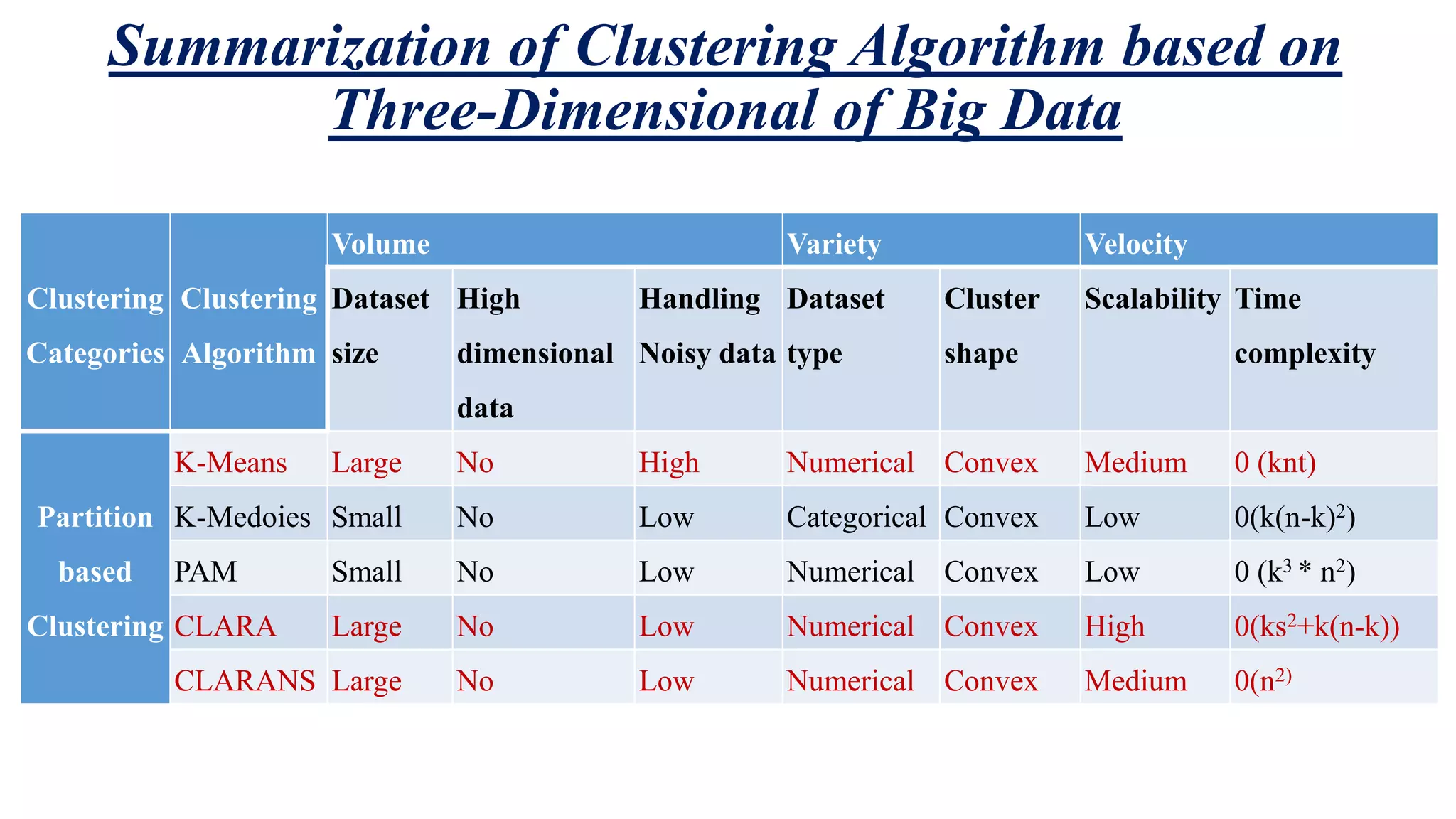
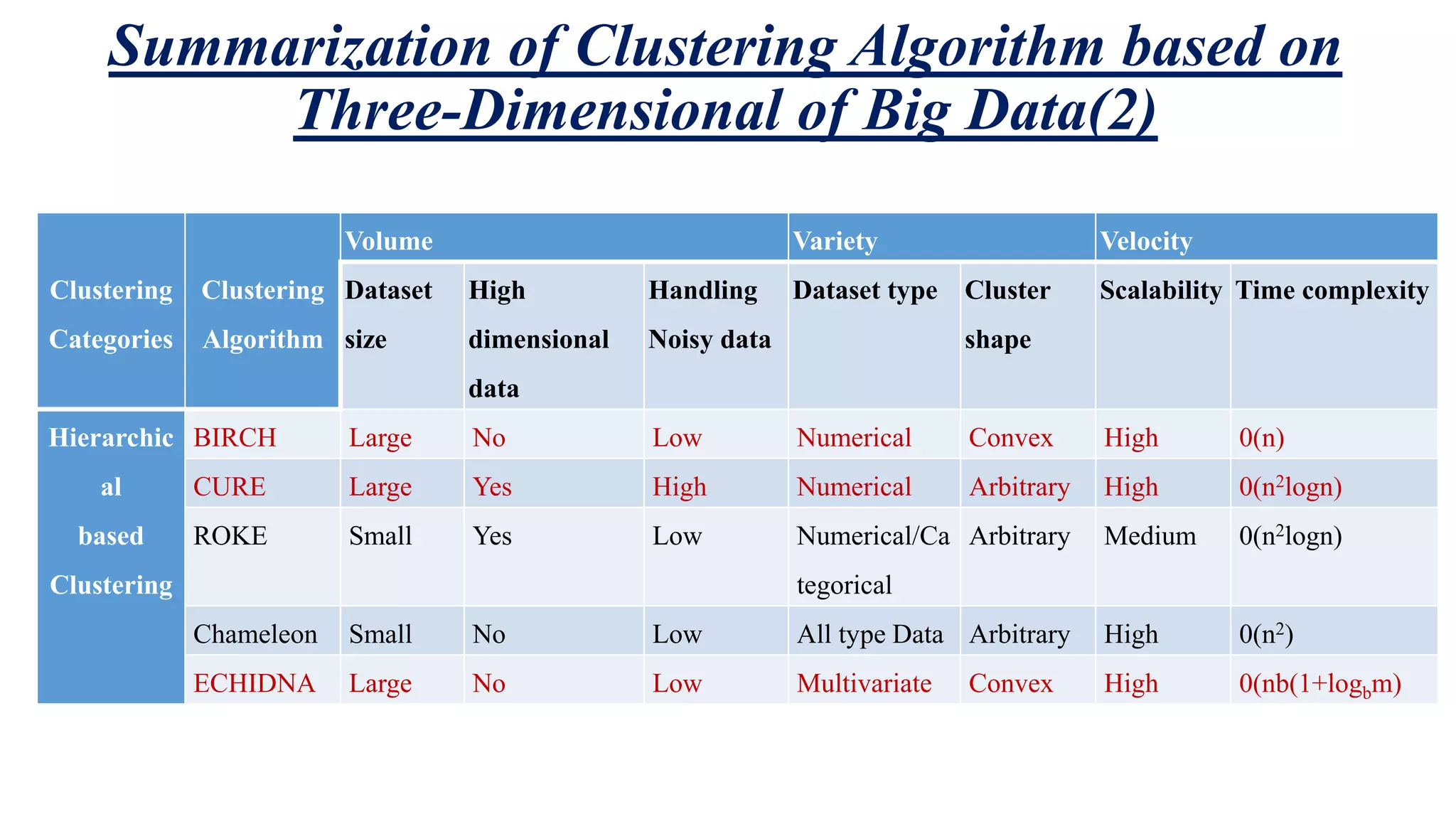
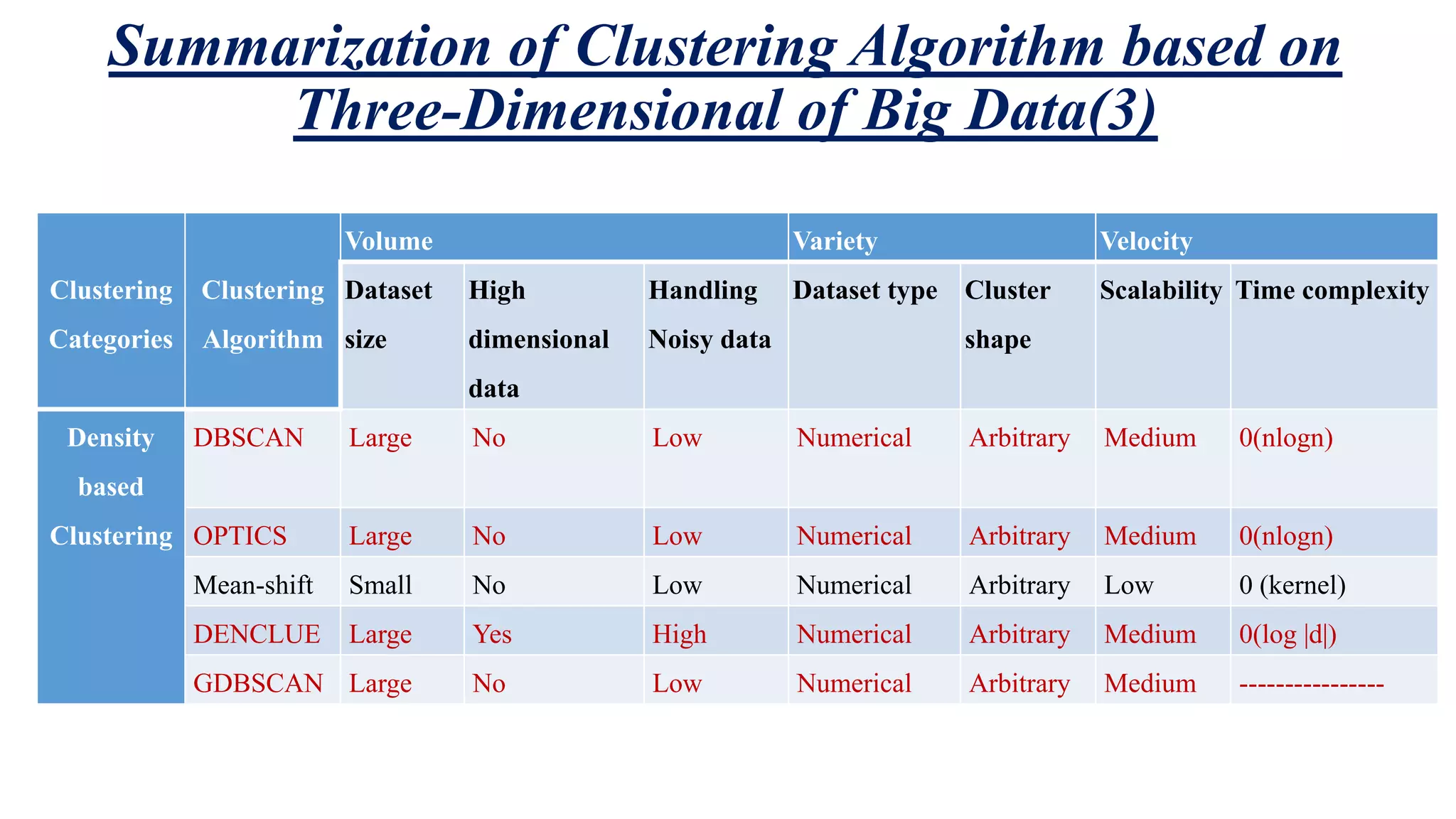
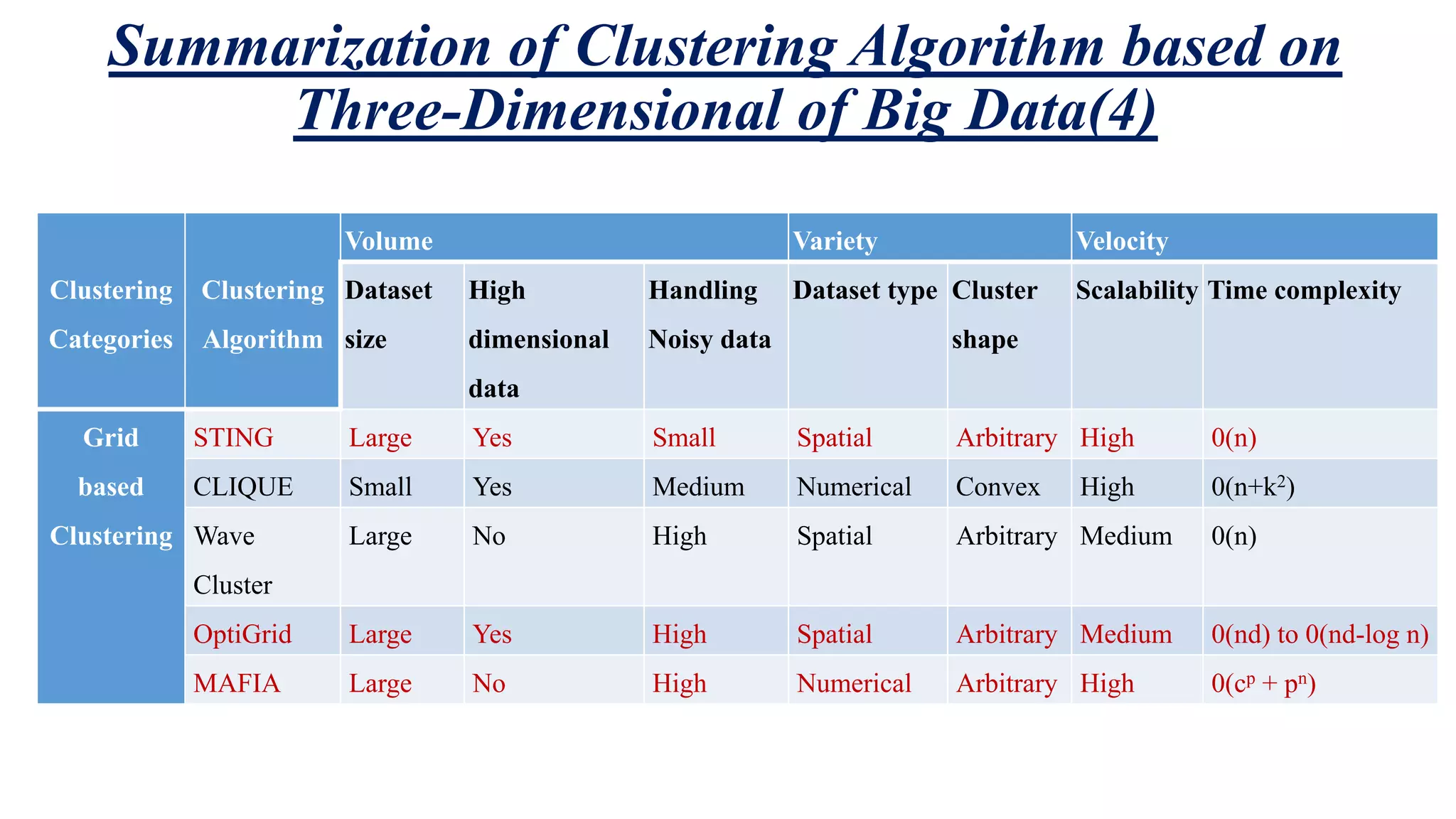
This document summarizes and analyzes clustering algorithms for big data mining. It discusses traditional clustering techniques (partitioning, hierarchical, density-based, etc.) and evaluates them based on their ability to handle big data's volume, variety, and velocity characteristics. The document also proposes a MapReduce framework for implementing clustering algorithms for big data in a parallel and distributed manner. It experimentally compares execution times of traditional k-means clustering versus k-means using the proposed MapReduce approach.












![References [1]. Sivarajah U. and Kamal M.M.: Critical analysis of Big Data challenges and analytical methods, Journal of Business Research (Elsevier), Vol 70, pp 263-286, DOI: 10.1016/j.jbusres.2016.08.001, (2017). [2]. Wasastjerna M.C.: The role of big data and digital privacy in merger review. European Competition Journal, vol. 14, no. 2-3, pp. 417- 444, DOI: 10.1080/17441056.2018.1533364, (2018). [3]. Gandomi A., and H. M.: Beyond the hype Big data