비선형적 자료구조 • 데이터insert/delete/search가 간편한 선형적 자료구조 두고 왜? • 사용에 분명한 목적성이 있는 자료구조. • 계층적 관계를 “표현”할 수 있다. • 즉, 트리의 구조로 이루어진 무엇인가를 표현하기가 쉽다. • 또한, 그 구조적 특성을 활용할 수 있다.
3.
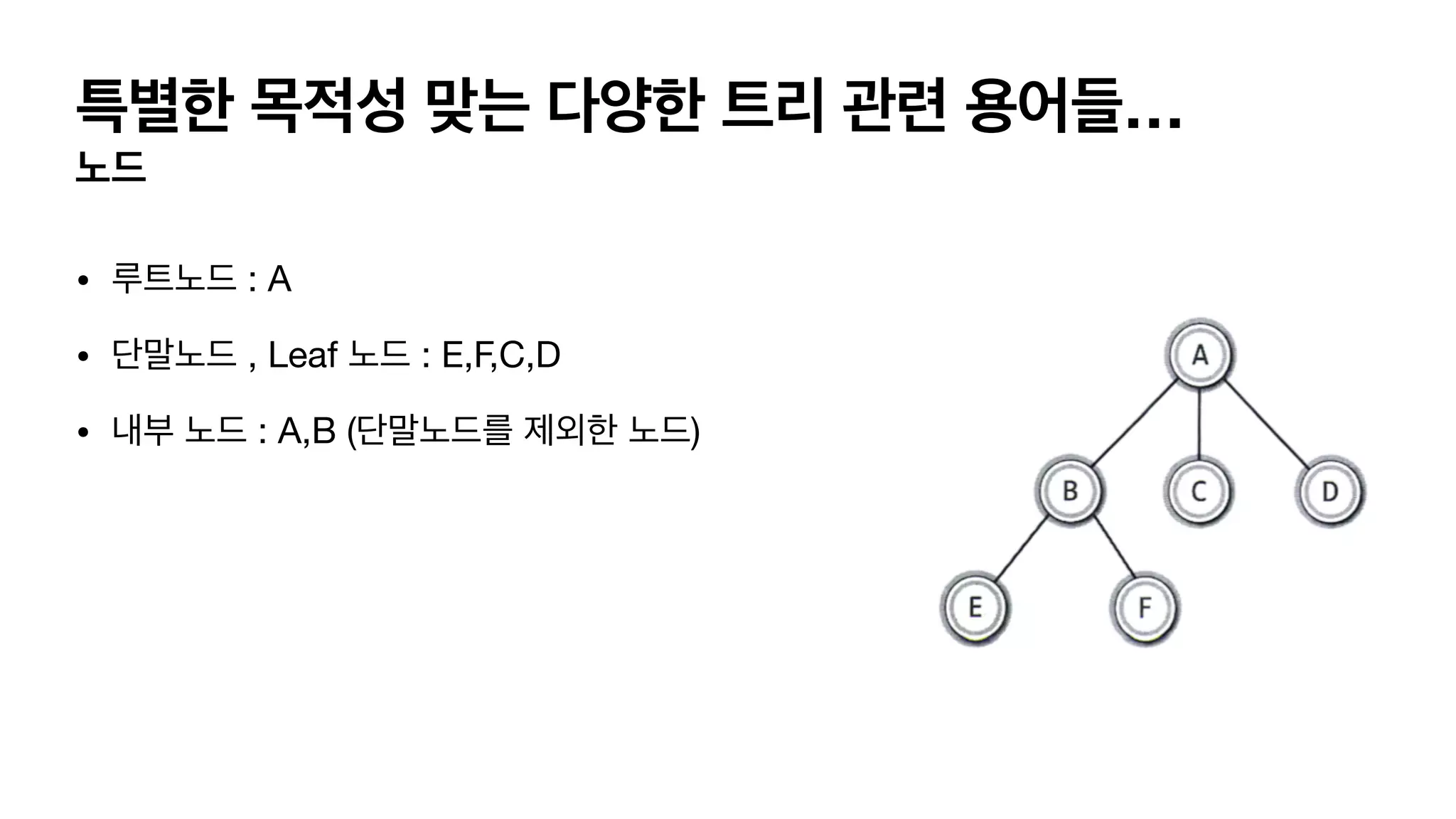
특별한 목적성 맞는다양한 트리 관련 용어들… 노드 • 루트노드 : A • 단말노드 , Leaf 노드 : E,F,C,D • 내부 노드 : A,B (단말노드를 제외한 노드)
4.
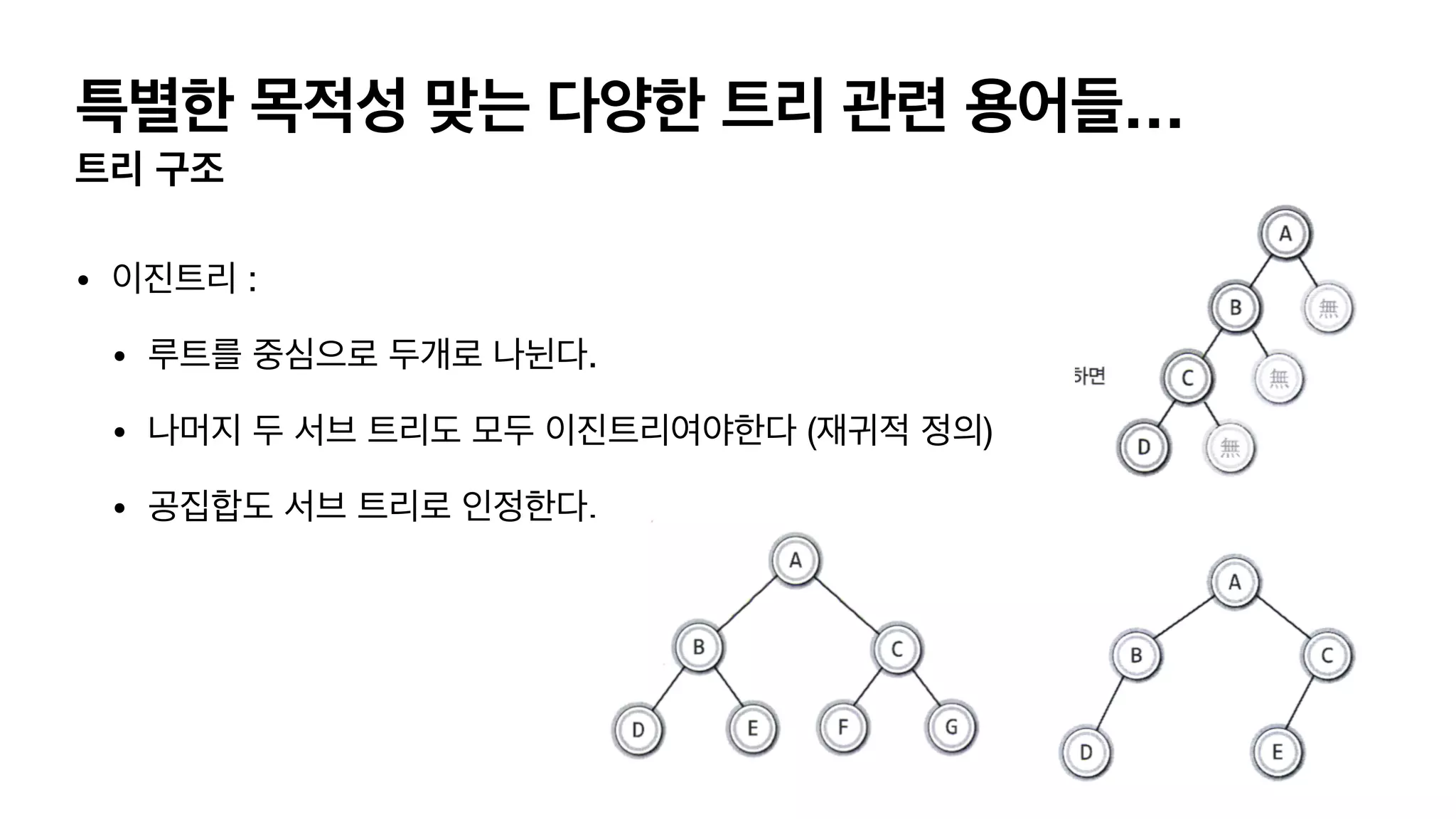
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 이진트리 : • 루트를 중심으로 두개로 나뉜다. • 나머지 두 서브 트리도 모두 이진트리여야한다 (재귀적 정의) • 공집합도 서브 트리로 인정한다.
5.
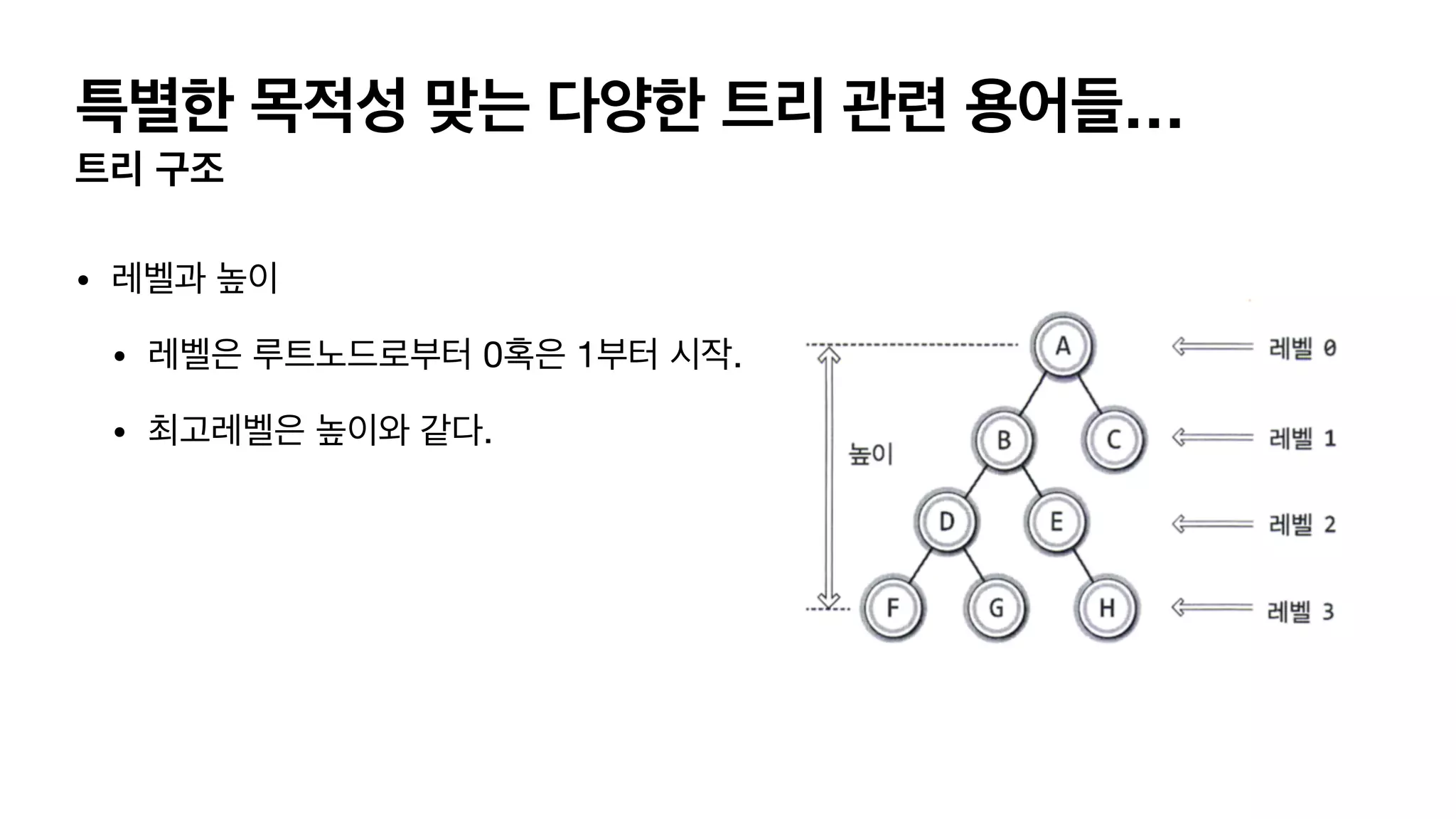
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 레벨과 높이 • 레벨은 루트노드로부터 0혹은 1부터 시작. • 최고레벨은 높이와 같다.
6.
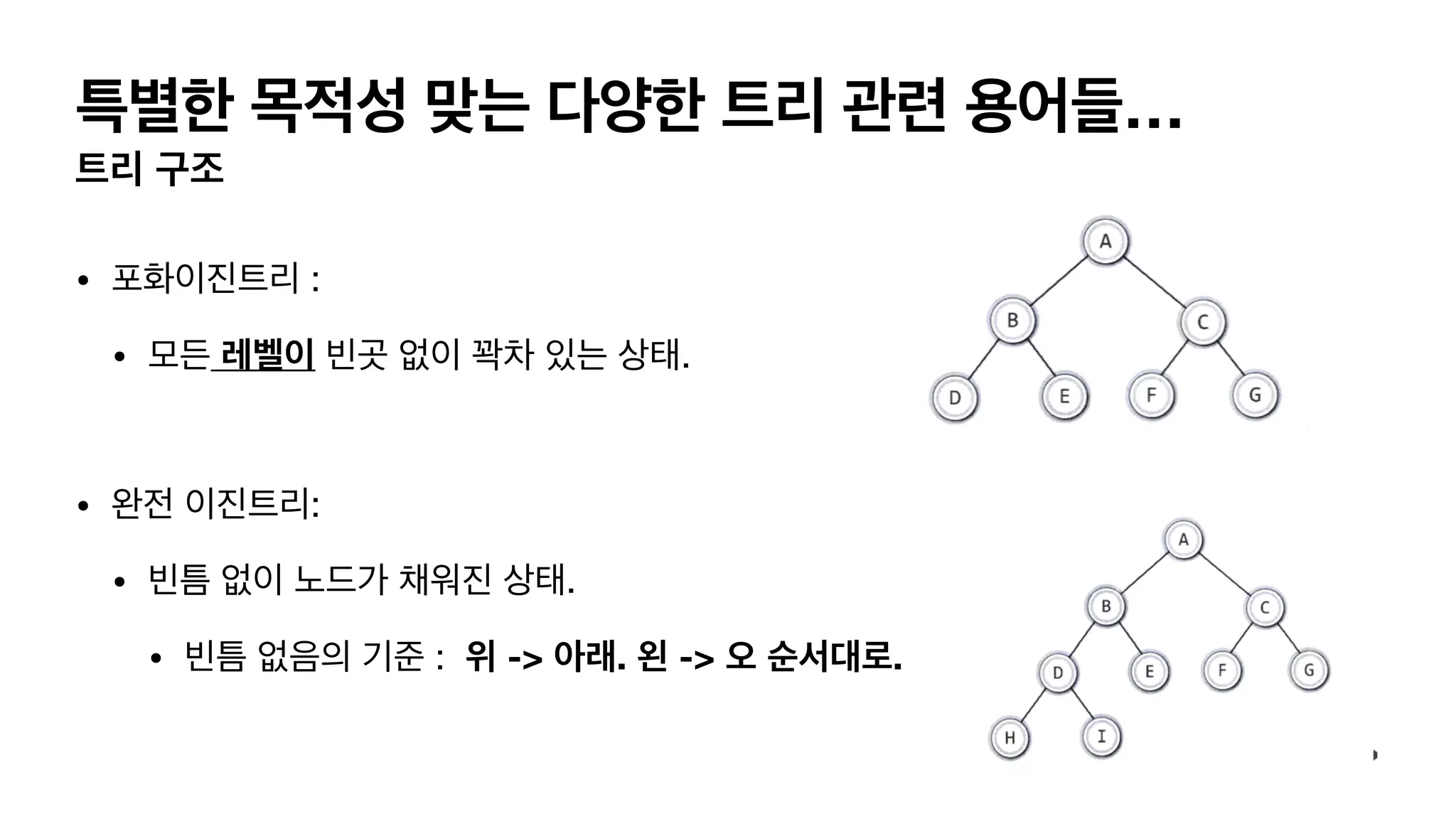
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 포화이진트리 : • 모든 레벨이 빈곳 없이 꽉차 있는 상태. • 완전 이진트리: • 빈틈 없이 노드가 채워진 상태. • 빈틈 없음의 기준 : 위 -> 아래. 왼 -> 오 순서대로.
7.
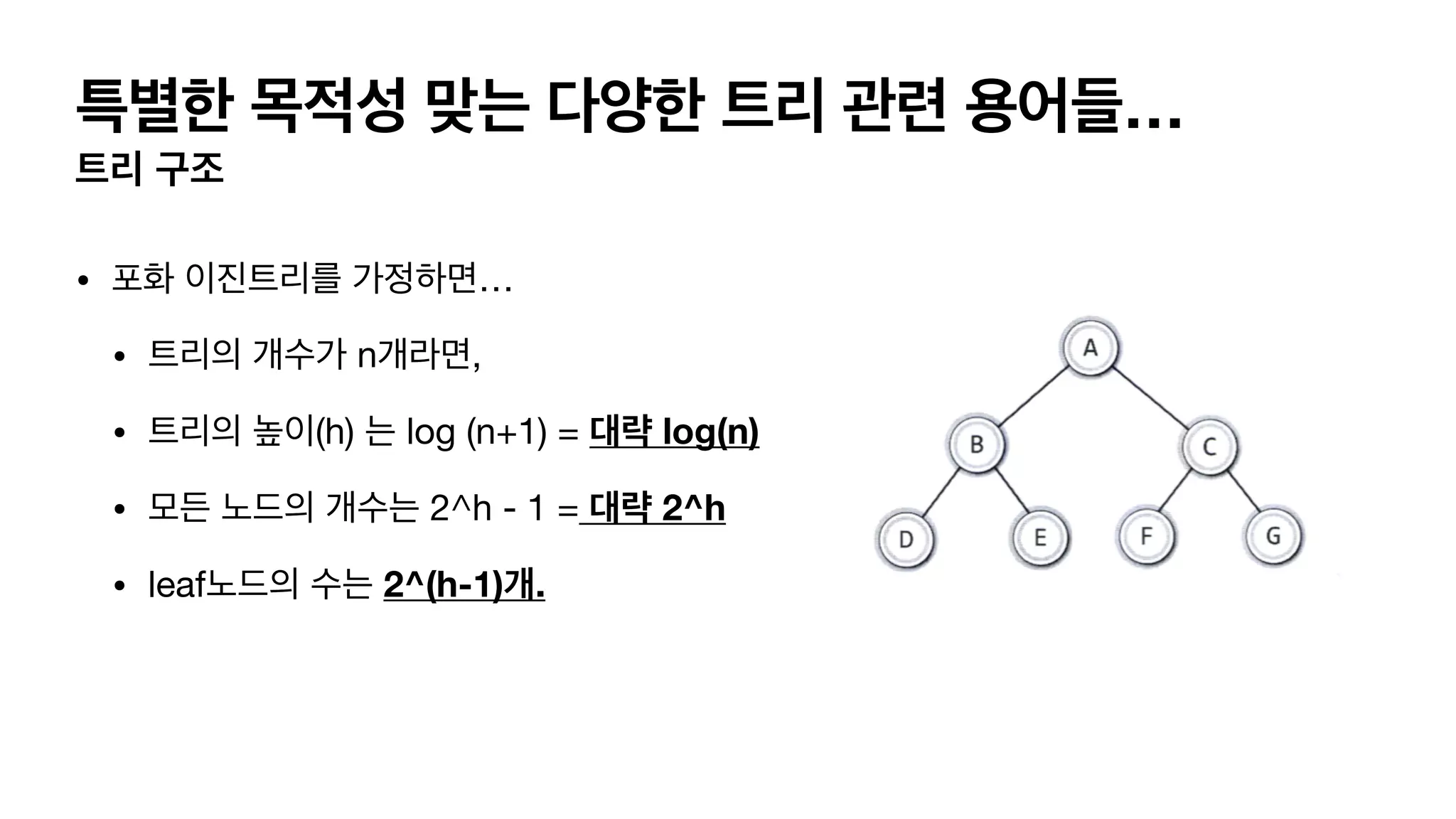
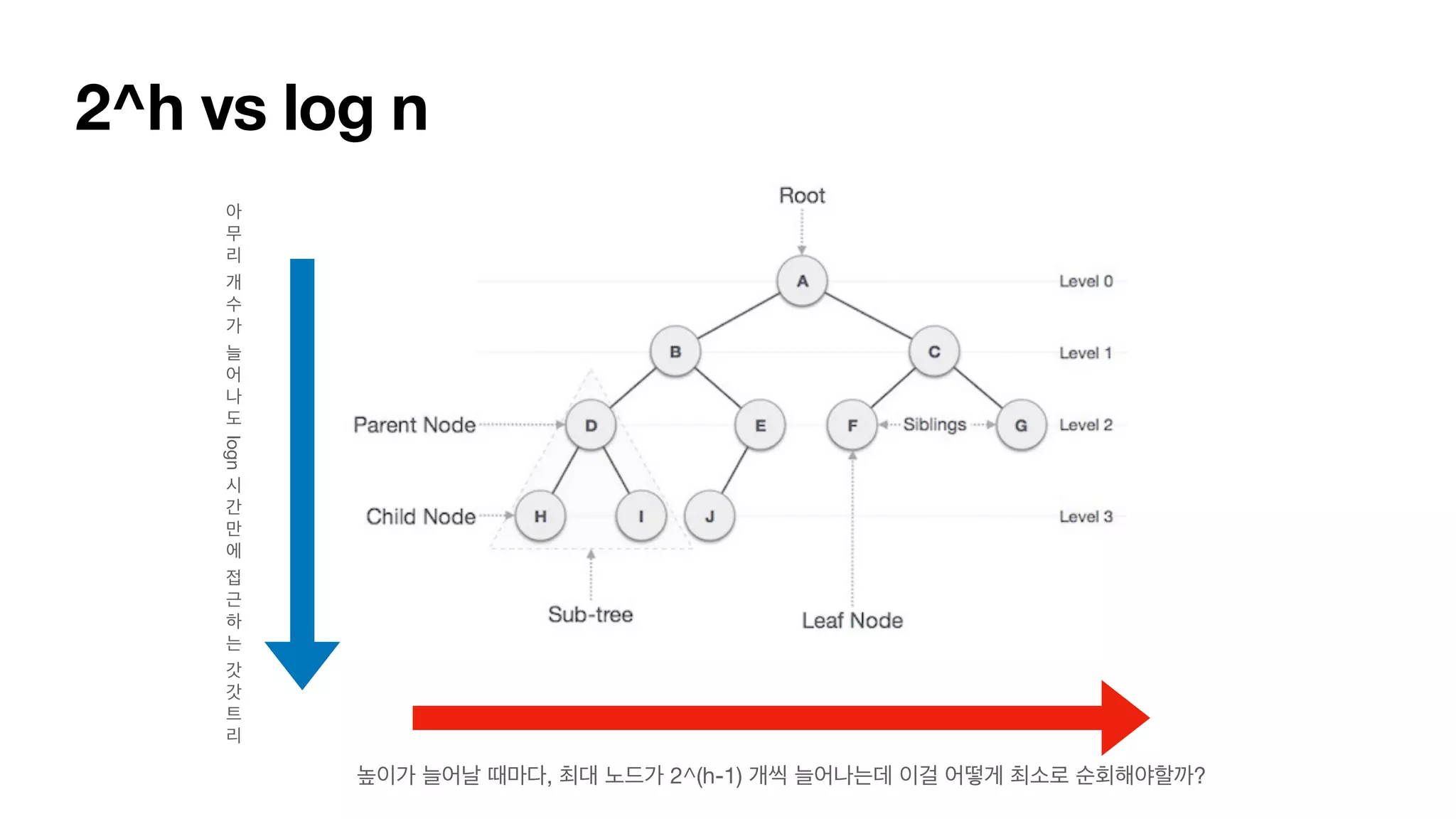
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 포화 이진트리를 가정하면… • 트리의 개수가 n개라면, • 트리의 높이(h) 는 log (n+1) = 대략 log(n) • 모든 노드의 개수는 2^h - 1 = 대략 2^h • leaf노드의 수는 2^(h-1)개.
8.
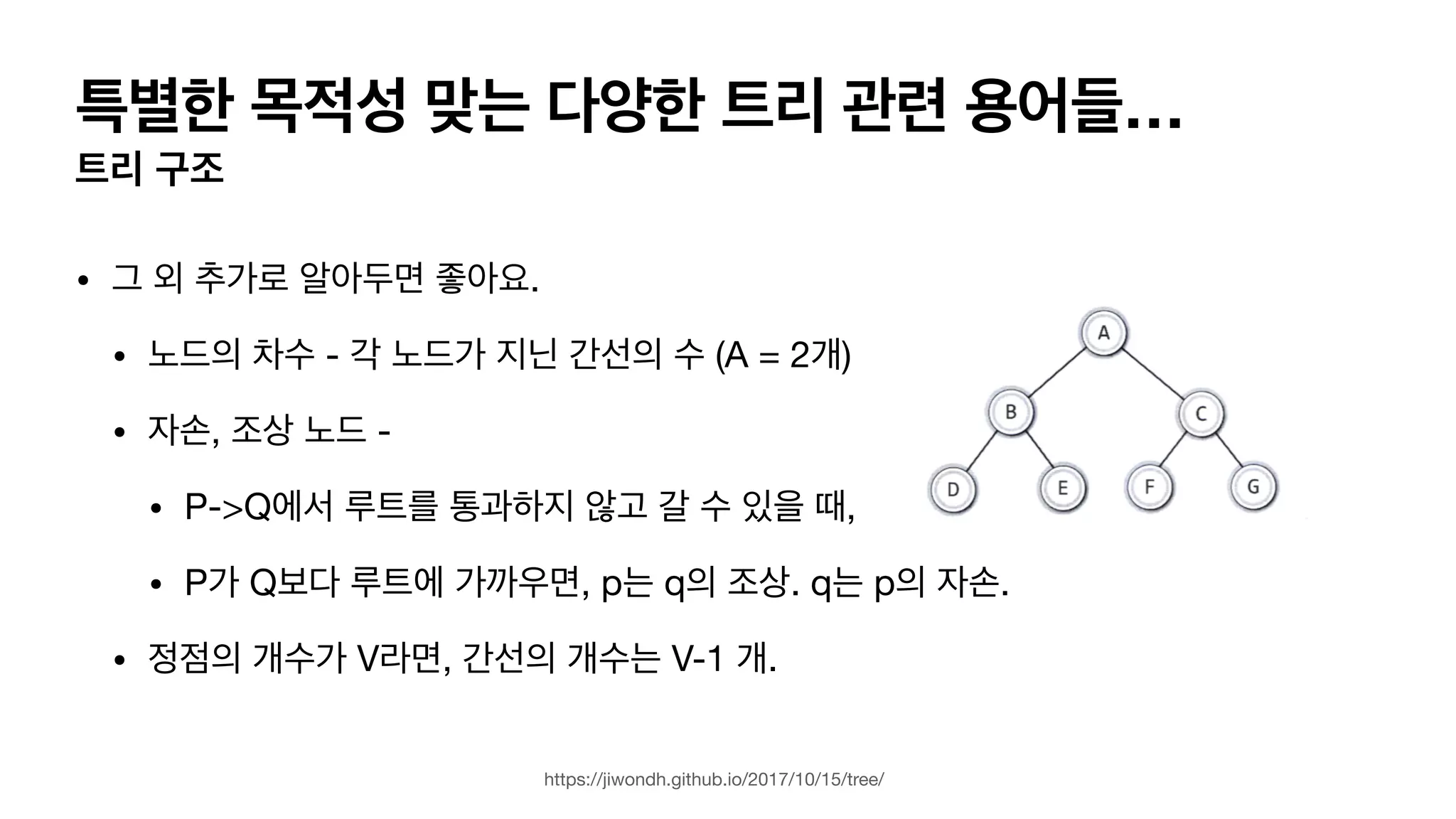
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 그 외 추가로 알아두면 좋아요. • 노드의 차수 - 각 노드가 지닌 간선의 수 (A = 2개) • 자손, 조상 노드 - • P->Q에서 루트를 통과하지 않고 갈 수 있을 때, • P가 Q보다 루트에 가까우면, p는 q의 조상. q는 p의 자손. • 정점의 개수가 V라면, 간선의 개수는 V-1 개. https://jiwondh.github.io/2017/10/15/tree/
9.
