Downloaded 266 times






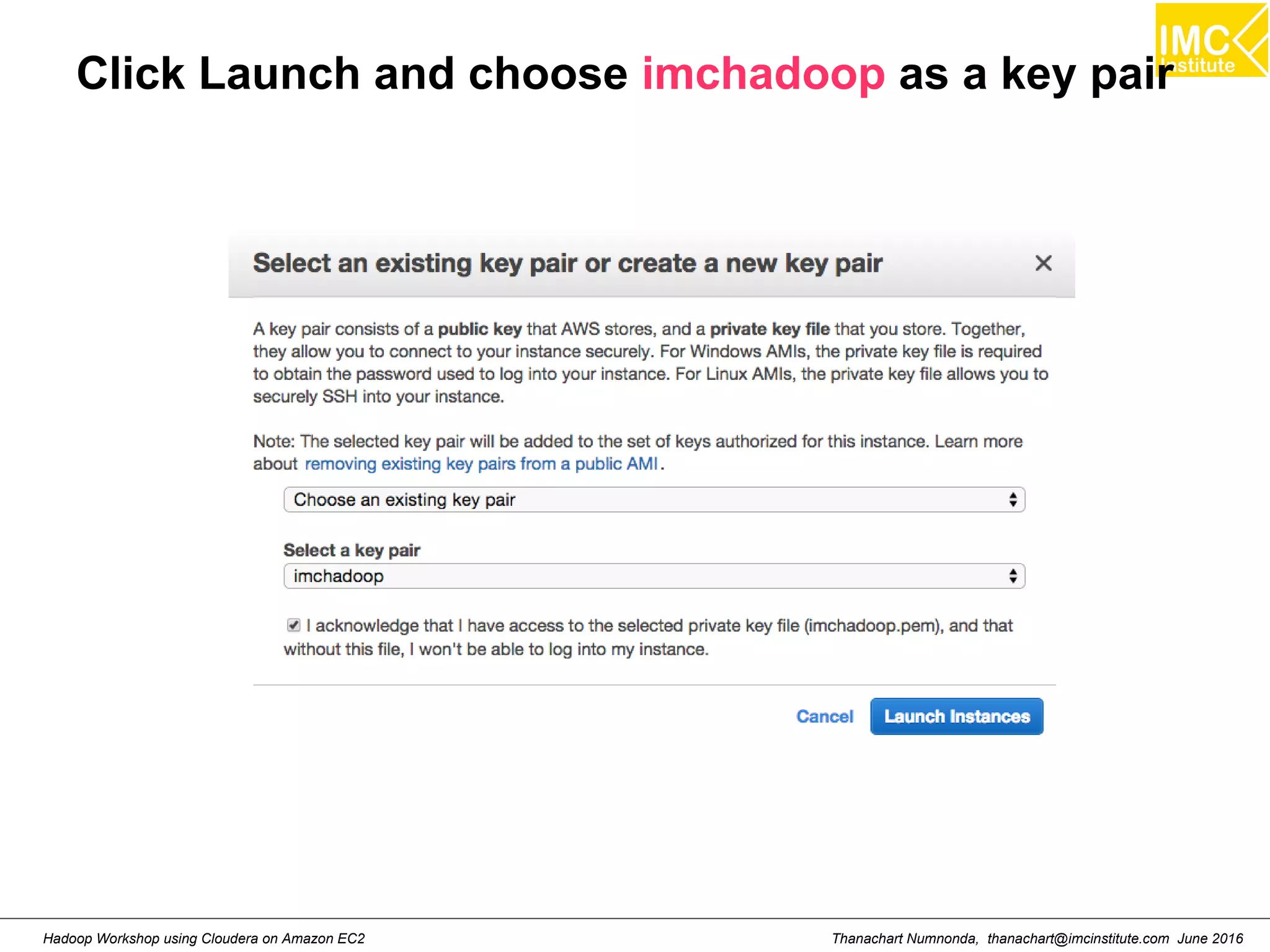
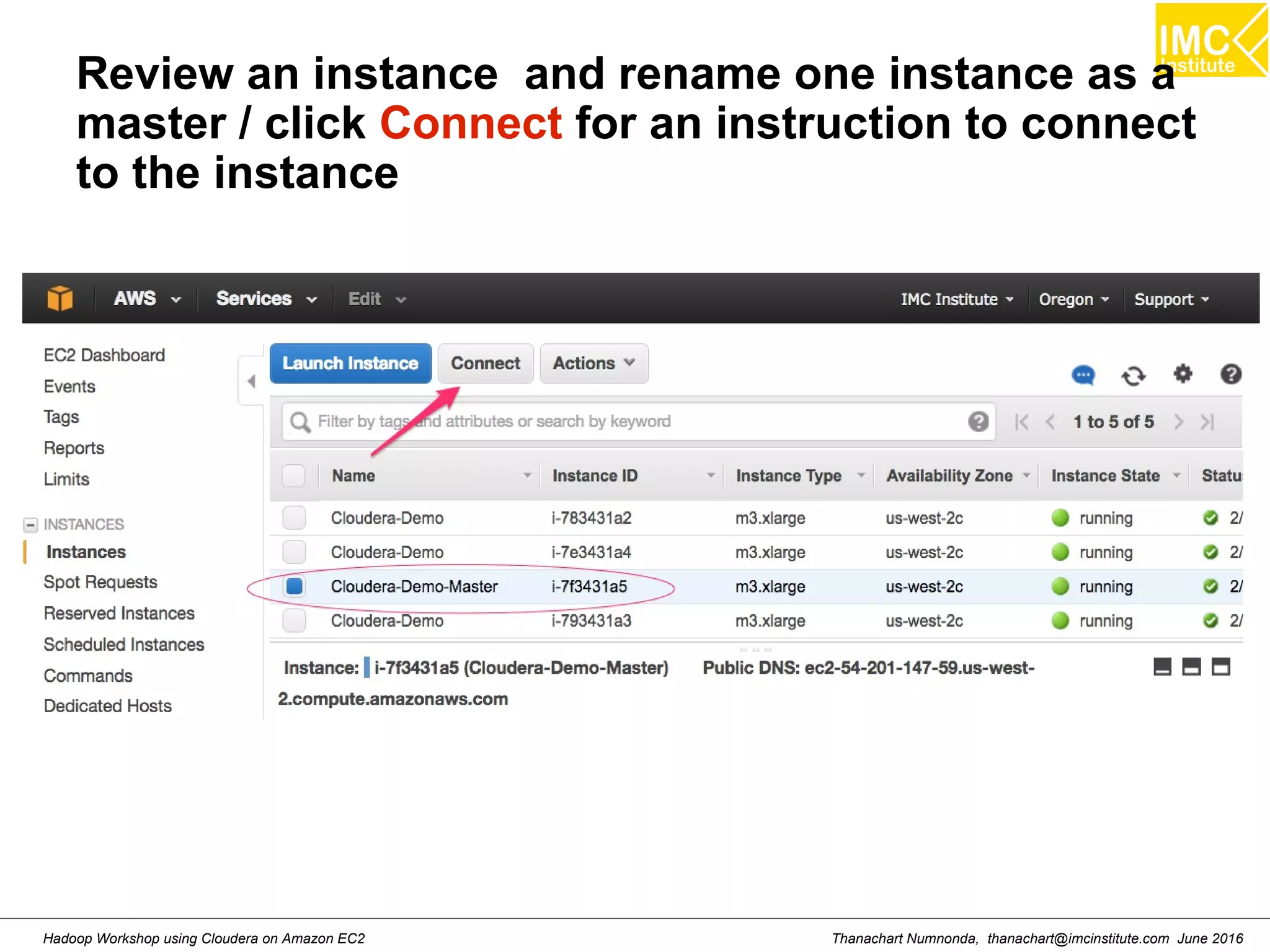
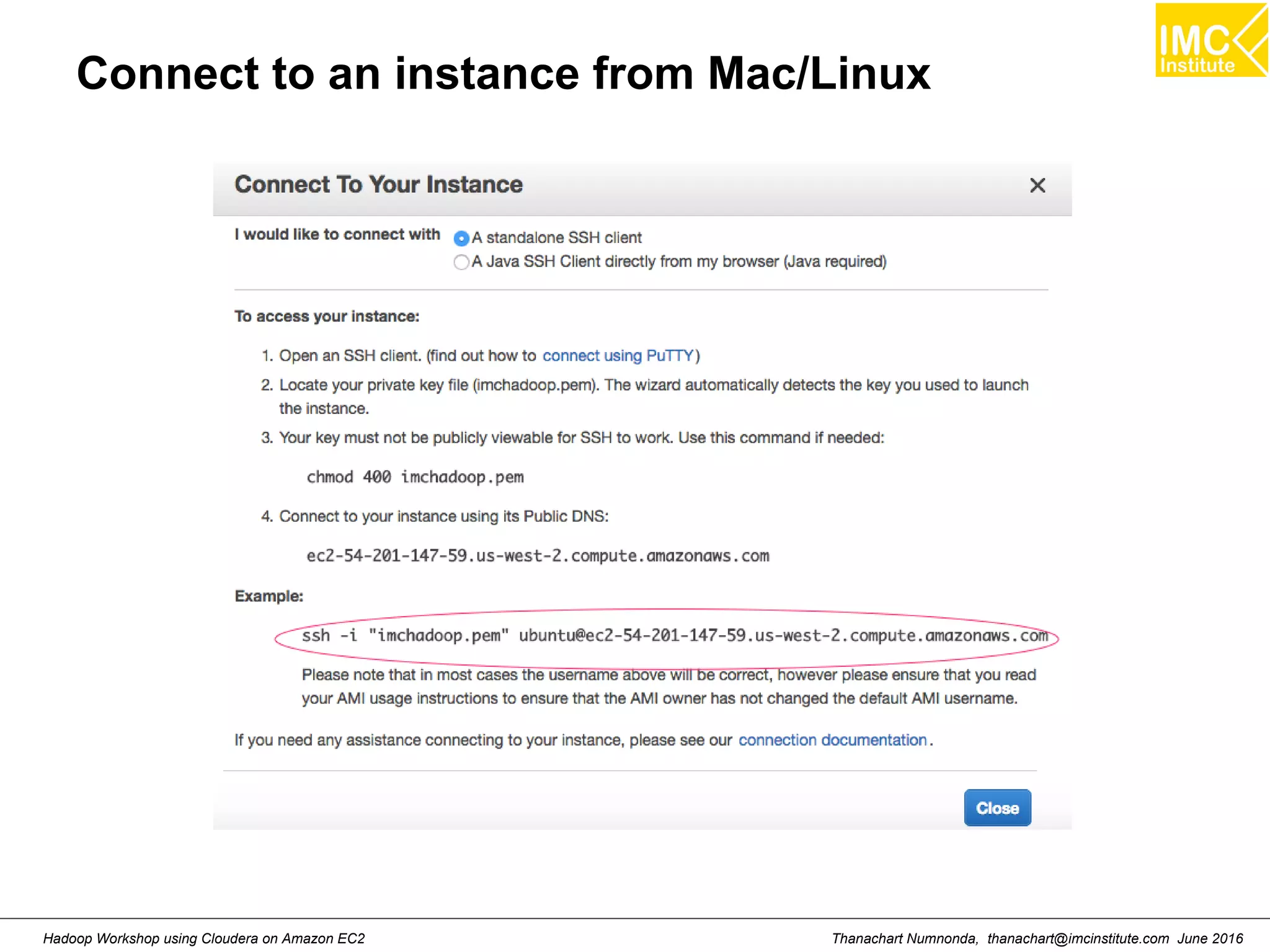
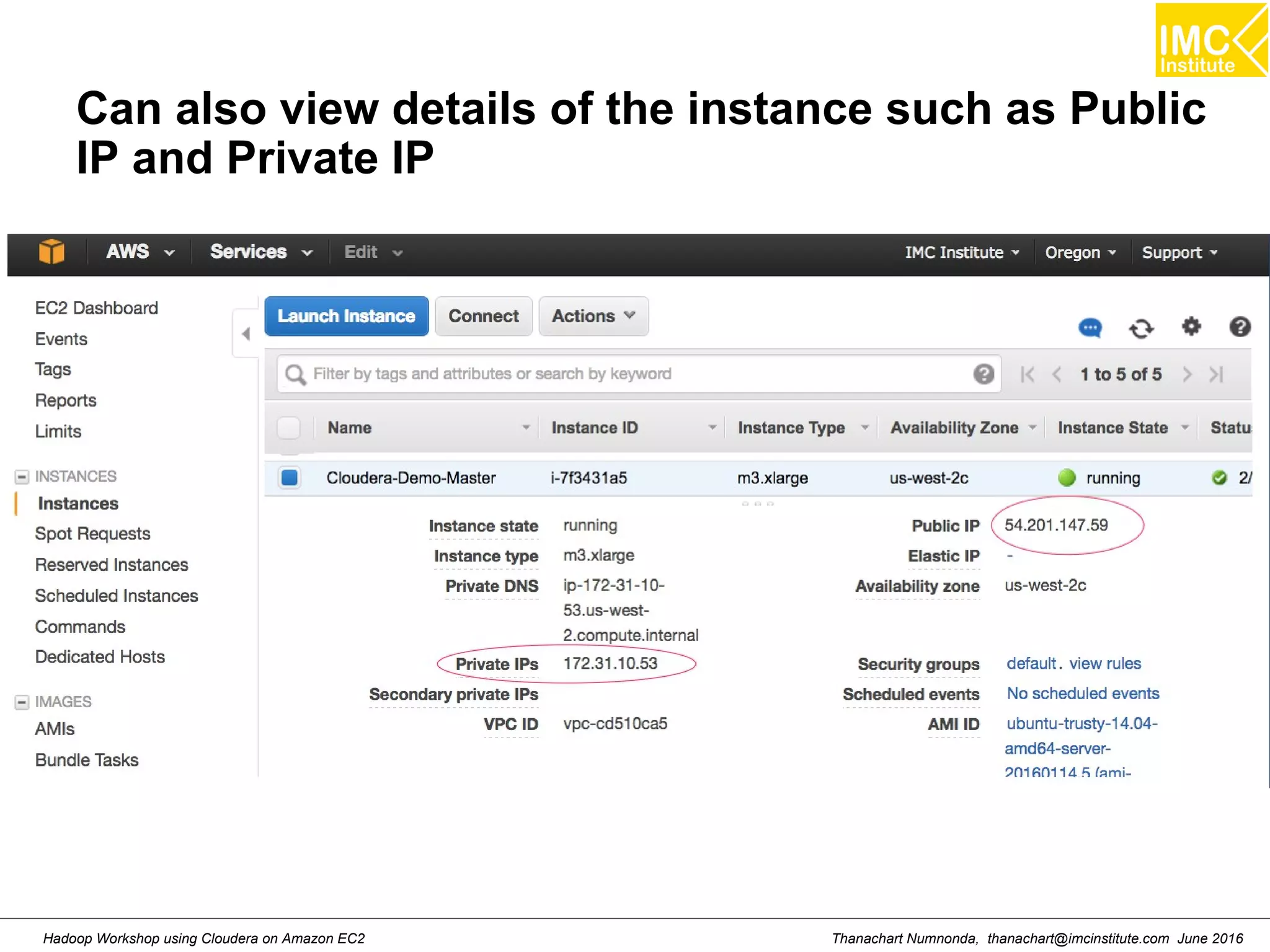






![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Run Cloudera quickstart ● Command: sudo docker run --hostname=quickstart.cloudera --privileged=true -t -i [OPTIONS] [IMAGE] /usr/bin/docker-quickstart Example: sudo docker run --hostname=quickstart.cloudera --privileged=true -t -i -p 8888:8888 cloudera/quickstart /usr/bin/docker-quickstart](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-27-2048.jpg)
























