This document presents a study on secure multi-authentication data classification models in cloud computing environments, focusing on the application of improved Bayesian techniques for data classification and encryption of sensitive data. It discusses cloud computing's architecture, deployment models (public, private, hybrid, and community), and the significance of data classification using machine learning algorithms to enhance security and optimize data management. The authors explore various security issues, risks, and proposed solutions pertinent to cloud environments, drawing on multiple literature sources while identifying gaps for future research.
![International Journal of Advances in Applied Sciences (IJAAS) Vol. 9, No. 3, September 2020, pp. 240~254 ISSN: 2252-8814, DOI: 10.11591/ijaas.v9.i3.pp240-254 240 Journal homepage: http://ijaas.iaescore.com A study secure multi authentication based data classification model in cloud based system Sakshi kaushal1 , Bala buksh2 1 Computer science Engineering, Career Point University, Himachal Pradesh, India 2 Computer Science Engineering, R N Modi Engineering College, Rajasthan, India Article Info ABSTRACT Article history: Received Jul 2, 2019 Revised Apr 13, 2020 Accepted May 15, 2020 Abstract: Cloud computing is the most popular term among enterprises and news. The concepts come true because of fast internet bandwidth and advanced cooperation technology. Resources on the cloud can be accessed through internet without self built infrastructure. Cloud computing is effectively managing the security in the cloud applications. Data classification is a machine learning technique used to predict the class of the unclassified data. Data mining uses different tools to know the unknown, valid patterns and relationships in the dataset. These tools are mathematical algorithms, statistical models and Machine Learning (ML) algorithms. In this paper author uses improved Bayesian technique to classify the data and encrypt the sensitive data using hybrid stagnography. The encrypted and non encrypted sensitive data is sent to cloud environment and evaluate the parameters with different encryption algorithms. Keywords: Bayesian technique Cloud computing Data mining Internet This is an open access article under the CC BY-SA license. Corresponding Author: Sakshi kaushal, Computer science Engineering, Career point university kota Rajasthan, Aalniya, Rajasthan 324005, India. Email: sksakshi.kaushal@gmail.com 1. INTRODUCTION The growth and use of internet services cloud computing becomes more and more popular in homes, academia, industry, and society [1]. Cloud computing is envisioned as the next-generation architecture of IT Enterprise, which main focus is to merge the economic service model with the evolutionary growth of many offered approaches and computing technologies, with distributed applications, information infrastructures and services consisting of pools of computers, storage resources and networks. Cloud computing has almost limitless capabilities in terms of processing power and storage [2]. Cloud computing offers a novel and promising paradigm for organization and provide information and communication technology (ICT) resources to remote users [3]. Client does not handle or control the cloud’s infrastructure so far, they have power over on operating systems, applications, storage space, and probably their components selection. A Cloud System defined at the lowest level as the difficult server, which having the substantial devices, processing unit and memory [4]. To give the distribution of existing services and applications, the Cloud server is auxiliary divided in multiple virtual machines [5]. Every virtual machine is definite with various specification and characterization. The logical partition of existing memory, resources and processing capabilities is done. The separation is based on the requirement of the application, user requirement and just before achieves the quality of services. In this type of environment, there can be multiple instances of related services, products and data. When a user enters](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-1-2048.jpg)