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 그 외 추가로 알아두면 좋아요. • 트리의 순회 : DFS의 출력 순서에 따라 세가지로 나눔. • 전위순회 : 노드 방문 -> 왼쪽 전위순회 (재귀) -> 오른쪽 전위순회 (재귀) • 중위순회 : 왼쪽 전위순회 (재귀) -> 노드 방문 -> 오른쪽 전위순회 (재귀) • 후위순회 :왼쪽 전위순회 (재귀) -> 오른쪽 전위순회 (재귀) -> 노드 방문 https://jiwondh.github.io/2017/10/15/tree/
10.
특별한 목적성 맞는다양한 트리 관련 용어들… 트리 구조 • 그 외 추가로 알아두면 좋아요. • 트리의 지름 : 트리 존재하는 경로 중에서 가장 긴것의 길이. • 한 정점 s에서 모든 정점까지의 거리를 구한다. 가장 긴 정점을 u라고 한다. • u에서 모든 정점까지의 거리를 구한다. 가장 긴 정점을 v라고 한다. • d(u,v)가 트리의 지름이다. https://jiwondh.github.io/2017/10/15/tree/
11.
과제 - 1 BinaryTree와 순회 구현하기 • int 값을 가지고 있는 이진 트리를 나타내는 Node 라는 클래스를 정의하세요 • int value, Node left, right를 가지고 있어야 합니다. • BinrayTree라는 클래스를 정의하고 주어진 노드를 기준으로 출력하는)와 dfs(Node node) 메소드를 구현하세요. • DFS는 전위순회, 중위순회, 후위순회를 모두 구현해 주세요. https://github.com/jiwoo-choi/java-live-study/tree/main/src/main/java/tree
탐색 Search • 탐색 :데이터를 찾는것. • 효율적인 탐색을 위해서 고민해봐야 할 세가지? • (1) 어디에 데이터를 담아야 효율적인 탐색이 가능한가? • (2) 어떻게 데이터를 탐색해야 효율적인 탐색이 가능한가? • (3) 그래서, 어떻게 데이터를 담는 과정을 결정 해야 (2)와 같은 효율적인 탐색 방법을 (1) 에서 할 수 있는지?
16.
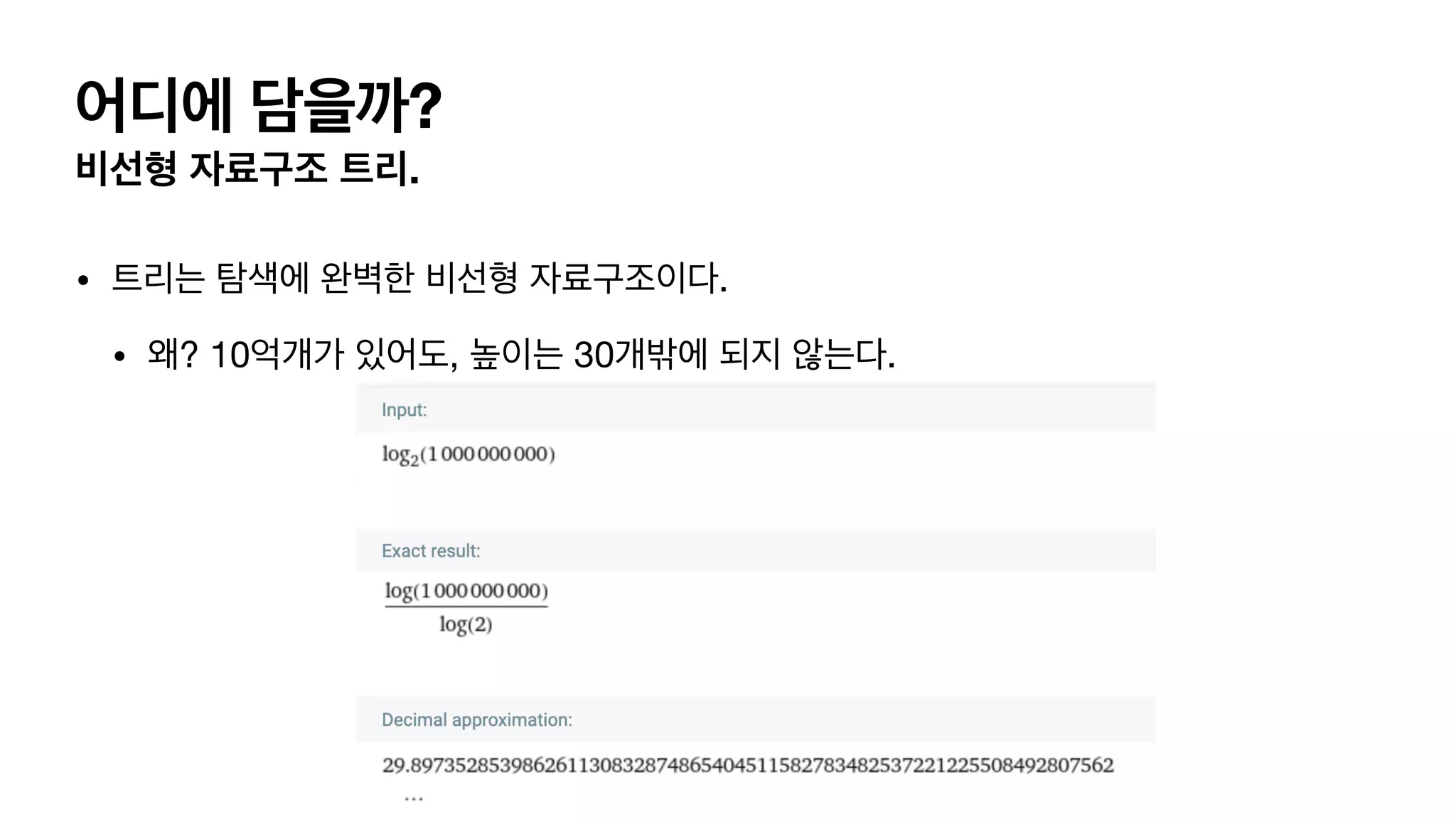
어디에 담을까? 비선형 자료구조트리. • 트리는 탐색에 완벽한 비선형 자료구조이다. • 왜? 10억개가 있어도, 높이는 30개밖에 되지 않는다.
17.
탐색 Search • 탐색 :데이터를 찾는것. • 효율적인 탐색을 위해서 고민해봐야 할 세가지? • (1) 어디에 데이터를 담아야 효율적인 탐색이 가능한가? 트리 • (2) 어떻게 데이터를 탐색해야 효율적인 탐색이 가능한가? • (3) 그래서, 어떻게 데이터를 담는 과정을 결정 해야 (2)와 같은 효율적인 탐색 방법을 (1) 에서 할 수 있는지?
탐색 Search • 탐색 :데이터를 찾는것. • 효율적인 탐색을 위해서 고민해봐야 할 세가지? • (1) 어디에 데이터를 담아야 효율적인 탐색이 가능한가? 트리 • (2) 어떻게 데이터를 탐색해야 효율적인 탐색이 가능한가? 찾고자 하는 데이터가 어디쯤 저장되었는지 알 수 있는 방법을 활용해야할것. • (3) 그래서, 어떻게 데이터를 담는 과정을 결정 해야 (2)와 같은 효율적인 탐색 방법을 (1) 에서 할 수 있는지?
22.
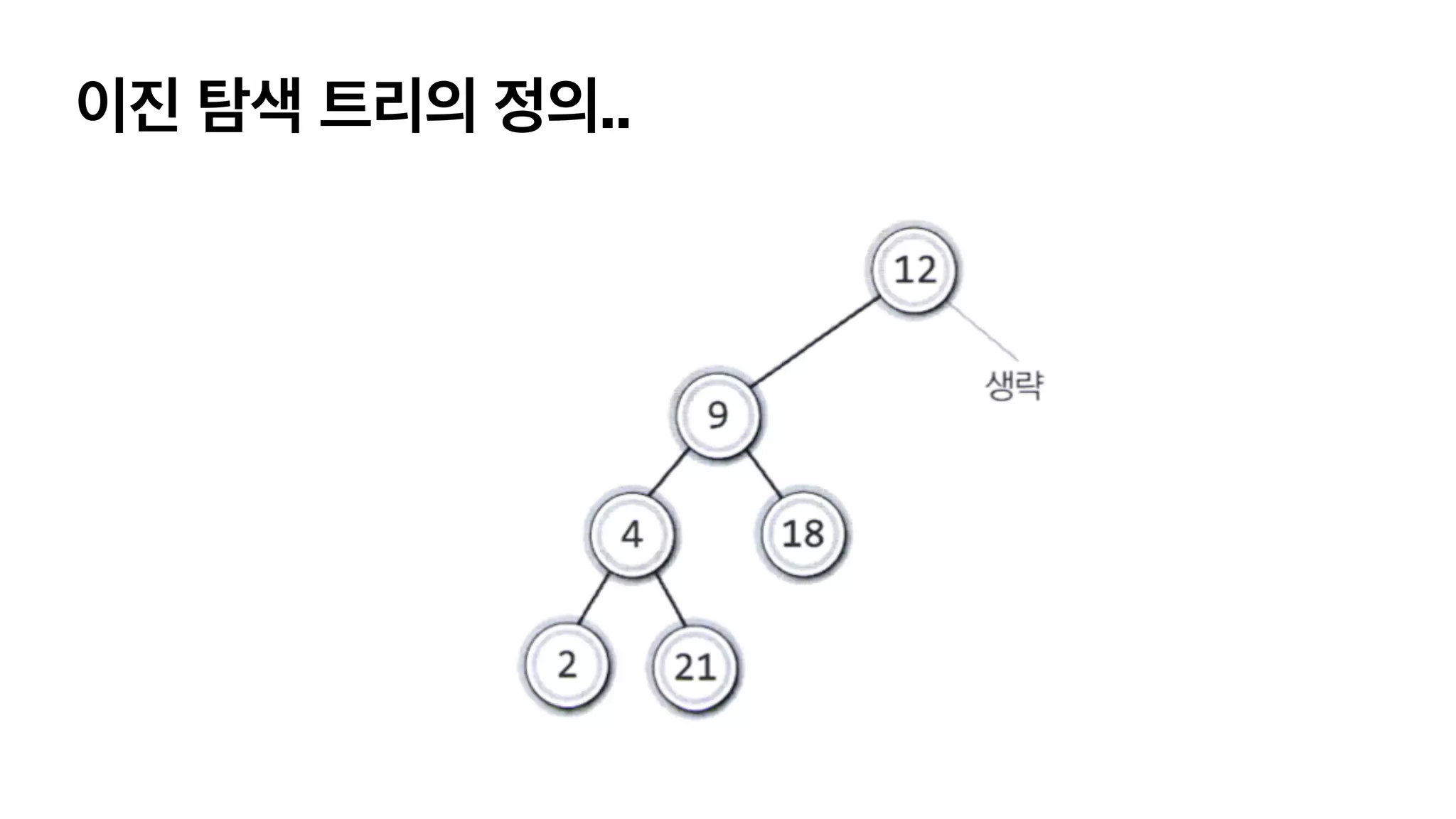
결론적으로, 어떻게 트리에담아나가야 할까? BST를 만들어보자. • 이진 트리에 담긴 키는 유일하다. • 루트노드의 키가 왼쪽 서브 트리를 구성하는 어떠한 노드보다 크다. • 루트노드의 키가 오른쪽 서브 트리를 구성하는 어떠한 노드보다 크다. • 왼쪽과 오른쪽 서브 트리도 이진 탐색 트리이다.
23.
이진 탐색 트리의정의중.. • 루트노드의 키가 왼쪽 서브 트리를 구성하는 어떠한 노드보다 크다. • 루트노드의 키가 오른쪽 서브 트리를 구성하는 어떠한 노드보다 크다. • 왼쪽 키값보다 크다 (X) • 왼쪽 전체보다 크다 (O)
과제 - 2BST 구현해보기 삽입 ,탐색, 삭제 규칙 정의하고 BST 구현해보기. • 삽입 규칙 : • 비교 대상이 없을 때까지 내려간다, 비교 대상이 없으면 새로운 노드 추가. O(log n) • 탐색 규칙: • 주어진 값보다 현재 노드가 크다면 왼쪽을 살필것, 아니면 오른쪽을 살필것. (O log n) • 삭제 규칙: • 1. 삭제할 노드가 단말 노드인 경우 -> 그냥 삭제 가능. • 2. 삭제할 노드가 하나의 자식 노드를 가지는 경우. -> ?? • 3. 삭제할 노드가 두개의 자식 노드를 가지고 있는 경우. -> ?? • 주어진 이진트리가 BST인지 판별 하는 방법 -> ??
26.
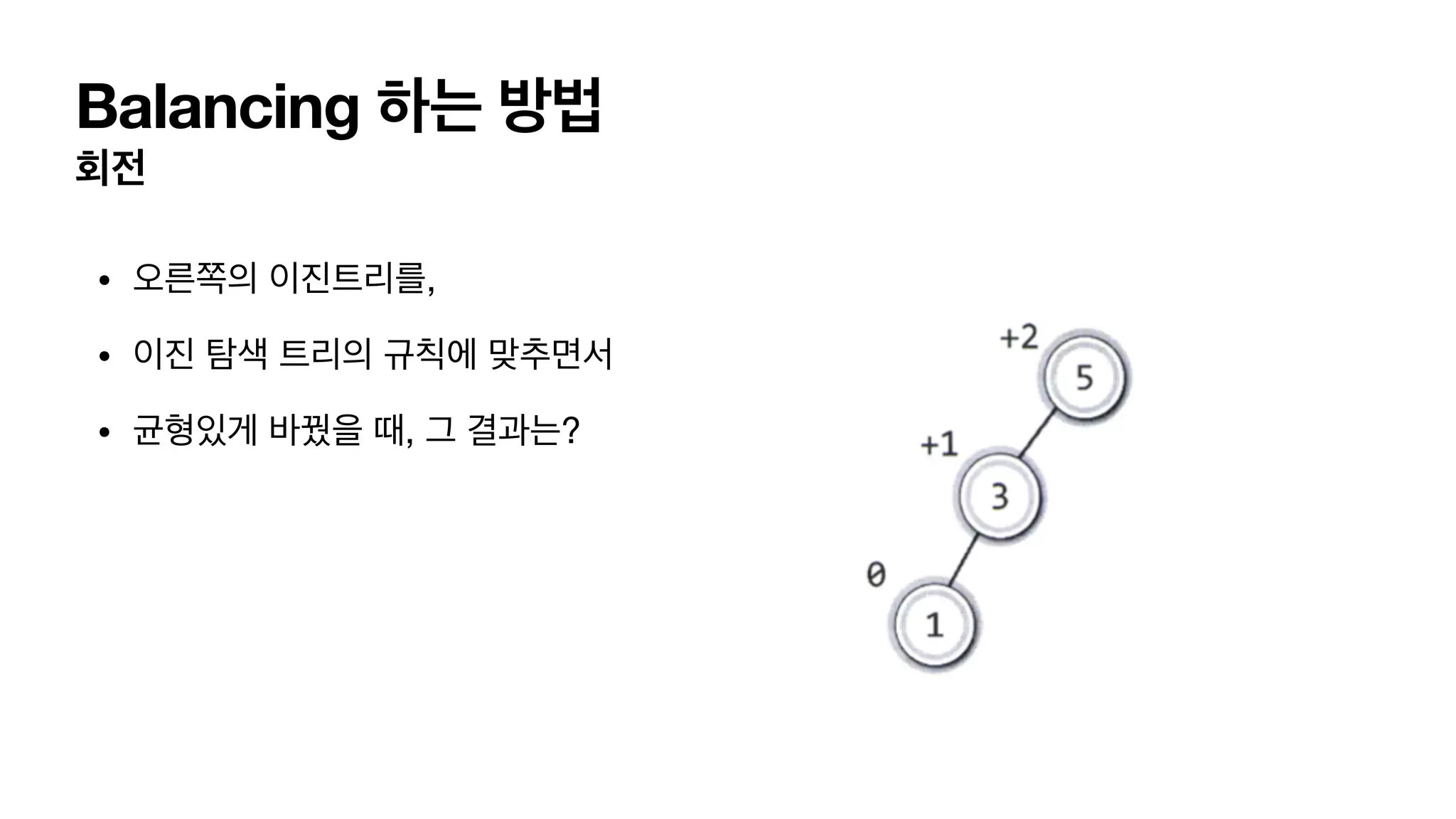
BST의 문제점 • 여러insert(), delete() 연산으로 트리가 아래와 같이 변형되었다고 해보자. • 키 5값을 찾기 위해서 걸린 시간은? • O(N) • 편향트리
27.
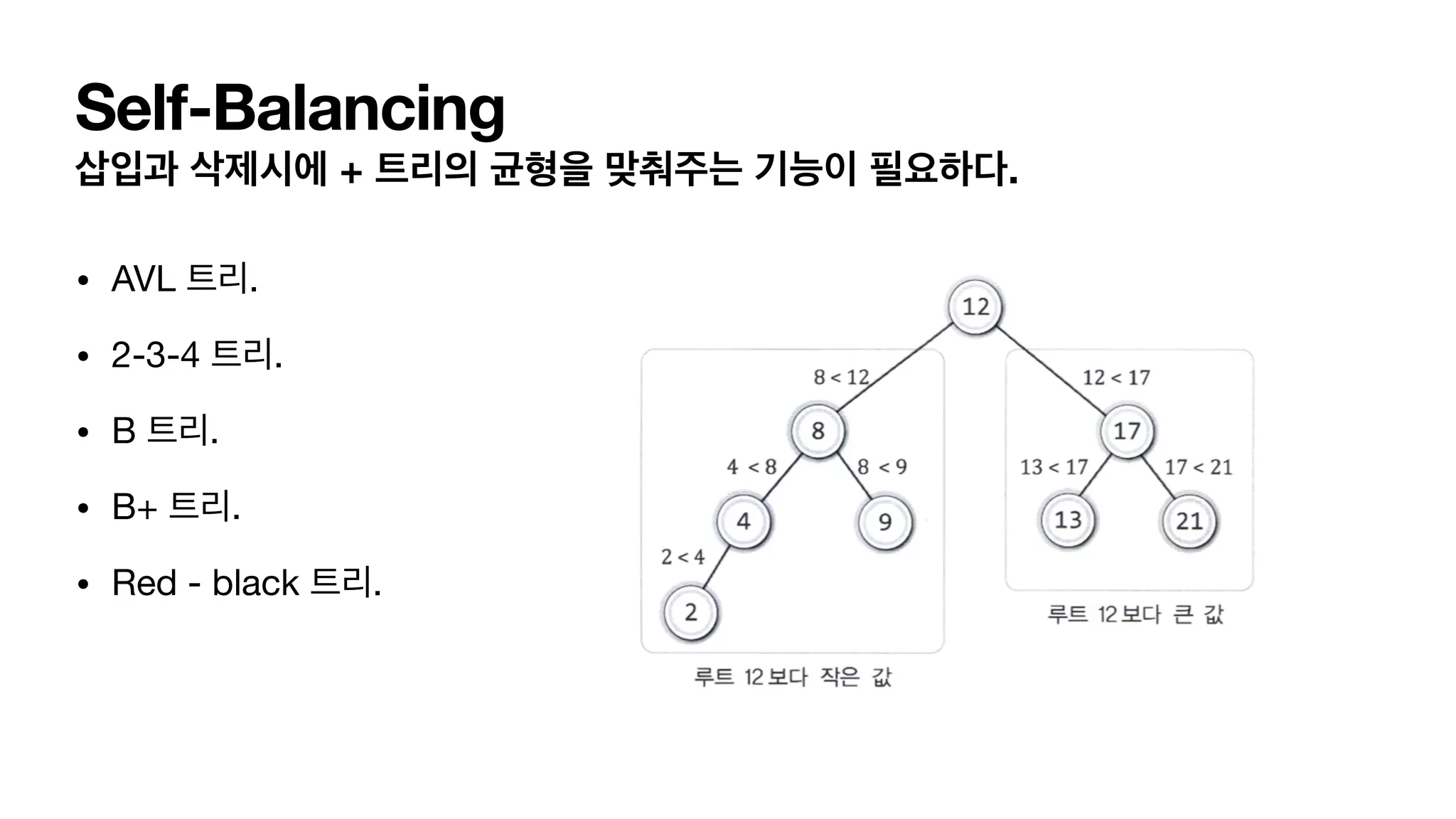
Self-Balancing 삽입과 삭제시에 +트리의 균형을 맞춰주는 기능이 필요하다. • AVL 트리. • 2-3-4 트리. • B 트리. • B+ 트리. • Red - black 트리.
28.
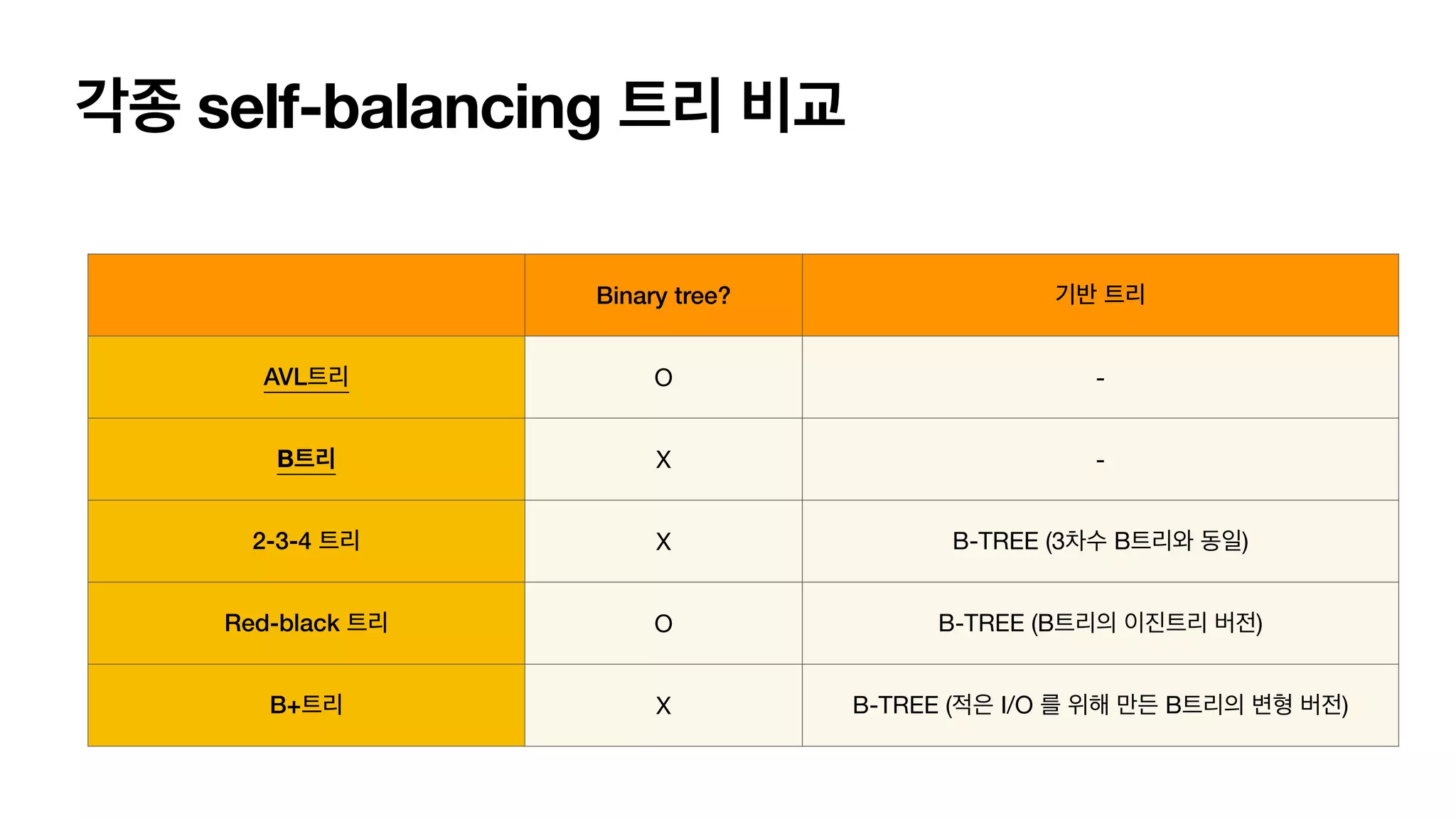
각종 self-balancing 트리비교 Binary tree? 기반 트리 AVL트리 O - B트리 X - 2-3-4 트리 X B-TREE (3차수 B트리와 동일) Red-black 트리 O B-TREE (B트리의 이진트리 버전) B+트리 X B-TREE (적은 I/O 를 위해 만든 B트리의 변형 버전)
29.
