Downloaded 113 times




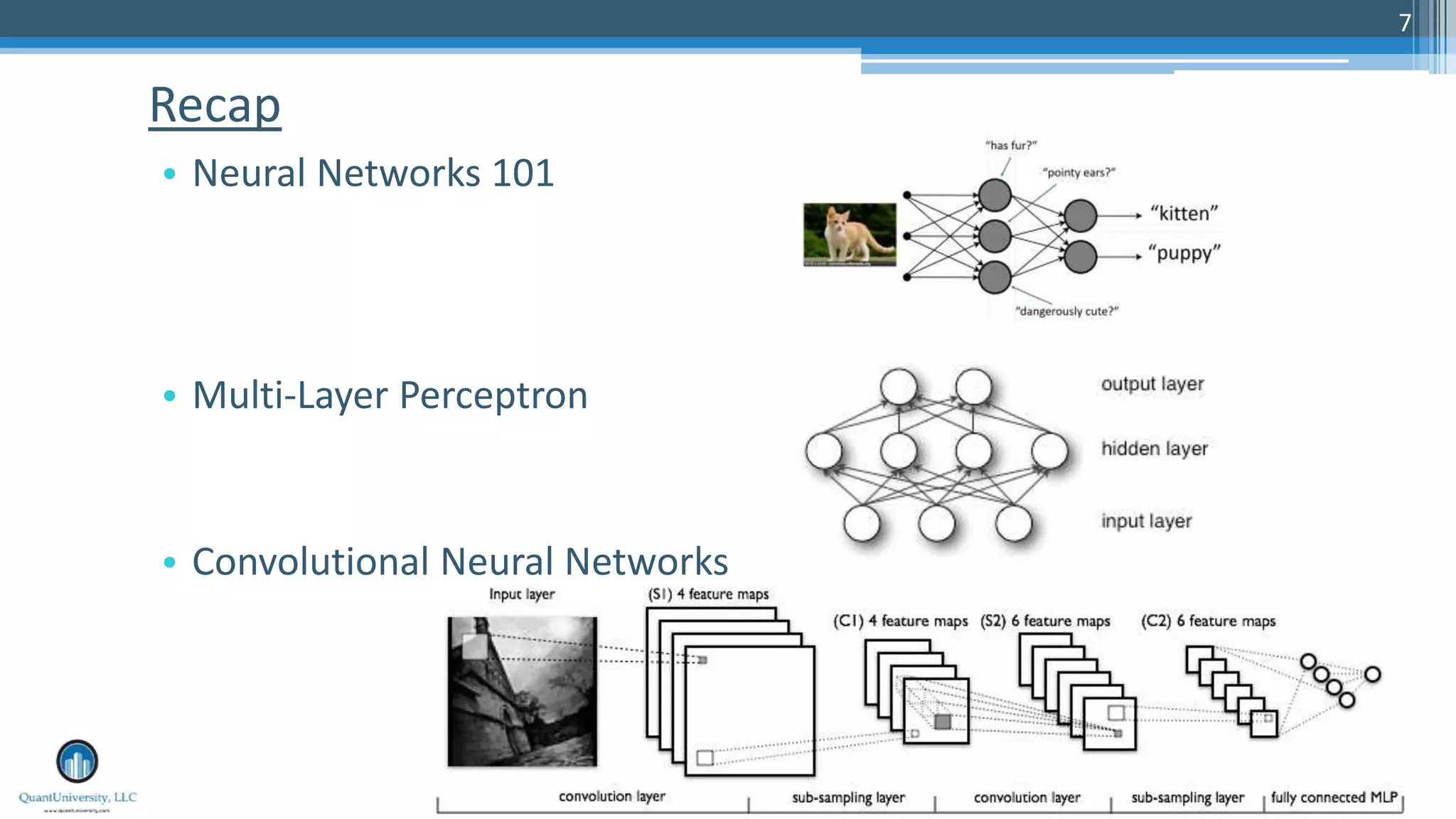

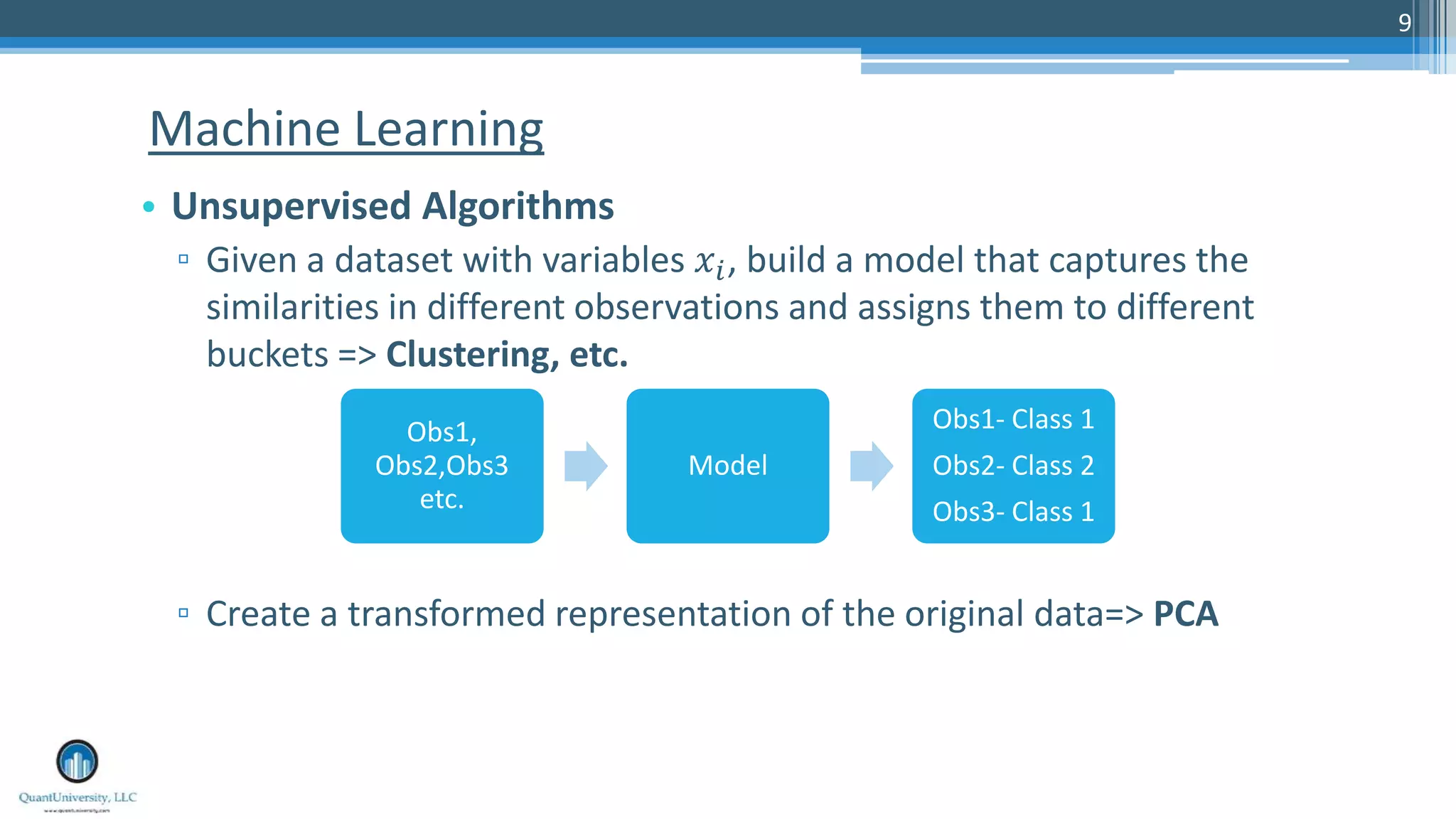


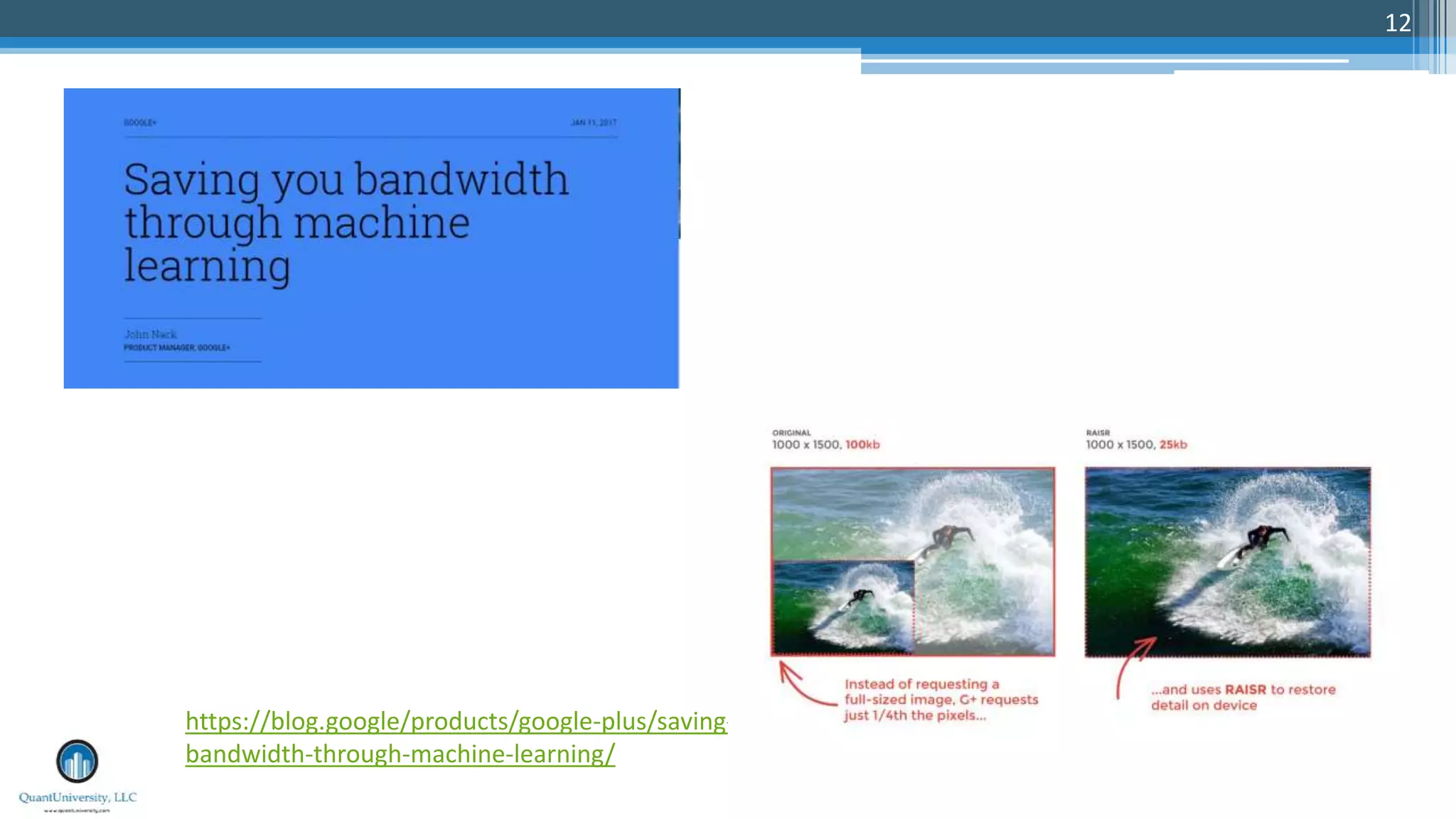
