Нейросети в трейдинге: Модели многократного уточнения прогнозов (Окончание)
Введение
Рынок не спешит раскрывать свои намерения. Он живёт в постоянном движении — гибком, текучем, часто непредсказуемом. Каждое изменение цены — это не случайный всплеск, а отражение множества взаимодействий, которые происходят между участниками рынка и информационными потоками. И если классические модели стараются уловить этот момент единым снимком, то современный подход RAFT (Recurrent All-Pairs Field Transforms) смотрит глубже. Он не делает прогноз один раз, а уточняет его многократно, вступая в диалог с данными.
Эта идея кажется почти философской. Мы привыкли, что модель выдаёт результат и отступает в сторону. RAFT же остаётся в процессе, будто опытный аналитик, который шаг за шагом проверяет свои предположения, сопоставляя каждое новое наблюдение с общей картиной происходящего. Вместо прямолинейной функции Вход — Выход здесь строится поле взаимосвязей, где каждый элемент влияет на другой. Такой подход не просто улучшает точность — он меняет само понимание прогнозирования. Результат становится не числом, а состоянием модели, отражением её внутреннего согласия с рынком.
В авторском варианте RAFT применялся для вычисления оптического потока — оценки движения между двумя кадрами изображения. Однако если отбросить технические детали, то сама логика метода удивительно созвучна задачам финансового анализа. Ведь и здесь мы имеем два состояния — прошлое и настоящее. Мы пытаемся понять, куда направлено движение. На место пикселей приходят котировки. На место оптических структур — ценовые паттерны. А на место кадров — временные срезы рынка. Таким образом, адаптация RAFT к задачам трейдинга становится закономерным шагом развития идей многократного уточнения прогнозов.
В предыдущих работах мы уже заложили основу. Первая статья была посвящена концепции многократных итераций и описанию общей архитектуры фреймворка. Вторая — разбору ключевых компонентов, от построения поля корреляций до рекуррентных блоков, управляющих процессом уточнения. Мы увидели, как модель может постепенно улучшать свои прогнозы, возвращаясь к исходным данным и проверяя каждую гипотезу заново.
Перед тем как продолжить работу, стоит ещё раз осмыслить, почему именно RAFT стал столь заметным шагом вперёд. Его главная сила — в способности моделировать полное поле парных взаимодействий. Вместо поиска локальных корреляций он сопоставляет все элементы между собой, создавая нечто вроде карты взаимных притяжений и отталкиваний. В финансовом контексте это означает, что каждый бар, каждая характеристика или индикатор рассматривается не изолированно, а в контексте всей истории, всех возможных связей. Это придаёт прогнозу устойчивость, а модели — системное мышление.
Следующим краеугольным элементом является итеративное уточнение. В отличие от одношаговых нейросетей, RAFT многократно обновляет оценку движения, или, в нашем случае, прогноз. После каждой итерации новая информация сверяется с общей картой взаимосвязей, и модель корректирует направление. Такая стратегия напоминает процесс аналитического рассуждения: сначала гипотеза, затем проверка, уточнение, и вновь проверка. Благодаря этому RAFT способен удерживать внимание на ключевых закономерностях, не теряя контекст и не впадая в переобучение.
Особую роль играет рекуррентный блок. Его задача — сохранять внутреннее состояние, то есть память модели, и управлять скоростью адаптации. В финансовых приложениях это можно трактовать как внутренний механизм управления доверием — насколько модель уверена в текущей оценке. Стоит ли пересматривать её, и как реагировать на изменение режима рынка. Таким образом, рекуррентный компонент превращается в нечто большее, чем технический элемент. Это регулятор интуиции, который удерживает баланс между новыми данными и накопленным опытом.
Не менее важен принцип многомасштабности. В оригинальной архитектуре RAFT применяется пирамидальное сжатие корреляции признаков. На каждом уровне происходит агрегация и уточнение информации с разным разрешением. Для рынка этот принцип особенно близок. Ведь краткосрочные флуктуации и долгосрочные тренды живут на разных временных горизонтах, но взаимно влияют друг на друга. Модель, способная учитывать это взаимодействие, ближе к реальности. Она видит отдельные движения и общий ритм рынка.
Реализация таких идей средствами MQL5 делает проект особенно ценным. MQL5 предоставляет мощные инструменты работы с временными рядами и прямой доступ к торговым данным, а OpenCL открывает возможности для параллельных вычислений. Объединяя их, мы получаем лабораторию для проверки фундаментальных концепций на реальных данных, без отрыва от практики трейдинга. Каждая итерация модели может быть протестирована в реальном времени.
Фреймворк RAFT интересен ещё и тем, что он универсален. Его принципы — построение поля взаимодействий, итеративное уточнение, рекуррентная память — не зависят от конкретной области. В трейдинге эти идеи позволяют построить систему, которая не просто делает прогноз, а учится его уточнять. Систему, которая не спешит с решением, а проверяет свои шаги. В эпоху, когда скорость и точность определяют успех на рынке, такое качество становится редким преимуществом.
Авторская визуализация фреймворка RAFT представлена ниже.

Объект верхнего уровня
В предыдущей статье мы завершили реализацию ключевых компонентов фреймворка RAFT. Теперь настал момент перейти к завершающему этапу: объединить всё в единую согласованную структуру, где каждый компонент будет не просто выполнять свою функцию, а взаимодействовать с остальными, образуя целостный механизм. Однако, прежде чем приступить к этой работе, стоит на минуту остановиться и осмыслить, что именно мы уже построили, и какие вопросы остаются открытыми.
