Downloaded 21 times


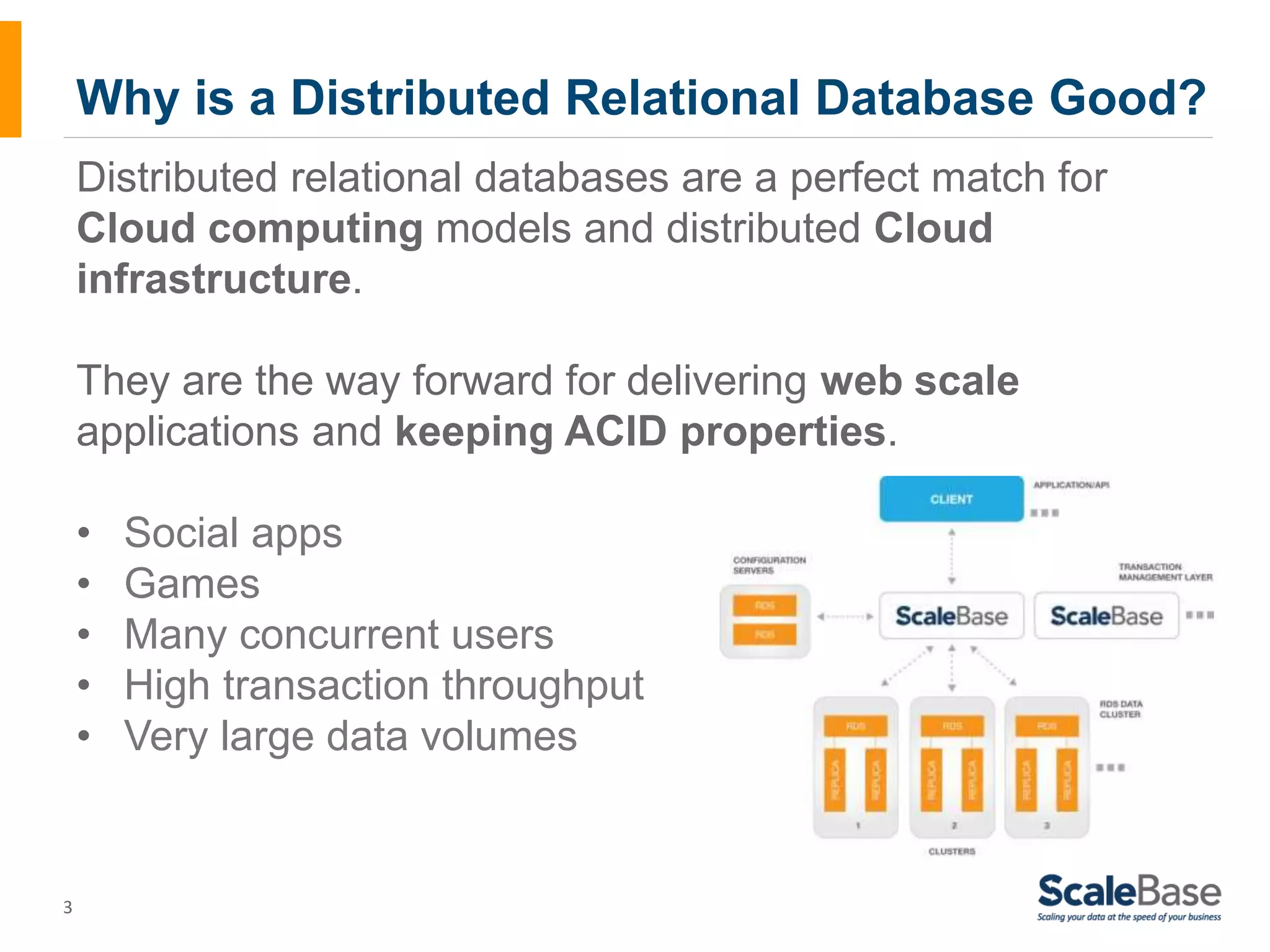












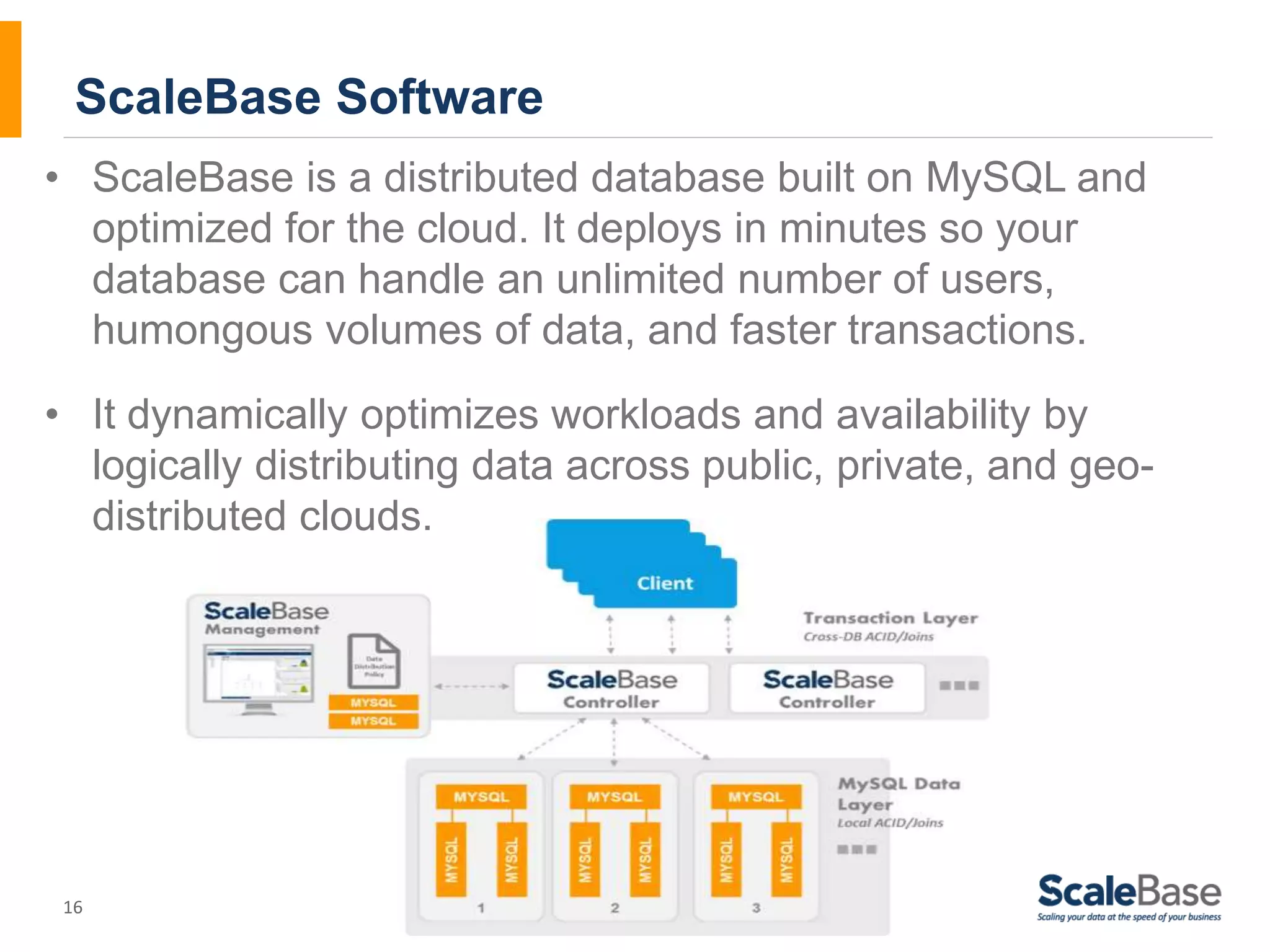




This document discusses how data distribution policies for distributed relational database systems (RDBMS) need to change and adapt over time to match evolving application usage patterns, workloads, and business needs. It outlines three stages in a data distribution policy's lifecycle where changes are needed: 1) changing demand and traffic loads, 2) changing application usage, and 3) new product capabilities. The key to adapting is regularly "rebalancing" the distributed database by modifying the data distribution policy using software that separates this logic from the application code.