Download as PDF, PPTX



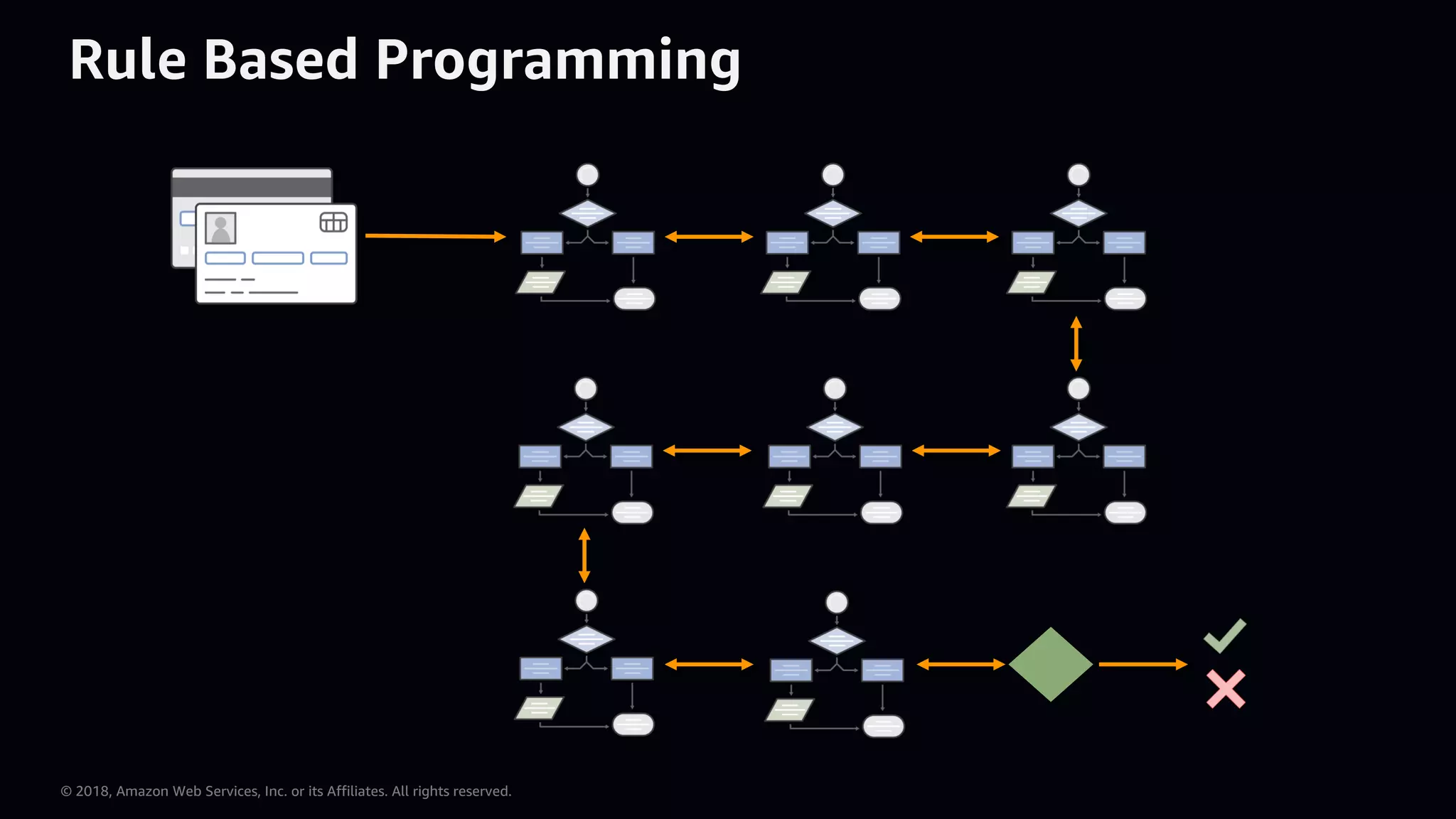

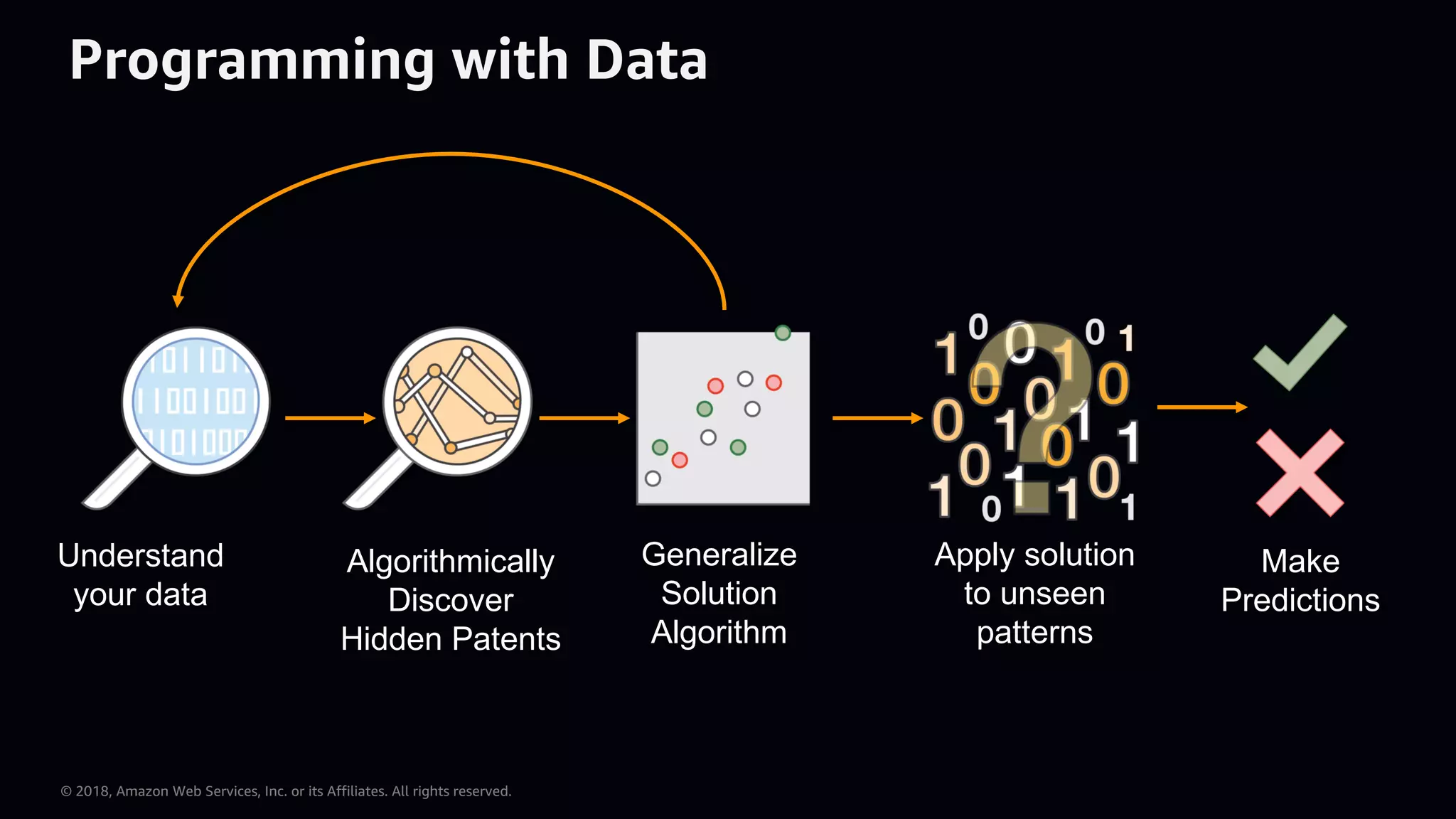

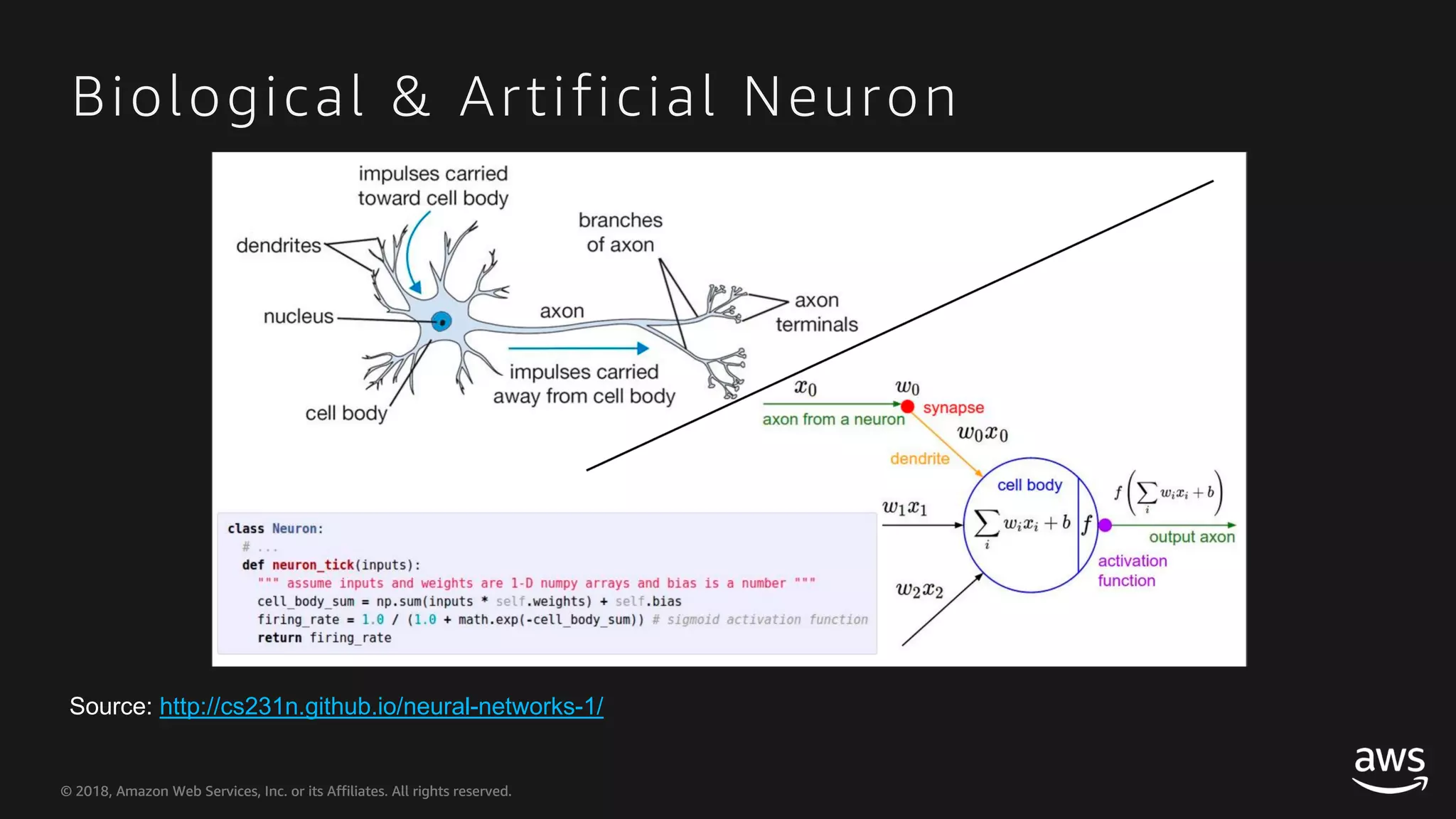
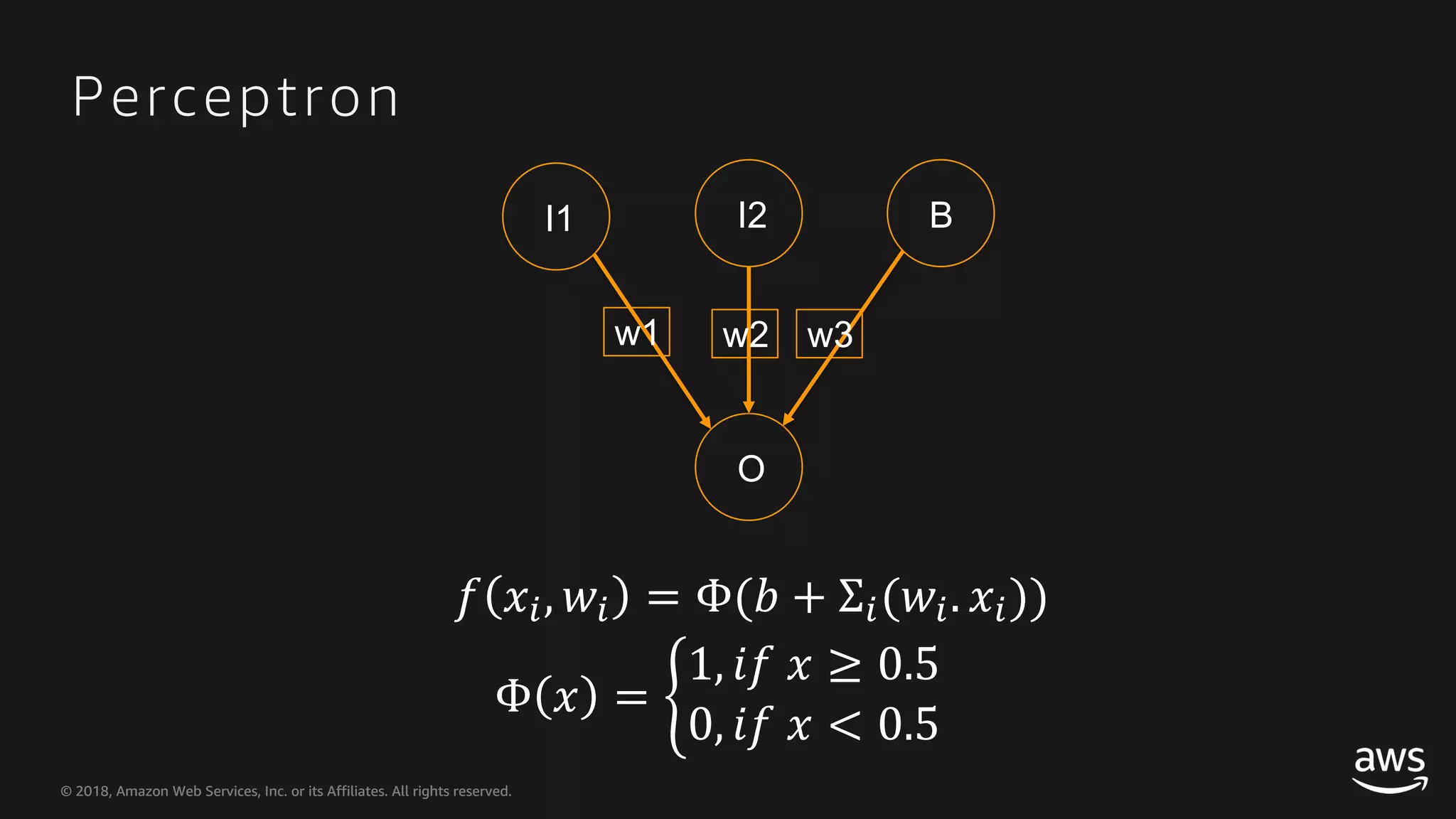
