Downloaded 328 times








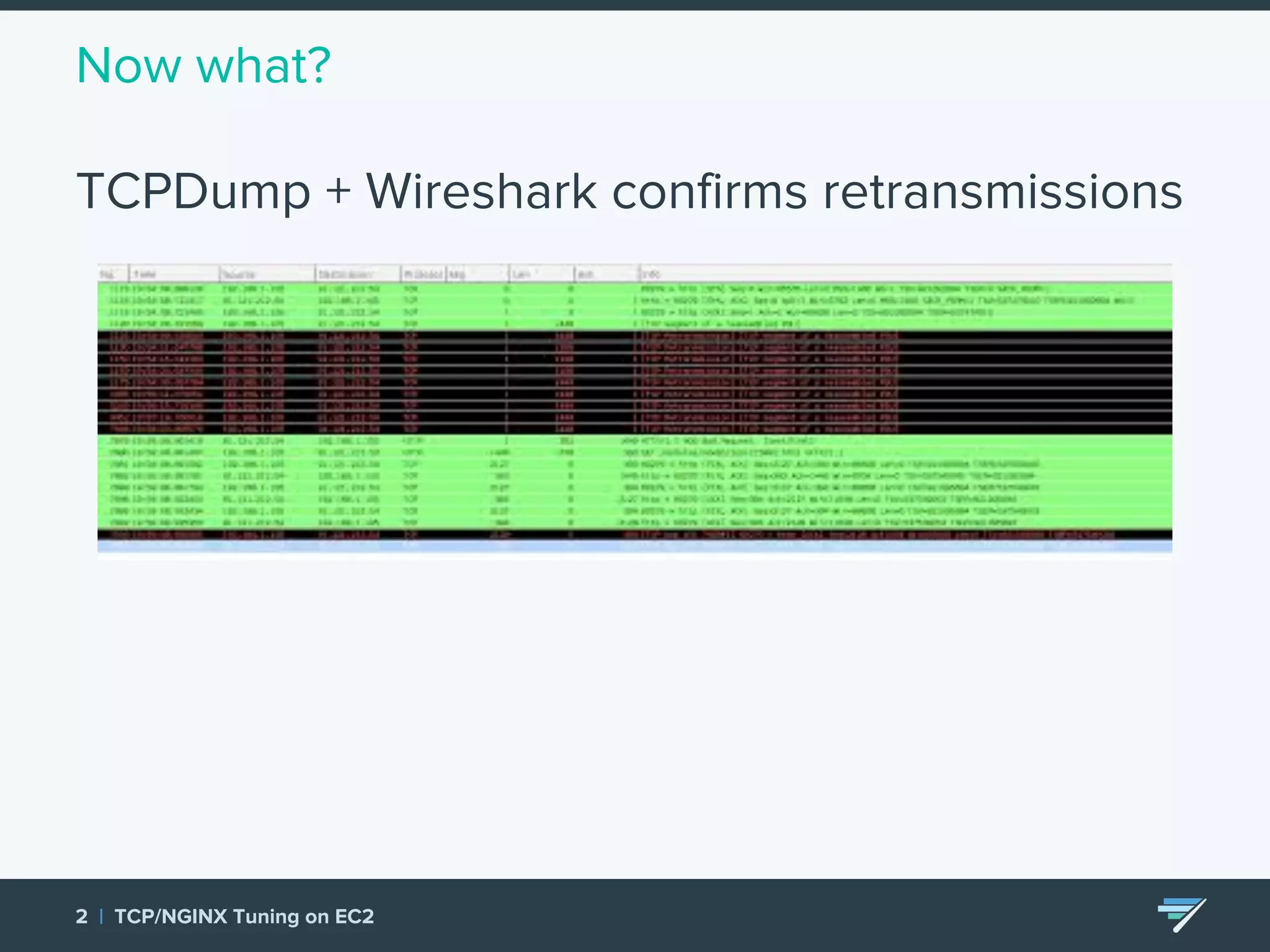


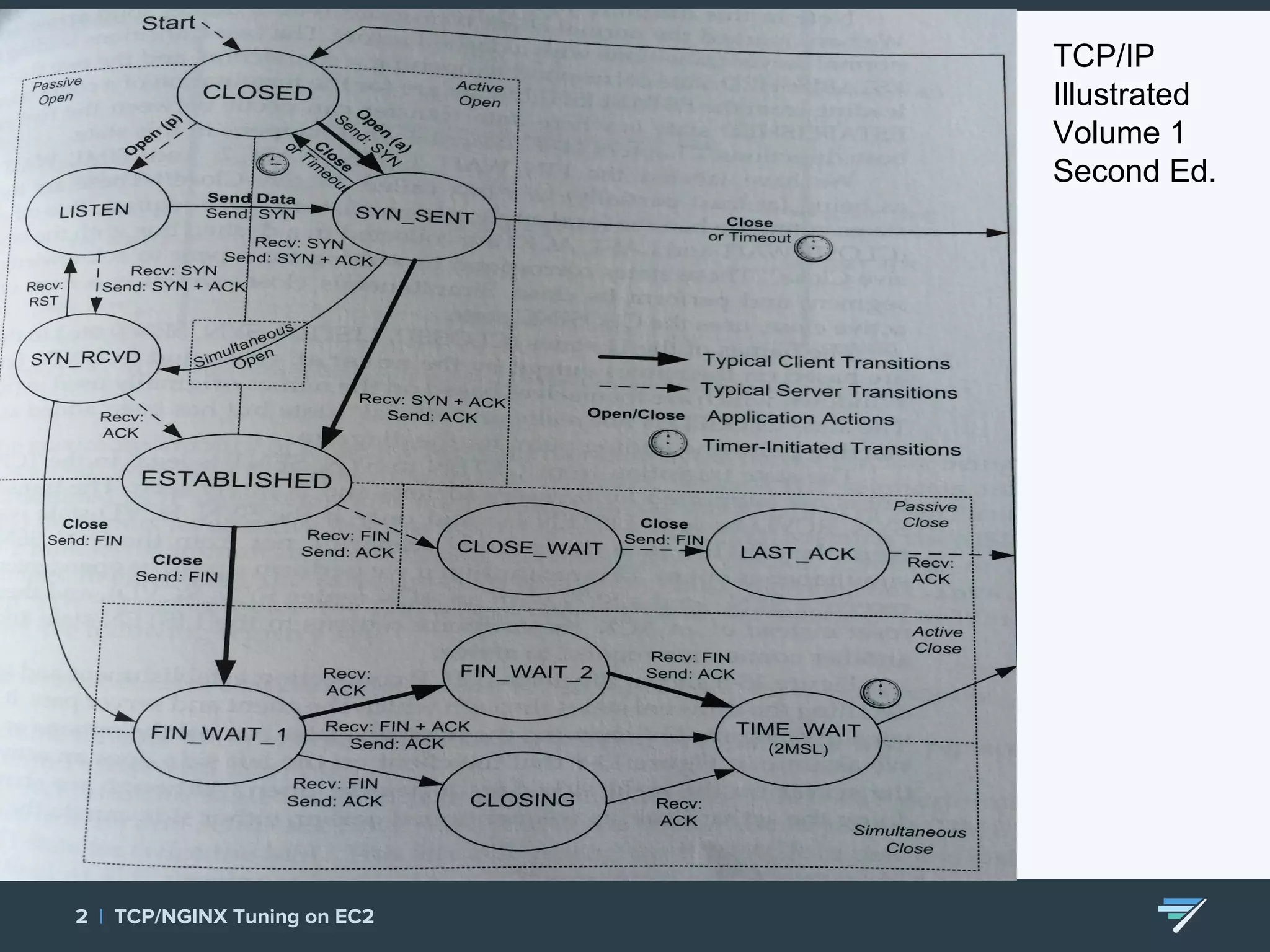


