When we're trying to classify things, we often run into a common but tricky problem: imbalanced datasets. Most machine learning models are designed to be accurate overall. If a model just learns to always guess 'not fraud,' it will be 99.9% accurate! But it will be completely useless because it will never catch any actual fraud. This is called the accuracy paradox: a high accuracy score that hides a poorly performing model. This PDF will walk you through, step-by-step, how to identify and handle this problem. We'll cover: How to properly measure a model's performance on imbalanced data. Techniques to balance your data by resampling. Visualizing the impact of these techniques with before and after plots. Algorithm-level approaches to tackle the problem.




![ If the minority class is rare but not valuable, intervention and balancing may be unnecessary. No single “imbalance ratio” threshold governs when to intervene, but as a rule of thumb, ratios below 10% (minority) usually warrant specialized handling. Diagnosing Dataset Issues Before Imbalance Treatment Before addressing the class imbalance directly, always check for outliers, skewness, missing values, and potential data leakage: Outlier Detection: Use visualization (sns.boxplot, sns.violinplot), Z-score/statistical methods (outliers often have Skewness: Significant skew can be detected by plotting histograms (sns.histplot), qqplots, and using statistical tests (e.g., Shapiro-Wilk, D’Agostino). Missing Values: Visualize with heatmaps or count nulls. Impute with SimpleImputer or domain-specific methods. Combinations: Address missing values and extreme outliers before resampling, or risk propagating noise/minimizing data utility in minority classes. Implementation Example: Outlier Removal With Z-Score import numpy as np from scipy import stats z_scores = np.abs(stats.zscore(X)) outliers = X[z_scores > 3] X_clean = X[~np.in1d(X, outliers).any(axis=1)] Visualizing Class Distribution and Data Issues Seaborn offers powerful plotting functions to visualize imbalance and other data health problems: Count Plot for Class Distribution: import seaborn as sns import matplotlib.pyplot as plt sns.countplot(x='target', data=df) plt.title('Class Distribution')](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-5-2048.jpg)
![plt.show() For severe imbalance, consider setting the Y-axis to logarithmic scale (plt.yscale('log')), as recommended in community best practices. Box Plots/Violin Plots for Outliers: sns.boxplot(y=X['feature']) sns.violinplot(y=X['feature']) Missing Values: sns.heatmap(df.isnull(), cbar=False) These diagnostic plots ensure that treatment for class imbalance is not mistakenly performed on corrupted data. Practical Approaches to Handling Imbalanced Datasets Data-Level Methods: Resampling The fundamental approach is to alter the training data to balance class distribution. Two main strategies exist: oversampling the minority class and undersampling the majority class. Oversampling: Increase Minority Samples Random Oversampling: Randomly duplicate minority class samples to balance classes. Pros: Simple and effective