![Int J Adv Appl Sci ISSN: 2252-8814 A study secure multi authentication based data classification model in cloud based system (Sakshi Kaushal) 241 to the Cloud System, here is the main requirement of identification of useful Cloud service for Cloud user. As also there is the necessity to process the user request successfully and reliably. Types of cloud To given a secure Cloud computing key a main decision is to focus which type of cloud to be implemented as shown in Figure 1. There are four types of cloud deployment models are a public, community, private and hybrid cloud [6, 7]. Figure 1. Types of cloud [2] a. Private cloud A private cloud is place up within an organization’s interior project datacenter. In the private cloud, virtual applications provided by cloud merchant and scalable resources are pooled together and presented for cloud users so that user share and use them. Deployment on the private cloud can be greatly more secure than that of the public cloud as of its specific internal experience only the organization and selected stakeholders have access to control on a specific Private cloud [8]. b. Hybrid cloud A hybrid cloud is a private cloud associated to one or other external cloud services, centrally provisioned, managed as a solitary unit, and restricted by a protected network. A hybrid cloud architecture combination of a public cloud and a private cloud [9]. It is also an open architecture which allows interfaces by means of other management systems. In the cloud deployment model, storage, platform, networking and software infrastructure are defined as services to facilitate up or down depending on the demand. c. Public cloud A public cloud is a model which gives users to access the cloud using interfaces by web browsers. A public cloud computing most commonly used cloud computing service [10]. It’s usually based on a pay-per- use model, like to a prepaid electricity metering system which is capable enough to supply for spikes in demand for cloud optimization. This helps client to enhance the match with their IT expenditure at operational level by declining its capital expenditure on IT infrastructure. Public clouds are not as much of secure than the other cloud models because it places an extra burden of ensuring that all data and applications accessed on the public cloud are not subjected to malevolent attacks.](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-2-2048.jpg)
![ ISSN: 2252-8814 Int J Adv Appl Sci, Vol. 9, No. 3, September 2020: 240 – 254 242 d. Community cloud The Cloud System can exist situate up particularly for a firm, organization, institution [11]. The rules for authentication, authorization and usage architecture can be defined exclusively for the organization users. The policy, requirement and access methods are defined only for the organization users. Such type of organization secret Cloud System is called Community Cloud. Data classification By classifying the data using supervised machine learning algorithm into sensitive data and non- sensitive data in order to reduce the data hiding time [12]. Data classification is done using improved Boosting algorithm which will classify the data according to the security requirement. Data classification is a machine learning technique used to predict the class of the unclassified data. Data mining uses different tools to know the unknown, valid patterns and relationships in the dataset. These tools are