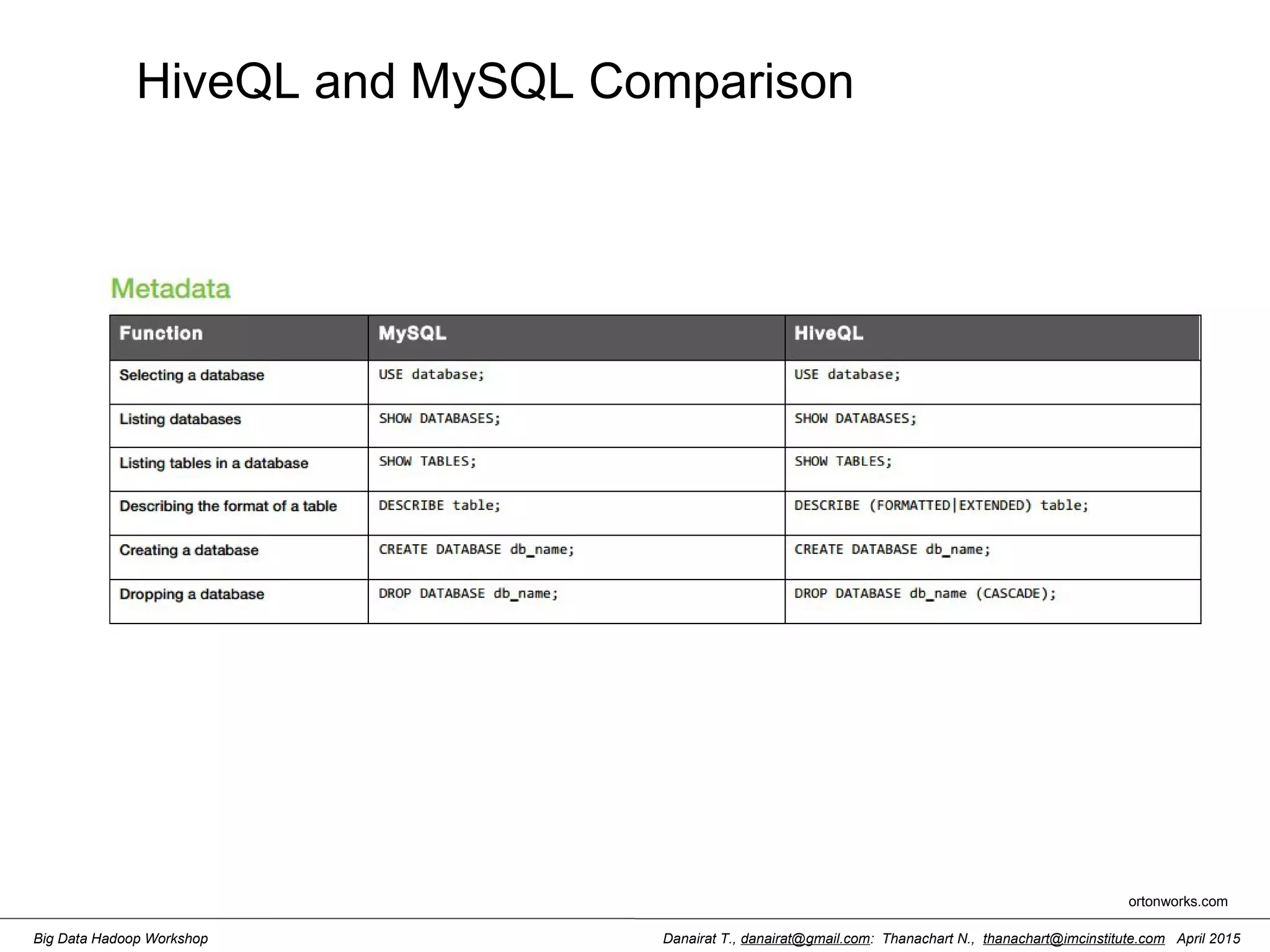
![Danairat T., danairat@gmail.com: Thanachart N., thanachart@imcinstitute.com April 2015Big Data Hadoop Workshop Hive Aggregate Functions Return Type Aggregation Function Name (Signature) Description BIGINT count(*), count(expr), count(DISTINCT expr[, expr_.]) count(*) - Returns the total number of retrieved rows, including rows containing NULL values; count(expr) - Returns the number of rows for which the supplied expression is non- NULL; count(DISTINCT expr[, expr]) - Returns the number of rows for which the supplied expression(s) are unique and non-NULL. DOUBLE sum(col), sum(DISTINCT col) returns the sum of the elements in the group or the sum of the distinct values of the column in the group DOUBLE avg(col), avg(DISTINCT col) returns the average of the elements in the group or the average of the distinct values of the column in the group DOUBLE min(col) returns the minimum value of the column in the group DOUBLE max(col) returns the maximum value of the column in the group hive.apache.org](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-77-2048.jpg)




![Danairat T., danairat@gmail.com: Thanachart N., thanachart@imcinstitute.com April 2015Big Data Hadoop Workshop Java JDBC for Hive import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveJdbcClient { private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { try { Class.forName(driverName); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); System.exit(1); } Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", ""); Statement stmt = con.createStatement(); String tableName = "testHiveDriverTable"; stmt.executeQuery("drop table " + tableName); ResultSet res = stmt.executeQuery("create table " + tableName + " (key int, value string)"); // show tables String sql = "show tables '" + tableName + "'"; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); if (res.next()) { System.out.println(res.getString(1)); } // describe table sql = "describe " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + "t" + res.getString(2)); }](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-82-2048.jpg)
![Danairat T., danairat@gmail.com: Thanachart N., thanachart@imcinstitute.com April 2015Big Data Hadoop Workshop Java JDBC for Hive import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveJdbcClient { private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { try { Class.forName(driverName); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); System.exit(1); } Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", ""); Statement stmt = con.createStatement(); String tableName = "testHiveDriverTable"; stmt.executeQuery("drop table " + tableName); ResultSet res = stmt.executeQuery("create table " + tableName + " (key int, value string)"); // show tables String sql = "show tables '" + tableName + "'"; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); if (res.next()) { System.out.println(res.getString(1)); } // describe table sql = "describe " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + "t" + res.getString(2)); }](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-83-2048.jpg)






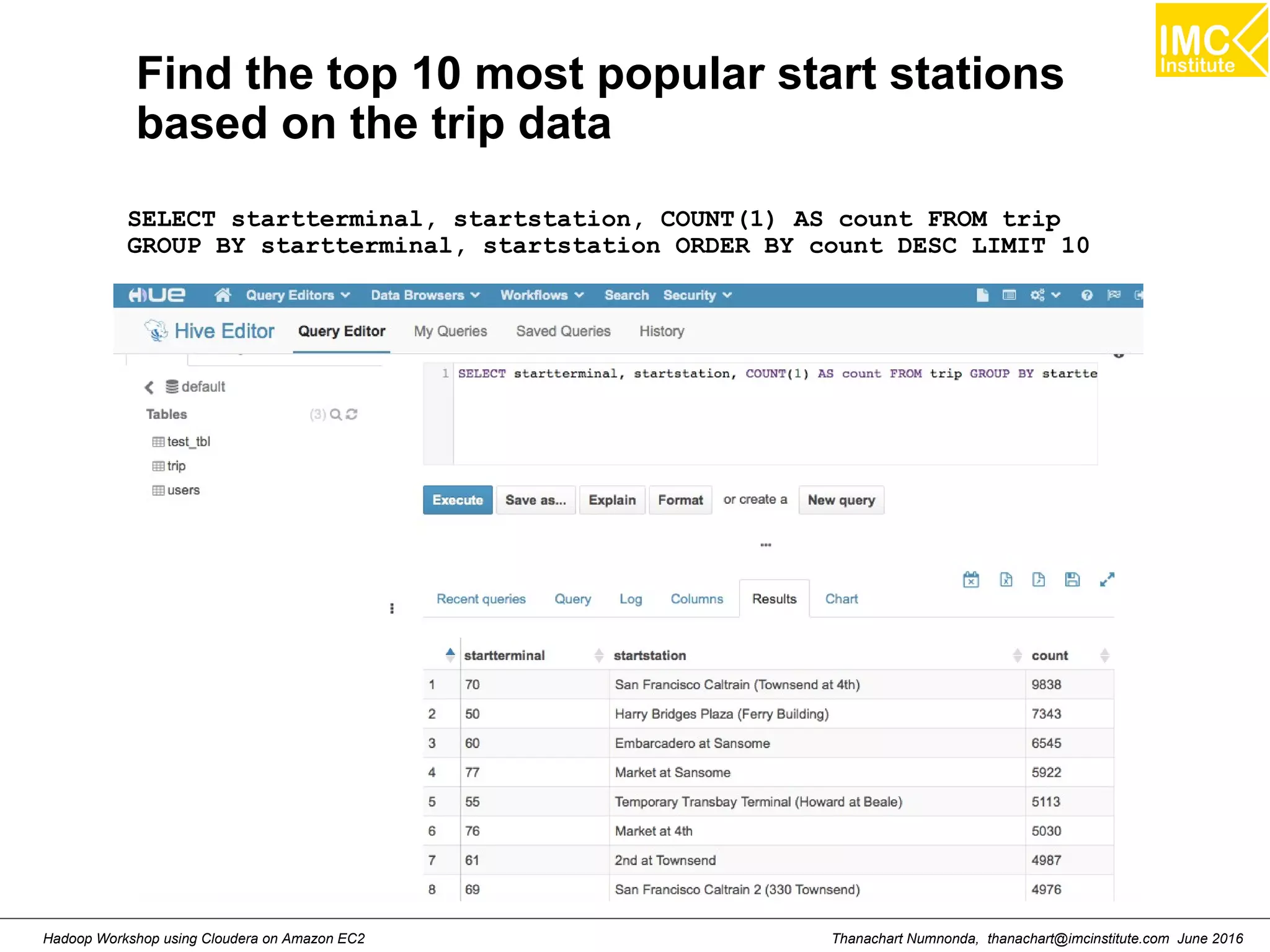
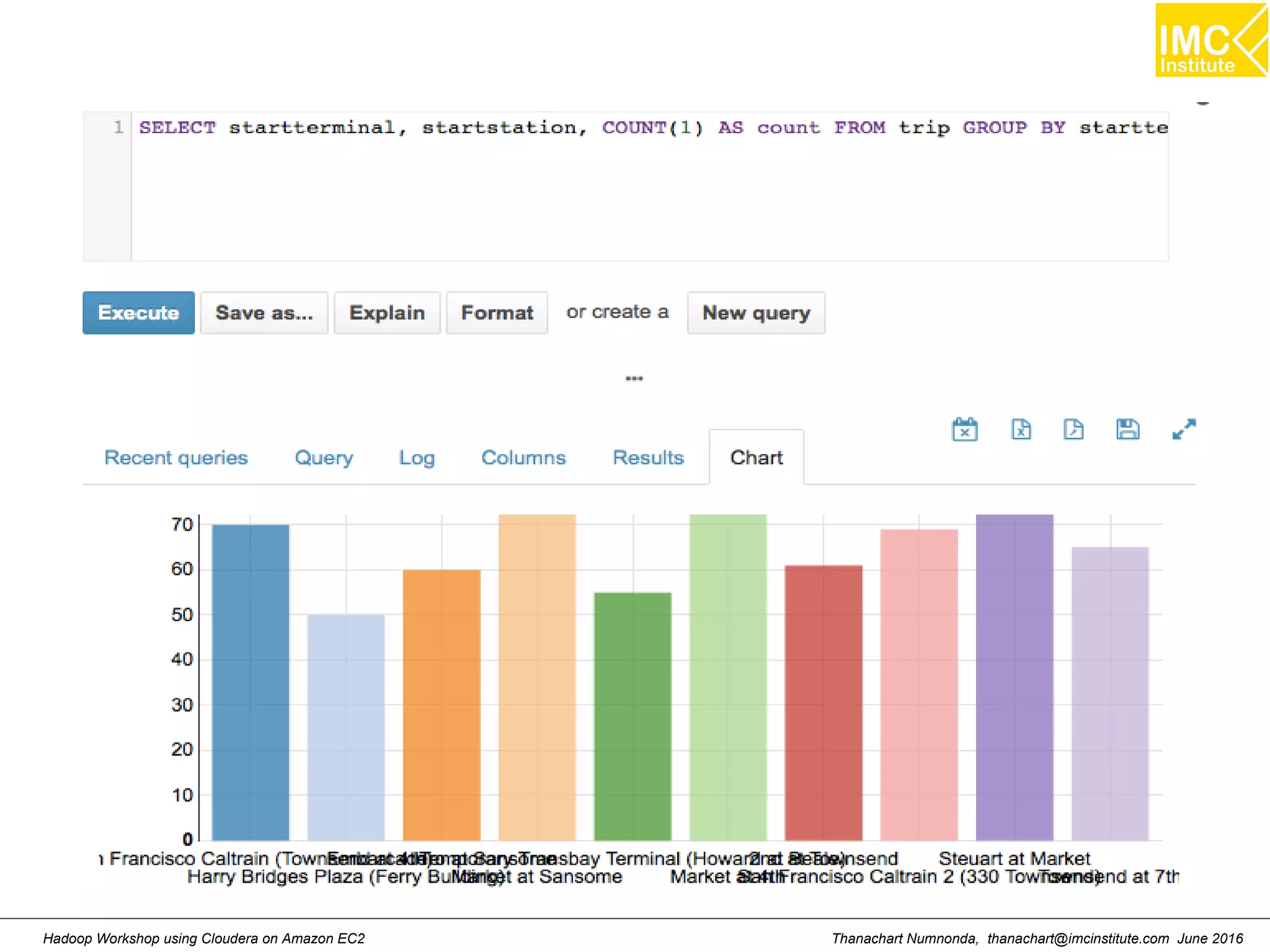
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Find the total number of trips and average duration (in minutes) of those trips, grouped by hour SELECT hour, COUNT(1) AS trips, ROUND(AVG(duration) / 60) AS avg_duration FROM ( SELECT CAST(SPLIT(SPLIT(t.startdate, ' ')[1], ':')[0] AS INT) AS hour, t.duration AS duration FROM `bikeshare`.`trips` t WHERE t.startterminal = 70 AND t.duration IS NOT NULL ) r GROUP BY hour ORDER BY hour ASC;](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-107-2048.jpg)


