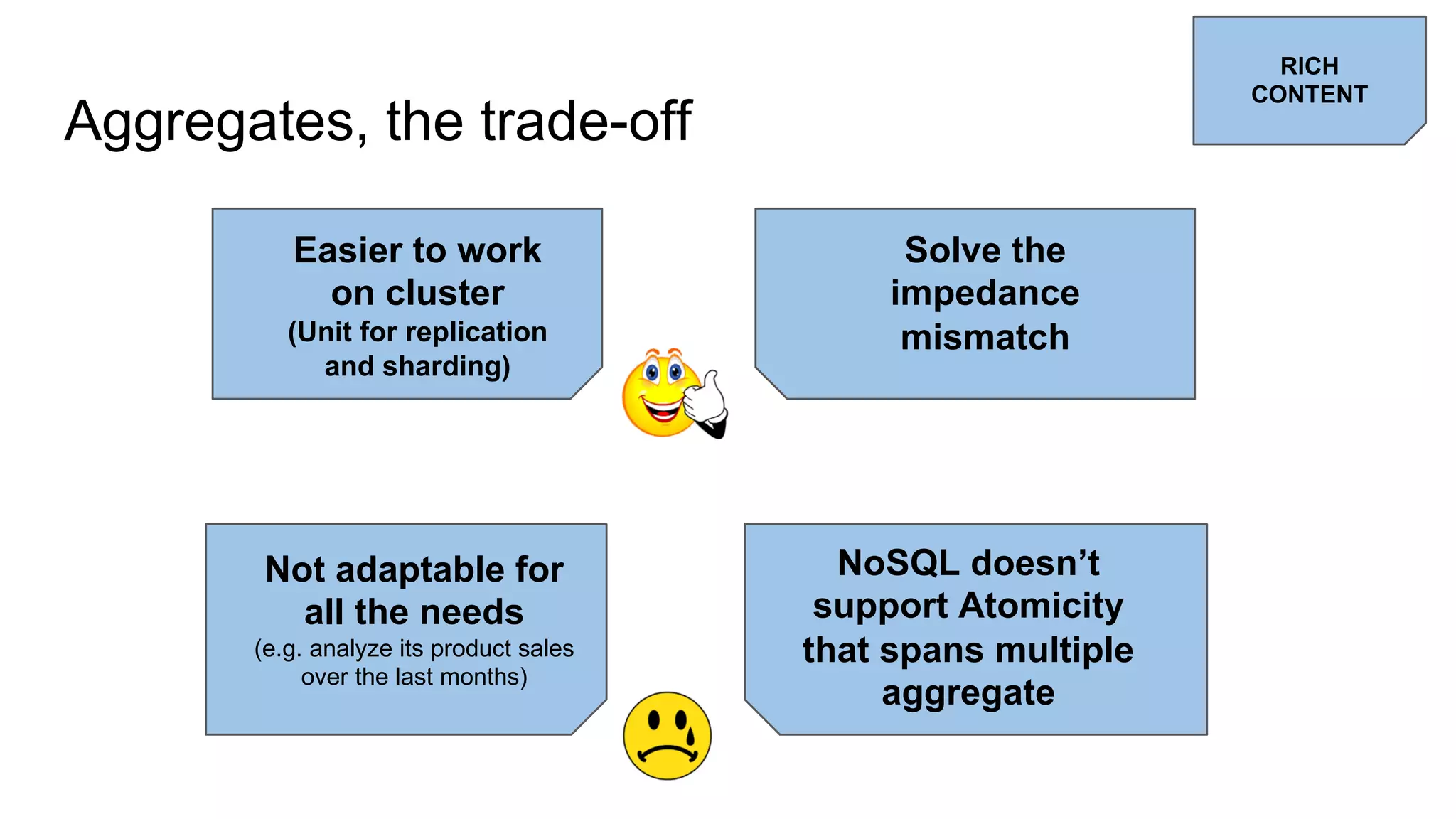
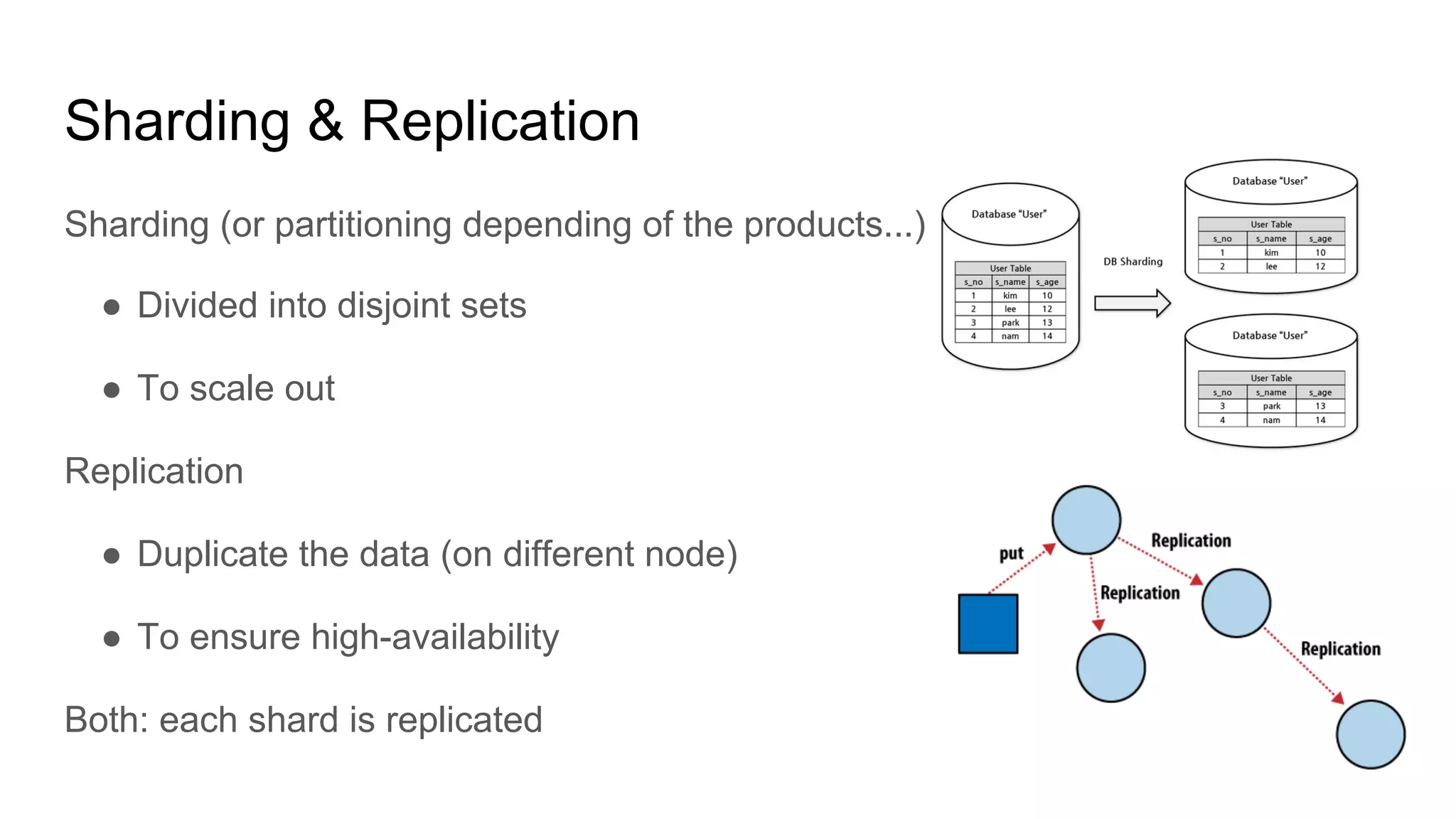
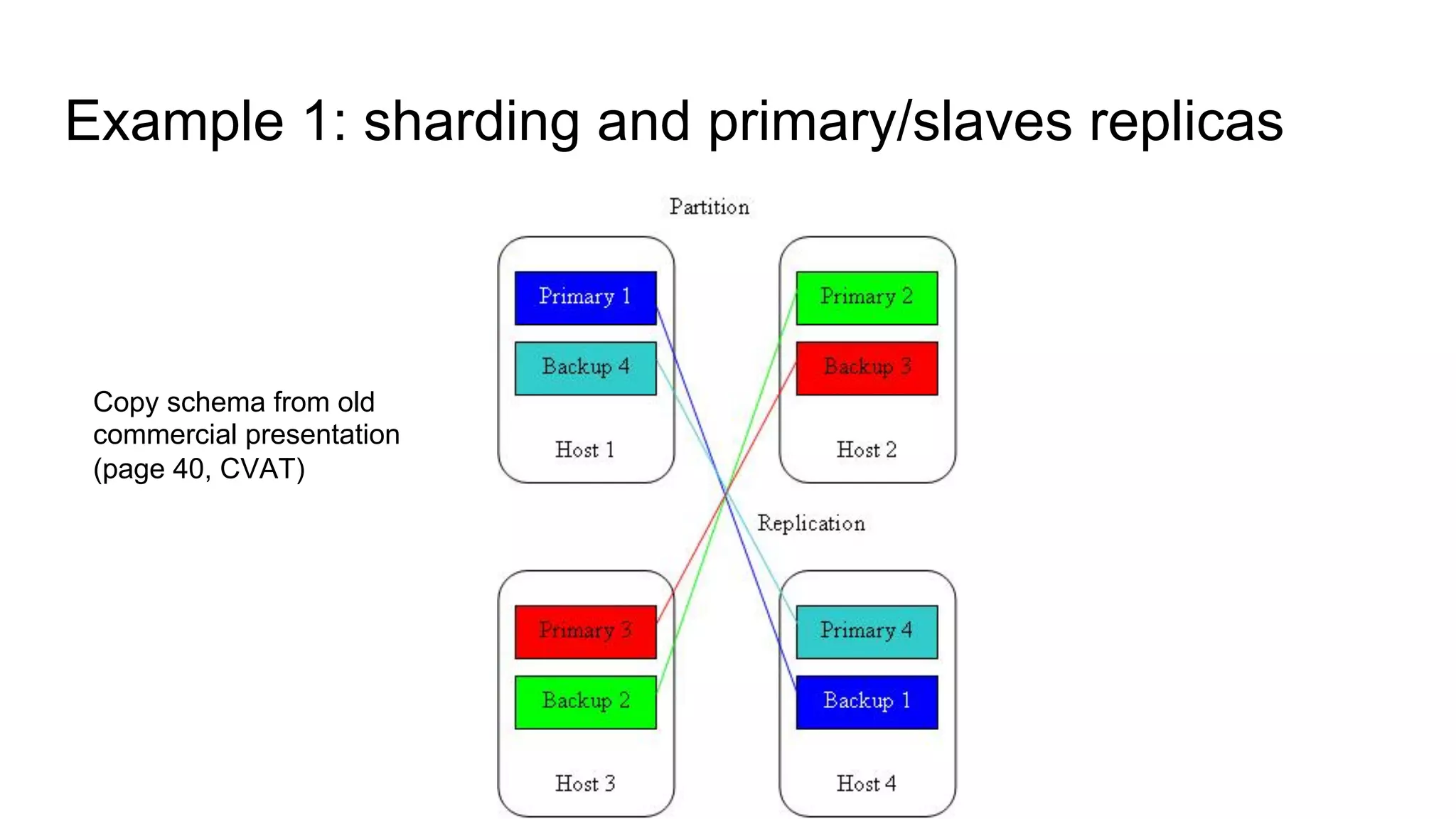
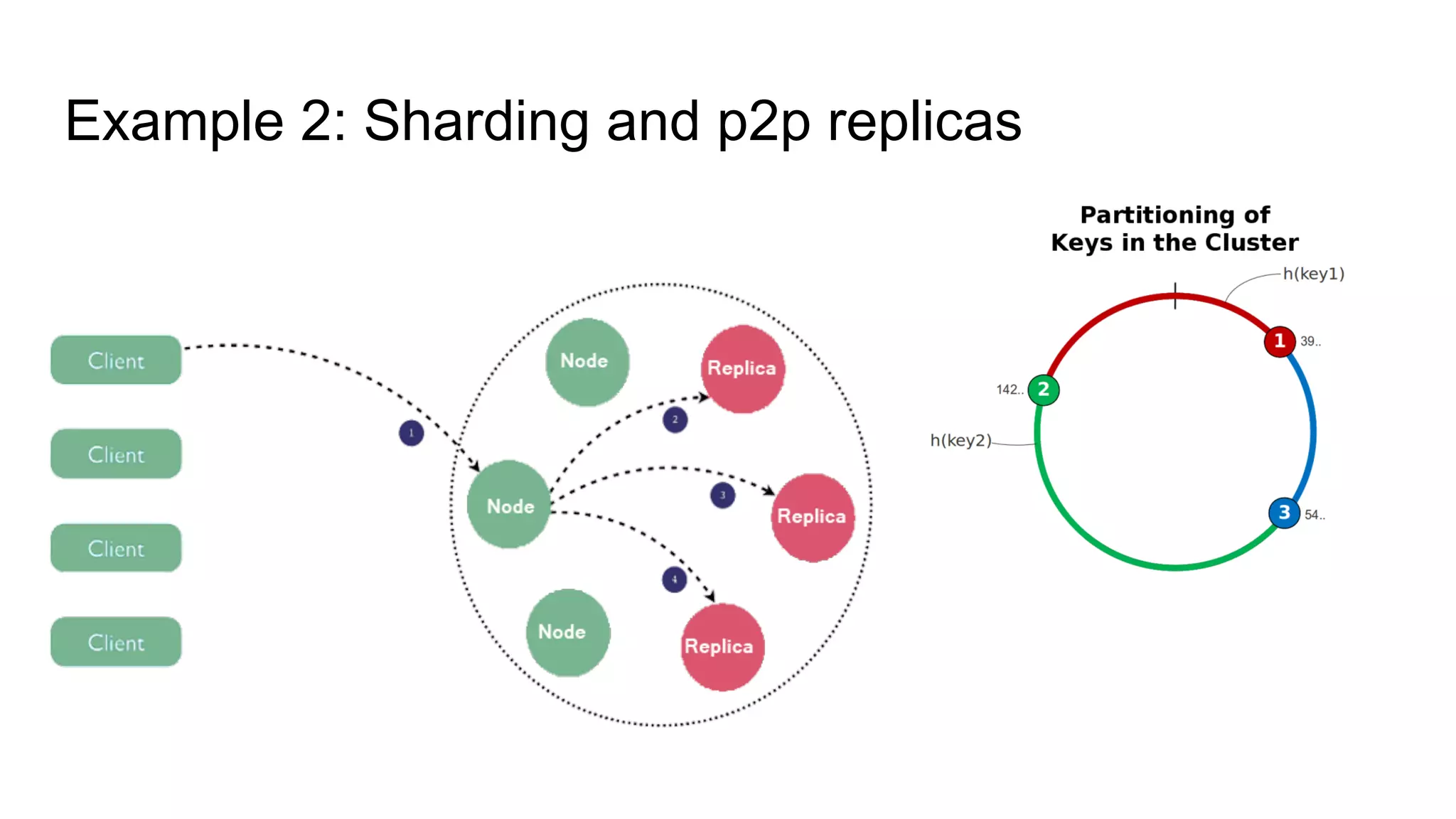
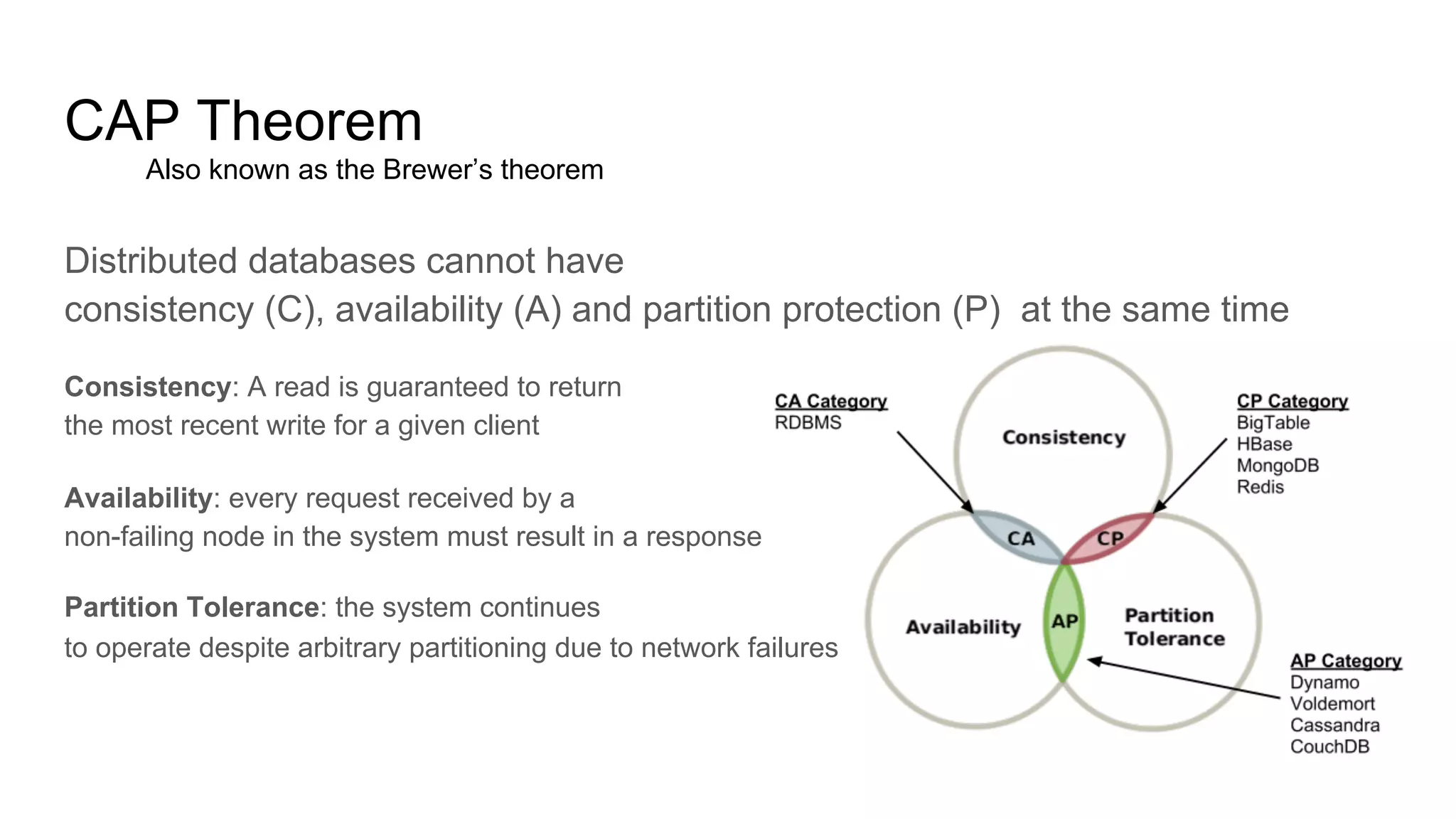
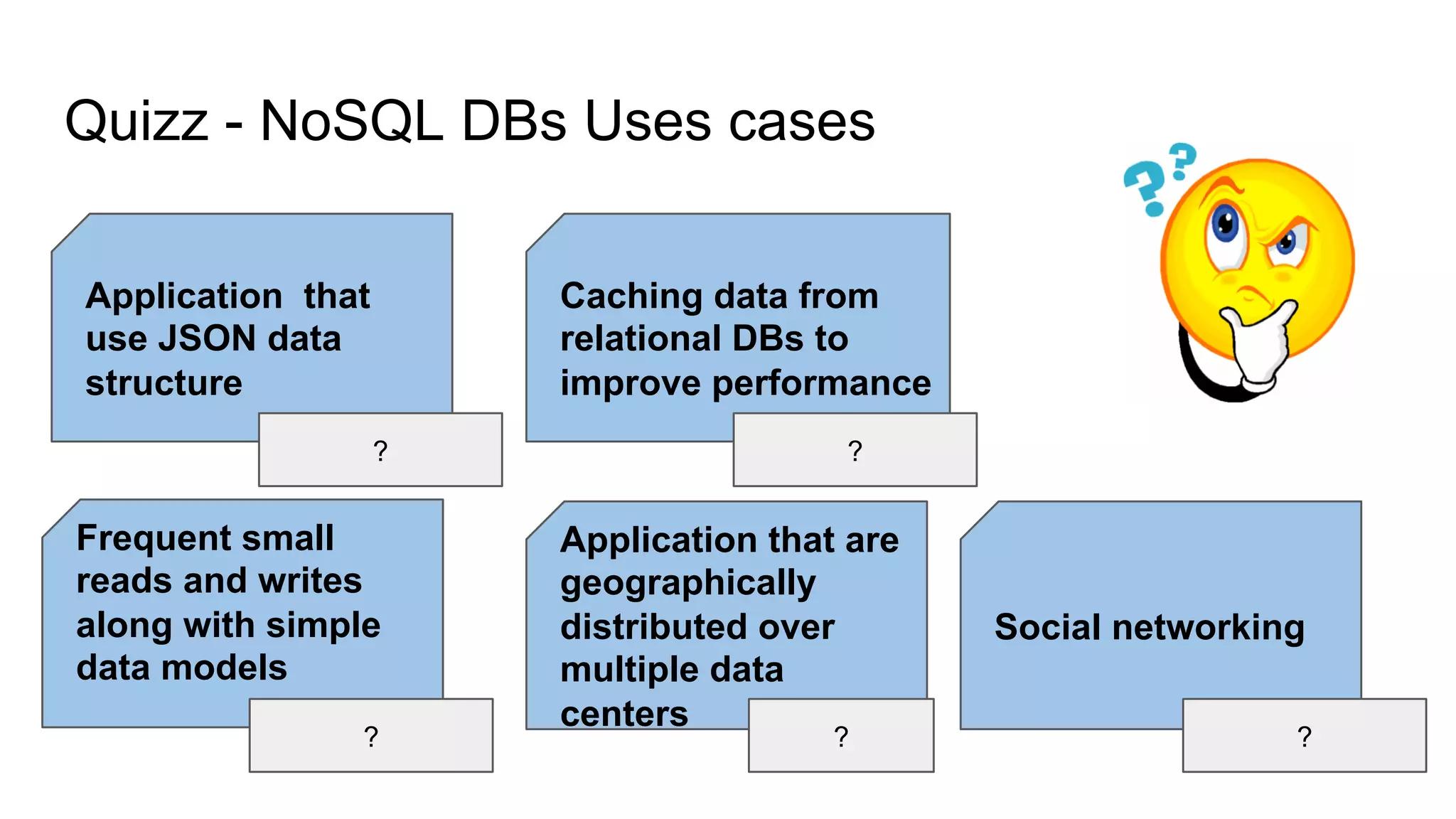
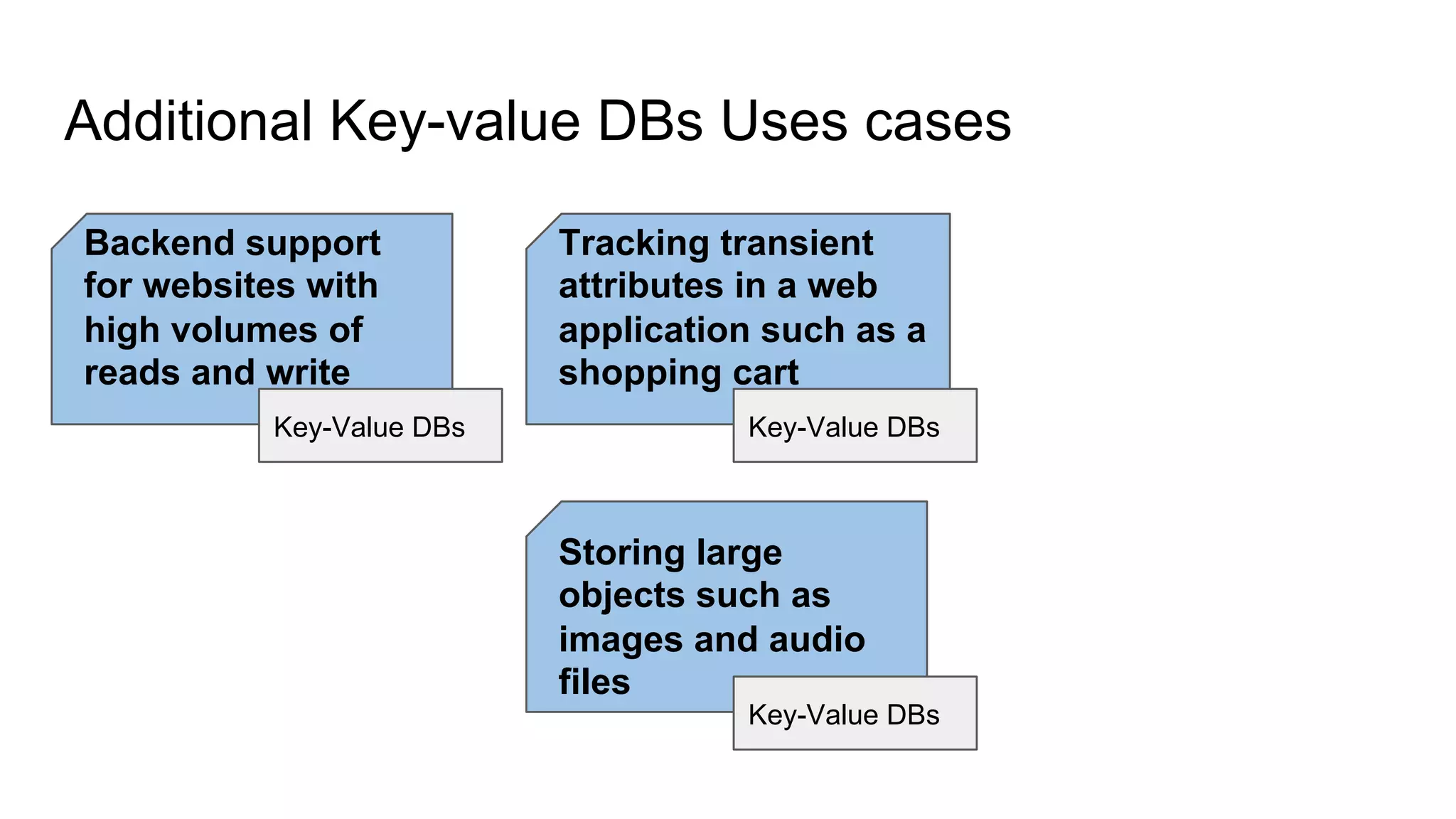
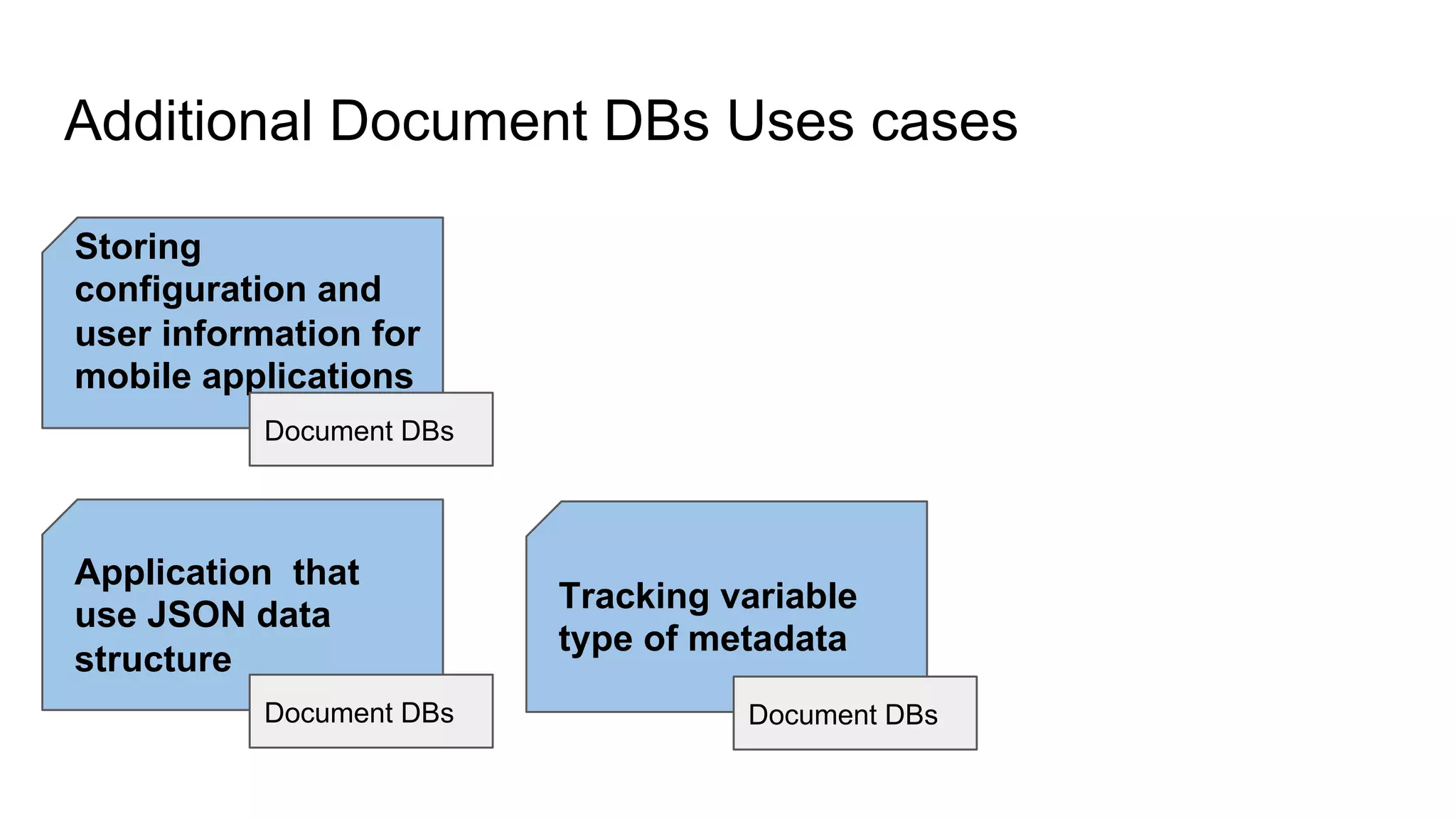
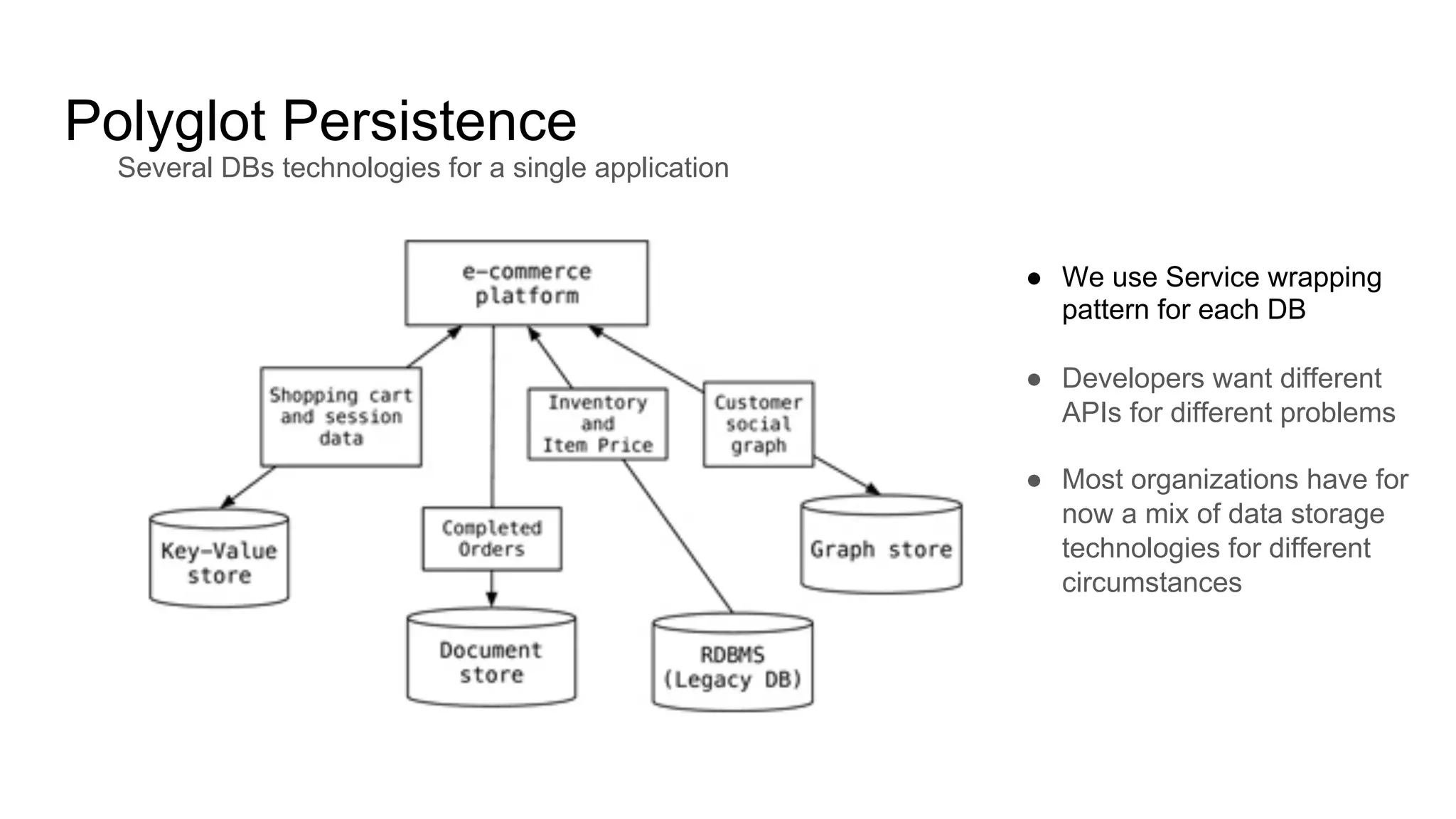
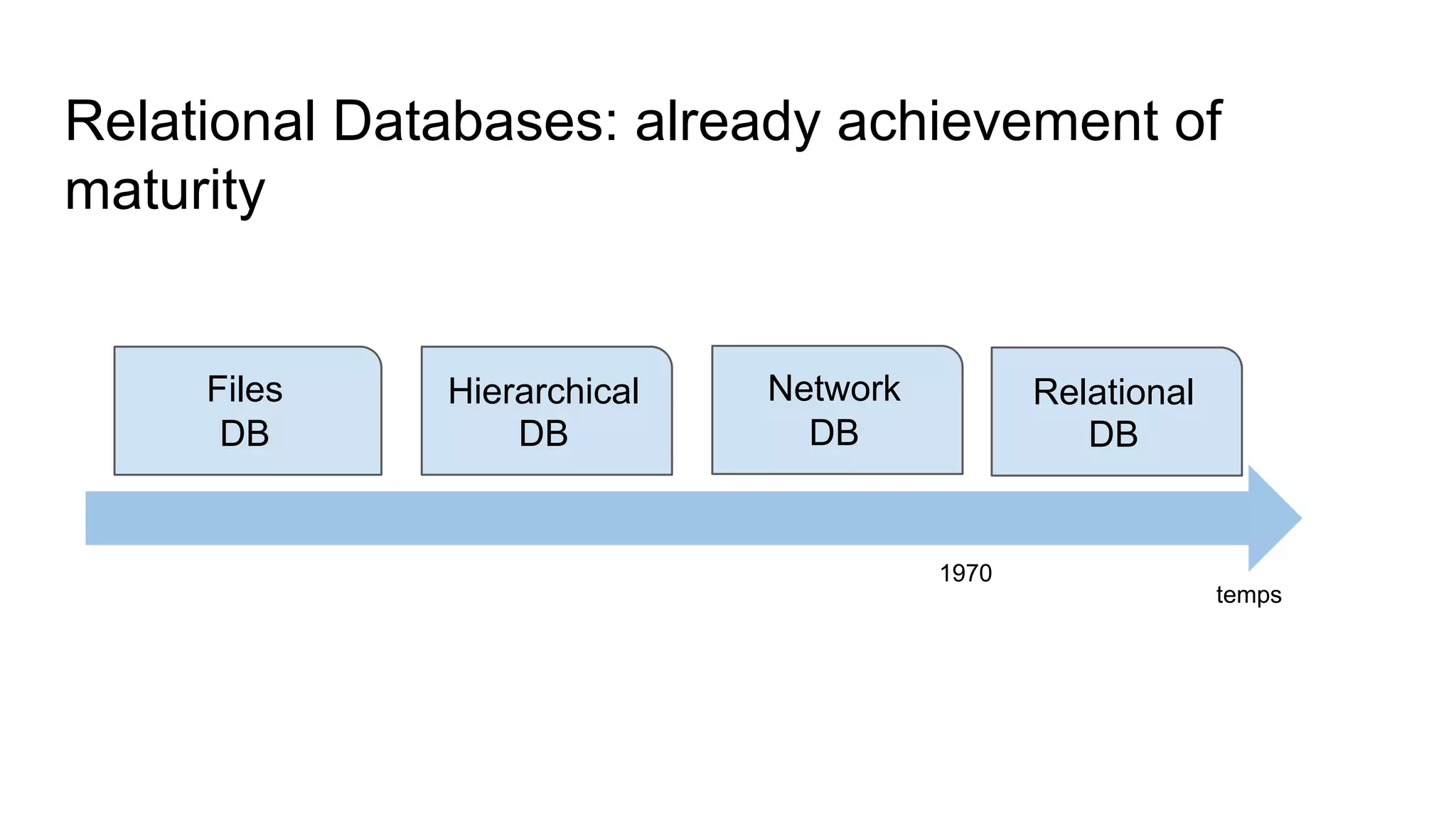
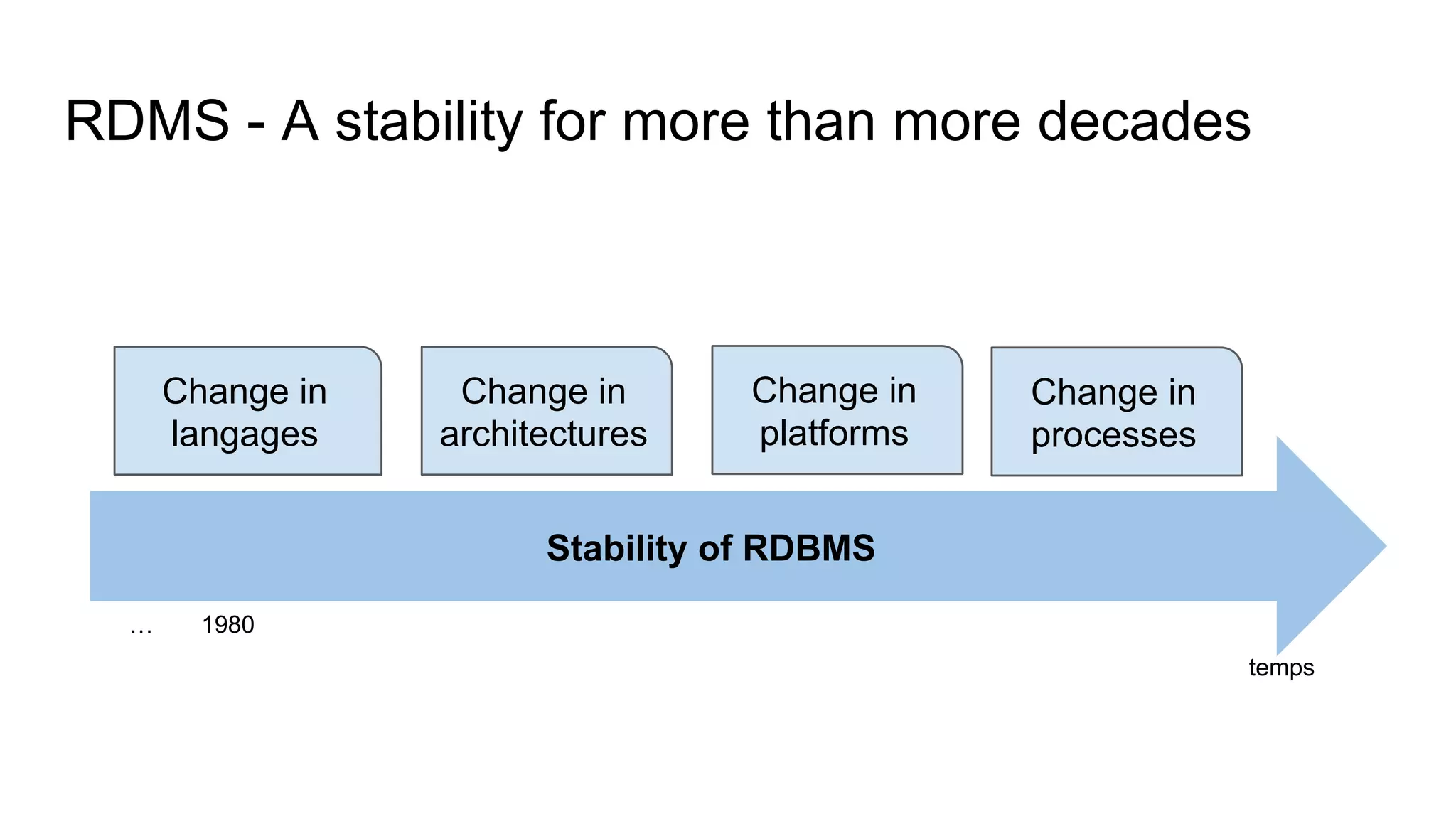
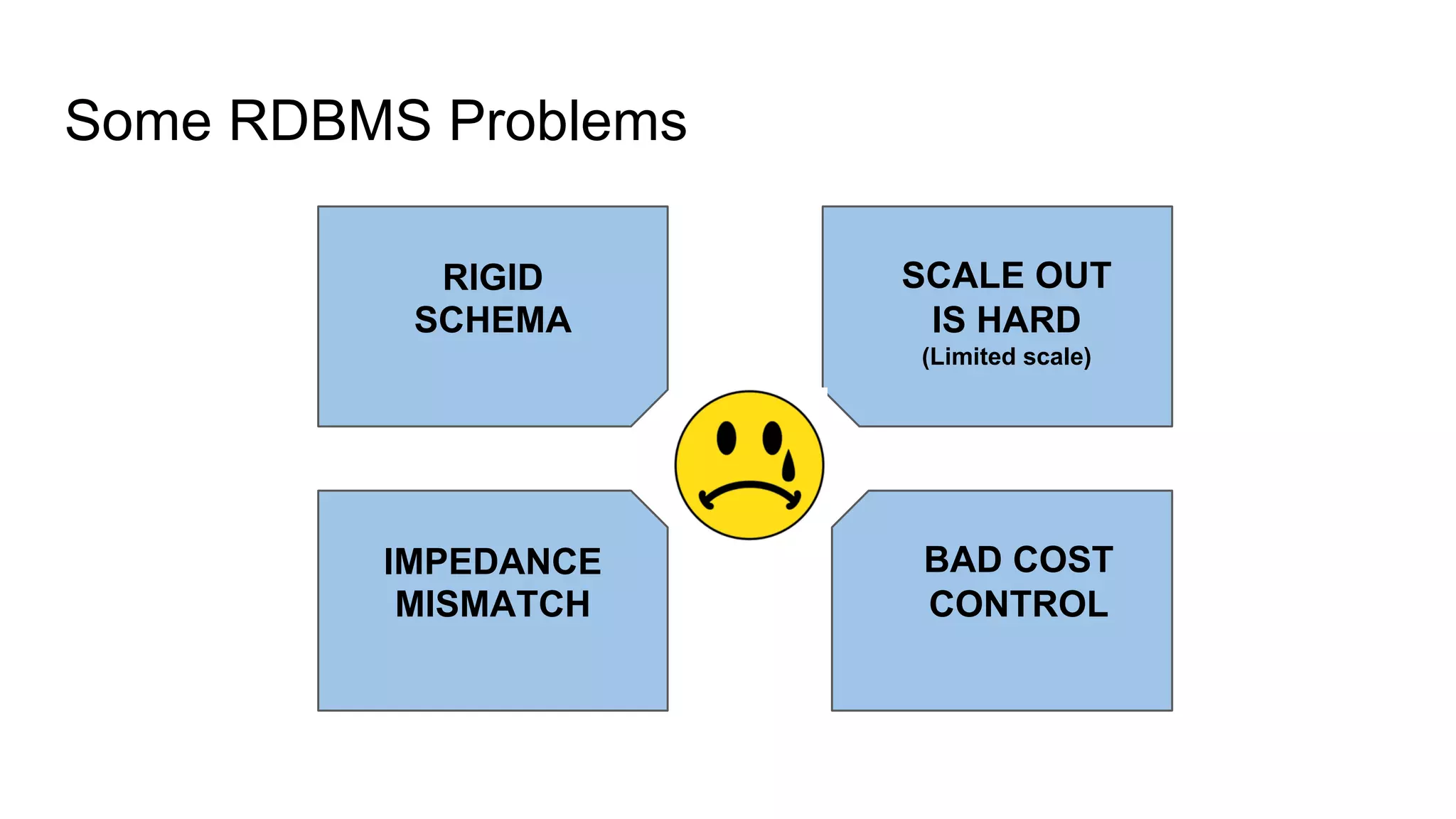
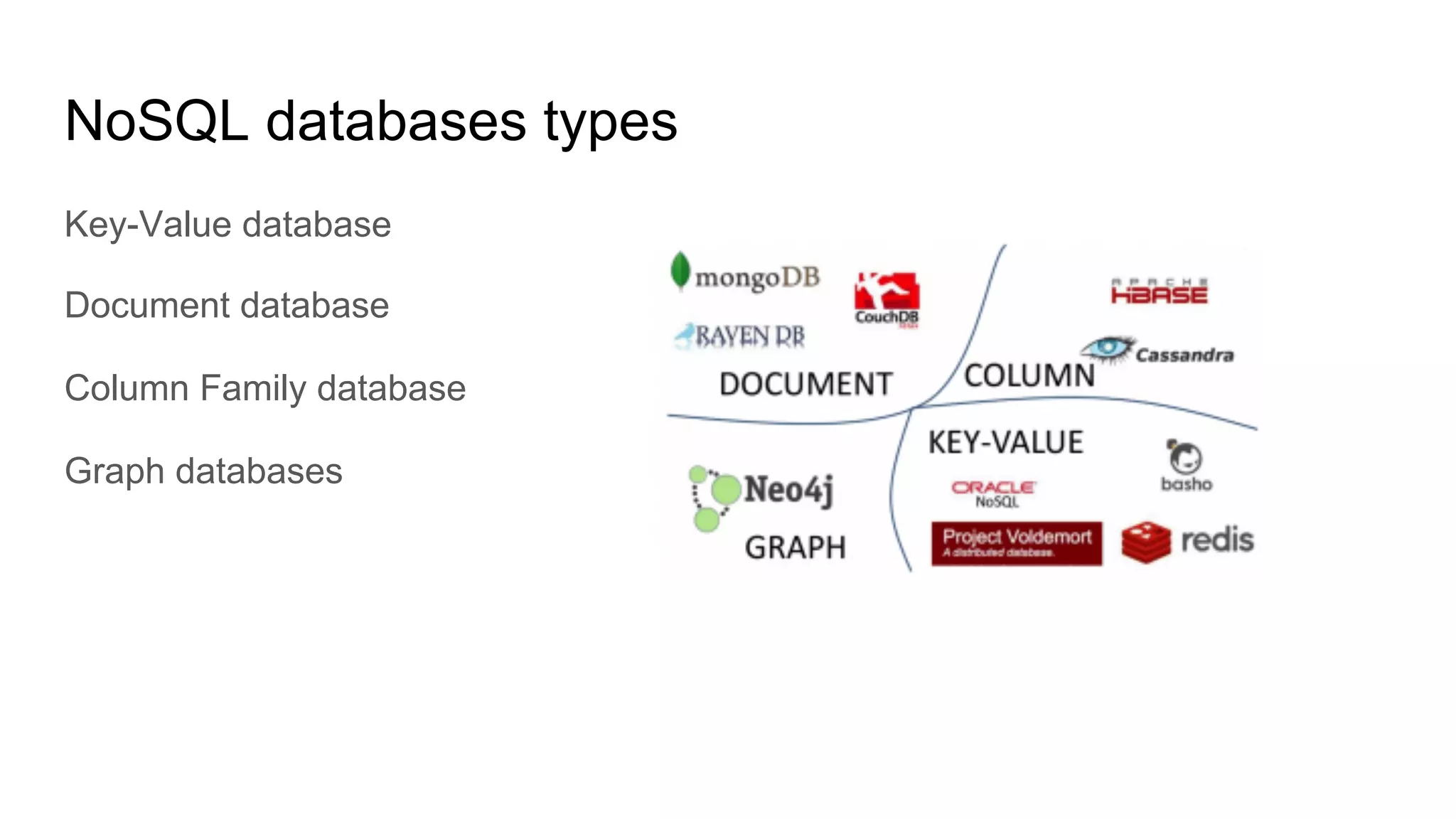
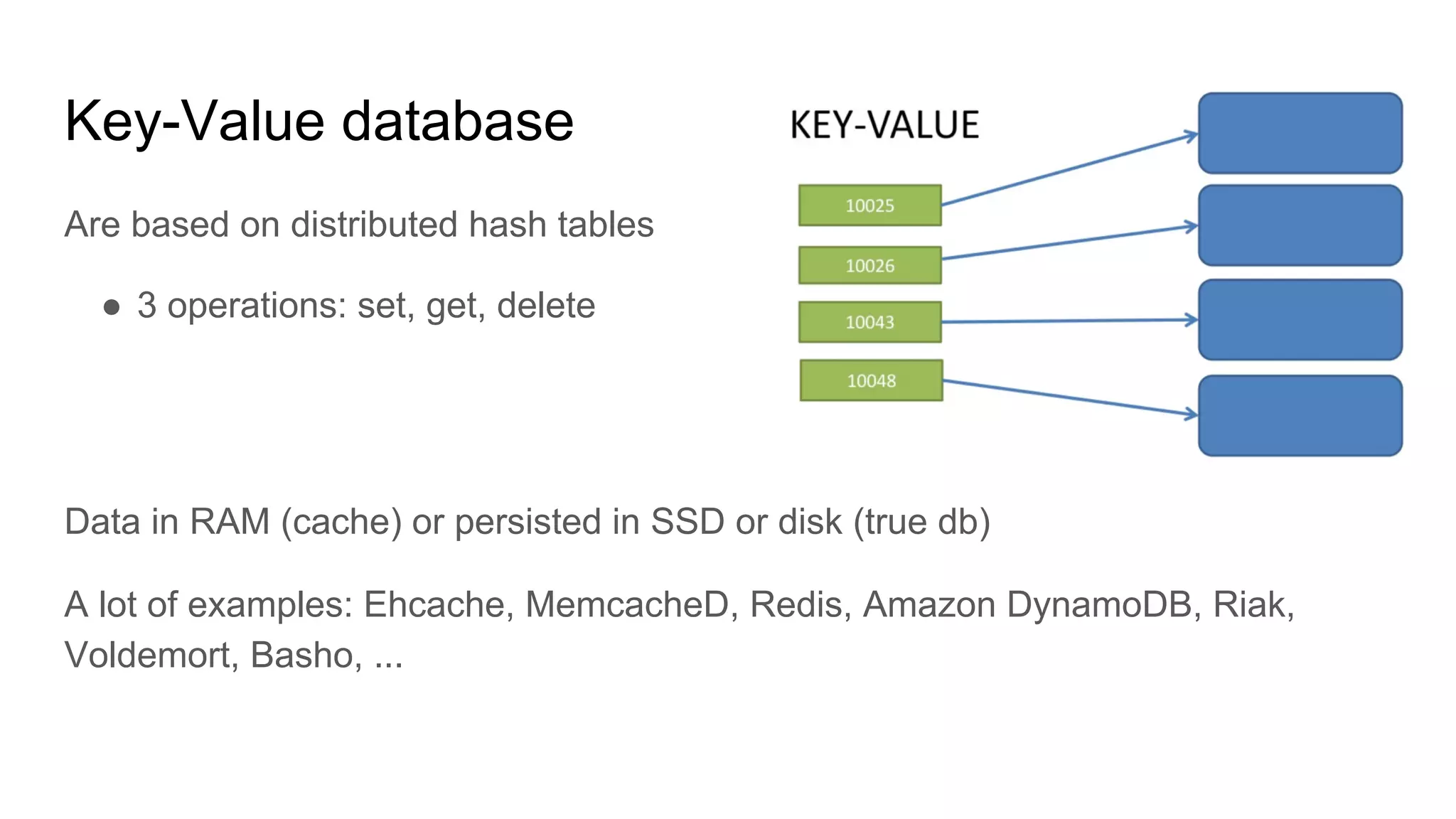
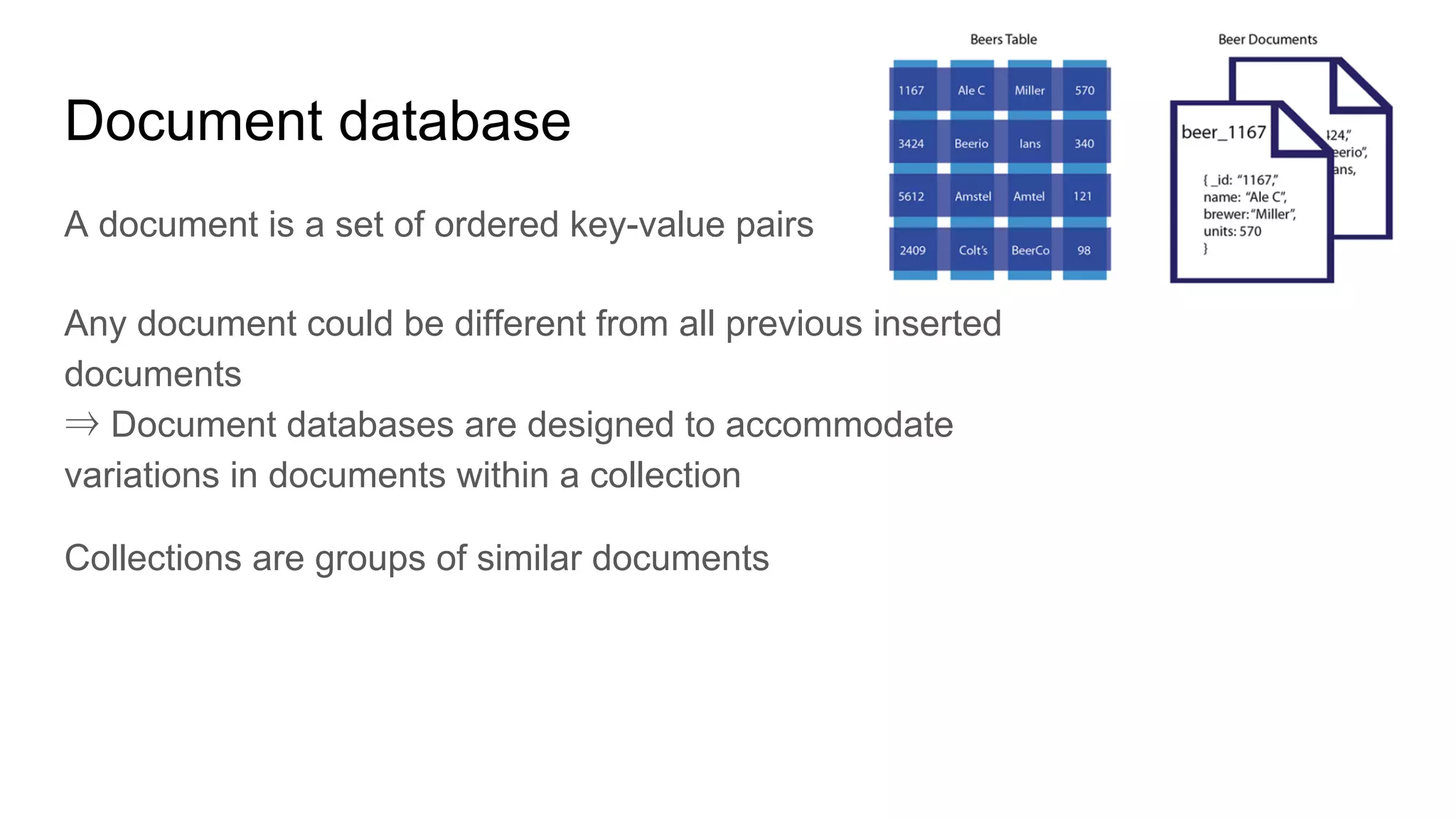
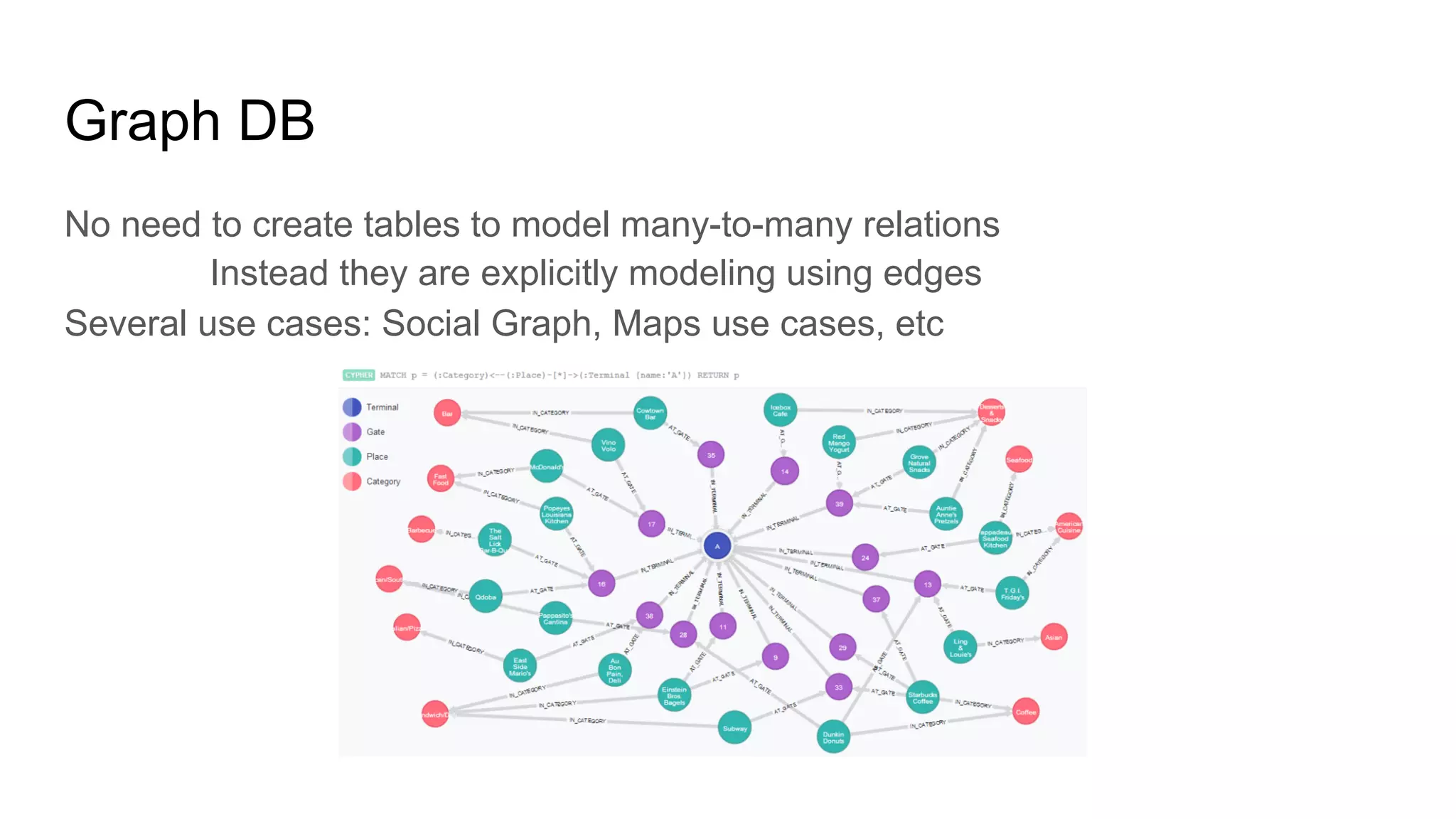
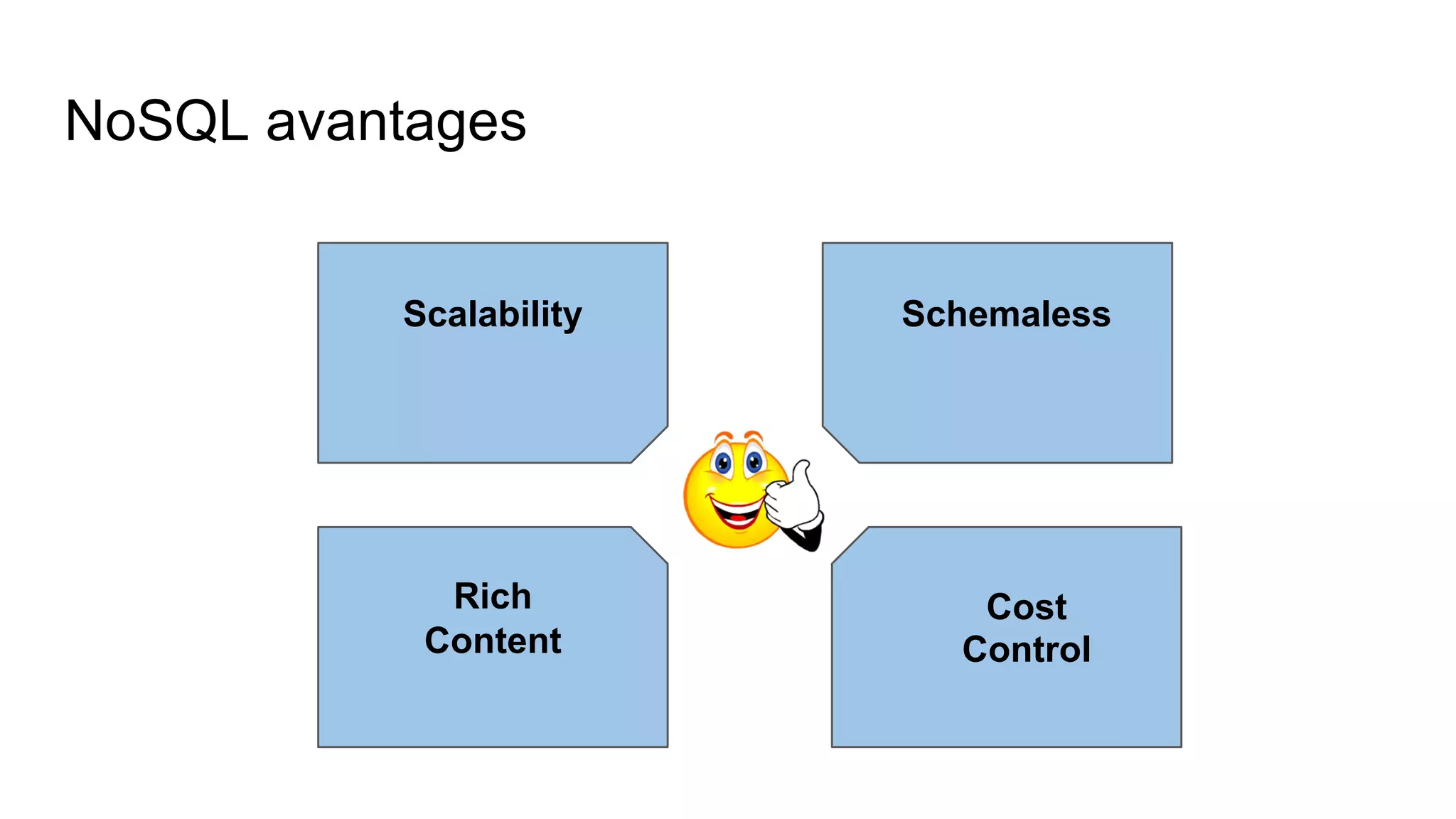
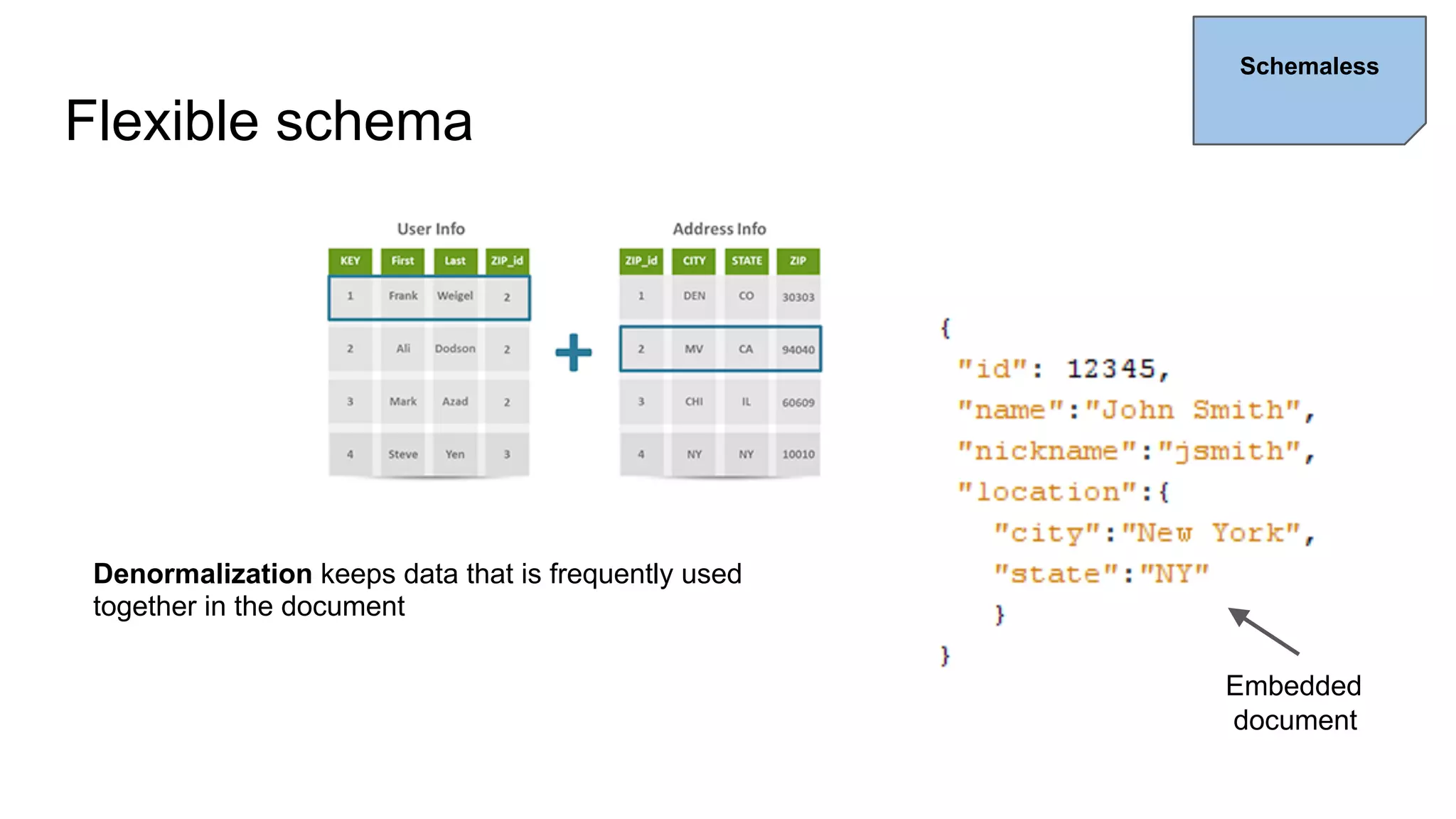
This document provides an overview of relational databases and the emergence of alternative database technologies like NoSQL. It discusses the dominance and stability of relational databases but also some of their limitations for certain use cases. It introduces NoSQL databases and why they emerged, focusing on their scalability and flexibility compared to relational databases. The document describes different types of NoSQL databases and how they handle concepts like schemas, transactions and scaling. It provides examples of when different database types may be more suitable and discusses additional concepts like aggregates, consistency models and sharding.




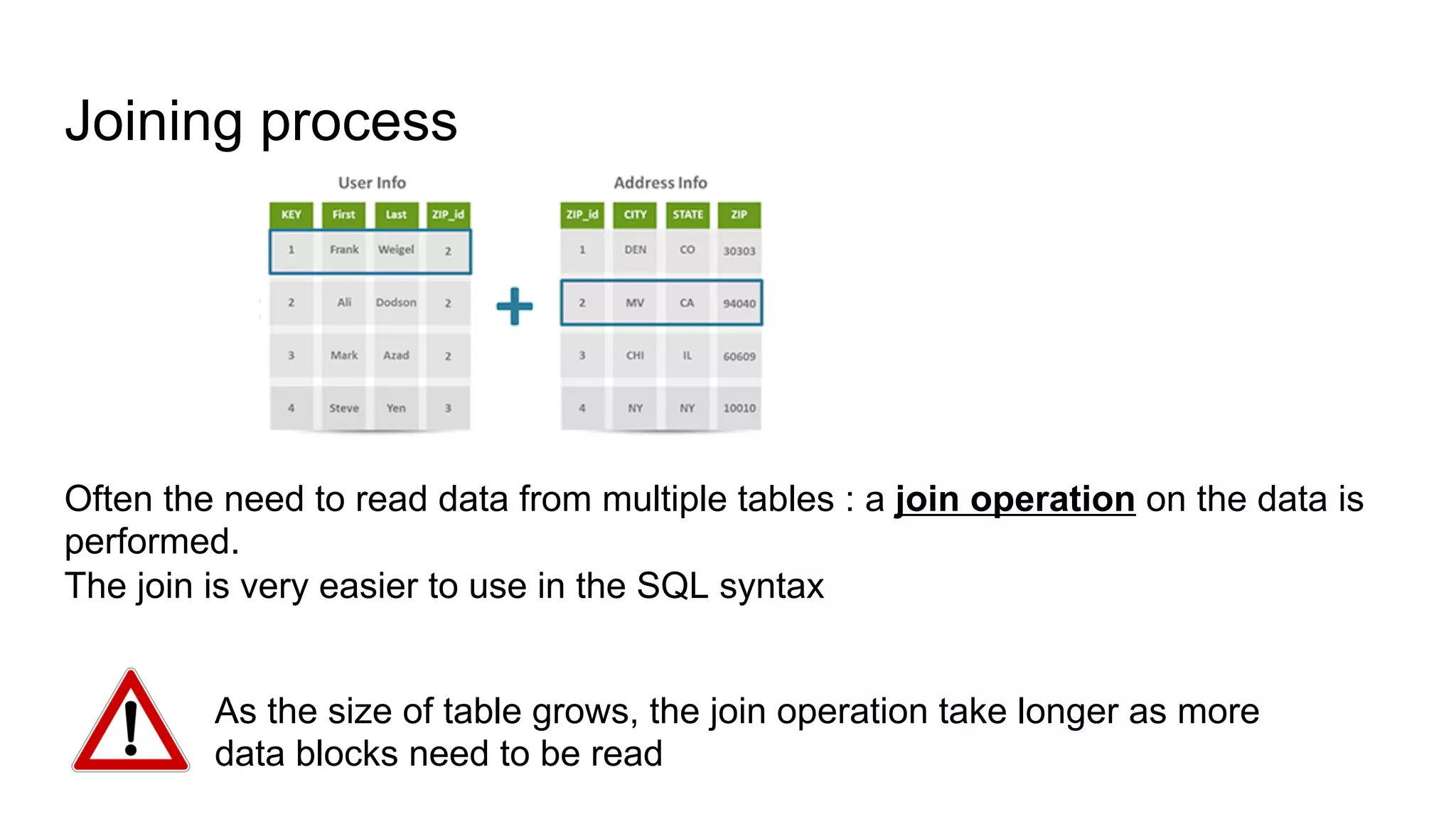
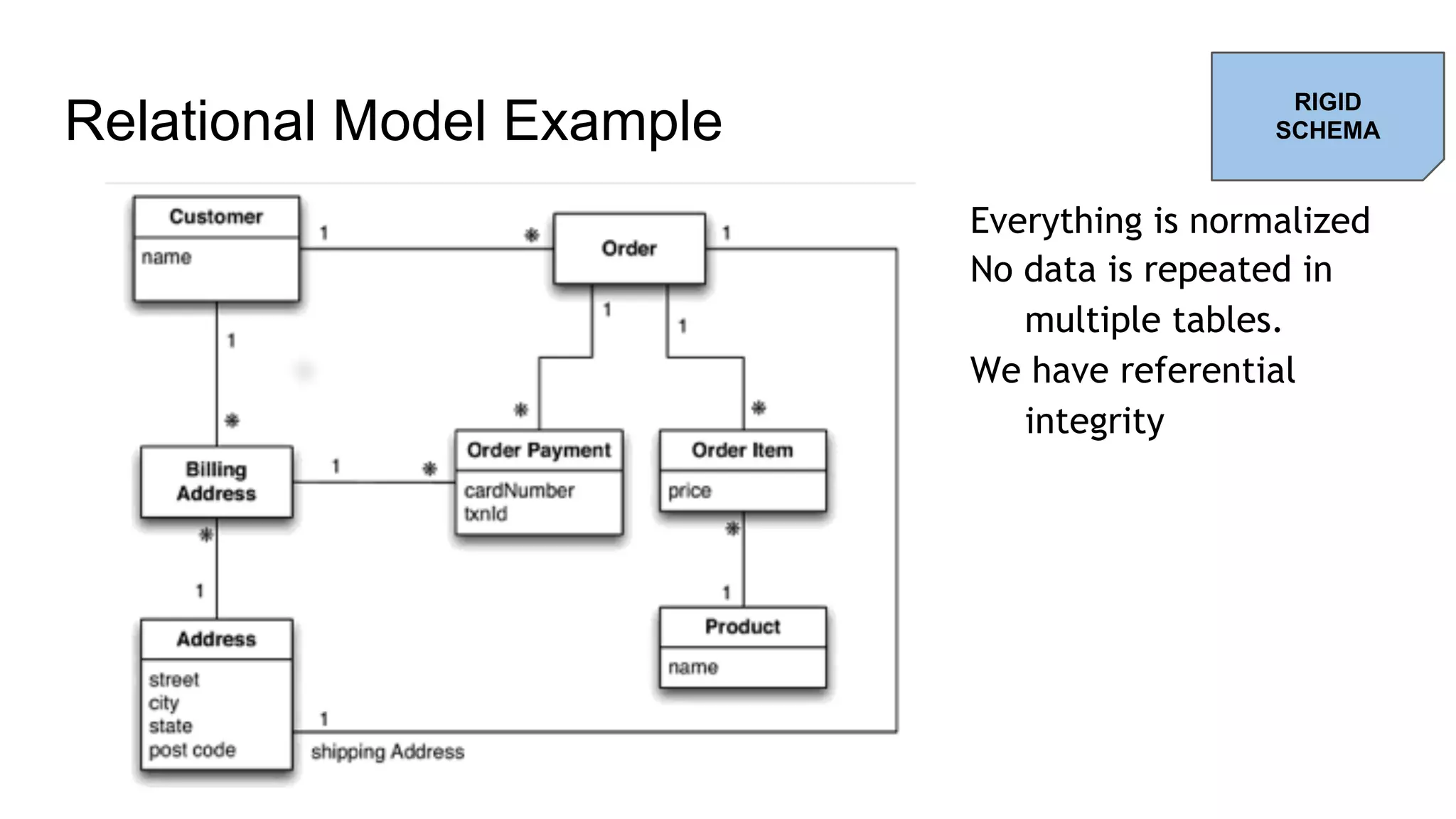










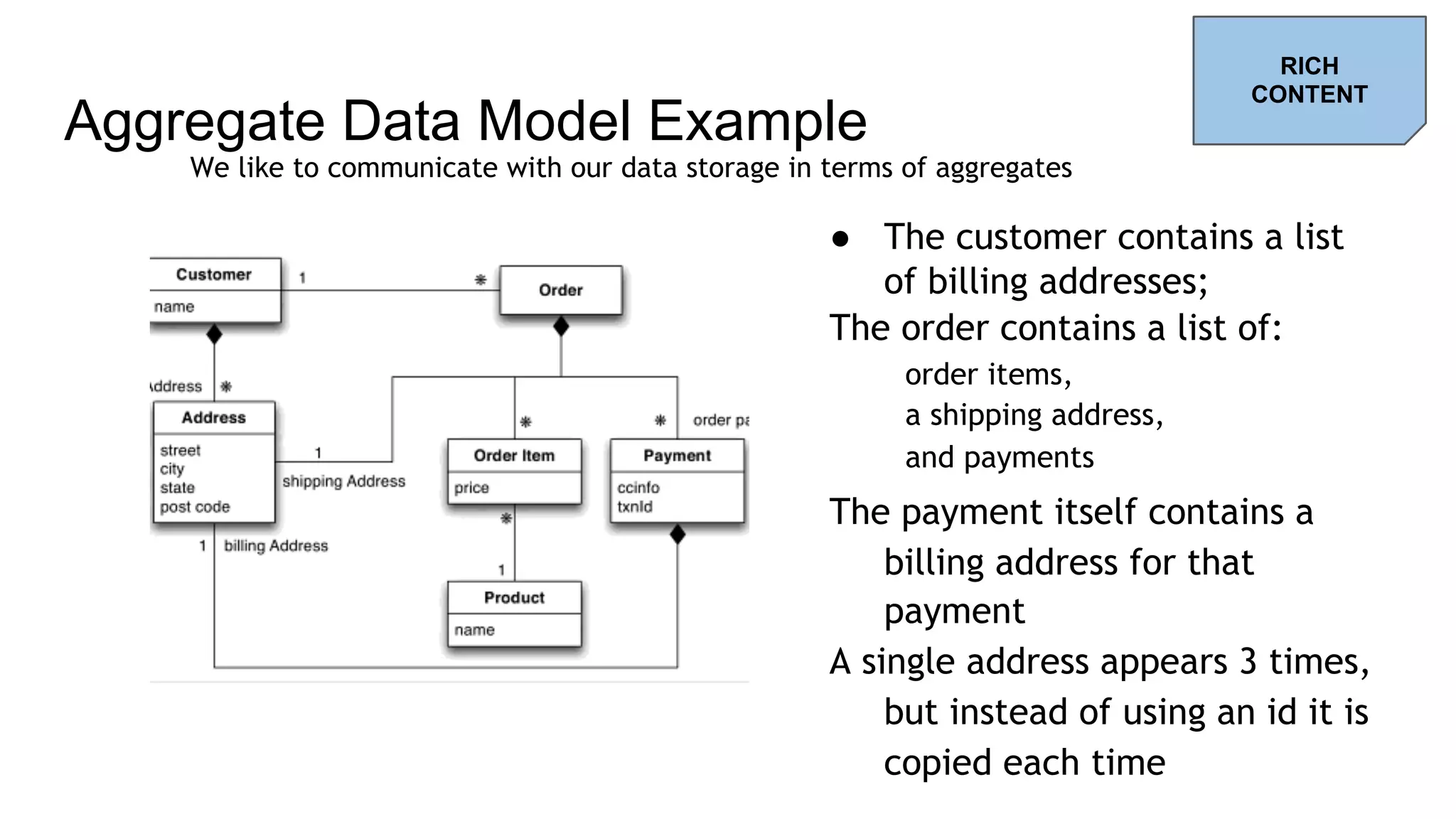

![Aggregate Boundaries Two aggregates: Customer and Order Links between aggregates are relationships Instead of using an id, a same data can be stored several times (e.g. the address) We can draw our aggregate differently //Customer { "id": 1, "name": "Fabio", "billingAddress": [ { "city": "Paris" } ] } //Orders { "id": 99, "customerId": 1, "orderItems": [ ..], "shippingAddress": [ {"city": "Paris”} ], "orderPayment": [ "billingAddress": [ {"city": "Paris”} ], …. ] } RICH CONTENT](https://image.slidesharecdn.com/beyondrelationaldatabasesv3-170501150307/75/Beyond-Relational-Databases-37-2048.jpg)