Downloaded 1,926 times








The document discusses the FP-Growth algorithm for frequent pattern mining. It improves upon the Apriori algorithm by not requiring candidate generation and only requiring two scans of the database. FP-Growth works by first building a compact FP-tree structure using two passes over the data, then extracting frequent itemsets directly from the FP-tree. An example is provided where an FP-tree is constructed from a sample transaction database and frequent patterns are generated from the tree. Advantages of FP-Growth include only needing two scans of data and faster runtime than Apriori, while a disadvantage is the FP-tree may not fit in memory.
Presentation by Shihab Rahman and Dolon Chanpa introduces FP Growth as a scalable technique for mining frequent patterns in databases.
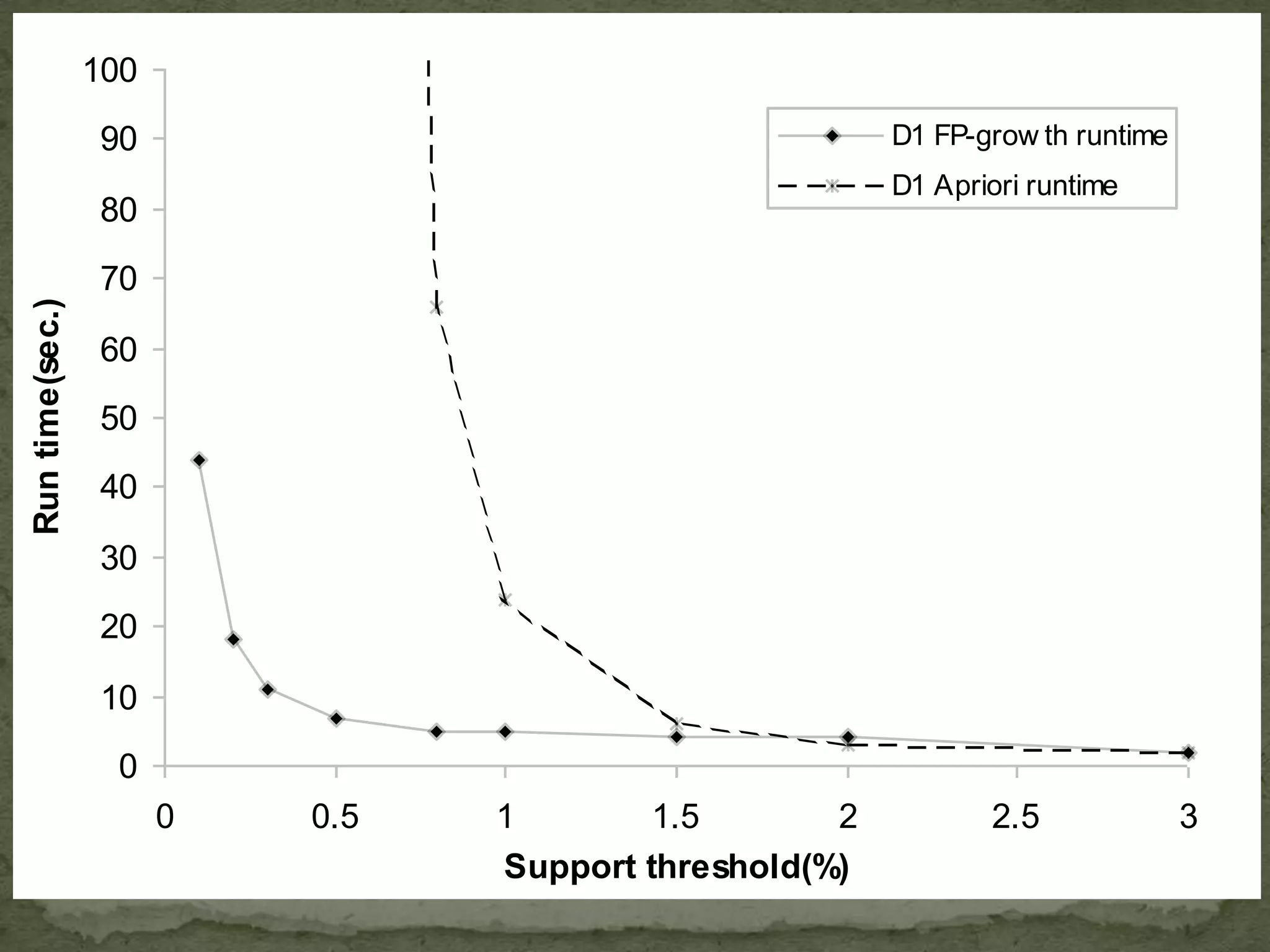