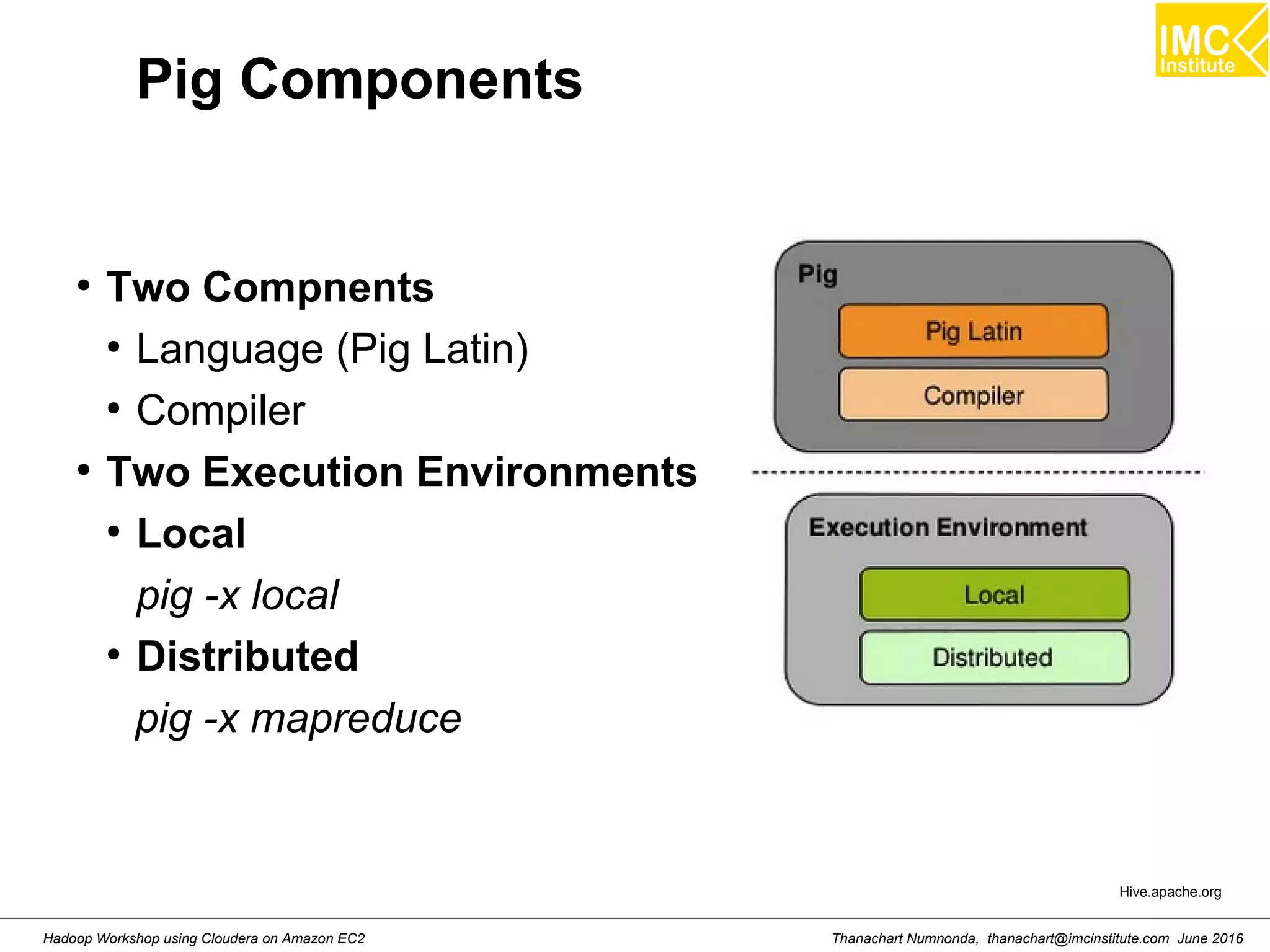

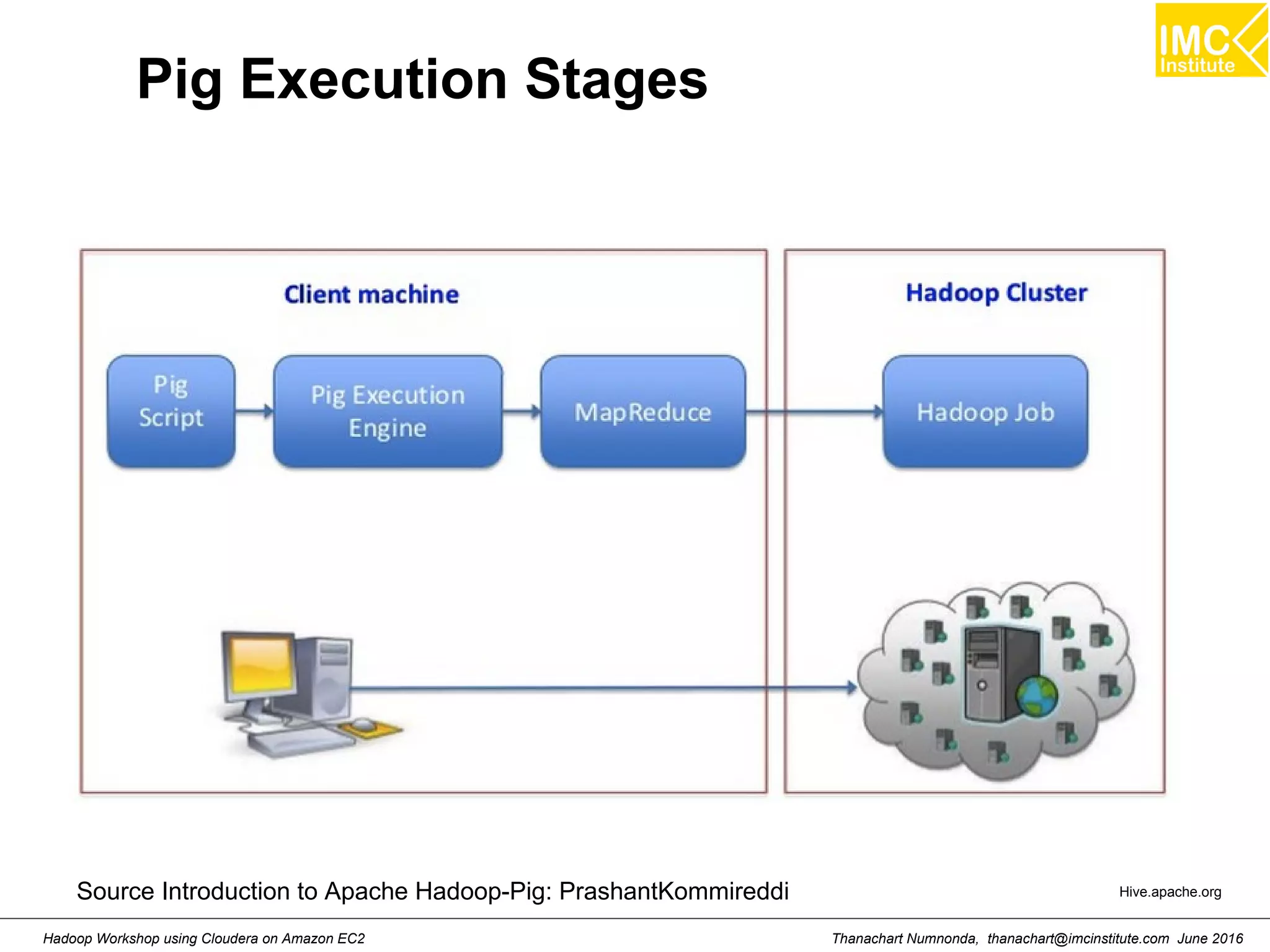

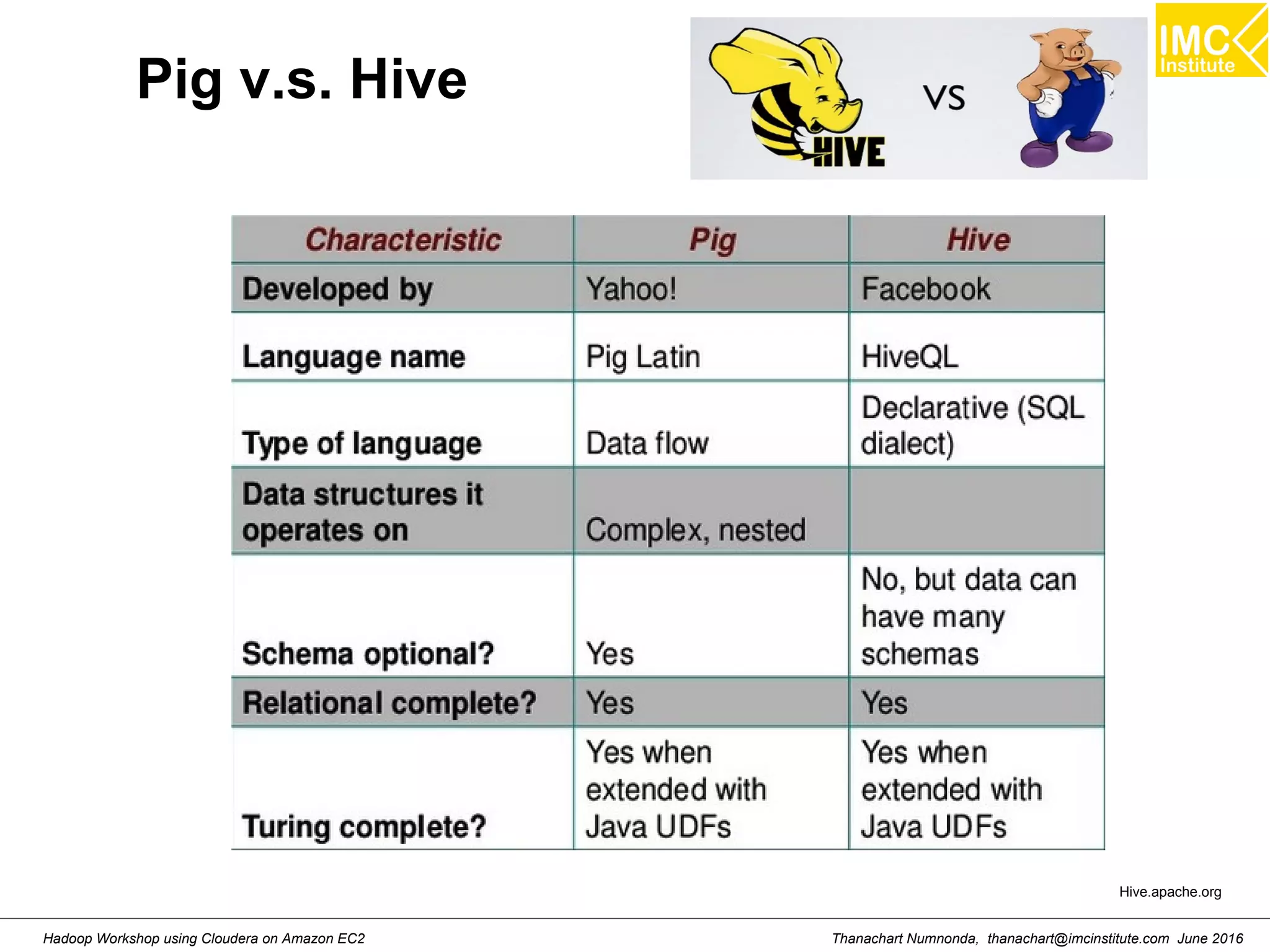

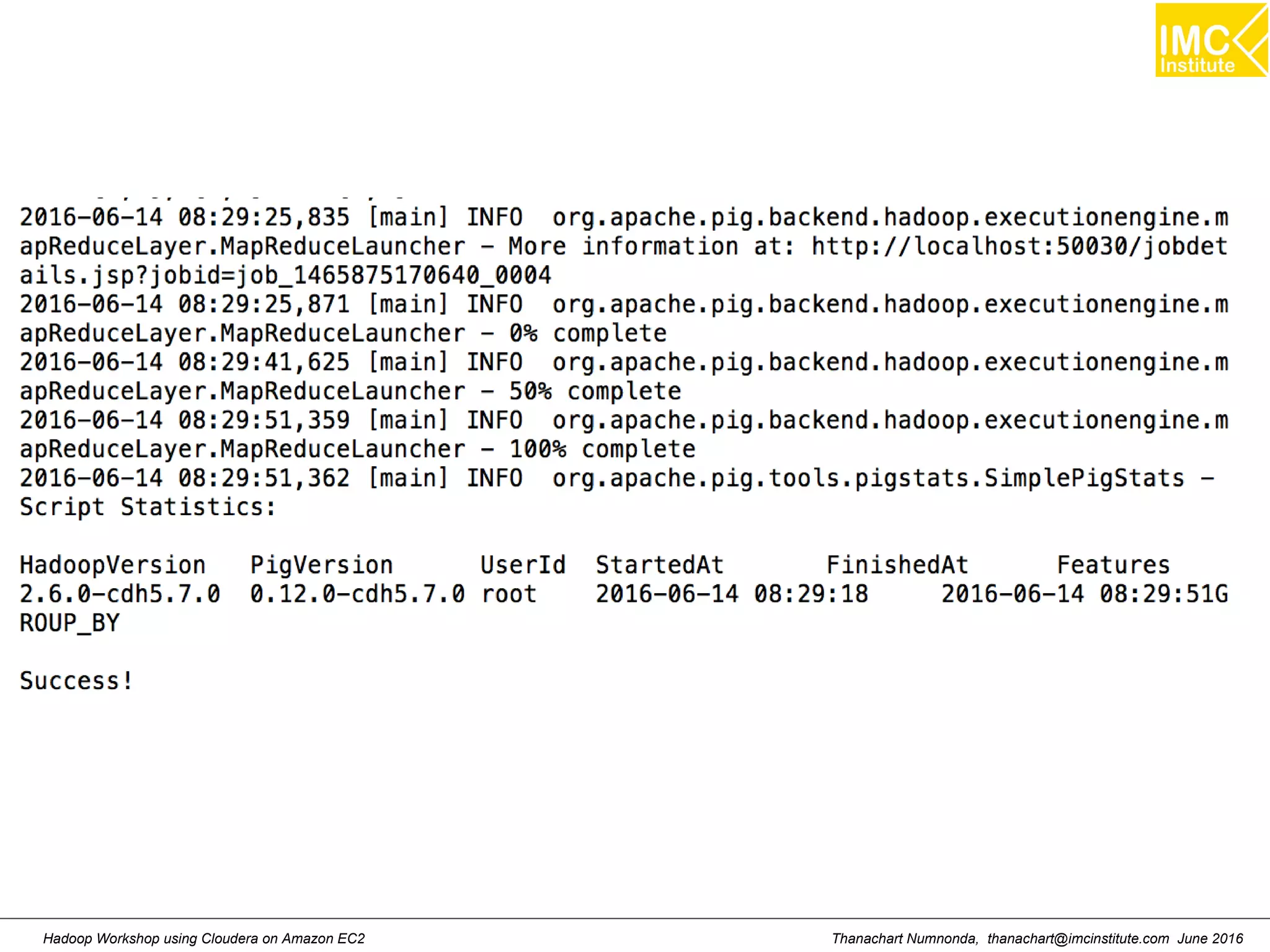
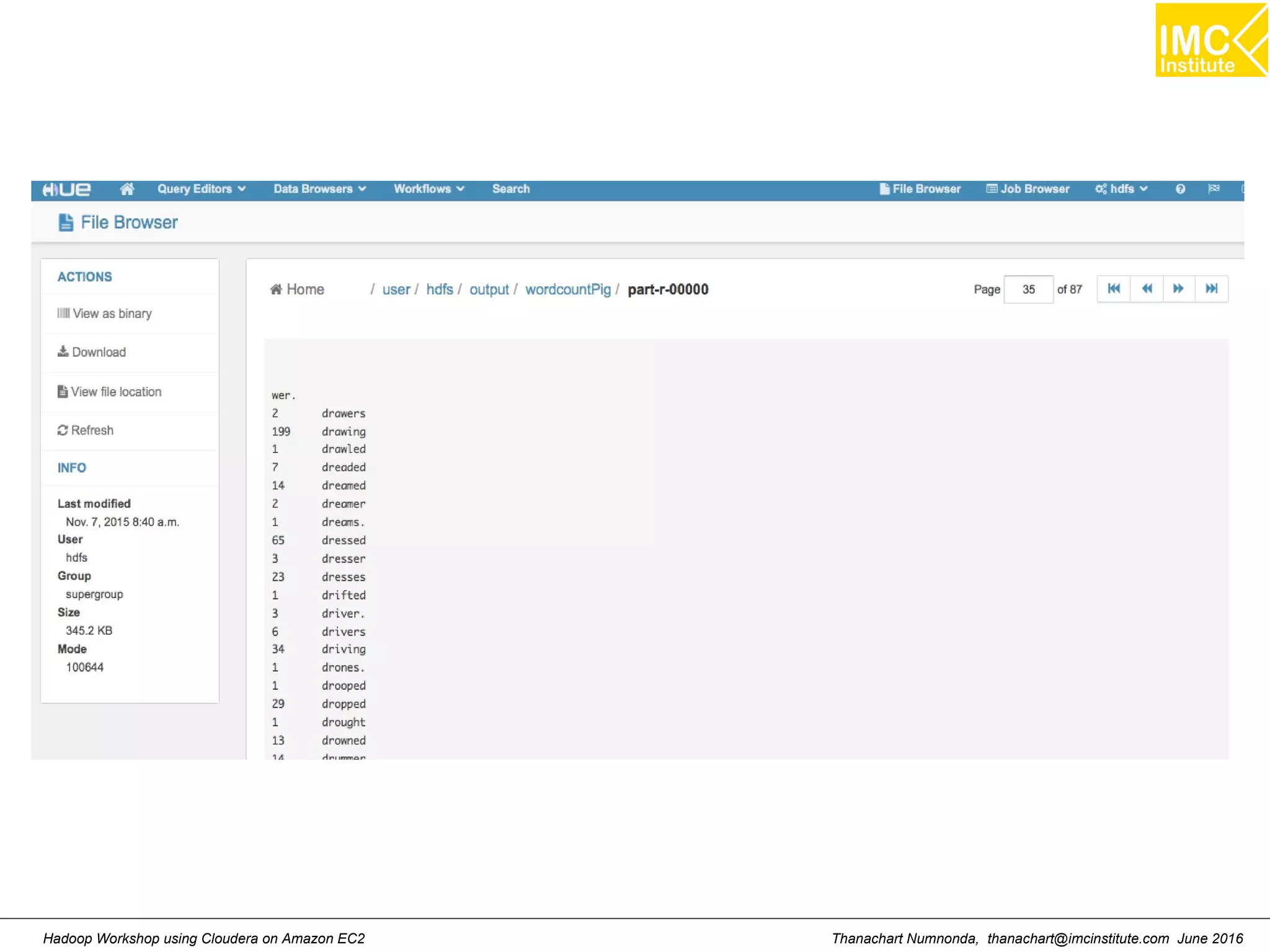
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Starting Pig Command Line $ pig -x mapreduce 2013-08-01 10:29:00,027 [main] INFO org.apache.pig.Main - Apache Pig version 0.11.1 (r1459641) compiled Mar 22 2013, 02:13:53 2013-08-01 10:29:00,027 [main] INFO org.apache.pig.Main - Logging error messages to: /home/hdadmin/pig_1375327740024.log 2013-08-01 10:29:00,066 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/hdadmin/.pigbootup not found 2013-08-01 10:29:00,212 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: file:/// grunt>](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-117-2048.jpg)