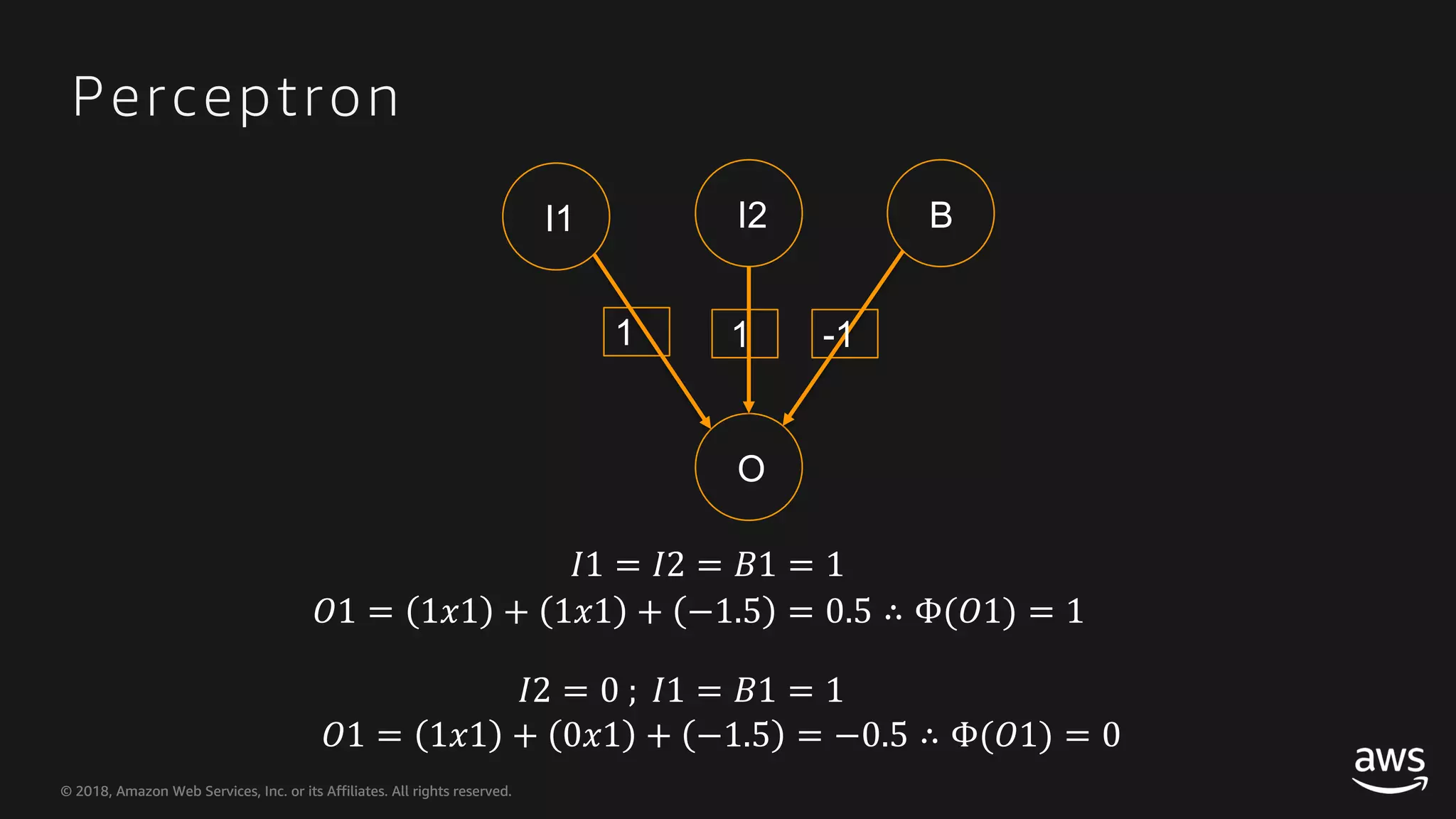
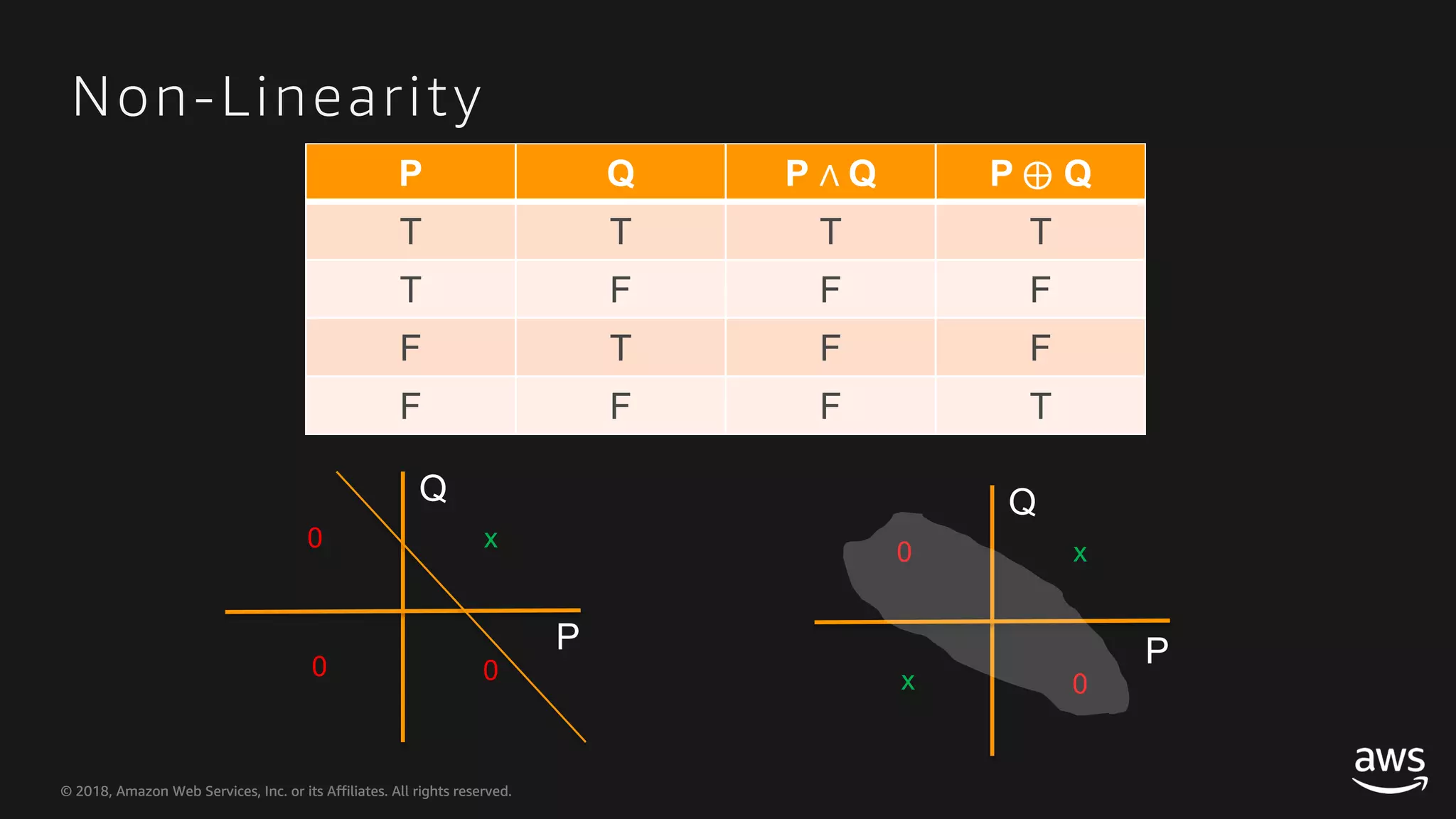
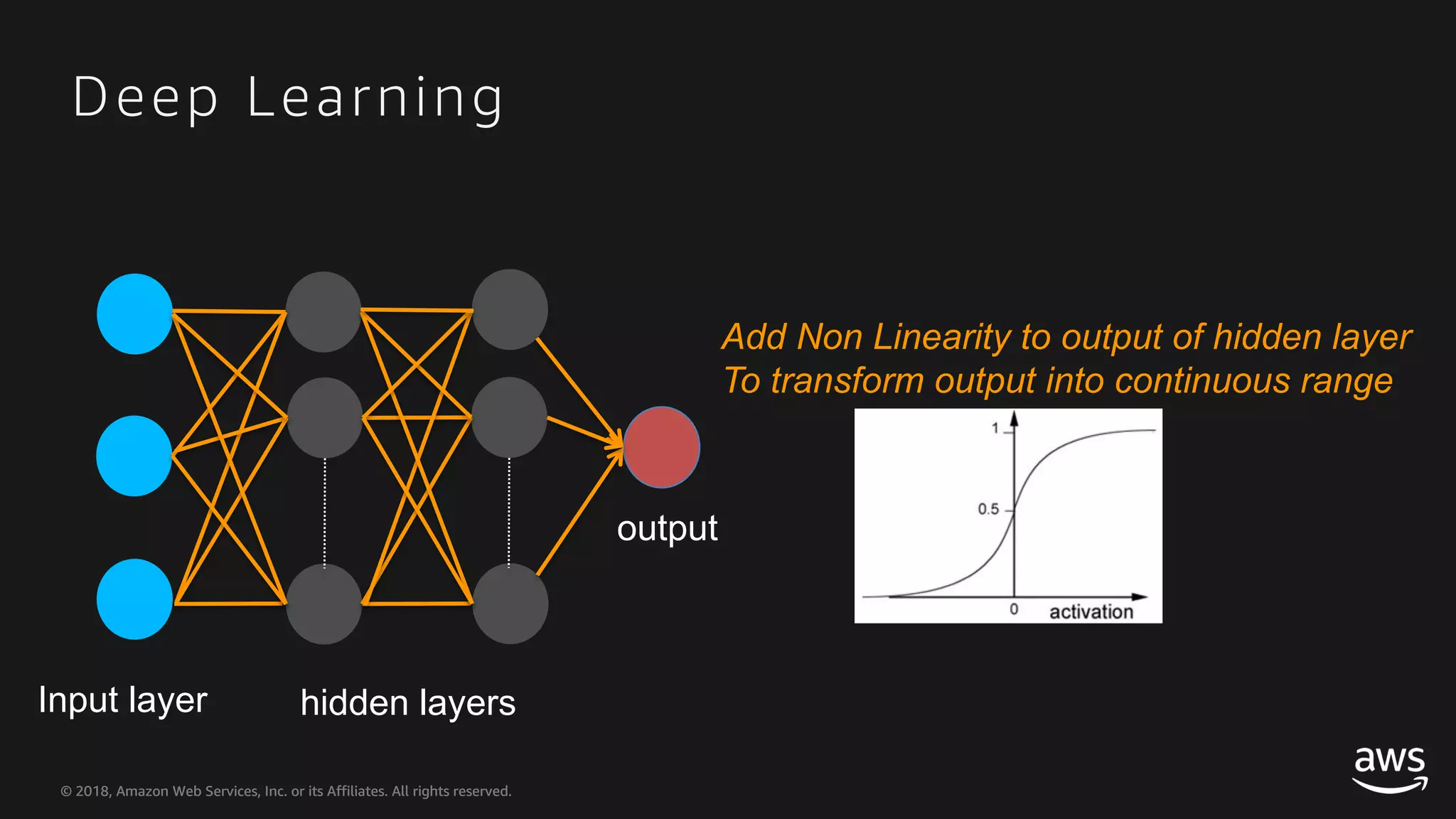
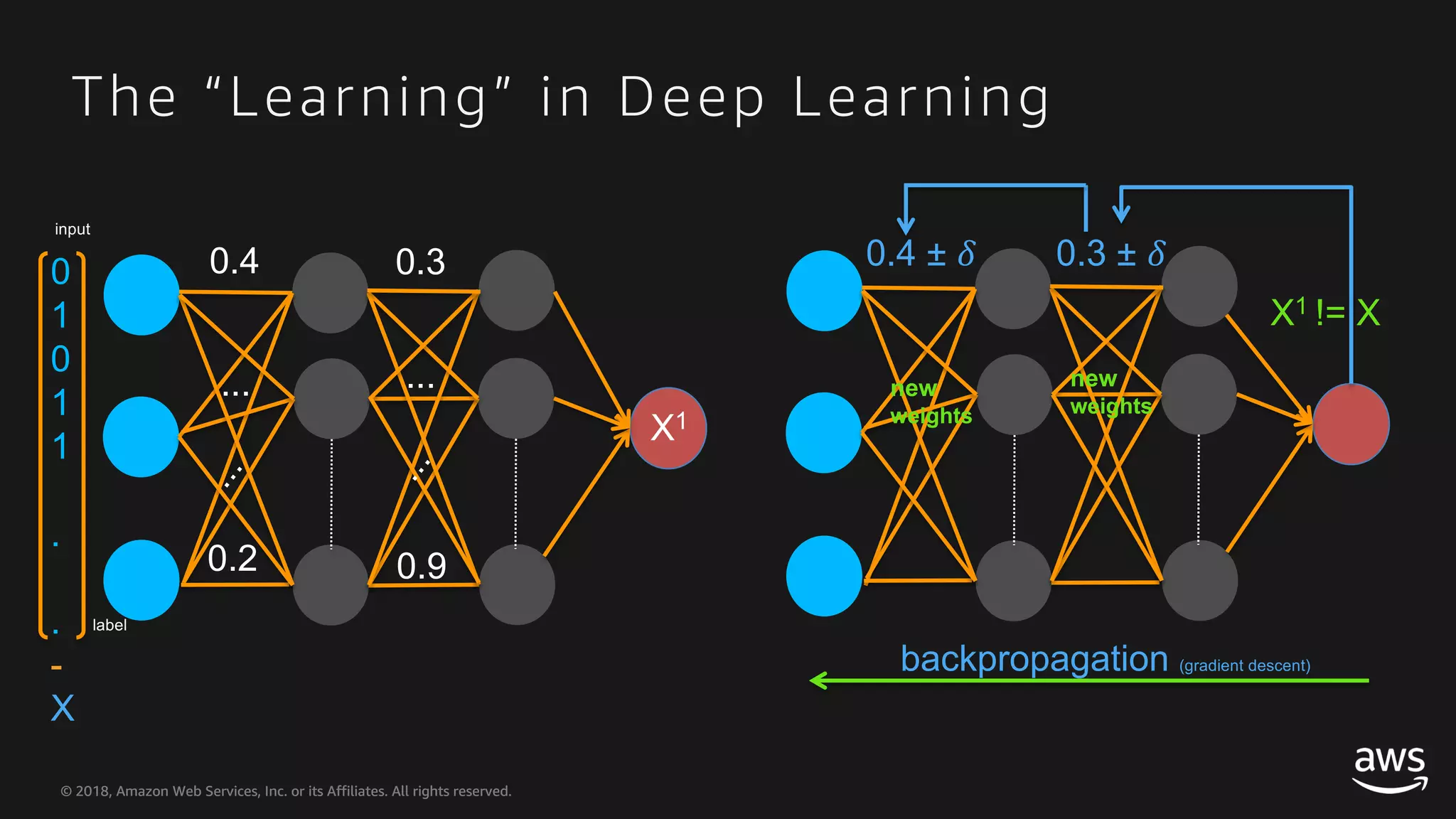
