文章 "未知概率密度函数的核密度估计"
致作者如果我们估算的不是分布的密度,而是分布函数,即密度的积分,就会得到更好的结果:首先,在数据上建立分布函数更容易,而且由于分布函数总是不递减的,并在 0 和 1 之间有界,因此对选择平滑算法(无论是核算法、样条算法、回归算法还是其他算法)的敏感性要低得多。对可用数据量的要求也降低了,而且降低了一个数量级。
必要时,还可以通过数值微分轻松获得密度。
如果有必要,密度可以很容易地通过数值微分得到。
也许吧我对此一无所知。我甚至没有尝试过通过cdf 来评估pdf 。使用微分法需要大幅提高cdf 估计的准确性,这种偏见很可能起了作用。此外,我也没有看到任何出版物对cdf->pdf 方法进行评估,或将其与其他方法进行比较。如果您能提供相关链接, 我将不胜感激。
也许吧我对此一无所知。我甚至没有尝试过通过cdf 估算pdf 。很有可能,使用微分法需要大幅提高cdf 估计精度的偏见起了作用。此外,我还没有看到任何出版物对cdf->pdf 方法进行评估,或将其与其他方法进行比较。如果您能提供链接, 我将不胜感激。
我无法提供参考文献,因为我没有。我将给出这些考虑因素。
在直接评估 pdf 时,我们必须事先将定义域划分为若干区间,这就存在两个问题:首先,我们不知道最好将定义域划分为多少个区间;其次,我们不知道最好使用哪种类型的网格(均匀 网格、......网格?如果说第二个问题人们还在尝试解决,比如使用量化分割法,那么对于第一个问题,在我看来,根本就没有通用的方法:我所知道的所有方法都有其局限性,当我们无法承受 "捅 "的方法时,它们在自动化任务中几乎没有用武之地。
而 cdf 估算则没有这些缺点。在这种情况下,函数的步长正好位于输入数据的位置,因此为插值器选择网格的问题也就不复存在了。一旦创建了网格,选择间隔数就不难了:我们已经 知道了最大间隔数(及其位置!!!),因此,通过细化,我们可以设置任何所需的精度,而且每次都是在最符合输入数据结构的自然网格上进行。
在实践中,当数据样本数不超过 100 个时,我曾使用这种技术来搜索经验分布的局部模态,得到了非常平滑的结果,从视觉上看,搜索的准确性被定义为相当定性,至少可以找到 2-4 个主要模态,几乎没有偏差。但我使用的是另一种平滑算法,我不喜欢核算法,原因有以下几点。
完全公平。但在我看来,除了一点,你显然没有注意到。
众所周知,"Kernel smooth "是 "内核平滑 "的意思。
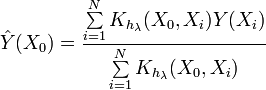
基于这种平滑法估计pdf 的方法可能是这样的(简化):
- 我们将输入序列划分为若干区间(聚类、分选)
- 平滑得到的直方图。
如果不喜欢核平滑,可以使用p-spline 等。(最好立即选择p-样条曲线)。
使用这种方法对pdf 进行估计,您所说的一切都会变得绝对合理。但即使在这种情况下,对于长度较大(大于 1000000)的序列,这种估算方法也能得到很好的结果。随着输入序列长度的减小,你提到的所有魅力开始越来越强烈地显现出来。
现在我们来看看核密度估计(KDE)的表达式
![]()
这个表达式与前面给出的表达式不同。正如你所看到的,这个表达式直接决定了给定点的概率密度函数 值。在这种情况下,最重要的是不需要划分区间。输入序列的值被直接使用。
至少,我是这样看待KDE 的 情况的。文章中给出的pdf 估算算法乍一看能很好地处理长度为 20-30 个元素的序列。有时您可能希望降低平滑程度。只需将代码中的
h=0.9*a/MathPow(N,0.2); //西尔弗曼的经验法则替换为
h=0.7*a/MathPow(N,0.2); //西尔弗曼的经验法则
最初的想法是不使用任何外部工具,即假定一切只能通过 MQL5 工具来实现。
这是所有自行车发明者的想法,无一例外。
看看相应的软件包在这方面有哪些功能,然后与您提供的功能进行比较 - 在交易中应用统计和计量经济学所需的功能微乎其微。
亲爱的亚历克斯
对你来说,从飞行的高度进行推理很容易。但请您想一想下面的内容:
该资源名为"www.mql5.com- 自动交易和交易策略测试"。 如 您所见,该网站名为mql5,而非 EViews,甚至不是MQ 或MT5。因此,不难推测该网站主要侧重于MQL5 编程语言的普及、调试和开发。这一点可以从网站上出现的 servicedesk 和放置的MQL5 参考信息中得到证实。
如果该网站名为 "交易策略集",而不属于 MQ。在这种情况下,描述 Exel、 R、 EVievs、Gauss、 Stata 等解决方案的出版物 就会出现在这样的网站上。
如果我在EViews 网站上发表了这篇文章,我可能会试着理解您责难的实质。但你我现在都不在EViews 上。
访问这个网站的人背景各不相同。他们有着不同的年龄、不同的教育背景和不同的专业。我想他们中的大多数人对计量经济学软件包都没有什么经验。你是否认为应该将这些人全部驱逐出本网站,比如 让他们 先学习EViews?