FP Growth improves upon Apriori by eliminating candidate generation and requiring only two database scans through building an FP-tree.
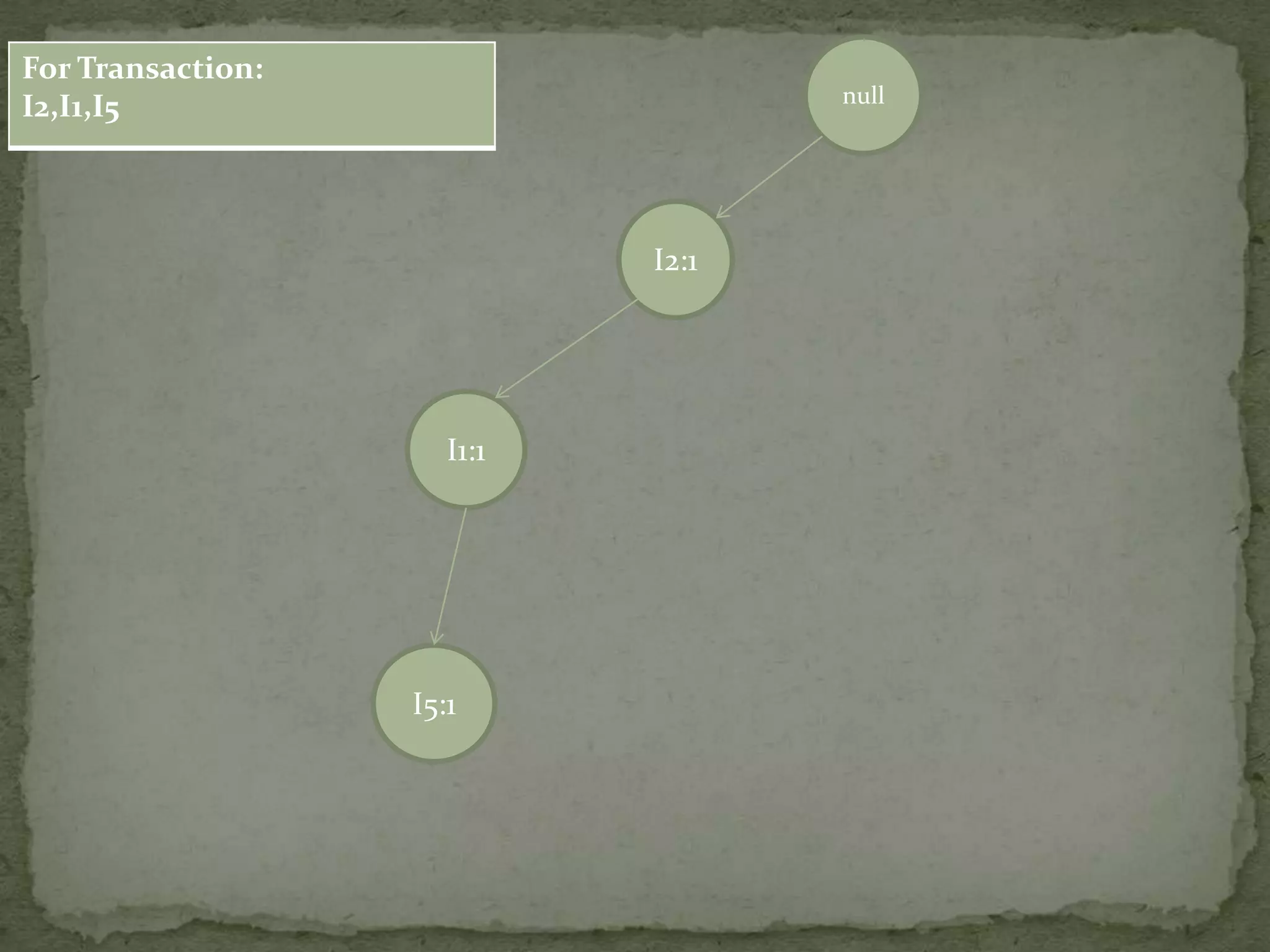
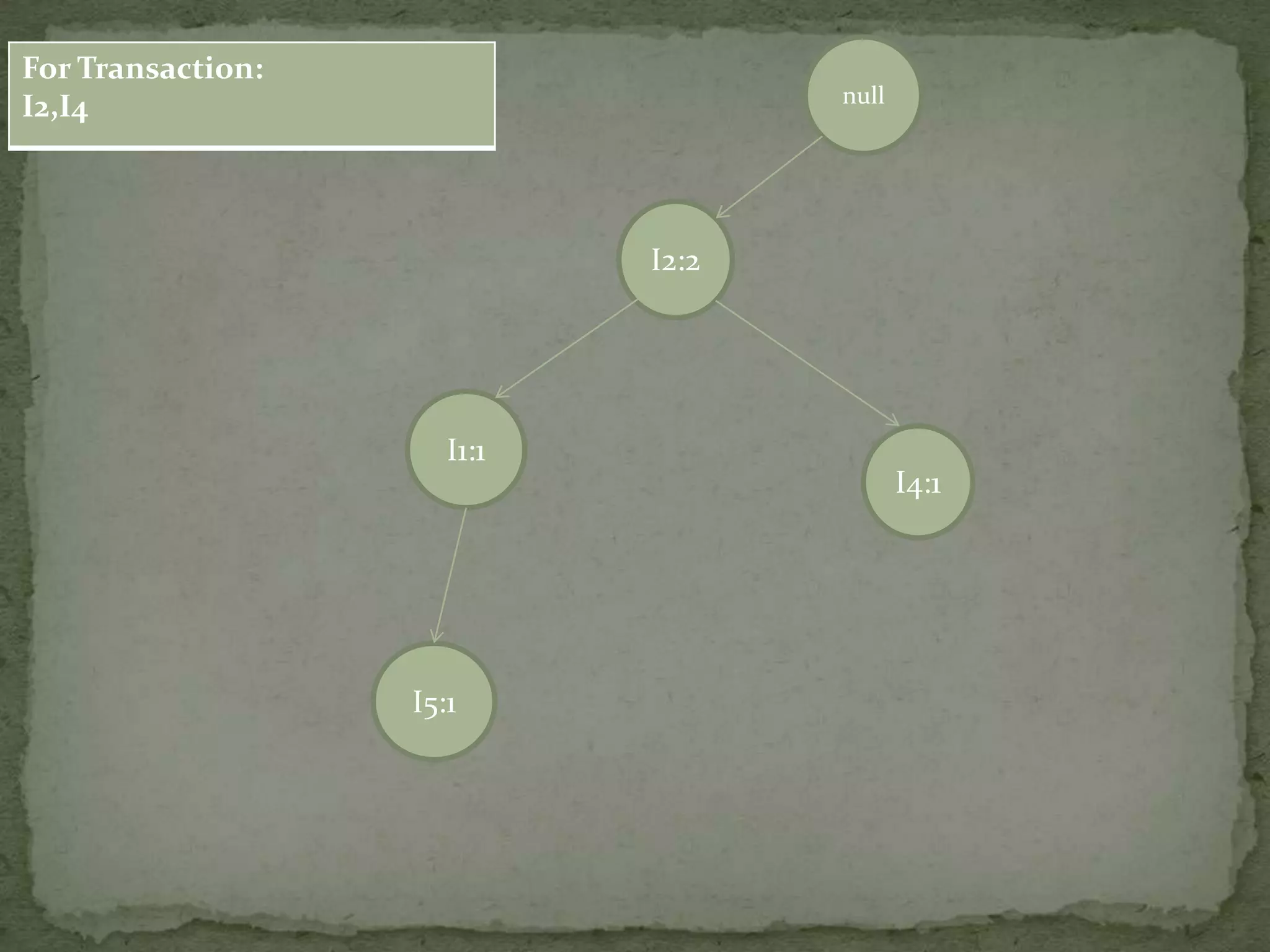
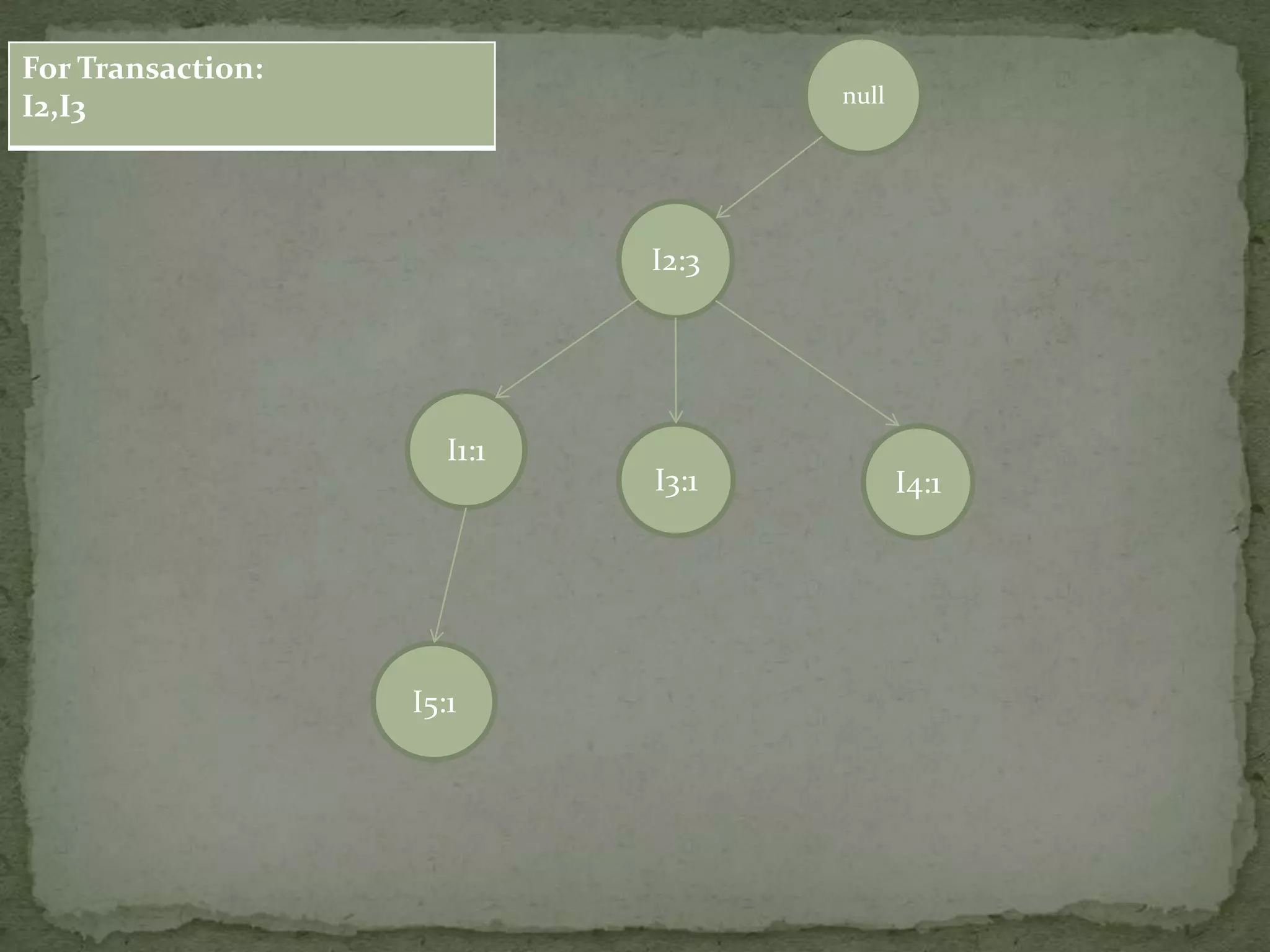
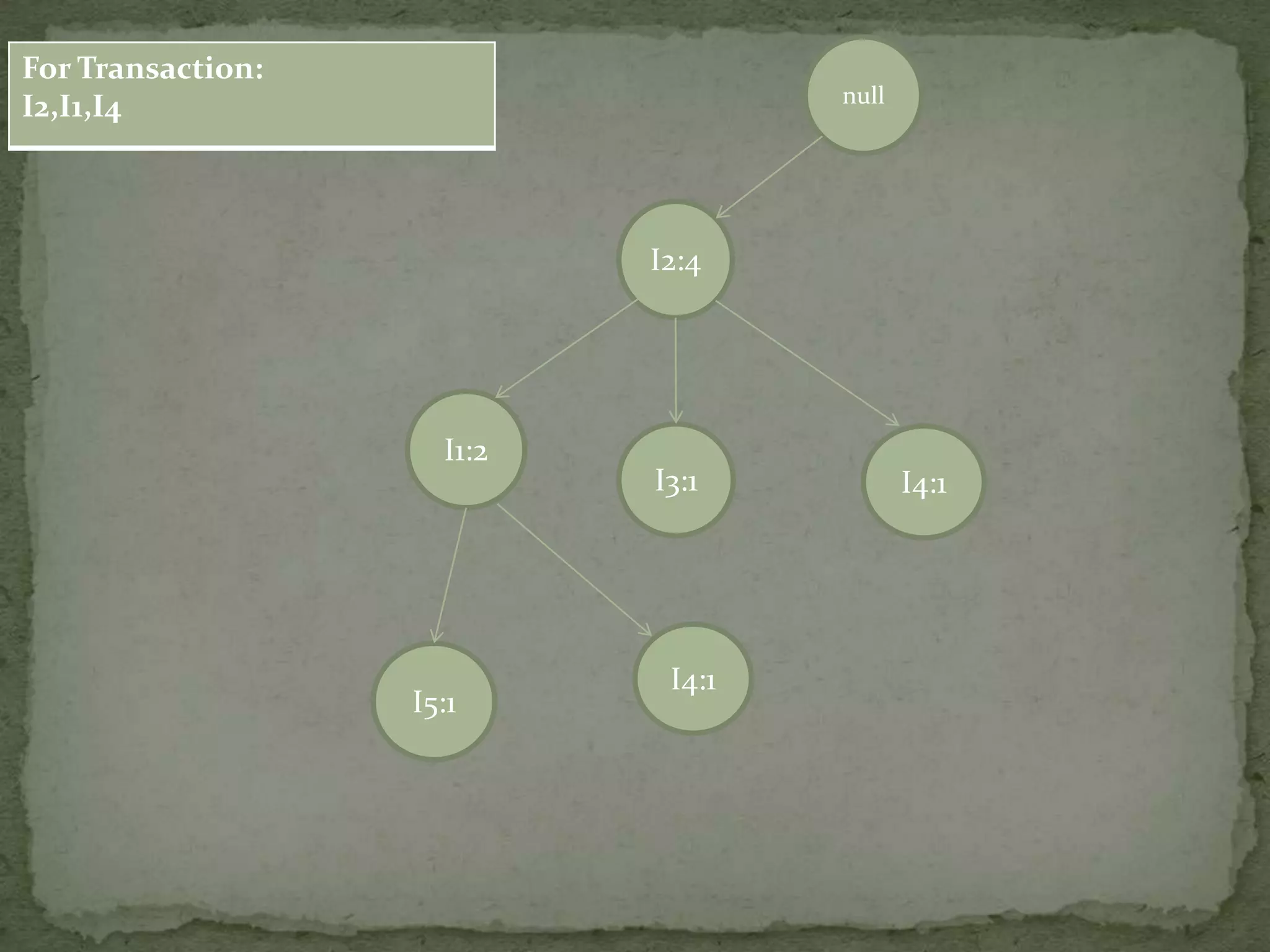
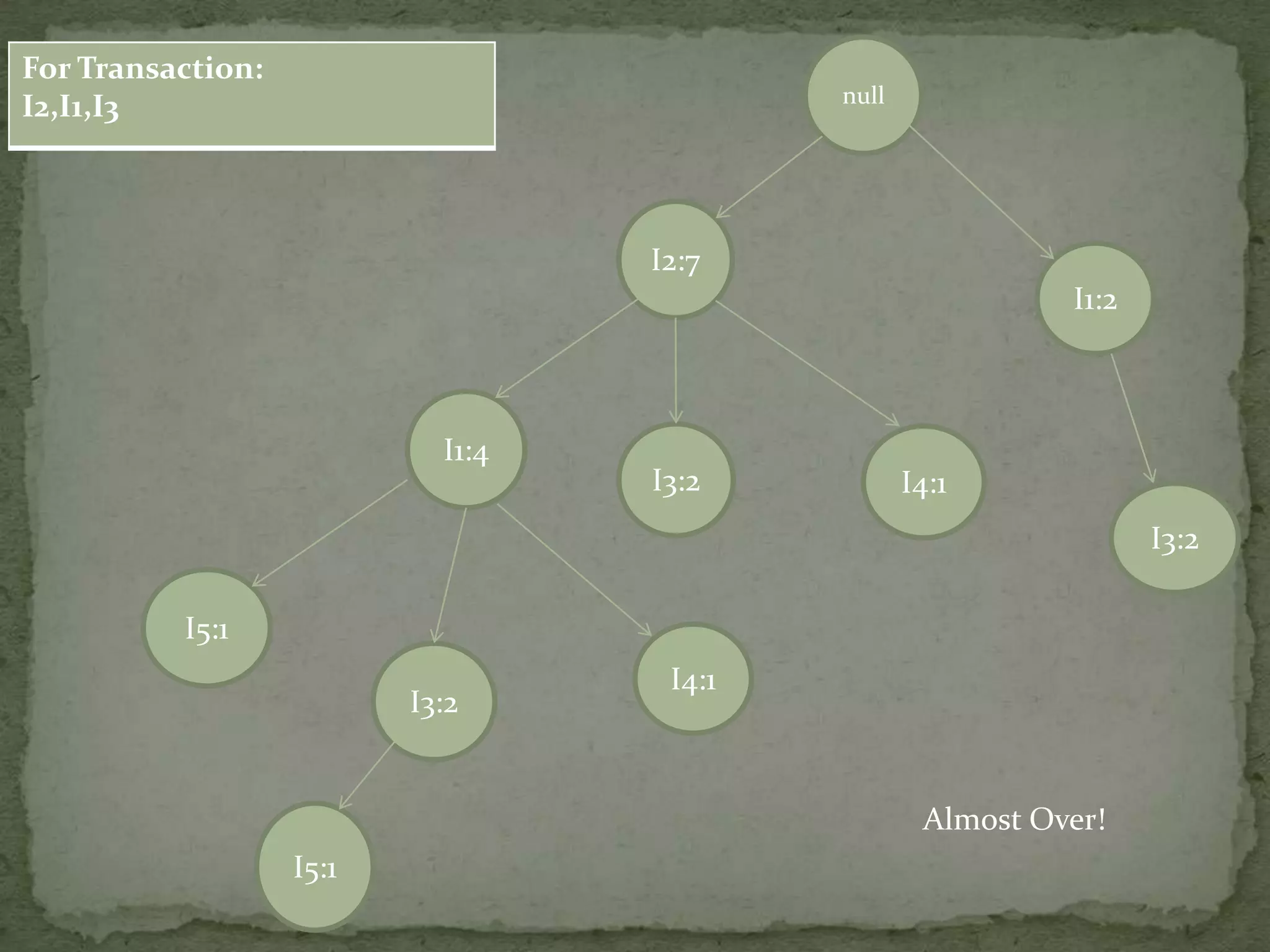
Illustrates a transaction table and the process of constructing an FP-tree based on transactions and support counts.
