Downloaded 217 times





![Page6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Apache NiFi • Powerful and reliable system to process and distribute data • Directed graphs of data routing and transformation • Web-based User Interface for creating, monitoring, & controlling data flows • Highly configurable - modify data flow at runtime, dynamically prioritize data • Data Provenance tracks data through entire system • Easily extensible through development of custom components [1] https://nifi.apache.org/](https://image.slidesharecdn.com/buildingdatapipelinesforsolrwithapachenifihwx-151001133012-lva1-app6892/75/Building-Data-Pipelines-for-Solr-with-Apache-NiFi-6-2048.jpg)






![Page16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Solr Update Handlers - JSON Solr-Style JSON… Add Documents [ { "id": "1”, "title": "Doc 1” }, { "id": "2”, "title": "Doc 2” } ] Commands { "add": { "doc": { "id": "1”, "title": { "boost": 2.3, "value": "Doc1” } } } }](https://image.slidesharecdn.com/buildingdatapipelinesforsolrwithapachenifihwx-151001133012-lva1-app6892/75/Building-Data-Pipelines-for-Solr-with-Apache-NiFi-16-2048.jpg)
![Page17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Solr Update Handlers - JSON Custom JSON • Transform custom JSON based on Solr schema • Define paths to split JSON into multiple Solr documents • Field mappings from JSON field name to Solr field name Produces two Solr documents: - John, Math, term1, 90 - John, Biology, term1, 86 split=/exams& f=name:/name& f=subject:/exams/subject& f=test:/exams/test& f=marks:/exams/marks { "name": "John", "exams": [ { "subject": "Math", "test" : "term1", "marks" : 90}, { "subject": "Biology", "test" : "term1", "marks" : 86} ] }](https://image.slidesharecdn.com/buildingdatapipelinesforsolrwithapachenifihwx-151001133012-lva1-app6892/75/Building-Data-Pipelines-for-Solr-with-Apache-NiFi-17-2048.jpg)






![Page26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Use Cases – Issue Commands 1. Generate a FlowFile on a cron, or timer, to initiate an action 2. Replace the contents of the FlowFile with a Solr command <delete> <query> timestamp:[* TO NOW-1HOUR] </query> </delete> 3. Send the command to the appropriate update handler](https://image.slidesharecdn.com/buildingdatapipelinesforsolrwithapachenifihwx-151001133012-lva1-app6892/75/Building-Data-Pipelines-for-Solr-with-Apache-NiFi-26-2048.jpg)




![Page34 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Sources [1] https://nifi.apache.org/ [2] https://cwiki.apache.org/confluence/display/solr/Uploading+Data+with+Index+Handlers [3] https://wiki.apache.org/solr/IntegratingSolr [4] http://lucidworks.com/blog/indexing-custom-json-data/](https://image.slidesharecdn.com/buildingdatapipelinesforsolrwithapachenifihwx-151001133012-lva1-app6892/75/Building-Data-Pipelines-for-Solr-with-Apache-NiFi-34-2048.jpg)


This document provides an overview of using Apache NiFi to build data pipelines that index data into Apache Solr. It introduces NiFi and its capabilities for data routing, transformation and monitoring. It describes how Solr accepts data through different update handlers like XML, JSON and CSV. It demonstrates how NiFi processors can be used to stream data to Solr via these update handlers. Example use cases are presented for indexing tweets, commands, logs and databases into Solr collections. Future enhancements are discussed like parsing documents and distributing commands across a Solr cluster.
Overview of the presentation and speaker introduction as a member of Hortonworks with expertise in Apache NiFi and Solr.
Highlighting difficulties in getting data into Solr, including data cleaning and deployment issues.
