Deep Learning isa part of Artificial Intelligence (AI) and Machine Learning (ML). • It teaches computers to learn from large amounts of data (like images, text, voice, numbers) just like humans learn from experience. • Called “deep” because it uses many layers of processing to learn patterns. Example: • Facebook uses deep learning to recognize faces in photos. • Netflix uses it to recommend movies based on what you watch. • In simple terms: Deep Learning = Teaching computers to think like the human brain using layers of learning.
3.
• Input Data→ Raw data (images, voice, text). • Layers of Neurons → The data passes through many "layers," each layer learning something new. • First layer → learns simple features (edges in an image, keywords in text). • Middle layers → learn combinations (shapes, grammar). • Last layer → gives final prediction (cat vs. dog, positive vs. negative review). • Output → The answer/result. • Deep Learning = A smart AI technique that learns from big data using neural networks, works like the brain, and is used in HR, Marketing, Manufacturing, Finance, and Healthcare.
4.
Common Applications (BusinessRelated) HR • Resume screening using AI. • Predicting employee turnover using deep learning models. Marketing • Customer sentiment analysis from social media. • Personalized product recommendations (Amazon, Netflix). Manufacturing • Predictive maintenance (machines failing early). • Quality control using image recognition in production lines.
5.
Healthcare • Diagnosing diseasesfrom X-rays, MRI scans. • Drug discovery. Finance • Fraud detection in online transactions. • Algorithmic trading.
6.
Advantages • Learns complexpatterns better than normal machine learning. • Works very well with images, videos, speech, and text. • Can make very accurate predictions if enough data is available. Disadvantages • Needs huge data and powerful computers. • Takes longer training time. • Works like a black box → hard to understand how exactly it makes decisions.
7.
• Suppose youwant to build a system to recognize cats vs. dogs in photos: • Traditional ML → You would program rules like “If ears are pointed and tail is straight, maybe it’s a cat.” • Deep Learning → You give the system 1,00,000 cat & dog photos. The system automatically learns features (ears, tails, face shapes) without you writing any rule.
8.
• A companywants to predict if employees will leave (attrition) or stay. • How Deep Learning helps: • Input data: employee records (age, salary, job role, performance, promotions, leave patterns, etc.). • Deep learning model: Neural networks learn hidden patterns like “employees with low promotion chances and long working hours are more likely to quit.” • Output: Prediction → “Stay” or “Leave.” • Benefit: HR can take action early (salary hike, promotion, training) to retain employees.
9.
• Example 2:Marketing (Customer Sentiment Analysis) • Question: A brand wants to know whether customers are happy or unhappy from social media comments. • How Deep Learning helps: • Input data: Tweets, Facebook posts, Google reviews. • Neural network reads words and tone (like “love,” “worst,” “amazing”). • Model predicts whether the review is Positive, Neutral, or Negative. • ✅ Benefit: Marketing team can improve customer service and brand reputation.
10.
Example 3: Manufacturing (DefectDetection in Products) Question: A car company wants to detect defective parts in its production line. How Deep Learning helps: Input data: Thousands of images of car parts. • Neural network learns to recognize cracks, scratches, or misaligned parts. • Output: Flags a product as “Defective” or “Good.” • Benefit: Saves cost, improves quality, and avoids faulty products reaching customers.
• What isa Neural Network? • A Neural Network is the basic building block of Deep Learning. • It is designed to work like the human brain – with “neurons” (nodes) connected by “links.” • Each neuron takes input, processes it, and passes it to the next neuron.
13.
Layers: Input Layer –takes data (like exam marks, customer details, product features). Hidden Layers – process the data step by step (like the brain thinking). Output Layer – gives the final result (like “Hire candidate” or “Not hire”). • Example: • In HR: A neural network can take inputs like skills, experience, and interview scores → predict whether the candidate will perform well. • In Marketing: It can learn customer purchase history → predict who will buy a new product.
14.
• Example 1:Neural Network in Banking (Loan Approval Prediction) Problem: • A bank wants to predict whether a customer’s loan application should be Approved or Rejected. Step 1: Input Data (Input Layer) • Customer details are given as input: • Age = 30 • Income = 60,000/month ₹ • Credit Score = 750 • Existing Loans = 1
15.