![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Find the total number of trips and average duration (in minutes) of those trips, grouped by hour SELECT hour, COUNT(1) AS trips, ROUND(AVG(duration) / 60) AS avg_duration FROM ( SELECT CAST(SPLIT(SPLIT(t.startdate, ' ')[1], ':')[0] AS INT) AS hour, t.duration AS duration FROM `bikeshare`.`trips` t WHERE t.startterminal = 70 AND t.duration IS NOT NULL ) r GROUP BY hour ORDER BY hour ASC;](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-131-2048.jpg)











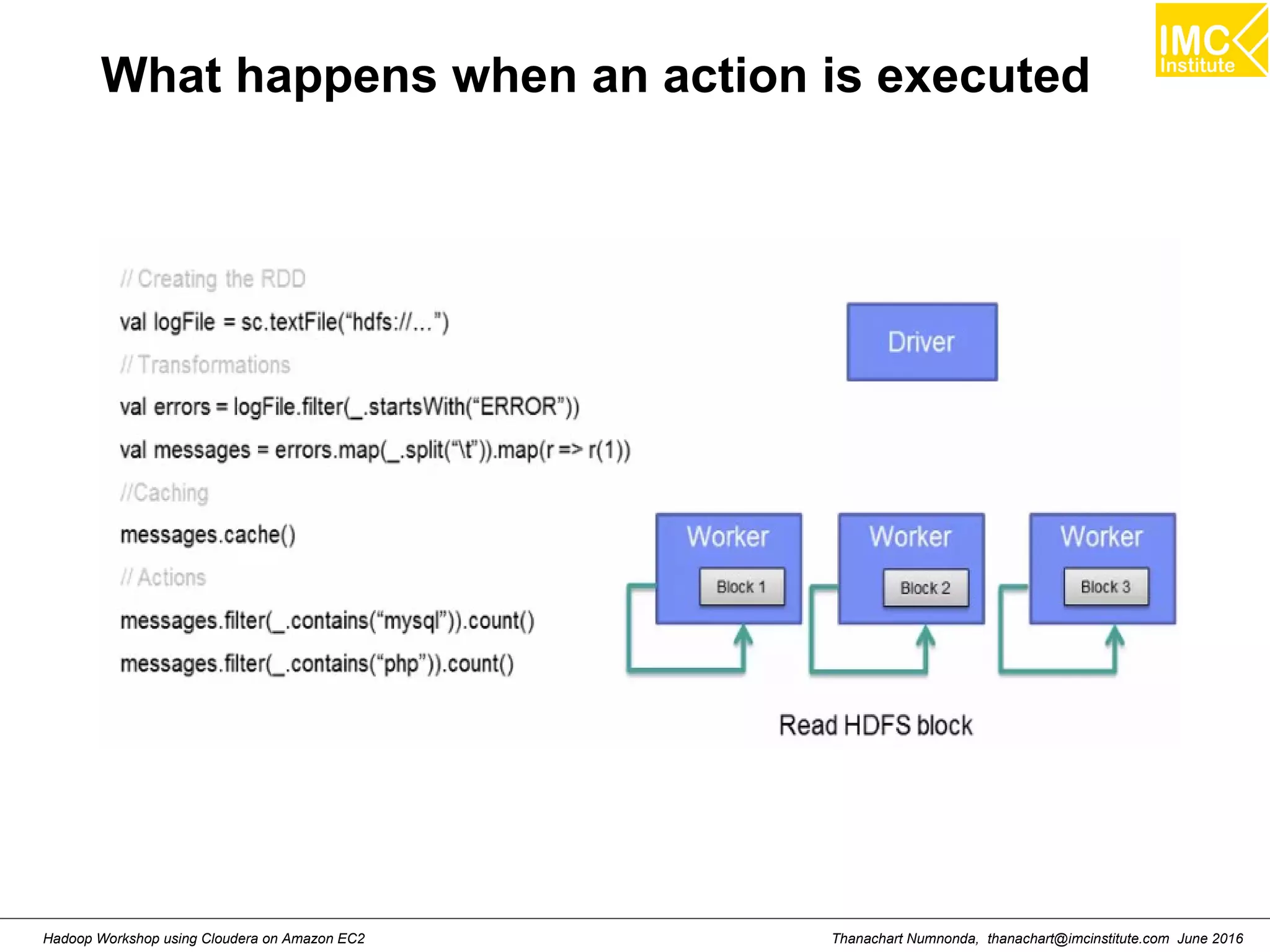
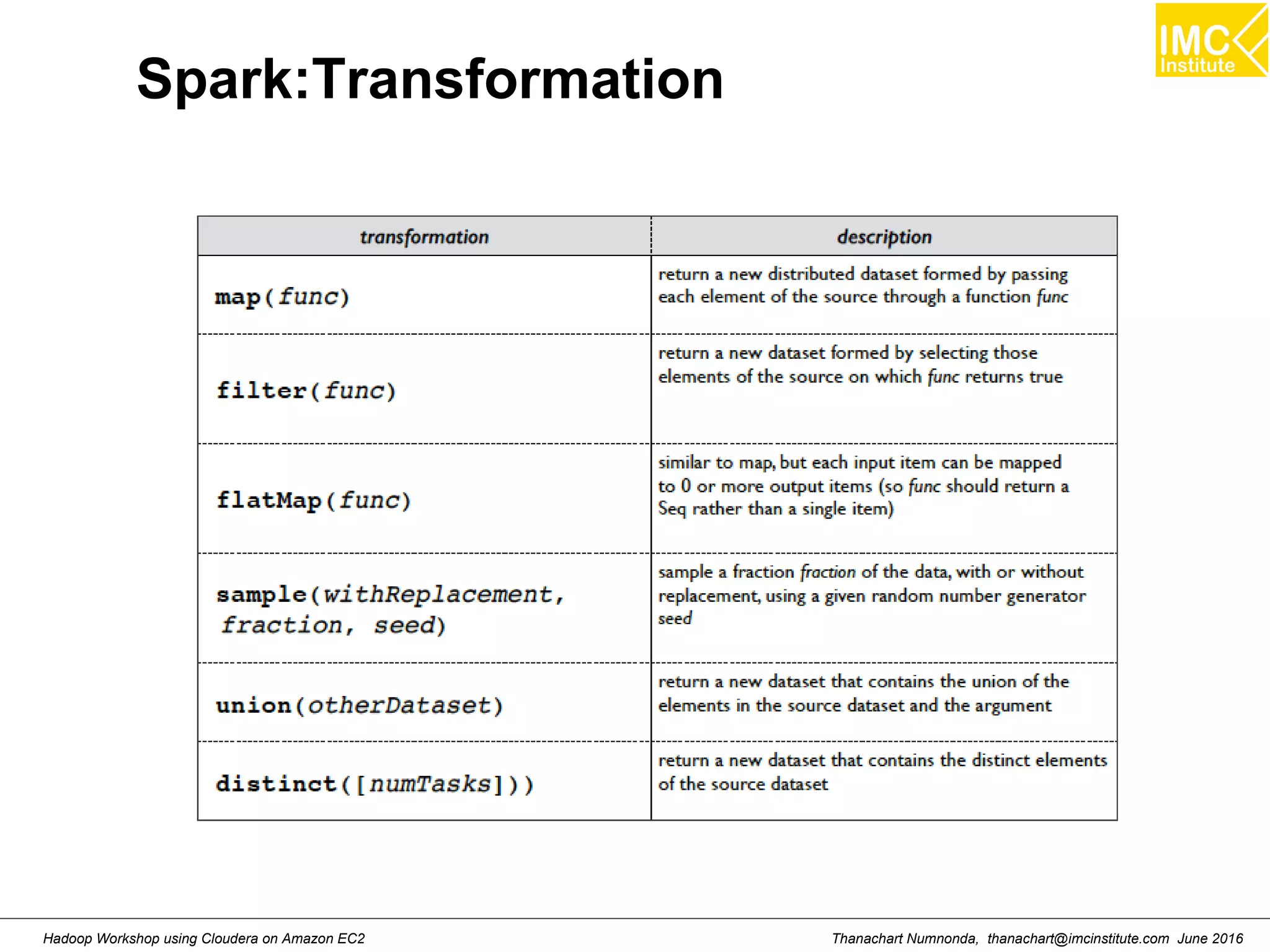
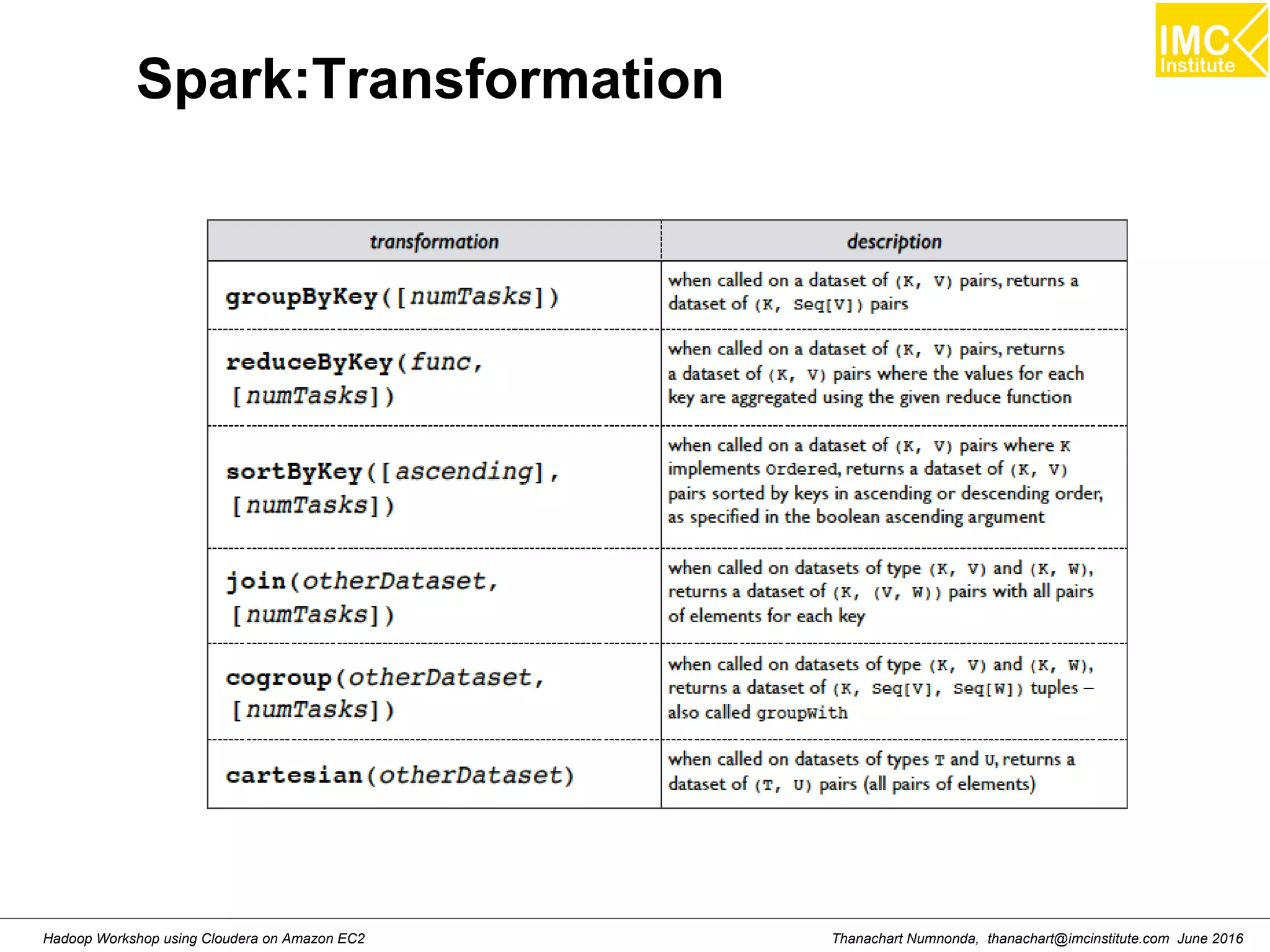

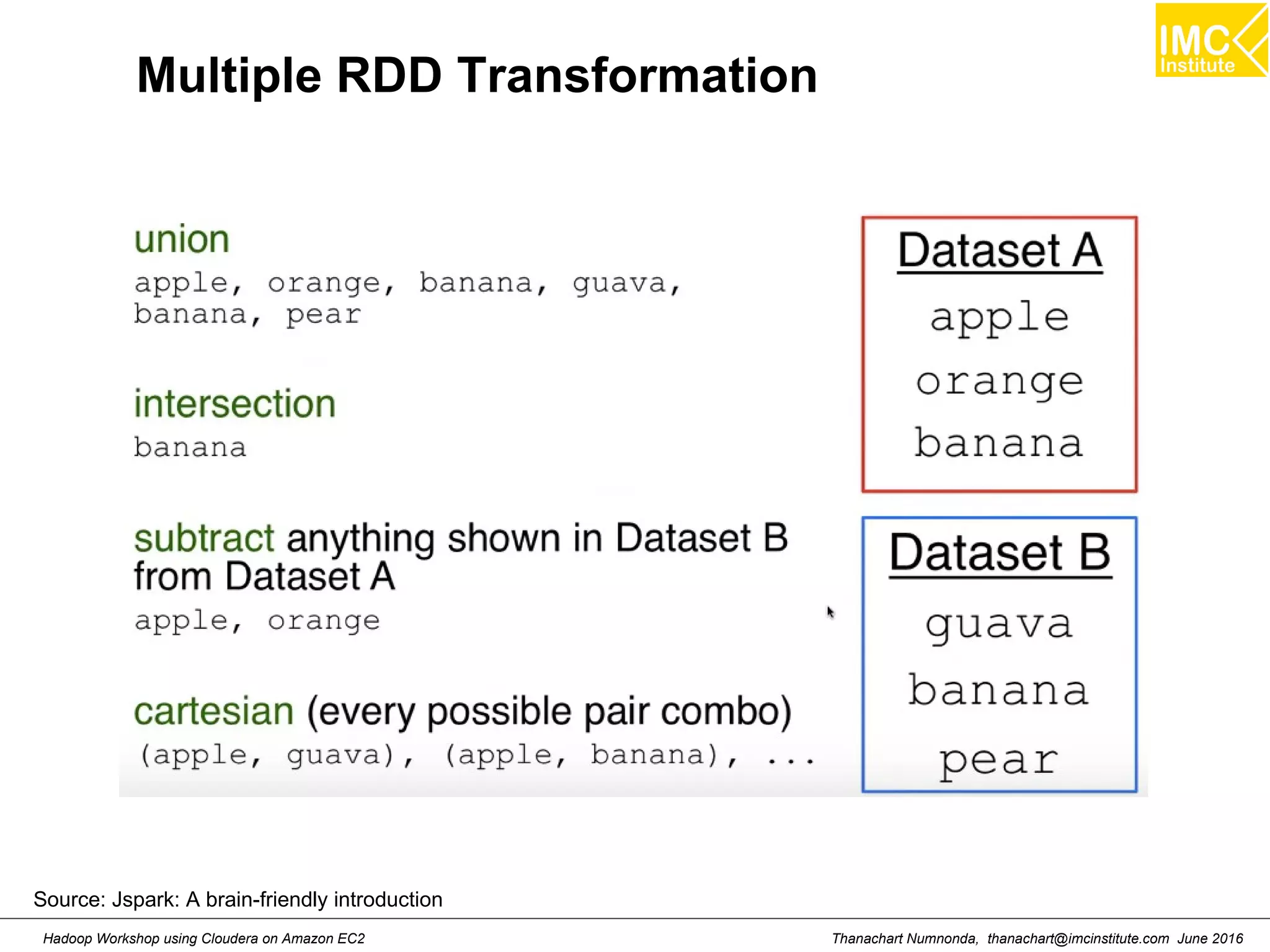










![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Map >>> a= [1,2,3] >>> def add1(x) : return x+1 >>> map(add1, a) Result: [2,3,4]](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-184-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Filter >>> a= [1,2,3,4] >>> def isOdd(x) : return x%2==1 >>> filter(isOdd, a) Result: [1,3]](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-185-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Reduce >>> a= [1,2,3,4] >>> def add(x,y) : return x+y >>> reduce(add, a) Result: 10](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-186-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 lambda >>> (lambda x: x + 1)(3) Result: 4 >>> map((lambda x: x + 1), [1,2,3]) Result: [2,3,4]](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-187-2048.jpg)