mathematical algorithms, statistical models and Machine Learning (ML) algorithms. Consequently, data mining consists on management, collection, prediction and analysis of the data. ML algorithms are described in two classes: supervised and unsupervised. a. Supervised learning In supervised learning, classes are already defined. For supervised learning, first, a test dataset is defined which belongs to different classes. These classes are properly labelled with a specific name. Most of the data mining algorithms are supervised learning with a specific target variable. The supervised algorithm is given many values to compare similarity or find the distance between the test dataset and the input value, so it learns which input value belongs to which class. b. Unsupervised learning In unsupervised learning classes are not already defined but classification of the data is performed automatically. The unsupervised algorithm looks for similarity between two items in order to find whether they can be characterized as forming a group. These groups are called clusters. In simple words, in unsupervised learning, “no target variable is identified”. The classification of data in the context of confidentiality is the classification of data based on its sensitivity level and the impact to the organization that data be disclosed only authorized users. The data classification helps determine what baseline security requirements/controls are appropriate for safeguarding that data. 2. LITERATURE REVIEW Singh et al. [13] clear a complete survey on different safety issues that affect communication in the Cloud environment. A complete discussion on main topics on Cloud System is given, which includes application, storage system, clustering technique. The Cloud System approval security and extra security concerns are too discussed by the authors. The module level deployment and related security impact are discussed by the authors. Authors also discussed the related faith and confidence with subject categorization. Different security threats and the future solutions are also suggested by the authors. The paper also recognized a few forensic tools used by previous researchers to path the security leakage [13]. The descriptive and relative survey is specified to recognize different security issues and threats. Several solutions set by previous researchers are too provided by the authors. The safety mixing to unusual layers of Cloud System is accessible and moderately provided the solutions and the concerns. Just the comparative and vivid review of work complete is given. No analytical explanations are provided by the authors. Faheem Z. et al. [14] explored a variety of types of inner and outer attacks so as to affect the Cloud network. Authors recognized the safety requirements in Cloud System in deepness and moderately possible mitigation methods are too defined based on previous studies. Authors had known the requirement of safety in Cloud System and virtual benefits. The assault impact and assault result are provided by the authors. Authors mostly provided a result against verification attack, sql injection attack, phishing attack, XML signature wrapping attack, etc. A lesson work on special attack forms and virtual solution methods is provided in the given work. The attack solutions or protection solutions are provided as the included layer to the Cloud System different exposure and avoidance-based approaches are too defined by the authors as the included Cloud service [15]. In future, a new attack detection or preventive method is required [14]. Abuhussein, Bedi, and Shiva proposed comparison between security and privacy attributes like backup, cloud employee trust, encryption, external network storage, access control, dedicated hardware and data isolation, monitoring, access computing services so consumers can make well educated choice cloud related insider threats lay in three](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-3-2048.jpg)
