Download to read offline







































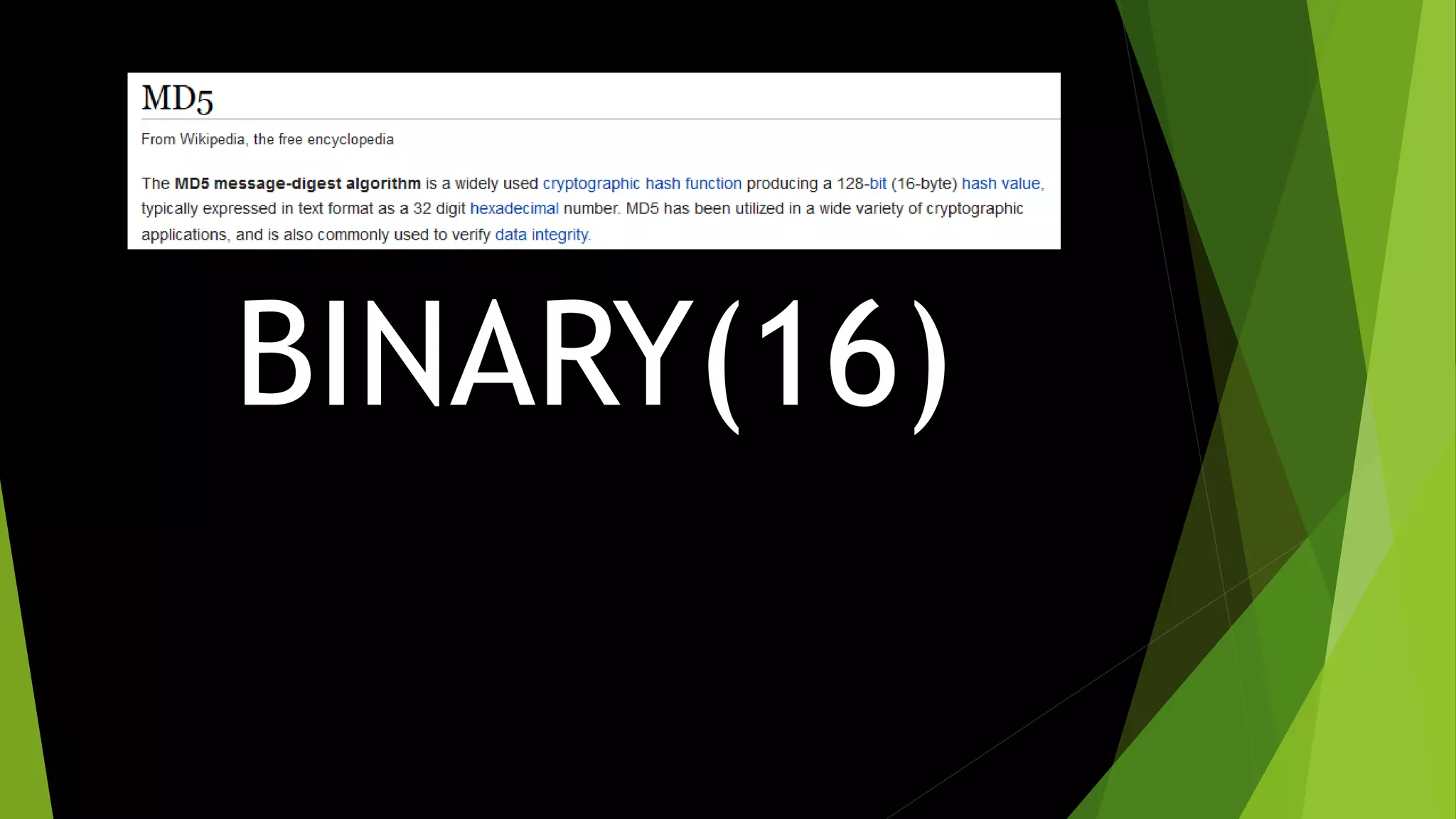








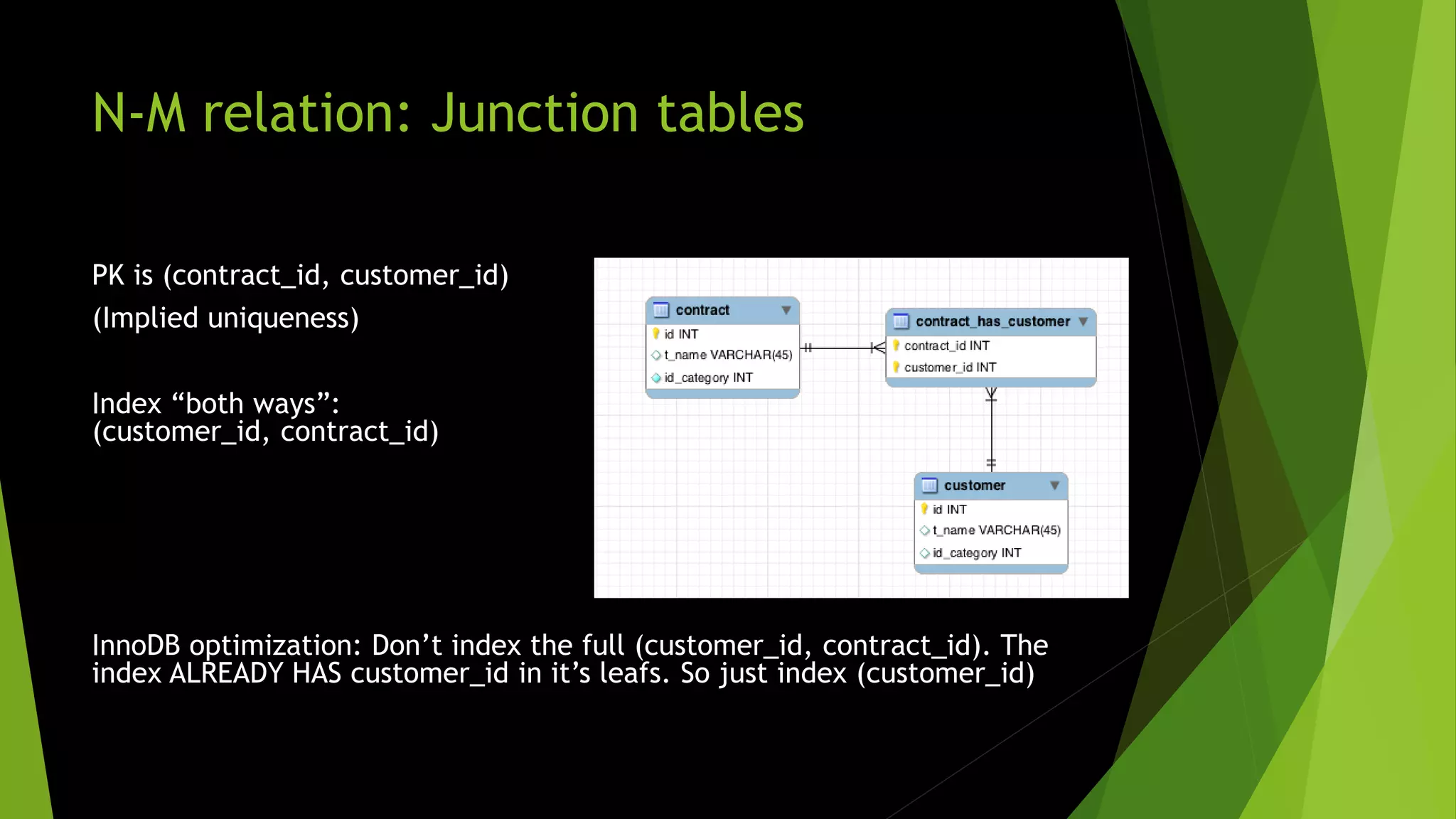












The document emphasizes the importance of proper database design and optimization, advising against default denormalization and promoting careful selection of data types to enhance performance and scalability. It covers topics such as the significance of efficient schema design, the impact of various data types on storage, and the value of indexing in query performance. Key takeaways include the recommendation to avoid overly large data types and to utilize surrogate keys effectively while maintaining optimal indexing strategies.