Downloaded 89 times






















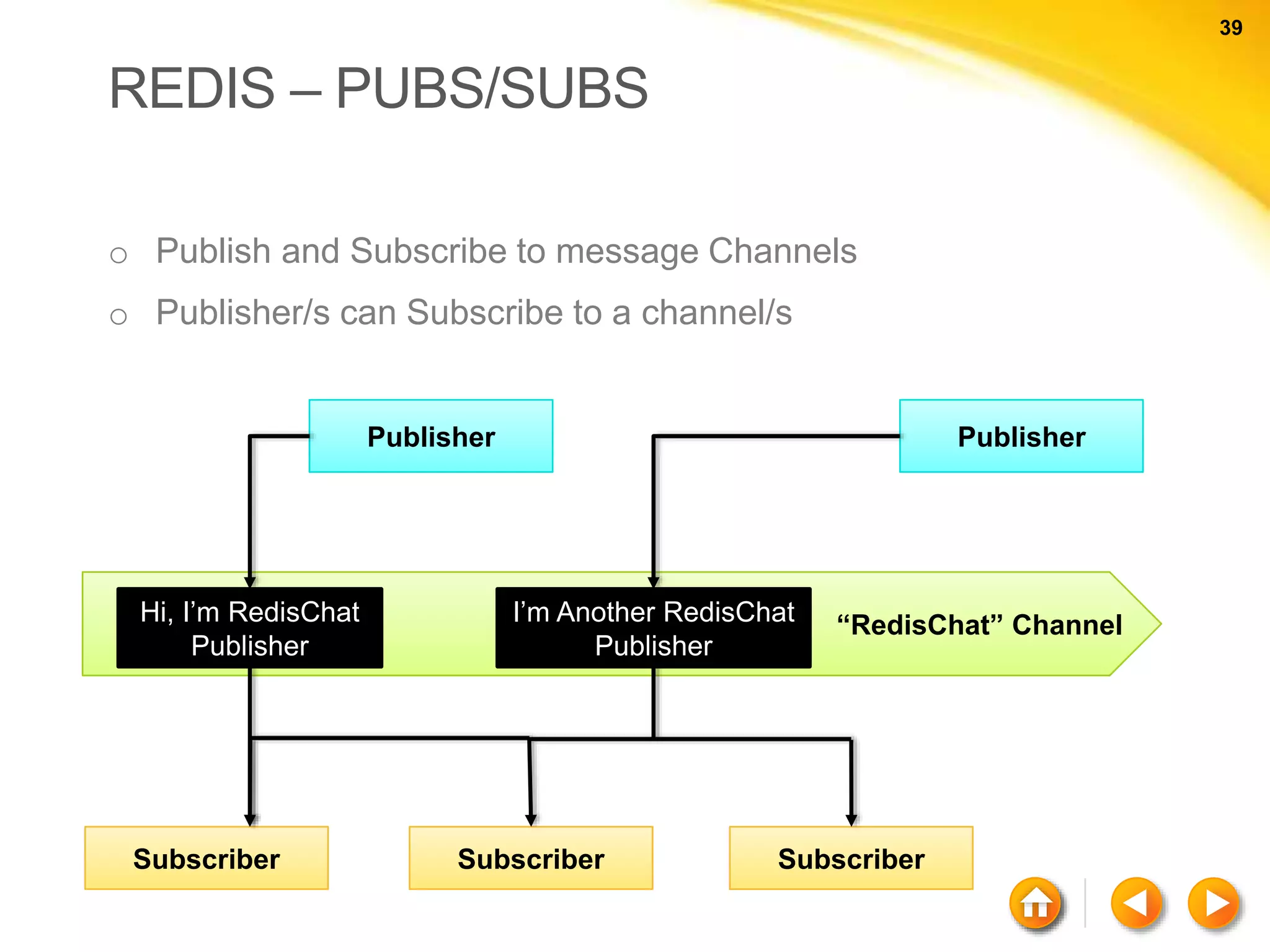




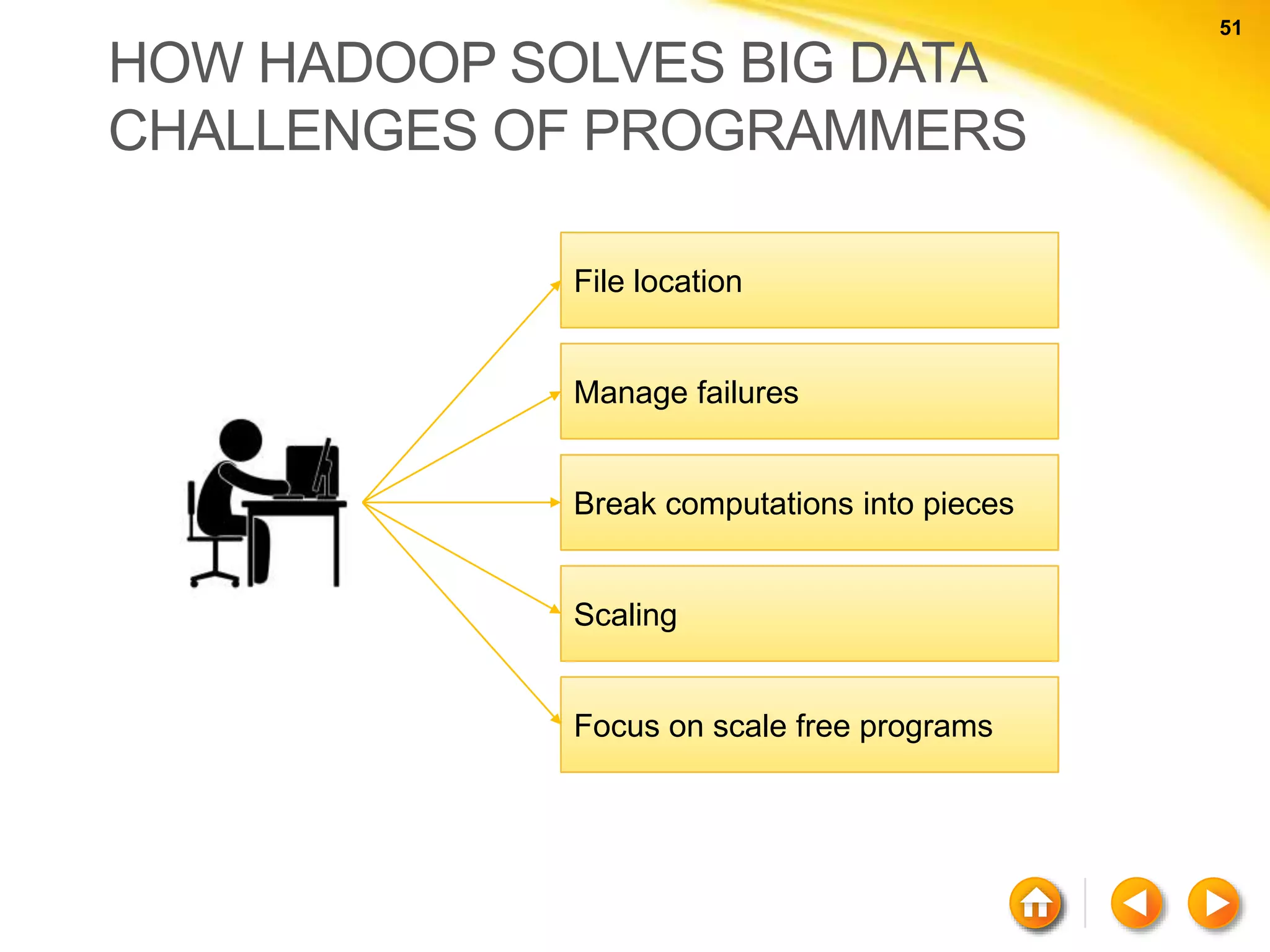


![59 59 NEO4J Cypher Basic Syntax (a) - [ r ] - > (b) a b r nodesrelation](https://image.slidesharecdn.com/nosql-150802023038-lva1-app6892/75/An-Intro-to-NoSQL-Databases-59-2048.jpg)