![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Transformations >>> nums = sc.parallelize([1,2,3]) >>> squared = nums.map(lambda x : x*x) >>> even = squared.filter(lambda x: x%2 == 0) >>> evens = nums.flatMap(lambda x: range(x))](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-197-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Actions >>> nums = sc.parallelize([1,2,3]) >>> nums.collect() >>> nums.take(2) >>> nums.count() >>> nums.reduce(lambda:x, y:x+y) >>> nums.saveAsTextFile("hdfs:///user/cloudera/output/test”)](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-198-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Key-Value Operations >>> pet = sc.parallelize([("cat",1),("dog",1),("cat",2)]) >>> pet2 = pet.reduceByKey(lambda x, y:x+y) >>> pet3 = pet.groupByKey() >>> pet4 = pet.sortByKey()](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-199-2048.jpg)

![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Spark Program : Find Big Spenders >>> file_rdd = sc.textFile("hdfs:///user/cloudera/input/toy_data.txt") >>> import json >>> json_rdd = file_rdd.map(lambda x: json.loads(x)) >>> big_spenders = json_rdd.map(lambda x: tuple((x.keys() [0],int(x.values()[0])))) >>> big_spenders.reduceByKey(lambda x,y: x + y).filter(lambda x: x[1] > 5).collect()](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-201-2048.jpg)





![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Spark Program : Finding best/worst airports >>> destination_rdd = airline_rows.map(lambda row: (row['Dest'],convert_float(row['ArrDelay']))) >>> origin_rdd = airline_rows.map(lambda row: (row['Origin'],convert_float(row['DepDelay']))) >>> destination_rdd.take(2) >>> origin_rdd.take(2)](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-212-2048.jpg)
![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Spark Program : Finding best/worst airports >>> import numpy as np >>> mean_delays_dest = destination_rdd.groupByKey().mapValues(lambda delays: np.mean(delays.data)) >>> mean_delays_dest.sortBy(lambda t:t[1], ascending=True).take(10) >>> mean_delays_dest.sortBy(lambda t:t[1], ascending=False).take(10)](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-213-2048.jpg)




![Thanachart Numnonda, thanachart@imcinstitute.com June 2016Hadoop Workshop using Cloudera on Amazon EC2 Spark SQL : Preparing data >>> import json >>> def type_conversion(d, columns) : ... for c in columns: ... d[c] = int(d[c]) ... return d ... >>> meal_typed = meals_json.map(lambda j:json.dumps(type_conversion(j, ['meal_id','price']))) >>> event_typed = events_json.map(lambda j:json.dumps(type_conversion(j, ['meal_id','userid']))](https://image.slidesharecdn.com/orngraurxpmv5sqjqgdq-signature-29a598b91cc67ee75ffb26876259b86587e682d469a84b7b2b82b89589f693c2-poli-160615012100/75/Big-data-processing-using-Cloudera-Quickstart-218-2048.jpg)








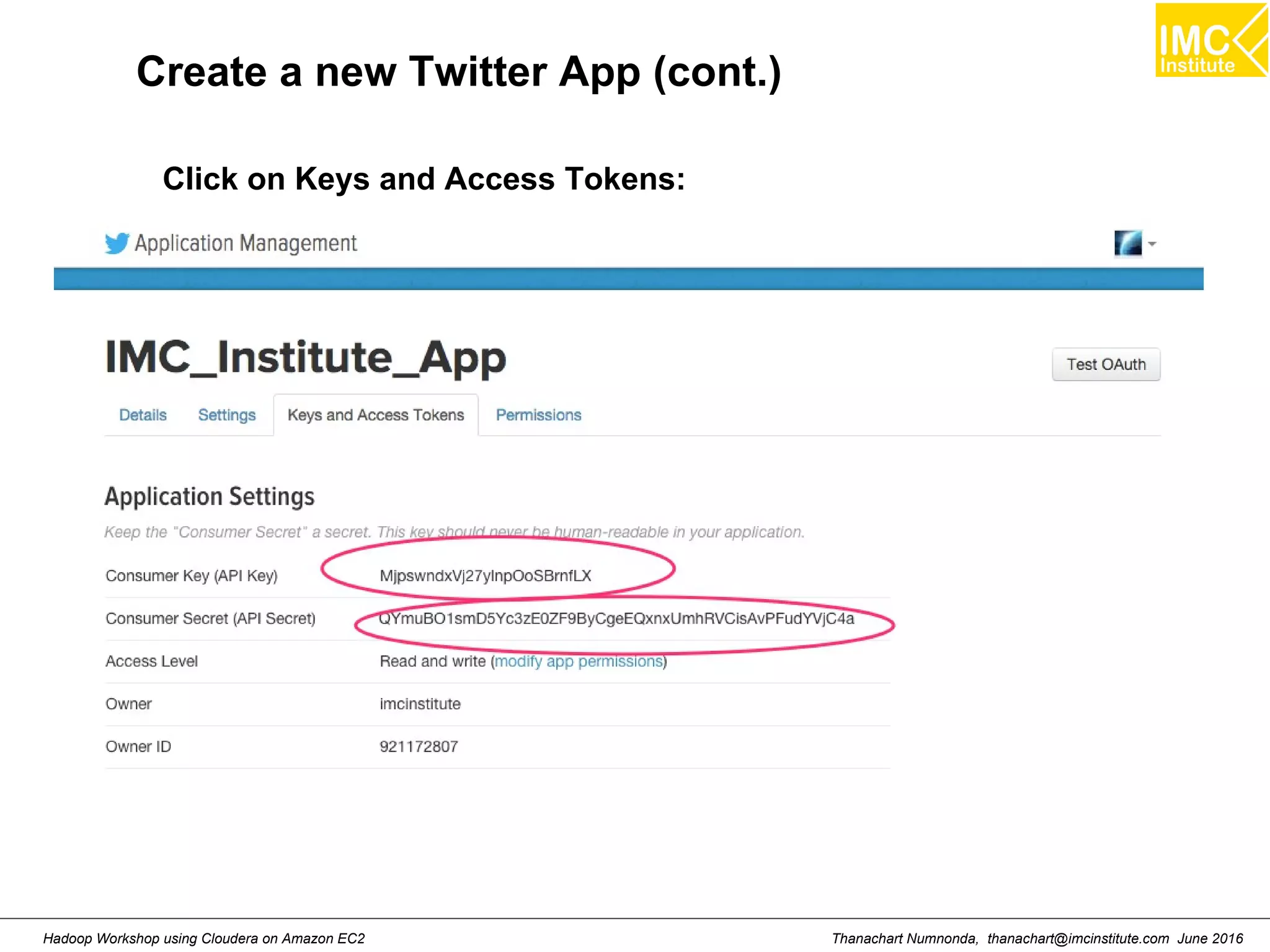
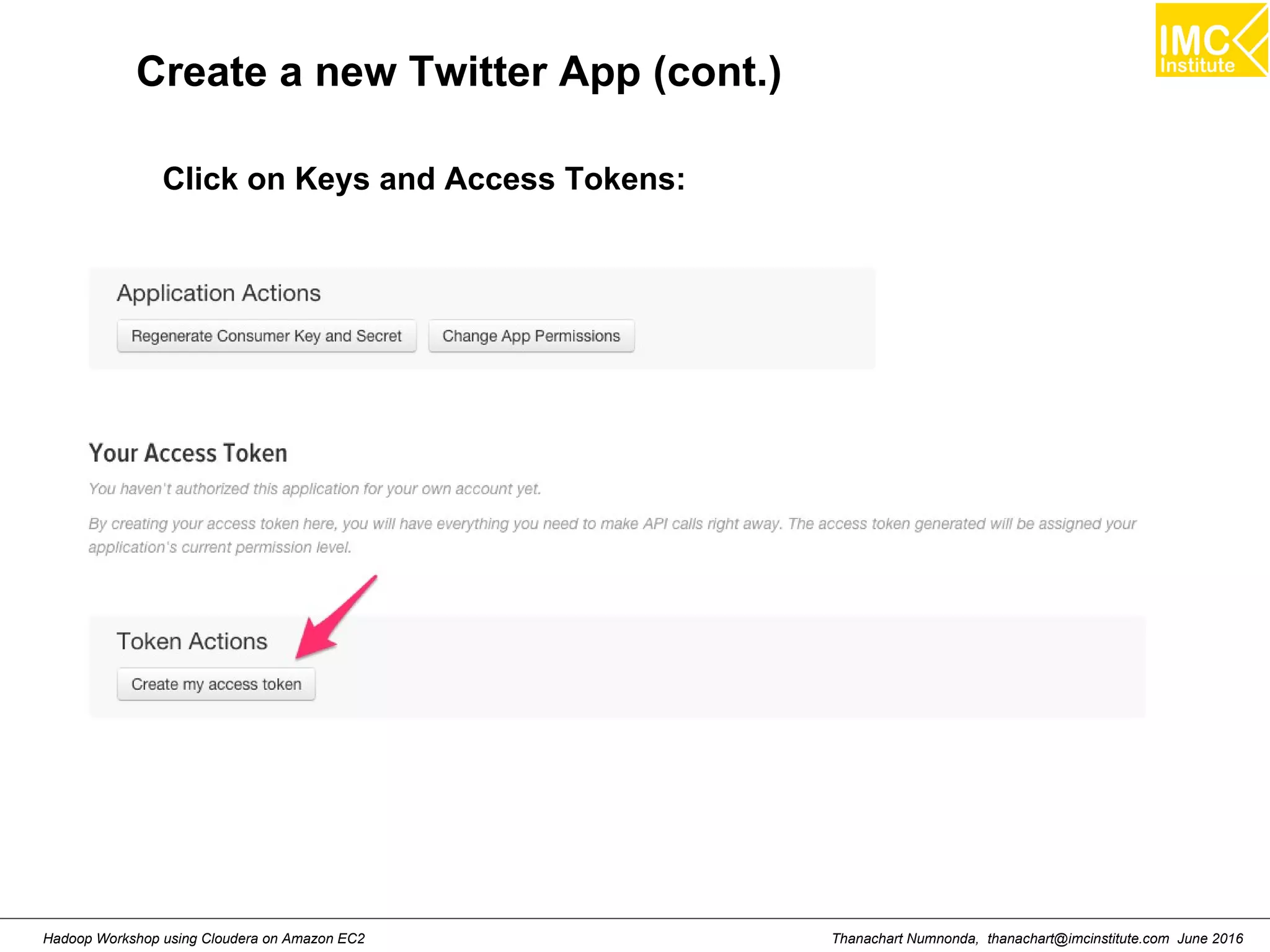
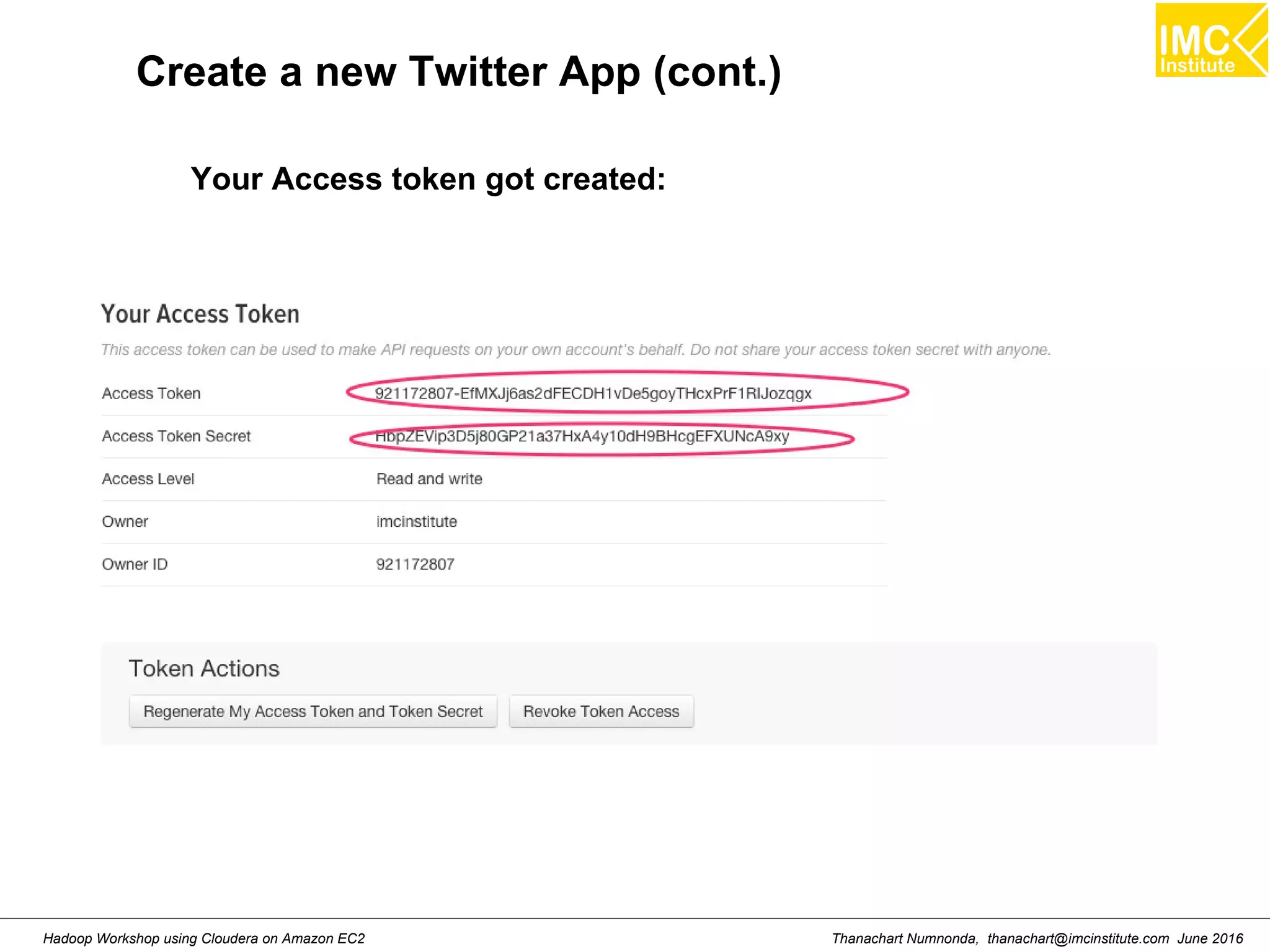



