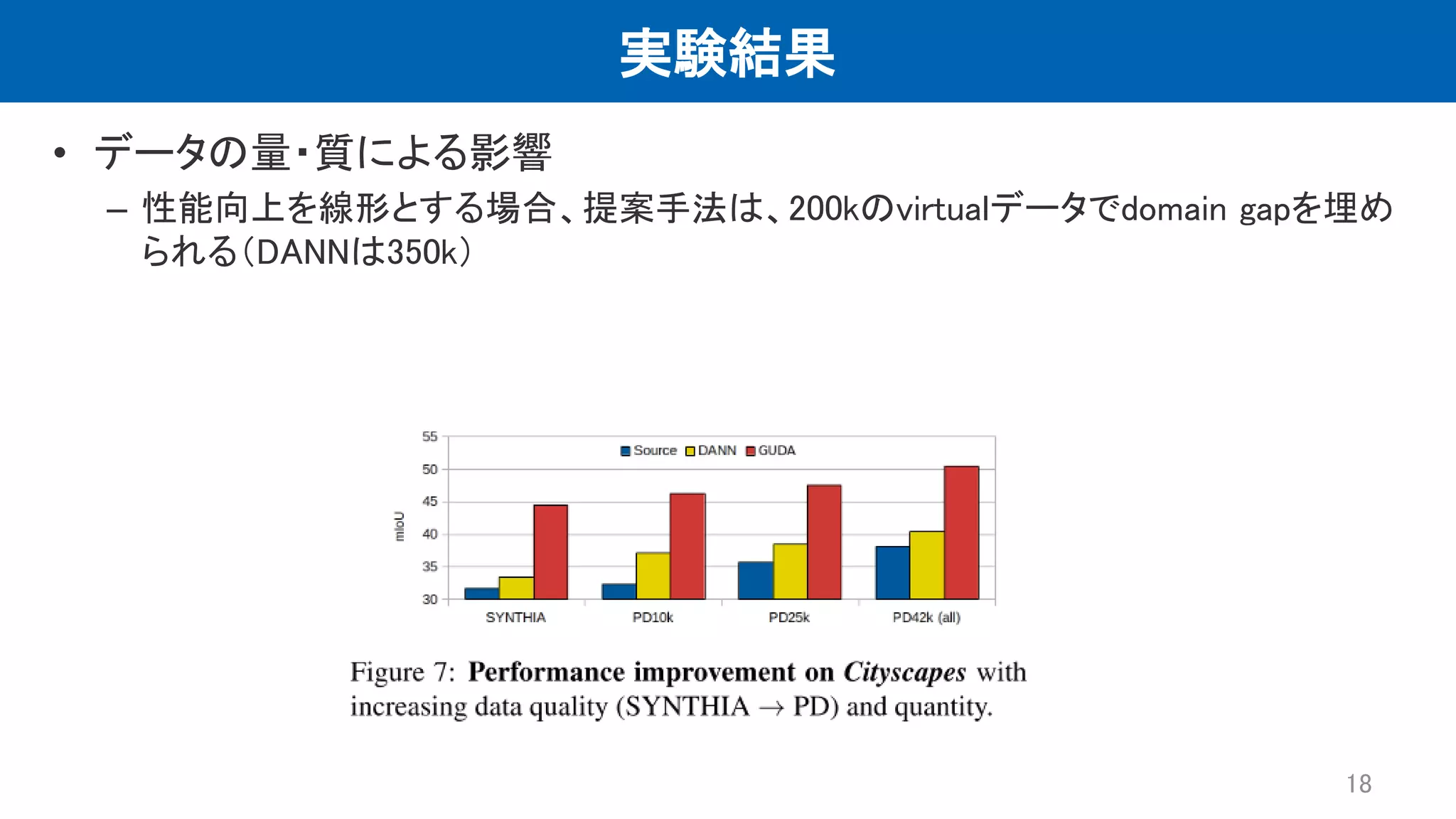
実験結果 • データの量・質による影響 – 性能向上を線形とする場合、提案手法は、200kのvirtualデータでdomain
gapを埋め られる(DANNは350k) 18
19.
