Downloaded 286 times
























![3. The Interactive Consistency Problem Every processor broadcasts its initial value to all other processors. The initial values of the processors may be different . A protocol for the interactive consistency problem should meet the following conditions: Agreement: All non-faulty processes must agree on the same array of values A[v1 : : : vn]. Validity: If processor Pi is non-faulty and its initial value is vi , then all non-faulty processes agree on vi as the ith element of the array A. If process j is faulty, then the non-faulty processes can agree on any value for A[j]. Termination: Each non-faulty process must eventually decide on the array A.](https://image.slidesharecdn.com/4-191003050127/75/Agreement-Protocols-distributed-File-Systems-Distributed-Shared-Memory-28-2048.jpg)




















































The document discusses distributed systems, focusing on agreement protocols, distributed resource management, and issues in distributed file systems and shared memory. It explains the necessity of agreement protocols for fault tolerance and synchronization in a distributed environment, covering various agreement problems such as Byzantine agreement and consensus, along with algorithms like the Lamport-Shostak-Pease algorithm. Additionally, it highlights the design issues in building distributed file systems and shared memory, emphasizing aspects like caching, consistency, scalability, and security.
Introduction to Distributed Systems and focus on Agreement Protocols and Resource Management.
Explanation of agreement protocols for cooperation in distributed systems ensuring reliability and fault tolerance.
Describes various problems requiring agreement protocols, like leader election, system models, and processor failure types.
Differentiates between authenticated and non-authenticated messages impacting agreement solutions.
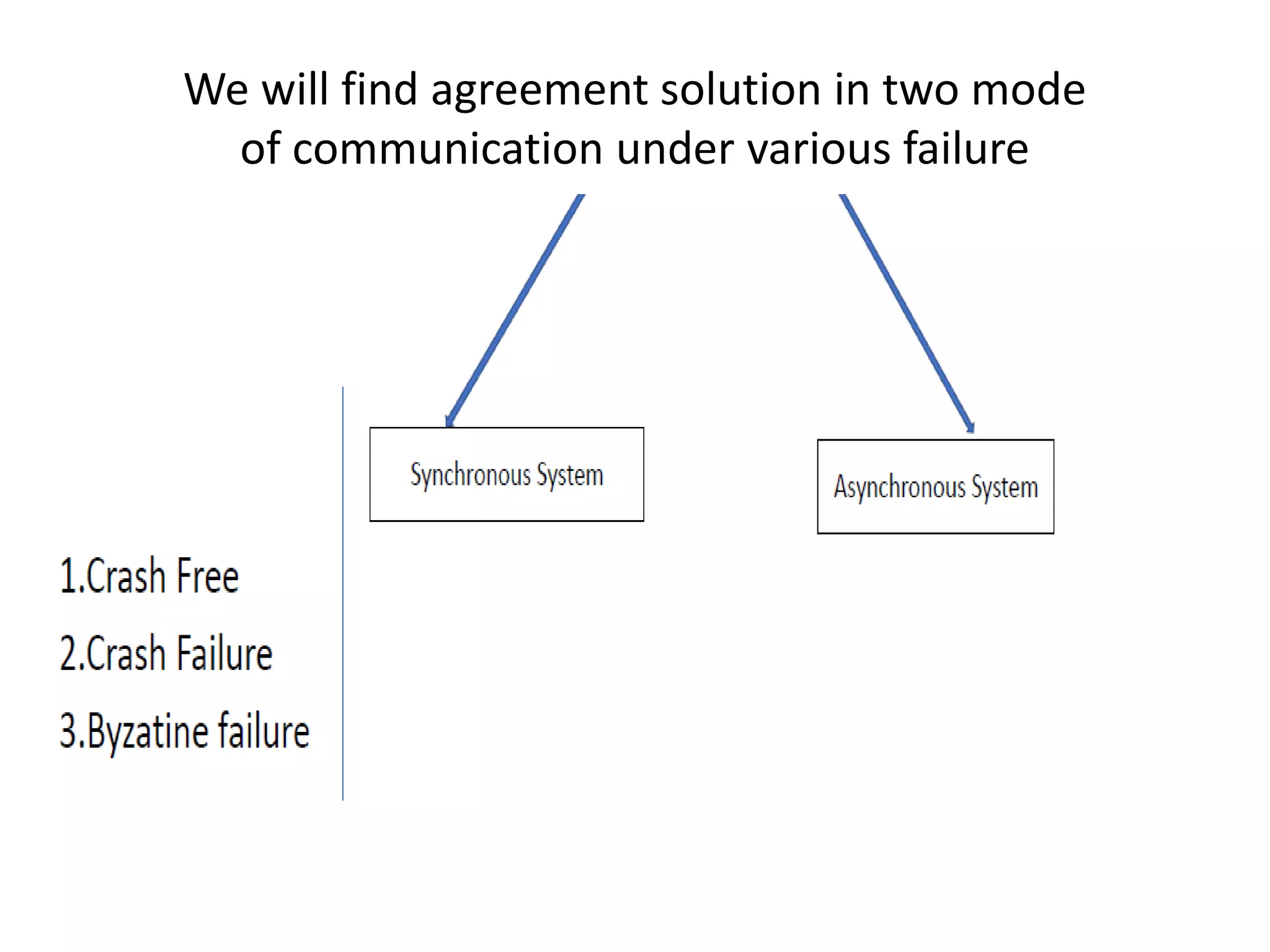
Discusses synchronous and asynchronous modes of communication in agreement protocols.
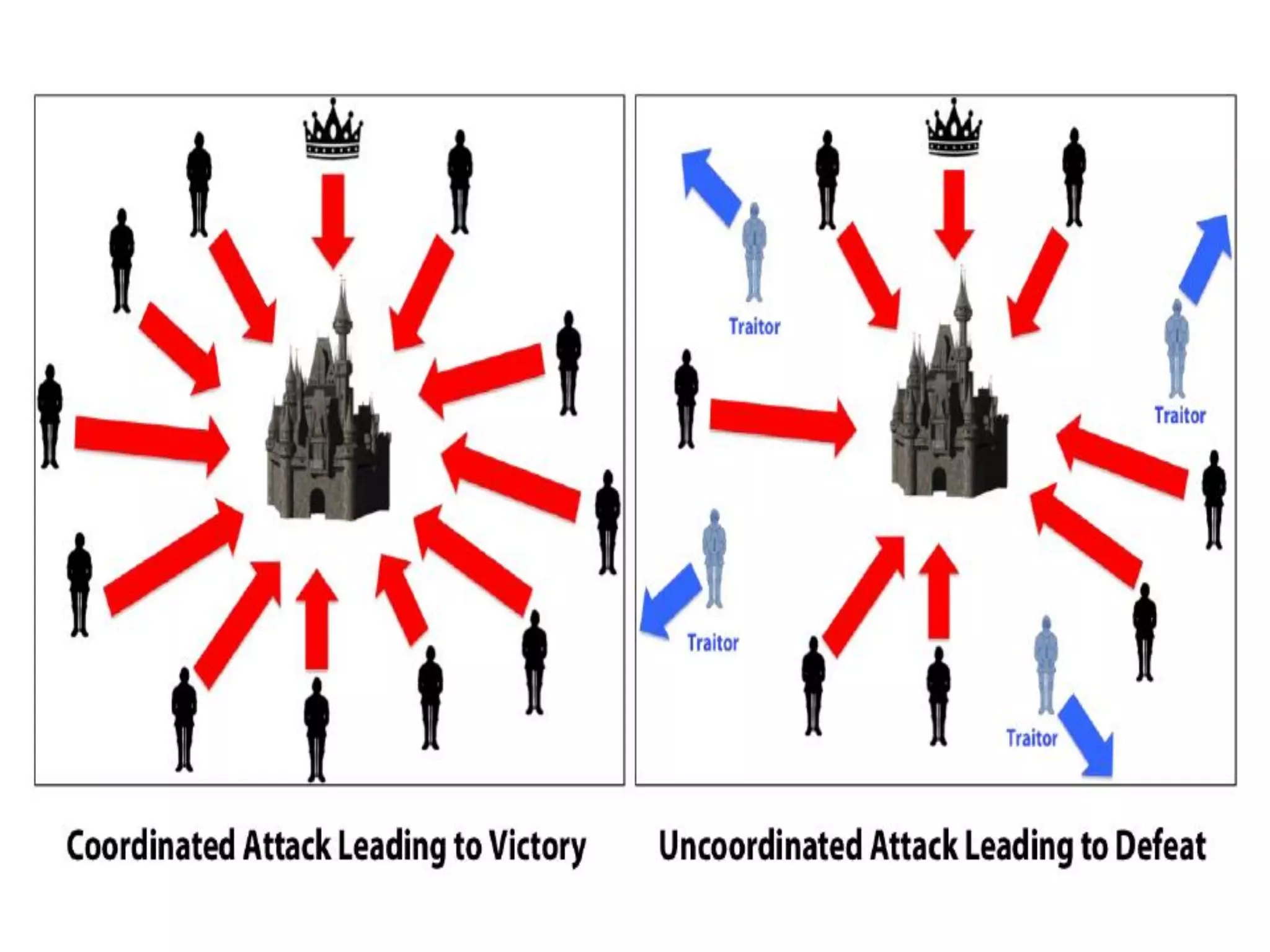
Introduction to the Byzantine Agreement Problem and its context based on historical Byzantine generals.