• Step 2:Hidden Layers (Learning Patterns) • The network learns important combinations: • Neuron 1: “High income + Good credit score → More chance of approval.” • Neuron 2: “Low income + Too many loans → High risk.” • Neuron 3: “Young age + Good repayment history → Safe customer.” • The weights adjust during training based on past loan approvals and defaults.
16.
• Step 3:Output Layer (Prediction) • The system predicts: • Approval = 85% • Rejection = 15% • ✅ Final Decision: Loan Approved • This helps banks reduce risk and speed up loan processing.
17.
• Example 2:Neural Network in Healthcare (Disease Prediction) Problem: • Doctors want to predict if a patient has Diabetes. • Step 1: Input Data (Input Layer) • Patient details are given as input: • Age = 45 • BMI (Body Mass Index) = 32 • Blood Sugar Level = 180 mg/dL • Family History = Yes
18.
• Step 2:Hidden Layers (Learning Patterns) • The network analyzes the data: • Neuron 1: “High BMI + High blood sugar → Strong indicator of diabetes.” • Neuron 2: “Family history + High age → Risk increases.” • Neuron 3: “Normal sugar + Healthy BMI → Lower risk.”
19.
• Step 3:Output Layer (Prediction) • The neural network predicts: • Diabetes = 78% • No Diabetes = 22% • ✅ Final Prediction: Diabetes Likely Doctors can take preventive action early.
• What isa Deep Networks (DFN)? • A Deep Forward Network is a type of Artificial Neural Network where information flows only in one direction: from input → hidden layers → output. • There are no loops or feedback connections. • It is widely used for prediction and classification tasks in HR, marketing, finance, healthcare, and manufacturing.
22.
• Neural Networks= All types of transport (cars, buses, trains, flights). • Deep Forward Network = Only cars (a type of transport). Scope: • Neural Network = General concept (umbrella term). • DFN = A specific kind of neural network (the simplest one).
23.
• Flow ofInformation: • Neural Network = Can include loops, feedback (like RNN, CNN). • DFN = Only forward direction, no feedback loops. • Use Case: • Neural Network = Any problem (images, text, speech, prediction). • DFN = Mostly used for simple classification or prediction problems.
24.
• Deep ForwardNetwork (DFN) – A Type of Neural Network A DFN (or Feedforward Neural Network) is one specific type of neural network. • In DFN, information flows only in one direction: • Input → Hidden Layers → Output • There are no loops or backward connections. • Example: Predicting whether a customer will buy a product.
25.
• Example 1– HR (Employee Attrition Prediction) • Problem: Predict whether an employee will stay or leave. • Input Layer: • Age, Salary, Years of Service, Job Satisfaction. • Hidden Layers: • Neuron 1 learns: “Low salary + low satisfaction → high chance of leaving.” • Neuron 2 learns: “High salary + long service → high chance of staying.” • Output Layer: • Stay = 0 • Leave = 1 • Prediction = Leave (with 80% probability). • ✅ Helps HR take action before the employee leaves.
26.
• Example 2– Marketing (Customer Purchase Prediction) • Problem: Predict whether a customer will buy a product after seeing an online ad. • Input Layer: • Age, Gender, Browsing History, Time spent on Ad. • Hidden Layers: • Neuron 1 learns: “Young age + more time spent on ad → higher purchase probability.” • Neuron 2 learns: “Past buying history → higher chance of buying again.” • Output Layer: • Buy = 1 • Not Buy = 0 • Prediction = Buy (with 65% probability). • ✅ Helps marketing teams target the right customers.