В оригинальной архитектуре RAFT заложена элегантная симметрия. Одна и та же архитектура энкодера признаков используется для двух потоков: основного и контекстного. Энкодер основного потока анализирует пару изображений, извлекая из них карты признаков, а затем определяет корреляции между ними. Контекстный энкодер работает лишь с одним изображением — исходным, создавая своего рода фундамент, с которого начинается прогноз. Это фундаментальное разделение ролей и делает архитектуру RAFT такой устойчивой: один поток отвечает за наблюдение изменений, другой — за удержание точки опоры.
Но в мире финансов всё гораздо подвижнее. Если в компьютерном зрении кадры фиксируют последовательность событий с чёткими границами, то рынок не знает остановок. Он не ждёт, пока модель успеет сделать снимок, а течёт непрерывно. Переливается из одного состояния в другое, как река после дождя, меняя русло под воздействием новых потоков информации. И здесь идея фиксированного контекста начинает буксовать. Невозможно заморозить состояние рынка, чтобы на его основе строить прогноз. То, что ещё минуту назад было актуальным, через час может потерять смысл.
Мы уже сталкивались с подобной проблемой, когда обсуждали использование фиксированного начального состояния в задачах прогнозирования временных рядов. Тогда решение нашлось естественным образом — мы ввели стек исторических состояний, который позволил модели опираться не на один момент, а на целую последовательность, создавая динамическую матрицу корреляций. Такой подход дал возможность видеть рынок не в кадре, а в движении, наблюдая, как прошлое взаимодействует с настоящим.
Однако при работе с контекстным потоком ситуация становится ещё интереснее. Контекст — это не просто вспомогательная информация. Это само понимание текущего режима рынка. А режимы, как известно, переменчивы. Волатильность растёт, ликвидность смещается, корреляции между активами то усиливаются, то исчезают. Зафиксировать контекст в таких условиях — значит обречь модель на слепоту. С другой стороны, попытка отслеживать контекст с помощью стека историй приводит к избыточной сложности и снижению производительности. Мы бы получили громоздкую структуру, которая теряет главный козырь RAFT — скорость и эффективность итераций.
Значит, нужно искать другой путь — более естественный, более гибкий. Путь, при котором сама модель способна понимать, как меняется контекст, и обновлять его без внешнего вмешательства. Идея проста, но глубока: дополнить контекстный энкодер рекуррентным блоком, который будет отслеживать состояние рынка в реальном времени. Такой блок сможет помнить недавние изменения, выявлять повторяющиеся закономерности и корректировать контекст по мере поступления новых данных.
Это решение, по сути, делает модель самонастраивающейся. Контекст перестаёт быть внешним параметром — он становится внутренним состоянием системы, живущим и дышащим вместе с рынком. Модель получает способность не просто реагировать на исходные данные, а адаптироваться, то есть осмысленно перестраивать своё восприятие происходящего.
Если угодно, рекуррентный блок становится аналогом кратковременной памяти аналитика: он помнит, что происходило недавно, но не обременён всей историей. Он держит фокус на актуальном, позволяя прогнозу оставаться точным даже в условиях быстро меняющейся динамики.
Это — важный шаг вперёд. Мы переходим от механического построения архитектуры к осмысленному моделированию адаптивного поведения. Ведь в трейдинге важно не просто вычислить движение, а понимать, почему оно меняется, и суметь подстроиться под новый режим. Рекуррентный контекстный энкодер позволит фреймворку RAFT приблизиться к этой цели.
Предложенные идеи мы воплощаем в объекте CNeuronRAFT, который становится центральным элементом нашей реализации. Именно здесь все ключевые компоненты фреймворка — Энкодеры, корреляционный блок, рекуррентный механизм и остаточные связи — сходятся в единую структуру, образуя динамическое ядро модели.
class CNeuronRAFT : public CNeuronSpikeActivation { protected: CLayer cEncoder; CLayer cContext; CLayer cCorrelation; CNeuronBaseOCL cConcatenated; CNeuronSpikeConvGRU2D cGRU; CNeuronSpikeResNeXtResidual cResidual; CLayer cG; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRAFT(void) {}; ~CNeuronRAFT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &units[], uint &chanels[], uint group_size, uint groups, uint stack_size, uint levels, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRAFT; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Представленная структура — не просто набор объектов. Это архитектурная экосистема, в которой каждый компонент выполняет роль в общей динамике.
cEncoder отвечает за первичное извлечение признаков из исходных данных. Это аналог визуального энкодера в оригинальном RAFT, адаптированный под финансовые временные ряды. Он превращает поток цен и показателей индикаторов в компактное многомерное представление, где каждая координата — это не число, а смысловая компонента рыночного движения.
cContext формирует контекстный поток. Его архитектуру дополняет рекуррентный модуль, призванный отслеживать эволюцию рыночного состояния во времени. Благодаря ему, контекст перестаёт быть статичным, он дышит, реагируя на новые события, и плавно перестраивается вместе с рынком, обеспечивая модели способность удерживать кратковременную память о динамике.
Далее следует cCorrelation, в котором строится матрица взаимных связей между признаками. То самое поле взаимодействий, на котором базируется вся философия RAFT. Здесь происходит сопоставление признаков текущего состояния с историческим стеком данных, накопленным за предыдущие периоды. Строится корреляционное поле — та самая основа, которая позволяет RAFT улавливать локальные сдвиги и целостную динамику процессов.