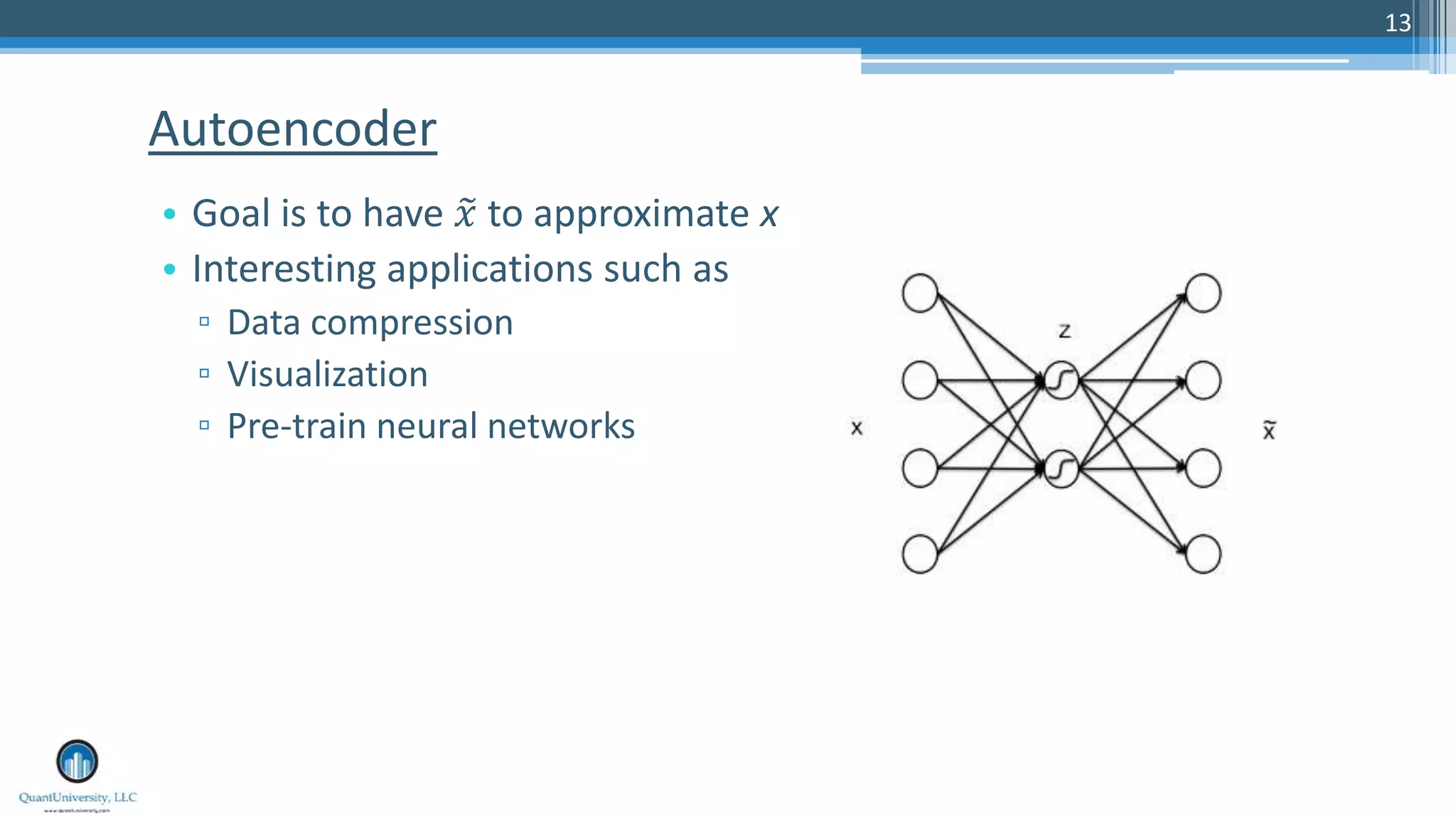
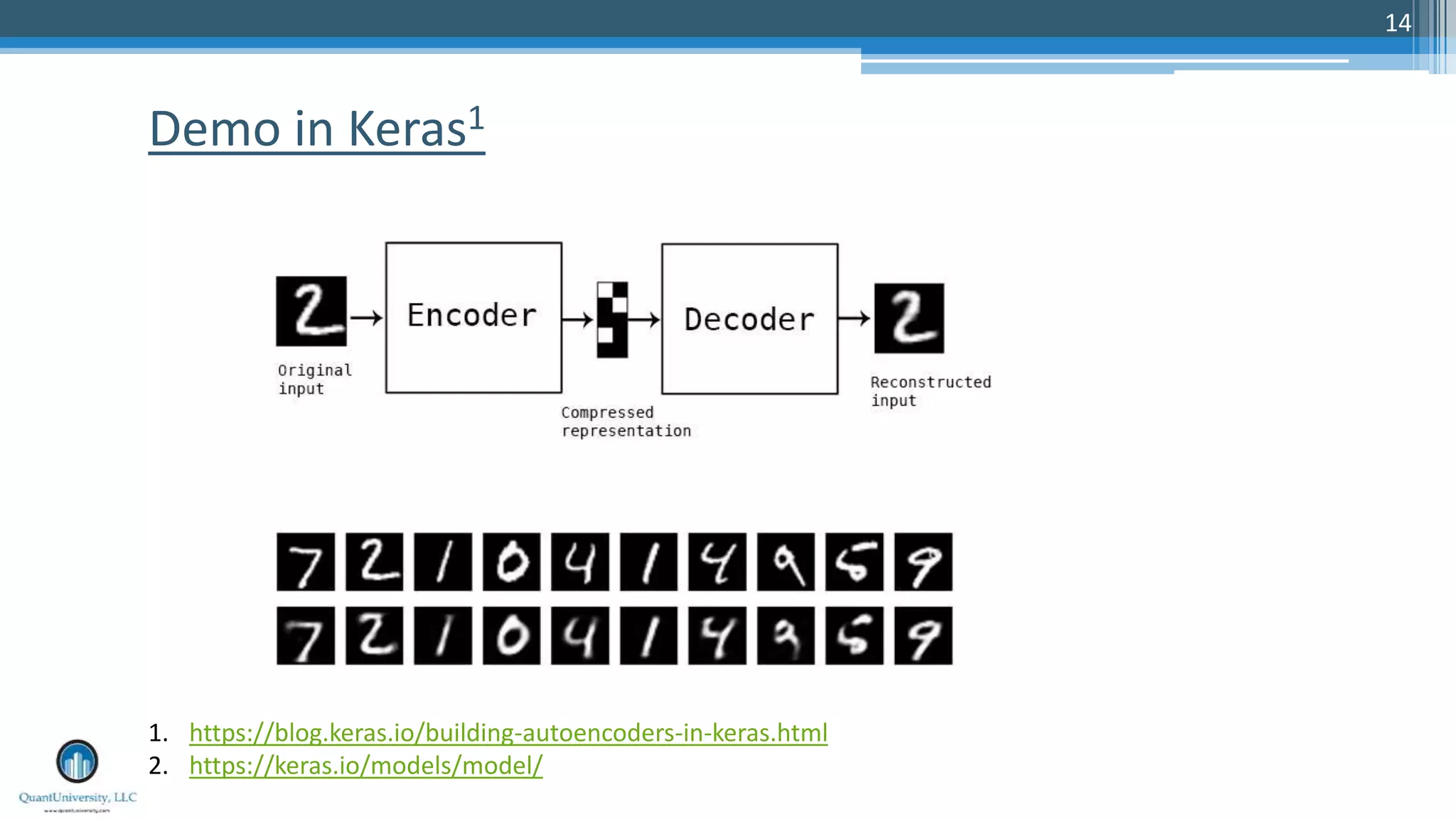

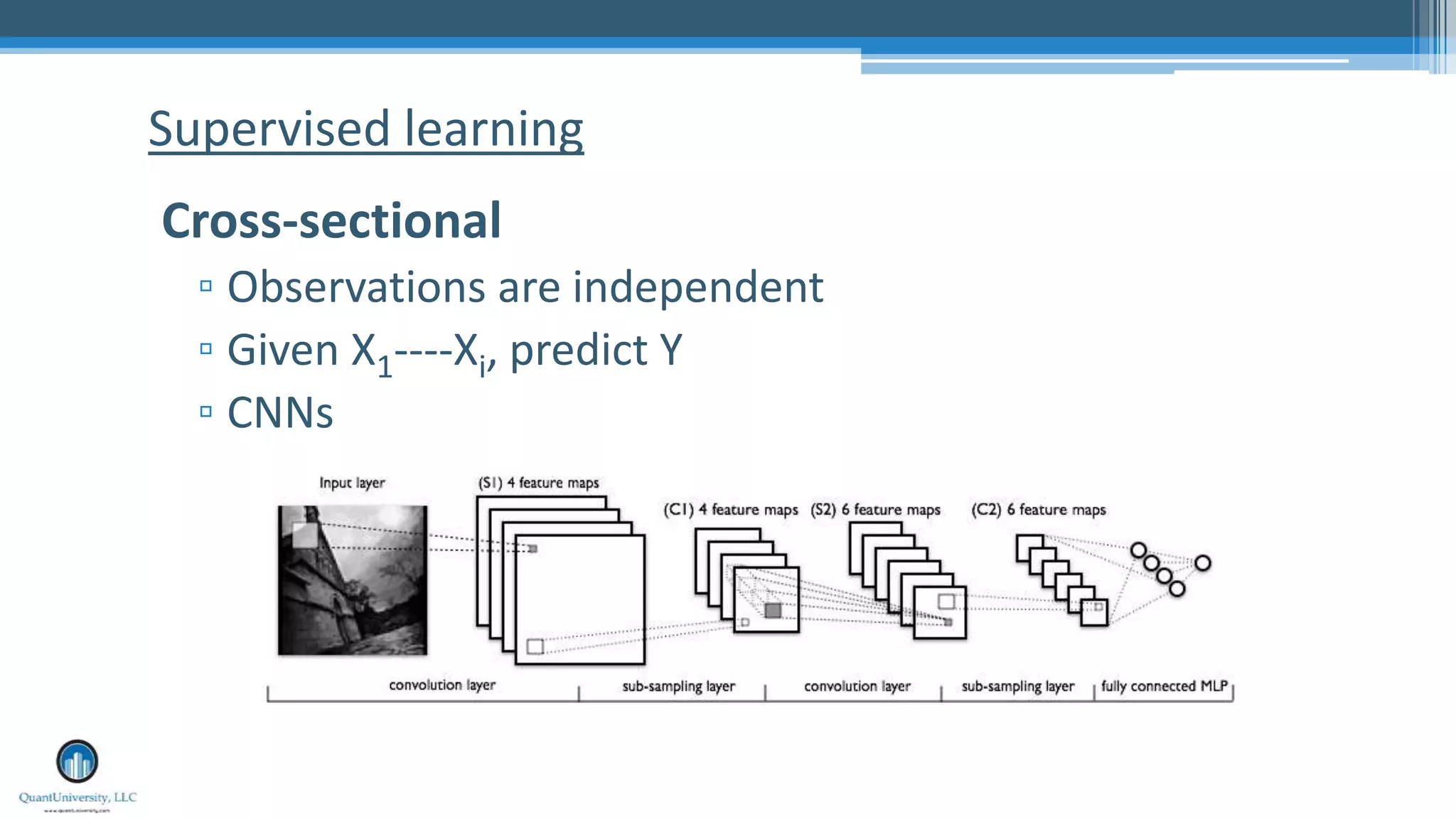