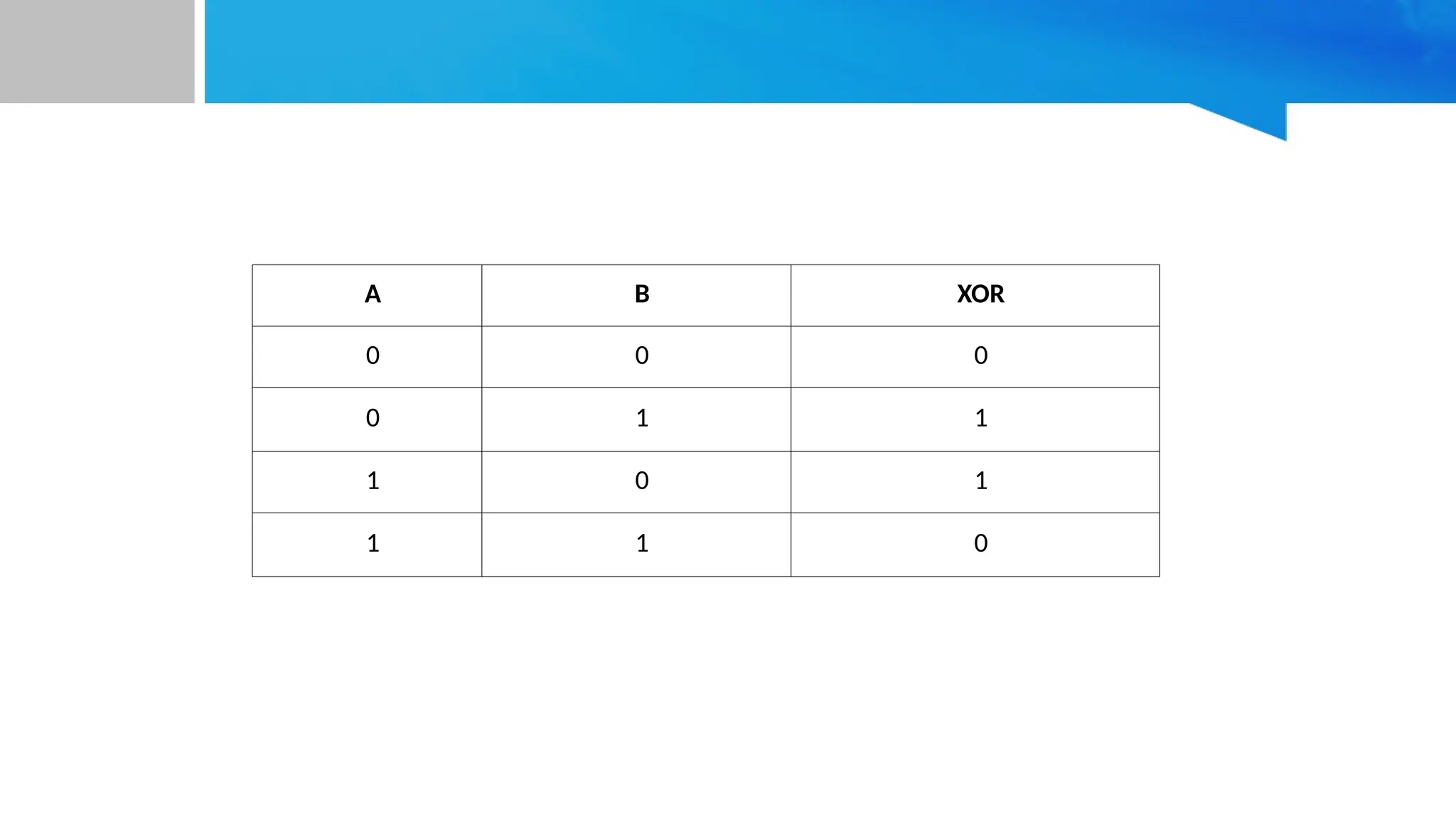
• 1. Whatis XOR? • XOR (Exclusive OR) is a logical operation. • Rule: Output is 1 if inputs are different, and 0 if inputs are the same. • Example truth table:
HR Domain • Problem:Predict whether an employee will leave the company (Attrition). • Inputs (A, B): • A = Job Satisfaction (High=1, Low=0) • B = Salary Satisfaction (High=1, Low=0) • Output (XOR): • If both are satisfied (0,0 or 1,1) → Employee stays (0) • If one is satisfied but not the other (0,1 or 1,0) → Employee leaves (1) • ✅ Deep Learning can learn this XOR-like relation by adjusting hidden neurons.
