Download to read offline
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395 -0056 Volume: 04 Issue: 03 | Mar -2017 www.irjet.net p-ISSN: 2395-0072 © 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 243 Algorithm for calculating relevance of documents in information retrieval systems Roberto Passailaigue Baquerizo1, Paúl Rodríguez Leyva2, Juan Pedro Febles3, Hubert Viltres Sala4, Vivian Estrada Sentí5 1Canciller Universidad Tecnológica (ECOTEC) Guayaquil, Ecuador 2Departamento de Soluciones Informáticas para Internet, Universidad de las Ciencias Informáticas, La Habana, Cuba 3Departamento Metodológico de Postgrado, Universidad de las Ciencias Informáticas, La Habana, Cuba 4Departamento de Preparación Profesional Universidad de las Ciencias Informáticas, La Habana, Cuba 3Departamento Metodológico de Postgrado, Universidad de las Ciencias Informáticas, La Habana, Cuba ---------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - This research belongs to the field of information retrieval and its main objective is the basis of an algorithm to assign the value of relevance to a document concerning a consultation inserted by users on information retrieval systems. The concept of relevance is a fundamental aspect in the design and development of information retrieval systems, because although these tools performathoroughsearchof the web, a correct structuring of documents and an efficient storage of the same, if the user it does not obtain the results that actually respond to its search needs, then the quality of the information retrieval system is penalized by the acceptance criteria of the users. The algorithm is based primarily on the classical mathematical expressions for calculating similarity between groups, known as the cosine, jaccard and dice formulas. It has the particularity variationof the similarity based on the relationship established between the search profile of users and categories of documents stored in information retrieval system. In order to get thesevariables are used text mining and web mining techniques allowing the processing of the information generated by the registration of user queries and metadata stored documents? The main contribution of the research is an algorithm to calculate the relevance of the documents that are provided as part of the responses to queries made by users Key Words: algorithm, similarity, queries, information retrieval systems, relevance 1. INTRODUCTION This document is template. We ask that authors followsome simple guidelines. In essence,weask youtomakeyourpaper look exactly like this document. The easiest way to do this is simply to download the template, and replace (copy-paste) the content with your own material. Number the reference items consecutively in square brackets (e.g. [1]). However the authors name can be used along with the reference number in the running text. The order of reference in the running text should match with the list of references at the end of the paper. Information Retrieval (IR) is not a new area, but is being developed since the late fifties. However,it now plays a more important role given the value of the information. It can be argued that having or not having the right information in a timely manner can lead to the success or failure of an operation. Therefore, the importance of information retrieval systems (SRI)canhandle -withcertain limitations - these situations effectively and efficiently [1]. From 1950 to the present many concepts have addressed this particular issue. According to Baeza Yates, one of the most experienced researchers in this field, the term "deals with representation, storage, organization and access to information elements". This concept is defined by Salton as "a field related to the structure, analysis, organization, storage, search and retrieval of information" [11]. Croft estimates that information retrieval is "the set of tasks by which the user locates and accesses information resources that are relevant to problem resolution." Documentary languages, abstract techniques, description of the](https://image.slidesharecdn.com/irjet-v4i350-171216110655/75/Algorithm-for-calculating-relevance-of-documents-in-information-retrieval-systems-1-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395 -0056 Volume: 04 Issue: 03 | Mar -2017 www.irjet.net