Details the step-by-step process of building an FP-tree with support counts from various transactions and emphasizes item frequency.
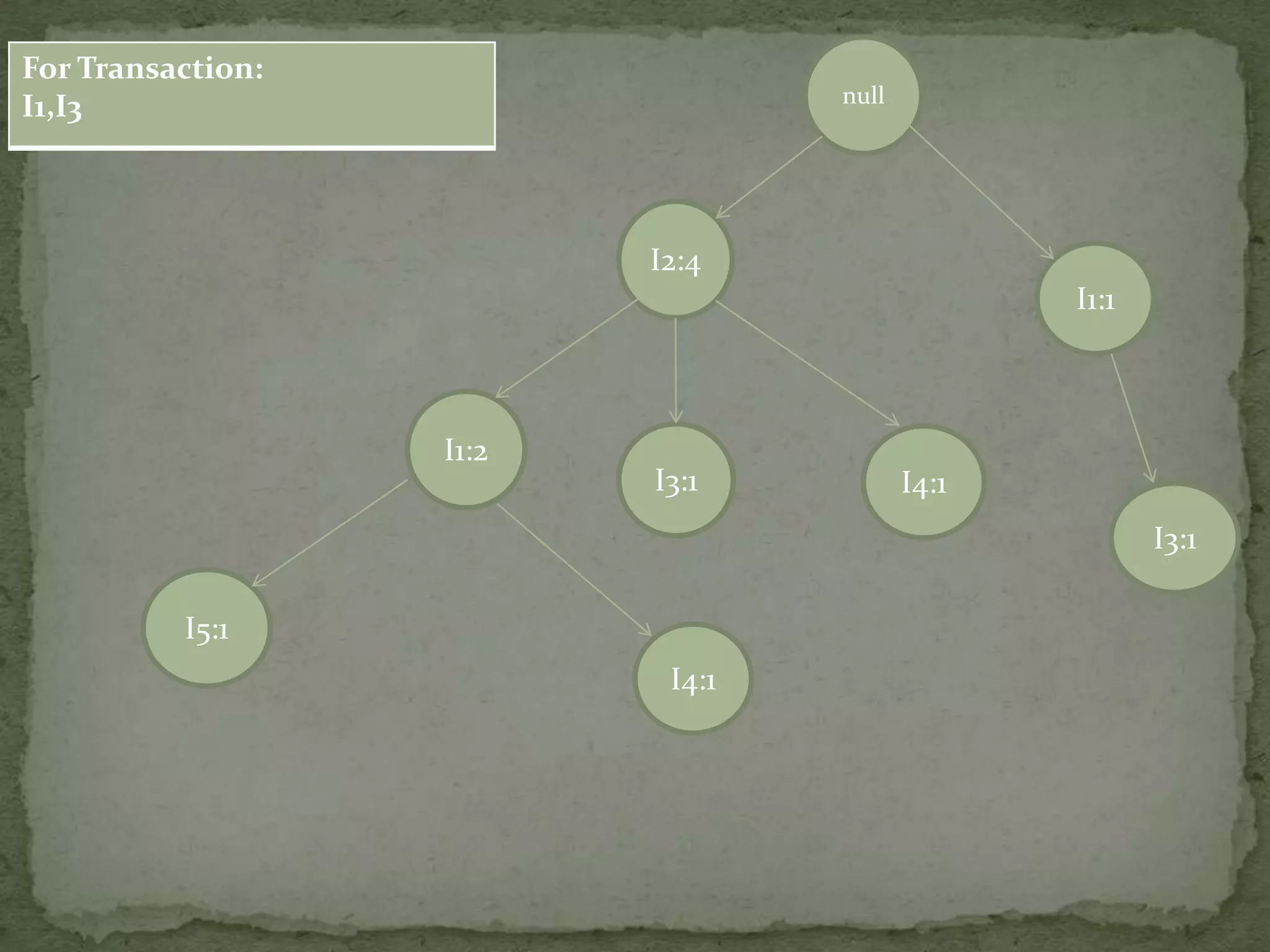