Компонент cConcatenated объединяет результаты работы энкодера, модуля корреляции с обновлённым контекстом, подготавливая их для подачи в рекуррентный блок cGRU. Этот модуль отвечает за итеративное уточнение прогноза. Он оценивает разницу между предыдущими и текущими состояниями, вносит коррекции и тем самым приближает модель к более точному решению.
Модуль cResidual выполняет роль стабилизирующего звена. Он не передаёт градиент, как в классических остаточных сетях, а обеспечивает согласованность между итерациями и предотвращает дрейф признаков при многократных обновлениях. Здесь важно понимать фундаментальное отличие RAFT от традиционных моделей прогнозирования. Алгоритм не предсказывает новое состояние напрямую, а генерирует дельту признаков — уточнение, описывающее изменение текущего состояния. Добавление этой прогнозной дельты к исходным данным и даёт нам желаемый результат.
Авторы фреймворка RAFT сознательно не проводят градиент ошибки по потоку остаточных связей. Исходное состояние рассматривается как свершившийся факт и не подлежит корректировке. Оптимизация распространяется лишь по обновляемым потокам — через корреляционные и рекуррентные блоки. Такой подход делает обучение устойчивым, исключает обратное искажение исходных данных и позволяет модели сосредоточиться на самой динамике изменений.
Компонент cG — завершающий блок обработки данных, формирующий итоговую карту прогнозных значений. Здесь сходятся все пути модели, и результат каждой итерации становится входом для следующего шага уточнения.
Инициализация всех внутренних компонентов нового объекта осуществляется в методе Init. Этот этап можно сравнить с моментом, когда оркестр собирается перед выступлением — каждый инструмент должен быть настроен, а дирижёр — готов задать ритм. Именно здесь создаётся и согласуется весь ансамбль нейронных блоков, из которых впоследствии рождается согласованная динамика модели.
bool CNeuronRAFT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &units[], uint &chanels[], uint group_size, uint groups, uint stack_size, uint levels, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units.Size() != chanels.Size()) return false; uint layers = units.Size() - 1; if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, units[layers]*chanels[layers], optimization_type, batch)) return false;
Процедура начинается с проверки корректности полученных параметров и вызова базовой инициализации родительского класса. Далее формируются все основные строительные блоки фреймворка: энкодеры, корреляционный модуль, рекуррентный узел и стабилизирующий блок остаточных связей.
Двухпотоковая структура — cEncoder и cContext — создаётся первой. В цикле формируются слои CNeuronSpikeResNeXtBlock, отвечающие за последовательное извлечение признаков.
int index = 0; CNeuronSpikeResNeXtBlock* resblock = NULL; CNeuronSpikeConvGRU2D* gru = NULL; CNeuronMultiScaleStackCorrelation* correlation = NULL; CNeuronBaseOCL* neuron = NULL; CNeuronBatchNormOCL* norm = NULL; //--- cEncoder.Clear(); cContext.Clear(); cCorrelation.Clear(); cG.Clear(); cEncoder.SetOpenCL(OpenCL); cContext.SetOpenCL(OpenCL); cCorrelation.SetOpenCL(OpenCL); cG.SetOpenCL(OpenCL); //--- for(uint i = 0; i < layers; i++) { resblock = new CNeuronSpikeResNeXtBlock(); if(!resblock || !resblock.Init(0, index, OpenCL, chanels[i], chanels[i + 1], units[i], units[i + 1], group_size, groups, optimization, iBatch) || !cEncoder.Add(resblock)) { DeleteObj(resblock) return false; } index++; resblock = new CNeuronSpikeResNeXtBlock(); if(!resblock || !resblock.Init(0, index, OpenCL, chanels[i], chanels[i + 1], units[i], units[i + 1], group_size, groups, optimization, iBatch) || !cContext.Add(resblock)) { DeleteObj(resblock) return false; } index++; }
Поток cEncoder анализирует признаки текущего состояния, а cContext — формирует адаптивное контекстное пространство, дополняемое рекуррентным блоком CNeuronSpikeConvGRU2D. Этот GRU-модуль придаёт фреймворку способность отслеживать временную динамику и корректировать контекст без фиксированного состояния — важнейшее свойство при работе с непрерывными рыночными данными.
gru = new CNeuronSpikeConvGRU2D(); if(!gru || !gru.Init(0, index, OpenCL, units[layers], chanels[layers], chanels[layers], optimization, iBatch) || !cContext.Add(gru)) { DeleteObj(gru) return false; } index++;
Далее создаётся модуль CNeuronMultiScaleStackCorrelation, который формирует матрицу корреляций между признаками текущего состояния и стеком исторических данных. Это центральный элемент архитектуры — аналог вычислительного поля сил, в котором проявляется взаимосвязь между прошлым и настоящим.
correlation = new CNeuronMultiScaleStackCorrelation(); if(!correlation || !correlation.Init(0, index, OpenCL, stack_size, chanels[layers], units[layers], levels, optimization, iBatch) || !cCorrelation.Add(correlation)) { DeleteObj(correlation) return false; } index++; resblock = new CNeuronSpikeResNeXtBlock(); if(!resblock || !resblock.Init(0, index, OpenCL, correlation.Neurons() / units[layers], chanels[layers], units[layers], units[layers], group_size, groups, optimization, iBatch) || !cCorrelation.Add(resblock)) { DeleteObj(resblock) return false; } index++;
На выходе блока добавляется слой CNeuronSpikeResNeXtBlock, усиливающий избирательность модели к наиболее значимым признакам.
