Downloaded 98 times






![Important Broker Configuration Settings (II) Name Description log.dirs Comma-separated list of paths on the local filesystem, where Kafka will persist the log segments log.retentions.[ms|minutes |hours] The number of milliseconds/minutes/hours to keep a log file before deleting it log.retention.bytes The maximum size of the log before deleting it log.segment.bytes The maximum size of a single log file broker.rack Rack of the broker. This will be used in rack aware replication assignment for fault tolerance. message.max.bytes The largest record batch size allowed by Kafka, defaults to 1MB see also: https://docs.confluent.io/current/installation/configuration/broker-configs.html](https://image.slidesharecdn.com/kafka-microservicses-librdkafka-architecture-v1-180810182422/75/Apache-Kafka-Event-Sourcing-Monitoring-Librdkafka-Scaling-Partitioning-18-2048.jpg)







![Kafka Producer – High Level Overview Producer Client Kafka Broker Movement Topic Partition 0 Partitione r Movement Topic Serializer Producer Record message 1 message 2 message 3 message 4 Batch Movement Topic Partition 1 message 1 message 2 message 3 Batch Partition 0 Partition 1 Retr y? Fail ? Topic Message [ Partition ] [ Key ] Value yes yes if can’t retry: throw exception successful: return metadata Compression(optional)](https://image.slidesharecdn.com/kafka-microservicses-librdkafka-architecture-v1-180810182422/75/Apache-Kafka-Event-Sourcing-Monitoring-Librdkafka-Scaling-Partitioning-37-2048.jpg)




![Consumer Using auto-commit mode • set auto.commit to true • set auto.commit.interval.ms to control the frequency of commits Commit current offsets • set auto.commit to false • Manually invoke commit() to commit the offsets when processing is done consumer.subscribe([topics]) while(true) msgs = consumer.poll(waitForMs) for (msg IN msgs) process(msg) consumer.close() consumer.subscribe([topics]) while(true) msgs = consumer.poll(waitForMs) for (msg IN msgs) process(msg) consumer.commit() consumer.close()](https://image.slidesharecdn.com/kafka-microservicses-librdkafka-architecture-v1-180810182422/75/Apache-Kafka-Event-Sourcing-Monitoring-Librdkafka-Scaling-Partitioning-49-2048.jpg)


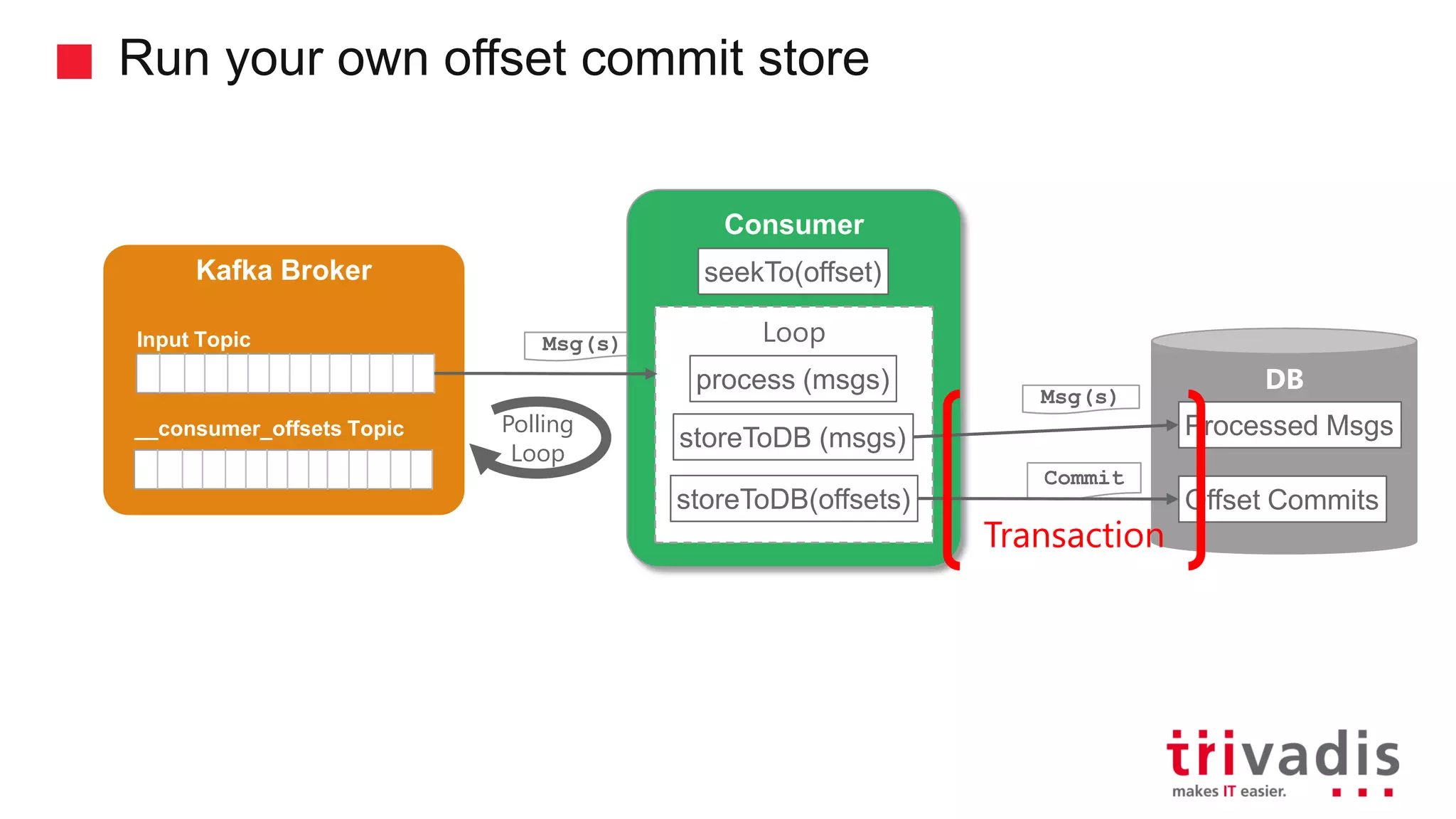
![Run your own offset commit store Processed messages stored in a target supporting transactions If using Kafka default offset commitment, potential for duplicates, if commit fails Store processed messages and offset in atomic action into same database consumer.subscribe([topics]) while(true) msgs = consumer.poll(waitForMs) for (msg IN msgs) process(msg) storeInDB(msg) consumer.commit(currentOffsets) consumer.close() consumer.subscribe([topics]) while(true) msgs = consumer.poll(waitForMs) for (msg IN msgs) process(msg) storeInDB(msg) storeInDBV(currentOffsets) consumer.close()](https://image.slidesharecdn.com/kafka-microservicses-librdkafka-architecture-v1-180810182422/75/Apache-Kafka-Event-Sourcing-Monitoring-Librdkafka-Scaling-Partitioning-53-2048.jpg)














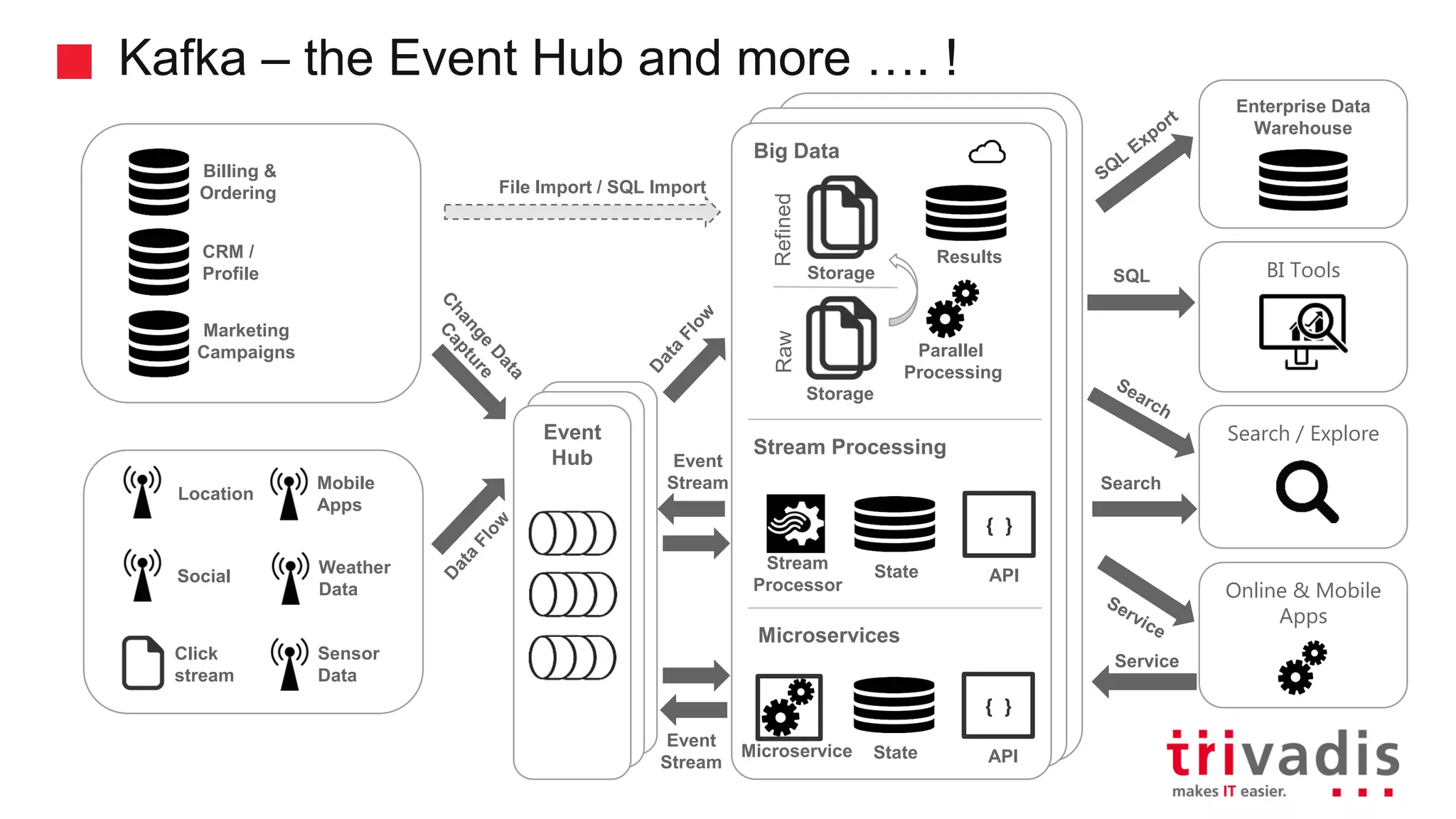



Apache Kafka is a distributed streaming platform. It provides a high-throughput distributed messaging system with publish-subscribe capabilities. The document discusses Kafka producers and consumers, Kafka clients in different programming languages, and important configuration settings for Kafka brokers and topics. It also demonstrates sending messages to Kafka topics from a Java producer and consuming messages from the console consumer.
Overview of Apache Kafka, its agenda, and speaker credentials.
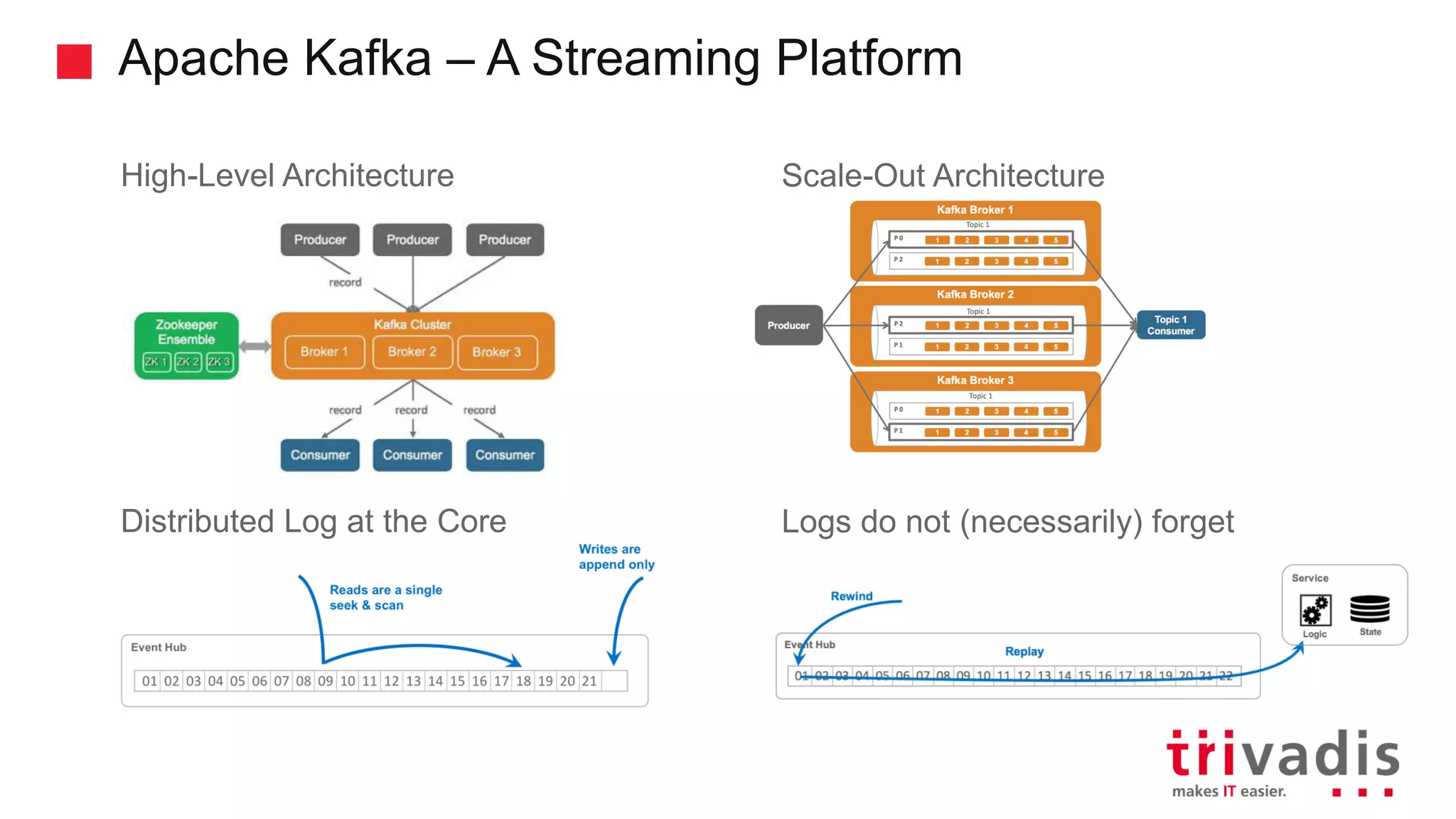
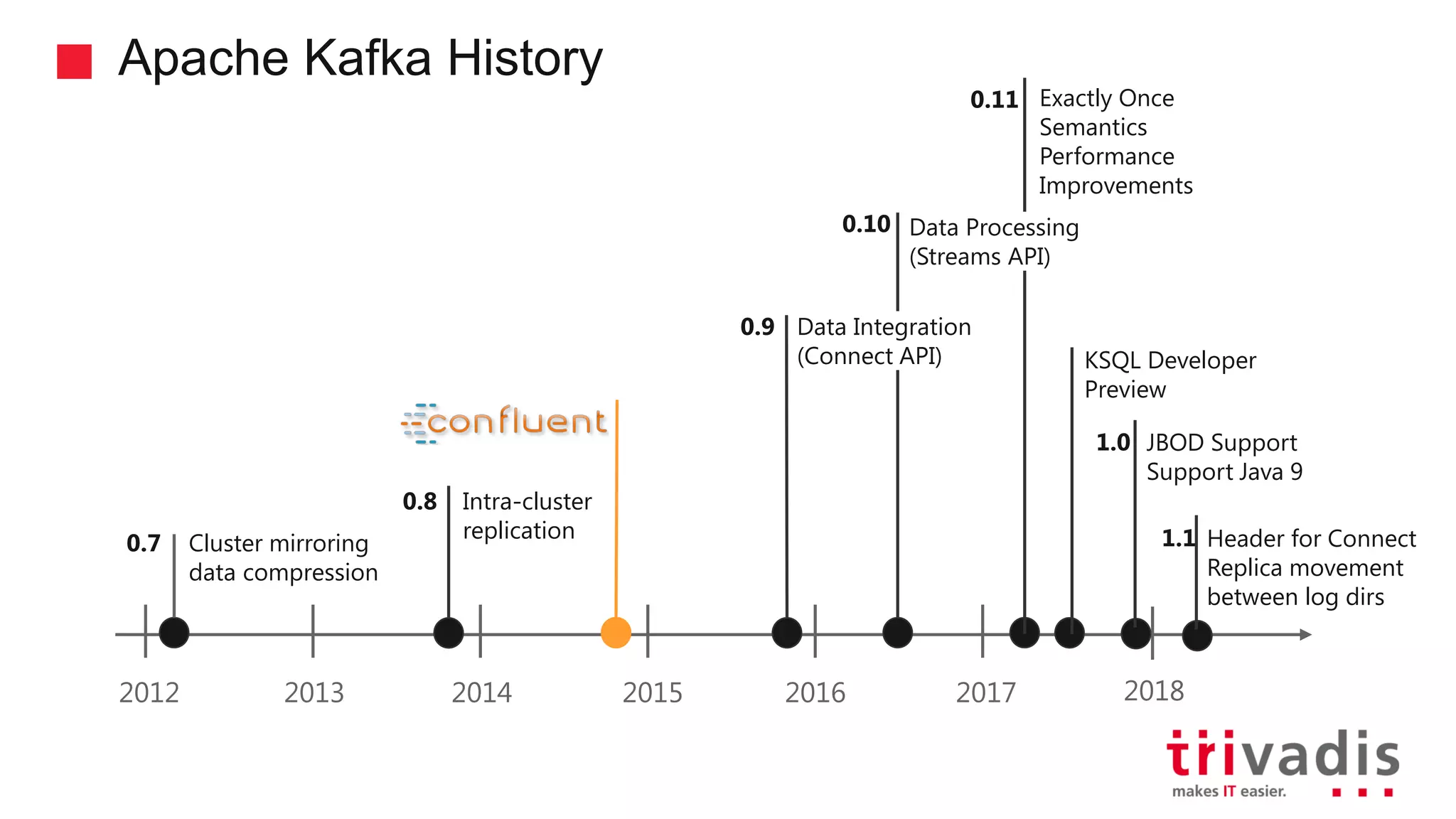
Definitions and historical development of Apache Kafka as a streaming platform.
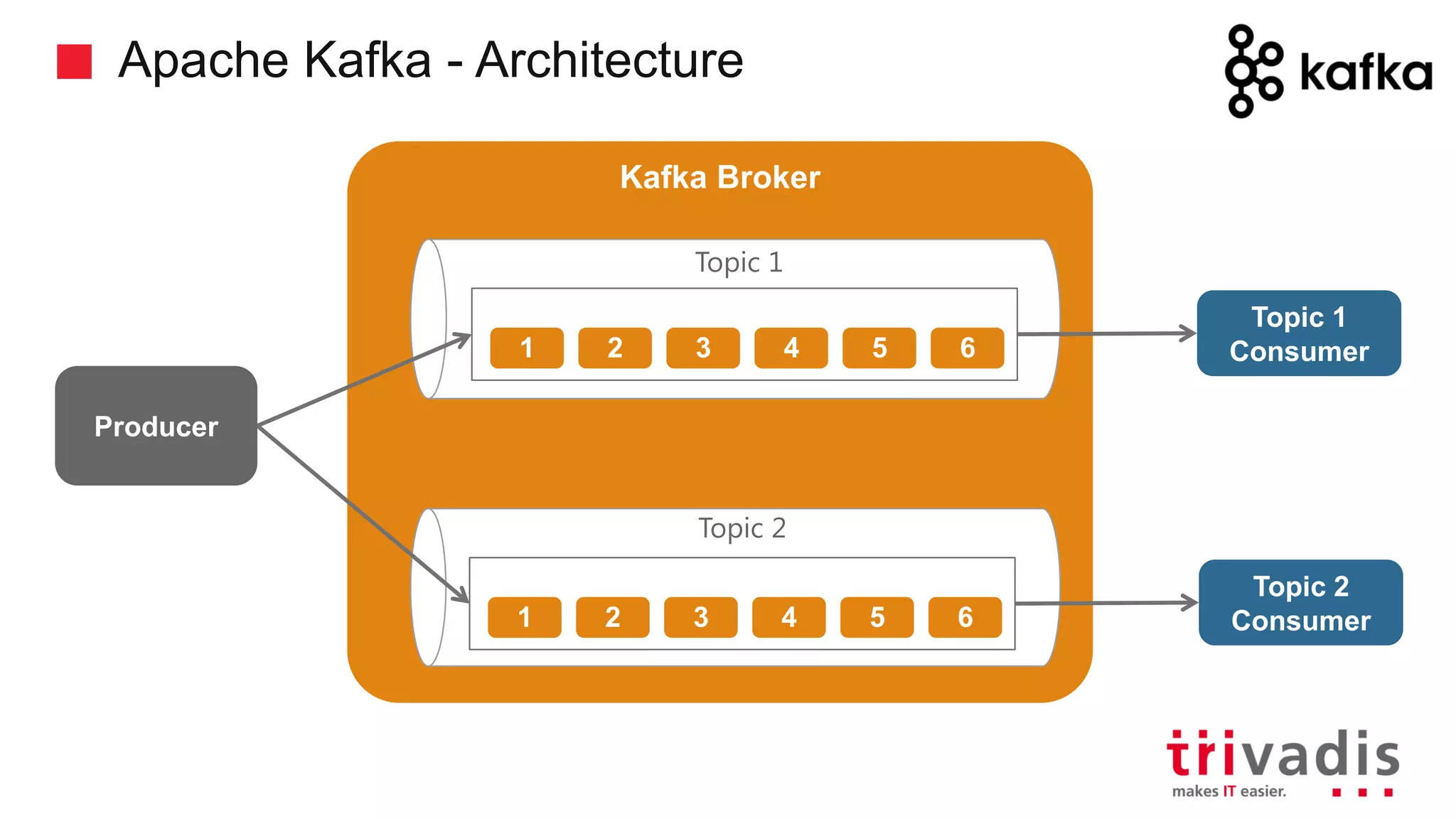
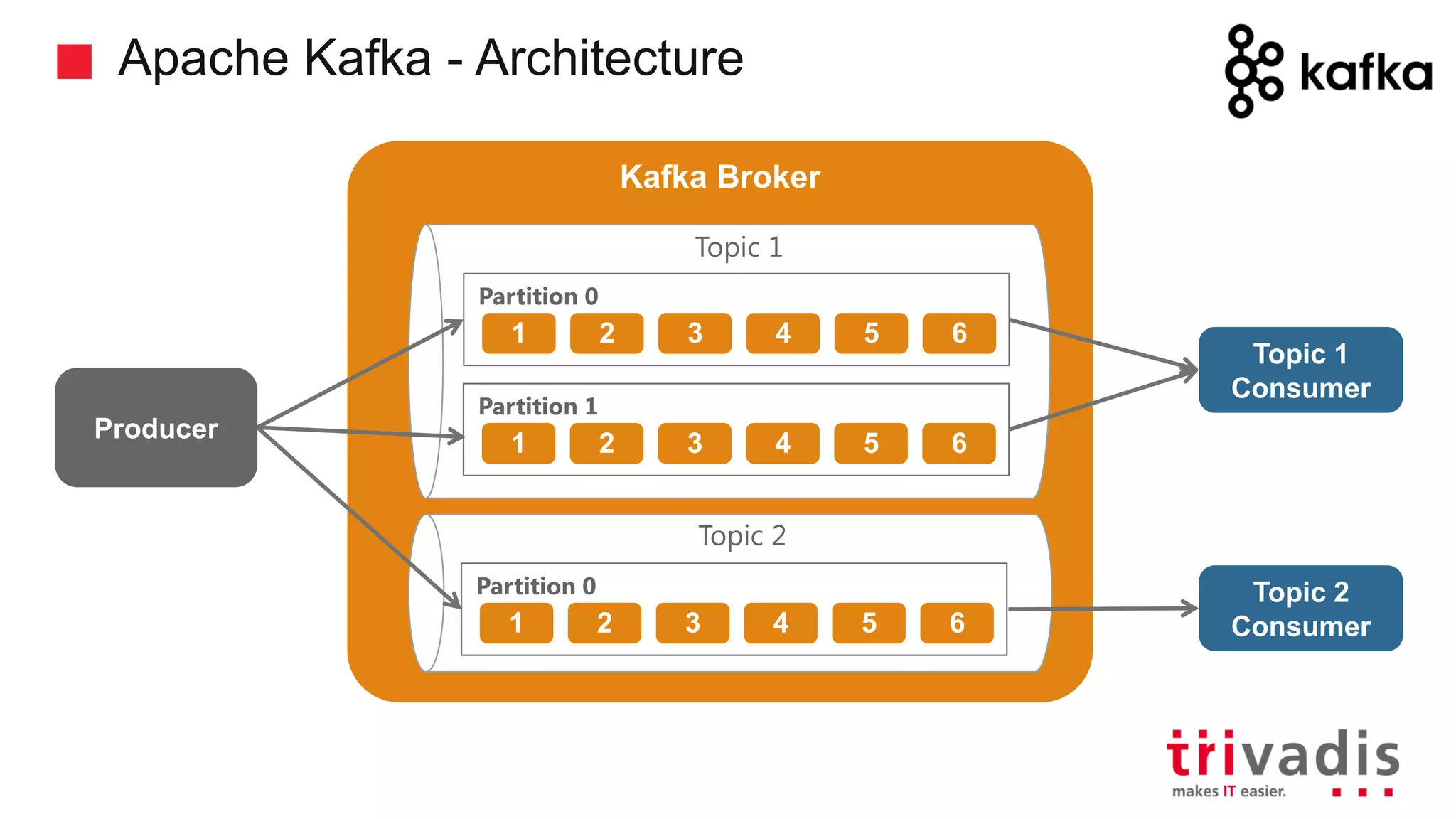
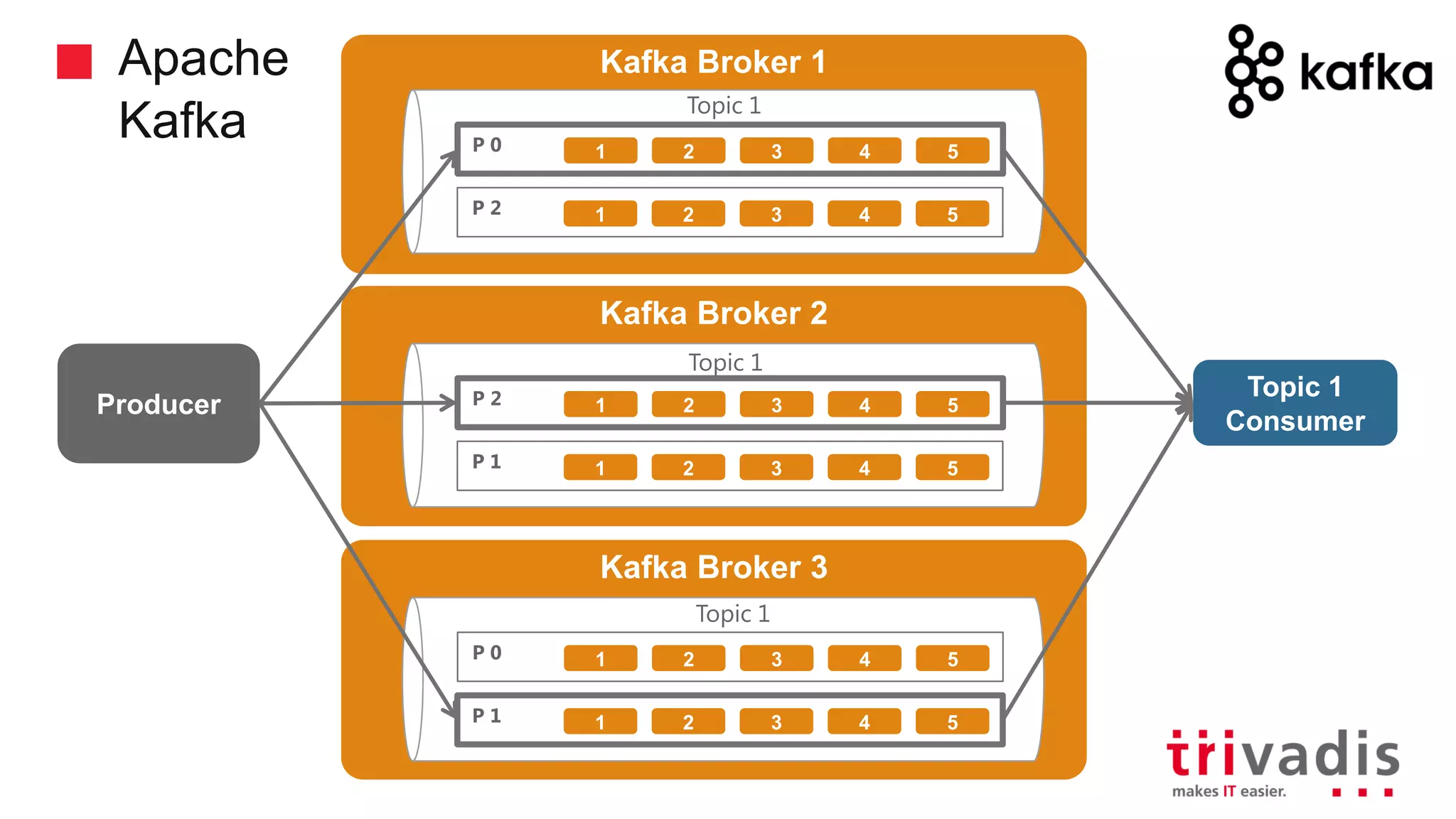
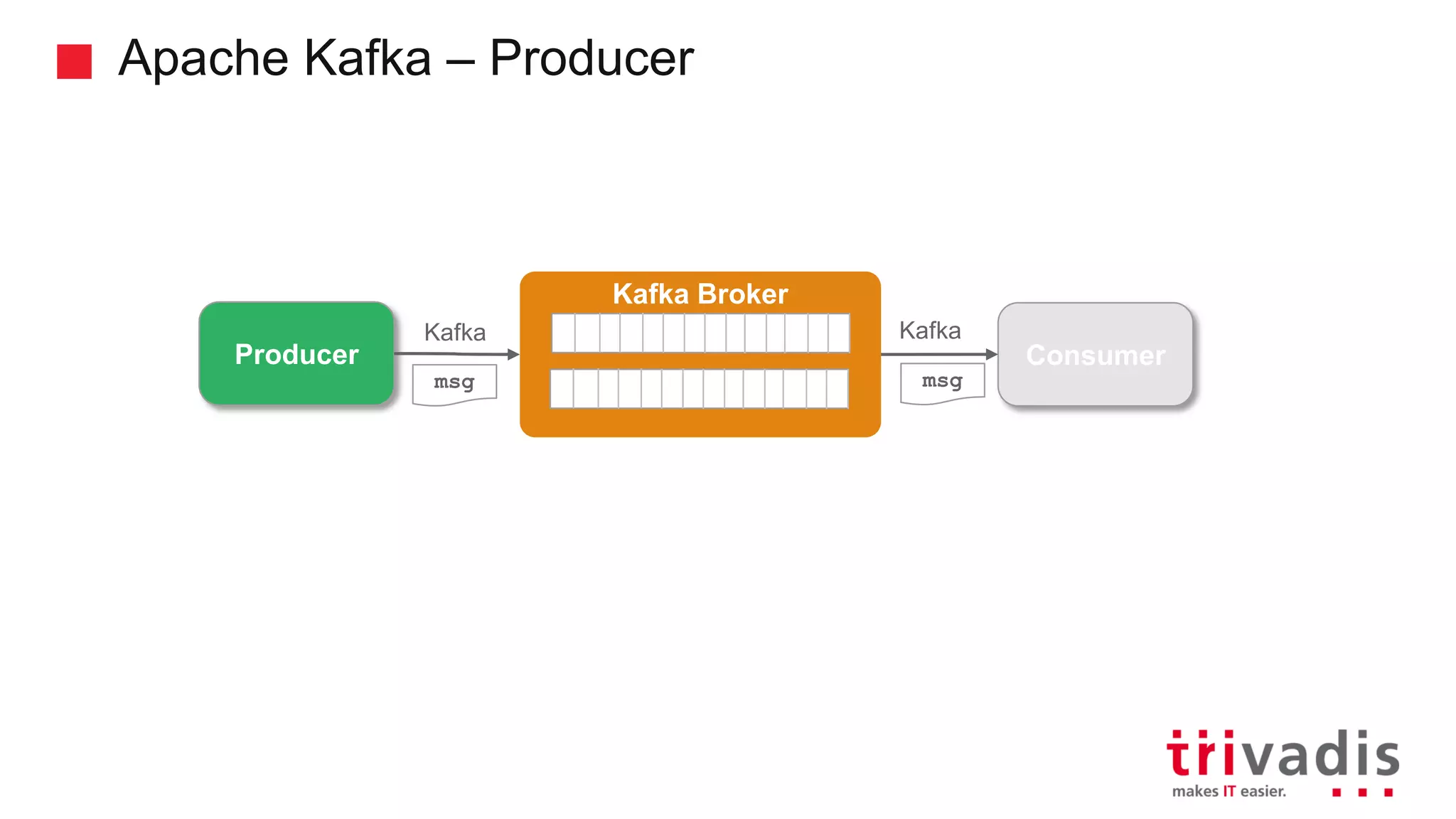
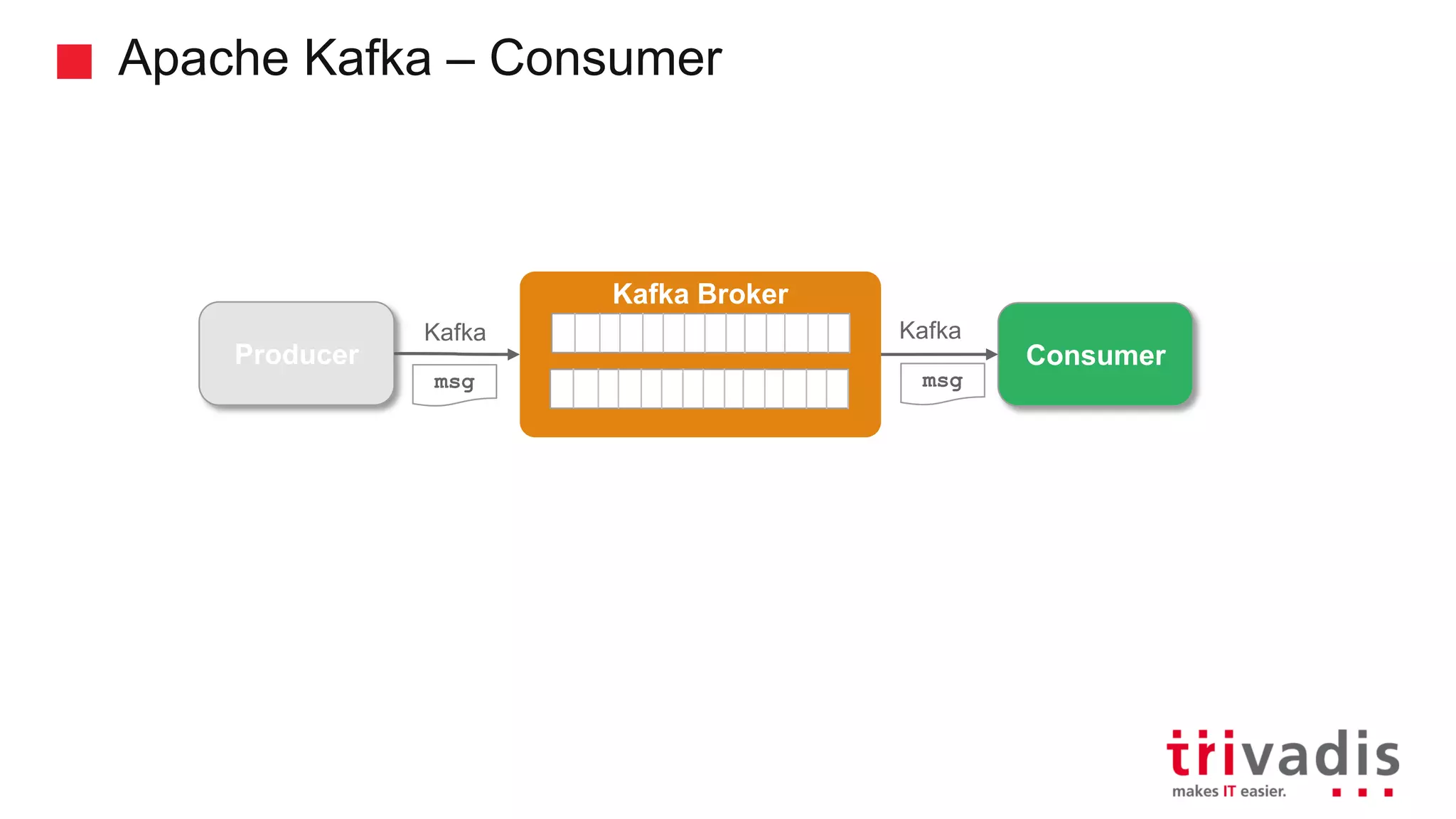
Overview of Kafka's architecture including brokers, topics, and producers.
