Download as PDF, PPTX




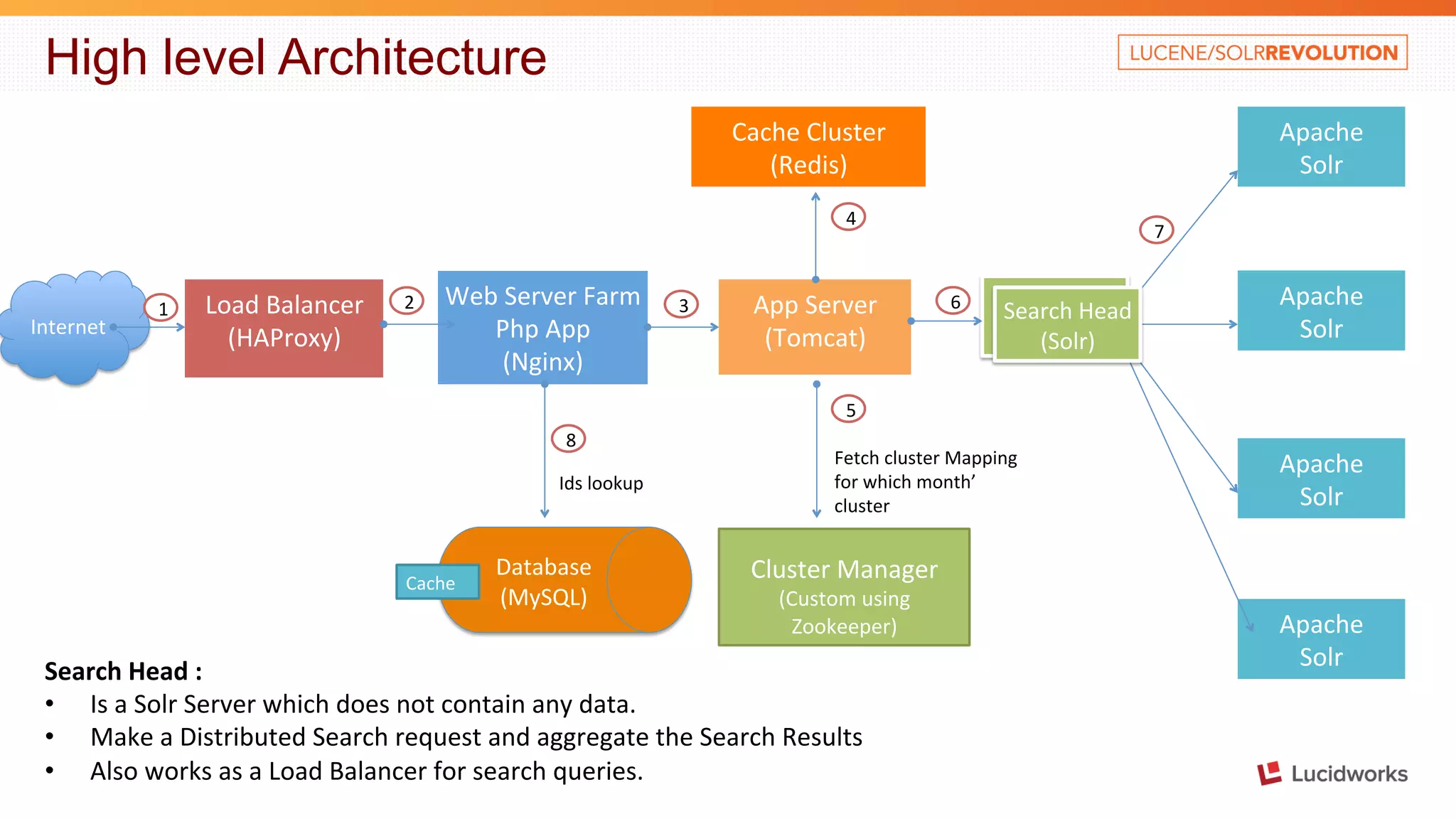


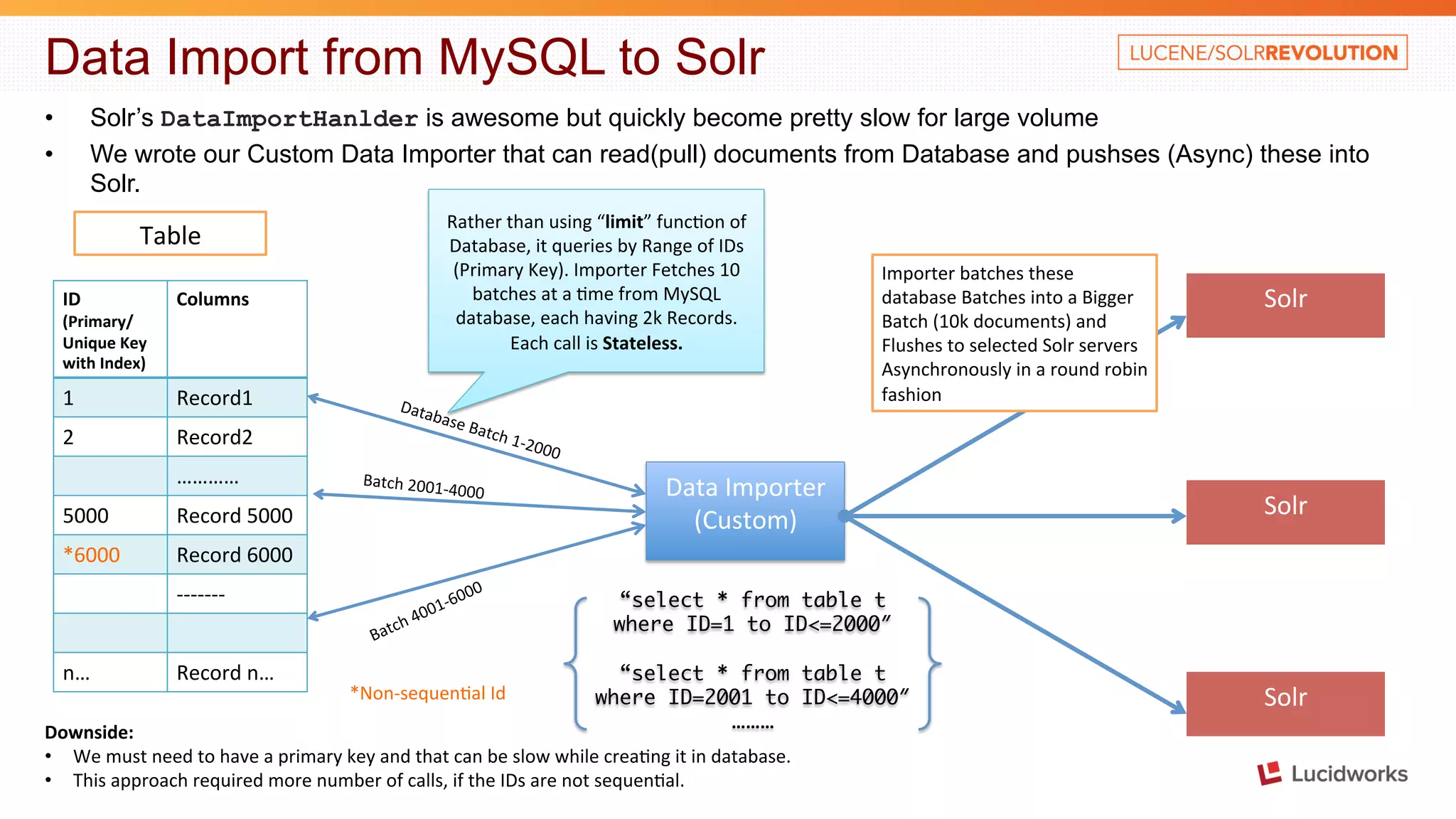


