Deep dive into the native multi model database ArangoDB
2 likes4,054 views

The document describes ArangoDB, a multi-model database that can function as a document store, key-value store, and graph database. It offers querying across these models using its AQL language. The document also discusses how ArangoDB is extensible through JavaScript, can run as a microservice using Foxx, and integrates with data center operating systems like Mesosphere DC/OS for resource management and fault tolerance.






















































Deep dive into the native multi model database ArangoDB
- 1. Deep dive into the native multi-model database ArangoDB Frank Celler Percona Live 2016, Santa Clara, 20 April 2016 www.arangodb.com
- 2. Overview
- 3. is a multi-model Database Features is a document store, a key/value store and a graph database, offers convenient queries (via HTTP/REST and AQL), including joins between different collections, and graph queries, with configurable consistency guarantees using transactions.
- 4. is a multi-model Database Features is a document store, a key/value store and a graph database, offers convenient queries (via HTTP/REST and AQL), including joins between different collections, and graph queries, with configurable consistency guarantees using transactions. =⇒ Allows polyglot persistence with multiple instances of a single technology.
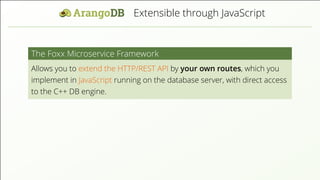
- 5. is extensible by JavaScript Code The Foxx Microservice Framework Allows you to extend the HTTP/REST API by your own routes, which you implement in JavaScript running on the database server, with direct access to the C++ DB engine.
- 6. is extensible by JavaScript Code The Foxx Microservice Framework Allows you to extend the HTTP/REST API by your own routes, which you implement in JavaScript running on the database server, with direct access to the C++ DB engine. Unprecedented possibilities for data centric services: custom-made complex queries or authorizations schema-validation push feeds, etc.
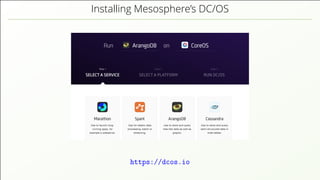
- 7. is a Data Center Operating System App These days, computing clusters run Data Center Operating Systems.
- 8. is a Data Center Operating System App These days, computing clusters run Data Center Operating Systems. Idea Distributed applications can be deployed as easily as one installs a mobile app on a phone.
- 9. is a Data Center Operating System App These days, computing clusters run Data Center Operating Systems. Idea Distributed applications can be deployed as easily as one installs a mobile app on a phone. Cluster resource management is automatic. This leads to significantly better resource utilization. Fault tolerance, self-healing and automatic failover is guaranteed.
- 10. Details
- 11. The Multi-Model Approach Multi-model database A multi-model database combines a document store with a graph database and is at the same time a key/value store, with a common query language for all three data models.
- 12. The Multi-Model Approach Multi-model database A multi-model database combines a document store with a graph database and is at the same time a key/value store, with a common query language for all three data models. Important: is able to compete with specialised products on their turf allows for polyglot persistence using a single database technology In a microservice architecture, there will be several different deployments.
- 14. Why is multi-model possible at all? Document stores and key/value stores Document stores: have primary key, are key/value stores. Without using secondary indexes, performance is nearly as good as with opaque data instead of JSON. Good horizontal scalability can be achieved for key lookups.