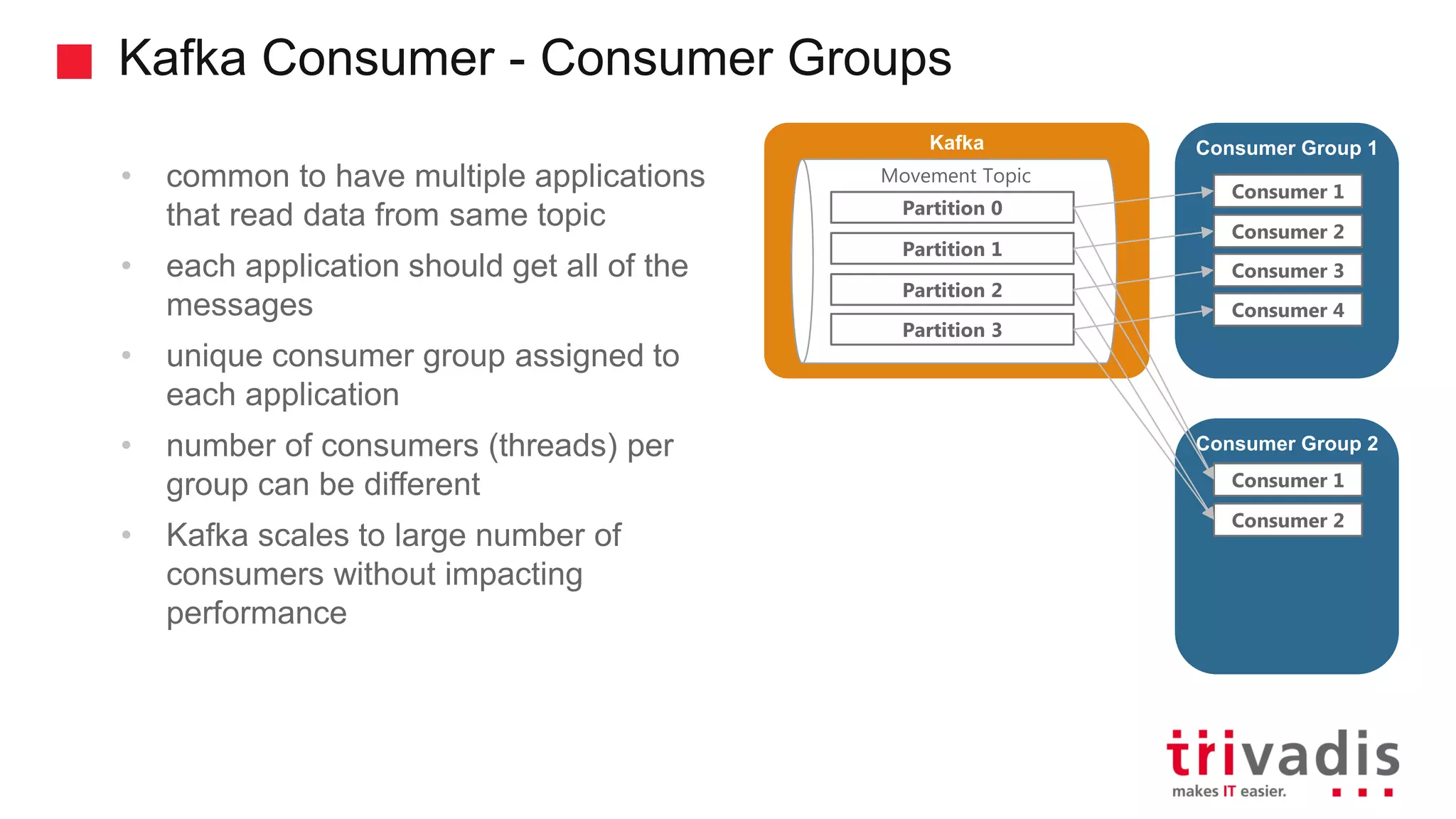
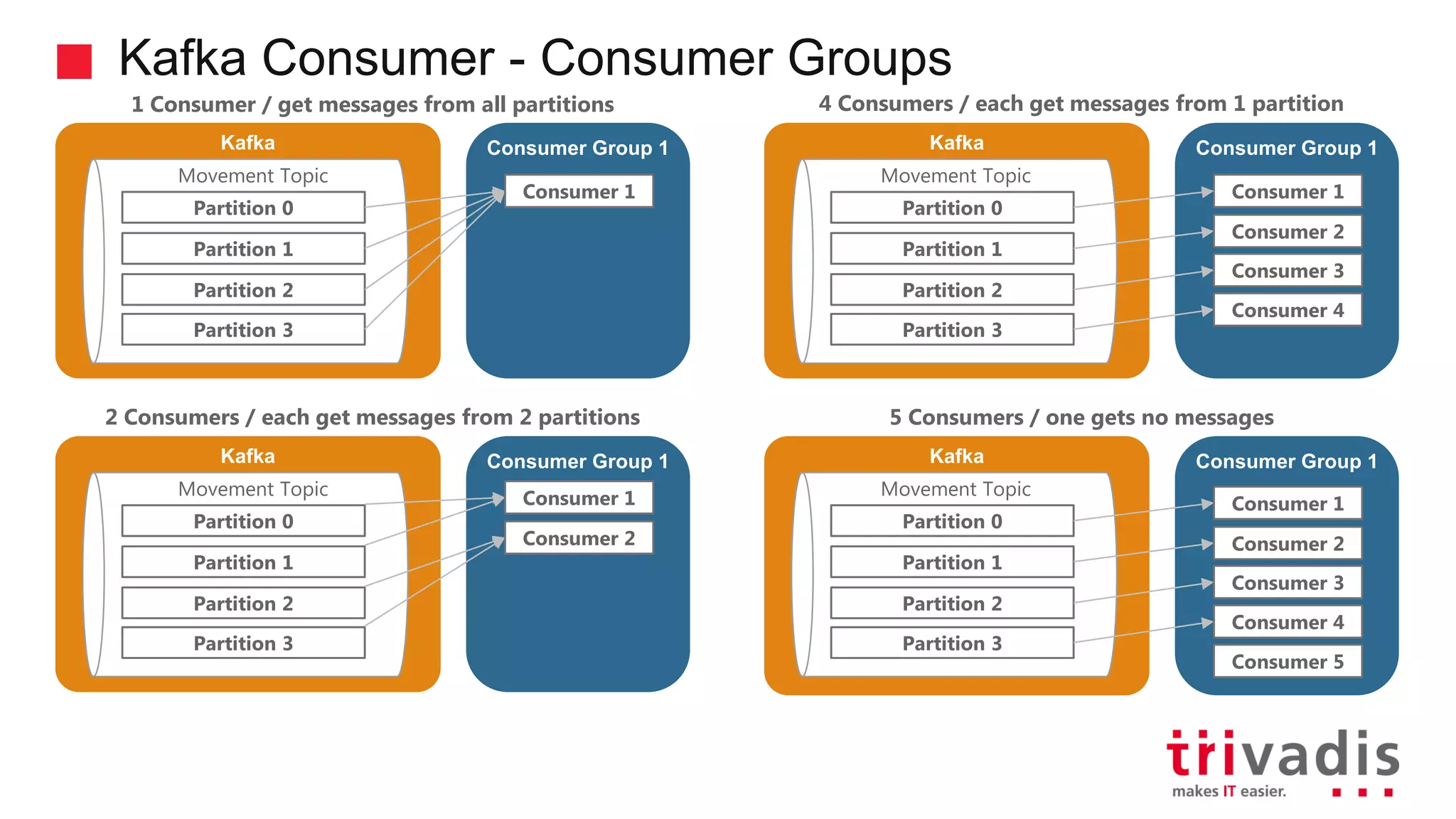
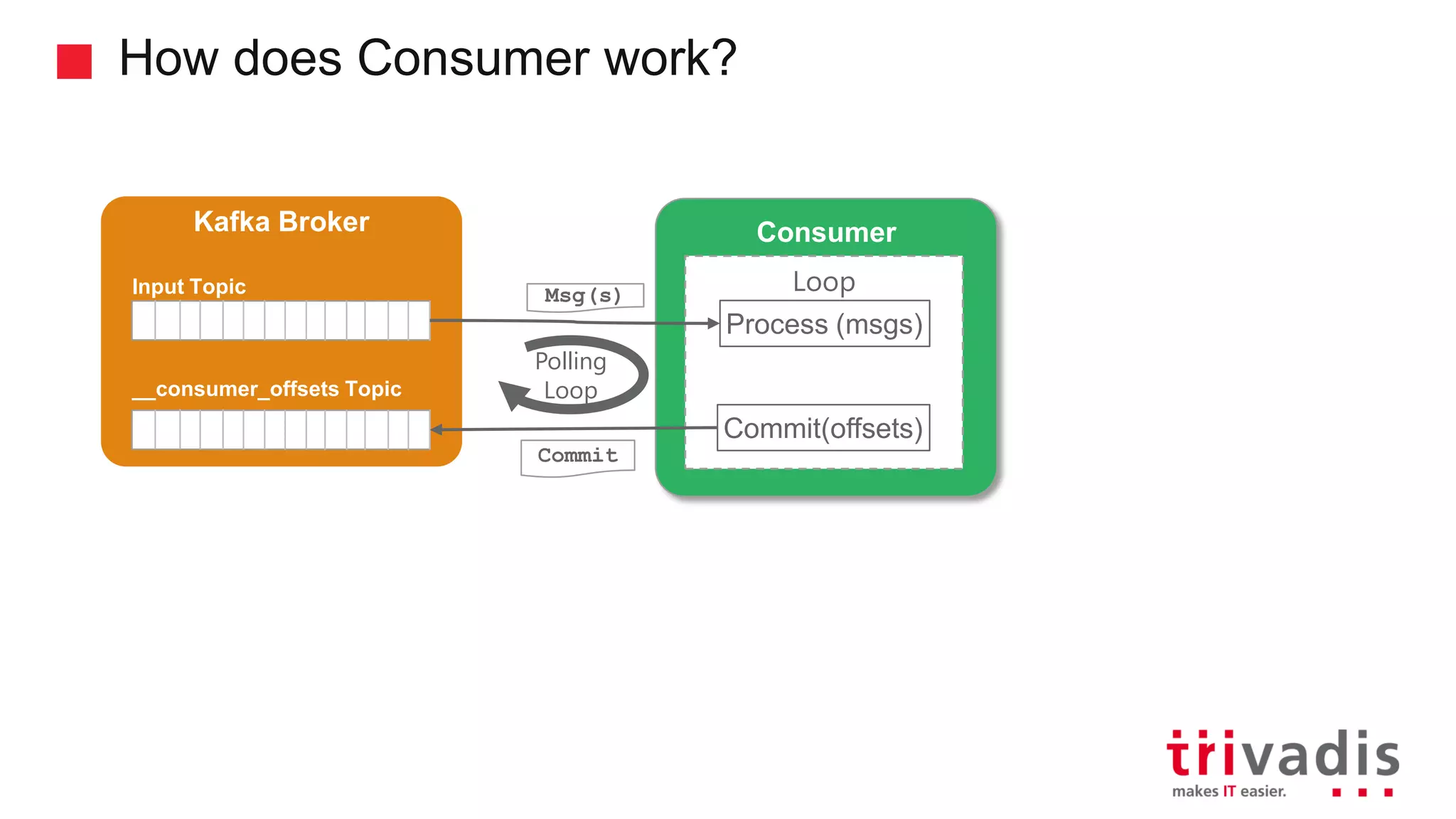
Explanation of consumer groups in Kafka, message consumption strategies, and scalability.
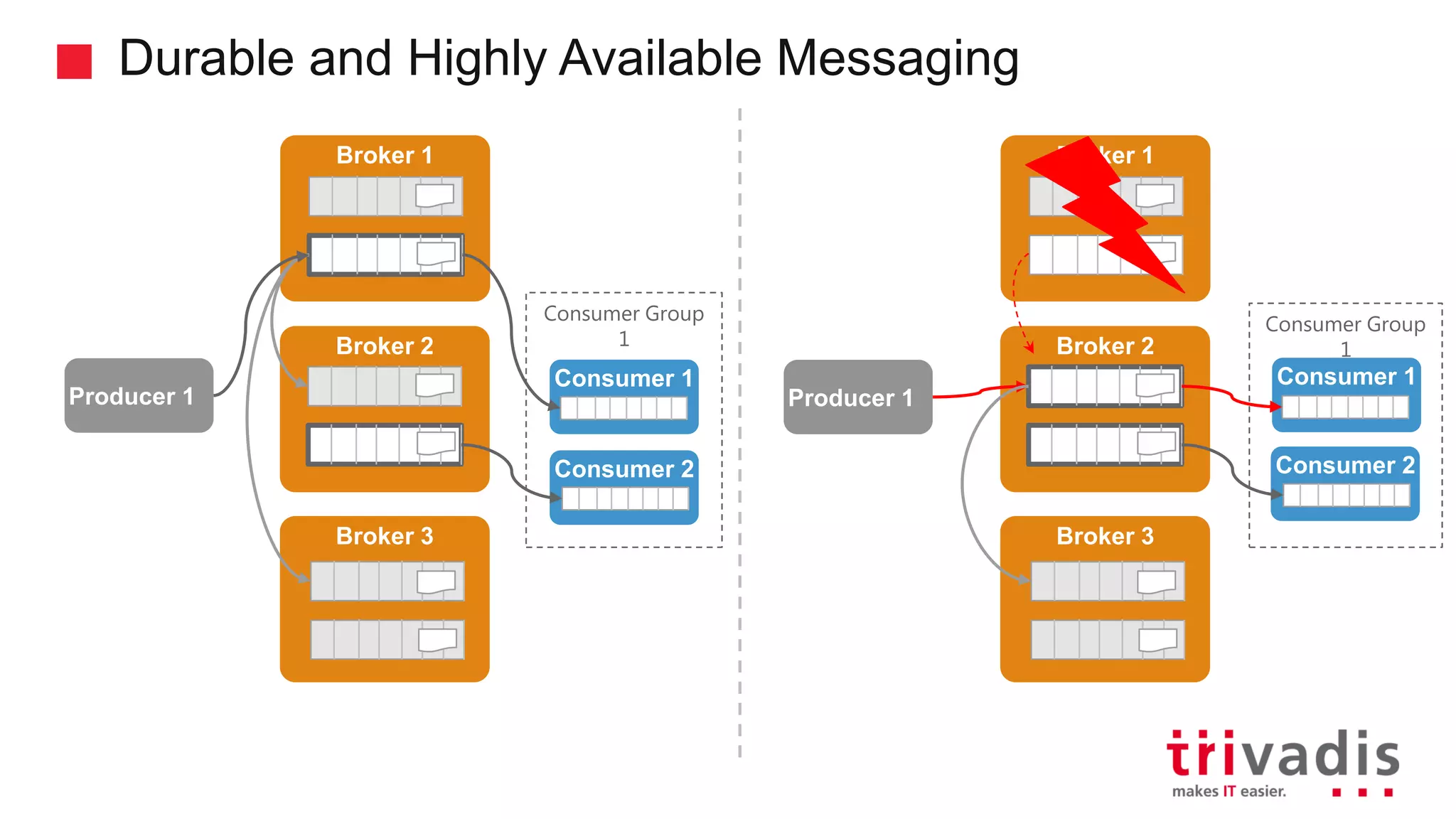
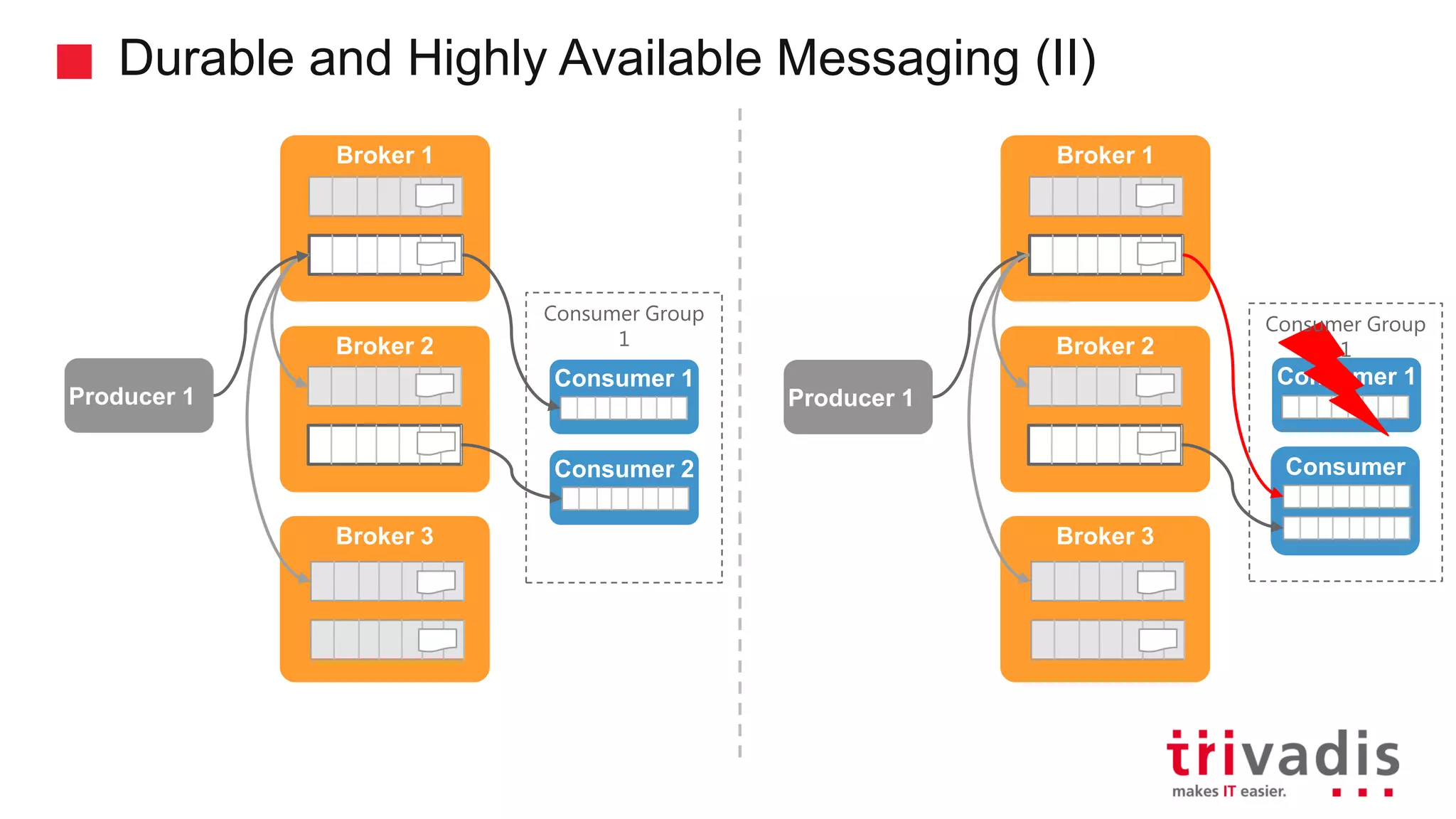
Durability and availability of messaging between producers and consumers.
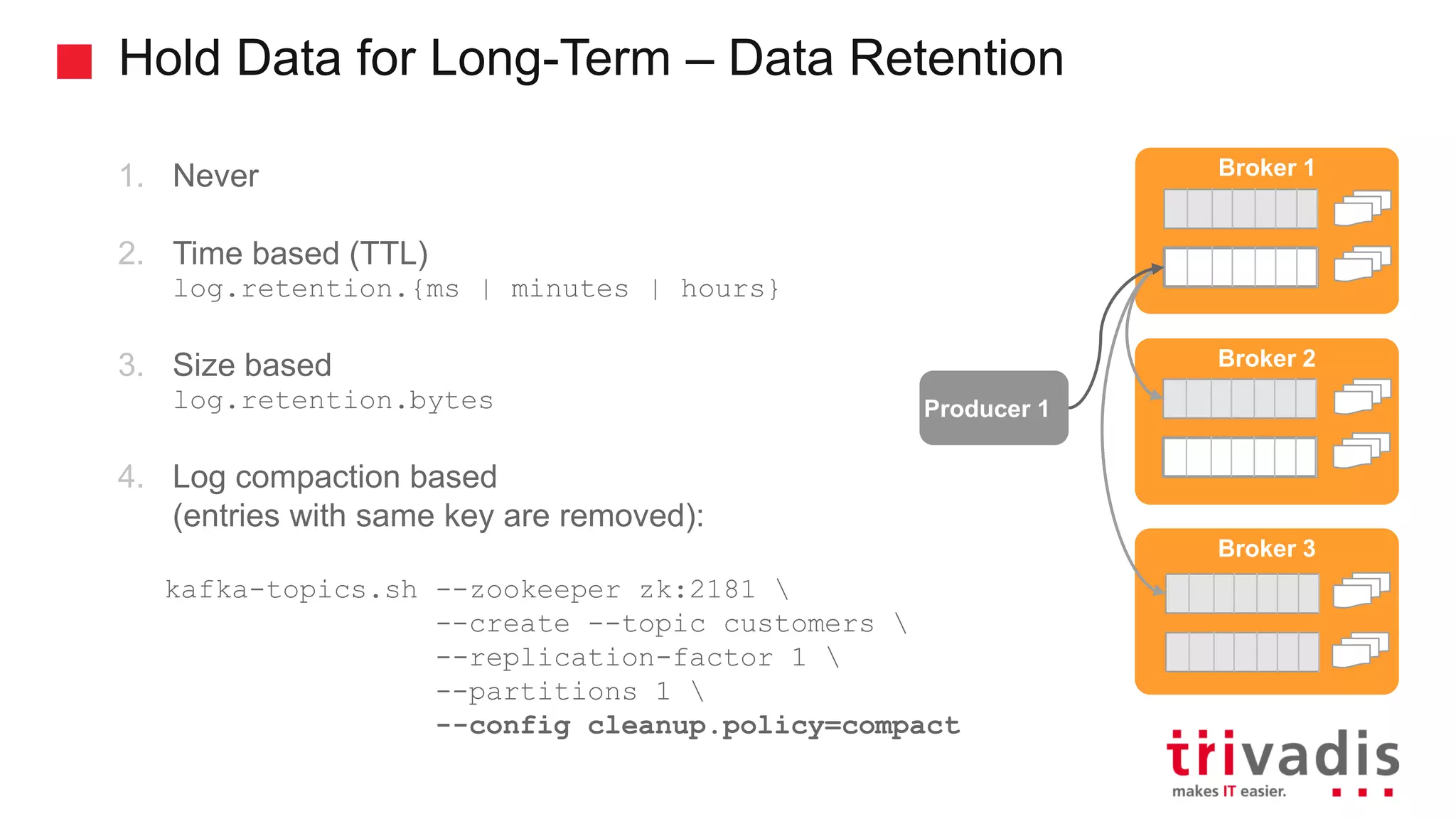
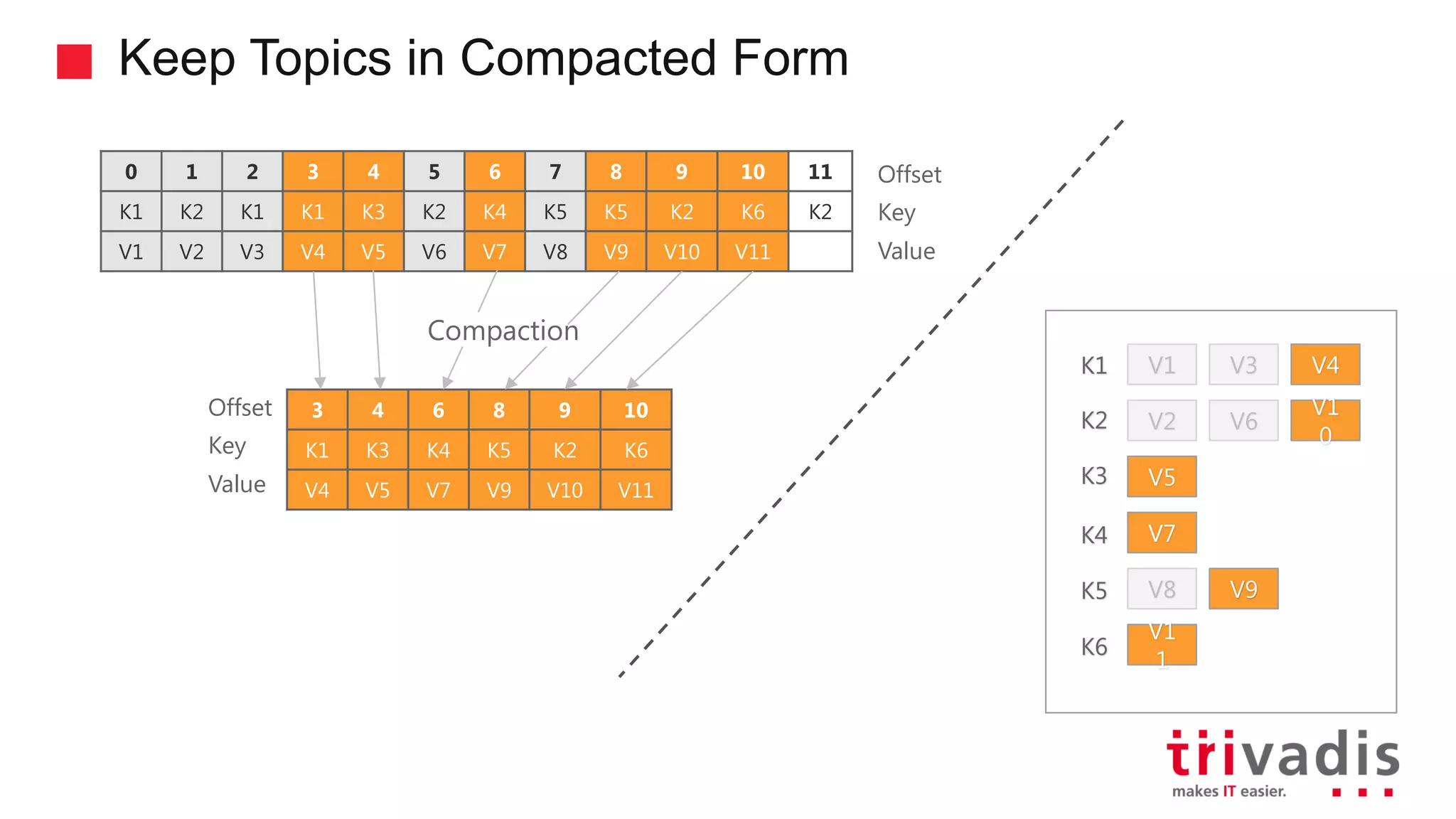
Data retention policies: time-based, size-based, and compaction.
Ways to provision Kafka environments on-premises or in the cloud.
