Download to read offline




![What are microservices? In computing, microservices is a software architecture style in which complex applications are composed of small, independent processes communicating with each other using language- agnostic APIs.[1] These services are small building blocks, highlydecoupled and focussed on doing a small task, facilitating a modular approach to system- building.[5]](https://image.slidesharecdn.com/designingdistributedsystems-160504102043/75/Designing-distributed-systems-5-2048.jpg)


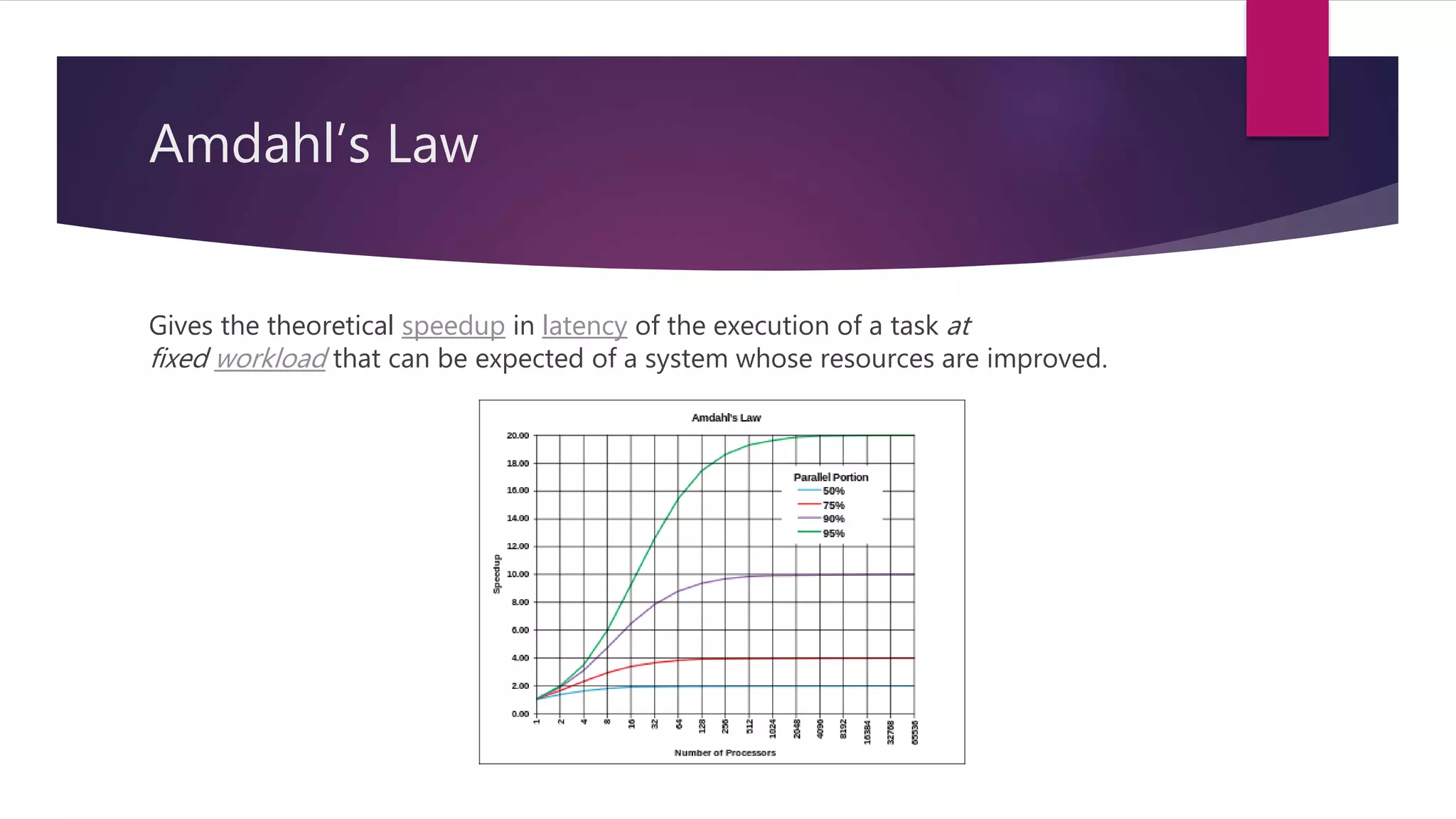


