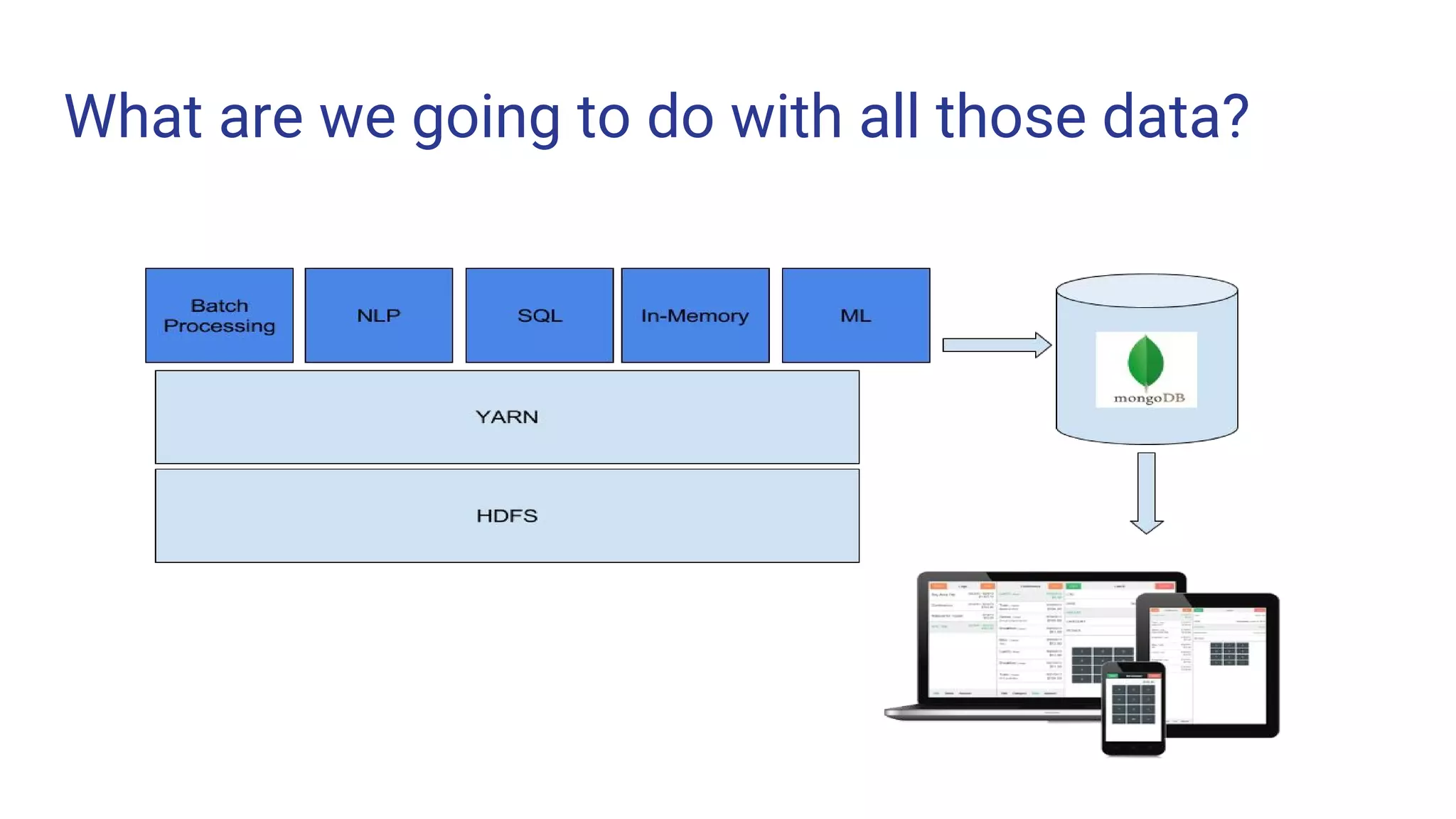
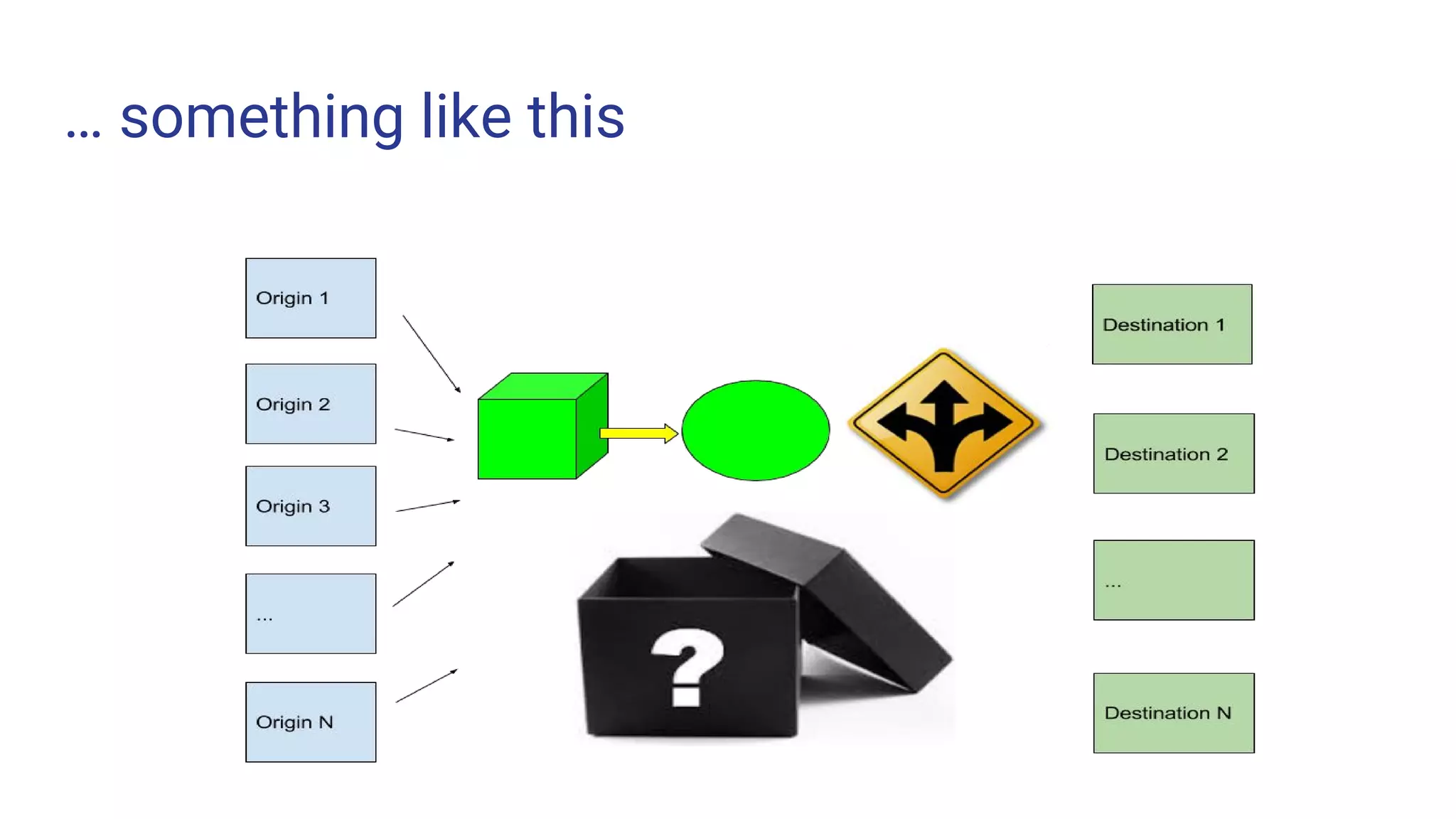
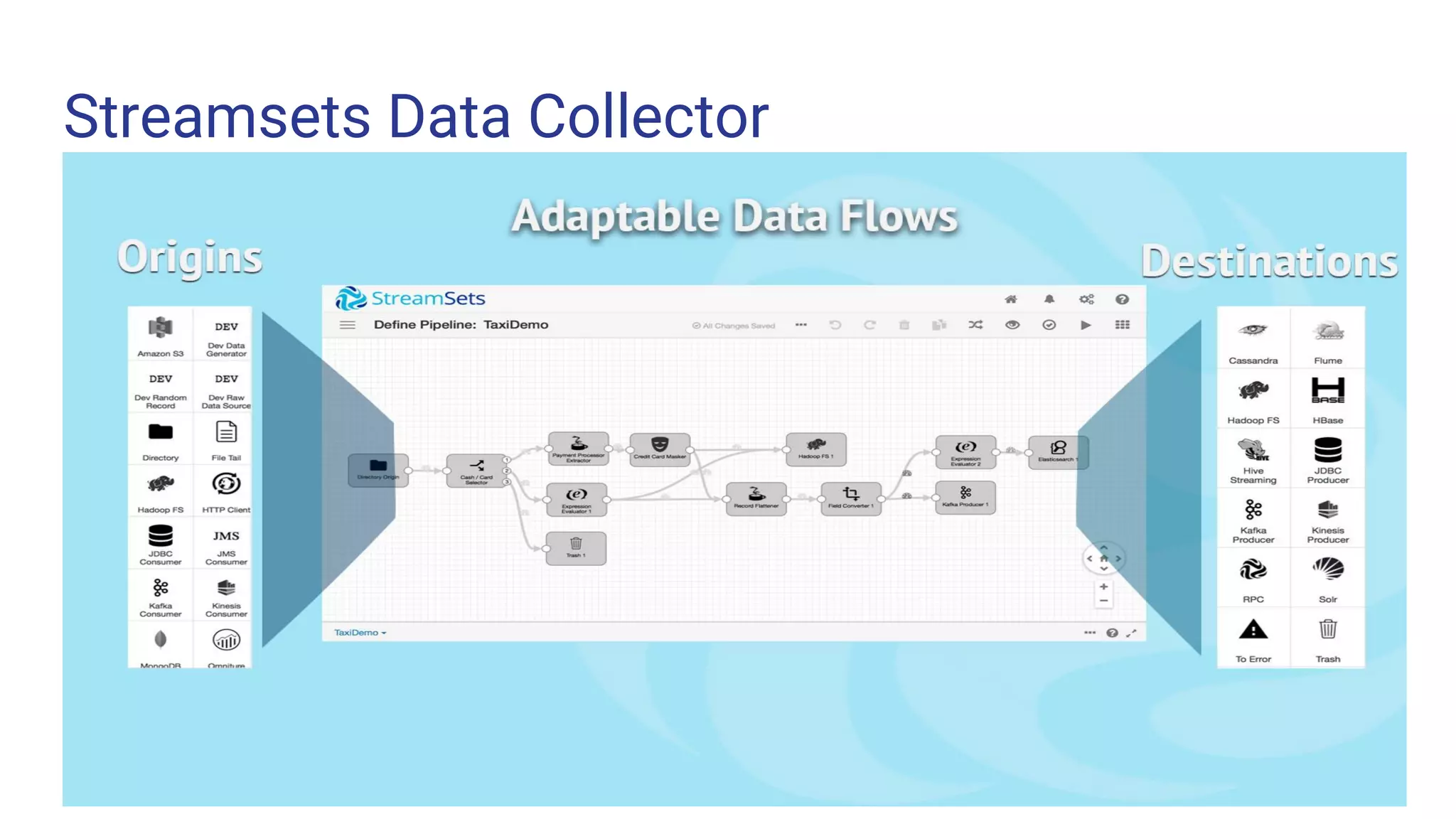