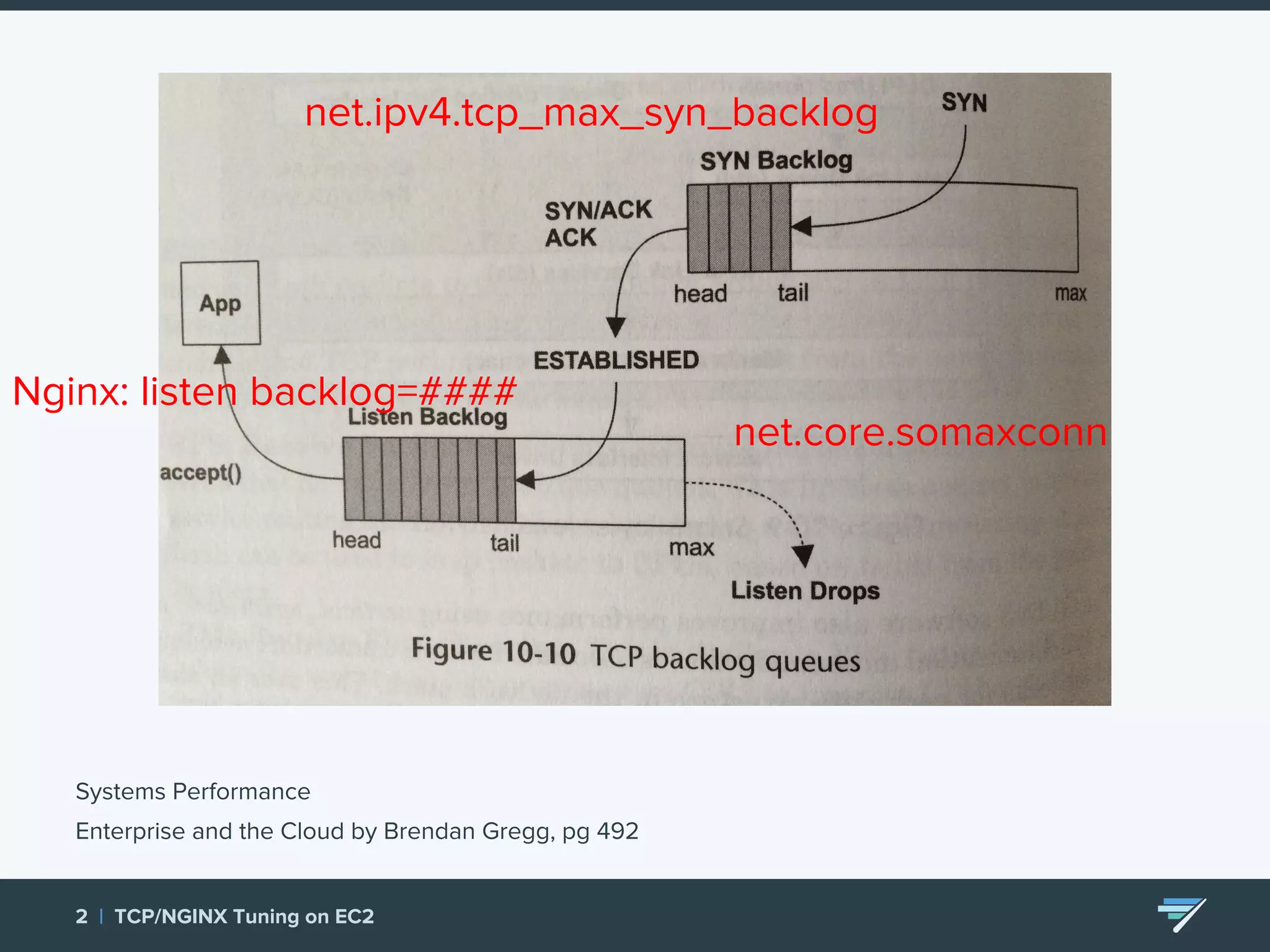


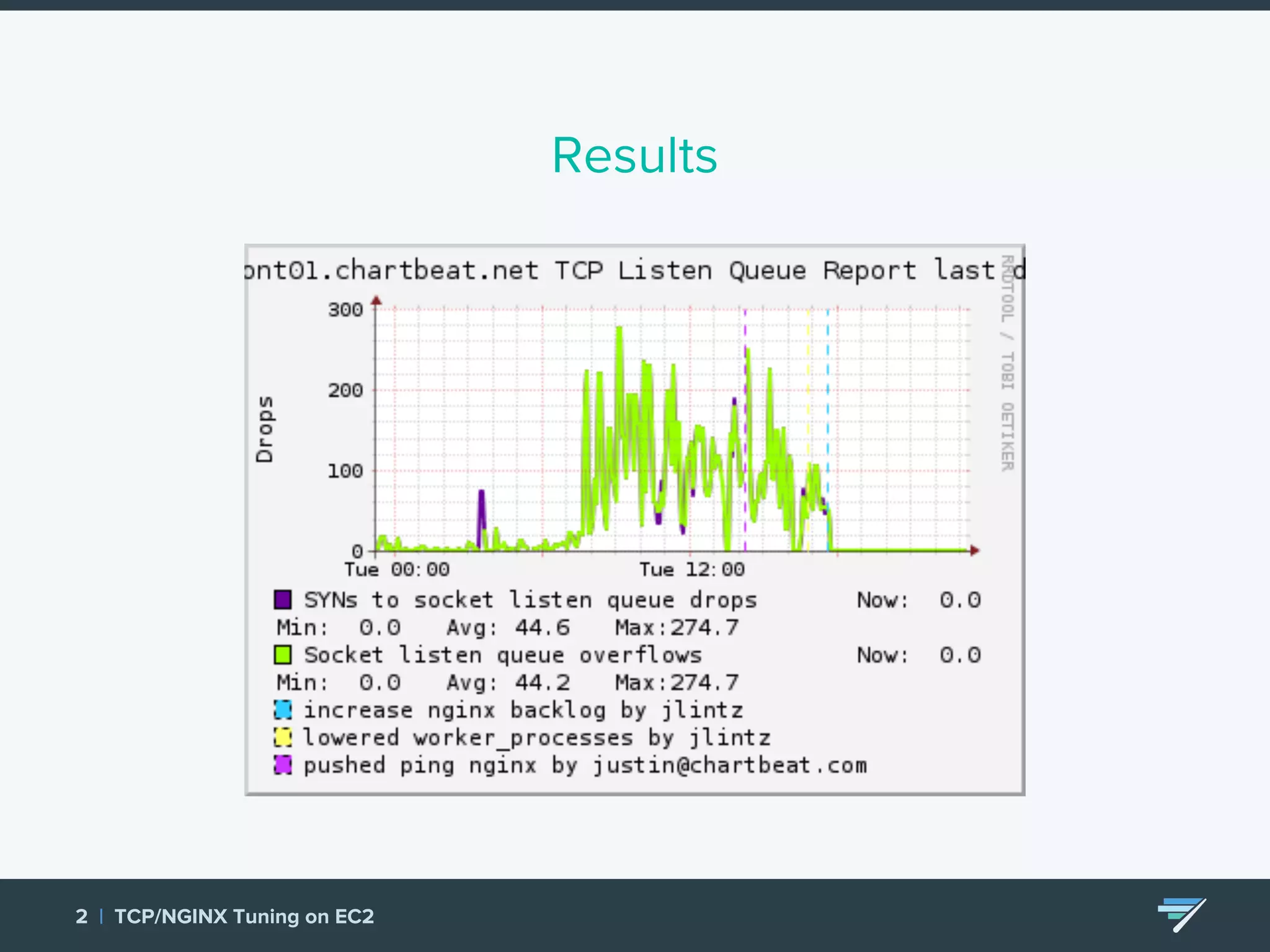

