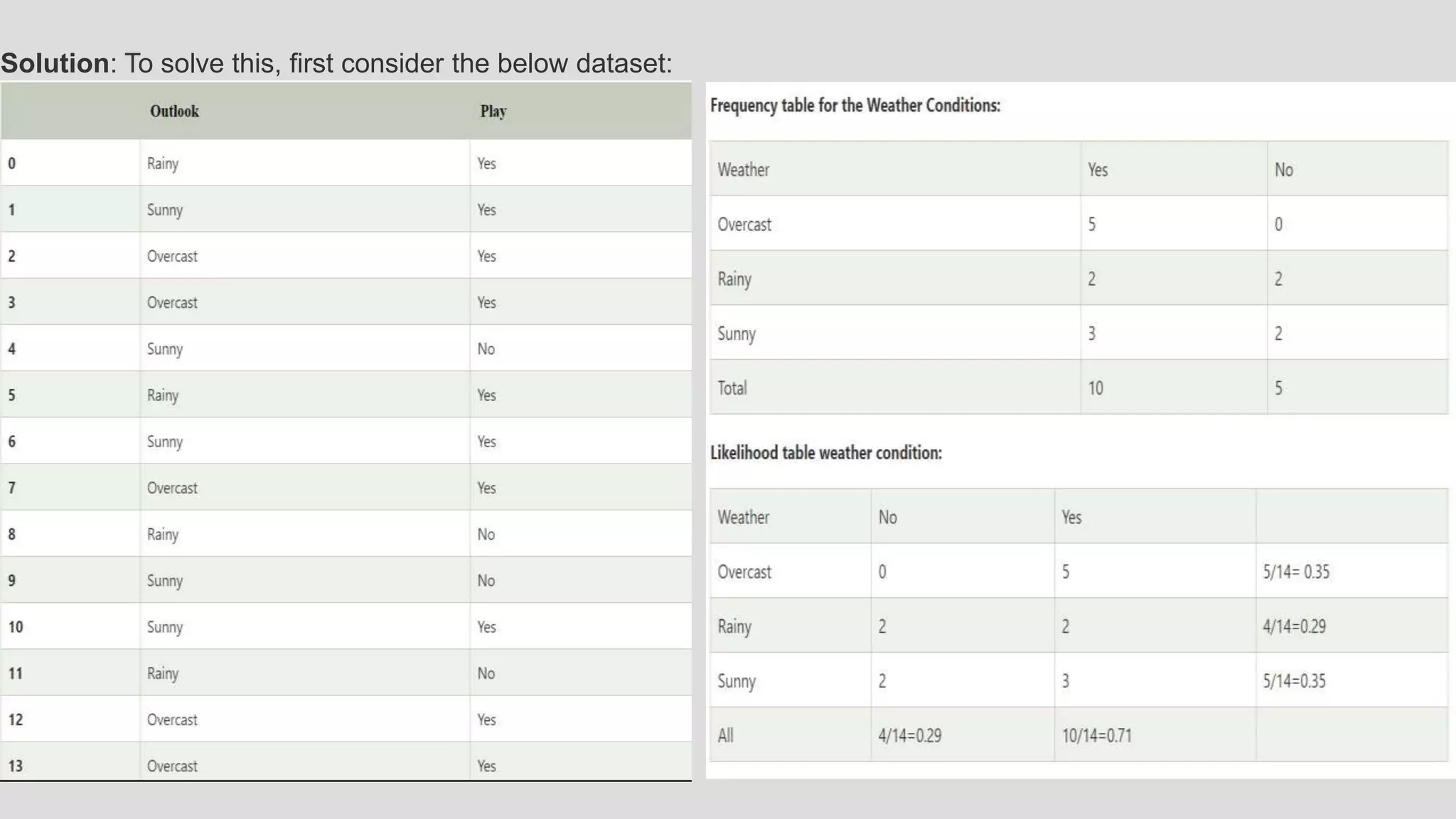
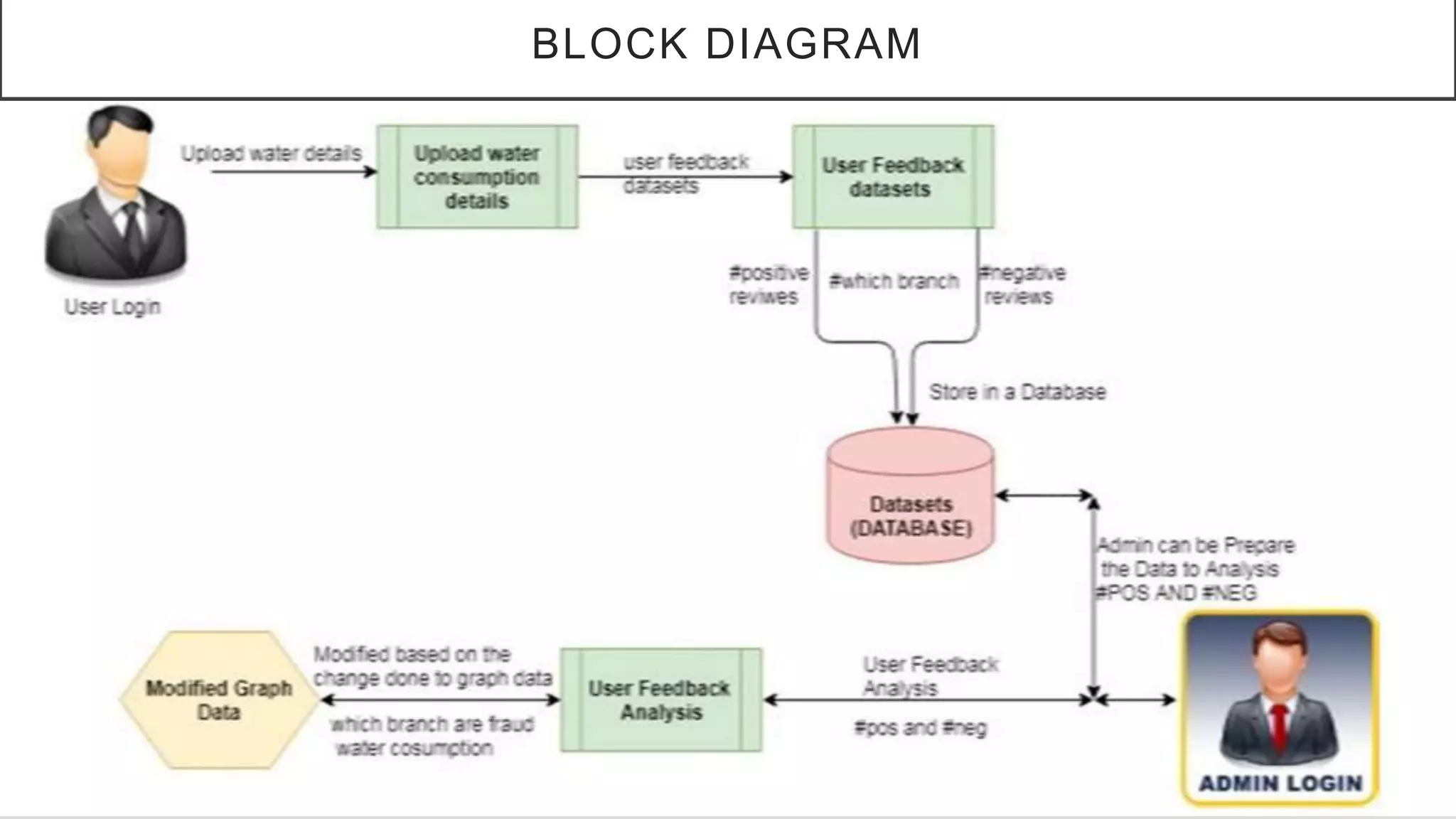
This document discusses detecting fraudulent water consumption behavior using data mining models. It proposes using decision tree and Bayesian classification techniques to analyze customer usage data and identify abnormal patterns indicative of fraud. The existing system causes losses from non-technical water losses. The proposed system focuses on applying decision trees and Bayesian classifiers to historical meter data to create a model for identifying suspicious fraudulent customers based on their water usage patterns.