![Int J Adv Appl Sci ISSN: 2252-8814 A study secure multi authentication based data classification model in cloud based system (Sakshi Kaushal) 243 groups: cloud provider administrator, employee in victim organization, who uses cloud resources to carry out attacks [16]. Derbeko et al. [17] defined the safety aspects for Cloud System beside a variety of attacks in actual time Cloud environment. The calculation is provided for MapReduce situation with communal and confidential Cloud specification. The privacy data computation, integrity analysis and accuracy of outcome are investigated by the authors. The constraint characterization and challenges of MapReduce scheme for data safety are discussed by the authors. The security and privacy control with master procedure are defined to attain superior safety aspects for Cloud System. Different safety methods, including authentication, authorization and access control observations are also provided by the authors [17]. With reference [18, 19] Tawalbeh, Darwazeh, Al-Qassas and Aldosari propose a secure cloud computing model based on data classification. The proposed cloud model minimizes the overhead and processing time needed to secure data through using different security mechanism with variable key sizes to provide the appropriate confidentiality level required for the data. They have stored data using three levels: basic, confidential and highly confidential level and providing different encryption algorithm to each level to secure the data. This proposed model was tested with different encryption algorithms and the simulation results showed the reliability and efficiency of the proposed framework. a. Review on the basis of authentication Cusack and Ghazizadeh [20] recognized the service access threat with the human behavior study Authors known the best behavioral belief for Cloud server with single sign in approval the individuality management and comparatively optimization to human actions are also provided. Authors evaluated the special risk factors below security solutions recommended These acknowledged risks take in human user risk, disclosure risk and service security risk. Trust behavior-based trust analysis process is provided to manage the access behavior. Contribution: - Safety measure and belief observations are provided based on the client behavior analysis. - A solo sign in approval is provided for efficient identity confirmation and management. Scope: - Only the way of sign in approval is provided, but authors perform not provide the real time implementation or analysis. In future, such real time execution can be applied to confirm the work. Yang et al. (2016) clear a full study work on GNFS algorithm for the Cloud System. beside with method exploration and analysis, a fresh block Wiedemann algorithm is too provided by the authors. The process is based on strip and cyclic partitioning to do block encoding. The defined process works on a similar block processing to decrease the processing time. The chronological block processing can be complete to improve the information encoding by the improved strip block form as a result that the information security can be enhanced [21]. Contribution: - A narrative widemann algorithm is providing with enhanced strip block giving out for data encoding. - The similar block processing process has improved the processing for encoding elevated volume data. Scope: - The assessment of the process is provided below block size and competence parameter. No attack consideration is given. In the future, analysis relation to extra parameters such as file type or the difficulty measures can be provided. b. Review