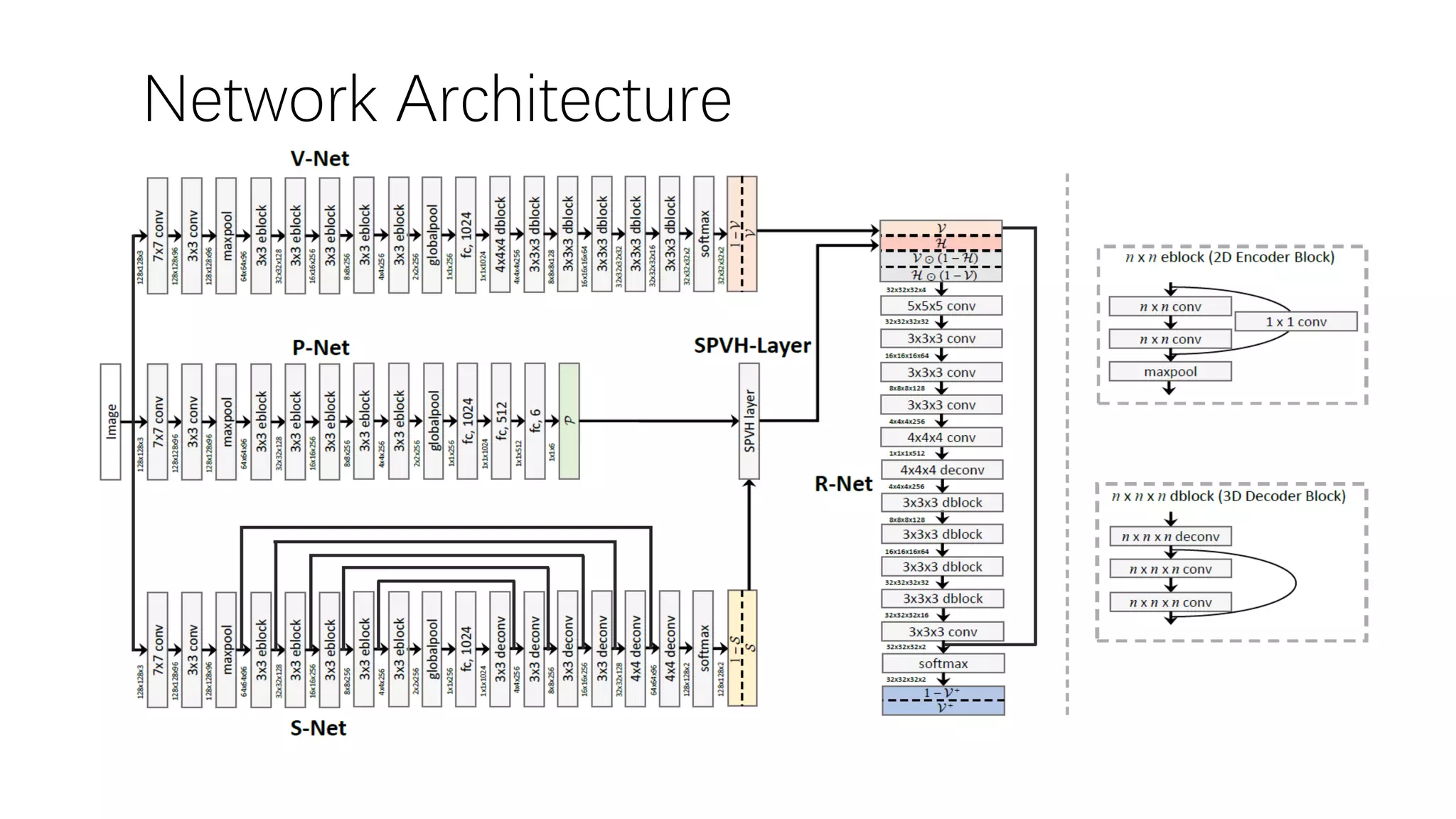
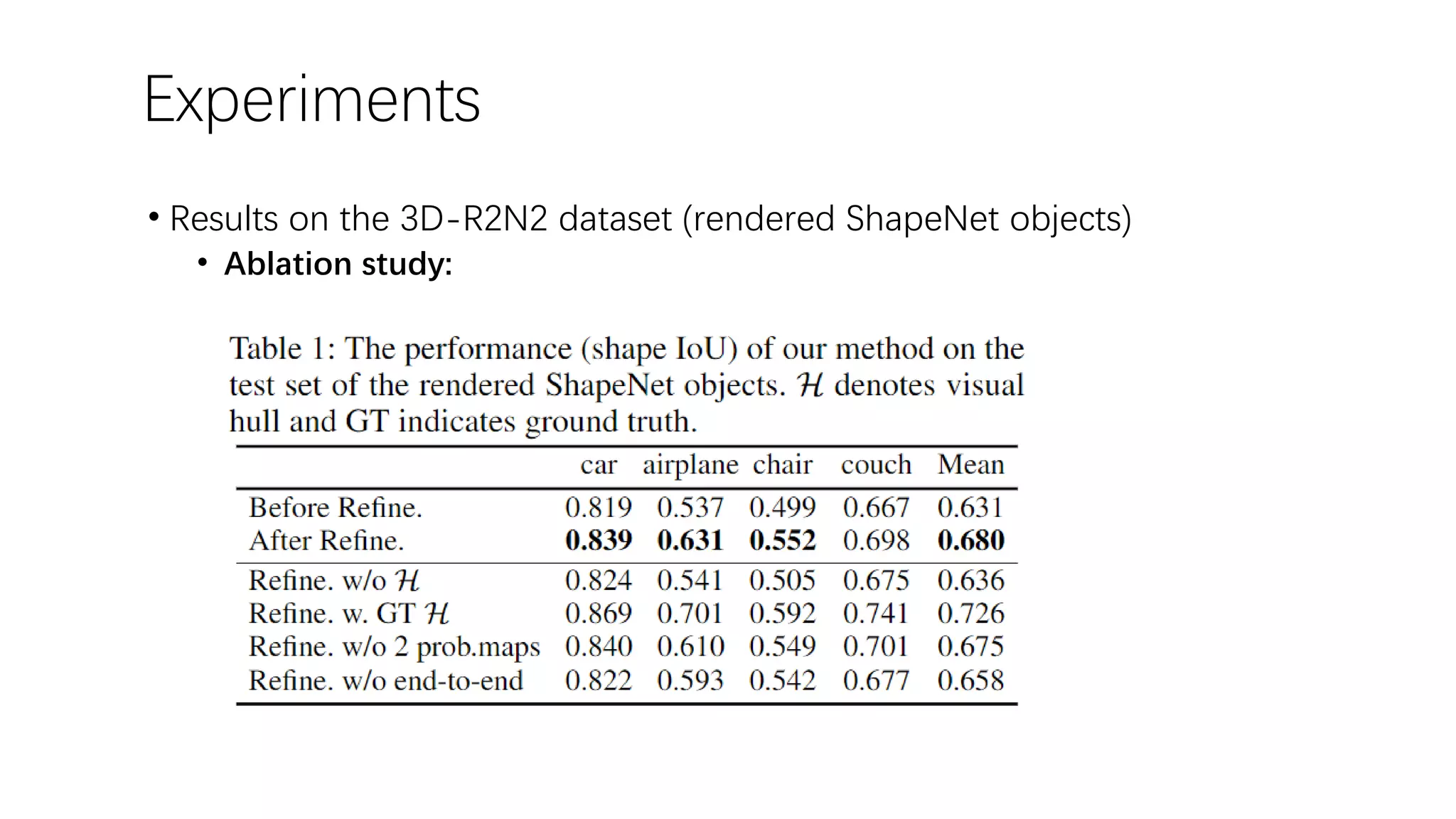
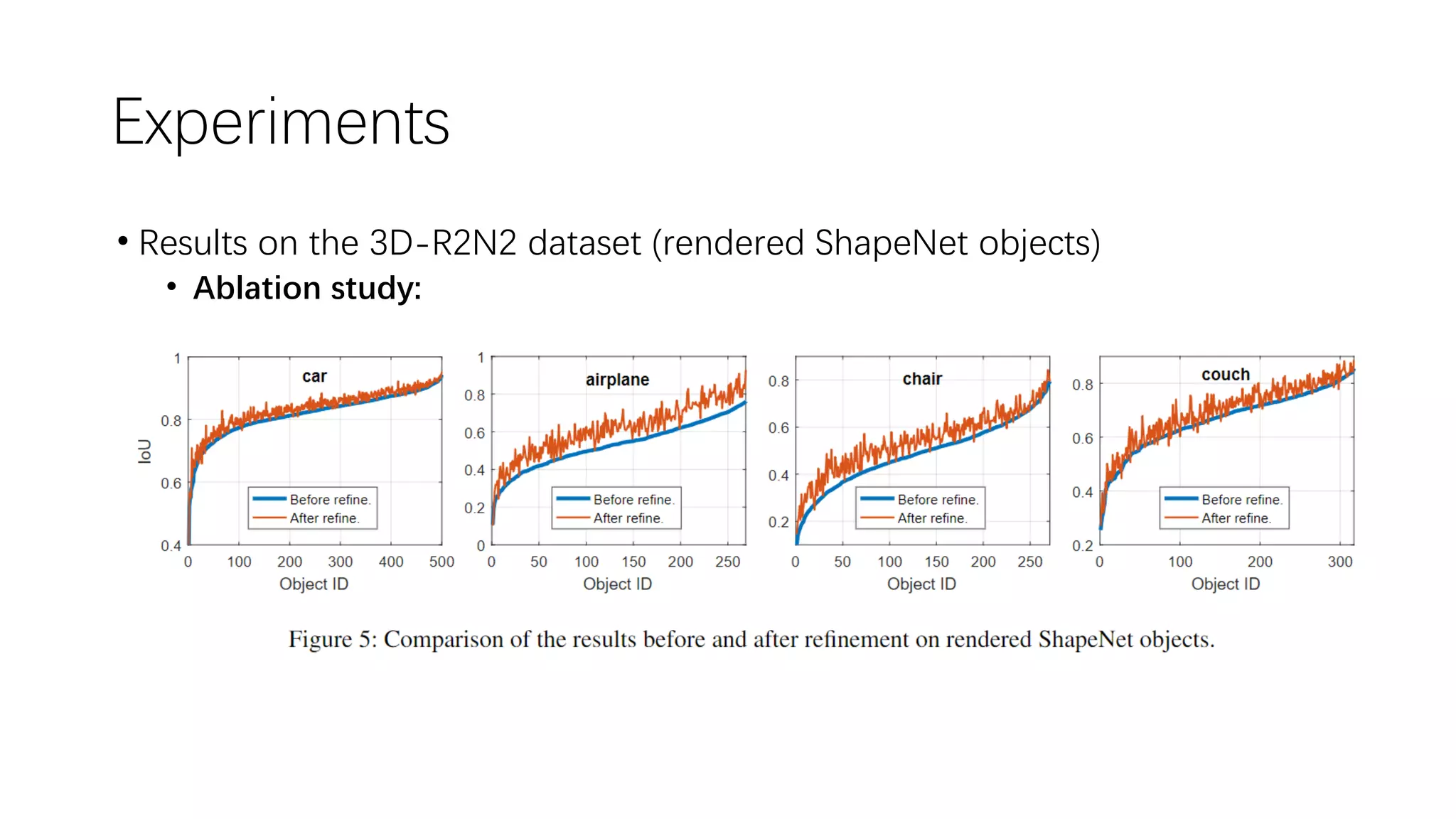
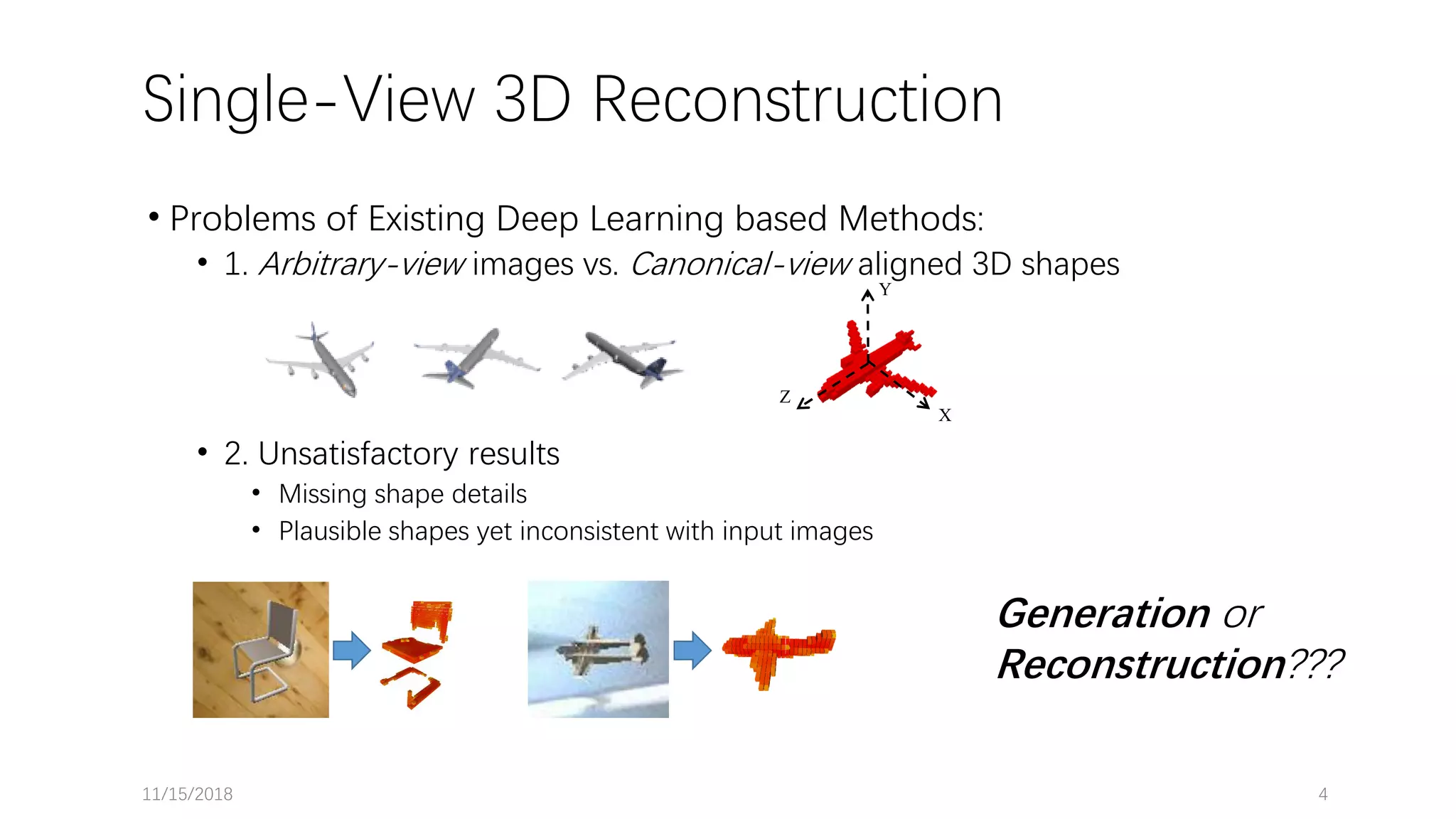
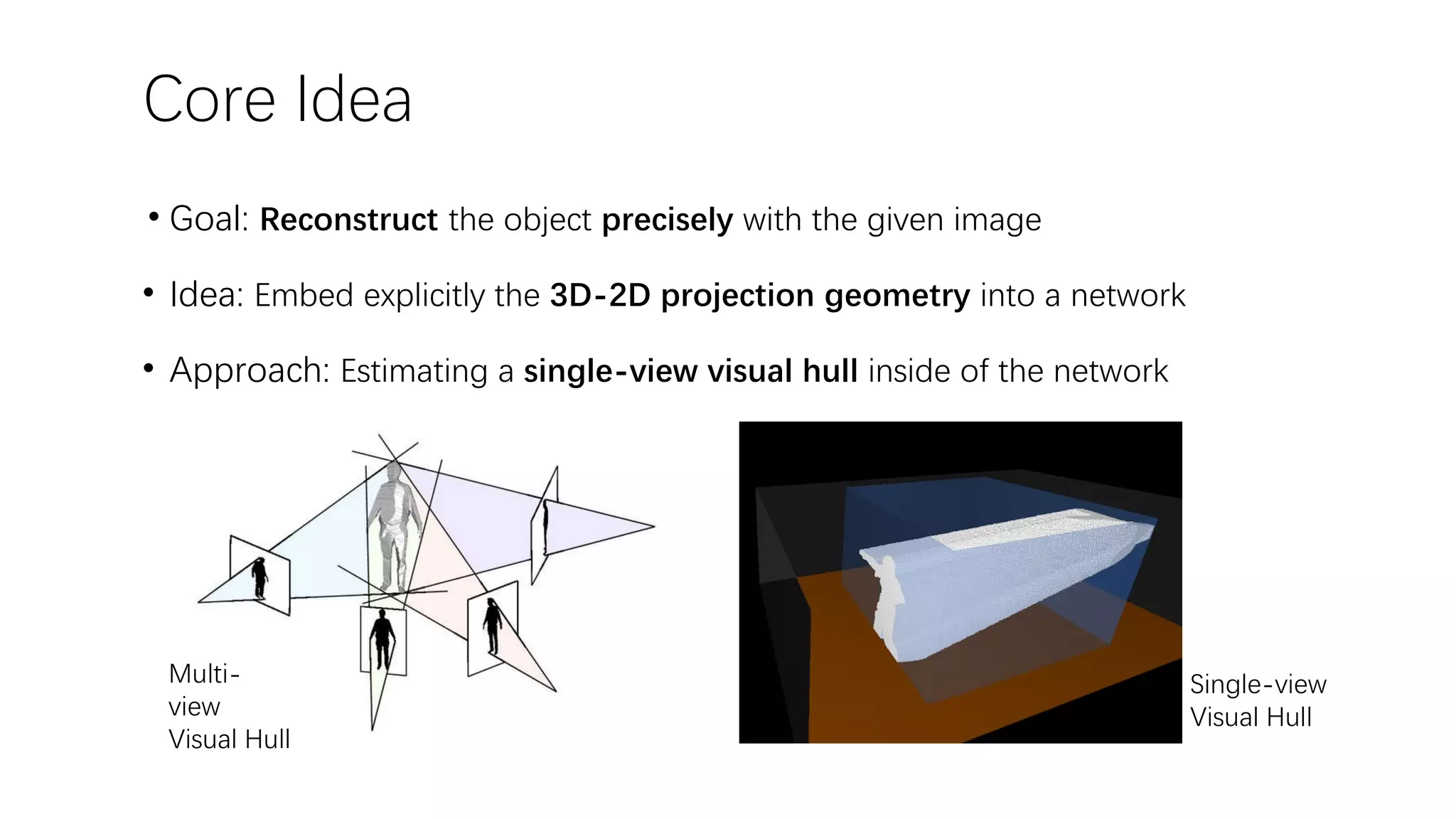
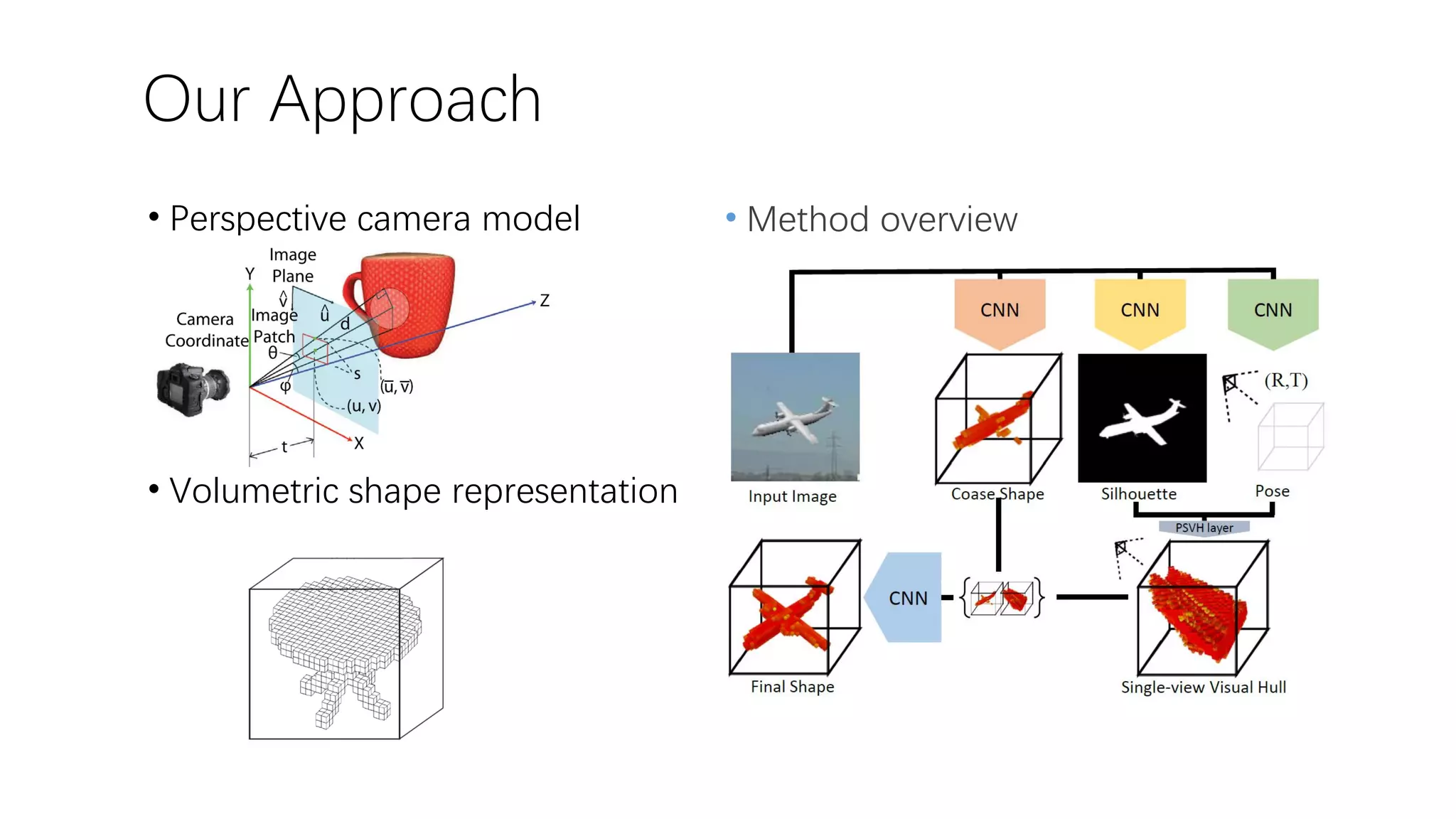
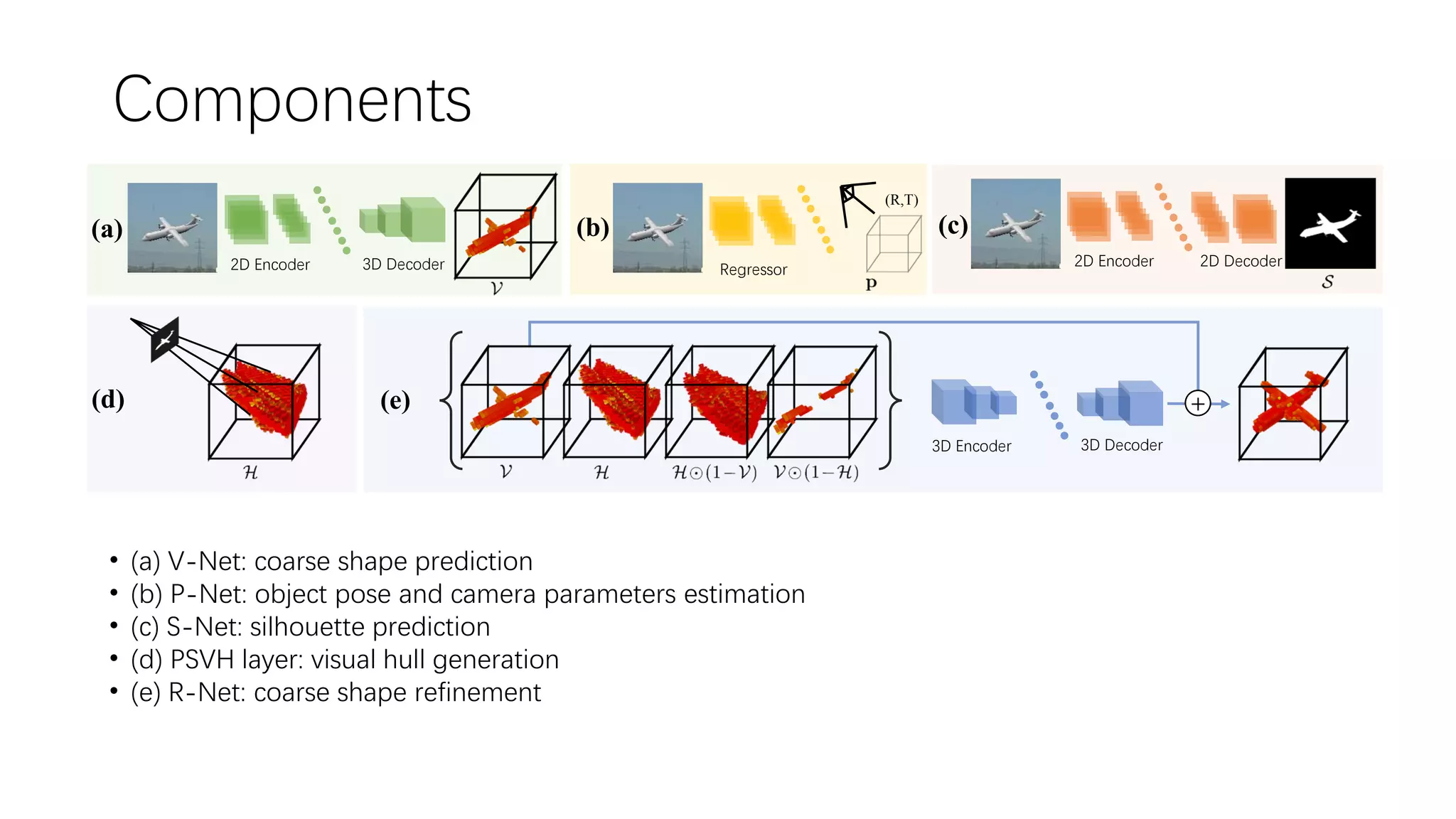