После блока генерации корреляционного поля формируется объединяющий узел cConcatenated, который сводит результаты трёх потоков — признаков, контекста и корреляций — в единый тензор.
if(!cConcatenated.Init(0, index, OpenCL, 3 * chanels[layers]*units[layers], optimization, iBatch)) return false; index++;
Затем данные передаются в cGRU, где происходит итеративное уточнение прогнозной дельты.
if(!cGRU.Init(0, index, OpenCL, units[layers], 3 * chanels[layers], chanels[layers], optimization, iBatch)) return false; index++;
Следом инициализируется стабилизирующий модуль cResidual. Его задача — удерживать структуру признакового пространства в устойчивом состоянии при множественных итерациях. В отличие от классических остаточных связей, здесь не происходит обратного распространения градиента — базовое состояние не корректируется, а используется как опорная точка, к которой прибавляется вычисленная моделью дельта признаков.
if(!cResidual.Init(0, index, OpenCL, chanels[0], chanels[layers], units[0], units[layers], optimization, iBatch)) return false; index++;
Заключительный блок cG объединяет всё в цельную систему, нормализуя выходной поток и подготавливая его к передаче на следующий уровень. Здесь же создаются и вспомогательные объекты — базовый нейрон и слой нормализации CNeuronBatchNormOCL, отвечающий за стабилизацию выходного распределения.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, Neurons(), optimization, iBatch) || !cG.Add(neuron)) { DeleteObj(neuron) return false; } neuron.SetActivationFunction(None); if(!neuron.SetGradient(cGRU.getGradient(), true) || !cResidual.SetGradient(cGRU.getGradient(), true)) return false; //--- index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, Neurons(), iBatch, optimization) || !cG.Add(norm)) { DeleteObj(norm) return false; } //--- return true; }
Таким образом, метод инициализации выстраивает логическую последовательность вычислительных шагов. Каждый модуль имеет своё чёткое предназначение: извлечение признаков, построение корреляций, рекуррентное уточнение контекста и формирование прогнозной дельты. Все эти элементы объединяются в единую структуру, готовую к обучению в реальных рыночных условиях.
Алгоритм прямого прохода реализован в методе feedForward. Это не просто вычислительный цикл, а живой процесс. Здесь модель оживает и начинает чувствовать рынок. Каждый блок вносит свою роль, и вместе они создают динамическую картину будущих изменений.
bool CNeuronRAFT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cResidual.FeedForward(NeuronOCL)) return false;
Процесс начинается с блока cResidual. Можно представить его как прочный фундамент или якорь. Он фиксирует текущее состояние признаков, создавая точку отсчёта для всех последующих изменений.
Следующий шаг — основной поток признаков, cEncoder. Каждый ResNeXt-блок здесь подобен внимательному исследователю, который сканирует рынок слой за слоем, выявляя важные паттерны и зависимости. На выходе формируется снимок текущего состояния — полный и детализированный, словно панорамная карта рынка в данный момент.
CNeuronBaseOCL* current = NULL; CNeuronBaseOCL* prev = NeuronOCL; for(int i = 0; i < cEncoder.Total(); i++) { current = cEncoder[i]; if(!current || !current. Feedforward(prev)) return false; prev = current; }
Параллельно работает поток контекста cContext. Если энкодер фиксирует момент, контекст — это наблюдатель, который помнит прошлое и видит тенденции. Его рекуррентный GRU-блок отслеживает, как рынок изменялся в последние шаги, и подстраивает прогноз под эти изменения. Контекст живёт и дышит вместе с рынком, обеспечивая непрерывную адаптацию модели.
prev = NeuronOCL; for(int i = 0; i < cContext.Total(); i++) { current = cContext[i]; if(!current || !current. Feedforward(prev)) return false; prev = current; }
Далее результаты работы Энкодера передаются в блоке cCorrelation. Здесь они добавляются в стек сохранения истории рыночных состояний и формируется многомасштабная матрица корреляций между признаками. Можно представить это как стратегическую карту, где каждая точка показывает, как вчерашние события влияют на сегодняшние. Именно здесь модель улавливает скрытые закономерности, выявляет силу и направление движения.
prev = cEncoder[-1]; for(int i = 0; i < cCorrelation.Total(); i++) { current = cCorrelation[i]; if(!current || !current. Feedforward(prev)) return false; prev = current; }
Все три потока — энкодер, контекст и корреляции — объединяются в узле cConcatenated. Это как штаб, где собираются все разведданные. Здесь сигнал консолидируется перед тем, как попасть на уточнение.
uint units = cGRU.GetUnits(); if(!Concat(cEncoder[-1].getOutput(), cContext[-1].getOutput(), cCorrelation[-1].getOutput(), cConcatenated.getOutput(), cEncoder[-1].Neurons() / units, cContext[-1].Neurons() / units, cCorrelation[-1].Neurons() / units, units)) return false;
Рекуррентный блок cGRU выступает командиром на этом этапе. Он анализирует совокупный сигнал и вычисляет дельту признаков — прогнозное изменение, которое добавляется к исходному состоянию, формируя итоговый прогноз.
if(!cGRU.FeedForward(cConcatenated.AsObject())) return false; //--- current = cG[0]; if(!current || !SumAndNormilize(cGRU.getOutput(), cResidual.getOutput(), current.getOutput(), cGRU.GetChanels(), false, 0, 0, 0, 1)) return false;
Затем сигнал поступает в блок cG, где происходит суммирование с выходом остаточной связи и нормализация. Можно представить это как тонкую балансировку весов — все потоки синхронизируются, устраняются смещения и шумы, обеспечивая устойчивость прогноза. Последовательное прохождение всех слоёв cG завершает процесс формирования результатов, которые теперь отражают не статичное состояние, а динамически уточнённую картину рынка.
prev = current; for(int i = 1; i < cG.Total(); i++) { current = cG[i]; if(!current || !current. Feedforward(prev)) return false; prev = current; } //--- return CNeuronSpikeActivation::feedforward(prev); }
В итоге feedForward превращает анализируемые данные в живую проекцию изменений, где каждый блок работает как отдельный аналитик. Но вместе они создают команду, способную видеть тенденции, предугадывать движения и адаптироваться к изменчивой рыночной среде. Модель не пытается предсказать будущее напрямую — она вычисляет дельту и шаг за шагом уточняет картину, позволяя прогнозу быть реалистичным и устойчивым.