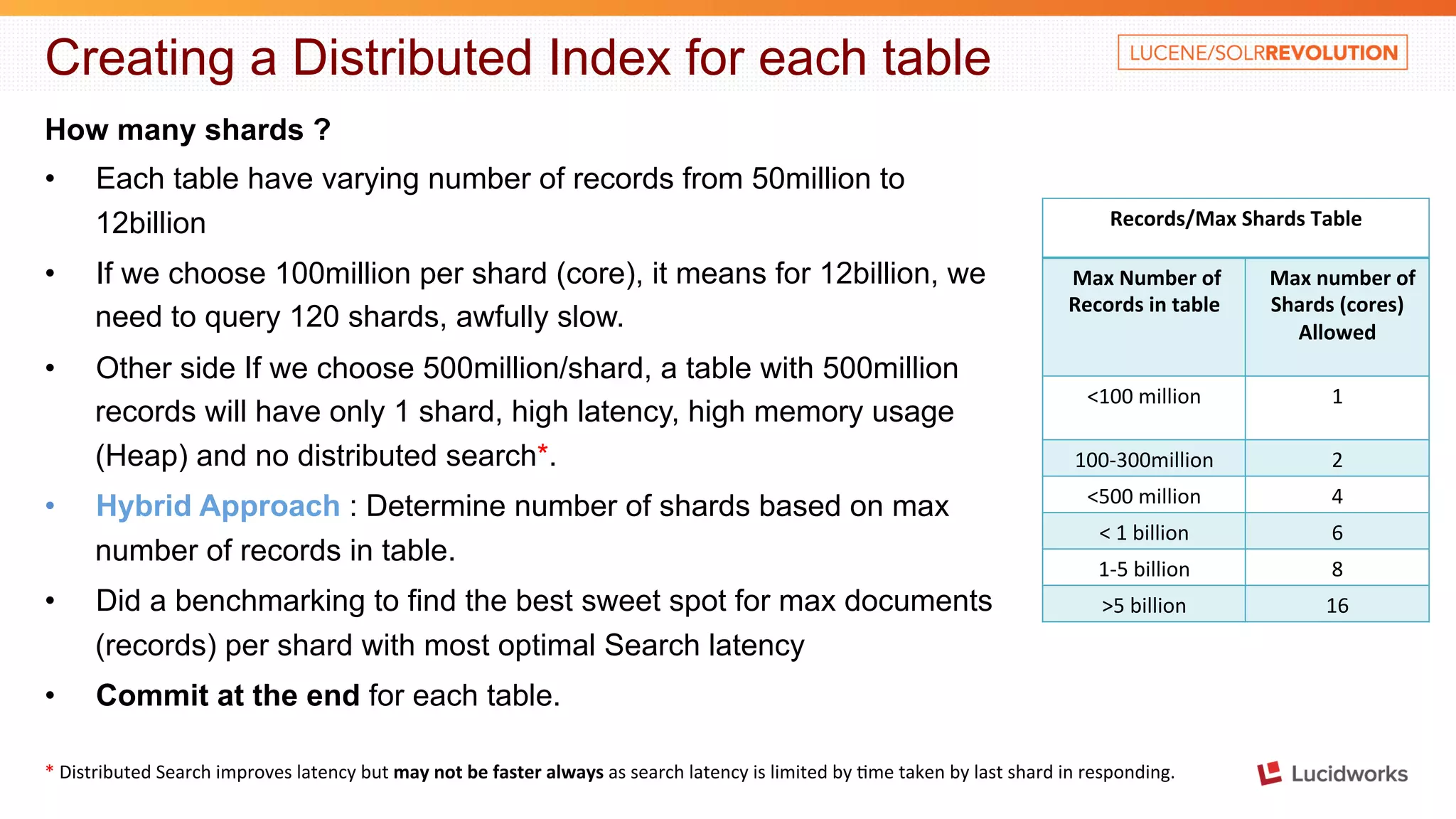

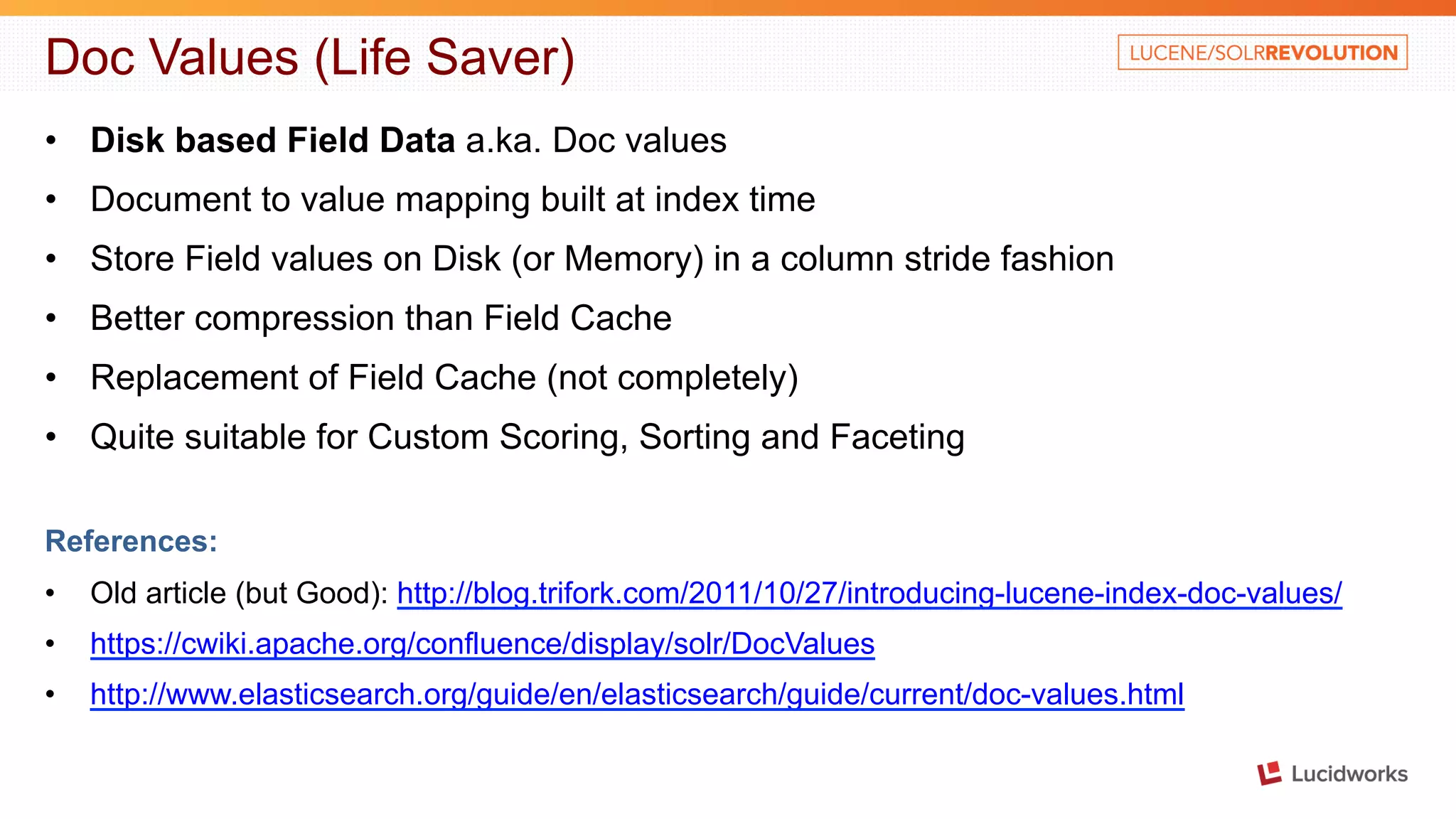

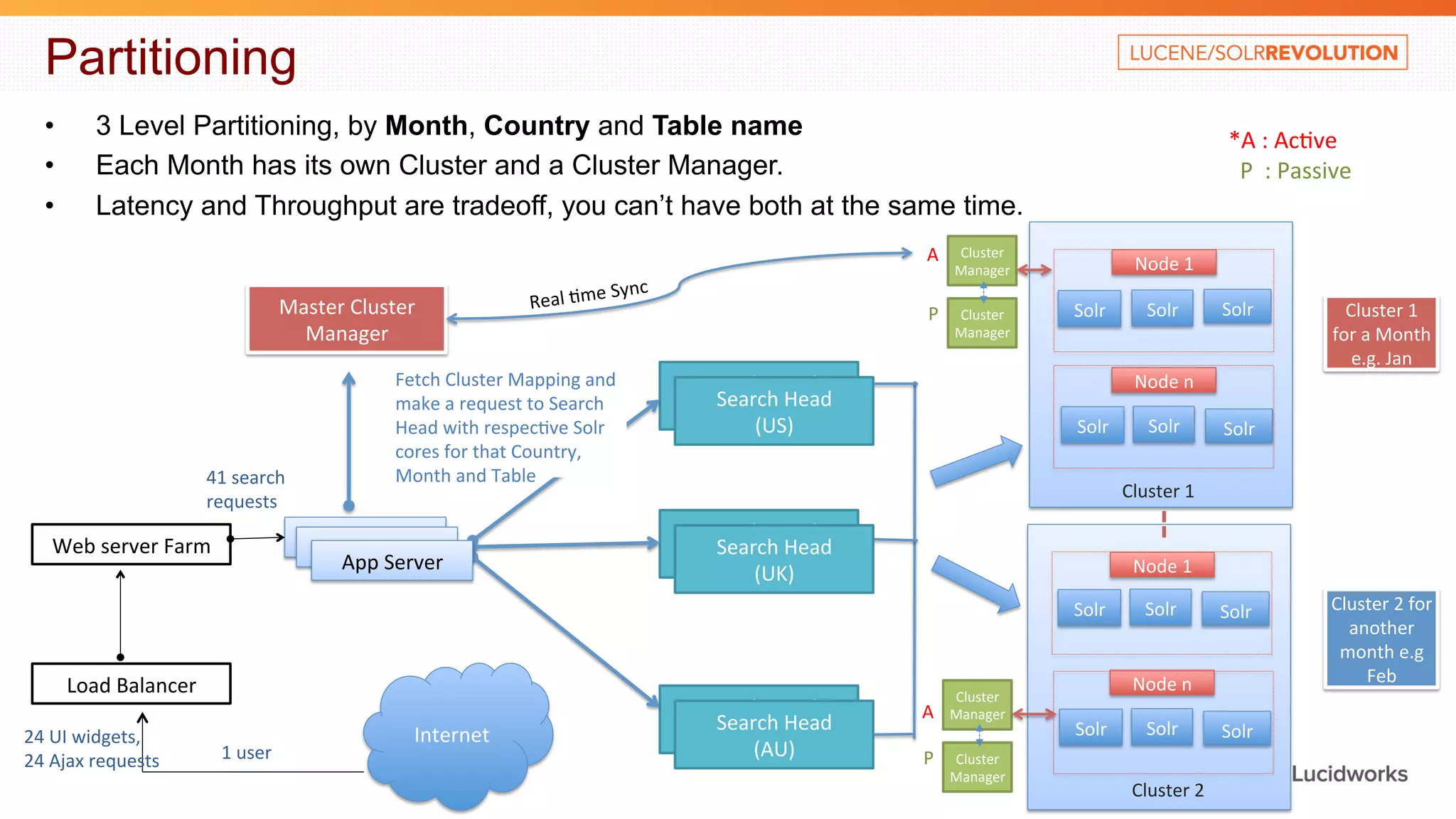