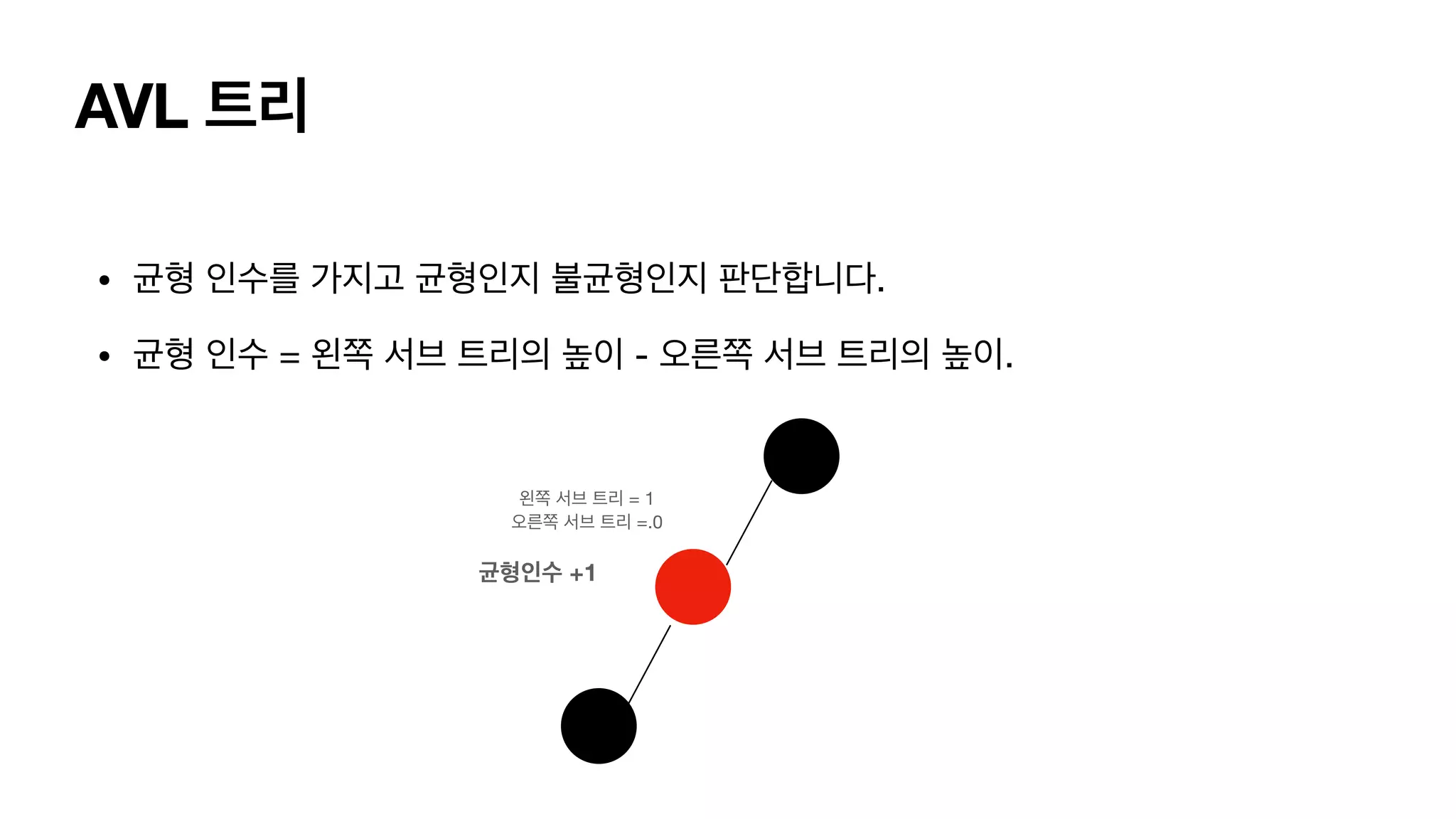
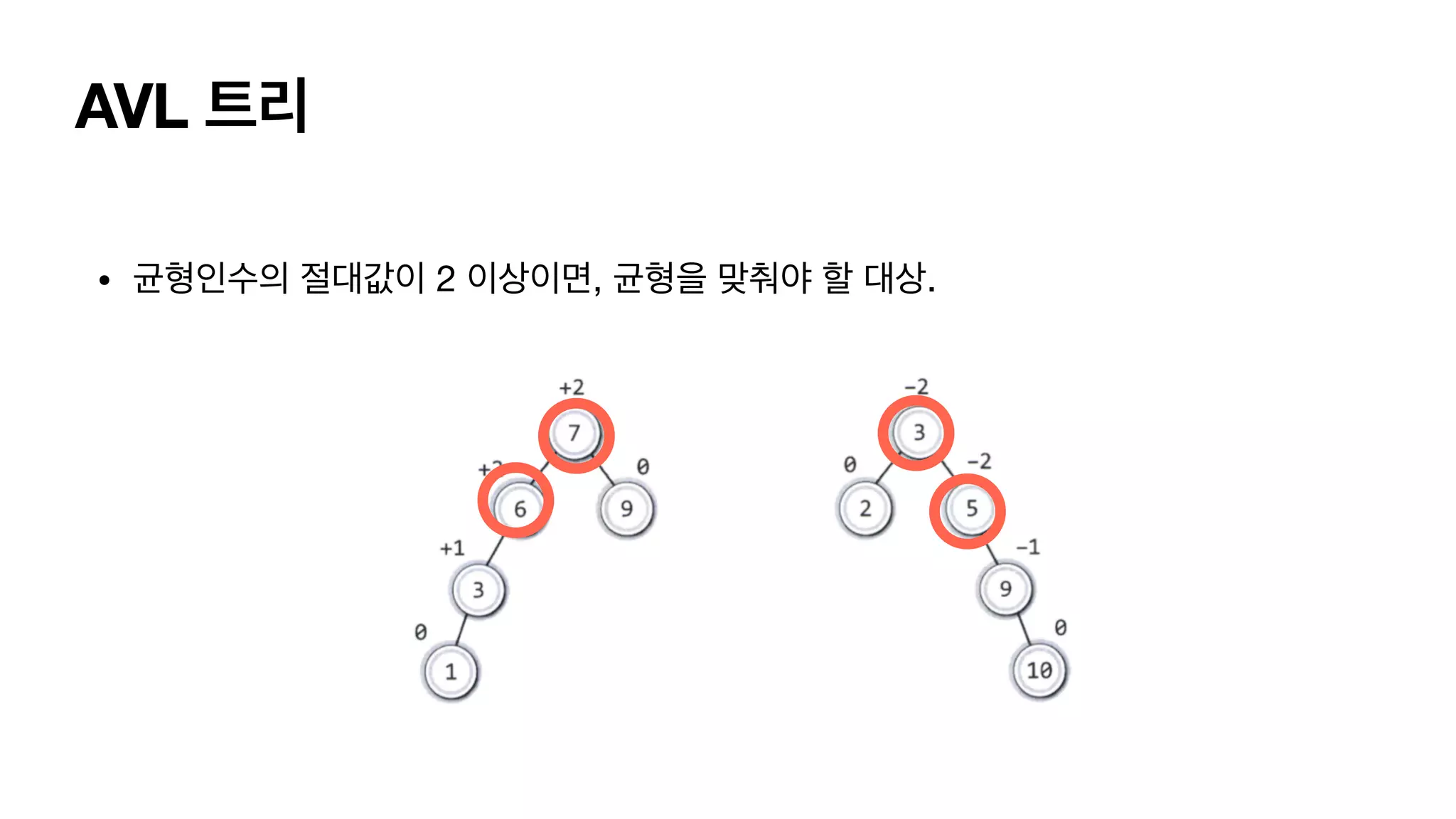
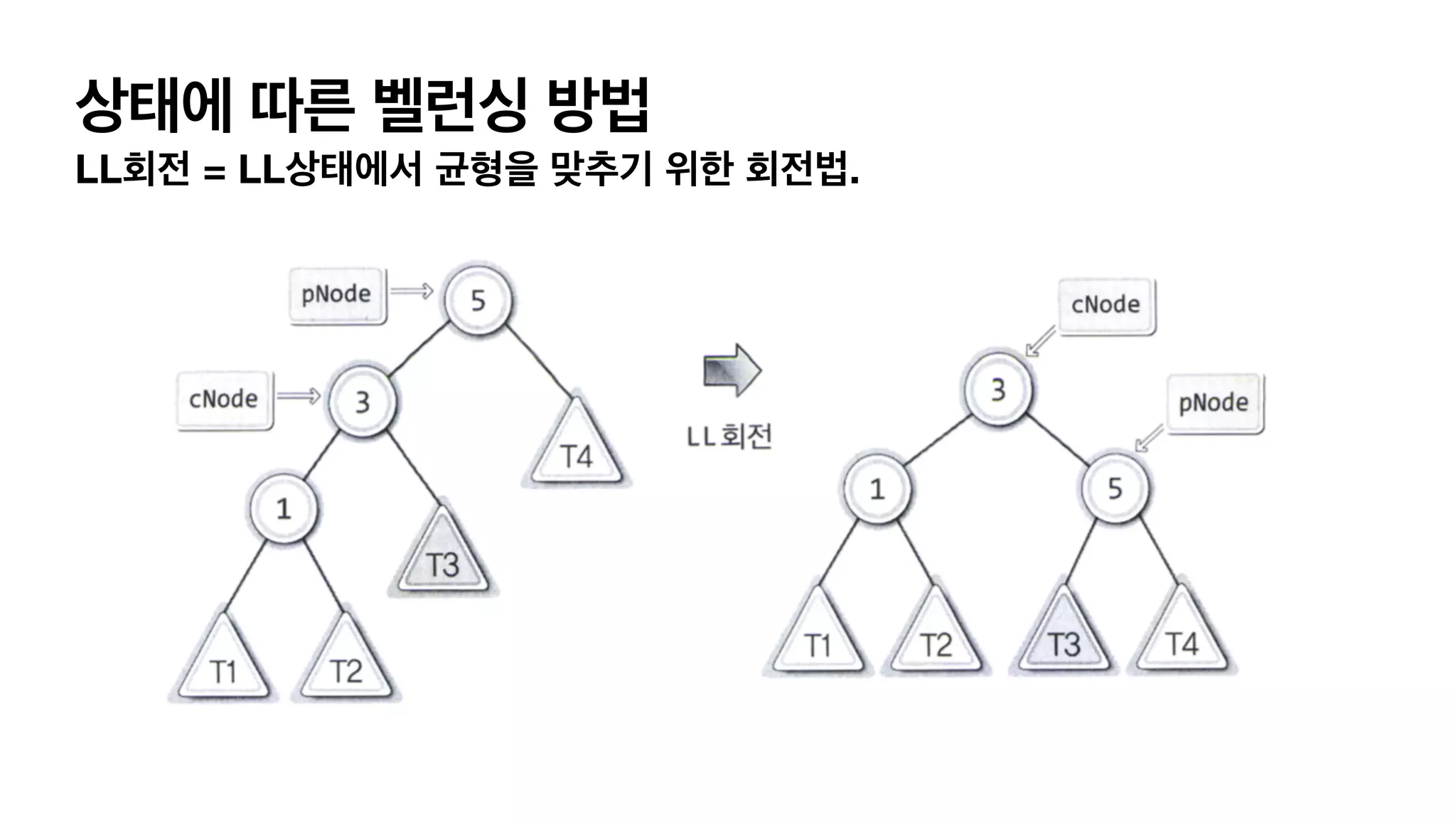
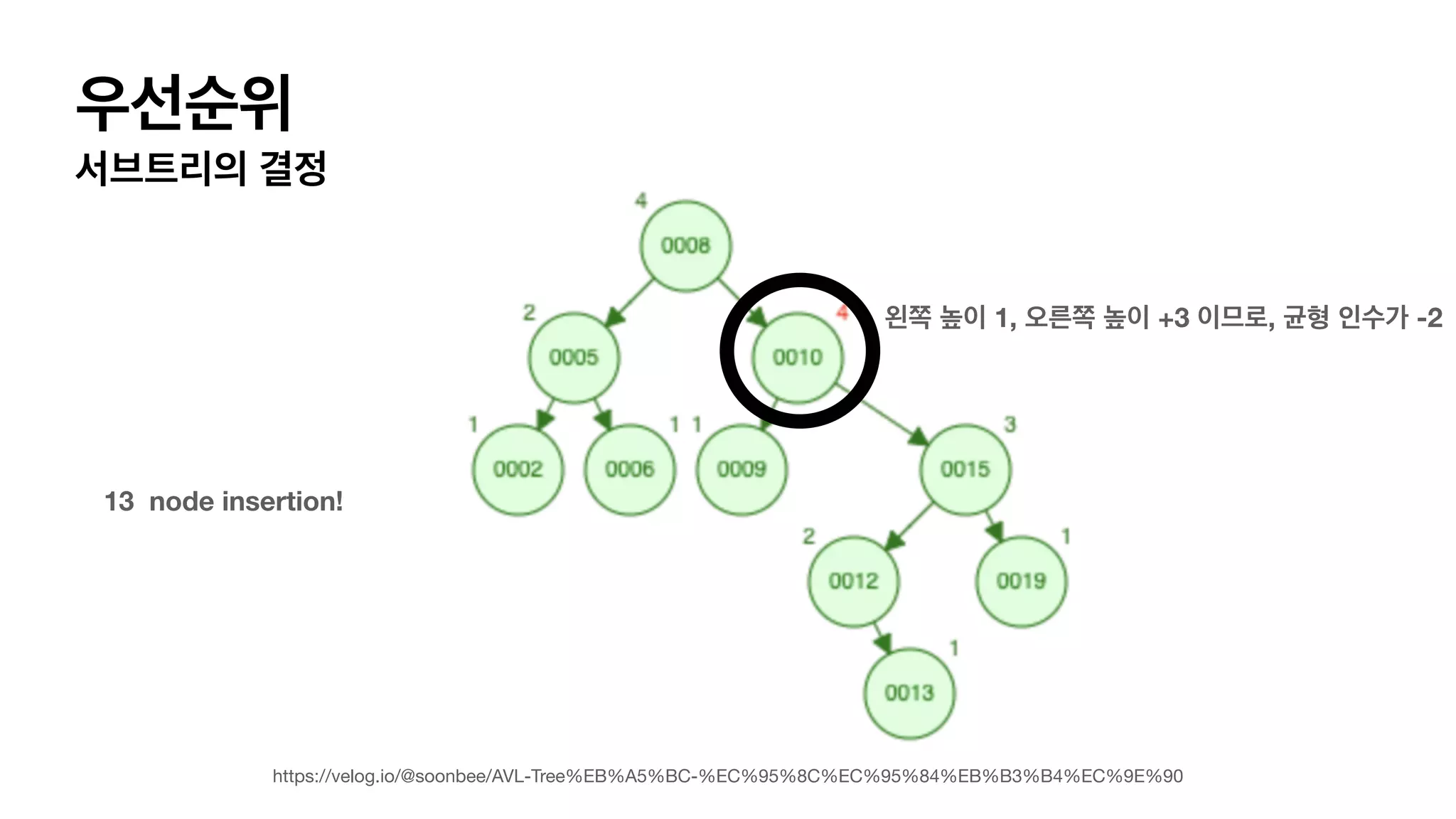
AVL 트리 • 균형인수를 가지고 균형인지 불균형인지 판단합니다. • 균형 인수 = 왼쪽 서브 트리의 높이 - 오른쪽 서브 트리의 높이.
30.
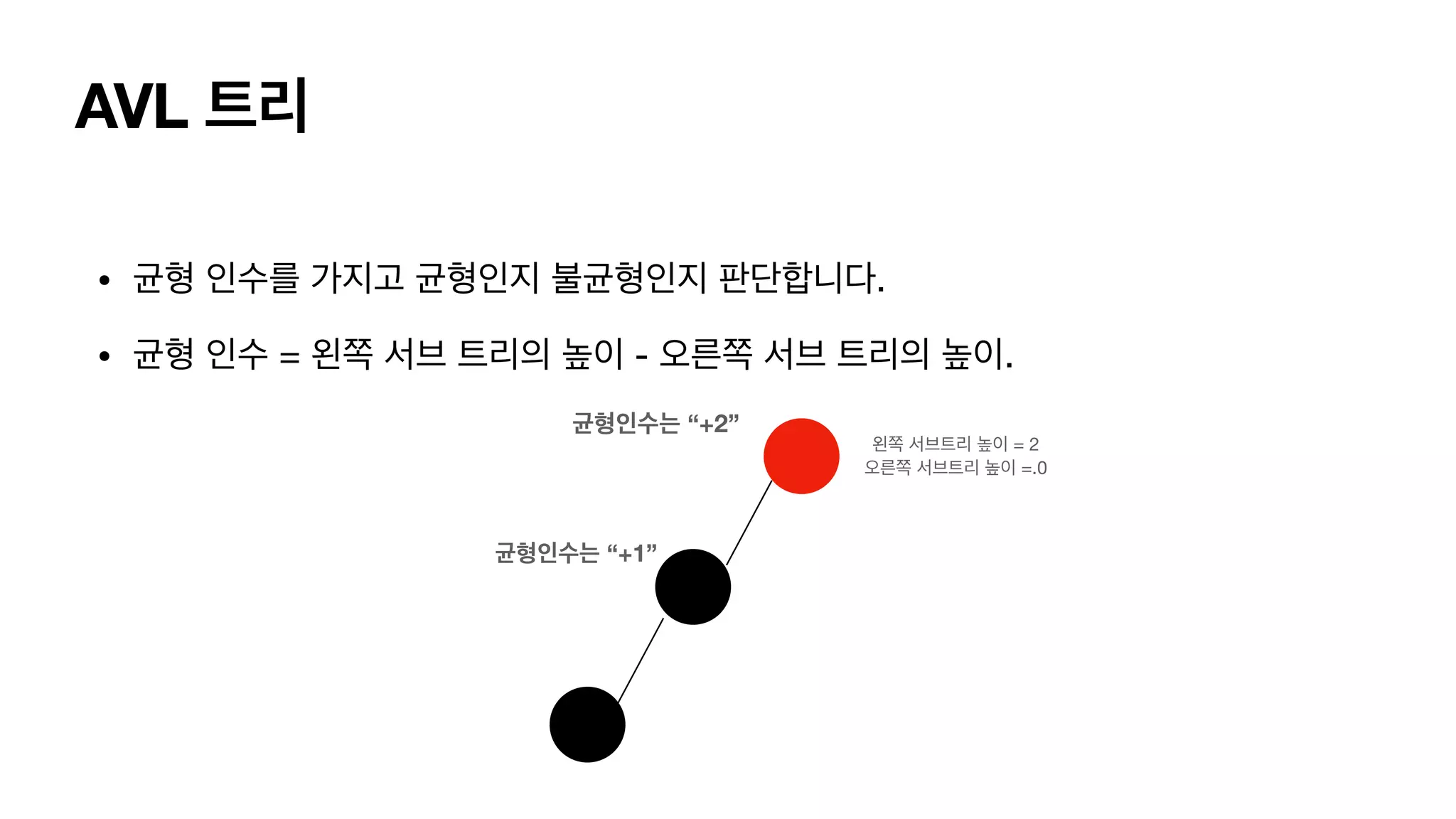
AVL 트리 • 균형인수를 가지고 균형인지 불균형인지 판단합니다. • 균형 인수 = 왼쪽 서브 트리의 높이 - 오른쪽 서브 트리의 높이. 왼쪽 서브 트리 = 1 오른쪽 서브 트리 =.0 균형인수 +1
31.