31.
• Example 2:Marketing Domain Problem: Predict whether a customer will purchase. • Inputs (A, B): • A = Discount Offered (Yes=1, No=0) • B = Brand Loyalty (Yes=1, No=0) • Output (XOR):
32.
• If customergets discount but no loyalty → Buy (1) • If loyal but no discount → Buy (1) • If both are loyal + discount (too much saturation) → No buy (0) • If neither loyalty nor discount → No buy (0) • ✅ Neural network hidden layers learn this non-linear XOR pattern for purchase prediction.
• What isGradient-Based Learning? • Gradient-Based Learning is a method used to train machine learning and deep learning models. • It works by minimizing errors (difference between actual and predicted results). • The key technique used is Gradient Descent.
35.
• 2. Whatis Gradient Descent? • A mathematical optimization algorithm. • It updates model parameters (weights) step by step to reduce the loss function (error). • Imagine climbing down a hill → each step moves toward the lowest point (minimum error).
36.
Steps in GradientDescent • Initialize Weights (random values). • Forward Pass – Predict output using current weights. • Calculate Loss – Find difference between prediction and actual value. • Compute Gradient – Slope/derivative shows the direction of steepest change. • Update Weights – Adjust weights opposite to gradient direction. • Repeat steps until loss is very small.
37.
• Importance inDeep Learning • Without gradient-based learning, neural networks cannot be trained. • It allows models to learn from data and improve predictions. • Used in HR analytics, marketing prediction, manufacturing defect detection, finance forecasting, etc.
38.
4. Types ofGradient Descent • Batch Gradient Descent – Uses the whole dataset for each update (accurate but slow). • Stochastic Gradient Descent (SGD) – Updates weights after each sample (faster, but noisy). • Mini-Batch Gradient Descent – Uses small groups of data at a time (balance of speed and accuracy).
39.
6. Example (SimpleUnderstanding) • HR Example: Predict employee attrition. • The model first guesses wrongly (say, predicts 80% chance employee will stay but actually they leave). • Error = difference between prediction and reality. • Gradient descent adjusts the weights (e.g., importance given to salary, job satisfaction) so the next prediction is better.
40.
• HR Example:Predicting Employee Attrition (No Calculations) • Suppose HR is building a model to predict if an employee will leave. • The model looks at factors like salary satisfaction and work–life balance. • 👉 Step 1 – First Guess (Wrong): • The model predicts that the employee will stay (because it gives more importance to salary), but in reality the employee leaves. • 👉 Step 2 – Error: • There is a gap between prediction and reality → this gap is called the error.
41.
• Step 3– Gradient Descent Adjustment: • The model checks where it went wrong and realizes: • It did not give enough importance to “work–life balance.” • It slightly overvalued salary satisfaction. • 👉 Step 4 – Learning: • The model adjusts its internal settings (weights). Now, it gives more importance to work–life balance as a reason for leaving. • 👉 Step 5 – Next Prediction (Better): • The next time a similar employee profile comes, the model is more likely to correctly predict that they will leave.
42.
• Meaning forHR: • Over time, the model learns patterns — like “poor work– life balance” and “low salary satisfaction” → higher chance of leaving. • This helps HR plan retention strategies like better engagement programs or flexible work policies.
• What areHidden Units? • Hidden units (or hidden neurons) are nodes inside the hidden layers of a neural network. • They are called hidden because we don’t directly see them — they work between input and output.
45.
• Role ofHidden Units: • They combine and transform inputs to detect patterns. • Each hidden unit applies a mathematical function to the input (like adding weights and applying an activation). • They allow the model to capture non-linear relationships (things that are not straight-line simple).
46.
Why Important? • Withouthidden units, a neural network is just a simple linear model. • With hidden units, networks can learn complex tasks (like speech recognition, image recognition, or predicting employee attrition). • Too Few Hidden Units → Underfitting: • The model is too simple, misses patterns. • Too Many Hidden Units → Overfitting: • The model memorizes training data but fails on new data. • Balance Needed.