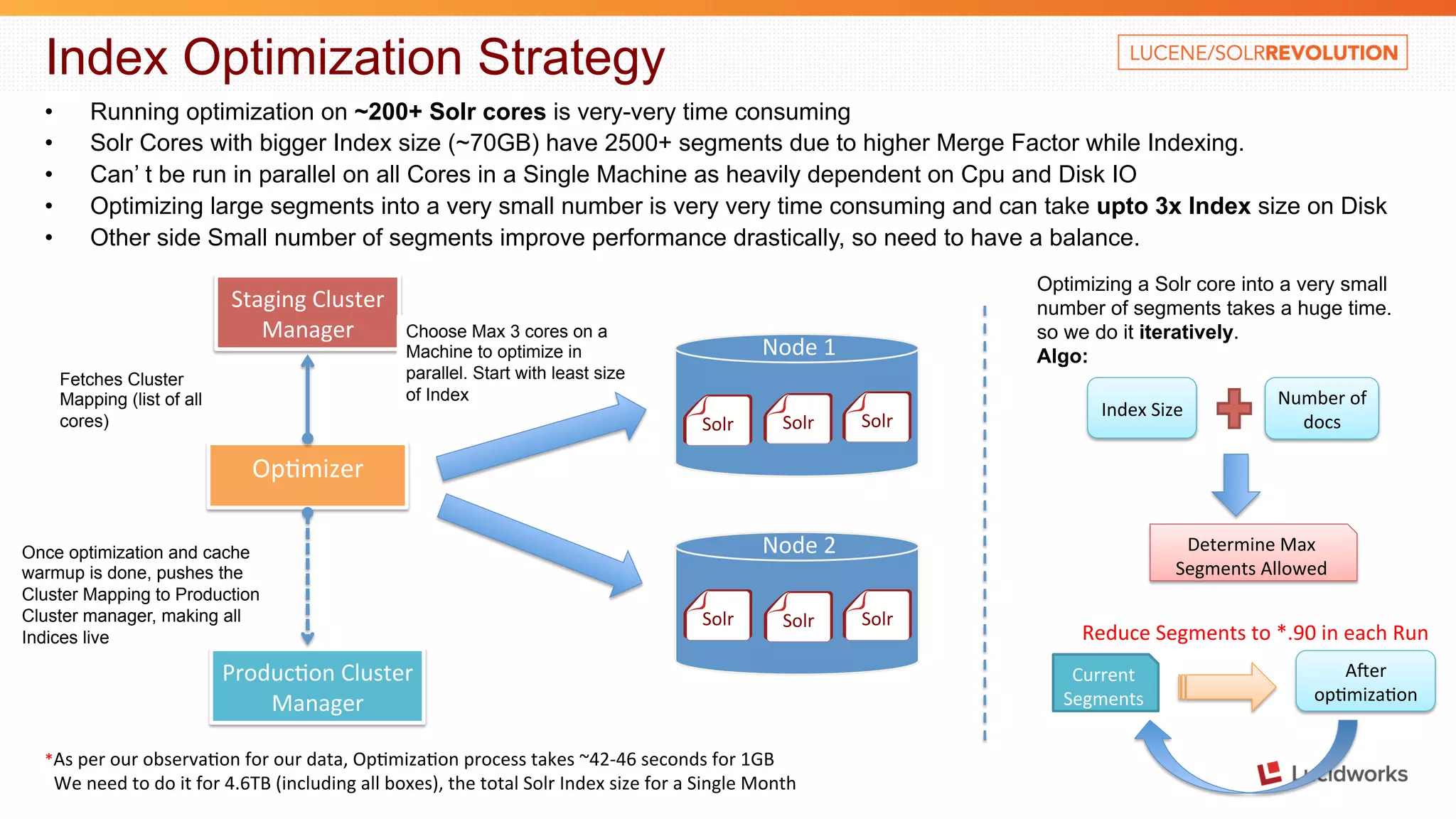



The document discusses building a large scale SEO/SEM application using Apache Solr. It describes some of the key challenges faced in indexing and searching over 40 billion records in the application's database each month. It discusses techniques used to optimize the data import process, create a distributed index across multiple tables, address out of memory errors, and improve search performance through partitioning, index optimization, and external caching.