Downloaded 15 times



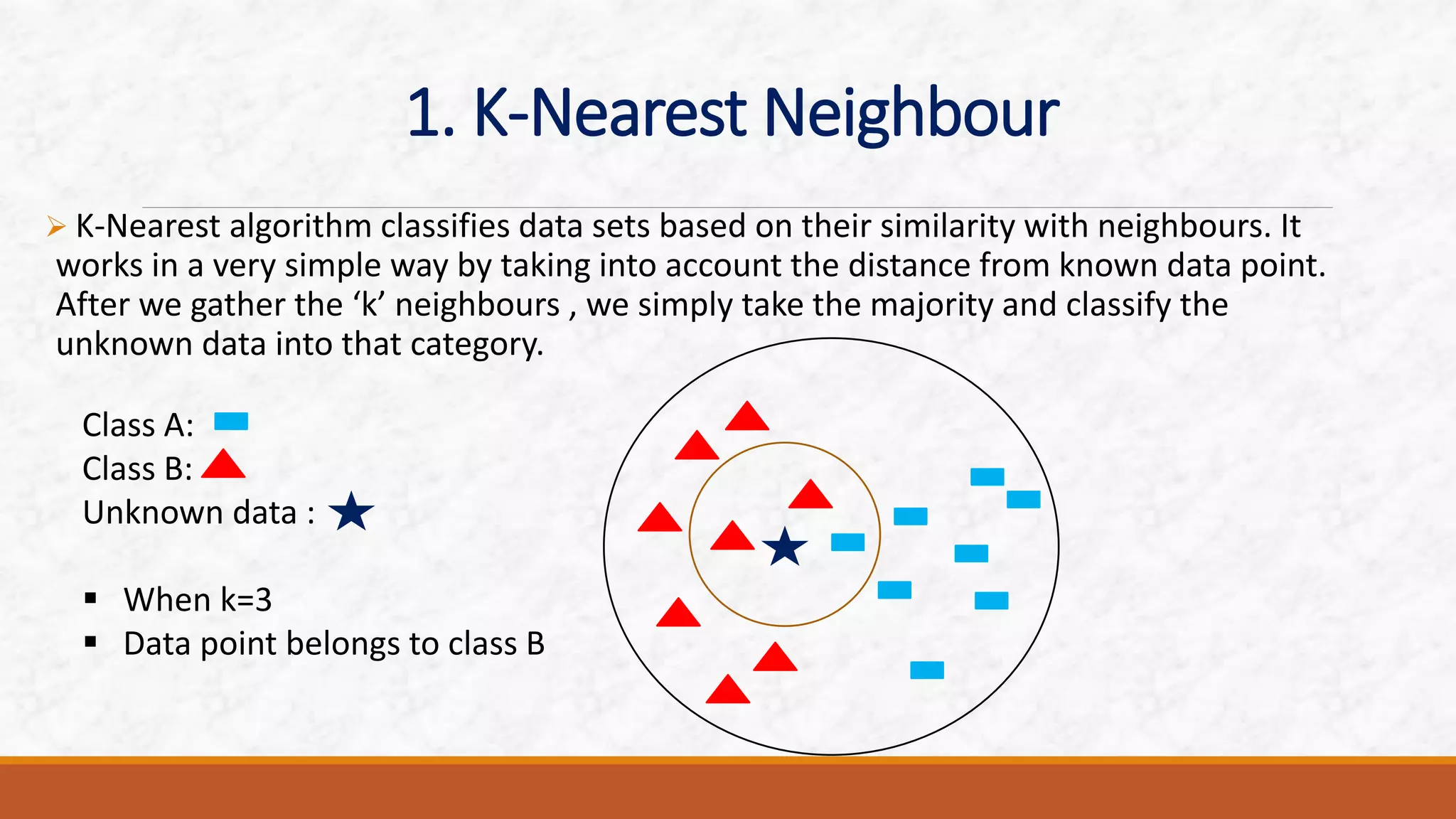

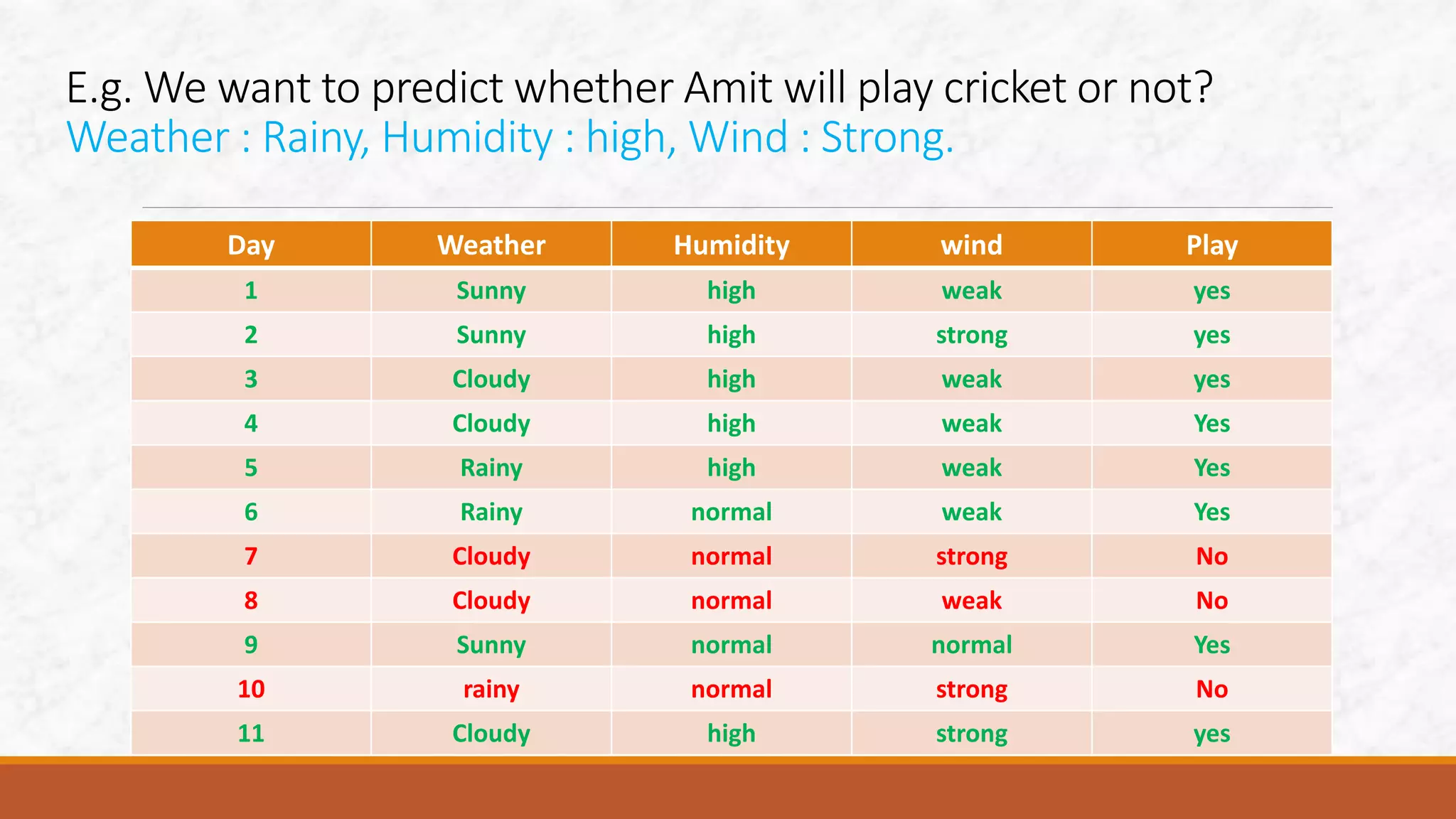
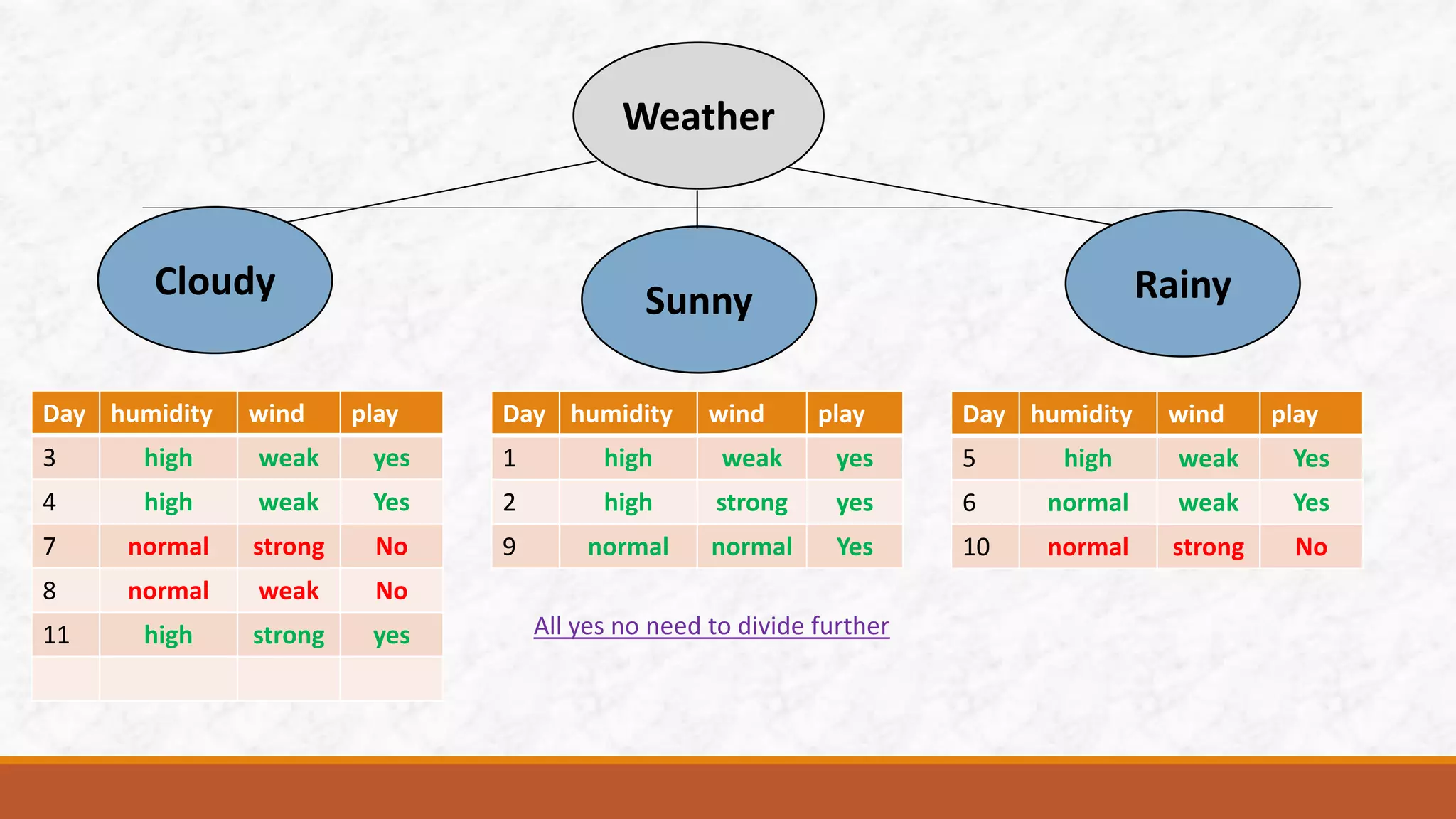
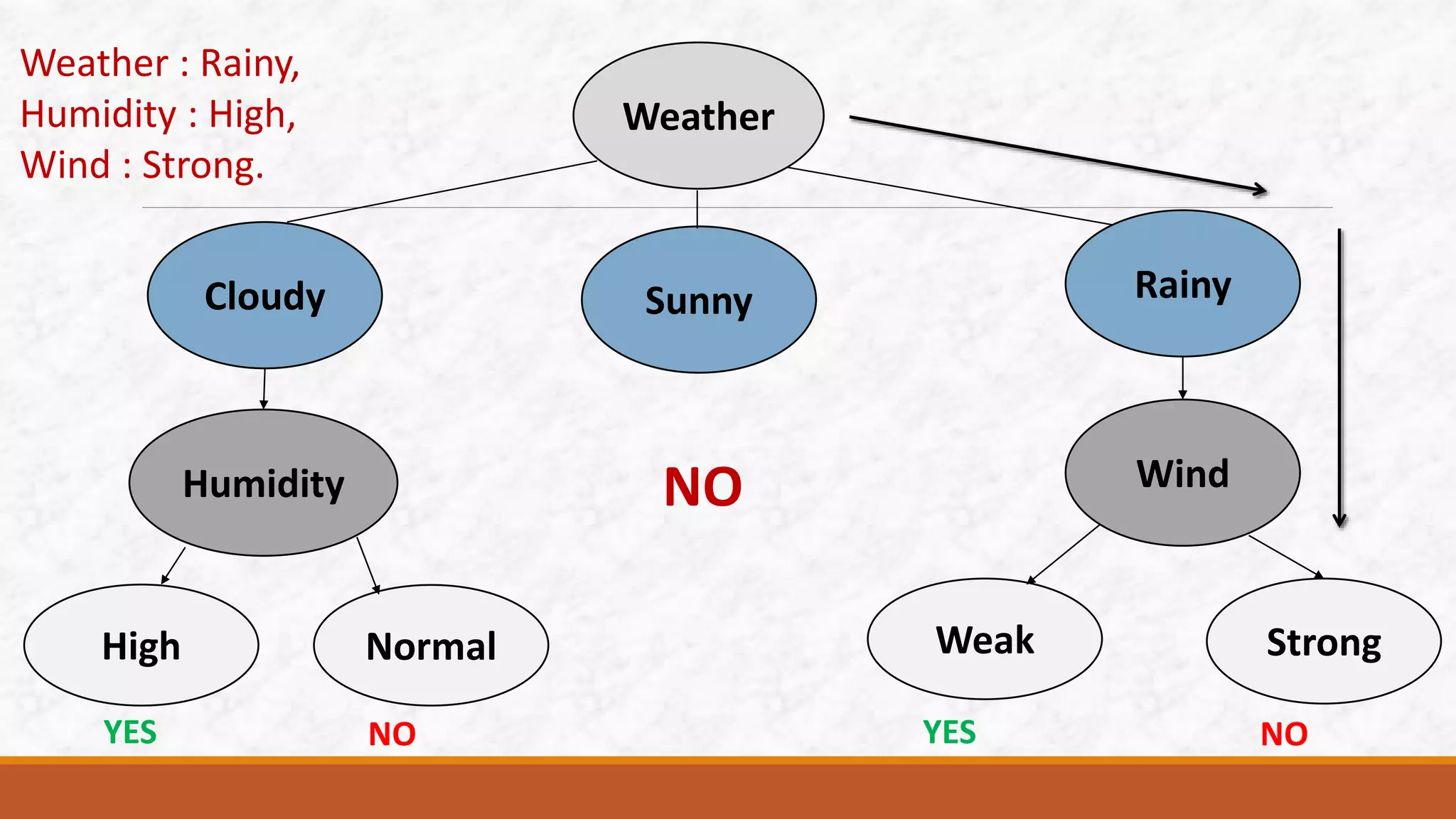




