Downloaded 185 times



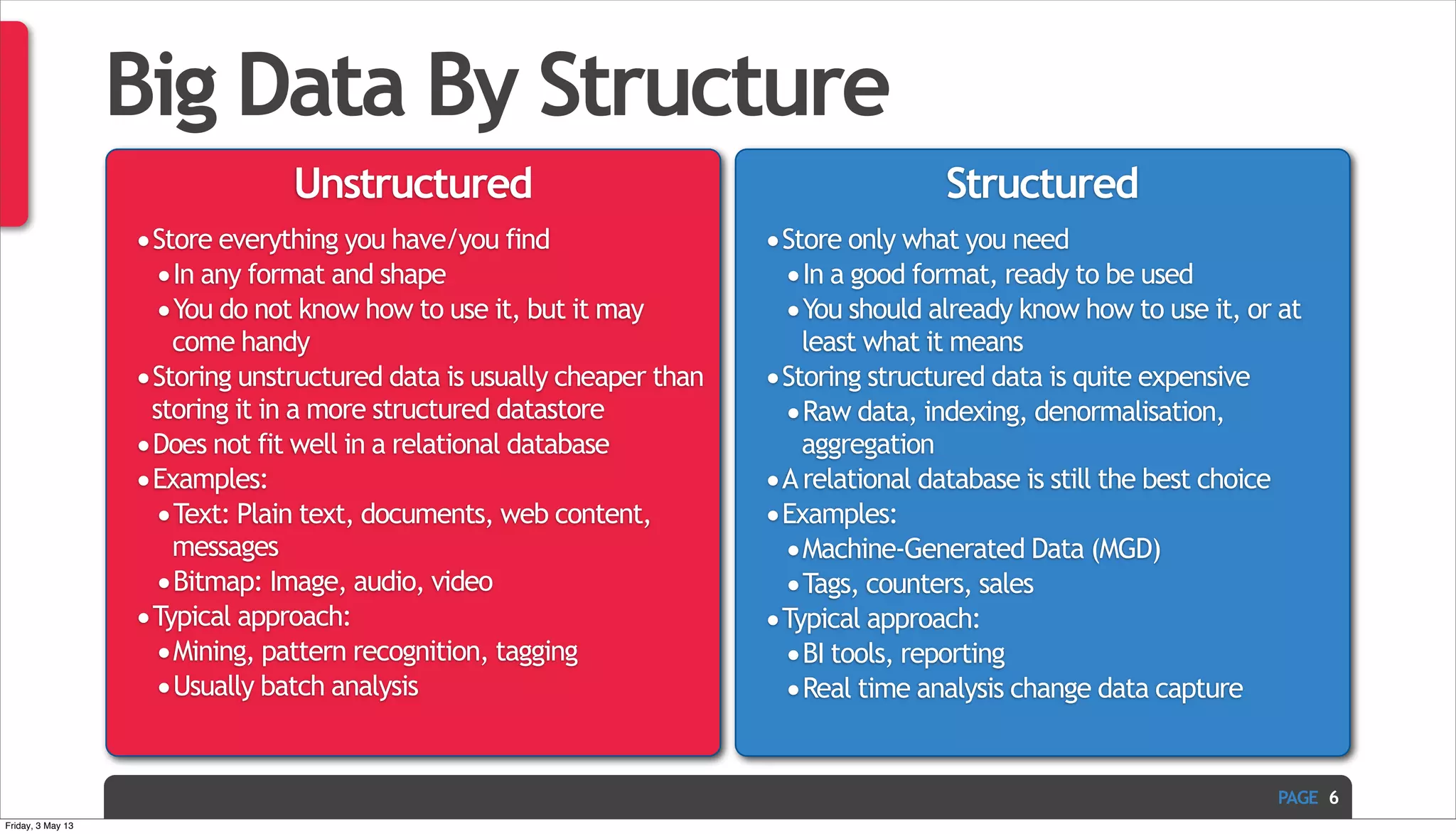
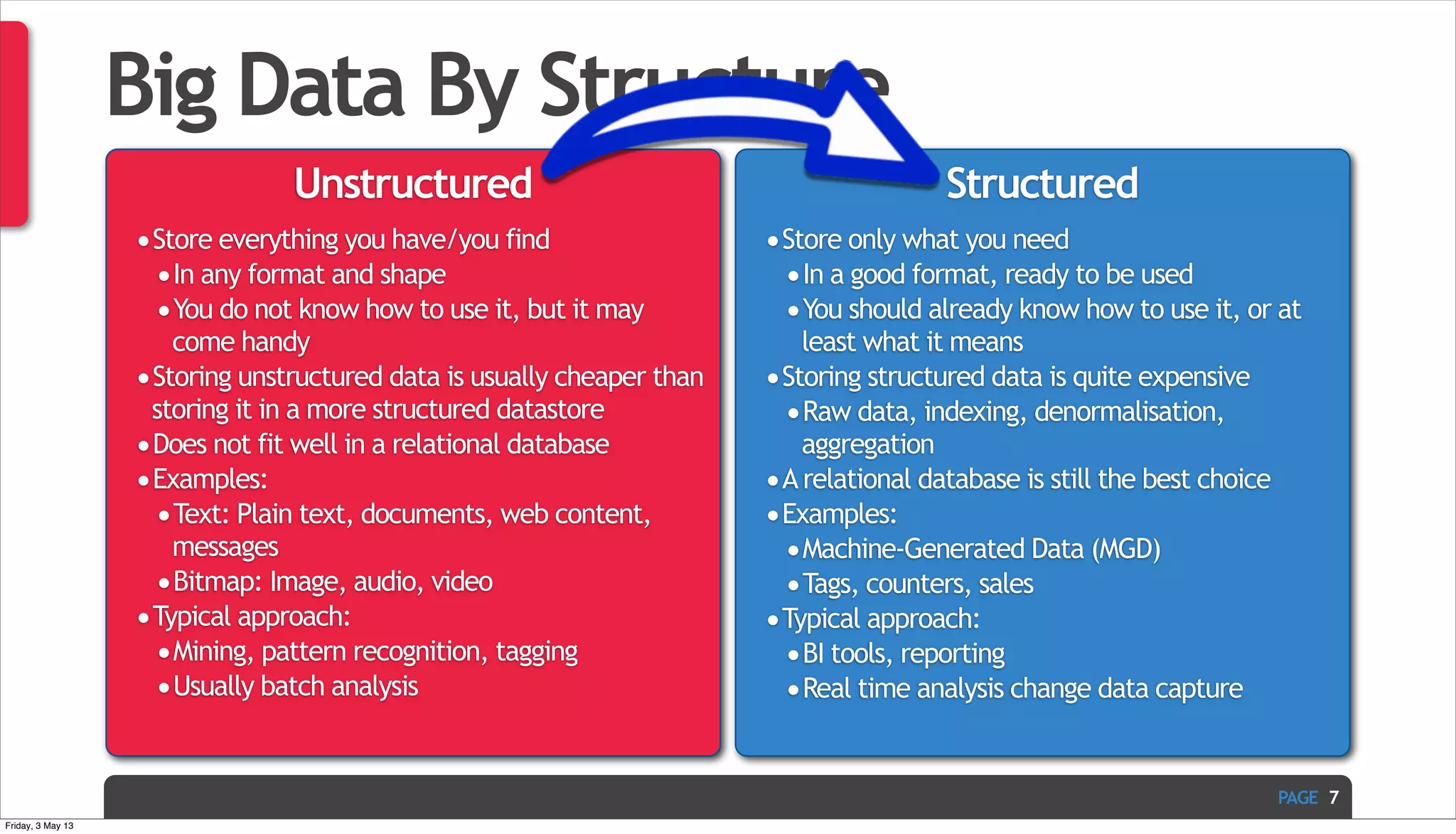




