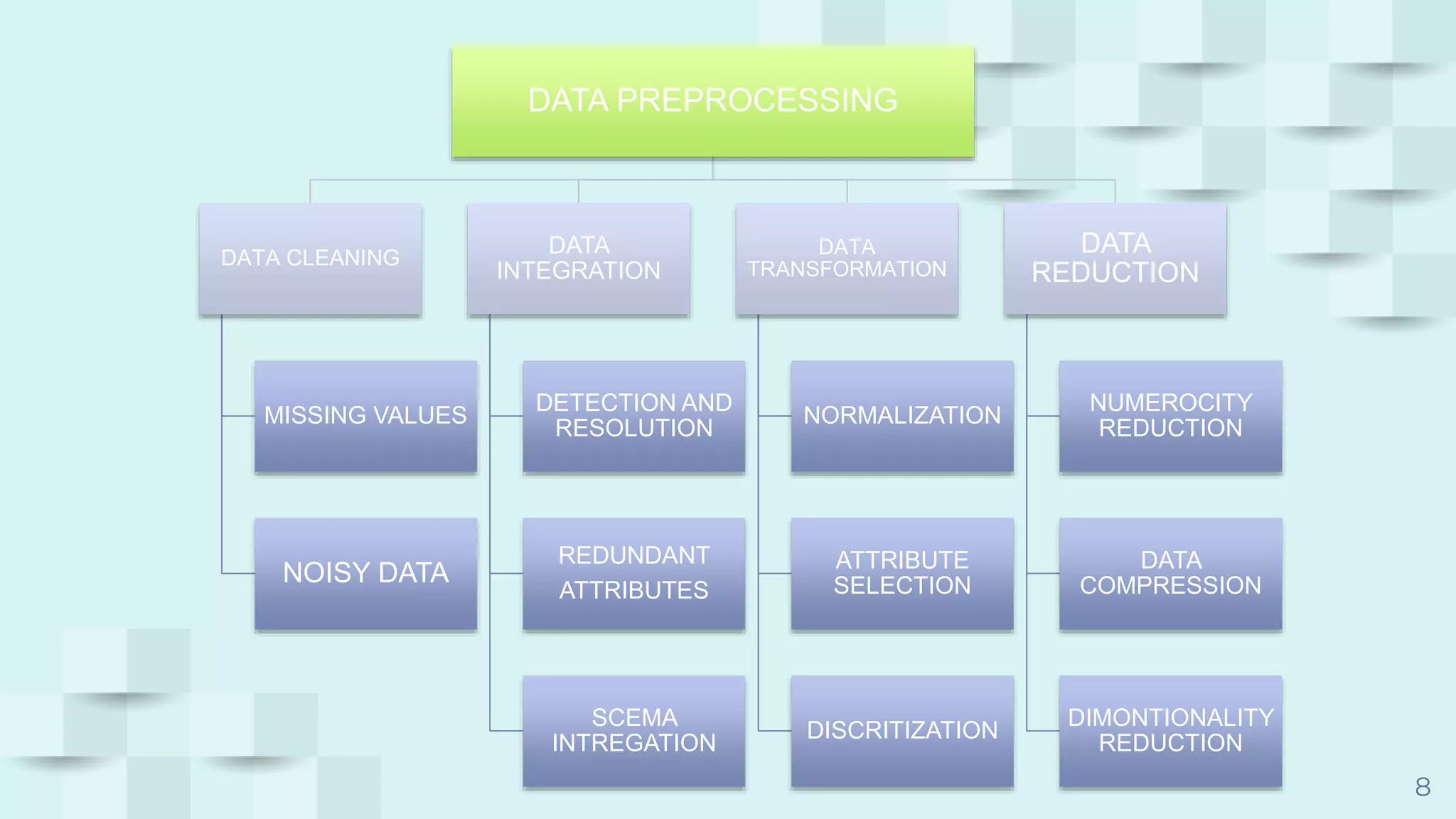
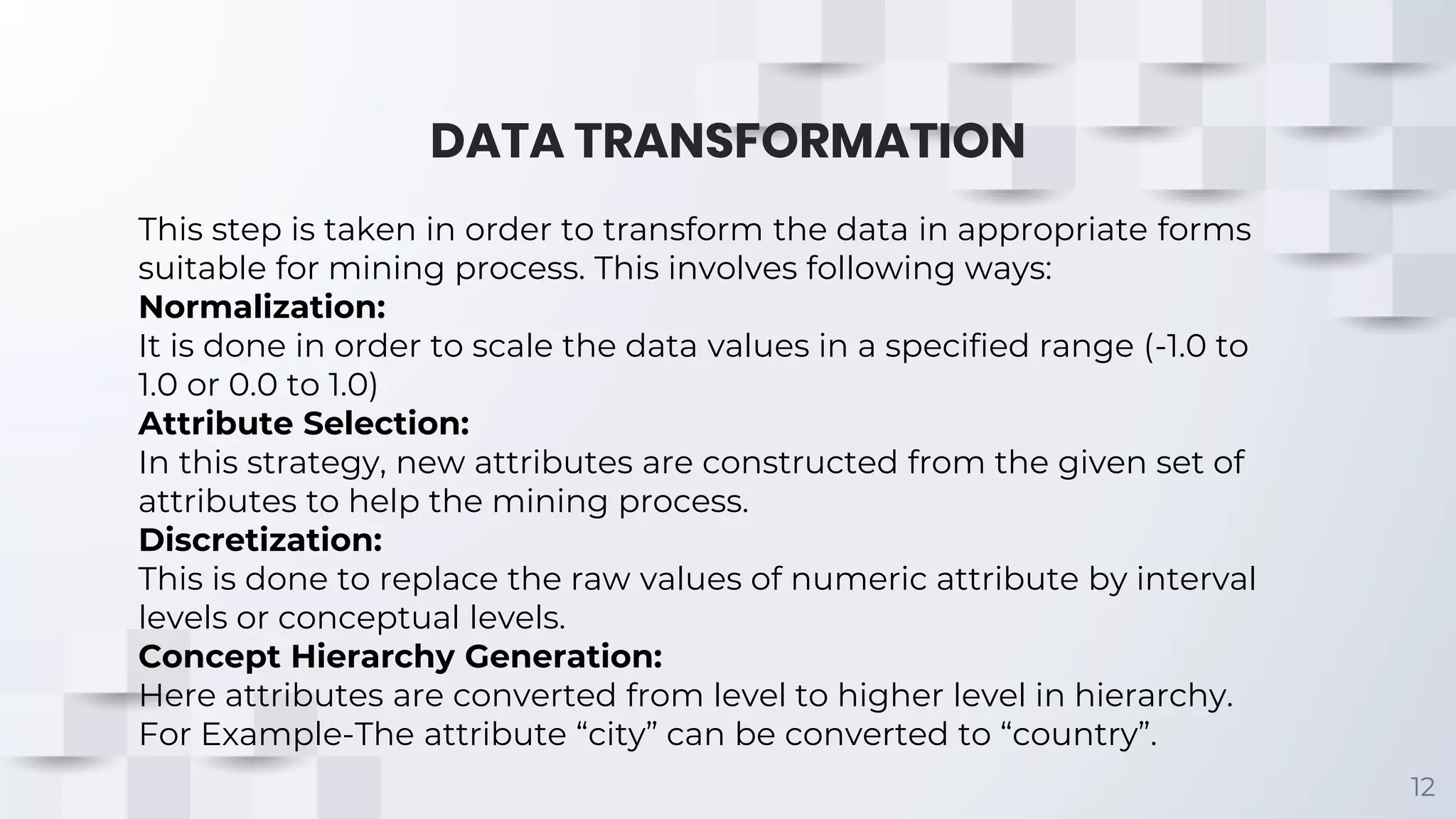
The document provides an overview of data preprocessing techniques essential for transforming raw data into usable formats, highlighting key areas such as data cleaning, data integration, data transformation, and data reduction. Specific strategies for handling missing values and noisy data are discussed, along with methods for integrating data from multiple sources and reducing data volume for analysis efficiency. Ultimately, these preprocessing steps enhance data mining effectiveness by preparing data appropriately for various analytical processes.