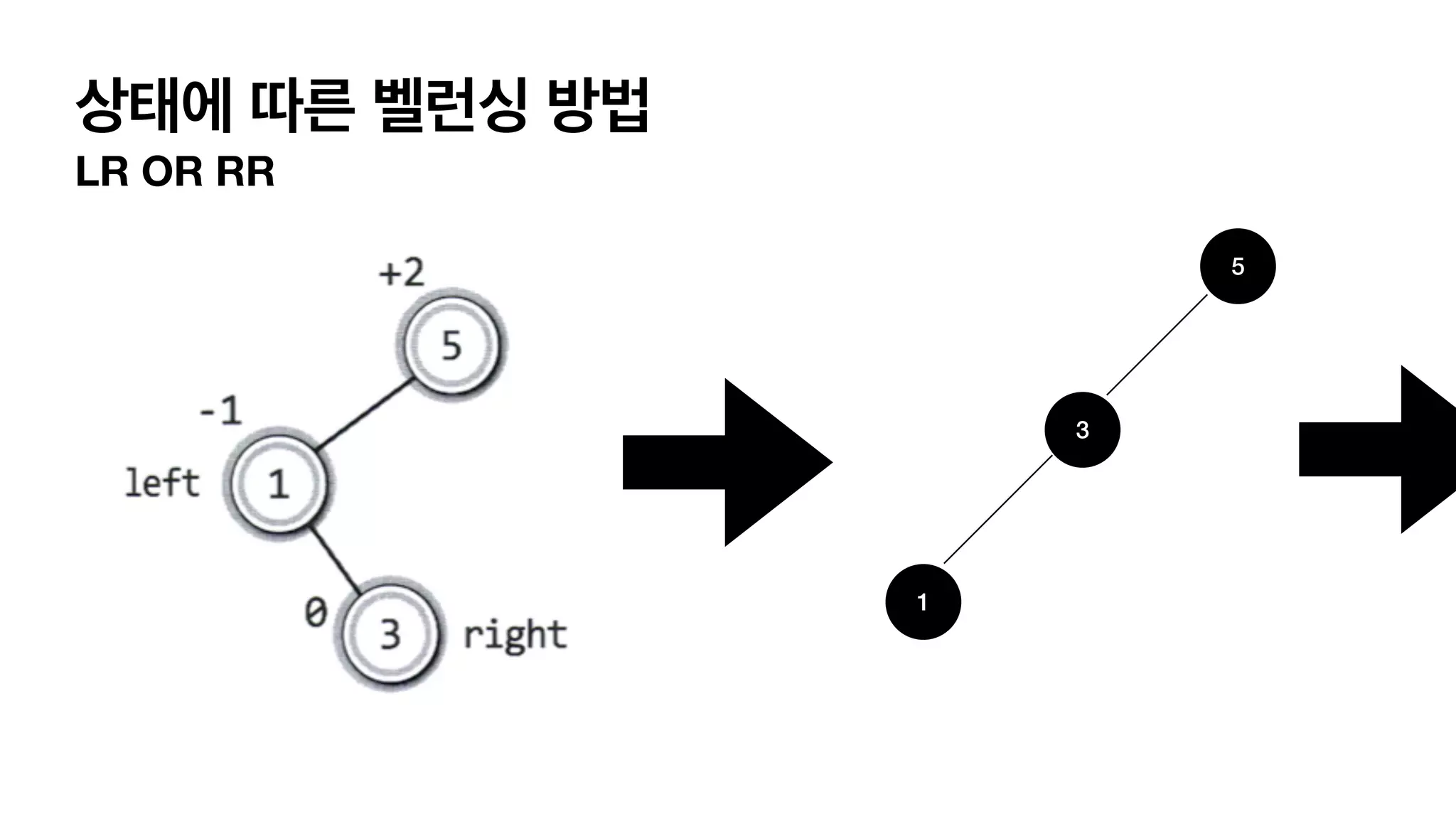
AVL 트리 • 균형인수를 가지고 균형인지 불균형인지 판단합니다. • 균형 인수 = 왼쪽 서브 트리의 높이 - 오른쪽 서브 트리의 높이. 왼쪽 서브트리 높이 = 2 오른쪽 서브트리 높이 =.0 균형인수는 “+2” 균형인수는 “+1”
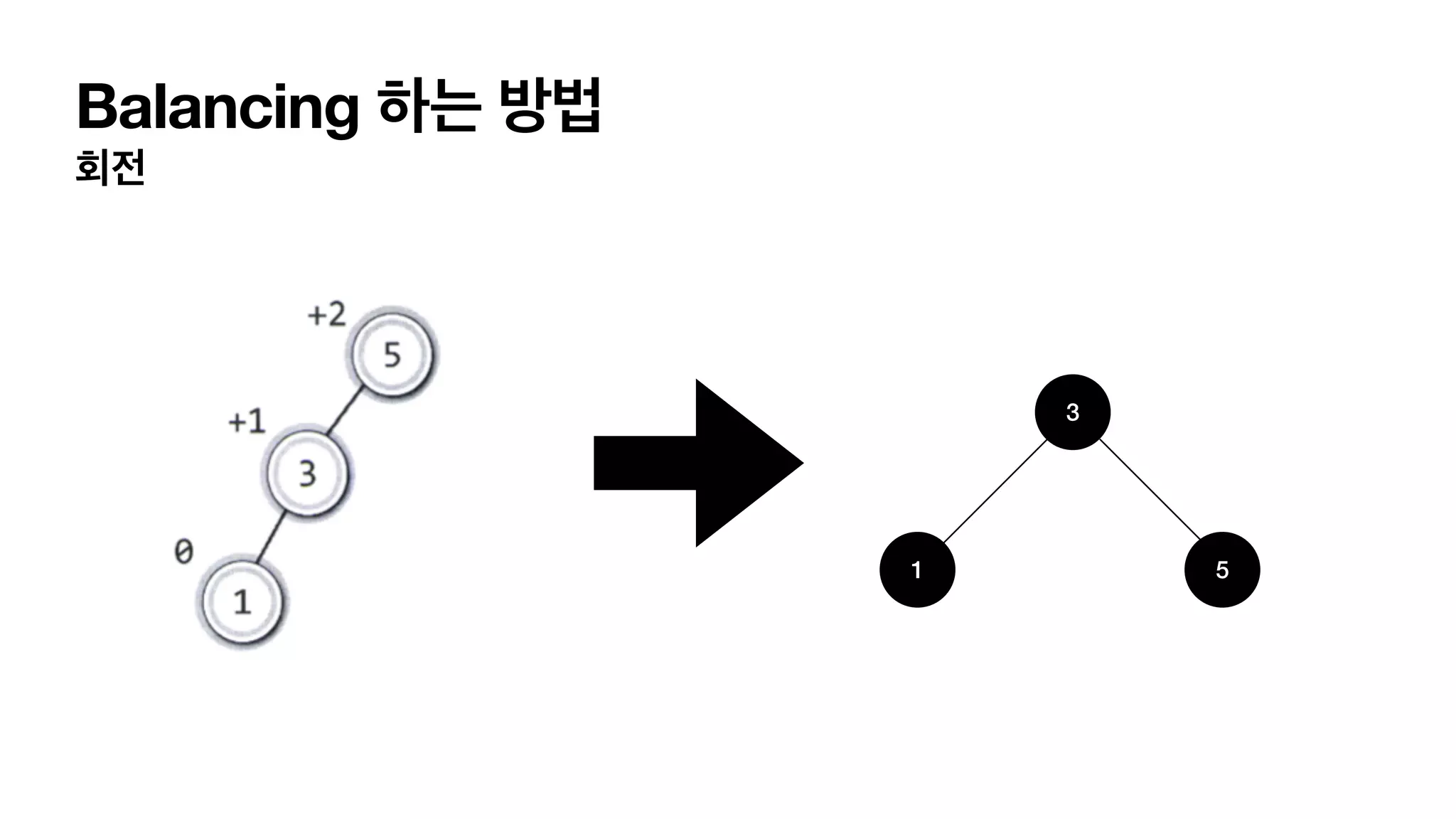
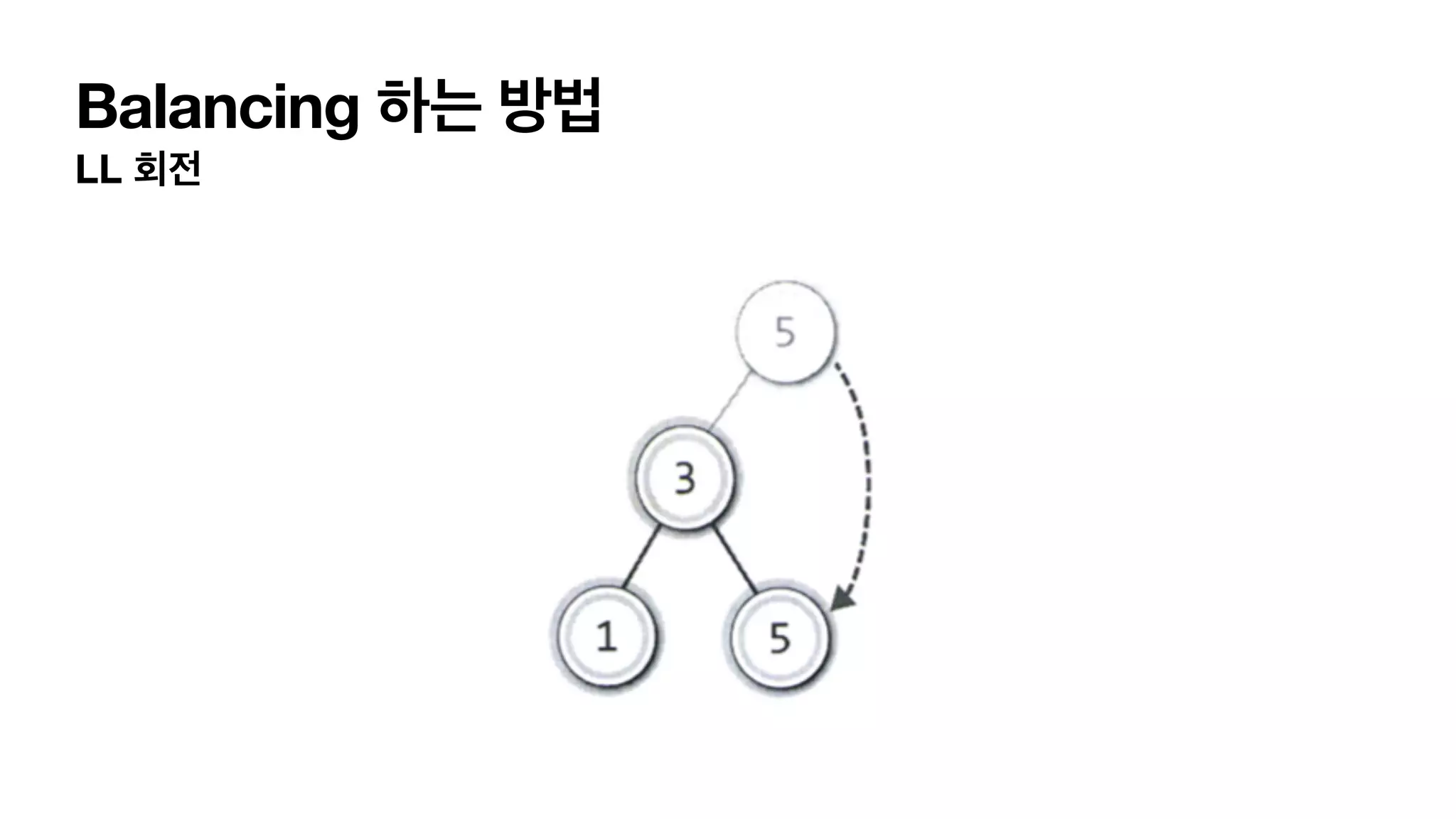
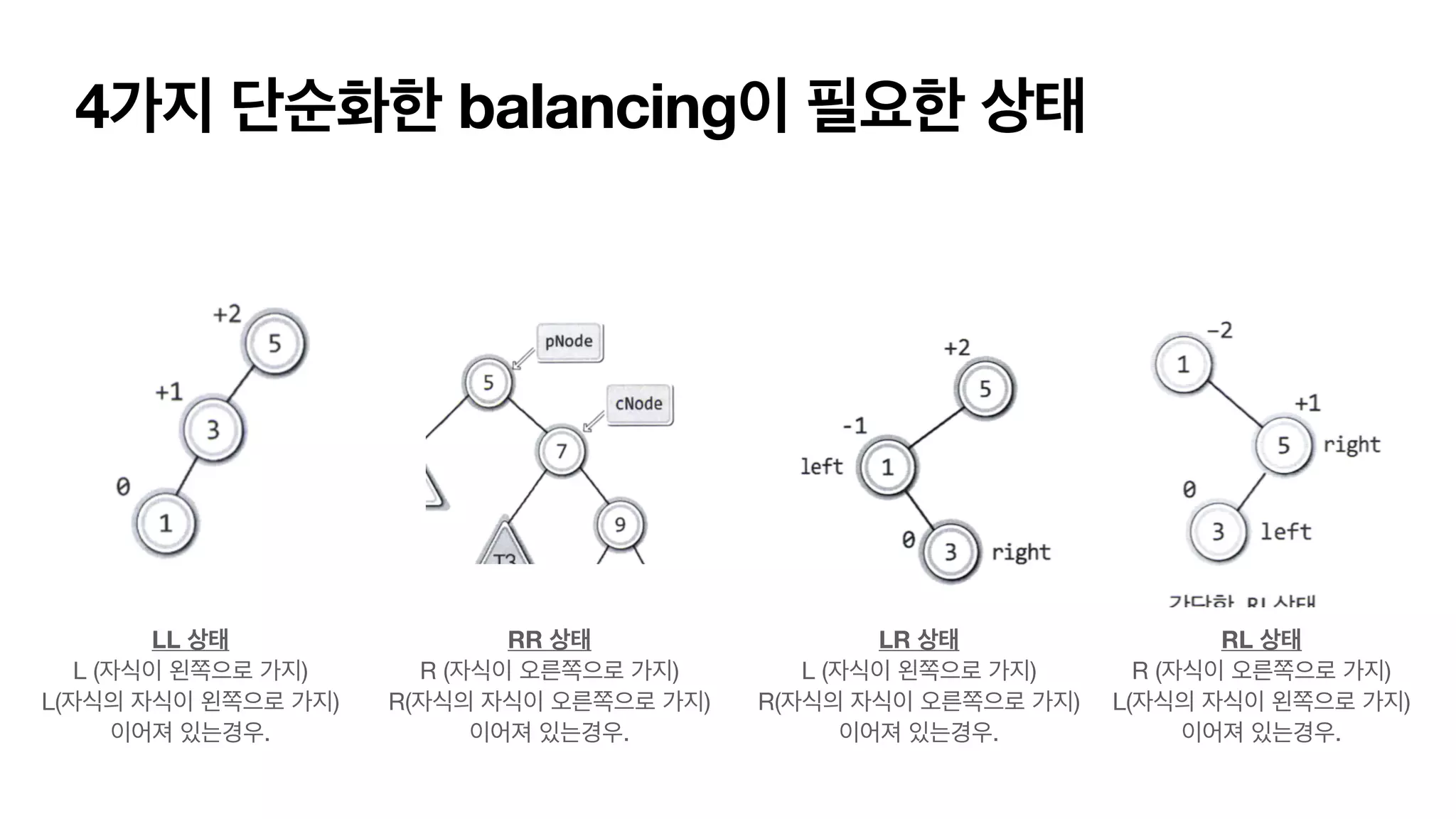
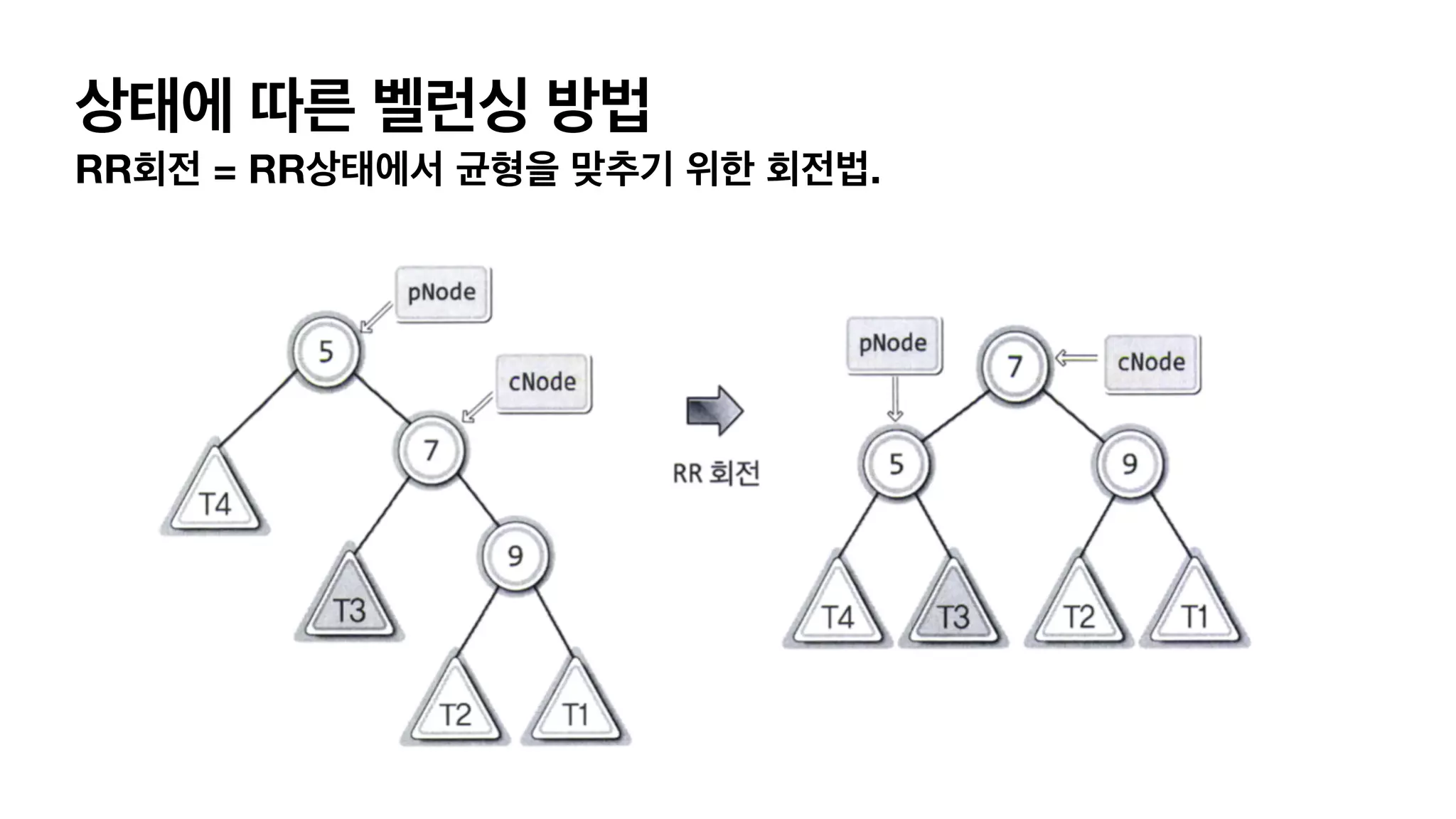
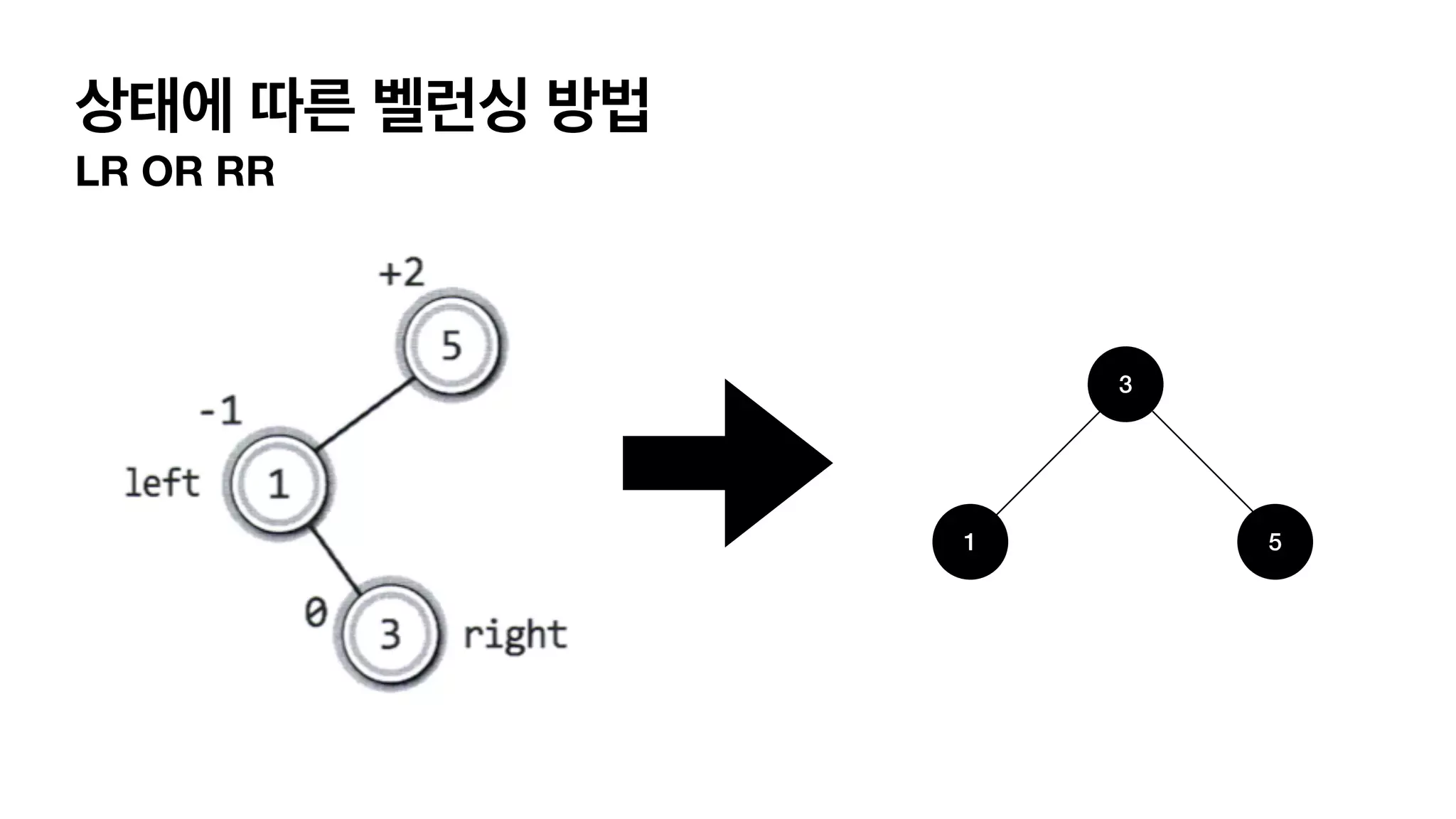
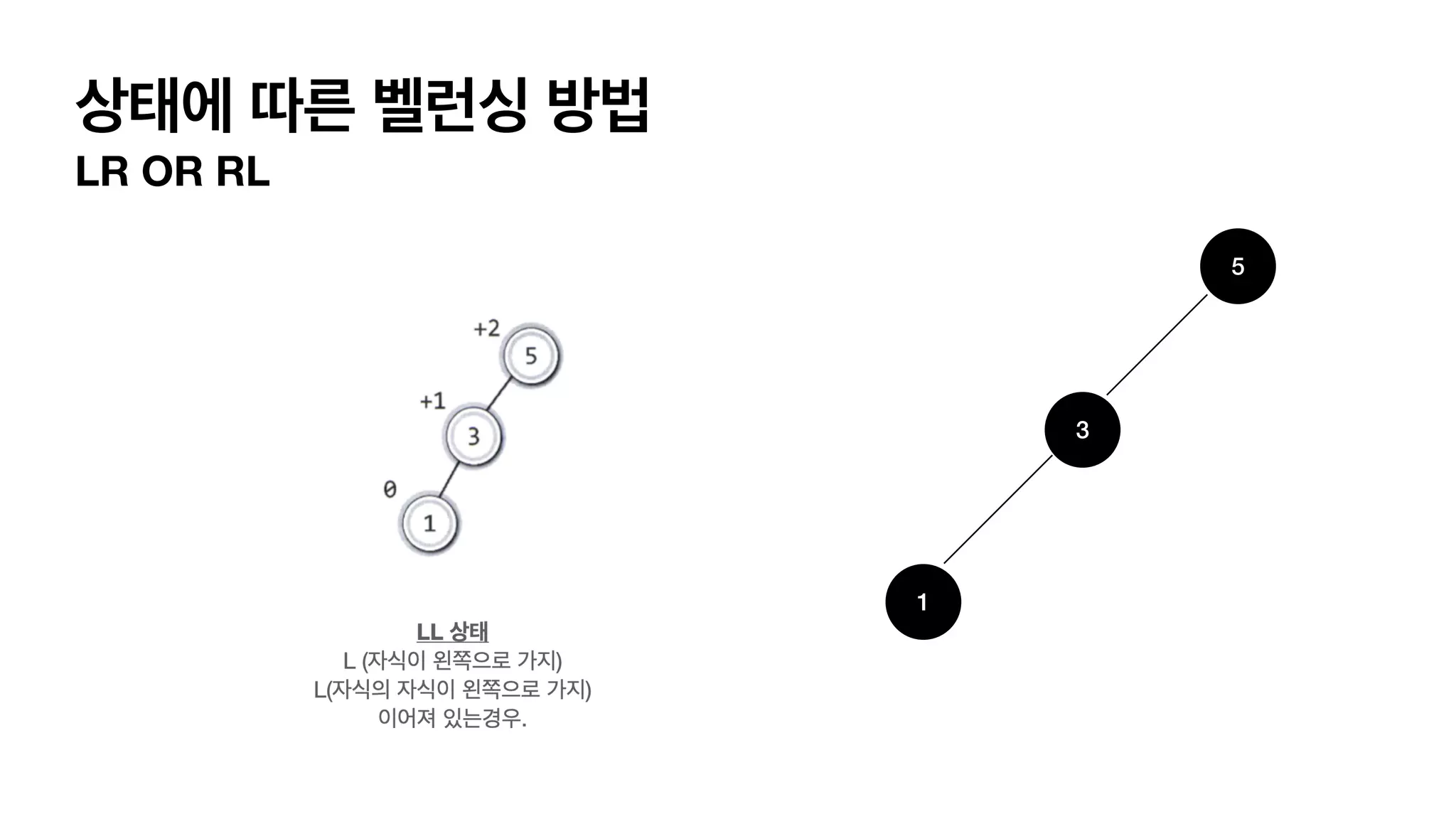
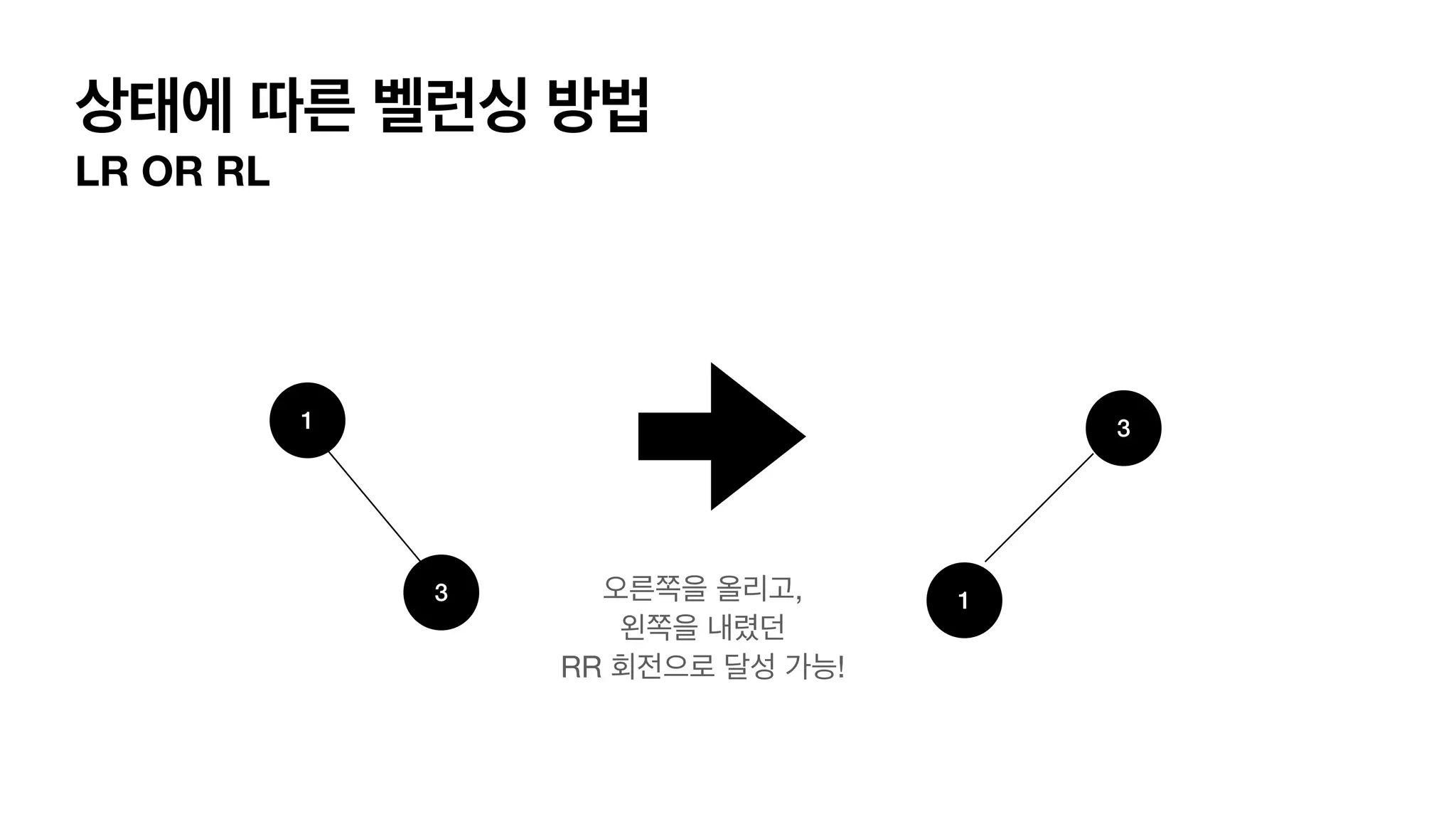
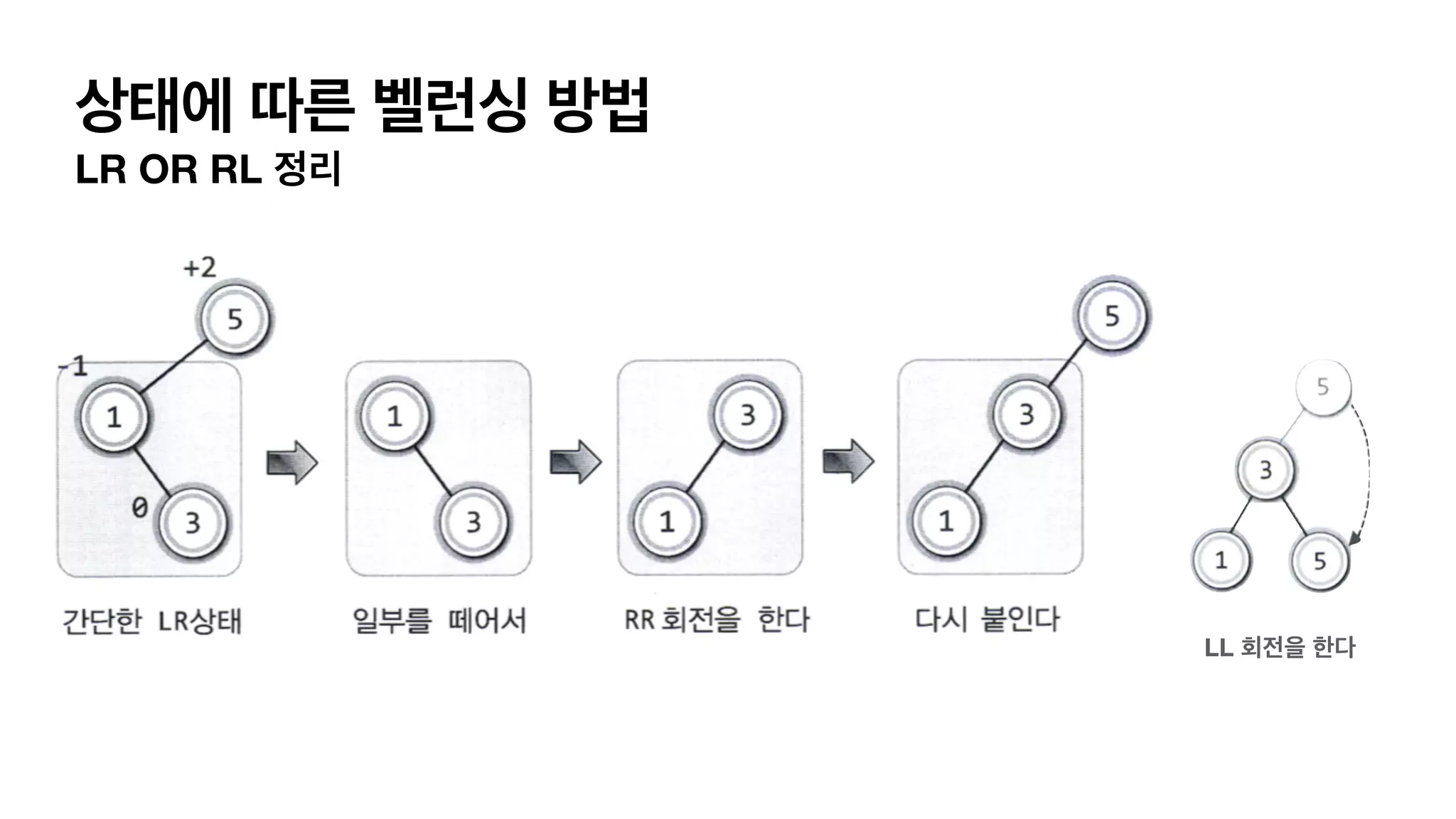
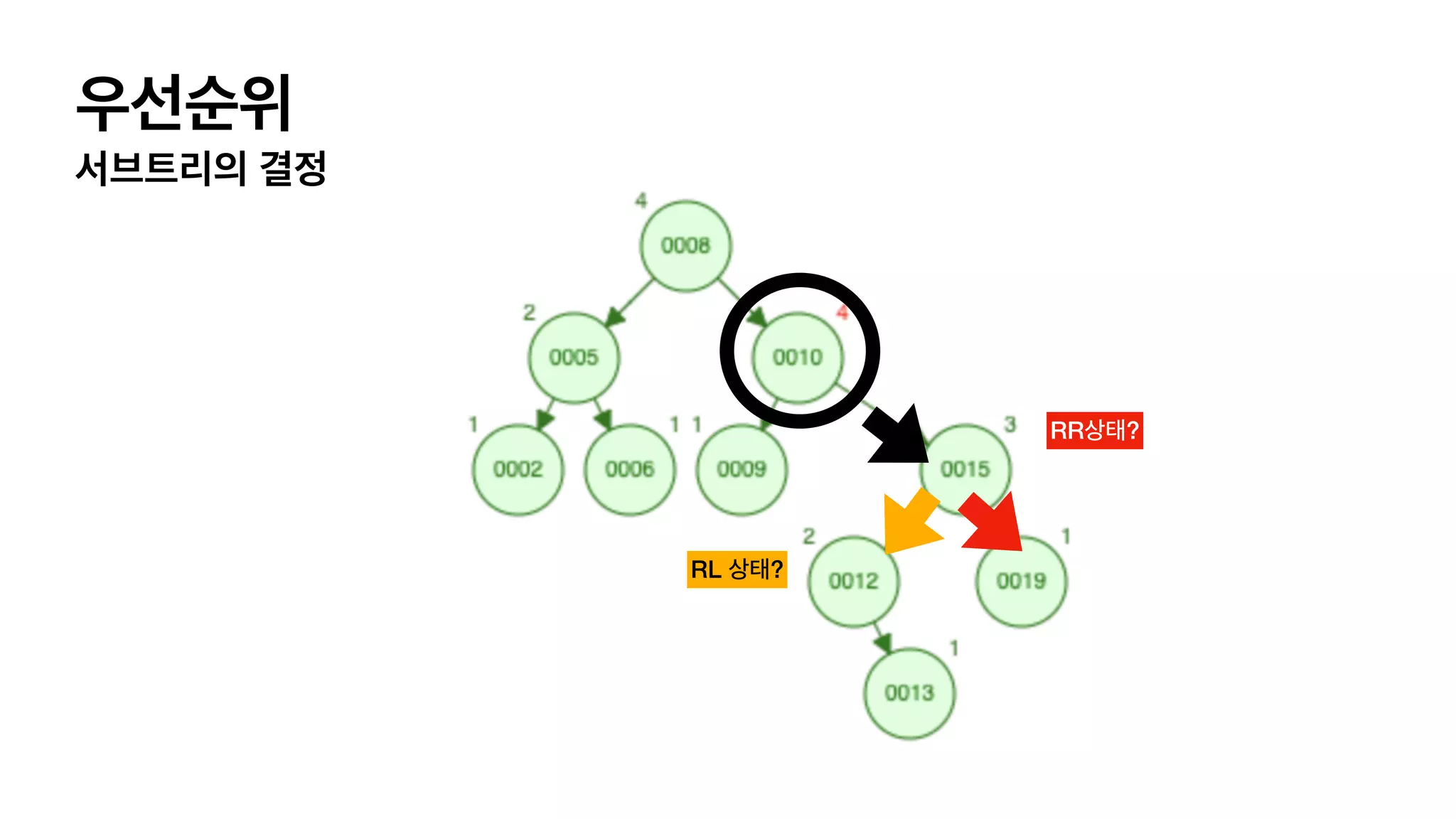
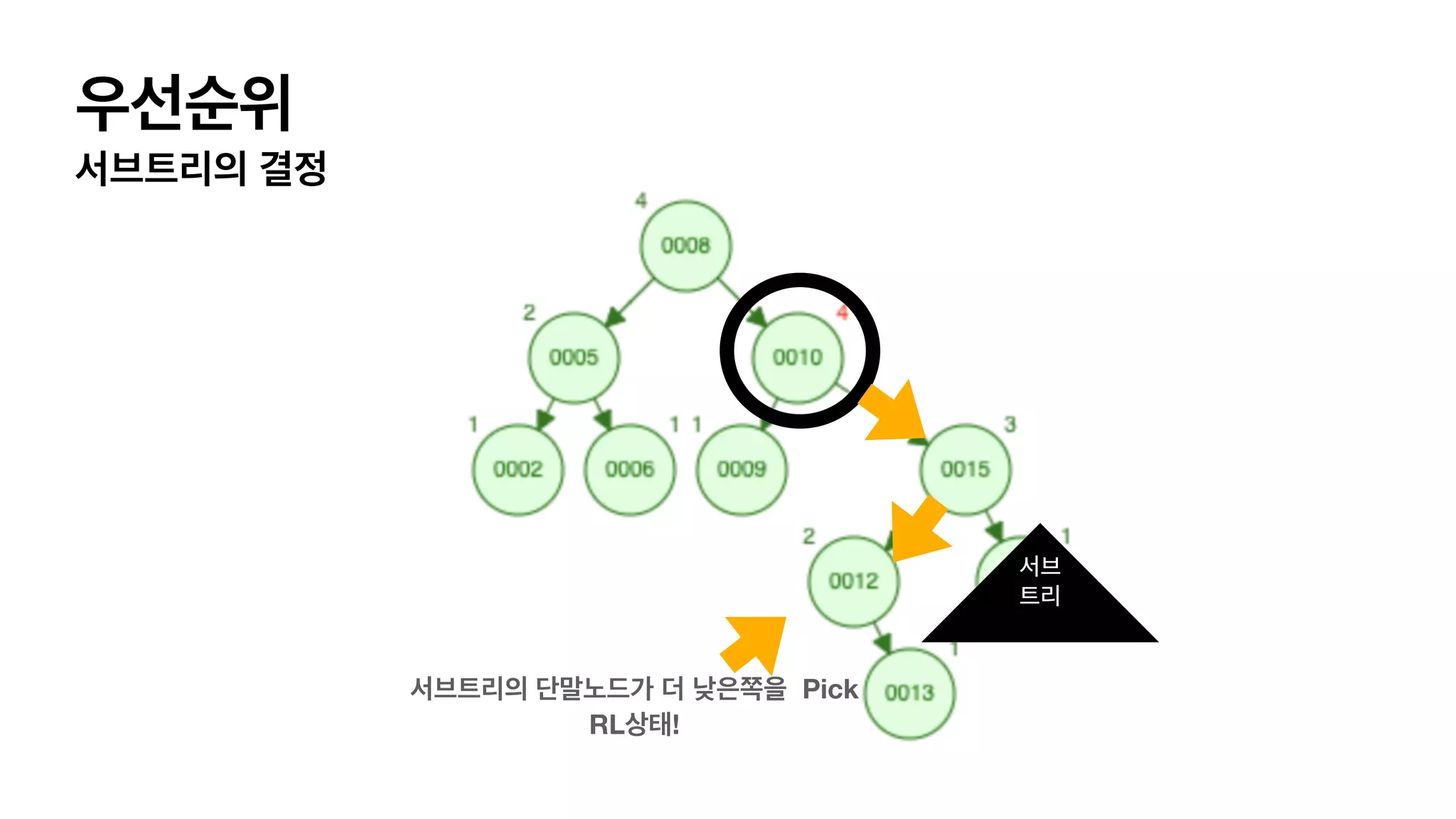
4가지 단순화한 balancing이필요한 상태 LL 상태 L (자식이 왼쪽으로 가지) L(자식의 자식이 왼쪽으로 가지) 이어져 있는경우. RR 상태 R (자식이 오른쪽으로 가지) R(자식의 자식이 오른쪽으로 가지) 이어져 있는경우. LR 상태 L (자식이 왼쪽으로 가지) R(자식의 자식이 오른쪽으로 가지) 이어져 있는경우. RL 상태 R (자식이 오른쪽으로 가지) L(자식의 자식이 왼쪽으로 가지) 이어져 있는경우.
면접 문제 1:AVL 트리의 시간 복잡도를 분석하고 이유를 알려주세요. • 삽입 연산 : • O(h) -> 이진 탐색의 삽입 속도 • O(1) -> 회전 속도 (단순하게 트리의 참조만 변경한다) • O(h) == O(log n) • 결론 : O(logn) • 삭제 연산 : 이진 탐색의 삭제 속도 O(h) + O(1) = O (logn) • 탐색 연산 : O(h) = O(log n)
49.
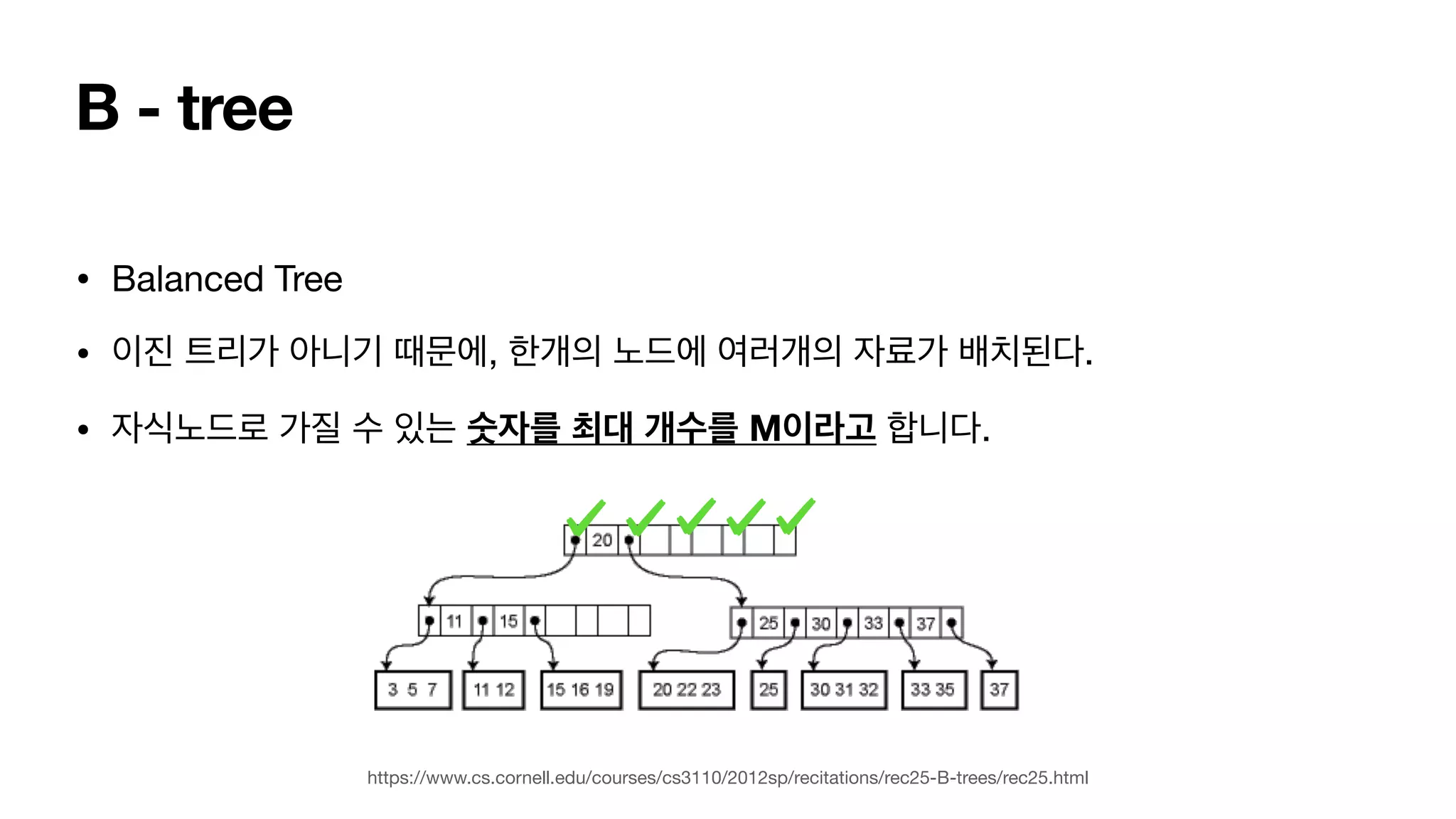
