Download to read offline





![Benchmark Results – single-node version Massive log data processing using I/O optimized PostgreSQL 2172.3 2159.6 2158.9 2086.0 2127.2 2104.3 1920.3 2023.4 2101.1 2126.9 1900.0 1960.3 2072.1 6149.4 6279.3 6282.5 5985.6 6055.3 6152.5 5479.3 6051.2 6061.5 6074.2 5813.7 5871.8 5800.1 0 1000 2000 3000 4000 5000 6000 7000 Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3 QueryProcessingThroughput[MB/sec] Star Schema Benchmark on NVMe-SSD + md-raid0 PgSQL9.6(SSDx3) PGStrom2.0(SSDx3) H/W Spec (3xSSD) SSD-to-GPU Direct SQL pulls out an awesome performance close to the H/W spec Measurement by the Star Schema Benchmark; which is a set of typical batch / reporting workloads. CPU: Intel Xeon E5-2650v4, RAM: 128GB, GPU: NVIDIA Tesla P40, SSD: Intel 750 (400GB; SeqRead 2.2GB/s)x3 Size of dataset is 353GB (sf: 401), to ensure I/O bounds workload](https://image.slidesharecdn.com/20181116equnixlogprocessingbypgsql-181201120711/75/20181116-Massive-Log-Processing-using-I-O-optimized-PostgreSQL-16-2048.jpg)

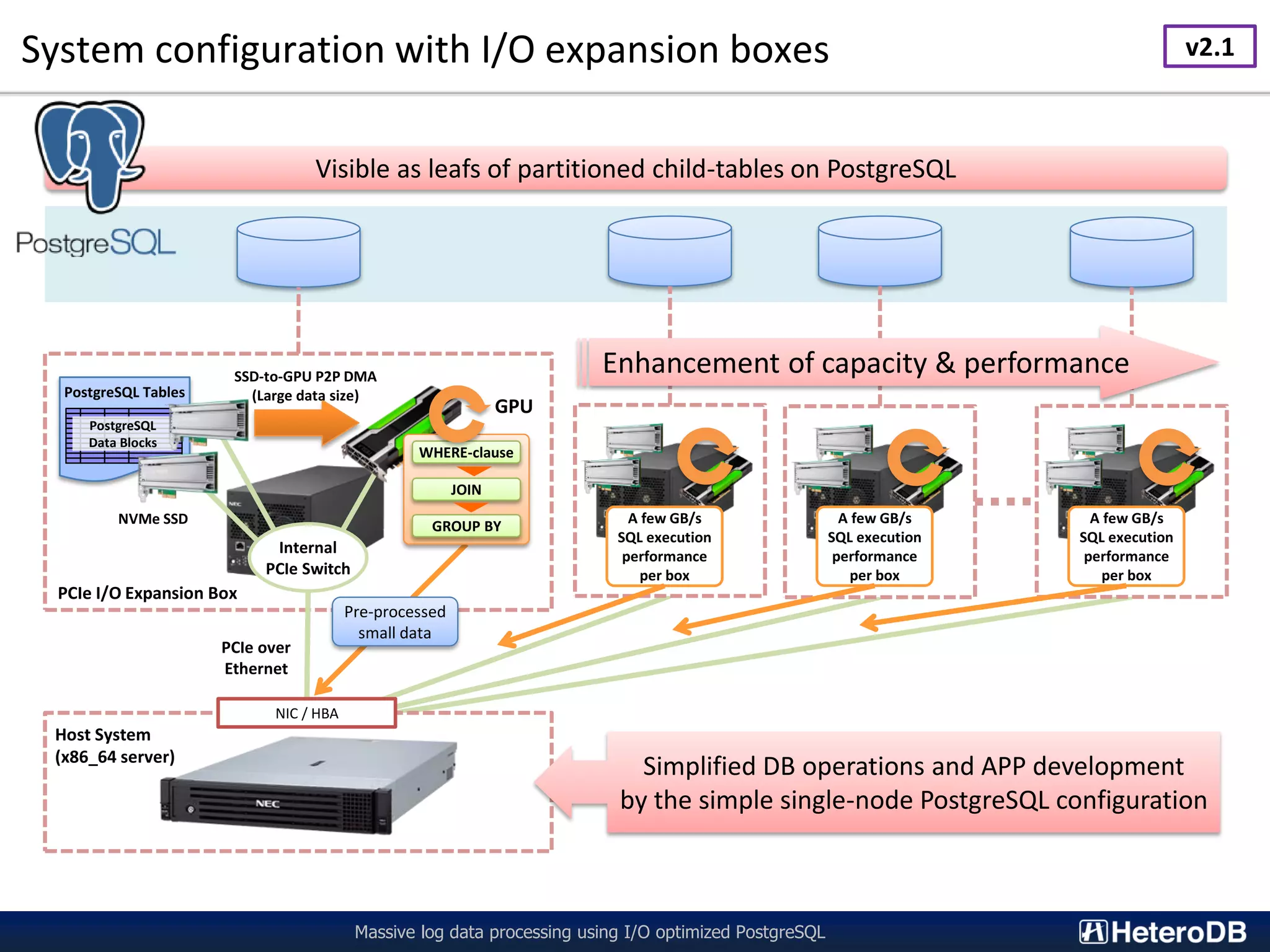

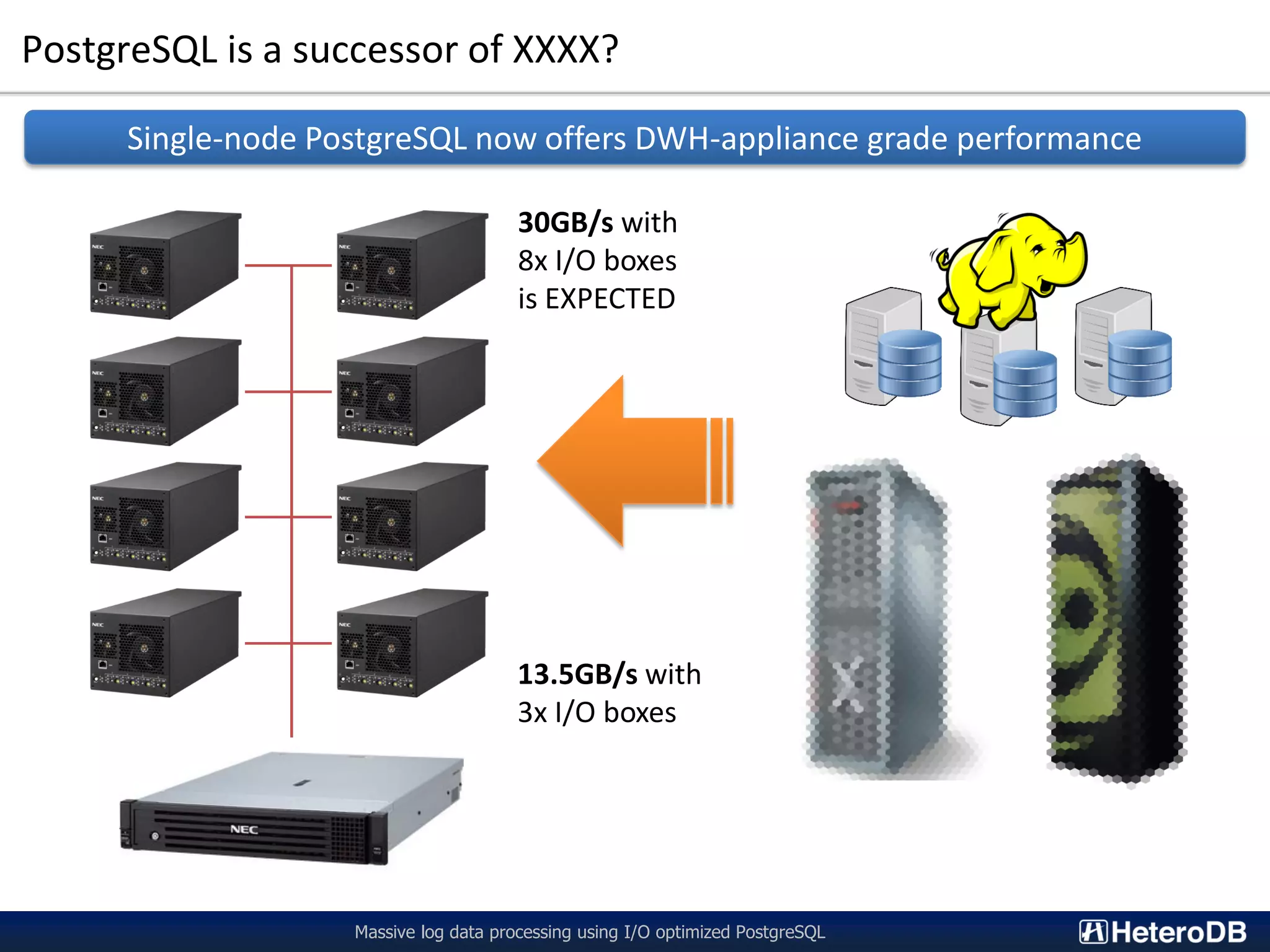