concepts methods and analytics. I.J. of Info. Man., vol. 35, no. 2, pp. 137 -144, DOI: 10.1016/j.ijinfomgt.2014.10.007, (2015). [4]. Pandey K.K.: Mining on Relationship in Big Data era Using Apriori Algorithm, Proc. Of NCDAMLS, pp. 55-60, ISBN: 978-93-5291- 457-9, (2018). [5]. Che D., P. Z., and S.M., and From Big Data to Big Data Mining Challenges Issues and Opportunities. LNCS, vol. 7827, pp. 1-12 , doi 10.1007/978-3-642-40270-8_1, (2013). [6]. Li N., Zeng L., Qing H., and Zhongzhi S.: Parallel Implementation of Apriori Algorithm Based on MapReduce. Proc of 13th IEEE ACIS International Conference on SEAIPDC, DOI: 10.1109/SNPD.2012.31, (2017). [7]. Oussous A., Benjelloun F.Z., Lahcen A.A., and Belfkih S.: Big Data technologies: A survey, Journal of King Saud University – Computer and Information Sciences, Vol-30, pp 431–448, DOI: 10.1016/j.jksuci.2017.06.001, (2018). [8]. Chen M., M.S., and L.Y.: Big Data A Survey. Mob. Netw. Appl., vol. 19, no. 2, pp. 171–209, doi 10.1007/s11036-013-0489-0, (2014). [9]. Gole S., and Tidke B.: A survey of Big Data in social media using data mining techniques. Proc. of IEEE ICACCS, doi 10.1109/ICACCS.2015.7324059, (2015). [10]. Elgendy N., and