После формирования прогноза, наступает следующий ключевой этап — распределение градиента ошибки. Его мы реализовали в методе calcInputGradients. Если прямой проход можно представить как оркестр, исполняющий произведение, то обратное распространение — это дирижёр, который оценивает каждый инструмент и корректирует его звучание, чтобы весь ансамбль сыграл точно.
bool CNeuronRAFT::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- if(!CNeuronSpikeActivation::calcInputGradients(cG[-1])) return false;
Метод начинается с проверки корректности указателя на объект исходных данных NeuronOCL. Без него модель не сможет корректно распределить градиенты, и весь процесс остановится — как если бы оркестр остался без партитуры.
Далее вызывается одноименный метод родительского класса, который задаёт начальную точку обратного распространения. Можно сказать, что это первый удар метронома: градиенты начинают течь по цепочке компонентов cG, от последнего к первому.
CNeuronBaseOCL* current = NULL; CNeuronBaseOCL* next = cG[-1]; for(int i = cG.Total() - 2; i >= 0; i--) { current = cG[i]; if(!current || !current.CalcHiddenGradients(next)) return false; next = current; }
Цикл проходит по элементам модуля cG в обратном порядке. Каждый слой получает сигнал от следующего, аккуратно распределяя ошибку. Этот процесс напоминает шаги опытного аналитика, который оценивает каждый уровень модели, сверяя прогноз с реальными результатами.
После слоёв cG градиент передаётся к блоку cResidual. Здесь ошибка распределяется относительно исходного состояния, сохраняя его как неизменный факт. Это ключевой момент: базовые признаки не модифицируются, а служат опорой для вычисления корректировок.
if(!NeuronOCL.CalcHiddenGradients(cResidual.AsObject())) return false;
Далее градиенты поступают в объединяющий узел cConcatenated. Отсюда они делятся на три потока — cEncoder, cContext и cCorrelation. Этот шаг можно представить как команду, которая распределяет задания между тремя аналитиками: каждому даётся своя часть данных для обработки.
if(!cConcatenated.CalcHiddenGradients(cGRU.AsObject())) return false; uint units = cGRU.GetChanels(); if(!DeConcat(cEncoder[-1].getGradient(), cContext[-1].getGradient(), cCorrelation[-1].getGradient(), cConcatenated.getGradient(), cEncoder[-1].Neurons() / units, cContext[-1].Neurons() / units, cCorrelation[-1].Neurons() / units, units)) return false;
Следующий блок — cCorrelation. Цикл проходит по слоям в обратном порядке, каждый слой корректирует свой градиент на основе сигнала от следующего. В этой части модель проверяет, как взаимодействие текущих и исторических признаков влияло на итоговый прогноз.
next = cCorrelation[-1]; for(int i = cCorrelation.Total() - 2; i >= 0; i--) { current = cCorrelation[i]; if(!current || !current.CalcHiddenGradients(next)) return false; next = current; }
Затем градиент поступает к энкодеру cEncoder. Здесь есть интересная особенность. Энкодер получает градиенты ошибки по 2 информационным потокам. Ранее он уже получил часть информации при деконкатенации градиентов ошибки рекуррентного блока, и, чтобы не потерять уже сохраненные значения, последний слой энкодера временно сохраняет указатель на буфер градиентов в локальную переменную (temp), а его место занимает свободный буфер. Затем вычисляем градиенты по магистрали модуля корреляции и суммируем их с сохраненными значениями.
current = cEncoder[-1]; if(!current) return false; CBufferFloat* temp = current.getGradient(); if(!current.SetGradient(current.getPrevOutput(), false) || !current.CalcHiddenGradients(next) || !SumAndNormilize(temp, current.getGradient(), temp, temp.Total() / units, false, 0, 0, 0, 1) || !current.SetGradient(temp, false)) return false;
Далее возвращаем указатели на буферы в исходное состояние и градиенты проходят через все остальные слои энкодера.
next = current; for(int i = cEncoder.Total() - 2; i >= 0; i--) { current = cEncoder[i]; if(!current || !current.CalcHiddenGradients(next)) return false; next = current; } if(!NeuronOCL.CalcHiddenGradients(next)) return false;
После обработки энкодера переходим к контекстному потоку cContext. Цикл проходит по компонентам в обратном порядке.
next = cContext[-1]; for(int i = cContext.Total() - 2; i >= 0; i--) { current = cContext[i]; if(!current || !current.CalcHiddenGradients(next)) return false; next = current; }
И финальная операция — передача градиентов на уровень объекта исходных данных NeuronOCL, где также используется аккуратное суммирование градиентов от двух информационных потоков.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.CalcHiddenGradients(next) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, 1, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
В результате метод calcInputGradients аккуратно распределяет ошибку по всей архитектуре объекта — от уровня результатов до энкодера, контекста и корреляций, корректируя только те части, которые подлежат обучению. Каждый блок выполняет свою роль: энкодеры анализируют локальные признаки, контекст учитывает историю, корреляции фиксируют связи между элементами, а остаточные блоки обеспечивают стабильность всей структуры. Такой подход гарантирует, что обучение проходит эффективно и без искажения исходных состояний, сохраняя живую динамику модели, которую мы наблюдали в прямом проходе.