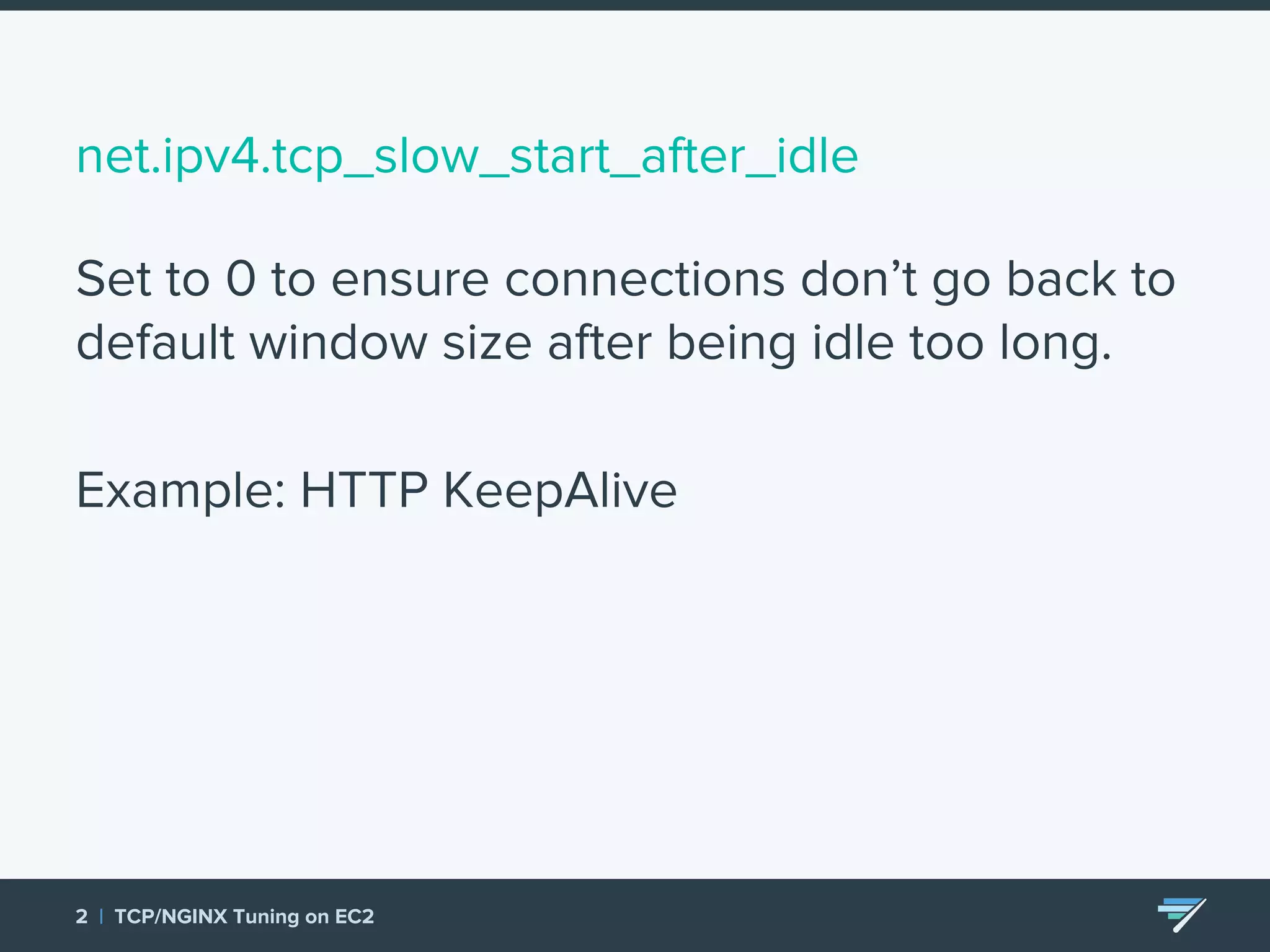



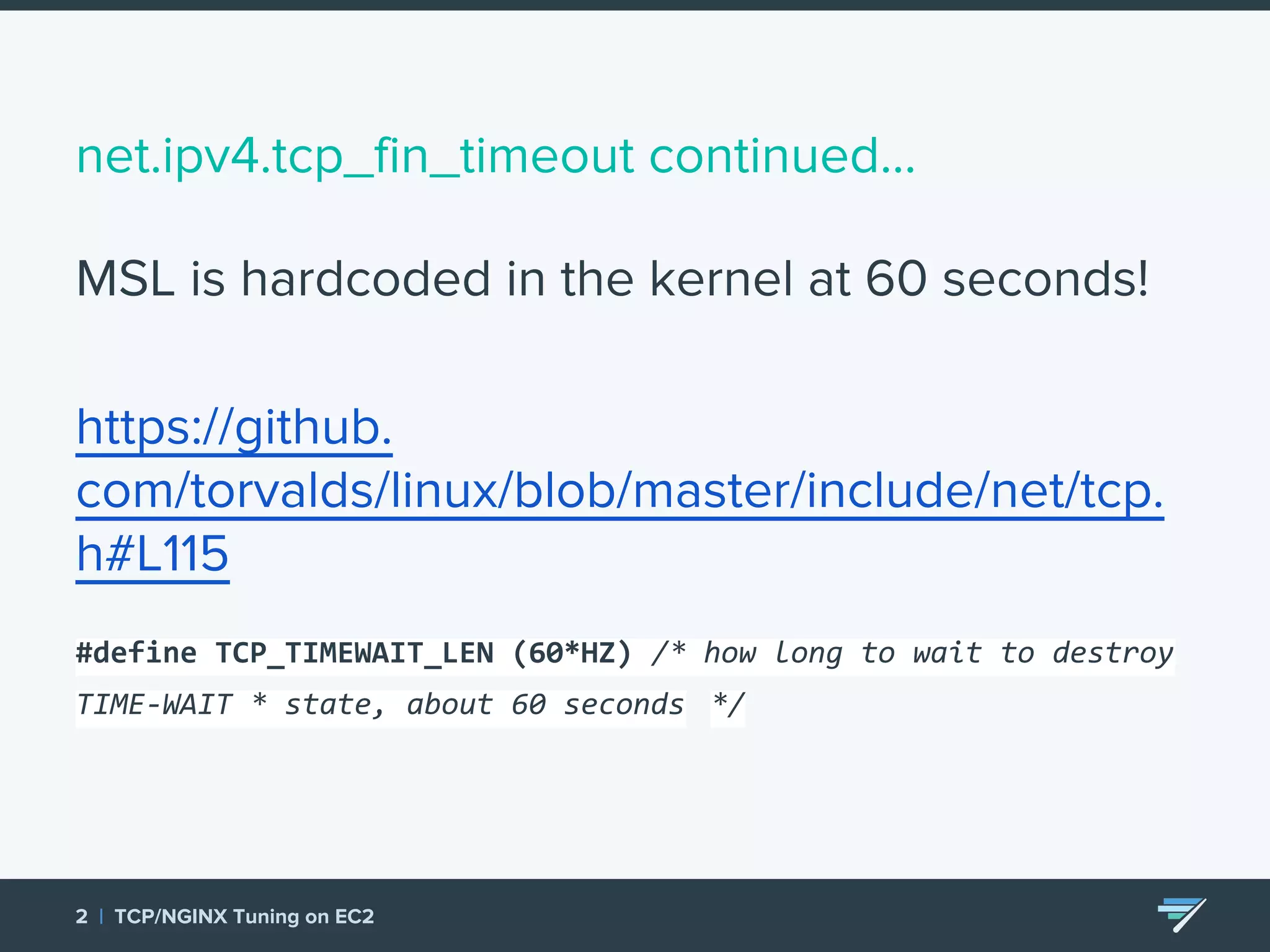