E. A.: Big Data Analytics A Literature Review Paper. LNAI, vol. 8557, pp. 214–227, doi 10.1007/978-3-319-08976- 8_16, (2014). [11]. Ozkose H., Ari E.S., and Gencer C.: Yesterday, Today and Tomorrow of Big Data, Procedia - Social and Behavioral Sciences, vol. 195, pp. 1042-1050, doi 10.1016/j.sbspro.2015.06.147, (2015).](https://image.slidesharecdn.com/kamleshkumarpandey173-190831143833/75/A-Comprehensive-Study-of-Clustering-Algorithms-for-Big-Data-Mining-with-MapReduce-Capability-19-2048.jpg)
![References [12]. Kaur P. and Kaur K., :Comparative Study of Techniquesand Issues in Data Clustering, Lecture Notes in Networks and Systems, Vol-8, pp 1-8, DOI 10.1007/978-981-10-3818-1_1,(2017). [13]. Nagpal A., Jatain A. and Gaur D.:Review based on Data Clustering Algorithms, Proc. of IEEE Conference on ICT, published by IEEE Xplore,pp 298-303, DOI: 10.1109/CICT.2013.6558109, (2013). [14]. Berkhin P.,:Survey of Clustering Data Mining Techniques, M. (eds) Grouping Multidimensional Data, pp. 25-71, doi 10.1007/3-540- 28349-8_2, (2006). [15]. Chen W.,OliverioJ.,Kim H.O, and Shen J., The Modeling and Simulation of Data Clustering Algorithms in Data Mining with Big Data, Journal of Industrial