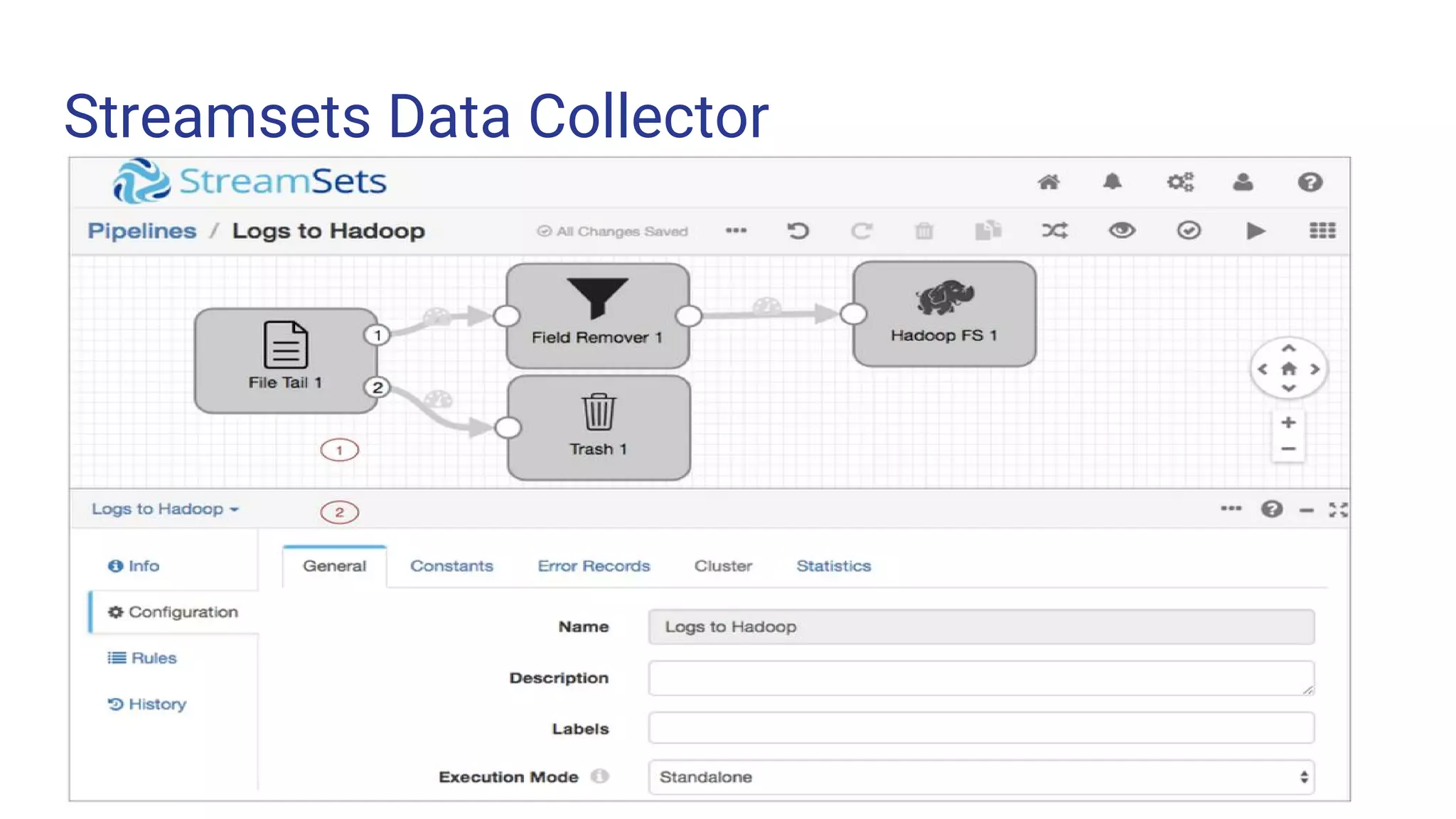
The document outlines the process of building a data pipeline for ingesting data into Hadoop using StreamSets Data Collector, addressing challenges like data redundancy and team skills. It emphasizes the need for a single tool that simplifies data ingestion while providing real-time monitoring and security features. It also includes a demo and links for further information on StreamSets Data Collector.