Последний этап оптимизации параметров — именно здесь модель корректирует свои внутренние веса, чтобы прогноз становился точнее. Алгоритм реализован в методе updateInputWeights, который можно сравнить с настройкой всех инструментов после репетиции.
bool CNeuronRAFT::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cResidual.UpdateInputWeights(NeuronOCL)) return false;
Процесс начинается с оптимизации остаточного блока cResidual. Он корректирует свои параметры, удерживая устойчивую опорную точку для всей архитектуры.
Далее весовые коэффициенты корректируются в основном потоке энкодера cEncoder. Каждый слой последовательно получает сигнал от предыдущего блока и обновляет свои параметры. Можно представить это как команду исследователей, которые, получив обратную связь, уточняют свои инструменты, улучшая качество извлечения признаков на следующем проходе.
CNeuronBaseOCL* current = NULL; CNeuronBaseOCL* prev = NeuronOCL; for(int i = 0; i < cEncoder.Total(); i++) { current = cEncoder[i]; if(!current || !current.UpdateInputWeights(prev)) return false; prev = current; }
Контекстный поток cContext обновляется аналогично. Здесь рекуррентный GRU использует накопленные градиенты для подстройки весов, учитывая временную динамику. Каждый слой контекста корректирует влияние прошлых состояний на текущие прогнозы, позволяя модели более гибко реагировать на изменчивость рынка.
prev = NeuronOCL; for(int i = 0; i < cContext.Total(); i++) { current = cContext[i]; if(!current || !current.UpdateInputWeights(prev)) return false; prev = current; }
Следующим шагом оптимизация проходит через блок корреляций cCorrelation. Каждый слой корректирует свои параметры в соответствии с сигналами, улучшая точность матрицы взаимодействий между текущими и историческими признаками. Таким образом, модель учится выявлять наиболее значимые связи и более точно учитывать прошлые тенденции.
prev = cEncoder[-1]; for(int i = 0; i < cCorrelation.Total(); i++) { current = cCorrelation[i]; if(!current || !current.UpdateInputWeights(prev)) return false; prev = current; }
Рекуррентный узел cGRU также обновляет свои веса на основе объединённого тензора cConcatenated. Здесь происходит ключевое уточнение: параметры GRU подстраиваются так, чтобы вычисляемая дельта признаков максимально точно отражала изменения текущего состояния.
if(!cGRU.UpdateInputWeights(cConcatenated.AsObject())) return false;
Наконец, блок cG проходит последовательное обновление всех слоёв, суммируя влияние корреляций, контекста и прямого потока признаков, и нормализует выходной сигнал. Этот финальный этап гарантирует, что каждый компонент модели синхронизирован и готов к следующему прямому проходу.
prev = cG[0]; for(int i = 1; i < cG.Total(); i++) { current = cG[i]; if(!current || !current.UpdateInputWeights(prev)) return false; prev = current; } //--- return CNeuronSpikeActivation::updateInputWeights(prev); }
В завершение вызывается одноименный метод родительского класса, который аккуратно завершает цикл оптимизации. В результате, веса всех компонентов обновлены, и модель готова к следующему шагу обучения или к прогнозированию на новых данных.
Во вложении представлен полный исходный код объекта с детальной реализацией всех его методов, демонстрирующий работу RAFT изнутри.
Архитектура моделей
Мы завершили работу по построению ключевых компонентов фреймворка RAFT и теперь переходим к формированию архитектуры обучаемых моделей. Как и раньше, наша цель — создать торговую систему, способную самостоятельно выстраивать стратегию и совершать операции на рынке.
Для обучения моделей мы используем подходы Актер-Критик, интегрируя возможности RAFT непосредственно в Энкодер состояния окружающей среды. Такой подход позволяет модели не просто реагировать на текущие признаки, а учитывать их динамику и взаимосвязи, выявляемые фреймворком. Одновременно мы применяем модуль STFS для отбора наиболее значимых признаков, что позволяет сосредоточить внимание модели на тех аспектах, которые реально влияют на результат.
Именно здесь проявляется первый ощутимый эффект от реализации подходов RAFT на уровне объекта верхнего уровня. Для интеграции в существующие архитектурные решения достаточно всего лишь подключить новый объект, и модель становится готовой к обучению практически без дополнительной доработки.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRAFT; { uint temp[] = {prev_out, // Chanels In 32, 64, 128 // Chanels Out }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In 128, 64, 32 // Units Out }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window = EmbeddingSize / 2; // Group size descr.step = NHeads; // Groups descr.count = StackSize; // Stack size descr.layers = 4; // Correlation's Levels descr.optimization = ADAM; descr.batch = BatchSize; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; //--- uint window = descr.windows[descr.windows.Size()-1]; uint count = descr.units[descr.units.Size()-1];
Все остальные компоненты архитектуры остаются неизменными, что существенно упрощает процесс и ускоряет переход от разработки к тестированию.