B - tree •Balanced Tree • 이진 트리가 아니기 때문에, 한개의 노드에 여러개의 자료가 배치된다. • 자식노드로 가질 수 있는 숫자를 최대 개수를 M이라고 합니다. https://www.cs.cornell.edu/courses/cs3110/2012sp/recitations/rec25-B-trees/rec25.html
50.
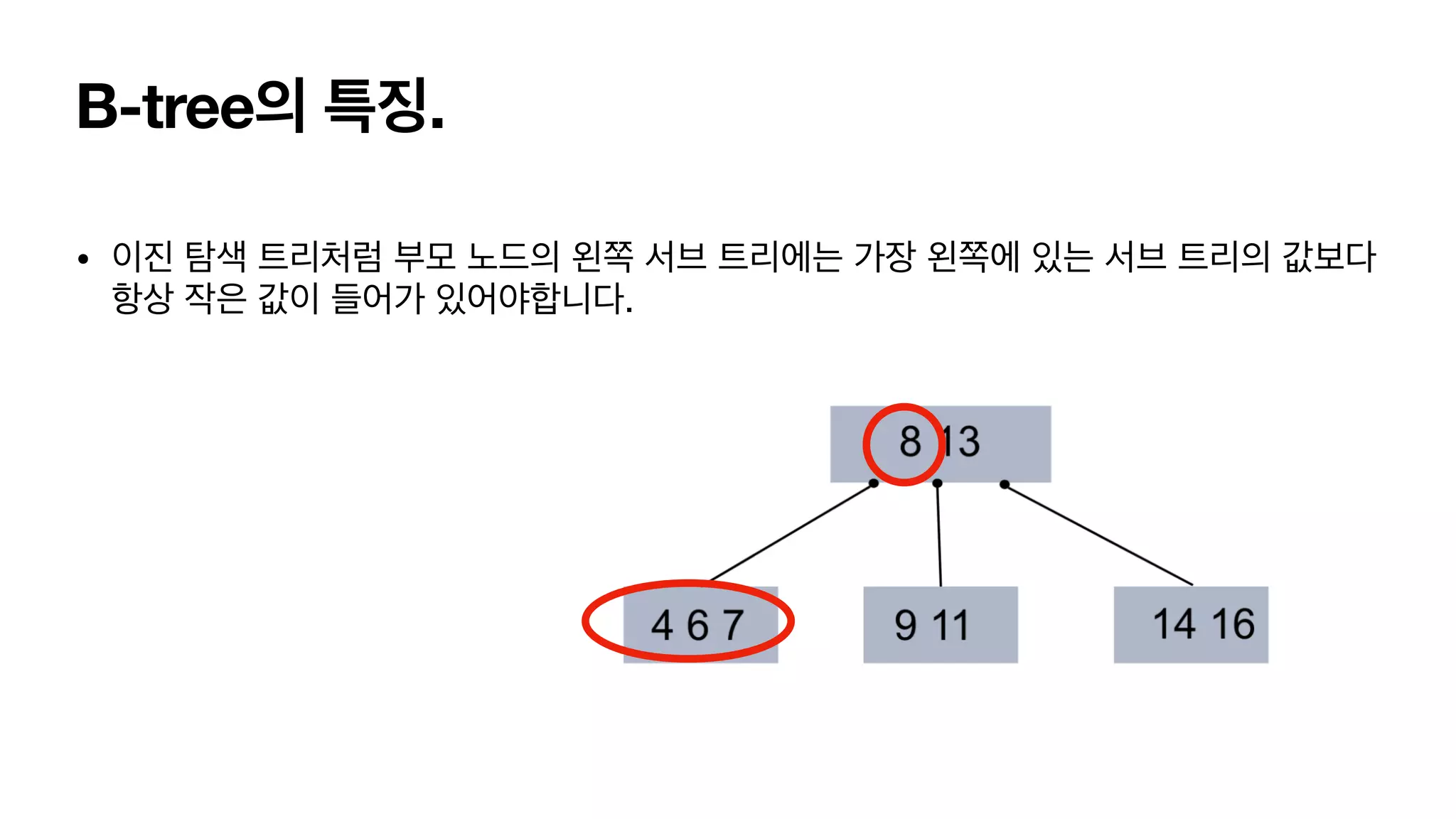
B-tree의 특징. • 이진탐색 트리처럼 부모 노드의 왼쪽 서브 트리에는 가장 왼쪽에 있는 서브 트리의 값보다 항상 작은 값이 들어가 있어야합니다.
51.
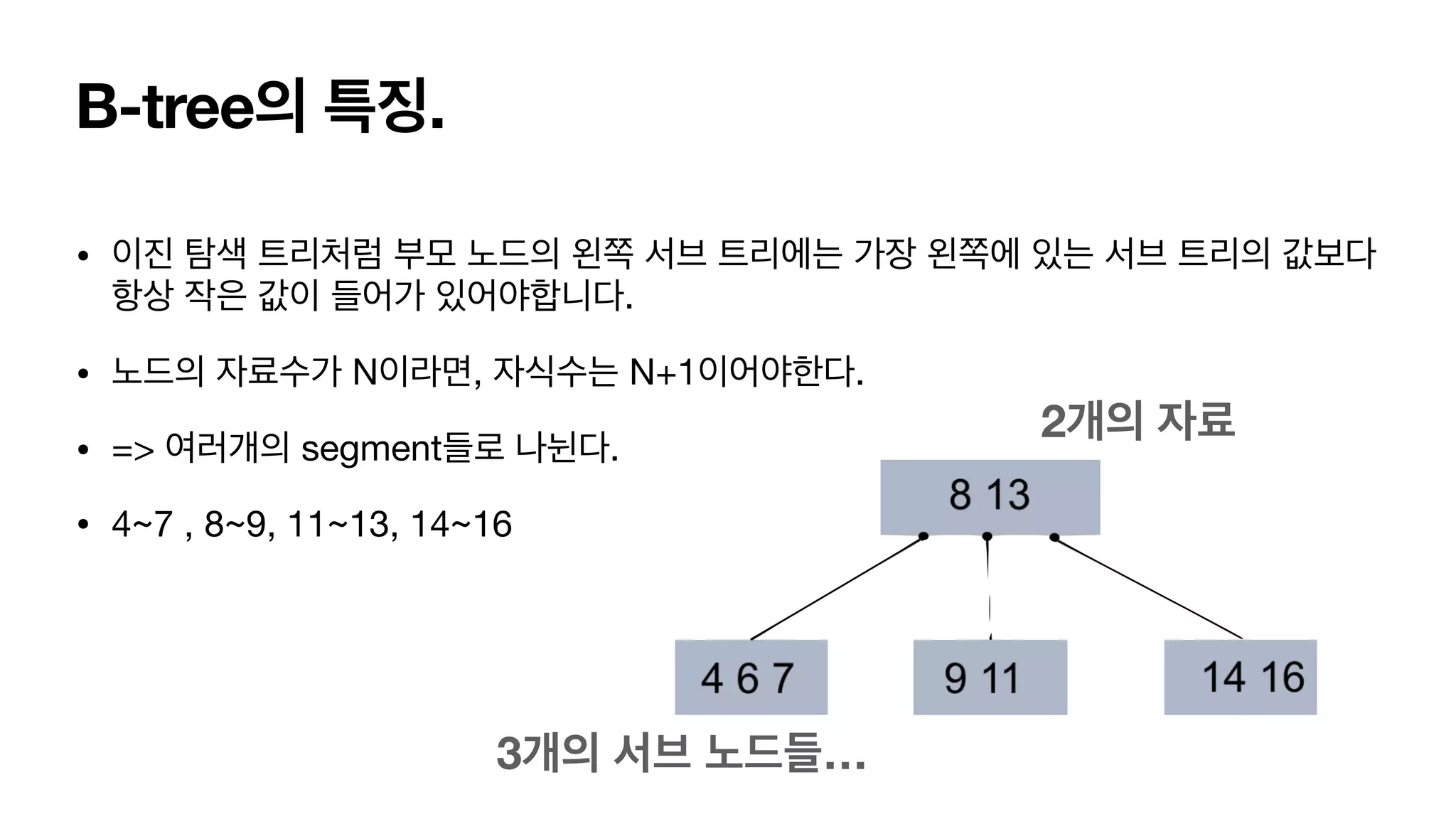
B-tree의 특징. • 이진탐색 트리처럼 부모 노드의 왼쪽 서브 트리에는 가장 왼쪽에 있는 서브 트리의 값보다 항상 작은 값이 들어가 있어야합니다. • 노드의 자료수가 N이라면, 자식수는 N+1이어야한다. • => 여러개의 segment들로 나뉜다. • 4~7 , 8~9, 11~13, 14~16 3개의 서브 노드들… 2개의 자료
52.
B-tree의 특징. • 이진탐색 트리처럼 부모 노드의 왼쪽 서브 트리에는 가장 왼쪽에 있는 서브 트리의 값보다 항상 작은 값이 들어가 있어야합니다. • 노드의 자료수가 N이라면, 자식수는 N+1이어야한다. • 각 노드의 자료수는 정렬되어있어야한다. • => BST같은 빠른 탐색의 효과를 내기 위해서는.. • => 정렬이 되어있어한다.
53.
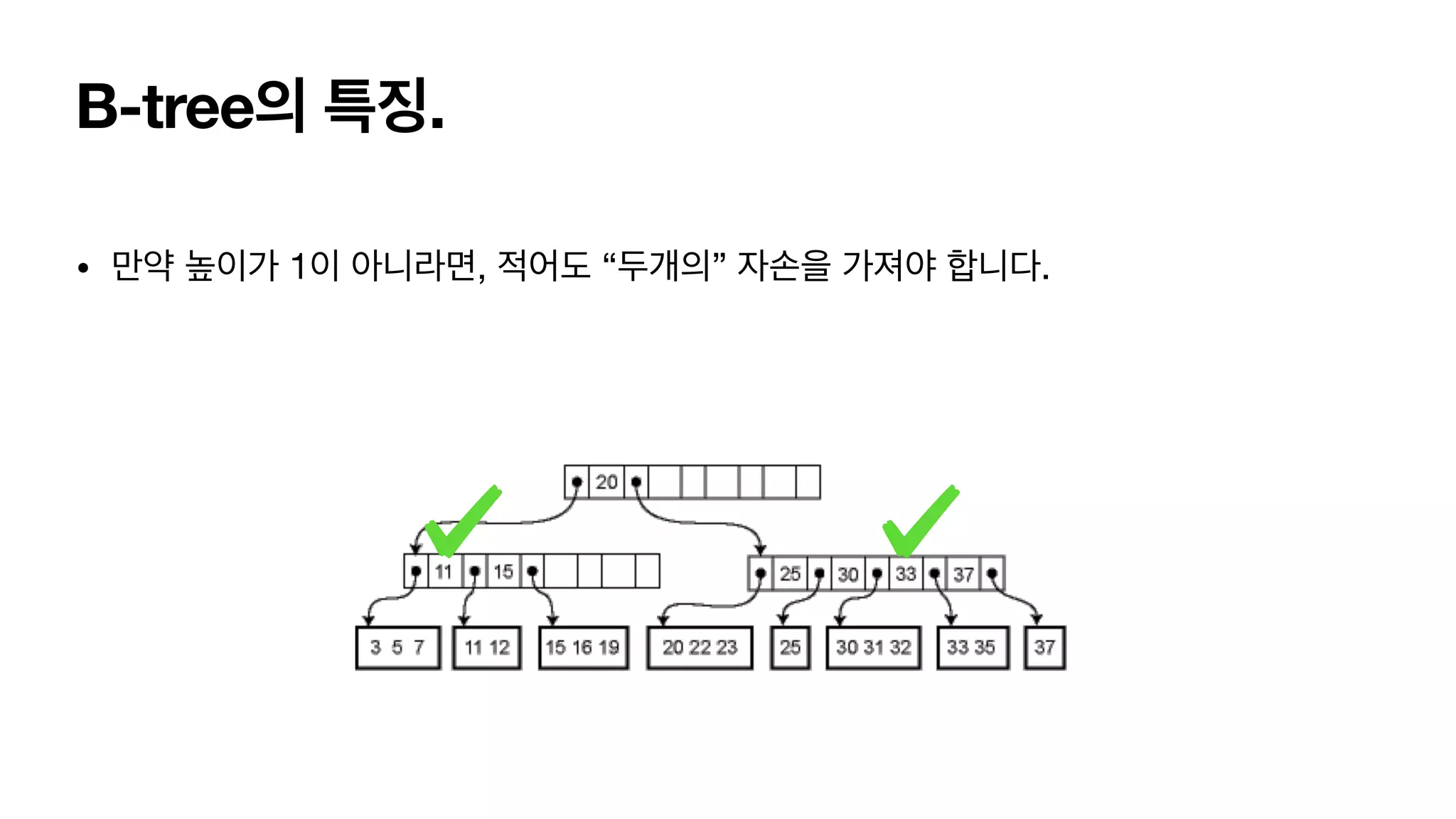
B-tree의 특징. • 이진탐색 트리처럼 부모 노드의 왼쪽 서브 트리에는 가장 왼쪽에 있는 서브 트리의 값보다 항상 작은 값이 들어가 있어야합니다. • 노드의 자료수가 N이라면, 자식수는 N+1이어야한다 • 각 노드의 자료수는 정렬되어있어야한다. • Root 노드와 단말노드를 제외한 모든 노드는 적어도 [M/2] 개의 Children을 보유하고 있어야합니다. 즉, 각 노드의 데이터 개수는 적어도 [M/2] - 1개를 가지고 있어야 하겠습 니다. • => 5차 B-tree라고하면 [M/2] = 2 - 1. (최소 1개씩 데이터 를 가지고 있자)
54.