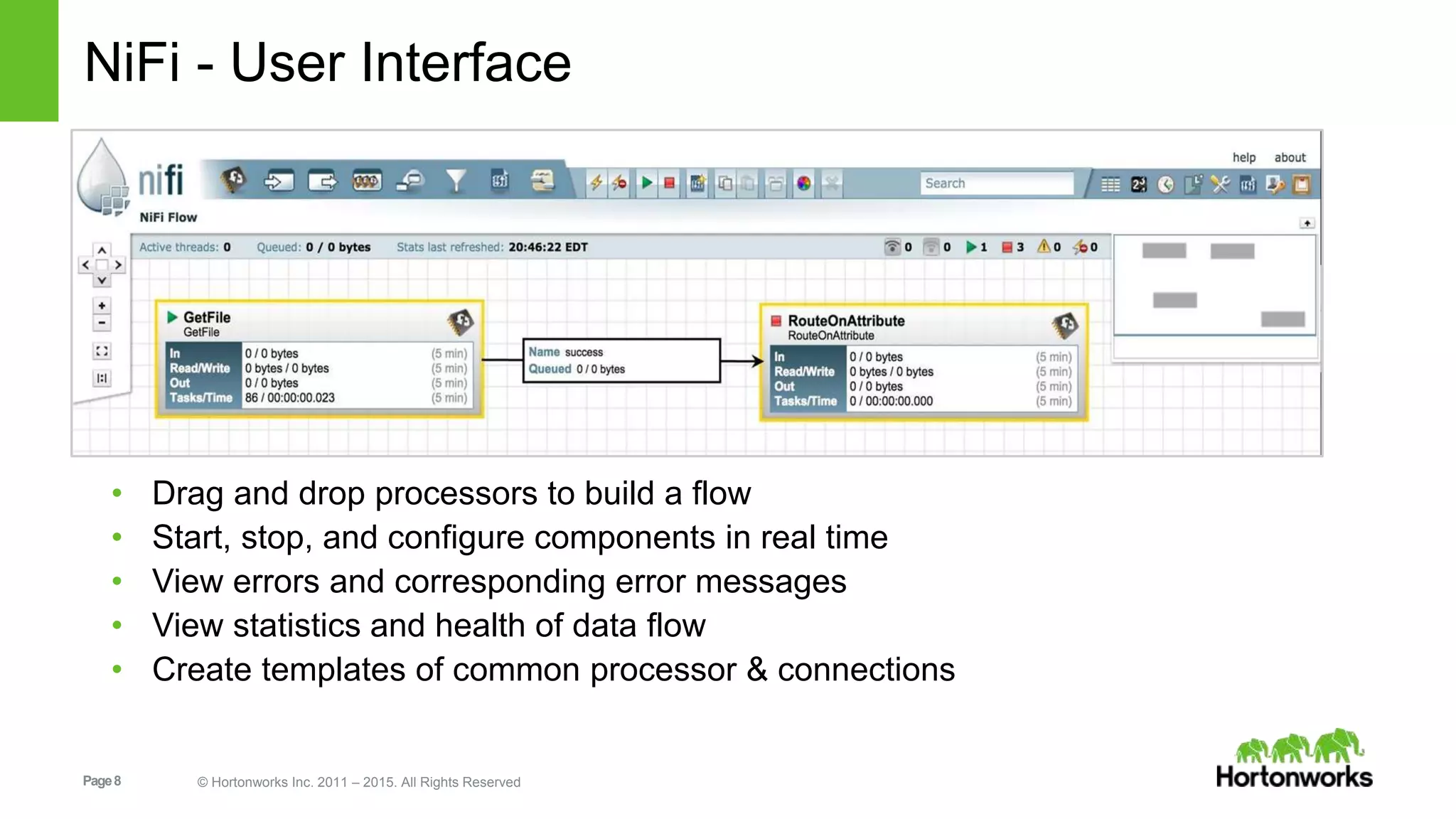
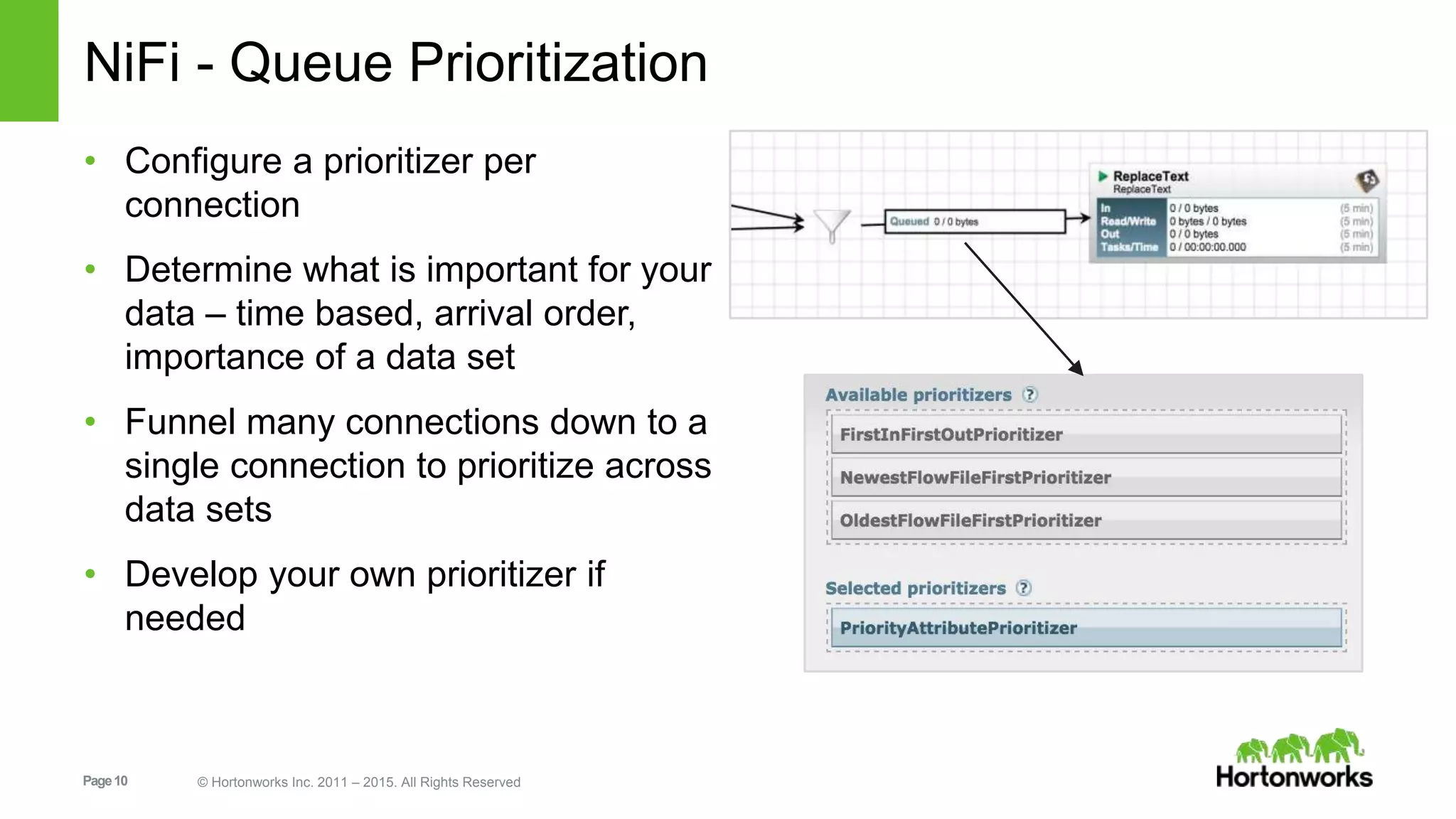
An introduction to Apache NiFi including its capabilities, user interface, data provenance, and extensibility.
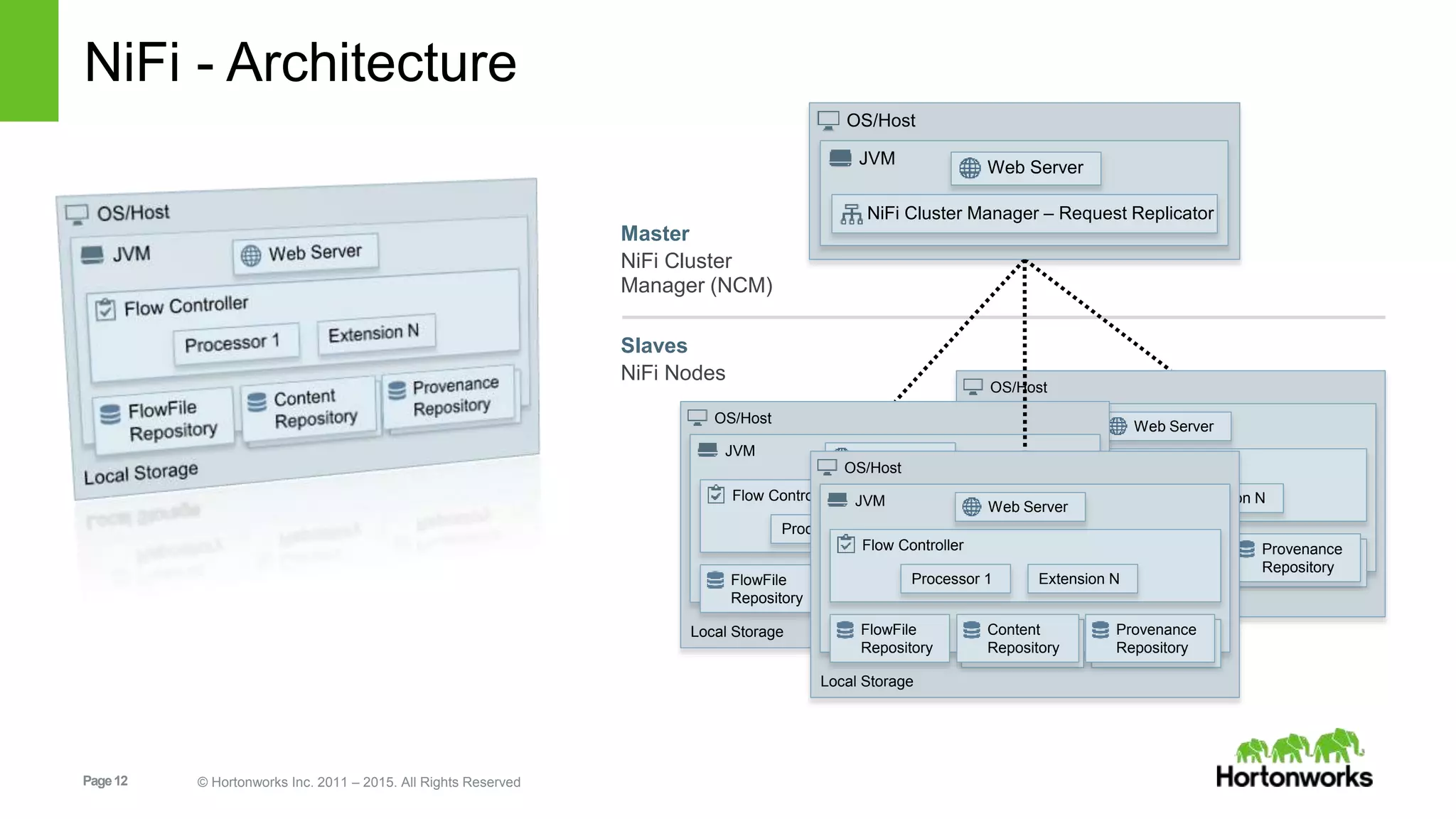
An overview of the architecture of NiFi, detailing its major components and data flow management.
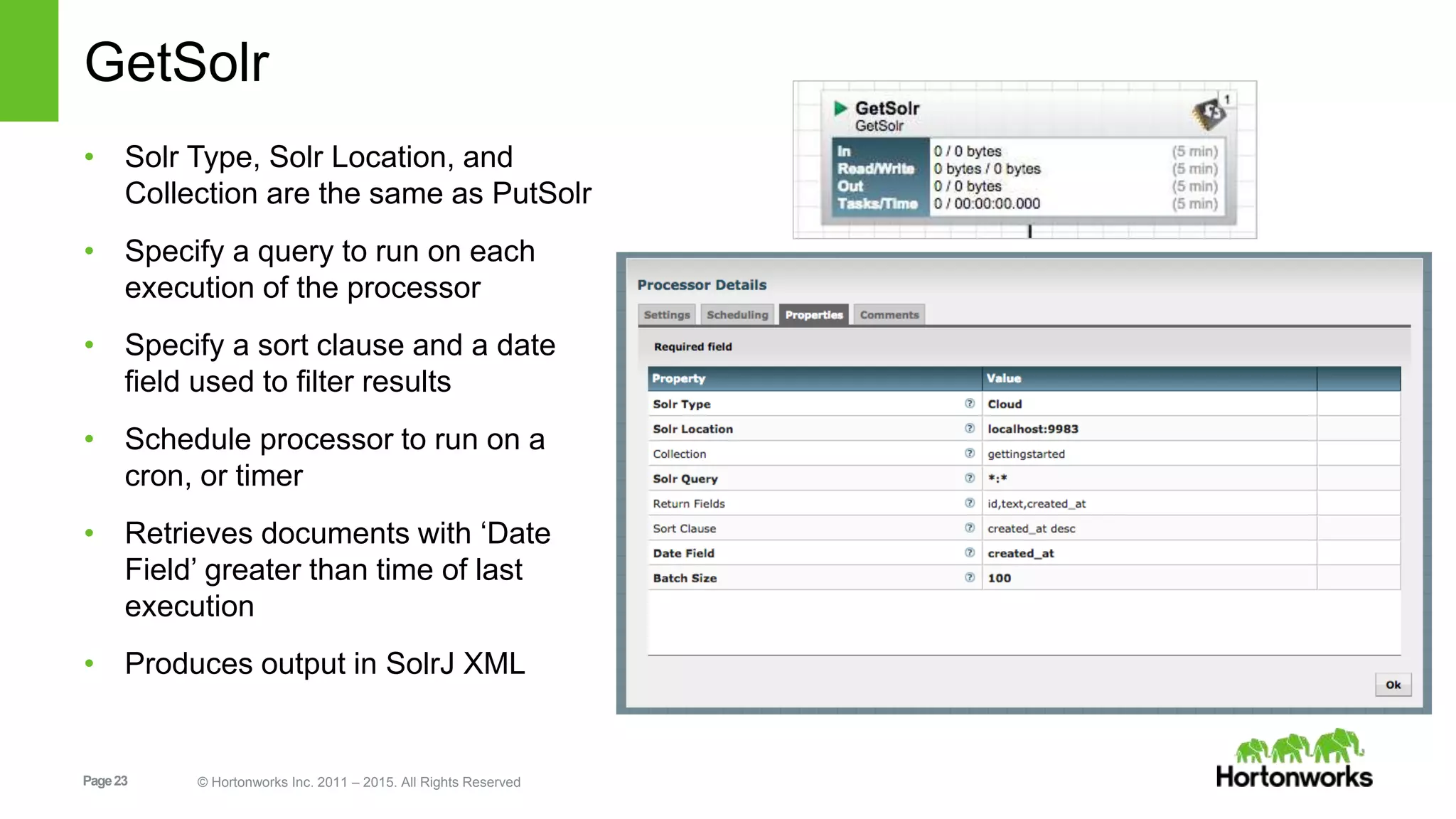
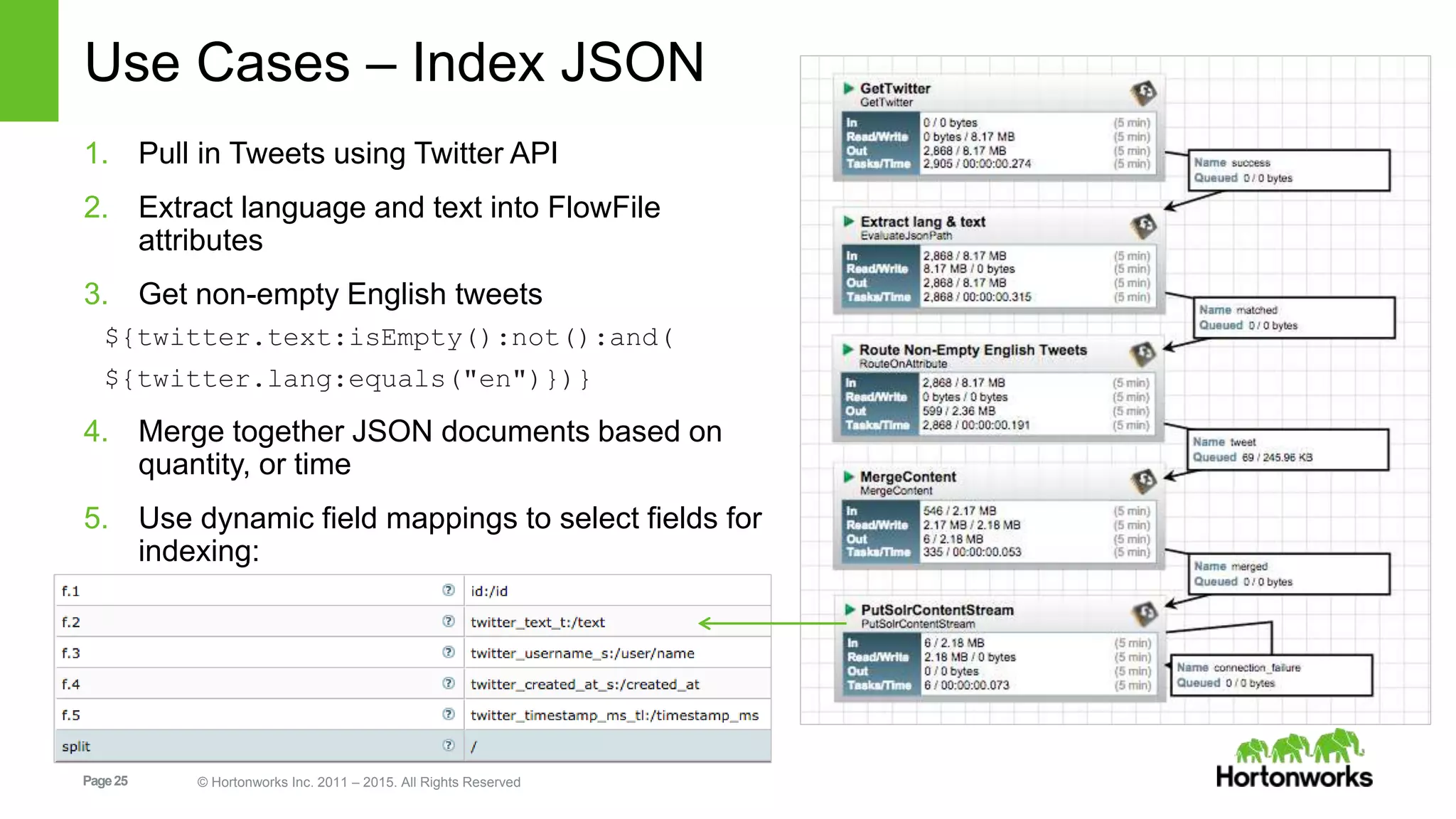
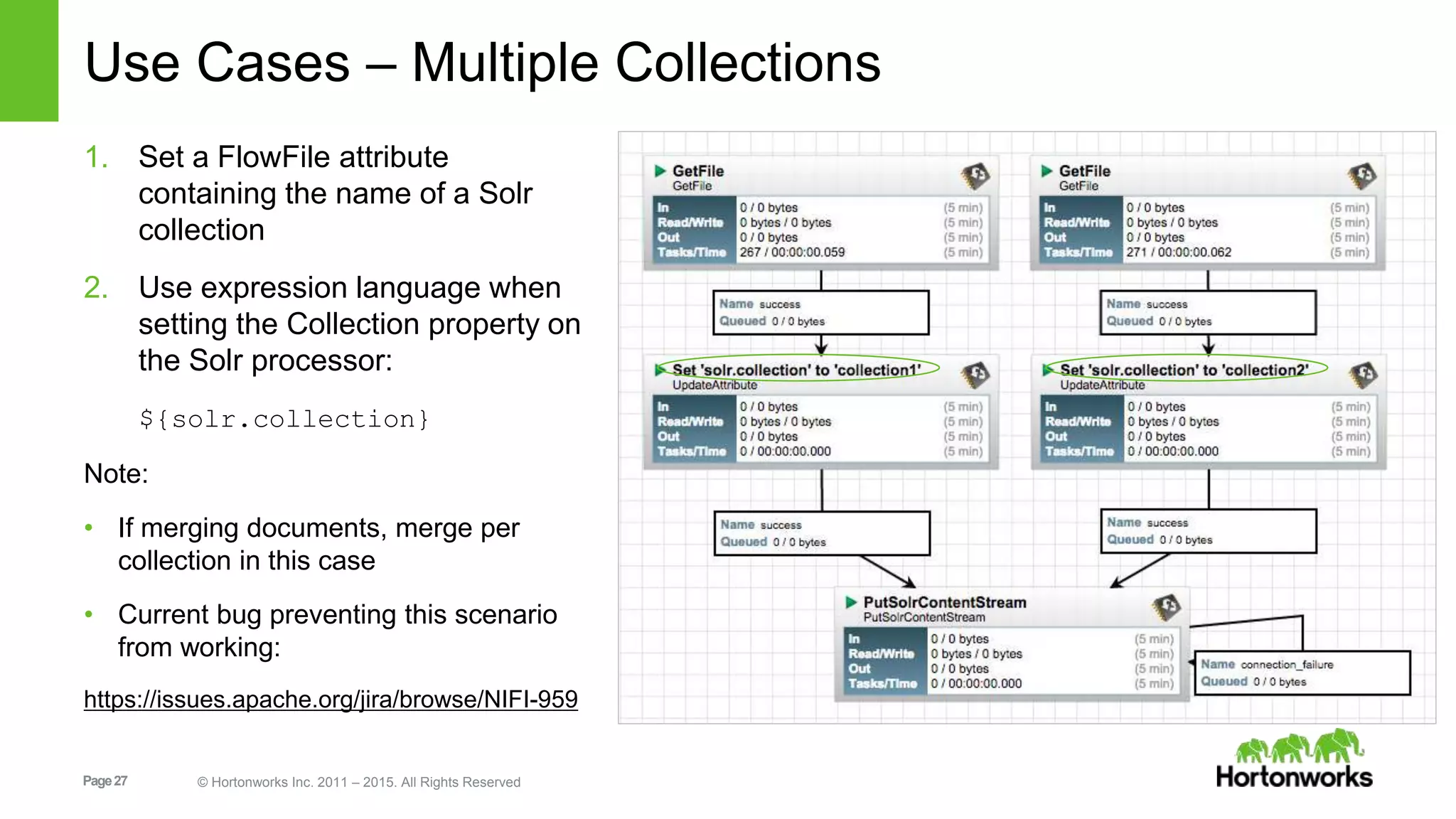
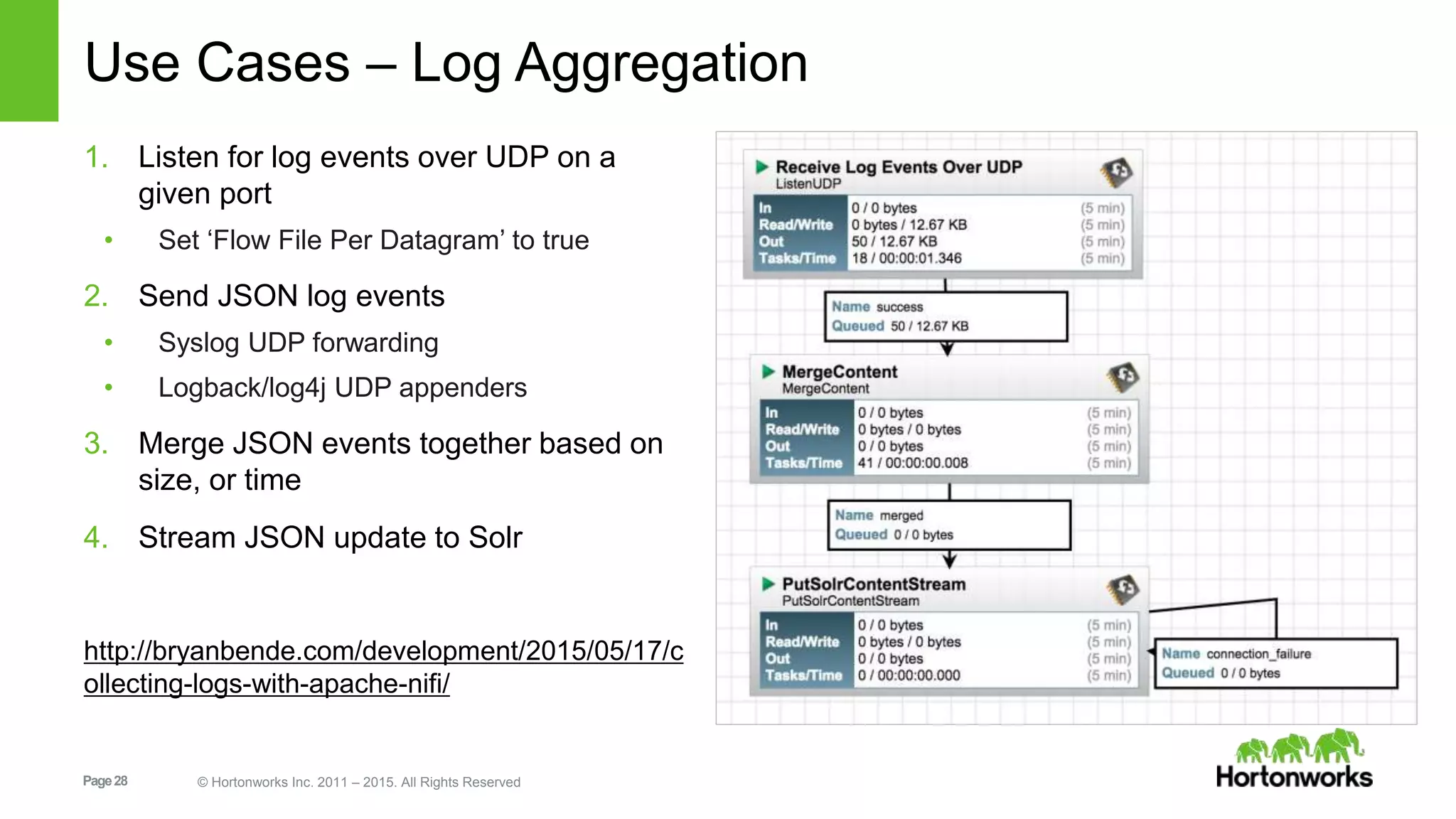
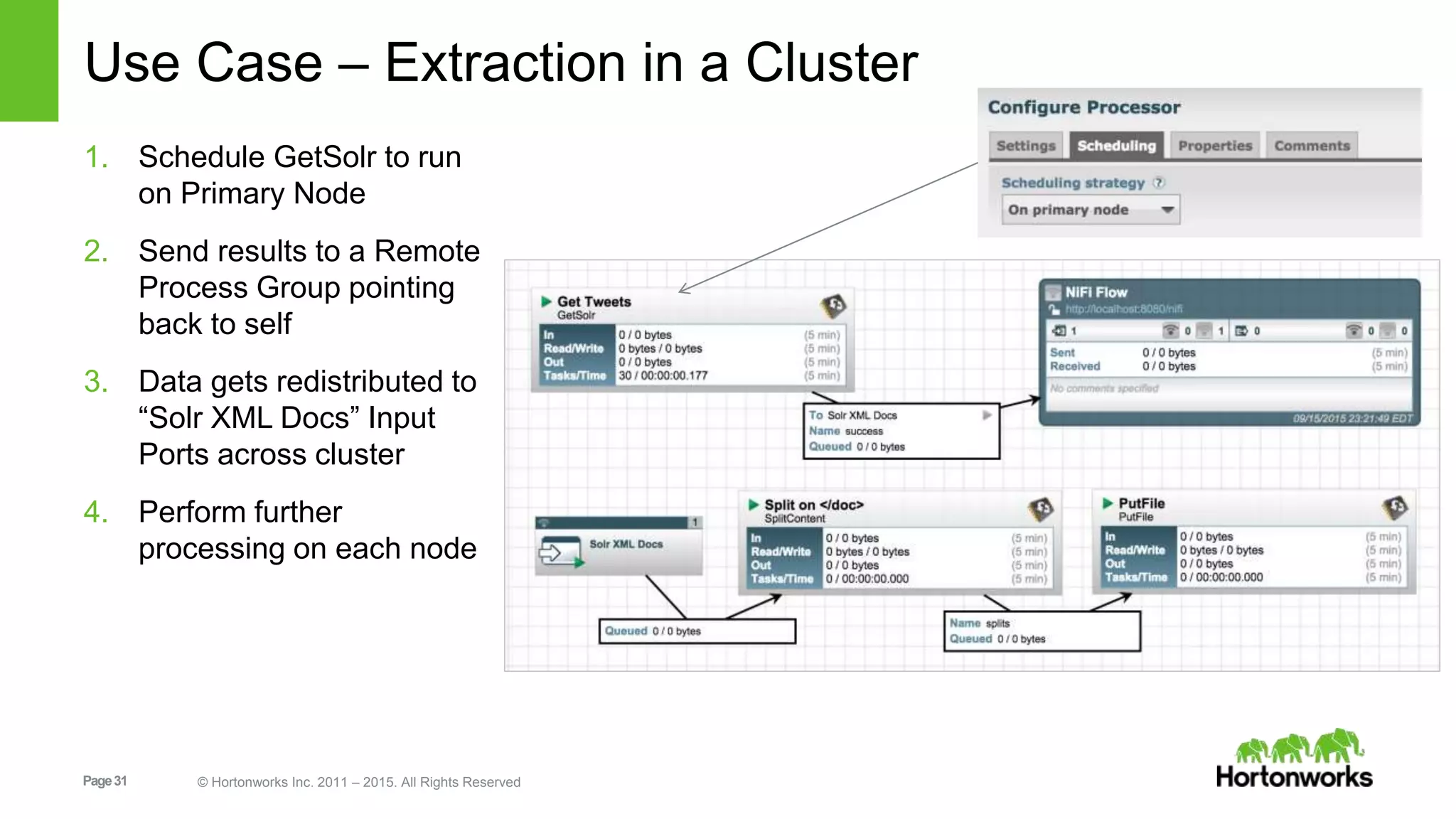
In-depth discussion on Solr's data indexing methods and various update handlers including XML, JSON, and CSV.Practical use cases for indexing and managing data in Solr using NiFi, covering tweets, JSON, logs, etc.
Summary of resources for learning Apache NiFi and Solr, including mailing lists and documentation.
Acknowledgment and thank you for the audience's attention.