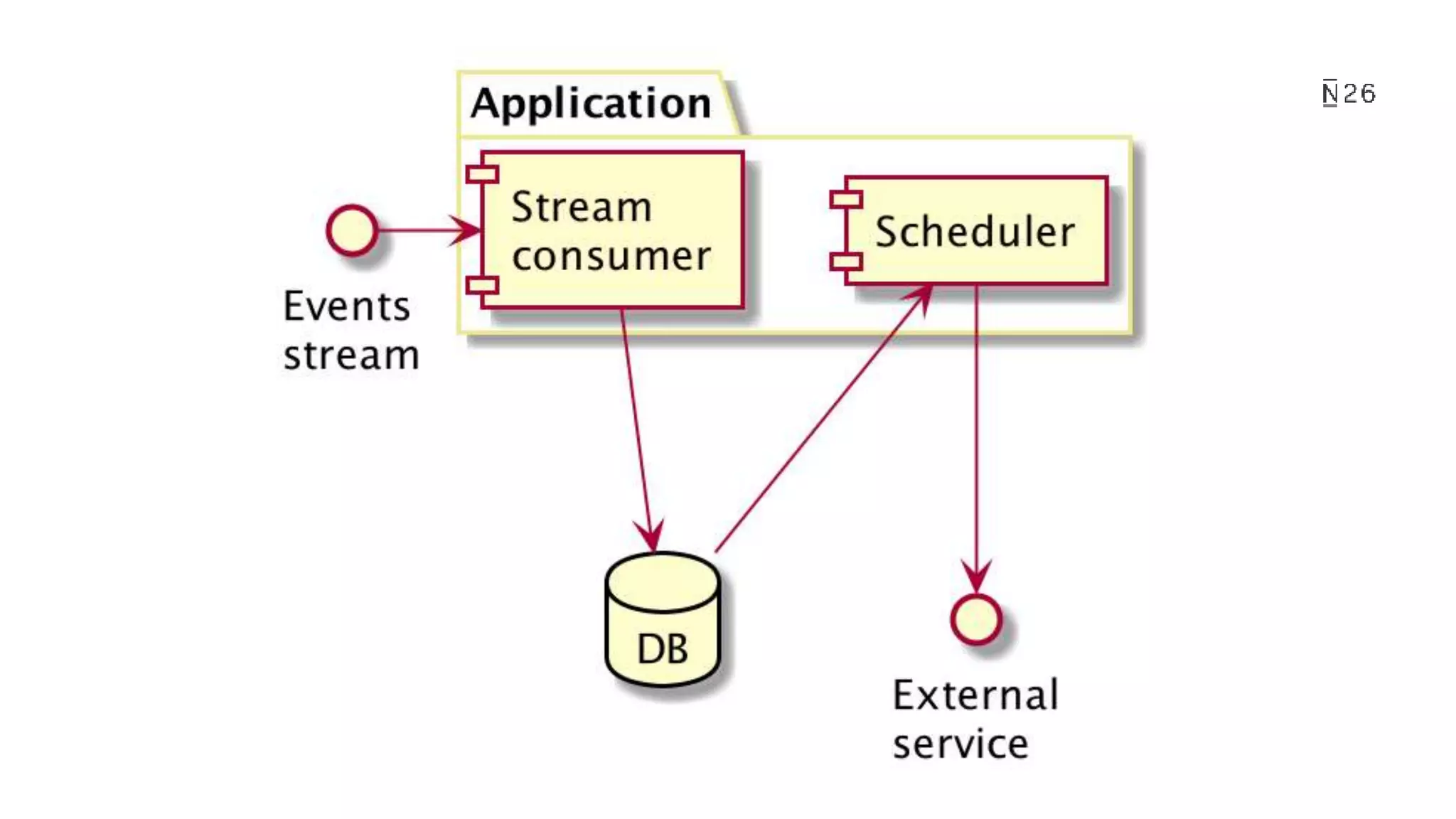
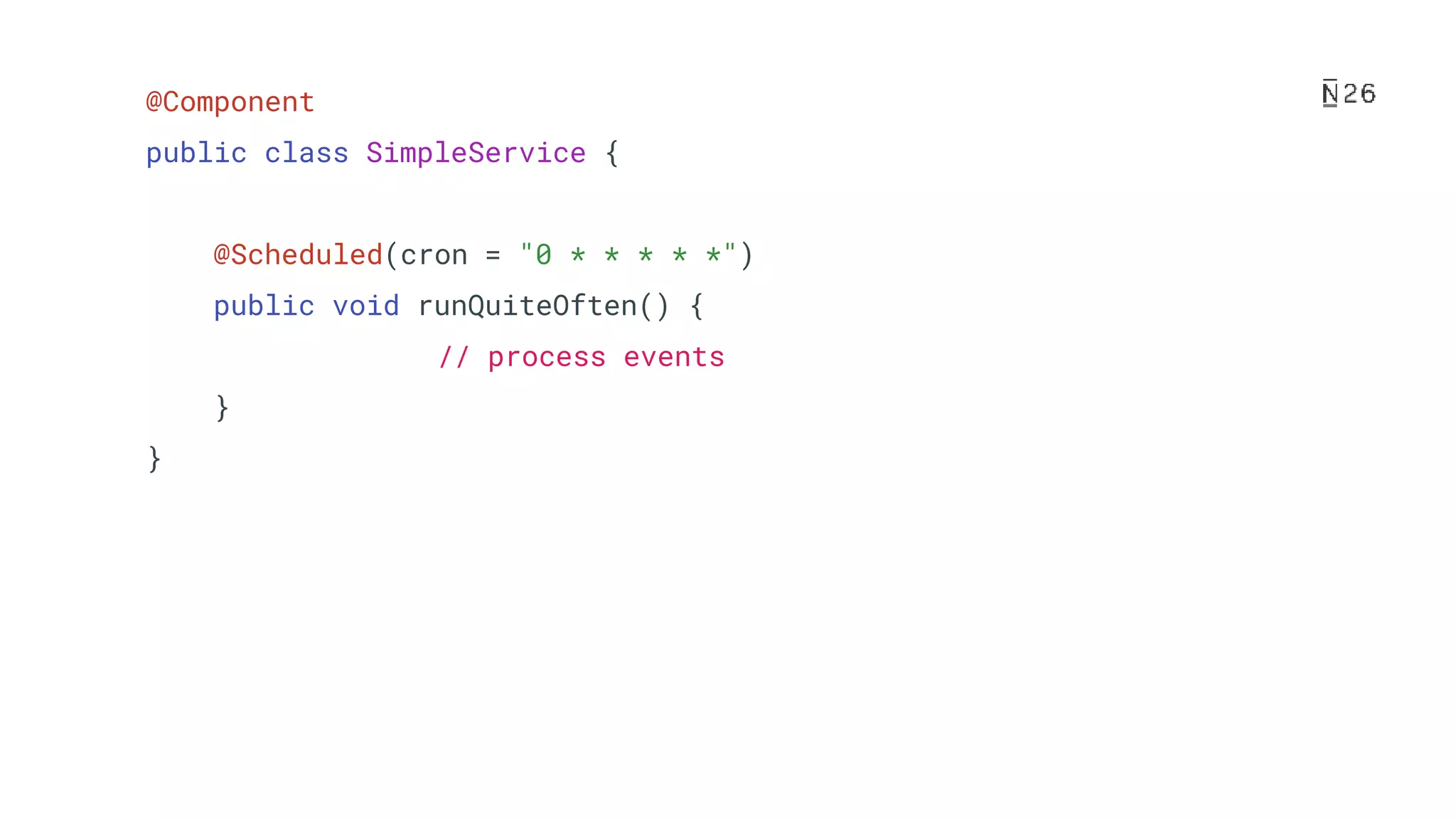