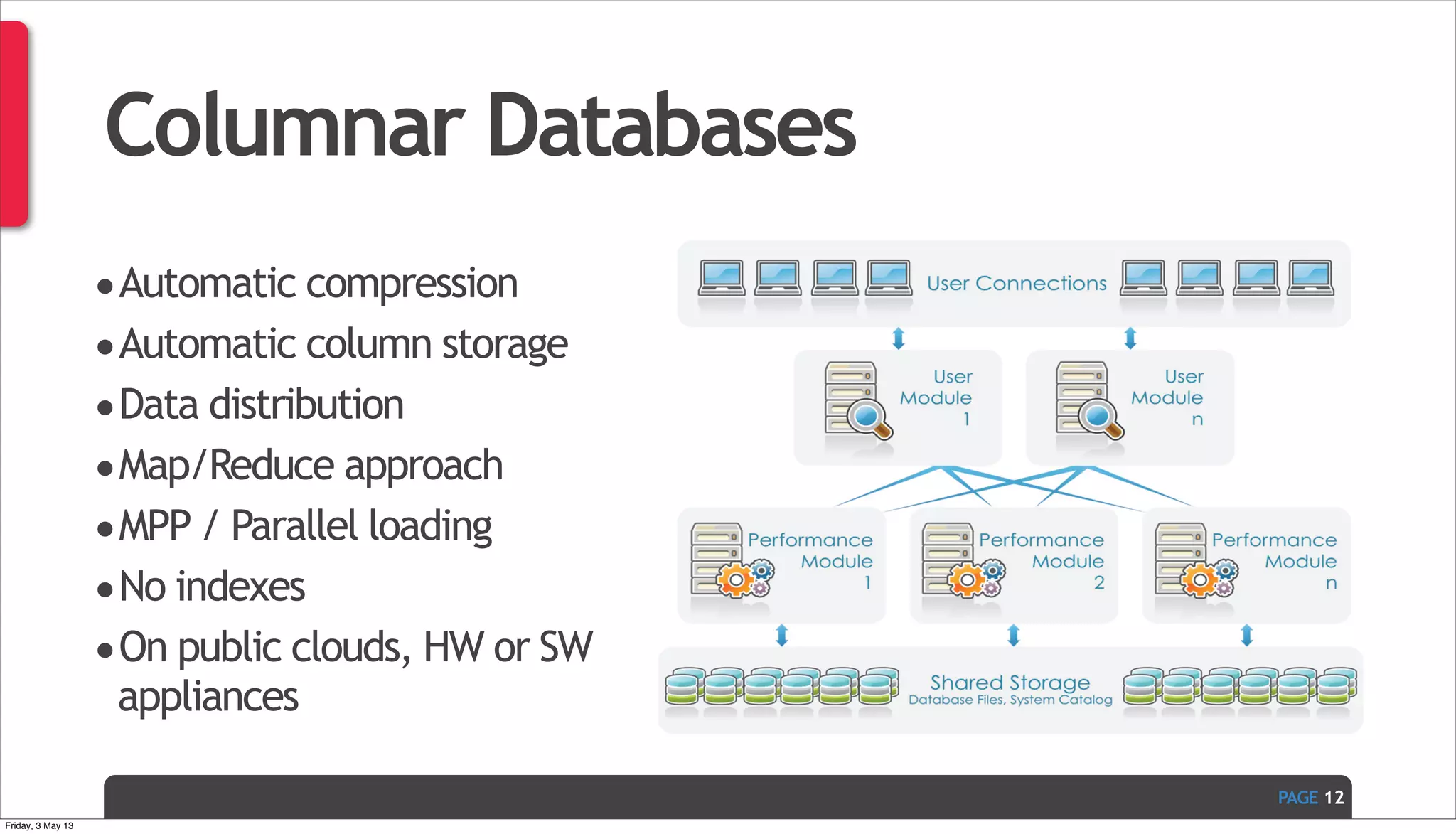
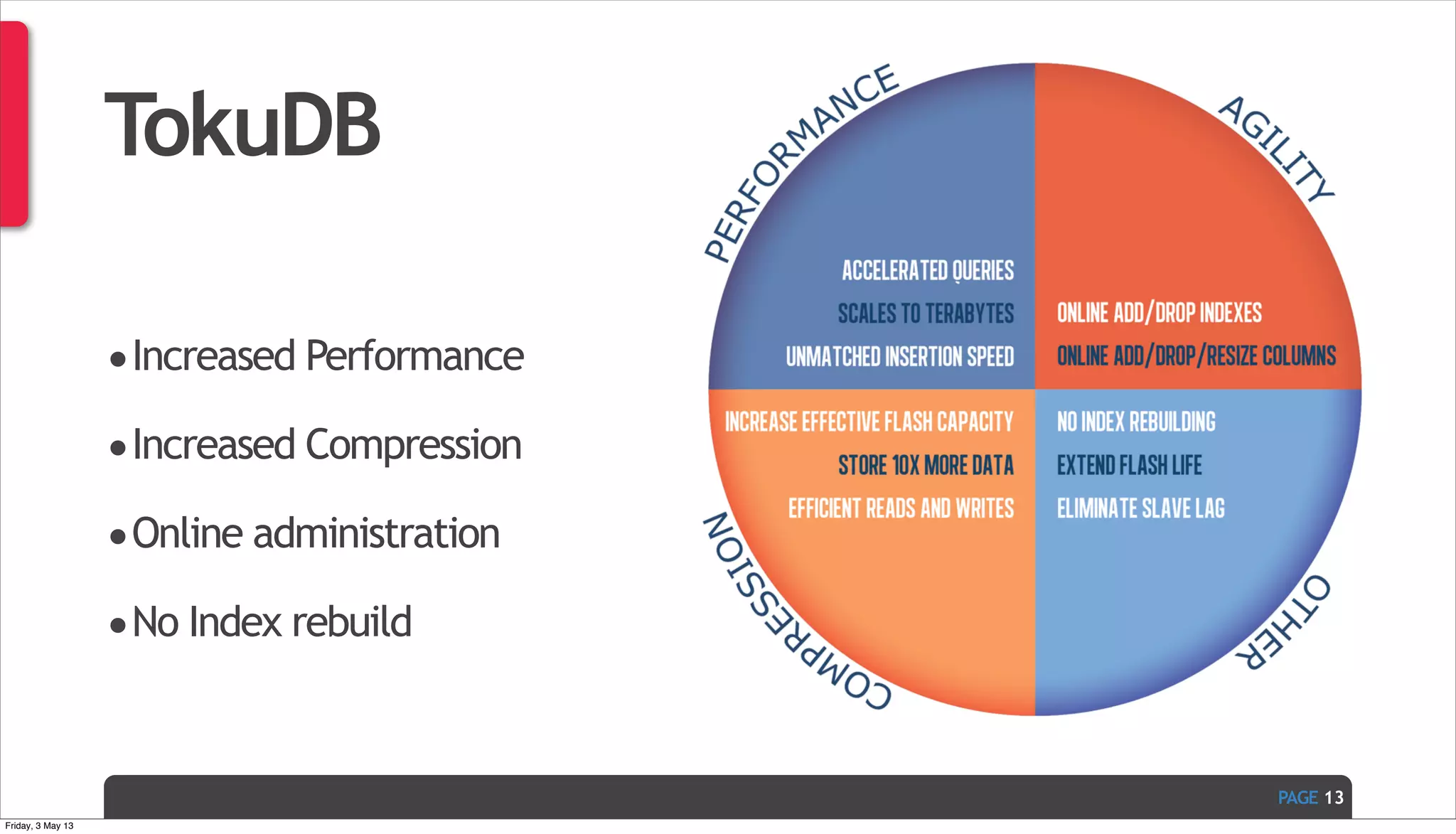