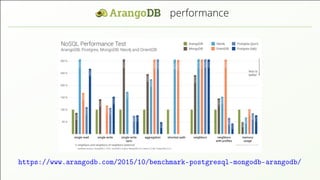
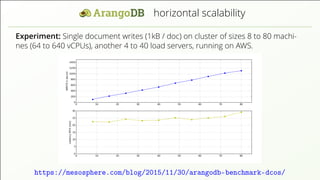
- 15. horizontal scalability Experiment: Single document writes (1kB / doc) on cluster of sizes 8 to 80 machi- nes (64 to 640 vCPUs), another 4 to 40 load servers, running on AWS. https://mesosphere.com/blog/2015/11/30/arangodb-benchmark-dcos/
- 16. Why is multi-model possible at all? Document stores and graph databases Graph database: would like to associate arbitrary data with vertices and edges, so JSON documents are a good choice. A good edge index, giving fast access to neighbours. This can be a secondary index. Graph support in the query language. Implementations of graph algorithms in the DB engine. https://www.arangodb.com/2016/04/ index-free-adjacency-hybrid-indexes-graph-databases/
- 17. Replication and Sharding ArangoDB provides (Version 2.8, January 2016) Sharding with automatic data distribution, easy setup of (asynchronous) replication (cluster and single), fault tolerance by automatic failover, full integration with Apache Mesos and Mesosphere DC/OS.
- 18. Replication and Sharding ArangoDB provides (Version 2.8, January 2016) Sharding with automatic data distribution, easy setup of (asynchronous) replication (cluster and single), fault tolerance by automatic failover, full integration with Apache Mesos and Mesosphere DC/OS. Work in progress (Version 3.0, RC in April 2016): synchronous replication in cluster mode, zero administration by a self-repairing and self-balancing cluster architecture.
- 19. Data-Center Operating Systems Resource Management Installation should be as easy as possible integration into the resource management of data-center gives better resource utilisation, full integration with Apache Mesos and Mesosphere DC/OS
- 20. Data-Center Operating Systems Resource Management Installation should be as easy as possible integration into the resource management of data-center gives better resource utilisation, full integration with Apache Mesos and Mesosphere DC/OS Work in progress Mesosphere DC/OS a very mature, Open-Source solution later this year integration also for Kubernetes, Docker-Swarm
- 24. Powerful query language AQL The built in Arango Query Language allows complex, powerful and convenient queries, with transaction semantics, allowing to do joins, AQL is independent of the driver used and offers protection against injections by design.
- 25. Extensible through JavaScript The Foxx Microservice Framework Allows you to extend the HTTP/REST API by your own routes, which you implement in JavaScript running on the database server, with direct access to the C++ DB engine.
- 26. Extensible through JavaScript The Foxx Microservice Framework Allows you to extend the HTTP/REST API by your own routes, which you implement in JavaScript running on the database server, with direct access to the C++ DB engine. Unprecedented possibilities for data centric services: complex queries or authorizations, schema-validation, push feeds, etc. easy deployment via web interface or REST API, automatic API description through Swagger =⇒ discoverability of services.
- 27. Use Cases
- 28. Use case: Aircraft fleet management
- 29. Use case: Aircraft fleet management One of our customers uses ArangoDB to store each part, component, unit or aircraft as a document model containment as a graph thus can easily find all parts of some component keep track of maintenance intervals perform queries orthogonal to the graph structure thereby getting good efficiency for all needed queries http://radar.oreilly.com/2015/07/ data-modeling-with-multi-model-databases.html
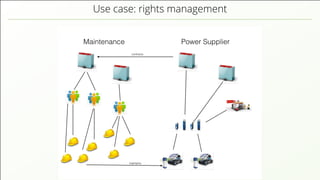
- 30. Use case: rights management
- 31. Use case: rights management Right managements in relational model is hard: looks like a forest at first then exceptions pop-up one company sub-contracts another for a special station an engineer works for two companies some-one needs special permissions when being a proxy much easier expressed as graph structure
- 33. Use case: e-commerce AboutYou uses ArangoDB to create channels showing new products allow recommendation to friends celebrities presenting new fashion blog about fashion products nightly business analysis news stream https://www.arangodb.com/case-studies/ aboutyou-data-driven-personalization-with-arangodb/
- 34. Action
- 35. First deployment: a simple key/value store A key/value store One collection “data”, indexes on “value” (sorted) and “name” (hash). Single document requests Indexes possible Range queries possible
- 36. Second deployment: a Microservice as a Foxx app A Foxx Microservice Simple TODO app, deployed from app store with web UI. REST/JSON API available Swagger generates API description automatically
- 37. Third deployment: a single server graph database A Graph Database Graph “worldCountry” with vertex collection “worldVertex” and edge collection “worldEdges”, links from cities to countries to continents to world. Show some graph traversals. Show graph viewer.