Specifications of agreement, validity, and termination in Byzantine agreement protocols.
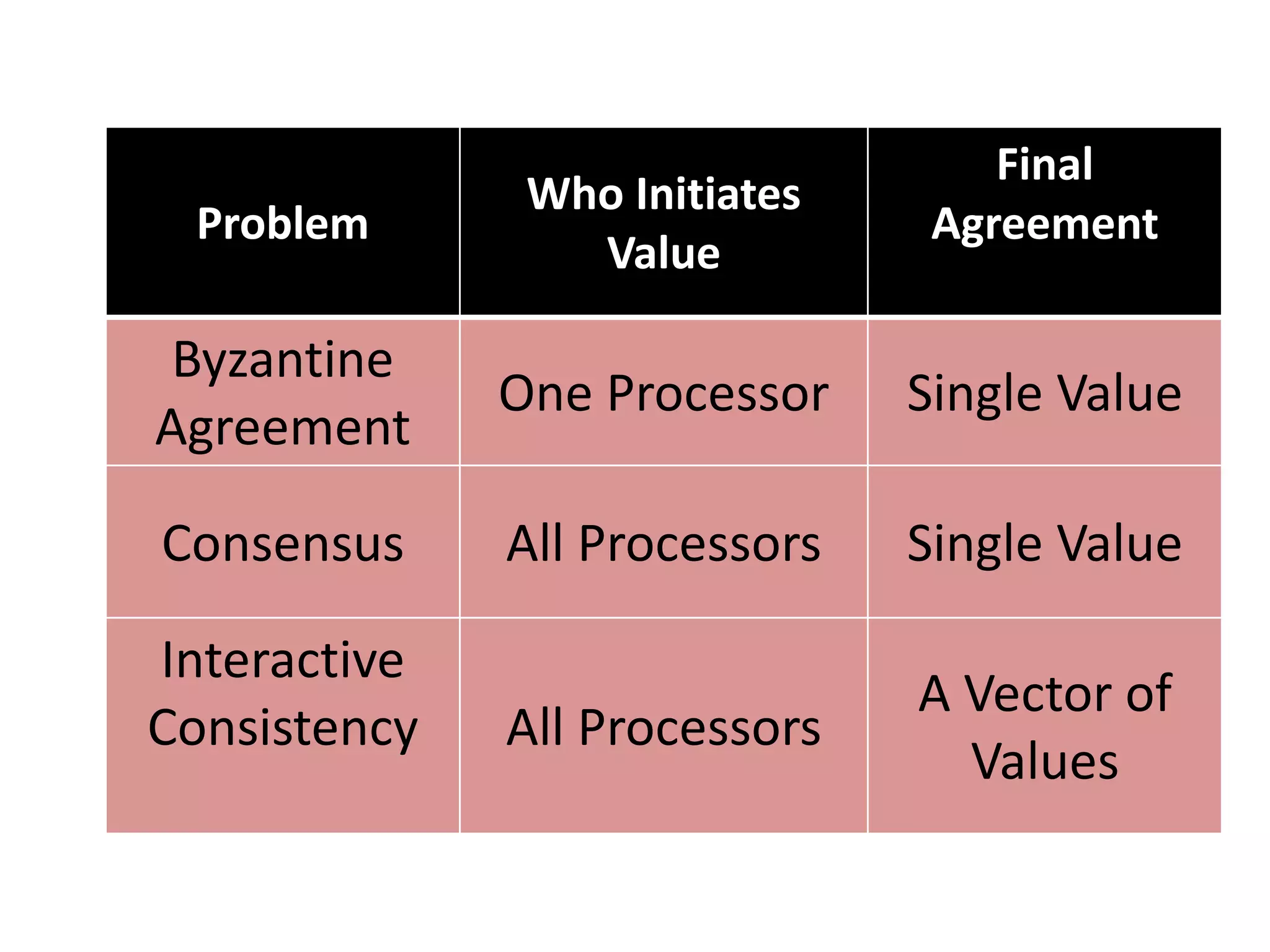
Description of Lamport-Shostak-Pease Algorithm and its mechanics for resolving Byzantine agreement challenges.Outlines the Consensus Problem and Interactive Consistency Problem, emphasizing agreement and termination conditions.
Metrics including time, message traffic, and storage that assess the efficiency of agreement protocols.