p-ISSN: 2395-0072 © 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 244 documentary object, etc. These tasks. "[4]Ontheotherhand, Korfhage defined IR as" the location and presentation to a user of information relevant to a need for information expressed as a question "[15]. From the concepts previously provided, it can be inferred that IR is the process of locating andstoringinformationthat is then accessed by users depending on the search needs of the same. One of the ways most used by users to access the entire cluster of information hosted on the web are search engines. These tools have a set of components that allow the crawling, indexing and visualization of the collected information as part of the responses offered to the users after they execute a query. They can also be defined as software agents, programs that reside in a computer (host) and have the mission of registering, classifying,indexingand storing documents in the most diverse sites in automated form. In addition, they present the possibility of accessing these databases for consultation.Theyordertheinformation [14]. A searcher employs different algorithms and methods to satisfy the need for information raised by a user in a natural language query specified through a set of keywords [6, 2]. Algorithms that provide relevant documentsina websearch system need to perform an analysisofthesedocuments.This process is based on the generation of an index of relevance between documents for the terms included in them. Generally the analysis performed to generate this index is performed by the search engine but the retrieval of the information is done by a web crawler or web spider [9]. In an interview with Baeza Yates, this researcher explains the following referring to the problematic of the IR, "the current objective is to try to understand the intention after the search. That is, what the person wants to do and personalize their search for that task. "However, classic information retrieval models do not handle variables such as usersearch preferences; so it is necessary a way to integrate this variable to the calculation of similarity that defines the relevance of the documents in such models. 2. MATERIALS AND METHODS Irjet Template sample paragraph .Define abbreviations and acronyms the first time they are used in the text, even after they have been defined in the abstract. Abbreviations such as IEEE, SI, MKS, CGS, sc, dc, and rms do not have to be defined. Do not use abbreviations in the title or heads unless they are unavoidable.Searchenginesorinformationretrieval systems have a number of components, each with a specific function, as shown in Figure 1. Many of these tools base their operation on theclassicmodelsofinformationretrieval.They are recognized as: Boolean Model: The Boolean model is one of the simplest informationretrievalmodelstouse.Itisbased on Boolean set theory and algebra. In this model the queries are logical expressions in which the operands are properties of the documents. Pure Boolean operators are conjunction, disjunction, and negation (AND, OR, NOT). In addition, most systems include proximity operators and simple regular expressions. In general, in these systems the user refines the query until the number of relevant documents retrieved is reasonable [7]. Fig – 1: Basic architecture of a search engine [15]. Probabilistic model [10]: This model is based on the fact that in the IR process it is intrinsically imprecise. Within the process itself, there are certain aspects that are non- deterministic, forexample:Therepresentationthatmakesa query of the need for information of the user. The representation of the documents in the system. With this in mind, the probabilistic model postulates that the best way to represent this is through probability theory. This model attempts to estimate the probability that, given a query q, a document d is relevant to that query. This is denoted as: P (Rel | d). The model tries to obtain a set of relevant documents (called R),whichshouldmaximizetheprobability of relevance. A document is considered relevant if its probability of being relevant, P (Rel | d), is greater than the probability of not being relevant, P (noRel | d) [3]. Vector model: Salton was the firsttoproposeSRI-basedvectorspace structures in the late 1960s within the framework of