- 38. Fourth deployment: a multi-model application A multi-model database Some data from a web shop. Show some queries.
- 39. AQL Internals
- 40. Life of a query Text and query parameters come from user
- 41. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST)
- 42. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters
- 43. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc.
- 44. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP)
- 45. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs
- 46. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster
- 47. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster Optimise distributed EXPs
- 48. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster Optimise distributed EXPs Estimate costs for all EXPs, and sort by ascending cost
- 49. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster Optimise distributed EXPs Estimate costs for all EXPs, and sort by ascending cost Instanciate “cheapest” plan, i.e. set up execution engine
- 50. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster Optimise distributed EXPs Estimate costs for all EXPs, and sort by ascending cost Instanciate “cheapest” plan, i.e. set up execution engine Distribute and link up engines on different servers
- 51. Life of a query Text and query parameters come from user Parse text, produce abstract syntax tree (AST) Substitute query parameters First optimisation: constant expressions, etc. Translate AST into an execution plan (EXP) Optimise one EXP, produce many, potentially better EXPs Reason about distribution in cluster Optimise distributed EXPs Estimate costs for all EXPs, and sort by ascending cost Instanciate “cheapest” plan, i.e. set up execution engine Distribute and link up engines on different servers Execute plan, provide cursor API
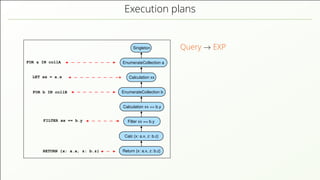
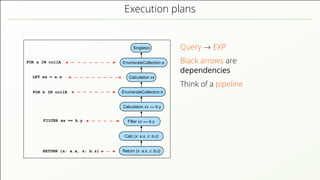
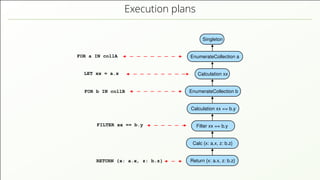
- 52. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP
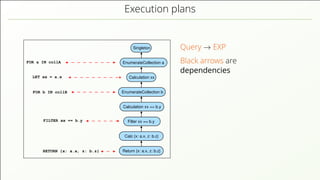
- 53. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP Black arrows are dependencies
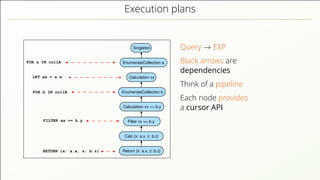
- 54. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP Black arrows are dependencies Think of a pipeline
- 55. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP Black arrows are dependencies Think of a pipeline Each node provides a cursor API
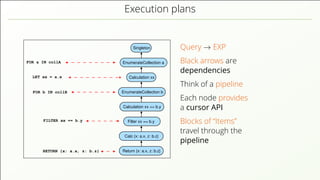
- 56. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP Black arrows are dependencies Think of a pipeline Each node provides a cursor API Blocks of “Items” travel through the pipeline
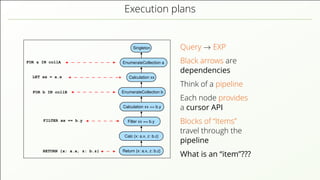
- 57. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x Query → EXP Black arrows are dependencies Think of a pipeline Each node provides a cursor API Blocks of “Items” travel through the pipeline What is an “item”???
