Download as PDF, PPTX







































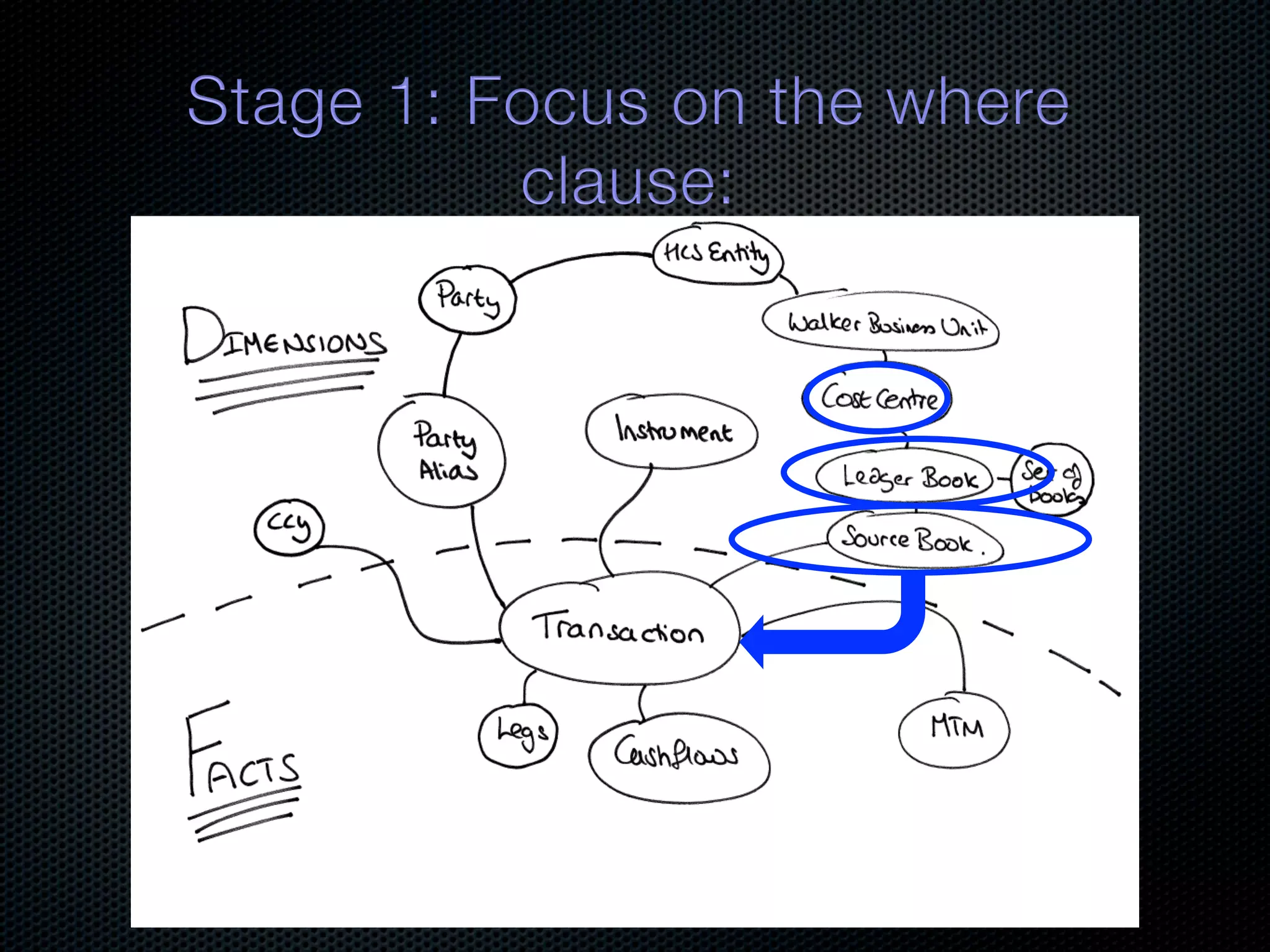
![Select Transaction, MTM, ReferenceData From MTM, Transaction, Ref Where Cost Centre = ‘CC1’ LBs[]=getLedgerBooksFor(CC1) SBs[]=getSourceBooksFor(LBs[]) So we have all the bottom level dimensions needed to query facts Transactions Mtms Cashflows