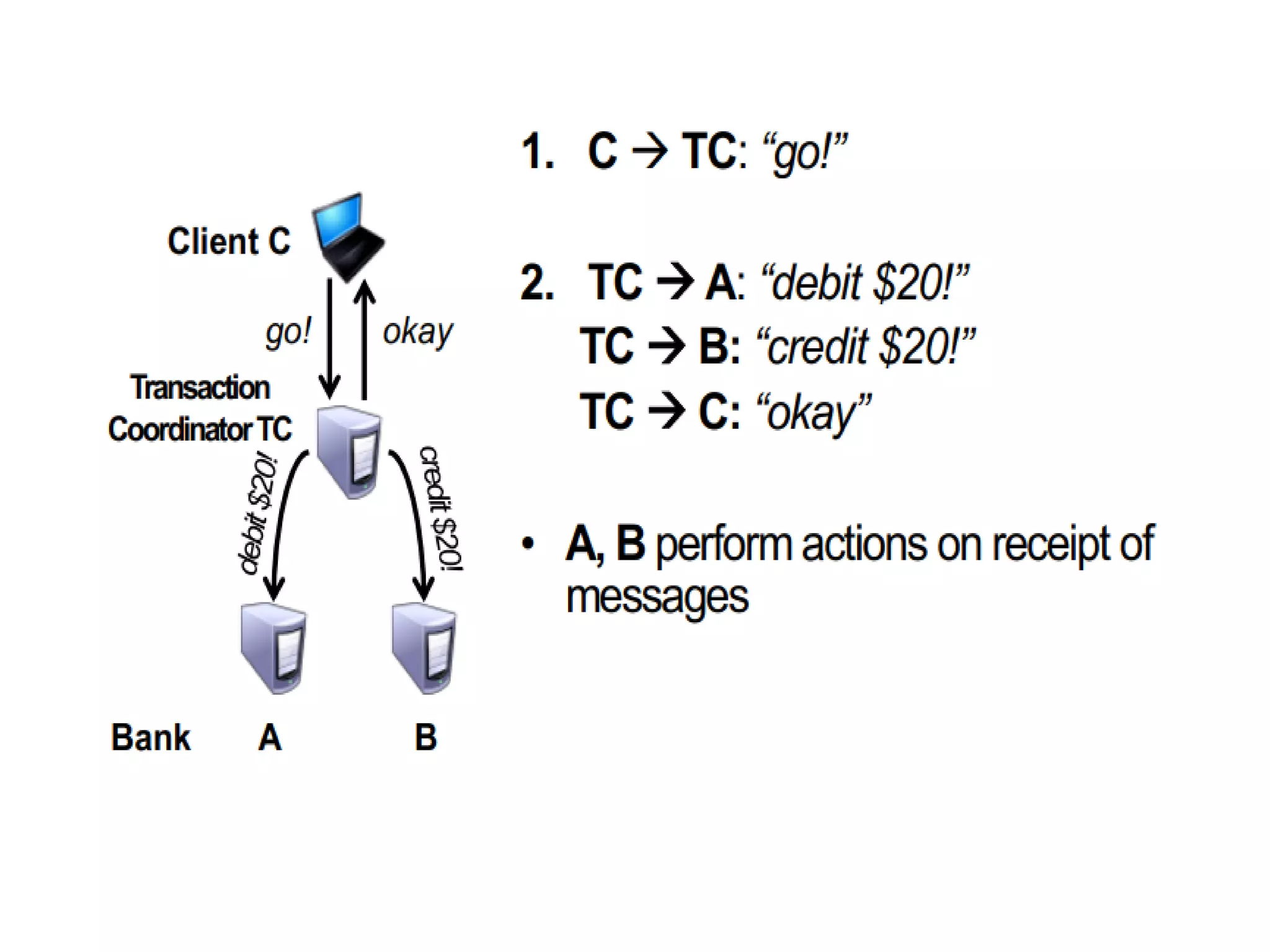
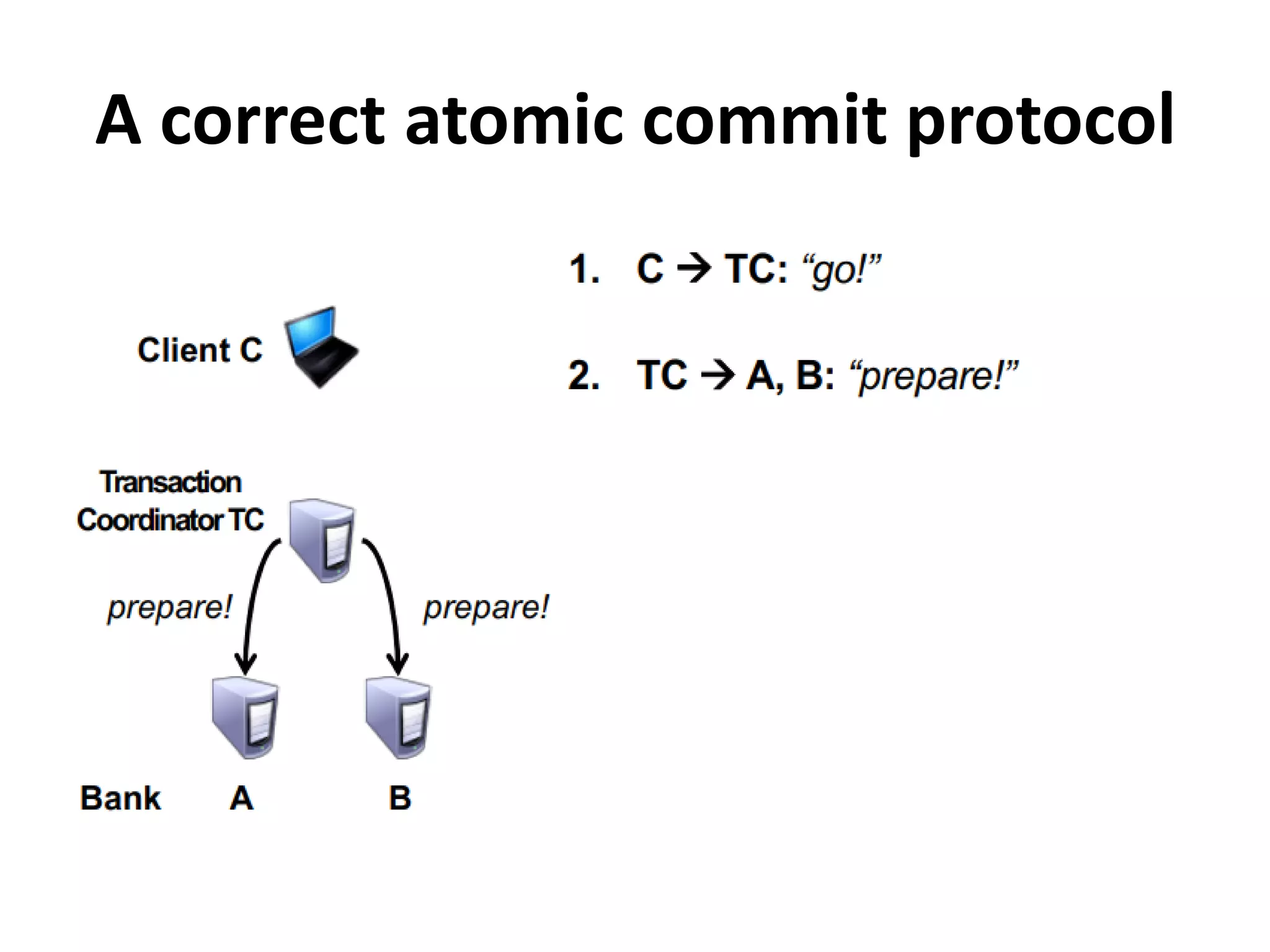
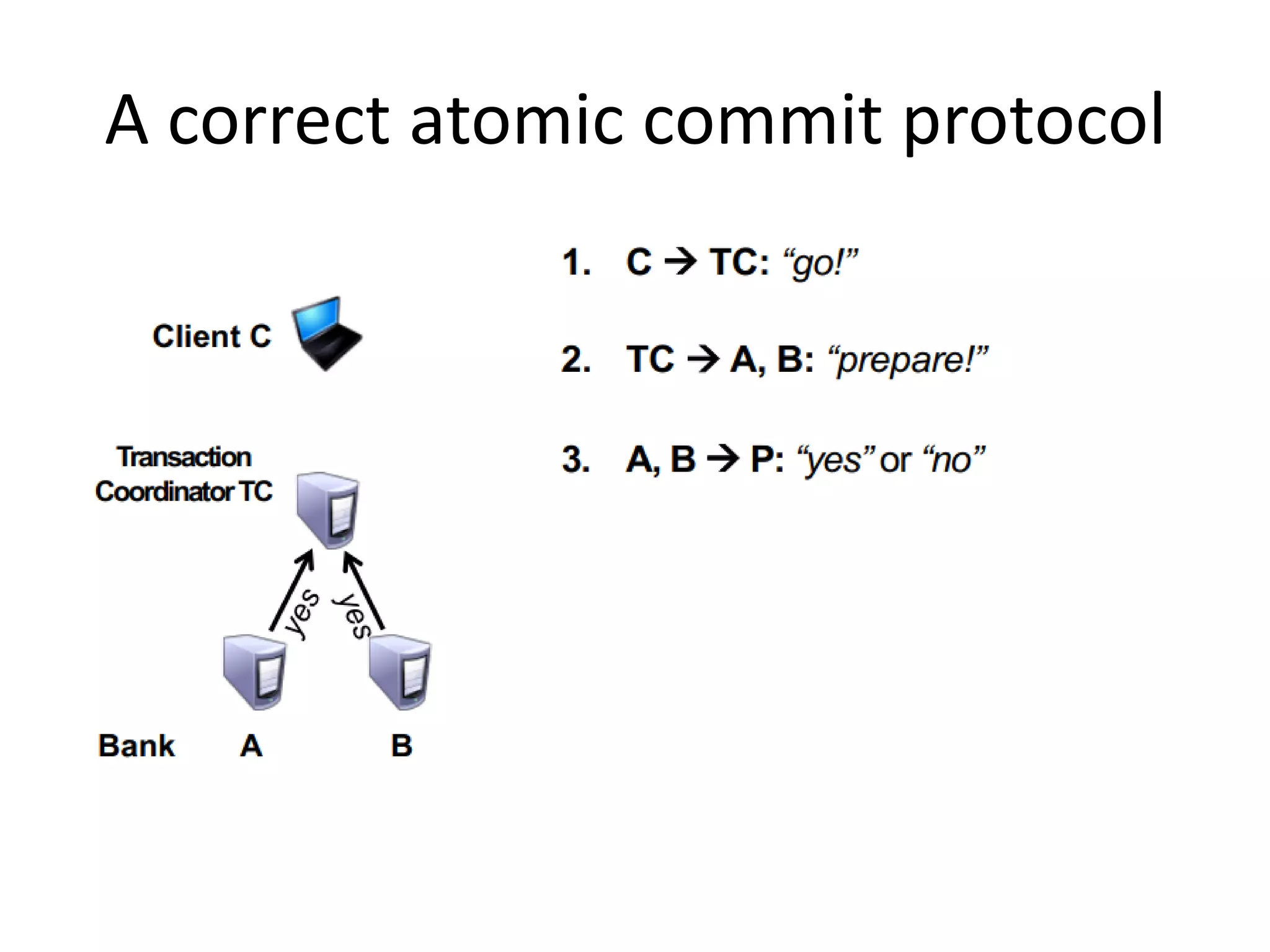
Highlights practical applications of agreement protocols in clock