After you train a model, you can use Elastic Algorithm Service (EAS) to quickly deploy it as an online inference service or an AI-powered web application. EAS supports heterogeneous resources and provides features such as automatic scaling, one-click stress testing, phased release, and real-time monitoring. These features ensure service stability and business continuity in high-concurrency scenarios at a lower cost.
EAS features
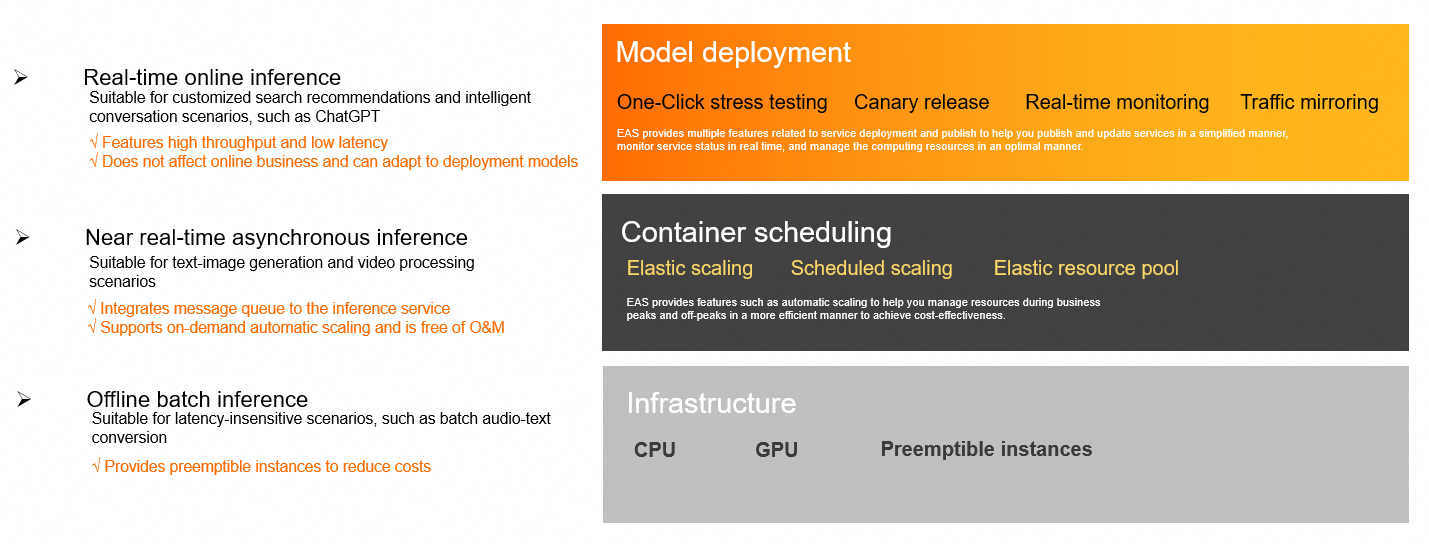
Billing
When you deploy services using EAS, you may be billed for computing resources, system disks, and dedicated gateways:
Computing resources: Includes public resources, dedicated resources, and Lingjun resources.
System disk (Optional): A free quota is available. This quota includes 30 GB for public resources and 200 GB for dedicated resources. You are billed separately for any additional system disk usage.
Dedicated gateway (Optional): Deployments use a free shared gateway by default. If you require features such as isolation, Resource Access Management, or a custom domain name, you can purchase a dedicated gateway. You must manually configure the dedicated gateway.
EAS supports two billing methods.
Pay-as-you-go: Billing is based on the service runtime, not the number of service invocations. This method is suitable for scenarios with uncertain or fluctuating demand.
Subscription: You pay in advance to receive a lower price. This method is suitable for long-term, stable business needs.
For Use Stable Diffusion web UI to deploy an AI painting service and Use ComfyUI to deploy an AI video generation model service, EAS provides a Serverless version. Service deployment is free. You are billed only for the actual inference duration during service invocations.