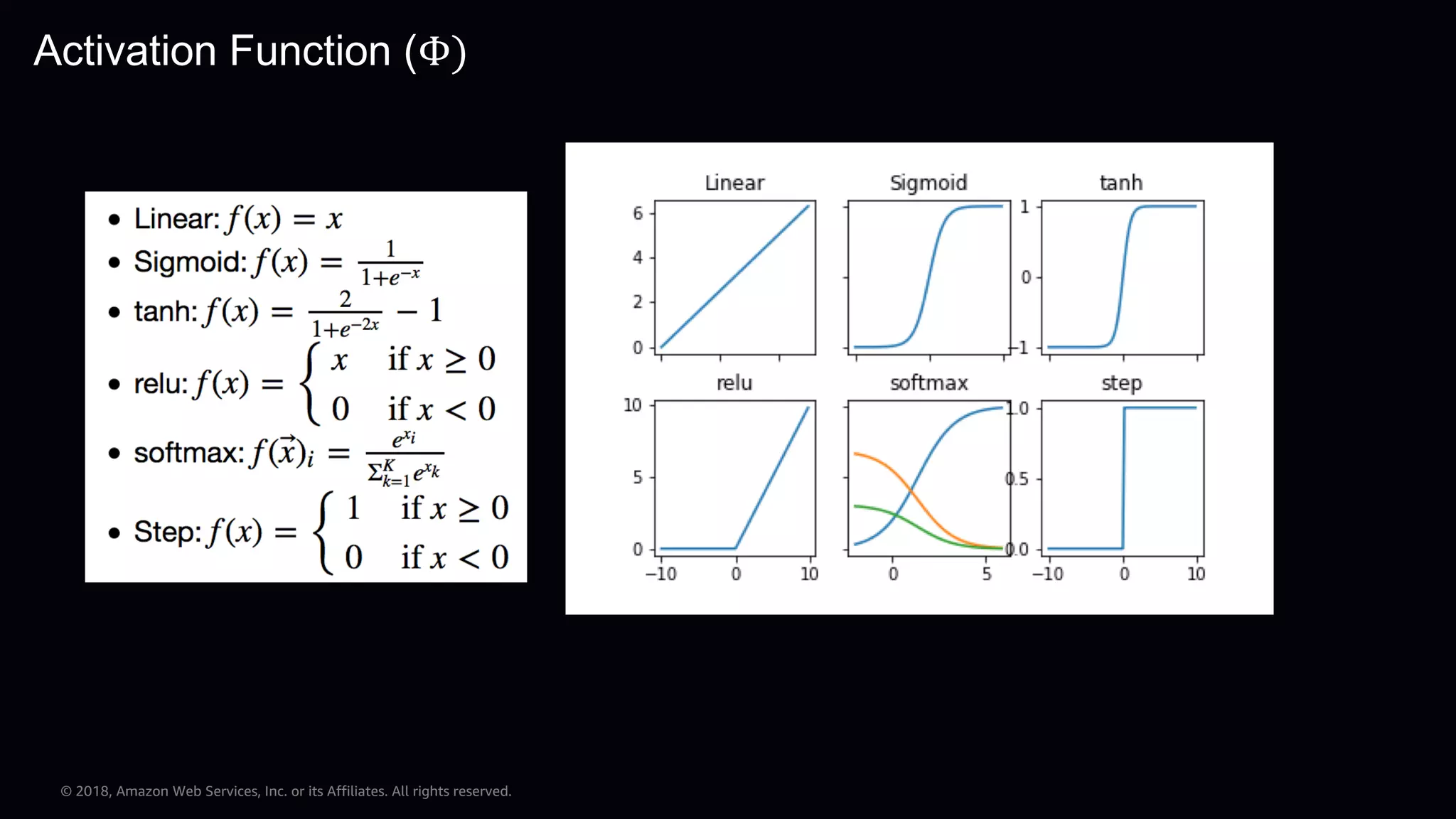

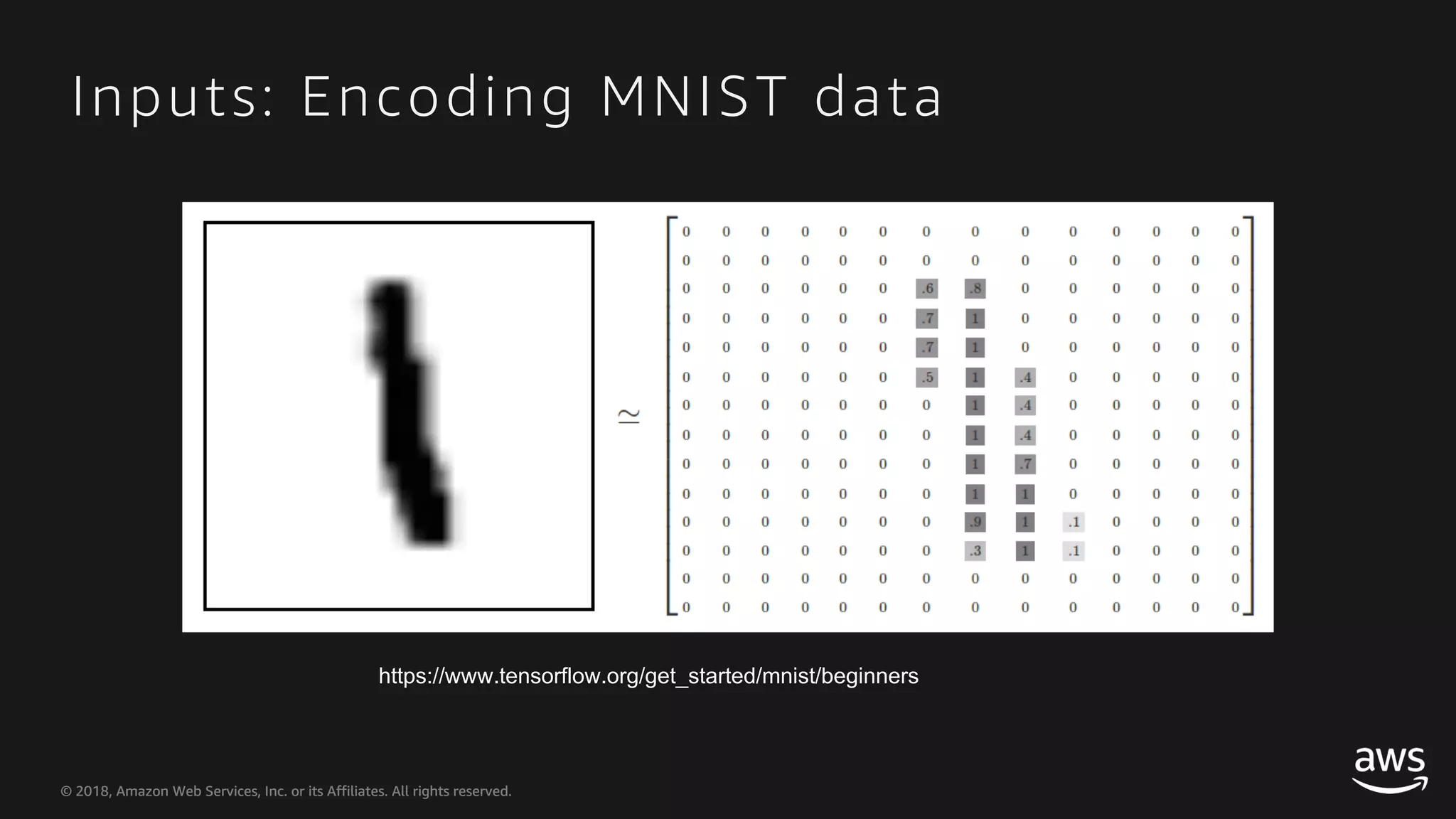

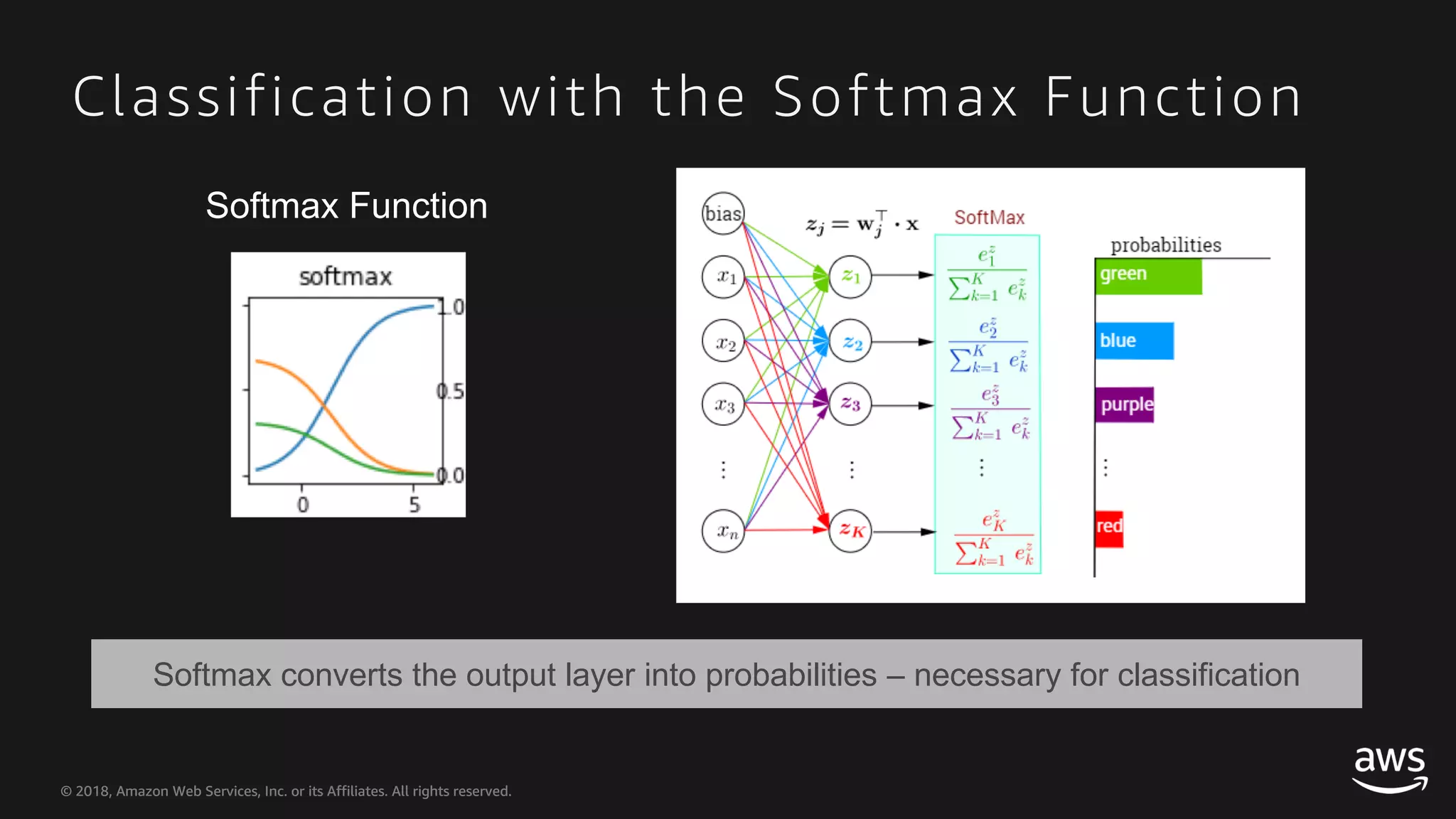

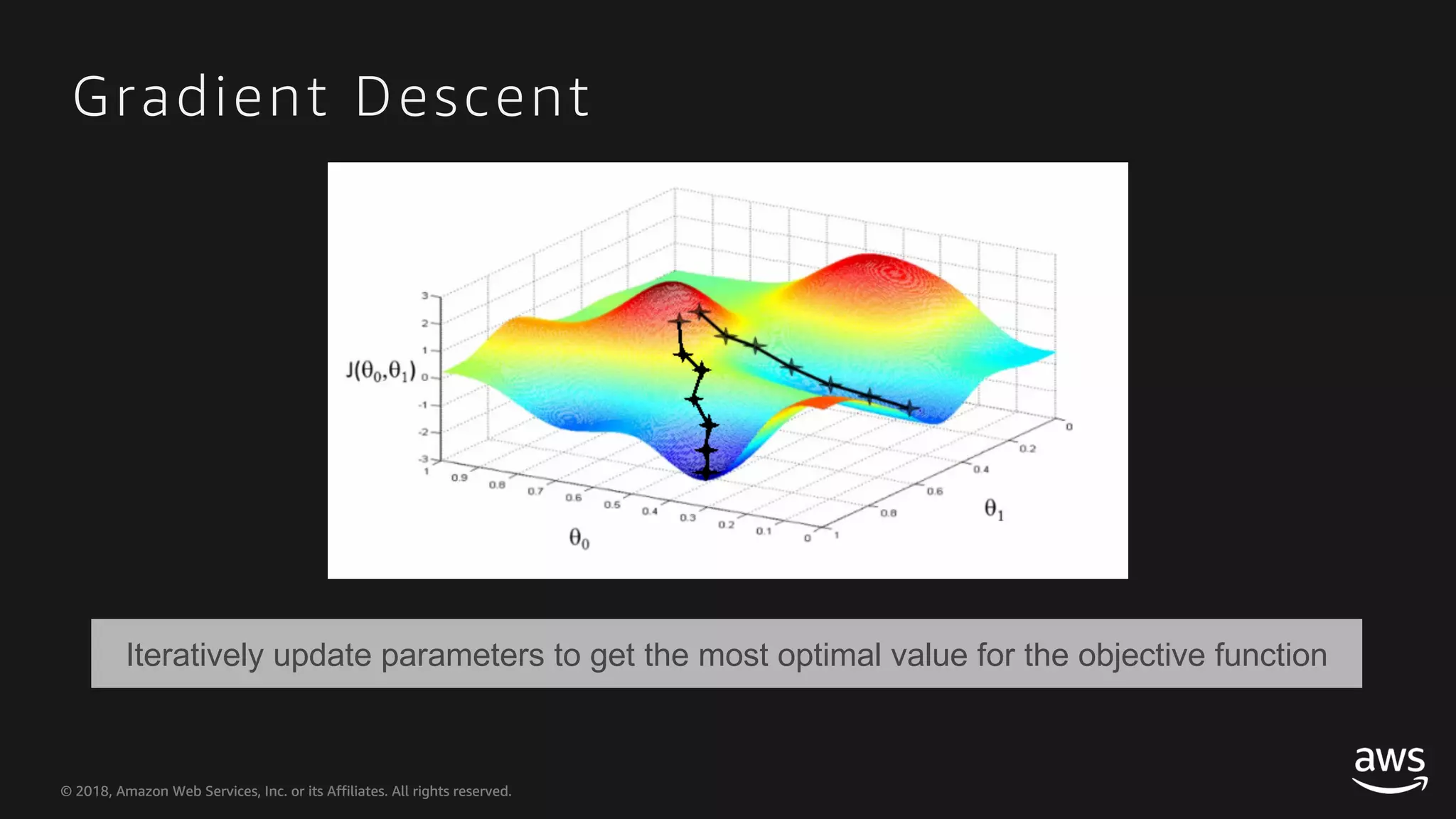
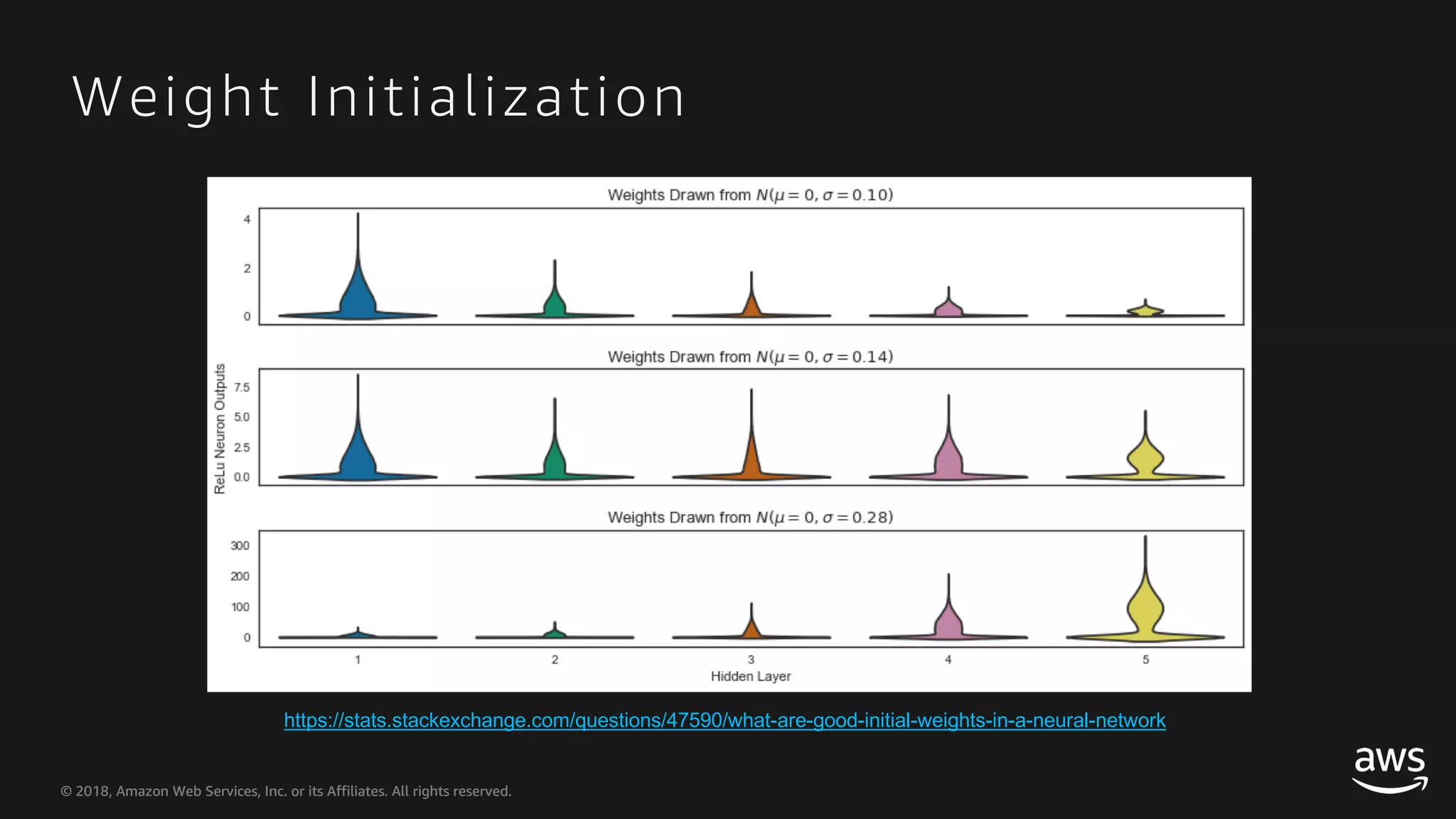