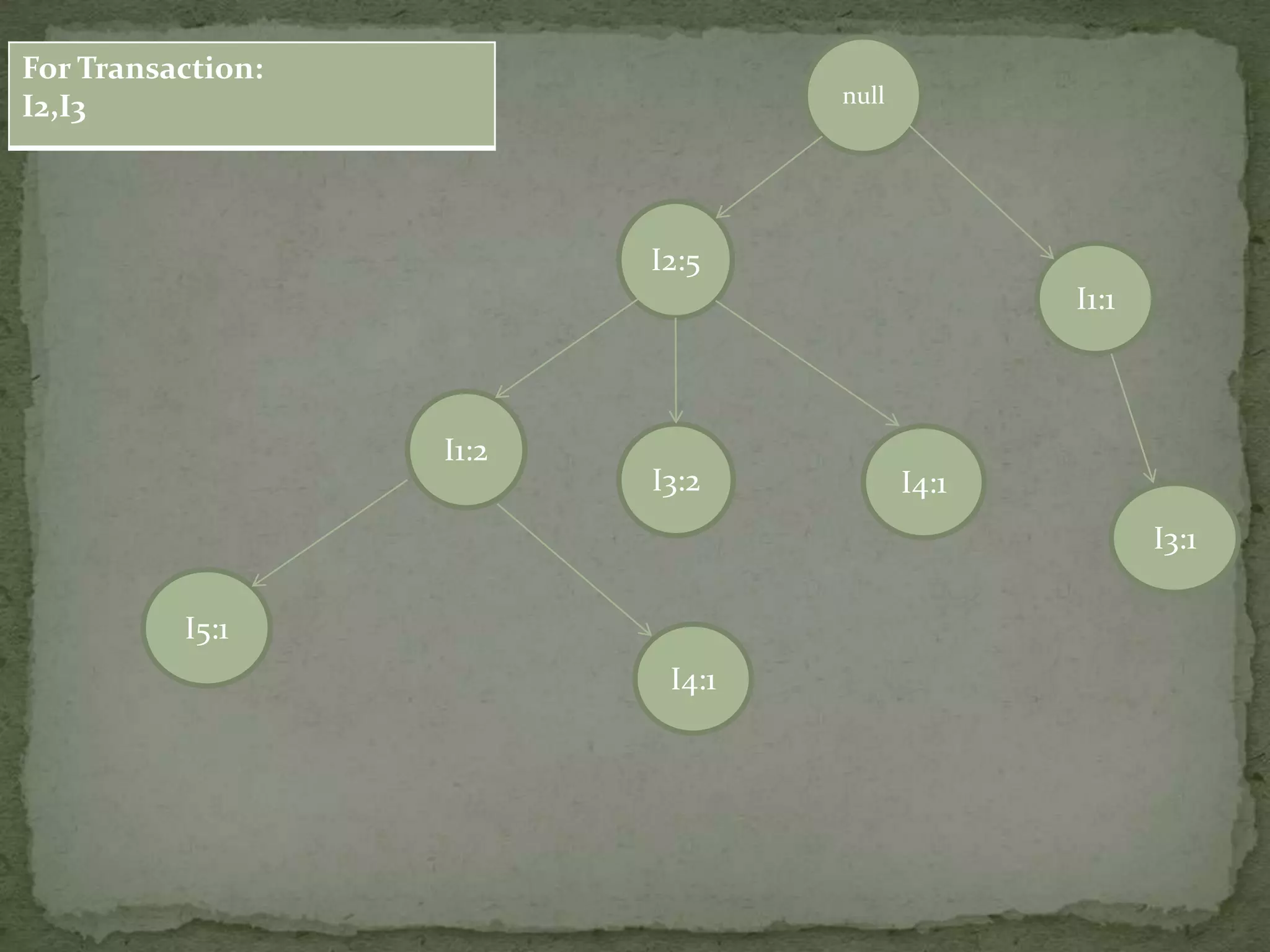
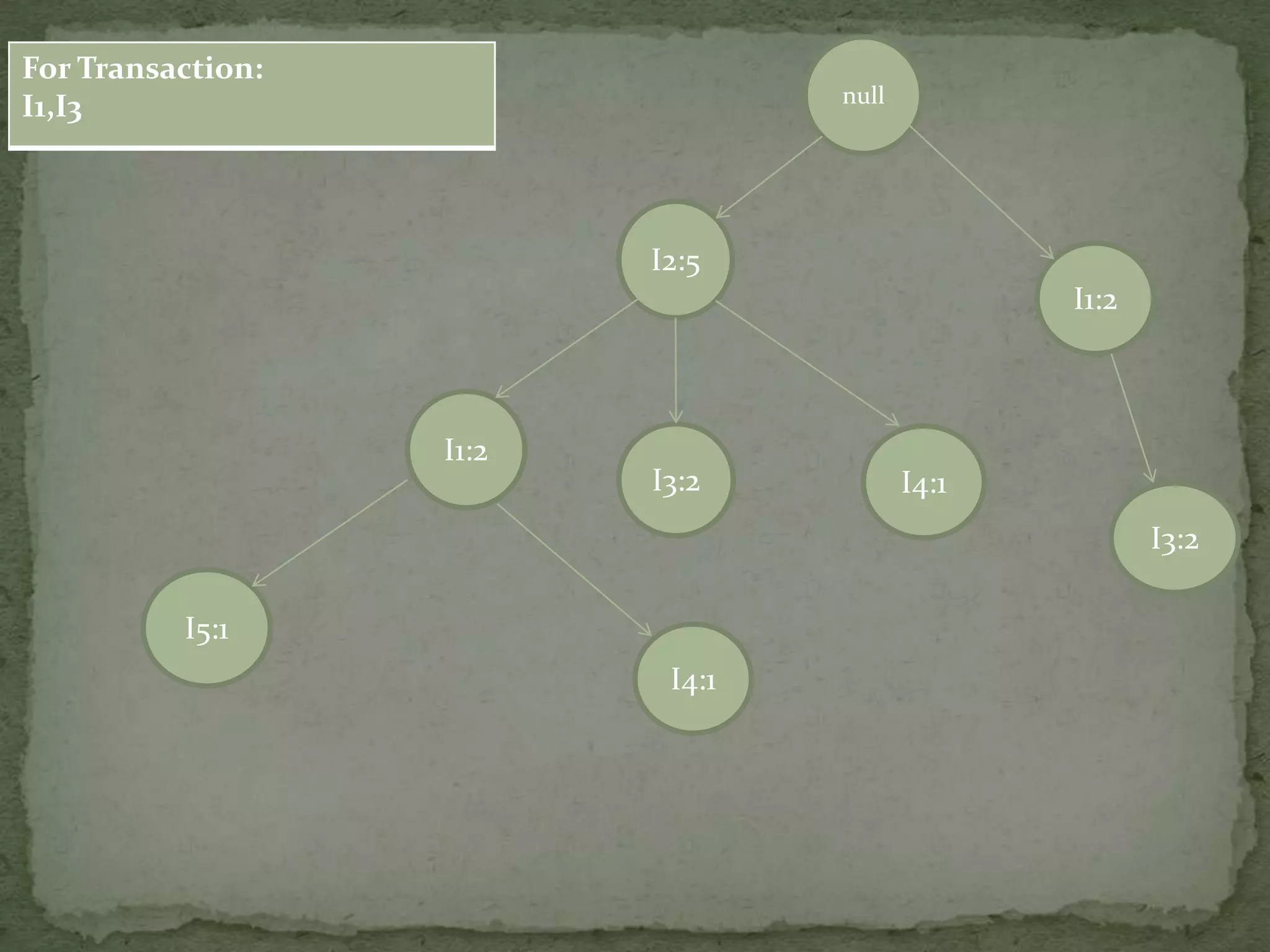
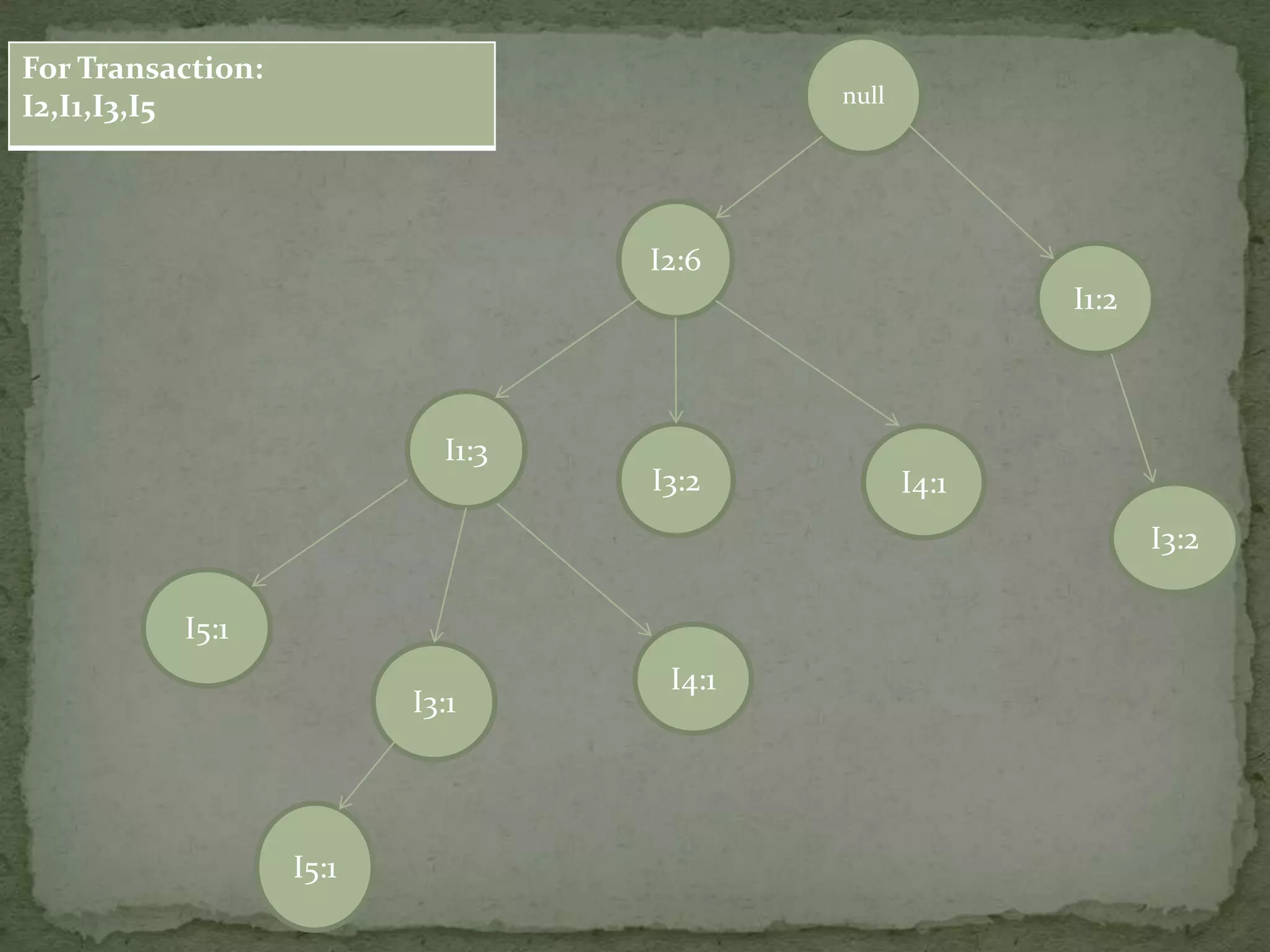
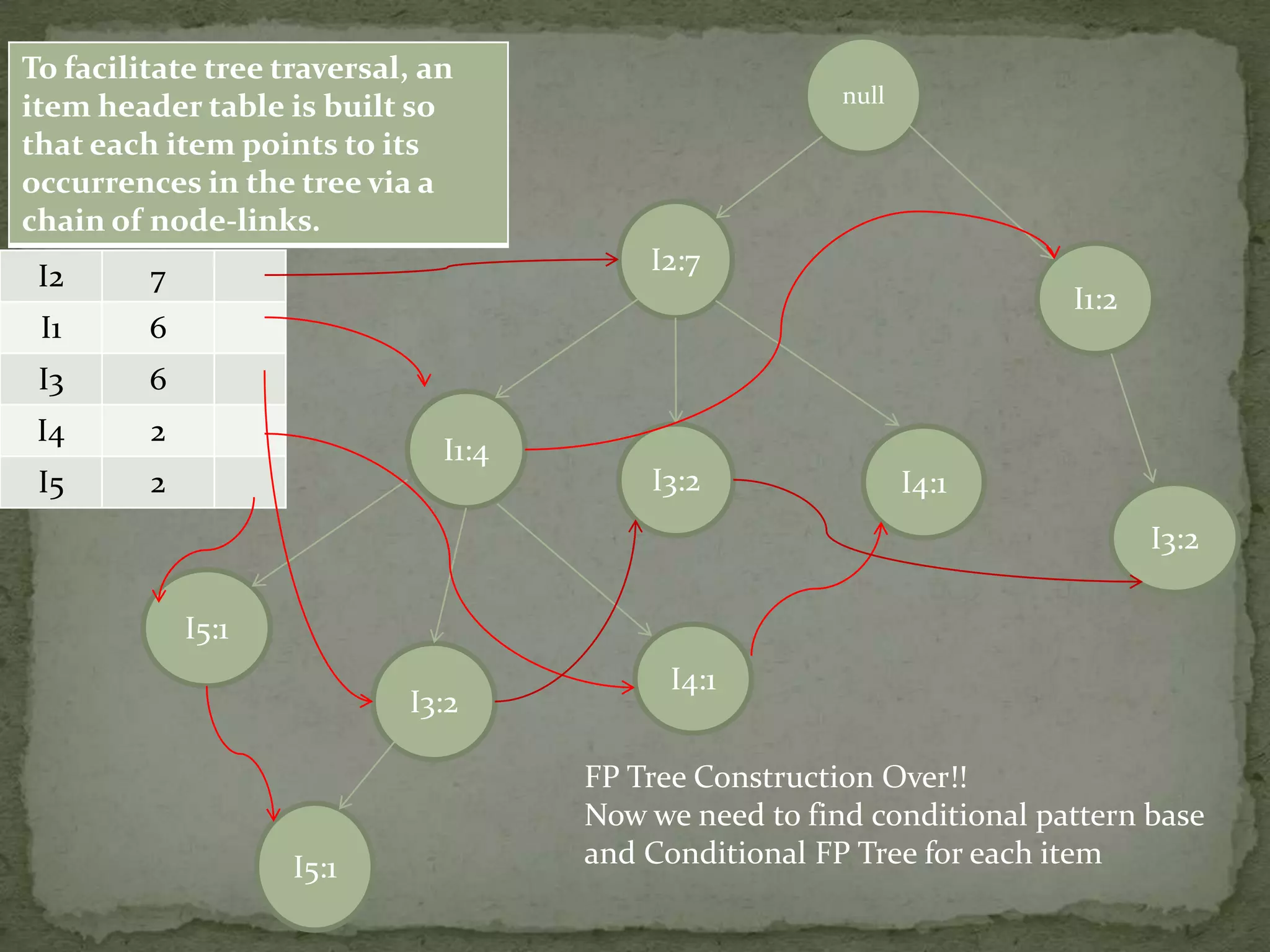