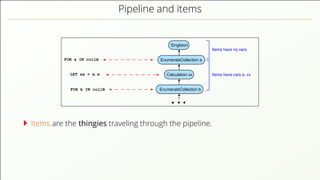
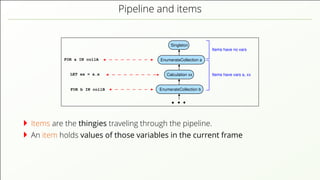
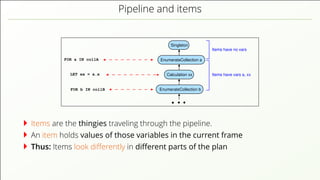
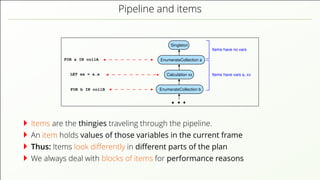
- 58. Pipeline and items FOR a IN collA EnumerateCollection a EnumerateCollection b Singleton Calculation xx FOR b IN collB LET xx = a.x Items have vars a, xx Items have no vars Items are the thingies traveling through the pipeline.
- 59. Pipeline and items FOR a IN collA EnumerateCollection a EnumerateCollection b Singleton Calculation xx FOR b IN collB LET xx = a.x Items have vars a, xx Items have no vars Items are the thingies traveling through the pipeline. An item holds values of those variables in the current frame
- 60. Pipeline and items FOR a IN collA EnumerateCollection a EnumerateCollection b Singleton Calculation xx FOR b IN collB LET xx = a.x Items have vars a, xx Items have no vars Items are the thingies traveling through the pipeline. An item holds values of those variables in the current frame Thus: Items look differently in different parts of the plan
- 61. Pipeline and items FOR a IN collA EnumerateCollection a EnumerateCollection b Singleton Calculation xx FOR b IN collB LET xx = a.x Items have vars a, xx Items have no vars Items are the thingies traveling through the pipeline. An item holds values of those variables in the current frame Thus: Items look differently in different parts of the plan We always deal with blocks of items for performance reasons
- 62. Execution plans FOR a IN collA RETURN {x: a.x, z: b.z} EnumerateCollection a EnumerateCollection b Calculation xx == b.y Filter xx == b.y Singleton Calculation xx Return {x: a.x, z: b.z} Calc {x: a.x, z: b.z} FILTER xx == b.y FOR b IN collB LET xx = a.x
- 63. Move filters up FOR a IN collA FOR b IN collB FILTER a.x == 10 FILTER a.u == b.v RETURN {u:a.u,w:b.w} Singleton EnumColl a EnumColl b Calc a.x == 10 Return {u:a.u,w:b.w} Filter a.u == b.v Calc a.u == b.v Filter a.x == 10
- 64. Move filters up FOR a IN collA FOR b IN collB FILTER a.x == 10 FILTER a.u == b.v RETURN {u:a.u,w:b.w} The result and behaviour does not change, if the first FILTER is pulled out of the inner FOR. Singleton EnumColl a EnumColl b Calc a.x == 10 Return {u:a.u,w:b.w} Filter a.u == b.v Calc a.u == b.v Filter a.x == 10
- 65. Move filters up FOR a IN collA FILTER a.x < 10 FOR b IN collB FILTER a.u == b.v RETURN {u:a.u,w:b.w} The result and behaviour does not change, if the first FILTER is pulled out of the inner FOR. However, the number of items trave- ling in the pipeline is decreased. Singleton EnumColl a Return {u:a.u,w:b.w} Filter a.u == b.v Calc a.u == b.v Calc a.x == 10 EnumColl b Filter a.x == 10
- 66. Move filters up FOR a IN collA FILTER a.x < 10 FOR b IN collB FILTER a.u == b.v RETURN {u:a.u,w:b.w} The result and behaviour does not change, if the first FILTER is pulled out of the inner FOR. However, the number of items trave- ling in the pipeline is decreased. Note that the two FOR statements could be interchanged! Singleton EnumColl a Return {u:a.u,w:b.w} Filter a.u == b.v Calc a.u == b.v Calc a.x == 10 EnumColl b Filter a.x == 10
- 67. Remove unnecessary calculations FOR a IN collA LET L = LENGTH(a.hobbies) FOR b IN collB FILTER a.u == b.v RETURN {h:a.hobbies,w:b.w} Singleton EnumColl a Calc L = ... EnumColl b Calc a.u == b.v Filter a.u == b.v Return {...}
- 68. Remove unnecessary calculations FOR a IN collA LET L = LENGTH(a.hobbies) FOR b IN collB FILTER a.u == b.v RETURN {h:a.hobbies,w:b.w} The Calculation of L is unnecessary! Singleton EnumColl a Calc L = ... EnumColl b Calc a.u == b.v Filter a.u == b.v Return {...}
- 69. Remove unnecessary calculations FOR a IN collA FOR b IN collB FILTER a.u == b.v RETURN {h:a.hobbies,w:b.w} The Calculation of L is unnecessary! (since it cannot throw an exception). Singleton EnumColl a EnumColl b Calc a.u == b.v Filter a.u == b.v Return {...}
- 70. Remove unnecessary calculations FOR a IN collA FOR b IN collB FILTER a.u == b.v RETURN {h:a.hobbies,w:b.w} The Calculation of L is unnecessary! (since it cannot throw an exception). Therefore we can just leave it out. Singleton EnumColl a EnumColl b Calc a.u == b.v Filter a.u == b.v Return {...}
- 71. Use index for FILTER and SORT FOR a IN collA FILTER a.x > 17 && a.x <= 23 && a.y == 10 SORT a.y, a.x RETURN a Singleton EnumColl a Filter ... Calc ... Sort a.y, a.x Return a
- 72. Use index for FILTER and SORT FOR a IN collA FILTER a.x > 17 && a.x <= 23 && a.y == 10 SORT a.y, a.x RETURN a Assume collA has a skiplist index on “y” and “x” (in this order), Singleton EnumColl a Filter ... Calc ... Sort a.y, a.x Return a
- 73. Use index for FILTER and SORT FOR a IN collA FILTER a.x > 17 && a.x <= 23 && a.y == 10 SORT a.y, a.x RETURN a Assume collA has a skiplist index on “y” and “x” (in this order), then we can read off the half-open interval between { y: 10, x: 17 } and { y: 10, x: 23 } from the skiplist index. Singleton Sort a.y, a.x Return a IndexRange a
- 74. Use index for FILTER and SORT FOR a IN collA FILTER a.x > 17 && a.x <= 23 && a.y == 10 SORT a.y, a.x RETURN a Assume collA has a skiplist index on “y” and “x” (in this order), then we can read off the half-open interval between { y: 10, x: 17 } and { y: 10, x: 23 } from the skiplist index. The result will automatically be sorted by y and then by x. Singleton Return a IndexRange a
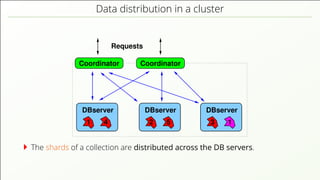
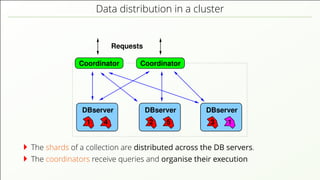
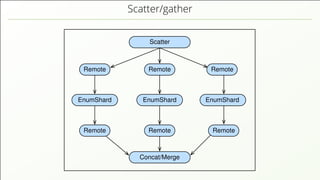
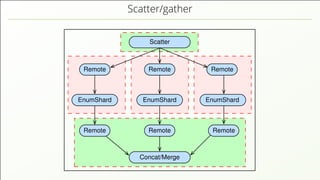
- 75. Data distribution in a cluster Requests DBserver DBserver DBserver CoordinatorCoordinator 4 2 5 3 11 The shards of a collection are distributed across the DB servers.
- 76. Data distribution in a cluster Requests DBserver DBserver DBserver CoordinatorCoordinator 4 2 5 3 11 The shards of a collection are distributed across the DB servers. The coordinators receive queries and organise their execution