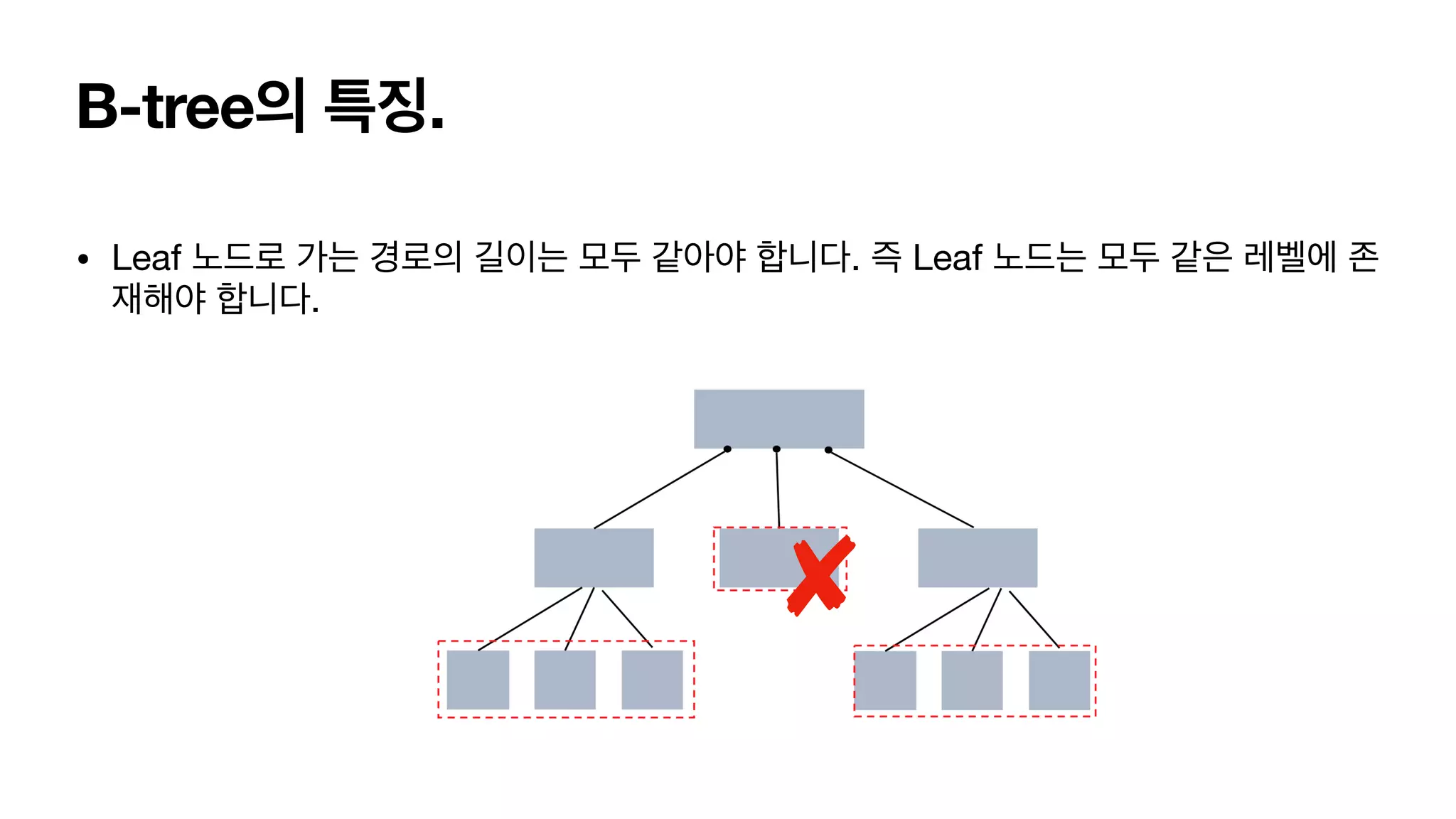
B-tree의 특징. • Leaf노드로 가는 경로의 길이는 모두 같아야 합니다. 즉 Leaf 노드는 모두 같은 레벨에 존 재해야 합니다.
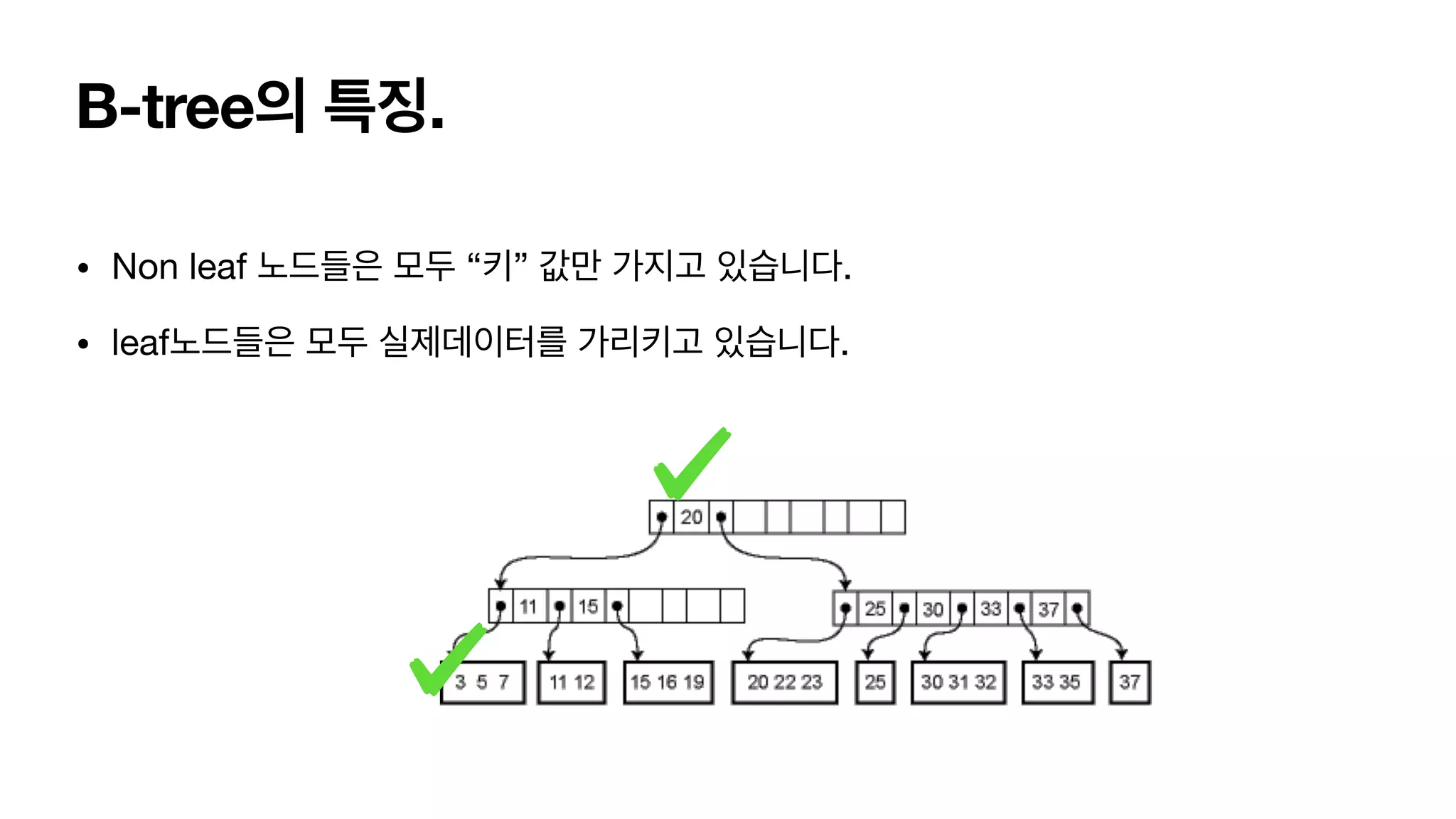
B-tree의 특징. • Nonleaf 노드들은 모두 “키” 값만 가지고 있습니다. • leaf노드들은 모두 실제데이터를 가리키고 있습니다.
57.
예시 : 5차B-tree • 자식노드로 가질 수 있는 최대 개수가 5라는 의미. • 즉, 5차 B-tree는 최대 5개의 자식노드를 가질 수 있고, 이는 최대 4개의 Key값을 가질 수 있다는 의미가 됨. • 루트노드와, 단말노드를 제외하곤 (모든 내부노드들이) 적어도 [M/2] = 5/2 - 1 = 1개 의 키값을 가지고 있어야 하고, [M/2] = 2개의 자손 노드를 가져야 합니다.
58.
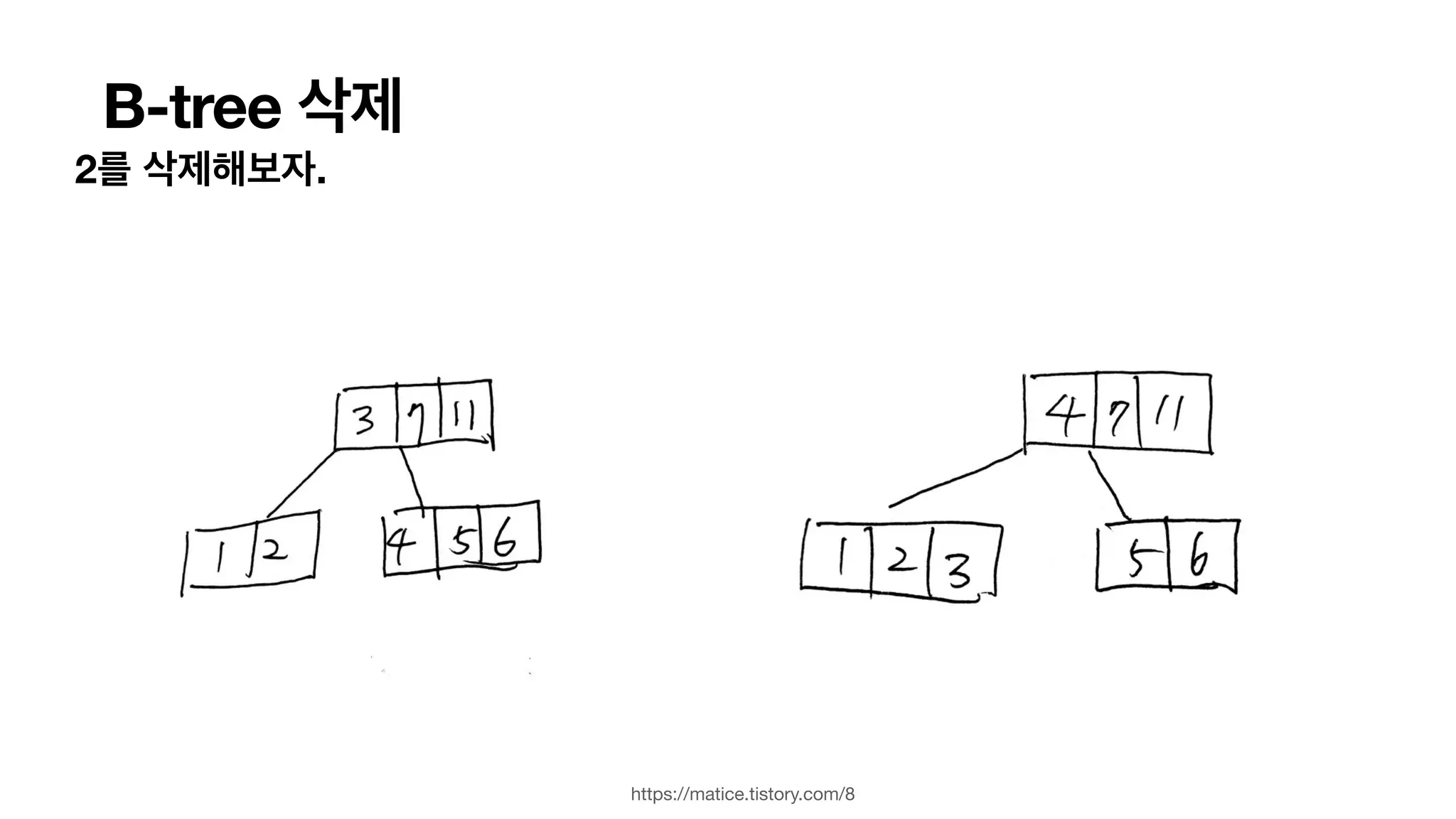
B-tree 삽입 삭제연산. Split & Merge • Split - 데이터가 꽉 찰 경우, 중간값을 기준으로 왼쪽/오른쪽 노드를 두개로 쪼갭니다. • Merge - B tree의 조건 (높이, 최소 데이터, 최소 children 수 등..) 맞지 않을경우,형제에게 빌리거나, 형제 와 결합하기 등으로 합쳐집니다. • Delete- 내부 노드의 경우, 삭제 후에 대체키를 찾습니다. (왼쪽 서브트리중 가장 큰 값, 오른쪽 서브트리중 가장 작은값) • 일단 insert/delete할곳을 Search합니다. • 들어갈 곳에 자리가 없으면 Split 합니다. • Insert/delete 하고 나서 B tree의 조건을 만족하지 않으면, Merge 를 하여서 균형을 맞춰줍니다.
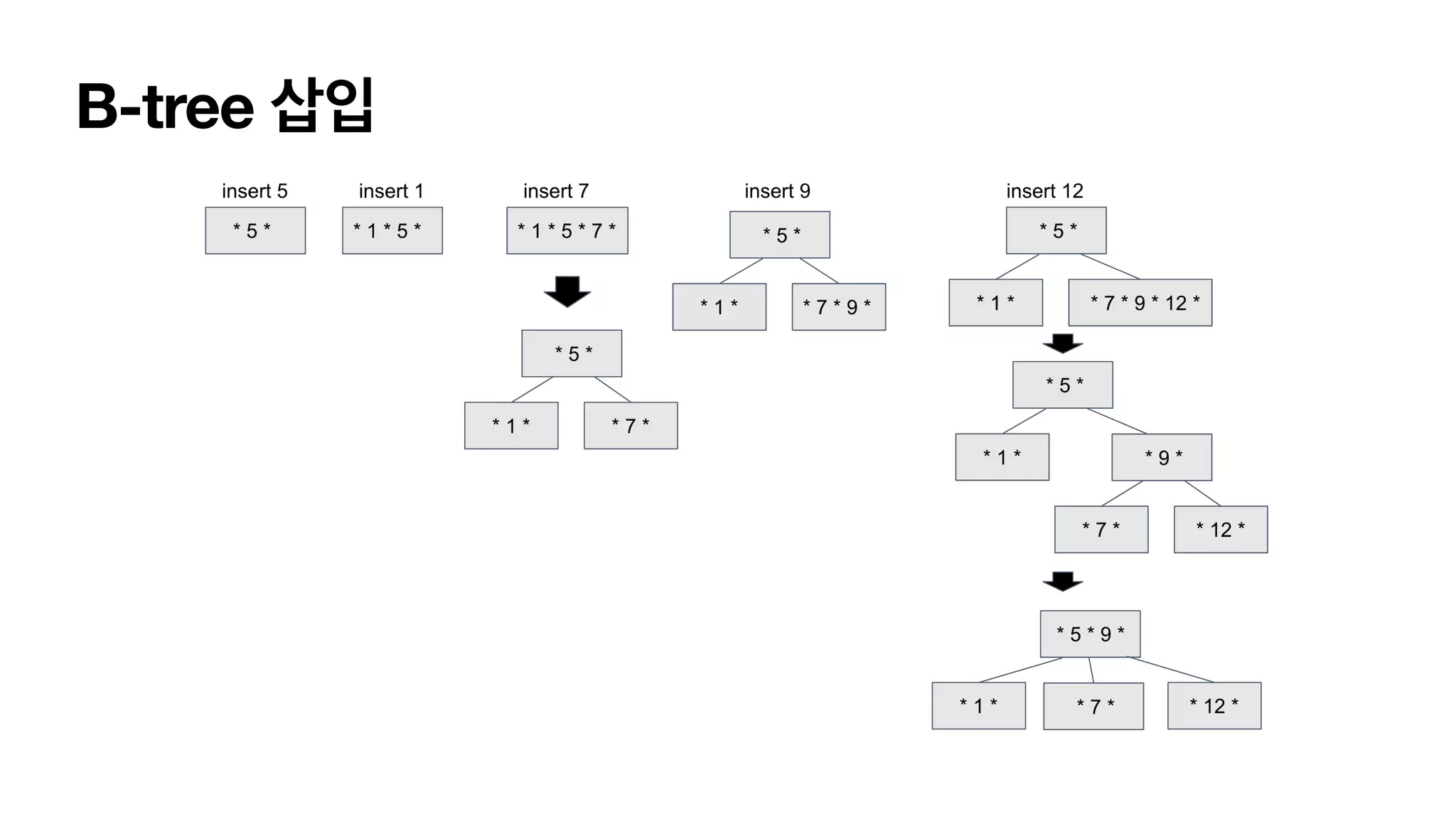
B-tree 삽입. • 데이터를탐색해 해당하는 Leaf 노드에 데이터를 삽입합니다. • Leaf 노드 데이터가 가득 차 있으면 노드를 분리합니다. • insert7 에서 노드가 1, 5, 7 로 가득찼습니다. • 정렬된 노드를 기준으로 중간값을 부모 노드로 해서 트리를 구성합니다. • 분리한 서브트리가 B-Tree조건에 맞지 않는다면 부모 노드로 올라가며 merge합니다. • insert12 에서 [9, 7, 12] 를 서브트리로 분리 하였으나 B-Tree 조건에 맞지 않습니다. • Leaf 노드가 모두 같은 레벨에 존재 하지 않습니다. • Root노드와 merge로 조건을 만족시켰습니다.
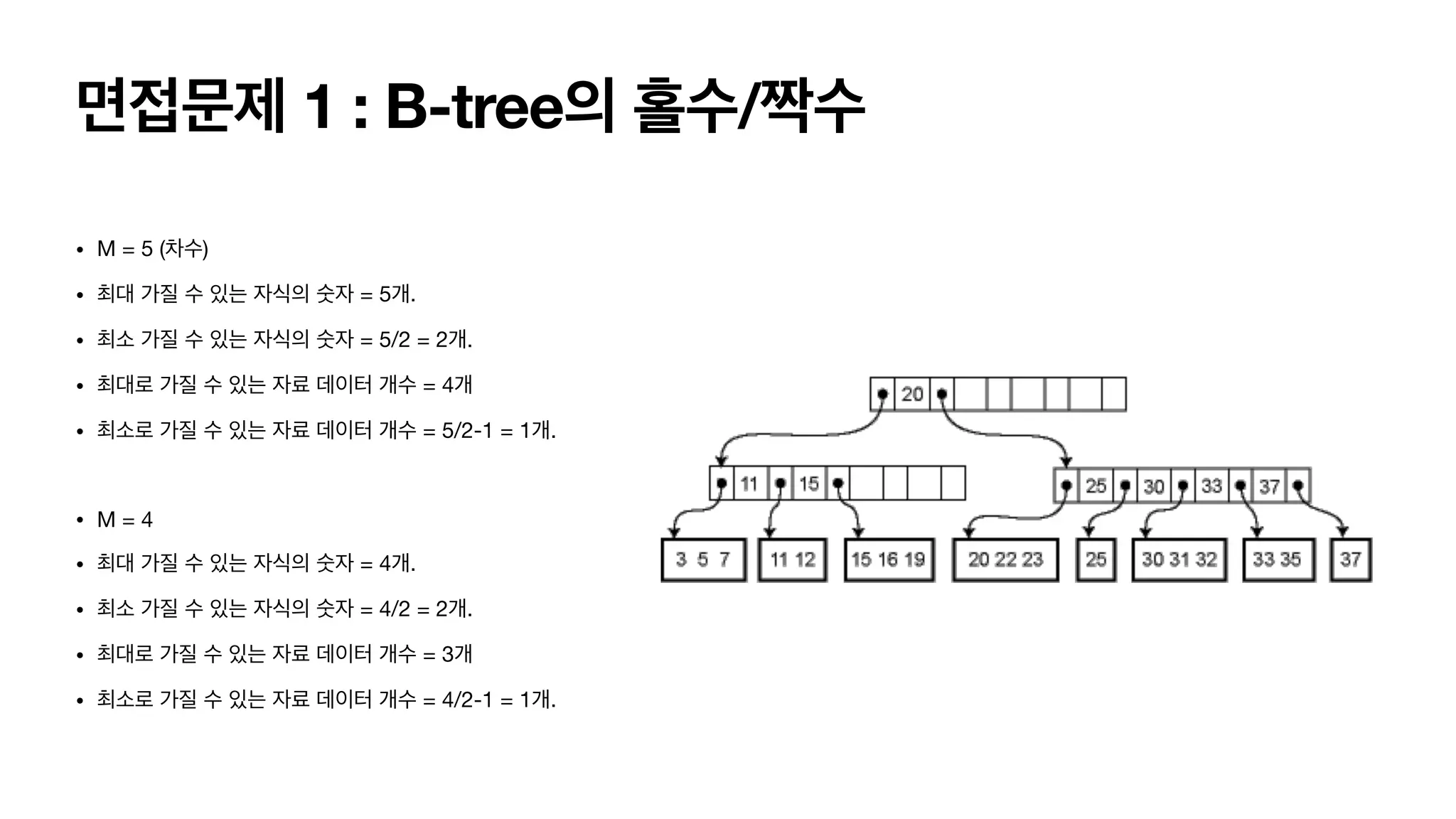
면접문제 1 :B-tree의 홀수/짝수 • B-tree는 차수가 짝수일때보다 홀수일 때, 구현 하는 알고리즘이 훨씬 쉽습니다. 왜 그럴 까요?
63.
면접문제 1 :B-tree의 홀수/짝수 • M = 5 (차수) • 최대 가질 수 있는 자식의 숫자 = 5개. • 최소 가질 수 있는 자식의 숫자 = 5/2 = 2개. • 최대로 가질 수 있는 자료 데이터 개수 = 4개 • 최소로 가질 수 있는 자료 데이터 개수 = 5/2-1 = 1개. • M = 4 • 최대 가질 수 있는 자식의 숫자 = 4개. • 최소 가질 수 있는 자식의 숫자 = 4/2 = 2개. • 최대로 가질 수 있는 자료 데이터 개수 = 3개 • 최소로 가질 수 있는 자료 데이터 개수 = 4/2-1 = 1개.
64.
면접문제 1 :B-tree의 홀수/짝수 • M = 4 , 최대 데이터 개수 3개 [ a, b, c ] • => split을 어떻게 할것? [a,b] [c] • => 편향된 트리를 만들 확률이 크다!, 편향된 트리를 어떻게 처리할것인가? • M = 5, 최대 데이터 개수 4개. [a,b,c,d] • => split은 [a,b] [c,d] 깔끔하게 떨어짐.
면접문제 2: B-tree가Binary Tree보다 우수한 점은 무엇일까요? • B tree는 디스크를 순차적으로 읽을 수 있도록 설계되었습니다. • 그에 비해 Binary Tree는 디스크를 순차적으로 읽지 않고, 랜덤하게 읽을 확률이 큽니다. • 랜덤으로 읽을경우 디스크에 저장된 데이터를 로드하기 위해 기다려야 하는데 대기 하 는 시간이 꽤 길어질 수 있습니다. • 따라서 B Tree는 Binary Tree보다 디스크I/O라는 측면에서 확실하게 빠르게 순차적으로 읽도록 구성한 자료구조입니다. • In-memory 방식을 채택한다고 한다고 하더라도, 여전히 유리한 자료구조인것은 틀림없 습니다. (처음에는 디스크가 너무 느려서, 인메모리 방식을 썼다고 합니다.)
67.