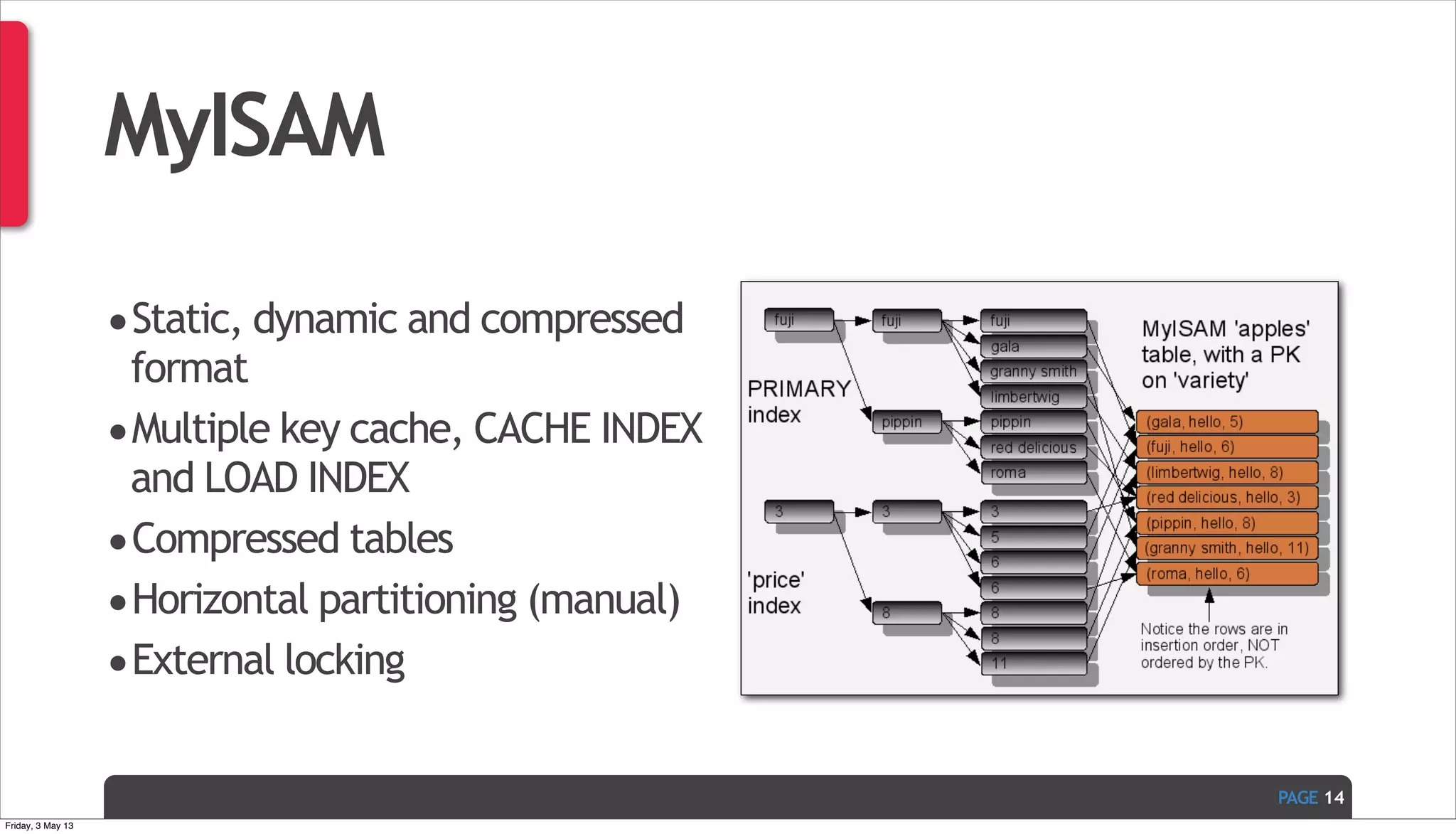




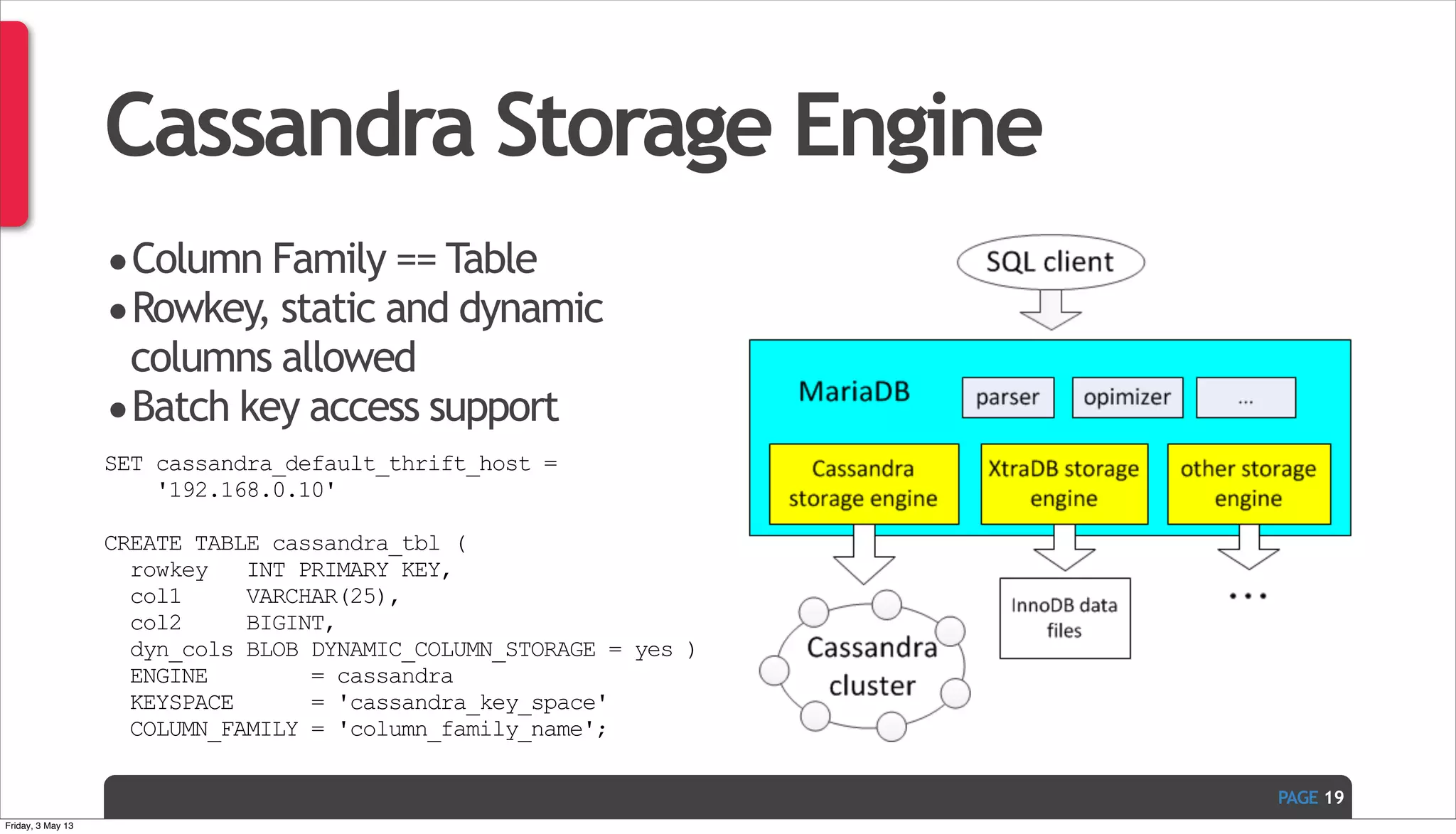



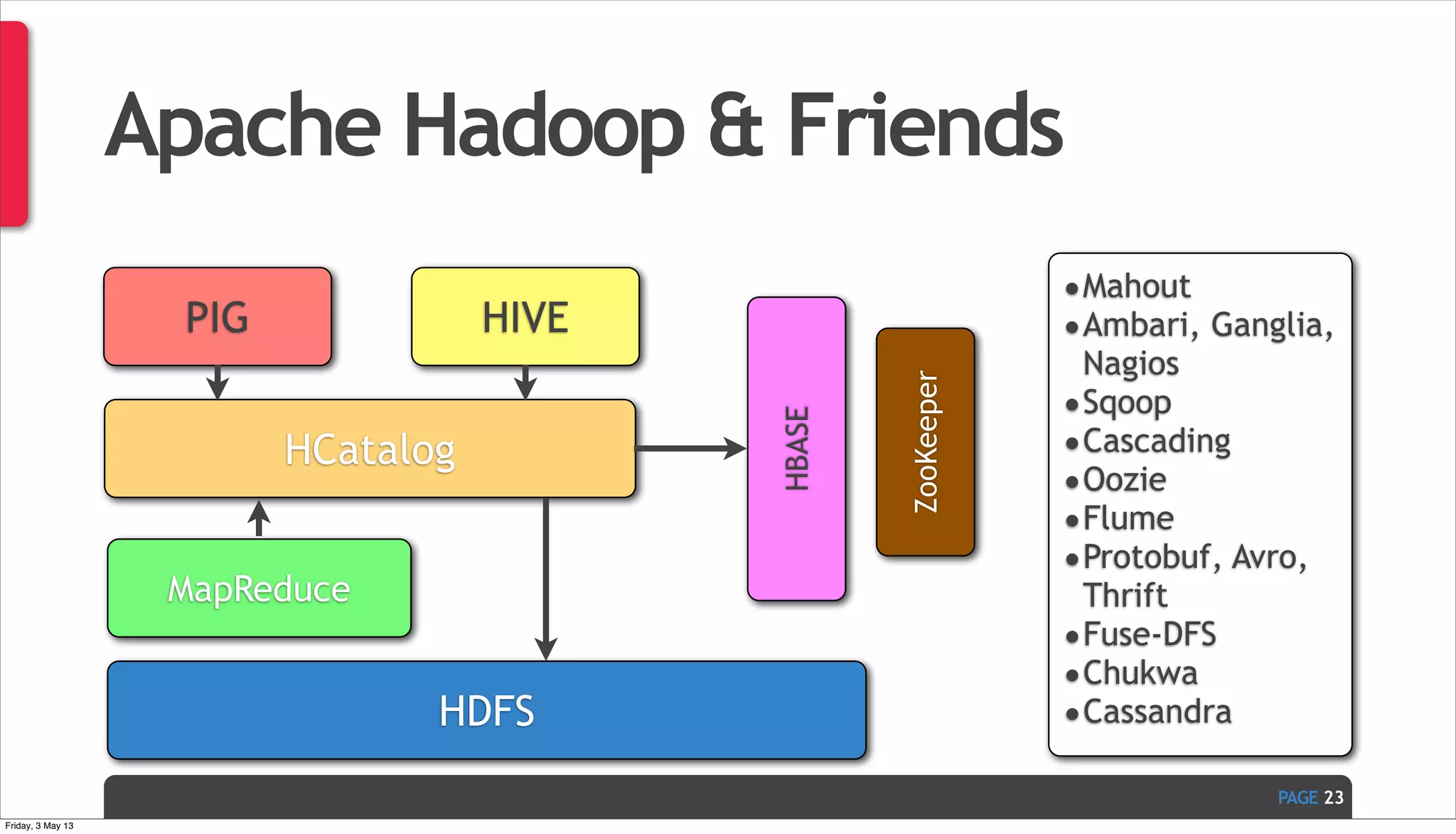