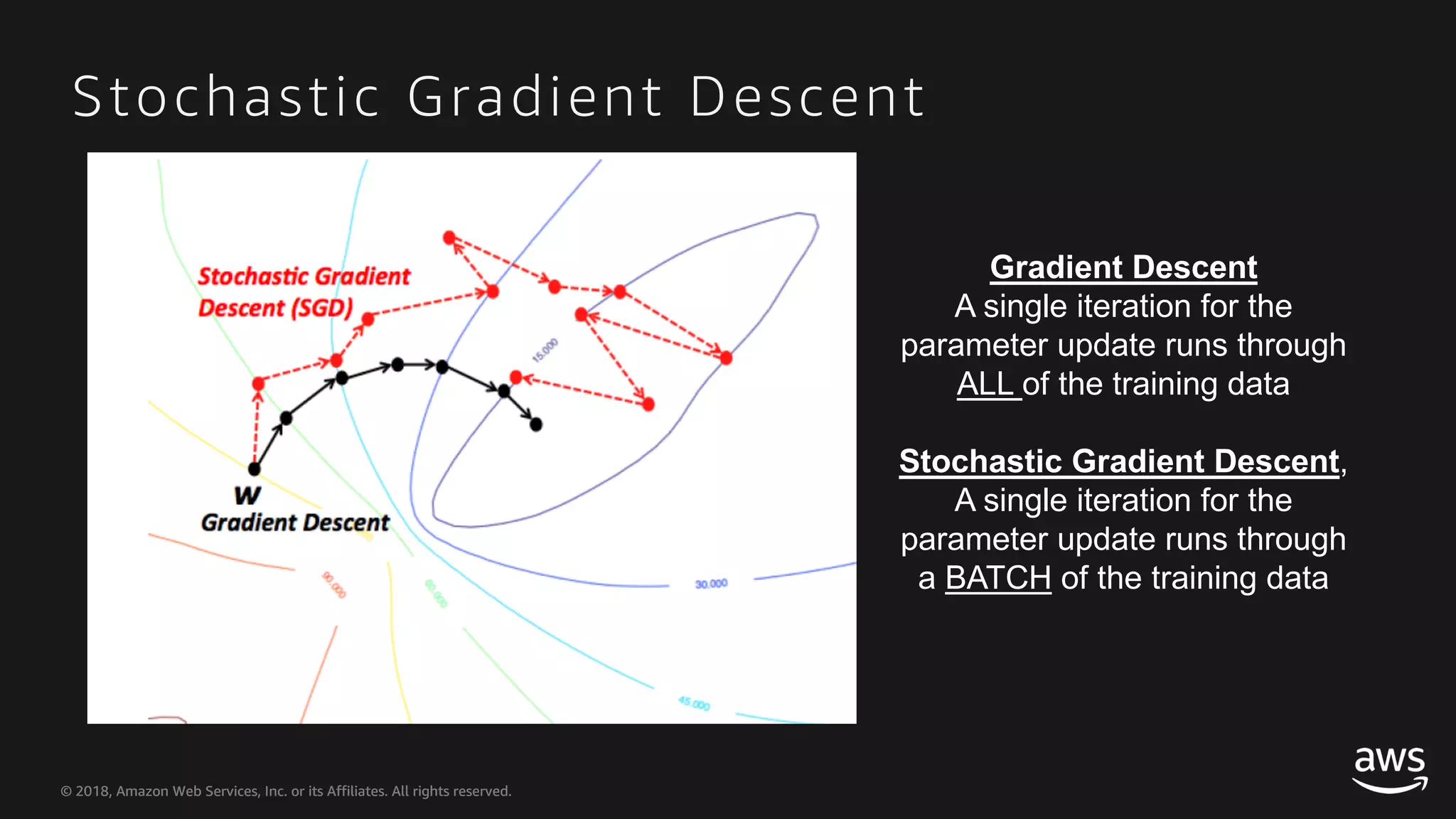
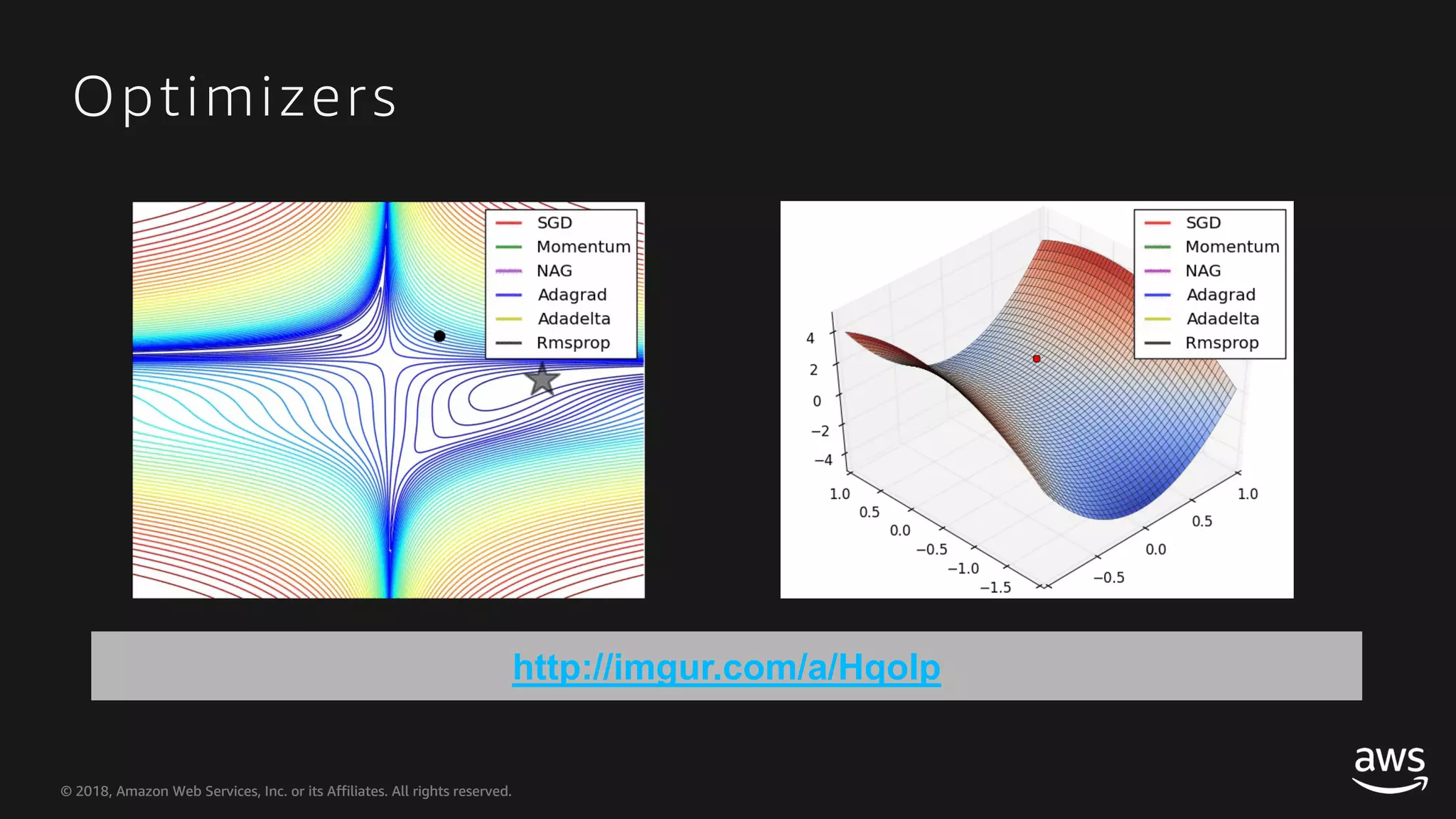
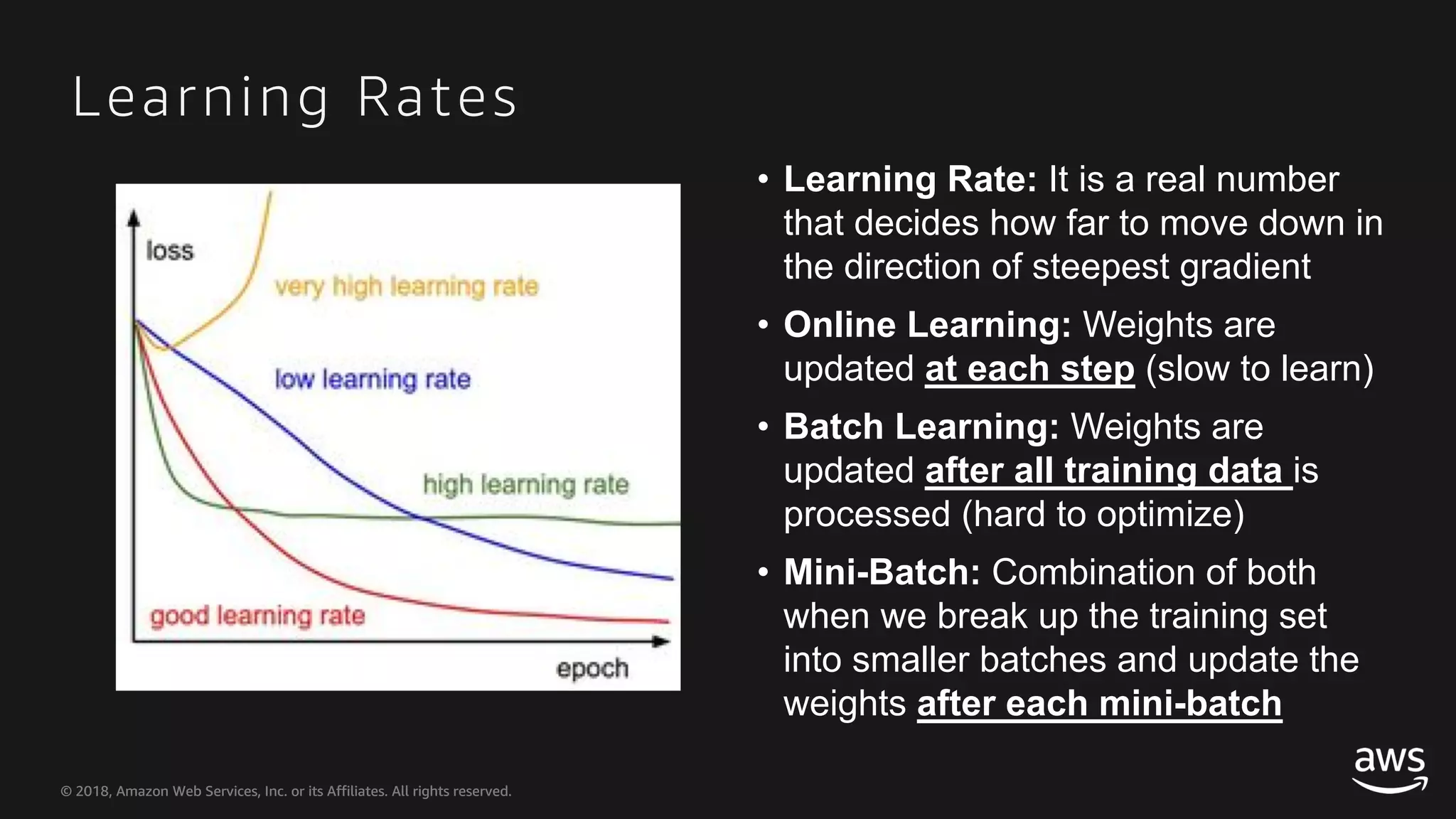

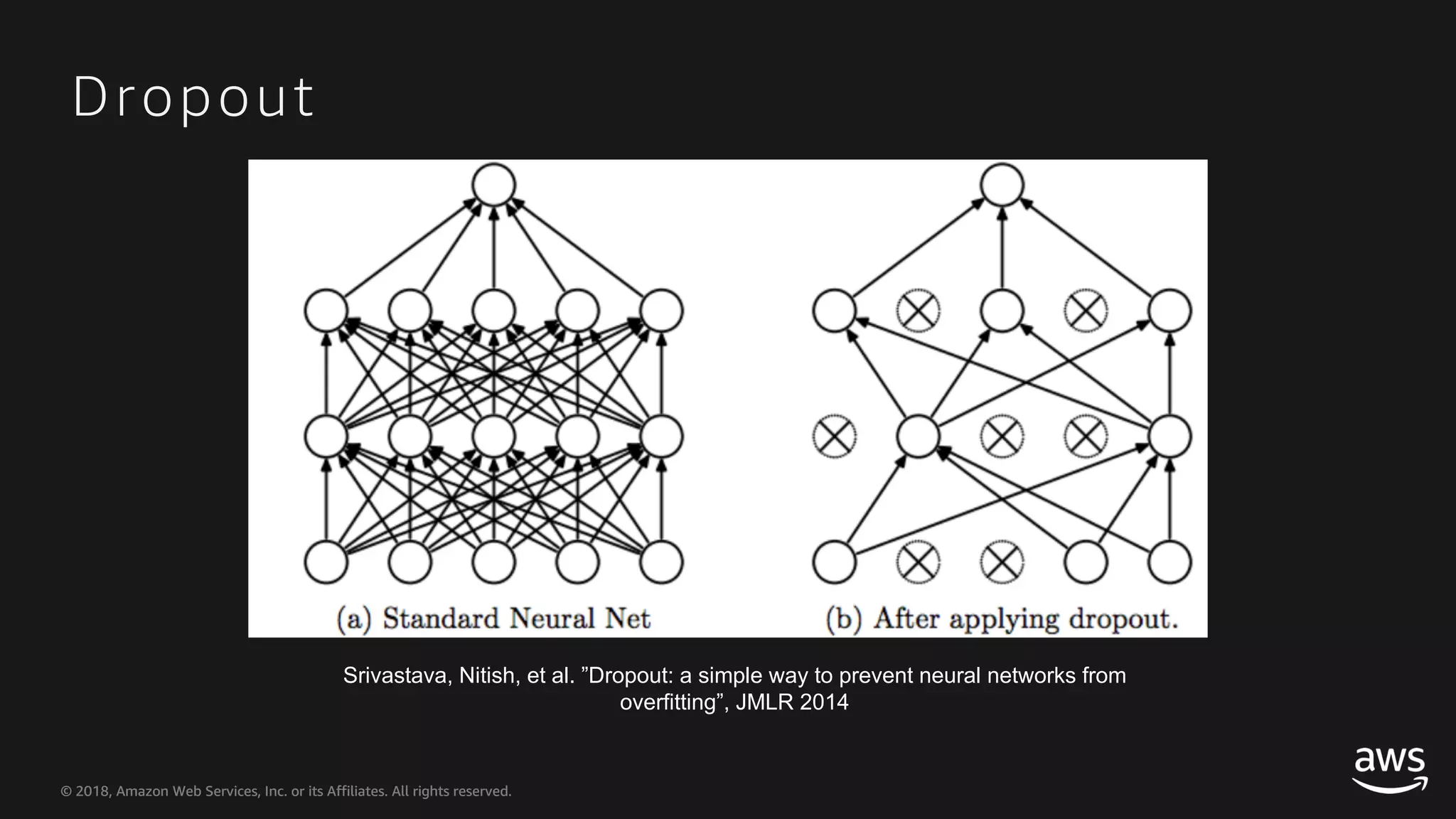