47.
• Examples ofHidden Units • 1. HR Example – Employee Attrition Prediction • Input: Salary, Age, Job Satisfaction, Workload. • Hidden Units: Learn patterns like: • “Low salary + High workload → risk of attrition.” • “Young age + Low satisfaction → risk of attrition.” • Output: Predicts whether the employee will Stay or Leave. • 👉 Here, hidden units are capturing relationships HR managers might not see directly.
48.
• 2. MarketingExample – Customer Buying Behavior • Input: Ad clicks, Browsing time, Discounts offered. • Hidden Units: Learn patterns like: • “More ad clicks + discount = higher chance of buying.” • “Browsing but no discount = low chance of buying.” • Output: Predicts whether the customer buys or does not buy.
• What isArchitecture Design? • It is about how we design the structure of a neural network — how many layers, how many hidden units, what type of activation functions, etc. • Just like a building needs a blueprint, a neural network needs an architecture.
52.
• Key Elementsof Architecture Design: • Input Layer – Where data enters the model (e.g., employee details, customer data, machine signals). • Hidden Layers – Layers in between that learn patterns using hidden units. • Output Layer – Gives the final prediction (e.g., “leave or stay,” “buy or not,” “failure or safe”). • Activation Functions – Decide how signals flow (ReLU, Sigmoid, Tanh). • Connections – How neurons are linked (fully connected, convolution, recurrent).
53.
• Simple Typesof Architectures: • Shallow Network: Few hidden layers → simple patterns. • Deep Network: Many hidden layers → complex patterns. • Specialized Architectures: CNN (images), RNN (sequences like time series, text).
54.
• Why isit Important? • The right architecture helps the model learn effectively. • Wrong design can lead to overfitting (too complex) or underfitting (too simple
55.
• Common activationfunctions: • Sigmoid → outputs between 0 and 1 (good for binary classification). • ReLU (Rectified Linear Unit) → outputs positive values only, helps deep networks train faster. • Tanh → outputs between -1 and +1, centered around 0. • Softmax → used for multi-class classification (e.g., predicting 3+ categories).
56.
• 1. HRExample – Employee Attrition Prediction • Problem: The HR department wants to predict whether an employee will stay or leave. • Input Layer: Data features such as age, years of experience, salary level, work–life balance score, and job satisfaction rating. • Hidden Layers: • First hidden layer combines inputs → e.g., it learns that younger employees with low salary are more likely to leave. • Second hidden layer refines the pattern → e.g., low work–life balance + high workload increases attrition risk. • Output Layer: Gives final prediction: Stay (0) or Leave (1).
57.
• Importance ofArchitecture Design: • If the network is too shallow (only 1 hidden layer), it might miss complex patterns. • If it is too deep (many unnecessary hidden layers), it may “memorize” instead of “learning” (overfitting). • 👉 Benefit to HR: Helps HR predict attrition early, so they can design retention strategies (salary revision, flexible hours, training).
58.
• 2. MarketingExample – Customer Churn Prediction • Problem: A retail company wants to know which customers are likely to stop buying (churn). • Input Layer: Customer data such as frequency of purchases, loyalty points, response to promotions, and social media engagement.
59.
• Hidden Layers: •First hidden layer combines behavior → e.g., low loyalty points + few recent purchases means customer may churn. • Second hidden layer adds more detail → e.g., did not respond to latest promotion + reduced engagement = stronger chance of churn.
60.
• Output Layer:Predicts Churn (Yes/No). • Importance of Architecture Design: • Too simple → only sees 1–2 factors (e.g., just purchase history). • Proper design → sees combined patterns like “low engagement + low purchase frequency” together.
61.
• 3. ManufacturingExample – Predictive Maintenance • Problem: A factory wants to predict if a machine will fail soon. • Input Layer: Sensor readings (temperature, vibration, noise level, pressure). • Hidden Layers: • First hidden layer learns basic relations → e.g., high temperature + high vibration indicates potential wear. • Second hidden layer refines → e.g., temperature rise + vibration + unusual noise pattern = very high failure risk.
62.