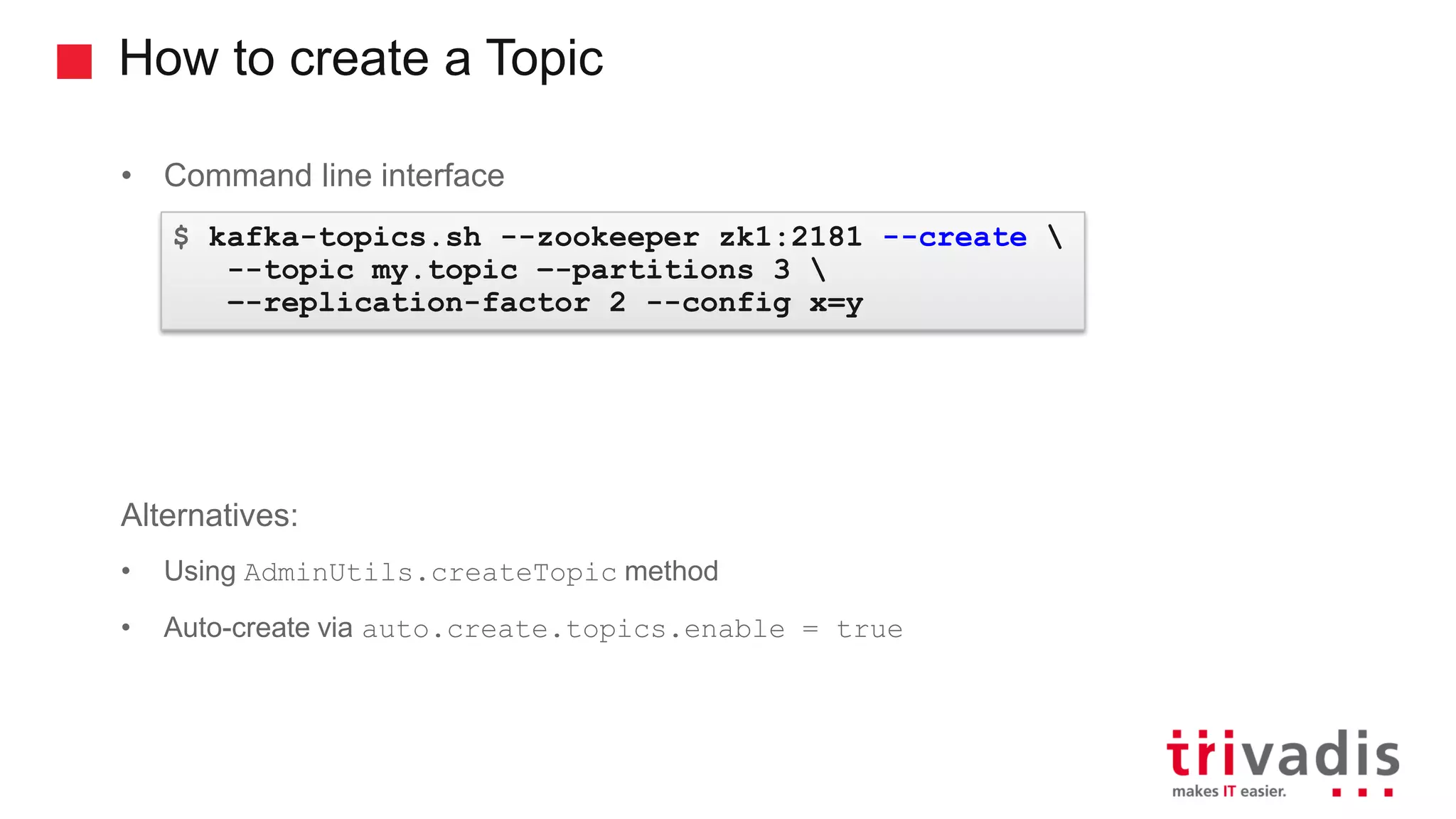
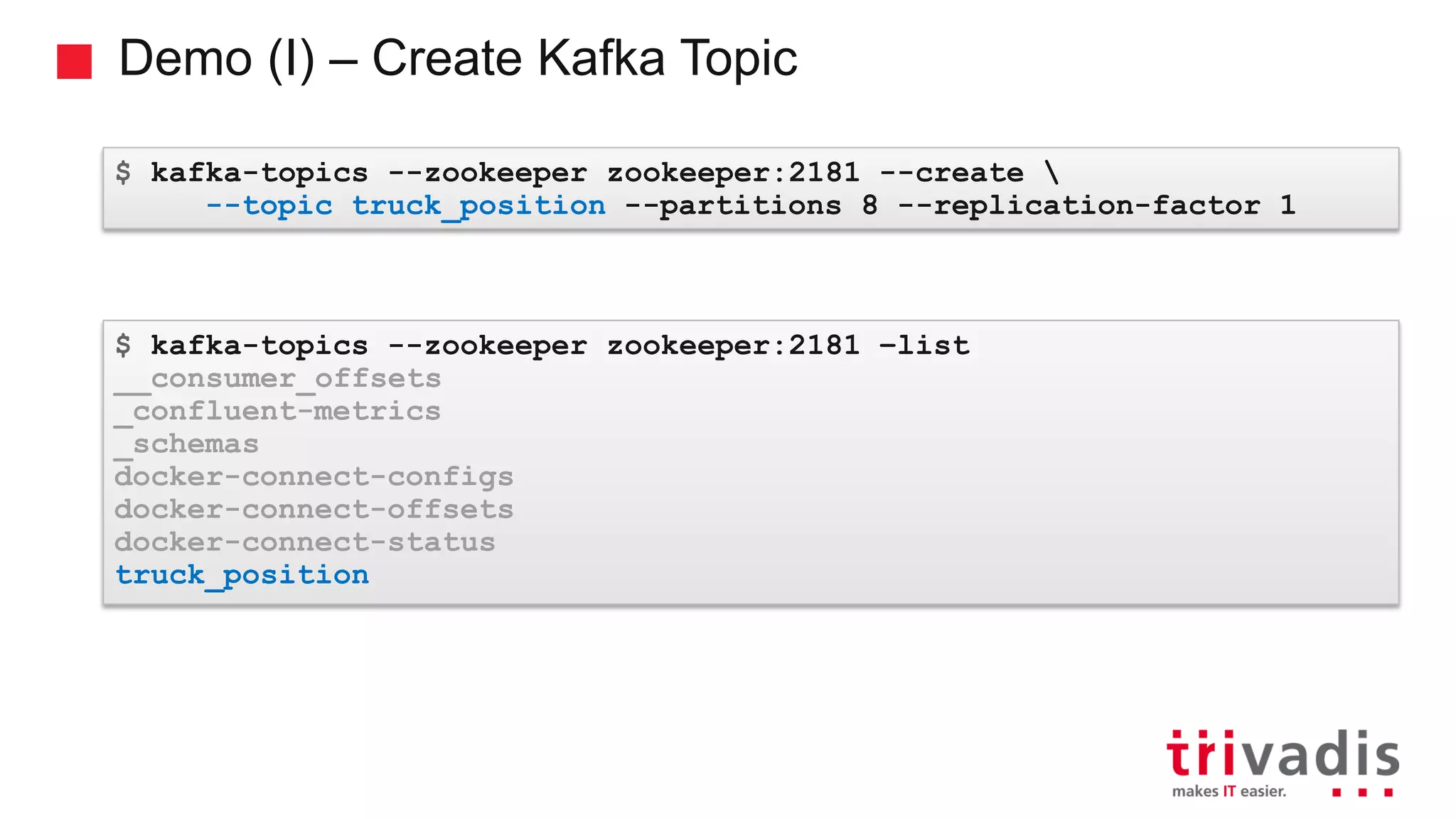
Methods to create Kafka topics and important configuration settings.
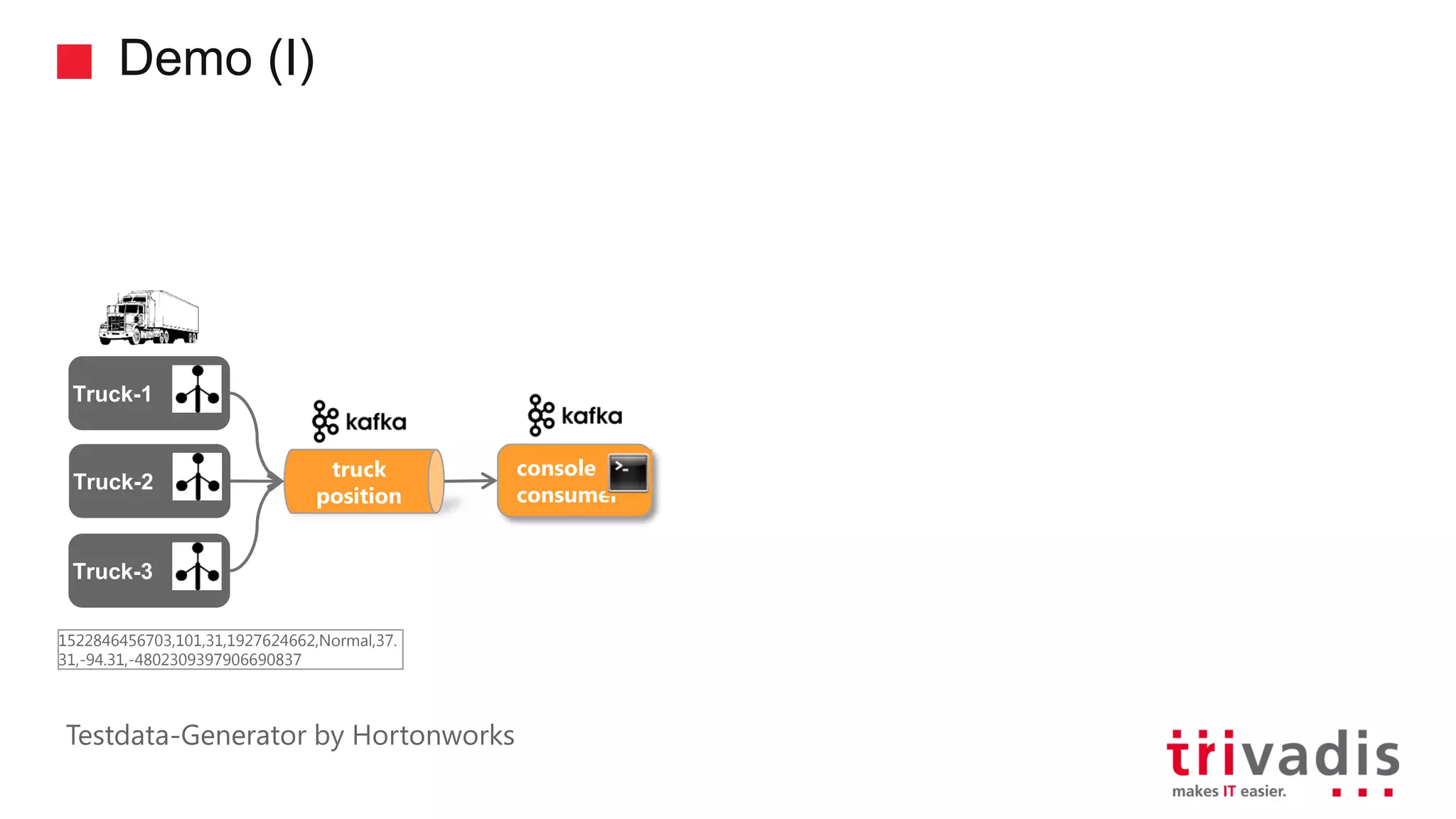
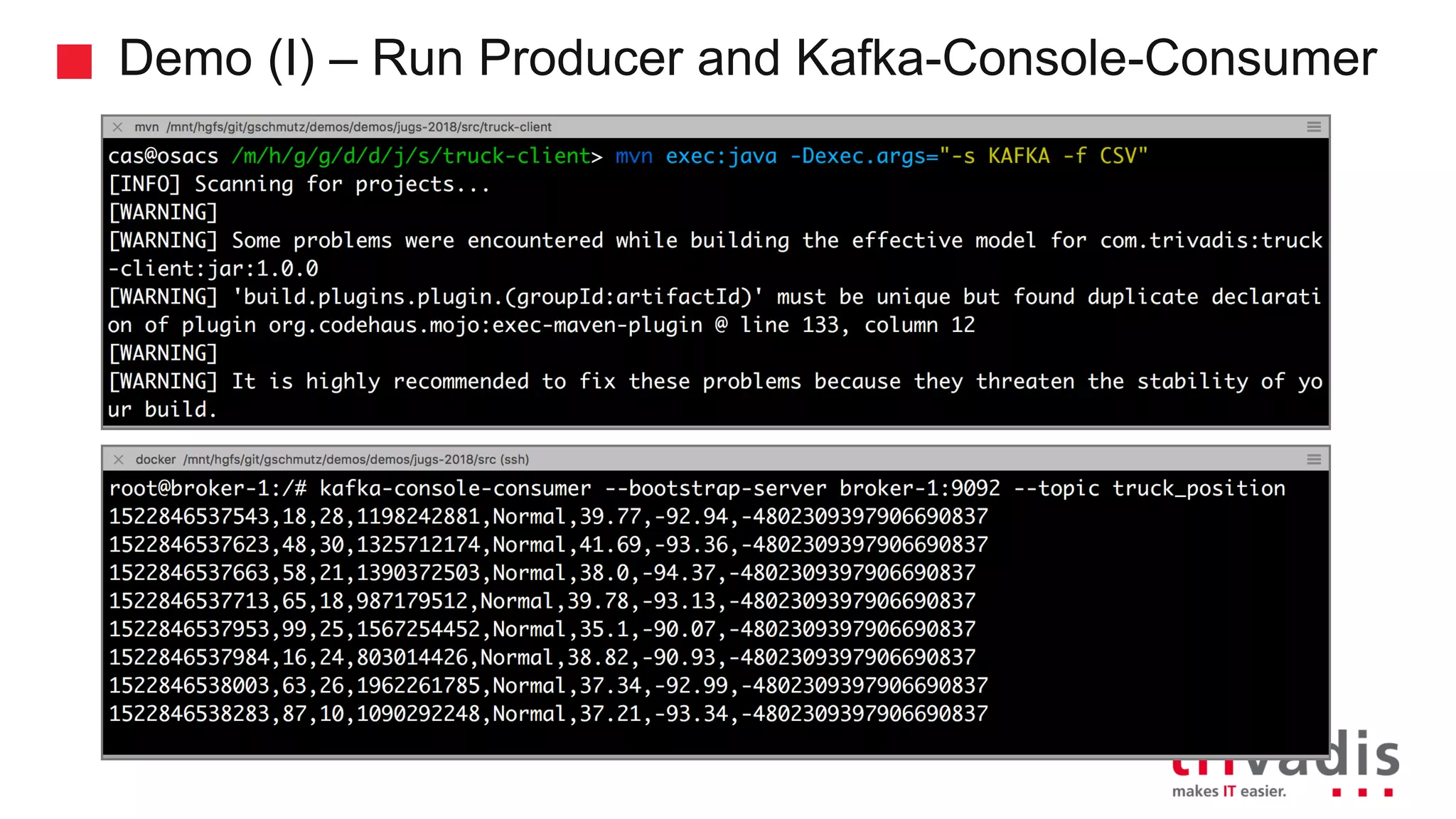
Demonstration of creating a Kafka topic and running producers/consumers.
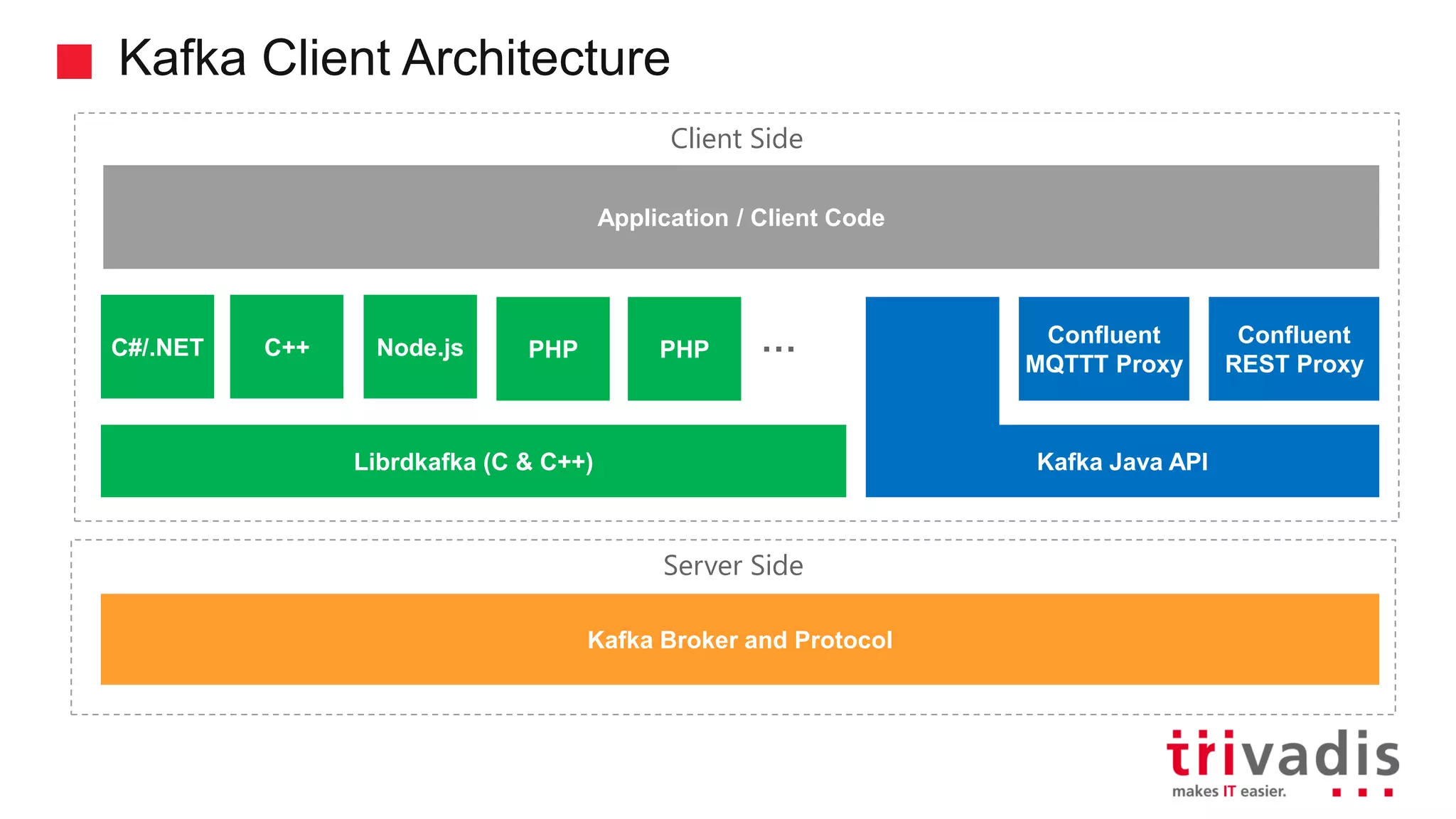
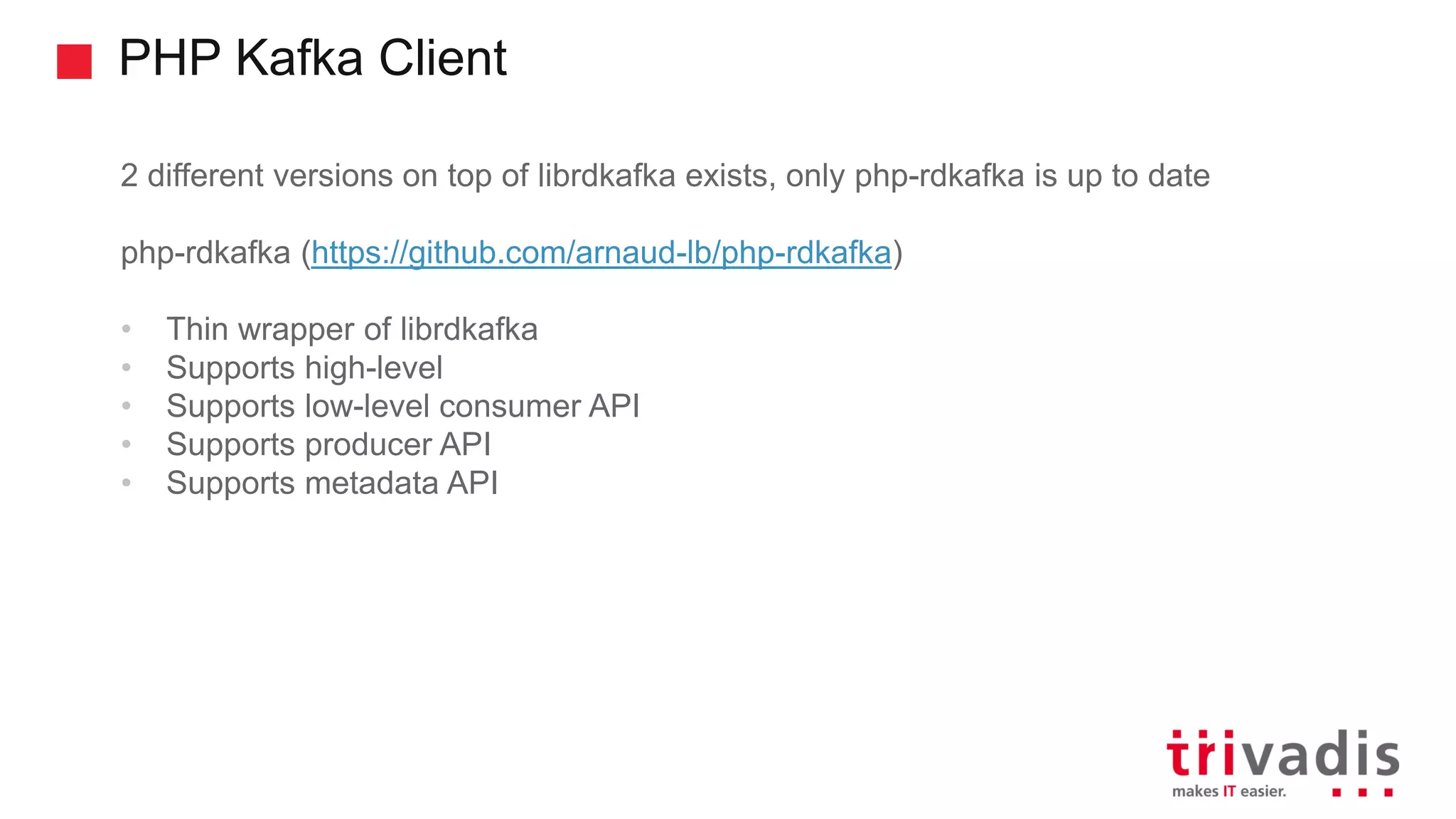
Overview of Kafka clients, focusing on various APIs and libraries.
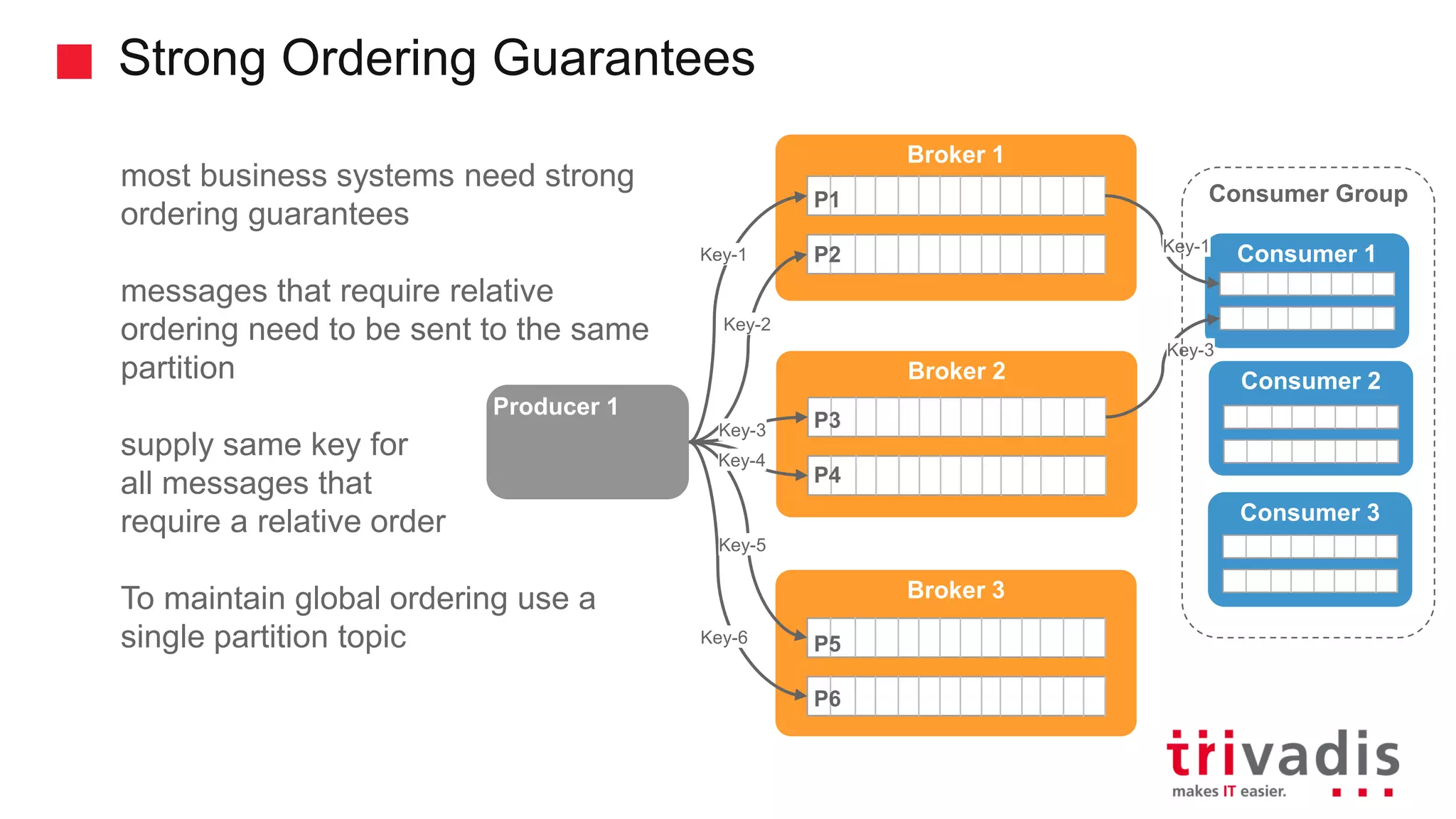
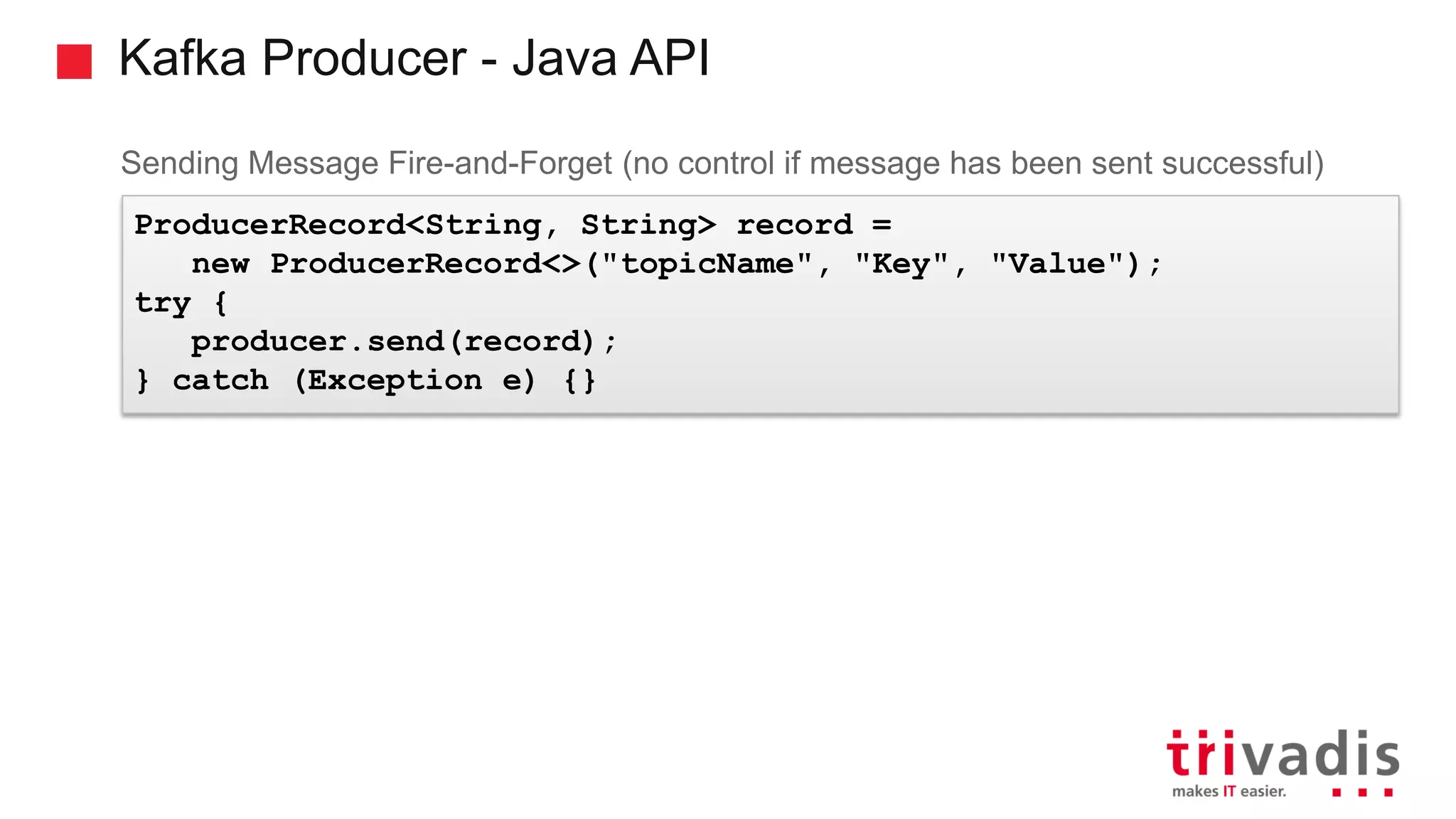
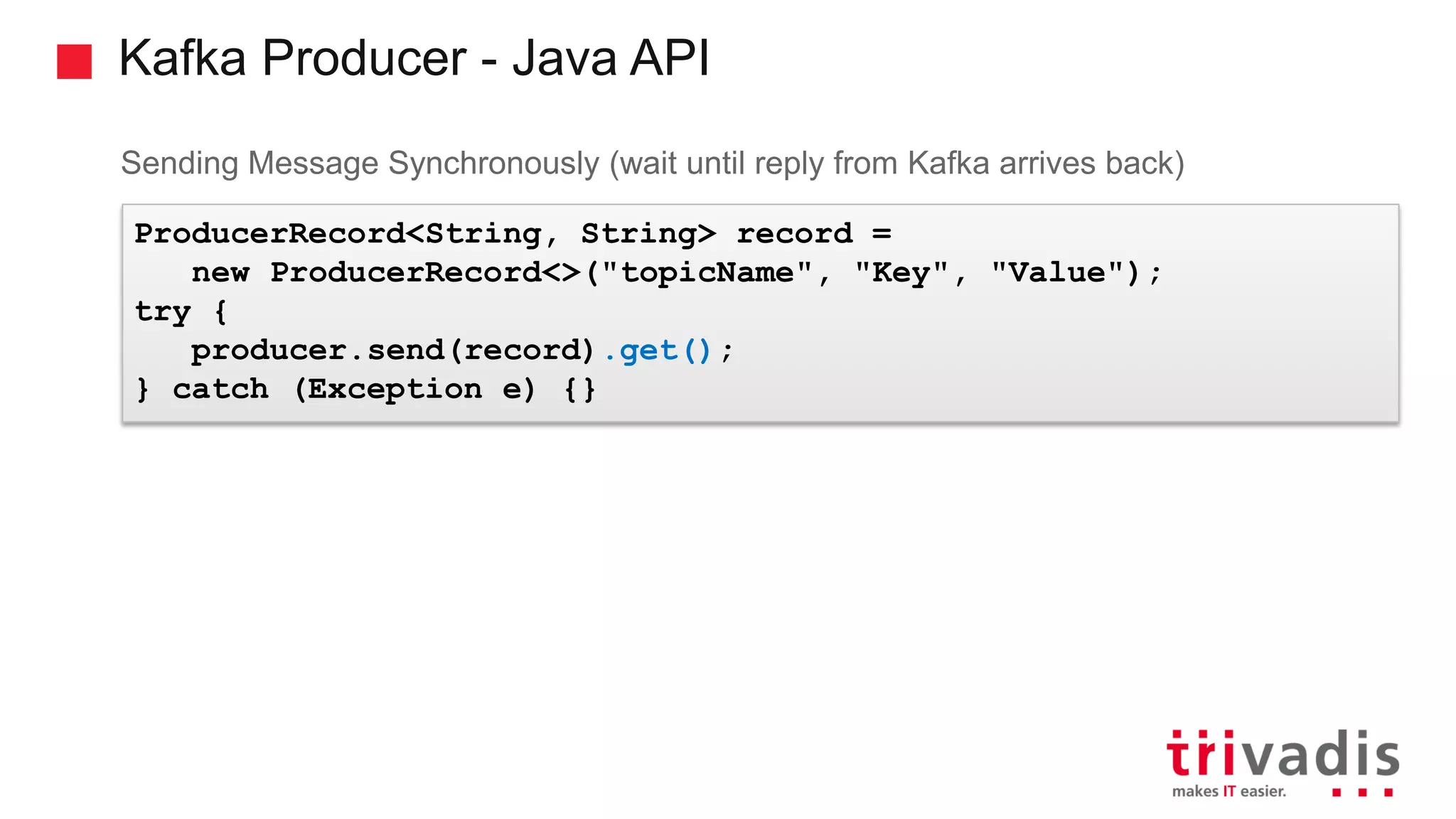
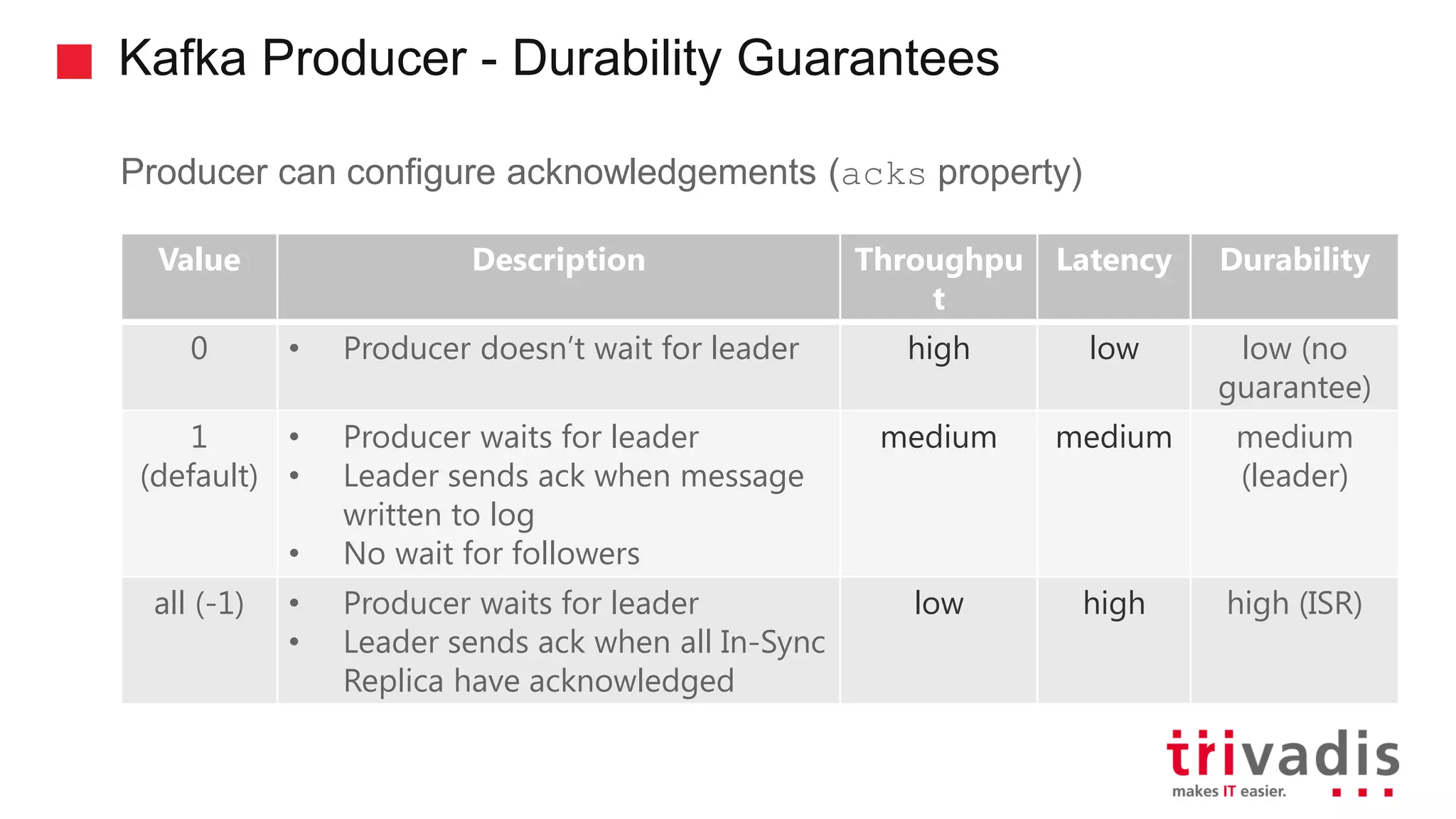
Functionality and guarantees of Kafka producers, message partitioning, and ordering.