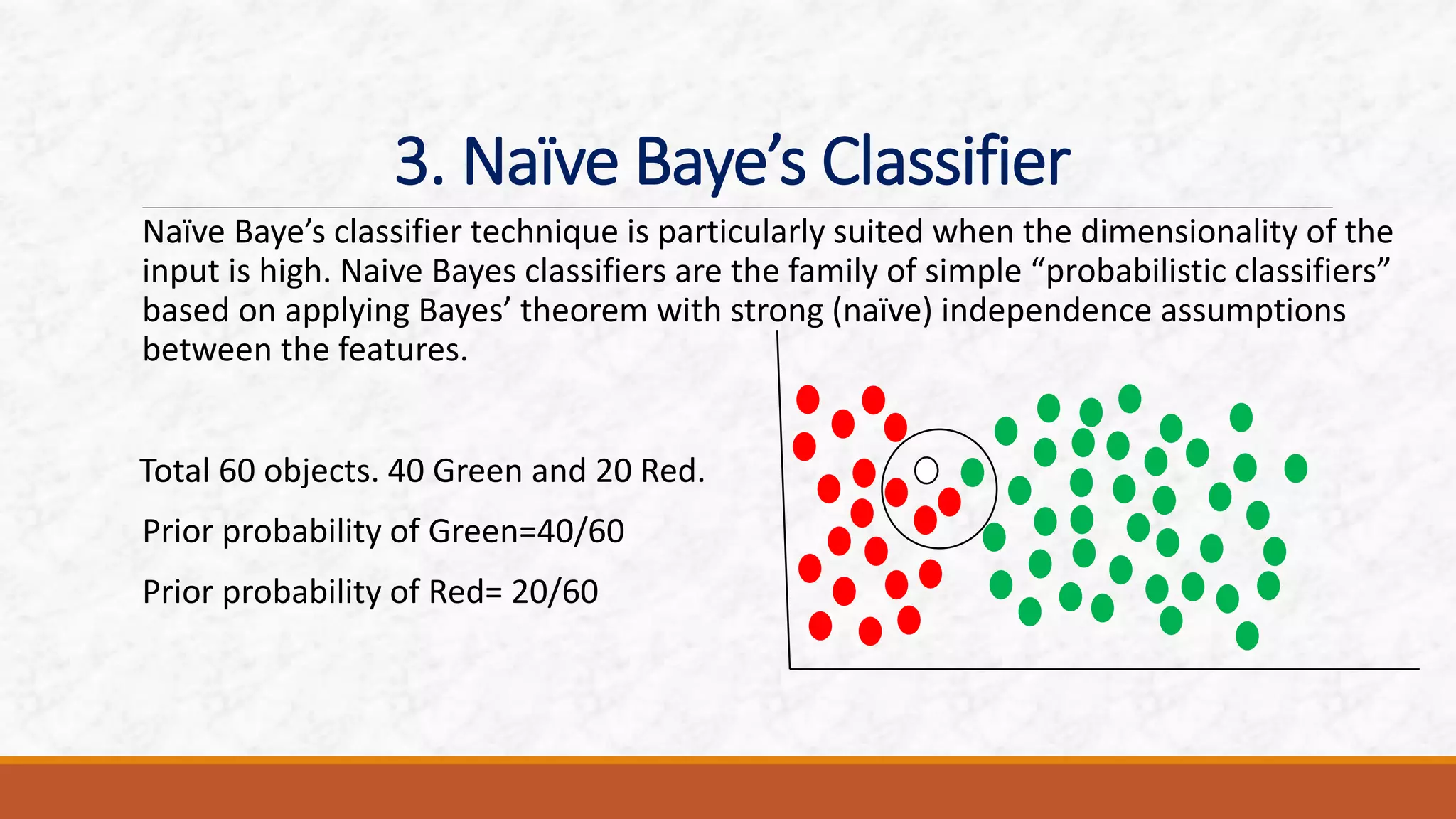



This document discusses various classification algorithms including k-nearest neighbors, decision trees, naive Bayes classifier, and logistic regression. It provides examples of how each algorithm works. For k-nearest neighbors, it shows how an unknown data point would be classified based on its nearest neighbors. For decision trees, it illustrates how a tree is built by splitting the data into subsets at each node until pure subsets are reached. It also provides an example decision tree to predict whether Amit will play cricket. For naive Bayes, it gives an example of calculating the probability of cancer given a patient is a smoker.