• Output Layer:Predicts Failure soon (1) or Safe (0). • Importance of Architecture Design: • Wrong design → model might focus only on temperature and miss combined signals. • Good design → captures multi-factor interactions (temperature + vibration + noise). • 👉 Benefit to Manufacturing: Prevents sudden breakdowns, reduces downtime, and saves costs.
63.
• HR Example– Employee Attrition 1 ️ 1️⃣ • Input Features: Age, Salary, Work-life balance, Job satisfaction. • Hidden Layer Activation (ReLU): • Example: If salary satisfaction is low, ReLU activates strongly (positive signal). • If not relevant (e.g., salary already high), ReLU returns 0 → ignores it. • Output Layer Activation (Sigmoid): • Predicts probability of Stay (0) or Leave (1). • Example: Sigmoid outputs 0.85 → 85% chance employee leaves. • 👉 ReLU captures hidden patterns, Sigmoid gives a final “yes/no” probability.
64.
• 3️Manufacturing Example– Predictive Maintenance • Input Features: Temperature, Vibration, Noise level. • Hidden Layer Activation (ReLU or Tanh): • Example: ReLU activates strongly when temperature + vibration exceed safe limits. • Tanh may be used if the signal needs to capture positive or negative deviations. • Output Layer Activation (Sigmoid): • Example: Machine failure probability = 0.92 → 92% risk of breakdown soon. • 👉 Maintenance team can schedule repair before failure happens.
• Regularization inDeep Learning • Regularization is a set of techniques used in deep learning to prevent overfitting. • 👉 Overfitting = when the model learns the training data too well (including noise and irrelevant details) and fails to perform well on new/unseen data. • 👉 Regularization helps the model to generalize better (work well on new data).
67.
• Types ofRegularization • L1 Regularization (Lasso): • Adds the absolute value of weights to the loss function. • Encourages sparsity (some weights become zero → irrelevant features are removed). • Example: In HR attrition, if "height" is an input but not useful, L1 can reduce its weight to zero.
68.
• L2 Regularization(Ridge): • Adds the square of weights to the loss function. • Keeps all weights small but not zero. • Example: In Marketing churn prediction, prevents any single factor (like discount usage) from dominating the model.
69.
• Dropout: • Randomlydrops some neurons during training. • Prevents the network from depending too much on specific neurons. • Example: In Manufacturing fault prediction, dropout ensures the model doesn’t overly rely only on "temperature" but considers vibration and noise too.
70.
• Early Stopping: •Stop training when performance on validation data stops improving. • Example: In HR attrition, if the model starts memorizing employee data after 50 epochs, training is stopped early.
71.
• Data Augmentation: •Increase training data artificially (e.g., rotating images, adding noise). • Mostly used in image/text domains. • Batch Normalization (indirect regularization): • Normalizes data inside the network layers, improves stability and prevents overfitting.
72.
• 1. HRExample – Employee Attrition Prediction • Scenario: An HR department wants to build a model to predict whether an employee will leave the company or stay. • Problem: The model starts overfitting → it learns from small details like “age = 29” or “employee ID pattern” (irrelevant for attrition).
73.
• Regularization TechniqueUsed: • L1 Regularization: The model drops useless features like "employee ID." • Dropout: During training, the model ignores some hidden neurons, forcing it to focus on important factors like salary, job satisfaction, and career growth. • Outcome: The model generalizes better and accurately predicts attrition across all employees, not just the training data. • ✅ Result for HR: HR can now identify employees at risk of leaving and design retention programs.
74.
• 3. ManufacturingExample – Machine Breakdown Prediction • Scenario: A factory uses sensors to predict when machines may fail. • Problem: The model overfits by focusing only on temperature data, ignoring other signals like vibration and noise levels.
75.
• Regularization TechniqueUsed: • Dropout: Forces the model not to rely only on temperature but also consider vibration and sound. • Batch Normalization: Stabilizes learning and prevents extreme weight values. • Outcome: The model now uses a combination of signals → predictions become more reliable. • ✅ Result for Manufacturing: Maintenance team gets accurate alerts, reducing downtime and costs.