![Benchmark (2/2) - Result of query execution performance Massive log data processing using I/O optimized PostgreSQL 13 SSBM queries to 1055GB database in total (a.k.a 351GB per I/O expansion box) Raw I/O data transfer without SQL execution was up to 9GB/s. In other words, SQL execution was faster than simple storage read with raw-I/O. 2,388 2,477 2,493 2,502 2,739 2,831 1,865 2,268 2,442 2,418 1,789 1,848 2,202 13,401 13,534 13,536 13,330 12,696 12,965 12,533 11,498 12,312 12,419 12,414 12,622 12,594 0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3 QueryExecutionThroughput[MB/s] Star Schema Benchmark for PgSQL v11beta3 / PG-Strom v2.1devel on NEC ExpEther x3 PostgreSQL v11beta3 PG-Strom v2.1devel Raw I/O Limitation max 13.5GB/s for query execution performance with 3x GPU/SSD units!! v2.1](https://image.slidesharecdn.com/20181116equnixlogprocessingbypgsql-181201120711/75/20181116-Massive-Log-Processing-using-I-O-optimized-PostgreSQL-27-2048.jpg)

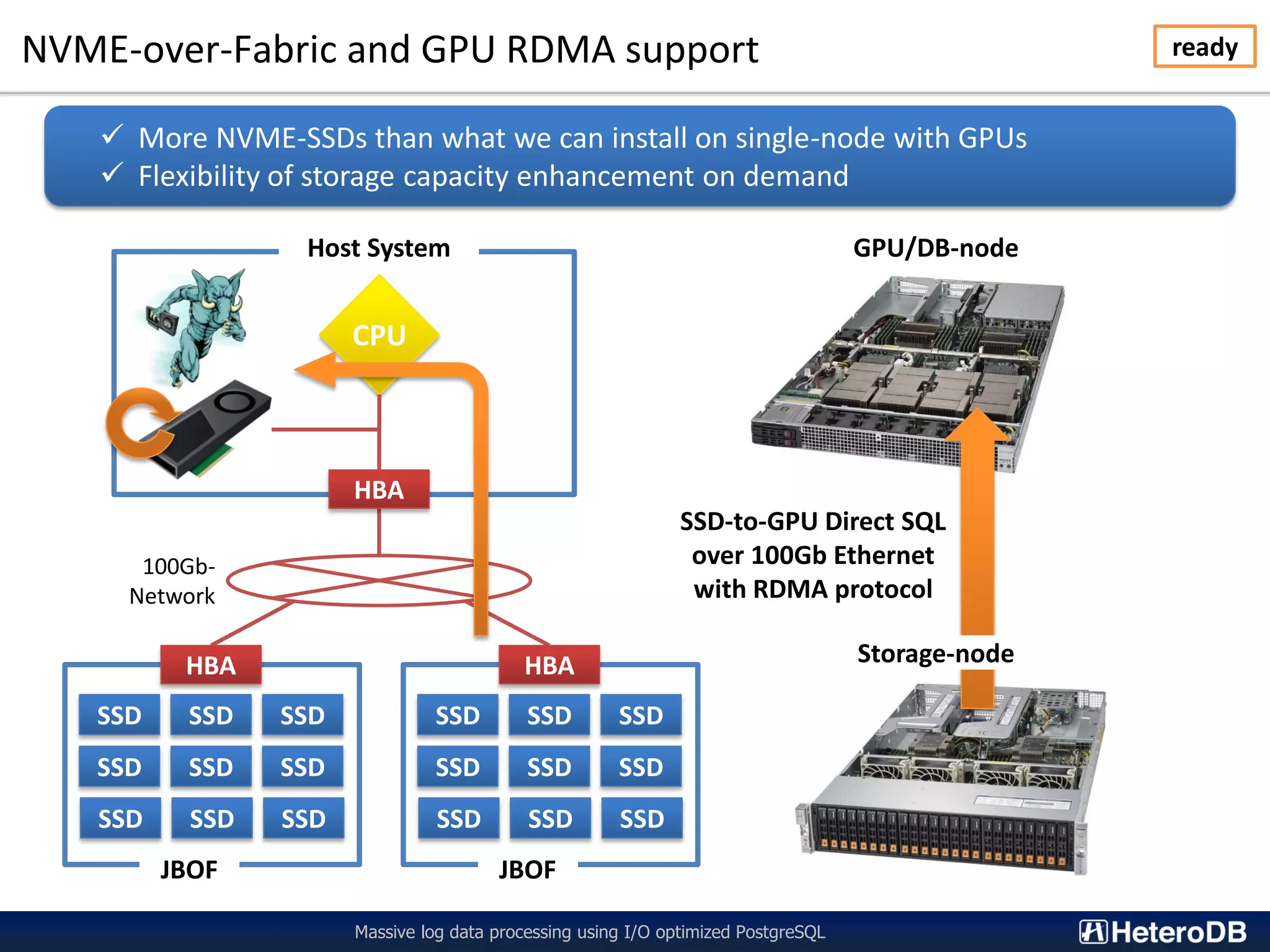
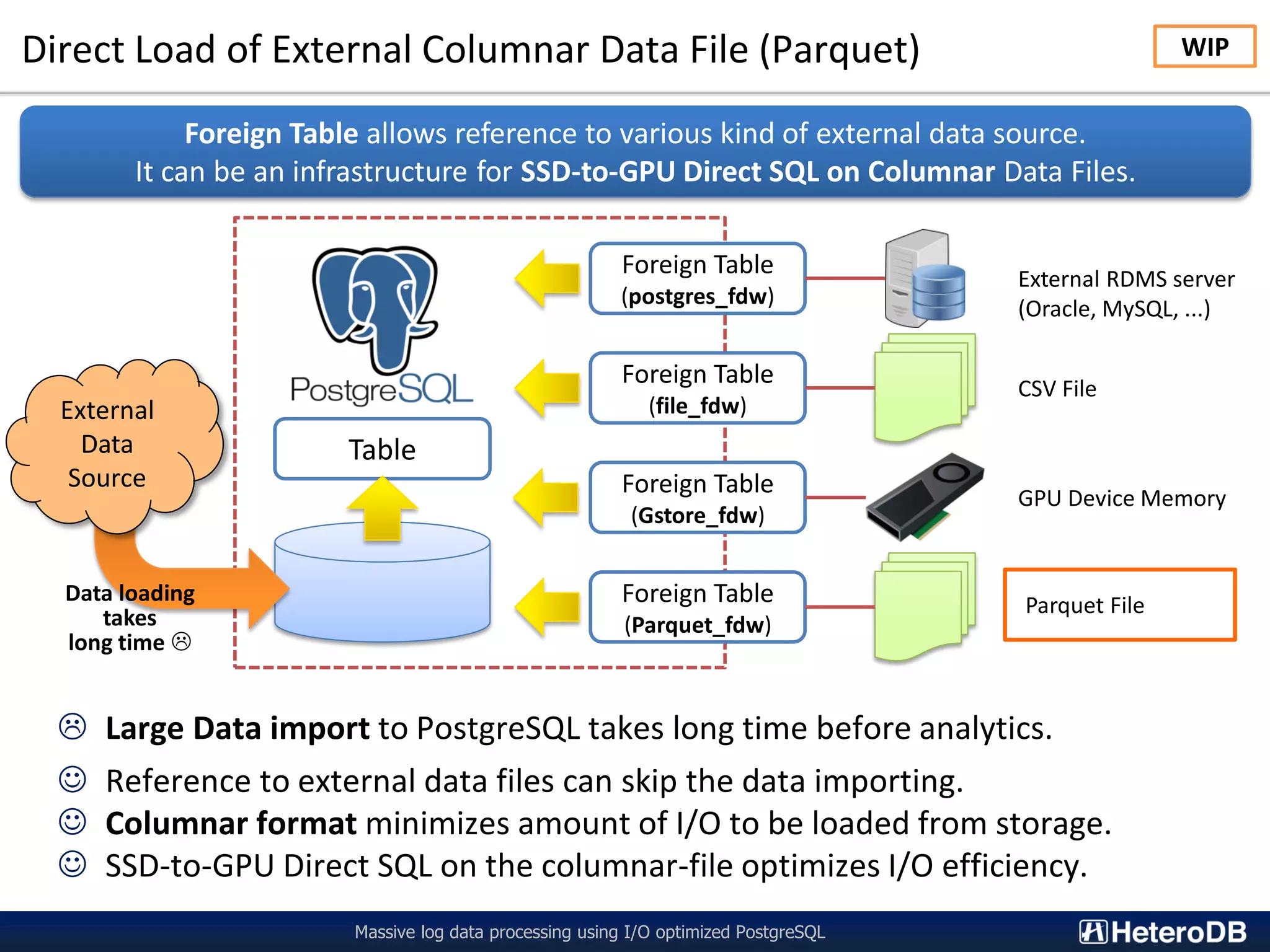
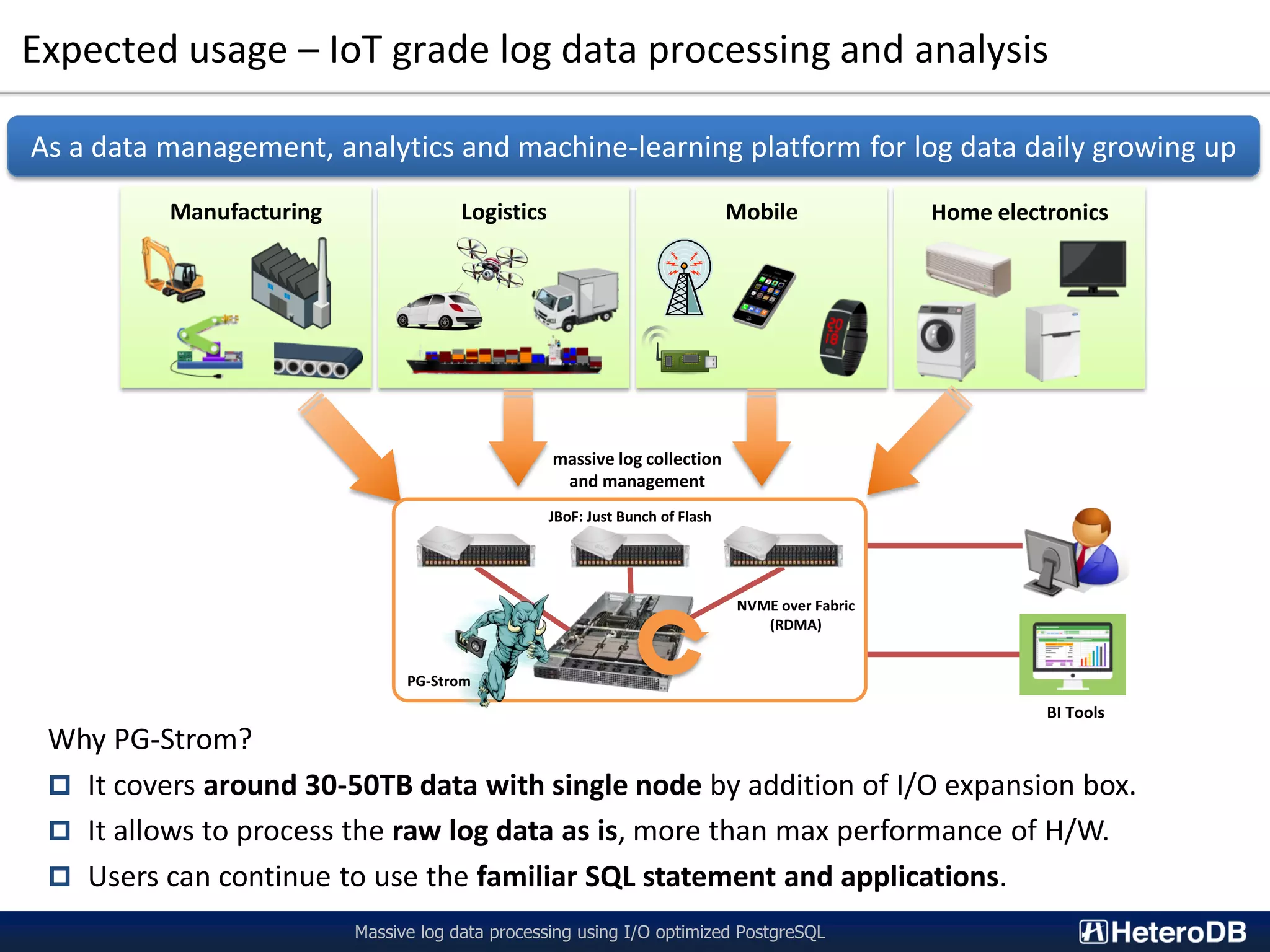