if dataset is small or minority is truly underrepresented. Cons: Risk of overfitting and less data diversity. Python Example: from imblearn.over_sampling import RandomOverSampler X_over, y_over = RandomOverSampler(random_state=42).fit_resample(X, y) SMOTE (Synthetic Minority Oversampling Technique): Instead of duplicating, creates synthetic new samples by interpolating between minority class neighbors. Pros: Less overfitting, more diversity than simple duplication.](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-6-2048.jpg)






![ Always supplement p-values with confidence intervals and effect sizes. Do not rely solely on passing a threshold for scientific or business decision-making. Assumption Checks, Diagnostics, and Visualization Key Assumptions Patterns are not driven by outliers, missing data, or data leakage. Test set is untouched by all resampling and preprocessing. Stratified train/test split is used to preserve imbalance characteristics in evaluation. Residual Analysis For regression models, check residuals for: o Constant variance (homoskedasticity) o Independence o Normality (via QQ plot, histograms) o Studentized residuals: Detect outliers if residual > ±3. Outlier and Distribution Visualizations: sns.boxplot, sns.violinplot, or sns.kdeplot to identify data spread and outliers. Class Distribution Visualization: sns.countplot(x='target', data=df) or histogram. Threshold Tuning with Visualization: Plot F1-score, precision, and recall as functions of threshold. import matplotlib.pyplot as plt thresholds = np.arange(0., 1.01, 0.01) f1_scores = [f1_score(y_test, y_proba > t) for t in thresholds] plt.plot(thresholds, f1_scores) plt.xlabel('Threshold') plt.ylabel('F1 Score') plt.show()](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-13-2048.jpg)
![Handling Imbalances with Outliers, Skewness, and Missing Data 1. Always handle severe outliers first: Outliers in the minority class especially can bias both data balancing and future model training. Remove or cap using Z-score, IQR, or robust estimators. 2. Address skewness: Log-transform or Box-Cox transform strongly skewed features to stabilize variance and enhance modeling robustness. 3. Handle missing data: Impute or drop based on missingness proportion and feature importance. Never let imputation amplify imbalance. Recommended sequence: preprocess → outlier removal → impute missing data → handle imbalance → model training. Example Pipeline: Handling Imbalanced Data in Python Let’s illustrate a typical workflow: import numpy as np import pandas as pd from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from imblearn.over_sampling import SMOTE from imblearn.ensemble import BalancedRandomForestClassifier from sklearn.metrics import classification_report, roc_auc_score import seaborn as sns import matplotlib.pyplot as plt from collections import Counter # 1. Generate imbalanced data X, y = make_classification(n_samples=1000, n_features=10, weights=[0.95, 0.05], n_classes=2, random_state=42) print("Original distribution:", Counter(y)) # 2. Visualize imbalance sns.countplot(x=y) plt.title('Class Distribution') plt.show() # 3. Split and stratify X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42) # 4. Apply SMOTE smote = SMOTE(random_state=42) X_train_res, y_train_res = smote.fit_resample(X_train, y_train) print("Resampled distribution:", Counter(y_train_res))](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-14-2048.jpg)
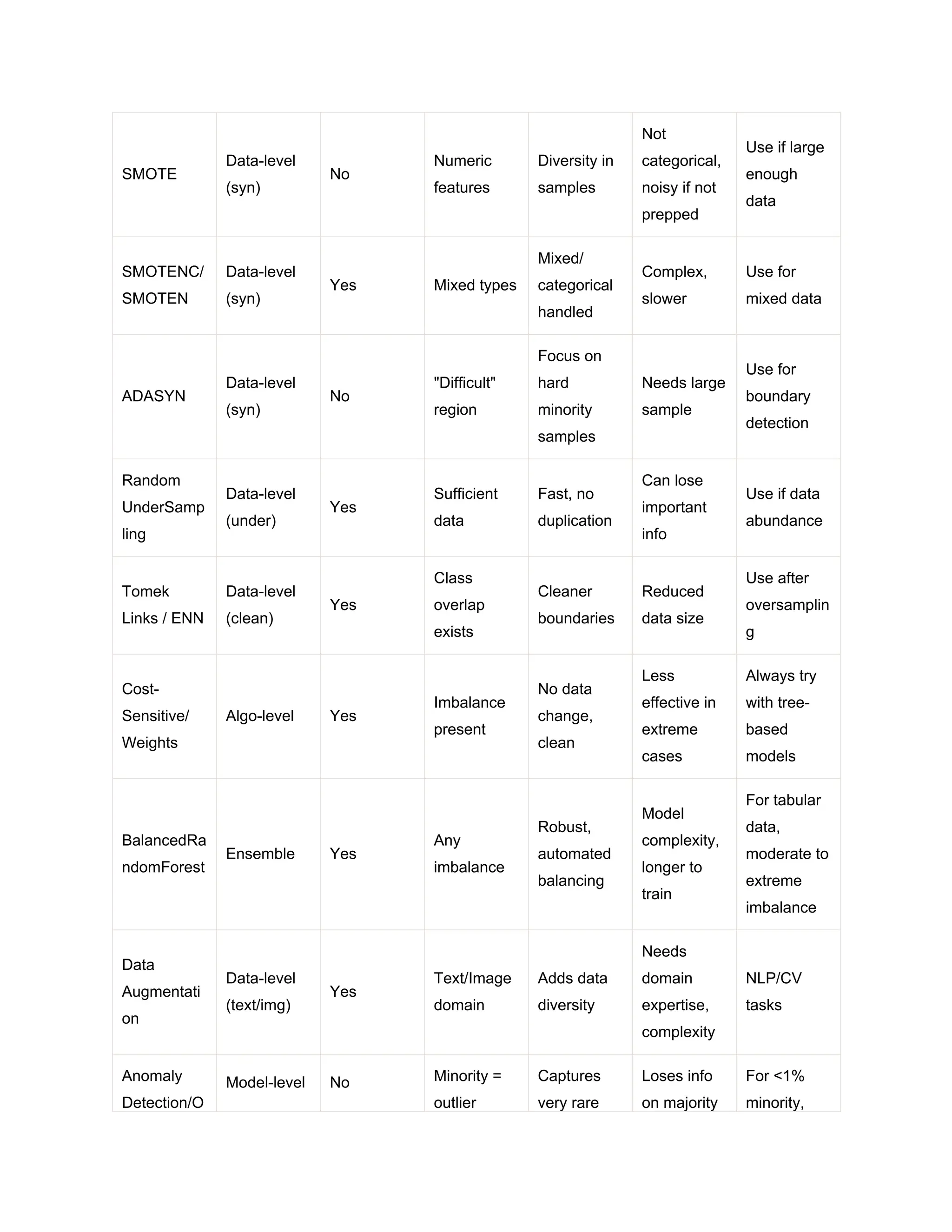
![# 5. Visualize after resampling sns.countplot(x=y_train_res) plt.title('Resampled Class Distribution') plt.show() # 6. Train a balanced random forest clf = BalancedRandomForestClassifier(random_state=42) clf.fit(X_train_res, y_train_res) y_pred = clf.predict(X_test) y_proba = clf.predict_proba(X_test)[:,1] # 7. Evaluate print(classification_report(y_test, y_pred)) print("AUC-ROC:", roc_auc_score(y_test, y_proba)) Expected output: Original distribution: Counter({0: 950, 1: 50}) Resampled distribution: Counter({0: 665, 1: 665}) precision recall f1-score support 0 0.99 0.99 0.99 285 1 0.75 0.70 0.72 15 accuracy 0.98 300 macro avg 0.87 0.84 0.86 300 weighted avg 0.98 0.98 0.98 300 AUC-ROC: 0.923 Analysis: After using SMOTE and a BalancedRandomForest, recall and F1-score on the minority class (“1”) have improved significantly-a more meaningful assessment of success than overall accuracy. Comparison Table: Imbalance Handling Techniques Technique Type Handles Categorical Assumption s Pros Cons Best Practice Random OverSampli ng Data-level (over) No Minority ≪ Majority Simple, no data loss Overfitting, duplicates Use when dataset small](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-15-2048.jpg)


![Confusion Matrix Heatmap: from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) sns.heatmap(cm, annot=True, fmt='d') F1 Score vs. Decision Threshold: thresholds = np.linspace(0, 1, 50) f1s = [f1_score(y_test, y_proba > t) for t in thresholds] plt.plot(thresholds, f1s) plt.xlabel('Threshold'); plt.ylabel('F1 Score') plt.show() Summary: End-to-End Guidelines Start with EDA: Visualize class imbalance, check for outliers, skew, and missing data. Preprocess Carefully: Outlier removal/capping, missing value imputation, standardized features if needed. Resample on Train Only: Use oversampling, undersampling, or hybrid strategies as fits the data and domain constraints. Algorithm Choices: Prefer ensemble methods and cost-sensitive learning; tune class weights. Hyperparameter and Threshold Optimization: Use grid search for best performance, especially for F1, recall, and precision metrics. Appropriate Metrics: Evaluate with precision, recall, F1-score, and AUC (ROC/PRC) on stratified test/validation sets. Diagnostics: Check feature importances, residuals, and outlier influence. Interpret Results with Domain Context: Don’t declare success on improved accuracy; ensure minority class detection is meaningful for your use-case. Run an online interactive notebook to learn ‘Handling Class Imbalance’ techniques](https://image.slidesharecdn.com/research-comprehensiveguidetohandlingimbalanceddatasetsindatascience-250817053854-6288fc44/75/Comprehensive-Guide-to-Handling-Imbalanced-Datasets-in-Data-Science-19-2048.jpg)