Partitioned](https://image.slidesharecdn.com/balancingreplicationandpartitioninginadistributedjavadatabase-111002223229-phpapp02/75/Balancing-Replication-and-Partitioning-in-a-Distributed-Java-Database-63-2048.jpg)
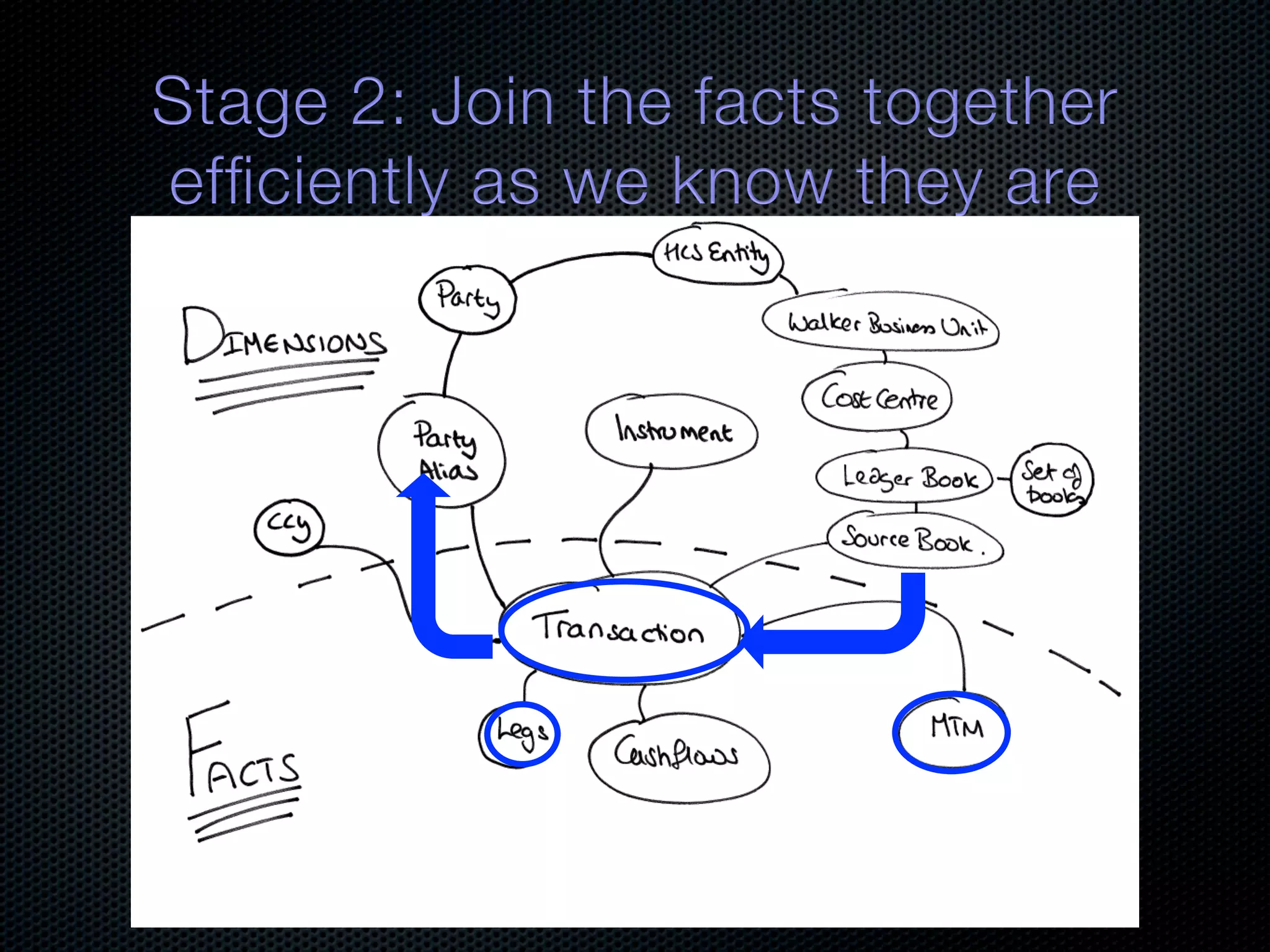
![Select Transaction, MTM, ReferenceData From MTM, Transaction, Ref Where Cost Centre = ‘CC1’ LBs[]=getLedgerBooksFor(CC1) SBs[]=getSourceBooksFor(LBs[]) So we have all the bottom