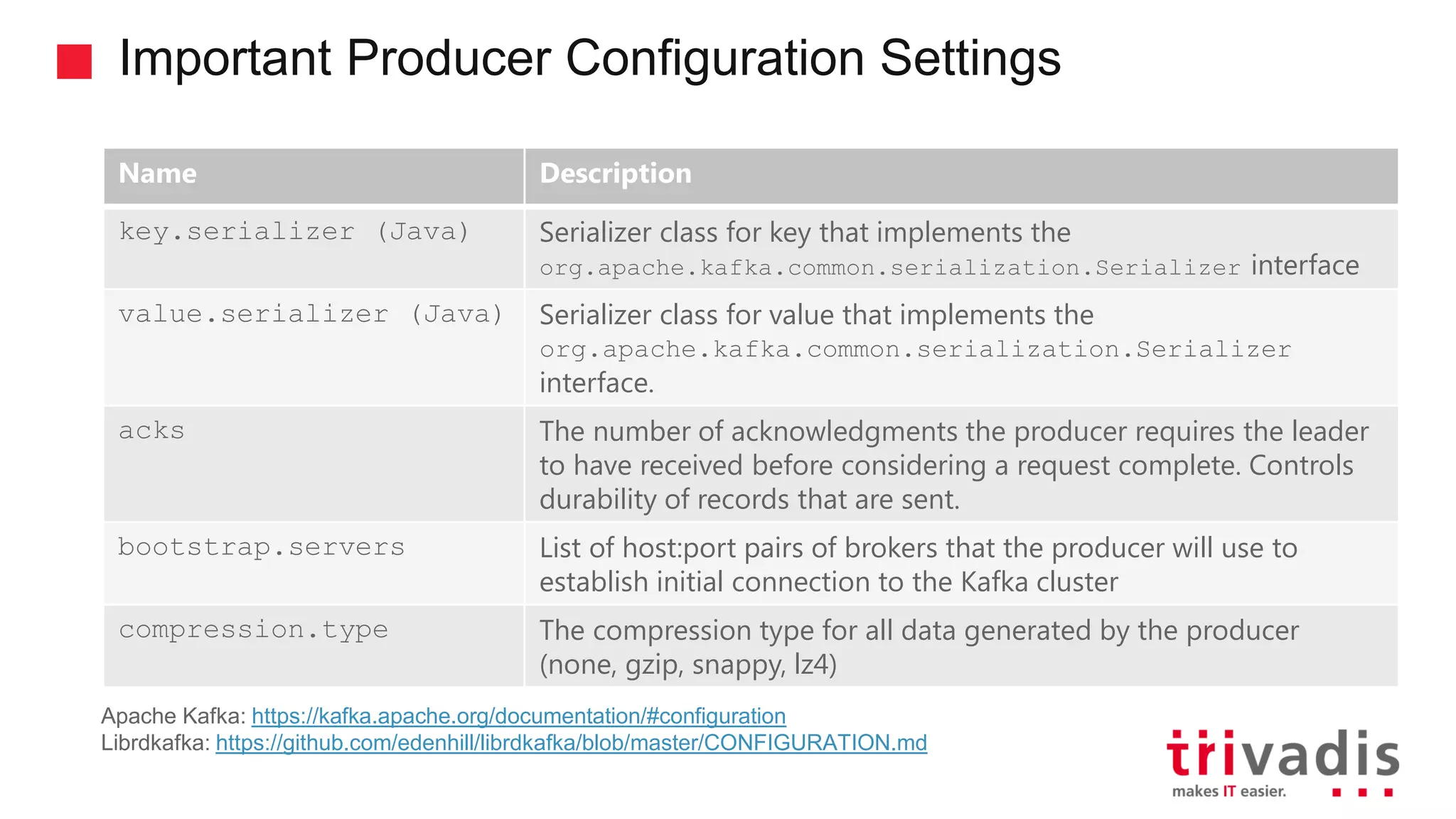
Critical configuration settings for Kafka producers regarding message durability.
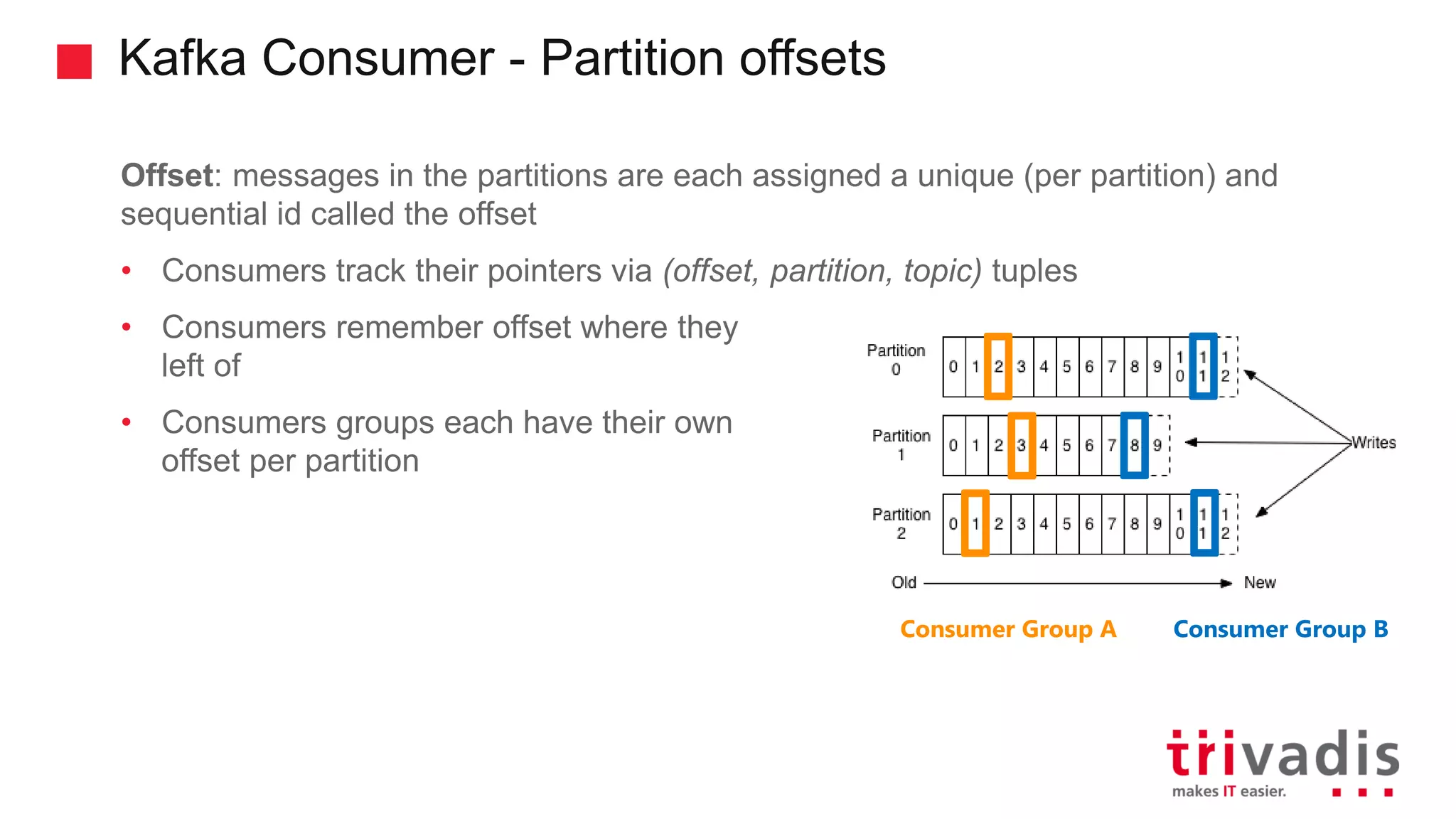
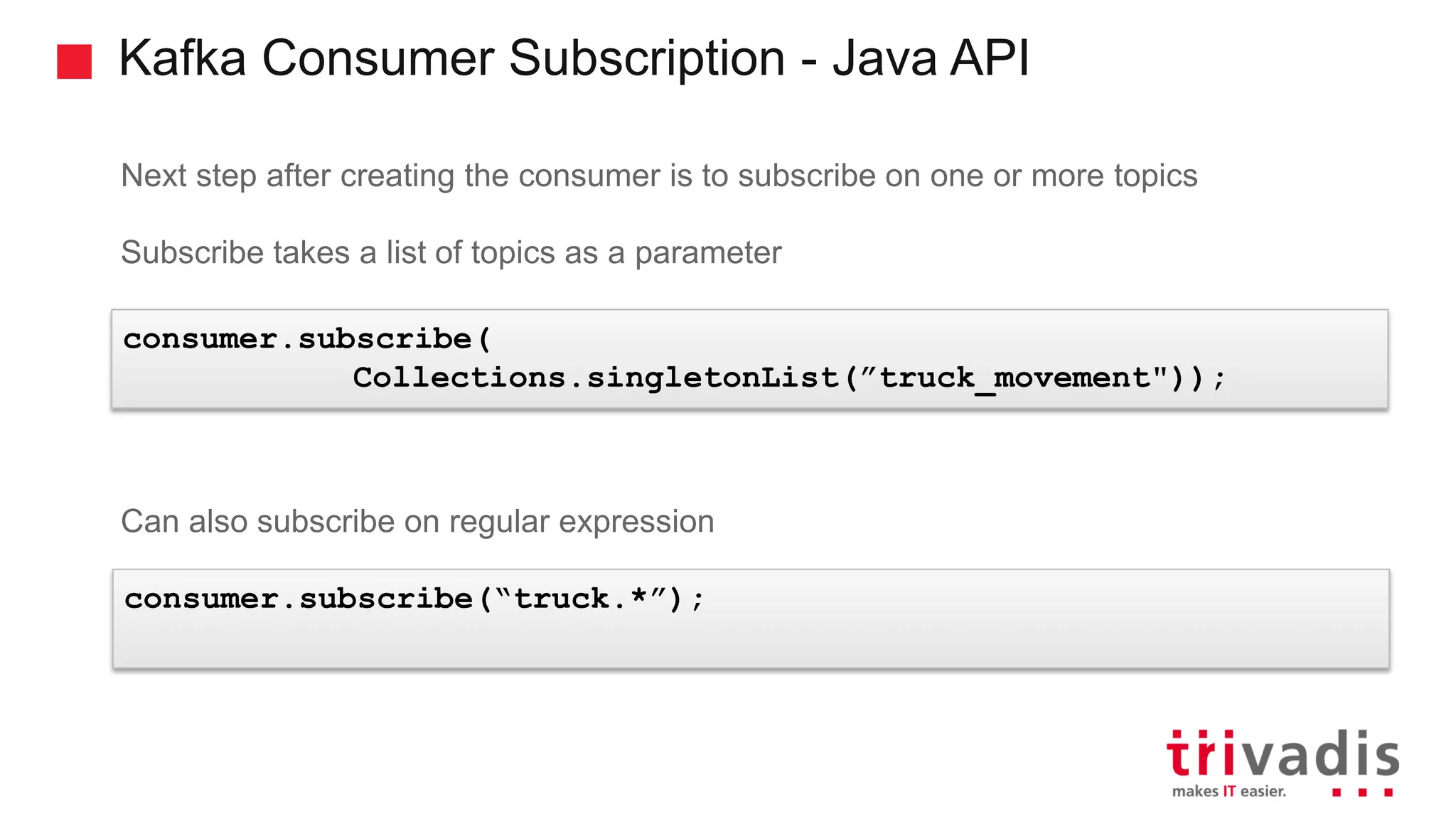
Introduction to Kafka consumers, offsets, and their tracking mechanisms.
Essential Kafka consumer settings for communication with brokers.
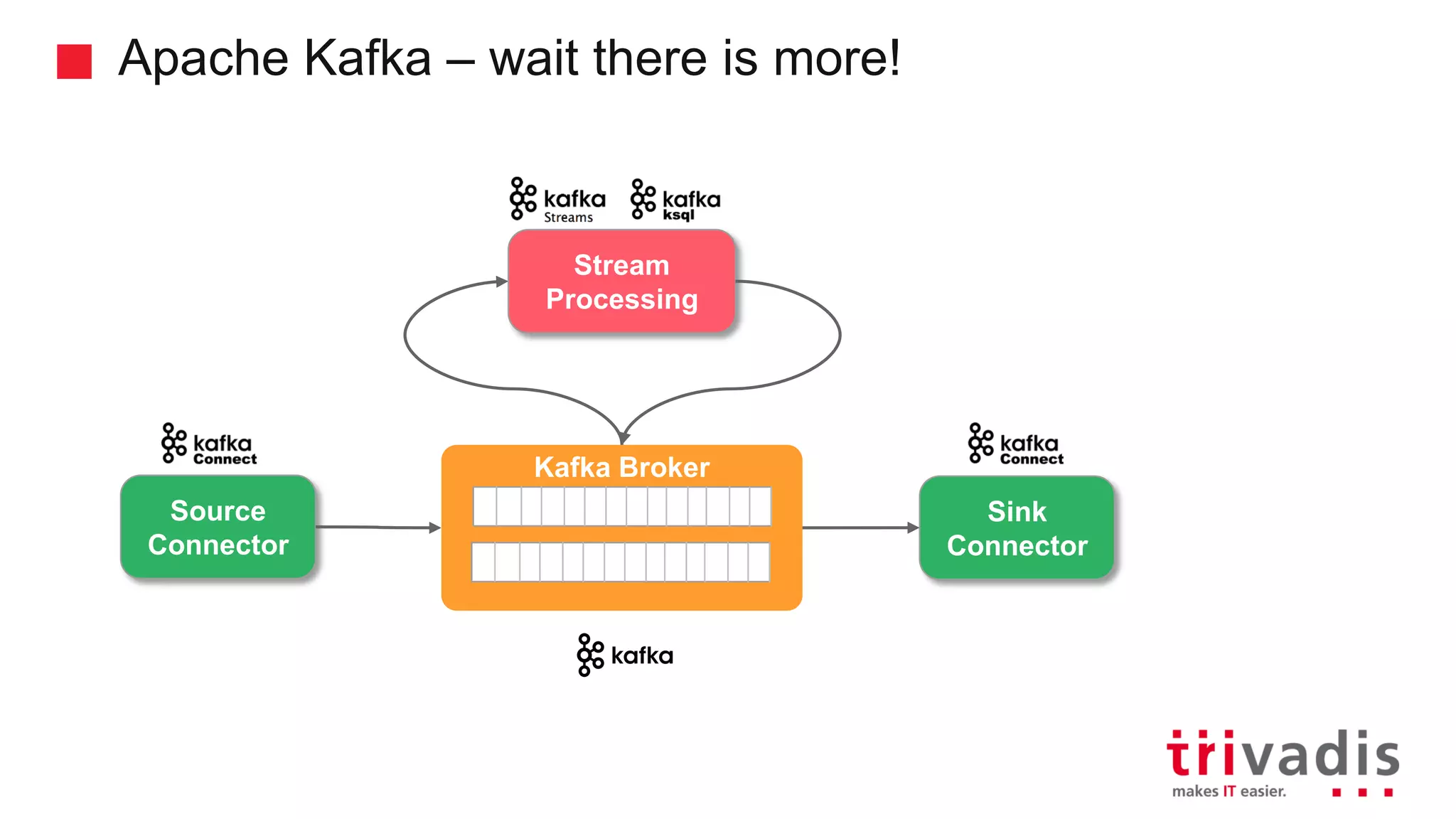
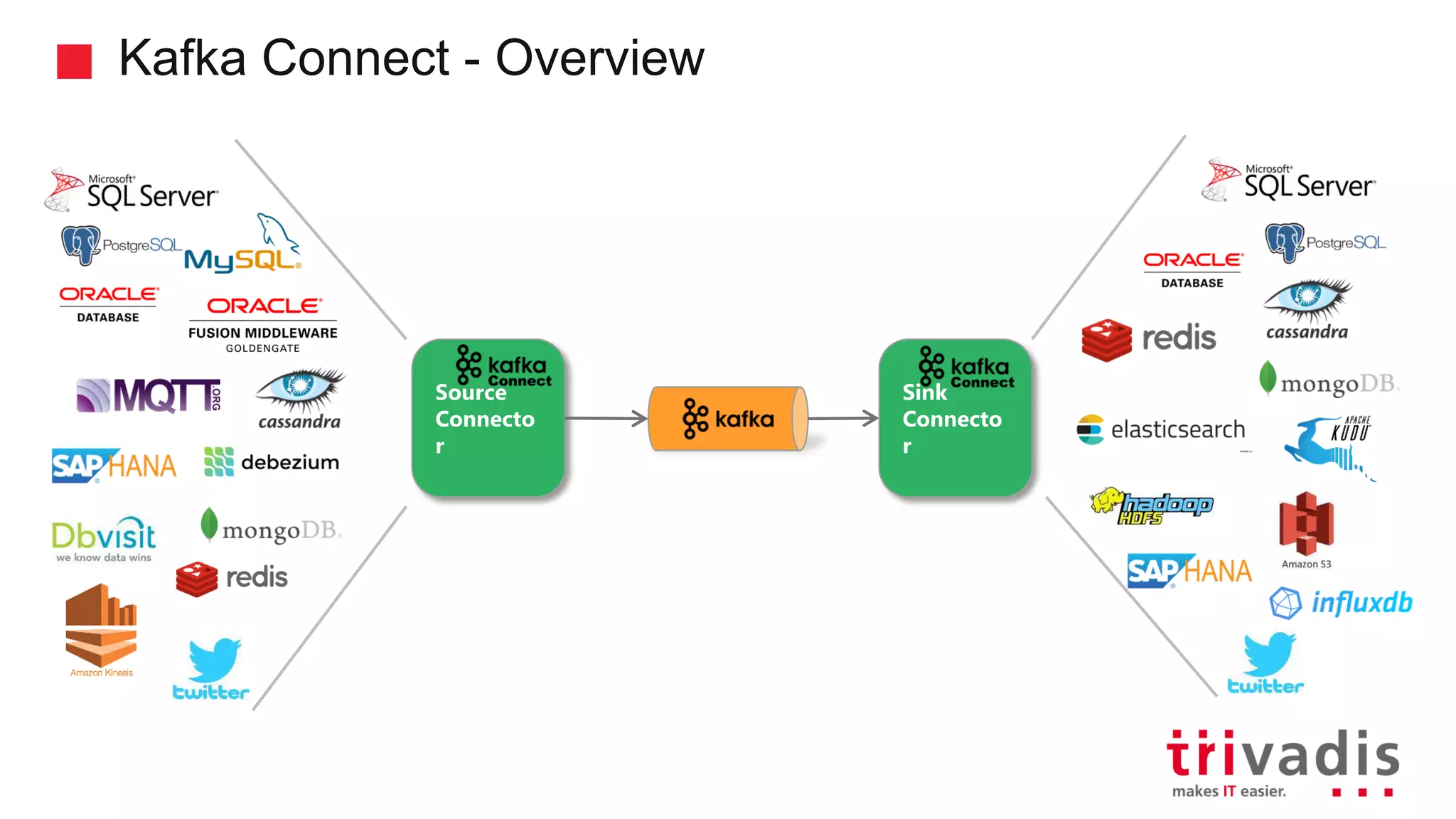
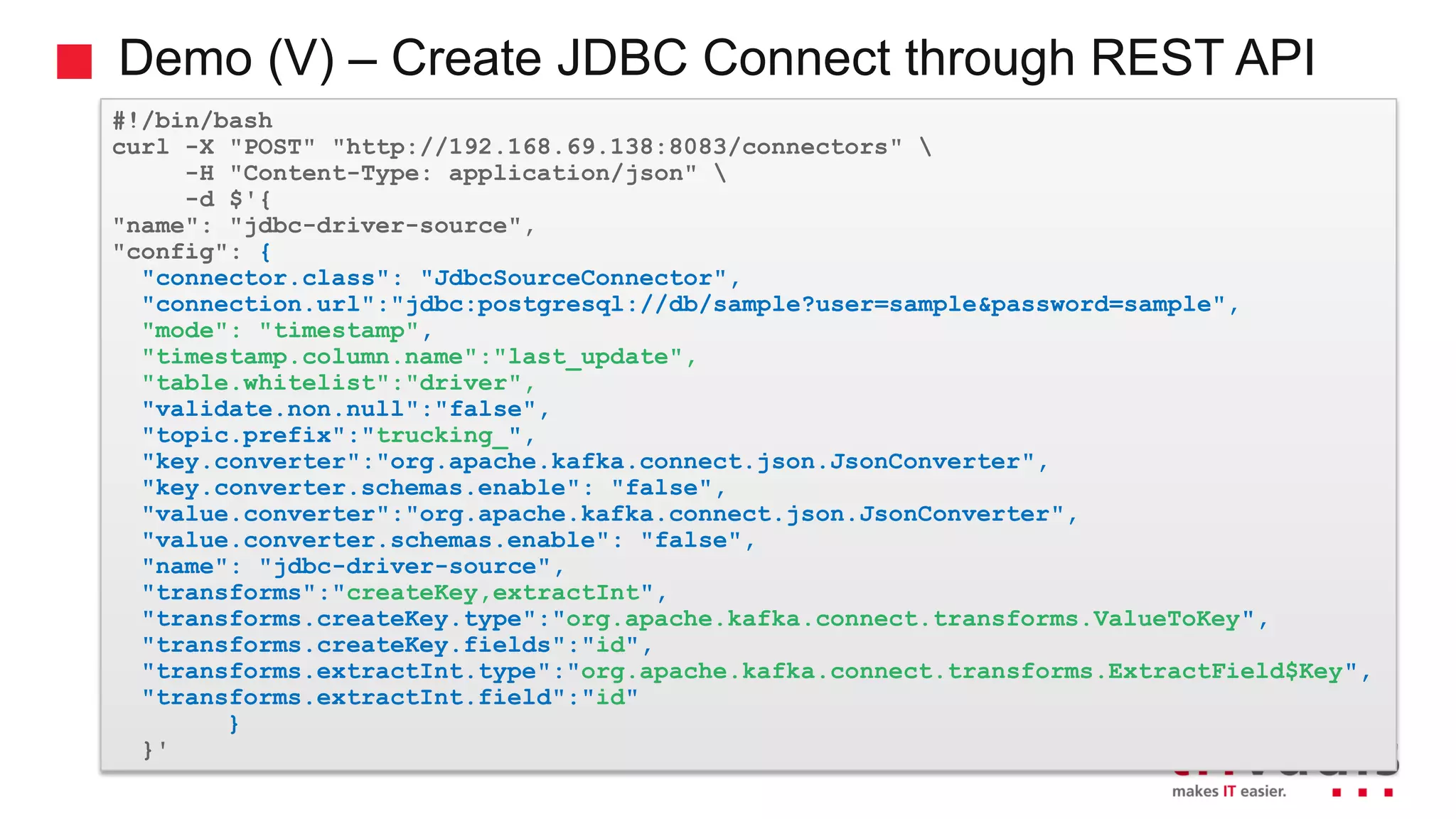
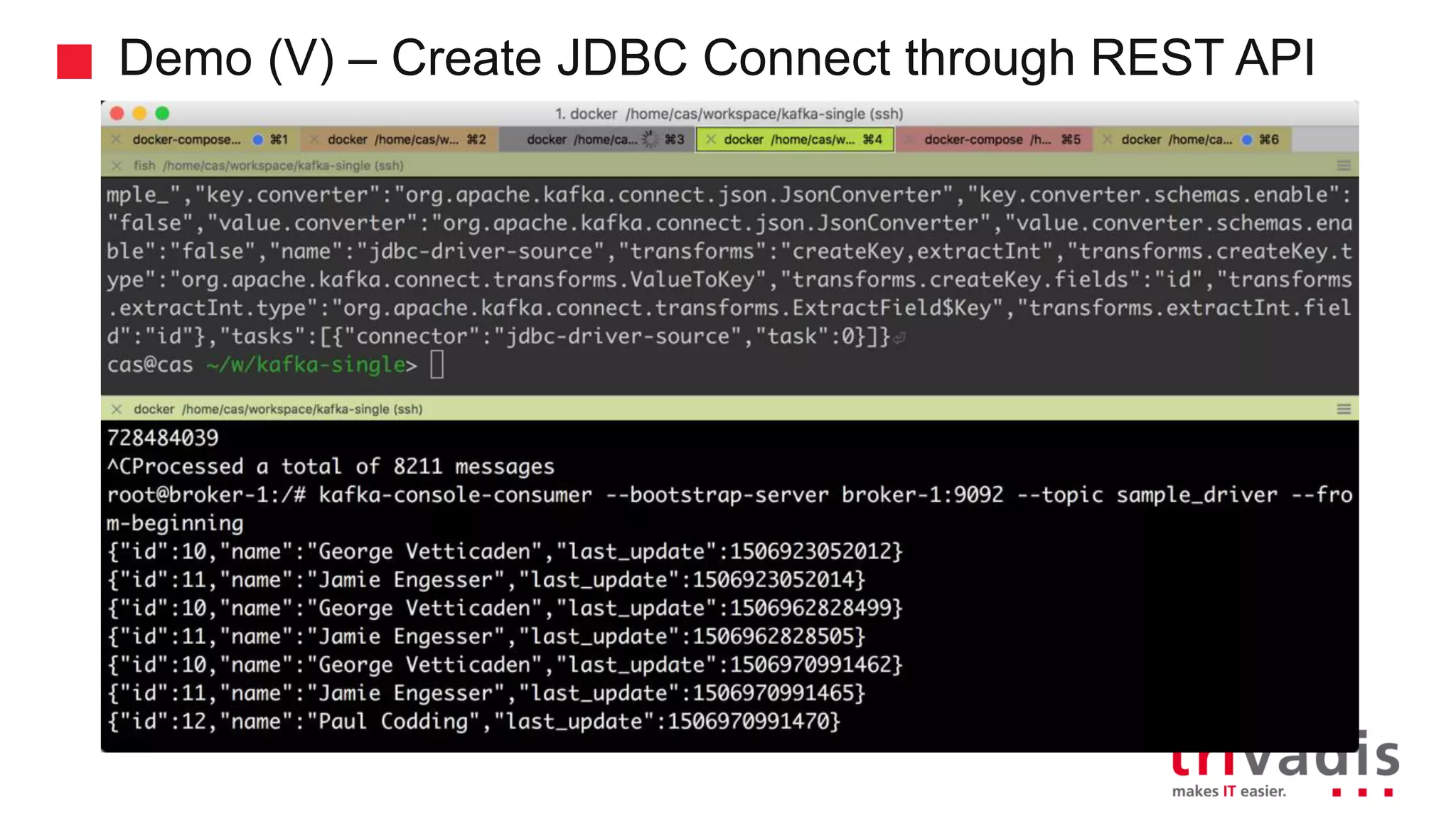
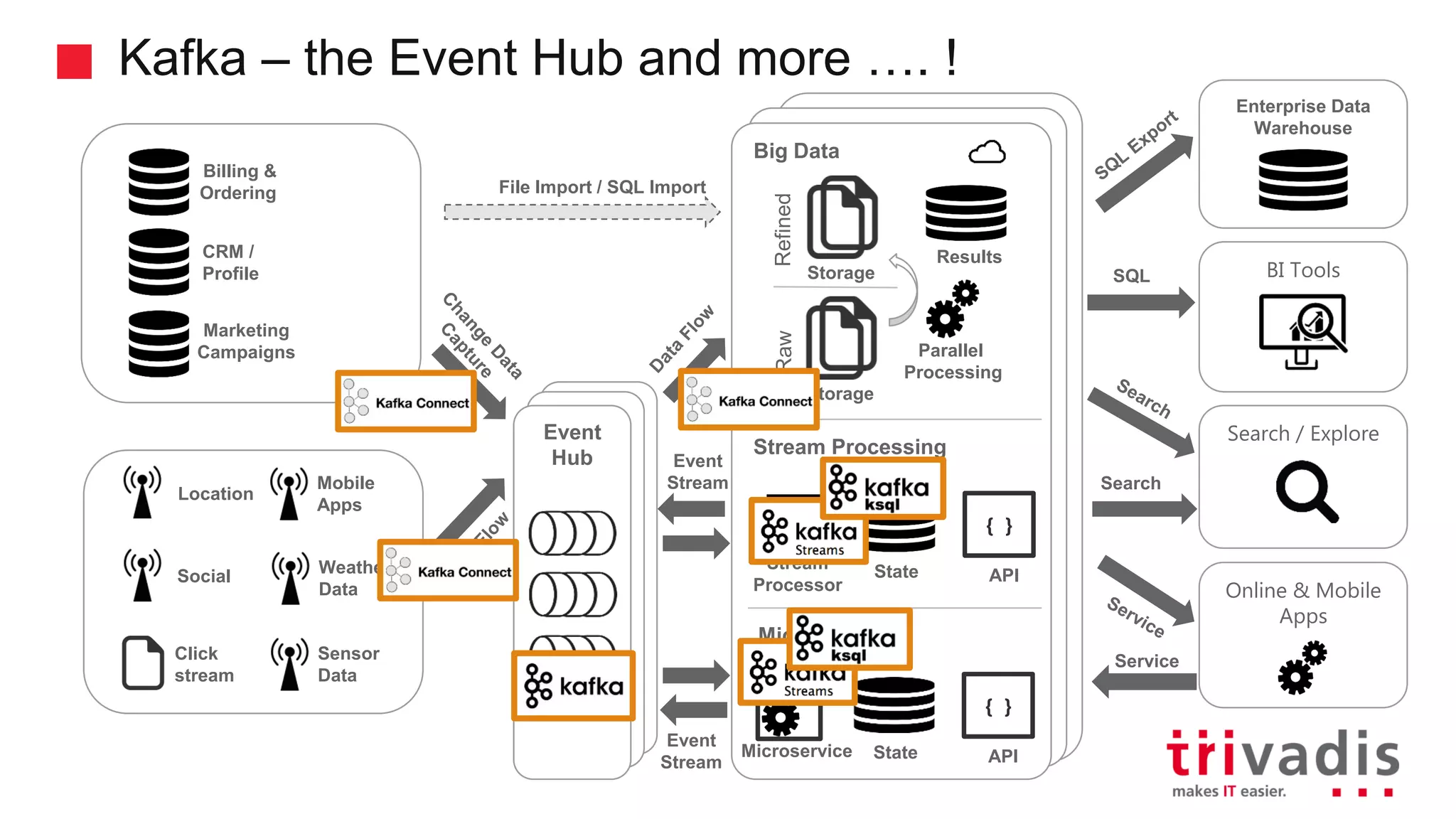
Overview of Kafka Connect and its role in data integration.
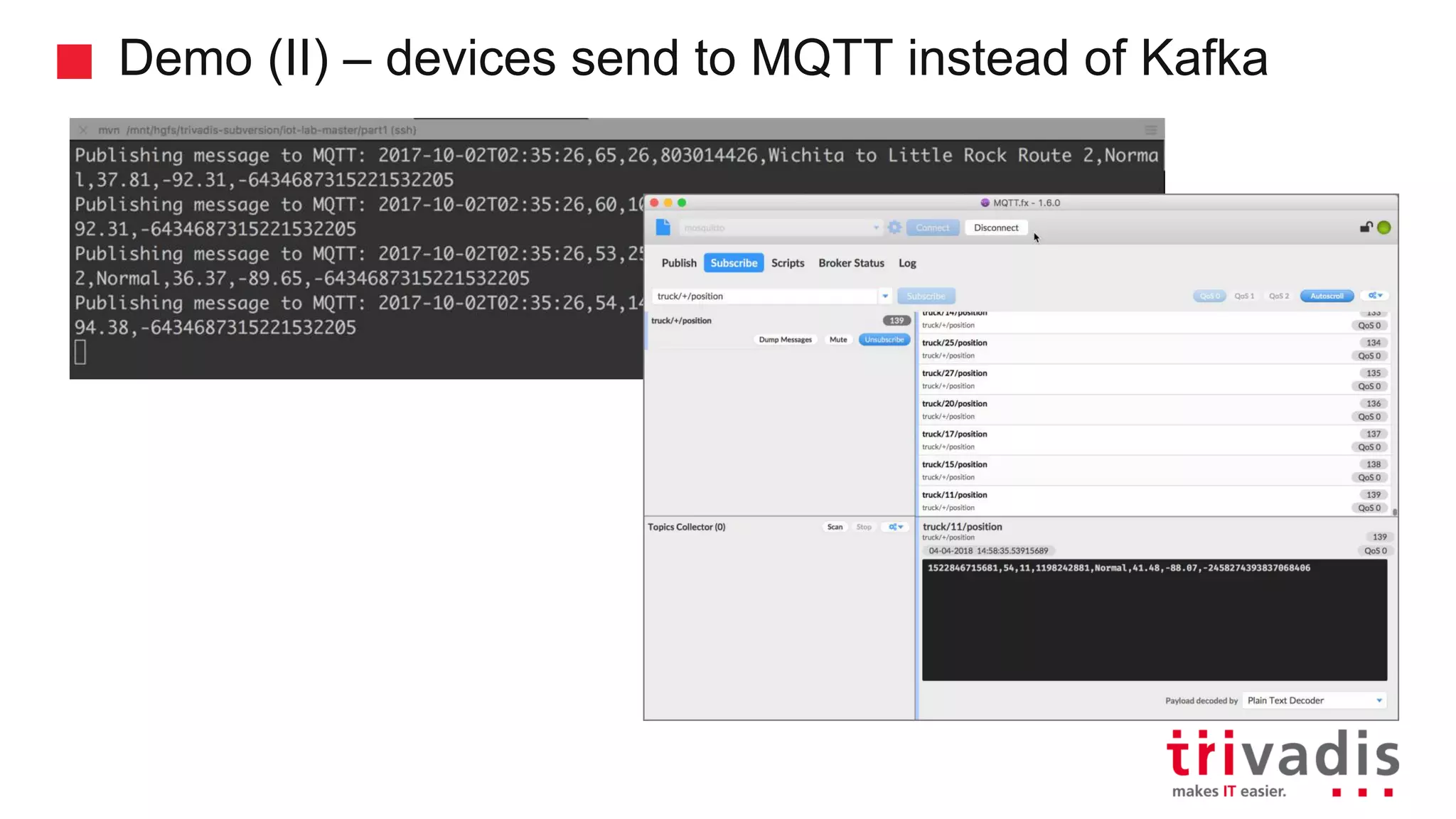
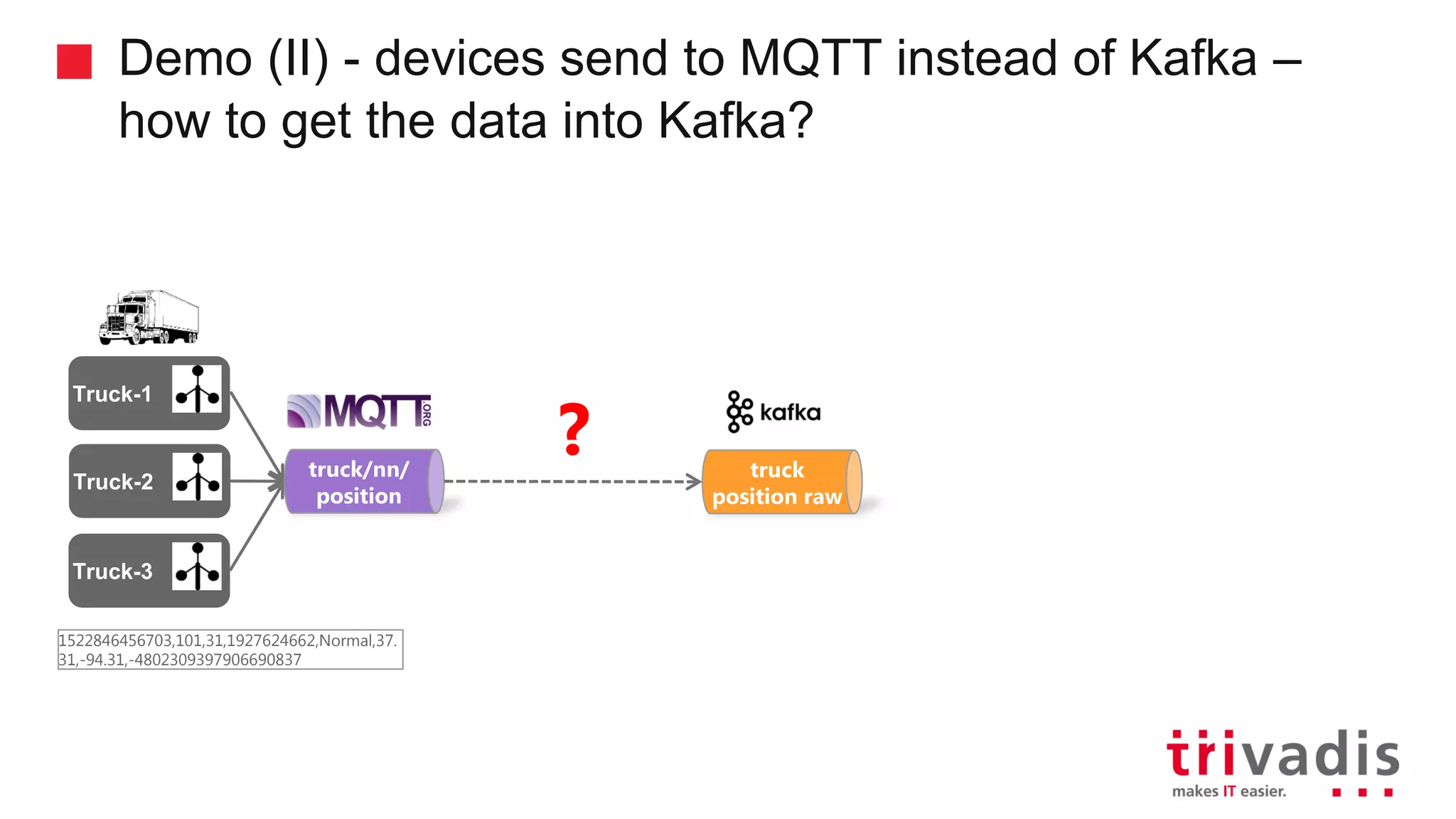
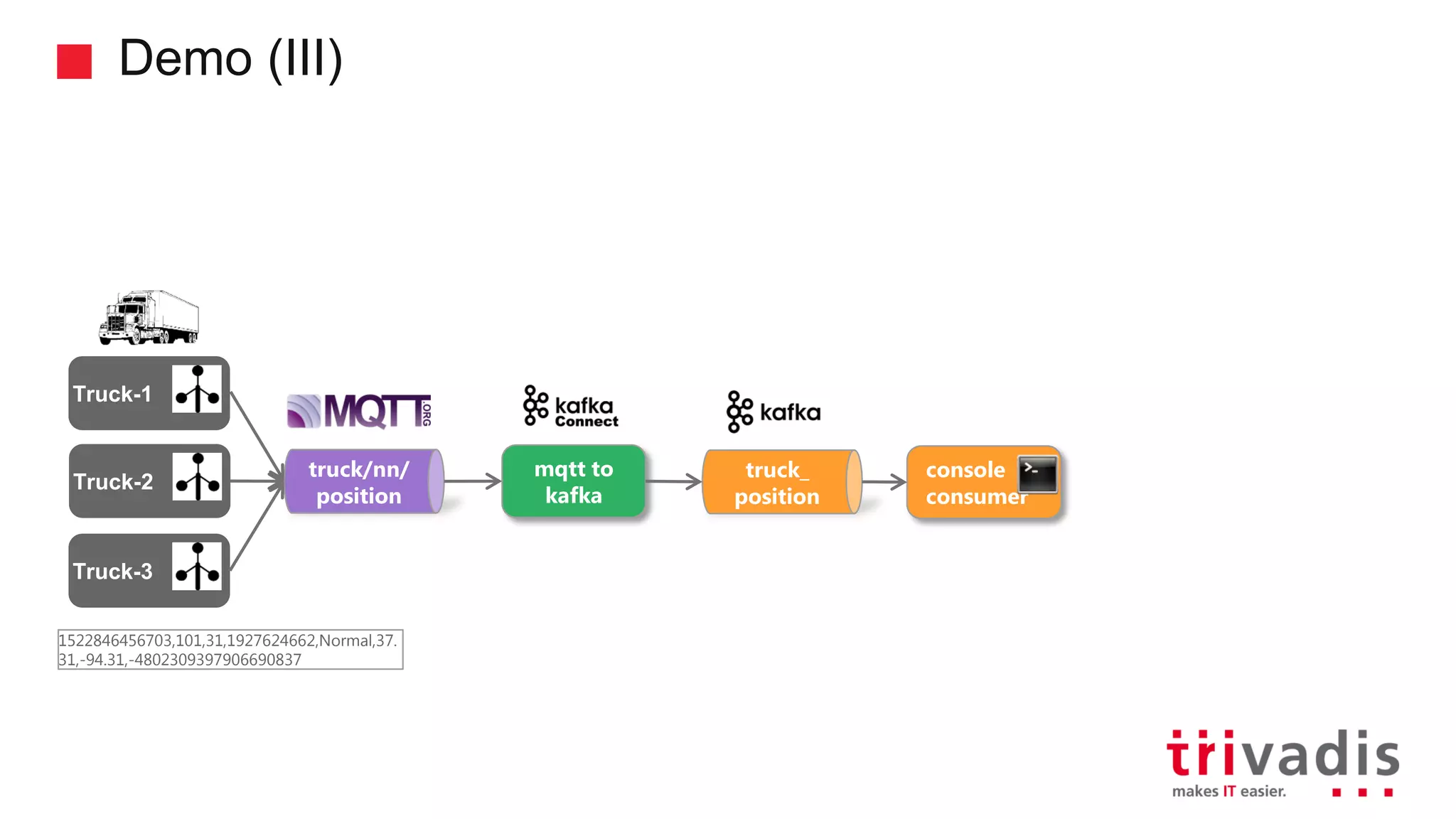
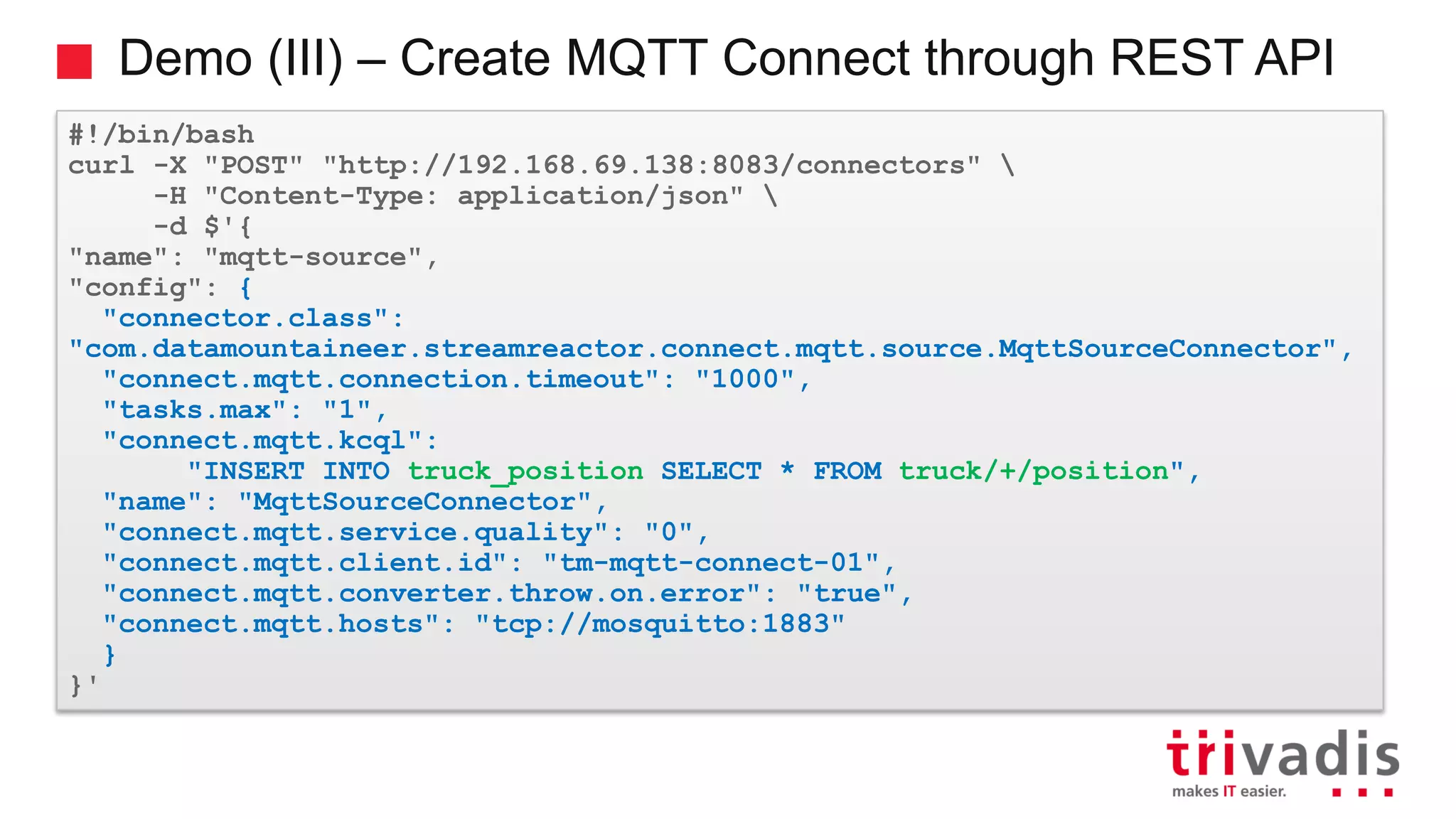
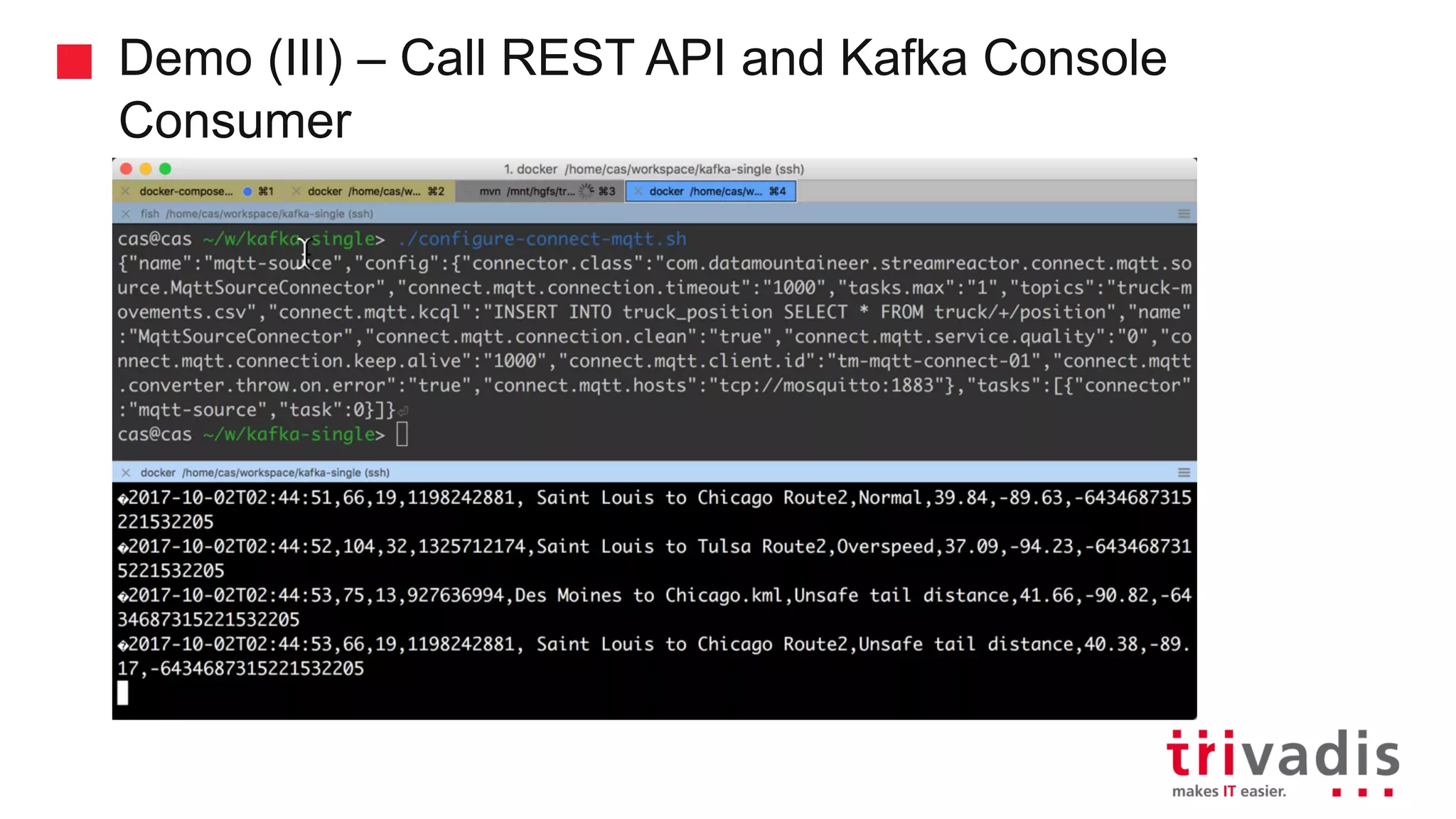
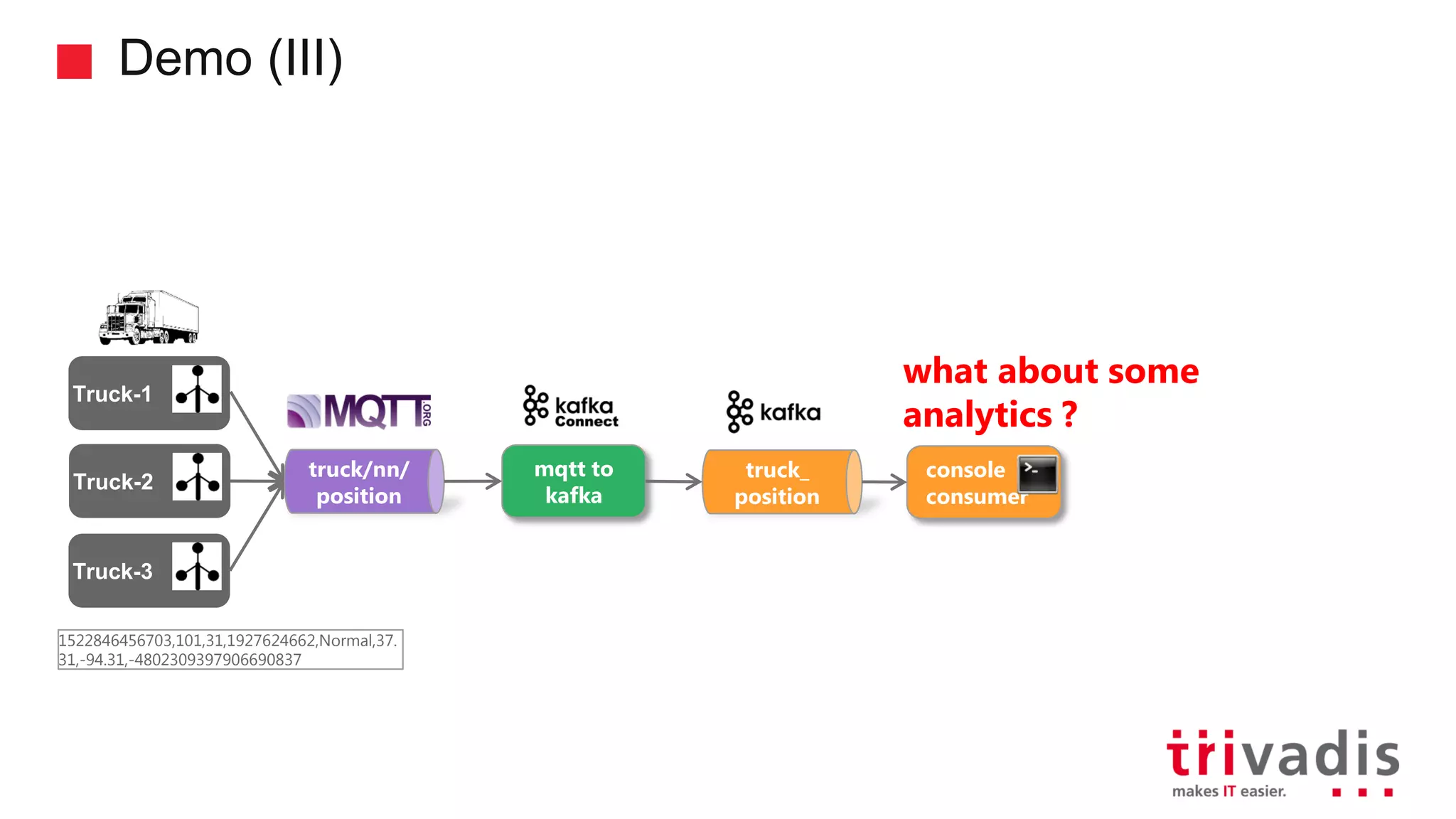
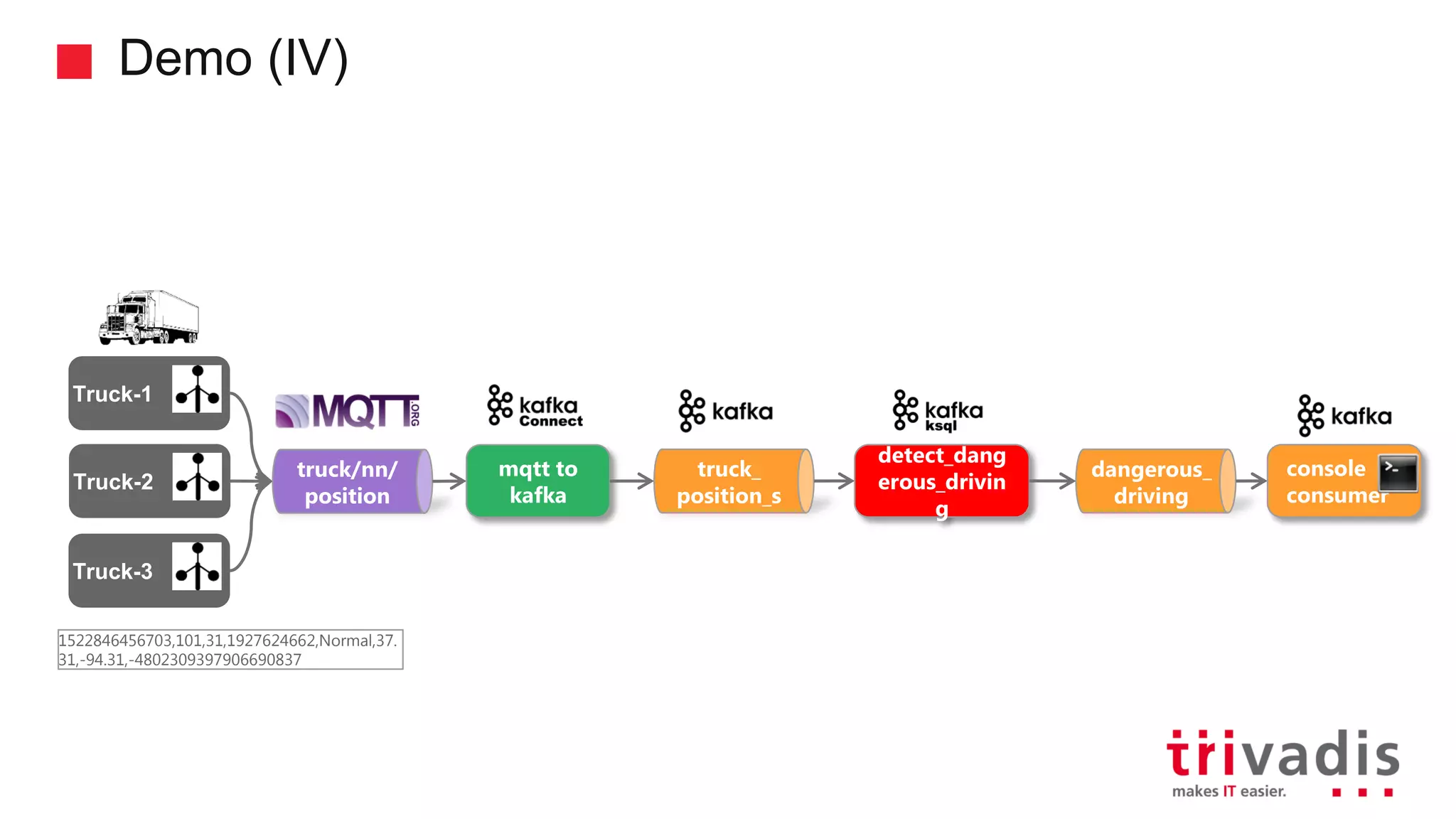
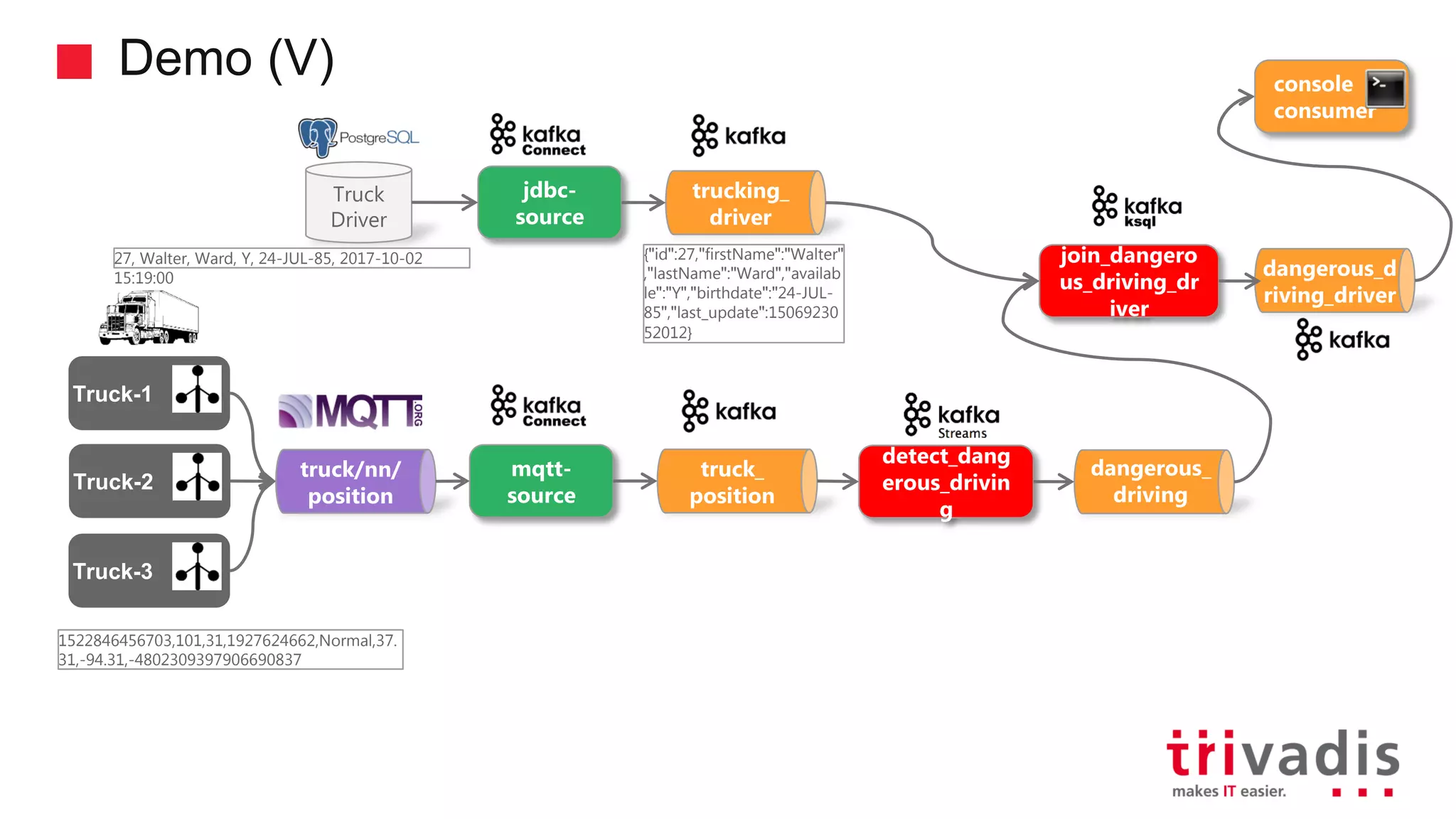
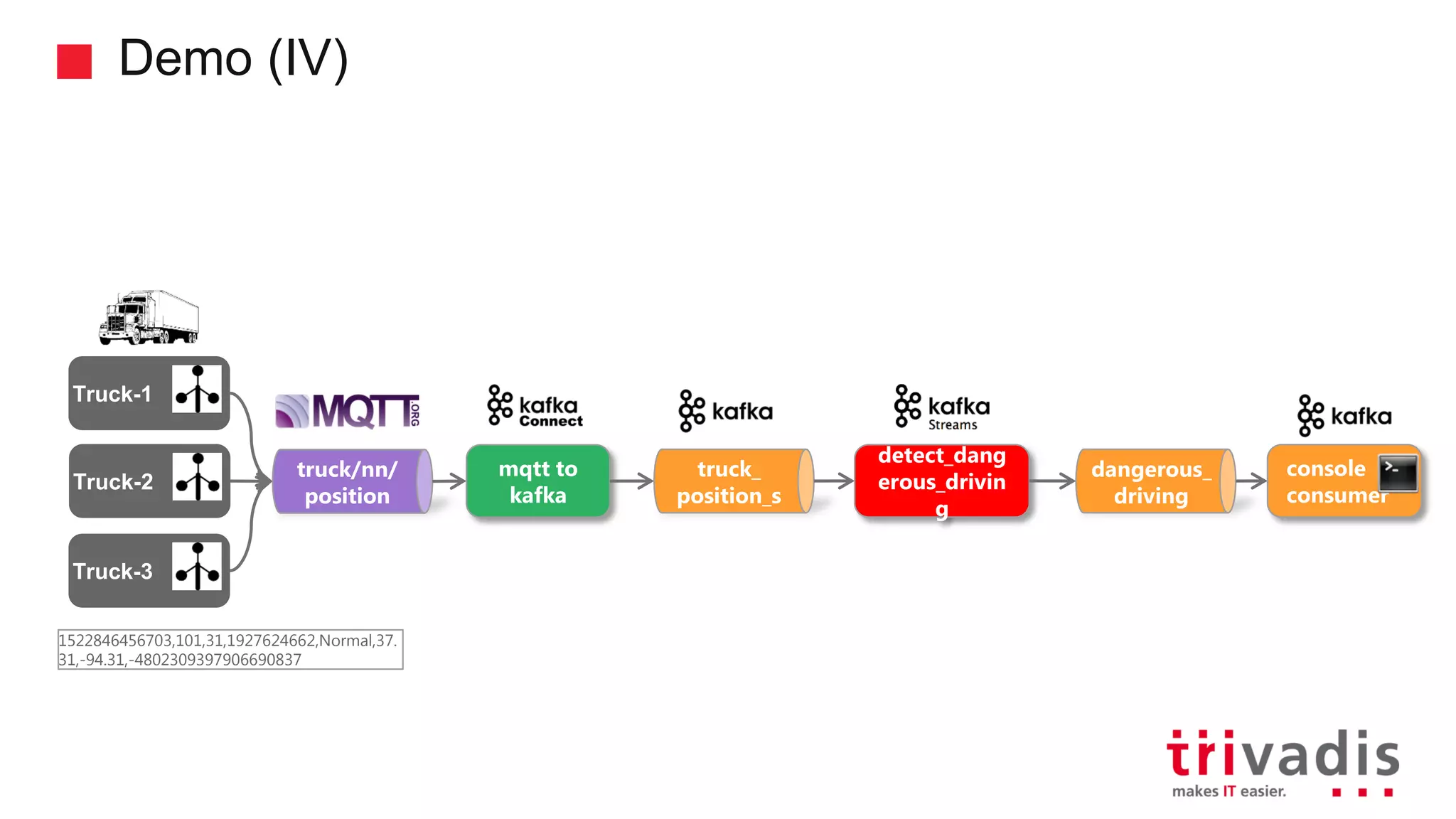
Demonstration of data ingestion from MQTT to Kafka.
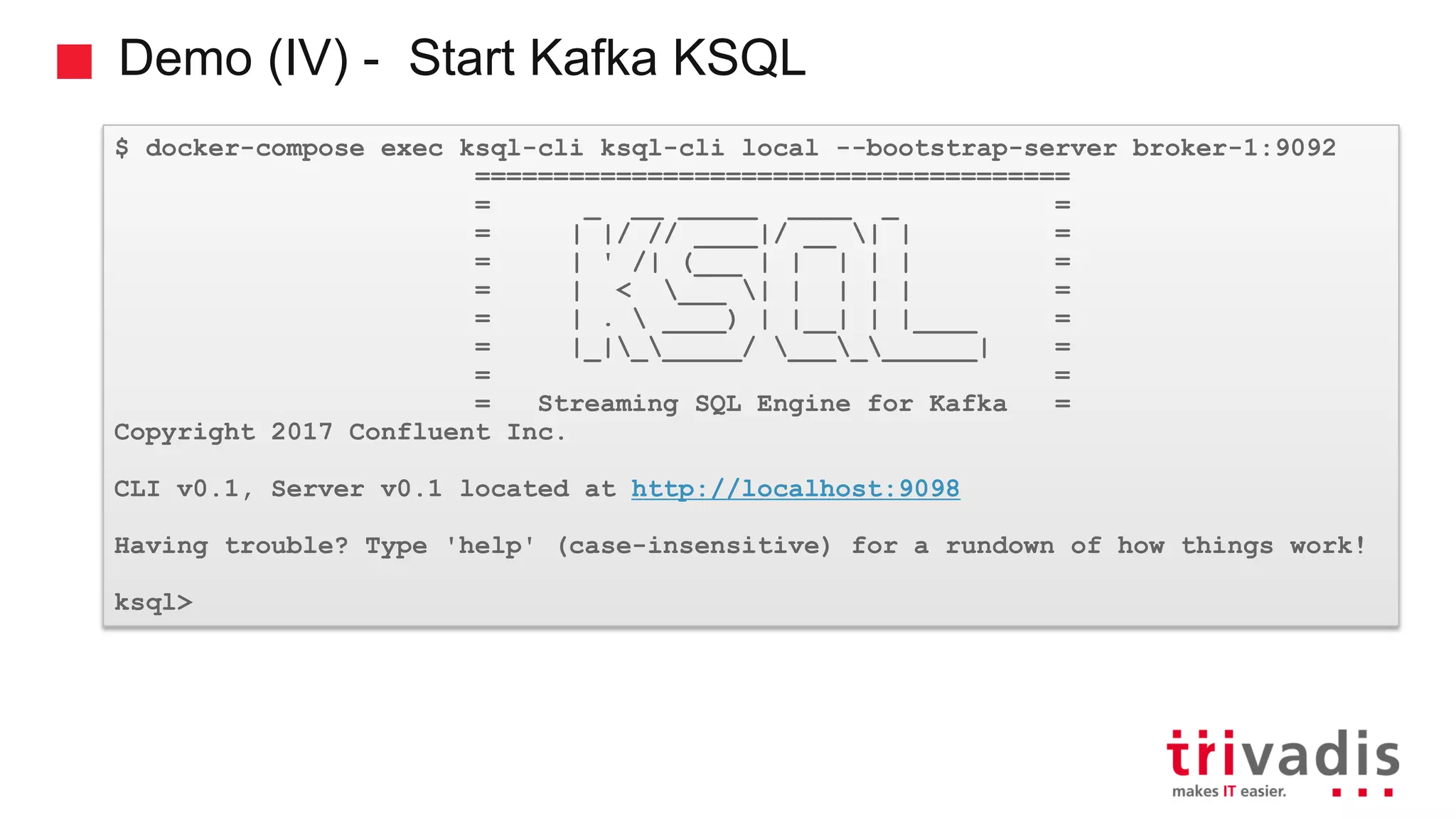
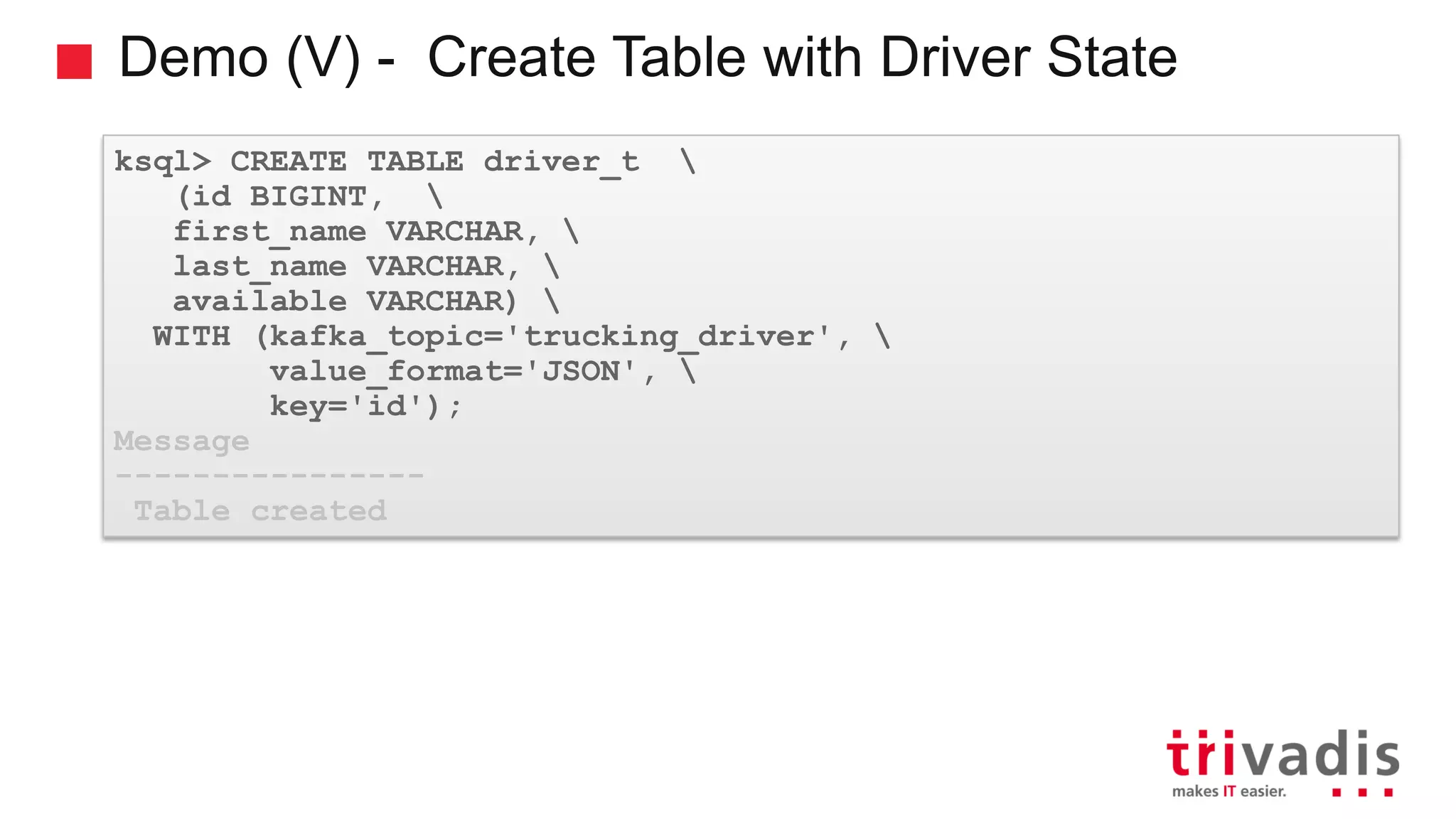
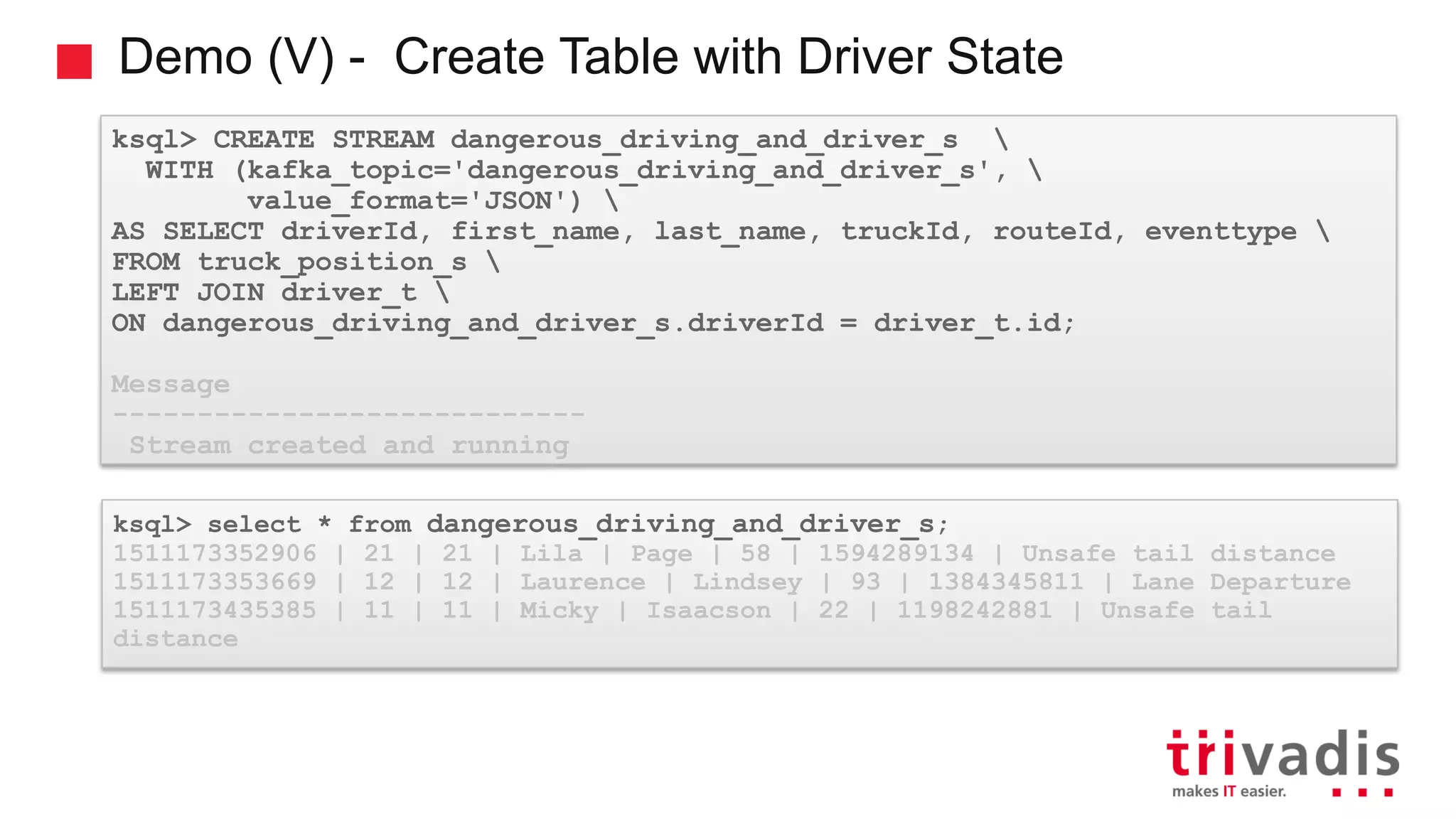
Introduction to KSQL, a SQL engine for real-time stream processing.
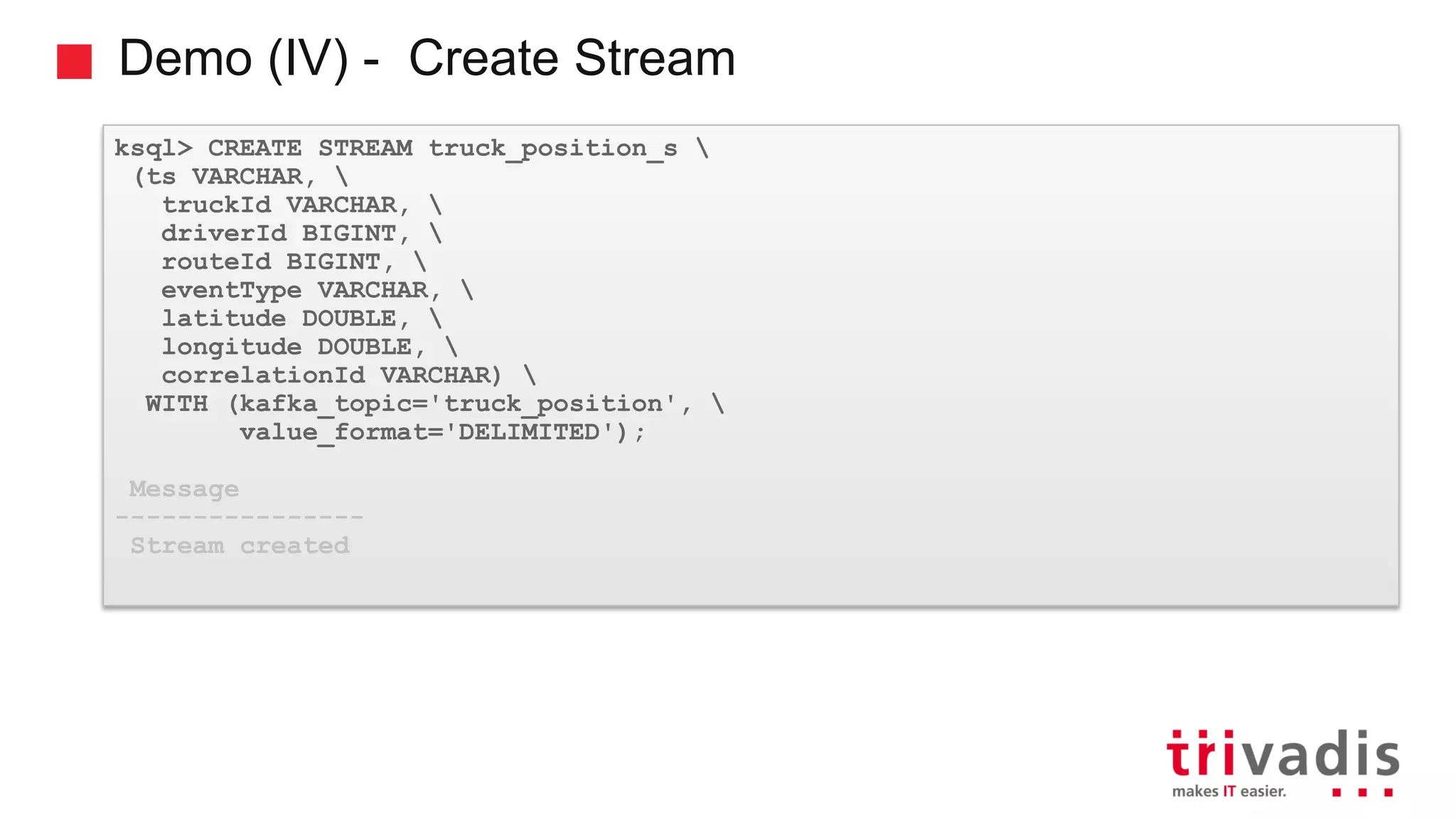
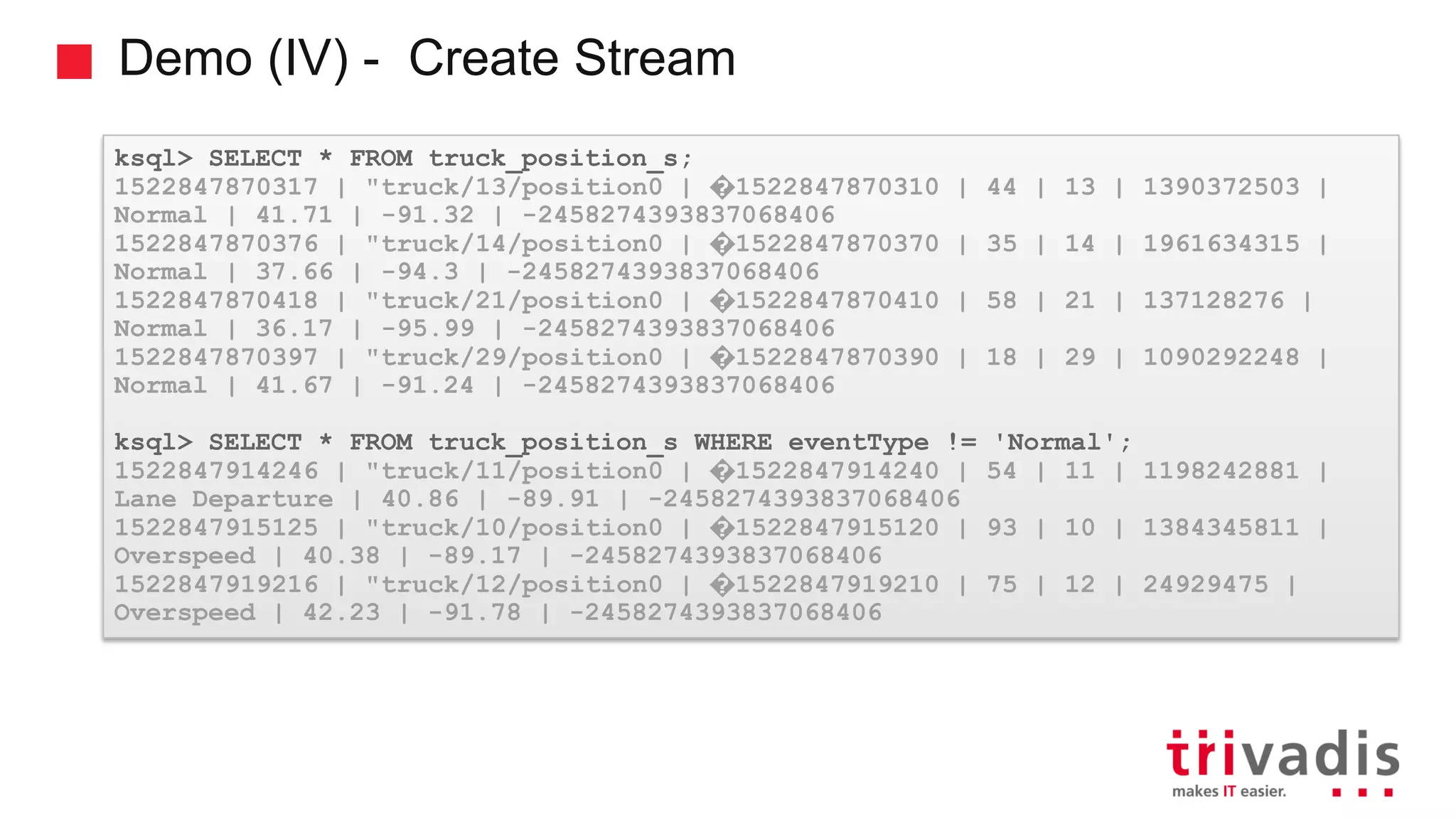
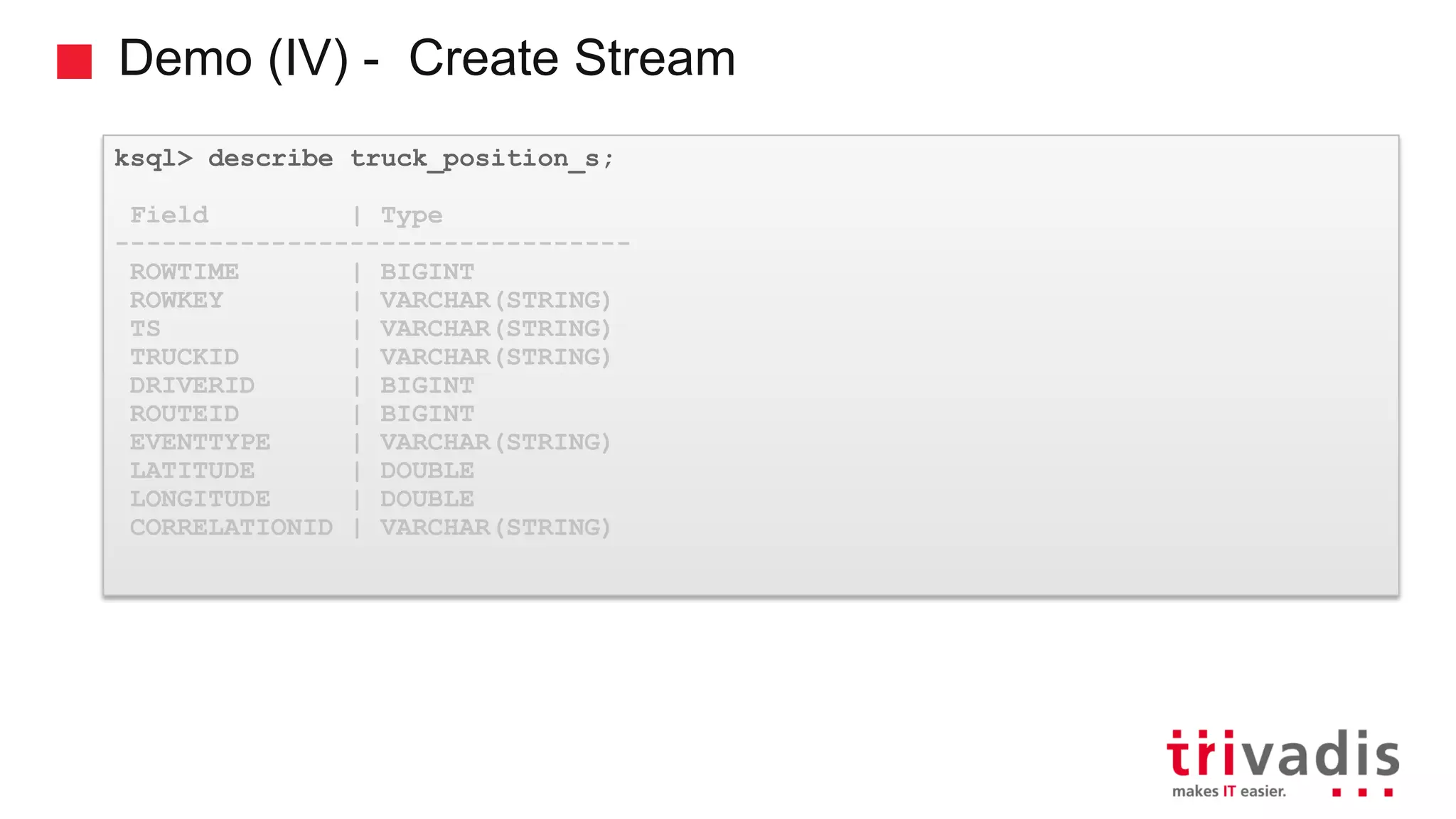
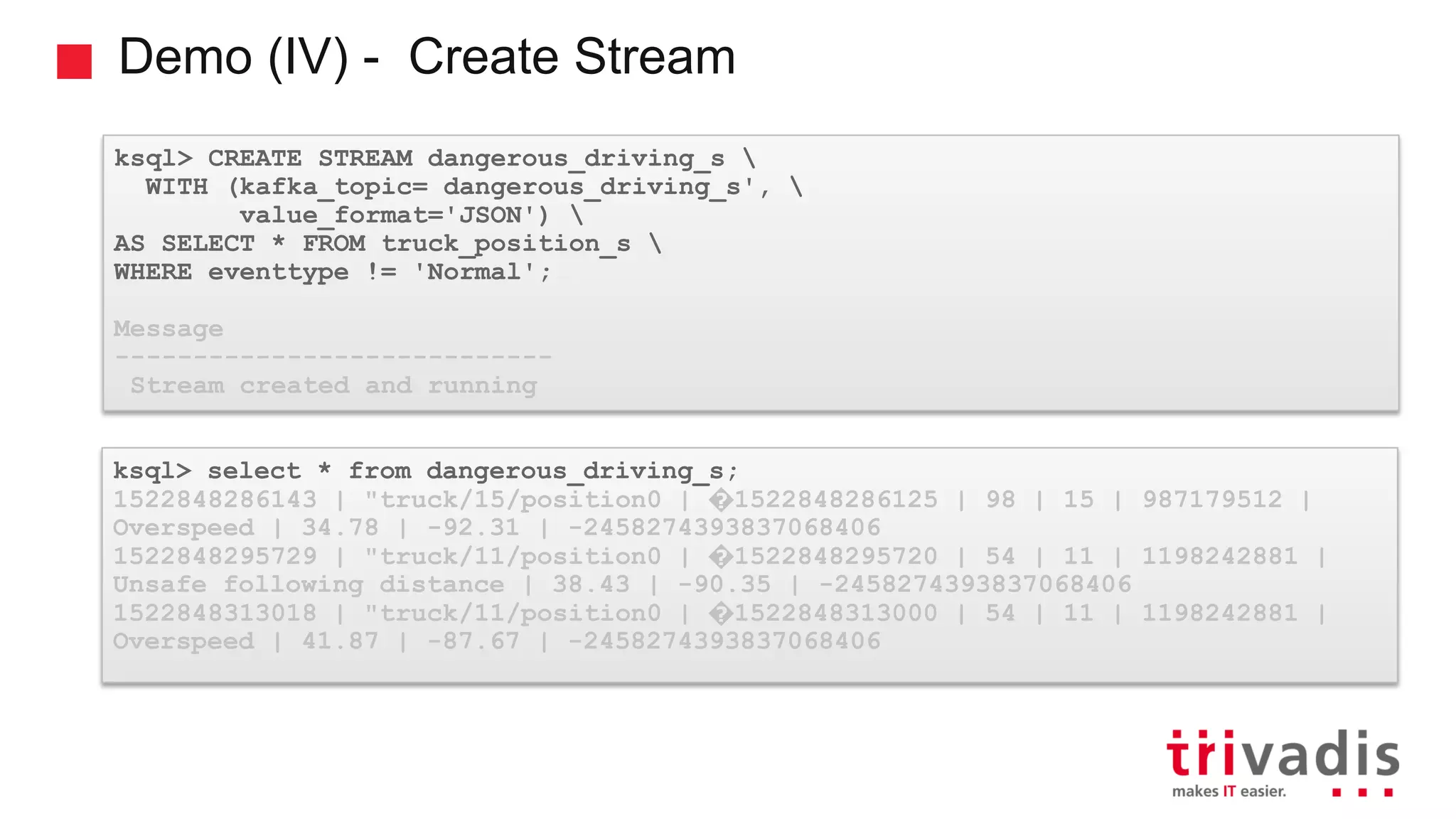
Various KSQL demonstrations for stream creation and data handling.