既然你自己发表过文章,就应该熟悉在本网站发表文章的程序。您不可能自行发表任何文章。您只能提交文章供考虑。网站管理部门会自行选择适合其总体概念的文章。在某些情况下,管理部门也会就他们感兴趣的主题订购文章。正如我已经说过的,管理部门有一个总体构想,并统计了对这一或那一出版物的请求数量。在这种情况下,我认为向我提出有关文章主题的要求是不恰当的。也许您应该与 MQ 代表讨论这些问题 ?
本网站发表的一些文章我并不感兴趣。我强调,不是文章不好,只是我不感兴趣。我通常不读这些文章,也不写评论。也许你应该为自己选择类似的行为方式?虽然我不敢给出建议,但还是按照你觉得更舒服的方式去做吧。
亲爱的亚历克斯
你从飞行的高度来推理很容易。但请您想一想下面的内容:
该资源名为"www.mql5.com- 自动交易和交易策略测试"。 如 您所见,该网站名为mql5,而非 EViews,甚至不是MQ 或MT5。因此,不难推测该网站主要侧重于MQL5 编程语言的普及、调试和开发。这一点可以从网站上出现的 servicedesk 和放置的MQL5 参考信息中得到证实。
如果该网站名为 "交易策略集",而不属于 MQ。在这种情况下,描述 Exel、 R、 EVievs、Gauss、 Stata 等解决方案的出版物 就会出现在这样的网站上。
如果我在EViews 网站上发表了这篇文章,我可能会试着理解您责难的实质。但你我现在都不在EViews 上。
访问这个网站的人背景各不相同。他们有着不同的年龄、不同的教育背景和不同的专业。我想他们中的大多数人对计量经济学软件包都没有什么经验。你是否认为应该将这些人全部驱逐出本网站,比如 让他们 先学习EViews?
既然你自己发表过文章,就应该熟悉在本网站发表文章的程序。您不可能自行发表任何文章。您只能提交文章供考虑。网站管理部门会自行选择适合其总体概念的文章。在某些情况下,管理部门也会就他们感兴趣的主题订购文章。正如我已经说过的,管理部门有一个总体构想,并统计了对这一或那一出版物的请求数量。在这种情况下,我认为向我提出有关文章主题的要求是不太妥当的。也许您应该与 MQ 代表讨论这些问题 ?
本网站发表的一些文章我并不感兴趣。我强调,不是文章不好,只是我不感兴趣。我通常不读这些文章,也不写评论。也许你应该为自己选择类似的行为方式?虽然我不敢给出建议,但还是按照你觉得更舒服的方式去做吧。
我不能接受你的回答,因为它完全不符合我的文章的本质。我试着解释一下我的观点。
1.Metaquotes 与此无关--他们提供了一个非常体面的工具,而且他们正在这样做。
2.我不知道对文章主题有任何限制。当然,在交易范围内。该网站有一个 "统计 "栏目,也就是说,他们对网站主题的理解比您宽泛得多,完全符合交易的内容和问题。不要再提 Metaquotes 了,我们继续讨论实质问题。
3. 我的帖子不是关于 "发展什么",而是关于 "如何发展"。对我来说,这才是与您的文章相关的根本所在。我不是在为 EViews 做宣传,我对它的评价很低--它很适合演示和培训,但我不认为你可以用它进行交易。我的链接是为了说明问题的严重性。
4.我从事编程工作已经很久了。40 年前,第一个程序库出现,40 年前,人们立即批评业余爱好者从现有软件包中重新编写程序。你不是第一个。但这个网站上有很多业余爱好者,他们都喜欢再造一辆自行车,所以我的反应才会如此强烈。
5.核评估问题是一个被嚼烂了的问题。如果你使用了别人的图书馆,你就有机会超越你在论文中解决的技术难题,也许还能为从业者 alsu 提出的问题提供解决方案,或者记住分布的视觉评价在其形式评价中起着非常重要的作用,或者从功能上进行扩展,等等。- 无论哪种方式,你都会更上一层楼。
我无意表达对您的冒犯。您的文章和发展值得尊敬,但我不能同意您的想法的实施技术 的方法论重点。
我之所以就您的文章发帖,是希望有人能用统计学和计量经济学的方法对 Metaquotes 终端进行系统性的补充。我向您推荐这样的人。
非常有趣非常有趣
你们接受请求吗?
不仅仅是开放源代码,最好是面向统计的代码。请关注 R。
非常有趣非常有趣
你们接受请求吗?
不仅仅是开放源代码,最好是面向统计的代码。请关注 R。
这里接受请求:https://www.mql5.com/ru/forum/6505。 想写什么就写什么。:)
- www.mql5.com
新文章 未知概率密度函数的核密度估计已发布:
本文主要介绍用于估计未知概率密度函数的核密度程序的创建。核密度估计方法被选择用于执行此任务。本文包含该方法的软件实现的源代码、其使用示例以及插图。
作者:Victor