면접문제 3: B-tree의시간 복잡도를 분석해주시고 그 이유를 알려주세요. • Search : 찾을 때는 총 m/2개 만큼 분리되므로, O(log m/2 (N)) => 즉, O(log n) • Insertion/Deletion : 간단하게 보이자면, BST와 비슷. Search (log n) 후에 split merge과정은 층 수 보다 적게 일어나게 되어있음. 따라서, O(logn + logn) = O(log n)
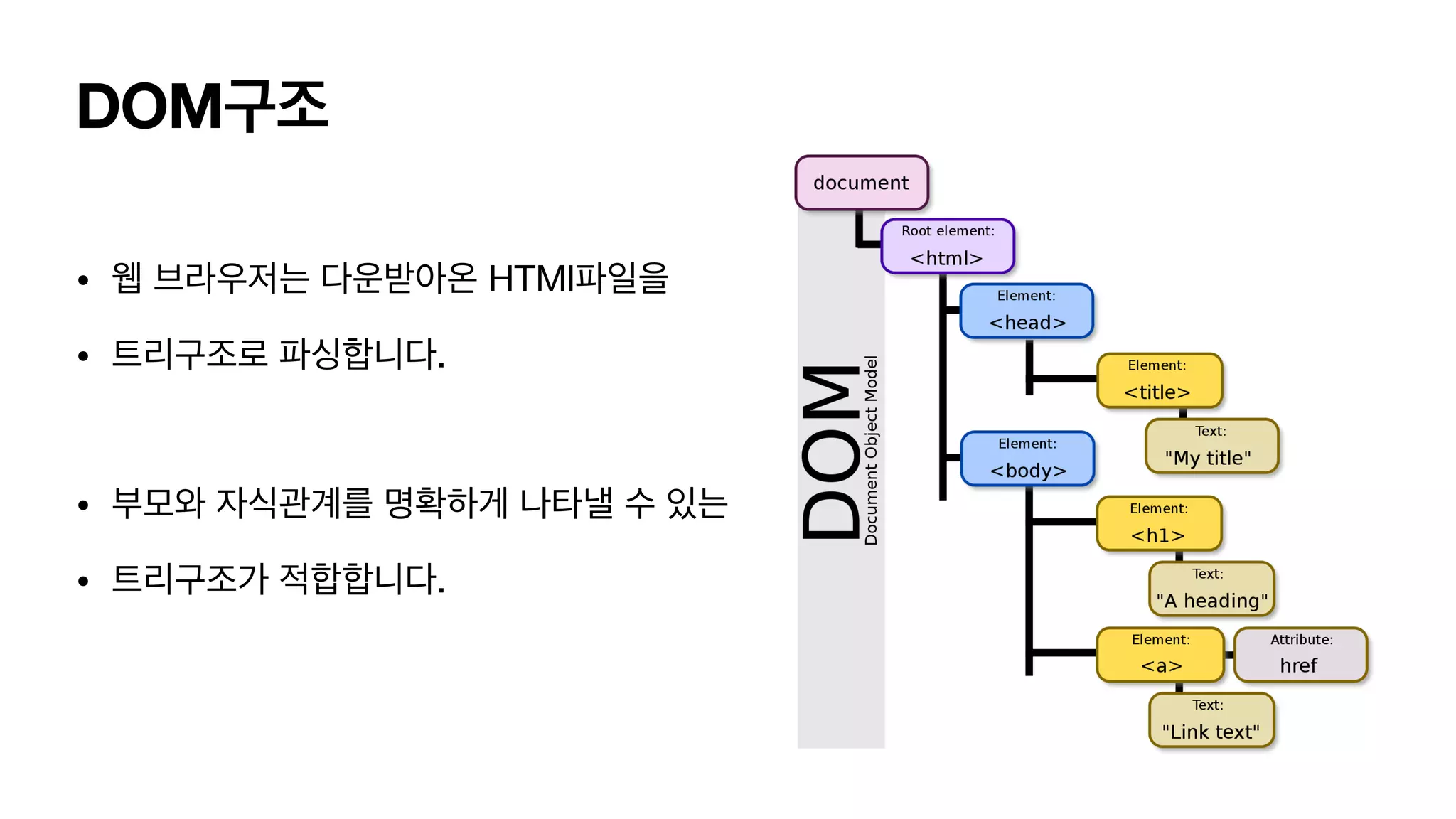
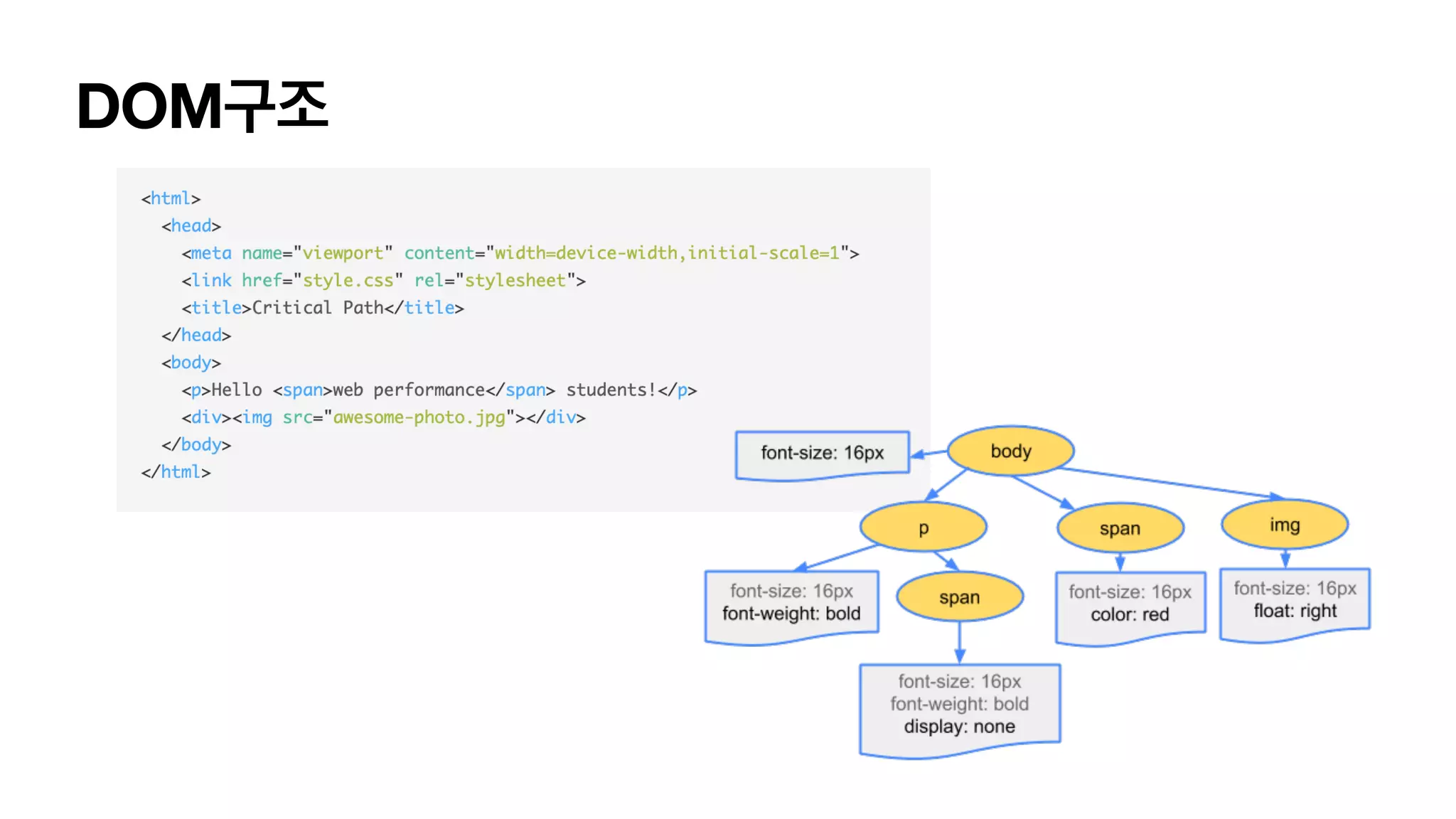
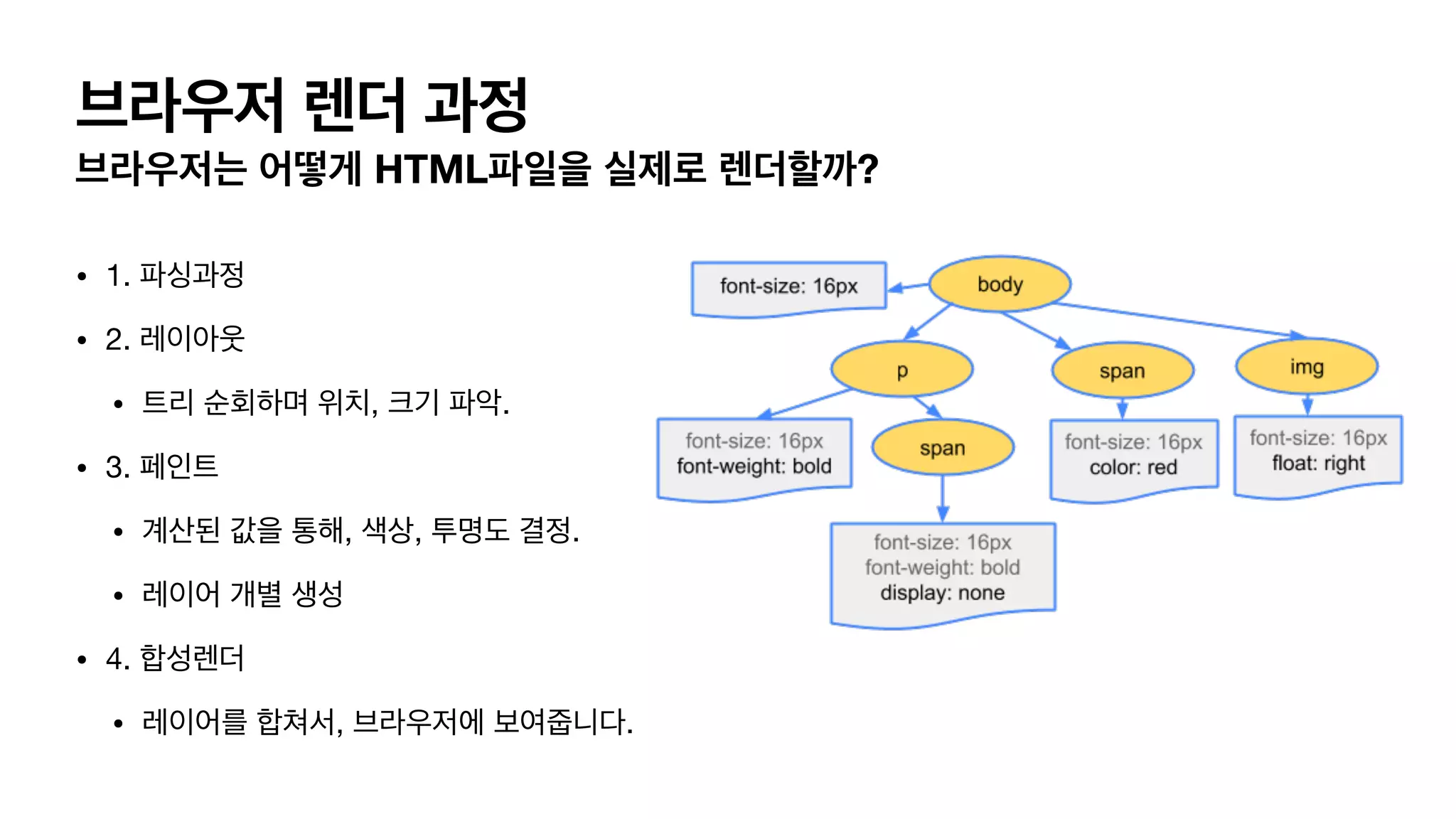
브라우저 렌더 과정 브라우저는어떻게 HTML파일을 실제로 렌더할까? • 1. 파싱과정 • 2. 레이아웃 • 트리 순회하며 위치, 크기 파악. • 3. 페인트 • 계산된 값을 통해, 색상, 투명도 결정. • 레이어 개별 생성 • 4. 합성렌더 • 레이어를 합쳐서, 브라우저에 보여줍니다.
73.
리페인트와 리플로우 DOM 트리에서변경이 경우 어떻게 처리할까? • 리페인트 : 각종 visibility (투명도, 색상) 변경이 동적으로 변경된경우, 트리 순회를 계산한 다. • 리플로우 : width, height 등 기하학적 특성이 변경한경우, 트리를 순회하며 다시 계산한 다. • 보통 리플로우 -> 리페인트, 혹은 기하학적 변경이 없다면 리페인트만 일어나곤 한다. • 리플로우, 리페인트 모두 비싼 cost 의 계산 방법이다. https://ui.toast.com/fe-guide/ko_PERFORMANCE
74.
리페인트와 리플로우 DOM 트리에서js를 통해 동적으로 변경이 경우 어떻게 처리될까? • 리페인트 : 각종 visibility (투명도, 색상) 변경이 동적으로 변경된경우, 트리 순회를 계산한 다. • 리플로우 : width, height 등 기하학적 특성이 변경한경우, 트리를 순회하며 다시 계산한 다. • 보통 리플로우 -> 리페인트, 혹은 기하학적 변경이 없다면 리페인트만 일어나곤 한다. • 리플로우, 리페인트 모두 비싼 cost 의 계산 방법이다.
75.
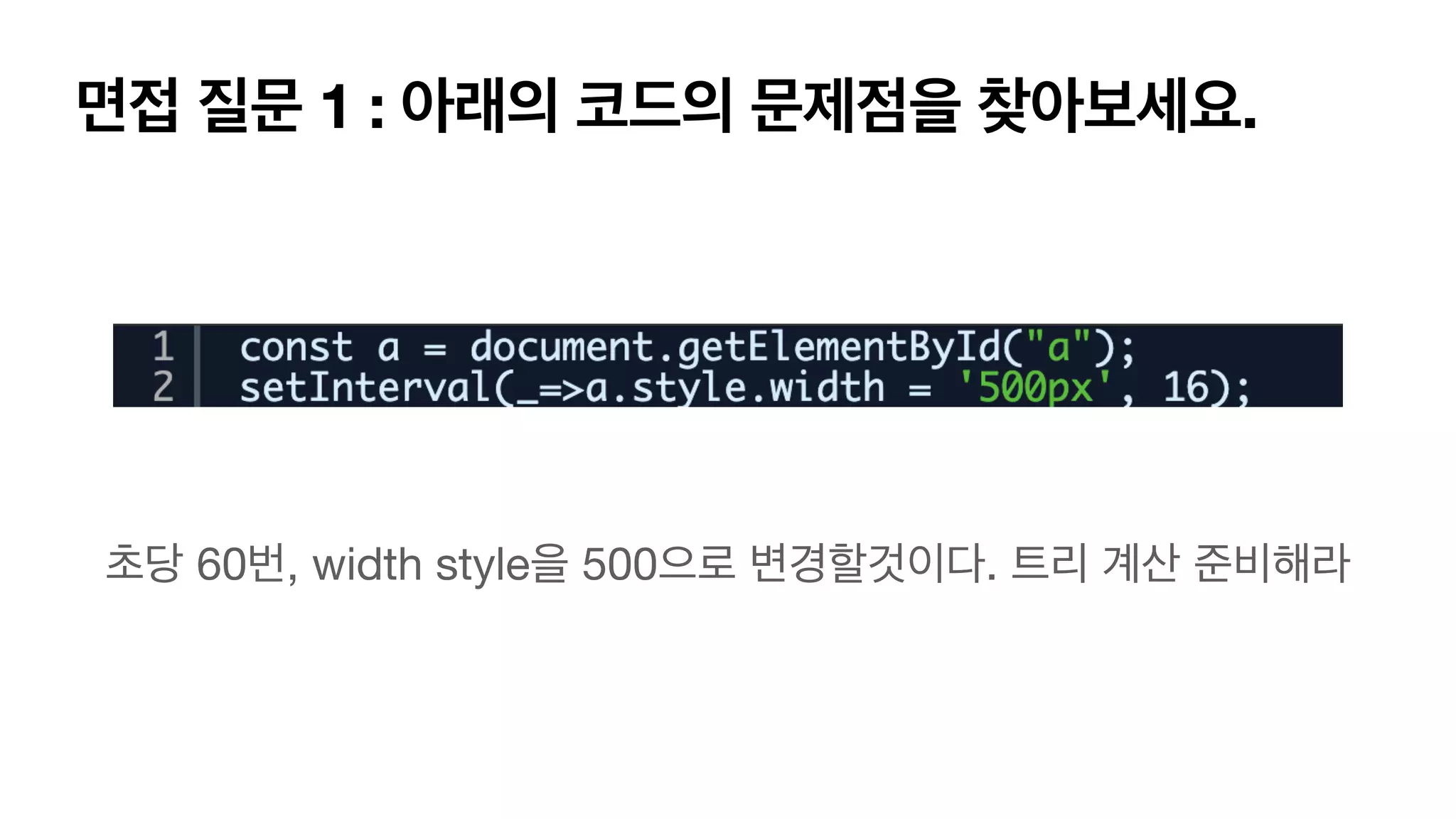
면접 질문 1: 아래의 코드의 문제점을 찾아보세요. https://www.bsidesoft.com/8267
76.
면접 질문 1: 아래의 코드의 문제점을 찾아보세요. 초당 60번, width style을 500으로 변경할것이다. 트리 계산 준비해라
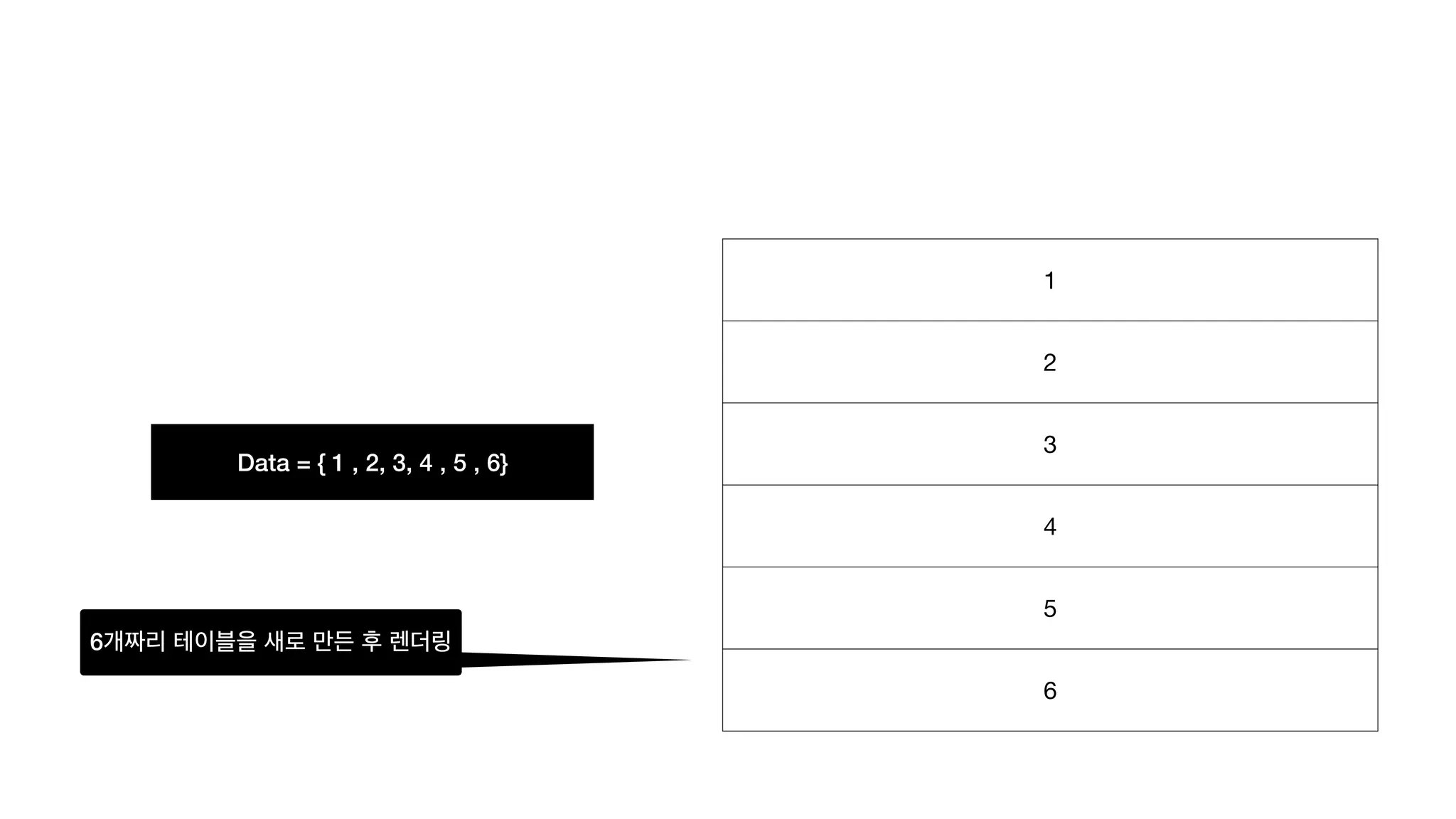
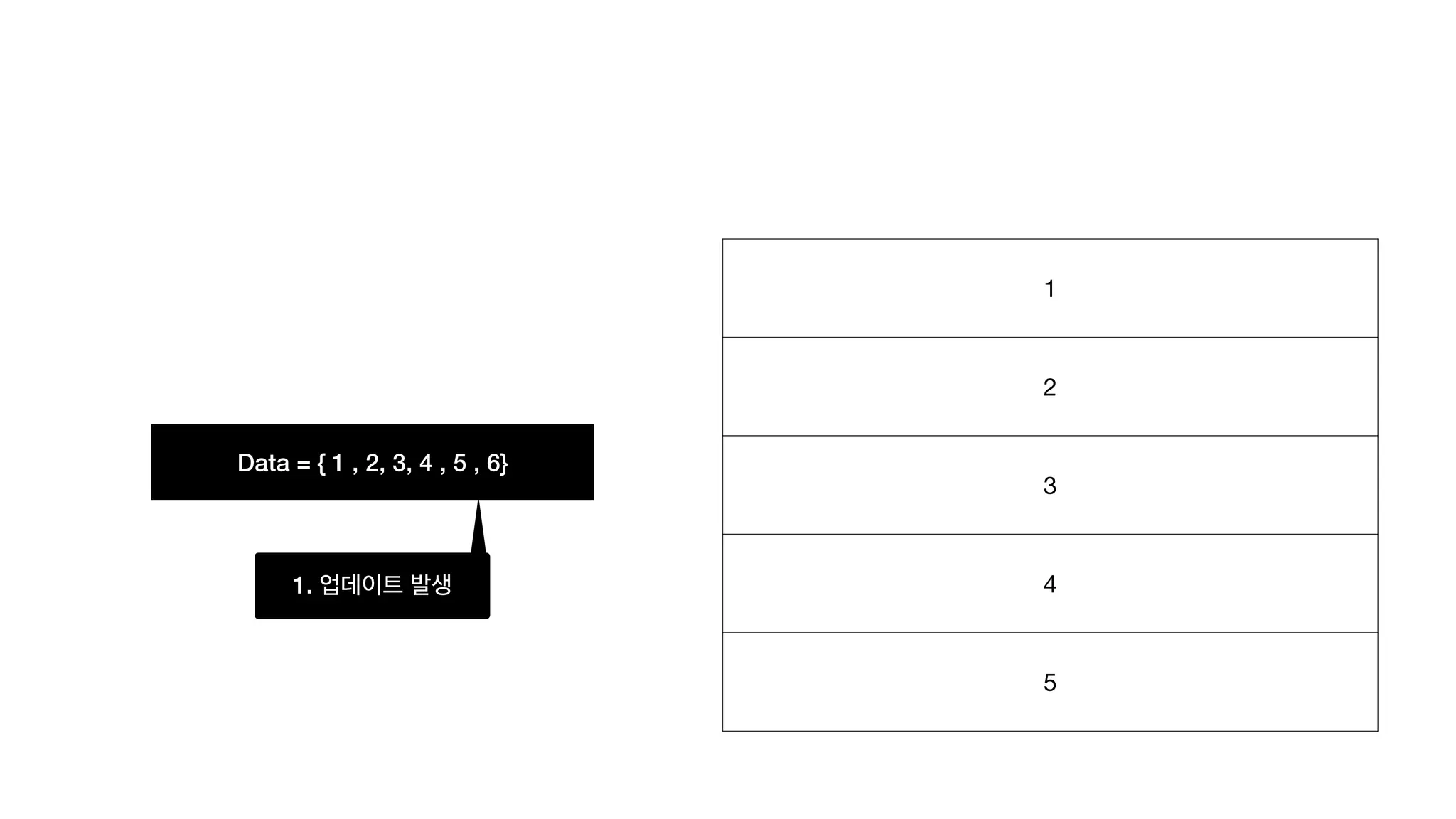
Data = {1 , 2, 3, 4 , 5 , 6} 6개짜리 테이블을 새로 만든 후 렌더링 1 2 3 4 5 6
87.
최적화 생각 안하고UI 짜기 가능. = 선언적 뷰 • 로직이 간단하긴 한데… • 탐색 필요없고, 그냥 테이블 생성 로직 하나로 모든걸 다 할 수 있다. • 매번 새롭게 그리는거 괜찮을까..? • 리플로우, 리페인트의 코스트는..?
88.