level dimensions needed to query facts Transactions Get all Transactions and Mtms MTMs (cluster side join) for the passed Source Books Cashflows Partitioned](https://image.slidesharecdn.com/balancingreplicationandpartitioninginadistributedjavadatabase-111002223229-phpapp02/75/Balancing-Replication-and-Partitioning-in-a-Distributed-Java-Database-64-2048.jpg)
![Select Transaction, MTM, ReferenceData From MTM, Transaction, Ref Where Cost Centre = ‘CC1’ Populate raw facts LBs[]=getLedgerBooksFor(CC1) (Transactions) with SBs[]=getSourceBooksFor(LBs[]) dimension data So we have all the bottom level before returning to dimensions needed to query facts client. Transactions Get all Transactions and Mtms MTMs (cluster side join) for the passed Source Books Cashflows Partitioned](https://image.slidesharecdn.com/balancingreplicationandpartitioninginadistributedjavadatabase-111002223229-phpapp02/75/Balancing-Replication-and-Partitioning-in-a-Distributed-Java-Database-66-2048.jpg)














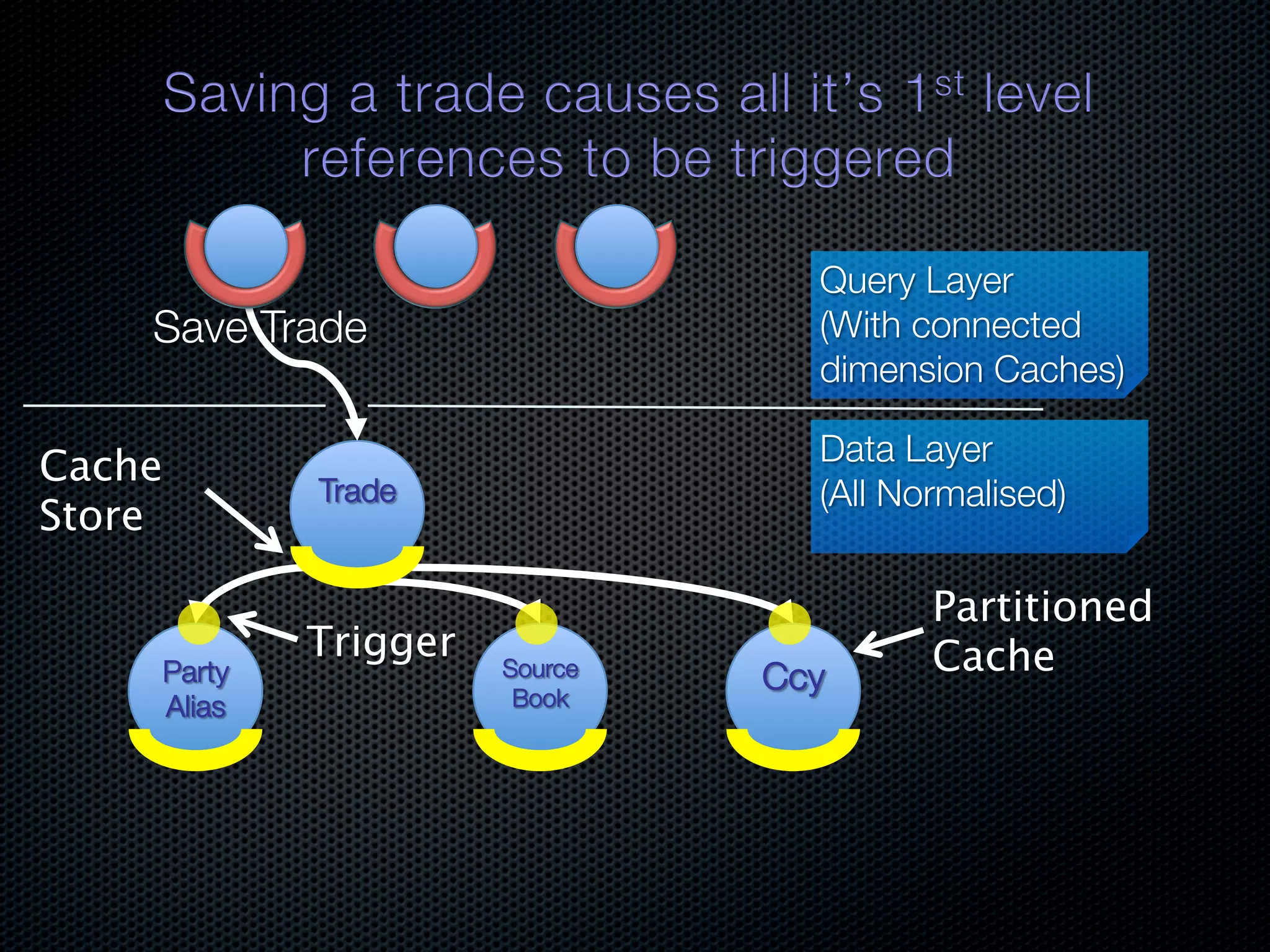
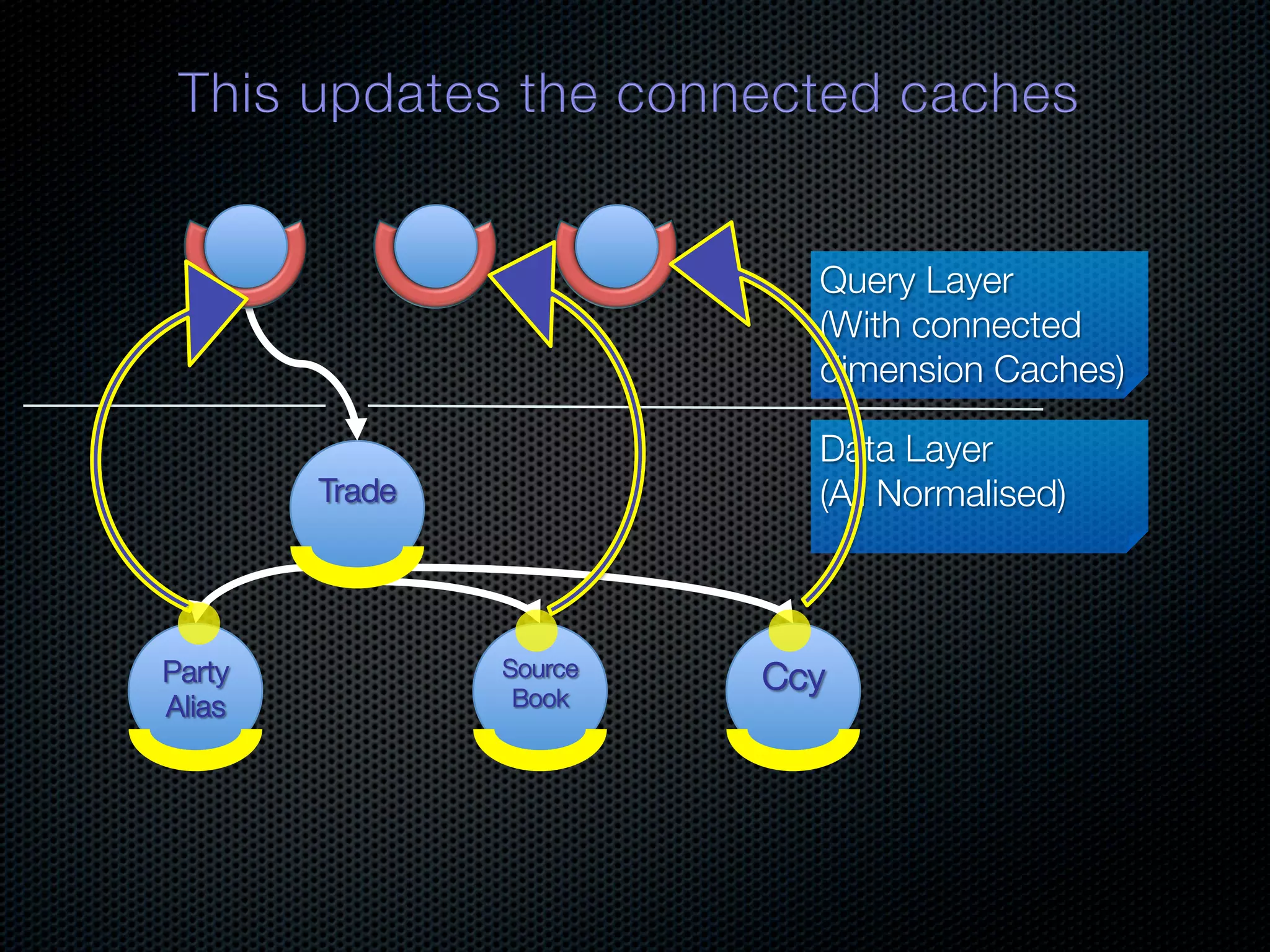
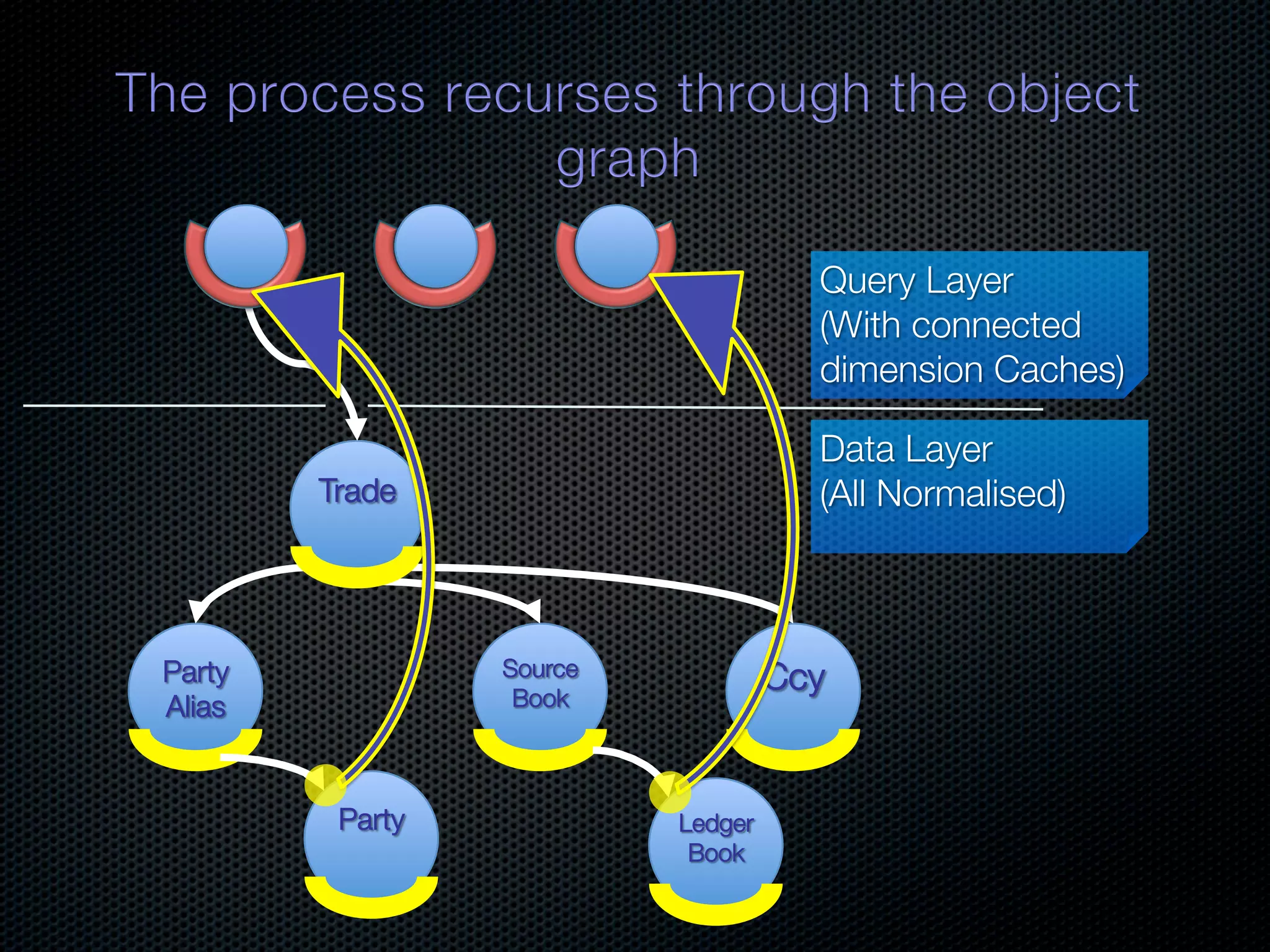


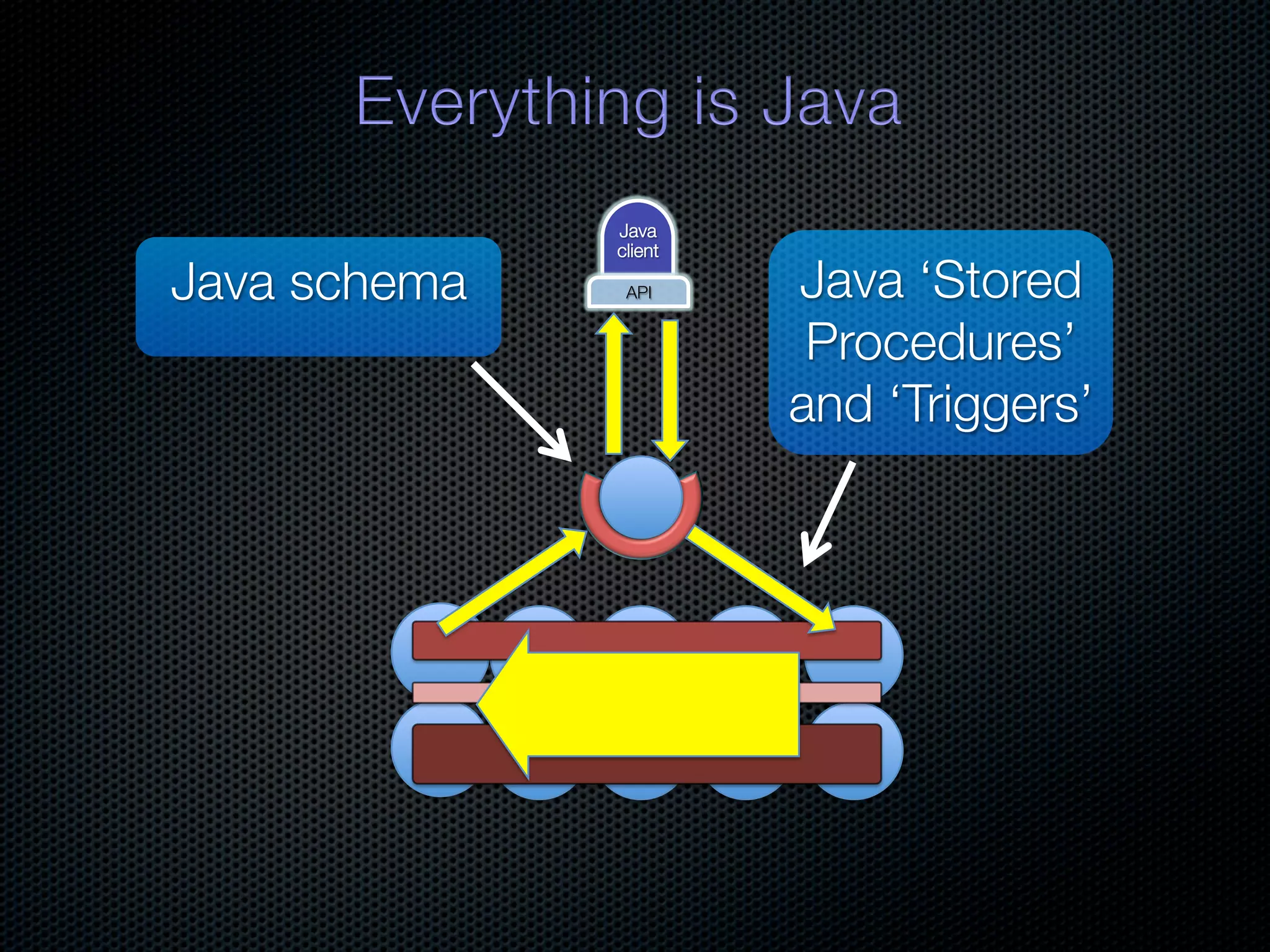