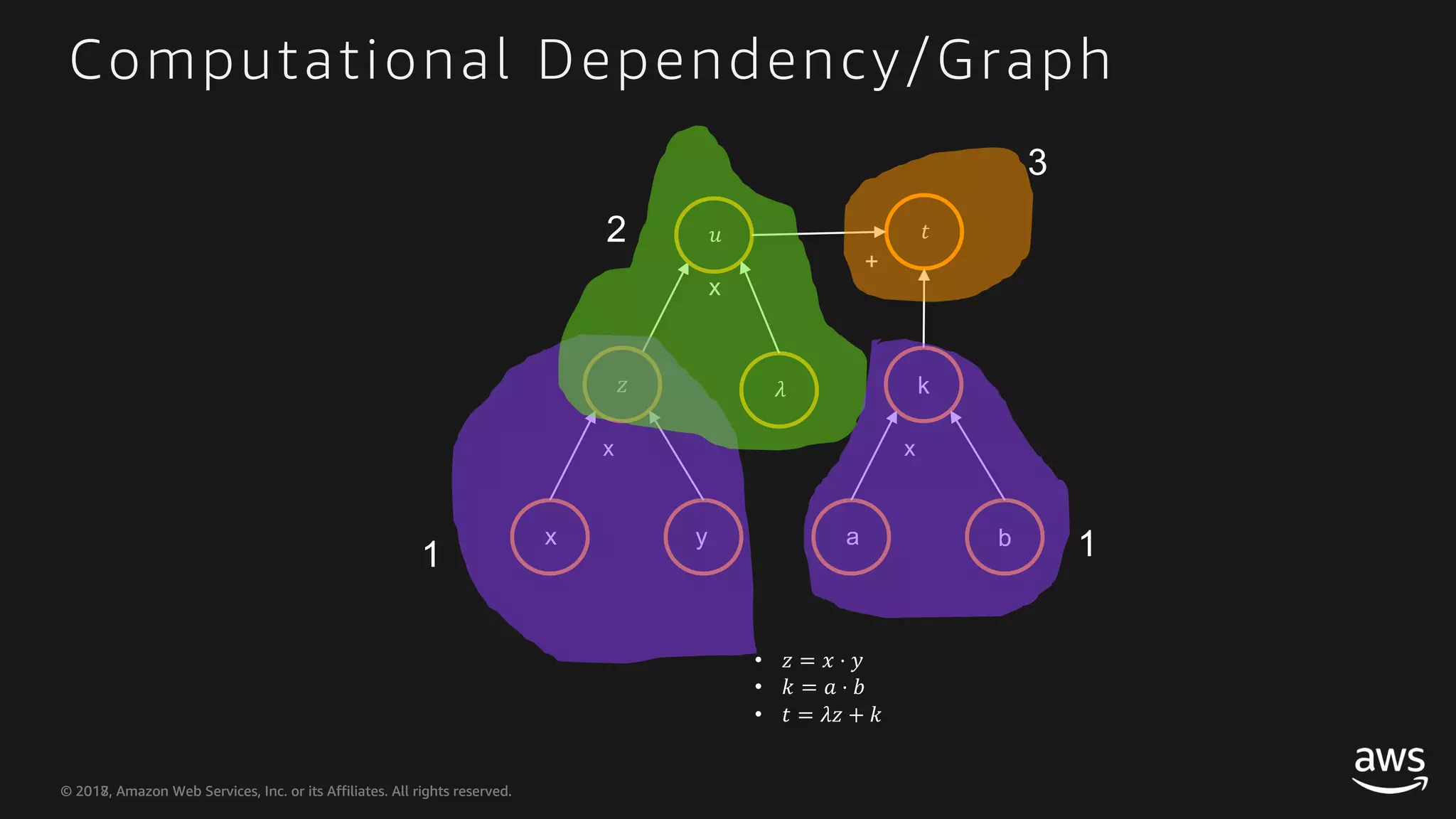

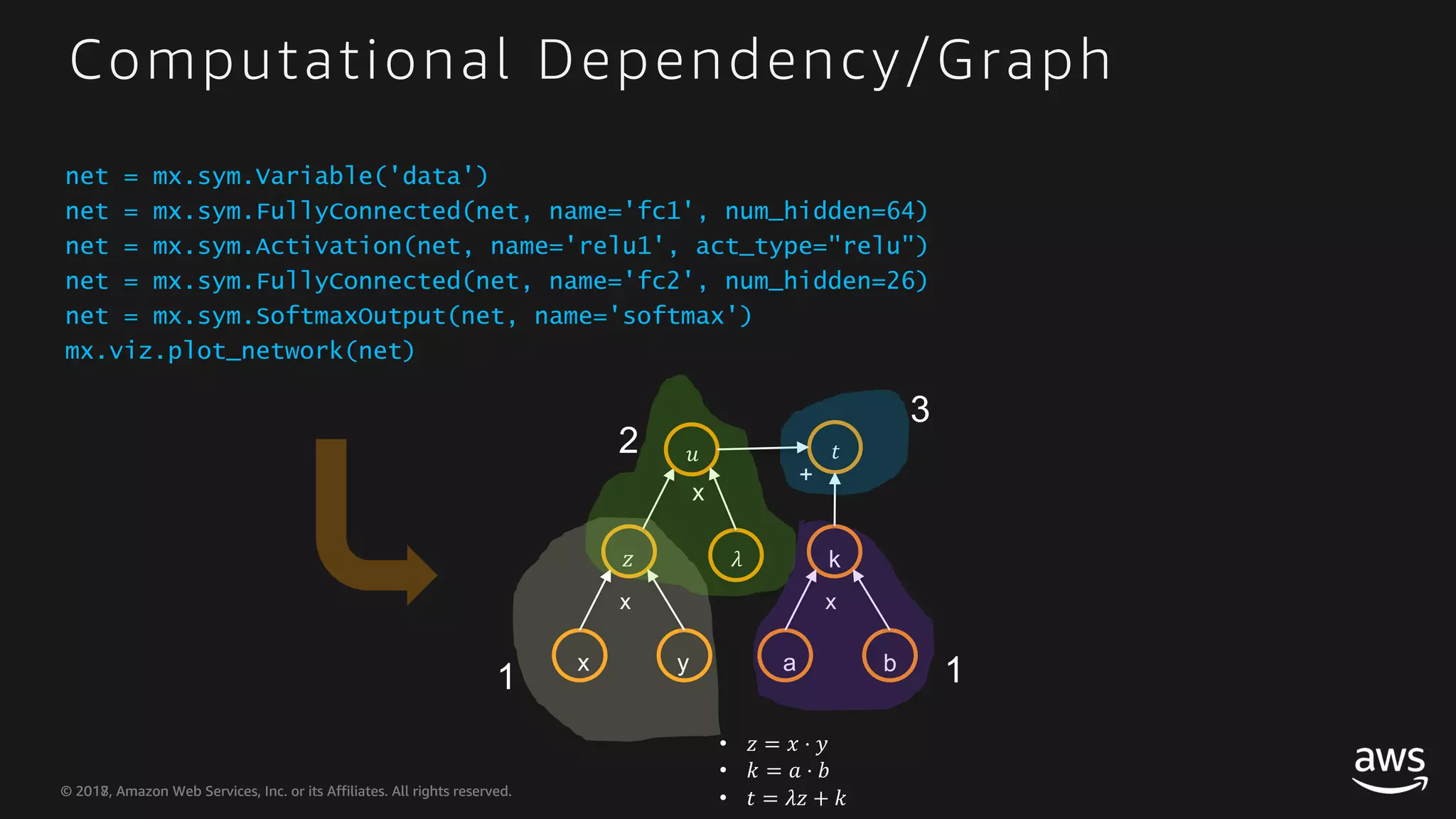
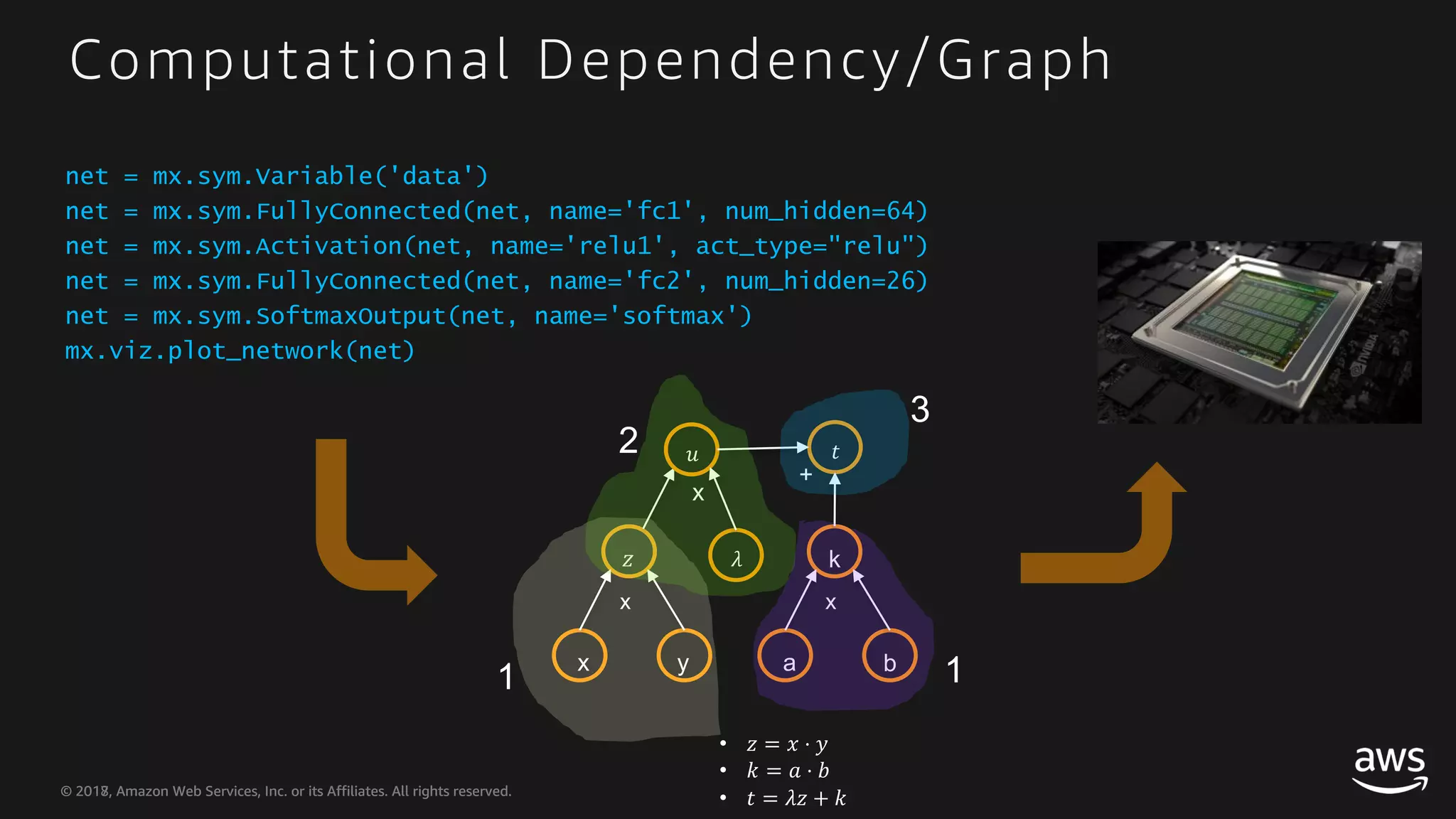
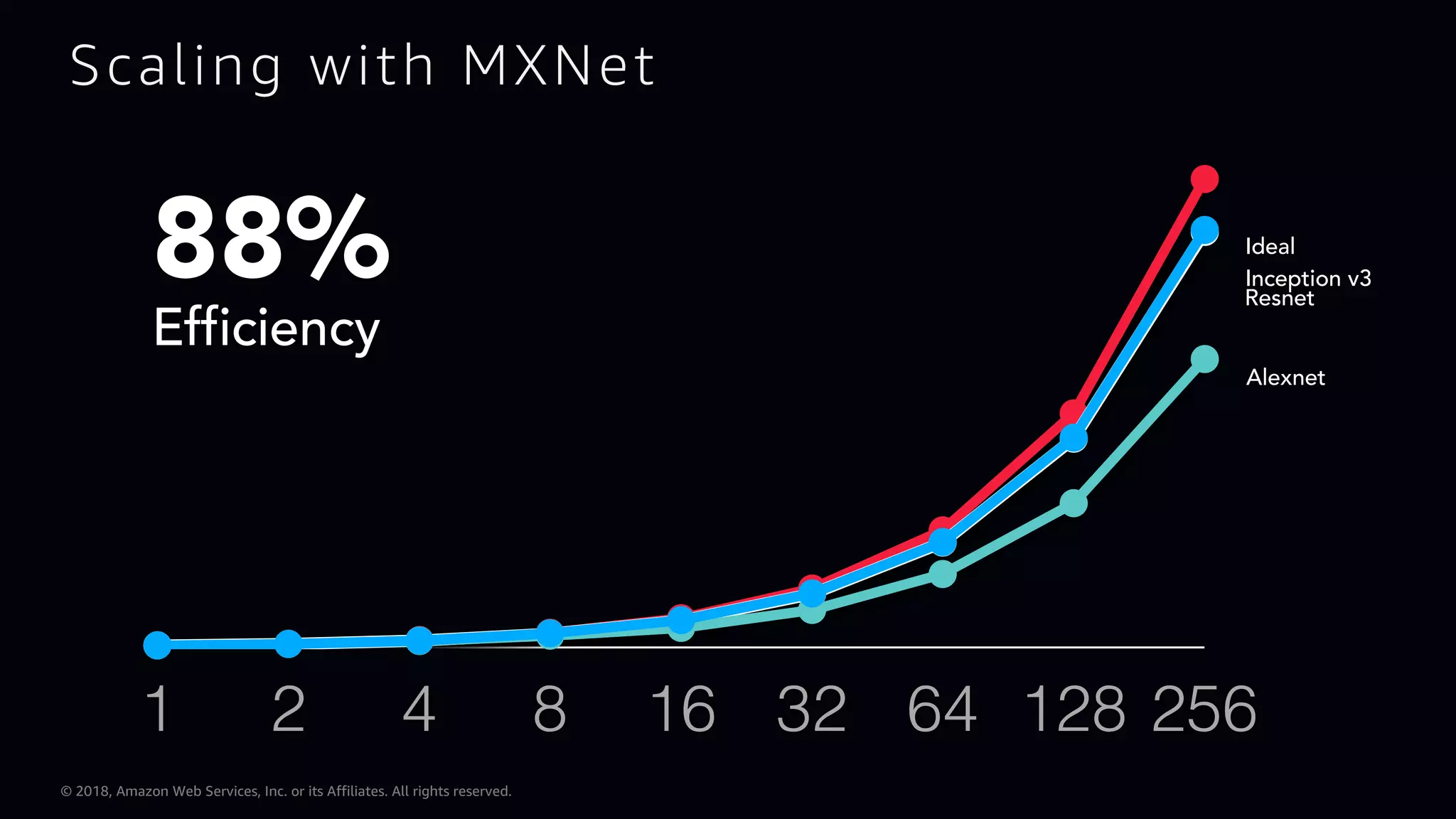
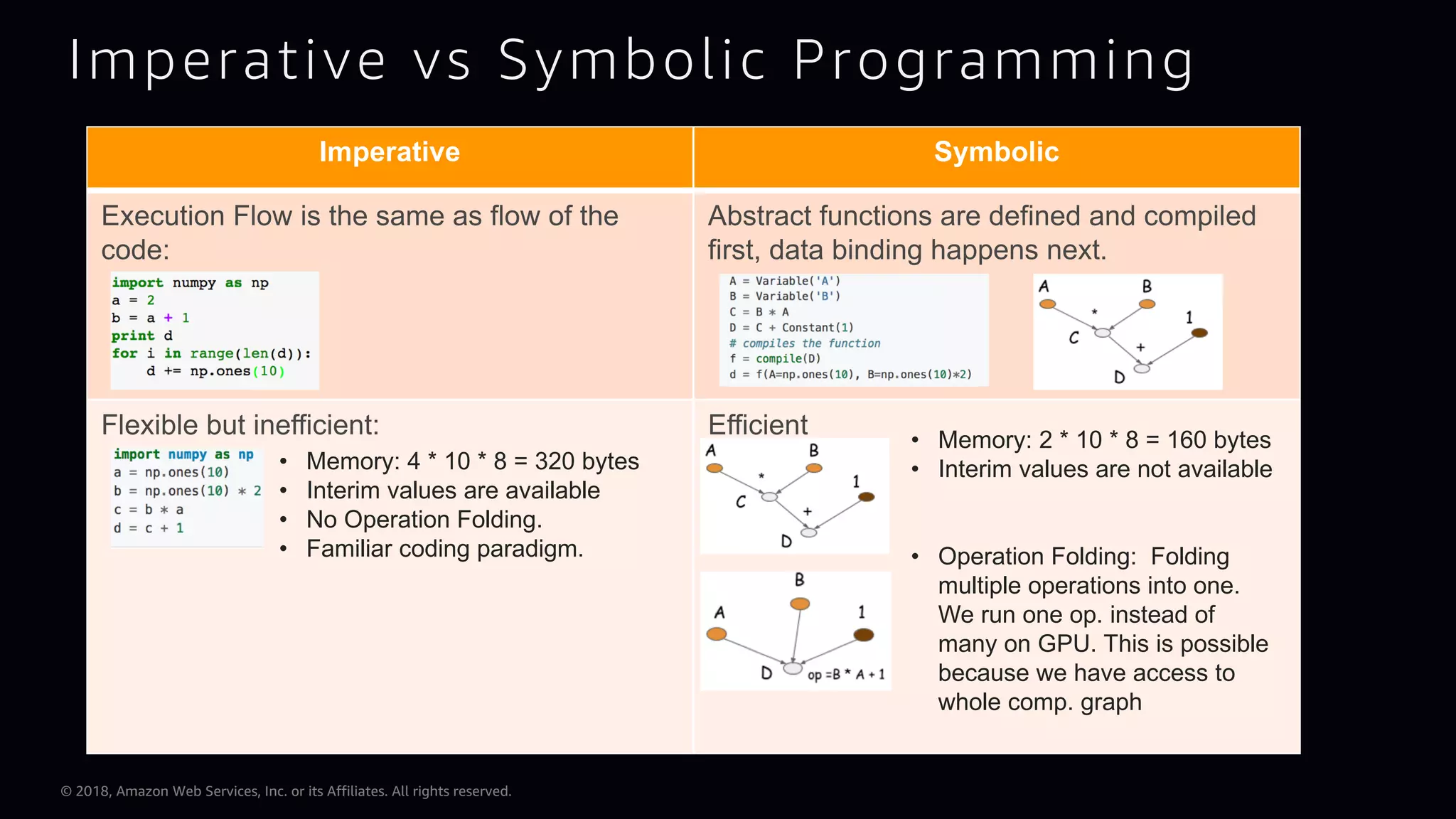