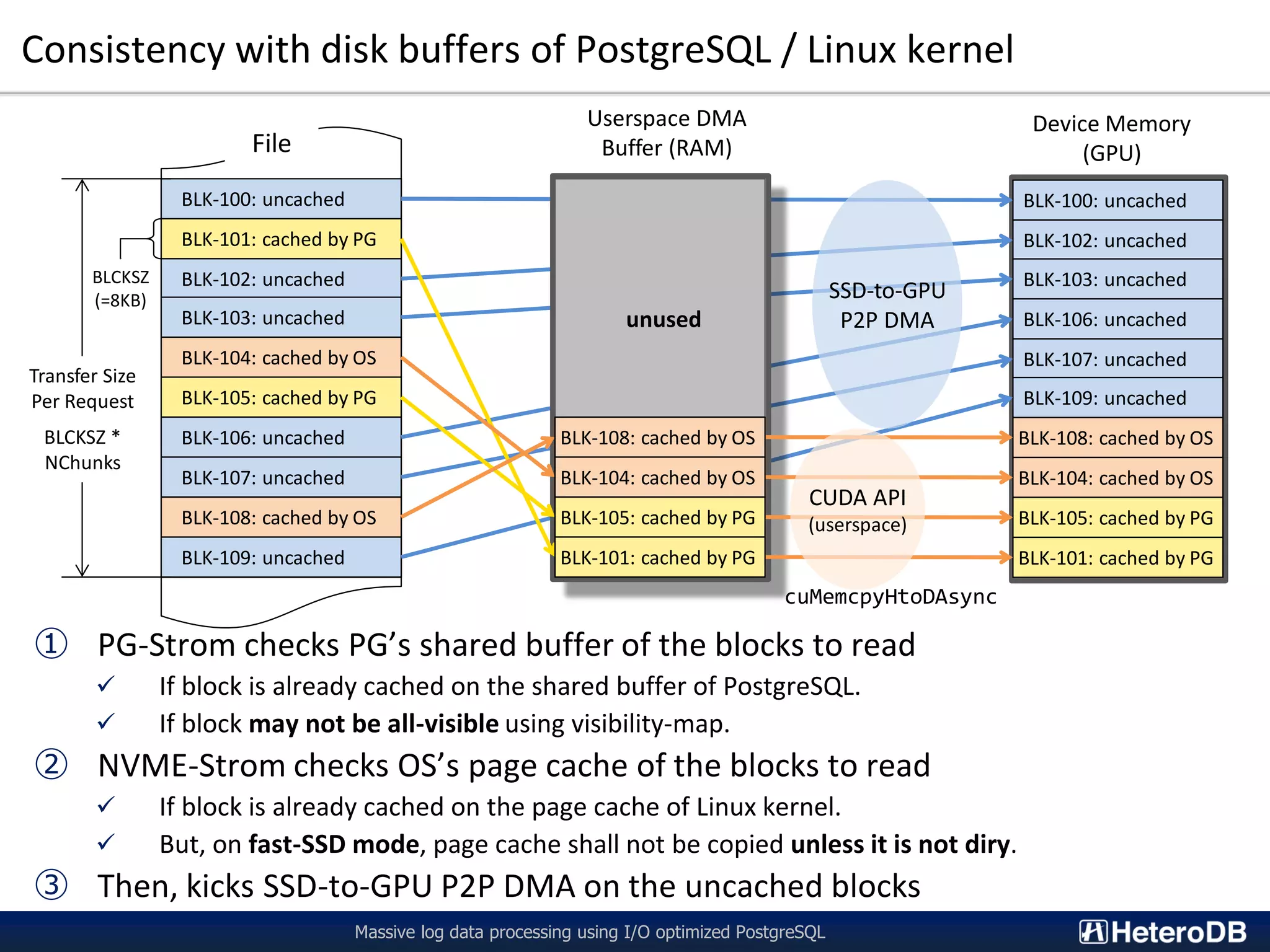


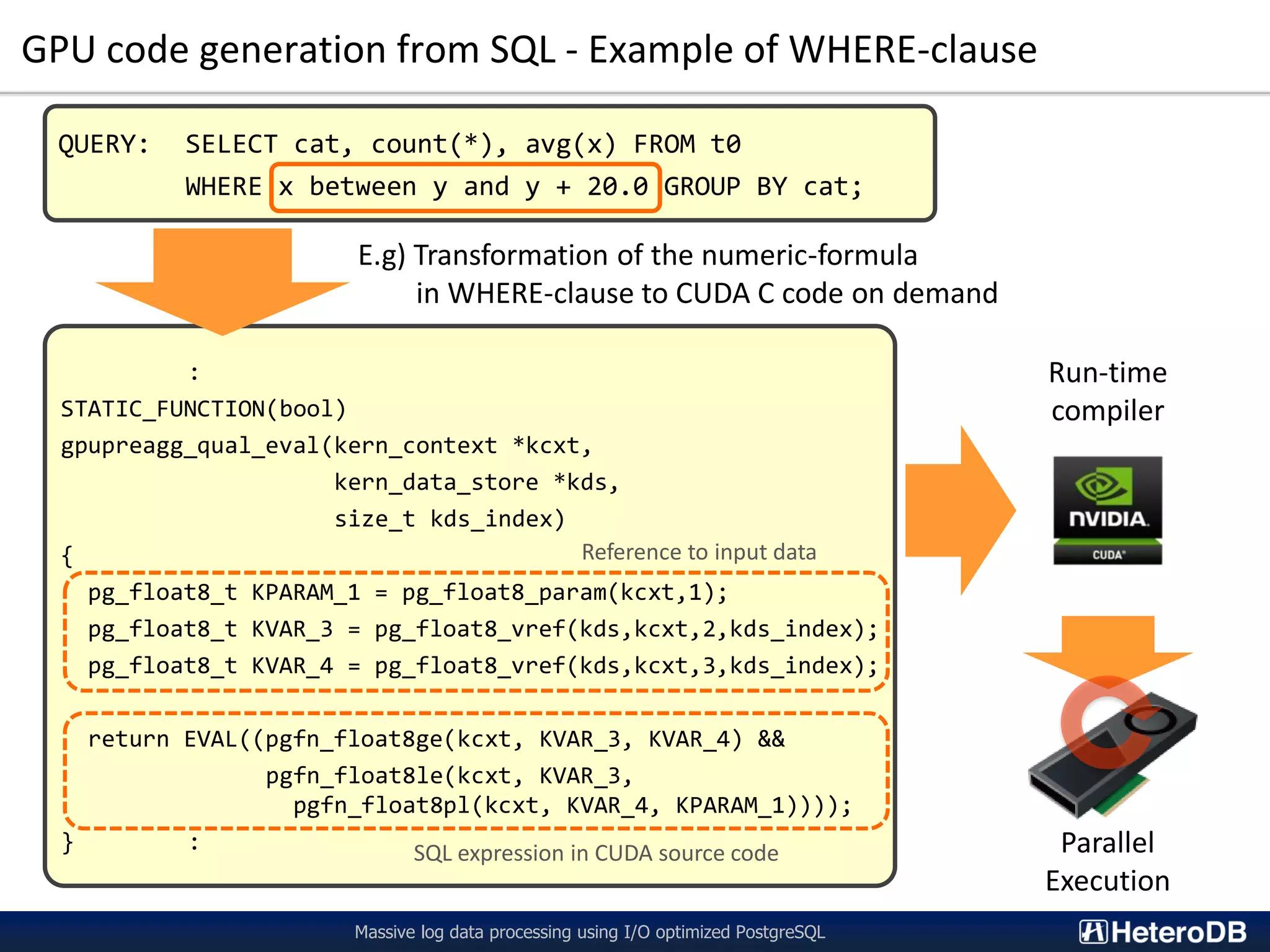
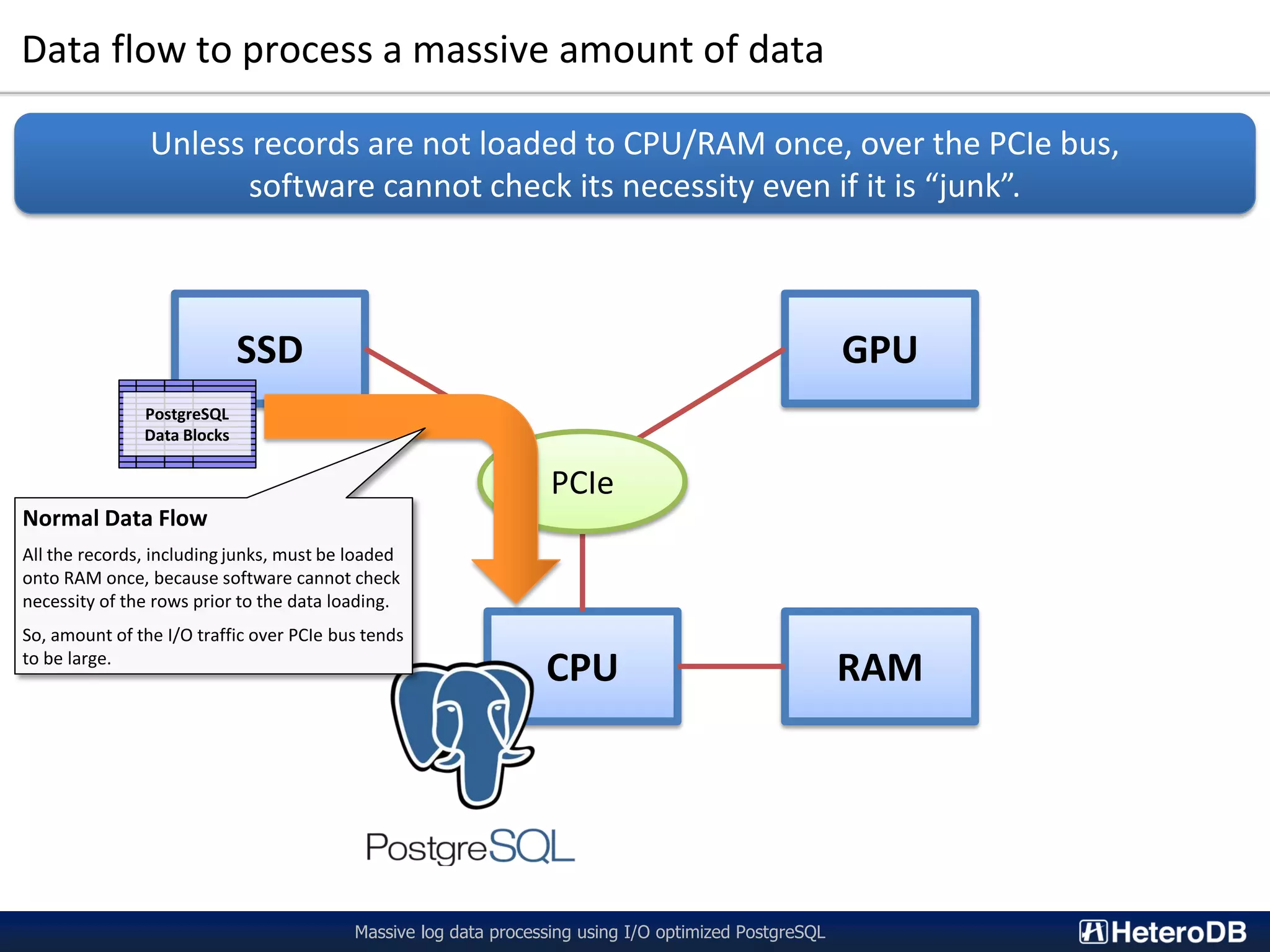
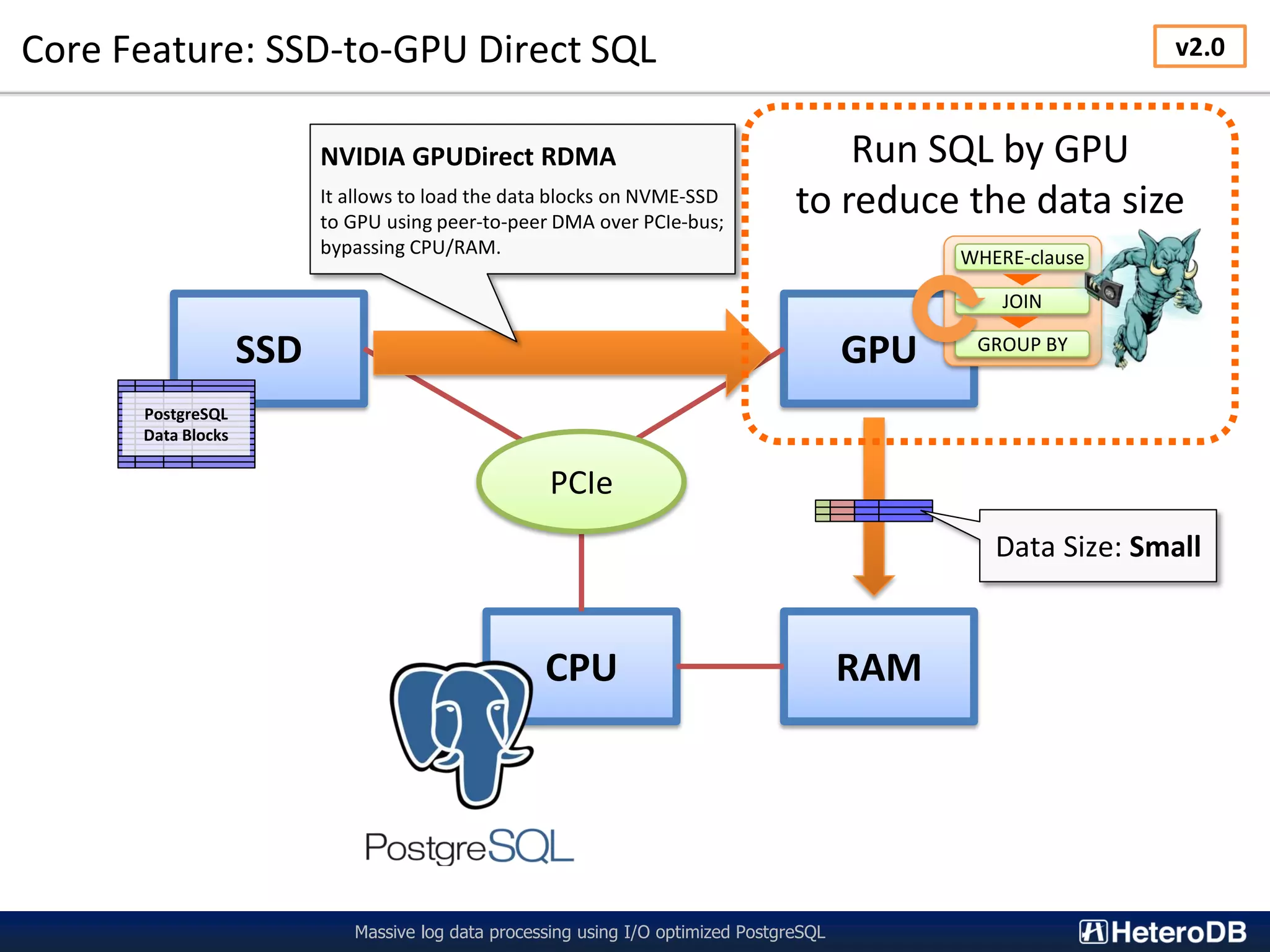
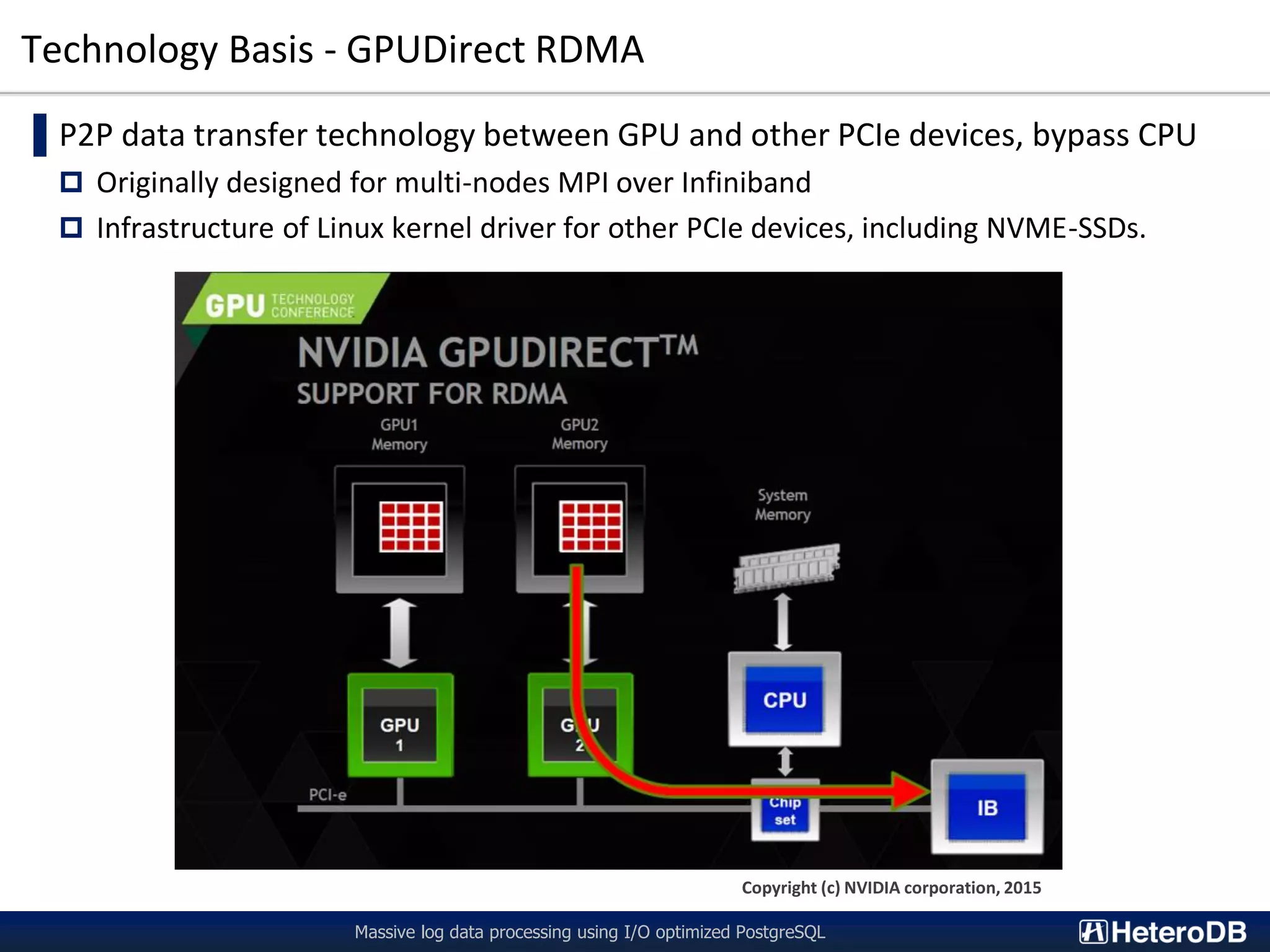
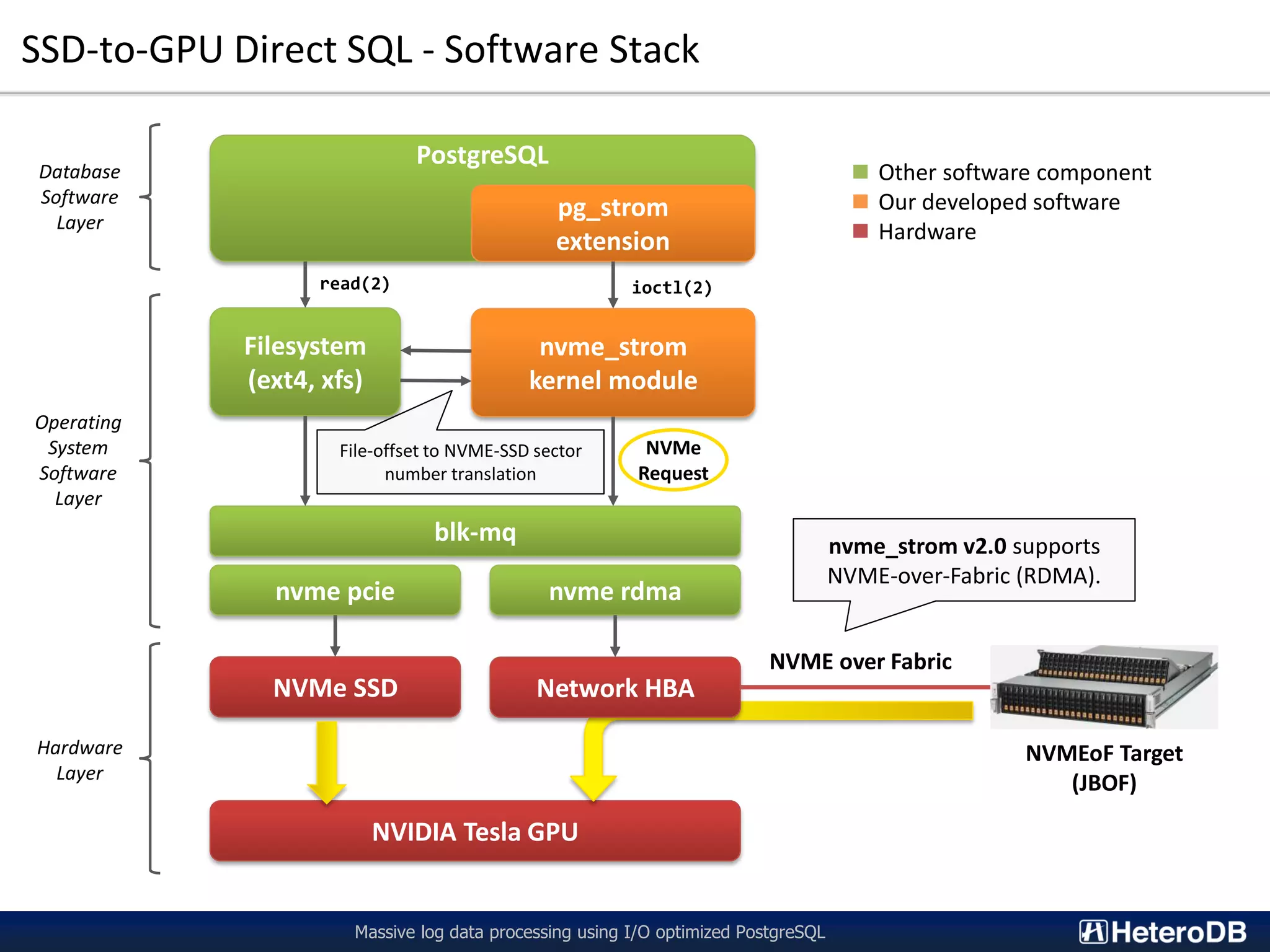
The document describes a technology called PG-Strom that uses GPU acceleration to optimize I/O performance for PostgreSQL. PG-Strom allows data to be transferred directly from NVMe SSDs to the GPU over the PCIe bus, bypassing the CPU and RAM. This reduces data movement and allows PostgreSQL queries to be partially executed directly on the GPU. Benchmark results show the approach can achieve throughput close to the theoretical hardware limits for a single server configuration processing large datasets.