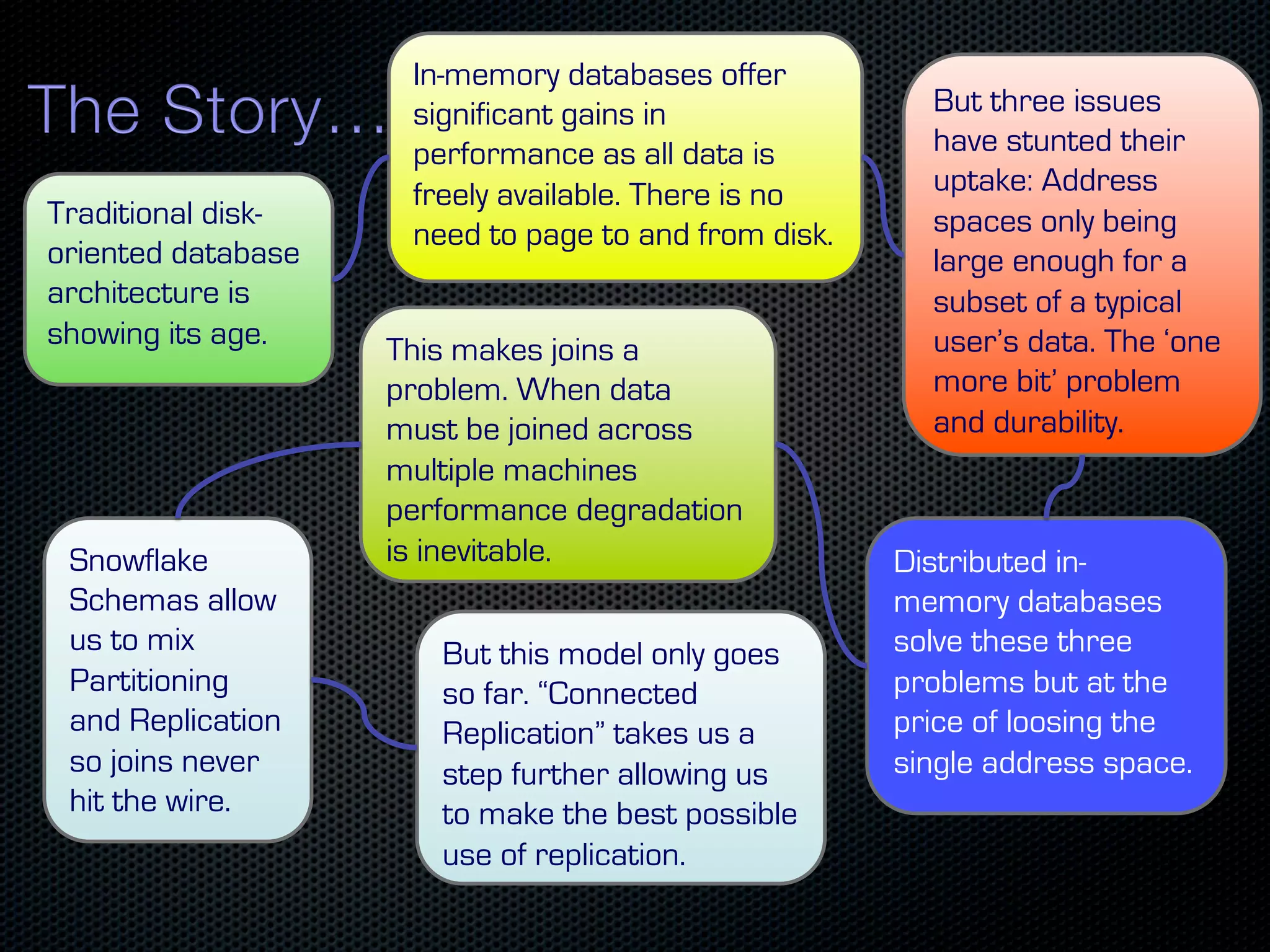
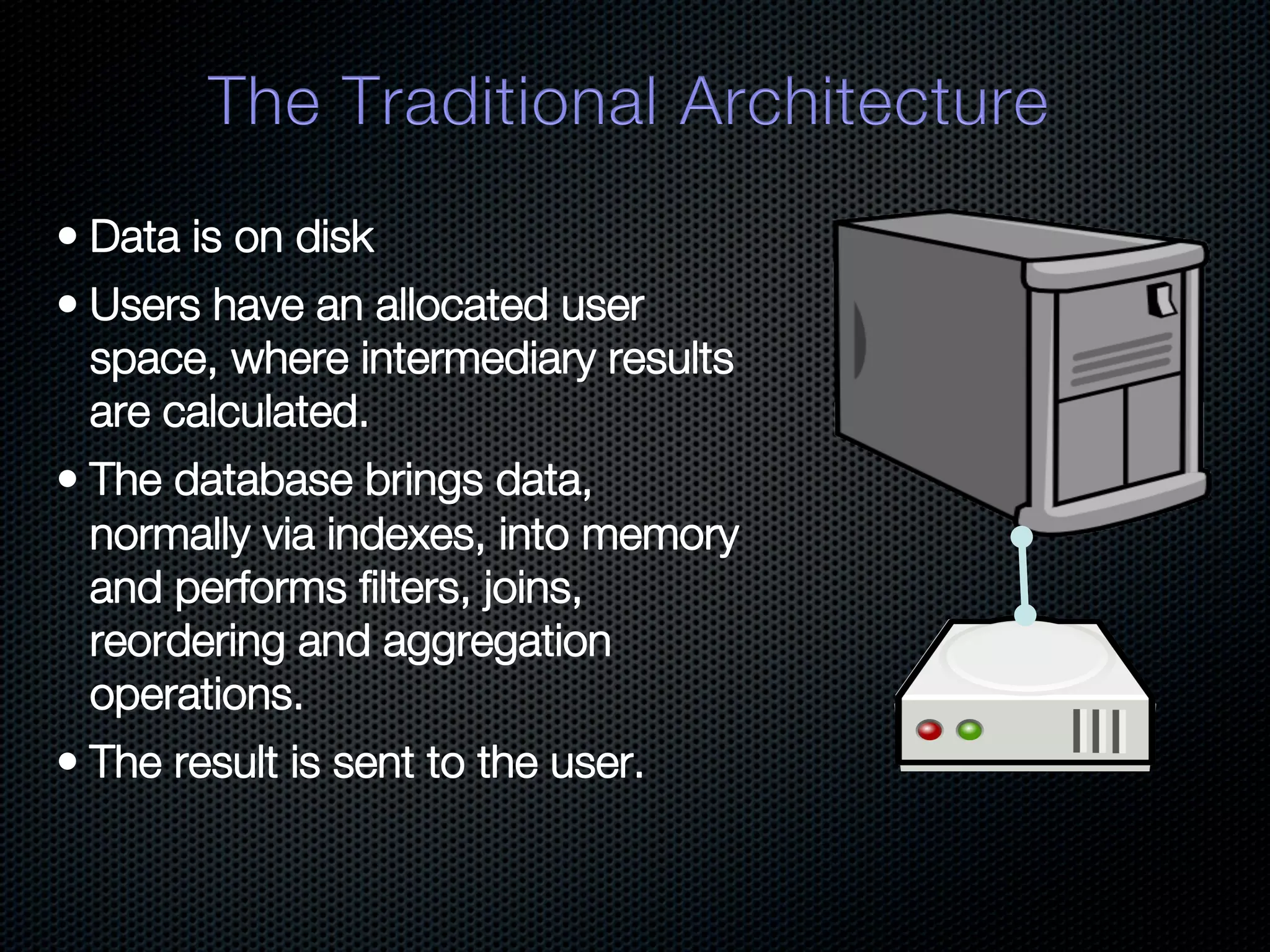
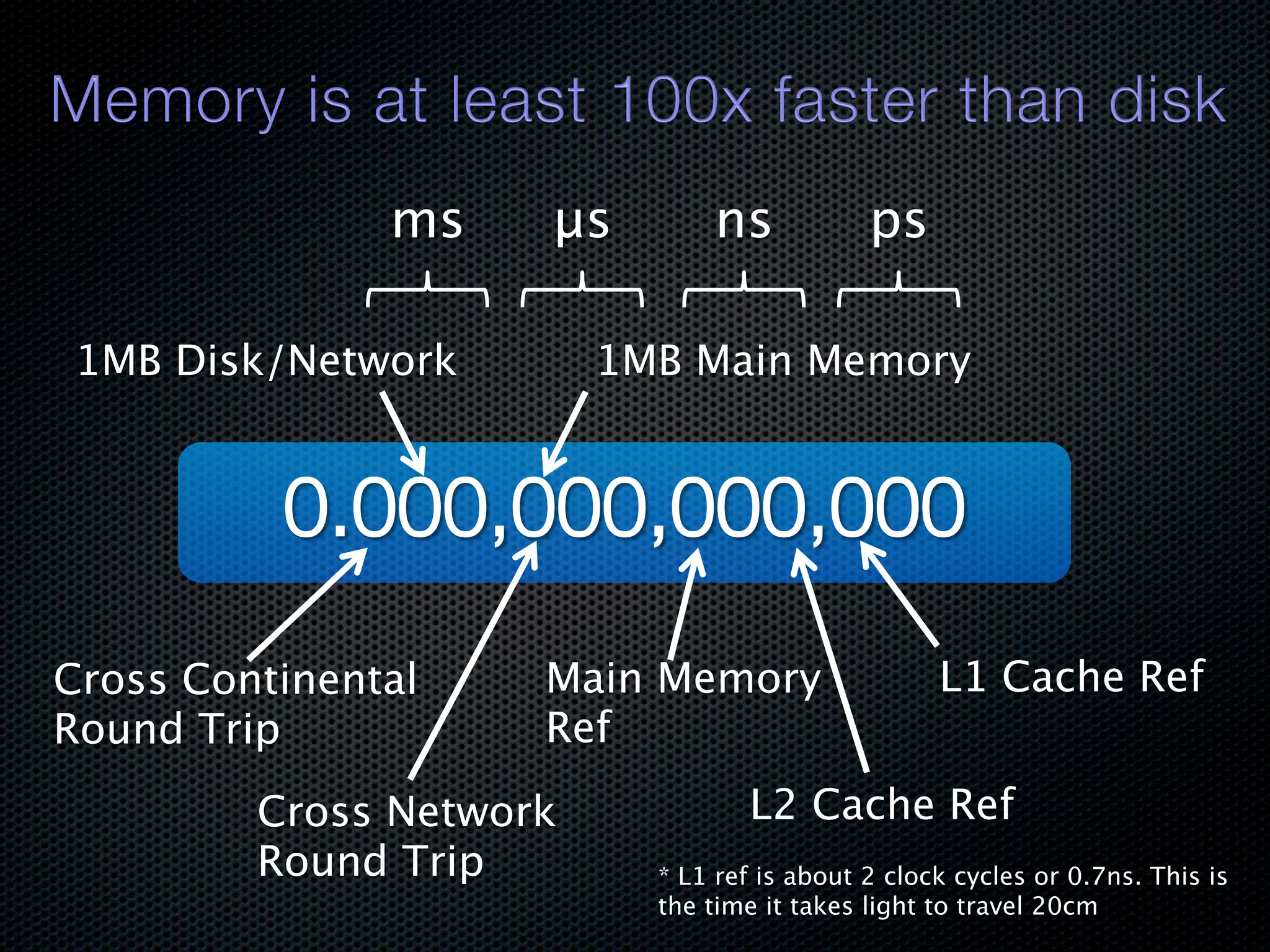
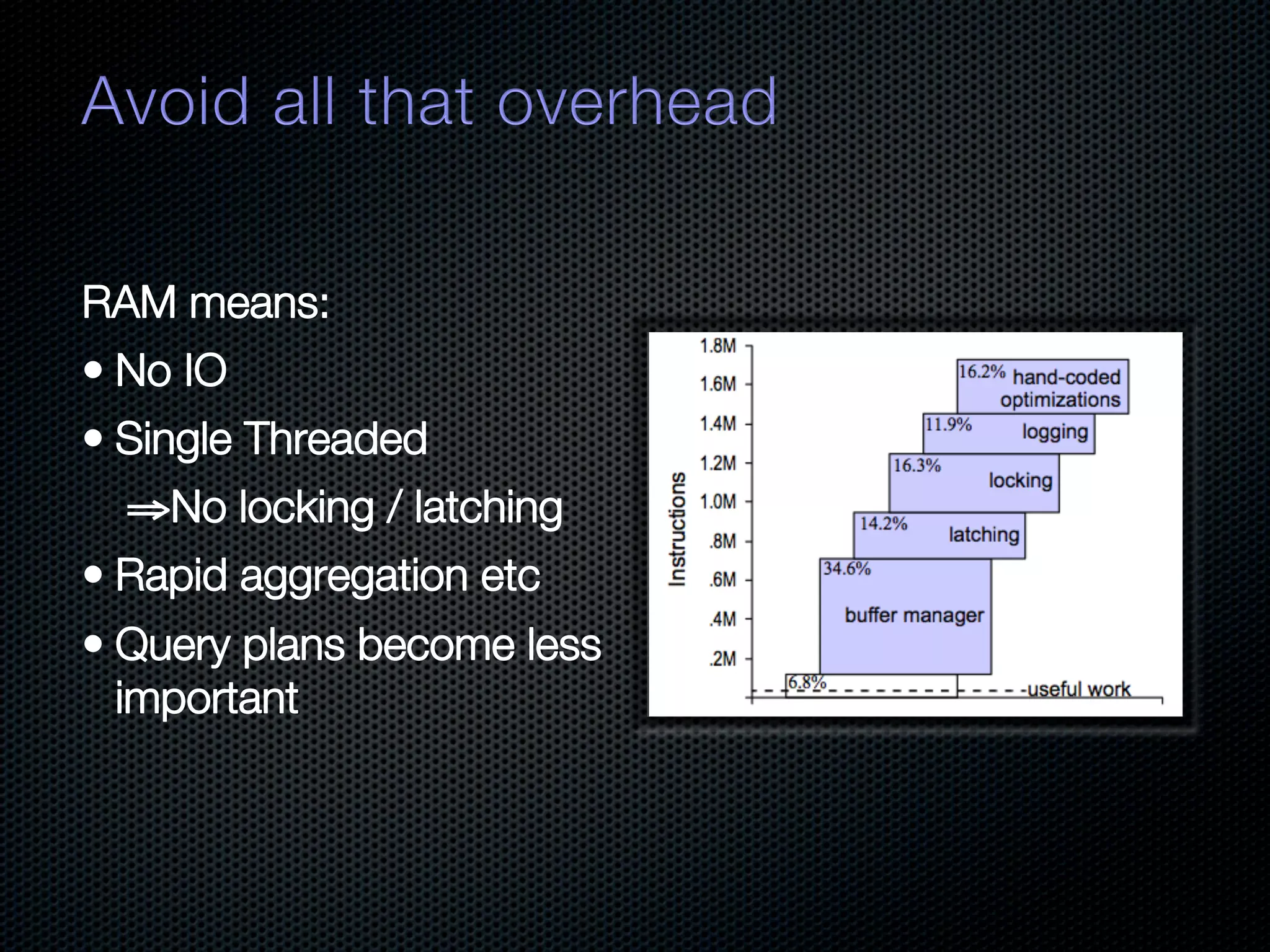
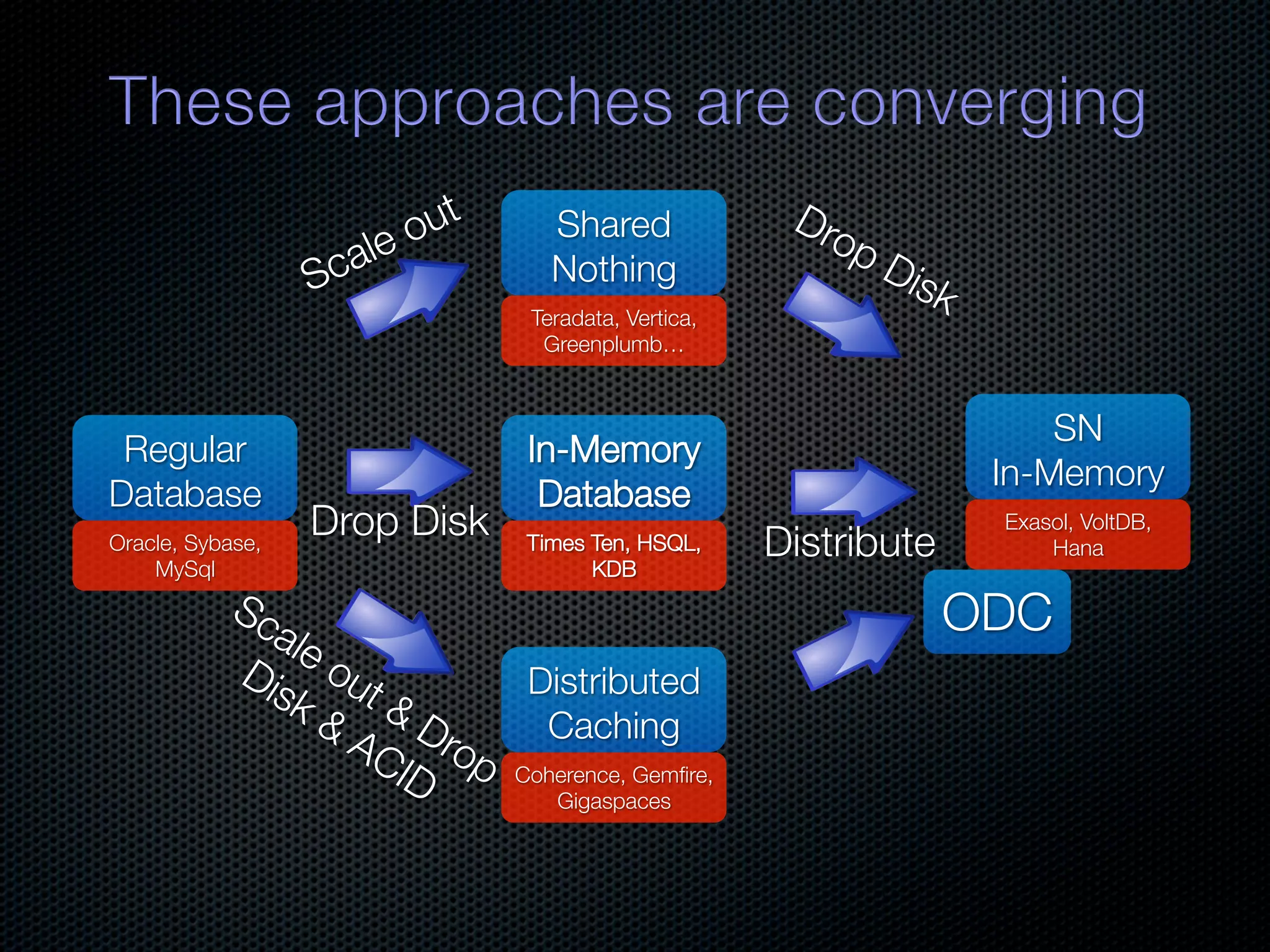
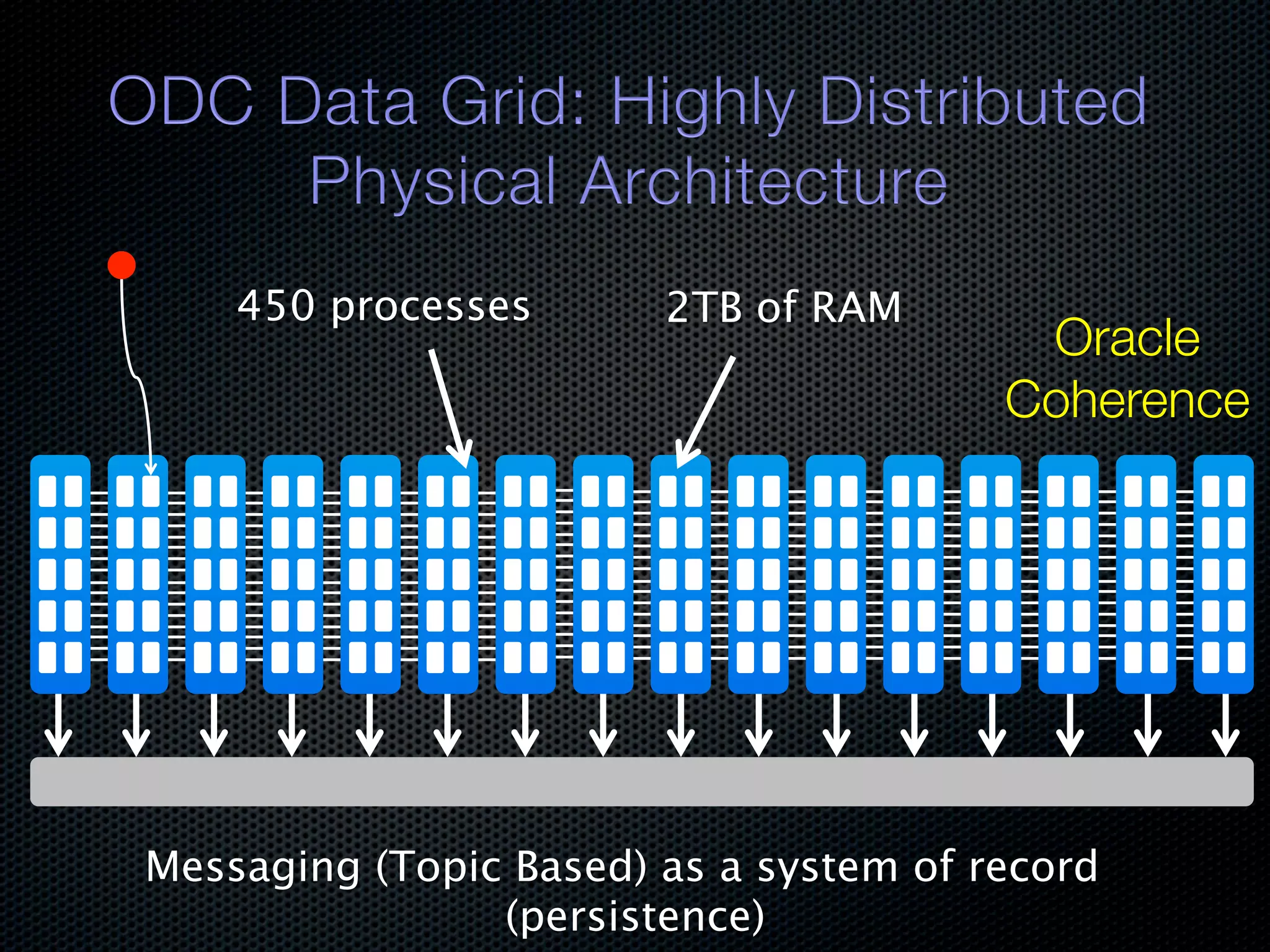
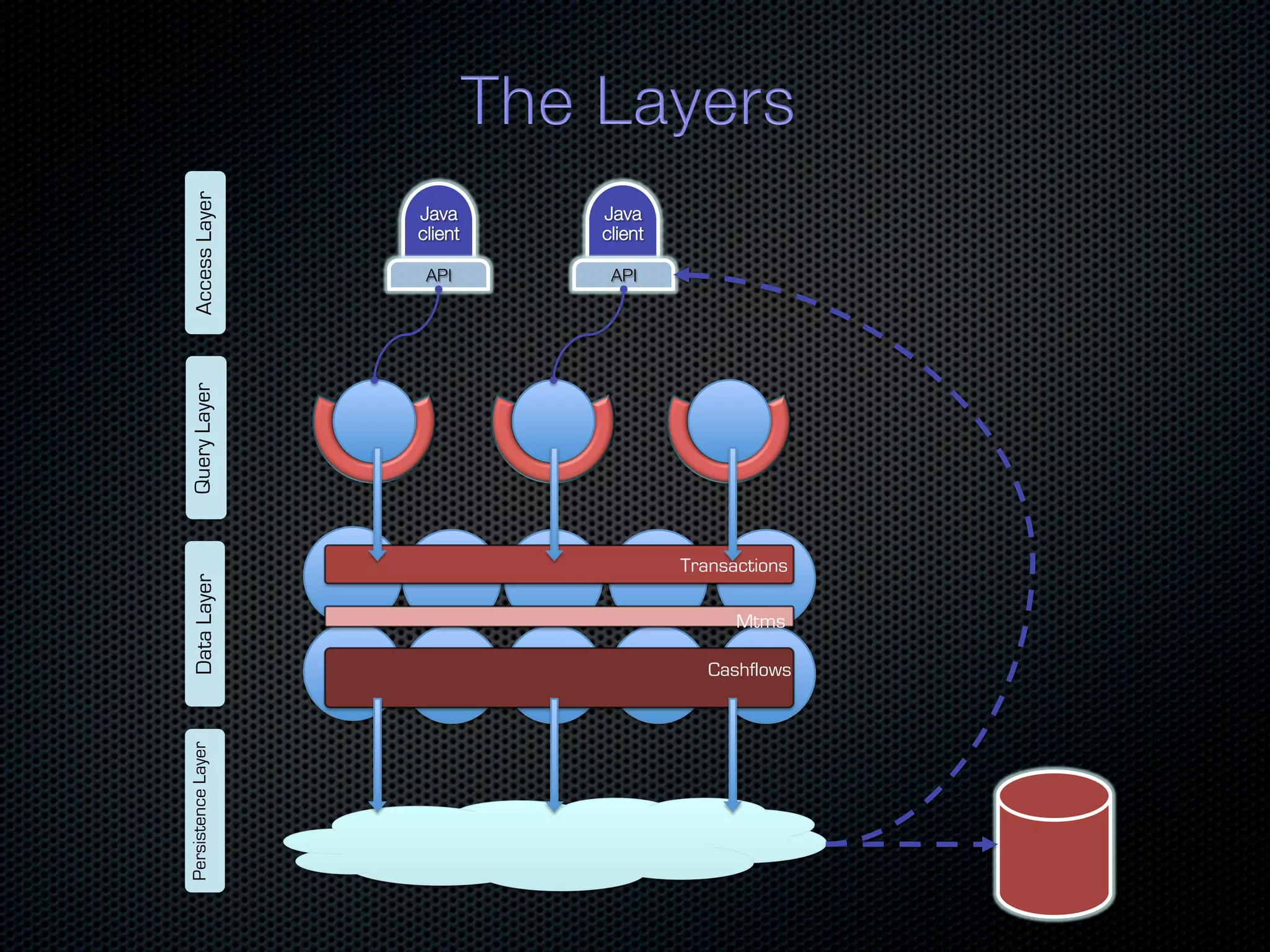
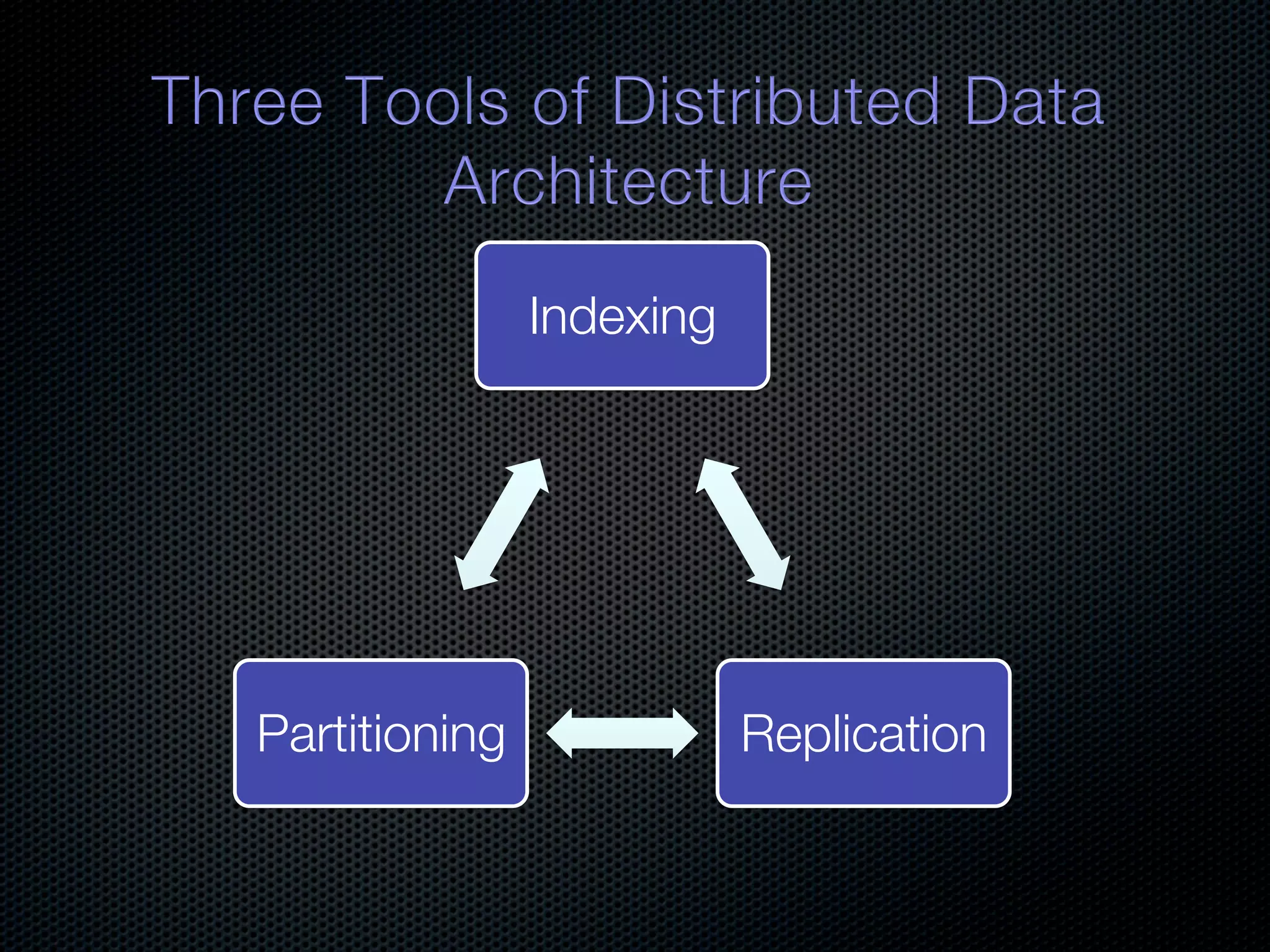
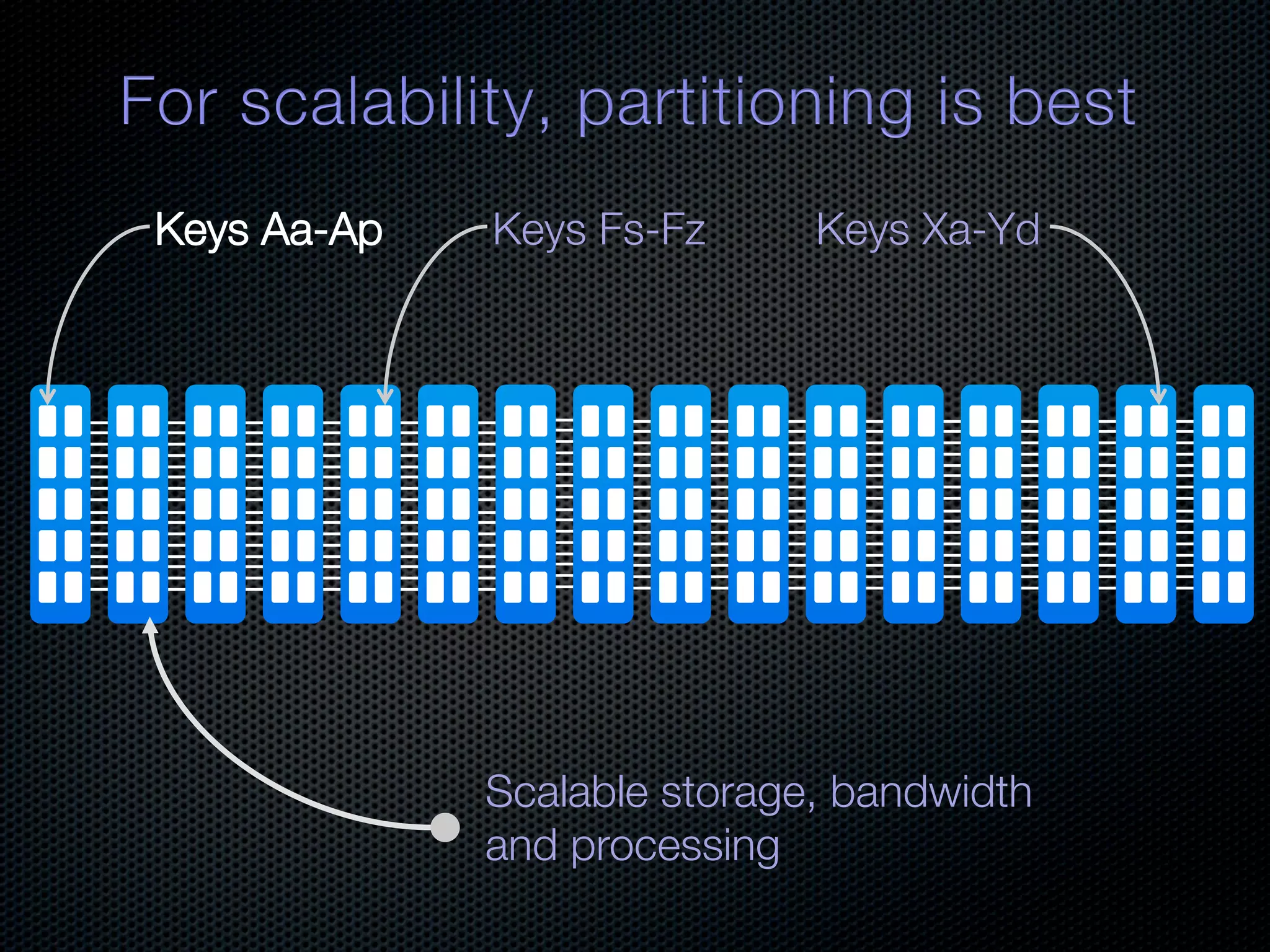
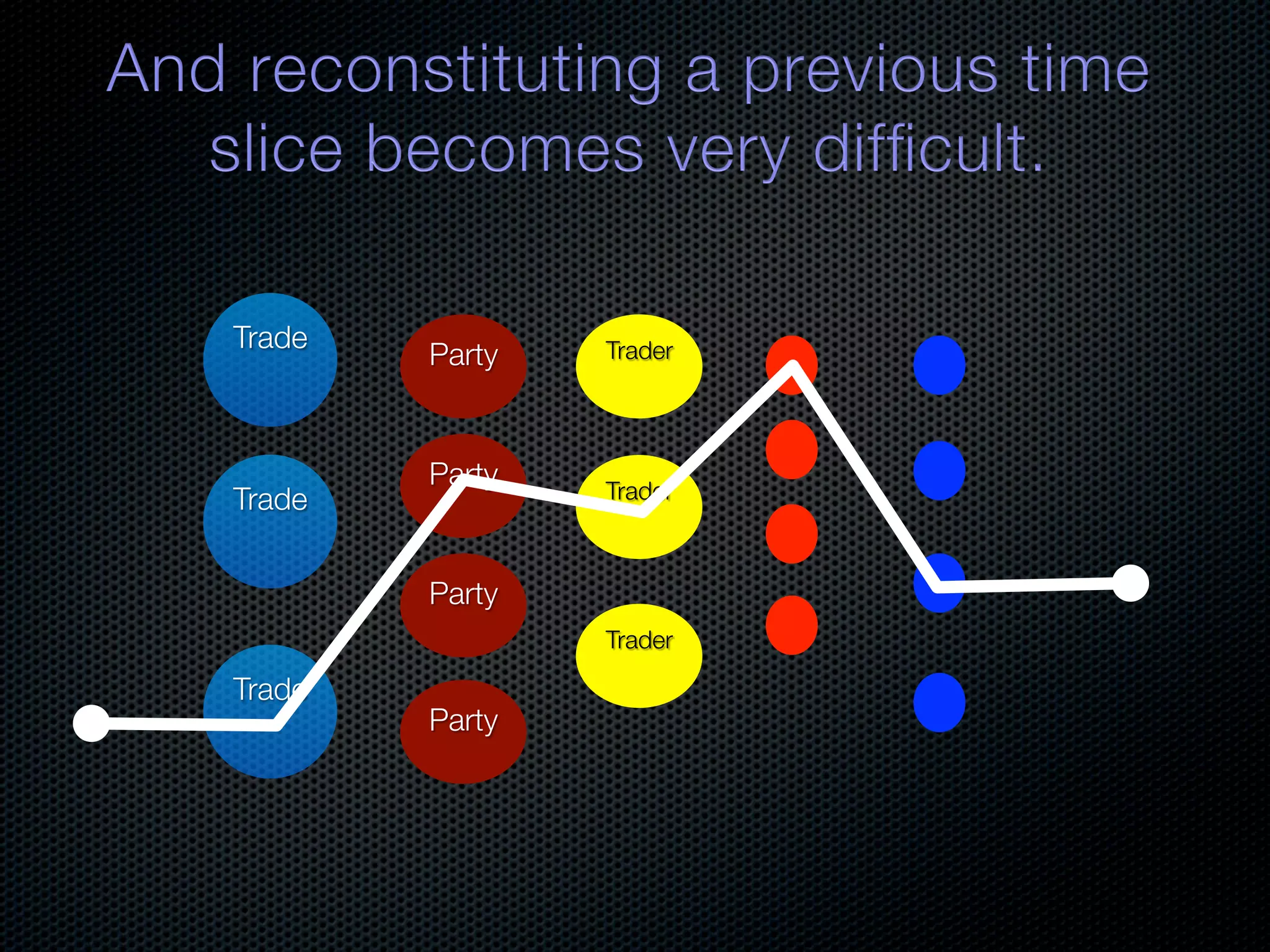