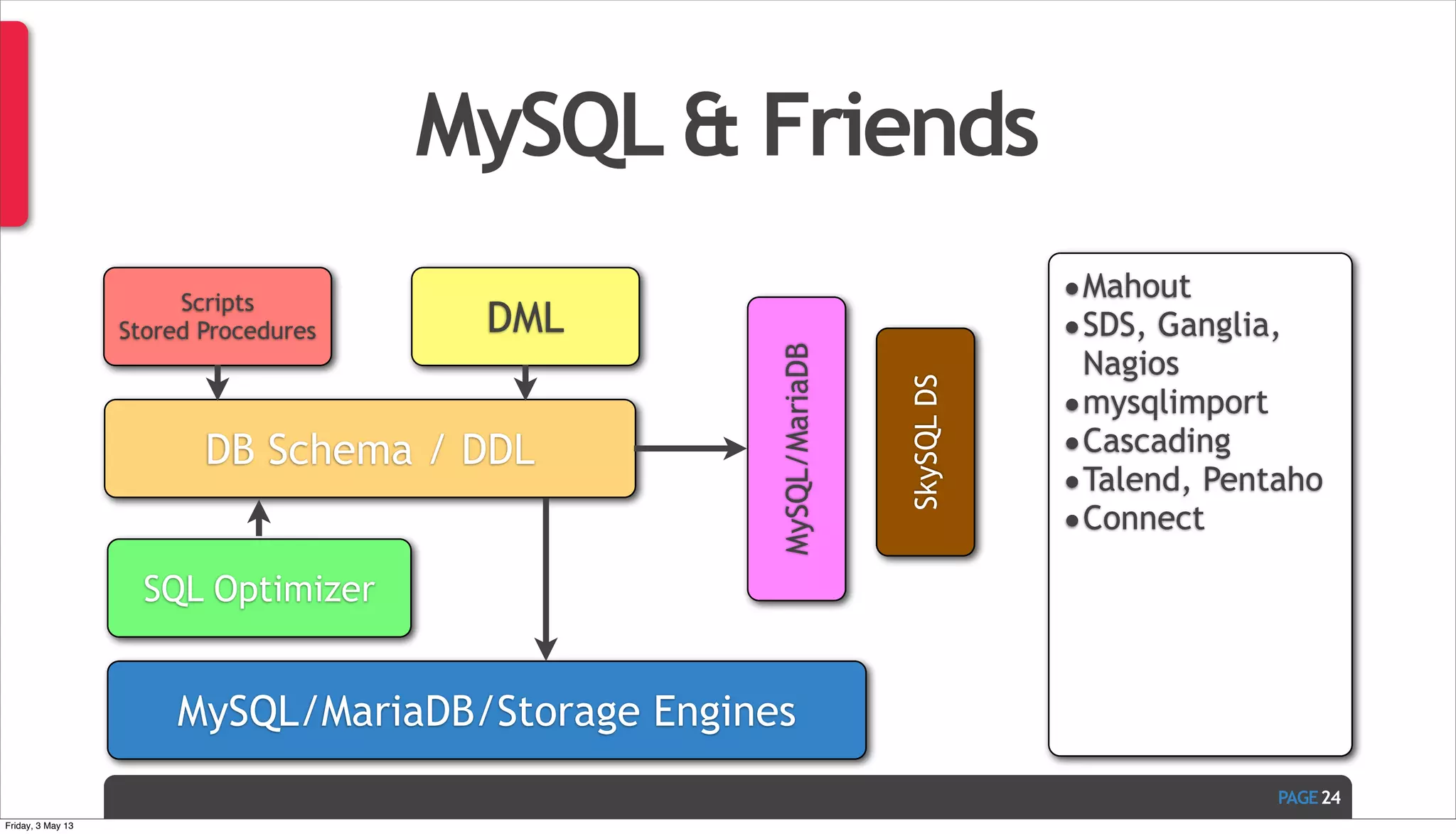



The document discusses Ivan Zoratti's presentation on using MySQL for big data. It defines big data and how it can be structured as either unstructured or structured data. It then outlines various technologies that can be used with MySQL like storage engines, partitioning, columnar databases, and the MariaDB optimizer. The presentation provides an overview of how these technologies can help manage large and complex data sets with MySQL.