The document presents a novel deep learning approach for single-view 3D object reconstruction utilizing a network that embeds 3D-2D projection geometry. Key components include a visual hull generation and a probabilistic layer for reconstructing object shapes, poses, and segmentations from a single RGB(D) image. The proposed method shows significant improvements over existing techniques, addressing limitations like missing details and inconsistencies with input images.


![Single-View 3D Reconstruction • Deep Learning based Methods: [Girdhar ECCV’16] [Choy ECCV’16] Other works: Yan NIPS’16; Wu NIPS’16; Tulsiani CVPR’17; Zhu ICCV’17…](https://image.slidesharecdn.com/deepsingle-view3dobjectreconstructionwithvisualhull-181114173650/75/Deep-single-view-3-d-object-reconstruction-with-visual-hull-3-2048.jpg)
![Projection Details The relationship between a 3D point (𝑋, 𝑌, 𝑍) and its projected pixel location (𝑢, 𝑣) on the image is (1) Where the camera intrinsic matrix , is the rotation matrix generated by three Euler angles, noted as , is the translation vector. For translation we estimate 𝑡 𝑍 and a 2D vector [𝑡 𝑢, 𝑡 𝑣] which centralizes the object on image plane, and obtain 𝑡 via 𝑡 𝑢 𝑓 ∗ 𝑡 𝑍, 𝑡 𝑣 𝑓 ∗ 𝑡 𝑍, 𝑡 𝑍 𝑇 . In summary, we parameterize the pose as a 6-D vector 𝑍 𝑢, 𝑣, 1 𝑇 = K(R 𝑋, 𝑌, 𝑍 𝑇 + 𝑡) K = 𝑓 0 𝑢0 0 𝑓 𝑣0 0 0 1 R ∈ SO(3) 𝑡 = 𝑡 𝑋, 𝑡 𝑌, 𝑡 𝑧 𝑇 ∈ ℝ3[𝜃1, 𝜃2, 𝜃3] 𝑝 = 𝜃1, 𝜃2, 𝜃3, 𝑡 𝑢, 𝑡 𝑣, 𝑡 𝑧 𝑇](https://image.slidesharecdn.com/deepsingle-view3dobjectreconstructionwithvisualhull-181114173650/75/Deep-single-view-3-d-object-reconstruction-with-visual-hull-8-2048.jpg)