on the basis of security assessment Modic et al. (2016) provided a learn of accessible Cloud security estimation methods for actual world applications. The document also defined a fresh security assessment way called Moving Intervals Process (MIP). The quantitative analysis process is also definite with processing method based on dissimilar security or accessibility parameters. A survey is also system to control different categories and structures based on the quantitative requirement. Authors identified the least maximum and actual time requirements and then comparatively perform the price specific measure. The manage measure is here defined in the form of scores [22]. Zhang (2014) has provided a better view of Cloud security below issue examination and financial impact on industry or the organization. The dynamic body-based livelihood control is discussed on static network. The domination specific threat and fulfillment rule are evaluated to get better the power of Cloud System. The danger evaluation-based value measures are provided to put in up long word practices to the Cloud System [23]. Kalloniatis (2013) has defined a reading work to know various security intimidation in Cloud System. The solitude and security issues are recognized with related properties. This paper also definite the process to](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-4-2048.jpg)
![ ISSN: 2252-8814 Int J Adv Appl Sci, Vol. 9, No. 3, September 2020: 240 – 254 244 provide security over Cloud System. Unusual threats on different Cloud service models are known by the author. The necessity engineering for Cloud System is too identified with essential challenges and characterization. The admission criticality and challenges are explored with threat evaluation and impact analysis [24]. c. Review on the basis of cloud security framework Ramachandran (2016) provided a broad descriptive study on various condition engineering ways and their management. The paper worked mostly on safety as a repair layer to get better the safety aspects and their sharing to the Cloud environment. The included service model with software development system is provided by the author. The logical research and obligation mapping are provided as an example which is being used in various models as integrated form. The safety privileges for every stakeholder is identified and provided the technique for the security requirement, method and maintenance [25]. Contribution: - A safety as service included Cloud System development representation is provided for scheme design and distribution. - The analytical copy is provided for the obligation of different stakeholders as well as procedure stages of Cloud System. Scope: - A generalized model is provided by risk rating and danger prioritization. - The business exact model with real time configuration is not provided. - In future, the job can be applied on on hand Cloud System application or environment. Chang et al. [21] defined an original security framework for Cloud System environment. The multi layered safety protection is provided next to different attacks with far above the ground level data concerns, including volume, veracity and velocity. Authors practical model for zero knowledge Cloud System that does not contain any user information. The information sharing, dependency and the data calculation are provided to attain effective block stage. The information encoding and the safe communication are provided by the authors. Authors also maintained the private fire storage and safe key management in storage space. The information sharing and approval is also going to through the key distribution methods. The concerns are also provided against a variety of attacks practical on unusual layers of Cloud System access. Contribution: - A hierarchy