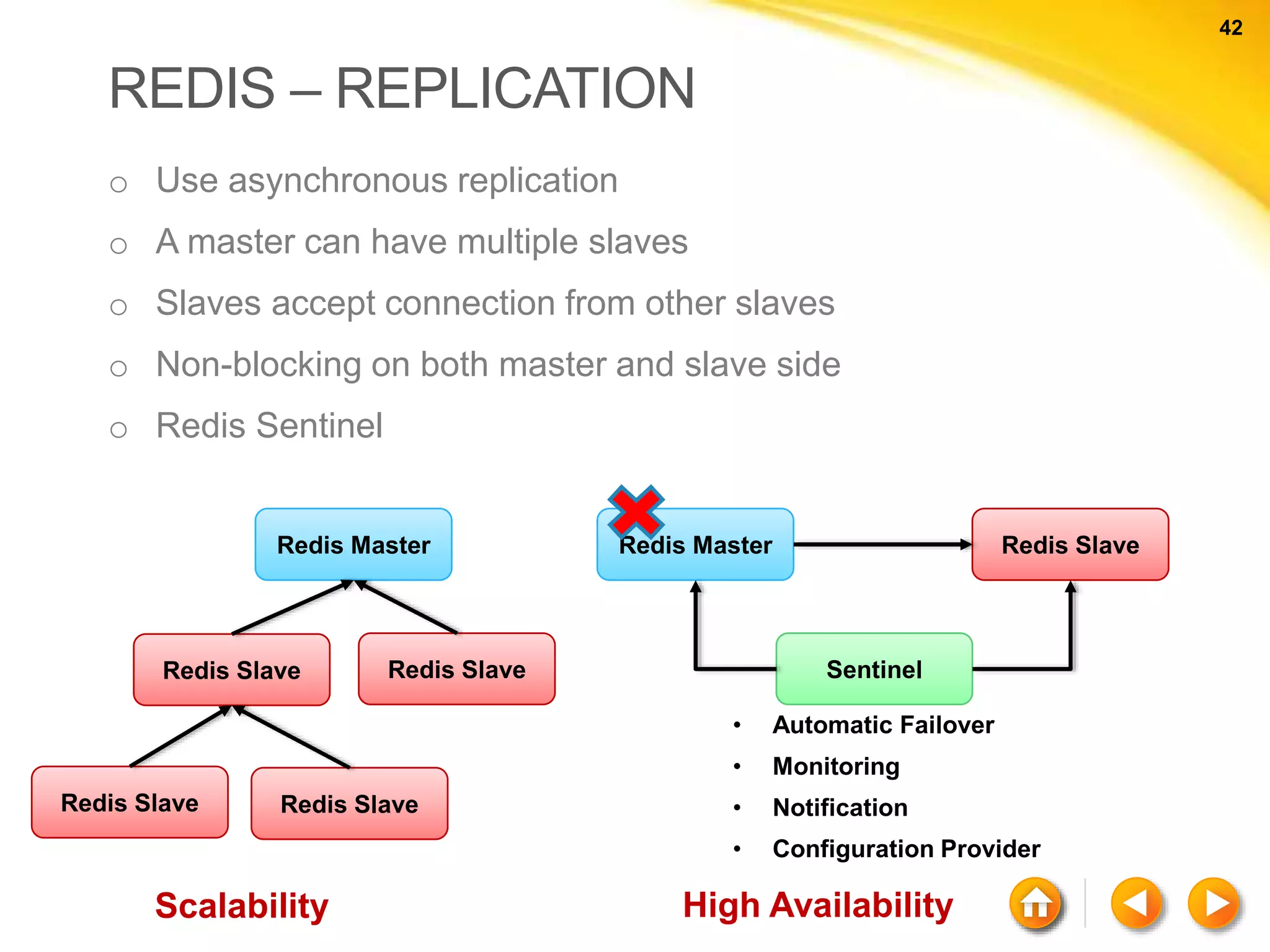
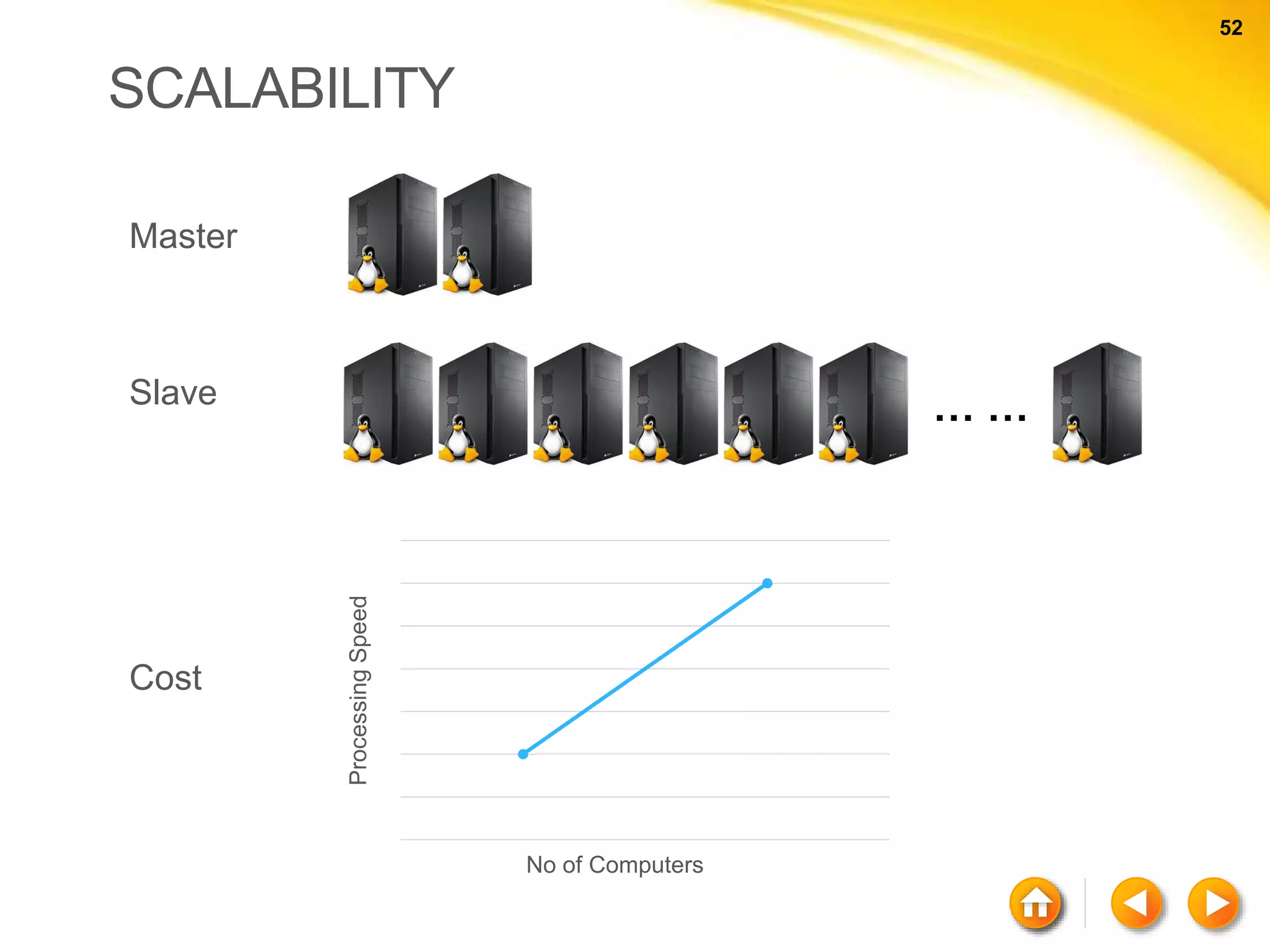
![60 60 NEO4J - CYPHER Node with properties ( a { name : “rajith”, born : 1989 } ) Relationships with properties ( a ) - [:WORKED_IN { roles:[“ASE”] } ] - > ( b ) Labels ( a : Person { name: “rajith”} )](https://image.slidesharecdn.com/nosql-150802023038-lva1-app6892/75/An-Intro-to-NoSQL-Databases-60-2048.jpg)
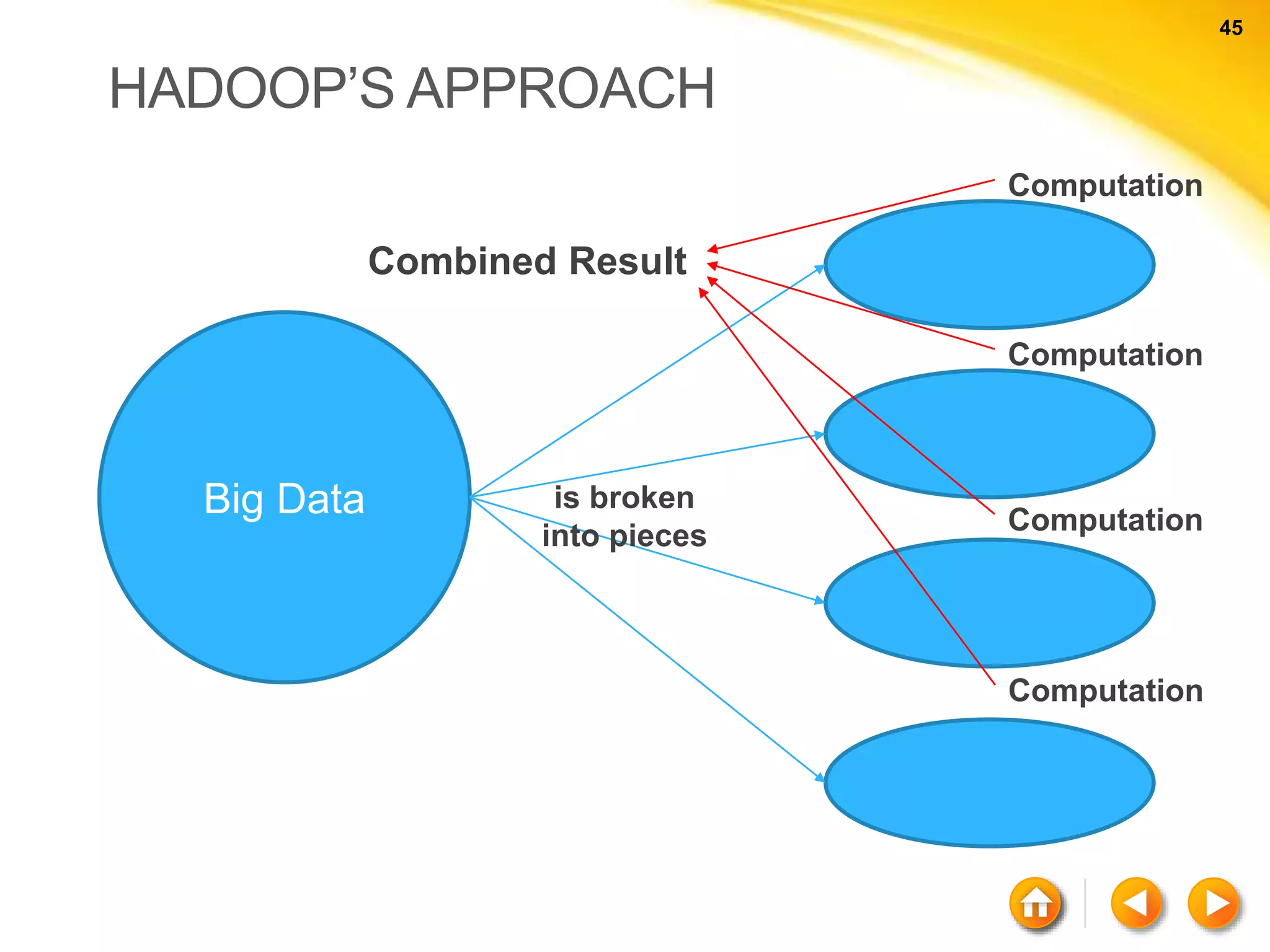
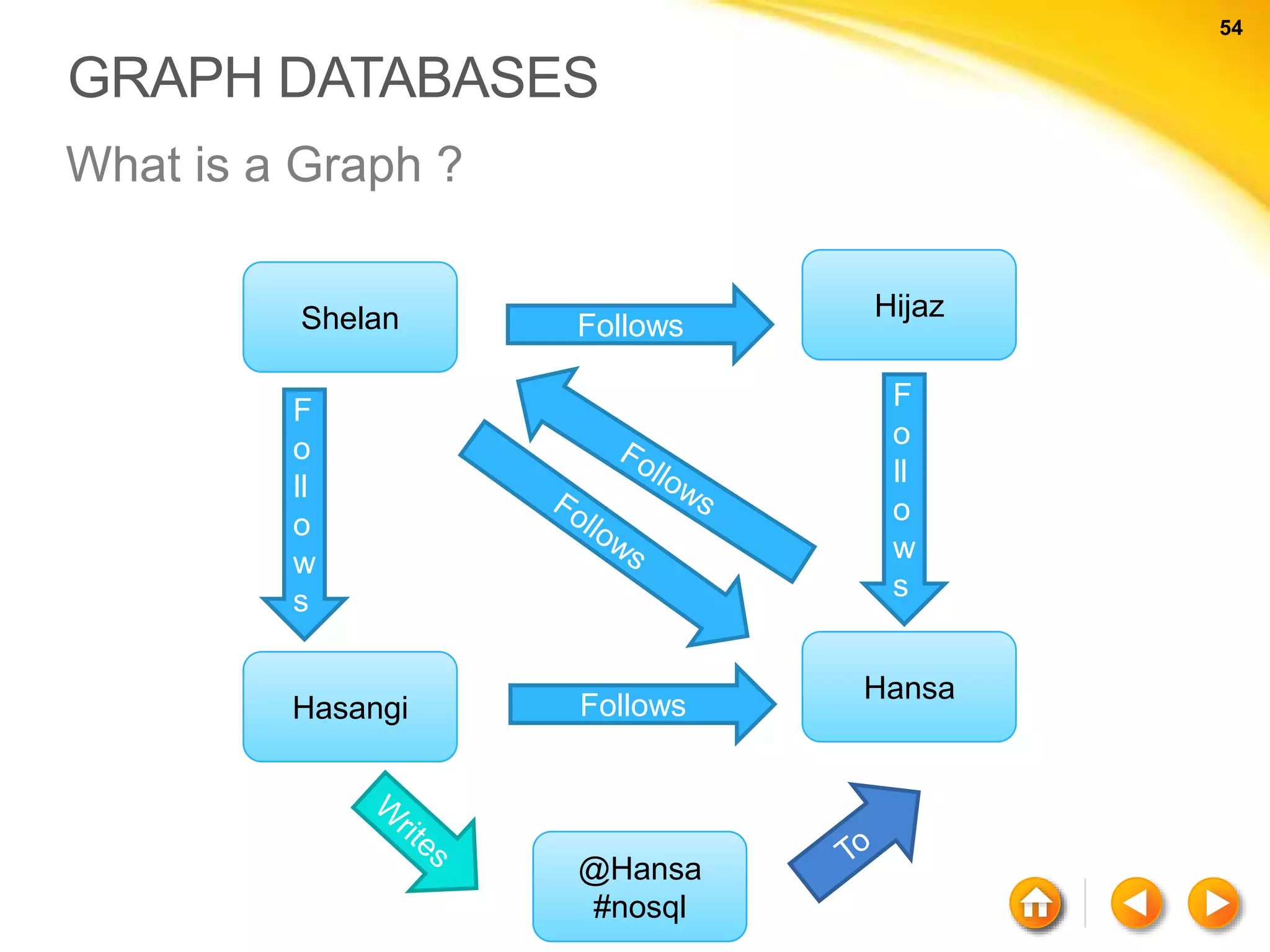
![61 61 NEO4J - CYPHER Quering with Cypher MATCH ( a ) - - > ( b ) RETURN a, b; MATCH ( a ) – [ r ] – > ( b ) RETURN a.name, type ( r ); Using Clauses MATCH ( a : Person) WHERE a.name = “rajith” RETURN a;](https://image.slidesharecdn.com/nosql-150802023038-lva1-app6892/75/An-Intro-to-NoSQL-Databases-61-2048.jpg)


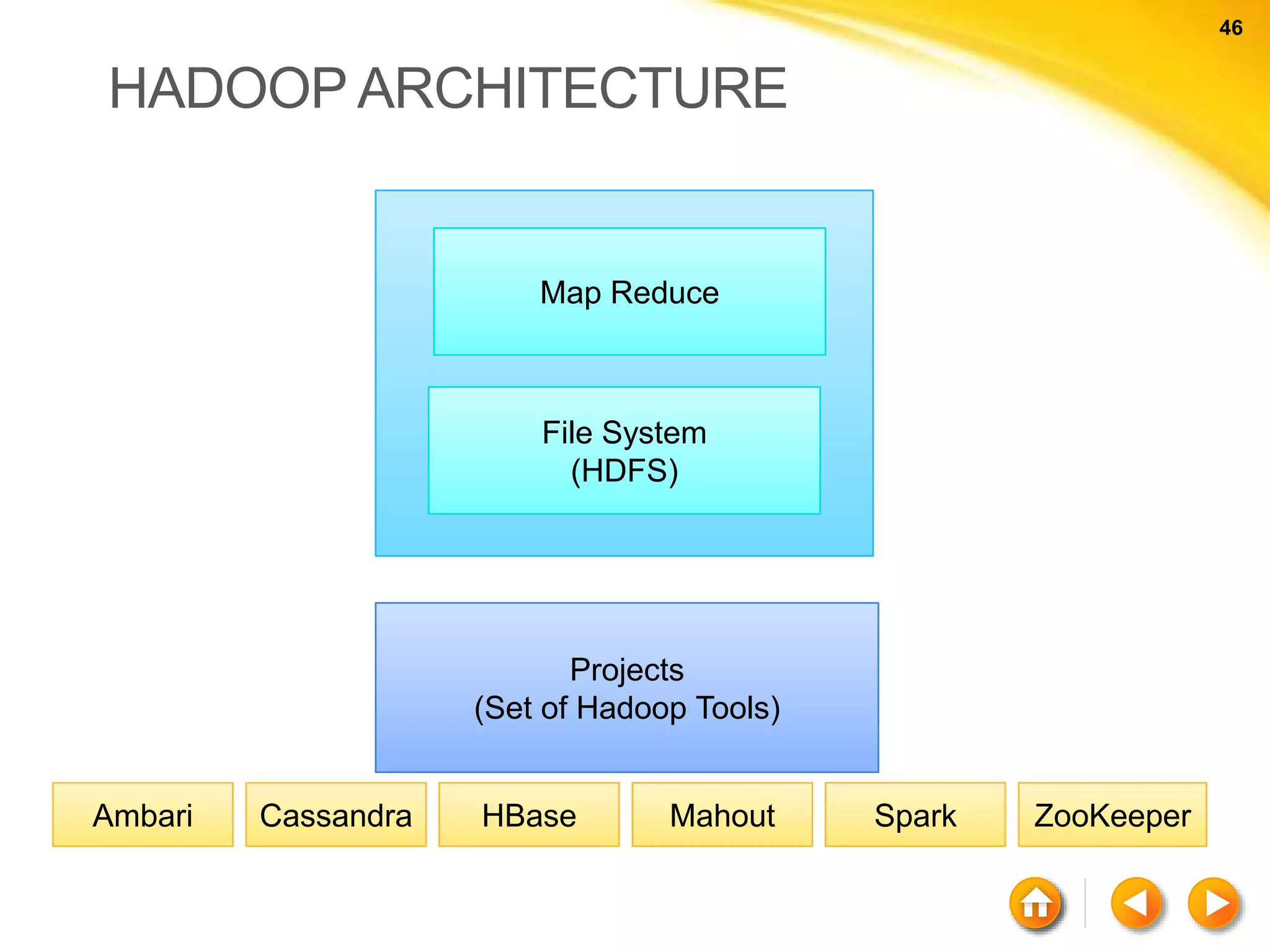
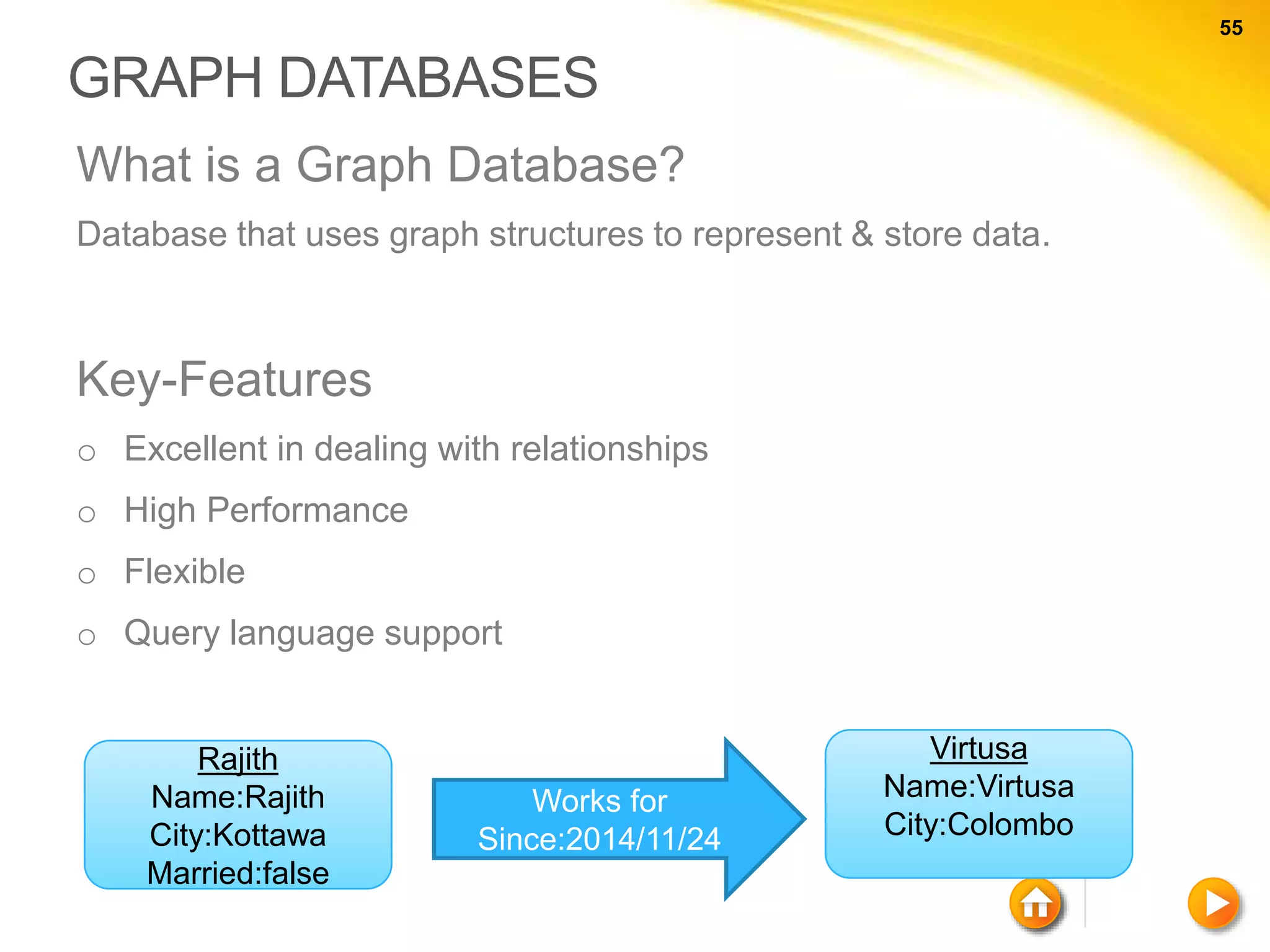
![64 64 KEYWORDS COMPARISON RDBMS MongoDB Database Database Table, View