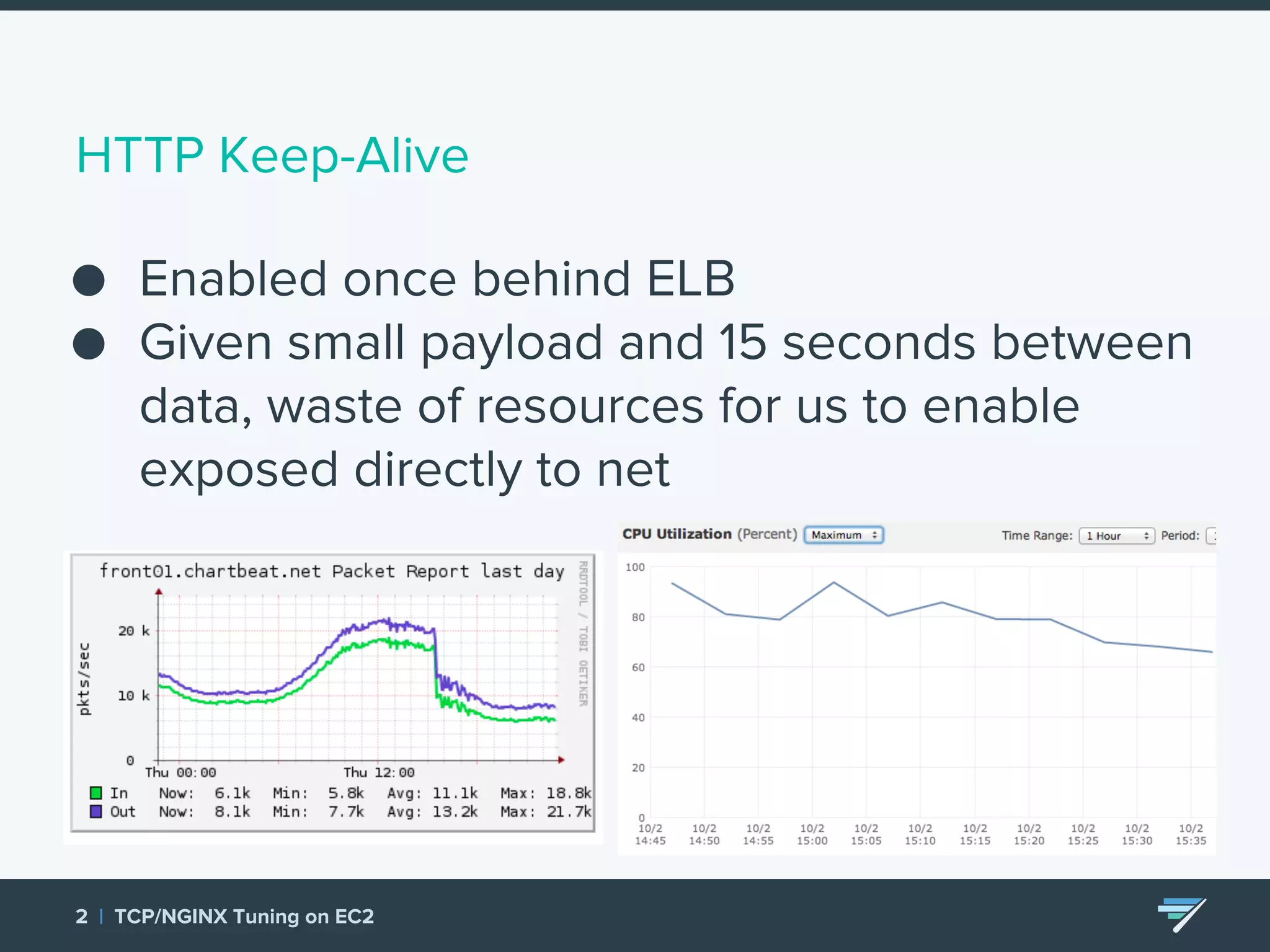


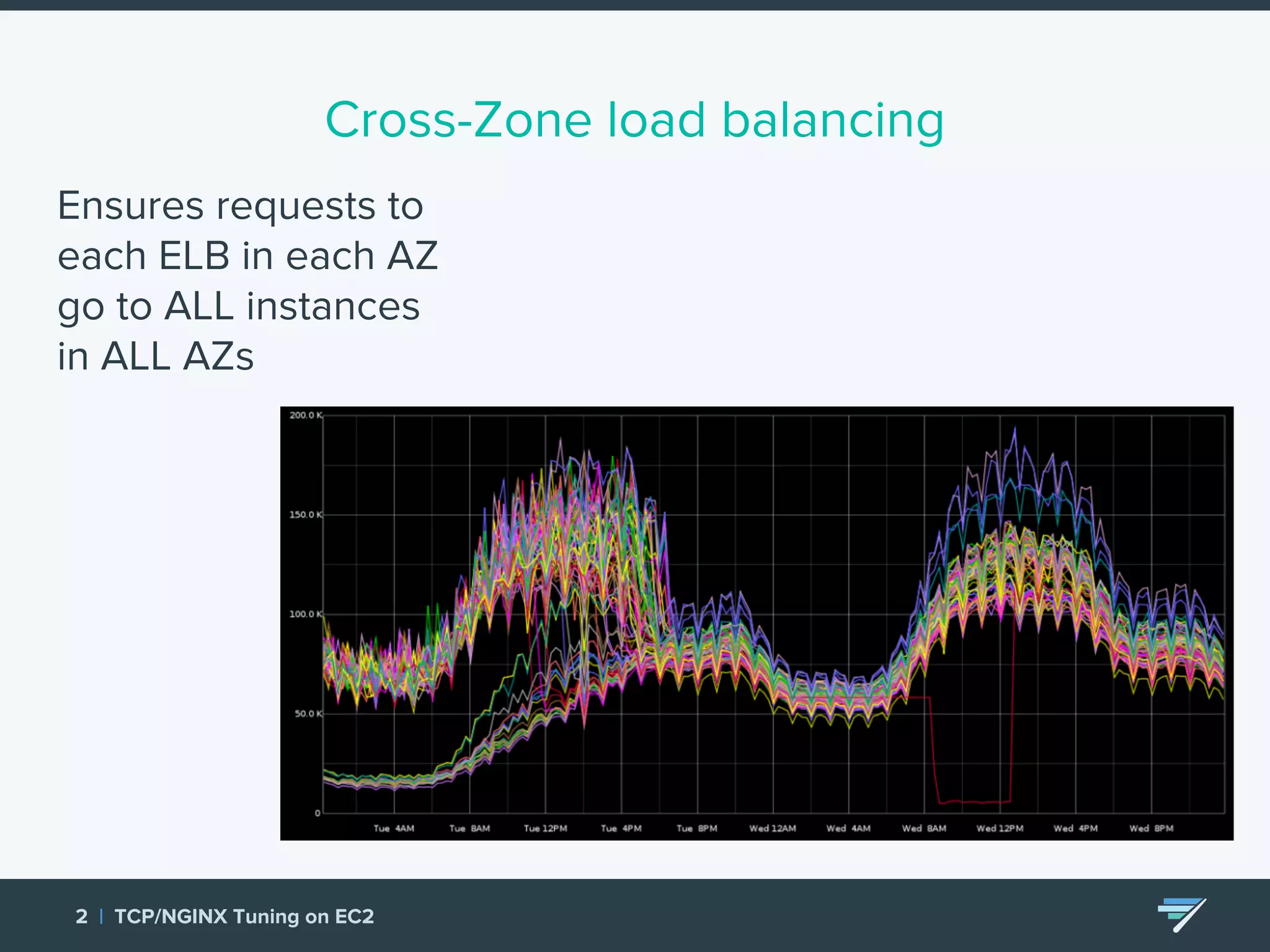







Chartbeat measures and monetizes attention on the web. They were experiencing slow load times and TCP retransmissions due to default system settings. Tuning various TCP, NGINX and EC2 ELB settings like increasing buffers, disabling Nagle's algorithm, and enabling HTTP keep-alive resolved the issues and improved performance. These included tuning settings like net.ipv4.tcp_max_syn_backlog, net.core.somaxconn, and nginx listen backlog values.