layer safety framework is provided to attain access control, attack preservation and encoded data storage. - The safe sharing of data is performed by means of key management and approval in Cloud file system. Scope: - The services can be extensive in the form of prototypes so that the use can be enhanced for different Cloud business models. Palmieri et al. [26] have done an adaptive sleuth energy-based analysis to identify DoS attack in Cloud data centers. Authors provided the service level analysis under availability, operation cost and energy parameters. Authors defined the problem to identify the DoS attack in network in early stage and to provide the attack resistive communication in Cloud network. The work is able to provide the analysis under availability and visibility parameters to give the analysis under pattern specific dynamic observation. The energy impact with potential effect is here analyzed for larger infrastructure to identify the attack in Cloud network. The attack ratio analysis and computation are defined to perform the attack detection. Authors estimated the attack effect with response time violation and determines the flow analysis-based service degradation. Authors provided the power management and consumption analysis to give the component level evaluation on Cloud environment. Authors provided an energy proportional system to reduce the peak power usage in attacked Cloud network and to reduce the effect of DoS attack. Chonka and Abawajy [27] have defined a work to detect and reduce the impact of DoS attack in web service driven Cloud network. Authors defined the security system to observe the channel communication under the common problem identification and to reduce the impact of DoS attack. A problem analysis for XML DoS attack is given as new defense system that can provide a solution with pre decision and learning based observation. The defined network attack is able to observe the network under training and testing criteria to provide the effective attack preserved solution in the DoS attack network. The scenario specific observation with specification of response 84 pattern is analyzed to generate the classification rules and to provide the attack preventive probabilistic solution. Michelin et al. (2014) used the authentication API to provide the Cloud communication solution against DoS attack. An unresponsive work behavior and relative protocol specific attack mapping are provided for REST applications. Authors identified the client behavior and relatively identified the malicious client in the network with response time observation. An attack specific Cloud management system is designed to define](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-5-2048.jpg)
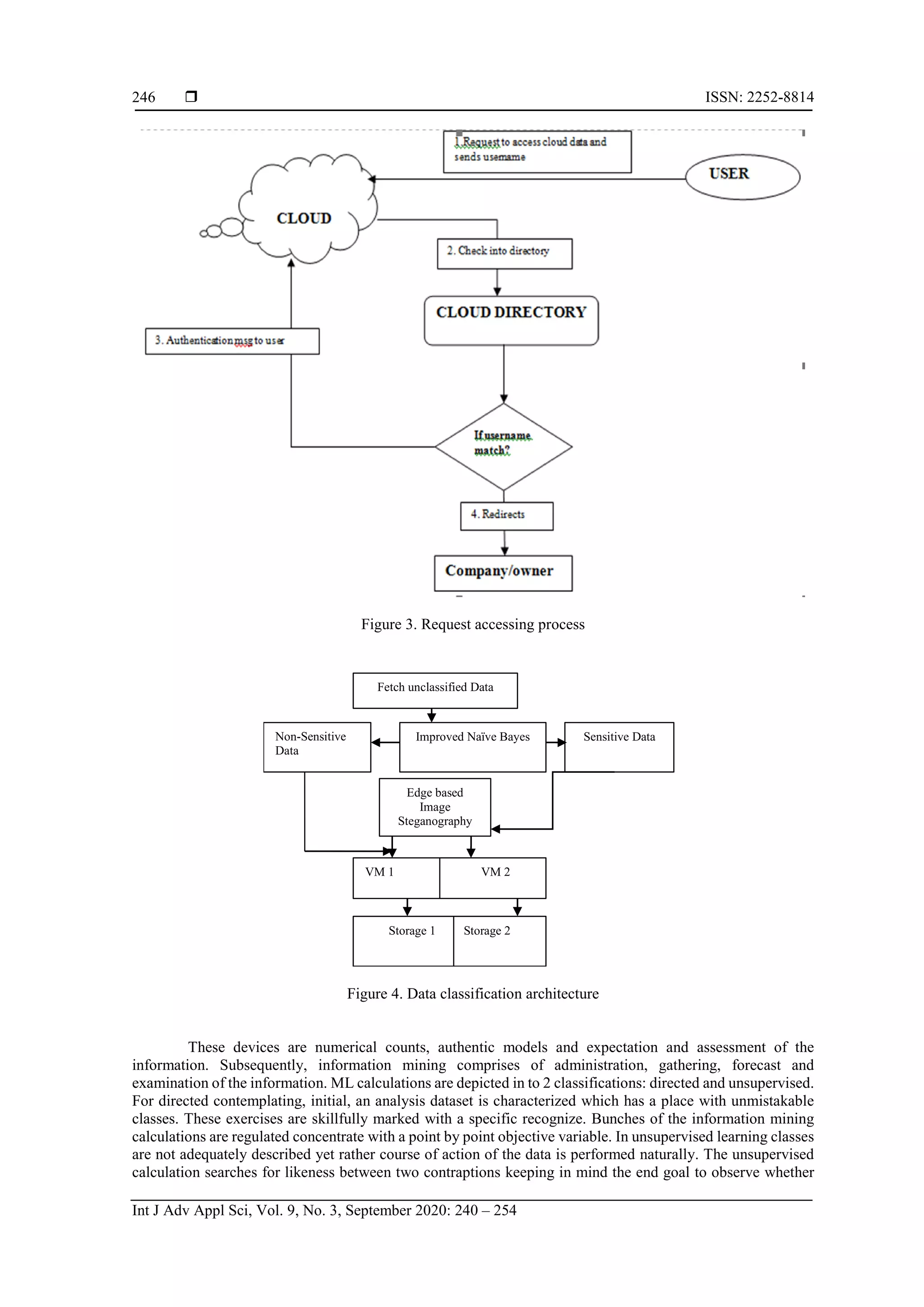
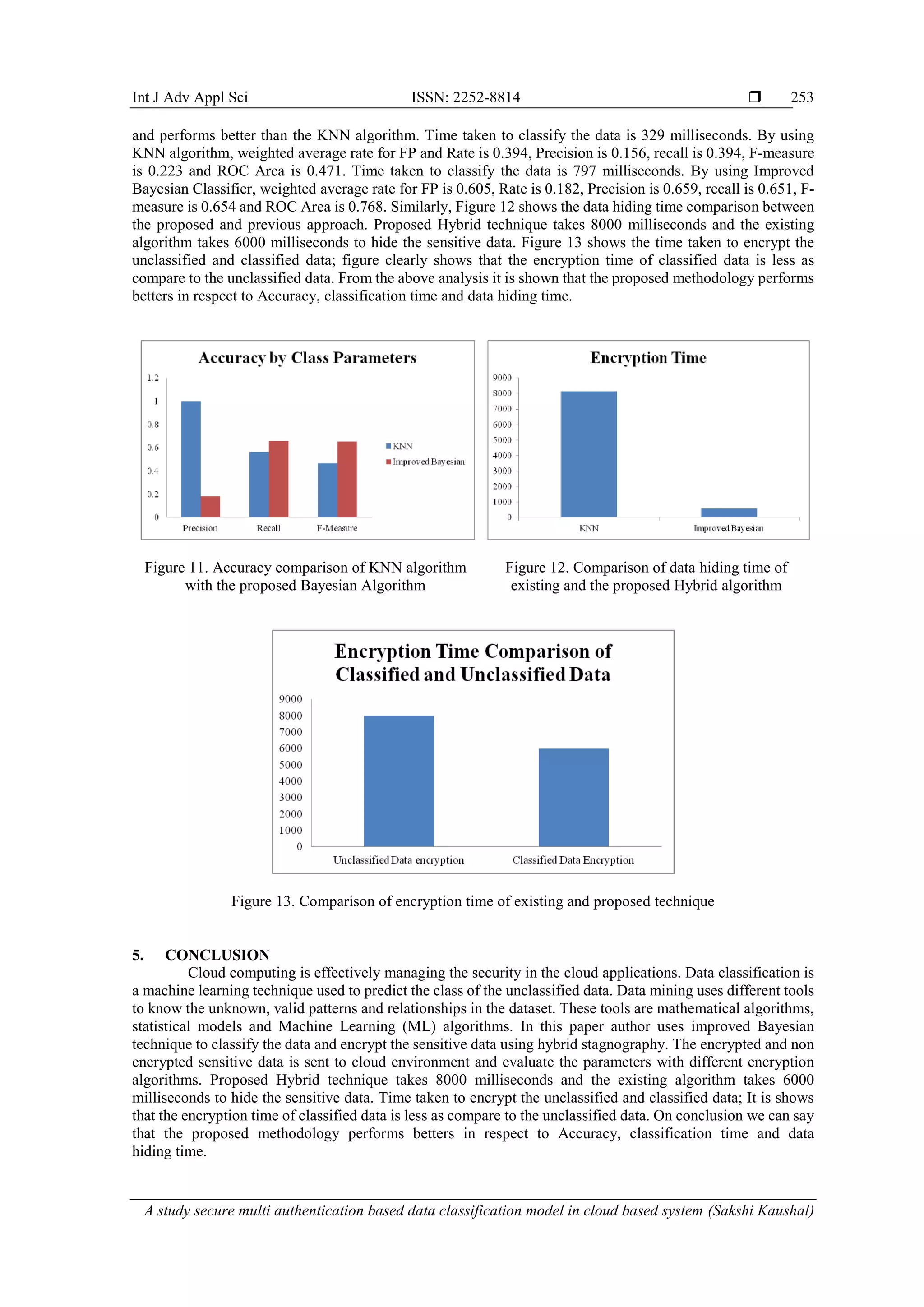
![Int J Adv Appl Sci ISSN: 2252-8814 A study secure multi authentication based data classification model in cloud based system (Sakshi Kaushal) 245 taxonomy for DDoS attack adaptation. An automated method is defined to analyze the network features and generate the attack features. Later on, all these features are combined to identify the victim type in the Cloud network. The attack scenario specific authentication measures have defined the solution against the DoS attack. At the early stage, the communication is monitored to identify the overload conditions and later on applied the filtration stage to generate the effective Cloud communication [21]. 