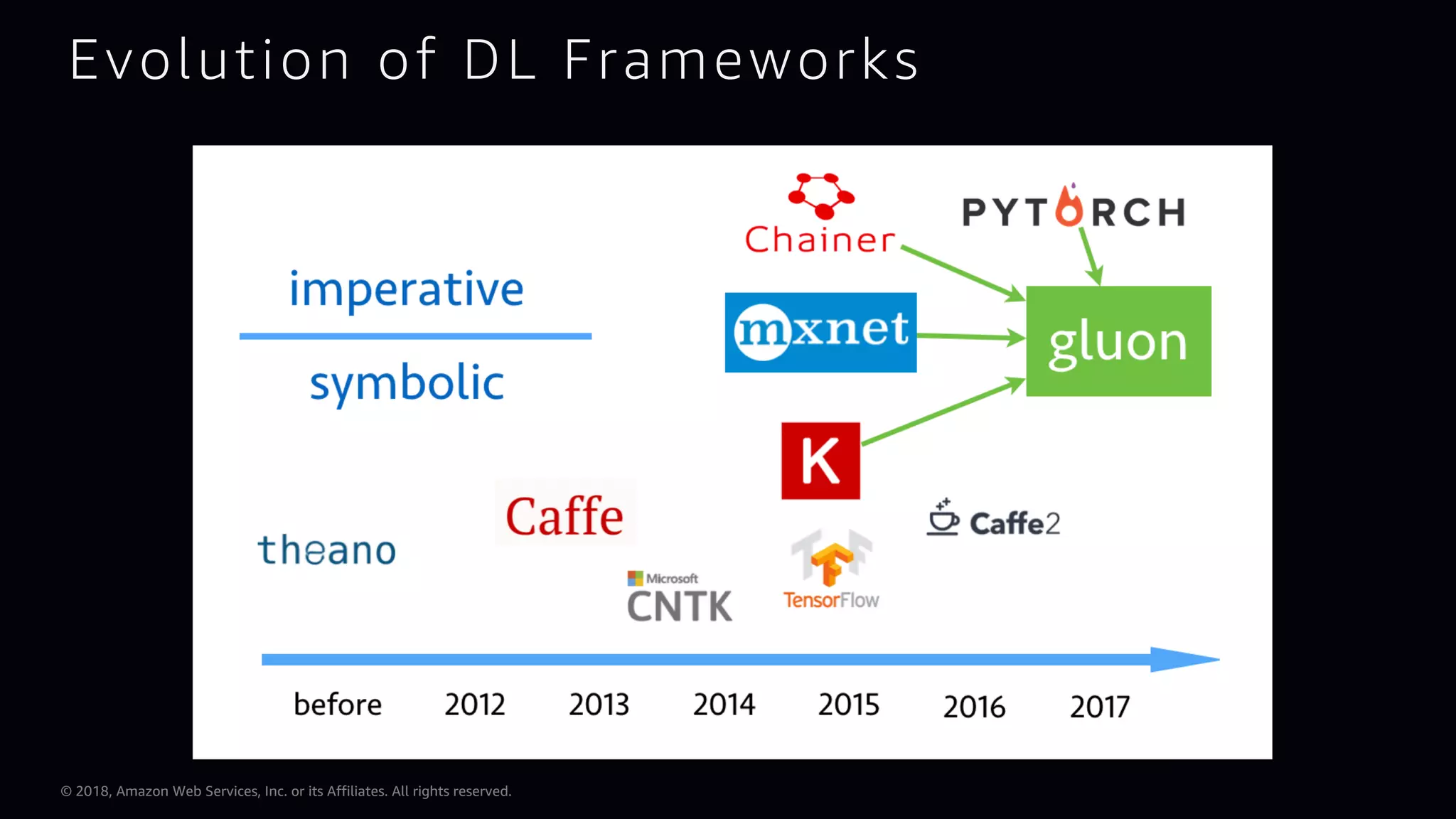








This document provides an overview of Apache MXNet and Gluon for building deep learning applications, covering key concepts such as neural networks, learning processes, gradient descent, and optimization techniques. It highlights the advantages of the Gluon API, including its flexibility and ease of use, along with updates on deep learning toolkits for computer vision and natural language processing. Additionally, it references resources for further learning and development within the MXNet framework.