В результате мы получаем модульную, гибкую и обучаемую систему, где RAFT выступает центральным ядром для анализа признаков и прогнозирования рыночной динамики, а остальные элементы архитектуры продолжают выполнять свои привычные функции, обеспечивая стабильность и предсказуемость работы модели.
Полное описание архитектуры обучаемых моделей вы найдете во вложении.
Тестирование
После того как архитектура обучаемой модели сформирована, а фреймворк RAFT интегрирован в Энкодер состояния, наступает этап обучения и тестирования. Здесь мы проверяем, насколько наша система способна адаптироваться к реальным рыночным условиям и самостоятельно выстраивать стратегию.
Первый этап обучения модели можно представить как репетицию новичка на исторической арене рынка. Мы используем данные валютной пары EURUSD с таймфреймом H1 за период с Января 2024 по Июнь 2025 года. В этом временном интервале модель получает историческую карту рынка и учится распознавать закономерности: динамику цен, объёмы сделок и скрытые взаимосвязи между ключевыми признаками. RAFT здесь выступает как опытный наставник: он формирует информативное состояние для Актёра и Критика, помогает модели вырабатывать собственную интуицию трейдера и постепенно накапливать стратегический опыт, позволяя прогнозировать движение рынка и оценивать риск каждой потенциальной сделки.
Следующий этап — онлайн-настройка в тестере стратегий MetaTrader 5. Переносим обучение в динамичную, почти живую среду. Модель обрабатывает данные свеча за свечой, реагируя на каждое движение цены. RAFT позволяет ей сохранять устойчивость на фоне шумовых колебаний, адаптироваться к резким всплескам и корректировать действия при низкой ликвидности. Базовая структура, сформированная на исторических данных, остаётся опорной, но модель учится гибко реагировать на текущую рыночную ситуацию, избегая переобучения и повышая точность прогнозов даже в нестабильной среде.
Финальный этап — тестирование проводится на полностью новых данных за Июль—Сентябрь 2025 года. Все параметры, полученные на предыдущих этапах, загружаются без изменений, что обеспечивает честную проверку способности модели к обобщению. Результаты тестирования представлены ниже.
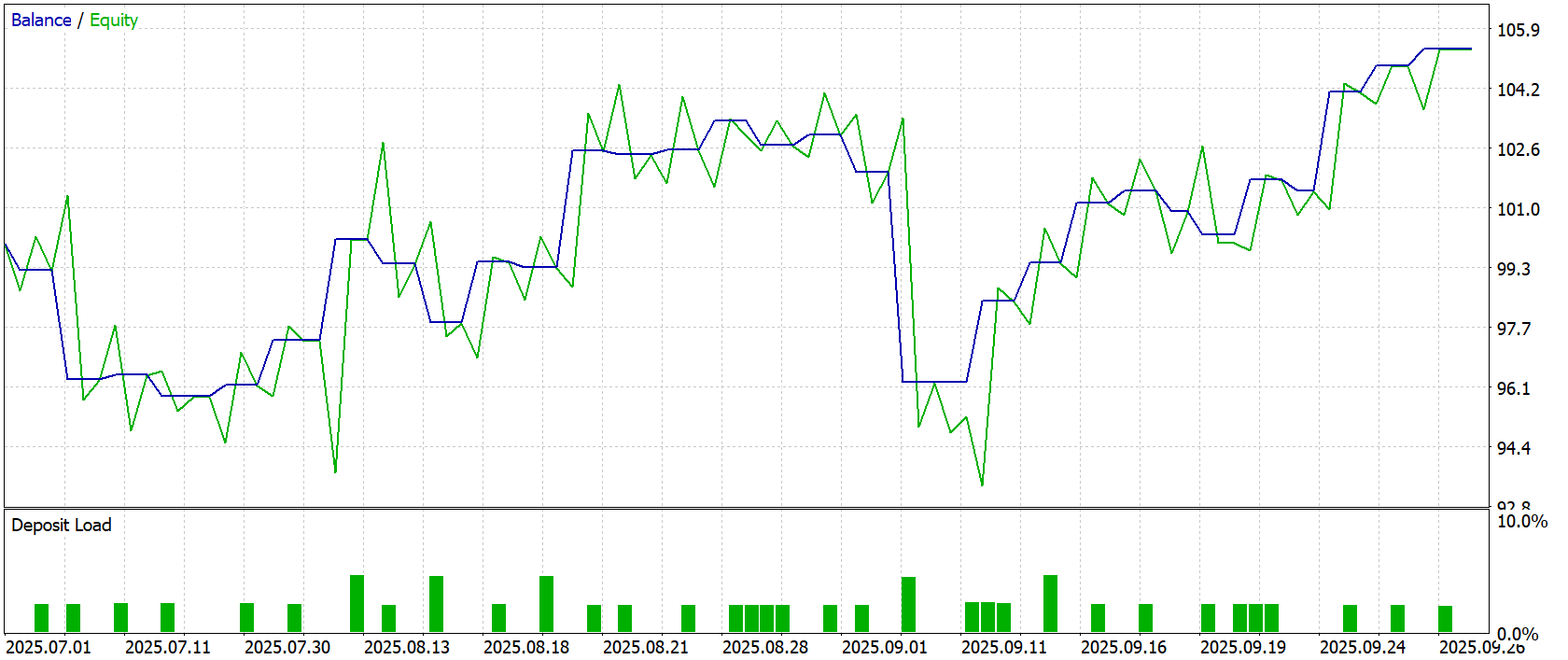
Результаты тестирования демонстрируют стабильность и адаптивность модели, построенной с использованием фреймворка RAFT. На графике Balance/Equity видно, что модель успешно удерживает положительную динамику капитала, несмотря на периодические колебания рынка. Оба показателя движутся согласованно, что говорит о сбалансированной работе модели и адекватном управлении риском.