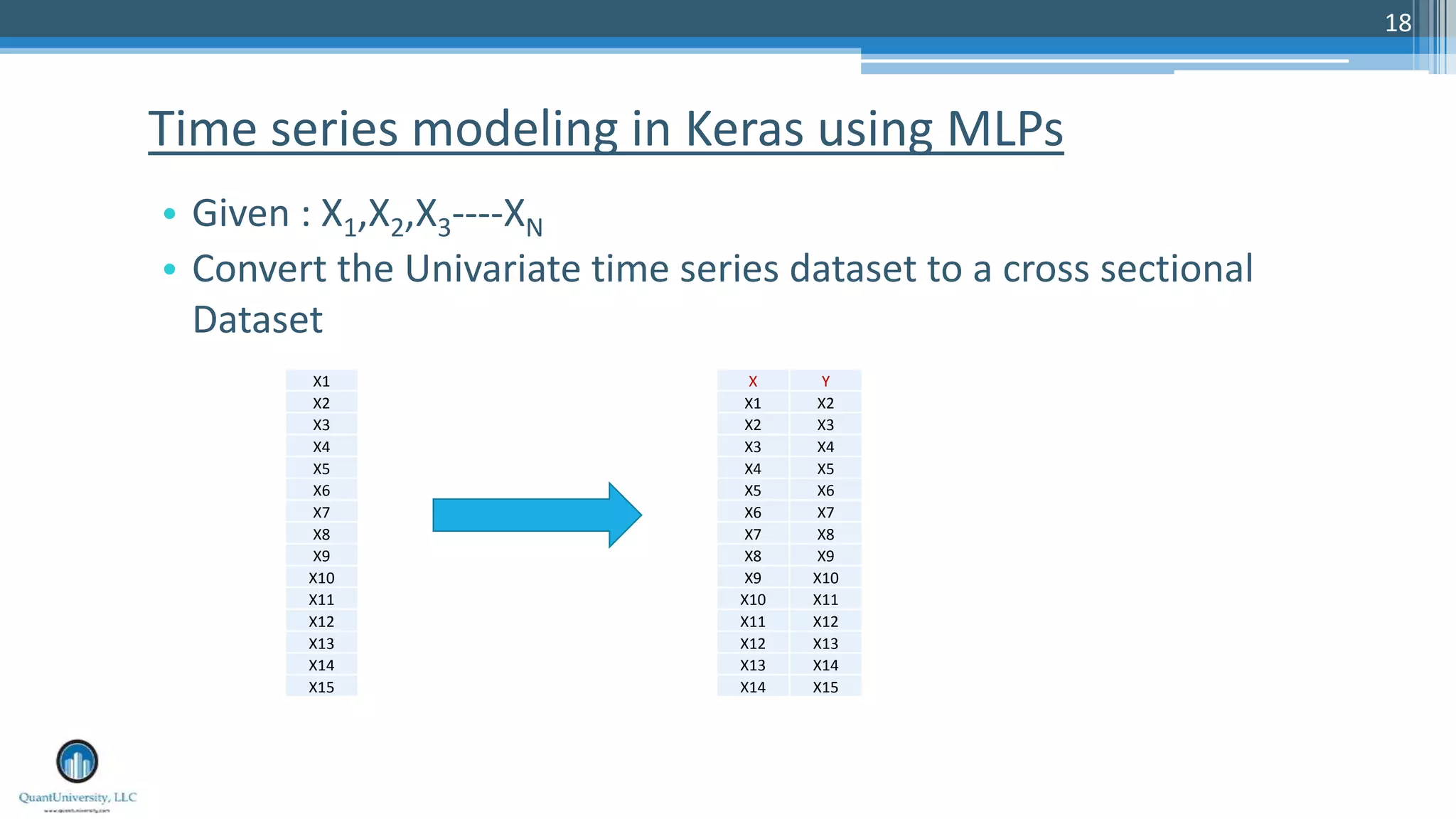
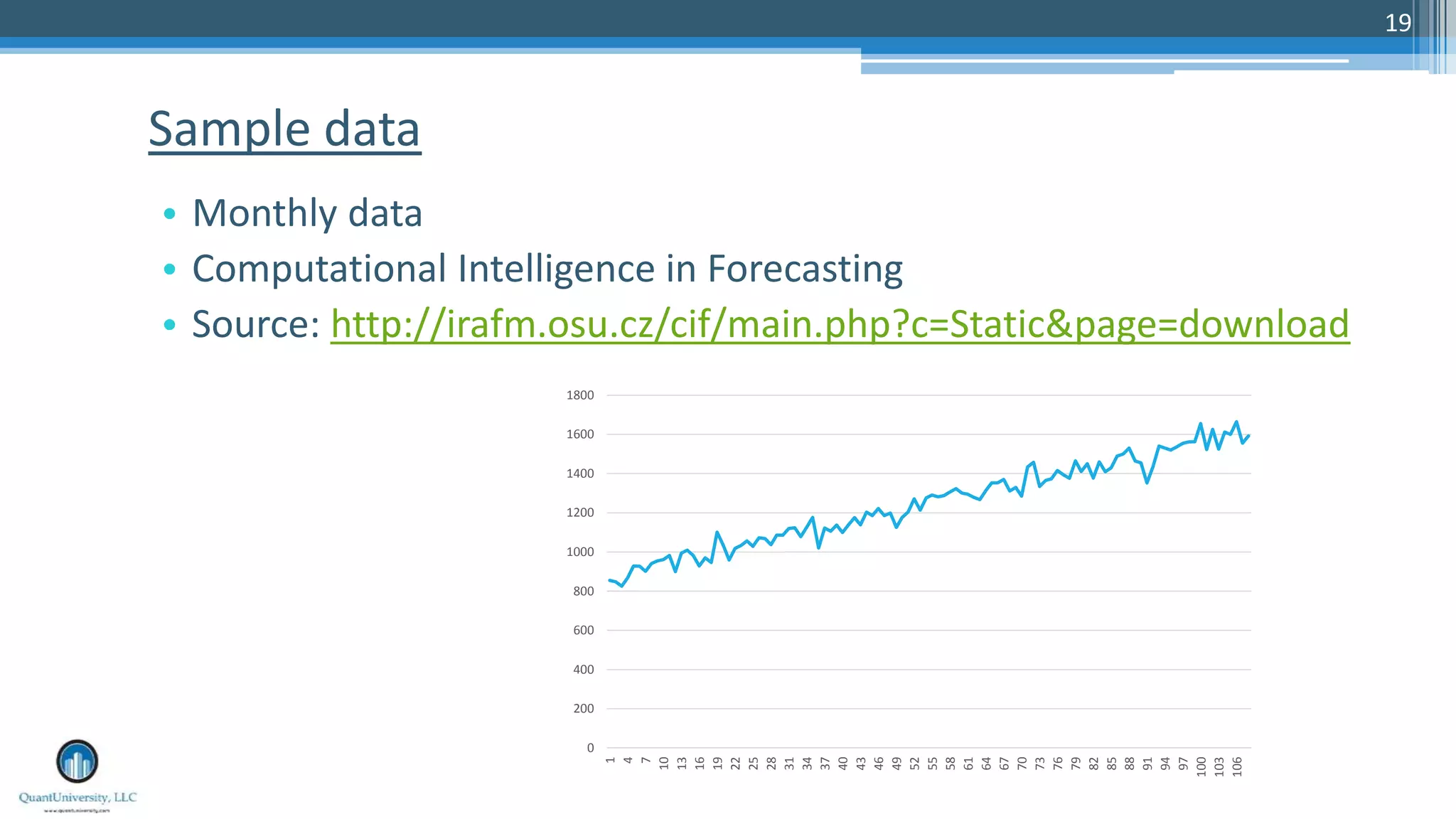

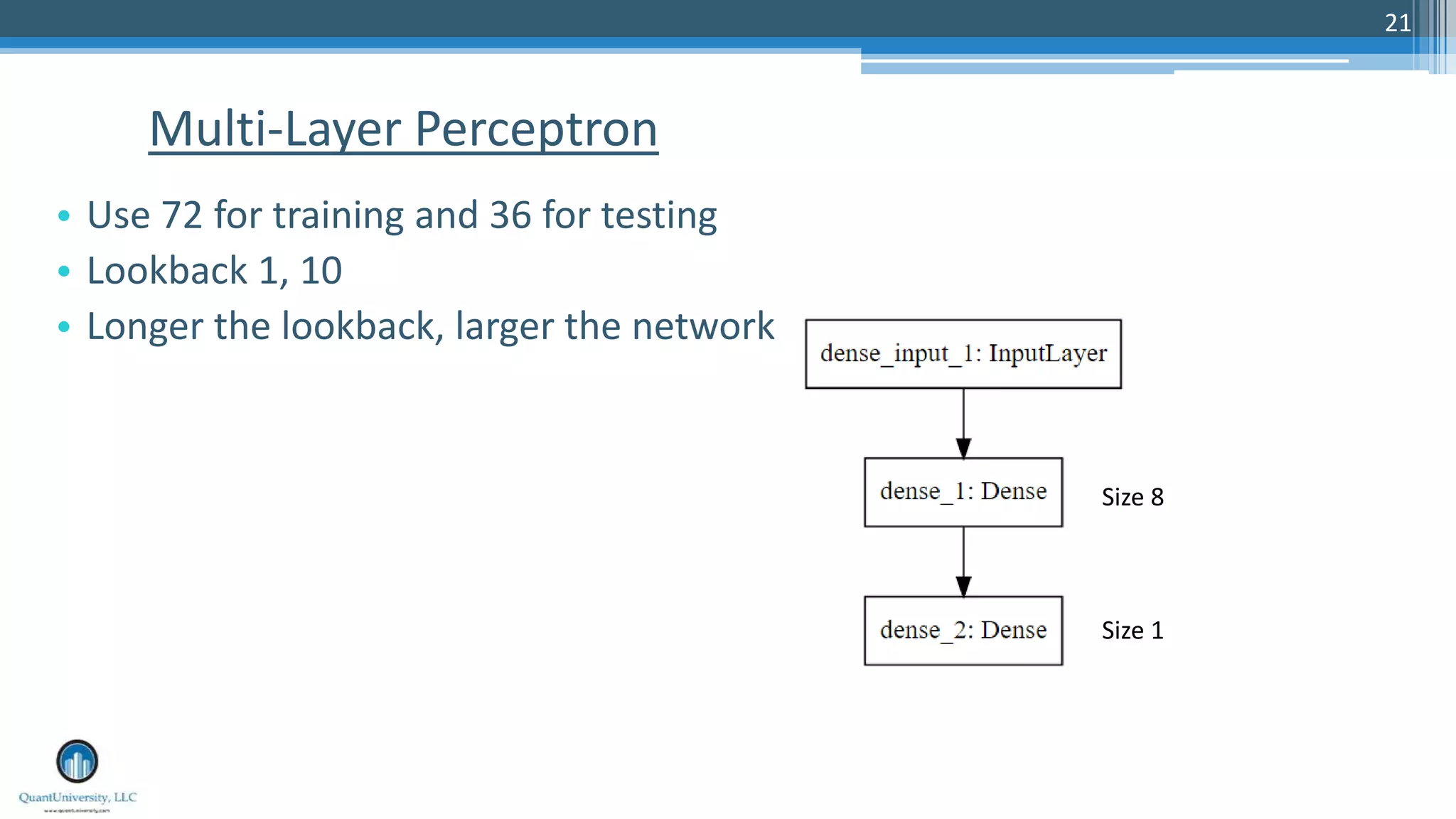
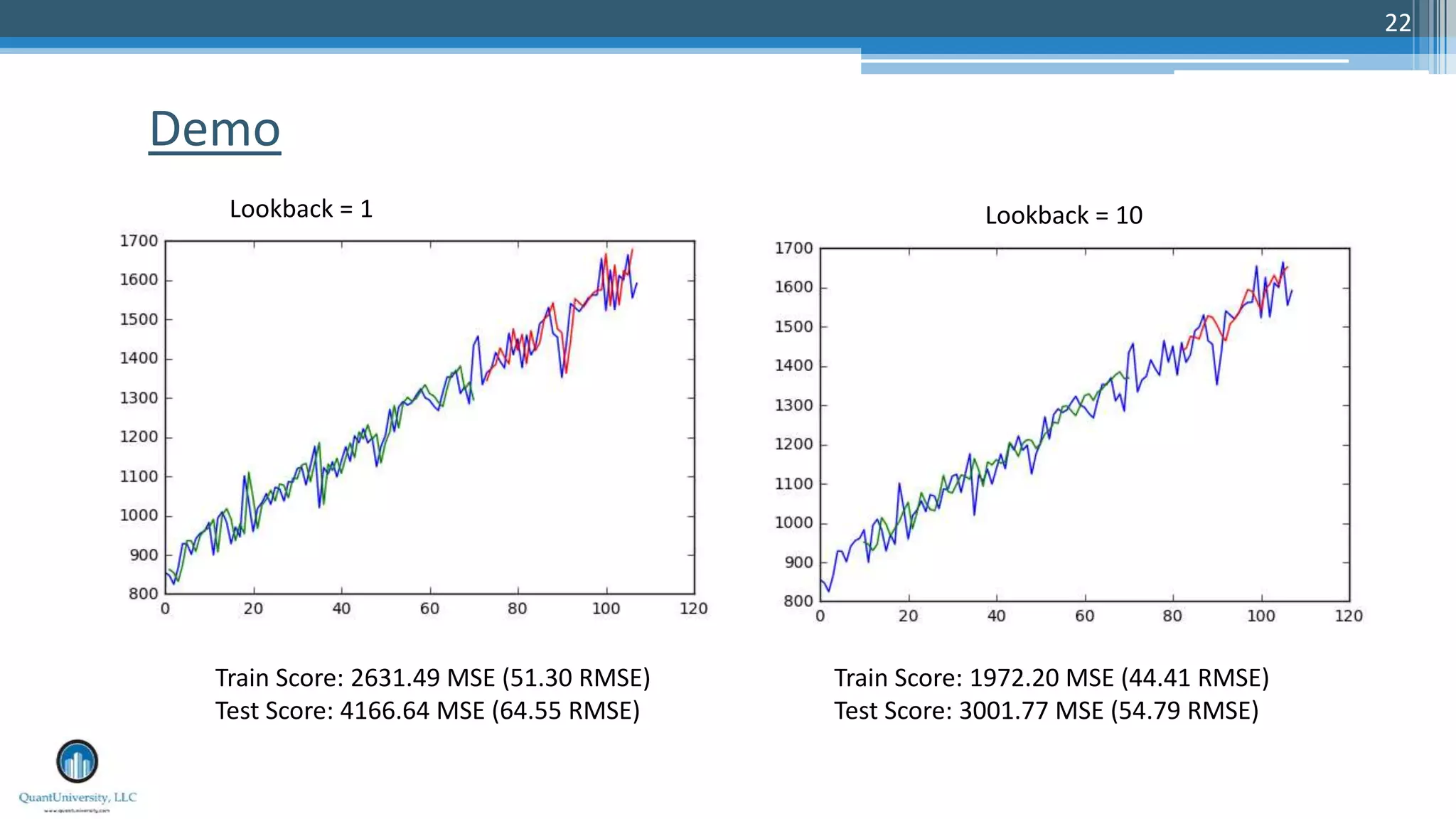




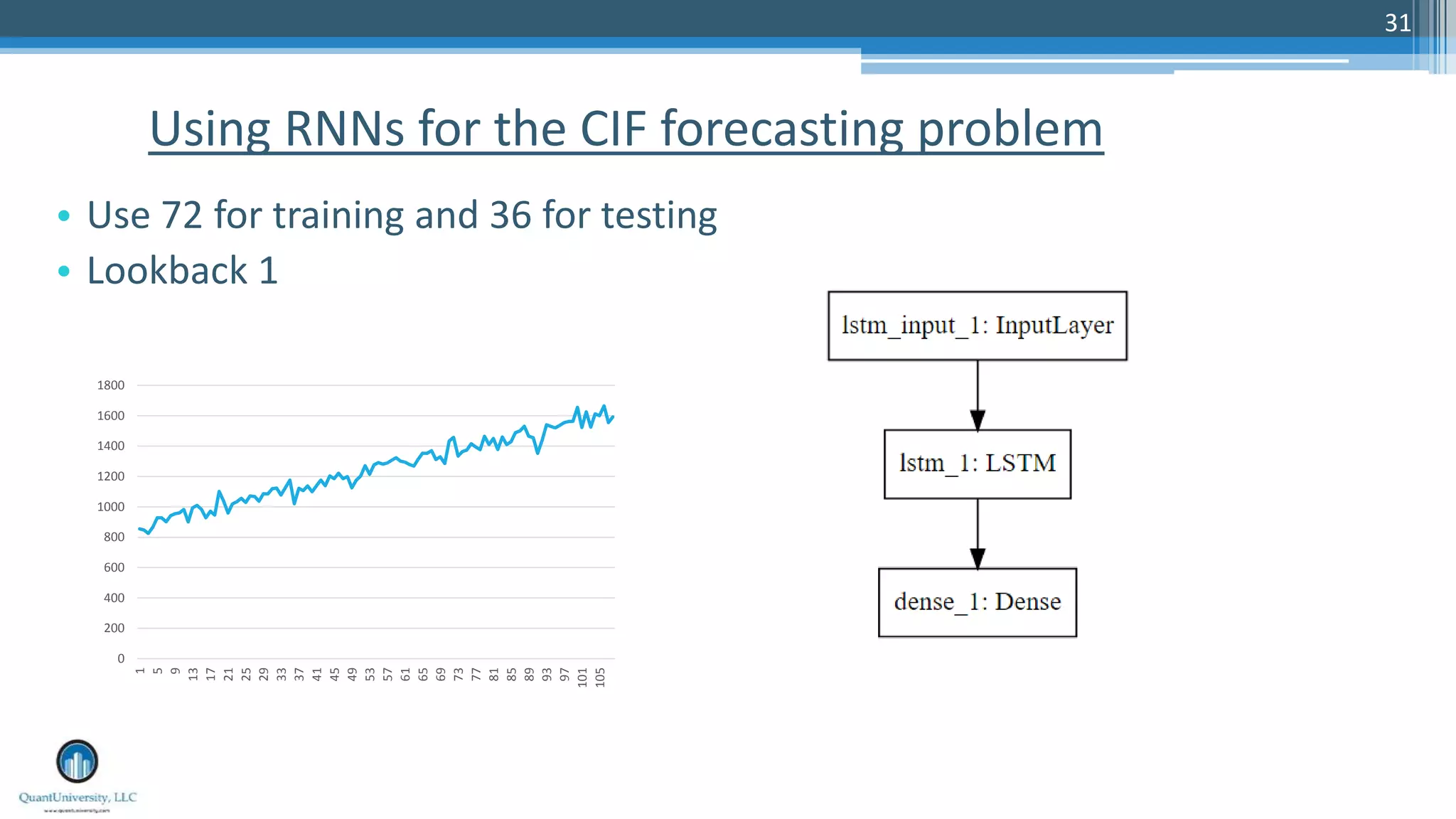
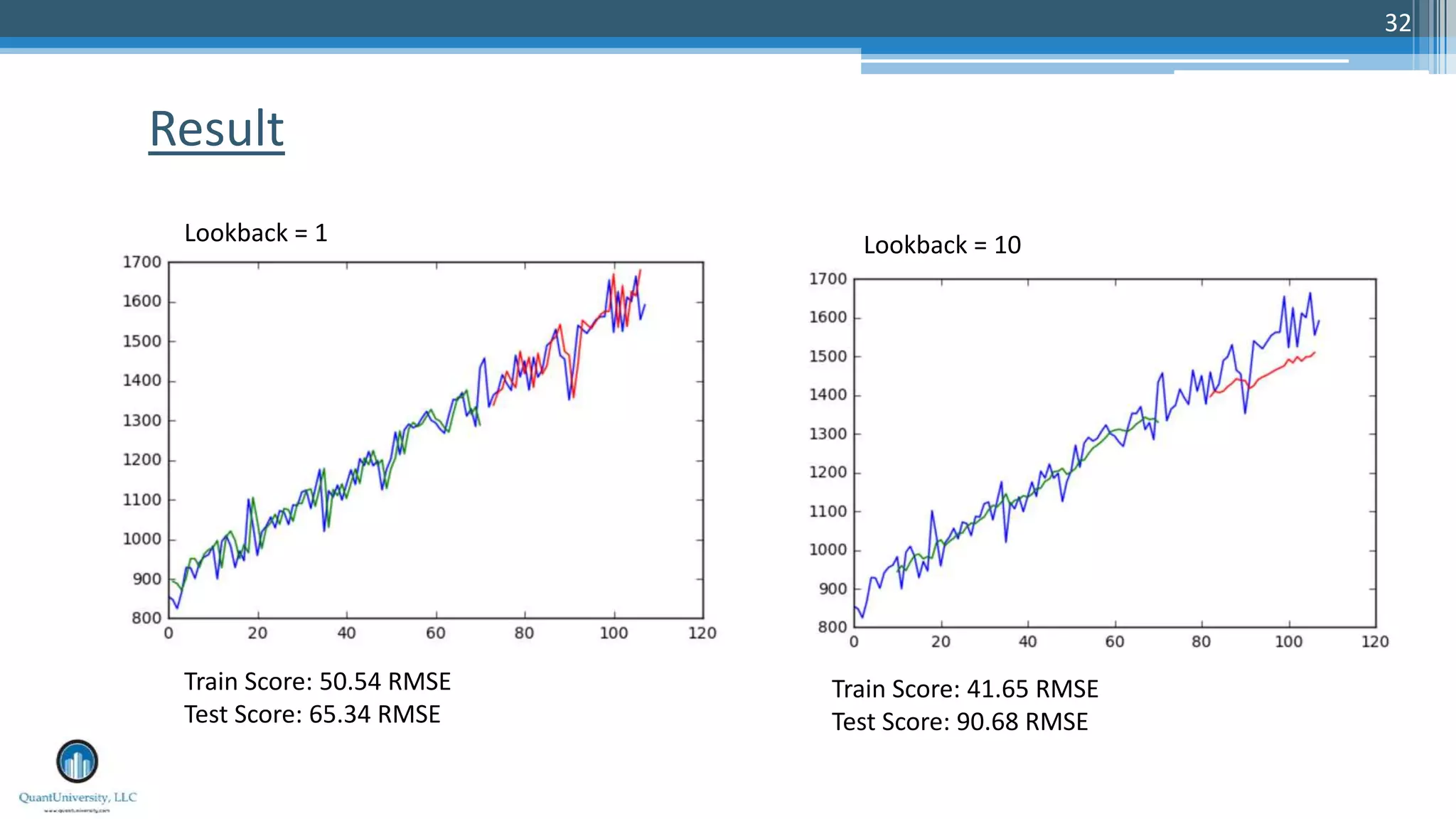



The document is a presentation by Sri Krishnamurthy at a Quantuniversity meetup, covering various aspects of deep learning, specifically focusing on neural networks, autoencoders, and recurrent neural networks (RNNs). It outlines upcoming workshops, provides a recap of concepts like supervised and unsupervised learning, and discusses practical applications of neural networks in areas such as sentiment analysis and forecasting. The presentation emphasizes the significance of tools like Keras for implementing deep learning techniques.