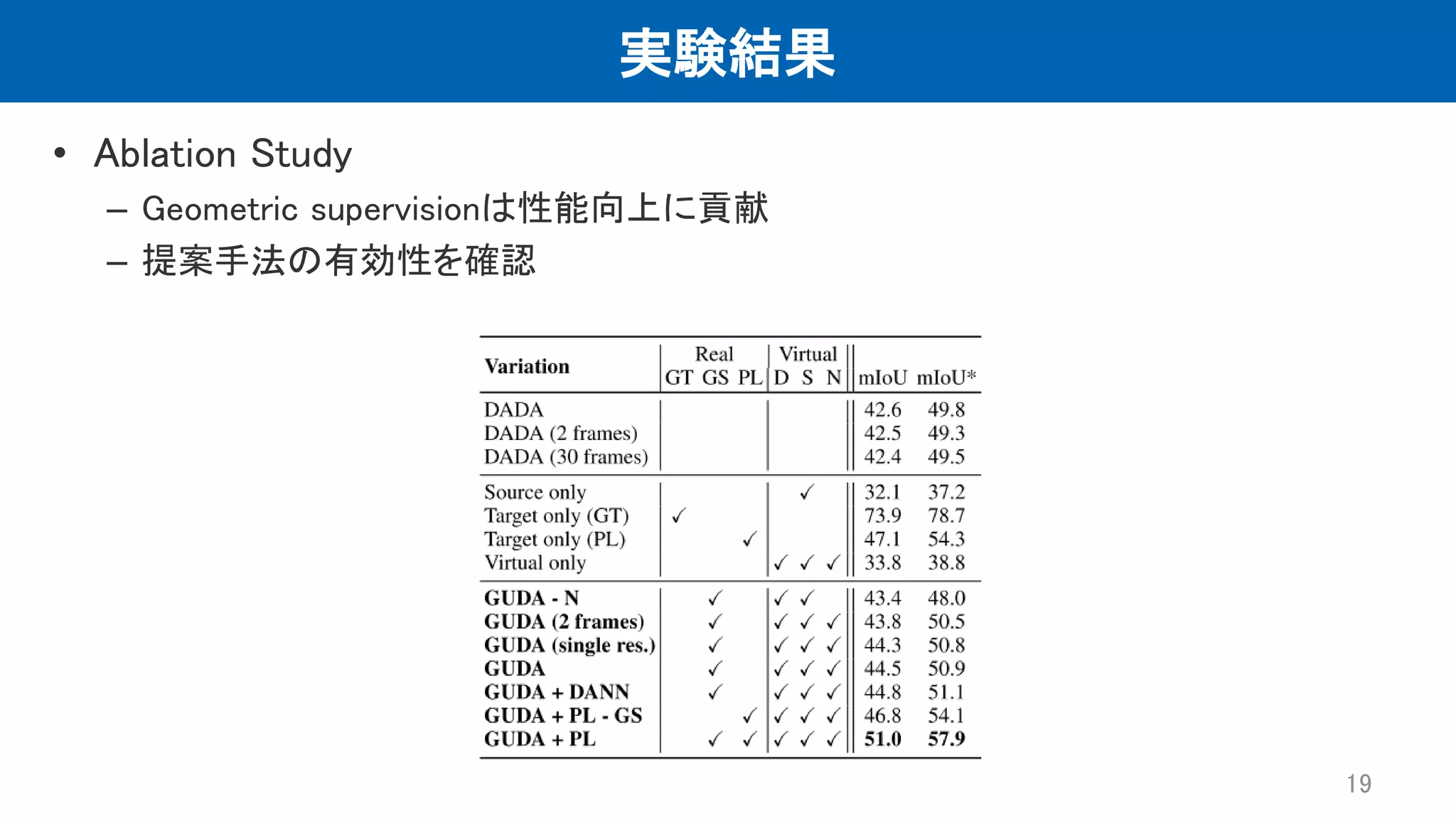
実験結果 • Ablation Study –
Geometric supervisionは性能向上に貢献 – 提案手法の有効性を確認 19
20.