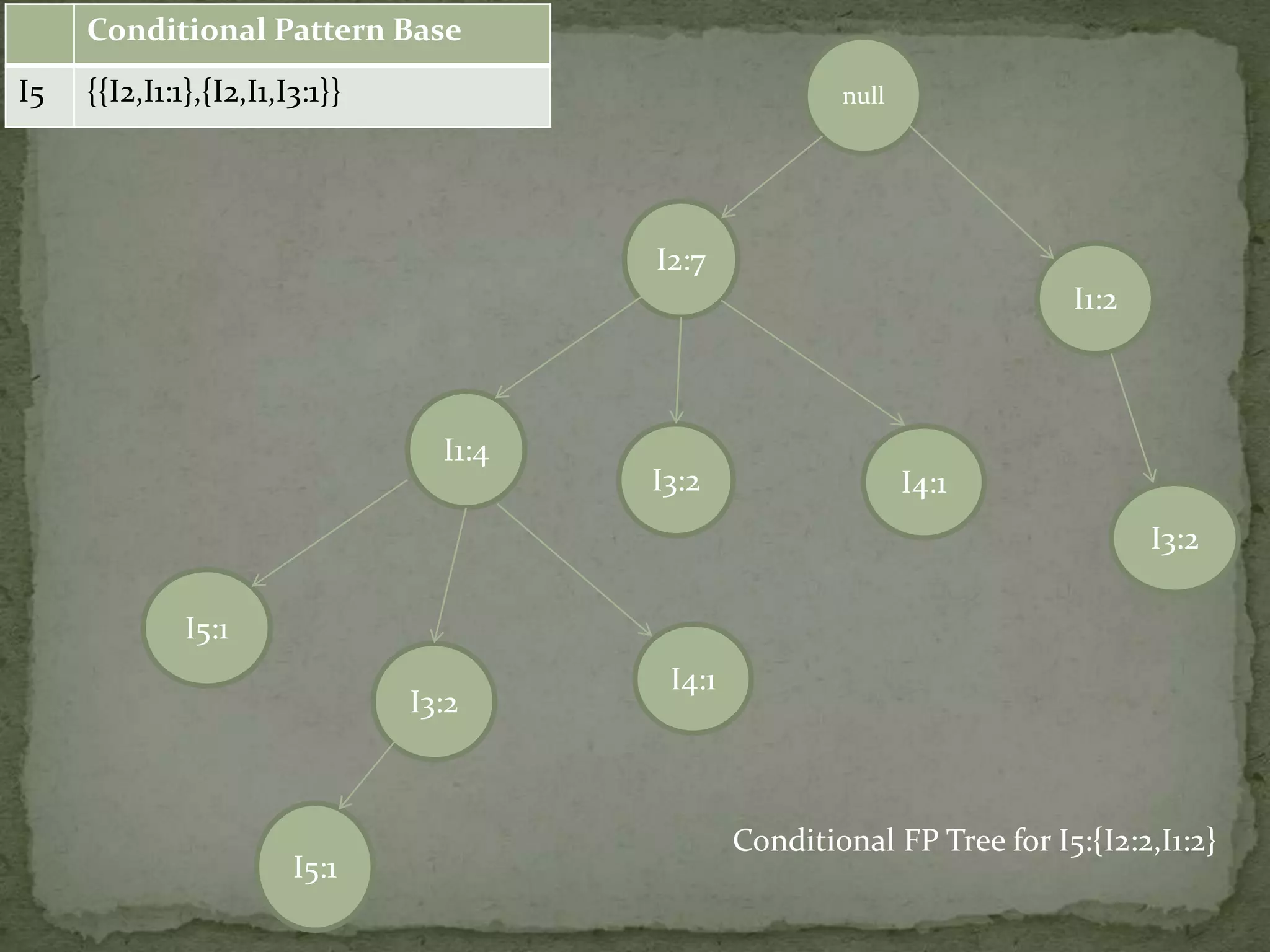
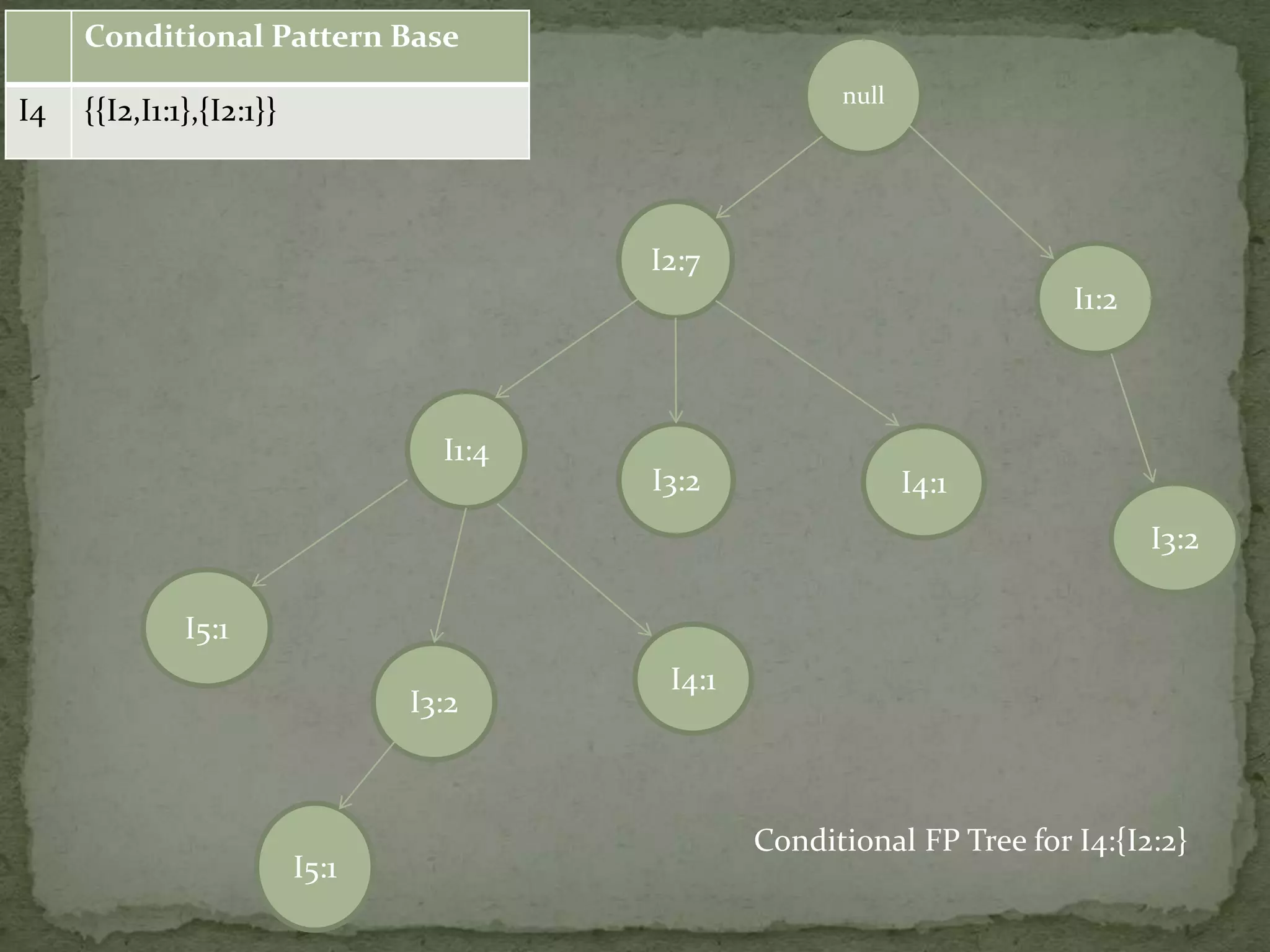
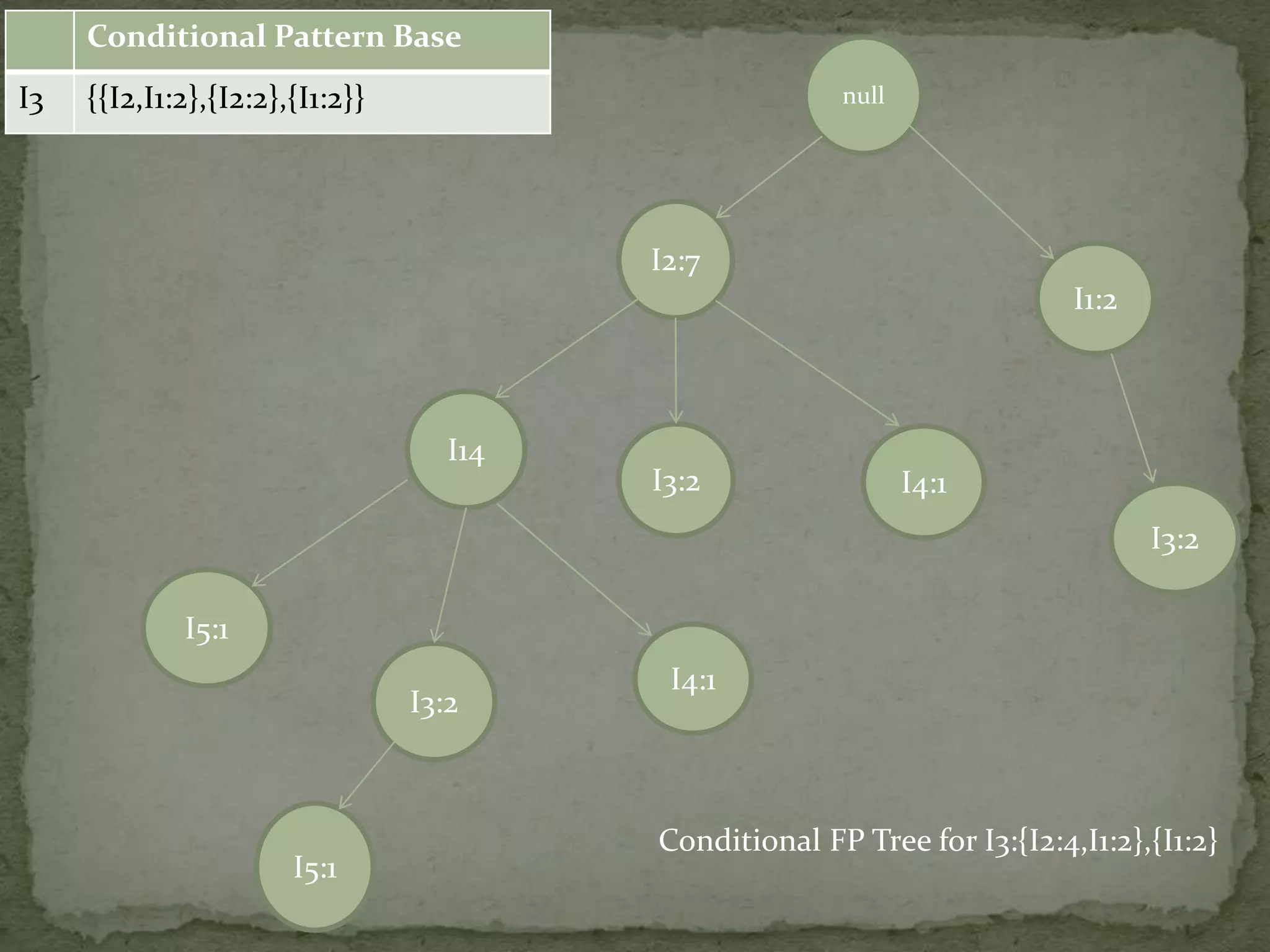
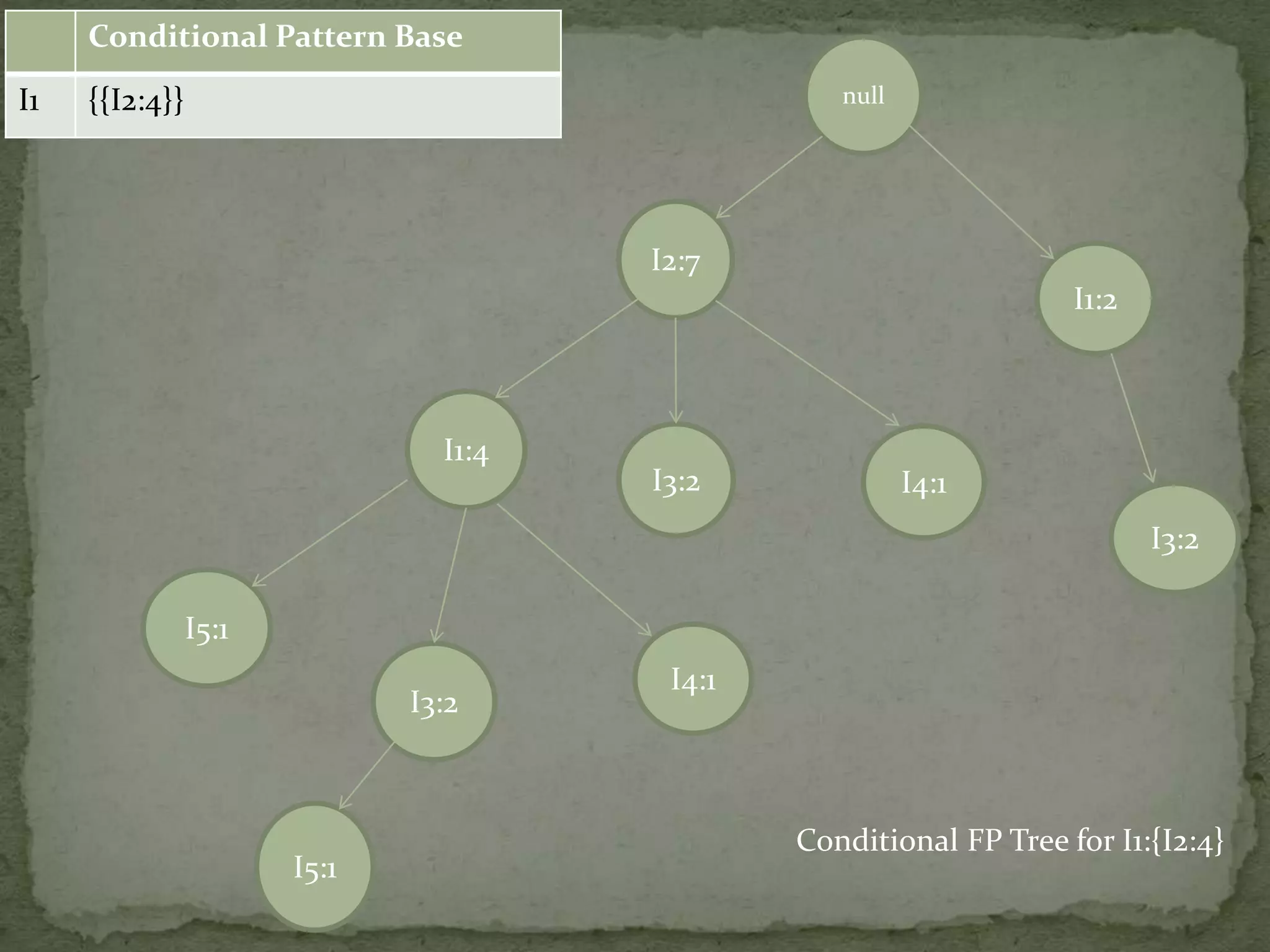
Discusses conditional pattern bases and FP trees for each item derived from the primary FP-tree, showing their structure.
Lists frequent patterns generated from the FP-tree, outlining the advantages and disadvantages of FP-Growth technique.
Ends with a thank you to the audience, concluding the presentation.