Downloaded 49 times








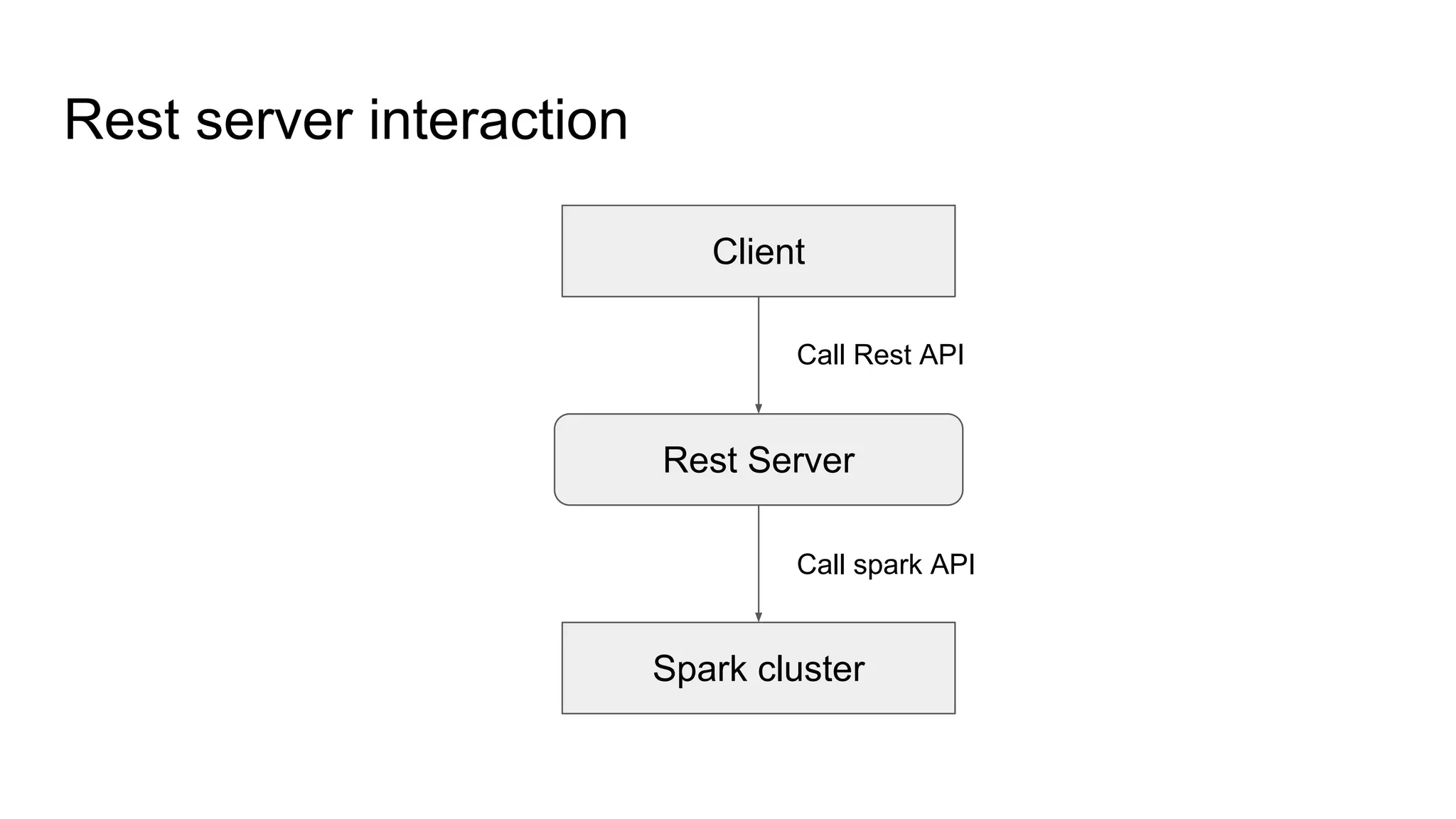








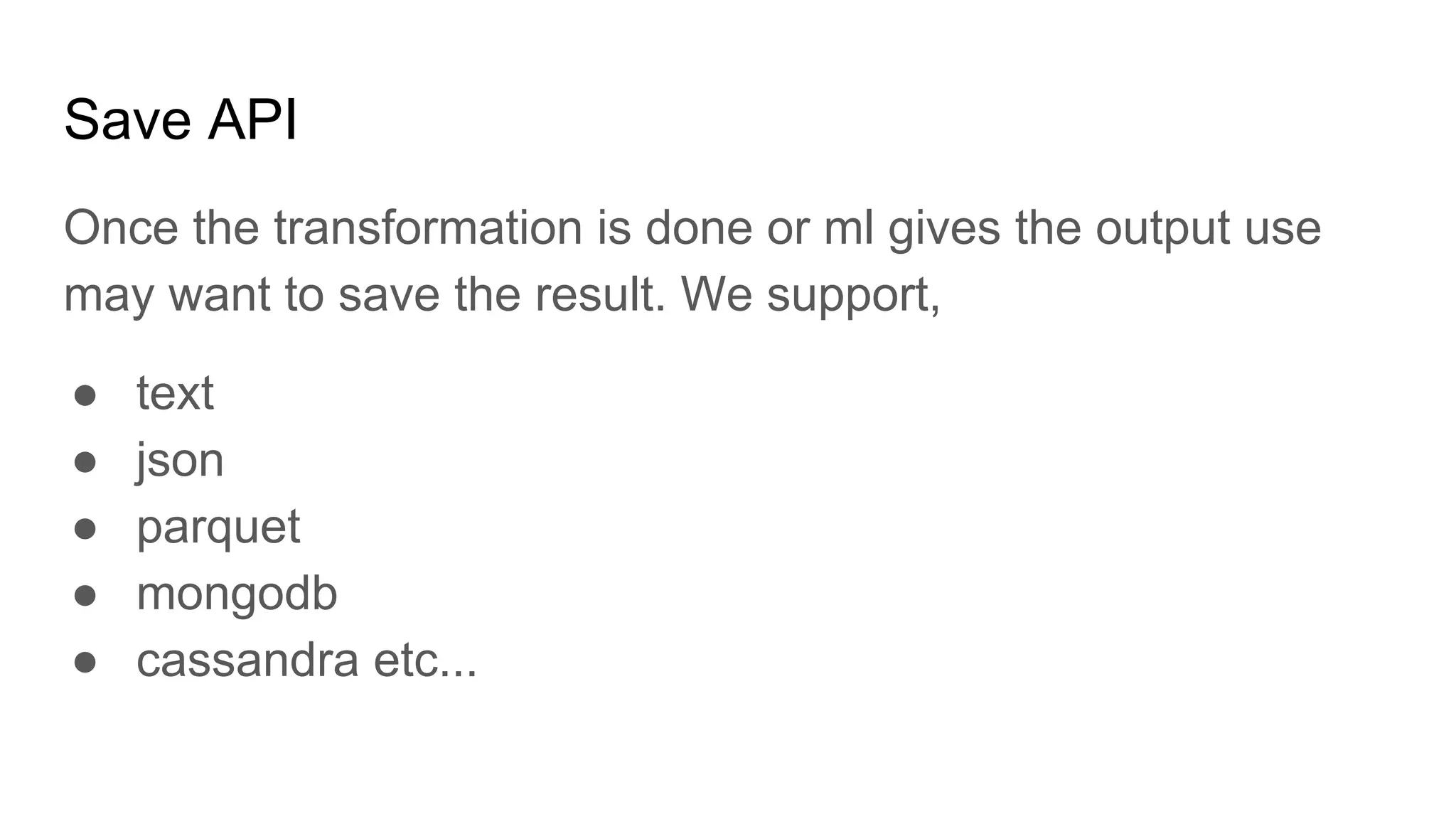



The document describes a big data analysis tool developed using Spark, focusing on data transformation and analysis through a REST API. It supports various data sources and machine learning functions while addressing challenges like standardizing inputs for different ML algorithms. The tool aims to provide a generic solution to help businesses leverage data effectively, though it acknowledges that no single solution can solve all big data challenges.