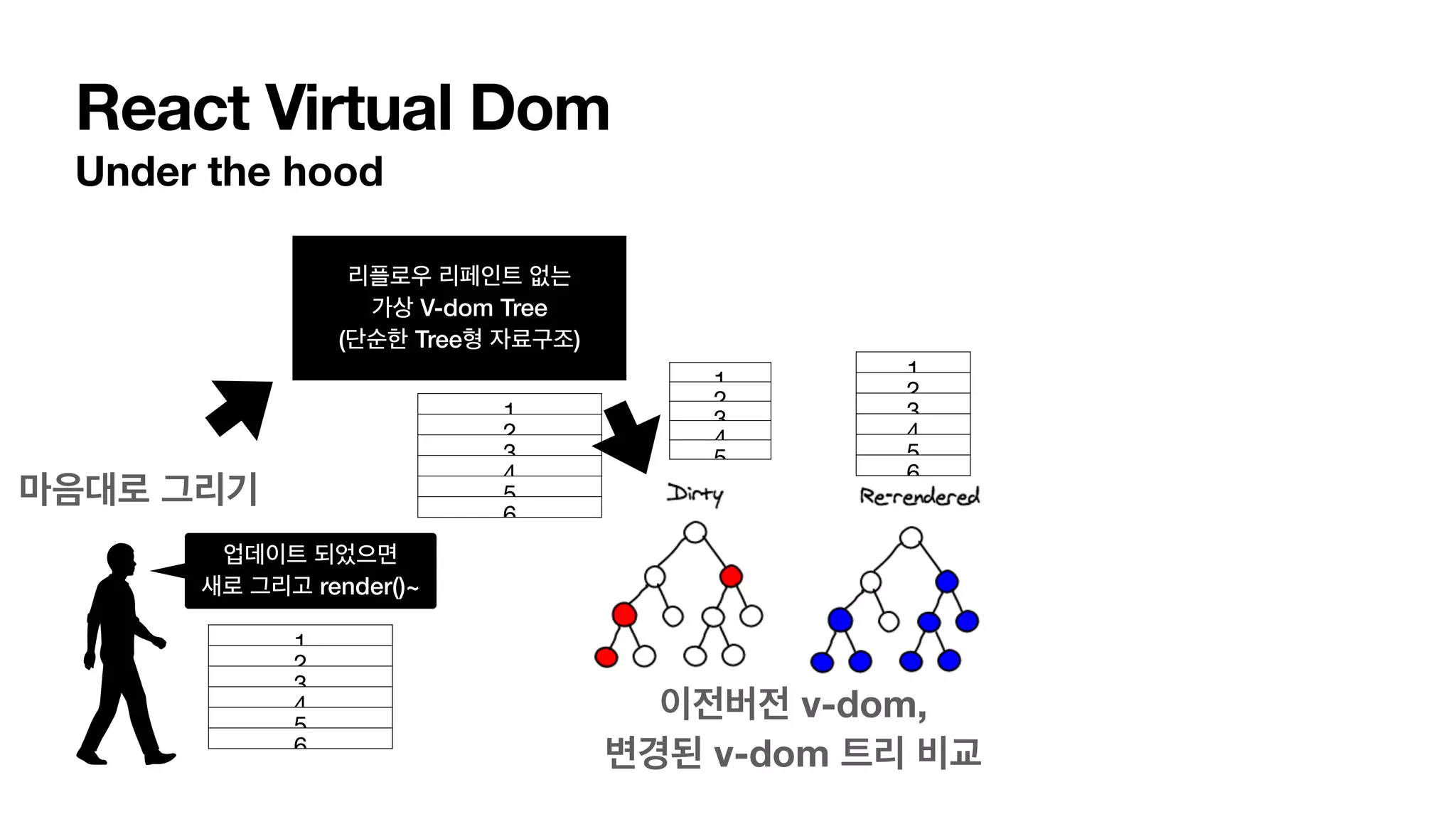
Virtual-dom • 리액트 개발환경에서는 실제 dom이 아닌 virtual-dom에 UI 업데이트를 한다. • virtual-dom은 단순한 트리 자료구조이다. • 따라서, DOM에서 일어날 법한 리페인트, 리플로우 등이 일어나질 않는다. https://stackover fl ow.com/questions/21109361/why-is-reacts-concept-of-virtual-dom-said-to-be-more-performant-than-dirty-mode https://stackover fl ow.com/questions/41409832/what-exactly-the-purpose-of-react-virtual-dom/41410004#41410004 https://stackover fl ow.com/questions/61245695/how-exactly-is-reacts-virtual-dom-faster https://calendar.perfplanet.com/2013/di ff / https://reactjs.org/docs/reconciliation.html
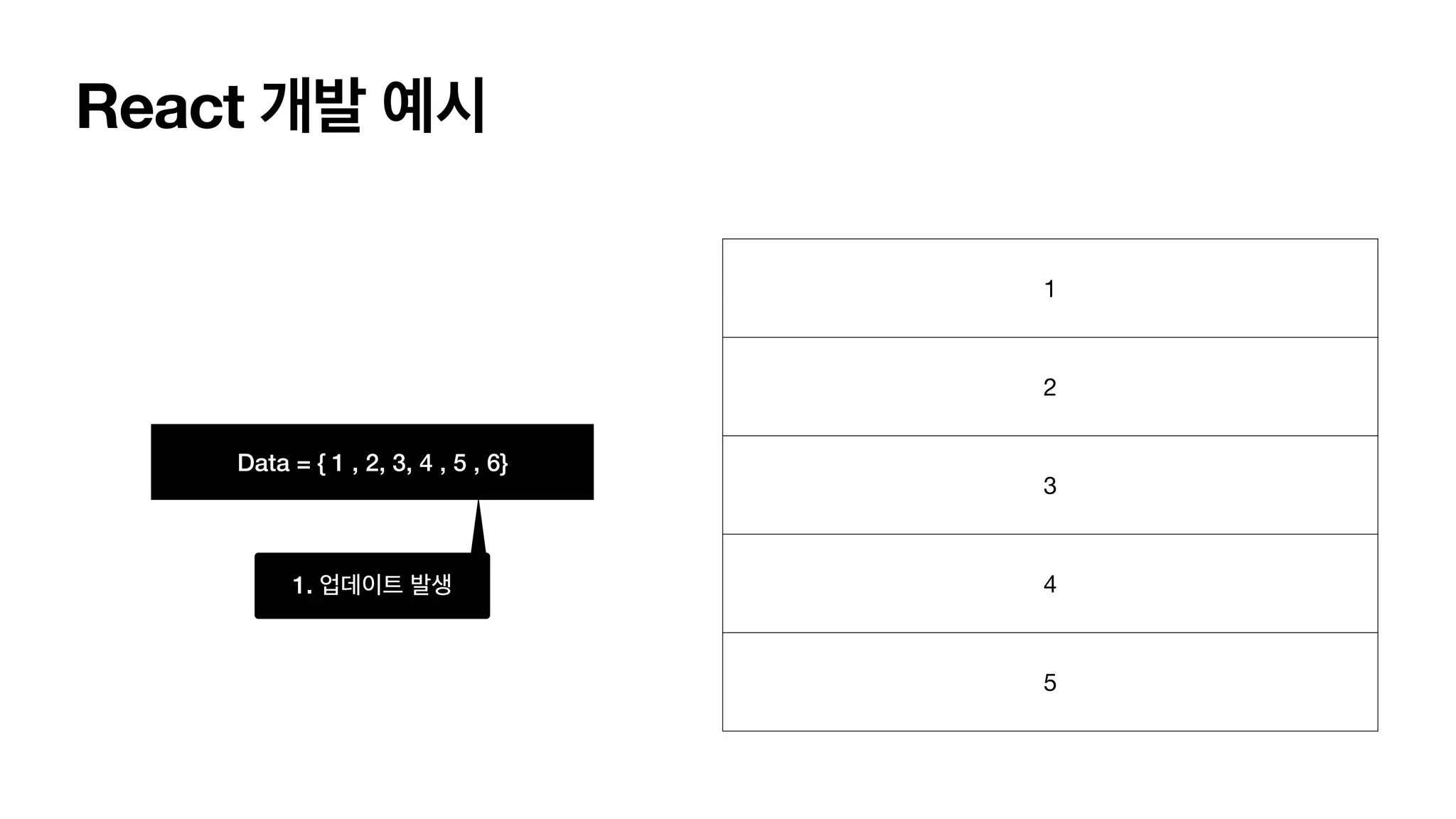
React Virtual Dom Underthe hood 리플로우 리페인트 없는 가상 V-dom Tree (단순한 Tree형 자료구조) 마음대로 그리기 1 2 3 4 5 6 업데이트 되었으면 새로 그리고 render()~ 1 2 3 4 5 6
91.
React Virtual Dom Underthe hood 리플로우 리페인트 없는 가상 V-dom Tree (단순한 Tree형 자료구조) 마음대로 그리기 이전버전 v-dom, 변경된 v-dom 트리 비교 1 2 3 4 5 6 업데이트 되었으면 새로 그리고 render()~ 1 2 3 4 5 6 1 2 3 4 5 1 2 3 4 5 6
92.
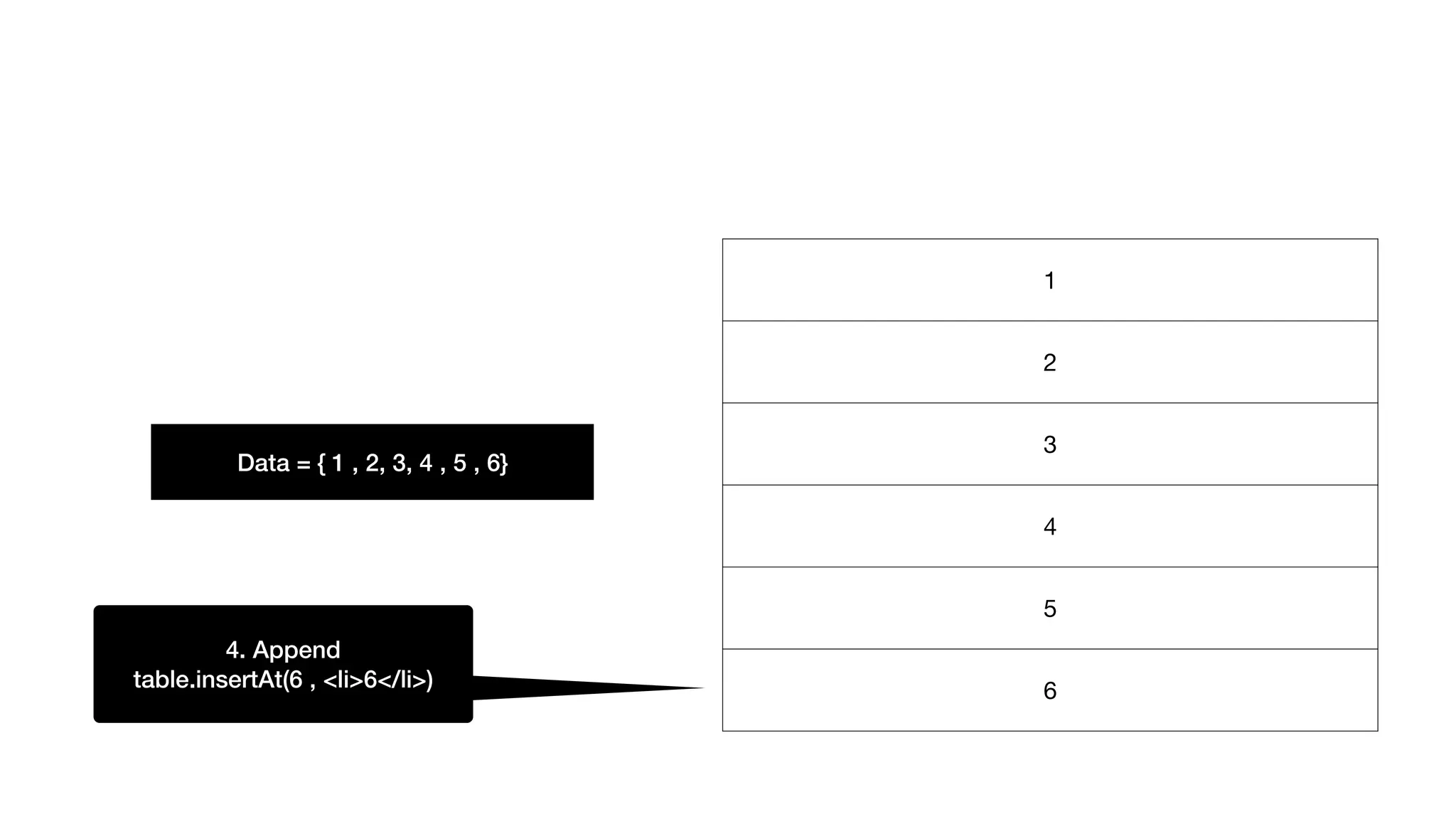
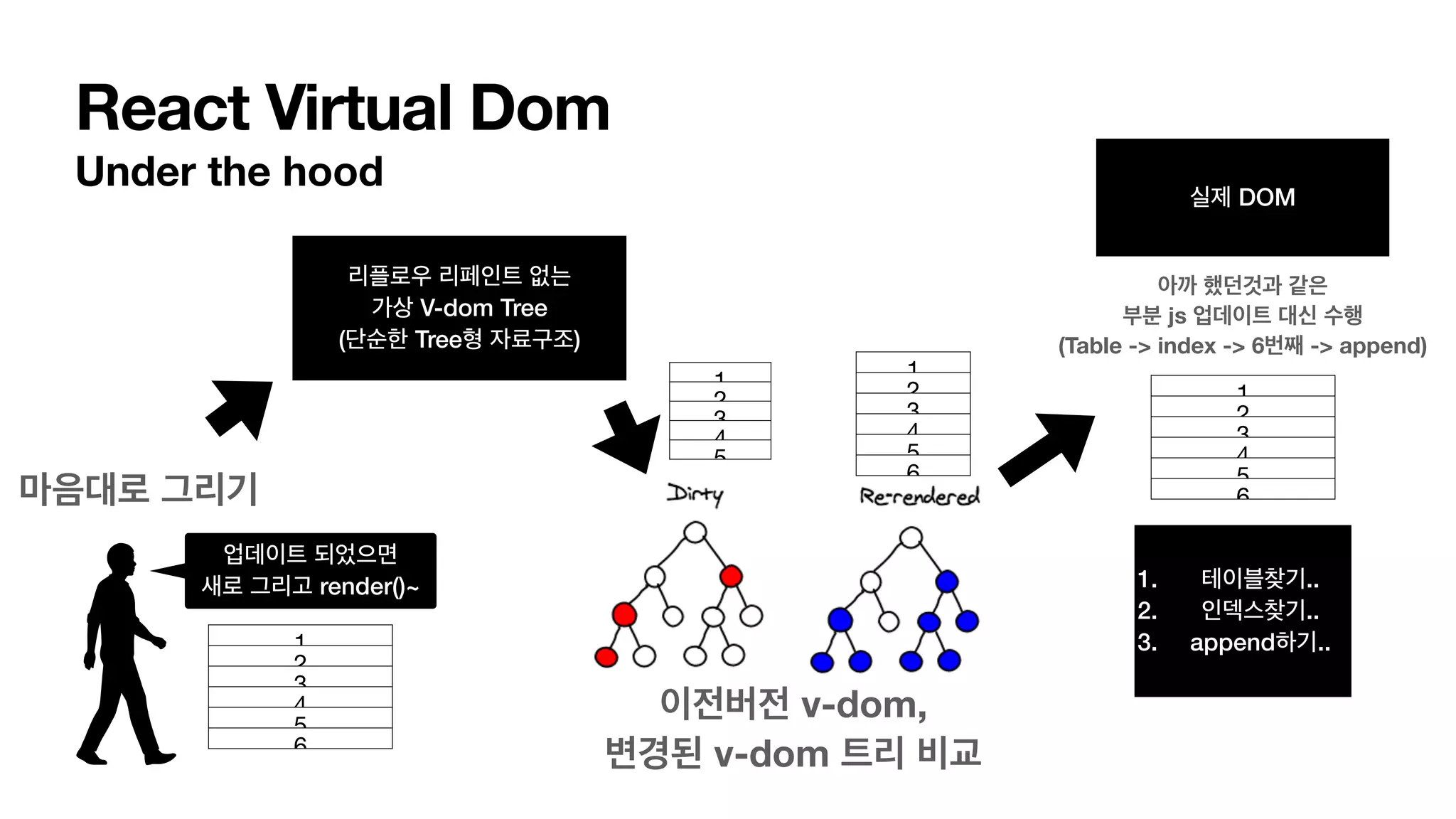
React Virtual Dom Underthe hood 리플로우 리페인트 없는 가상 V-dom Tree (단순한 Tree형 자료구조) 실제 DOM 마음대로 그리기 이전버전 v-dom, 변경된 v-dom 트리 비교 아까 했던것과 같은 부분 js 업데이트 대신 수행 (Table -> index -> 6번째 -> append) 1 2 3 4 5 6 1 2 3 4 5 6 1. 테이블찾기.. 2. 인덱스찾기.. 3. append하기.. 업데이트 되었으면 새로 그리고 render()~ 1 2 3 4 5 1 2 3 4 5 6
93.
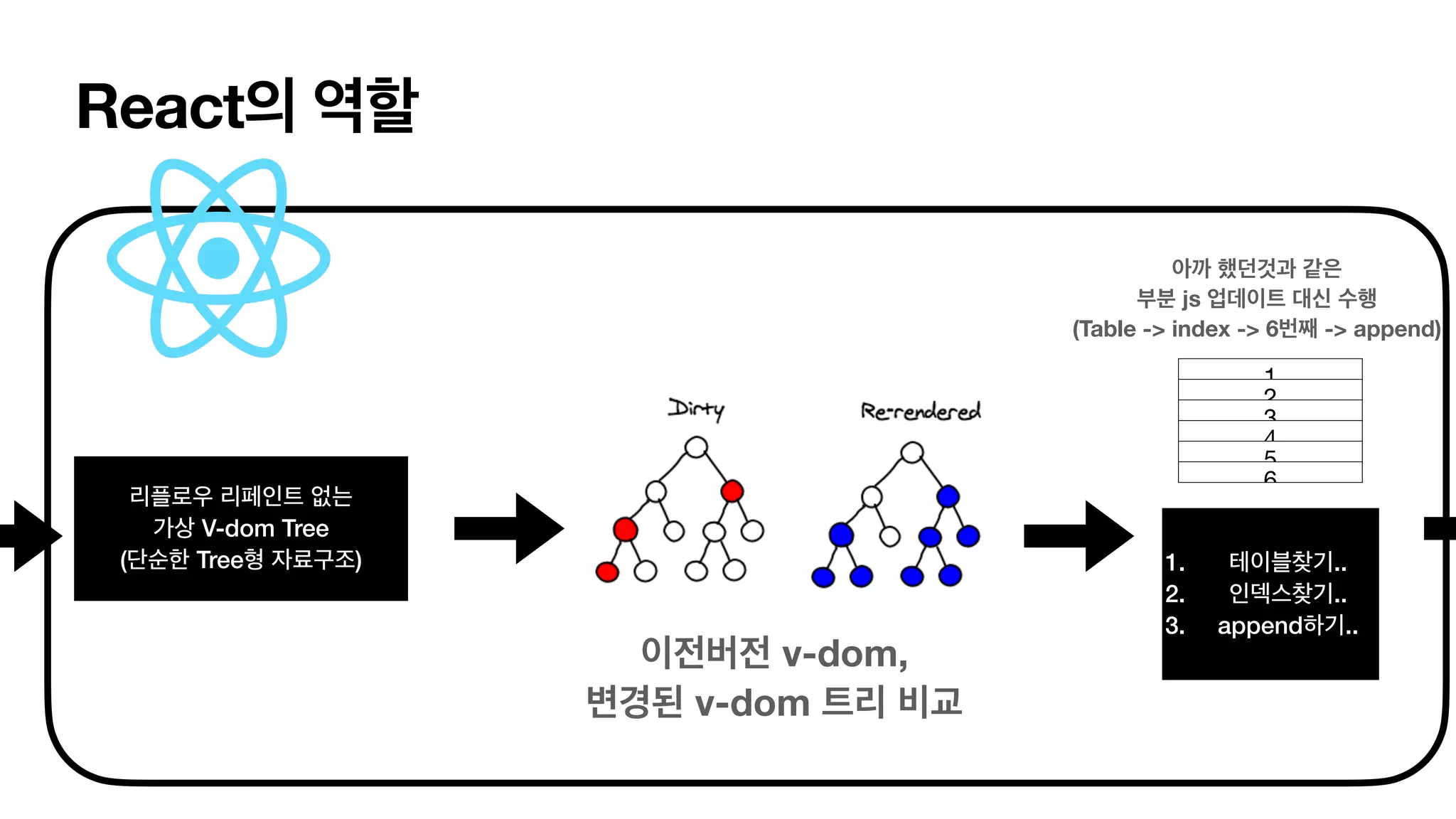
React의 역할 리플로우 리페인트없는 가상 V-dom Tree (단순한 Tree형 자료구조) 이전버전 v-dom, 변경된 v-dom 트리 비교 아까 했던것과 같은 부분 js 업데이트 대신 수행 (Table -> index -> 6번째 -> append) 1 2 3 4 5 6 1. 테이블찾기.. 2. 인덱스찾기.. 3. append하기..
94.
그래서, 트리랑 무슨상관? Di ff 알고리즘. •이런 방식이 가능한 이유 = 트리 비교 연산 (di ff ) 가 효율적이기 때문! • 트리 비교 연산은 전통적으로 O(n^3)이 걸린다고 함. • 리액트는 몇가지 가정과 함께, O(N)으로 줄임. v-dom의 트리 전체 순회를 최대한으로 줄이고 최적화 함. • 리액트 개발자는 선언적 뷰를 이용해서 개발 로직을 간단하게 한만큼 리액트의 휴리스틱 di ff 알 고리즘을 최대한 존중해줘야함. • 즉, 리액트의 방식에 맞춘 최적화는 필수 적임. • 함수 컴포넌트, useMemo (렌더링 최소화), shouldComponentUpdate() (di f 최소화) 등..
95.
면접질문 2. 리액트왜썼어요? • 리액트의 장점은 굉장히 많다. • 그중 한가지. V-dom을 통해 실제 DOM을 추상화를 해놨다. • 개발자들은 UI로직을 쉽게 선언적으로 개발할 수 있게 되는데 큰 밑바탕이 됨. • 하지만, 이런 v-dom을 사용하면, 리액트가 어떻게 di ff 하는지를 파악하고, 어떻게 리액트가 최적화 하는지, 리액트 가 최적화 할 수 있도록 고민해야함. • 1) key Props를 꼭 써줘서, 여러 리스트들 사이에서 렌더링을 최소한 할 수 있도록… • 1) shouldComponentUpdate()를 사용해서, di f 를 최소한으로 만들어줄것… • 2) useMemo등으로 리액트가 실수로 같은 뷰를 재 랜더링 요청하지 않도록 할것… • 등등…



















![B-tree의 특징. • 이진 탐색 트리처럼 부모 노드의 왼쪽 서브 트리에는 가장 왼쪽에 있는 서브 트리의 값보다 항상 작은 값이 들어가 있어야합니다. • 노드의 자료수가 N이라면, 자식수는 N+1이어야한다 • 각 노드의 자료수는 정렬되어있어야한다. • Root 노드와 단말노드를 제외한 모든 노드는 적어도 [M/2] 개의 Children을 보유하고 있어야합니다. 즉, 각 노드의 데이터 개수는 적어도 [M/2] - 1개를 가지고 있어야 하겠습 니다. • => 5차 B-tree라고하면 [M/2] = 2 - 1. (최소 1개씩 데이터 를 가지고 있자)](https://image.slidesharecdn.com/ttt-210131112835/75/CS-Study-Data-Structure-Tree-53-2048.jpg)
![예시 : 5차 B-tree • 자식노드로 가질 수 있는 최대 개수가 5라는 의미. • 즉, 5차 B-tree는 최대 5개의 자식노드를 가질 수 있고, 이는 최대 4개의 Key값을 가질 수 있다는 의미가 됨. • 루트노드와, 단말노드를 제외하곤 (모든 내부노드들이) 적어도 [M/2] = 5/2 - 1 = 1개 의 키값을 가지고 있어야 하고, [M/2] = 2개의 자손 노드를 가져야 합니다.](https://image.slidesharecdn.com/ttt-210131112835/75/CS-Study-Data-Structure-Tree-57-2048.jpg)

![B-tree 삽입. • 데이터를 탐색해 해당하는 Leaf 노드에 데이터를 삽입합니다. • Leaf 노드 데이터가 가득 차 있으면 노드를 분리합니다. • insert7 에서 노드가 1, 5, 7 로 가득찼습니다. • 정렬된 노드를 기준으로 중간값을 부모 노드로 해서 트리를 구성합니다. • 분리한 서브트리가 B-Tree조건에 맞지 않는다면 부모 노드로 올라가며 merge합니다. • insert12 에서 [9, 7, 12] 를 서브트리로 분리 하였으나 B-Tree 조건에 맞지 않습니다. • Leaf 노드가 모두 같은 레벨에 존재 하지 않습니다. • Root노드와 merge로 조건을 만족시켰습니다.](https://image.slidesharecdn.com/ttt-210131112835/75/CS-Study-Data-Structure-Tree-60-2048.jpg)

![면접문제 1 : B-tree의 홀수/짝수 • M = 4 , 최대 데이터 개수 3개 [ a, b, c ] • => split을 어떻게 할것? [a,b] [c] • => 편향된 트리를 만들 확률이 크다!, 편향된 트리를 어떻게 처리할것인가? • M = 5, 최대 데이터 개수 4개. [a,b,c,d] • => split은 [a,b] [c,d] 깔끔하게 떨어짐.](https://image.slidesharecdn.com/ttt-210131112835/75/CS-Study-Data-Structure-Tree-64-2048.jpg)










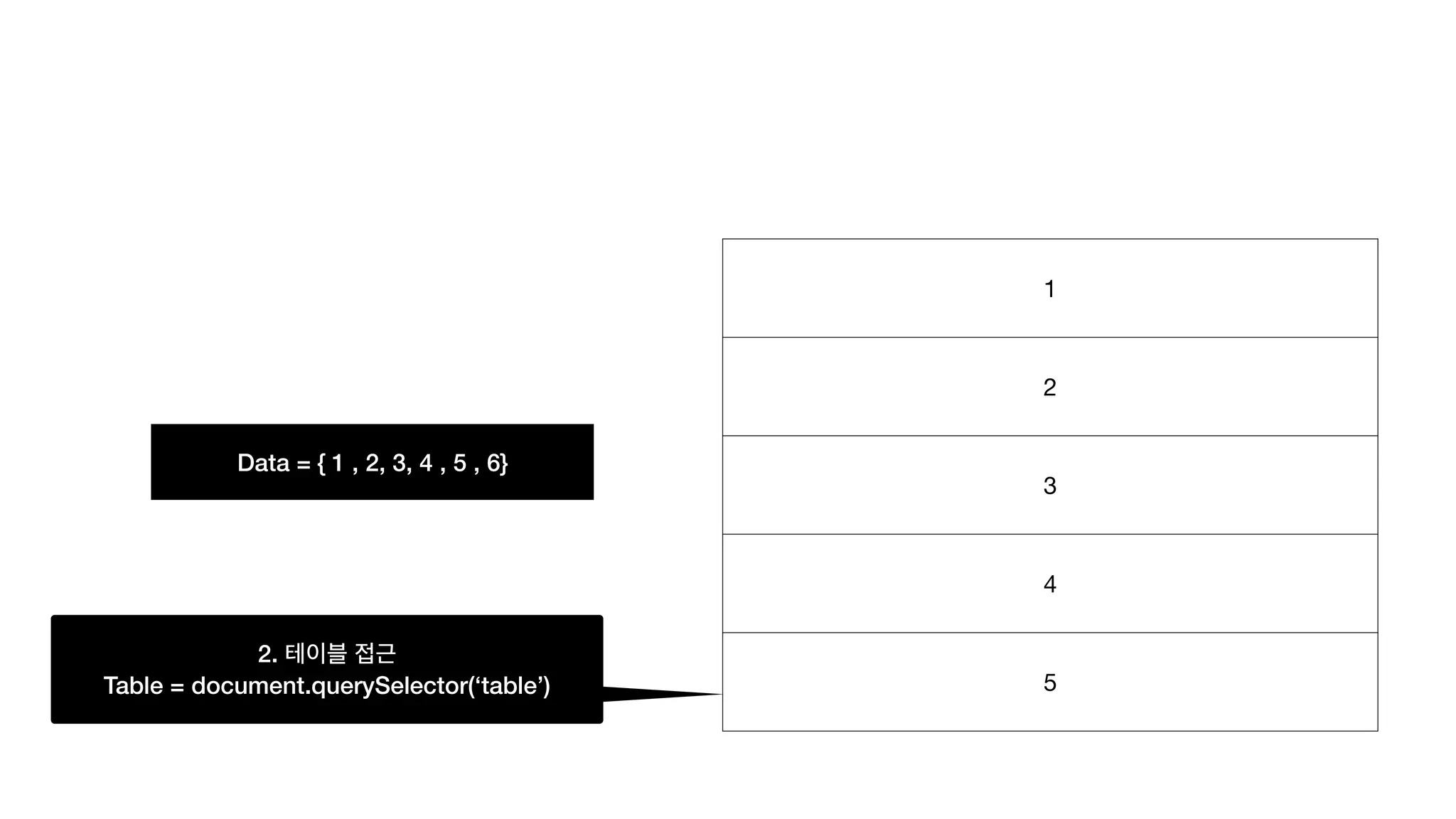
![Data = { 1 , 2, 3, 4 , 5 , 6} 1 2 3 4 5 3. 인덱스 찾기
table[lastIndex]](https://image.slidesharecdn.com/ttt-210131112835/75/CS-Study-Data-Structure-Tree-81-2048.jpg)