Download as KEY, PPTX











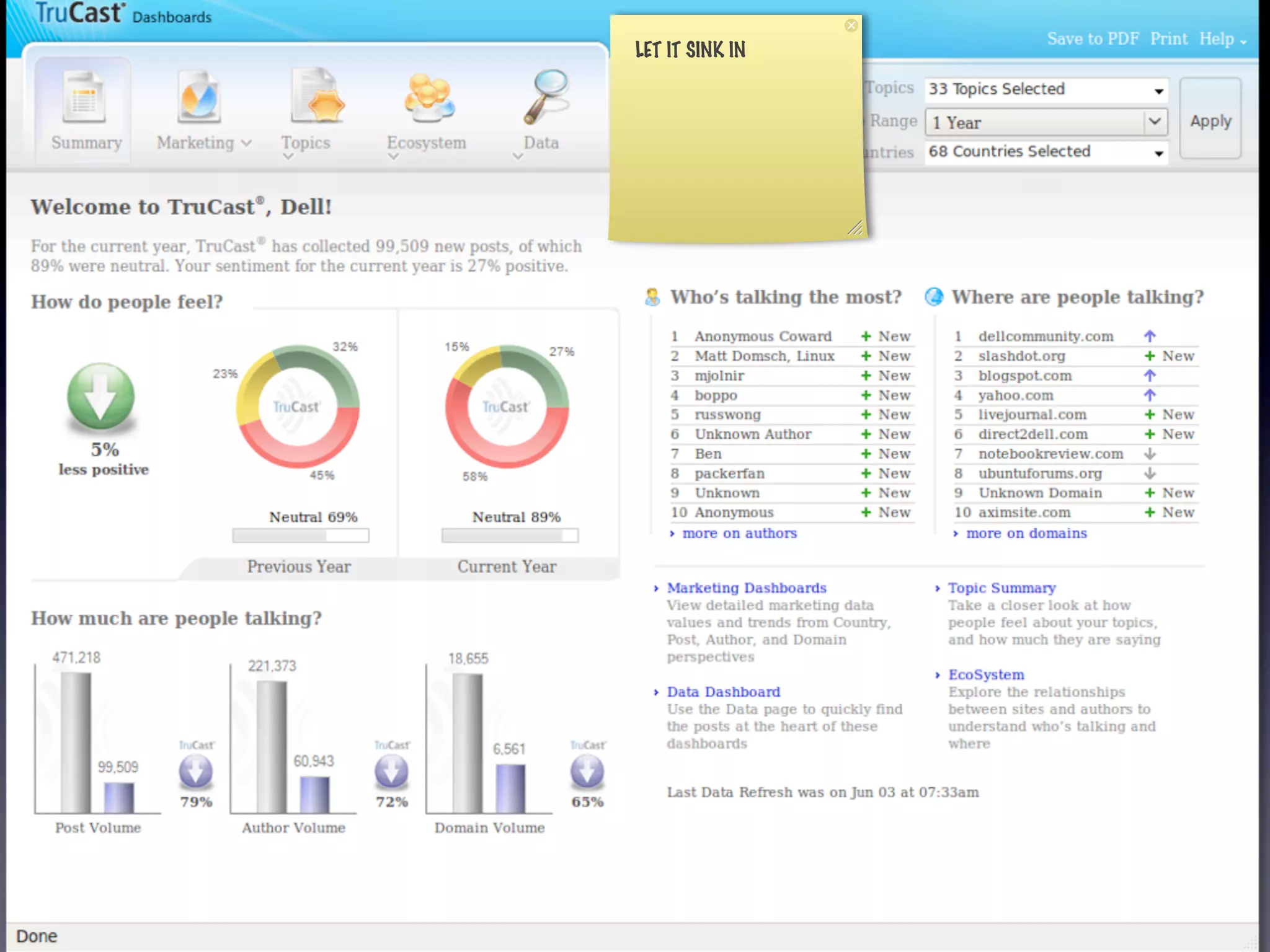
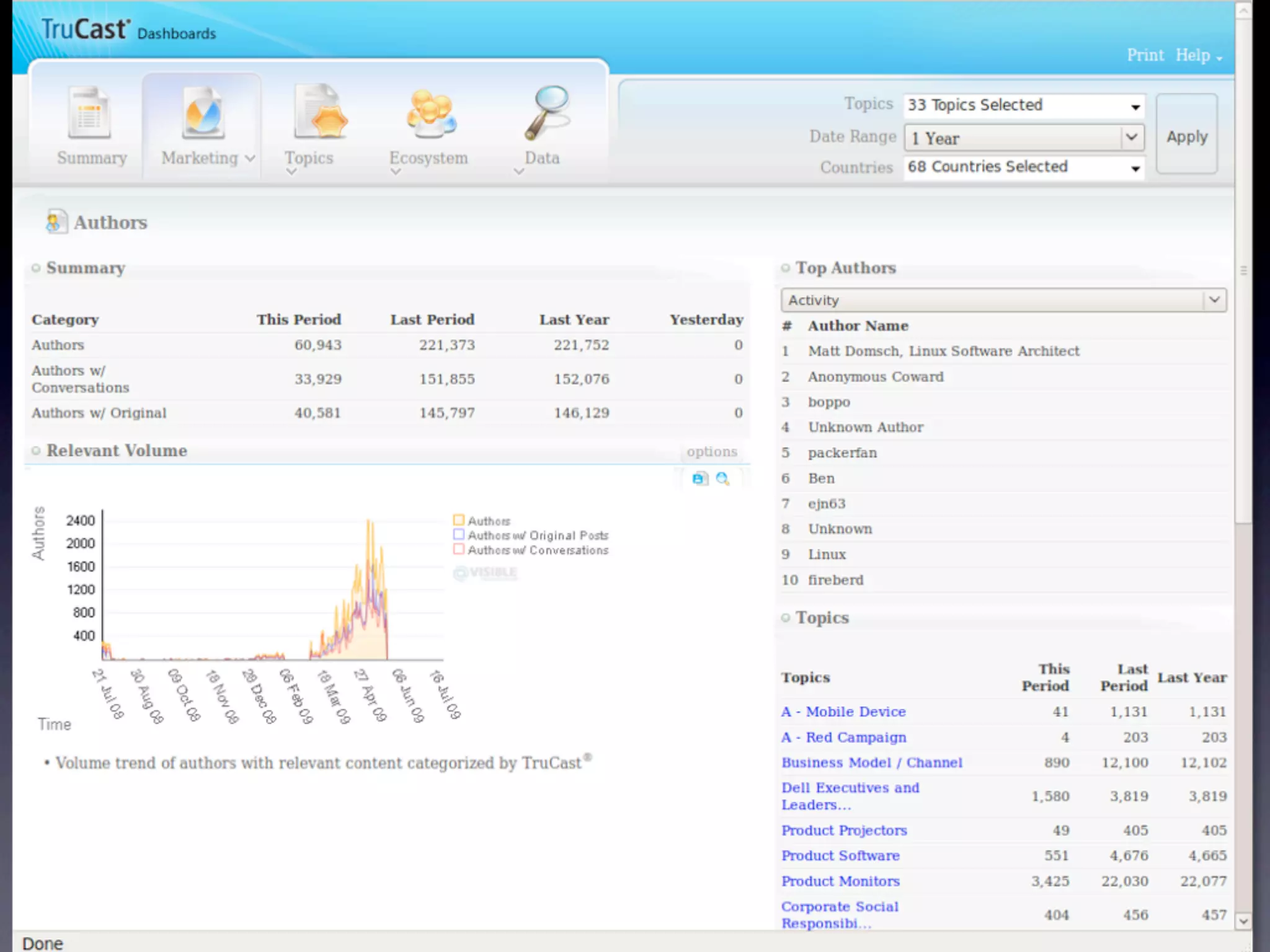