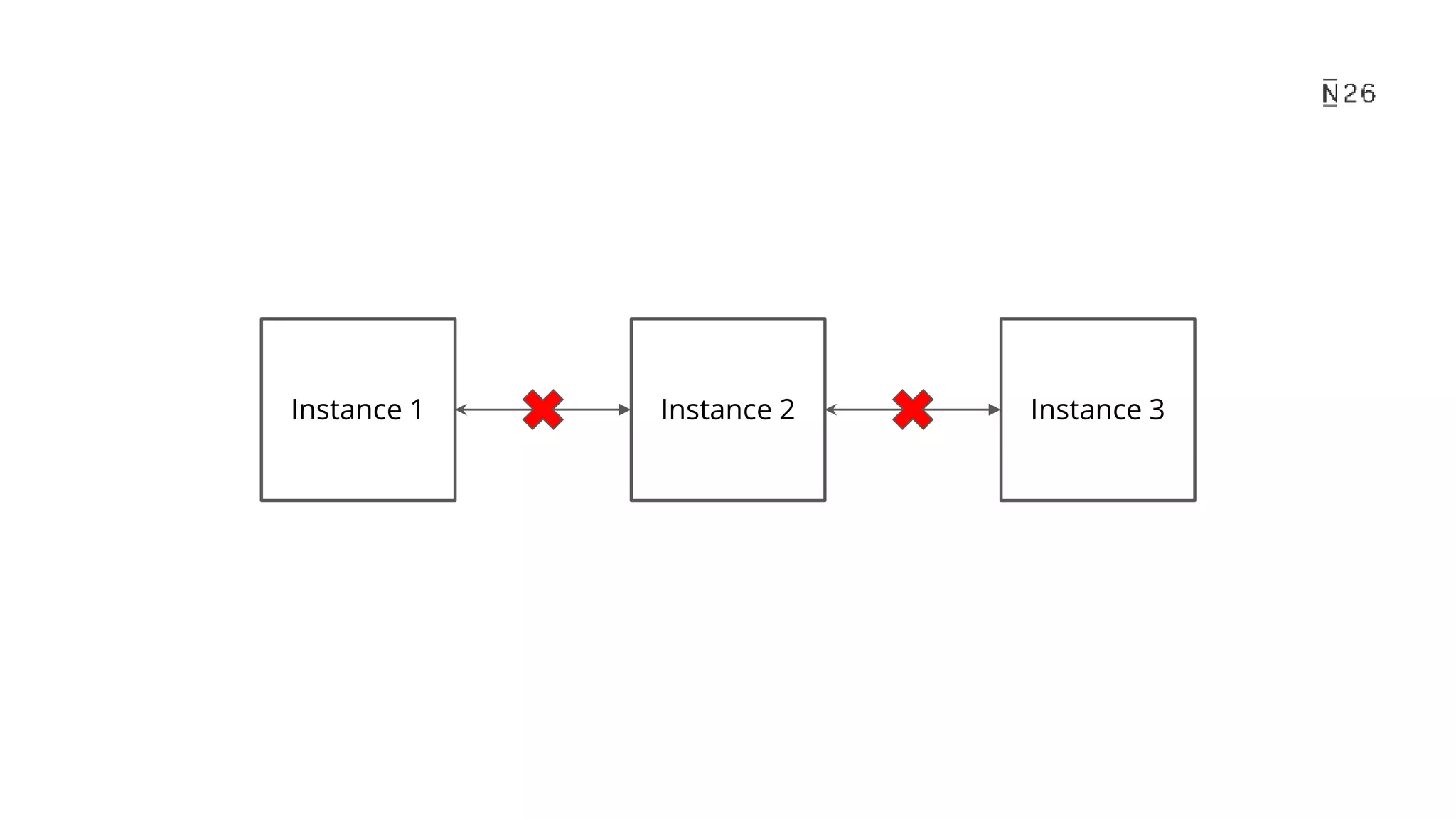
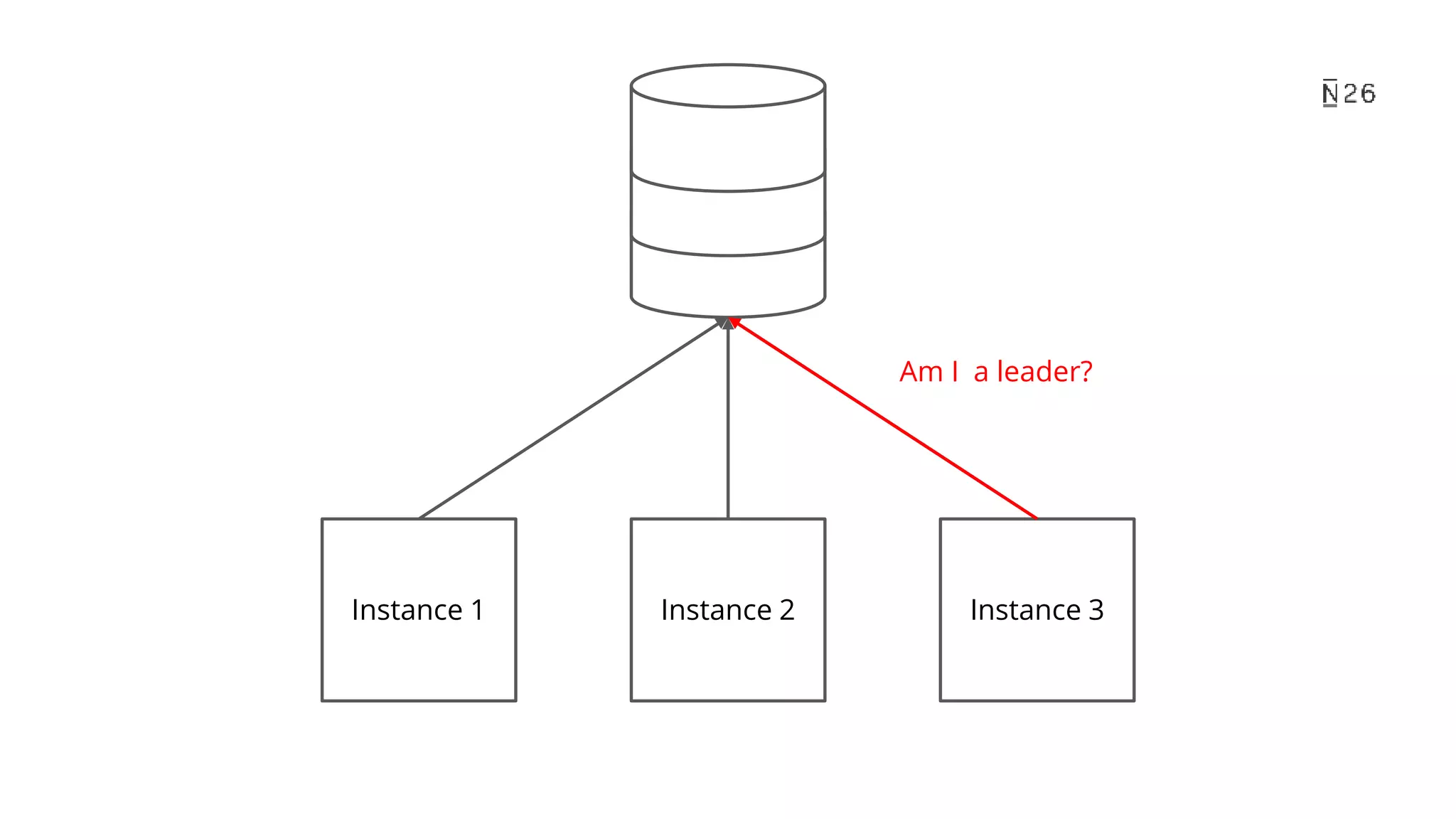
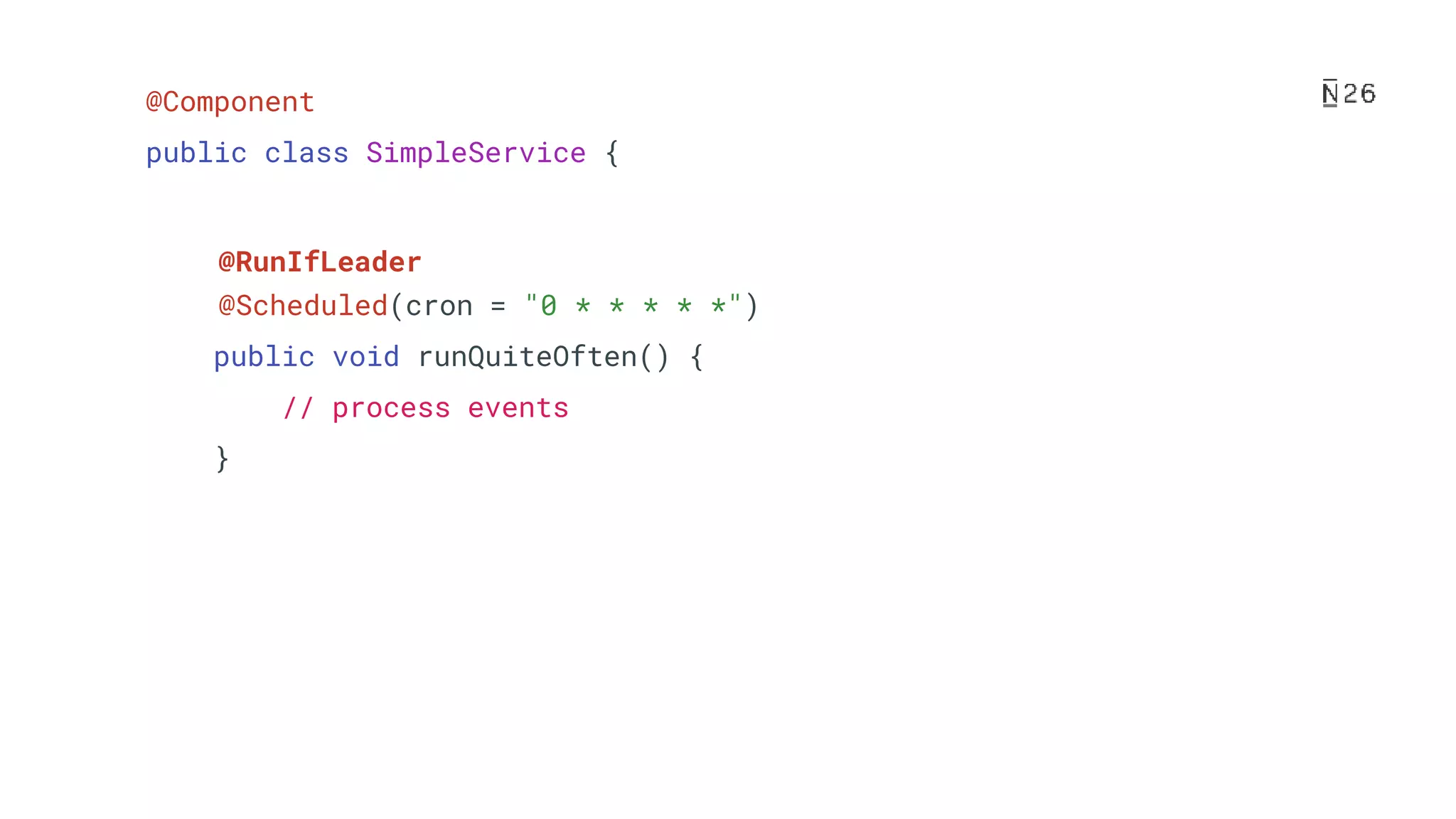