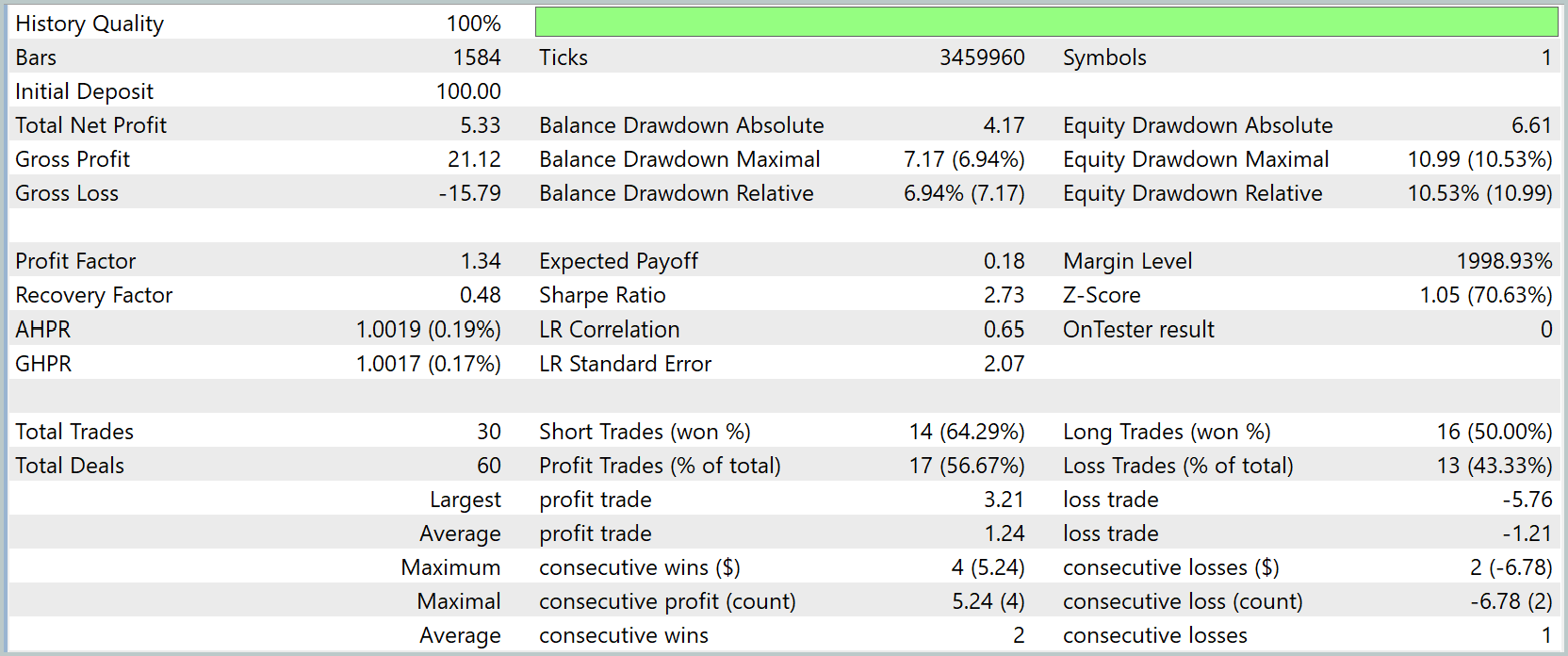
На этапе тестирования с начальным депозитом 100.0USD модель обеспечила чистую прибыль 5.33USD, при этом максимальная просадка по балансу составила 7.17%, а по equity — 10.53%, что свидетельствует о разумной консервативной стратегии и низком риске относительно объёма капитала. Общий коэффициент прибыль/убыток (Profit Factor) равен 1.34, подтверждая положительное соотношение между получаемой прибылью и понесёнными потерями.
Анализ торговых операций показывает, что из 30 совершённых сделок 17 оказались прибыльными (56.67%), при этом короткие позиции сработали лучше — 64.29% выигрышных сделок, а длинные — 50.0%. Средняя прибыль на сделку составляет 1.24USD, а средний убыток — 1.21USD. Это демонстрирует сбалансированность стратегии. Максимальная последовательная прибыль достигла 5.24USD за 4 сделки, а максимальная убыточная последовательность — 6.78USD за 2 сделки.
В целом, модель показывает устойчивую положительную динамику капитала, способность гибко реагировать на изменения рыночной конъюнктуры и эффективное управление рисками. RAFT, интегрированный в Энкодер состояния, обеспечивает информативное представление рыночных признаков и позволяет системе принимать обоснованные решения даже в условиях нестабильного рынка. Однако, перед использованием модели на реальных рынках необходимо провести дополнительный комплекс всестороннего тестирования стратегии с использованием более репрезентативной выборки.
Заключение
Фреймворк RAFT показал себя как мощный инструмент для анализа и прогнозирования финансовых временных рядов. Его гибкая и оптимизированная архитектура обеспечивает достойную точность прогнозов, стабильность работы и простоту масштабирования на новые задачи. RAFT объединяет ключевые компоненты в единую систему, ускоряя обработку данных, снижая риски ошибок и облегчая создание эффективных торговых стратегий. Эти преимущества делают его незаменимым помощником для трейдера и исследователя, стремящихся к надежным и быстрым решениям.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |