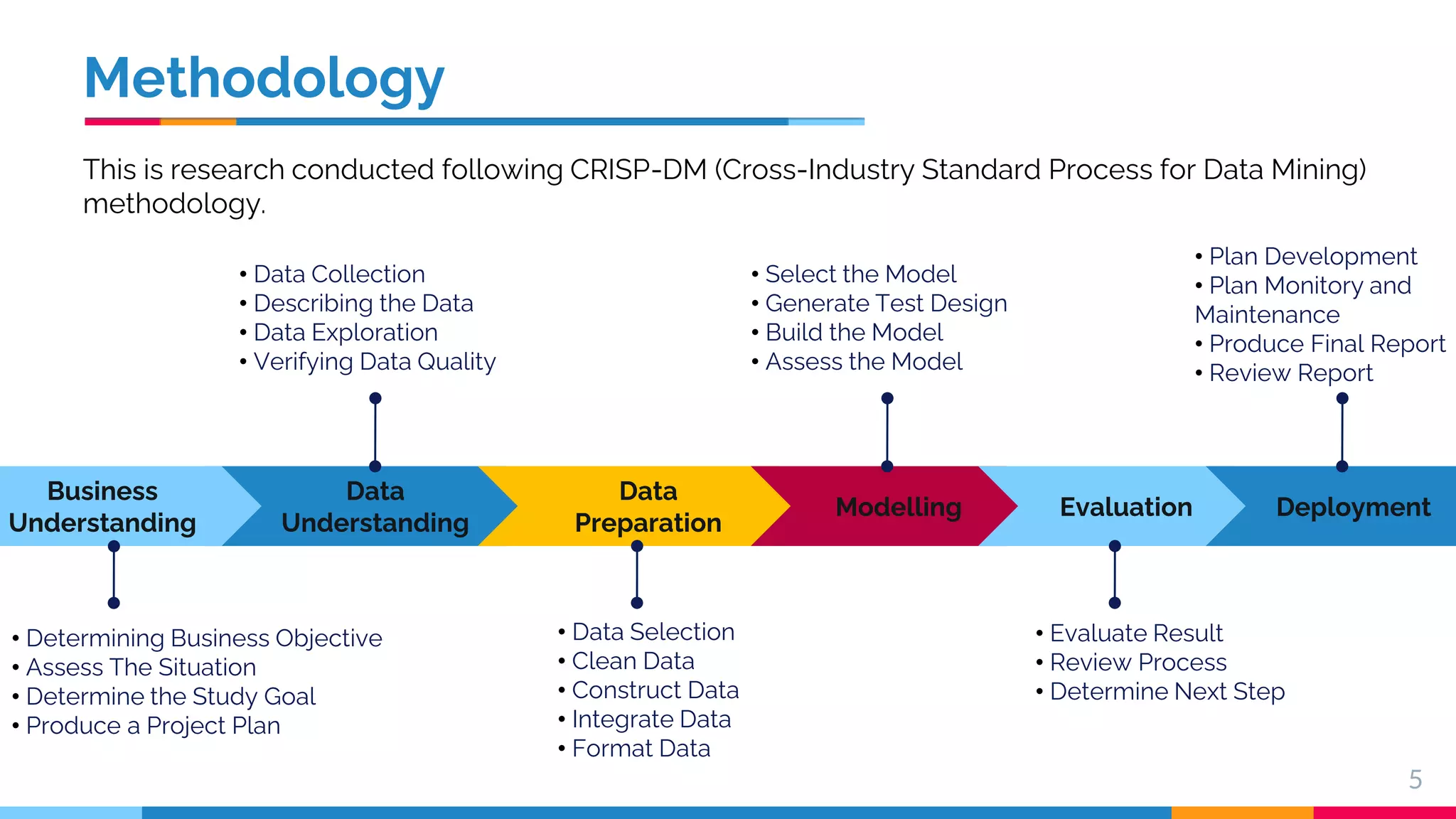
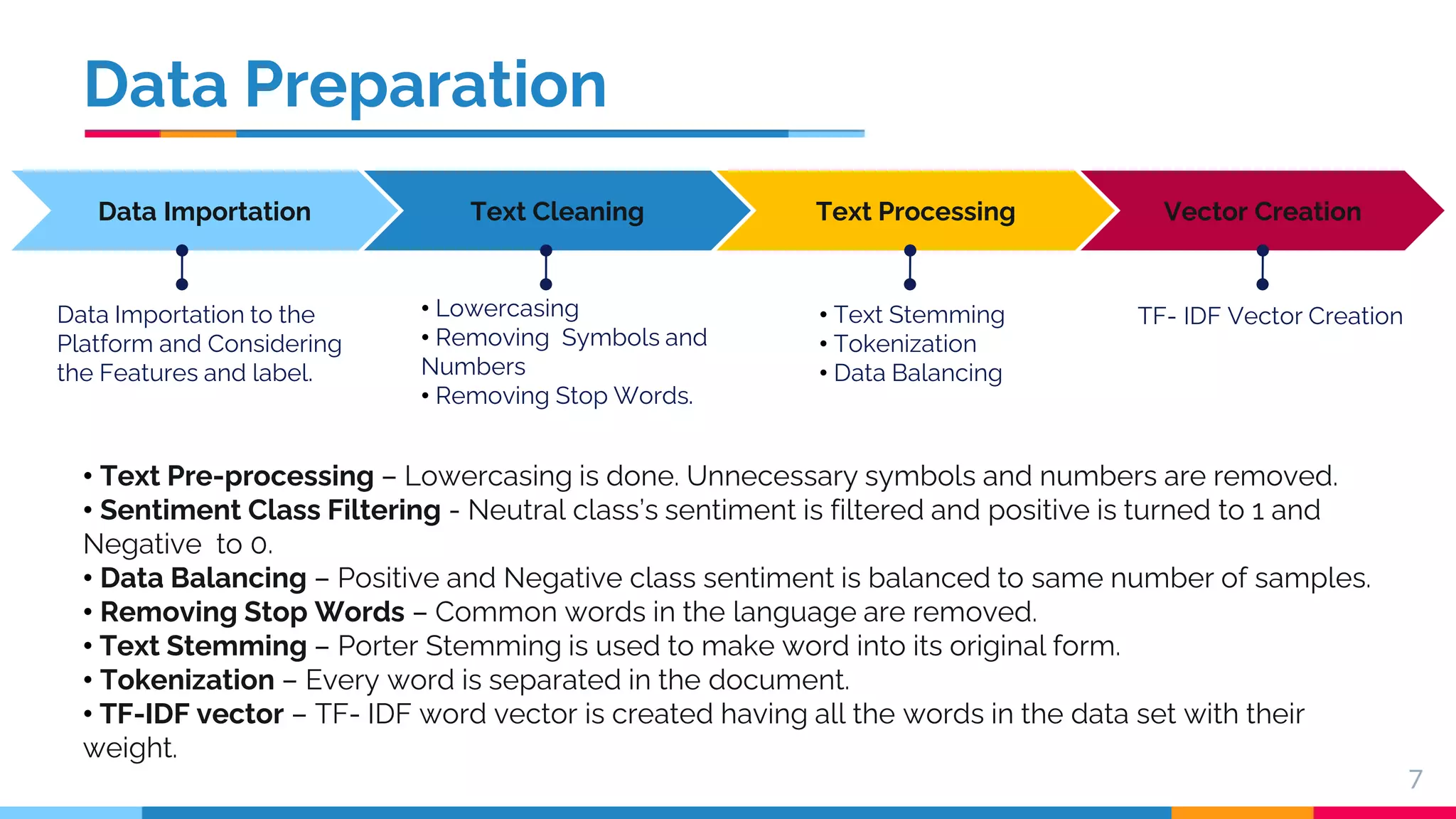
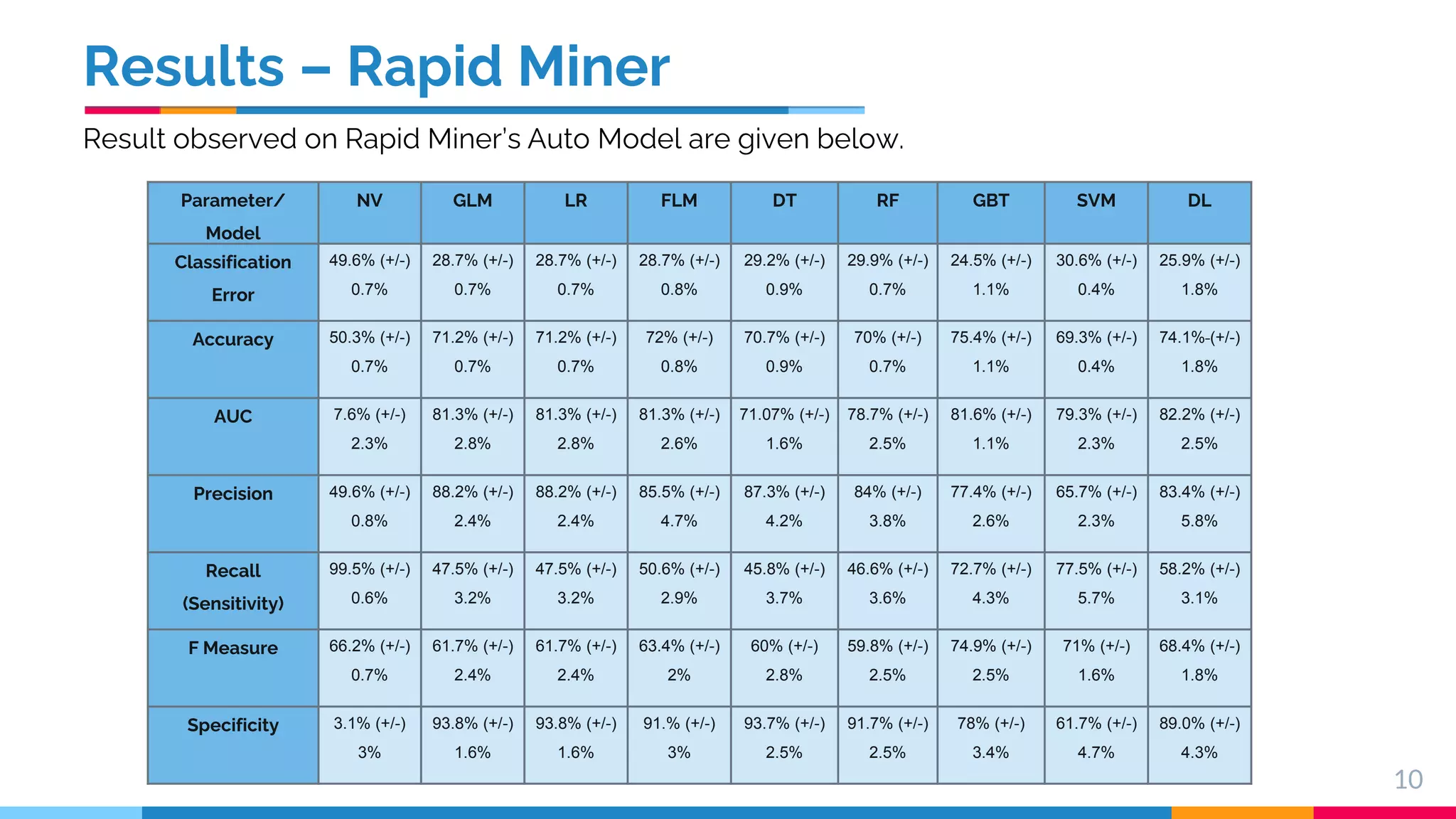
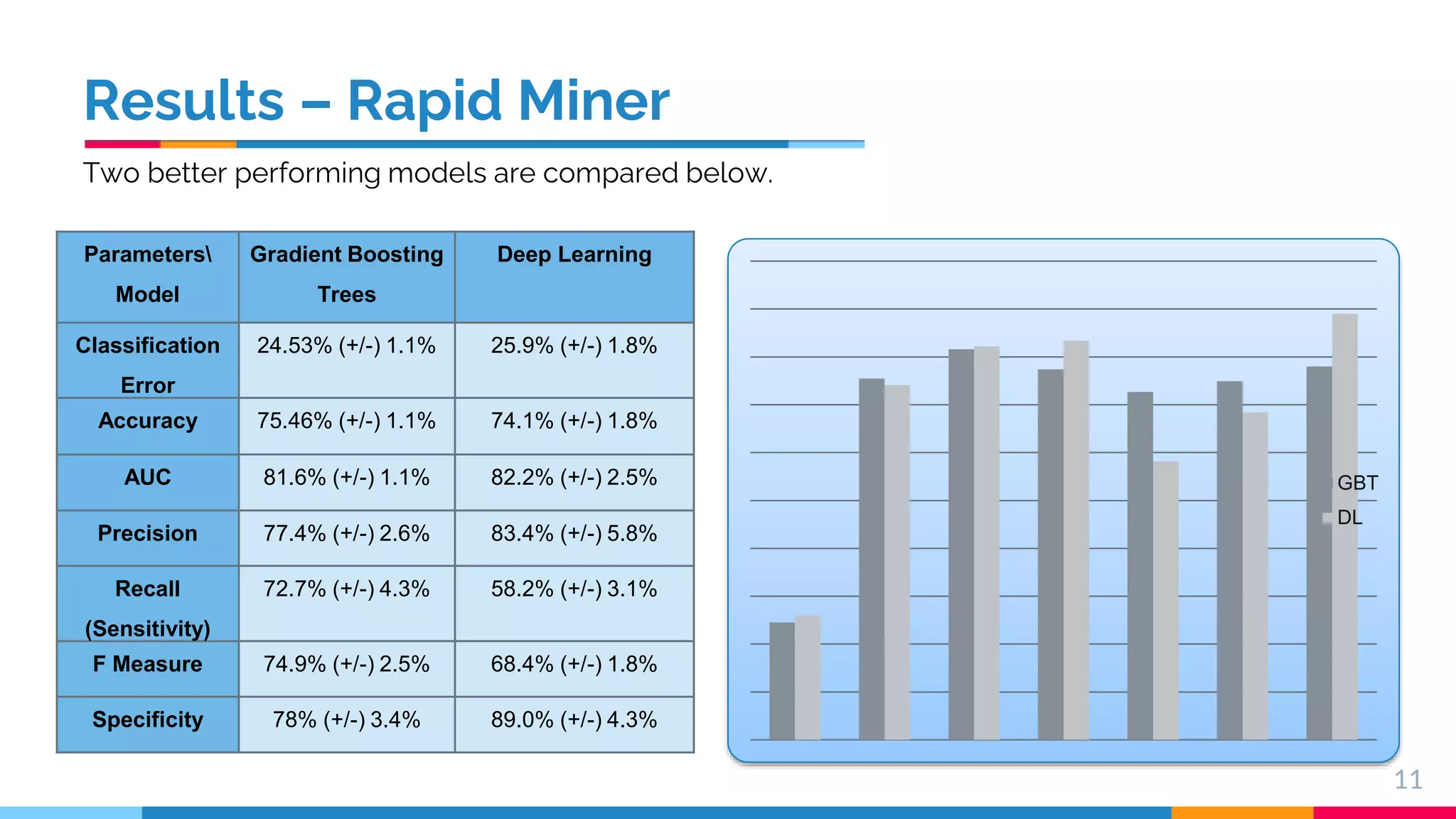
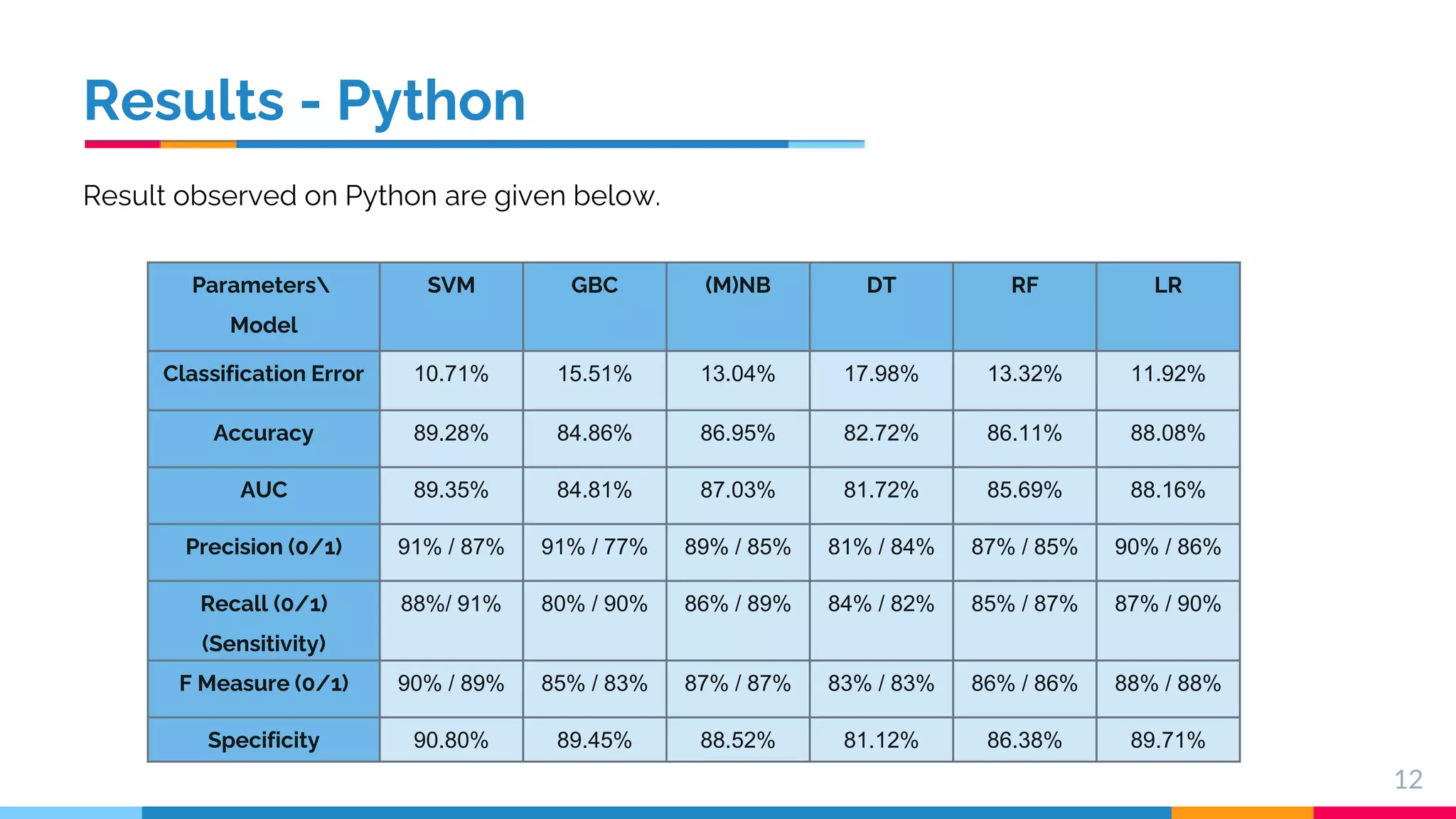
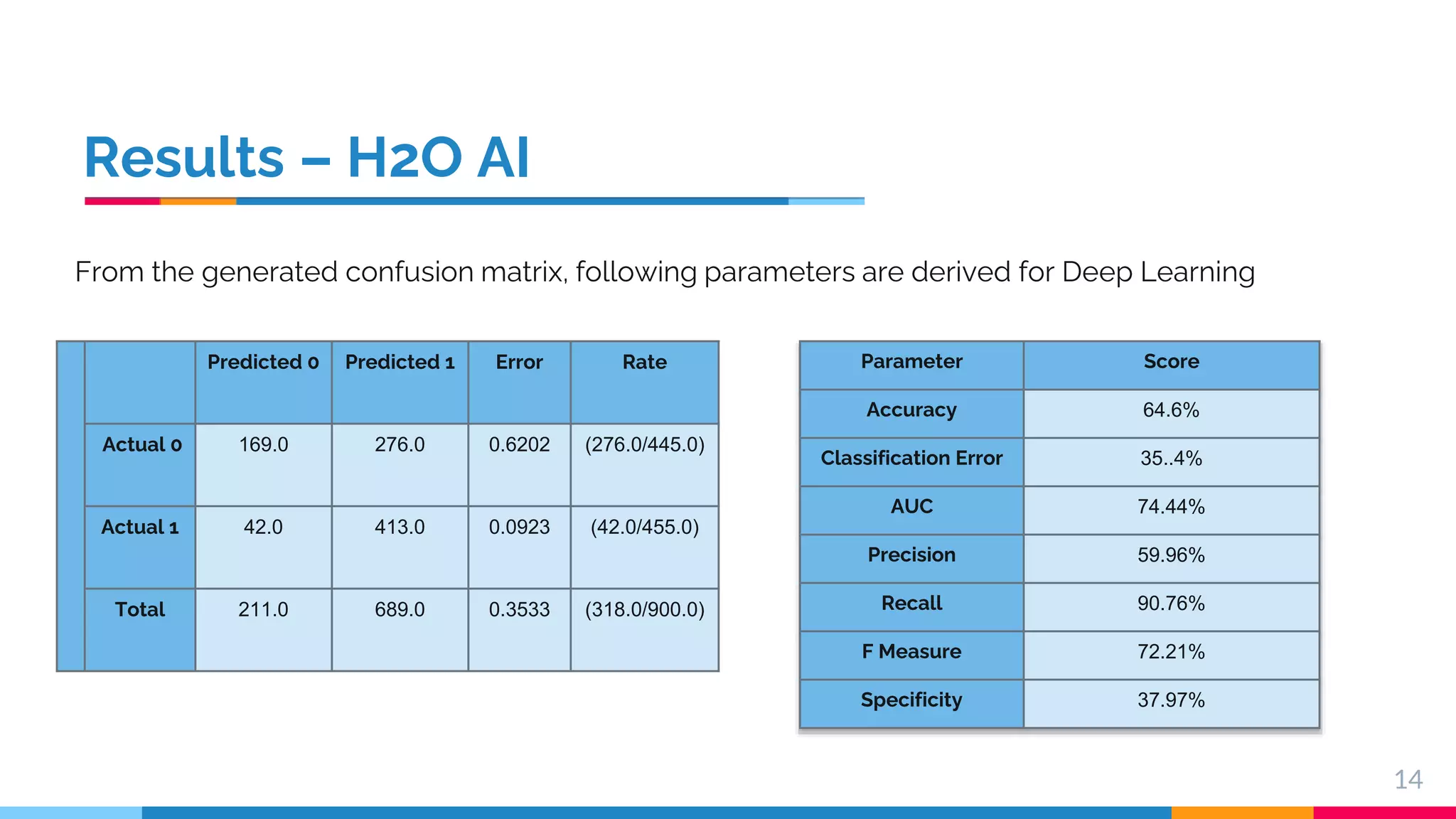
This document presents a comparative study of machine learning algorithms for sentiment analysis using tf-idf vector creation, focusing on the selection of the best-performing models. The research uses a 'twitter airline' dataset comprising 14 features and emphasizes the evaluation metrics like accuracy and classification error to compare models such as Support Vector Machine (SVM) and Gradient Boosting Trees. It concludes that SVM outperforms traditional models, while future work will explore advanced techniques like Recurrent Neural Networks for further improvements.