synchronization and atomic commit in distributed databases.
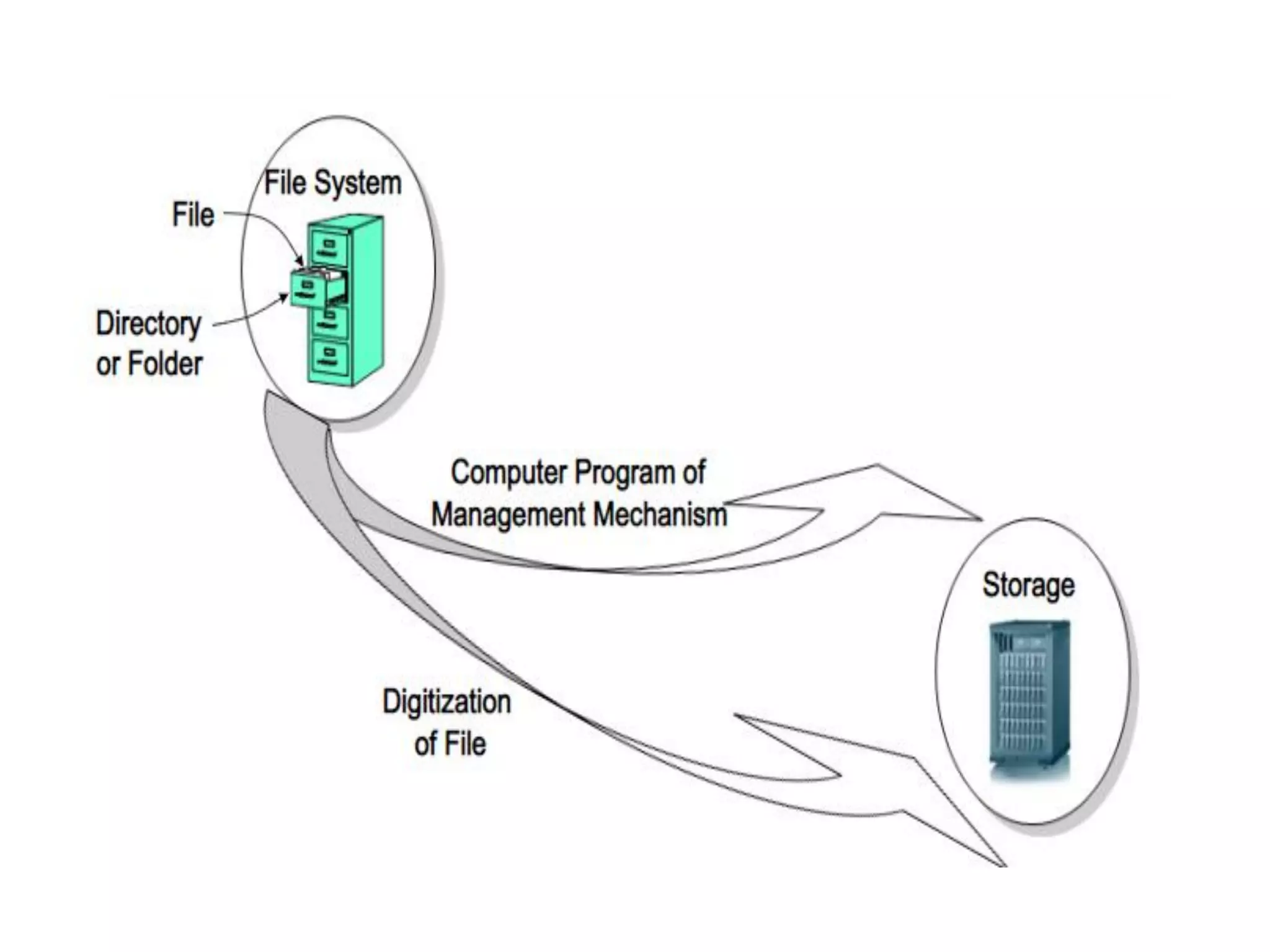
Introduction to Distributed Resource Management focusing on distributed file systems and shared memory.