Integration and Management: Innovation and Entrepreneurship, DOI:10.1142/S2424862218500173,(2018). [16]. Xu R.,and Wunsch D. : Survey of Clustering Algorithms, IEEE TRANSACTIONS ON NEURAL NETWORKS, Vol. 16, Issue 3, pp 645-678, (2005). [17]. Xu D., and Tian Y.: A Comprehensive Survey of Clustering Algorithms, Annals of Data Science, Vol 2, Issue 2, pp 165–193,DOI: 10.1007/s40745-015-0040-1,(2015). [18]. Pandove D.and Goel S.: A Comprehensive Study on ClusteringApproaches for Big Data Mining, Proc. Of IEEE ICECS, pp 1333- 1338,(2015). [19]. Fahad A; Alshatri N, Tari Z, Alamri A, Khalil I, AND ZomayaA.Y.,:A Survey of Clustering Algorithms for BigData: Taxonomy and Empirical Analysis, IEEE Transactions on Emerging Topics in Computing, Vol 2, Issue 3,pp 267 - 279, DOI: 10.1109/TETC.2014.2330519 , (2014). [20]. Jain A. K., Murty M. N. and Flynn P. J., Data clustering: a review, ACM Computing Surveys, Vol 31,Issue 3, pp 264-323, DOI: 10.1145/331499.331504,(1999). [21]. Shirkhorshidi A.S., Aghabozorgi S, Wah T.Y. and HerawanT.:Big Data Clustering: A Review, published by Lecture Notes in Computer Science(Springer), Vol 8583, DOI: 10.1007/978-3-319-09156-3_49,(2014).](https://image.slidesharecdn.com/kamleshkumarpandey173-190831143833/75/A-Comprehensive-Study-of-Clustering-Algorithms-for-Big-Data-Mining-with-MapReduce-Capability-20-2048.jpg)
![References [22]. Berkhin P., A Survey of Clustering Data Mining Techniques, Grouping Multidimensional Data (Springer), DOI: 10.1007/3-540-28349- 8_2 (2006). [23]. Pujari A.K, Rajesh K. & Reddy D.S.: Clustering Techniques in Data Mining—A Survey, IETE Journal of Research, vol 47, Issue 1-2, pp 19-28, DOI: 10.1080/03772063.2001.11416199,(2001). [24]. Dave M., and Gianey R. : Different Clustering Algorithms for Big Data Analytics: A Review, Proc of IEEE SMART, pp 328-333,(2016). [25]. Macqueen J.: Some methods for classification and analysis of multivariate observations. Proceedings 5th Berkeley Symposium on Mathematical Statistics Probability, Vol 1,pp 281–297,(1967). [26]. Emani C.K., Cullot N. and Nicolle C: Understandable Big Data: A survey, Computer Science Review, Vol-17, pp 70-81, DOI: dx.doi.org/10.1016/j.cosrev.2015.05.002, (2015).](https://image.slidesharecdn.com/kamleshkumarpandey173-190831143833/75/A-Comprehensive-Study-of-Clustering-Algorithms-for-Big-Data-Mining-with-MapReduce-Capability-21-2048.jpg)