Collection Row Document (JSON, BSON) Column Field Index Index Join Embedded Document Foreign Key Reference Partition Shard > db.user.findOne({age:39}) { "_id" : ObjectId("5114e0bd42…"), "first" : "John", "last" : "Doe", "age" : 39, "interests" : [ "Reading", "Mountain Biking ] "favorites": { "color": "Blue", "sport": "Soccer"} }](https://image.slidesharecdn.com/nosql-150802023038-lva1-app6892/75/An-Intro-to-NoSQL-Databases-64-2048.jpg)






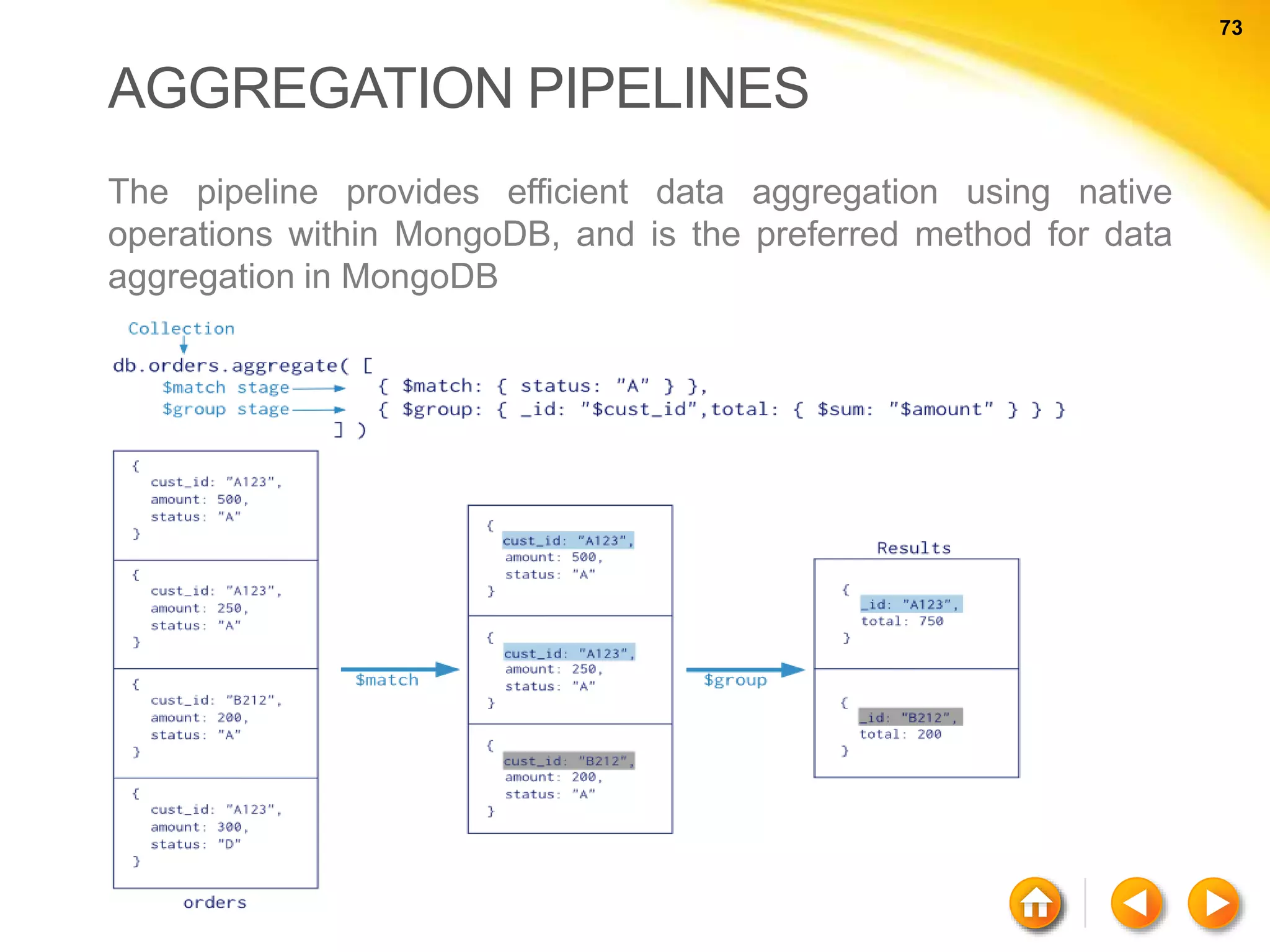
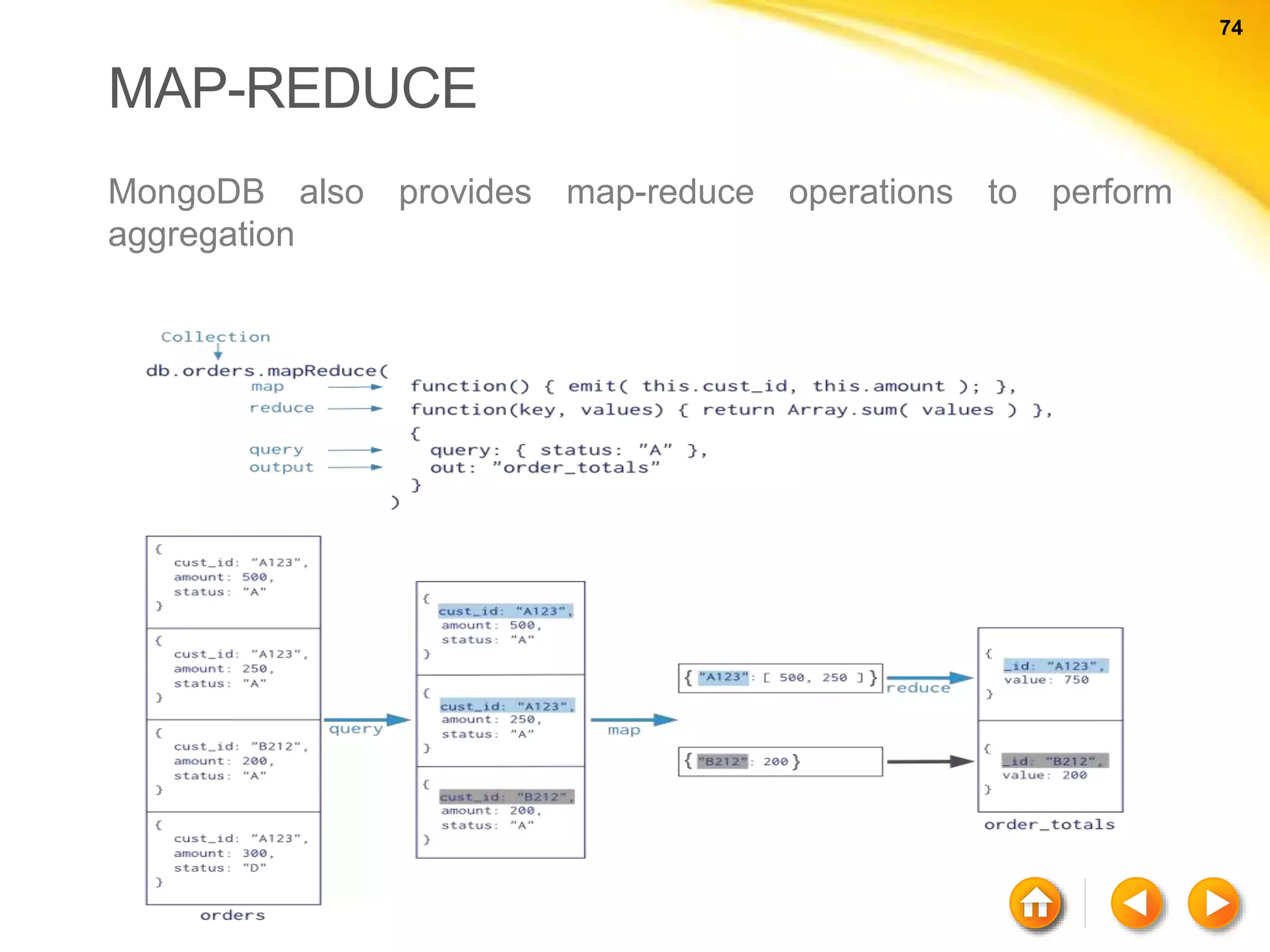

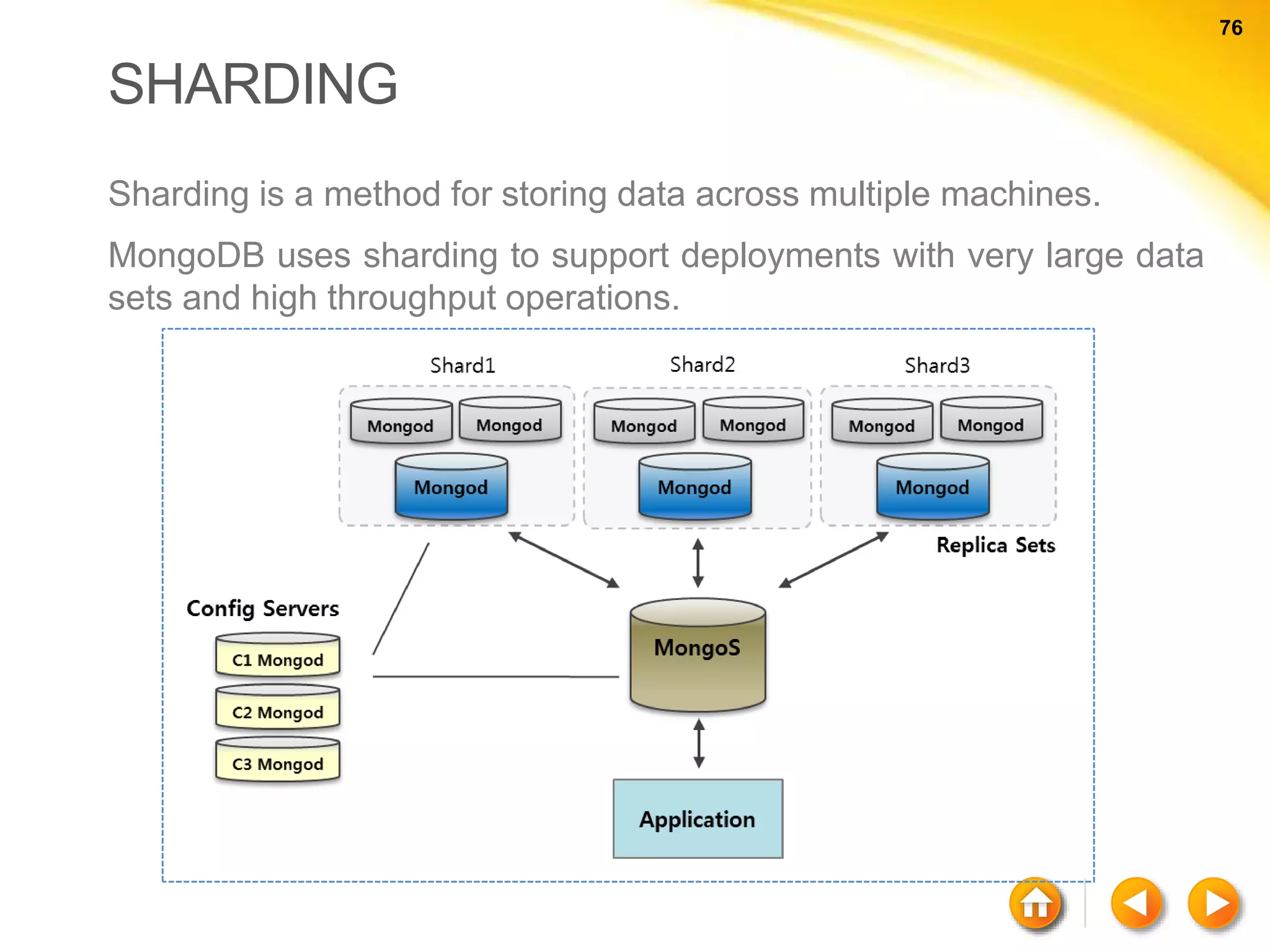


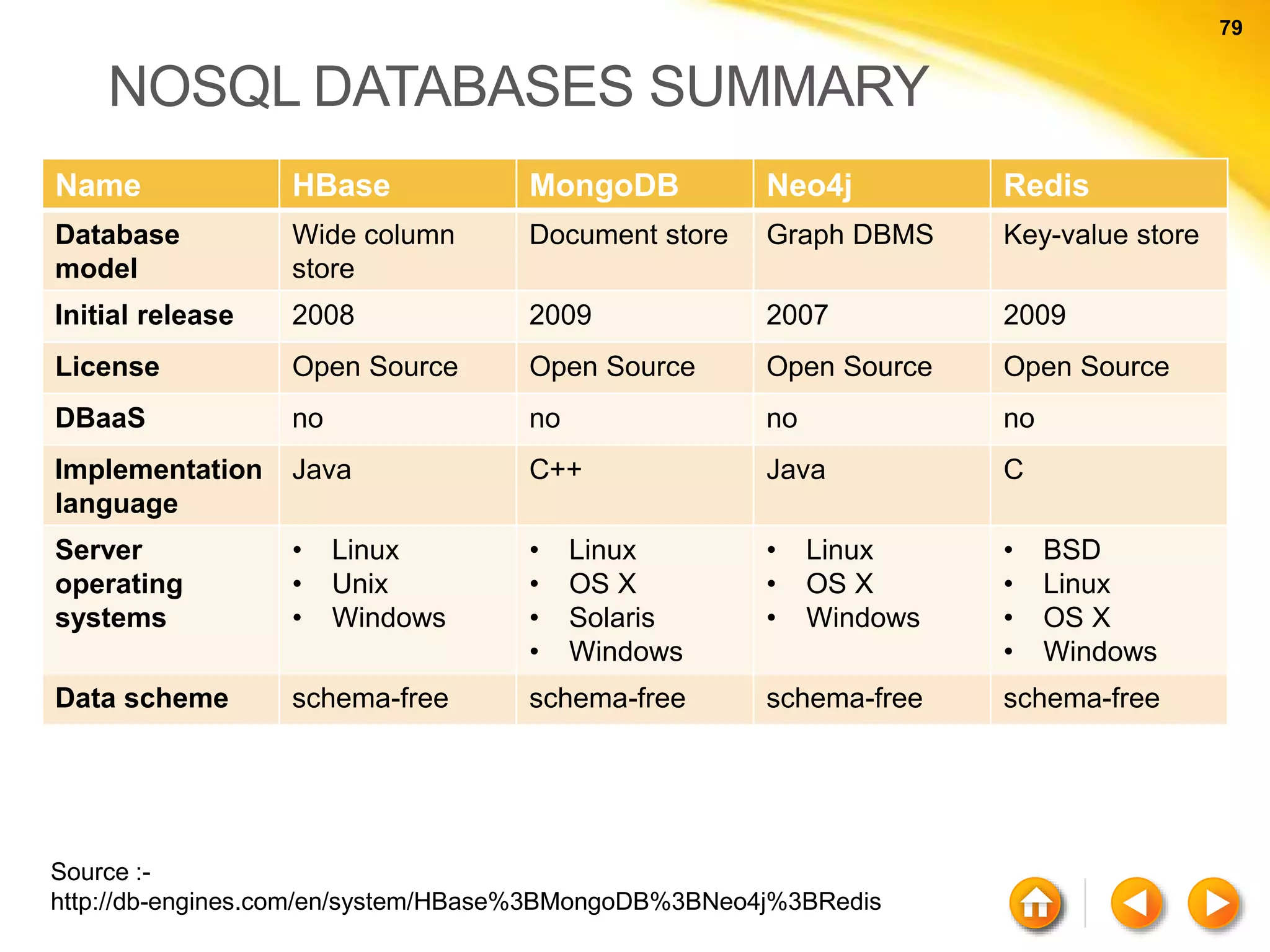