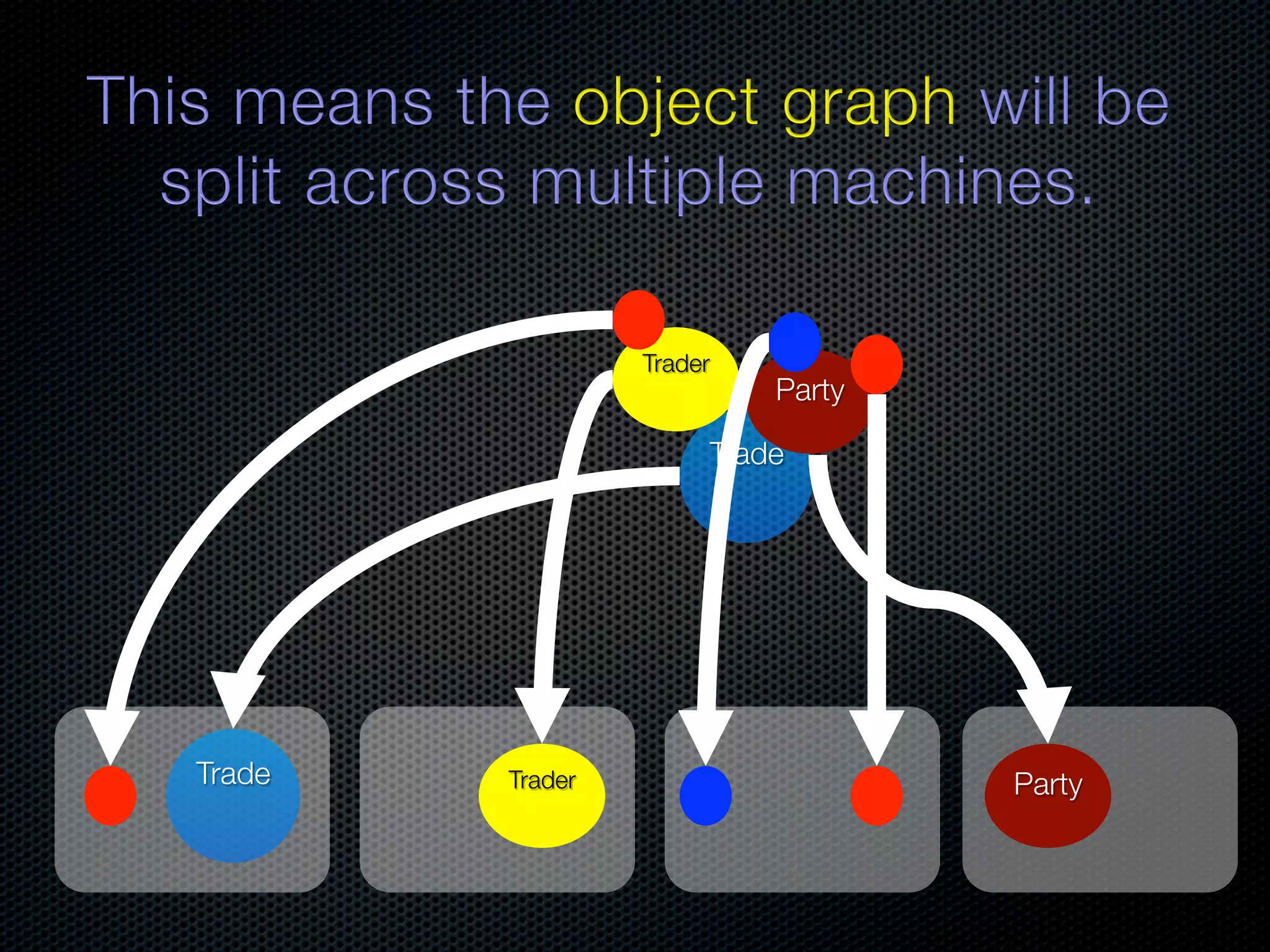
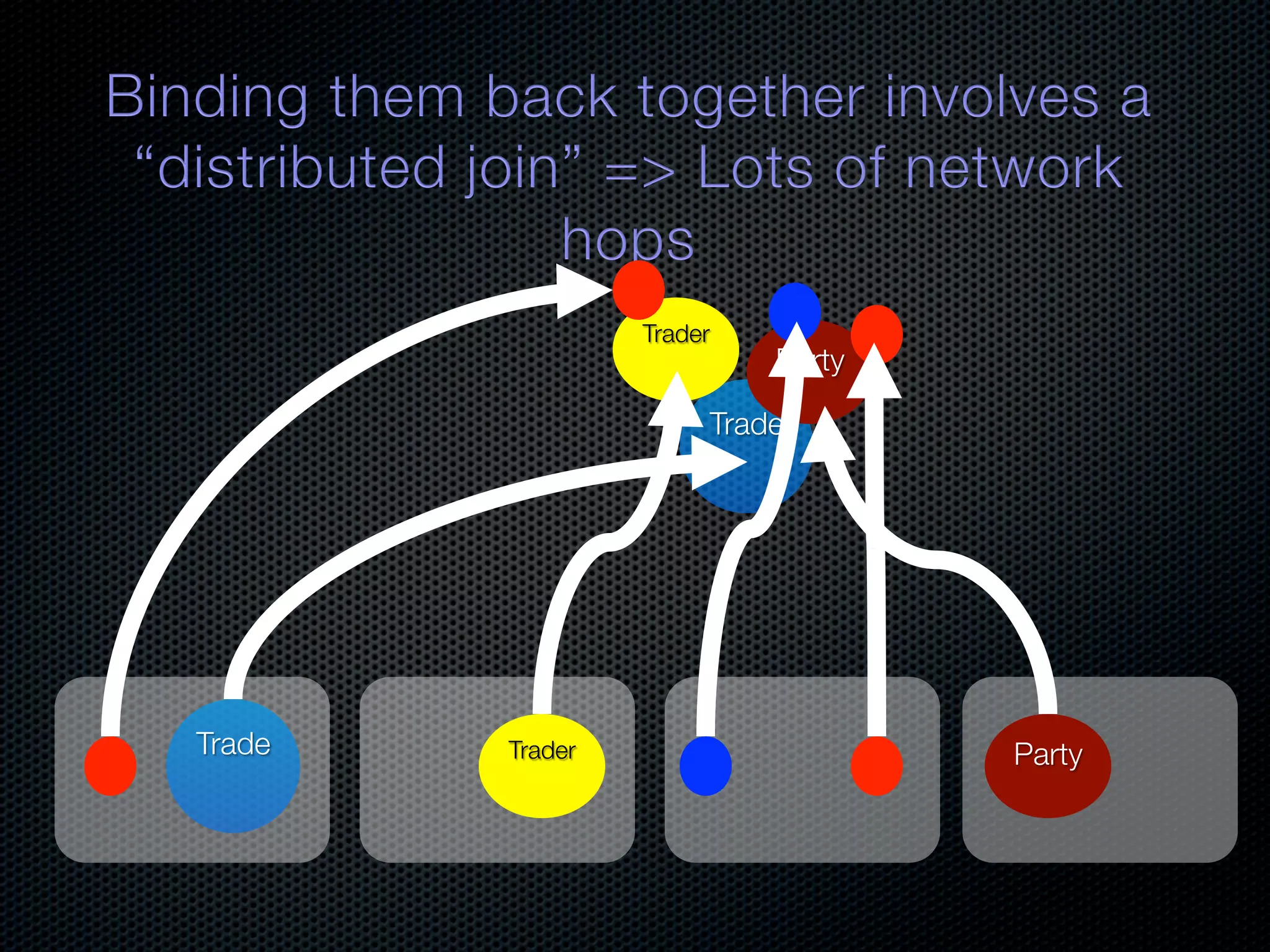
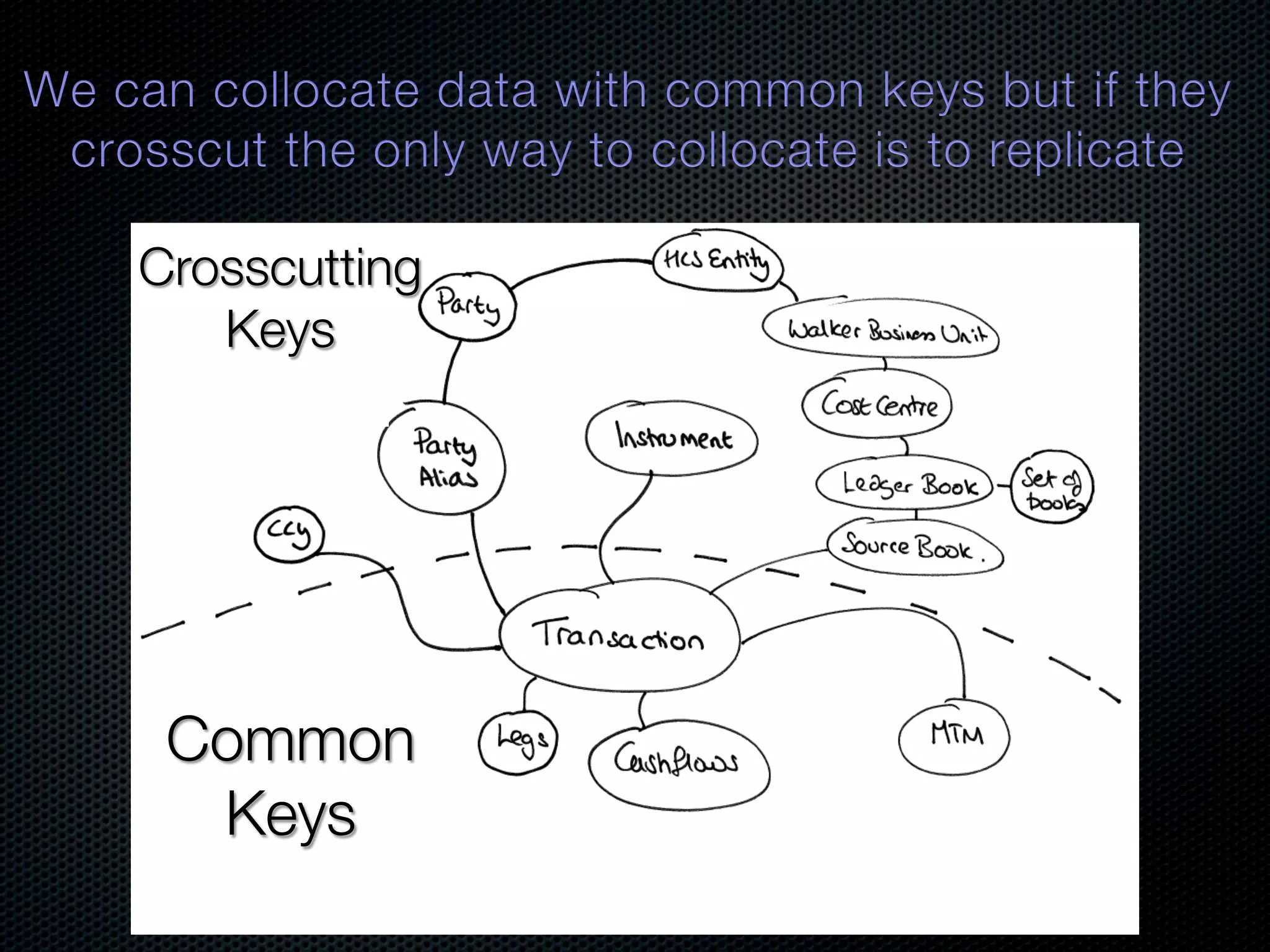
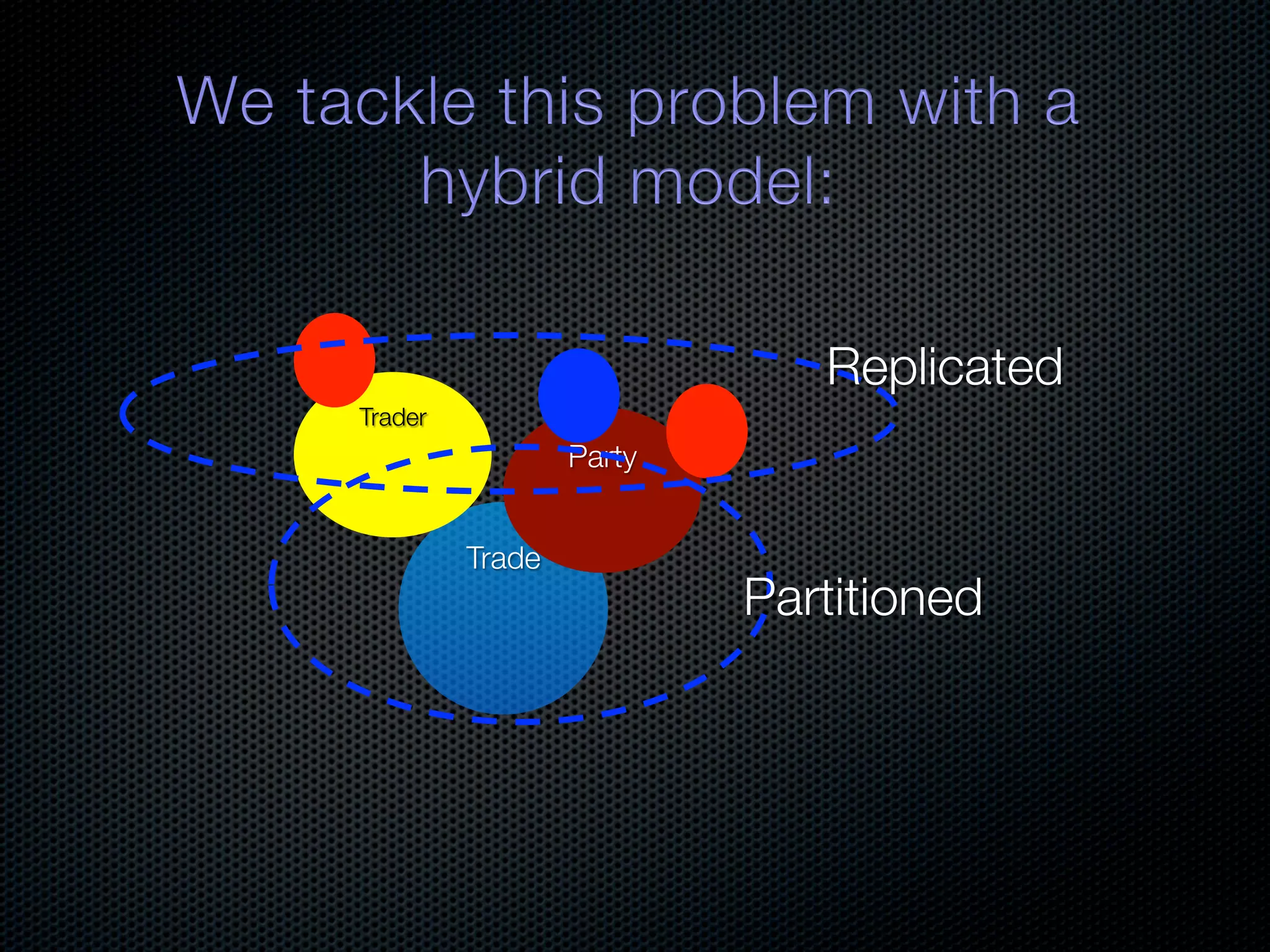
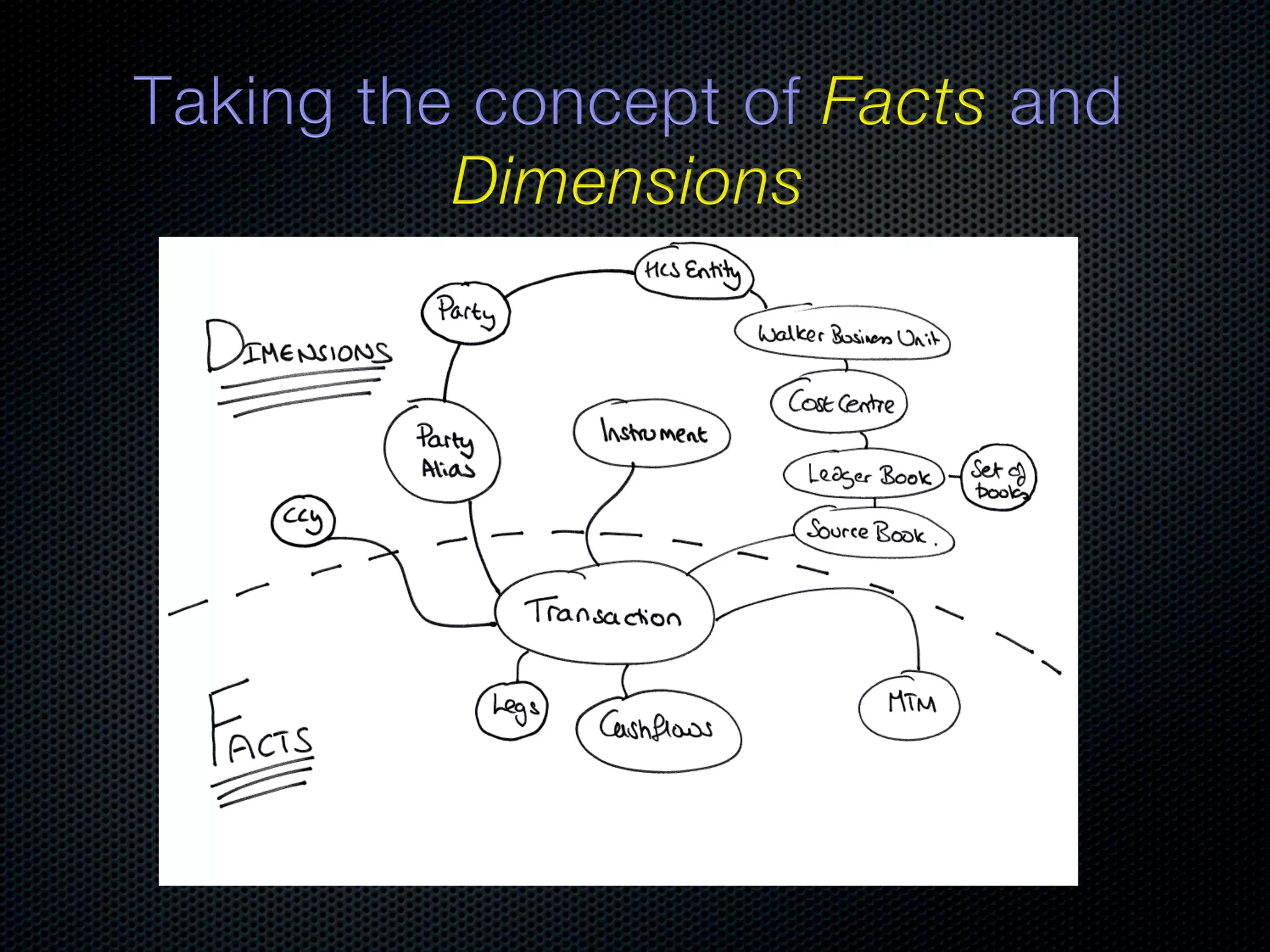
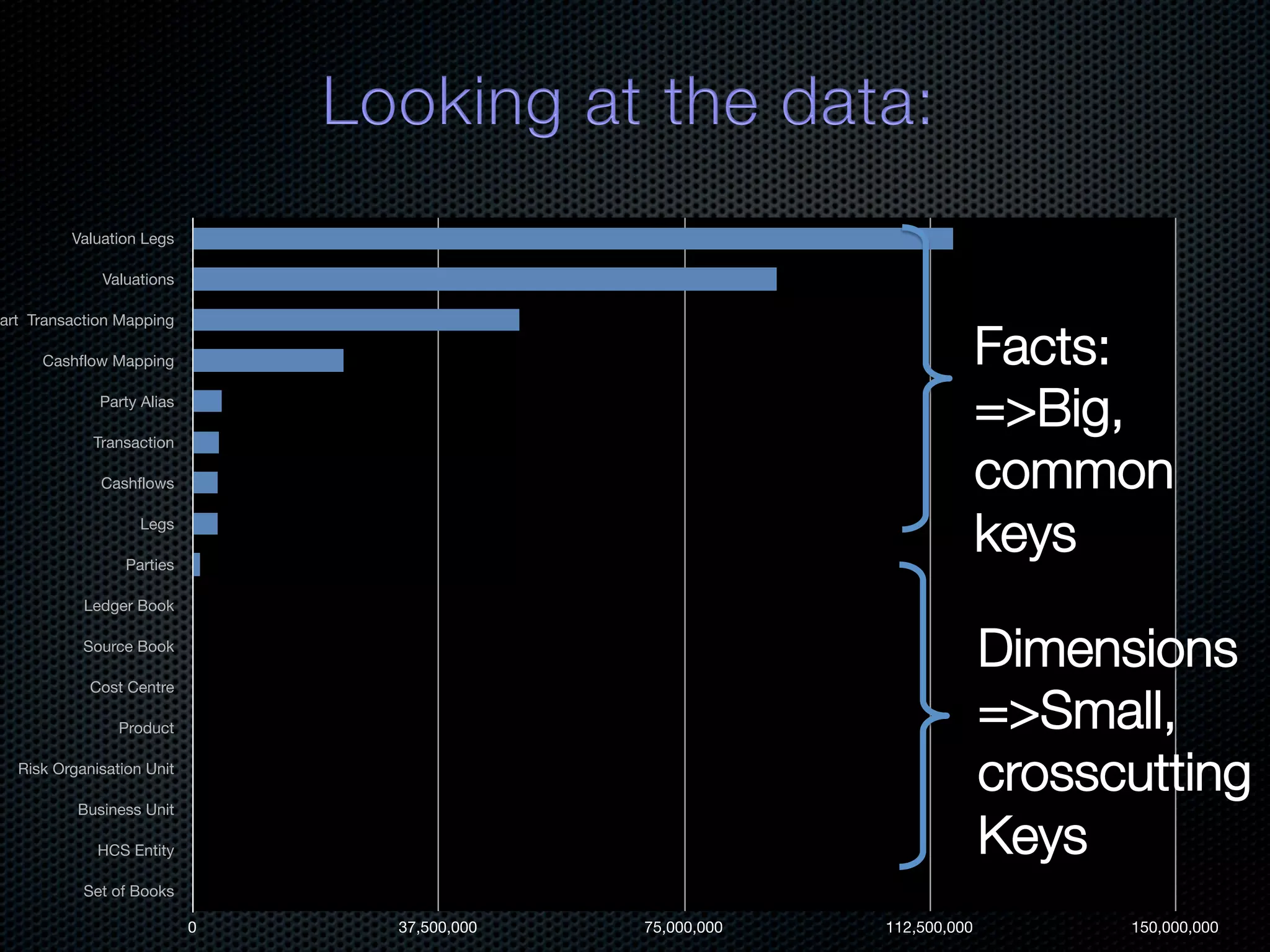
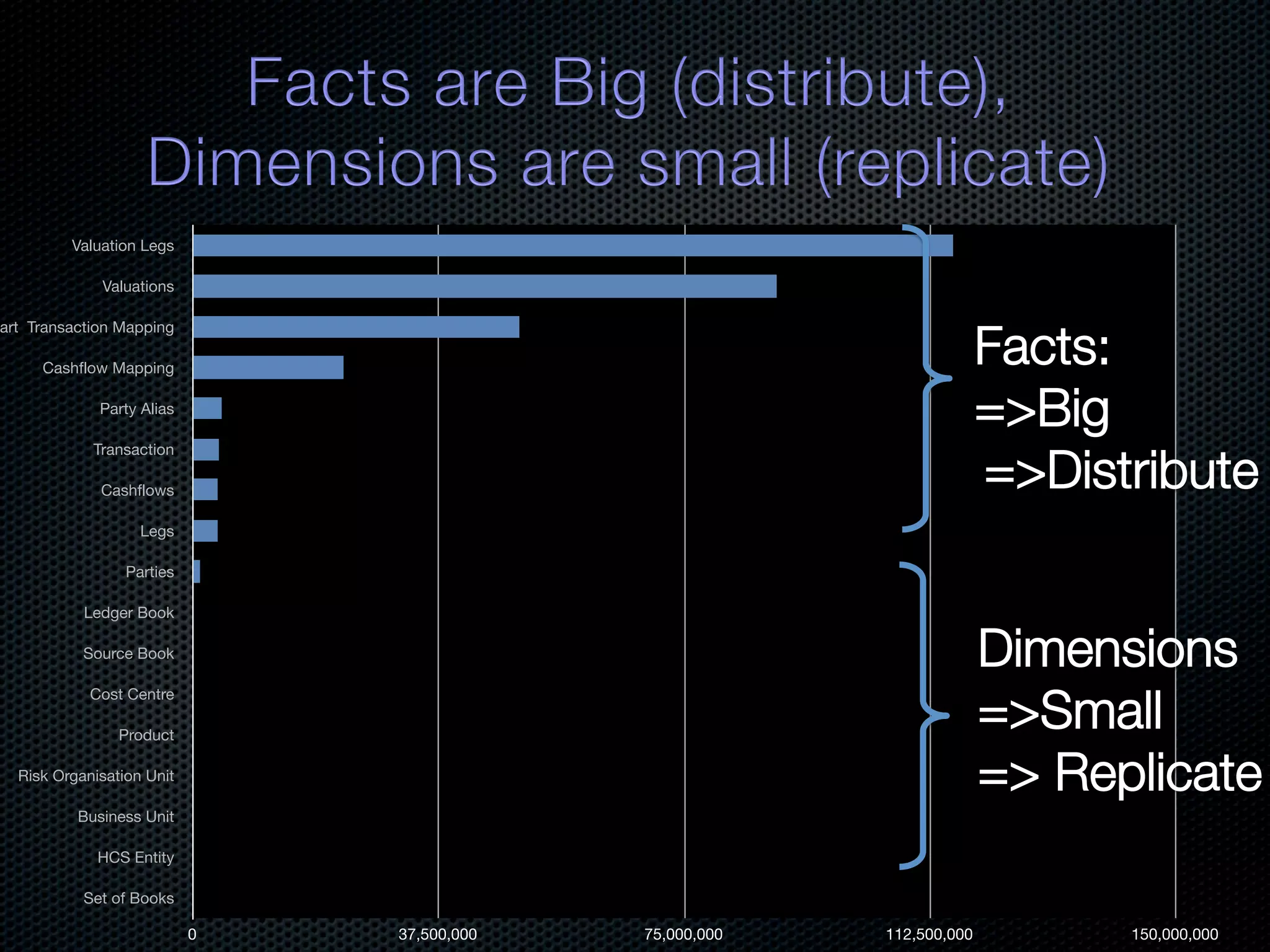
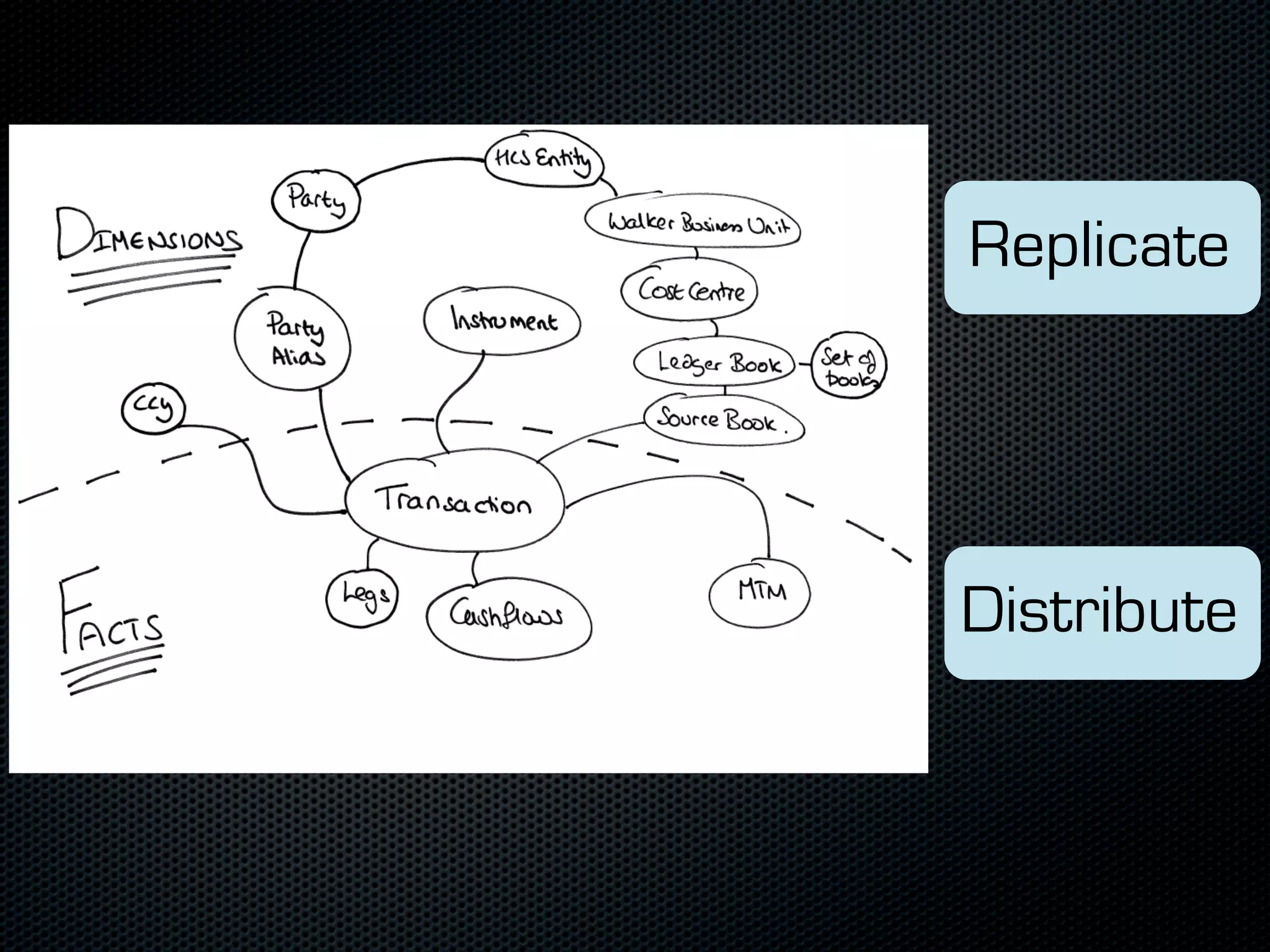
In-memory databases enhance performance but face challenges with data durability and complexity due to traditional disk-based architectures. The document discusses how techniques like partitioning and connected replication can alleviate issues related to joins across distributed systems while maintaining efficient data access. It emphasizes the use of snowflake schemas and caching strategies to optimize data processing in a multi-node environment.