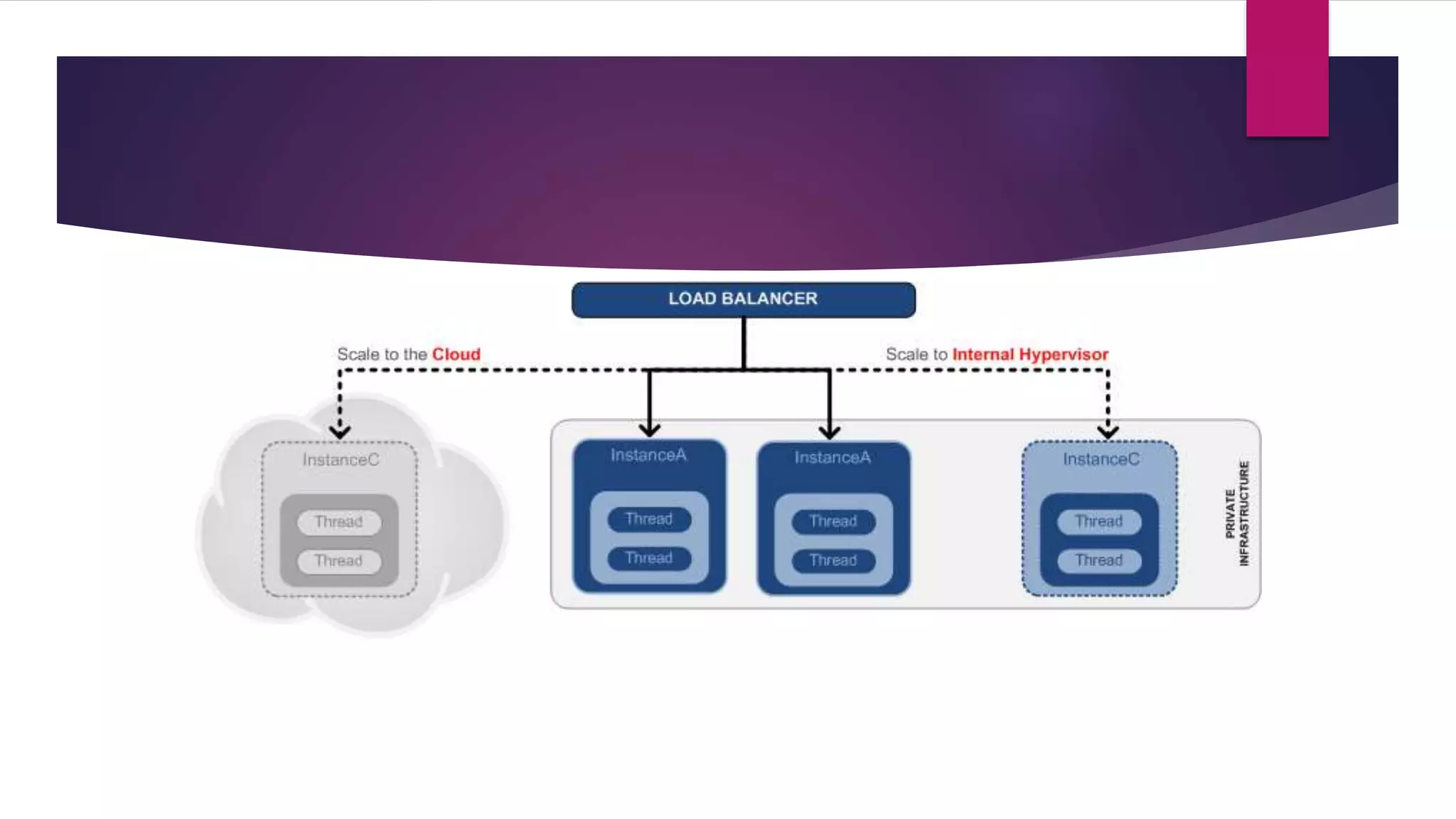





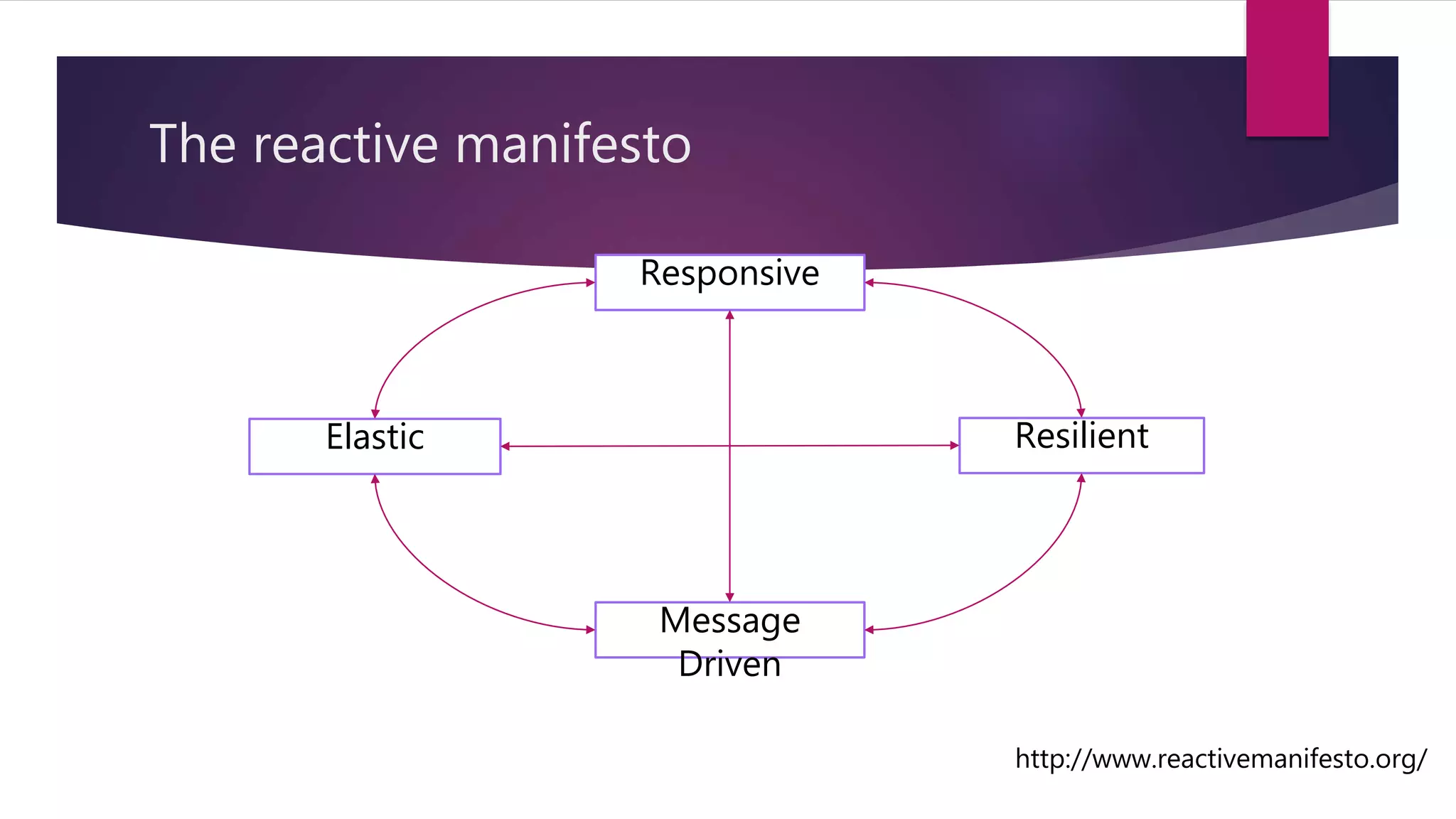



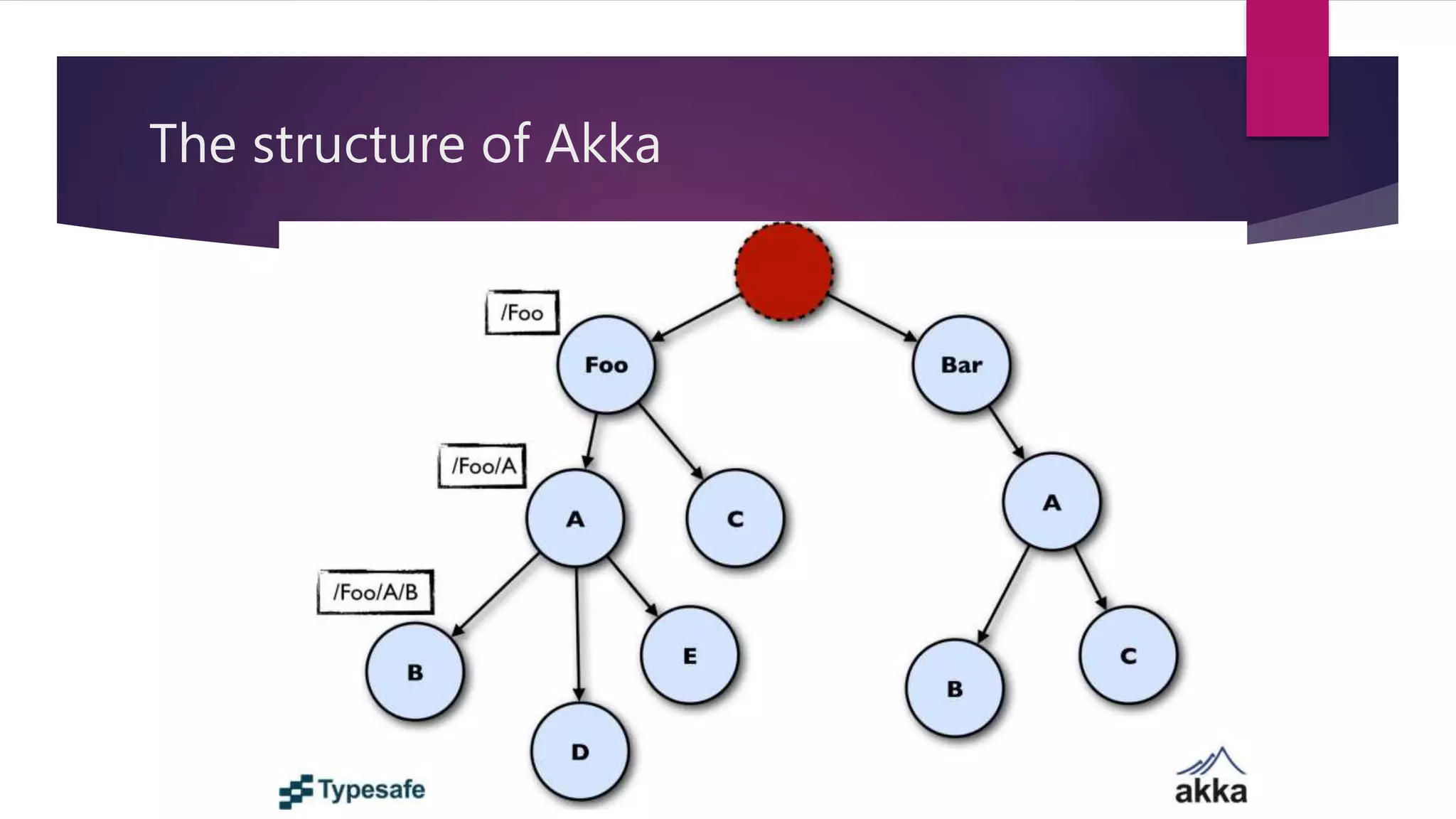







This document summarizes a talk on designing distributed systems. It discusses distributed computing paradigms like microservices and cloud computing. It also covers reactive system principles from the Reactive Manifesto like being responsive, resilient and message-driven. It then explains the actor model used in frameworks like Akka, where actors communicate asynchronously through message passing. It provides examples of using actors for concurrency and fault tolerance.