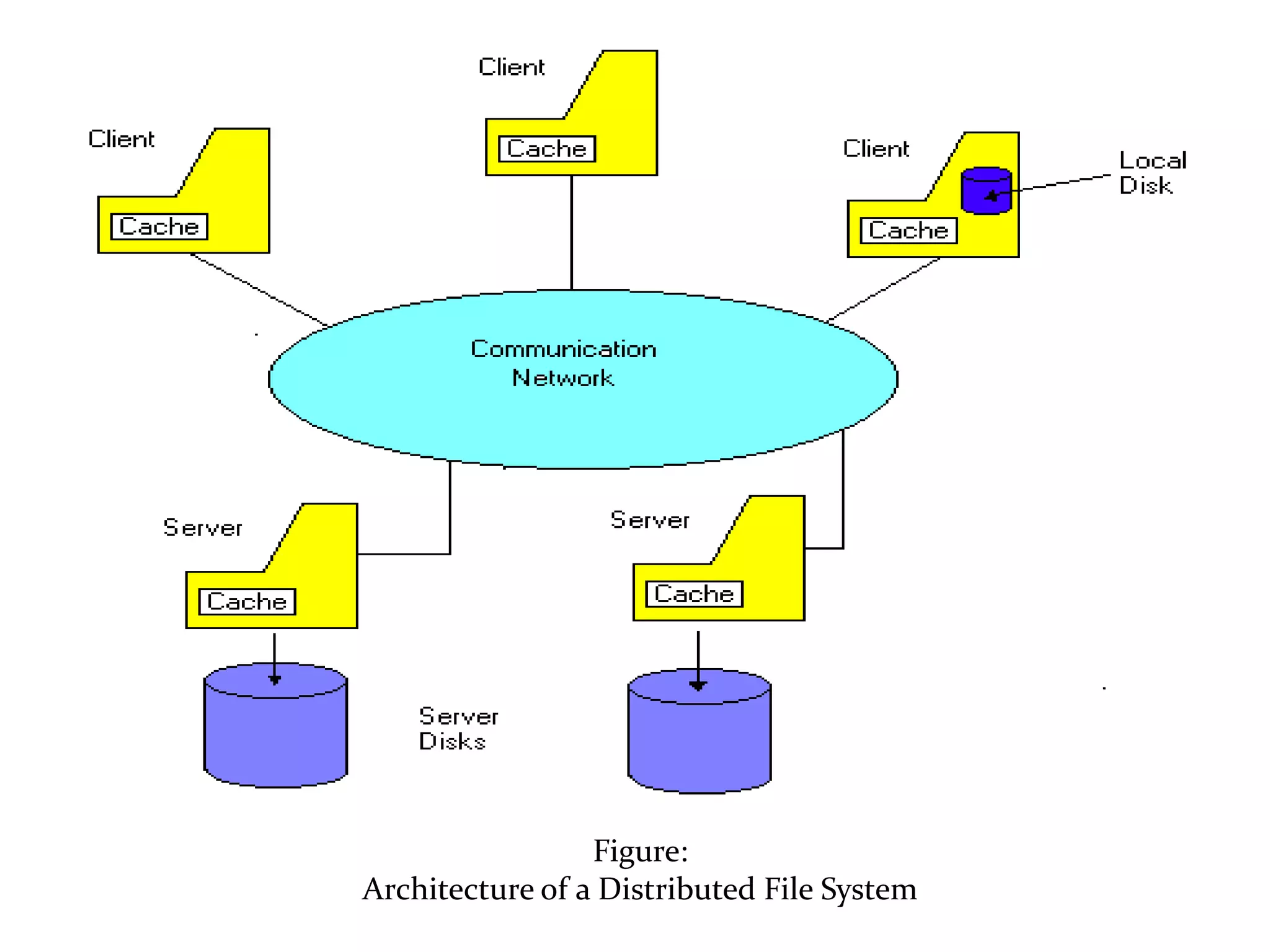
Architecture and operation of distributed file systems, emphasizing network transparency and high availability.
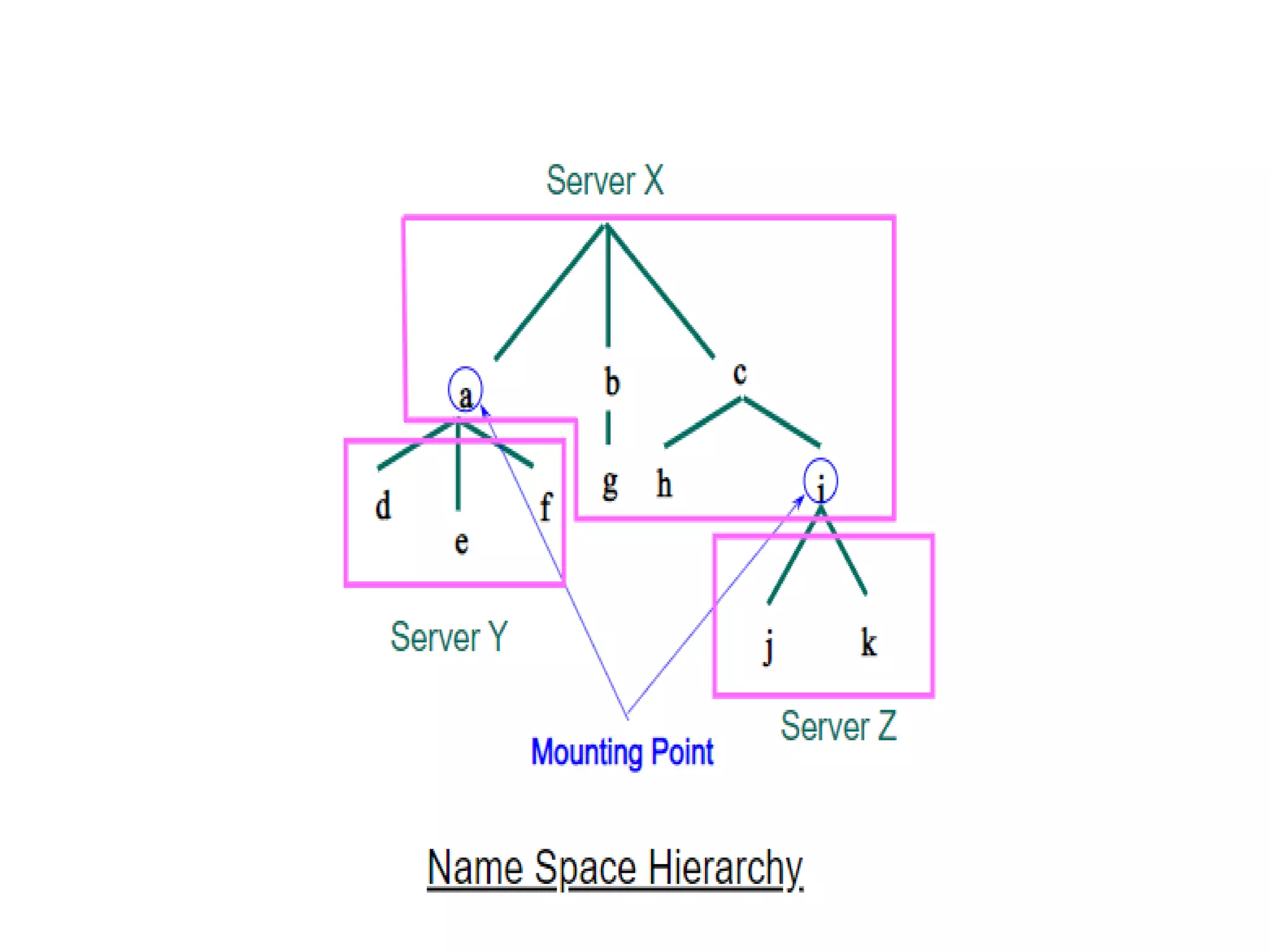
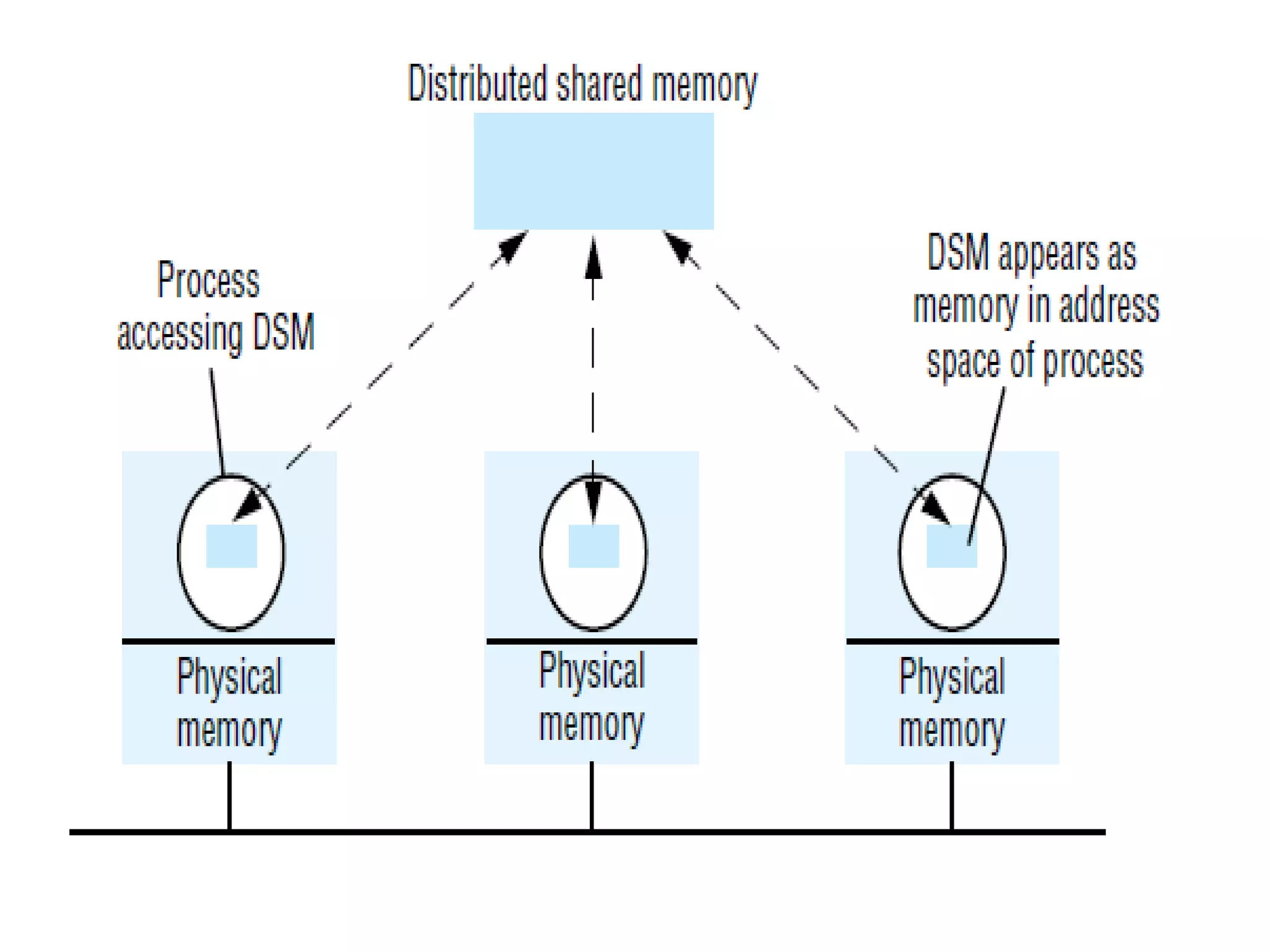
Examines issues like naming, caching, replication, availability, and consistency in distributed file systems.Various mechanisms including mounting, caching, hints, bulk data transfer, and encryption relevant to file systems.Concept of distributed shared memory providing a coherent shared address space across distributed systems.
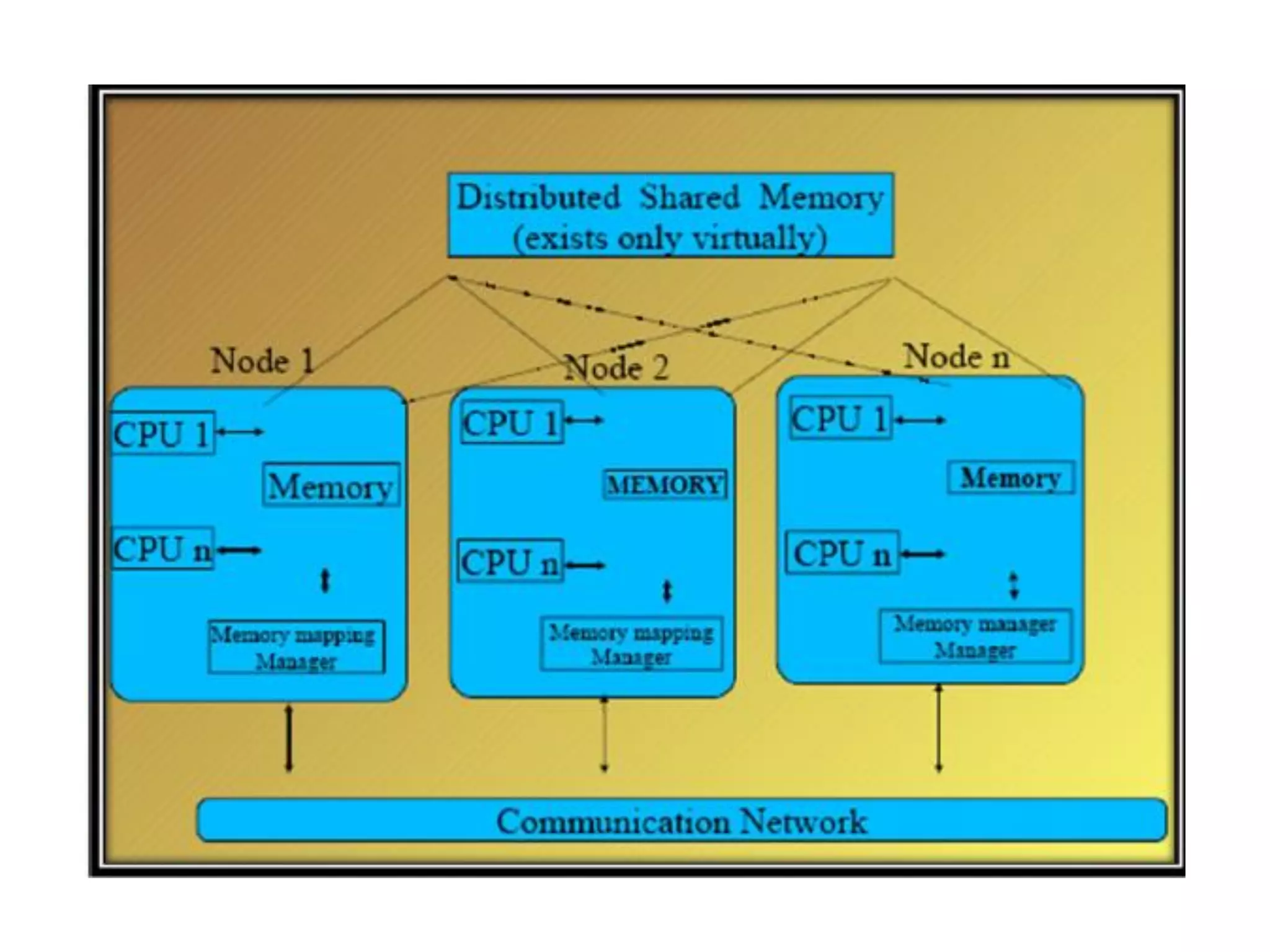
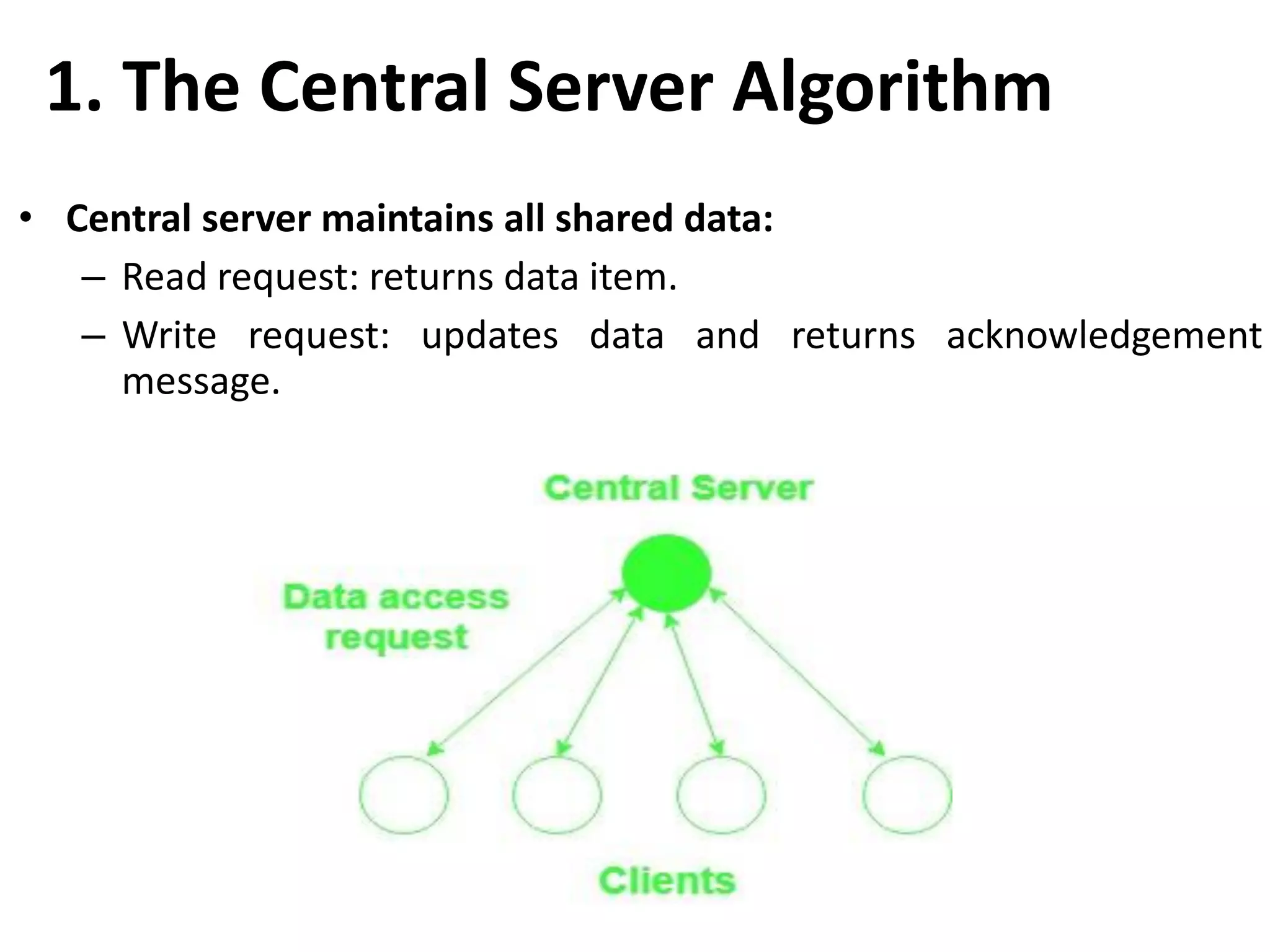
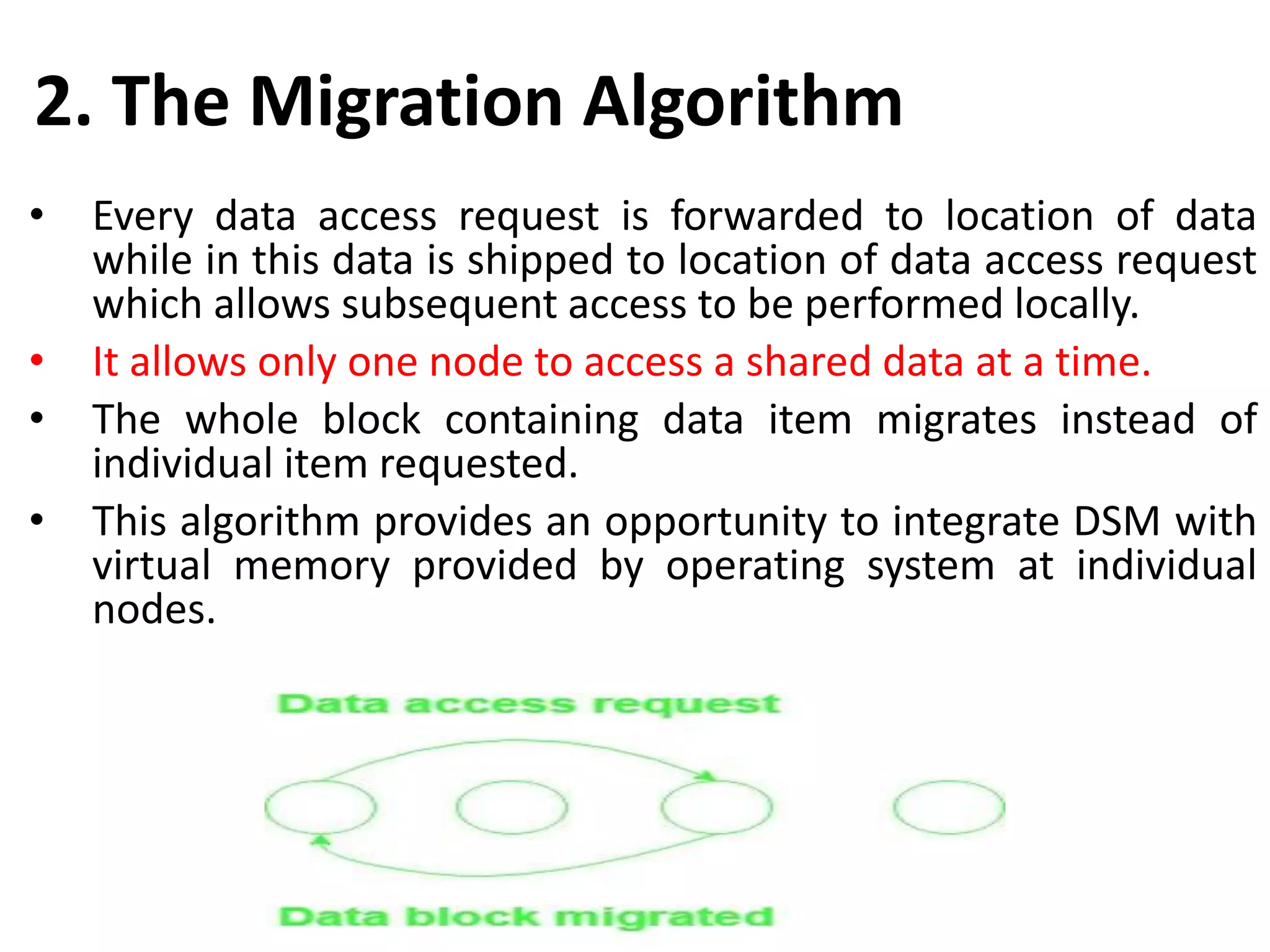
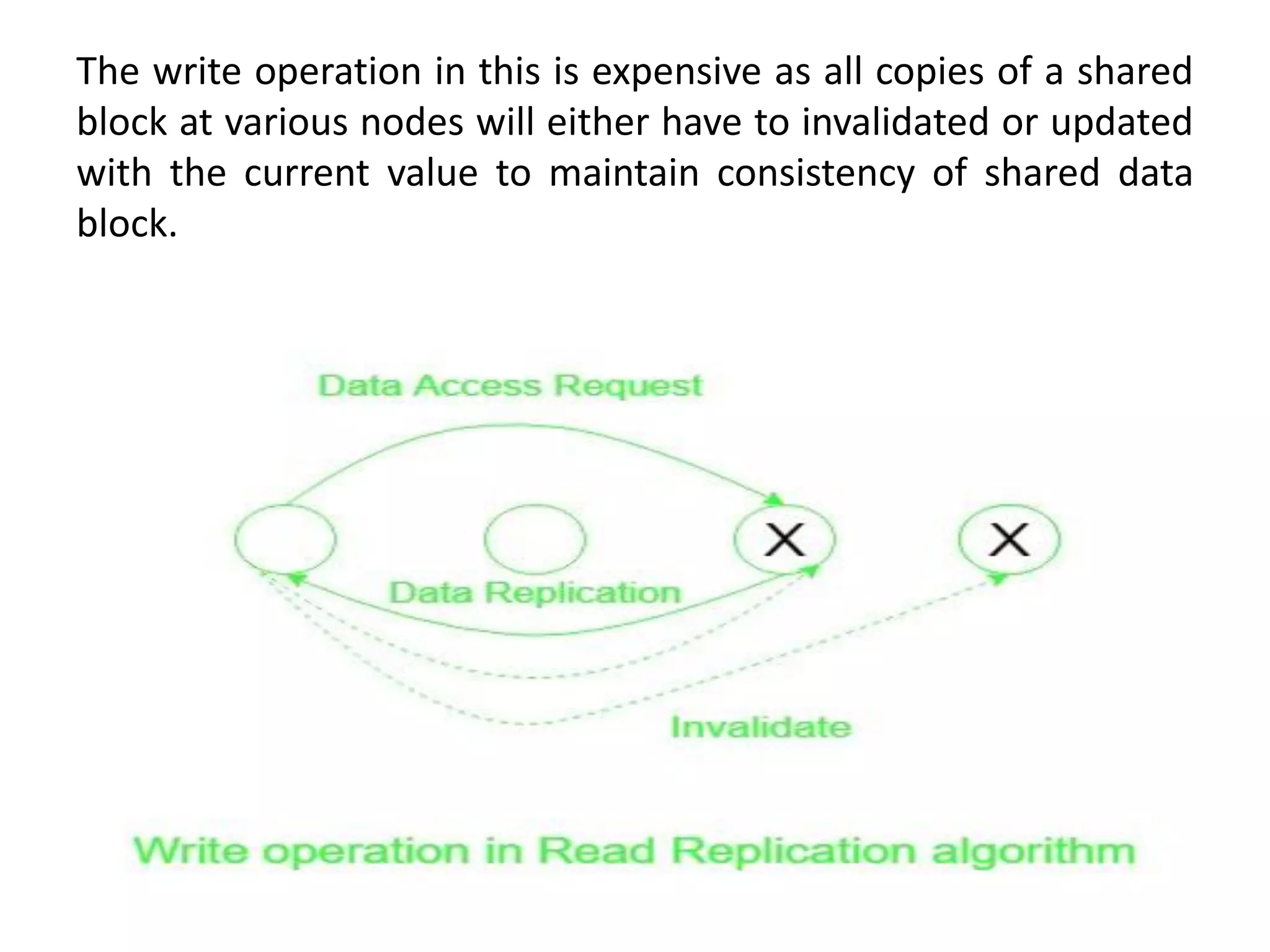
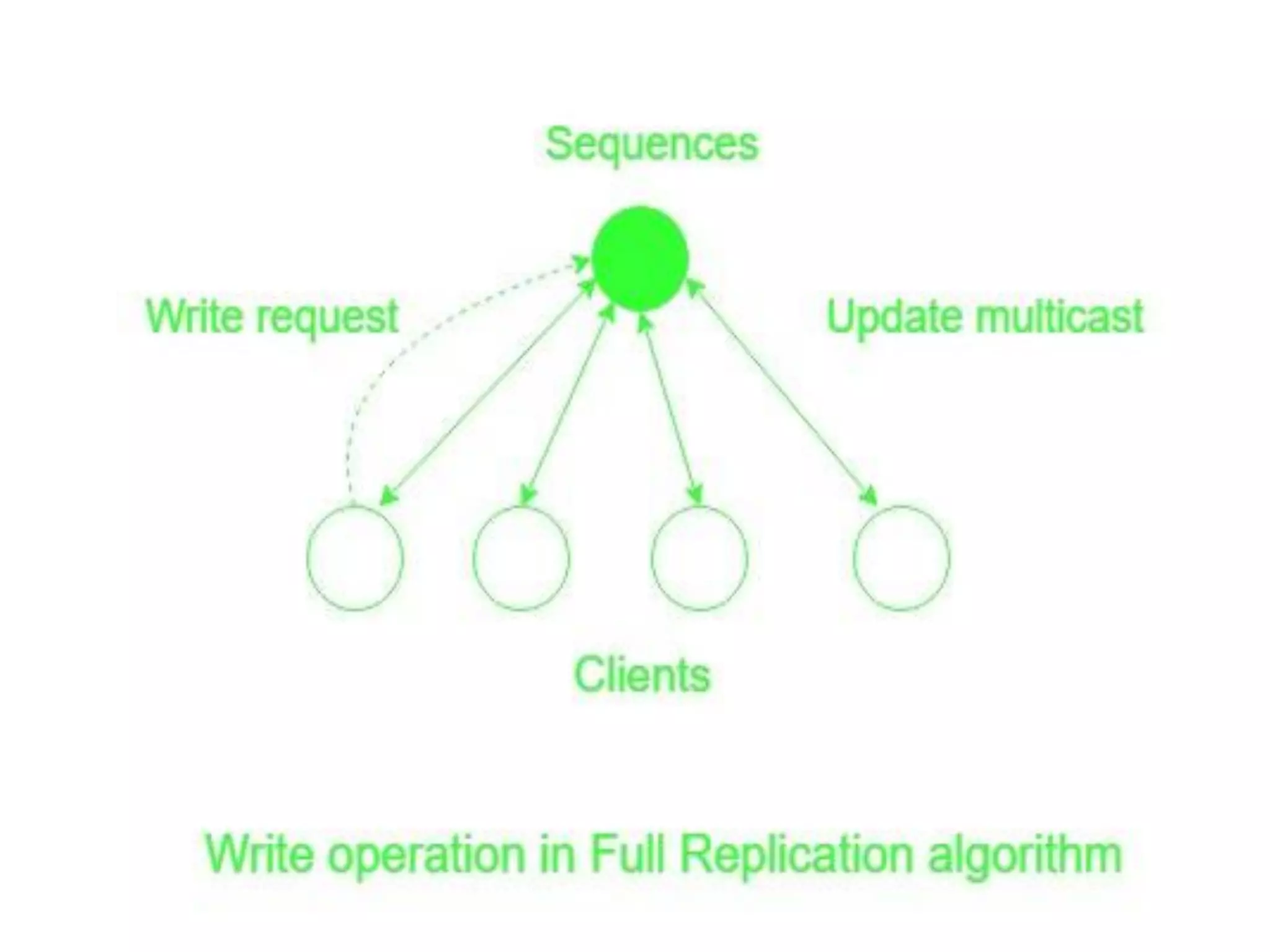
Describes the architecture, advantages, and critical design issues of implementing distributed shared memory.Overview of algorithms for DSM implementation including the Central Server, Migration, Read-Replication, and Full-Replication.