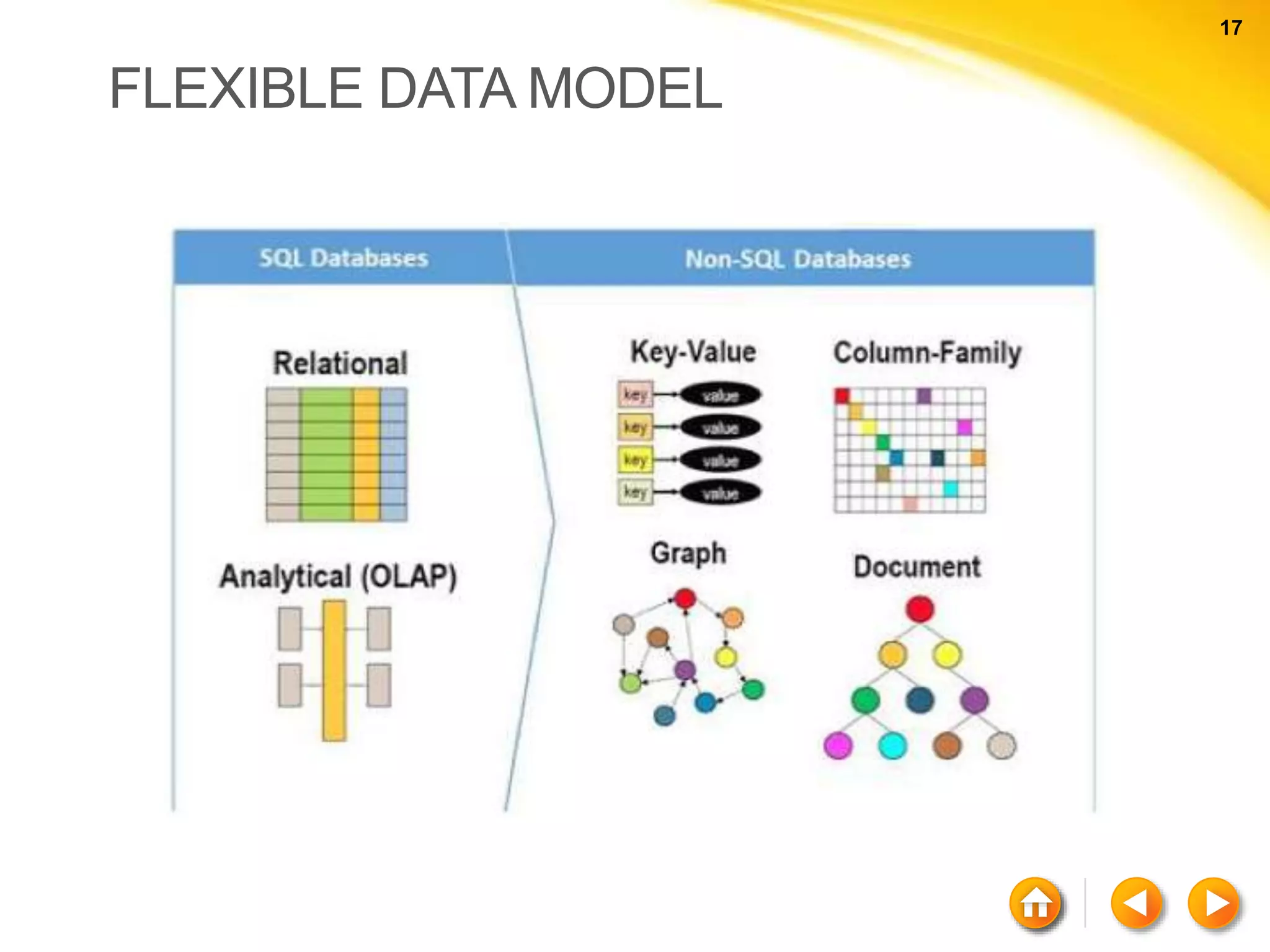
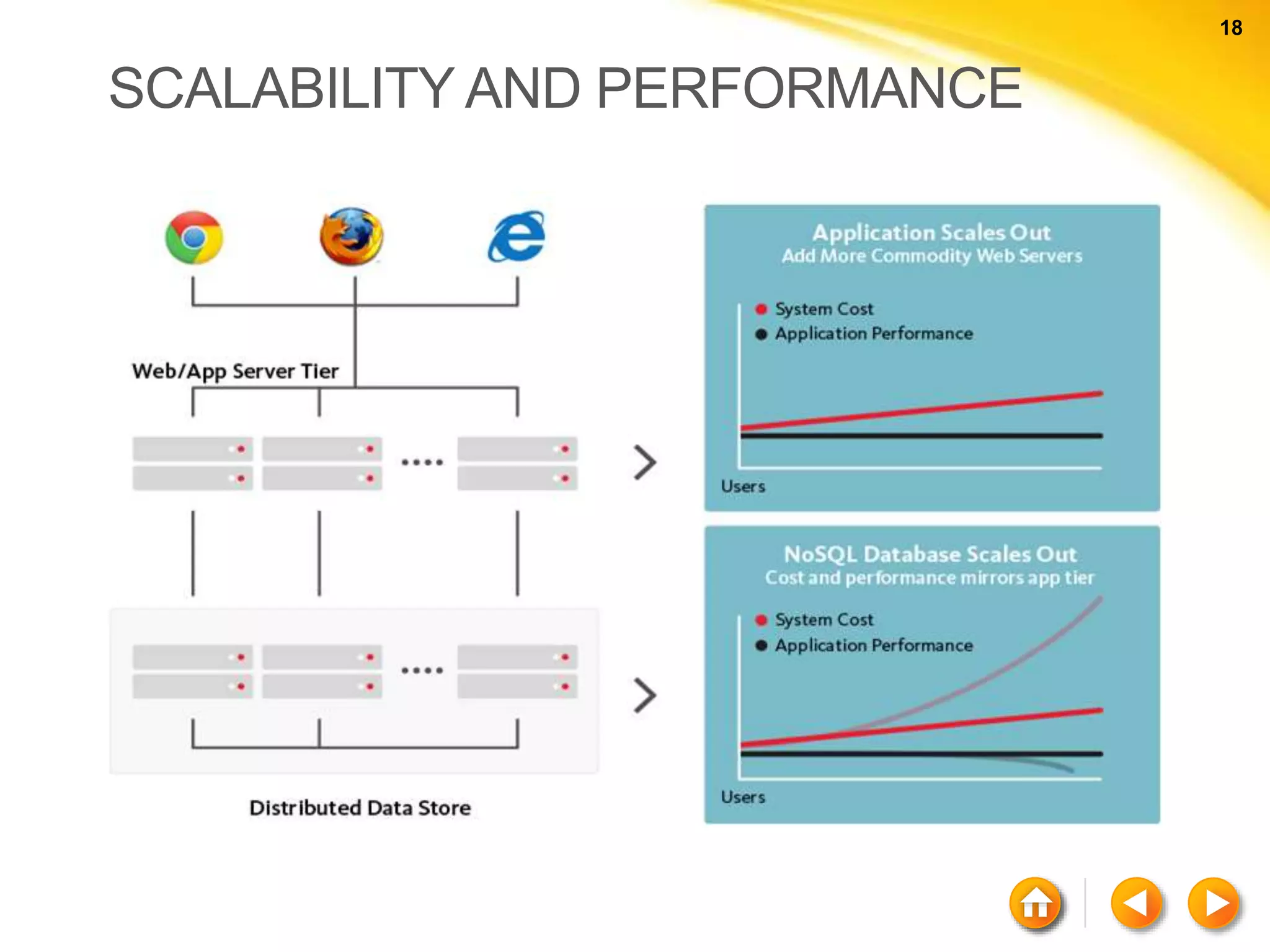
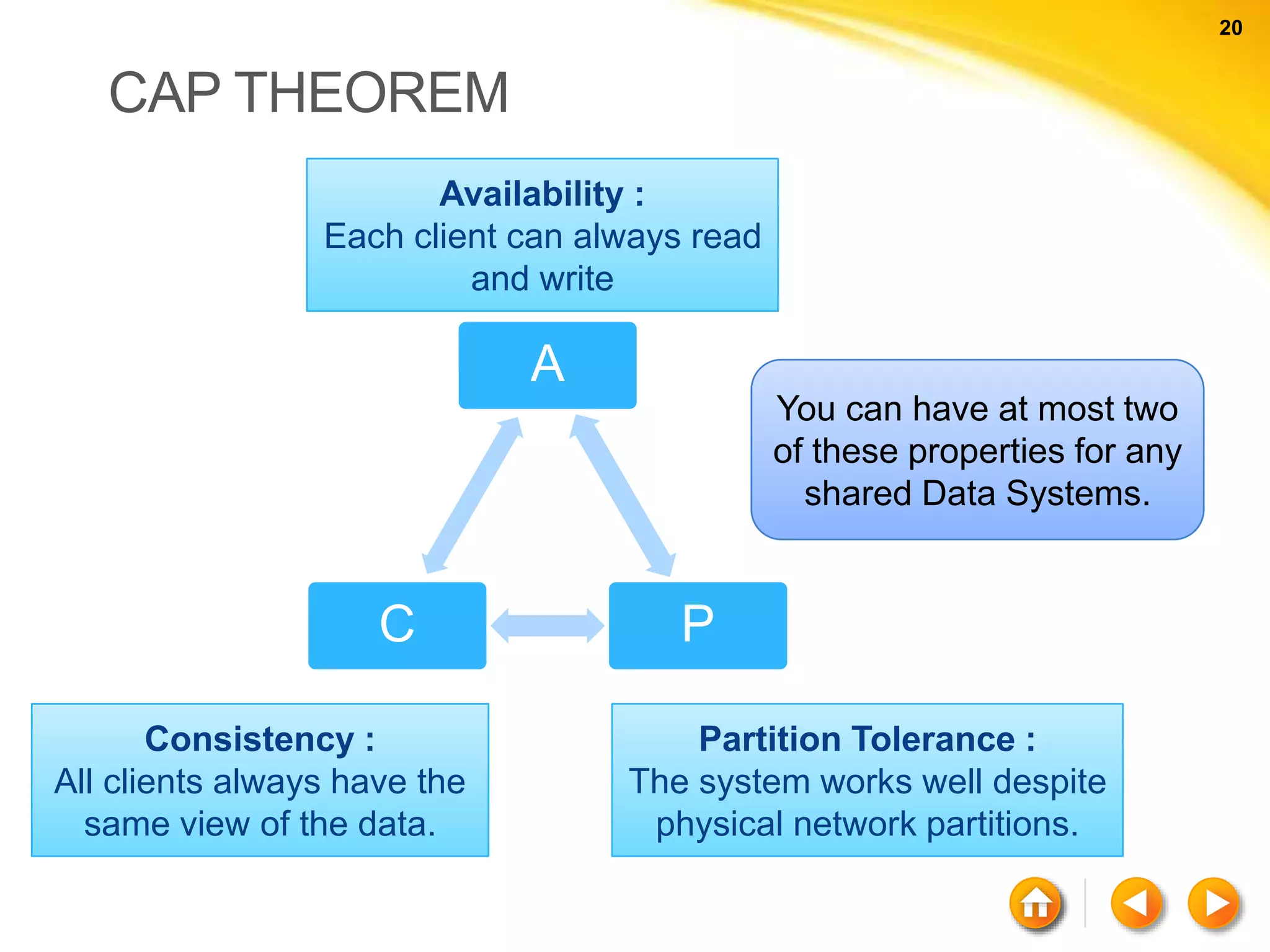
The document discusses various aspects of NoSQL and relational database management systems (RDBMS), highlighting key differences such as schema requirements and data structures. It covers categories of NoSQL databases, including key-value stores, document stores, wide-column stores, and graph databases, along with specific examples and their advantages. Additionally, it addresses concepts like ACID properties, the CAP theorem, and various features like replication, indexing, and data modeling in NoSQL environments.