3. RESEARCH METHOD 3.1. Phases of proposed model The proposed display is executed as specified in the accompanying stages to meet every one of the targets portrayed that are vital piece of this contextual investigation. a. Creating virtual environment First stage is to make a virtual domain where there is introduction of cloud servers, information specialists, virtual machines and assignments. b. Authentication level Figure 2 For recovery of information, the client needs to enroll himself with organization/association to get a legitimate username and secret phrase which is additionally put away at database of the organization/association. Figure 2. Process of registration Figure 3 it portrays the transmission of client demand to cloud. The cloud checks if the client has entered amend username and secret phrase is validated into its database. In the event that yes then it then just the client is endorsed to utilize the cloud information. For confirmation process, the validated clients are coordinated with the as of now existed information put away at cloud catalogs. Client needs to give its username, secret key and answer the security question, if answers given by the client is right, at that point he is allowed to get to the cloud. c. Secure authentication using image sequencing To take care of the issue of security in distributed computing, we will send these two route strategies for stopping security ruptures on distributed computing. One is giving privacy at different levels of clients like proprietor, administrator and third-party utilizing image sequence base secret key that gives privacy from validation assaults at client end. Information Hiding Architecture use for safely transmitting the information over the cloud condition This secret key depends on the groupings of a few pictures. It is more secure in light of the fact that arrangement of pictures is change without fail. Essentially that password is basically use for confirmation reason. Just authentic client will permit entering in cloud, in the event that they enter the right arrangement of picture. After verification, amid access of information tasks this interface will again tell the client arrangement, this time pictures gets rearrange, in view of succession of pictures secret word will likewise be change. d. Proposed data classification architecture Figure 4 is showing classification of data is a machine learning system used to anticipate the class of the unclassified data. Information mining utilizes one of kind instruments to get a handle on the obscure, genuine examples and connections inside the dataset.](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-6-2048.jpg)






![ ISSN: 2252-8814 Int J Adv Appl Sci, Vol. 9, No. 3, September 2020: 240 – 254 254 REFERENCES [1] Data, B., “For better or worse: 90% of world’s data generated over last two years,” SCIENCE DAILY, 2013. [Online]. Available: https://www.sciencedaily.com/releases/2013/05/130522085217.htm [2] Botta, A., De Donato, W., Persico, V., & Pescapé, A., “Integration of cloud computing and internet of things: A survey,” Future generation computer systems, vol. 56, pp. 684-700, 2016. [3] Mastelic, T., Oleksiak, A., Claussen, H., Brandic, I., Pierson, J. M., & Vasilakos, A. V., “Cloud computing: Survey on energy efficiency,” Acm computing surveys (csur), vol. 47, no. 2, pp. 1-36, 2014. [4] Messerli, A. J., Voccio, P., & Hincher, J. C. U.S. Patent No. 9,563,480. Washington, DC: U.S. Patent and Trademark Office, 2017. [5] Farahnakian, et al, “Using ant colony system to consolidate VMs for green cloud computing,” IEEE Transactions on Services Computing, vol. 8, no. 2, pp. 187-198, 2015. [6] Botta, A., De Donato, W., Persico, V., & Pescapé, A., “Integration of cloud computing and internet of things: a survey,” Future generation computer systems, vol. 56, pp. 684-700, 2016. [7] Wang, B., Zheng, Y., Lou, W., & Hou, Y. T., “DDoS attack protection in the era of cloud computing and software- defined networking,” Computer Networks, vol. 81, pp. 308-319, 2015. [8] Puthal, D., Sahoo, B. P. S., Mishra, S., & Swain, S., “Cloud computing features, issues, and challenges: a