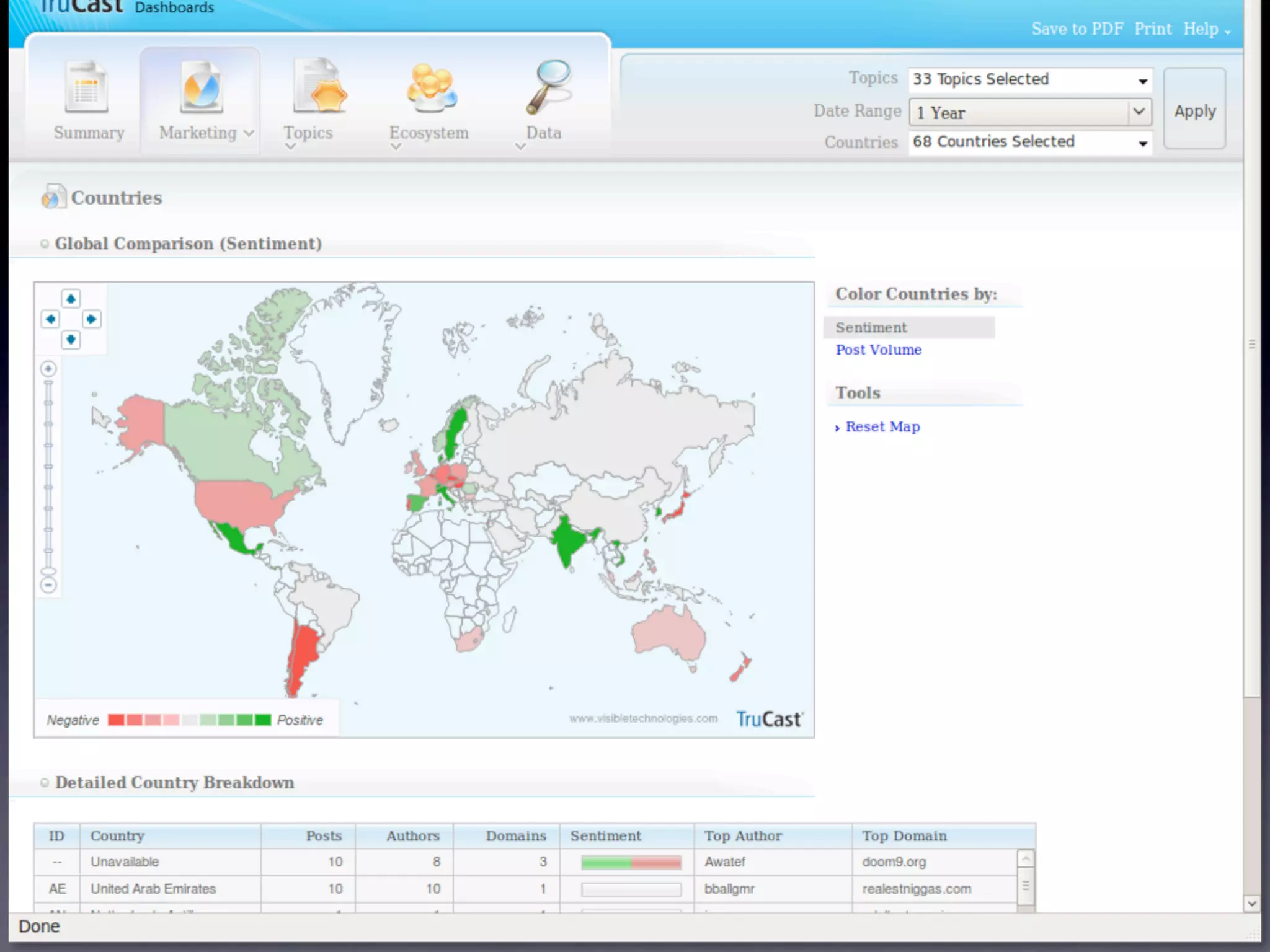































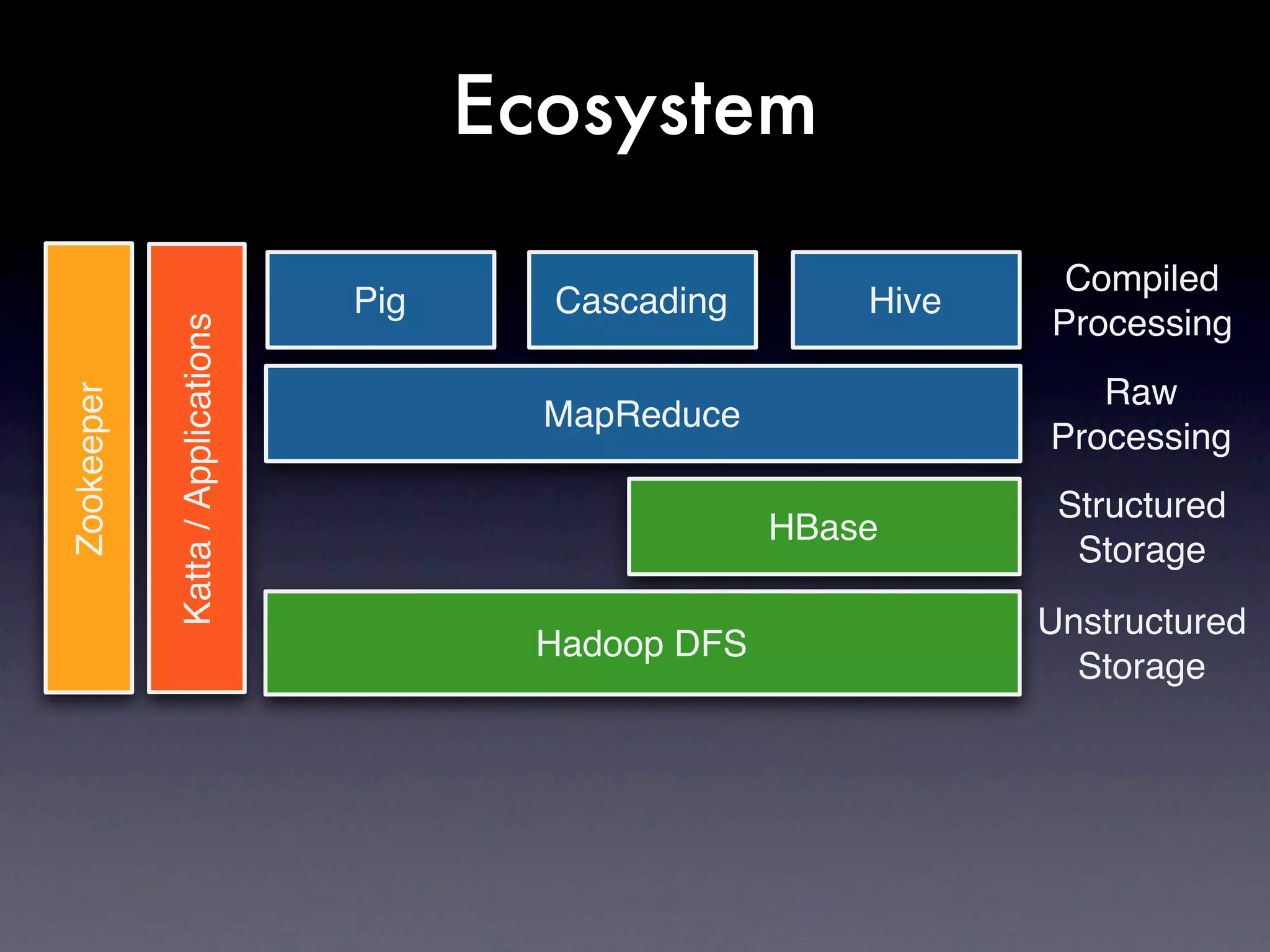