If you use other Alibaba Cloud services, such as Elastic IP, OSS, or NAS, you will incur charges for those services.

For more information, see Billing of Elastic Algorithm Service (EAS).
Usage workflow
Step 1: Preparations
Prepare inference resources
You can select a suitable EAS resource type based on your model size, concurrency requirements, and budget. If you use dedicated resources or Lingjun resources, you must purchase them before use. For more information about resource selection and purchase, see Overview of EAS deployment resources.
Prepare model and code files
Prepare the trained model, code processing files, and other dependencies. Then, upload the files to a specified cloud storage product, such as OSS. You must also configure storage settings to access the data required for service deployment.
Step 2: Deploy a service
Deployment tools: You can deploy and manage services using the console, the EASCMD command line, or an SDK.
Console: The console provides custom deployment and scenario-based deployment methods. The console is easy to use and suitable for beginners.
EASCMD command line: This tool supports operations such as creating, updating, and viewing services. It is suitable for algorithm engineers who are familiar with EAS deployment.
SDK: The SDK is suitable for large-scale, unified scheduling and O&M.
Deployment methods: EAS supports image-based deployment (recommended) and processor-based deployment. For more information about the differences between these methods, see Deployment principles.
Step 3: Invoke and stress test the service
If you deploy the model as a WebUI application, you can open the interactive page in a browser from the console to directly experience the capabilities of the model.
If you deploy the model as an API service:
You can send HTTP requests using online service debugging to verify that the inference feature works as expected.
You can use an API to make synchronous or asynchronous calls. EAS supports multiple service invocation methods, such as shared gateways, dedicated gateways, and direct connections.
You can use the built-in stress testing tool in EAS to perform one-click stress tests on the deployed service. This helps you test the performance of the service under pressure and understand its model inference processing capacity. For more information about stress testing, see Automatic stress testing.
Step 4: Monitor and scale the service
After the service is running, you can enable service monitoring and alerts. This helps you stay informed about resource usage, performance metrics, and potential anomalies to ensure that the service runs smoothly.
You can also enable horizontal or scheduled automatic scaling to dynamically manage the computing resources of your online service in real time. For more information, see Service Auto Scaling.
Step 5: Asynchronous inference service
For time-consuming requests, such as text-to-image generation or video processing, you can use asynchronous inference. In this mode, a queue service receives requests. After a request is processed, the results are written to an output queue. The client then asynchronously retrieves the results. This method prevents request backlogs and data loss, and improves system throughput. EAS supports automatic scaling based on the queue backlog to intelligently adjust the number of instances. For more information, see Asynchronous inference services.
Step 6: Update the service
In the inference service list, find the service that you want to update, and then click Update in the Actions column.
The service is temporarily interrupted during the update. This may cause requests that depend on this service to fail. Proceed with caution.
After the update is complete, you can click the current version number to view the Version Information or switch the service version.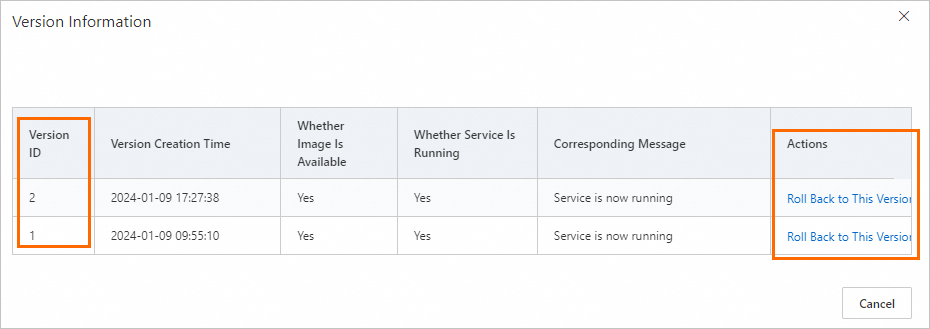
FAQ
If you encounter problems during service deployment or invocation, see FAQ about EAS for solutions.
References
For more EAS use cases, see EAS use case summary.