big picture,” 2015 International Conference on Computational Intelligence and Networks, pp. 116-123, 2015. [9] Li, J., Li, Y. K., Chen, X., Lee, P. P., & Lou, W., “A hybrid cloud approach for secure authorized deduplication,” IEEE Transactions on Parallel and Distributed Systems, vol. 26, no. 5, pp. 1206-1216, 2015. [10] Chou, D. C., “Cloud computing: A value creation model,” Com. Standards & Interfaces, vol. 38, pp. 72-77, 2015. [11] Ali, M., Khan, S. U., & Vasilakos, A. V., “Security in cloud computing: Opportunities and challenges,” Information sciences, vol. 305, pp. 357-383, 2015. [12] Ang, J. C., Mirzal, A., Haron, H., & Hamed, H. N. A., “Supervised, unsupervised, and semi-supervised feature selection: a review on gene selection,” IEEE/ACM transactions on computational biology and bioinformatics, vol. 13, no. 5, pp. 971-989, 2016. [13] Saurabh Singh, Young-Sik Jeong, Jong Hyuk Park, “A survey on cloud computing security: issues, threats, and solutions,” Journal of Network and Computer Applications, vol. 75, pp. 200-222, 2016. [14] Faheem Zafar, et al, “A survey of Cloud Computing data integrity schemes: Design challenges, taxonomy and future trends,” Computers & Security, vol. 65, pp. 29-49, 2016. [15] A Platform Computing Whitepaper, Enterprise Cloud Computing: Transforming IT, Platform Computing, 2009. [16] NITS, “Guidelines on Security and Privacy in Public Cloud Computing,” [Online]. Available http://csrc.nist.gov /publications/nistpubs/800-144/SP800-144.pdf, retrieved on Sep 29, 2012. [17] Philip Derbeko, Shlomi Dolev, Ehud Gudes, Shantanu Sharma, “Security and privacy aspects in mapreduce on clouds: a survey,” Computer Science Review, vol. 20, pp. 1-28, 2016. [18] Ogigau-Neamtiu F., “Cloud computing security issues,” Journal of Defense Resources Management, vol. 3, no. 2, pp. 141-148, 2012. [19] Wu J, Ping L, Ge X, Wang Y, Fu J, “Cloud storage as the infrastructure of cloud computing,” International Conference on Intelligent Computing and Cognitive Informatics (ICICCI), pp. 380-383, 2010. [20] Brian Cusack, Eghbal Ghazizadeh, “Evaluating single sign-on security failure in Cloud services,” Business Horizons, vol. 59, no. 6, pp. 605-614, 2016. [21] Laurence T. Yang, et al, “Parallel GNFS algorithm integrated with parallel block wiedemann algorithm for RSA security in cloud computing, information sciences,” Information Sciences, vol. 387, pp. 254-265, 2016. [22] Jolanda Modic, Ruben Trapero, Ahmed Taha, Jesus Luna, Miha Stopar, Neeraj Suri, “Novel efficient techniques for real-time cloud security assessment,” Computers & Security, vol. 62, pp. 1-18, 2016. [23] Christos Kalloniatis, Haralambos Mouratidis, Manousakis Vassilis, Shareeful Islam, Stefanos Gritzalis, Evangelia Kavakli, “Towards the design of secure and privacy-oriented information systems in the Cloud: Identifying the major concepts,” Computer Standards & Interfaces, vol. 36, no. 4, pp. 759-775, 2014. [24] Chunming Rong, Son T. Nguyen, Martin Gilje Jaatun, “Beyond lightning: A survey on security challenges in cloud computing,” Computers & Electrical Engineering, vol. 39, no. 1, pp. 47-54, 2013. [25] Lofstrand M, ‘The VeriScale Architecture: Elasticity and Efficiency for Private Clouds”, Sun Microsystems, Sun BluePrint, 2009. [26] Vahid Ashktoraband Seyed Reza Taghizadeh. “Security threats and countermeasures in cloud computing,” International Journal of Application or Innovation in Engineering & Management, vol. 1, no. 2, pp. 234-245, 2012. [27] Brian Cusack, Eghbal Ghazizadeh, “Evaluating single sign-on security failure in cloud services,” Business Horizons, vol. 59, no. 6, pp. 605-614, 2016.](https://image.slidesharecdn.com/10-20245-37589-1-rv-astudysecureedilham-rev-201021071840/75/A-study-secure-multi-authentication-based-data-classification-model-in-cloud-based-system-15-2048.jpg)