Downloaded 53 times

![Program compilation 4 case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Optimizer Type extraction stack Task scheduling Dataflow metadata Pre-flight (Client) Master Data Source orders.tbl Filter Map DataSource lineitem.tbl Join Hybrid Hash buildHT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph Independent of batch or streaming job deploy operators track intermediate results](https://image.slidesharecdn.com/flinkstreamingsparkandfriends-150619085123-lva1-app6891/75/Apache-Flink-Overview-at-SF-Spark-and-Friends-4-2048.jpg)
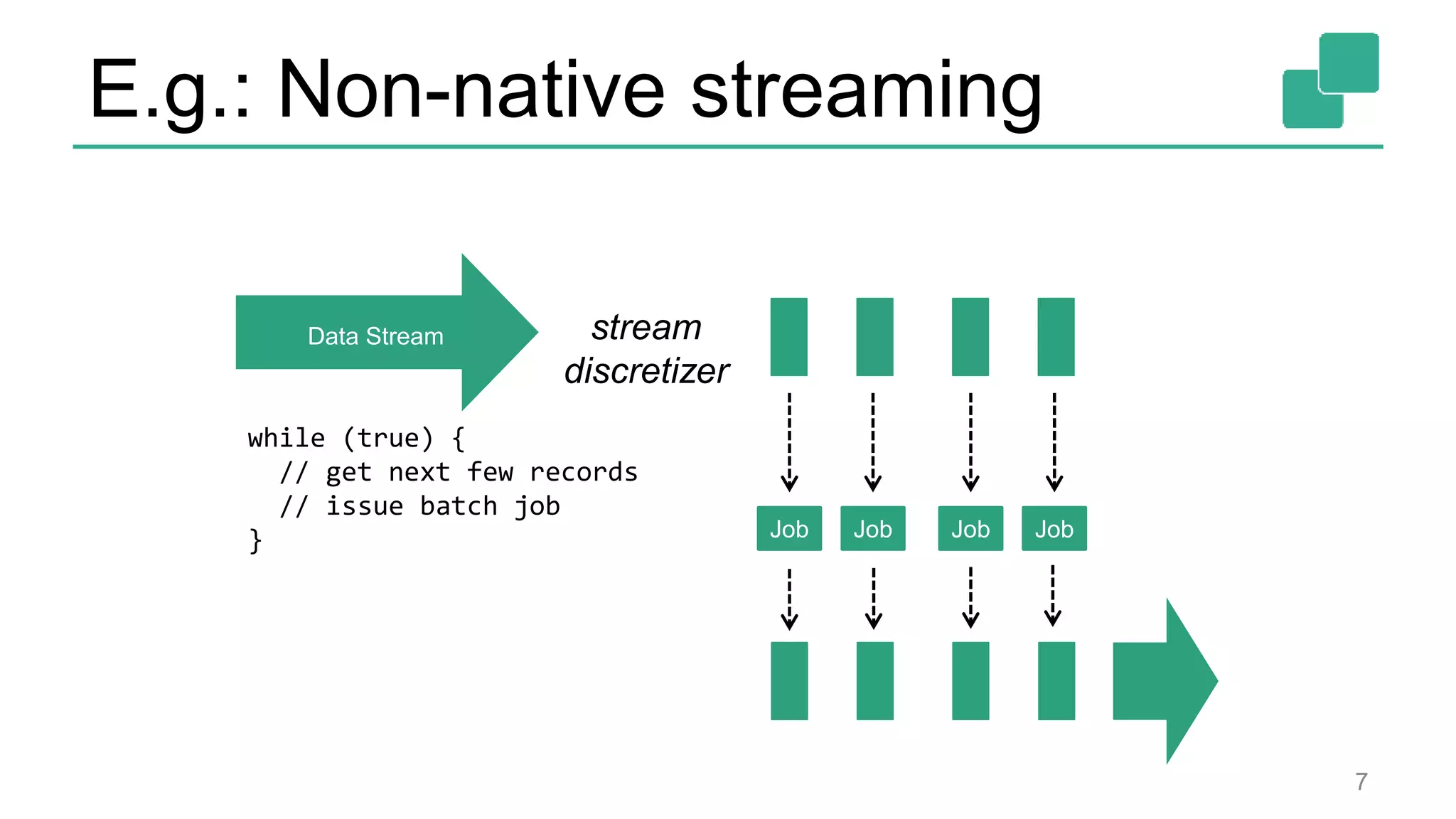
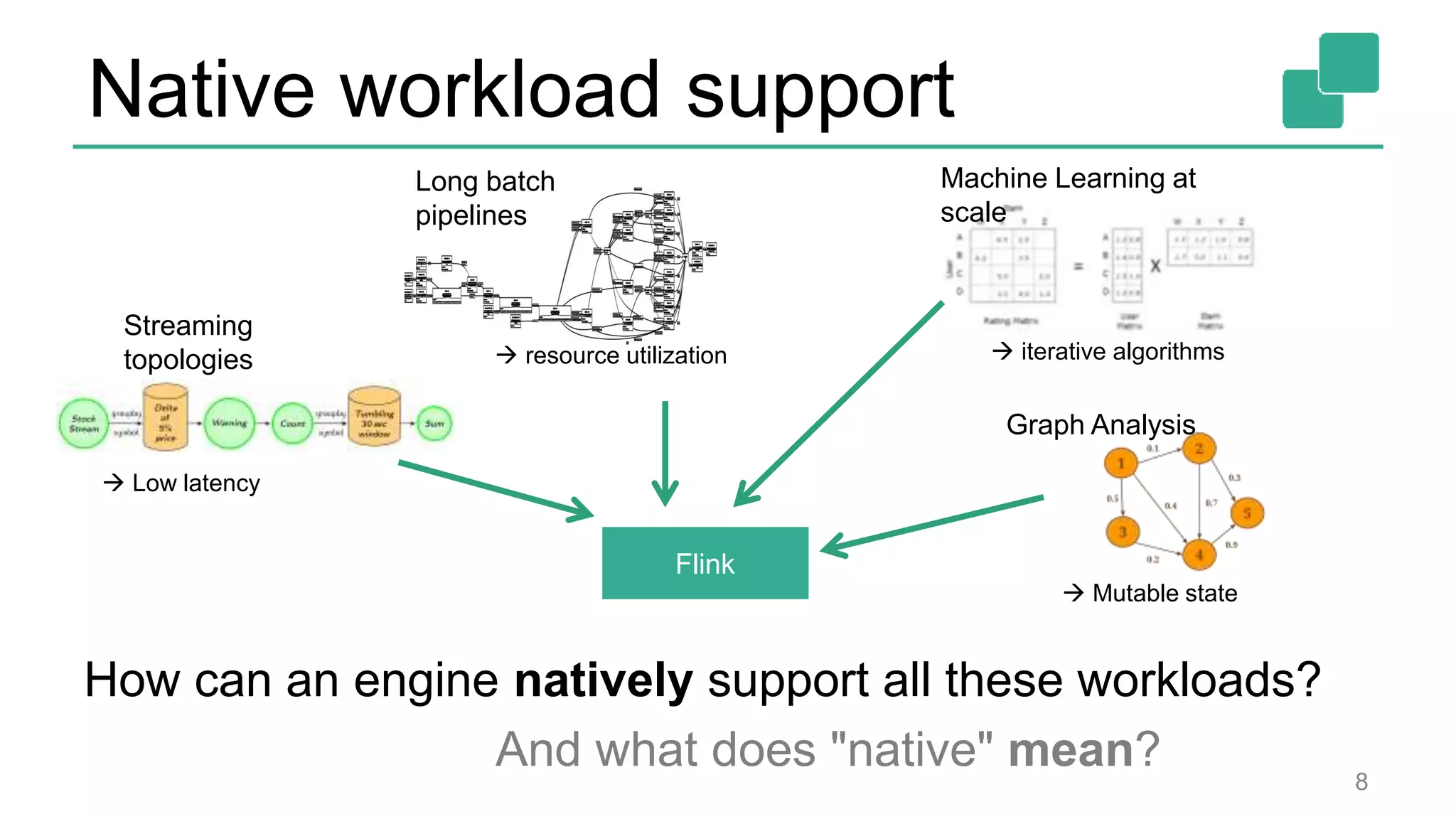


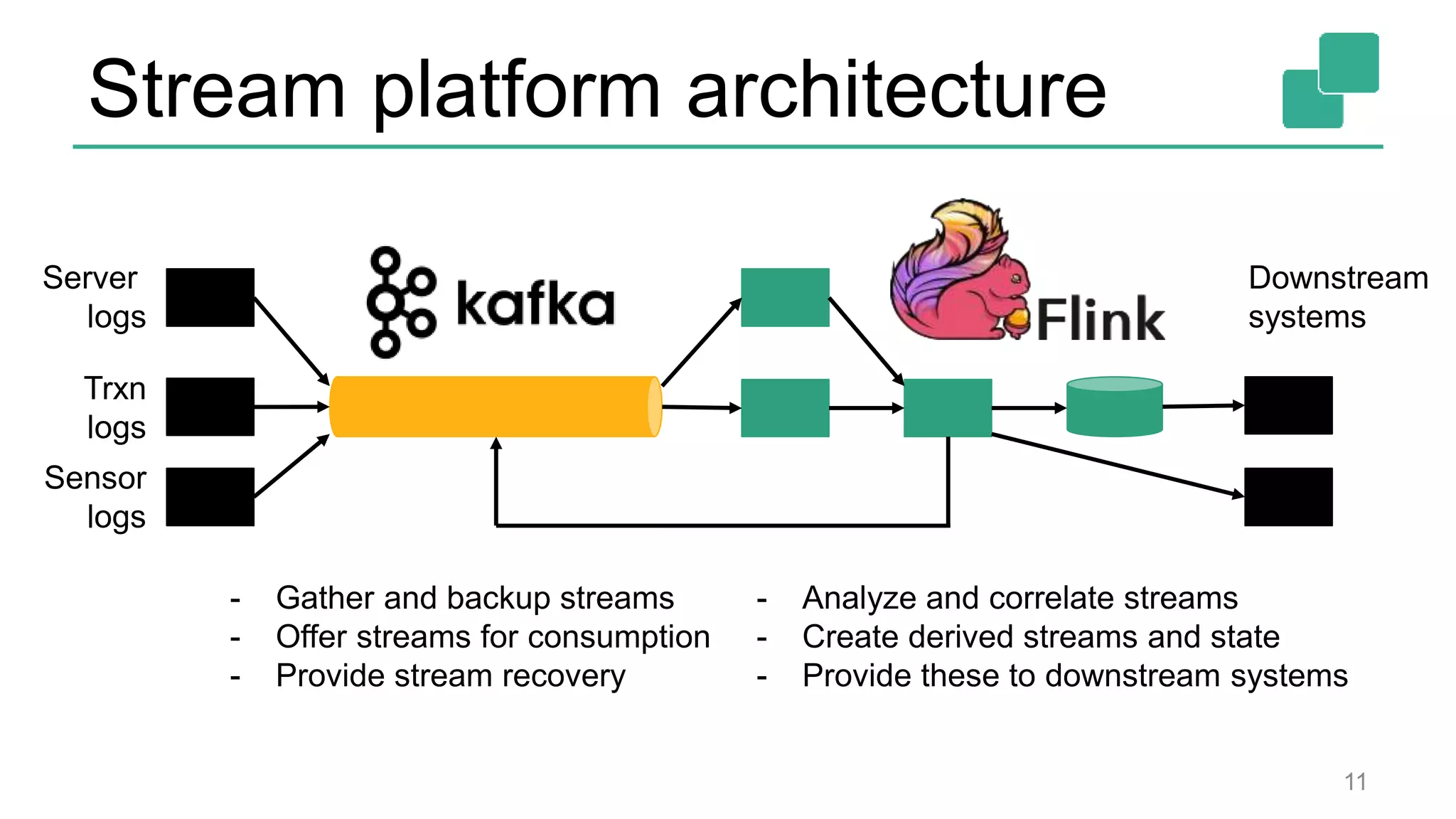
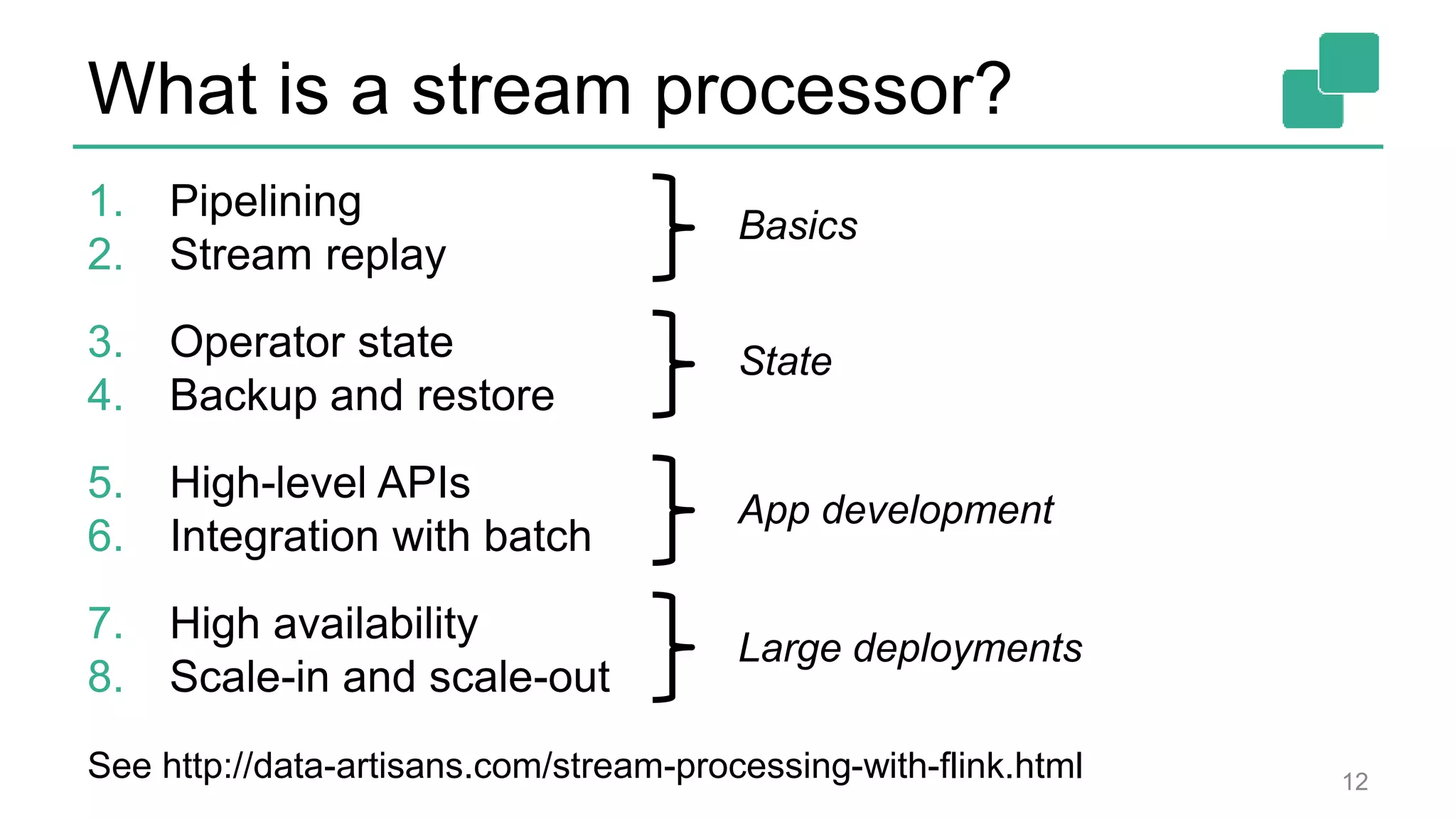




![DataStream API 24 case class Word (word: String, frequency: Int) val lines: DataStream[String] = env.fromSocketStream(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS)) .groupBy("word").sum("frequency") .print() val lines: DataSet[String] = env.readTextFile(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .groupBy("word").sum("frequency") .print() DataSet API (batch): DataStream API (streaming):](https://image.slidesharecdn.com/flinkstreamingsparkandfriends-150619085123-lva1-app6891/75/Apache-Flink-Overview-at-SF-Spark-and-Friends-24-2048.jpg)



![More Engine Features 35 Automatic Optimization / Static Code Analysis Closed Loop Iterations Stateful Iterations DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT prob e broadc ast forward Combine GroupRed sort DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT prob e hash-part [0] hash-part [0] hash-part [0,1] GroupRed sort forward](https://image.slidesharecdn.com/flinkstreamingsparkandfriends-150619085123-lva1-app6891/75/Apache-Flink-Overview-at-SF-Spark-and-Friends-35-2048.jpg)




Apache Flink is a robust stream processing framework designed for handling both batch and streaming data with low latency and high resource utilization. It features advanced capabilities like stateful operations, fault tolerance, and various APIs for data processing. The document outlines the architectural principles, functionalities, and future roadmap of Flink as a top-level project of the Apache Software Foundation.