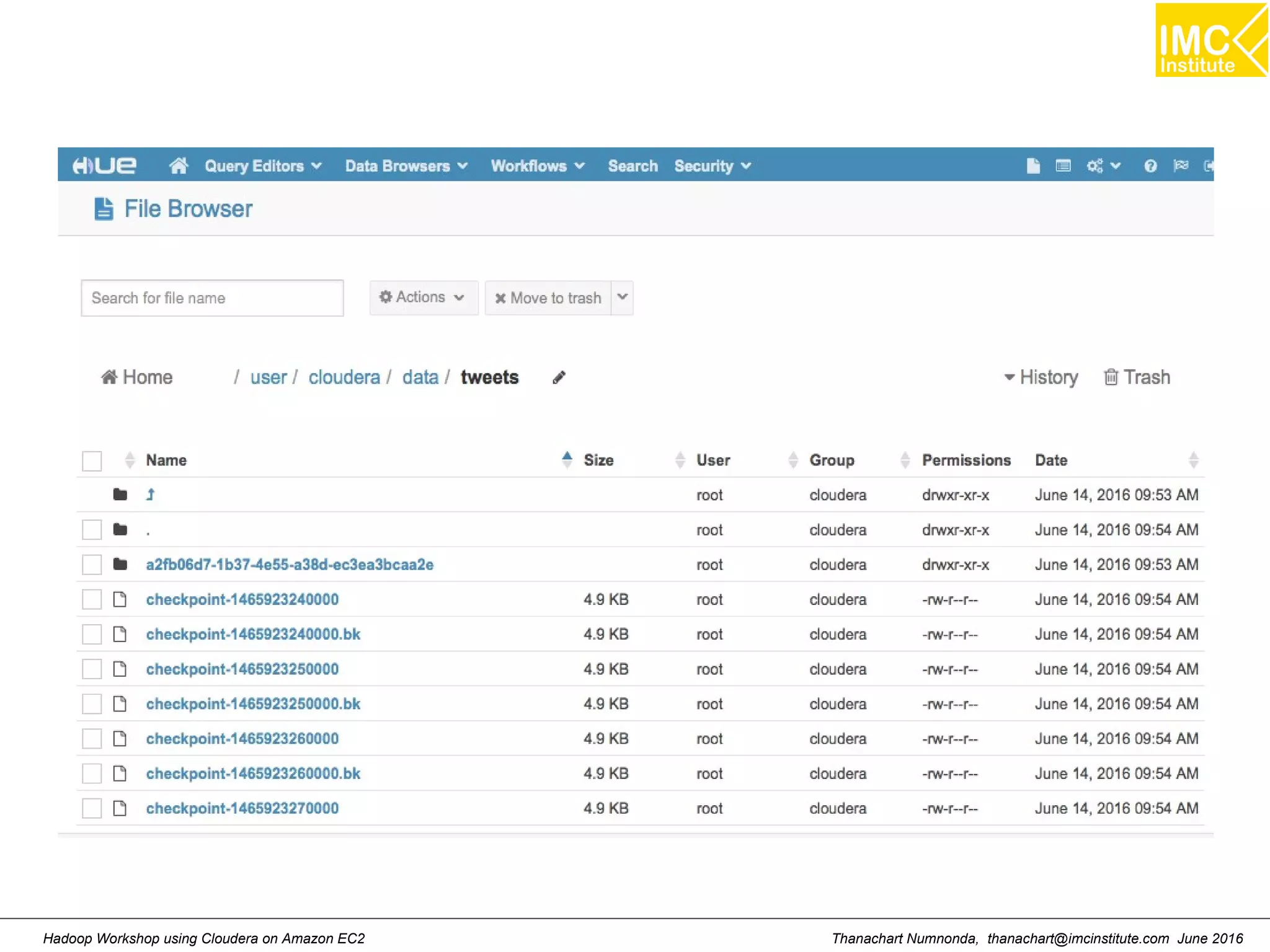


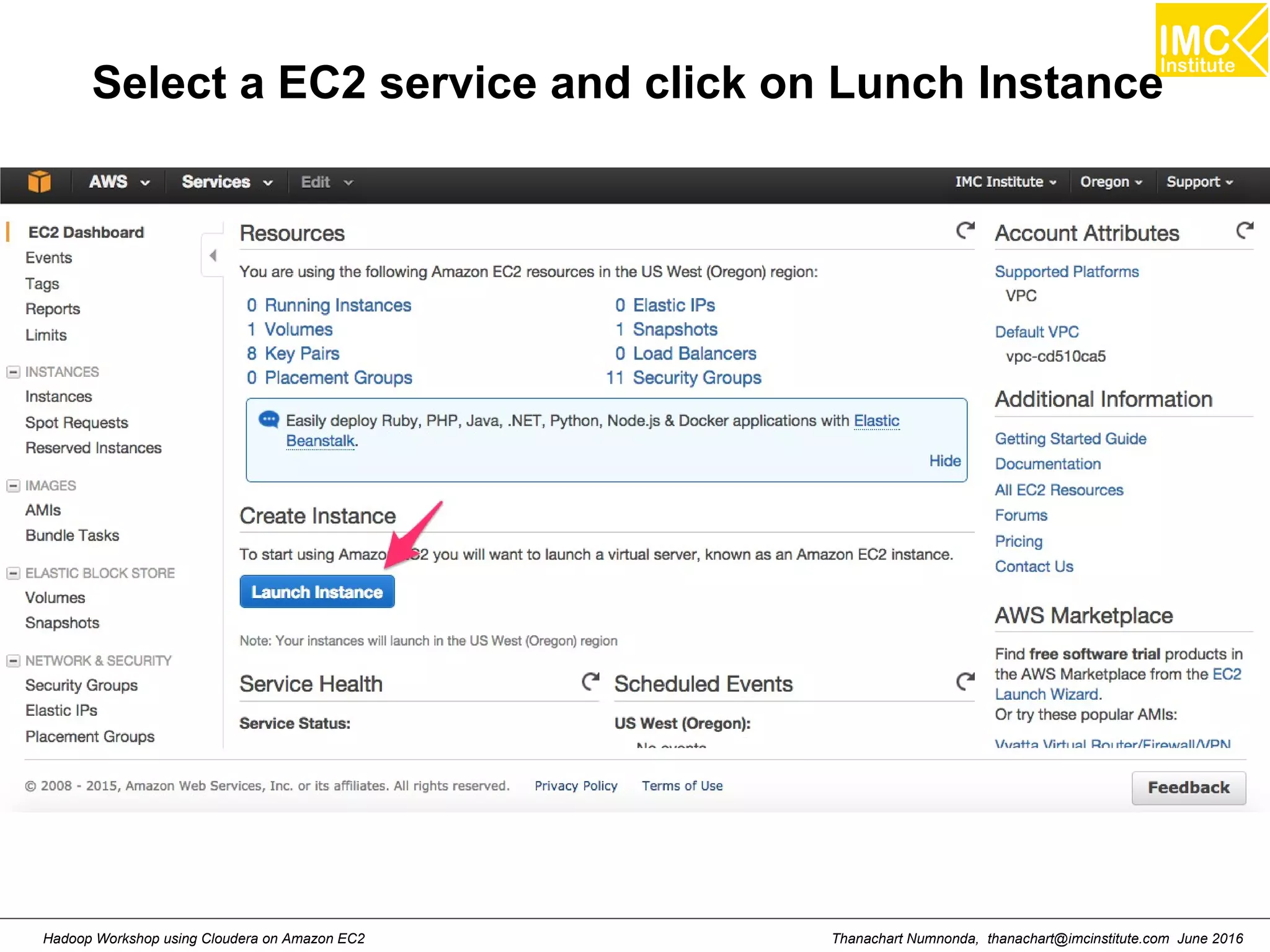
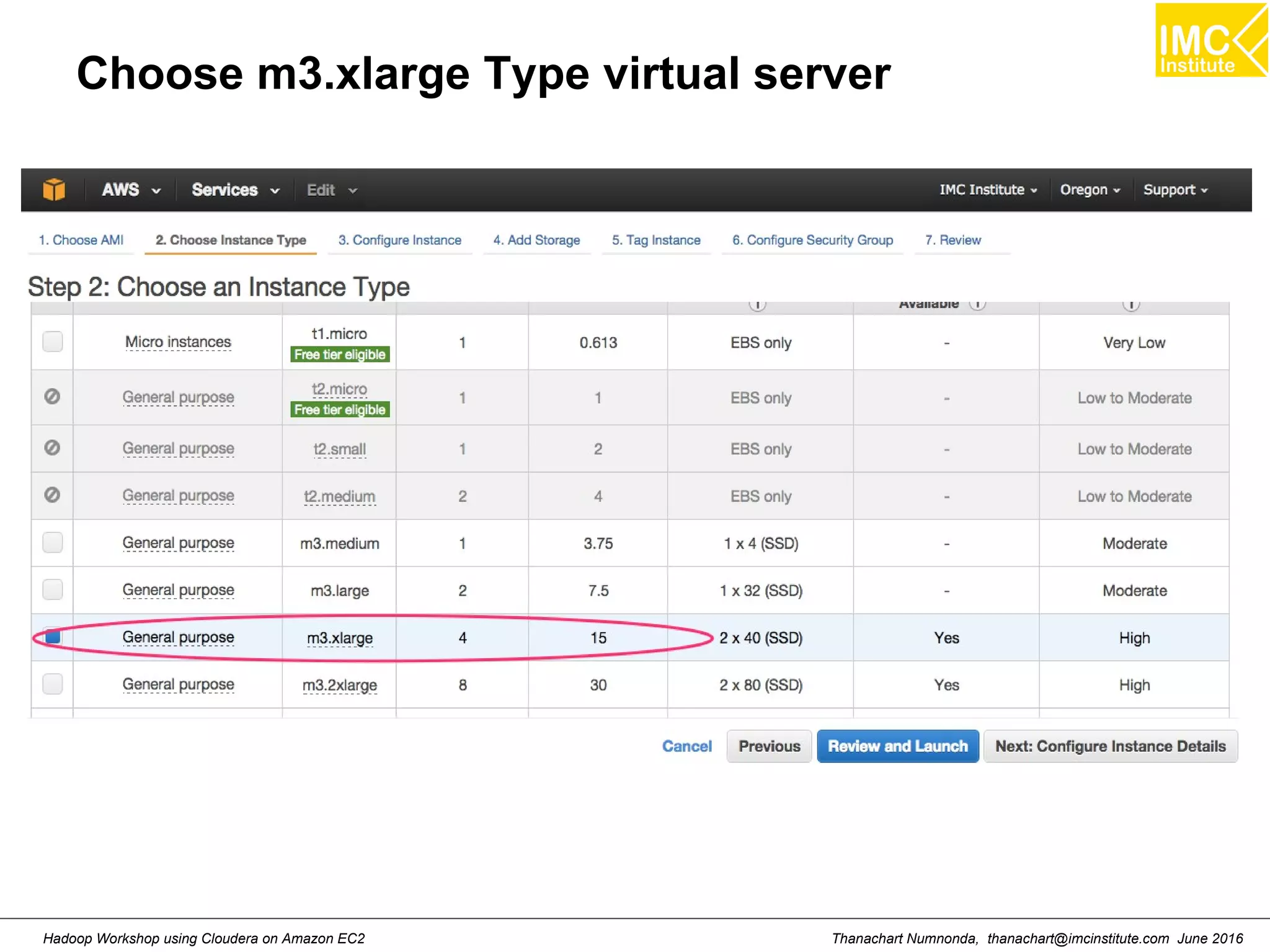
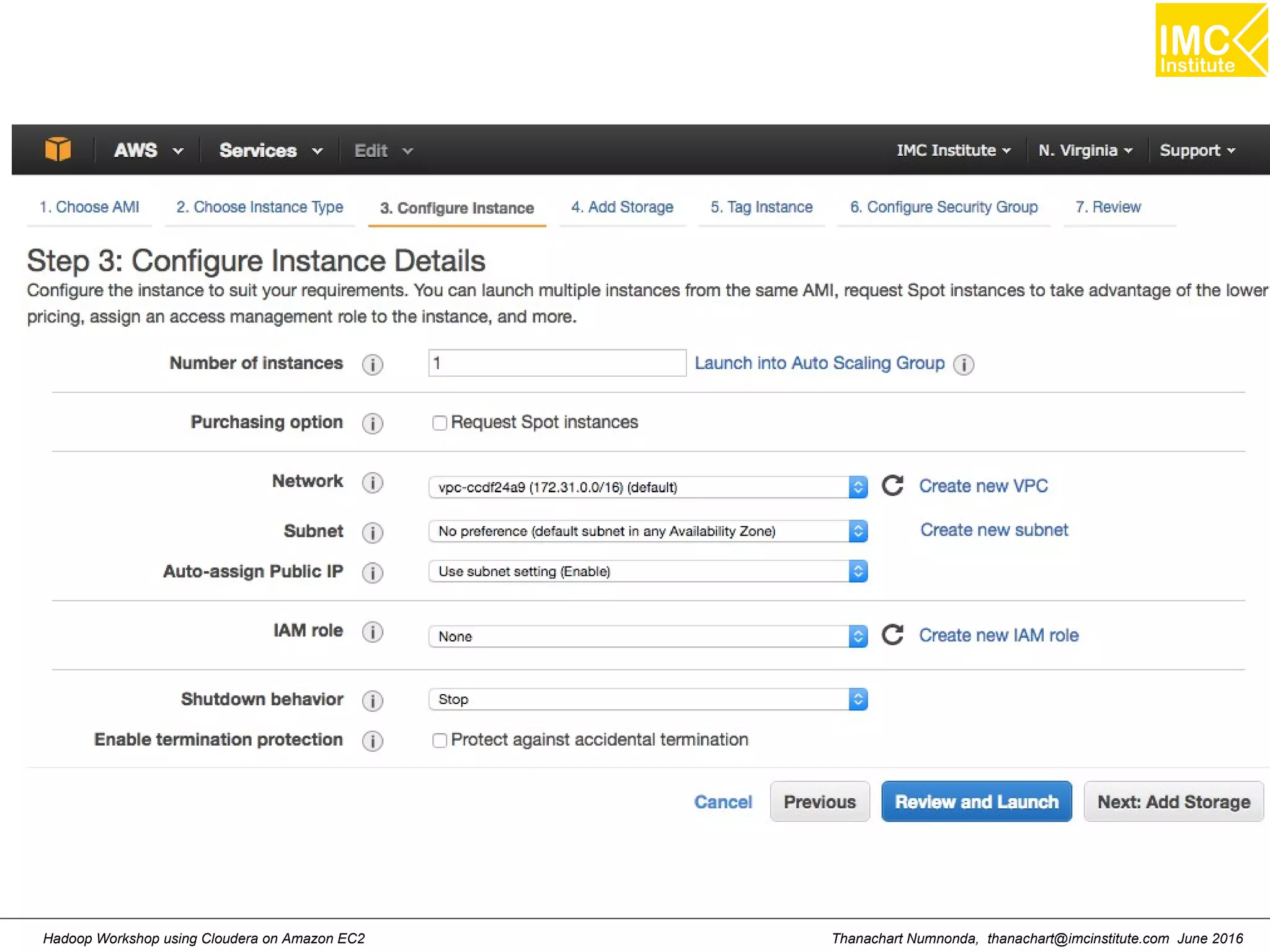
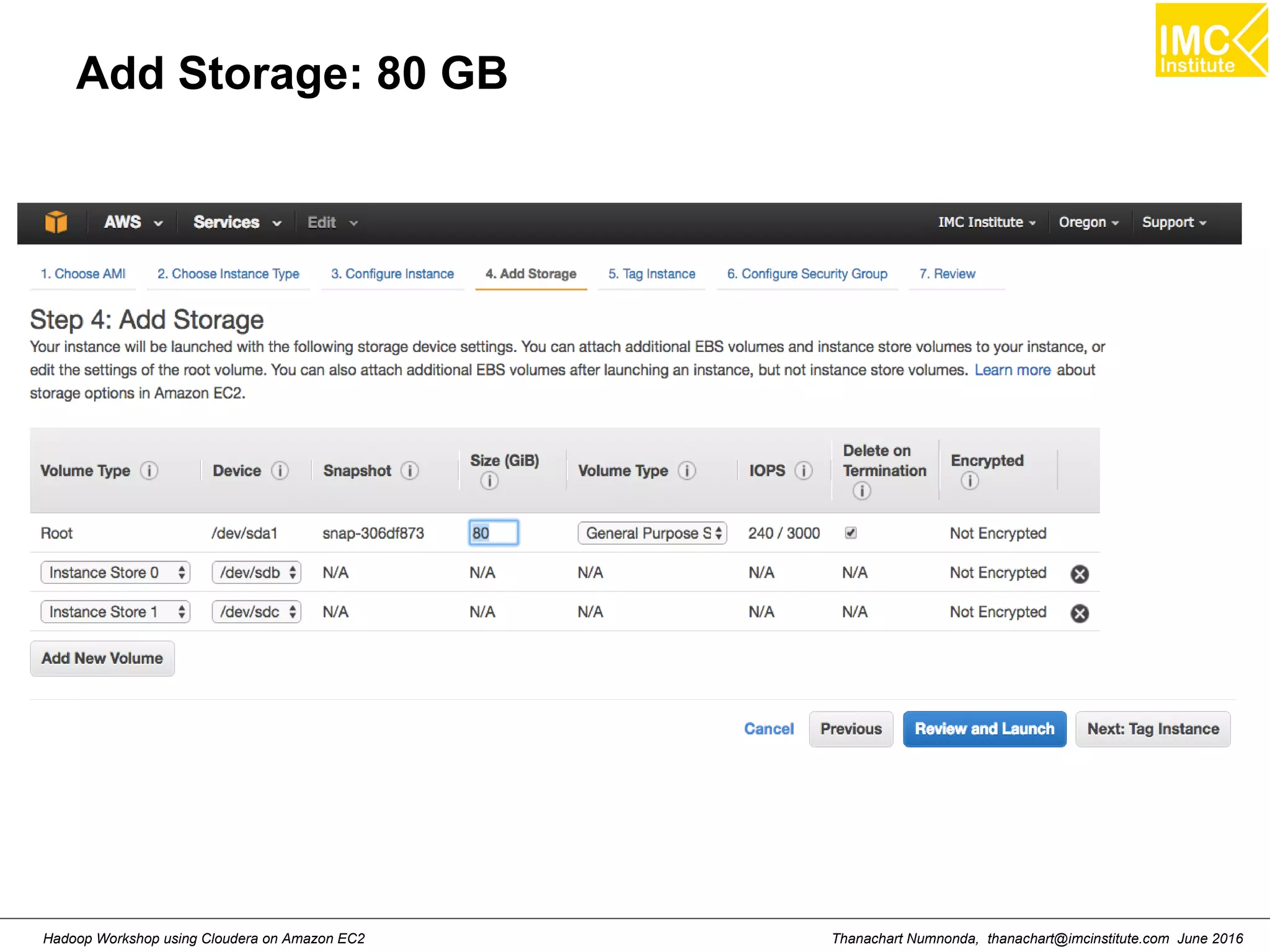
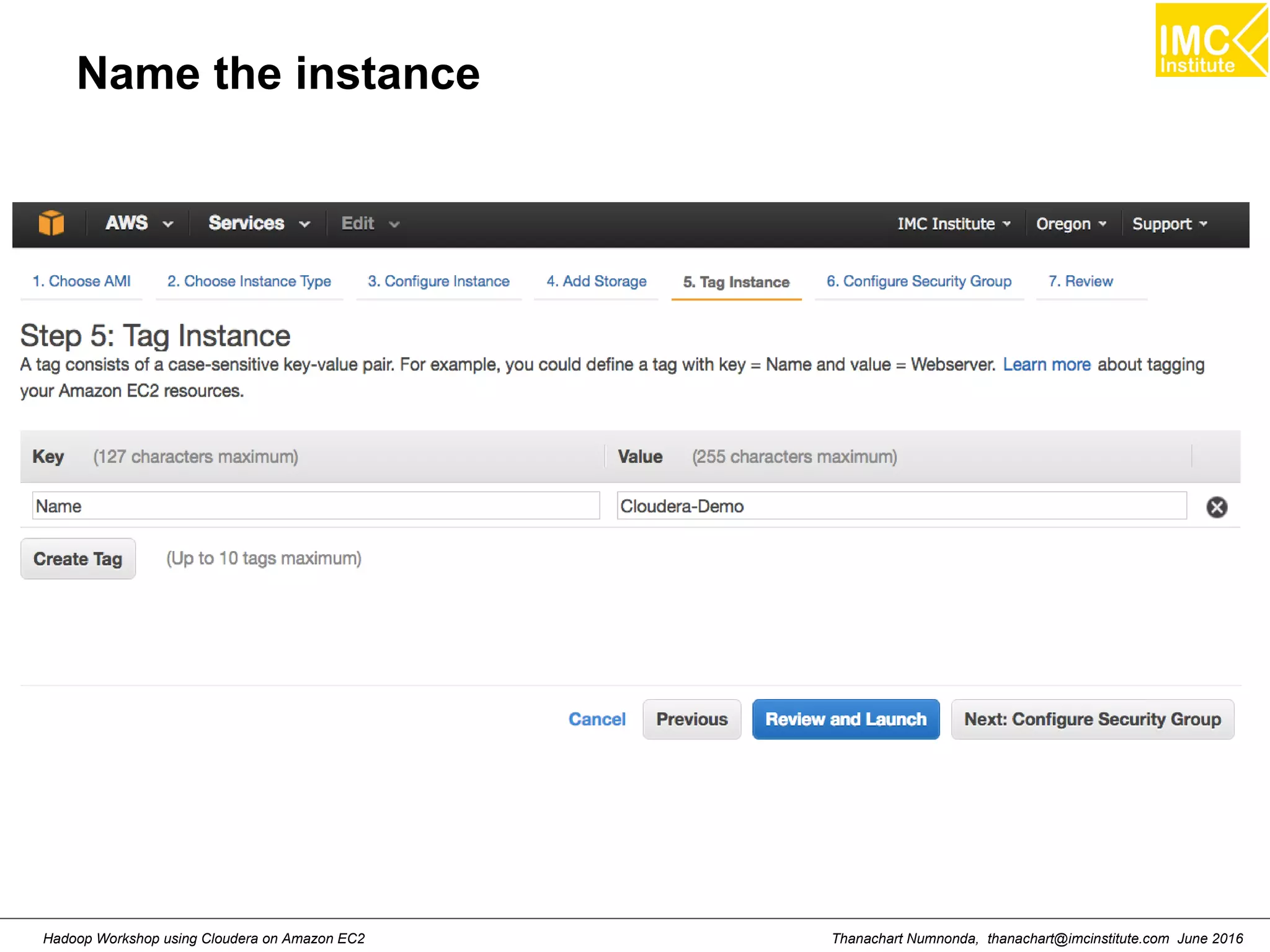
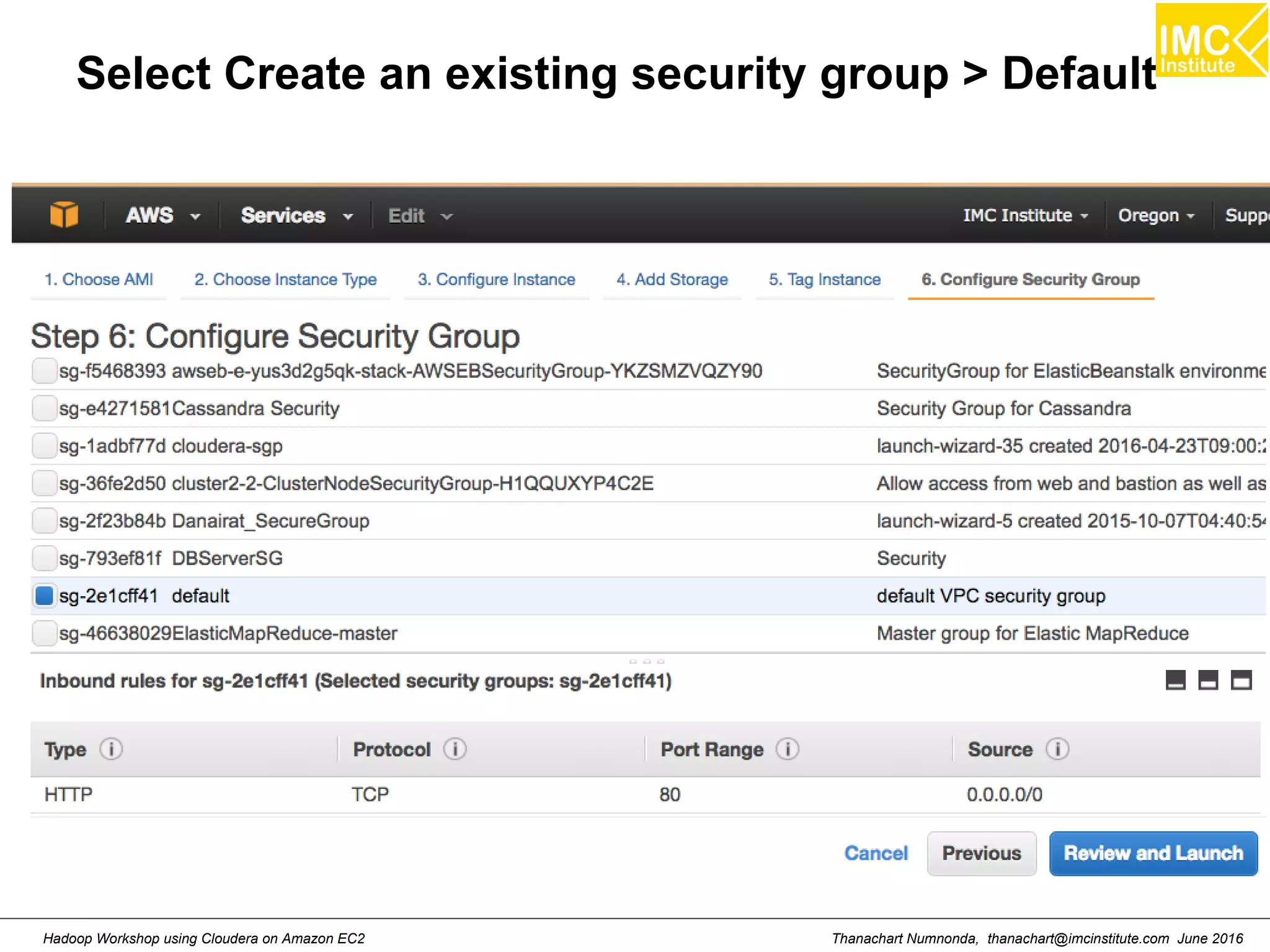
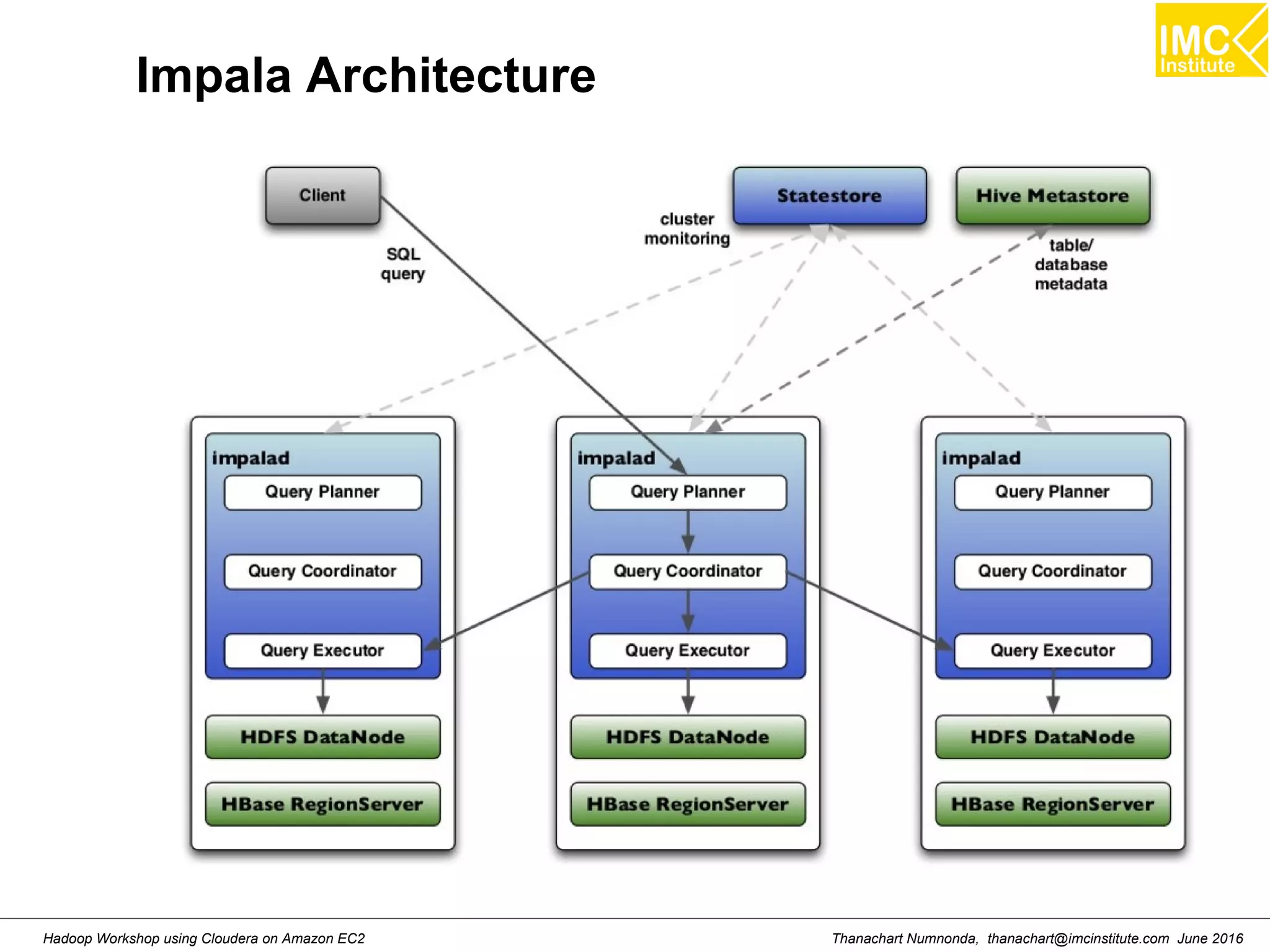
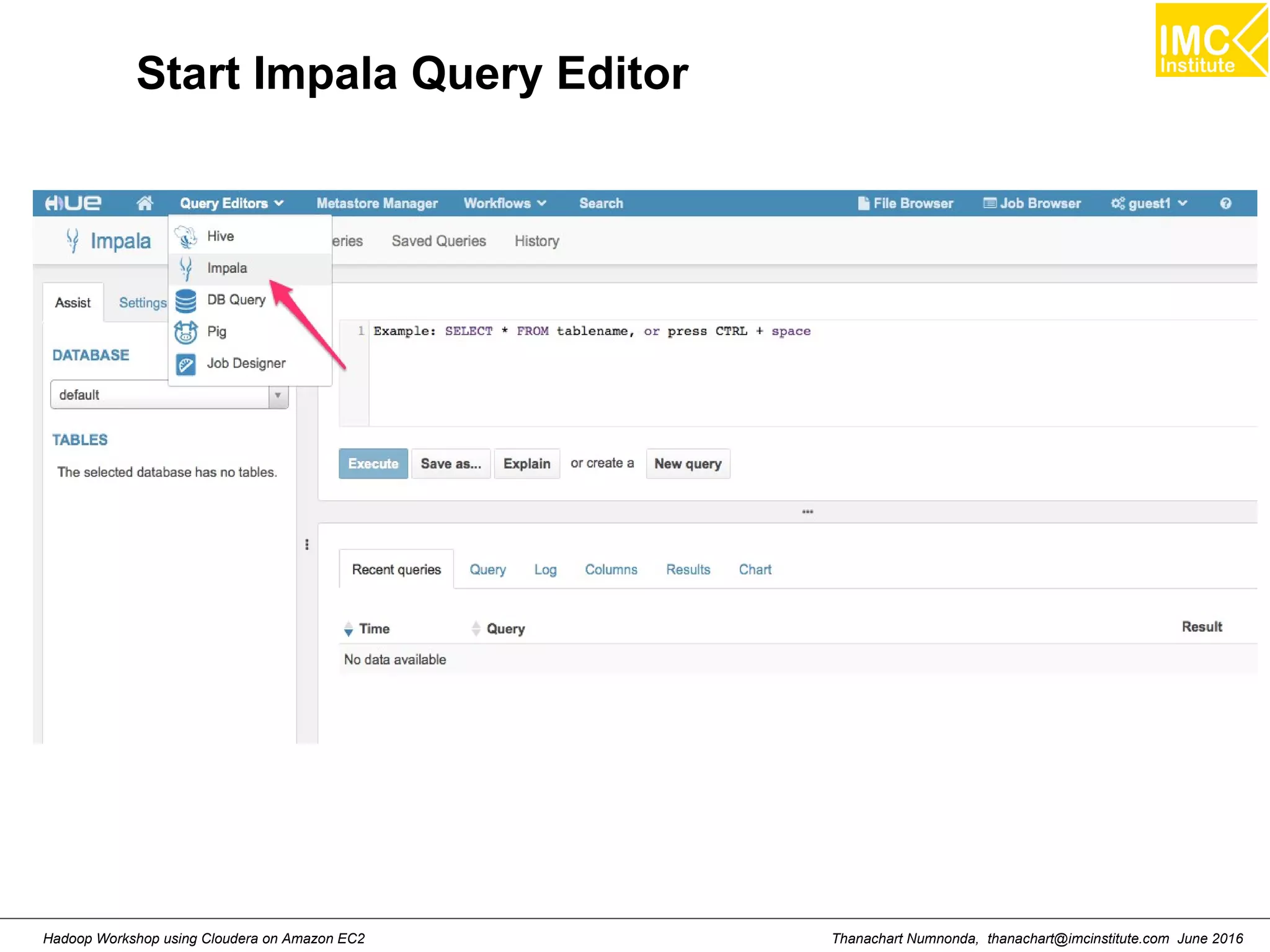
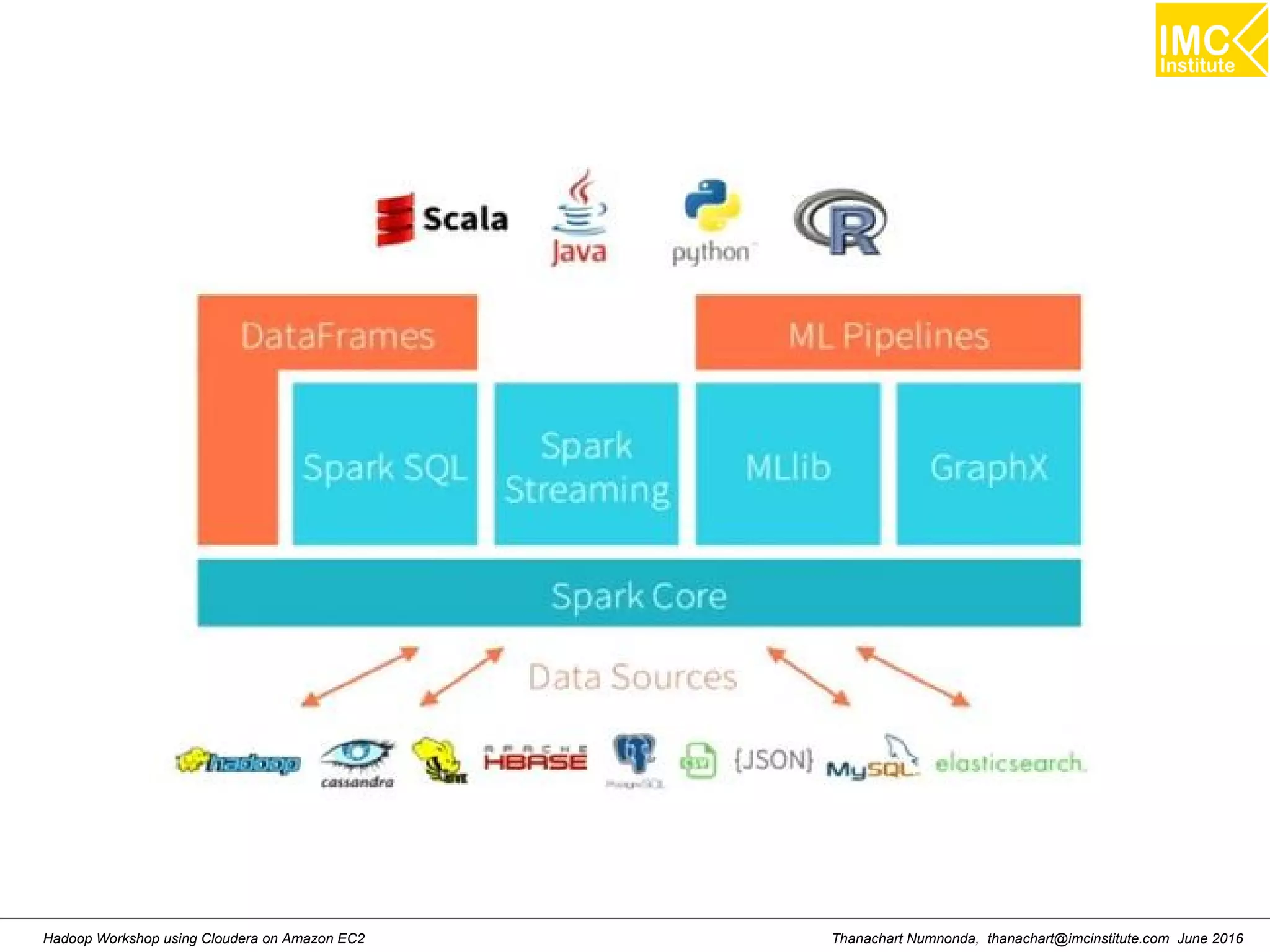
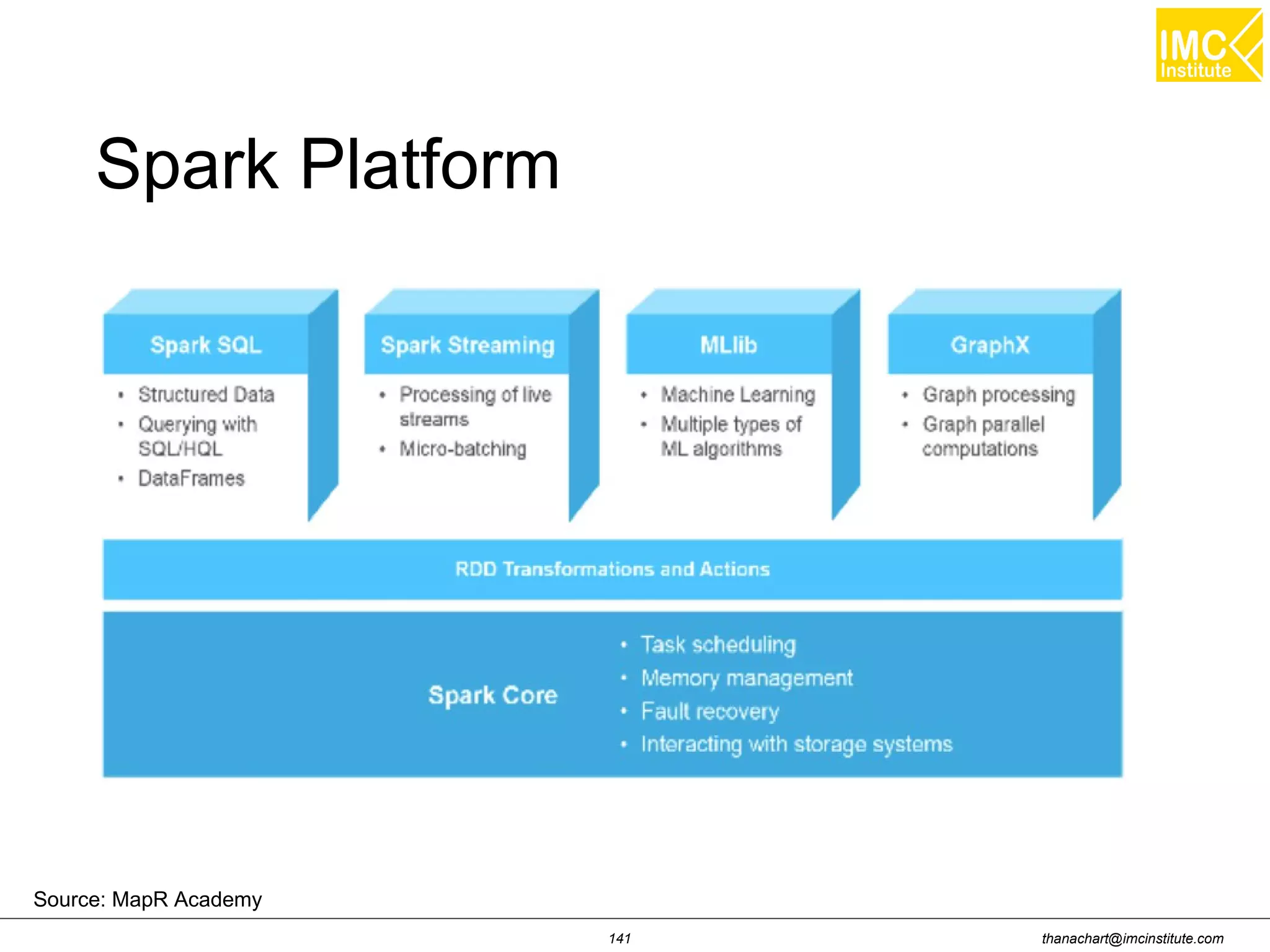
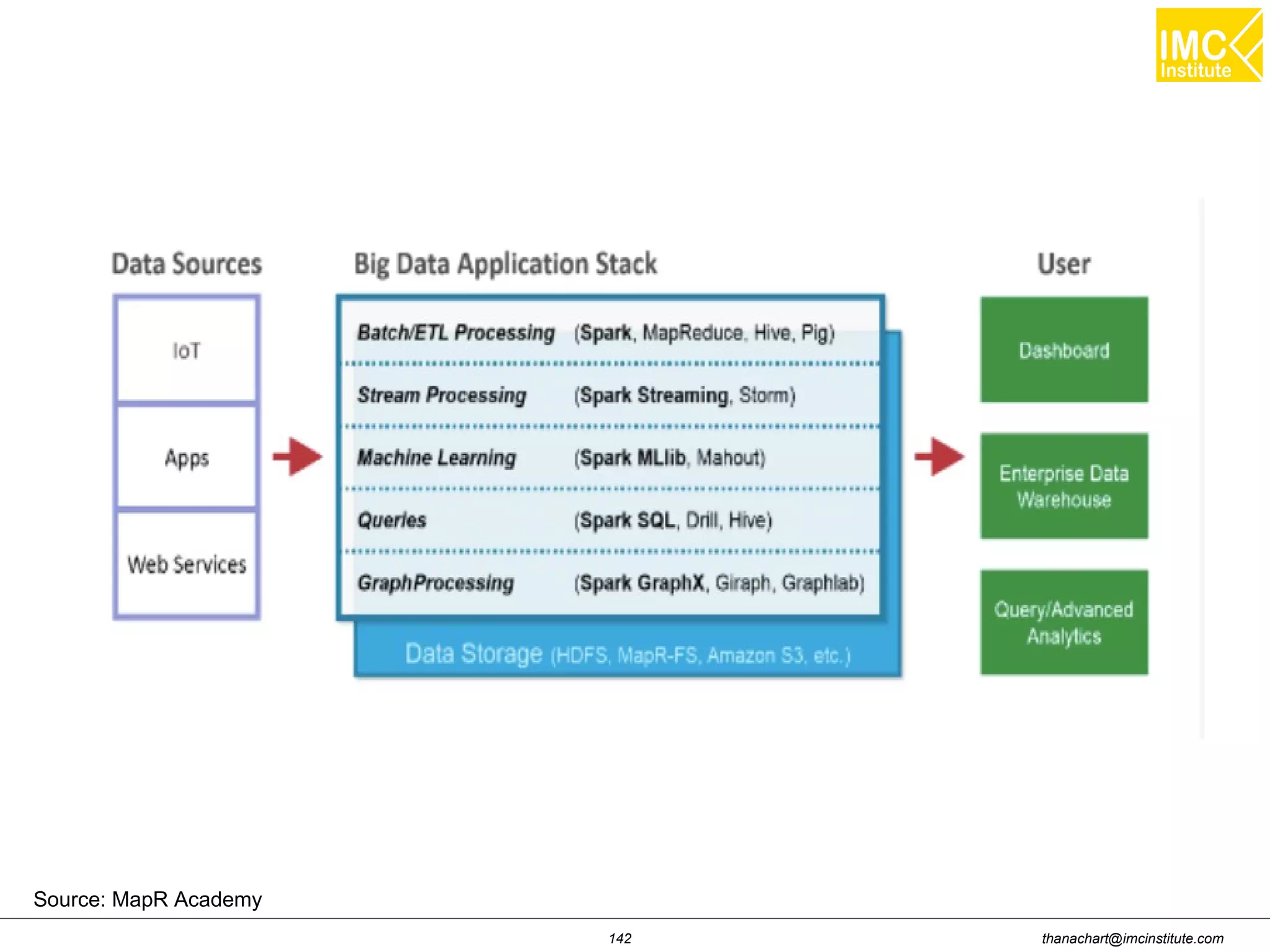
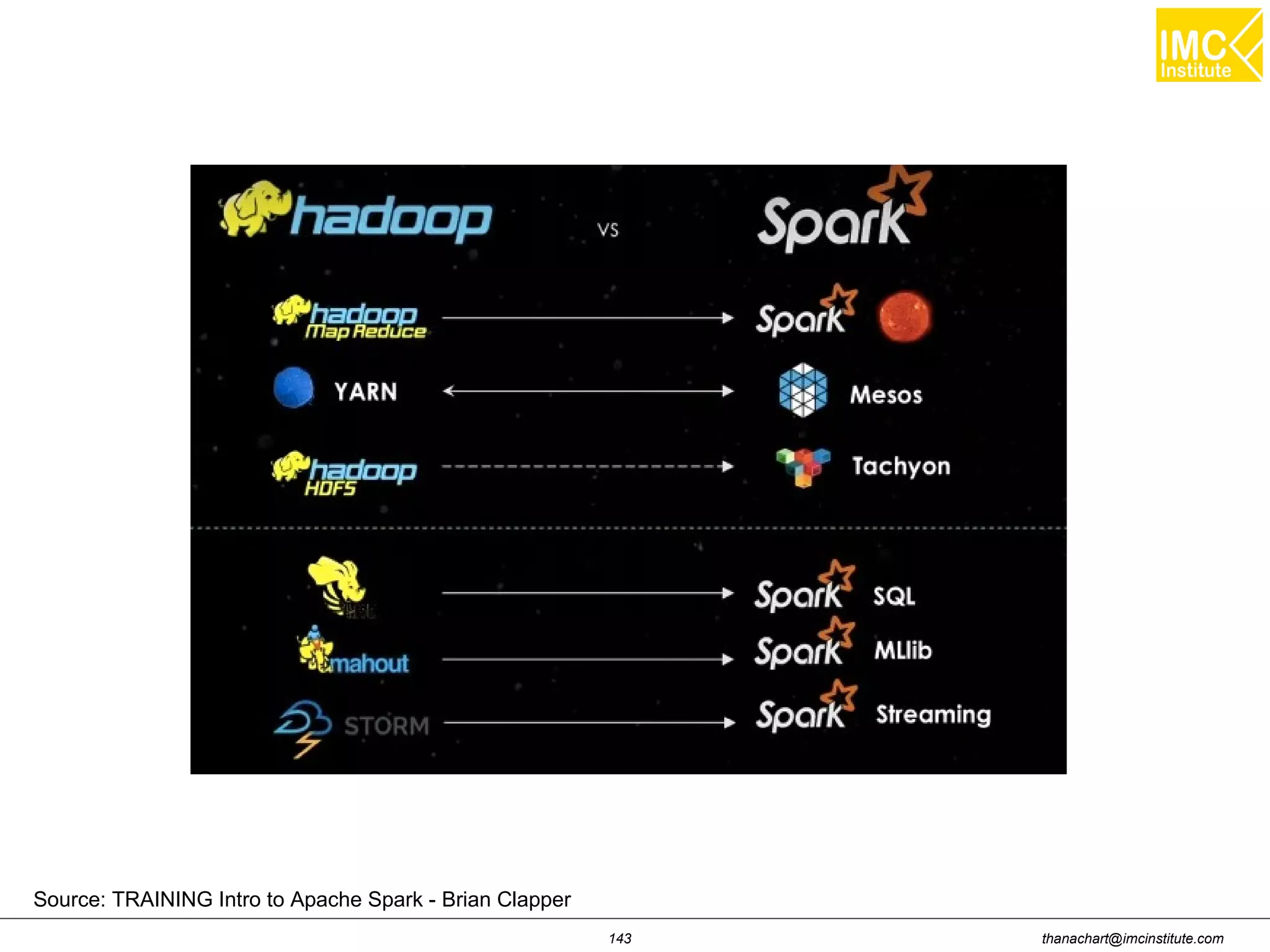
This document outlines a hands-on workshop for using Cloudera Quickstart with a Docker container to process big data. It discusses launching an AWS EC2 instance, installing Docker on Ubuntu, pulling the Cloudera Quickstart Docker image, and using various big data tools including HDFS, Hive, Pig, Impala, Spark, Spark SQL and Spark Streaming. The workshop will use a Cloudera cluster on EC2 consisting of a master node and three worker nodes to demonstrate importing and exporting data to HDFS, writing MapReduce programs, and using tools like Hive.