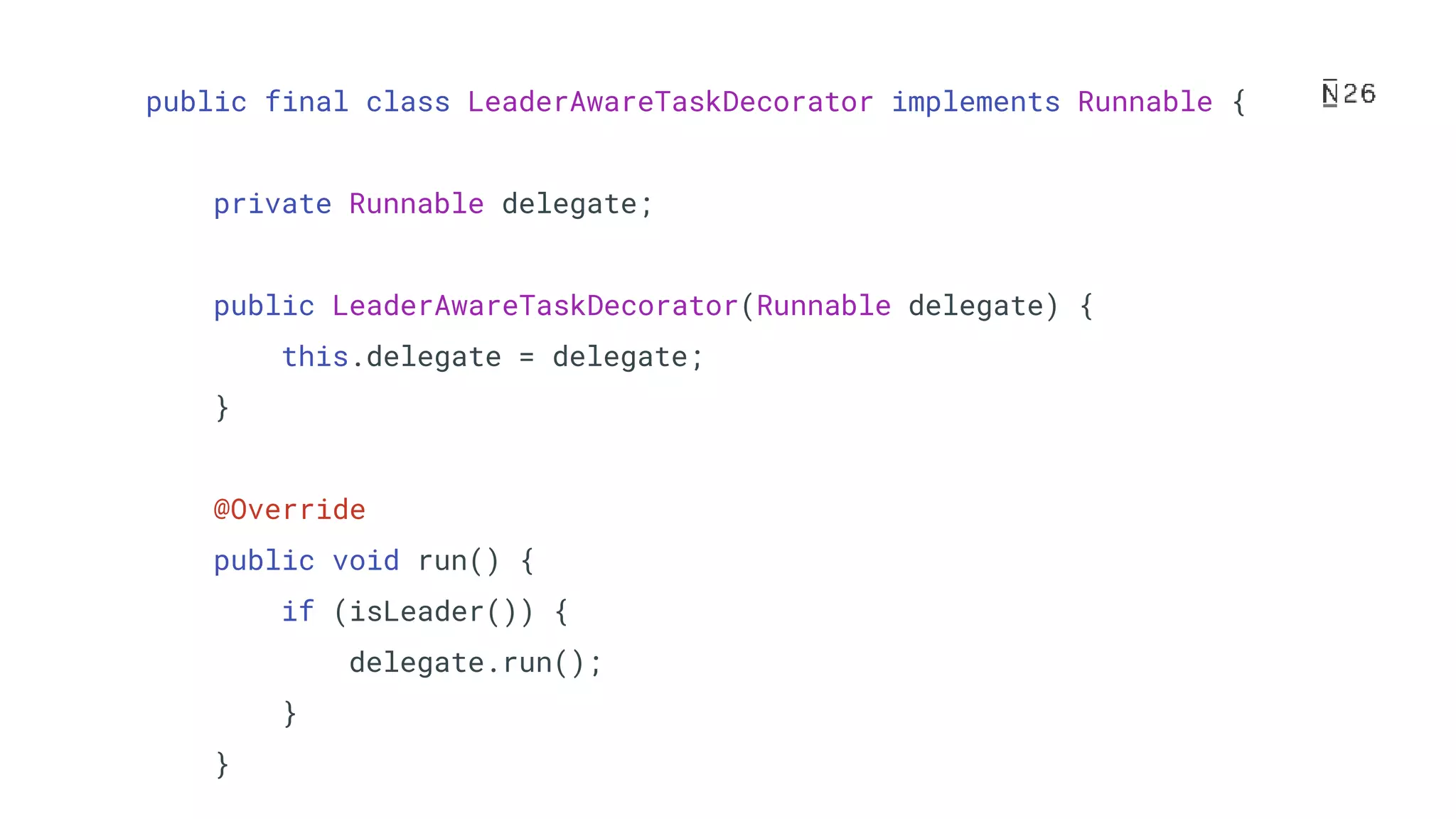
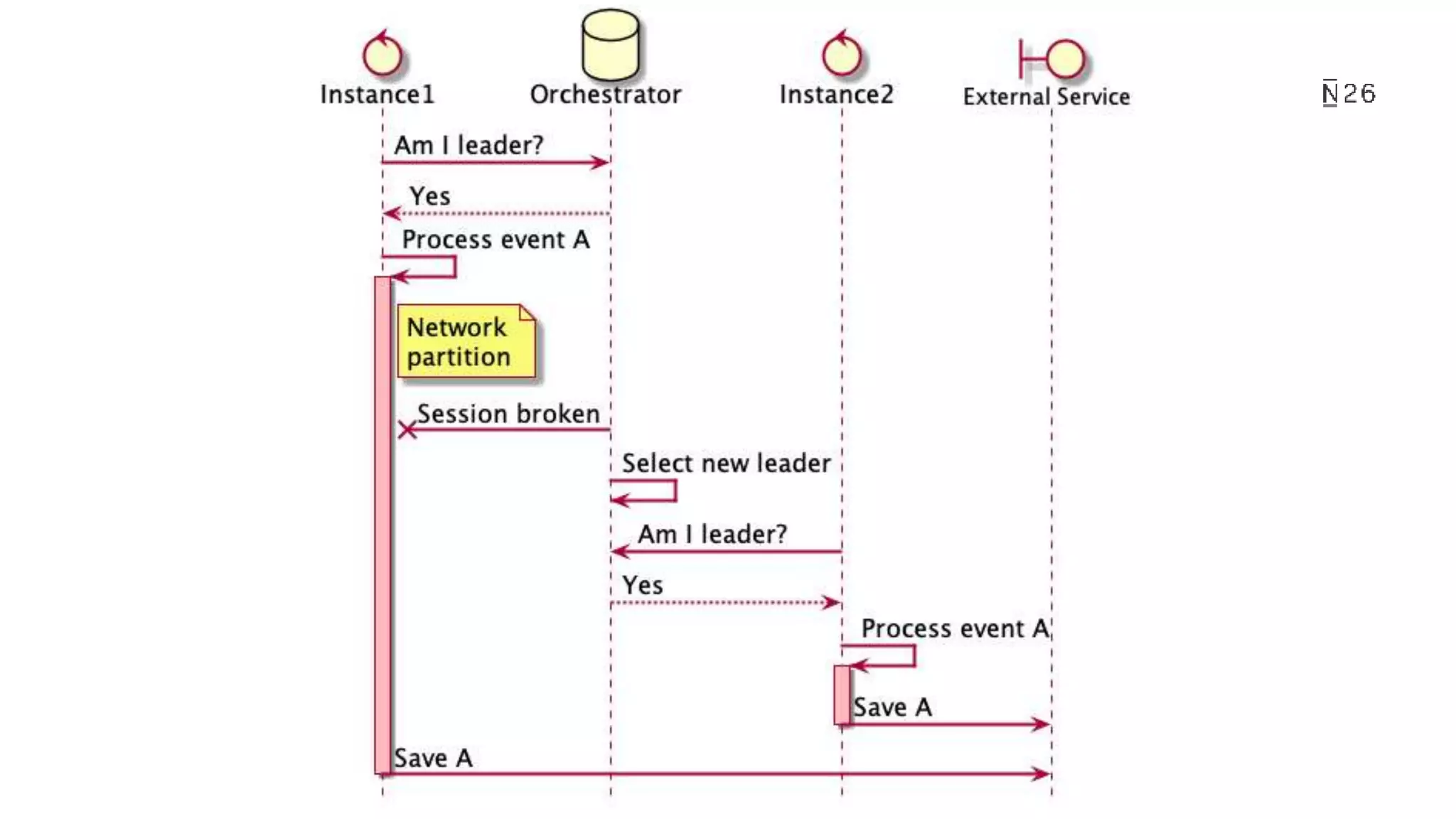
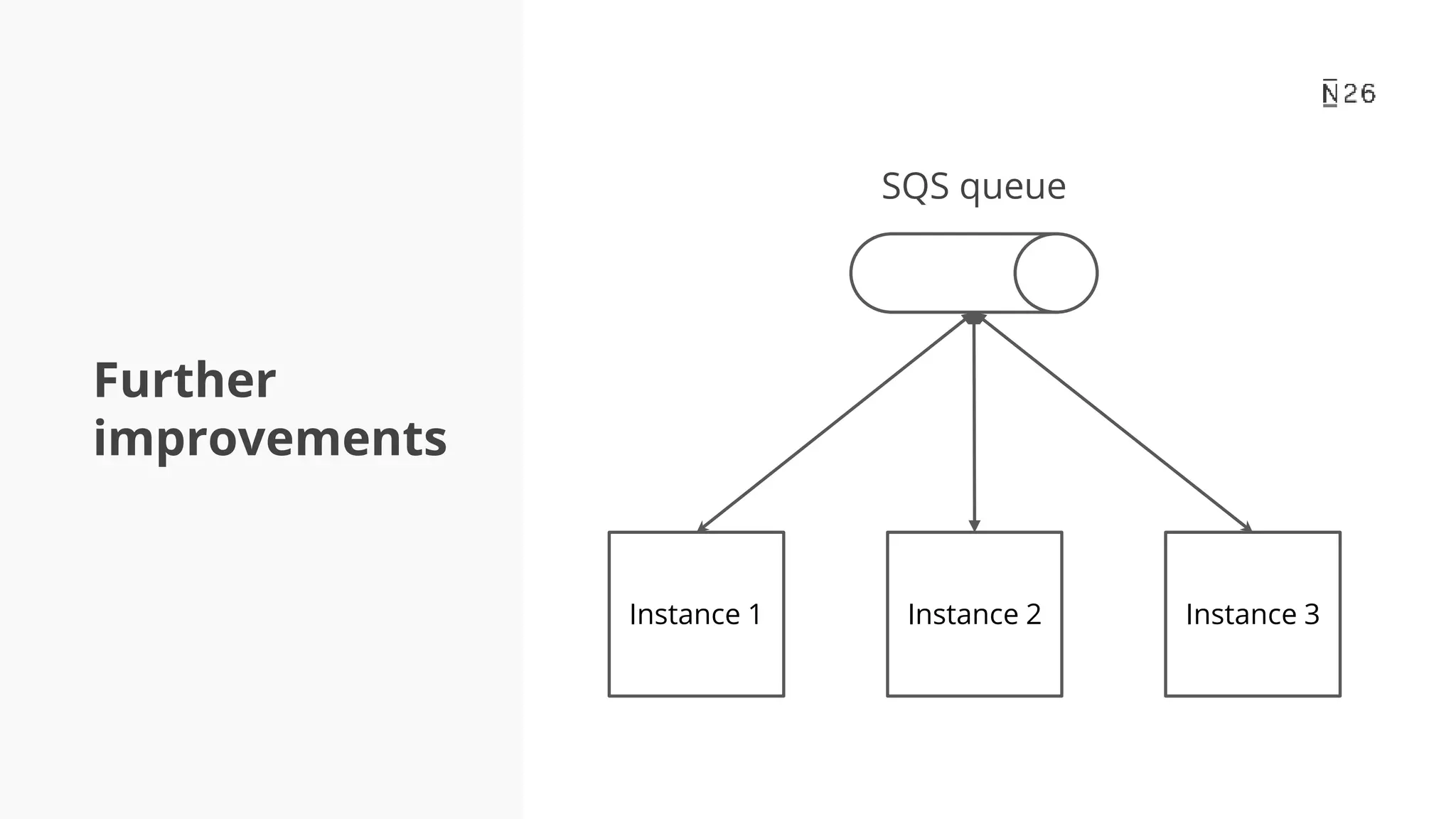
The document discusses building resilient scheduling in distributed systems using Spring, focusing on concepts like leader election, aspect-oriented programming, and programmatic task scheduling. It highlights improvements in job distribution, the benefits of centralizing task scheduling, and strategies for increasing system resilience and observability. The presentation concludes with lessons learned and references for further reading.