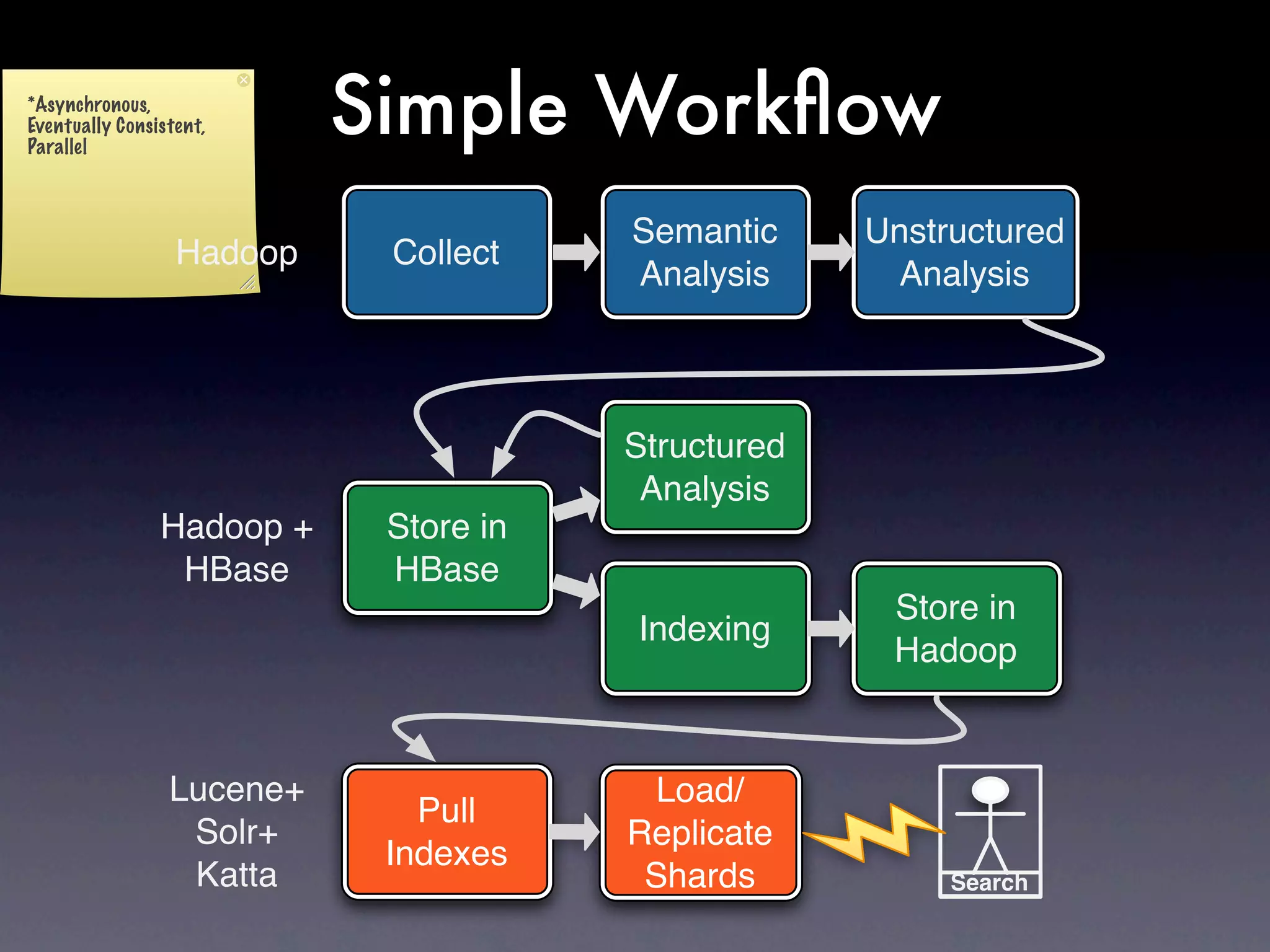
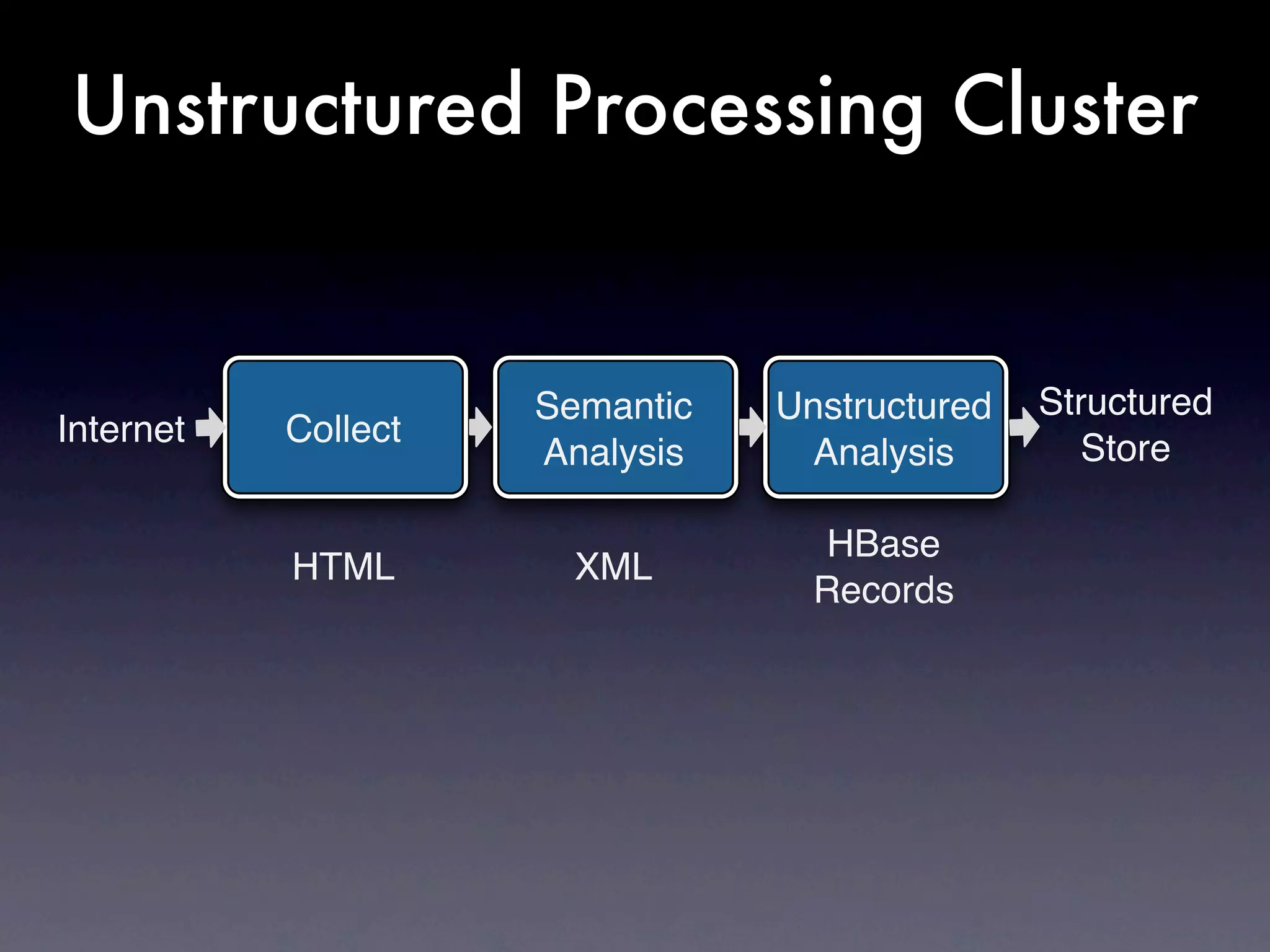




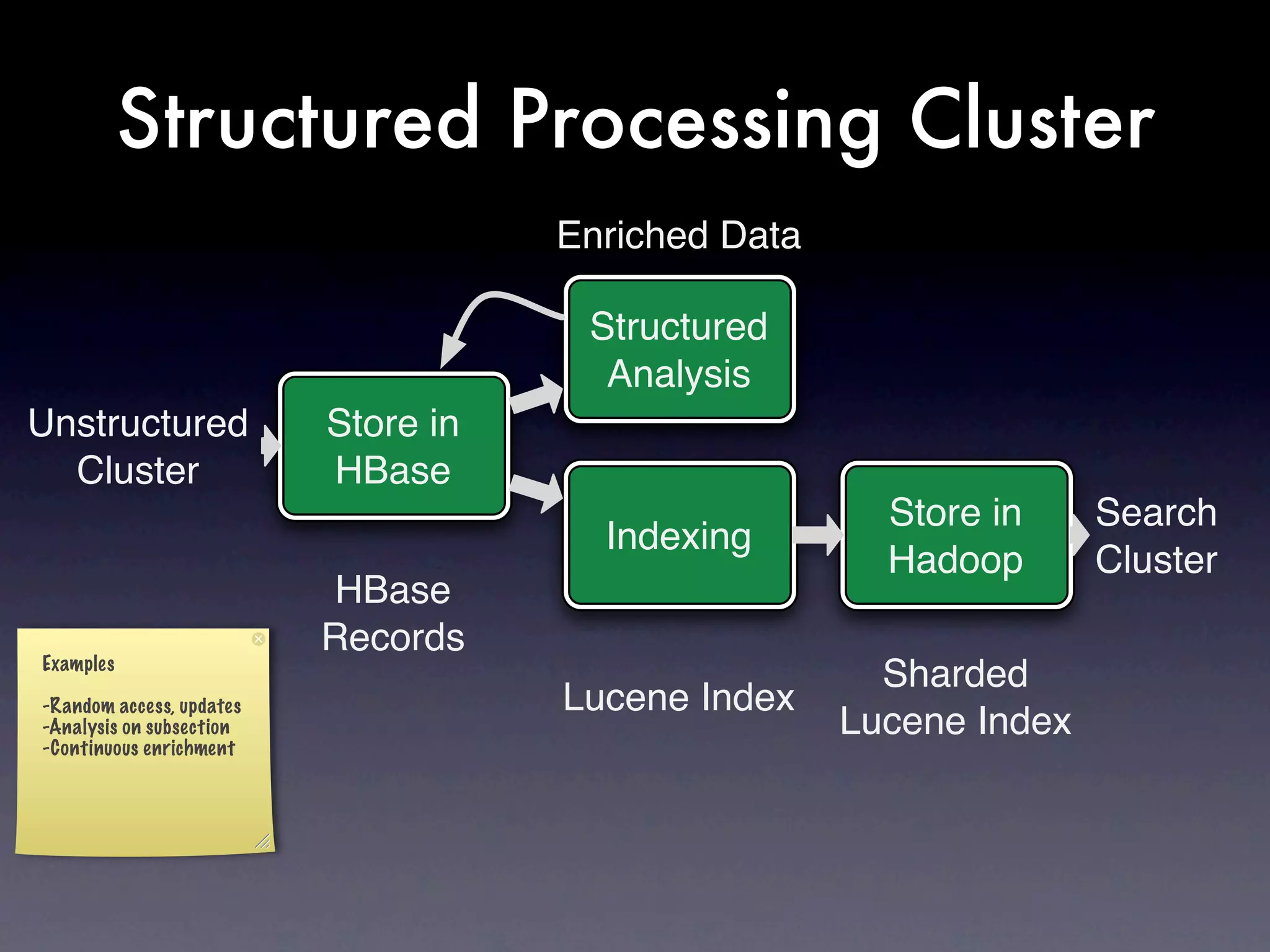