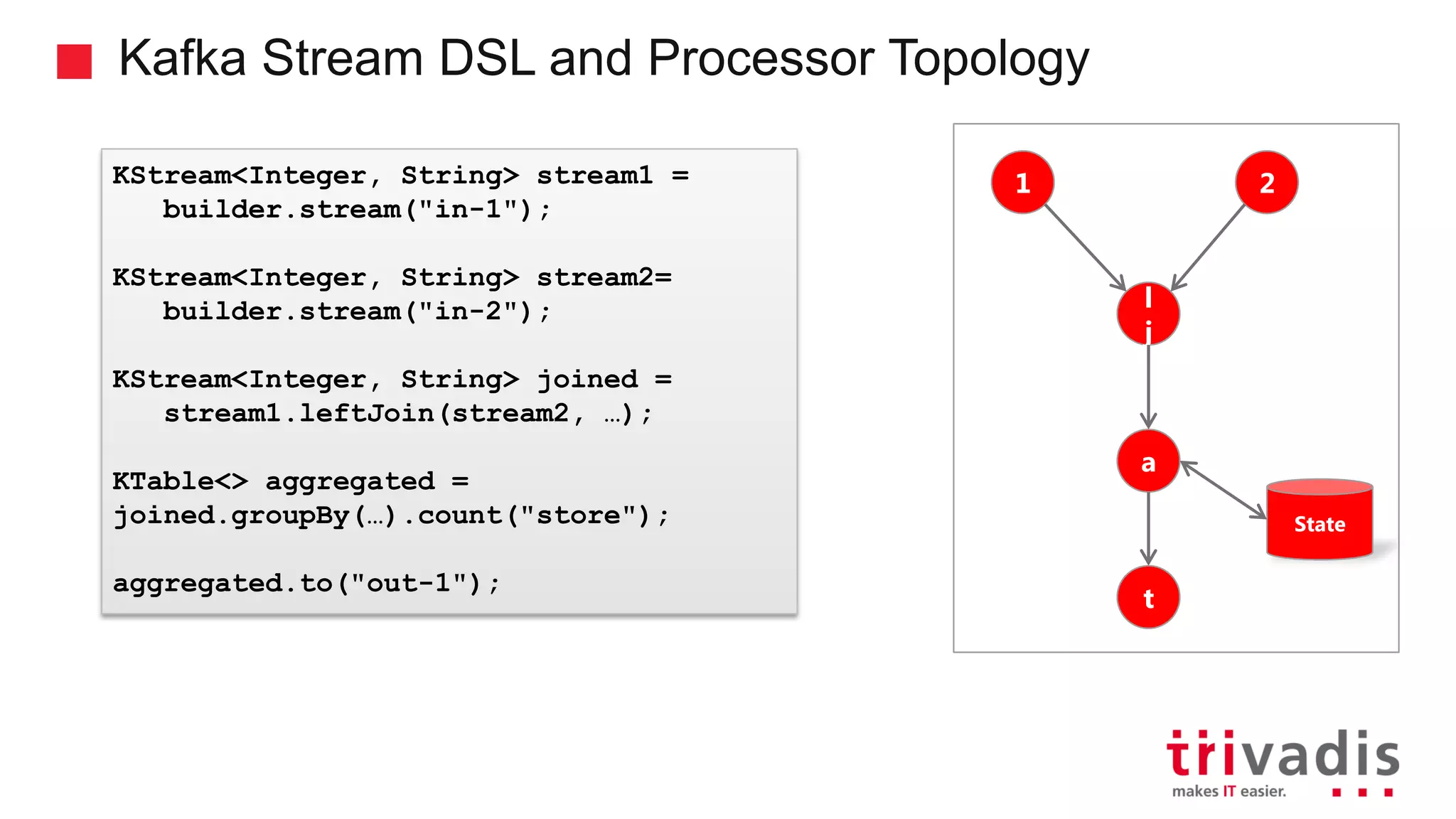
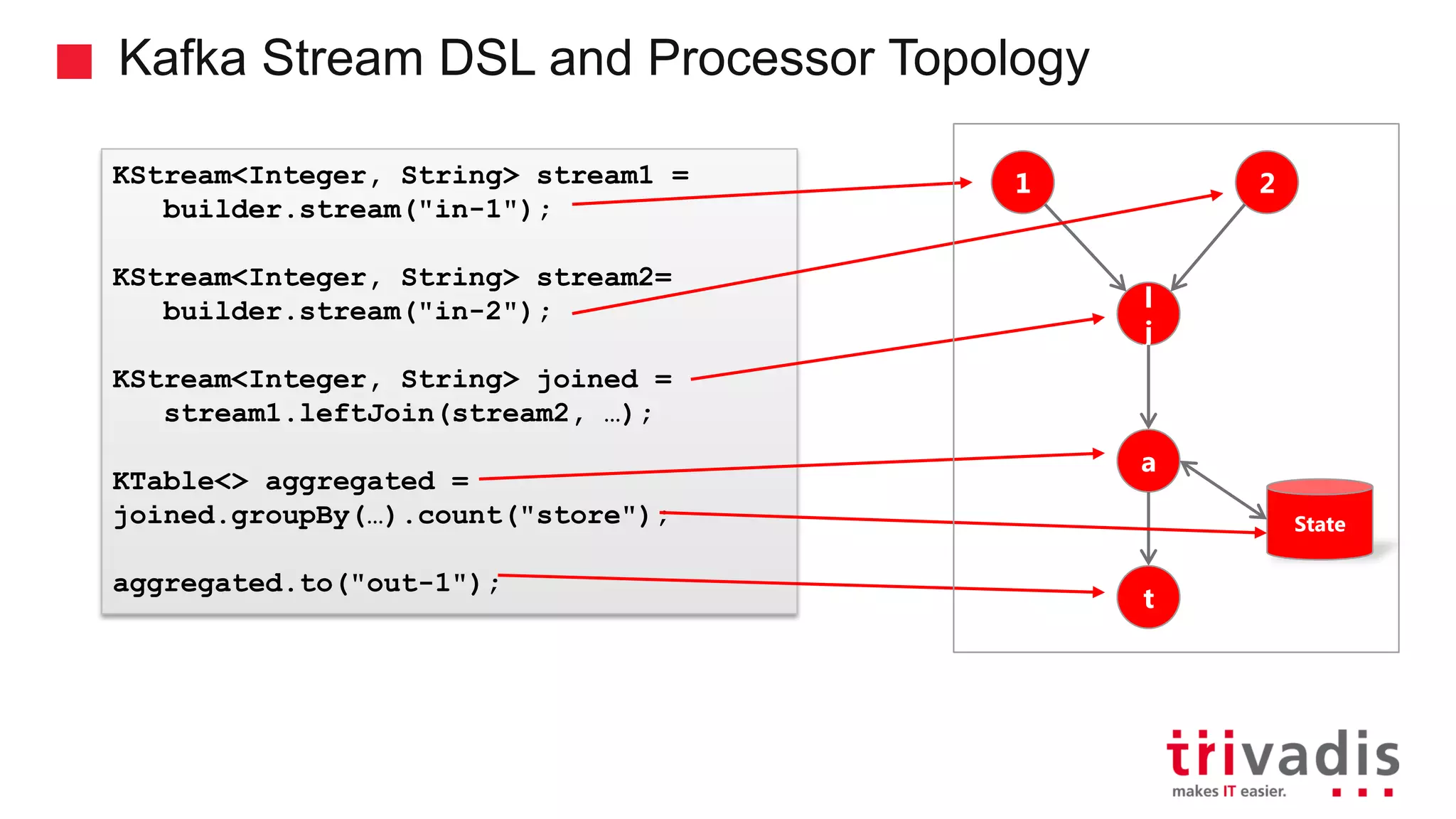
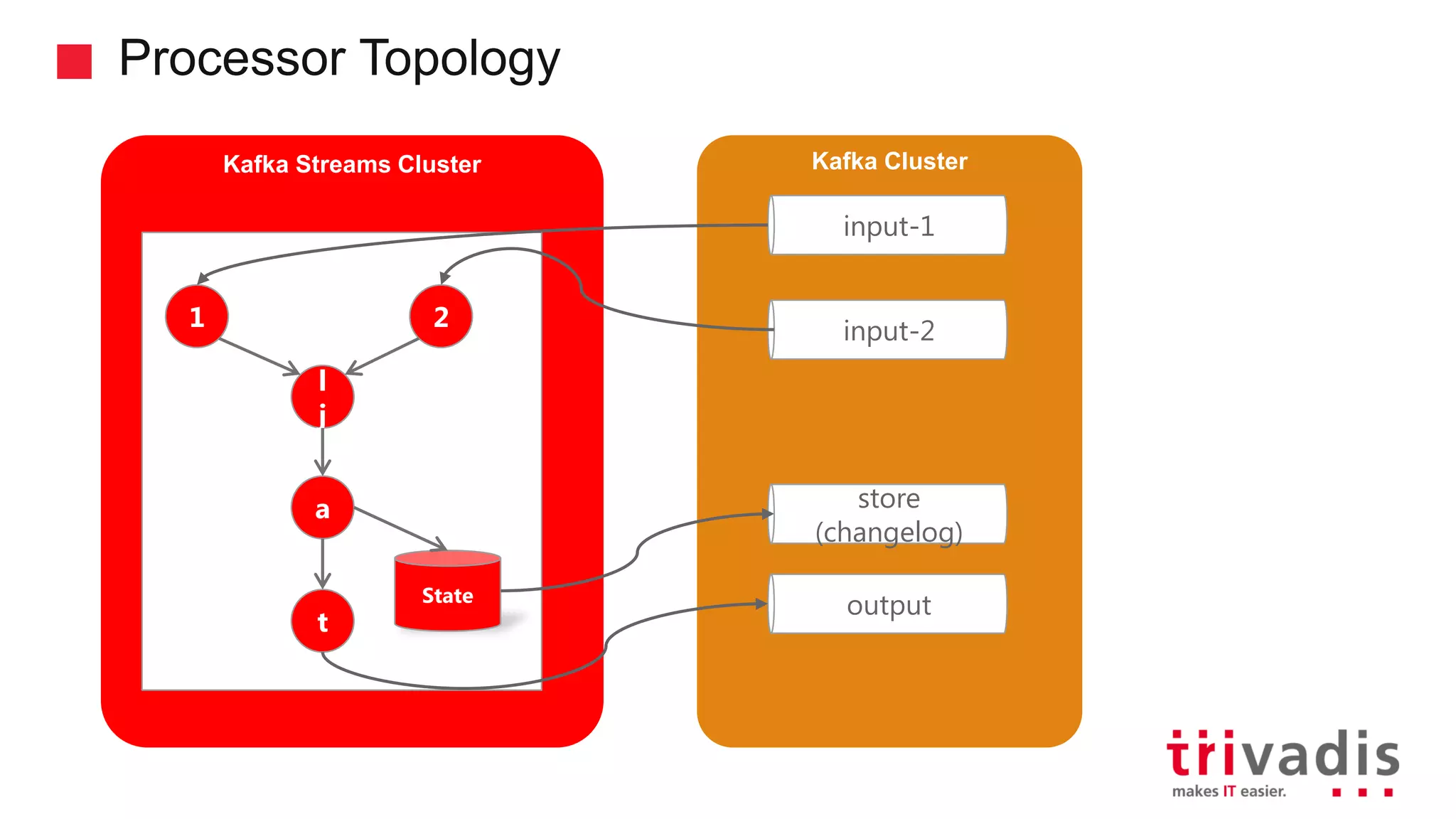
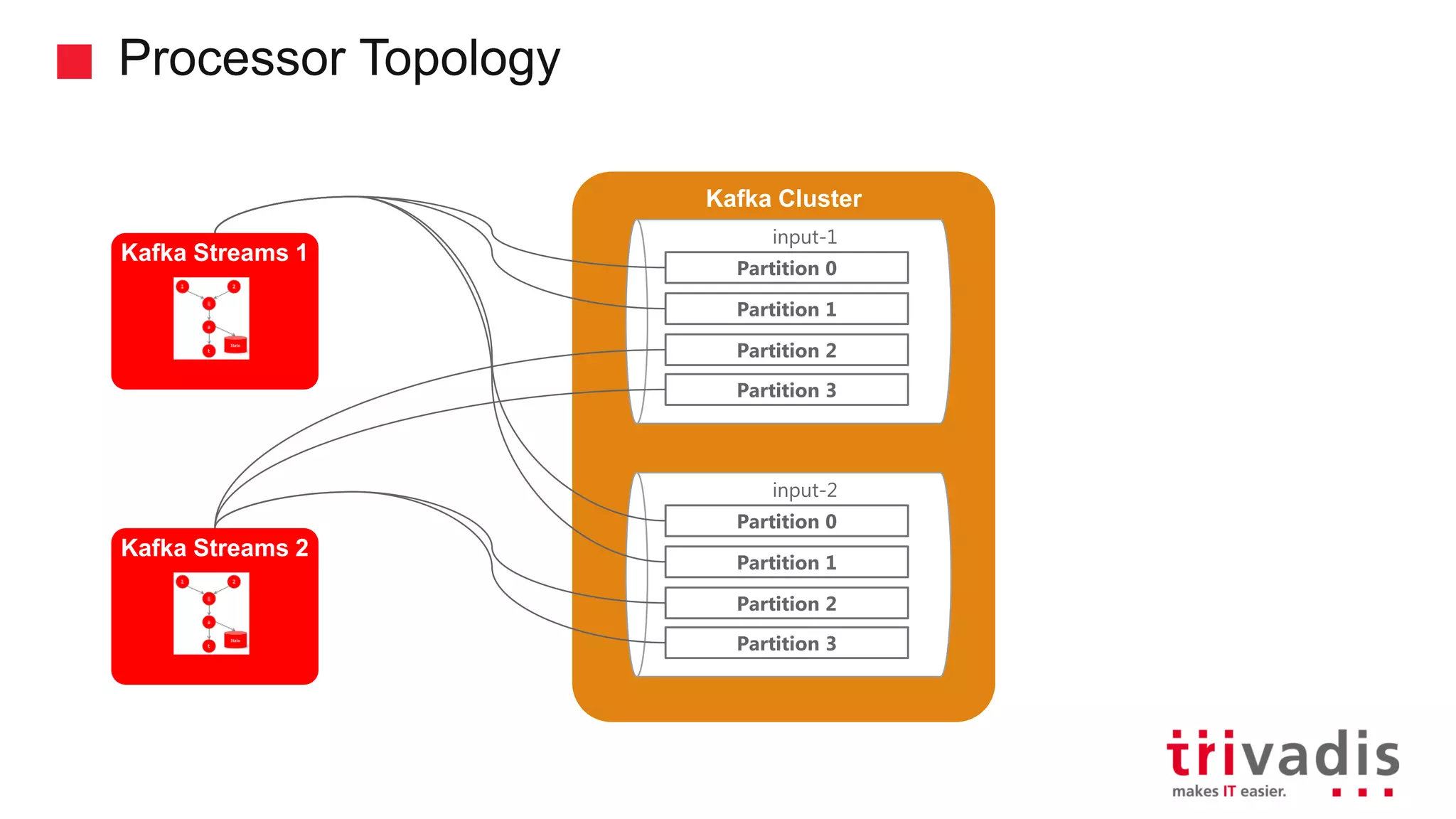
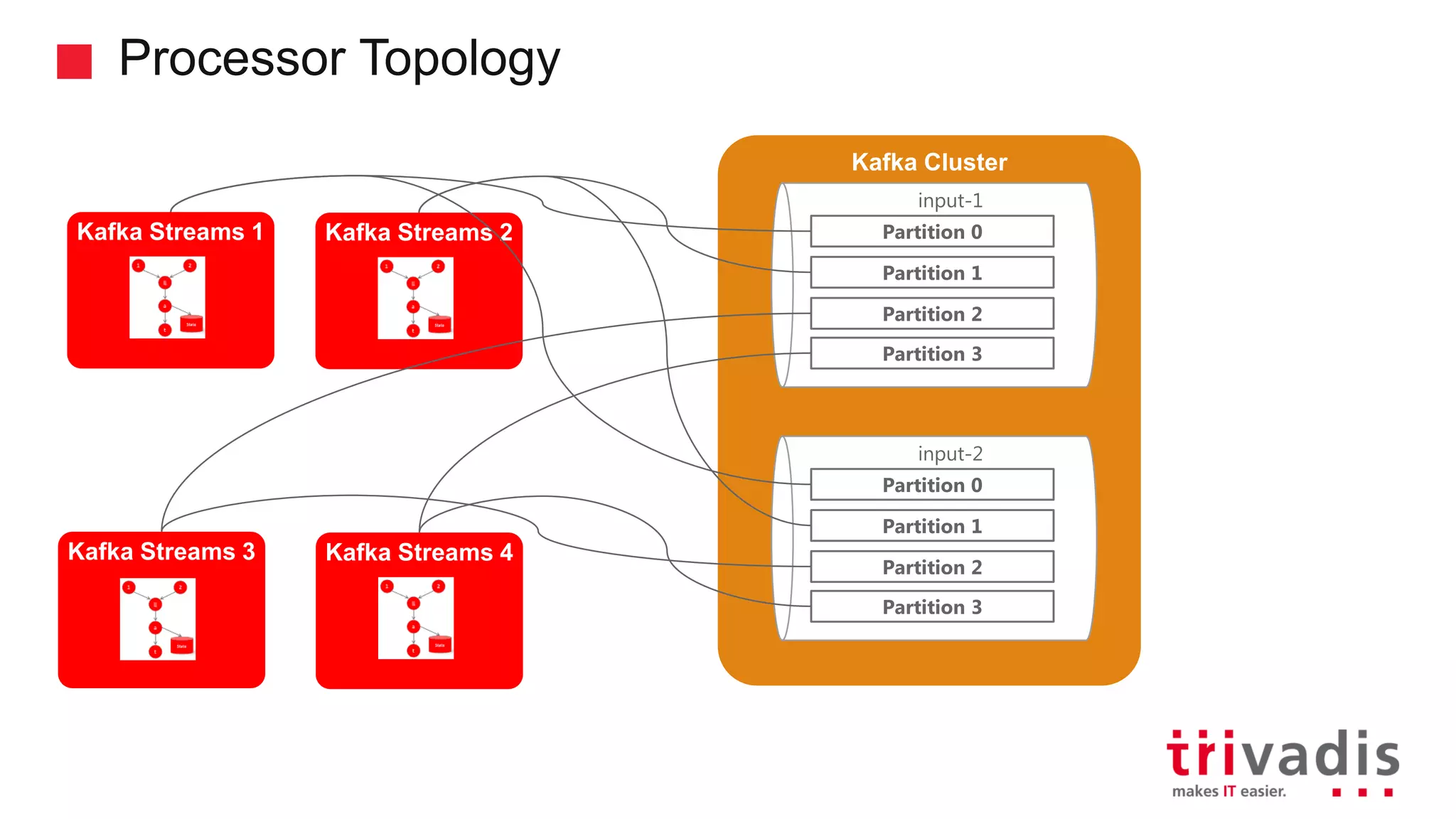
Kafka Streams as a lightweight library and its event processing model.
Key features of Kafka Streams including fault tolerance and stateful computations.
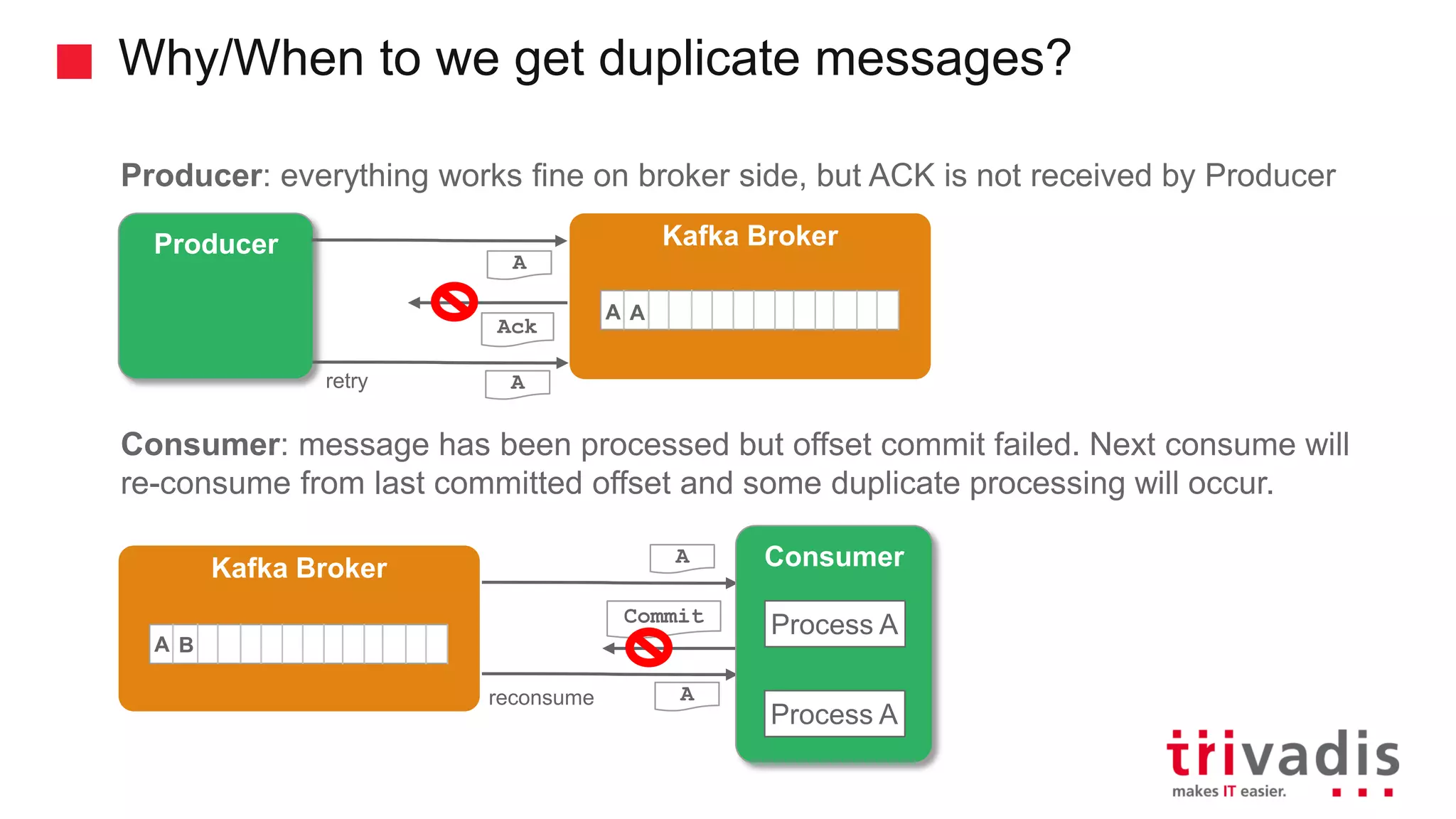
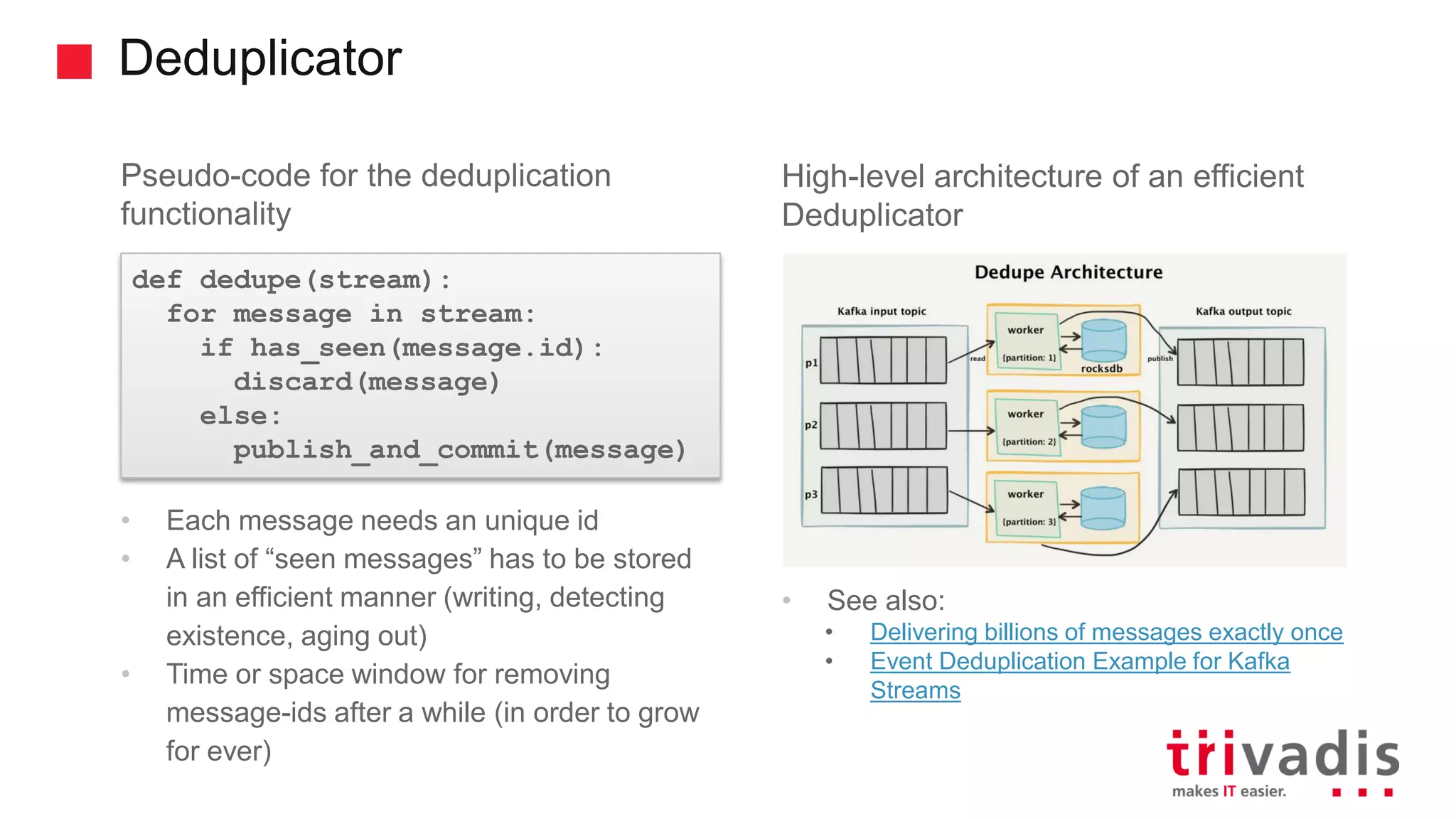
Understanding duplicate messages in Kafka and strategies to handle them.
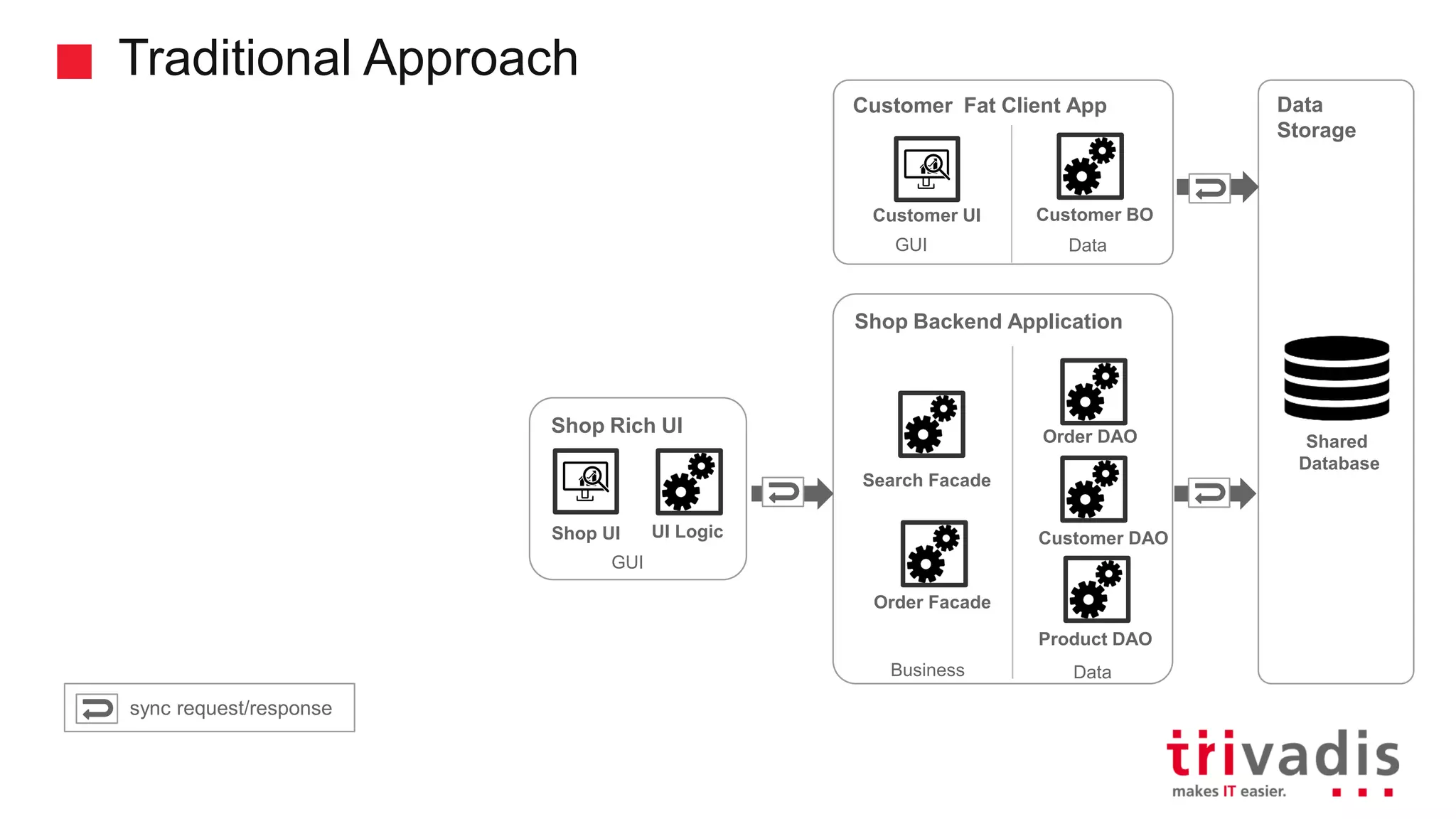
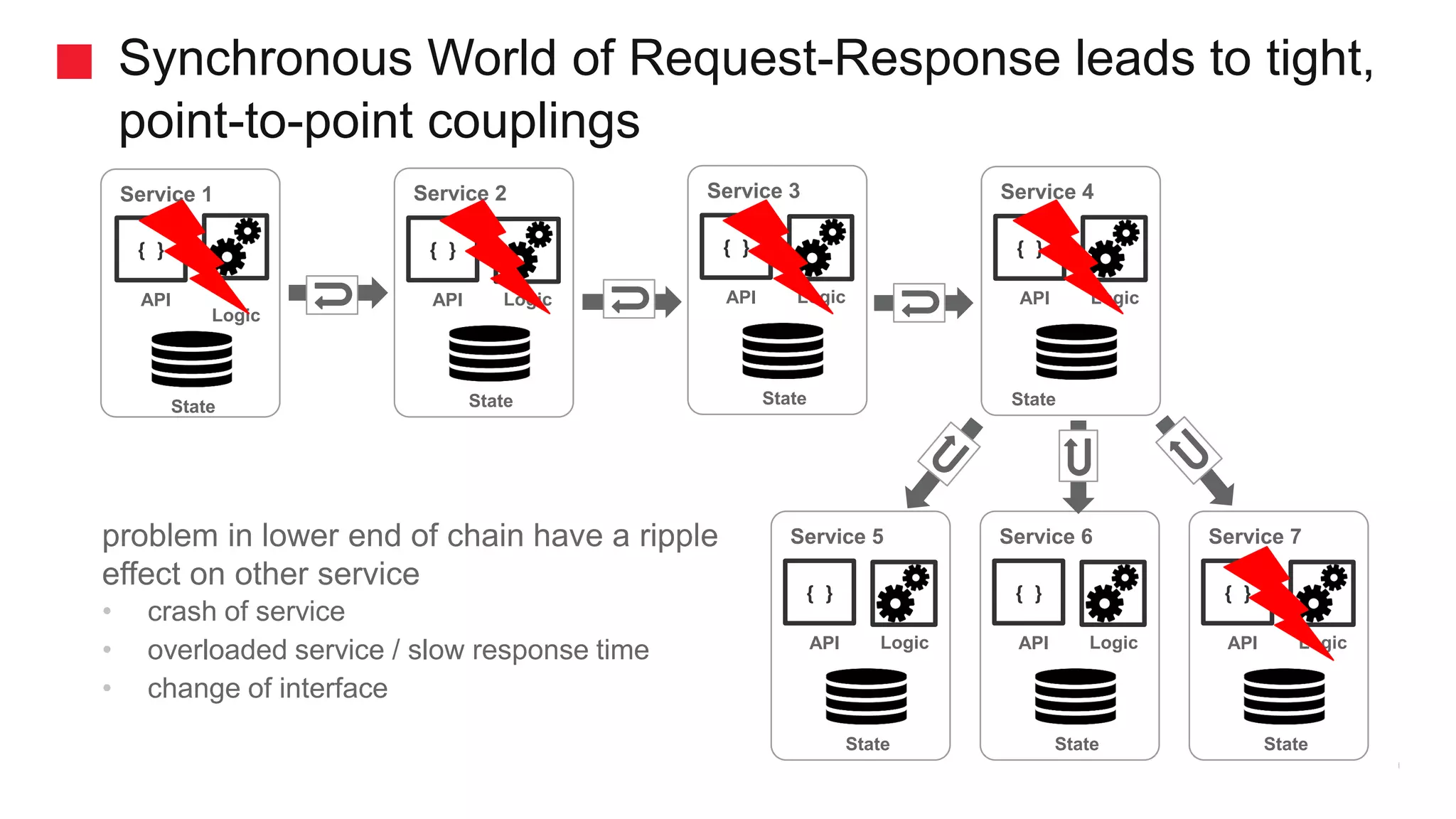
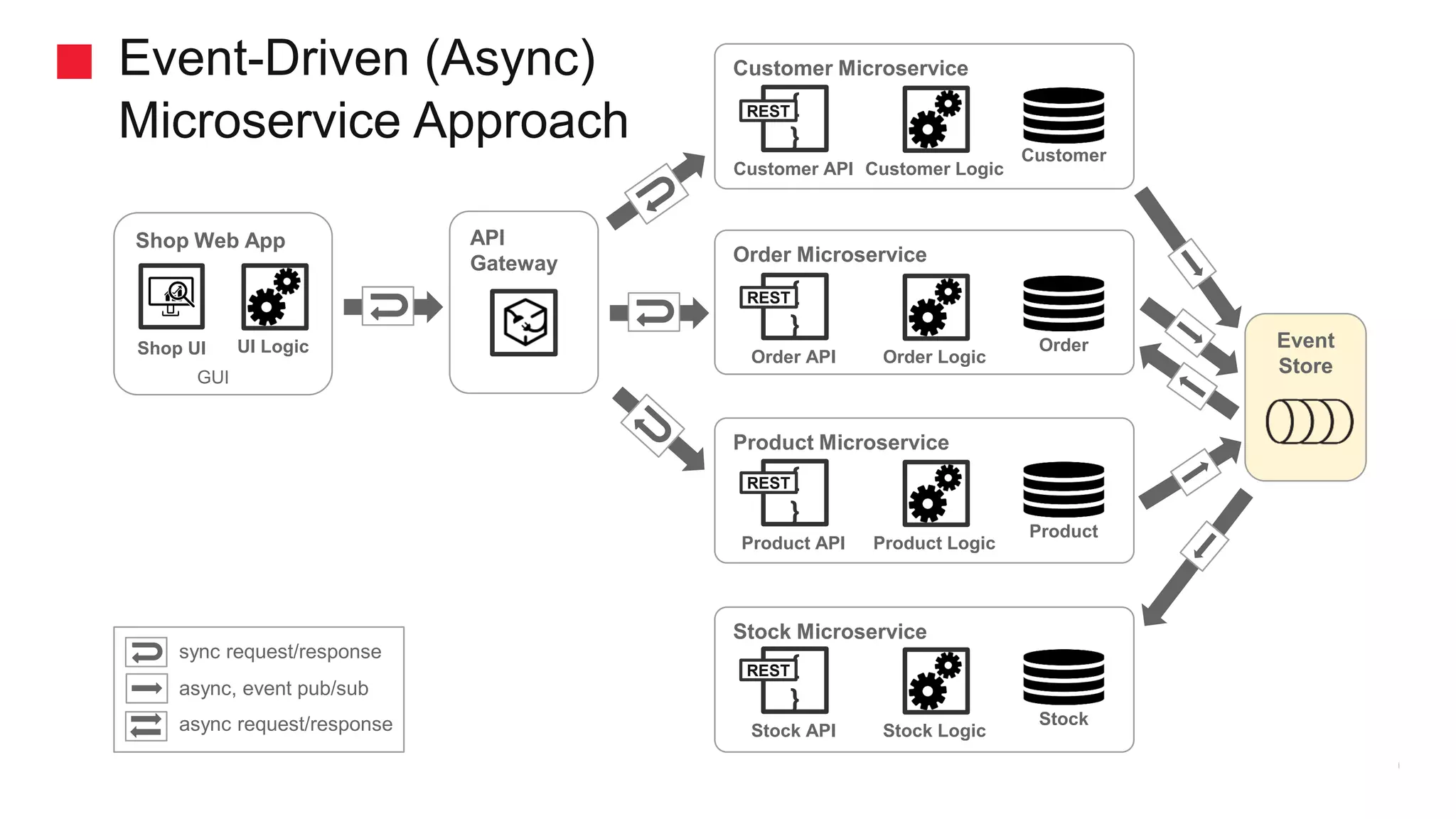
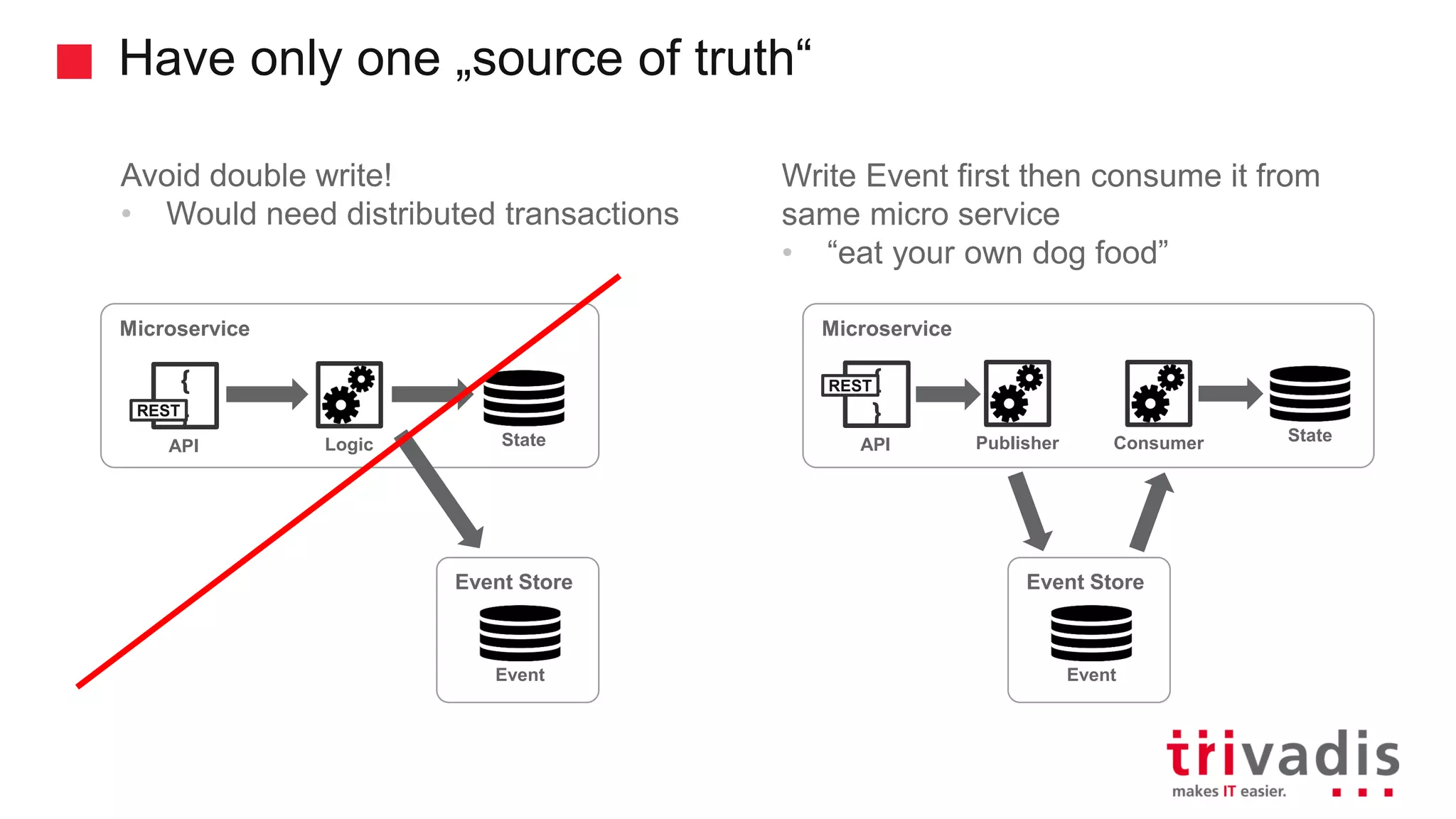
Transitioning from traditional to microservices architecture using Kafka.
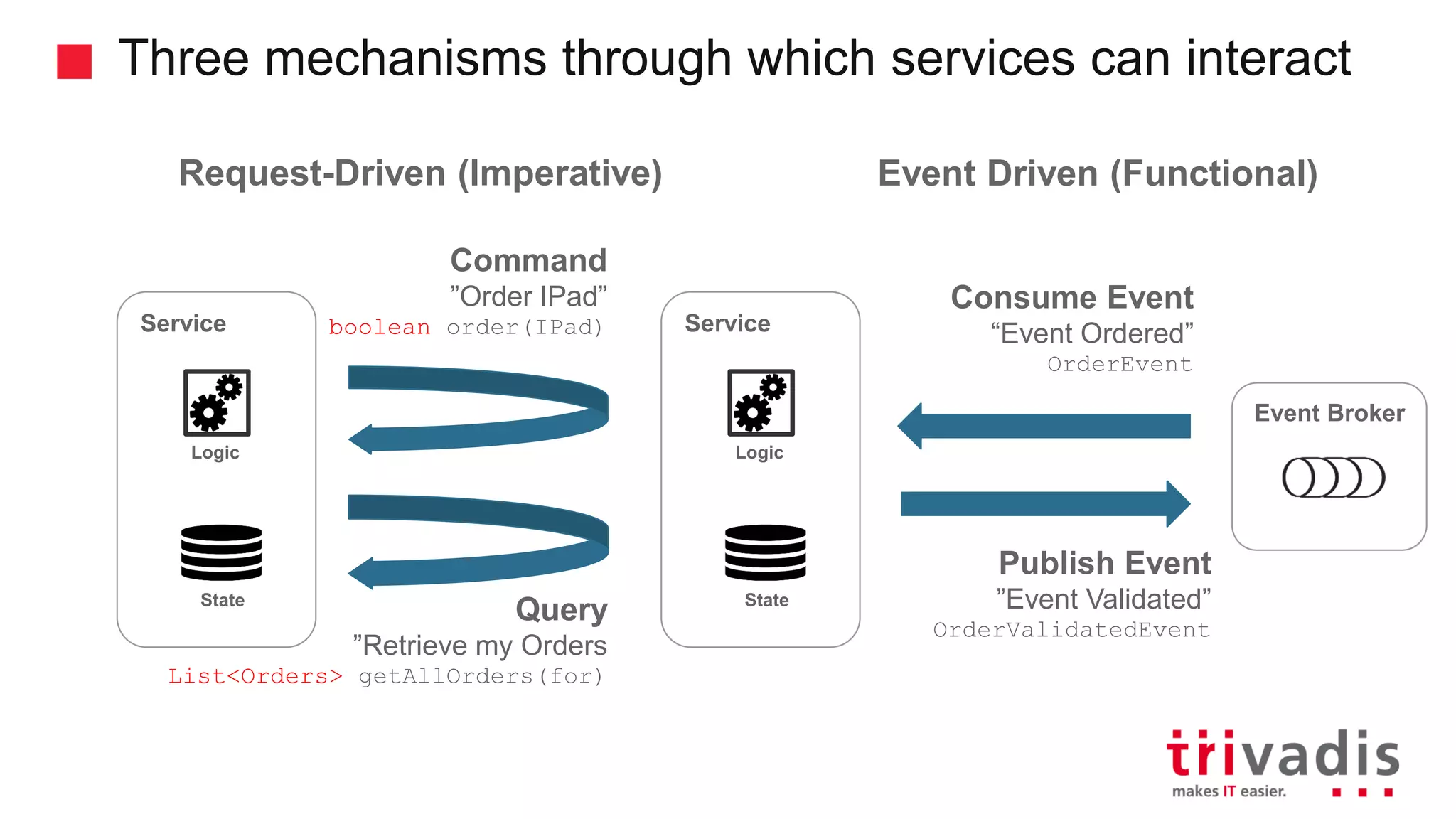
Mechanisms for service interactions and the benefits of an event-driven architecture.
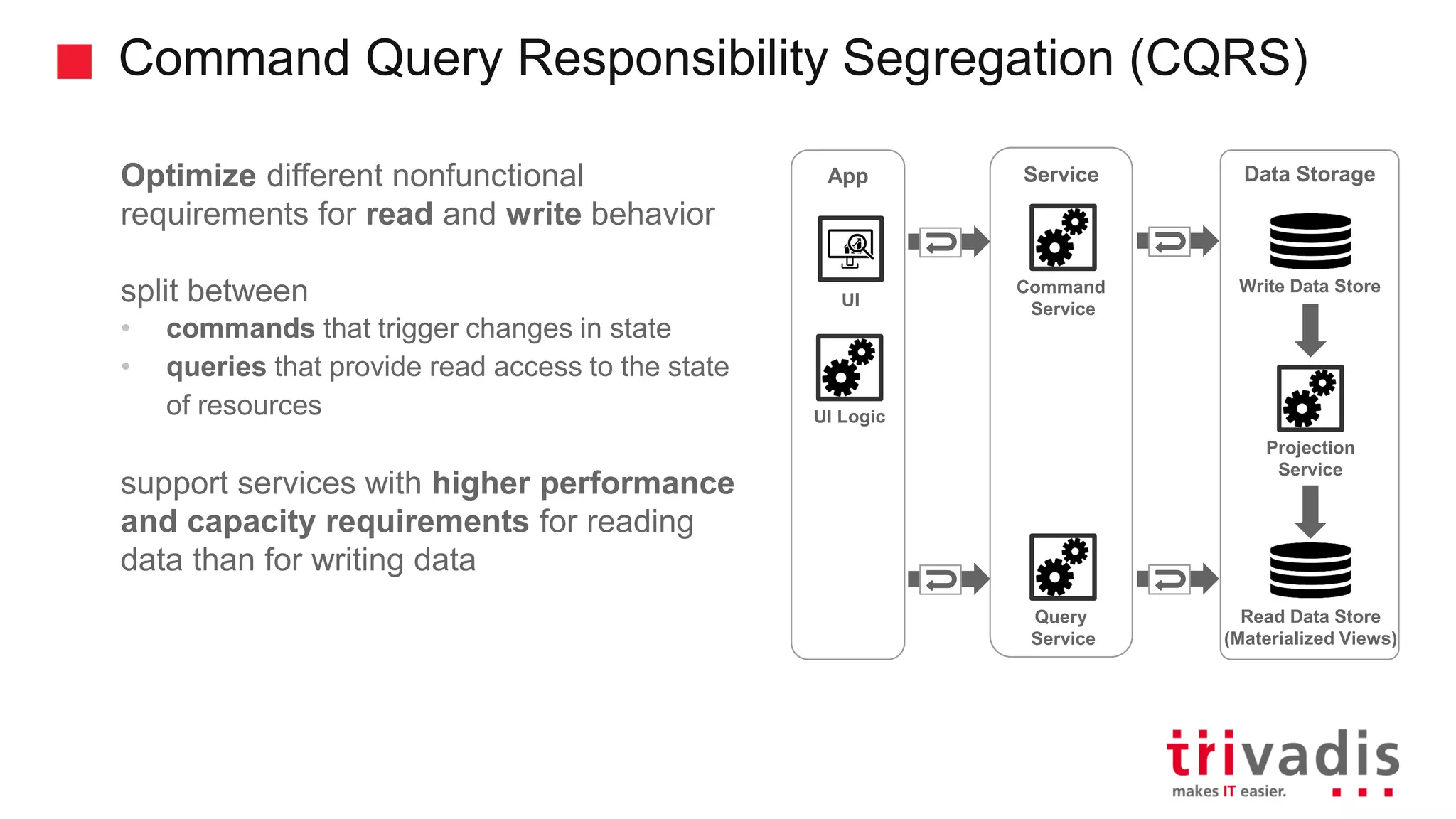
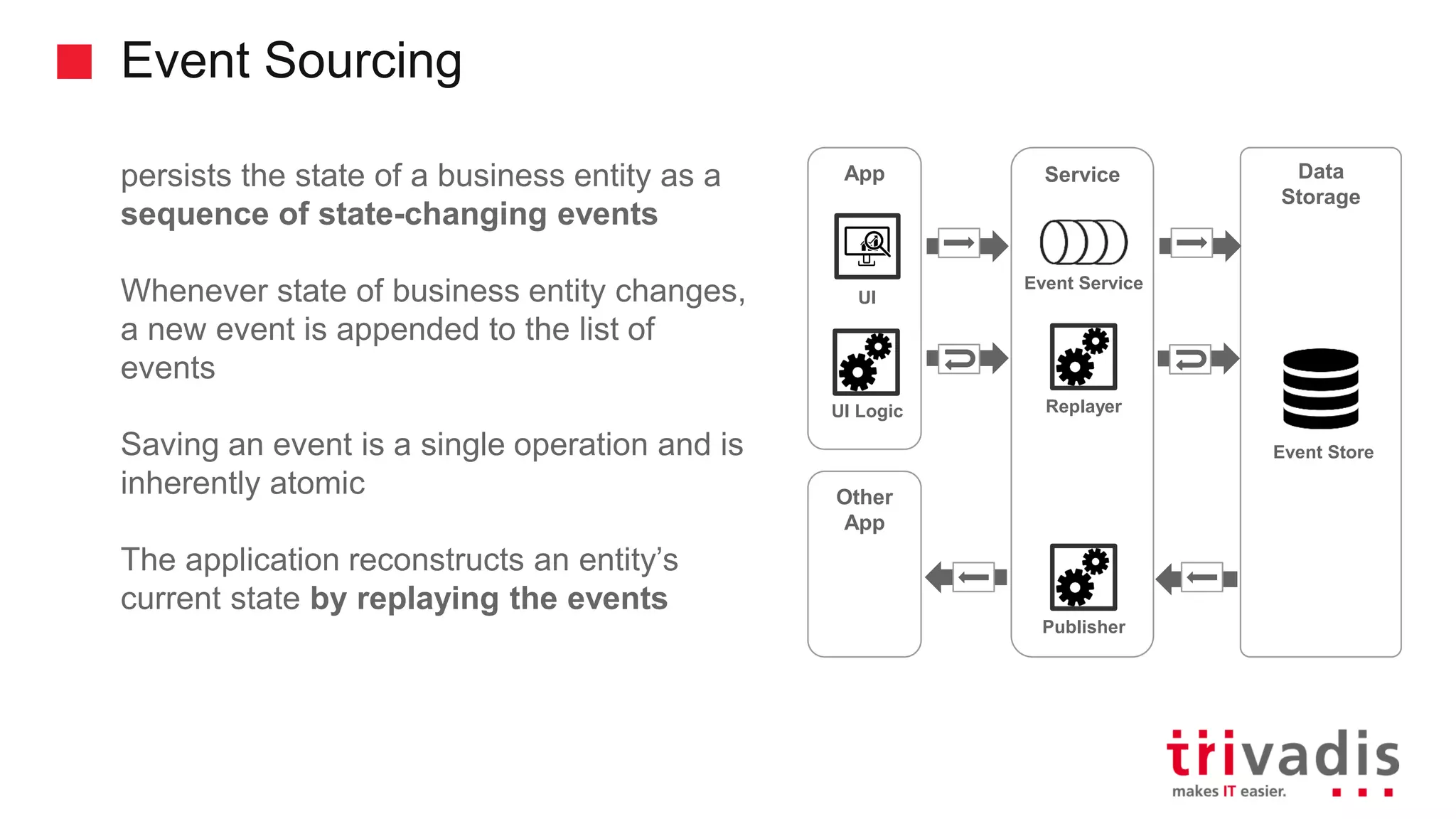
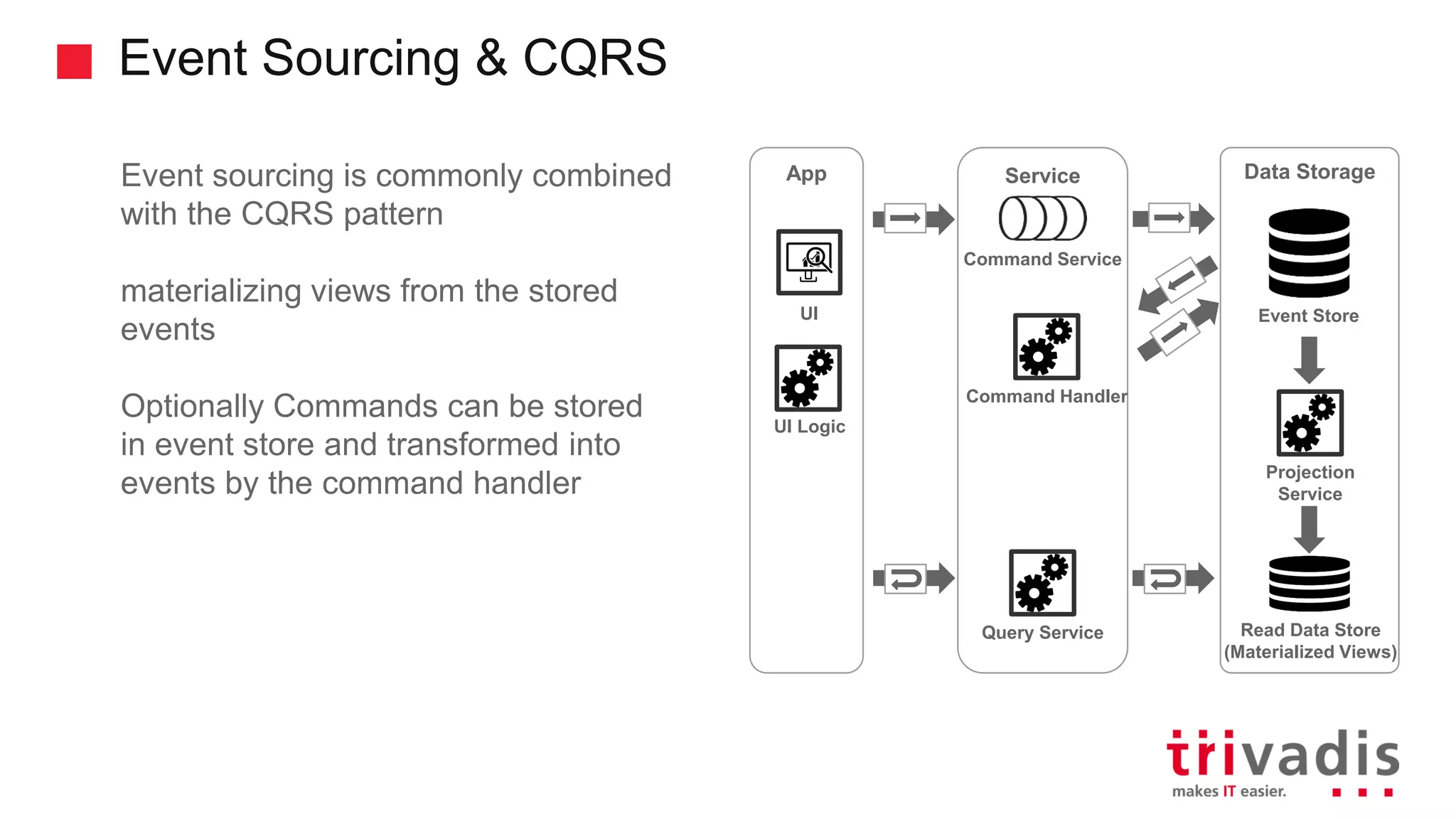
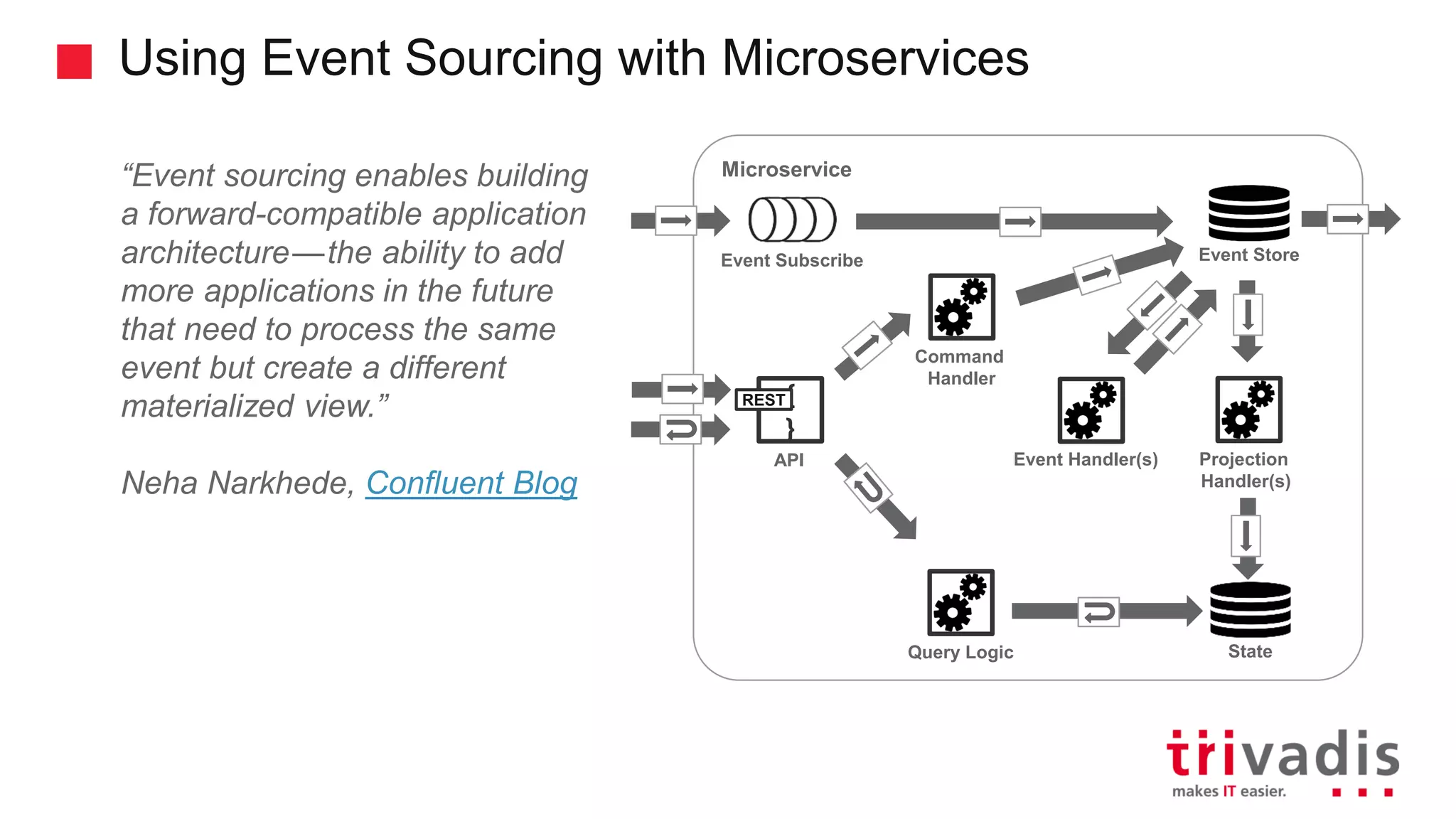
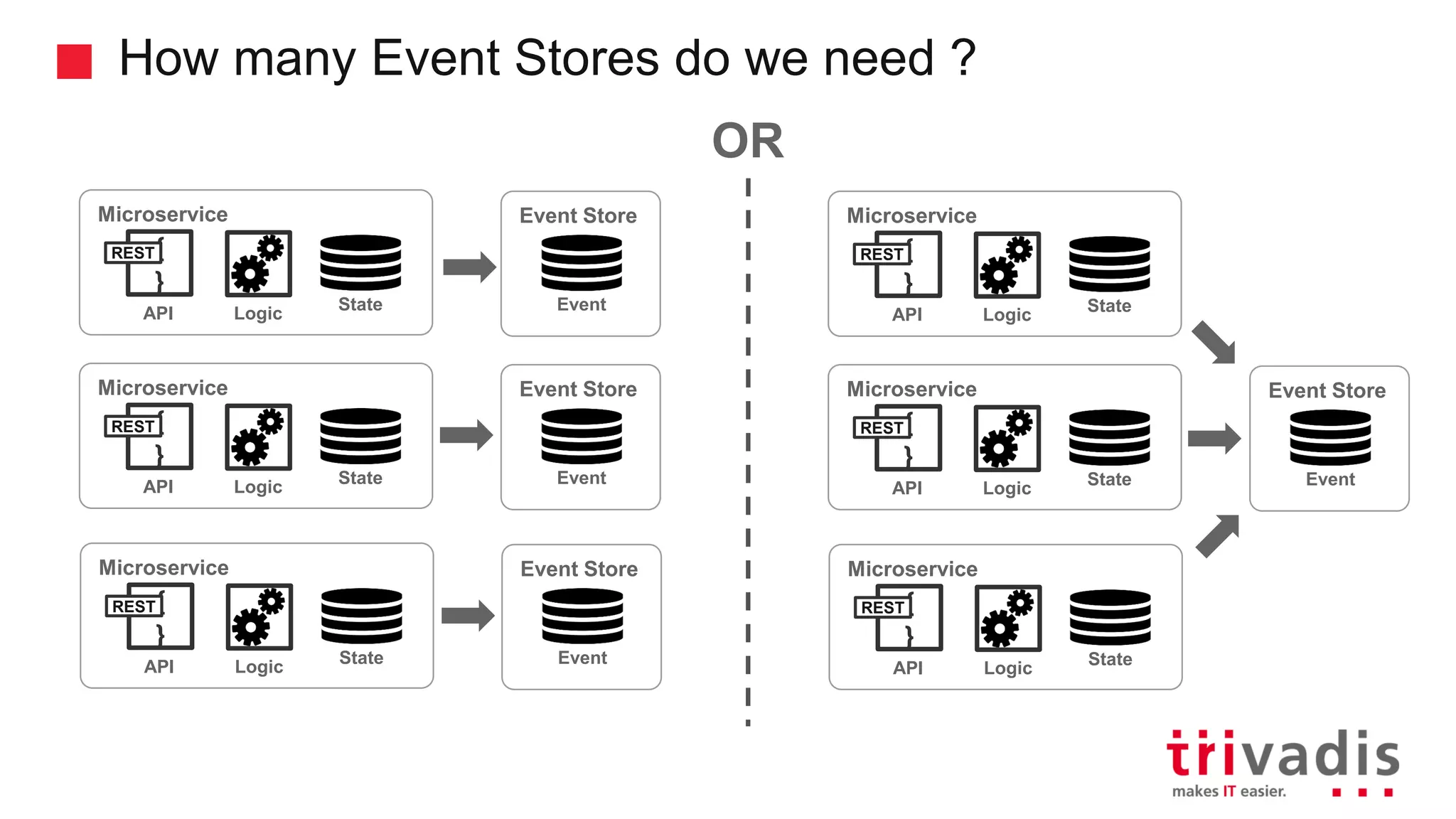
Introduction to CQRS and event sourcing concepts in modern application design.
Final thoughts emphasizing the need for proper technology usage.