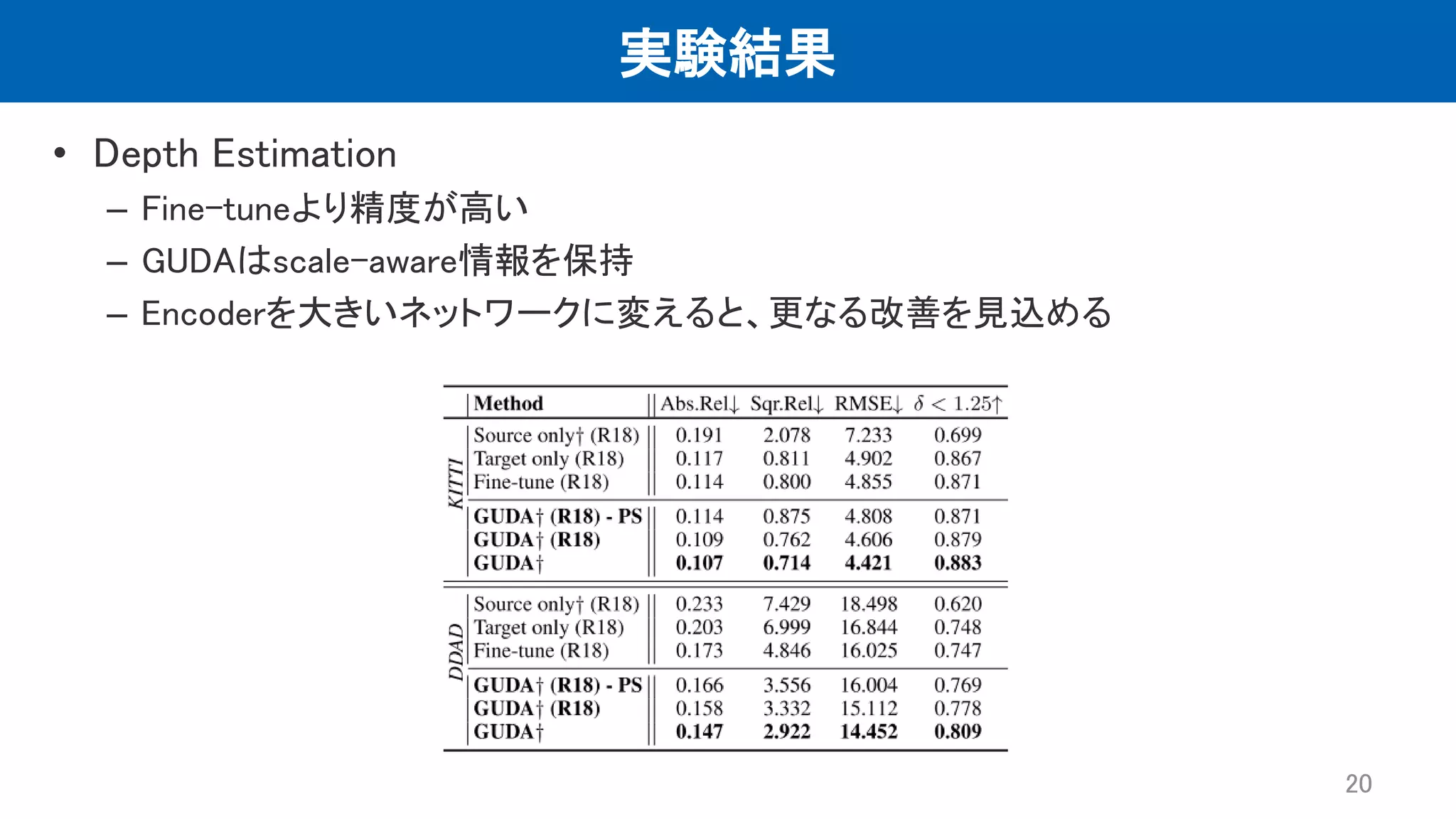
実験結果 • Depth Estimation –
Fine-tuneより精度が高い – GUDAはscale-aware情報を保持 – Encoderを大きいネットワークに変えると、更なる改善を見込める 20
21.
実験結果 • 定性評価 21
22.
まとめ • geometric taskをセグメンテーションとのmulti-task
learningにすることがDAに 有効 • Self-supervised learningで、教師なしかつ、ドメイン情報を学習する必要がな いDAを実現 • 動画を対象になるため、単写真タスクは適用できない(?) 22
Download
![DEEP LEARNING JP [DL Papers] Geometric Unsupervised Domain Adaptation for Semantic Segmentation Yuting Lin, Kokusai Kogyo Co., Ltd.(国際航業) http://deeplearning.jp/ 1](https://image.slidesharecdn.com/20220121gudalin-220121050547/75/DL-Geometric-Unsupervised-Domain-Adaptation-for-Semantic-Segmentation-1-2048.jpg)












![実験の設定 • ネットワーク – Shared backbone: ResNet101 w/ ImageNet pre-trained – Depth/semantic decoder: [1] – Pose encoder: ResNet18 w/ ImageNet pre-trained – Pose decoder: conv layers数個 • Datasets – Real datasets: Cityscapes, KITTI, DDAD – Virtual datasets: SYNTHIA, VKITTI2, Parallel Domain, GTA5 15 [1] Digging Into Self-Supervised Monocular Depth Estimation. https://arxiv.org/pdf/1806.01260.pdf](https://image.slidesharecdn.com/20220121gudalin-220121050547/75/DL-Geometric-Unsupervised-Domain-Adaptation-for-Semantic-Segmentation-15-2048.jpg)