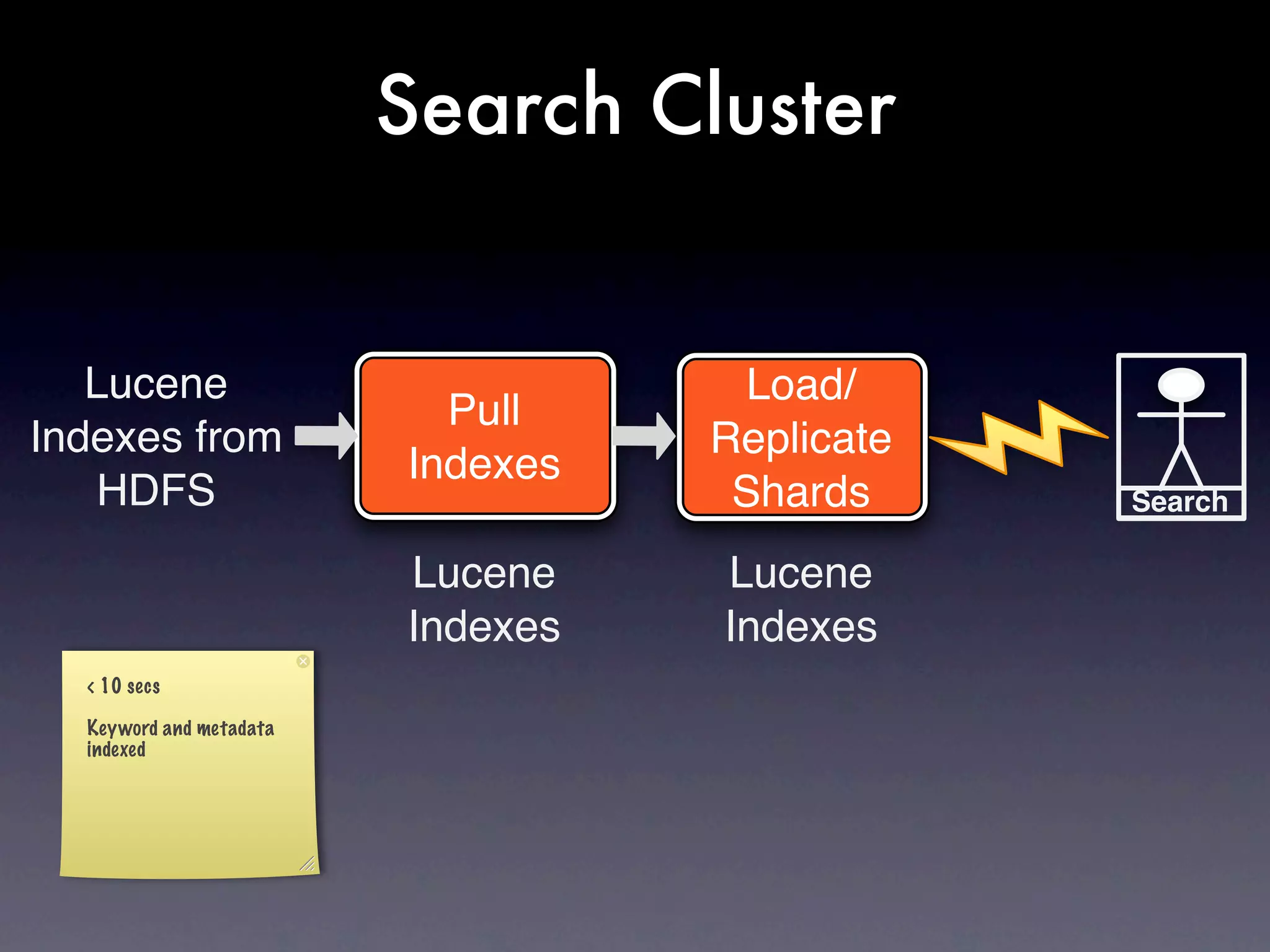




























The document discusses the building of a business focused on open-source distributed computing, emphasizing the importance of scalability and the transition from traditional RDBMS to more flexible and efficient data handling solutions. It outlines the challenges and sacrifices associated with various data processing methods, including Hadoop and NoSQL technologies like HBase. The goal is to create a platform capable of analyzing any data with linear costs while addressing issues of latency and structure.