the SMART project. Since documents can be represented asterm vectors, documents can be placed in a vector space of m dimensions, with as many dimensions as components have the vector [13]. The fundamental idea on which the vector model is based is to consider that both the key terms with respect to a document and the queries can be represented through a vector in a space ofhigh dimensionality.Therefore, to evaluate the similarity between a document and a query; simply make acomparison of thevectorsthatrepresentthem [12]. The three models have algorithms that allow ordering documents taking into account the relevance in relation to a query inserted by the user. Inthis modeltheusefulwordsare selected, which are usually all the terms of the texts, except the empty words; this processisenrichedusingtechniquesof tagging and labeling. The similarity in the vector model corresponds to the angle between thevectorofthedocument and the vector of the query. If the angle betweenbothvectors is 0 °, they are identical, whereas if the angle is 90°,theyhave](https://image.slidesharecdn.com/irjet-v4i350-171216110655/75/Algorithm-for-calculating-relevance-of-documents-in-information-retrieval-systems-2-2048.jpg)
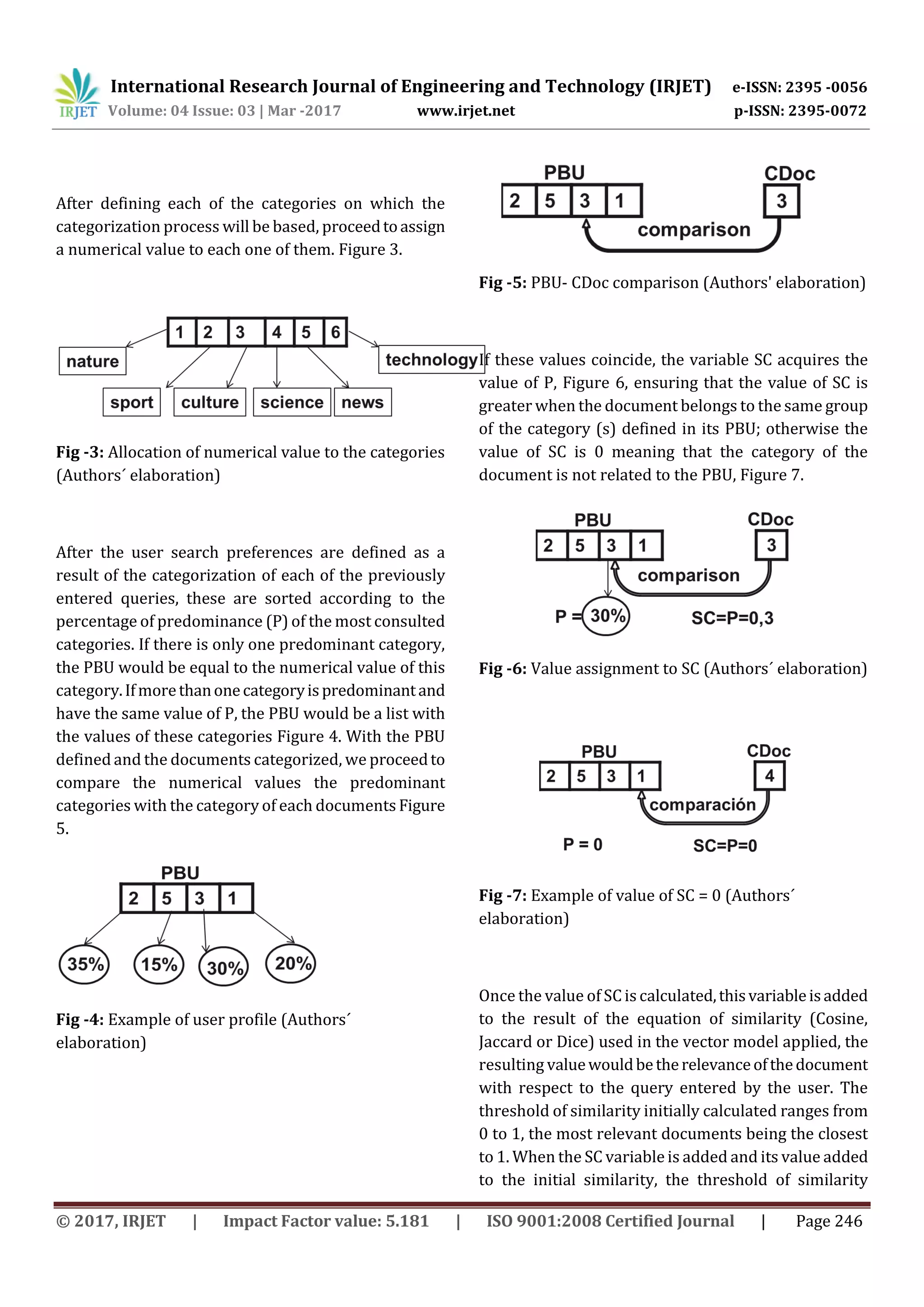
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395 -0056 Volume: 04 Issue: 03 | Mar -2017 www.irjet.net p-ISSN: 2395-0072 © 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 245 absolutely nothing in common. The main advantages of the vector model are the following [10]:Allowpartialhits,since a document can be considered relevant even if it does not include all the terms of the query. The ordering of results is based on several factors: frequency of terms, importance of terms and withoutprioritizinglongerdocuments.Inaddition, it allows an efficient implementation for large collections of documents. The documentsarelocatedindimensionalvector spaces defined by the same terms. Thus ifeachtermdefinesa dimension and the frequency of that term defines a linear scale along that dimension, queries and documents can be represented by vectors in the resulting space. Each term of the queries and documents isweightedbyassigningthemthe inverse value of the frequency of the term in the documents of the collection (IDF - Inverse Document Frequency). This value is calculated using the following equation [8]: Equation 1. Calculating the idf Where N is the number of documentsinthecollectionand nt is the number of documents where the term t appears. The weight of a term t in the document vector is given by the equation: [8] Equation 2. Calculation of the weight of a term Where, f t, d is the absolute frequency of the term t, in the current document. The search algorithmacceptsas inputa query expression or query of a user and will verify in the index which documents can satisfy it. Then, a ranking algorithm will determine the relevance of each document and return a list with the answer. It is established that the firstitemofsaidlist corresponds to the most relevant document regarding the query and so on in decreasing order [15]. With the elements for the retrieval of documents, wecan calculatethesimilarity between a vector of weightsof the terms of the queryq,anda vector of weights of the terms of document d, with the following equations [8]: Equation 3. Cosine Equation 4. Jaccard Equation 5. Dice With the application of these equations we obtain a similarity value between 0 and 1 that allows assigning a relevance to a document with respect to a query. 3. RESULTS AND DISCUSSION The algorithm proposed below allows to add to the equations of similarity presented aboveavariable(SC) that relates the user search preferences or search profile (PBU) to the categories of stored documents (CDoc). In order to obtainthePBUandthustoestablish which category (s) are the most sought by the users and also to obtain the categories of the documents stored CDoc, the use of web mining techniques is proposed. Figure 2. Web mining (MW) refers essentially to the discoveryandanalysisofinformation from users on the web, with the aim of discovering patterns of behavior [16]. Fig - 2: Web mining process [5]](https://image.slidesharecdn.com/irjet-v4i350-171216110655/75/Algorithm-for-calculating-relevance-of-documents-in-information-retrieval-systems-3-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395 -0056 Volume: 04 Issue: 03 | Mar -2017 www.irjet.net p-ISSN: 2395-0072 © 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 247 1’st Author Photo increases from 0 to 2 Figure 8, the most relevant documents are those close to 2. In this way it is guaranteed to provide users with more accurate and better results related to their search preferences. Fig -8: Similarity threshold (Authors´ elaboration) 4. CONCLUSIONS As fundamental conclusions of the investigation it can be said that: The vector IR model has mechanisms that allow a structuring of documents and user queries that create concrete bases for the process of calculatingrelevance. The classic formulas for calculatingsimilaritydonotby themselves satisfy the problem of assigning relevance to documents in an SRI. The use of web mining to process the information stored in an SRI allows inferring important data such as the search profile of users and the category of each indexed document. A proposal of relevance calculation was obtained that integrates variables such as the PBU and CDoc, which allow users toprovideanswersthataremorerelatedto their search needs. REFERENCES [1] Baeza-Yates, r. Y Ribeiro-Neto, b. (1999). Modern Information Retrieval. ACM Press.Addison Wesley. [2] Blázquez Ochando. (2013). Manual Técnicas avanzadas de recuperación de información: procesos, técnicas y métodos. Madrid. ISBN 978-84-695-8030-1. [3] Cacheda, M. (2008). Introduction to the Classic Models of Information Retrieval. Revista General de Información y Documentación. (18):365-374. [4] Croft, W.B. (1987). Approaches to intelligentinformation retrieval. Information Proccesing & Management, 23, 4, pp. 249-254. [5] Fuentes Reyes, Sady C.; Ruiz Lobaina, Marina. (2007). Minería Web: un recurso insoslayable para el profesional de la información. Acimed, vol. 16,no4,p.0- 0. [6] Jaimes, l. G y Vega Riveros. F. (2005). Modelos clásicos de recuperación de la información. [7] Machado García, Neili. (2015). Uso de la similitud semántica para la recuperación de información geoespacial. Página 18. [8] Monsalve, Luz Stella Garcia. (2012). Experimento de recuperación de información usando las medidas de similitud Cosine, jaccard y Dice. TECCIENCIA, vol. 6, no 12, p. 14-24. [9] Pino Toledano, David. (2014). Creación de un crawler semántico y distribuible para su aplicación en un buscador web. [10] Reyna, Yunior César Fonseca. (2012). Recuperación de la información: taxonomía de sus modelos. Revista Cubana de Ciencias Informáticas, vol. 6, no 2. [11] Salton, G. Y MC Gill, m.j. (1983). Introduction to Modern Information Retrieval. New York. Mc Graw-HillComputer Series. Seco Naveiras, Diego. (2009). Técnicas de indexación y recuperación de documentos utilizando referencias geográficas y textuales. [12] Sequera, José Luis Castillo. (2010). Nueva propuesta evolutiva para el agrupamiento de documentos en sistemas de recuperación de información. Tesis Doctoral. Universidad de Alcalá. Página 23, 3 párrafo. [13] Seroubian, Mabel. (2013). Buscadores: cómo usar las herramientas de búsqueda en Internet. Informatio. Revista del Instituto de Información de la Facultad de Información y Comunicación, no 2. [14] Tolosa, Gabriel H.; Bordignon, Fernando R. (2008). Introducción a la Recuperación de Información. [15] Vásquez, Augusto Cortez; Fernández,CayoLeón.(2016). Aprendizaje de perfiles de usuario web para modelizar interfaces adaptativas. Theorema, segunda época,2016, no 3, p. 155-164. BIOGRAPHIES Ph.D Education,CancillerUniversity ECOTEC, Ecuador Ph.D Computing, Adviser postgraduate, Habana, Cuba Ph.D Computing, Adviser postgraduate, Habana, Cuba uthor Photo or Photo](https://image.slidesharecdn.com/irjet-v4i350-171216110655/75/Algorithm-for-calculating-relevance-of-documents-in-information-retrieval-systems-5-2048.jpg)

The document proposes an algorithm to calculate the relevance of documents returned in response to user queries in information retrieval systems. It is based on classical similarity formulas like cosine, Jaccard, and dice that calculate similarity between document and query vectors. The algorithm aims to integrate user search preferences as a variable in determining document relevance, as classic models do not account for this. It uses text and web mining techniques to process user query and document metadata.